
Что такое процессор и память
Инструмент проще, чем машина. Зачастую инструментом работают руками, а машину приводит в действие паровая сила или животное.
Компьютер тоже можно назвать машиной, только вместо паровой силы здесь электричество. Но программирование сделало компьютер таким же простым, как любой инструмент.
Процессор — это сердце/мозг любого компьютера. Его основное назначение — арифметические и логические операции, и прежде чем погрузиться в дебри процессора, нужно разобраться в его основных компонентах и принципах их работы.
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Функции CPU
Какие функции выполняет центральный процессор CPU? Главная функция ― управление всеми операциями компьютера: от простейших сложений чисел на калькуляторе до запуска компьютерных игр. Если рассматривать основные функции центрального процессора подробнее, CPU:
- получает данные из оперативной памяти, выполняет с ними арифметические и логические операции, передаёт их на внешние устройства,
- формирует сигналы, необходимые для работы внутренних узлов и внешних устройств,
- временно хранит результаты выполненных операций, переданных сигналов и других данных,
- принимает запросы от внешних устройств и обрабатывает их.
Выполнение инструкций
Инструкции хранятся в ОЗУ в последовательном порядке. Для гипотетического процессора инструкция состоит из кода операции и адреса памяти/регистра. Внутри управляющего устройства есть два регистра инструкций, в которые загружается код команды и адрес текущей исполняемой команды. Ещё в процессоре есть дополнительные регистры, которые хранят в себе последние 4 бита выполненных инструкций.
Ниже рассмотрен пример набора команд, который суммирует два числа:
- LOAD_A 8 . Это команда сохраняет в ОЗУ данные, скажем, . Первые 4 бита — код операции. Именно он определяет инструкцию. Эти данные помещаются в регистры инструкций УУ. Команда декодируется в инструкцию load_A — поместить данные 1000 (последние 4 бита команды) в регистр A .
- LOAD_B 2 . Ситуация, аналогичная прошлой. Здесь помещается число 2 ( 0010 ) в регистр B .
- ADD B A . Команда суммирует два числа (точнее прибавляет значение регистра B в регистр A ). УУ сообщает АЛУ, что нужно выполнить операцию суммирования и поместить результат обратно в регистр A .
- STORE_A 23 . Сохраняем значение регистра A в ячейку памяти с адресом 23 .
Вот такие операции нужны, чтобы сложить два числа.
Все данные между процессором, регистрами, памятью и I/O-устройствами (устройствами ввода-вывода) передаются по шинам. Чтобы загрузить в память только что обработанные данные, процессор помещает адрес в шину адреса и данные в шину данных. Потом нужно дать разрешение на запись на шине управления.

У процессора есть механизм сохранения инструкций в кэш. Как мы выяснили ранее, за секунду процессор может выполнить миллиарды инструкций. Поэтому если бы каждая инструкция хранилась в ОЗУ, то её изъятие оттуда занимало бы больше времени, чем её обработка. Поэтому для ускорения работы процессор хранит часть инструкций и данных в кэше.
Если данные в кэше и памяти не совпадают, то они помечаются грязными битами (англ. dirty bit).
Устройство управления
Устройство управления (УУ) помогает процессору контролировать и выполнять инструкции. УУ сообщает компонентам, что именно нужно делать. В соответствии с инструкциями он координирует работу с другими частями компьютера, включая второй основной компонент — арифметико-логическое устройство (АЛУ). Все инструкции вначале поступают именно на устройство управления.
Существует два типа реализации УУ:
- УУ на жёсткой логике (англ. hardwired control units). Характер работы определяется внутренним электрическим строением — устройством печатной платы или кристалла. Соответственно, модификация такого УУ без физического вмешательства невозможна.
- УУ с микропрограммным управлением (англ. microprogrammable control units). Может быть запрограммирован для тех или иных целей. Программная часть сохраняется в памяти УУ.
УУ на жёсткой логике быстрее, но УУ с микропрограммным управлением обладает более гибкой функциональностью.
Из чего состоит CPU
Центральный процессор состоит из 3-х частей:
- Ядро процессора, которое выполняет основную работу. Оно позволяет читать, расшифровывать, выполнять и отправлять инструкции. Ядро состоит из следующих частей:
- Арифметико-логическое устройство (АЛУ). Выполняет основные математические и логические операции. Все вычисления производятся в двоичной системе.
- Устройство управления (УУ). Управляет работой CPU с помощью электрических сигналов. От него зависит согласованность работы всех частей процессора и его связь с внешними устройствами.
Каждое ядро может выполнять только одну задачу, хоть и за долю секунды. Одноядерный процессор выполняет каждую задачу последовательно. Для современного объёма операций этого мало, поэтому ценятся CPU с более чем одним ядром, чтобы выполнять несколько задач одновременно. Например, двухъядерный выполняет две задачи одновременно, трехъядерный ― три и т. д.
- Запоминающее устройство. Это небольшая внутренняя память центрального процессора. Она состоит из регистров и кеш-памяти. В регистрах хранятся текущие команды, данные, промежуточные результаты операции. В кеш-память загружаются часто используемые команды и данные из оперативной памяти. Обратиться в кеш быстрее, чем в оперативную память, поэтому объём кеш-памяти влияет на скорость выполнения запросов.
- Шины ― это каналы, по которым передаётся информация. Они как рельсы для перевозки данных.

Главной характеристикой процессора является производительность. Она зависит от двух параметров: тактовая частота и разрядность.
Тактовая частота ― число выполненных операций в секунду. Измеряется в мегагерцах (МГц — миллион тактов в секунду ) и гигагерцах (ГГц — миллиард тактов в секунду). Чем больше тактовая частота, тем быстрее работает машина.
Разрядность ― количество информации (байт), которое можно передать за такт. Разрядность процессора бывает 8, 16, 32, 64 бита. Современные процессоры 32-х и 64-битные.
Что такое кэш?
TL;DR: это небольшая, но очень быстрая память, расположенная в непосредственной близости от логических блоков центрального процессора.
Однако мы, разумеется, можем узнать о кэше гораздо больше…
Давайте начнём с воображаемой волшебной системы хранения: она бесконечно быстра, может одновременно обрабатывать бесконечное количество операций передачи данных и всегда обеспечивает надёжное и безопасное хранение данных. Конечно же, ничего подобного и близко не существует, однако если бы это было так, то структура процессора была бы гораздо проще.
Процессорам бы тогда требовались только логические блоки для сложения, умножения и т.п, а также система управления передачей данных, ведь наша теоретическая система хранения способна мгновенно передавать и получать все необходимые числа; ни одному из логических блоков не приходится простаивать в ожидании передачи данных.
Но, как мы знаем, такой волшебной технологии хранения не существует. Вместо неё у нас есть жёсткие диски или твердотельные накопители, и даже самые лучшие из них далеки от возможностей обработки, необходимых для современного процессора.

Великий Т'Фон хранения данных
Причина этого заключается в том, что современные процессоры невероятно быстры — им требуется всего один тактовый цикл для сложения двух 64-битных целочисленных значений; если процессор работает с частотой 4 ГГЦ, то это составляет всего 0,00000000025 секунды, или четверть наносекунды.
В то же время, вращающемуся жёсткому диску требуются тысячи наносекунд только для нахождения данных на дисках, не говоря уже об их передаче, а твердотельным накопителям — десятки или сотни наносекунд.
Очевидно, что такие приводы невозможно встроить внутрь процессоров, поэтому между ними будет присутствовать физическое разделение. Поэтому ещё добавляется время на перемещение данных, что усугубляет ситуацию.

Увы, но это Великий А'Туин хранения данных
Именно поэтому нам нужна ещё одна система хранения данных, расположенная между процессором и основным накопителем. Она должна быть быстрее накопителя, способна одновременно управлять множеством операций передачи данных и находиться намного ближе к процессору.
Ну, у нас уже есть такая система, и она называется ОЗУ (RAM); она присутствует в каждом компьютере и выполняет именно эту задачу.
Почти все такие хранилища имеют тип DRAM (dynamic random access memory); они способны передавать данные гораздо быстрее, чем любой накопитель.

Однако, несмотря на свою огромную скорость, DRAM не способна хранить такие объёмы данных.
Одни из самых крупных чипов памяти DDR4, разработанных Micron, хранят 32 Гбит, или 4 ГБ данных; самые крупные жёсткие диски хранят в 4 000 раз больше.
Итак, хоть мы и повысили скорость нашей сети данных, нам потребуются дополнительные системы (аппаратные и программные), чтобы разобраться, какие данные должны храниться в ограниченном объёме DRAM, готовые к обработке процессором.
DRAM могут изготавливаться в корпусе чипа (это называется встроенной (embedded) DRAM). Однако процессоры довольно малы, поэтому в них не удастся поместить много памяти.

10 МБ DRAM слева от графического процессора Xbox 360. Источник: CPU Grave Yard
Подавляющее большинство DRAM расположено в непосредственной близости от процессора, подключено к материнской плате и всегда является самым близким к процессору компонентом. Тем не менее, эта память всё равно недостаточно быстра…
DRAM требуется примерно 100 наносекунд для нахождения данных, но, по крайней мере, она способна передавать миллиарды битов в секунду. Похоже, нам нужна ещё одна ступень памяти, которую можно разместить между блоками процессора и DRAM.
На сцене появляется оставшаяся ступень: SRAM (static random access memory). DRAM использует микроскопические конденсаторы для хранения данных в виде электрического заряда, а SRAM для той же задачи применяет транзисторы, которые работают с той же скоростью, что и логические блоки процессора (примерно в 10 раз быстрее, чем DRAM).

Разумеется, у SRAM есть недостаток, и он опять-таки связан с пространством.
Память на основе транзисторов занимает гораздо больше места, чем DRAM: в том же размере, что чип DDR4 на 4 ГБ, можно получить меньше 100 МБ SRAM. Но поскольку она производится по тому же технологическому процессу, что и CPU, память SRAM можно встроить прямо внутрь процессора, максимально близко к логическим блокам.
С каждой дополнительной ступенью мы увеличивали скорость перемещаемых данных ценой хранимого объёма. Мы можем продолжить и добавлять новые ступени,, которые будут быстрее, но меньше.
И так мы добрались до более строгого определения понятия кэша: это набор блоков SRAM, расположенных внутри процессора; они обеспечивают максимальную занятость процессора благодаря передаче и сохранению данных с очень высокими скоростями. Вас устраивает такое определение? Отлично, потому что дальше всё будет намного сложнее!
Производители CPU
На рынке есть два основных производителя центральных процессоров ― Intel и AMD.

Продукты Intel — дорогие, но имеют высокую производительность. Потребляют меньше энергии, следовательно меньше перегреваются. Имеют хорошую связь с оперативной памятью.
Продукты AMD значительно отстают от Intel, однако стоят дешевле. Они требуют много энергии и хуже взаимодействуют с оперативной памятью по сравнению с процессорами от Intel.

Процессор — это устройство, предназначенное для автоматического считывания команд программы, их расшифровки и выполнения.
Название «процессор» происходит от английского глагола to process — обрабатывать. Процессор, изготовленный в виде микросхемы — электронной схемы на одном кристалле кремния, — называется микропроцессором (рис. 2.1).

Рис. 2.1
В любой процессор обязательно включены две важные части:
• арифметико-логическое устройство (АЛУ), в котором выполняется обработка данных;
• устройство управления (УУ), которое выполняет программу в автоматическом режиме (без участия человека) и обеспечивает согласованную работу всех узлов компьютера.
Программа — это последовательность команд процессора.
Примеры простейших команд — сложение или деление чисел, копирование данных из одного места памяти в другое. Процессор также может сравнить два числа, определить, какое из них больше (меньше), и даже перейти по результатам этого сравнения к разным частям программы.
Выполнение каждой команды состоит из элементарных действий, которые называются микрокомандами. Простые команды состоят из нескольких микрокоманд, более сложные (например, умножение) могут включать несколько десятков микрокоманд. Разбиение команд на микрокоманды в различных процессорах может быть сделано по-разному.
Каждая из микрокоманд запускается с помощью управляющего импульса от источника (генератора) импульсов. Интервал между двумя соседними импульсами называется тактом (рис. 2.2). Очевидно, что чем чаще поступают импульсы, тем быстрее будет выполняться программа. Поэтому скорость поступления тактовых импульсов может быть характеристикой быстродействия процессора.
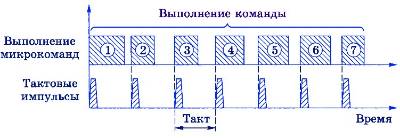
Рис. 2.2
Тактовая частота — это количество тактовых импульсов в секунду.
Обычно процессор выполняет за один такт одну простую команду (например, сложение двух чисел). Тогда при тактовой частоте 4 ГГц (4 гигагерца, т. е. 4 миллиарда импульсов в секунду) за одну секунду выполняется около 4 миллиардов таких операций.
Другая характеристика быстродействия процессора — его разрядность. Как вы знаете, все данные хранятся в компьютере в виде цепочек нулей и единиц. Каждый элемент памяти, куда можно записать 0 или 1, называется битом, потому что хранит 1 бит информации.
Разрядность — это максимальное количество битов, которые процессор способен обработать за одну команду.
Современные компьютеры за одну команду могут обработать 64 бита данных.
Как вы думаете, почему увеличение разрядности процессора может привести к ускорению обработки данных? В каких задачах оно может оказаться бесполезным?

Следующая страница Память

Cкачать материалы урока
Память (ОЗУ)
ОЗУ (оперативное запоминающее устройство, англ. RAM) — это большая группа этих самых регистров, соединённых вместе. Память у такого хранилища непостоянная и данные оттуда пропадают при отключении питания. ОЗУ принимает адрес ячейки памяти, в которую нужно поместить данные, сами данные и флаг записи/чтения, который приводит в действие триггеры.
Прим. перев. Оперативная память бывает статической и динамической — SRAM и DRAM соответственно. В статической памяти ячейками являются триггеры, а в динамической — конденсаторы. SRAM быстрее, а DRAM дешевле.
Два основных компонента процессора
Прерывания
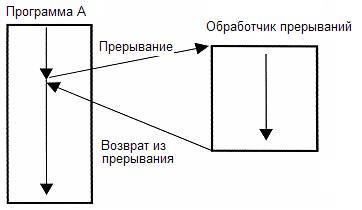
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Команды (инструкции)
Команды — это фактические действия, которые компьютер должен выполнять. Они бывают нескольких типов:
- Арифметические: сложение, вычитание, умножение и т. д.
- Логические: И (логическое умножение/конъюнкция), ИЛИ (логическое суммирование/дизъюнкция), отрицание и т. д.
- Информационные: move , input , outptut , load и store .
- Команды перехода: goto , if . goto , call и return .
- Команда останова: halt .
Прим. перев. На самом деле все арифметические операции в АЛУ могут быть созданы на основе всего двух: сложение и сдвиг. Однако чем больше базовых операций поддерживает АЛУ, тем оно быстрее.
Инструкции предоставляются компьютеру на языке ассемблера или генерируются компилятором высокоуровневых языков.
В процессоре инструкции реализуются на аппаратном уровне. За один такт одноядерный процессор может выполнить одну элементарную (базовую) инструкцию.
Группу инструкций принято называть набором команд (англ. instruction set).
Регистры
Регистр — минимальная ячейка памяти данных. Регистры состоят из триггеров (англ. latches/flip-flops). Триггеры, в свою очередь, состоят из логических элементов и могут хранить в себе 1 бит информации.
Прим. перев. Триггеры могут быть синхронные и асинхронные. Асинхронные могут менять своё состояние в любой момент, а синхронные только во время положительного/отрицательного перепада на входе синхронизации.
По функциональному назначению триггеры делятся на несколько групп:
- RS-триггер: сохраняет своё состояние при нулевых уровнях на обоих входах и изменяет его при установке единице на одном из входов (Reset/Set — Сброс/Установка).
- JK-триггер: идентичен RS-триггеру за исключением того, что при подаче единиц сразу на два входа триггер меняет своё состояние на противоположное (счётный режим).
- T-триггер: меняет своё состояние на противоположное при каждом такте на его единственном входе.
- D-триггер: запоминает состояние на входе в момент синхронизации. Асинхронные D-триггеры смысла не имеют.
Для хранения промежуточных данных ОЗУ не подходит, т. к. это замедлит работу процессора. Промежуточные данные отсылаются в регистры по шине. В них могут храниться команды, выходные данные и даже адреса ячеек памяти.
Принцип действия RS-триггера
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
В этой статье мы рассмотрим, что такое процессор CPU, какие у него функции и из чего он состоит.
В каждом вычислительном устройстве (ПК, смартфон, фотоаппарат) есть центр, который отвечает за правильную работу машины ― процессор.
В широком смысле процессор ― это устройство, которое выполняет вычислительные и логические операции с данными. Чаще всего этот термин используется для обозначения центрального процессора устройства. Расшифровка CPU ― Central Processing Unit (центральное обрабатывающее устройство). Это самая важная часть компьютера. Его мозг. Он выглядит как квадрат размером приблизительно 5x5 см:

Что значит CPU на процессоре
С обратной стороны CPU находятся ножки, с помощью которых он крепится к материнской плате:

Назначение и характеристика процессора
От мощности центрального процессора зависит скорость обработки команд и продуктивность работы других составляющих компьютера. Например, можно купить современную видеокарту, но она не сможет показать свои возможности, если управляется слабым CPU.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Кэш: многоуровневая парковка

На приведённом выше изображении процессор (CPU) обозначен прямоугольником с пунктирной границей. Слева расположены ALU (arithmetic logic units, арифметико-логические устройства); это структуры, выполняющие математические операции. Хотя строго говоря, они не являются кэшем, ближайший к ALU уровень памяти — это регистры (они упорядочены в регистровый файл).
Каждый из них хранит одно число, например, 64-битное целое число; само значение может быть элементом каких-нибудь данных, кодом определённой инструкции или адресом памяти каких-то других данных.
Регистровый файл в десктопных процессорах довольно мал, например, в каждом из ядер Intel Core i9-9900K есть по два банка таких файлов, а тот, который предназначен для целых чисел, содержит всего 180 64-битных целых чисел. Другой регистровый файл для векторов (небольших массивов чисел) содержит 168 256-битных элементов. То есть общий регистровый файл каждого ядра чуть меньше 7 КБ. Для сравнения: регистровый файл потоковых мультипроцессоров (так в GPU называются аналоги ядер CPU) Nvidia GeForce RTX 2080 Ti имеет размер 256 КБ.
Регистры, как и кэш, являются SRAM, но их скорость не превышает скорость обслуживаемых ими ALU; они передают данные за один тактовый цикл. Но они не предназначены для хранения больших объёмов данных (только одного элемента), поэтому рядом с ними всегда есть более крупные блоки памяти: это кэш первого уровня (Level 1).

Одно ядро процессора Intel Skylake. Источник: Wikichip
На изображении выше представлен увеличенный снимок одного из ядер десктопного процессора Intel Skylake.
ALU и регистровые файлы расположены слева и обведены зелёной рамкой. В верхней части фотографии белым обозначен кэш данных первого уровня (Level 1 Data cache). Он не содержит много информации, всего 32 КБ, но как и регистры, он расположен очень близко к логическим блокам и работает на одной скорости с ними.
Ещё одним белым прямоугольником справа показан кэш инструкций первого уровня (Level 1 Instruction cache), тоже имеющий размер 32 КБ. Как понятно из названия, в нём хранятся различные команды, готовые к разбиению на более мелкие микрооперации (обычно обозначаемые μops), которые должны выполнять ALU. Для них тоже существует кэш, который можно классифицировать как Level 0, потому что он меньше (содержит всего 1 500 операций) и ближе, чем кэши L1.
Вы можете задаться вопросом: почему эти блоки SRAM настолько малы? Почему они не имеют размер в мегабайт? Вместе кэши данных и инструкций занимают почти такую же площадь на чипе, что основные логические блоки, поэтому их увеличение приведёт к повышению общей площади кристалла.
Но основная причина их размера в несколько килобайт заключается в том, что при увеличении ёмкости памяти повышается время, необходимое для поиска и получения данных. Кэшу L1 нужно быть очень быстрым, поэтому необходимо достичь компромисса между размером и скоростью — в лучшем случае для получения данных из этого кэша требуется около 5 тактовых циклов (для значений с плавающей запятой больше).

Кэш L2 процессора Skylake: 256 КБ SRAM
Но если бы это был единственный кэш внутри процессора, то его производительность наткнулась бы на неожиданное препятствие. Именно поэтому в ядра встраивается еще один уровень памяти: кэш Level 2. Это обобщённый блок хранения, содержащий инструкции и данные.
Он всегда больше, чем Level 1: в процессорах AMD Zen 2 он занимает до 512 КБ, чтобы кэши нижнего уровня обеспечивались достаточным объёмом данных. Однако большой размер требует жертв — для поиска и передачи данных из этого кэша требуется примерно в два раза больше времени по сравнению с Level 1.
Во времена первого Intel Pentium кэш Level 2 был отдельным чипом, или устанавливаемым на отдельной небольшой плате (как ОЗУ DIMM), или встроенным в основную материнскую плату. Постепенно он перебрался в корпус самого процессора, и, наконец, полностью интегрировался в кристалл чипа; это произошло в эпоху таких процессоров, как Pentium III и AMD K6-III.
За этим достижением вскоре последовал ещё один уровень кэша, необходимый для поддержки более низких уровней, и появился он как раз вовремя — в эпоху расцвета многоядерных чипов.

Чип Intel Kaby Lake. Источник: Wikichip
На этом изображении чипа Intel Kaby Lake в левой части показаны четыре ядра (интегрированный GPU занимает почти половину кристалла и находится справа). Каждое ядро имеет свой «личный» набор кэшей Level 1 и 2 (выделены белыми и жёлтым прямоугольниками), но у них также есть и третий комплект блоков SRAM.
Кэш третьего уровня (Level 3), хоть и расположен непосредственно рядом с одним ядром, является полностью общим для всех остальных — каждое ядро свободно может получать доступ к содержимому кэша L3 другого ядра. Он намного больше (от 2 до 32 МБ), но и намного медленнее, в среднем более 30 циклов, особенно когда ядру нужно использовать данные, находящиеся в блоке кэша, расположенного на большом расстоянии.
Ниже показано одно ядро архитектуры AMD Zen 2: кэши Level 1 данных и инструкций по 32 КБ (в белых прямоугольниках), кэш Level 2 на 512 КБ (в жёлтых прямоугольниках) и огромный блок кэша L3 на 4 МБ (в красном прямоугольнике).

Увеличенный снимок одного ядра процессора AMD Zen 2. Источник: Fritzchens Fritz
Но постойте: как 32 КБ могут занимать больше физического пространства чем 512 КБ? Если Level 1 хранит так мало данных, почему он непропорционально велик по сравнению с кэшами L2 и L3?
Не только числа
Кэш повышает производительность, ускоряя передачу данных в логические блоки и храня поблизости копию часто используемых инструкций и данных. Хранящаяся в кэше информация разделена на две части: сами данные и место, где они изначально располагаются в системной памяти/накопителе — такой адрес называется тег кэша (cache tag).
Когда процессор выполняет операцию, которой нужно считать или записать данные из/в память, то он начинает с проверки тегов в кэше Level 1. Если нужные данные там есть (произошло кэш-попадание (cache hit)), то доступ к этим данным выполняется почти сразу же. Промах кэша (cache miss) возникает, если требуемый тег не найден на самом нижнем уровне кэша.
В кэше L1 создаётся новый тег, а за дело берётся остальная часть архитектуры процессора выполняющая поиск в других уровнях кэша (при необходимости вплоть до основного накопителя) данных для этого тега. Но чтобы освободить пространство в кэше L1 под этот новый тег, что-то обязательно нужно перебросить в L2.
Это приводит к почти постоянному перемешиванию данных, выполняемому всего за несколько тактовых циклов. Единственный способ добиться этого — создание сложной структуры вокруг SRAM для обработки управления данными. Иными словами, если бы ядро процессора состояло всего из одного ALU, то кэш L1 был бы гораздо проще, но поскольку их десятки (и многие из них жонглируют двумя потоками инструкций), то для перемещения данных кэшу требуется множество соединений.

Для изучения информации кэша в процессоре вашего компьютера можно использовать бесплатные программы, например CPU-Z. Но что означает вся эта информация? Важным элементом является метка set associative (множественно-ассоциативный) — она указывает на правила, применяемые для копирования блоков данных из системной памяти в кэш.
Представленная выше информация кэша относится к Intel Core i7-9700K. Каждый из его кэшей Level 1 разделён на 64 небольших блока, называемые sets, и каждый из этих блоков ещё разбит на строки кэша (cache lines) (размером 64 байта). «Set associative» означает, что блок данных из системы привязывается к строкам кэша в одном конкретном сете, и не может свободно привязываться к какому-то другому месту.

Инклюзивный кэш L1+L2, victim cache L3, политики write-back, есть даже ECC. Источник: Fritzchens Fritz
Ещё один аспект сложности кэша связан с тем, как хранятся данные между разными уровнями. Правила задаются в inclusion policy (политике инклюзивности). Например, процессоры Intel Core имеют полностью инклюзивные кэши L1+L3. Это означает, что одни данные в Level 1, например, могут присутствовать в Level 3. Может показаться, что это пустая трата ценного пространства кэша, однако преимущество заключается в том, что если процессор совершает промах при поиске тега в нижнем уровне, ему не потребуется обыскивать верхний уровень для нахождения данных.
В тех же самых процессорах кэш L2 неинклюзивен: все хранящиеся там данные не копируются ни на какой другой уровень. Это экономит место, но приводит к тому, что системе памяти чипа нужно искать ненайденный тег в L3 (который всегда намного больше). Victim caches (кэши-жертвы) имеют похожий принцип, но они используются для хранения информации, переносимой с более низких уровней. Например, процессоры AMD Zen 2 используют victim cache L3, который просто хранит данные из L2.
Существуют и другие политики для кэша, например, при которых данные записываются и в кэш, и основную системную память. Они называются политиками записи (write policies); большинство современных процессоров использует кэши write-back — это означает, что когда данные записываются на уровень кэшей, происходит задержка перед записью их копии в системную память. Чаще всего эта пауза длится в течение того времени, пока данные остаются в кэше — ОЗУ получает эту информацию только при «выталкивании» из кэша.

Графический процессор Nvidia GA100, имеющий 20 МБ кэша L1 и 40 МБ кэша L2
Для проектировщиков процессоров выбор объёма, типа и политики кэшей является вопросом уравновешивания стремления к повышению мощности процессора с увеличением его сложности и занимаемым чипом пространством. Если бы можно было создать 1000-канальные ассоциативные кэши Level 1 на 20 МБ такими, чтобы они при этом не занимали площадь Манхэттена (и не потребляли столько же энергии), то у нас у всех бы были компьютеры с такими чипами!
Самый нижний уровень кэшей в современных процессорах за последнее десятилетие практически не изменился. Однако кэш Level 3 продолжает расти в размерах. Если бы десять лет назад у вас было 999 долларов на Intel i7-980X, то вы могли бы получить кэш размером 12 МБ. Сегодня за половину этой суммы можно приобрести 64 МБ.
Подведём итог: кэш — это абсолютно необходимое и потрясающее устройство. Мы не рассматривали другие типы кэшей в CPU и GPU (например, буферы ассоциативной трансляции или кэши текстур), но поскольку все они имеют такую же простую структуру и расположение уровней, разобраться в них будет несложно.
Был ли у вас компьютер с кэшем L2 на материнской плате? Как насчёт слотовых Pentium II и Celeron (например, 300a) на дочерних платах? Помните свой первый процессор с общим L3?
На правах рекламы
Наша компания предлагает в аренду серверы с процессорами от Intel и AMD. В последнем случае — это эпичные серверы! VDS с AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Хранение информации — регистры и память
Как говорилось ранее, процессор выполняет поступающие на него команды. Команды в большинстве случаев работают с данными, которые могут быть промежуточными, входными или выходными. Все эти данные вместе с инструкциями сохраняются в регистрах и памяти.
Поток инструкций
Современные процессоры могут параллельно обрабатывать несколько команд. Пока одна инструкция находится в стадии декодирования, процессор может успеть получить другую инструкцию.

Однако такое решение подходит только для тех инструкций, которые не зависят друг от друга.
Если процессор многоядерный, это означает, что фактически в нём находятся несколько отдельных процессоров с некоторыми общими ресурсами, например кэшем.

Во всех центральных процессорах любого компьютера, будь то дешёвый ноутбук или сервер за миллионы долларов, есть устройство под названием «кэш». И с очень большой вероятностью он обладает несколькими уровнями.
Наверно, он важен, иначе зачем бы его устанавливать? Но что же делает кэш, и для чего ему разные уровни? И что означает «12-канальный ассоциативный кэш» (12-way set associative)?
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Тактирование процессора
Быстродействие компьютера определяется тактовой частотой его процессора. Тактовая частота — количество тактов (соответственно и исполняемых команд) за секунду.
Частота нынешних процессоров измеряется в ГГц (Гигагерцы). 1 ГГц = 10⁹ Гц — миллиард операций в секунду.
Чтобы уменьшить время выполнения программы, нужно либо оптимизировать (уменьшить) её, либо увеличить тактовую частоту. У части процессоров есть возможность увеличить частоту (разогнать процессор), однако такие действия физически влияют на процессор и нередко вызывают перегрев и выход из строя.
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Арифметико-логическое устройство
Это устройство, как ни странно, выполняет все арифметические и логические операции, например сложение, вычитание, логическое ИЛИ и т. п. АЛУ состоит из логических элементов, которые и выполняют эти операции.

Большинство логических элементов имеют два входа и один выход.
Ниже приведена схема полусумматора, у которой два входа и два выхода. A и B здесь являются входами, S — выходом, C — переносом (в старший разряд).
Схема арифметического полусумматора
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Читайте также: