
Что такое risc процессоры
процессор PowerPC — процессор PowerPCБ Базируется на RISK архитектуре. Применяется в компьютерах PowerMac (Apple Computer) и некоторых компьютерах фирмы IBM. Последняя из ныне здравствующих процессорных RISC архитектур это, конечно же, знаменитая PowerPC, детище… … Справочник технического переводчика
RISC — У этого термина существуют и другие значения, см. RISC (значения). RISC (англ. restricted (reduced) instruction set computer[1][2] компьютер с сокращённым набором команд) архитектура процессора, в которой быстродействие… … Википедия
RISC (процессоры) — RISC (англ. Reduced Instruction Set Computing) вычисления с сокращённым набором команд. Это концепция проектирования процессоров, которая во главу ставит следующий принцип: более компактные и простые инструкции выполняются быстрее. Простая… … Википедия
RISC iX — Разработчик Acorn Computers Семейство ОС Unix подобная Первый выпуск 1988 Поддерживаемые языки Си, ассемблер ARM Поддерживаемые платформы Acorn Archimedes … Википедия
процессор с набором команд уменьшенной сложности — Процессор с архитектурой Crisp, например микропроцессор 80376. (Ср. CISC, RISC.) [Е.С.Алексеев, А.А.Мячев. Англо русский толковый словарь по системотехнике ЭВМ. Москва 1993] Тематики информационные технологии в целом EN complexity reduced… … Справочник технического переводчика
процессор (микропроцессор) с упрощенным (сокращенным) набором команд — Например ARM, SPARC. (Ср. CISC.) [Е.С.Алексеев, А.А.Мячев. Англо русский толковый словарь по системотехнике ЭВМ. Москва 1993] Тематики информационные технологии в целом EN reduced instruction set computerRISC … Справочник технического переводчика
Процессор — У этого термина существуют и другие значения, см. Процессор (значения). Запрос «ЦП» перенаправляется сюда; см. также другие значения. Intel Celeron 1100 Socket 370 в корпусе FC PGA2, вид снизу … Википедия
RISC OS — У этого термина существуют и другие значения, см. RISC (значения). RISC OS Скриншот RISC OS 4 Разработчик … Википедия
Процессор в памяти — В этой статье не хватает ссылок на источники информации. Информация должна быть проверяема, иначе она может быть поставлена под сомнение и удалена. Вы можете … Википедия
Центральный процессор — Intel 80486DX2 в керамическом корпусе PGA. Intel Celeron 400 socket 370 в пластиковом корпусе PPGA, вид снизу. Intel Celeron 400 socket 370 в пластиковом корпусе PPGA, вид сверху … Википедия
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Философия RISC
В середине 1970-х разные исследователи (в частности, из IBM) показали, что большинство комбинаций инструкций и ортогональных методов адресации не использовались в большинстве программ, порождаемых компиляторами того времени. Также было обнаружено, что в некоторых архитектурах с микрокодной реализацией сложные операции зачастую были медленнее последовательности более простых операций, выполняющих те же действия. Это было вызвано, в частности, тем, что многие архитектуры разрабатывались в спешке и хорошо оптимизировался микрокод только тех инструкций, которые использовались чаще. [3]
Поскольку многие реальные программы тратят большинство своего времени на выполнение простых операций, многие исследователи решили сфокусироваться на том, чтобы сделать эти операции максимально быстрыми. Тактовая частота процессора ограничена временем, которое процессор тратит на выполнение наиболее медленных шагов в процессе обработки любой инструкции; уменьшение длительности таких шагов даёт общее повышение частоты, а также зачастую ускоряет выполнение и других инструкций за счёт более эффективной конвейеризации. [4] Фокусирование на простых инструкциях и ведёт к архитектуре RISC, цель которой — сделать инструкции настолько простыми, чтобы они легко конвейеризировались и тратили не более одного такта на каждом шаге конвейера на высоких частотах.
Позднее было отмечено, что наиболее значимая характеристика RISC в разделении инструкций для обработки данных и обращения к памяти — обращение к памяти идёт только через инструкции load и store, а все прочие инструкции ограничены внутренними регистрами. Это упростило архитектуру процессоров: позволило инструкциям иметь фиксированную длину, упростило конвейеры и изолировало логику, имеющую дело с задержками при доступе к памяти, только в двух инструкциях. В результате RISC-архитектуры стали называть также архитектурами load/store. [5]
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Количество инструкций
Нередко слова «сокращённый набор команд» понимаются как минимизация количества инструкций в системе команд. В действительности, инструкций у многих RISC-процессоров больше, чем у CISC-процессоров. [6] [7] Некоторые RISC-процессоры вроде транспьютеров фирмы INMOS (англ.) имеют наборы команд не меньше, чем, например, у CISC-процессоров IBM System/370; и наоборот — CISC-процессор DEC PDP-8 имеет только 8 основных и несколько расширенных инструкций.
На самом деле, термин «сокращённый» в названии описывает тот факт, что сокращён объём (и время) работы, выполняемый каждой отдельной инструкцией — как максимум один цикл доступа к памяти, — тогда как сложные инструкции CISC-процессоров могут требовать сотен циклов доступа к памяти для своего выполнения. [8]
Некоторые архитектуры, специально разработанные для минимизации количества инструкций, сильно отличаются от классических RISC-архитектур и получили другие названия: Minimal instruction set computer (MISC), Zero instruction set computer (ZISC), Ultimate RISC (также называемый OISC), Transport triggered architecture (TTA) и т. п.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )

Мы где-то в начале статьи написали, что архитектур ы RISC и CISC очень похожи и грань между ними слегка размыта. Да, у обеих архитектур диаметрально противоположный подход к использованию процессора, но конкуренция тоже делает свое дело. Поэтому CISC и RISC стали «перенимать» друг у друга лучшие решения. К примеру, конвейеризация раньше никогда не была доступной в CISC, но именно этот процесс был способен «уничтожить» эту архитектуру на корню, поэтому создателям CISC нужно было срочно предпринять и сэмулировать конвейеризацию в своих процессорах. Что они и сделали: они «разбили» сложные инструкции CISC на более простые и назвали этот процесс «микрооперации». Это не конвейеризация и ничего общего с RISC-инструкциями не имеет, но работает по такому же принципу, что также ускоряет работу CISC-процессоров.
Конвейер в RISC практически постоянно заполнен инструкциями, а микрооперации в CISC не могут организовать постоянное заполнение конвейера, поэтому возникало очень много «пустот». Из-за этого разработчики CISC пошли на дополнительный трюк, так называемый гипертрединг. Гипертрединг позволил CISC-процессору выполнять сразу несколько потоков инструкций. В этом случае если один поток не способен «наполнить» конвейер, то для этого берутся инструкции из других потоков.
Разработчики RISC заметили, что гипертрединг — это хорошо. А в их архитектуре редко, но иногда проскакивает «пустота» в конвейере, поэтому они внедрили гипертрединг и в своих процессорах.
Такое «копирование функционала» сделало свое дело: архитектура RISC и архитектура CISC стали очень похожи. Но при этом многие специалисты пророчат светлое будущее именно архитектуре RISC.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
RISC (англ. restricted (reduced) instruction set computer [1] [2] — компьютер с сокращённым набором команд) — архитектура процессора, в которой быстродействие увеличивается за счёт упрощения инструкций, чтобы их декодирование было более простым, а время выполнения — короче. Первые RISC-процессоры даже не имели инструкций умножения и деления. Это также облегчает повышение тактовой частоты и делает более эффективной суперскалярность (распараллеливание инструкций между несколькими исполнительными блоками).
Наборы инструкций в более ранних архитектурах для облегчения ручного написания программ на языках ассемблеров или прямо в машинных кодах, а также для упрощения реализации компиляторов, выполняли как можно больше работы. Нередко в наборы включались инструкции для прямой поддержки конструкций языков высокого уровня. Другая особенность этих наборов — большинство инструкций, как правило, допускали все возможные методы адресации (т. н. «ортогональность системы команд (англ.)») — к примеру, и операнды, и результат в арифметических операциях доступны не только в регистрах, но и через непосредственную адресацию, и прямо в памяти. Позднее такие архитектуры были названы CISC (англ. Complex instruction set computer ).
Однако многие компиляторы не задействовали все возможности таких наборов инструкций, а на сложные методы адресации уходит много времени из-за дополнительных обращений к медленной памяти. Было показано, что такие функции лучше исполнять последовательностью более простых инструкций, если при этом процессор упрощается и в нём остаётся место для большего числа регистров, за счёт которых можно сократить количество обращений к памяти. В первых архитектурах, причисляемых к RISC, большинство инструкций для упрощения декодирования имеют одинаковую длину и похожую структуру, арифметические операции работают только с регистрами, а работа с памятью идёт через отдельные инструкции загрузки (load) и сохранения (store). Эти свойства и позволили лучше сбалансировать этапы конвейеризации, сделав конвейеры в RISC значительно более эффективными и позволив поднять тактовую частоту.
Другие архитектуры
За годы после появления архитектуры RISC были реализованы и другие альтернативы — например, VLIW, MISC, OISC, массово-параллельная обработка, систолическая матрица (англ. Systolic array ), переконфигурируемые вычисления (англ. Reconfigurable computing ), потоковая архитектура (англ. Dataflow architecture ).
-
архитектуры (первоначально — большие ЭВМ конца 1960-х годов, в микропроцессорах — Sun SPARC, начиная с Pentium использованы в семействе x86). Распараллеливание исполнения команд между несколькими устройствами исполнения, причём решение о параллельном исполнении двух или более команд принимается аппаратурой процессора на этапе исполнения. Эффективное использование такой архитектуры требует специальной оптимизации машинного кода в компиляторе для генерации пар независимых команд (когда результат одной команды не является аргументом другой).
- Архитектуры VLIW (very long instruction word — очень длинное слово команды). Отличаются от суперскалярной архитектуры тем, что решение о распараллеливании принимается не аппаратурой на этапе исполнения, а компилятором на этапе генерации кода. Команды очень длинны и содержат явные инструкции по распараллеливанию нескольких субкоманд на несколько устройств исполнения. Элементы архитектуры содержались в серии PA-RISC. VLIW-процессором в его классическом виде является Itanium. Разработка эффективного компилятора для VLIW является сложнейшей задачей. Преимущество VLIW перед суперскалярной архитектурой заключается в том, что компилятор может быть более развитым, нежели устройства управления процессора, и он способен хранить больше контекстной информации для принятия более верных решений по оптимизации.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Последние годы
Как оказалось в начале 1990-х годов, RISC-архитектуры позволяют получить большую производительность, чем CISC, за счёт использования суперскалярного и VLIW-подхода, а также за счёт возможности серьёзного повышения тактовой частоты и упрощения кристалла с высвобождением площади под кэш, достигающий огромных ёмкостей. Также, RISC-архитектуры позволили сильно снизить энергопотребление процессора за счёт уменьшения числа транзисторов.
Первое время RISC-архитектуры с трудом принимались рынком из-за отсутствия программного обеспечения для них. Эта проблема была решена переносом UNIX-подобных операционных систем (SunOS) на RISC-архитектуры.
В настоящее время многие архитектуры процессоров являются RISC-подобными, к примеру, ARM, DEC Alpha, SPARC, AVR, MIPS, POWER и PowerPC. Наиболее широко используемые в настольных компьютерах процессоры архитектуры x86 ранее являлись CISC-процессорами, однако новые процессоры, начиная с Intel 486DX, являются CISC-процессорами с RISC-ядром [источник не указан 699 дней] . Они непосредственно перед исполнением преобразуют CISC-инструкции x86-процессоров в более простой набор внутренних инструкций RISC.
После того, как процессоры архитектуры x86 были переведены на суперскалярную RISC-архитектуру, можно сказать, что большинство существующих ныне процессоров основаны на архитектуре RISC.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Содержание
Иные архитектурные решения, типичные для RISC
- Спекулятивное исполнение. При встрече с командой условного перехода процессор исполняет (или, по крайней мере, читает в кэш инструкций) сразу обе ветви до тех пор, пока не окончится вычисление управляющего выражения перехода. Позволяет отказаться от простоев конвейера при условных переходах.
- Переименование регистров. Каждый регистр процессора на самом деле представляет собой несколько параллельных регистров, хранящих несколько версий значения. Используется для реализации спекулятивного исполнения.
Прерывания
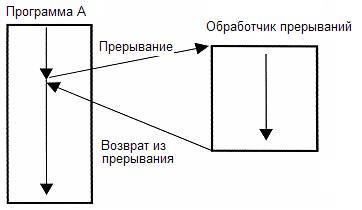
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Начало развития RISC-архитектуры
Первая система, которая может быть названа RISC-системой, — суперкомпьютер CDC 6600, который был создан в 1964 году, за десять лет до появления соответствующего термина. CDC 6600 имел RISC-архитектуру всего с двумя режимами адресации («регистр+регистр» и «регистр+непосредственное значение») и 74 кодами команд (тогда как 8086 имел 400 кодов команд). В CDC 6600 было 11 конвейерных устройств арифметической и логической обработки, а также пять устройств загрузки и два устройства хранения. Память была многоблочной, поэтому все устройства загрузки-хранения могли работать одновременно. Базовая тактовая частота/частота выдачи команд была в 10 раз выше, чем время доступа к памяти. Джим Торнтон и Сеймур Крэй, разработчики CDC 6600, создали для него мощный процессор, позволявший быстро обрабатывать большие объёмы цифровых данных. Главный процессор поддерживался десятью простыми периферийными процессорами, выполнявшими операции ввода-вывода и другие функции ОС. [9] Позднее появилась шутка, что термин RISC на самом деле расшифровывается как «Really invented by Seymour Cray» («на самом деле придуман Сеймуром Крэем»).
Ещё одна ранняя RISC-машина — миникомпьютер Data General Nova, разработанный в 1968 году.
Первая попытка создать RISC-процессор на чипе была предпринята в IBM в 1975 году. Эта работа привела к созданию семейства процессоров IBM 801, которые широко использовались в различных устройствах IBM. 801-й в конце концов был выпущен в форме чипа под именем ROMP в 1981 году. ROMP расшифровывается как Research OPD (Office Product Division) Micro Processor, то есть «исследовательский микропроцессор», разработанный в департаменте офисных разработок. Как следует из названия, процессор был разработан для «мини»-задач, и когда в 1986 году IBM выпустила на его базе компьютер IBM RT-PC, он работал не слишком хорошо. Однако за выпуском 801-го процессора последовало несколько исследовательских проектов, в результате одного из которых появилась система POWER.
Однако наиболее известные RISC-системы были разработаны в рамках университетских исследовательских программ, финансировавшихся программой DARPA VLSI. [источник не указан 76 дней] [уточнить]
Проект RISC в Университете Беркли был начат в 1980 году под руководством Дэвида Паттерсона и Карло Секвина. Исследования базировались на использовании конвейерной обработки и агрессивного использования техники регистрового окна. В обычном процессоре имеется небольшое количество регистров и программа может использовать любой регистр в любое время. В процессоре, использующем технологии регистрового окна, очень большое количество регистров (например, 128), но программы могут использовать ограниченное количество (например, только 8 в каждый момент времени).
Проект RISC произвёл на свет процессор RISC-I в 1982 году. В нём было 44 420 транзисторов (для сравнения: в CISC-процессорах того времени их было около 100 тыс.). RISC-I имел всего 32 инструкции, но превосходил по скорости работы любой одночиповый процессор того времени. Через год, в 1983 году, был выпущен RISC-II, который состоял из 40 760 транзисторов, использовал 39 инструкций и работал в три раза быстрее RISC-I.
Практически в то же время, в 1981 году, Джон Хеннесси начал аналогичный проект, названный «MIPS-архитектура» в Стэнфордском университете. Создатель MIPS практически полностью сфокусировался на конвейерной обработке, попытавшись «выжать всё» из этой технологии. Конвейерная обработка использовалась и в других продуктах, некоторые идеи, реализованные в MIPS, позволили разработанному чипу работать значительно быстрее аналогов. Наиболее важным было требование выполнения любой из инструкций процессора за один такт. Это требование позволило конвейеру работать на гораздо бо́льших скоростях передачи данных и привело к значительному ускорению работы процессора. С другой стороны, исполнение этого требования имело негативный побочный эффект в виде удаления из набора инструкций таких полезных операций, как умножение или деление.
В первые годы попытки развития RISC-архитектуры были хорошо известны, однако оставались в рамках породивших их университетских исследовательских лабораторий. Многие в компьютерной индустрии считали, что преимущества RISC-процессоров не проявятся при использовании в реальных продуктах из-за низкой эффективности использования памяти в составных инструкциях. Однако с 1986 года исследовательские проекты RISC начали выпускать первые работающие продукты.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Ссылки
| Это заготовка статьи о компьютерах. Вы можете помочь проекту, исправив и дополнив её. Это примечание по возможности следует заменить более точным. |
| Процессорные архитектуры на базе RISC-технологий | |
|---|---|