
Что такое распараллеливание процессора
Для отключения данного рекламного блока вам необходимо зарегистрироваться или войти с учетной записью социальной сети.
| Конфигурация компьютера | |
| Процессор: Intel Core i5 2500K | |
| Материнская плата: ASRock Fata1ty Professional P67 | |
| Память: DDR3 Corsair XMS3 16Gb | |
| HDD: Crucial C300 SSD64Gb SATA3, Crucial M500 120Gb | |
| Видеокарта: Gigabyte GF GTX 1070Ti Gaming G8 | |
| Звук: Realtek + Creative SB X-Fi Surround 5.1 Pro | |
| Блок питания: Cheiftech CFT750 | |
| CD/DVD: NEC | |
| Монитор: 22" LG IPS226 + 19" Viewmate (Likom) Ceemax K903X (CRT) | |
| Ноутбук/нетбук: Asus N53 | |
| ОС: Windows 10 Pro |
-------
Бякурай вам в Бякуган!
PEBN3OP, Я же приложил скриншот. Там все есть.
WSonic, Я все это читал, но особо не понял, в чем их суть) мне бы это объяснить на нормальном языке, а не компьютерном)
| Конфигурация компьютера | |
| Процессор: Intel Core i5 2500K | |
| Материнская плата: ASRock Fata1ty Professional P67 | |
| Память: DDR3 Corsair XMS3 16Gb | |
| HDD: Crucial C300 SSD64Gb SATA3, Crucial M500 120Gb | |
| Видеокарта: Gigabyte GF GTX 1070Ti Gaming G8 | |
| Звук: Realtek + Creative SB X-Fi Surround 5.1 Pro | |
| Блок питания: Cheiftech CFT750 | |
| CD/DVD: NEC | |
| Монитор: 22" LG IPS226 + 19" Viewmate (Likom) Ceemax K903X (CRT) | |
| Ноутбук/нетбук: Asus N53 | |
| ОС: Windows 10 Pro |
| WSonic, Я все это читал, но особо не понял, в чем их суть) мне бы это объяснить на нормальном языке, а не компьютерном) » |
"объясни мне сейчас пожалей дypака
а pаспятье оставь на потом" (c)
Ладно я не спаситель, и не онемею . пусть будет на Вашем языке:
1) Любой современный процессор имеющий больше одного ядра, теоретически имеет возможность распараллеливать исполняемые процессы - ключевые слова здесь - теоретически и возможность - что определяется конкретными программами - т.е. большинство игр умеют использовать 2 ядра это и есть распараллеливание.
2) Виртуализация - используется для виртуальных машин, и учитывая Ваши вопросы - Вы вряд ли понимаете что это такое и зачем это Вам может быть нужно, однако:
| Для использования Intel Virtualization Technology необходим компьютер с процессором Intel, BIOS, монитором виртуальных машин (VMM), а для некоторых моделей с определенным программным обеспечением с поддержкой этой технологии. |
основных технологий там две Vt-x и Vt-d, официально поддержка VT-d есть только у чипсетов Q-серии (материнка должна называться например Q77), однако некоторые производители добавляют эту технологию в материнки с другими чипсетами, в этом случае это должно быть указано на коробке или мануалке от материнской платы (гарантии что это будет работать нет), что до Vt-x - то она часто просто выключена в БИОС-е по умолчанию (кстати как и VT-d).
Ну вот как то так - лучше не объясню.

Распараллелить решение задачи можно на нескольких уровнях. Между этими уровнями нет четкой границы и конкретную технологию распараллеливания, бывает сложно отнести к одному из них. Приведенное здесь деление условно и служит, чтобы продемонстрировать разнообразие подходов к задаче распараллеливания.
Распараллеливание на уровне задач

Часто распараллеливание на этом уровне является самым простым и при этом самым эффективным. Такое распараллеливание возможно в тех случаях, когда решаемая задача естественным образом состоит из независимых подзадач, каждую из которых можно решить отдельно. Хорошим примером может быть сжатие аудио-альбома. Каждая запись может обрабатываться отдельно, так как она никак не связана с другими.
Распараллеливание на уровне задач нам демонстрирует операционная система, запуская на многоядерной машине программы на разных ядрах. Если первая программа показывает нам фильм, а вторая является файлообменным клиентом, то операционная система спокойно сможет организовать их параллельную работу.
Другими примерами распараллеливания на этом уровне абстракции является параллельная компиляция файлов в Visual Studio 2008, обработка данных в пакетных режимах.
Как было сказано выше, данный вид распараллеливания прост и в ряде случаев весьма эффективен. Но если мы имеем дело с однородной задачей, то данный вид распараллеливания не применим. Операционная система никак не может ускорить программу, использующую только один процессор, сколько бы ядер ни было бы при этом доступно. Программа, разбивающая кодирование звука и изображения в видеофильме на две задачи ничего не получит от третьего или четвертого ядра. Что бы распараллелить однородные задачи, нужно спуститься на уровень ниже.
Уровень параллелизма данных

Название модели «параллелизм данных» происходит оттого, что параллелизм заключается в применении одной и той же операции к множеству элементов данных. Параллелизм данных демонстрирует архиватор, использующий для упаковки несколько ядер процессора. Данные разбиваются на блоки, которые единообразным образом обрабатываются (упаковываются) на разных узлах.
Данный вид параллелизма широко используется при решении задач численного моделирования. Счетная область представлена в виде ячеек, описывающих состояние среды в соответствующих точках пространства — давление, плотность, процентное соотношение газов, температура и так далее. Количество таких ячеек может быть огромным — миллионы и миллиарды. Каждая из этих ячеек должна быть обработана одним и тем же способом. Здесь модель параллелизма по данным крайне удобна, так как позволяет загрузить каждое ядро, выделив ему определенный набор ячеек. Счетная область разбивается на геометрические объекты, например параллелепипеды, и ячейки, вошедшие в эту область, отдаются на обработку определенному ядру. В математической физике такой тип параллелизма называют геометрическим параллелизмом.

Хотя геометрический параллелизм может показаться похожим на распараллеливание на уровне задач, он является более сложным в реализации. В случае задач моделирования необходимо передавать данные получаемые на границах геометрических областей другим ядрам. Часто используются специальные методы повышения скорости расчета, за счет балансировки нагрузки между вычислительными узлами.
В ряде алгоритмов скорость вычисления, где активно протекают процессы, занимает больше времени, чем там, где среда спокойна. Как показано на рисунке, разбив счетную область на неравные части можно получить более равномерную загрузку ядер. Ядра 1, 2, и 3 обрабатывают маленькие области, где движется тело, а ядро 4 обрабатывает большую область, которая еще не подверглось возмущению. Все это требует дополнительного анализа и создания алгоритма балансировки.

Наградой за такое усложнение является возможность решать задачи длительного движения объектов за приемлемое время расчета. Примером может служить старт ракеты.
Уровень распараллеливания алгоритмов

Следующий уровень, это распараллеливание отдельных процедур и алгоритмов. Сюда можно отнести алгоритмы параллельной сортировки, умножение матриц, решение системы линейных уравнений. На этом уровне абстракций удобно использовать такую технологию параллельного программирования, как OpenMP.
OpenMP (Open Multi-Processing) — это набор директив компилятора, библиотечных процедур и переменных окружения, которые предназначены для программирования многопоточных приложений на многопроцессорных системах. В OpenMP используется модель параллельного выполнения «ветвление-слияние». Программа OpenMP начинается как единственный поток выполнения, называемый начальным потоком. Когда поток встречает параллельную конструкцию, он создает новую группу потоков, состоящую из себя и некоторого числа дополнительных потоков, и становится главным в новой группе. Все члены новой группы (включая главный поток) выполняют код внутри параллельной конструкции. В конце параллельной конструкции имеется неявный барьер. После параллельной конструкции выполнение пользовательского кода продолжает только главный поток. В параллельный регион могут быть вложены другие параллельные регионы.
За счет идеи «инкрементального распараллеливания» OpenMP идеально подходит для разработчиков, желающих быстро распараллелить свои вычислительные программы с большими параллельными циклами. Разработчик не создает новую параллельную программу, а просто последовательно добавляет в текст последовательной программы OpenMP-директивы.
Задача реализации параллельных алгоритмов достаточно сложна и поэтому существует достаточно большое количество библиотек параллельных алгоритмов, позволяющих строить программы как из кубиков, не вдаваясь в устройство реализаций параллельной обработки данных.
Параллелизм на уровне инструкций
Наиболее низкий уровень параллелизма, осуществляемый на уровне параллельной обработки процессором нескольких инструкций. На этом же уровне находится пакетная обработка нескольких элементов данных одной командой процессора. Речь идет о технологиях MMX, SSE, SSE2 и так далее. Этот вид параллельности иногда выделяют в еще более глубокий уровень распараллеливания – параллелизм на уровне битов.
Программа представляет собой поток инструкций выполняемых процессором. Можно изменить порядок этих инструкций, распределить их по группам, которые будут выполняться параллельно, без изменения результата работы всей программы. Это и называется параллелизмом на уровне инструкций. Для реализации данного вида параллелизма в микропроцессорах используется несколько конвейеров команд, такие технологии как предсказание команд, переименование регистров.
Программист редко заглядывает на этот уровень. Да и в этом нет смысла. Работу по расположению команд в наиболее удобной последовательности для процессора выполняет компилятор. Интерес этот уровень распараллеливания может представлять только для узкой группы специалистов, выжимающие все возможности из SSEx или разработчиков компиляторов.
Сейчас почти невозможно найти современную компьютерную систему без многоядерного процессора. Даже недорогие мобильные телефоны предлагают пару ядер под капотом. Идея многоядерных систем проста: это относительно эффективная технология для масштабирования потенциальной производительности процессора. Эта технология стала широкодоступной около двадцати лет назад, и теперь каждый современный разработчик способен создать приложение с параллельным выполнением для использования такой системы. На наш взгляд, сложность параллельного программирования часто недооценивается.
В этой статье мы попробуем разработать простейшее приложение, использующее для распараллеливания средства C++ и сравнить его с версией, использующей Intel oneTBB.
Операционные системы и язык C++ предоставляют интерфейсы для создания потоков, которые потенциально могут выполнять один и тот же или различные наборы инструкций одновременно.
Основными источниками проблем многопоточного выполнения являются data races (гонки данных) и race conditions (состояние гонки). Простыми словами, C++ определяет data race как одновременные и несинхронизированные доступы к одной и той же ячейке памяти, при этом один из доступов модифицирует данные. В то время как race conditions является более общим термином, описывающим ситуацию, когда результат выполнения программы зависит от последовательности или времени выполнения потоков.
Основная проблема race conditions заключается в том, что они могут быть незаметны во время разработки программного обеспечения и могут исчезнуть во время отладки. Такое поведение часто приводит к ситуации, когда приложение считается законченным и корректным, но у конечного пользователя периодически возникают проблемы, часто неясного характера. Для решения проблемы data race, C++ предоставляет набор интерфейсов, таких как атомарные операции и примитивы для создания критических секций (мьютексы).
Атомарные операции — это мощный инструмент, который позволяет избежать data races и создавать эффективные алгоритмы синхронизации. Однако, это создает замысловатую модель памяти C++, которая представляет собой еще один уровень сложности.
Использование мьютекса зачастую намного проще, чем использование атомарных операций. Он позволяет создать критическую секцию, которая может быть выполнена не более чем одним потоком в любой данный момент времени. Кроме того, продвинутые мьютексы, такие как shared_lock , в некоторых случаях могут повысить эффективность, позволяя группе потоков исполнять критическую секцию, если мьютекс не захвачен в эксклюзивное использование.
Давайте попытаемся распараллелить простую задачу вычисления суммы элементов массива. Решение этой проблемы в однопоточной программе может выглядеть следующим образом:
int summarize(const std::vector& vec)
Выполнение алгоритма в однопоточной программе:
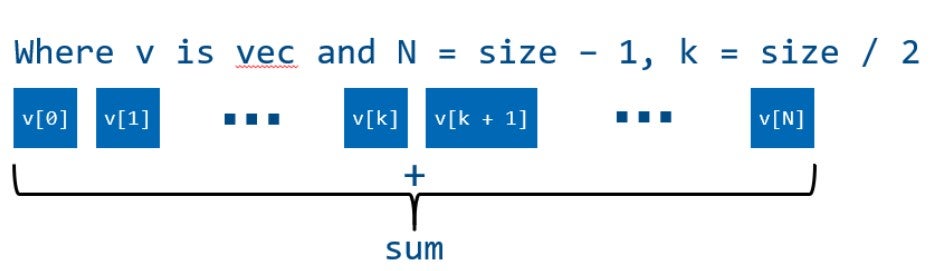
Для того чтобы исполнить алгоритм параллельно, нам нужно разделить его на независимые части, которые могут обрабатываться независимо друг от друга. Самый простой подход состоит в том, чтобы разделить обрабатываемые элементы на несколько частей и обработать каждую часть в своем собственном потоке.
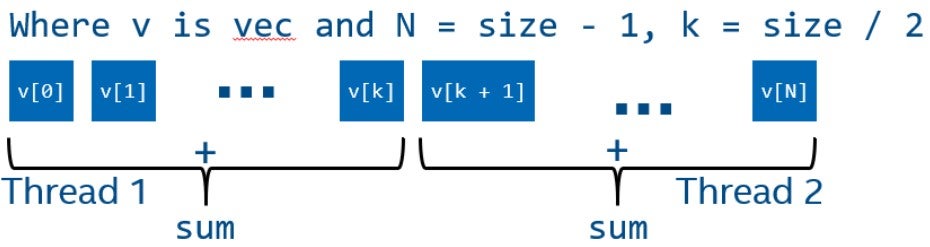
Однако в этом коде есть сложность, которая не позволяет нам просто разделить массив на две равные части и обрабатывать его параллельно. Все элементы суммируются в одну переменную, доступ к которой приведёт к data race, потому что один из потоков может записывать эту переменную одновременно с другим потоком, считывающим или записывающим в данную переменную.
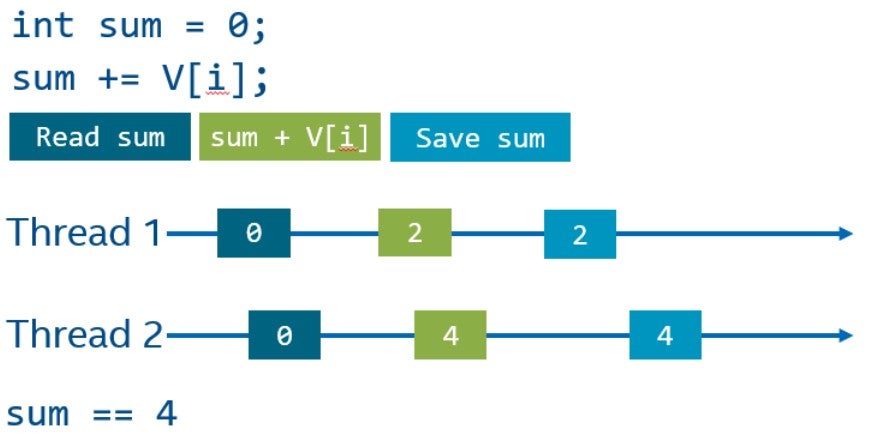
Составной оператор (оператор +=), по сути, состоит из трех операций: чтение из памяти, операция сложения и сохранение результата в памяти. Эти операции могут выполняться параллельно разными потоками, что может привести к неожиданным результатам. На следующем рисунке показан возможный порядок операций на временной шкале двух потоков. Основная сложность заключается в том, что оба потока могут не получить результат операций другого потока и перезаписать данные. C++ трактует такие ситуации как data race, и поведение программы, в таких случаях, не определено. Например, в результате мы можем получить четыре, ожидая шесть (как показано на рисунке). В худшем случае данные могут быть в непредсказуемом состоянии.
Существует много способов борьбы с data race, давайте рассмотрим самый простой из них - мьютекс.
Мьютекс имеет два основных интерфейса: блокировка (lock) и разблокировка (unclock). Блокировка переводит мьютекс в эксклюзивное владение, а разблокировка освобождает его, делая доступным для других потоков. Поток, который не может заблокировать мьютекс, будет остановлен, ожидая, пока другой поток освободит данный мьютекс.
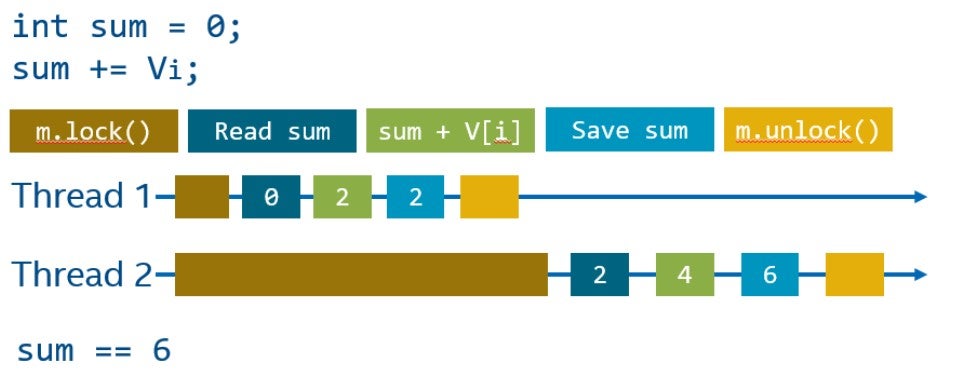
Код, защищенный мьютексом, также называется критической секцией. Важное наблюдение состоит в том, что второй поток, который не смог заблокировать мьютекс, не будет делать ничего полезного, во время того, пока первый поток находится в критической секции. Таким образом, размер критической секции может значительно повлиять на общую производительность системы.
Давайте попробуем сделать наш последовательный пример параллельным. Для создания потоков используем библиотеку из стандартной библиотеки C++.
int summarize(const std::vector& vec)
int num_threads = 2;
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе (т.е. вызван mutex.unlock())
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
// Нам нужно дождаться всех потоков
// до разрушения std::vector
Запустив нашу программу, мы, вероятно, увидим неверный результат. Причина в том, что с помощью мьютекса мы защитили себя от data race при вычислении суммы, но основной поток может считывать переменную sum, в то время как другие потоки изменяют ее. Даже если мы защитим чтение с помощью мьютекса, это приведет к другой неочевидной сложности, называемой race condition: чтение, защищённое с помощью мьютекса, не гарантирует логическую корректность алгоритма. В нашем случае мы не дожидаемся полного завершения вычислений. Чтобы решить эту проблему, мы должны дождаться завершения потоков, прежде чем считывать результат. Однако, в данном случае мьютекс не требуется для чтения общей суммы , потому что синхронизация вычислений выполняется во время ожидания потоков (с помощью функции join).
int summarize(const std::vector& vec)
int num_threads = 2;
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
// Нам нужно дождатьсявсех потоков до
Этот подход к распараллеливанию, очевидно, будет работать медленнее, чем последовательная версия, потому что для каждого sum += vec[i] мы берем мьютекс std:: lock_guard lock (m) . Таким образом, мы полностью упорядочиваем вычисления, т. е. разрешаем работать только одному потоку в любой момент времени. Чтобы избежать этого, мы можем сначала выполнить локальное суммирование в каждом потоке, а в конце вычислений добавить результат к глобальной сумме.
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим origin rangeитерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
int local_sum = 0;
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
Этот простой пример демонстрирует, что параллельное программирование приводит к ряду проблем, которые невозможно наблюдать в последовательной программе. Более того, эти проблемы не всегда легко обнаружить, и они не всегда очевидны. Библиотеки, такие как oneTBB, упрощают параллельное программирование во многих аспектах. Для наглядности наш пример можно переписать с помощью parallel_reduce , который не требует каких-либо специальных синхронизаций и механизмов, чтобы избежать race conditions:
int summarize(const std::vector& vec)
int sum = tbb::parallel_reduce(tbb::blocked_range, 0,
[&vec] (const auto& r, int init)
for (auto i = r.begin(); i != r.end(); ++i)
Хотя этот пример относительно небольшой, он показывает набор значительных упрощений, которые предоставляет oneTBB. Например, oneTBB автоматически создаст набор потоков, которые будут повторно использоваться между несколькими вызовами параллельных алгоритмов. Кроме того, parallel_reduce реализует все необходимые синхронизации, а пользователю достаточно описать требуемую операцию свертки, например, std::plus .
oneTBB использует подход, основанный на work stealing алгоритме распределения задач, предоставляя обобщенные параллельные алгоритмы, применимые для широкого спектра приложений. Основное преимущество подхода oneTBB заключается в том, что он позволяет легко создавать параллелизм в различных независимых компонентах приложения.
В нашей серии статей мы продемонстрируем, как oneTBB можно использовать для динамической балансировки нагрузки и распараллеливания графов. Помимо параллелизма задач на процессоре, мы покажем, как oneTBB можно использовать в качестве уровня абстракции для балансировки вычислений между несколькими разнородными устройствами, такими как GPU.
Мы давно уже живем в мире многоядерных процессоров и многозадачных приложений и знаем, что наиболее очевидным способом увеличения производительности является распараллеливание выполняемых задач на несколько потоков или процессов. Точнее настолько насколько позволяют, в первую очередь, ресурсы процессора. Однако, неискушенный или даже опытный разработчик может столкнуться с рядом подводных камней в, казалось бы, очевидной ситуации. В данной статье автор взял простейший код, замерил его производительность в одном потоке, распараллелил его, справедливо ожидая улучшения результатов, но что-то пошло не так…
Начинаем пример
Ниже мы напишем простейшее приложение на java (автор использовал java 14, но и java 8 подойдет вполне), замерим его производительность, используя счетчики внутри приложения, и попробуем улучшить результат, выполняя код в несколько потоков. Все что потребуется для воспроизведения примера — любая среда разработки на java или просто jdk и утилита visualvm, которая поможет нам выполнить диагностику возникших проблем. В примере намеренно не используются различные бенчмарки для замера производительности и прочие продвинутые средства — в данном случае они излишни. Тестовый пример запускался под Windows на процессоре Intel Core i7 с 4-мя физическими и с 8 логическими ядрами.
Итак, создадим простое приложение, которое в цикле будет выполнять нагружающую процессор вычислительную задачу, а именно, вычисление факториала. Причем каждая задача тоже в цикле будет вычислять факториал числа, лежащего в диапазоне от 1 до 25. Плавающий диапазон взят, чтобы больше приблизить пример к реальности. Ниже приведен код функции work():
Функция получает на вход количество циклов вычисления факториала, задаваемых константой:
После выполнения определенного количества задач, указанных в переменной
Логируется количество выполненных задач и общее время их выполнения
Функция work() также использует:
Нужно отметить, что разовое выполнение функции work() в один поток занимает примерно 20 мс, поэтому синхронизированное обращение к общей переменной counter в конце, которое могло бы являться узким местом, не создает проблем, так как происходит для каждого потока не чаще чем раз 20 мс, что существенно превышает время выполнения counter.incrementAndGet(). Другими словами, конкуренция между потоками, связанная с обращением к синхронизированному счетчику, не должна оказать существенного влияния на результаты эксперимента и ей можно пренебречь.
Давайте запустим в один поток следующий код и посмотрим на результат:
В консоли мы видим следующий вывод:
10 Задач выполнено за 0 секунд
…
100 Задач выполнено за 2 секунд
…
500 Задач выполнено за 10 секунд
Итак, в один поток мы получили производительность равную 50 задачам в секунду или 20 мс на задачу.
Распараллеливание кода
Если в один поток мы получили производительность X, то на 4 процессорах, при отсутствии дополнительной нагрузки, можно ожидать, что производительность составит примерно 4*X, то есть увеличится в 4 раза. Это кажется вполне логичным. Что ж попробуем!
Вводим простой пул с фиксированным числом потоков:
Мы будем менять в диапазоне от 1 до 16 и фиксировать результат.
Переделываем код запуска:
По-умолчанию, размер очереди задач в пуле потоков составляет Integer.MAX_VALUE, мы добавляем в пул потоков не более Integer.MAX_VALUE задач, поэтому очередь задач переполниться не должна.
Поехали!
Для начала установим константу POOL_SIZE в 8 потоков:
запустим приложение и посмотрим на консоль:
10 Задач выполнено за 3 секунд
20 Задач выполнено за 6 секунд
30 Задач выполнено за 8 секунд
40 Задач выполнено за 10 секунд
50 Задач выполнено за 14 секунд
60 Задач выполнено за 16 секунд
70 Задач выполнено за 19 секунд
80 Задач выполнено за 20 секунд
90 Задач выполнено за 23 секунд
100 Задач выполнено за 24 секунд
110 Задач выполнено за 26 секунд
120 Задач выполнено за 28 секунд
130 Задач выполнено за 29 секунд
140 Задач выполнено за 31 секунд
150 Задач выполнено за 33 секунд
160 Задач выполнено за 36 секунд
170 Задач выполнено за 46 секунд
Прежде чем разбираться с причинами такого странного поведения программы, давайте поймем динамику и снимем лог последовательно для 4-х и 16 потоков, установив константу POOL_SIZE в соответствующие значения.
Лог для 4-х потоков:
10 Задач выполнено за 2 секунд
20 Задач выполнено за 4 секунд
30 Задач выполнено за 6 секунд
40 Задач выполнено за 8 секунд
50 Задач выполнено за 10 секунд
60 Задач выполнено за 13 секунд
70 Задач выполнено за 15 секунд
80 Задач выполнено за 18 секунд
90 Задач выполнено за 21 секунд
100 Задач выполнено за 33 секунд
Первый 90 задач завершились примерно за такое же время как и для 8 потоков, потом еще 12 секунд потребовалось на выполнение еще 10 задач и приложение зависло.
Лог для 16 потоков:
10 Задач выполнено за 2 секунд
20 Задач выполнено за 3 секунд
30 Задач выполнено за 6 секунд
40 Задач выполнено за 8 секунд
…
290 Задач выполнено за 51 секунд
300 Задач выполнено за 52 секунд
310 Задач выполнено за 63 секунд
После выполнения 310 задач приложение зависло и, как и в предыдущих случаях, последние 10 задач выполнялись более чем за 10 секунд.
Распараллеливание выполнения задач приводит к деградации производительности в 10 и более раз
Во всех случаях приложение зависает и чем меньше потоков тем зависает быстрее (к этому факту мы еще вернемся)
Поиск проблем
Очевидно, что с нашим кодом что-то не то. Но как найти причину? Для этого воспользуемся утилитой visualvm. Причем запустим ее до выполнения нашего приложения, а запустив приложение переключимся на нужный java-процесс в интерфейсе visualvm. Приложение можно запускать прямо из среды разработки. Конечно, это в общем случае неправильно, но в нашем примере не окажет влияния на результат.
Первым делом смотрим на вкладку Monitor и видим, что с памятью происходит творится что-то неладное.

Меньше чем за минуту 4Гб памяти просто закончились! Поэтому приложение и встало. Но куда ушла память?
Повторно запускаем приложение и нажимаем кнопку Heap Dump на вкладке Monitor. После снятия и открытия дампа памяти видим:

В разделе Classes by Size of Instances более 1 Гб занимает класс LinkedBlockingQueue$Node. Это не что иное как одна вершина очереди задач пула потоков. Второй по размеру класс — это сама задача добавляемая в пул потоков. В подтверждение этому в разделе Classes By Number of Instances видим соответствие количества экземпляров первого и второго классов (соответствие не совсем точное, видимо, из-за того, что сначала создается задача, а потом только новая вершина очереди, и из-за разницы во времени умноженной на количество потоков имеем небольшое несоответствие количества экземпляров).
А теперь посчитаем. Мы создаем в цикле примерно 2 млрд задач (Integer.MAX_VALUE), то есть примерно 2Гб задач. Задачи выполняются медленнее чем создаются, поэтому размер очереди все время растет. Даже если на каждую задачу потребовалось бы всего 8 байт памяти, то максимальный размер очереди составил бы:
При общем размере кучи в 4 Гб неудивительно, что памяти не хватило. На самом деле, если не прерывать выполнение приложения, лог которого остановился, через некоторое время мы увидели бы знаменитую OutOfMemoryError и даже без visualvm, просто посмотрев на код, могли бы догадаться куда уходит память.
Давайте вспомним, что чем меньшим количеством потоков выполнялись задачи, тем быстрее приложение останавливалось. Теперь мы можем попытаться это объяснить. Чем меньше количество потоков, тем быстрее работает приложение (почему — нам это еще предстоит выяснить) и тем быстрее заполняется очередь задач и переполняется память.
Что ж устранить проблему с переполнением памяти очень просто. Давайте вместо Integer.MaxValue заведем константу:
И изменим код следующим образом:
Теперь остается запустить приложение и убедиться, что с памятью все в порядке:
Продолжаем анализ
Снова запускаем наше приложение последовательно увеличивая количество потоков и фиксируем результат.
1 поток — 500 Задач за 10 секунд
2 потока — 500 задач за 21 секунду
4 потока — 500 Задач за 37 секунд
8 потоков — 500 Задач за 49 секунд
16 потоков — 500 Задач за 57 секунд
Как мы видим, время выполнения 500 задач при увеличении числа потоков не уменьшается, а увеличивается, при этом, скорость выполнения каждой порции из 10 задач равномерная и потоки теперь не зависают.
Еще раз воспользуемся утилитой visualvm и снимем дамп потоков в процессе выполнения приложения. Для наиболее точной картины дамп лучше снять при работе на 16 потоках. Для анализа дампов потоков есть разные утилиты, но в нашем случае можно просто в интерфейсе visualvm пролистать все потоки с названиями «pool-1-thread-1», «pool-1-thread-2» и.т.д и увидеть следующее:

Большинство потоков в момент снятия дампа выполняют генерацию очередного случайного числа для вычисления факториала. Выходит, это наиболее затратная по времени функция. Почему же? Чтобы разобраться, залезем в исходный код Random.next() и увидим следующее:
Изменим код функции work() следующим образом:
и снова проверим производительность на разном количестве потоков:
1 поток — 1000 задач за 17 секунд
2 потока — 1000 задач за 10 секунд
4 потока — 1000 задач за 5 секунд
8 потоков — 1000 задач за 4 секунд
16 потоков — 1000 задач за 4 секунд
Теперь результат близок к нашим ожиданиям. Производительность на 4 потоках увеличилась примерно в 4 раза. Далее рост производительности практически прекратился поскольку распараллеливание ограничено ресурсами процессора. Взглянем на графики нагрузки процессора, снятые через visualvm при работе на 4-х и 8 потоках.

Если говорить о практике, то можно отметить два важных момента:
Обычно распараллеливание эффективно, когда число потоков до 2-х раз превышает число ядер процессора (разумеется, при отсутствии другой нагрузки на процессор)
Утилизация CPU на практике не должна превышать 80% для обеспечения отказоустойчивости
Уменьшение конкуренции между потоками
Увлекшись разговорами о производительности, мы забыли одну существенную вещь. Поменяв в коде вызов RandomUtils.nextInt() на константу, мы изменили бизнес логику нашего приложения. Давайте, вернемся к прежнему алгоритму, избежав при этом проблемы с производительностью. Мы выяснили, что вызов RandomUtils.nextInt() приводит к тому, что каждый из потоков использует одну и ту же переменную seed для генерации случайного числа, а, между тем, делать это совершенно необязательно. Использование в нашем примере вместо
решит проблему с конкуренцией. Теперь каждый поток будет использовать свою собственный экземпляр внутренней переменной, необходимой для генерации очередного случайного числа.
Использование отдельной переменной для каждого потока, вместо синхронизированного доступа к единственному экземпляру класса, разделяемому между потоками, распространенный прием для улучшения производительности за счет уменьшения конкуренции между потоками. Для хранения значений переменных в разрезе потока можно использовать класс java.lang.ThreadLocal, хотя есть и более продвинутые средства, например, Mapped Diagnostic Context.
В заключении хотелось бы отметить, что снижение конкуренции между потоками это не только техническая, но и логическая задача. В нашем примере, каждый поток без проблем может использовать свой экземпляр переменной, но что если нам нужен один экземпляр на всех, например, общий счетчик? В этом случае, пришлось бы провести рефакторинг самого алгоритма. Например, хранить счетчик в разрезе каждого потока и периодически или по запросу рассчитывать значение общего счетчика на основании значений счетчиков для каждого потока.
Заключение
Итак, можно выделить 3 пункта, которые влияют на производительность параллельной обработки:
Для отключения данного рекламного блока вам необходимо зарегистрироваться или войти с учетной записью социальной сети.
| Конфигурация компьютера | |
| Процессор: Intel Core i5 2500K | |
| Материнская плата: ASRock Fata1ty Professional P67 | |
| Память: DDR3 Corsair XMS3 16Gb | |
| HDD: Crucial C300 SSD64Gb SATA3, Crucial M500 120Gb | |
| Видеокарта: Gigabyte GF GTX 1070Ti Gaming G8 | |
| Звук: Realtek + Creative SB X-Fi Surround 5.1 Pro | |
| Блок питания: Cheiftech CFT750 | |
| CD/DVD: NEC | |
| Монитор: 22" LG IPS226 + 19" Viewmate (Likom) Ceemax K903X (CRT) | |
| Ноутбук/нетбук: Asus N53 | |
| ОС: Windows 10 Pro |
-------
Бякурай вам в Бякуган!
PEBN3OP, Я же приложил скриншот. Там все есть.
WSonic, Я все это читал, но особо не понял, в чем их суть) мне бы это объяснить на нормальном языке, а не компьютерном)
| Конфигурация компьютера | |
| Процессор: Intel Core i5 2500K | |
| Материнская плата: ASRock Fata1ty Professional P67 | |
| Память: DDR3 Corsair XMS3 16Gb | |
| HDD: Crucial C300 SSD64Gb SATA3, Crucial M500 120Gb | |
| Видеокарта: Gigabyte GF GTX 1070Ti Gaming G8 | |
| Звук: Realtek + Creative SB X-Fi Surround 5.1 Pro | |
| Блок питания: Cheiftech CFT750 | |
| CD/DVD: NEC | |
| Монитор: 22" LG IPS226 + 19" Viewmate (Likom) Ceemax K903X (CRT) | |
| Ноутбук/нетбук: Asus N53 | |
| ОС: Windows 10 Pro |
| WSonic, Я все это читал, но особо не понял, в чем их суть) мне бы это объяснить на нормальном языке, а не компьютерном) » |
"объясни мне сейчас пожалей дypака
а pаспятье оставь на потом" (c)
Ладно я не спаситель, и не онемею . пусть будет на Вашем языке:
1) Любой современный процессор имеющий больше одного ядра, теоретически имеет возможность распараллеливать исполняемые процессы - ключевые слова здесь - теоретически и возможность - что определяется конкретными программами - т.е. большинство игр умеют использовать 2 ядра это и есть распараллеливание.
2) Виртуализация - используется для виртуальных машин, и учитывая Ваши вопросы - Вы вряд ли понимаете что это такое и зачем это Вам может быть нужно, однако:
| Для использования Intel Virtualization Technology необходим компьютер с процессором Intel, BIOS, монитором виртуальных машин (VMM), а для некоторых моделей с определенным программным обеспечением с поддержкой этой технологии. |
основных технологий там две Vt-x и Vt-d, официально поддержка VT-d есть только у чипсетов Q-серии (материнка должна называться например Q77), однако некоторые производители добавляют эту технологию в материнки с другими чипсетами, в этом случае это должно быть указано на коробке или мануалке от материнской платы (гарантии что это будет работать нет), что до Vt-x - то она часто просто выключена в БИОС-е по умолчанию (кстати как и VT-d).
Ну вот как то так - лучше не объясню.
Читайте также: