
Что такое планирование загрузки процессора cpu scheduling
Данная заметка является переводом статьи из блога компании Scout. В статье дается простое и наглядное объяснение такого понятия, как load average . Статья ориентирована на начинающих Linux-администраторов, но, возможно, будет полезна и более опытным админам. Заинтересовавшимся добро пожаловать под кат.
Вероятно, Вы уже знакомы с понятием load average . Load average — это три числа, отображаемые при выполнении команд top и uptime . Выглядят они примерно так:
Большинство интуитивно понимают, что эти три числа обозначают средние значения загрузки процессора на прогрессивно увеличивающихся временных промежутках (одна, пять и пятнадцать минут) и чем меньше их значения — тем лучше. Большие числа свидетельствуют о слишком большой нагрузке на сервер. Но какие значения считать предельными? Какие значения являются «плохими», а какие — «хорошими»? Когда Вам следует просто волноваться о занчениях средней загрузки, а когда следует бросать другие дела и решать проблему так быстро, как это возможно?
Для начала, давайте разберемся, что же означает load average . Рассмотрим простейший случай: предположим, что у нас в наличии один сервер с одноядерным процессором.
Аналогия транспортного потока
- 0.00 означает, что на мосту нет ни одной машины. Фактически, значения от 0.00 до 1.00 означают отсутствие очереди. Подъезжающая машина может воспользоваться мостом без ожидания;
- 1.00 означает, что на мосту находится как раз столько автомобилей, сколько он может вместить. Все еще идет хорошо, но, в случае увеличения потока машин, возможны проблемы;
- Значения, превышающие 1.00 означают наличие очереди на въезде. Насколько большой? Например, значение 2.00 показывает, что в очереди стоит столько же автомобилей, сколько движется по мосту. 3.00 означает, что мост полностью занят и в очереди ожидает в два раза больше машин, чем он может вместить. И так далее.
Так Вы говорите, 1.00 — идеальное значание load average?
- Практическое правило «Требуется присмотр»: 0.70. Если среднее значение загрузки постоянно превышает 0.70, следует выяснить причину такого поведения системы во избежании проблем в будущем;
- Практическое правило «Почини это немедленно!»: 1.00. Если средняя загрузка системы превышает 1.00, необходимо срочно найти причину и устранить ее. В противном случае, Вы рискуете быть разбуженным посреди ночи и это точно не будет весело;
- Практическое правило «Щас же 3 ночи. ШОЗАНАХ. »: 5.00. Если среднее значение загрузки процессора превышает 5.00, у Вас серьезные проблемы. Сервер может подвисать или работать очень медленно. Скорее всего, это произойдет в худший из возможных моментов. Например, посреди ночи или когда Вы выступаете с докладом на конференции.
Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
У Вас четырехпроцессорная система? Все в порядке, если load average равен 3.00.
В мультипроцессорных системах загрузка вычисляется относительно количества доступных процессорных ядер. 100% загрузка обозначается числом 1.00 для одноядерной машины, числом 2.00 для двуядерной, 4.00 для четырехъядерной и т.д.
Если вернуться к нашей аналогии с мостом, 1.00 означает «одну полностью загруженную полосу движения». Если на мосту всего одна полоса, 1.00 означает, что мост загружен на 100%, если же в наличии две полосы, он загружен всего на 50%.
То же самое с процессорами. 1.00 означает 100% загрузки одноядерного процессора. 2.00 — 100% загрузки двуядерного и т.д.
Многоядерность vs. многопроцессорность
- «Количество ядер = максимальная загрузка». На многоядерной системе, загрузка не должна превышать количества доступных ядер;
- «Ядра — они и в Африке ядра». То, как ядра распределены по процессорам — неважно. Два четырехъядерных = четыре двуядерных = восем одноядерных процессоров. Имеет значение лишь общее число ядер.
Сведем все вместе
Давайте посмотрим на средние значения загрузки с помощью команды uptime :
Здесь представлены показатели для системы с четырехъядерным процессором и мы видим, что имеется большой запас по нагрузке. Я даже не буду задумываться о ней, пока load average не превысит 3.70.
Какое среднее значение мне следует контролировать? Для одной, пяти или 15 минут?
Для значений, о которых мы говорили раньше (1.00 — почини это немедленно и т.д.), следует рассматривать временные промежутки в пять и 15 минут. Если загрузка Вашей системы превышает 1.00 на интервале в одну минуту, все в порядке. Если же загрузка превышает 1.00 на пяти- или 15-минутном интервале, Вам следует начать принимать меры (конечно, Вам следует также принимать во внимание количество ядер в Вашей системе).
Количество ядер важно для правильно понимания load average. Как мне его узнать?
Команда cat /proc/cpuinfo выводит информацию обо всех процессорах в вашей системе. Чтобы узнать количество ядер, «скормите» ее вывод утилите grep :
Примечания переводчика
Выше представлен перевод самой статьи. Также много интересной информации можно почерпнуть из комментариев к ней. Так, один из комментаторов говорит о том, что не для каждой системы важно иметь запас по производтельности и не допускать значения загрузки выше 0.70 — иногда нам нужно чтобы сервер работал «на всю катушку» и в таких случаях load average = 1.00 — то, что доктор прописал.
Хабраюзер dukelion добавил в комментариях ценное замечание, что в некоторых сценариях, для достижения максимального КПД «железа», стоит держать значение load average несколько выше 1.00 в ущерб эффективности работы каждого отдельного процесса.
Хабраюзер enemo в комментариях добавил замечание о том, что высокий показатель load average может быть вызван большим количеством процессов, выполняющих в данный момент операции чтения/записи. То есть, load average > 1.00 на одноядерной машине не всегда говорит о том, что в Вашей системе отсутствует запас по загрузке процессора. Требуется более внимательное изучение причин такого показателя. Кстати, это хорошая тема для нового поста на Хабре :-)
Хабраюзер esvaf в комментариях интересуется, как интерпретировать значения load average в случае использования процессора с технологией HyperThreading. Однозначного ответа на данный момент я не нашел. В данной статье утверждается, что процессор, который имеет два виртуальных ядра при одном физическом, будет на 10-30% более производительным, чем простой одноядерный. Если принимать такое допущение за истину, считаю, при интерпретации load average стоит брать в расчет только количество физических ядер.
Shortest Job First (SJF) – это алгоритм, в котором процесс с наименьшим временем выполнения выбирается для следующего выполнения. Этот способ планирования может быть упреждающим или не упреждающим. Это значительно сокращает среднее время ожидания для других процессов, ожидающих выполнения. Полная форма SJF – самая короткая работа в первую очередь.
Существует два основных типа методов SJF:
Из этого руководства по операционной системе вы узнаете:
Самая короткая работа в первую очередь
SJF – это полная форма (сначала самое короткое задание) – это алгоритм планирования, в котором процесс с наименьшим временем выполнения должен быть выбран для выполнения следующим. Этот способ планирования может быть упреждающим или не упреждающим. Это значительно сокращает среднее время ожидания для других процессов, ожидающих выполнения.
Характеристики метода FCFS:
- Он предлагает неперегрузочный и упреждающий алгоритм планирования.
- Задания всегда выполняются в порядке поступления
- Это легко реализовать и использовать.
- Однако этот метод имеет низкую производительность, а общее время ожидания довольно велико.
Типы планирования процессора
Вот два вида методов планирования:

Круглый Робин Планирование
Round Robin – это алгоритм планирования вытесняющих процессов.
Каждому процессу предоставляется определенное время для выполнения, оно называется квантом .
Как только процесс выполняется в течение заданного периода времени, он прерывается, и другой процесс выполняется в течение заданного периода времени.
Переключение контекста используется для сохранения состояний вытесненных процессов.
Round Robin – это алгоритм планирования вытесняющих процессов.
Каждому процессу предоставляется определенное время для выполнения, оно называется квантом .
Как только процесс выполняется в течение заданного периода времени, он прерывается, и другой процесс выполняется в течение заданного периода времени.
Переключение контекста используется для сохранения состояний вытесненных процессов.
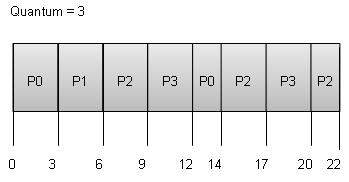
Время ожидания каждого процесса выглядит следующим образом –
| Процесс | Время ожидания: Время обслуживания – Время прибытия |
|---|---|
| P0 | (0 – 0) + (12 – 3) = 9 |
| P1 | (3 – 1) = 2 |
| P2 | (6 – 2) + (14 – 9) + (20 – 17) = 12 |
| P3 | (9 – 3) + (17 – 12) = 11 |
Среднее время ожидания: (9 + 2 + 12 + 11) / 4 = 8,5
Характеристики SJF Scheduling
- Это связано с каждой работой как единица времени для выполнения.
- В этом методе, когда ЦП доступен, следующий процесс или задание с наименьшим временем завершения будет выполняться первым.
- Реализуется с не преимущественной политикой.
- Этот метод алгоритма полезен для пакетной обработки, где ожидание выполнения заданий не является критическим.
- Это улучшает вывод заданий, предлагая более короткие задания, которые должны выполняться первыми, которые в основном имеют более короткое время выполнения.
Приоритетное планирование
Приоритетное планирование – это метод планирования процессов на основе приоритета. В этом методе планировщик выбирает задачи для работы в соответствии с приоритетом.
Приоритетное планирование также помогает ОС задействовать приоритетные назначения. Процессы с более высоким приоритетом должны выполняться в первую очередь, тогда как задания с равными приоритетами выполняются на основе циклического перебора или FCFS. Приоритет может быть решен на основе требований к памяти, времени и т. Д.
Непланирующее планирование
В этом типе метода планирования ЦП был выделен для определенного процесса. Процесс, который держит ЦП занятым, освободит ЦП либо переключением контекста, либо завершением. Это единственный метод, который можно использовать для различных аппаратных платформ. Это потому, что ему не нужно специальное оборудование (например, таймер), например, упреждающее планирование.
Характеристики SJF Scheduling
- Это связано с каждой работой как единица времени для выполнения.
- Этот метод алгоритма полезен для пакетной обработки, где ожидание выполнения заданий не является критическим.
- Это может повысить пропускную способность процесса, поскольку вначале выполняется более короткое задание, что, возможно, требует короткого времени выполнения.
- Это улучшает вывод заданий, предлагая более короткие задания, которые должны выполняться первыми, которые в основном имеют более короткое время выполнения.
Не вытесняющий SJF
В не вытесняющем планировании, когда цикл ЦП выделен для обработки, процесс удерживает его, пока не достигнет состояния ожидания или не завершится.
Рассмотрим следующие пять процессов, каждый из которых имеет свое уникальное время пакета и время прибытия.
| Очередь процессов | Время взрыва | Время прибытия |
| P1 | 6 | 2 |
| P2 | 2 | 5 |
| P3 | 8 | 1 |
| P4 | 3 | 0 |
| P5 | 4 | 4 |
Шаг 0) Во время = 0, P4 прибывает и начинает выполнение.

Шаг 1) В момент времени = 1 приходит процесс P3. Но P4 по-прежнему нужно 2 исполнительных блока для завершения. Это продолжит исполнение.

Шаг 2) В момент времени = 2, процесс P1 прибывает и добавляется в очередь ожидания. P4 продолжит исполнение.

Шаг 3) В момент времени = 3 процесс P4 завершит свое выполнение. Время всплеска P3 и P1 сравнивается. Процесс P1 выполняется, потому что его время пакета меньше по сравнению с P3.

Шаг 4) В момент времени = 4, процесс P5 прибывает и добавляется в очередь ожидания. P1 продолжит выполнение.

Шаг 5) Во время = 5, процесс P2 прибывает и добавляется в очередь ожидания. P1 продолжит выполнение.

Шаг 6) В момент времени = 9 процесс P1 завершит свое выполнение. Время всплеска P3, P5 и P2 сравнивается. Процесс P2 выполняется, потому что его время пакета является самым низким.

Шаг 7) В момент времени = 10 выполняется P2, а P3 и P5 находятся в очереди ожидания.

Шаг 8) В момент времени = 11 процесс P2 завершит свое выполнение. Время всплеска P3 и P5 сравнивается. Процесс P5 выполняется, потому что его время пакета меньше.

Шаг 9) В момент времени 15 процесс P5 завершит свое выполнение.

Шаг 10) В момент времени 23 процесс P3 завершит свое выполнение.

Шаг 11) Давайте подсчитаем среднее время ожидания для приведенного выше примера.
Характеристики кругового планирования
- Round Robin – гибридная модель с часовым механизмом
- Временной интервал должен быть минимальным, который назначается для конкретной задачи, подлежащей обработке. Однако это может варьироваться для разных процессов.
- Это система реального времени, которая реагирует на событие в течение определенного времени.
Самое короткое оставшееся время
Наименьшее оставшееся время (SRT) является преимущественной версией алгоритма SJN.
Процессор выделяется для задания, наиболее близкого к завершению, но ему может предшествовать более новое готовое задание с более коротким временем до завершения.
Невозможно реализовать в интерактивных системах, где необходимое время ЦП неизвестно.
Он часто используется в пакетных средах, где короткие задания должны отдавать предпочтение.
Наименьшее оставшееся время (SRT) является преимущественной версией алгоритма SJN.
Процессор выделяется для задания, наиболее близкого к завершению, но ему может предшествовать более новое готовое задание с более коротким временем до завершения.
Невозможно реализовать в интерактивных системах, где необходимое время ЦП неизвестно.
Он часто используется в пакетных средах, где короткие задания должны отдавать предпочтение.
Важные термины планирования ЦП
- Время пакета / время выполнения: это время, необходимое процессу для завершения выполнения. Это также называется временем выполнения.
- Время прибытия: когда процесс переходит в состояние готовности
- Время окончания: когда процесс завершен и выход из системы
- Мультипрограммирование: количество программ, которые могут присутствовать в памяти одновременно.
- Работа: Это тип программы без какого-либо взаимодействия с пользователем.
- Пользователь: Это своего рода программа с взаимодействием с пользователем.
- Процесс: это ссылка, которая используется как для работы, так и для пользователя.
- Пакетный цикл CPU / IO: характеризует выполнение процесса, которое чередуется между процессором и операциями ввода-вывода. Время ЦП обычно меньше времени ввода-вывода.
Типы алгоритмов планирования ЦП
Существует в основном шесть типов алгоритмов планирования процессов
- First Come First Serve (FCFS)
- Планирование с кратчайшим рабочим заданием (SJF)
- Самое короткое оставшееся время
- Приоритетное планирование
- Круглый Робин Планирование
- Многоуровневое планирование очередей

Характеристики метода планирования СТО:
- Этот метод в основном применяется в пакетных средах, где предпочтение отдается коротким работам.
- Это не идеальный метод для его реализации в общей системе, где требуемое время ЦП неизвестно.
- Связать с каждым процессом как длину его следующего всплеска ЦП. Так что операционная система использует эти длины, что помогает планировать процесс в кратчайшие сроки.
Упреждающий SJF
В Preemptive SJF Scheduling задания помещаются в готовую очередь по мере их поступления. Процесс с самым коротким временем пакета начинает выполнение. Если приходит процесс с еще более коротким временем пакетной обработки, текущий процесс удаляется или освобождается от выполнения, а более короткому заданию назначается цикл ЦП.
Рассмотрим следующие пять процессов:
| Очередь процессов | Время взрыва | Время прибытия |
| P1 | 6 | 2 |
| P2 | 2 | 5 |
| P3 | 8 | 1 |
| P4 | 3 | 0 |
| P5 | 4 | 4 |
Шаг 0) Во время = 0, P4 прибывает и начинает выполнение.
| Очередь процессов | Время взрыва | Время прибытия |
| P1 | 6 | 2 |
| P2 | 2 | 5 |
| P3 | 8 | 1 |
| P4 | 3 | 0 |
| P5 | 4 | 4 |

Шаг 1) В момент времени = 1 приходит процесс P3. Но, у P4 есть более короткое время взрыва. Это продолжит исполнение.

Шаг 2) Во время = 2, процесс P1 прибывает с временем пакета = 6. Время пакета больше, чем у P4. Следовательно, P4 продолжит выполнение.

Шаг 3) В момент времени = 3 процесс P4 завершит свое выполнение. Время всплеска P3 и P1 сравнивается. Процесс P1 выполняется, потому что его время пакета меньше.

Шаг 4) В момент времени = 4, процесс P5 прибудет. Время взрыва P3, P5 и P1 сравнивается. Процесс P5 выполняется, потому что его время пакета является самым низким. Процесс P1 выгружен.
| Очередь процессов | Время взрыва | Время прибытия |
| P1 | 5 из 6 осталось | 2 |
| P2 | 2 | 5 |
| P3 | 8 | 1 |
| P4 | 3 | 0 |
| P5 | 4 | 4 |

Шаг 5) Во время = 5, процесс P2 прибудет. Время посылки P1, P2, P3 и P5 сравнивается. Процесс P2 выполняется, потому что его время пакета меньше. Процесс P5 прерывается.
| Очередь процессов | Время взрыва | Время прибытия |
| P1 | 5 из 6 осталось | 2 |
| P2 | 2 | 5 |
| P3 | 8 | 1 |
| P4 | 3 | 0 |
| P5 | 3 из 4 осталось | 4 |

Шаг 6) В момент времени = 6 выполняется P2.

Шаг 7) В момент времени = 7 P2 завершает свое выполнение. Время взрыва P1, P3 и P5 сравнивается. Процесс P5 выполняется, потому что его время пакета меньше.
| Очередь процессов | Время взрыва | Время прибытия |
| P1 | 5 из 6 осталось | 2 |
| P2 | 2 | 5 |
| P3 | 8 | 1 |
| P4 | 3 | 0 |
| P5 | 3 из 4 осталось | 4 |

Шаг 8) В момент времени = 10, P5 завершит свое выполнение. Время взрыва P1 и P3 сравнивается. Процесс P1 выполняется, потому что его время пакета меньше.

Шаг 9) В момент времени = 15 P1 завершает свое выполнение. P3 – единственный оставшийся процесс. Это начнет выполнение.

Шаг 10) В момент времени = 23 P3 заканчивает свое выполнение.

Шаг 11) Давайте подсчитаем среднее время ожидания для приведенного выше примера.
Планирование ЦП – это процесс определения того, какому процессу будет принадлежать ЦП для выполнения, пока другой процесс находится в режиме ожидания. Основная задача планирования ЦП состоит в том, чтобы гарантировать, что всякий раз, когда ЦП остается бездействующим, ОС, по крайней мере, выбирает один из процессов, доступных в готовой очереди для выполнения. Процесс выбора будет выполняться планировщиком ЦП. Он выбирает один из процессов в памяти, которые готовы к выполнению.
Из этого руководства по планированию ЦП вы узнаете:
Когда планирование является упреждающим или не вытесняющим?
Чтобы определить, является ли планирование приоритетным или не преимущественным, рассмотрите следующие четыре параметра:
- Процесс переключается из режима ожидания в состояние ожидания.
- Конкретный процесс переключается из рабочего состояния в состояние готовности.
- Конкретный процесс переключается из состояния ожидания в состояние готовности.
- Процесс завершил свое выполнение и завершился.
Применяются только условия 1 и 4, планирование называется без вытеснения.
Все остальные расписания являются преимущественными.
Что такое диспетчер?
Это модуль, который обеспечивает управление процессором для процесса. Диспетчер должен быть быстрым, чтобы он мог работать при каждом переключении контекста. Задержка отправки – это время, необходимое планировщику ЦП для остановки одного процесса и запуска другого.
Функции, выполняемые Диспетчером:
- Переключение контекста
- Переключение в режим пользователя
- Перемещение в правильное место во вновь загруженной программе.
▍Введение
Для того чтобы понять Core Scheduling и для чего он нужен, стоит разобраться, как работают многозадачные системы, и как они развивались.
На современных компьютерах одновременно могут работать сотни, а то и тысячи программ одновременно. Монопольный доступ к процессору и памяти остались в прошлом, и на данный момент практически нигде не используется кроме микроконтроллеров и RT(Real Time) задач.
Изначально все процессоры были одноядерными, и могли выполнять только одну задачу одновременно. Практически сразу появилась необходимость выполнять несколько задач одновременно на одноядерном процессоре. Для этого был придуман scheduler, он же планировщик в операционных системах, который занимается переключением задач и управляет ресурсами компьютера. Ядро операционной системы всегда работает с большими привилегиями, чем пользовательские программы, такой режим работы называют Ring 0. Поэтому планировщик может в любой момент приостанавливать выполнение одной задачи и перейти к выполнению следующей. В нём существует специальная очередь задач, в которую добавляются все работающие программы и обработчики ядра, например, обработчик прерываний. Изначально эта очередь была простая, как очередь в магазине, и каждая программа выполнялась по очереди, как бы подходя к кассе в магазине. Каждая задача, после того, как выполнила свою работу, должна была явно уведомить планировщик, что задача завершила свою работу и планировщик может переключиться на следующую задачу. Такую очередь называют FIFO — First In First Out первым пришёл, первым ушёл. А такую многозадачность называют совместной или кооперативной многозадачностью.
Дальше очередь стала более сложной и появились приоритеты с вытеснением, задачи с более высоким приоритетом могут встать в очереди перед задачами с более низким приоритетом, или некоторые задачи вовсе могут быть пропущены в этом цикле обхода очереди. Простой пример такой очереди, когда в очереди к директору компании стоят сотрудники, но приходит какой-нибудь проверяющий, или какое-то важное лицо, и всех просят подождать, пока директор пообщается с этим более важным человеком. А могут и вовсе кого-то выгнать из кабинета начальника: -«Семён Семёнович, незамедлительно покиньте кабинет директора, к нему министр тяжёлой промышленности приехал!». Решение о переключении задач при такой многозадачности принимает OC. Через запрограммированные промежутки времени по таймеру происходит прерывание, и запускается планировщик, который переключает процессор на выполнение следующей задачи. Такую многозадачность называют вытесняющая многозадачность или PREEMPT, preemptive multitasking.
Каждая задача в ядре Linux описывается структурой task_struct, а список задач хранится в виде циклического двусвязного списка (Связный список). Описание структуры task_struct можно найти в файле: include/linux/sched.h исходников ядра. task_struct ещё называют дескриптором процесса и в нём находится вся важная информация об исполняемом процессе. Мы не будем углубляться в эту тему слишком глубоко, так как это тема отдельной статьи. Но вы всегда можете найти комментарии и пояснения к коду, в файле: include/linux/sched.h , и изучить эту тему самостоятельно. Умение читать исходные коды ядра, является очень важным навыком для каждого разработчика, который хочет углубиться в программирование ядра Linux. Часть полезной информации также можно найти в официальной документации ядра Linux — Scheduler, но всё же лучше смотреть исходные коды ядра.

Со временем системы стали многоядерными и имели количество потоков выполнения — равное количеству ядер процессора или количеству процессоров, в случае с одноядерными процессорами, что, в свою очередь, повысило возможности компьютеров и количество выполняемых задач одновременно. Чтобы уменьшить накладные расходы переключения задач в ОС, разработчики процессоров придумали простое и элегантное решение, переложили часть функций на процессор. Так были придуманы Intel Hyper-Threading (Intel HT) и AMD Simultaneous Multithreading (AMD SMT).
Технологии очень простые: Теперь вместо реальных ядер процессор начал показывать виртуальные ядра в количестве реальных ядер умноженных на 2. Процессоры с 1 ядром начали иметь 2 виртуальных процессора (2 потока выполнения), которые видит ОС. Теперь в процессоре, имея два потока выполнения на каждое ядро, ядро процессора может не простаивать, когда один из потоков спит, а переключится на второй поток. Тем самым процессор будет переключаться между потоками с минимальными задержками, и по максимуму использовать возможности каждого ядра.
Как работают Intel HT и AMD SMT можно понять по картинкам ниже. Первая картинка показывает, как занята очередь процессора при выполнении двух задач, а на второй картинке показана временная диаграмма, и что в случае с Intel HT и AMD SMT на обе задачи суммарно было потрачено меньше времени.


На самом деле, в некоторых случаях это решение является очень спорным и не даёт какого-либо выигрыша производительности. Но в некоторых задачах всё же есть заметный выигрыш, например, в виртуализации. Ничего не предвещало беды, но, как говорится, беда подкралась неожиданно…
Долгое время никто не замечал главной проблемы этой технологии. Все потоки используют одни и те же кэши и аппаратные возможности процессора. Это открыло уязвимость, что один процесс может извлекать данные, наблюдая за изменениями кэша другим процессом. Только с ростом потребностей бизнеса и популяризации виртуализации, такая уязвимость стала чаще обсуждаться. Единственным способом безопасно запускать два процесса не доверяющих друг-другу стало отключение Intel HT и AMD SMT. С появлением уязвимостей класса Spectre данная проблема ещё больше усугубилась и поставила облачных провайдеров перед очень тяжелым выбором: отключить Intel HT и AMD SMT? И даже вызывало сильное раздражение, так как клиенты — бизнес требуют безопасности их данных. Но что же это для них значило? Конечно же, увеличение затрат и миллионные потери прибыли. Если при наличии Intel HT и AMD SMT они могли иметь больше клиентов чем ядер, и клиенты могли балансироваться между ядрами и выравнивать нагрузку на процессор, то теперь все облачные технологии готовы были заключить в жесткие рамки количества реальных ядер. И тут облачные провайдеры задумались не на шутку, как сделать так чтобы оставить включенными Intel HT и AMD SMT, сделать данные клиента безопаснее, например, закрытые ключи шифрования и пароли. Так появился на свет Core Scheduling, который безопасно может выполнять потоки.
Круглый Робин Планирование
Round Robin – самый старый, самый простой алгоритм планирования. Название этого алгоритма происходит от принципа циклического перебора, когда каждый человек получает равную долю чего-то по очереди. Он в основном используется для планирования алгоритмов в многозадачном режиме. Этот метод алгоритма помогает без голодания выполнения процессов.
Упреждающее планирование
В упреждающем планировании задачи в основном назначаются с их приоритетами. Иногда важно запустить задачу с более высоким приоритетом перед другой задачей с более низким приоритетом, даже если задача с более низким приоритетом все еще выполняется. Задача с более низким приоритетом удерживается некоторое время и возобновляется, когда задача с более высоким приоритетом завершает свое выполнение.
First Come First Serve (FCFS)
- Задания выполняются в порядке поступления.
- Это не упреждающий, упреждающий алгоритм планирования.
- Легко понять и реализовать.
- Его реализация основана на очереди FIFO.
- Низкая производительность, так как среднее время ожидания велико.
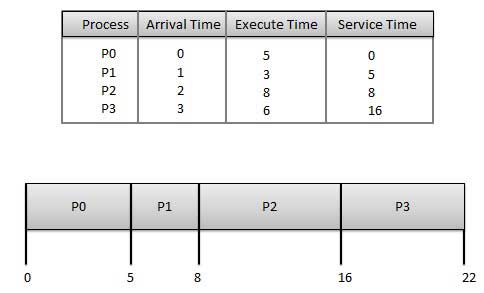
Время ожидания каждого процесса выглядит следующим образом –
| Процесс | Время ожидания: Время обслуживания – Время прибытия |
|---|---|
| P0 | 0 – 0 = 0 |
| P1 | 5 – 1 = 4 |
| P2 | 8 – 2 = 6 |
| P3 | 16 – 3 = 13 |
Среднее время ожидания: (0 + 4 + 6 + 13) / 4 = 5,75
Минимизировать:
Время ожидания: Время ожидания – это количество, которое конкретный процесс должен ждать в очереди готовности.
Время ответа. Это количество времени, за которое запрос был отправлен до получения первого ответа.
Время выполнения: Время выполнения – это количество времени, необходимое для выполнения определенного процесса. Это вычисление общего времени, потраченного на ожидание попадания в память, ожидание в очереди и выполнение на процессоре. Период между временем представления процесса и временем завершения является временем выполнения.
Максимизация:
Использование ЦП: использование ЦП является основной задачей, в которой операционная система должна убедиться, что ЦП остается максимально загруженным. Может варьироваться от 0 до 100 процентов. Однако для ОСРВ она может составлять от 40 процентов для низкого уровня и до 90 процентов для системы высокого уровня.
Пропускная способность: число процессов, которые завершают свое выполнение за единицу времени, известно. Пропускная способность. Таким образом, когда процессор занят выполнением процесса, в это время работа выполняется, и работа, выполненная за единицу времени, называется пропускной способностью.
Интервальный таймер
Таймер прерывания – это метод, тесно связанный с вытеснением. Когда определенный процесс получает распределение ЦП, таймер может быть установлен на указанный интервал. И прерывание по таймеру, и прерывание вынуждают процесс возвращать ЦП до завершения его загрузки.
Большая часть многопрограммной операционной системы использует ту или иную форму таймера, чтобы процесс не связывал систему вечно.
Самое короткое оставшееся время
Полная форма СТО – самое короткое оставшееся время. Это также известно как упреждающее планирование SJF. В этом методе процесс будет назначен задаче, наиболее близкой к ее завершению. Этот метод не позволяет более новому процессу состояния готовности удерживать завершение более старого процесса.
Приоритетное планирование
Приоритетное планирование – это алгоритм без вытеснения и один из самых распространенных алгоритмов планирования в пакетных системах.
Каждому процессу назначается приоритет. Процесс с наивысшим приоритетом должен выполняться первым и так далее.
Процессы с одинаковым приоритетом выполняются по принципу «первым пришел – первым обслужен».
Приоритет может быть решен на основе требований к памяти, времени или любых других ресурсов.
Приоритетное планирование – это алгоритм без вытеснения и один из самых распространенных алгоритмов планирования в пакетных системах.
Каждому процессу назначается приоритет. Процесс с наивысшим приоритетом должен выполняться первым и так далее.
Процессы с одинаковым приоритетом выполняются по принципу «первым пришел – первым обслужен».
Приоритет может быть решен на основе требований к памяти, времени или любых других ресурсов.
Дано: таблица процессов, их время прибытия, время выполнения и приоритет. Здесь мы рассматриваем 1 является самым низким приоритетом.
| Процесс | Время прибытия | Время исполнения | приоритет | Время обслуживания |
|---|---|---|---|---|
| P0 | 0 | 5 | 1 | 0 |
| P1 | 1 | 3 | 2 | 11 |
| P2 | 2 | 8 | 1 | 14 |
| P3 | 3 | 6 | 3 | 5 |

Время ожидания каждого процесса выглядит следующим образом –
| Процесс | Время ожидания |
|---|---|
| P0 | 0 – 0 = 0 |
| P1 | 11 – 1 = 10 |
| P2 | 14 – 2 = 12 |
| P3 | 5 – 3 = 2 |
Среднее время ожидания: (0 + 10 + 12 + 2) / 4 = 24/4 = 6
Критерии планирования процессора
Алгоритм планирования ЦП пытается максимизировать и минимизировать следующее:

Планирование многоуровневых очередей
Этот алгоритм разделяет готовую очередь на различные отдельные очереди. В этом методе процессы назначаются в очередь на основе определенного свойства процесса, такого как приоритет процесса, размер памяти и т. Д.
Тем не менее, это не независимый алгоритм ОС планирования, поскольку он должен использовать другие типы алгоритмов для планирования заданий.
Планировщик процессов планирует различные процессы, которые должны быть назначены ЦПУ на основе определенных алгоритмов планирования. Существует шесть популярных алгоритмов планирования процессов, которые мы собираемся обсудить в этой главе:
- Планирование «первым пришел – первым обслужен» (FCFS)
- Планирование Shortest-Job-Next (SJN)
- Приоритетное планирование
- Самое короткое оставшееся время
- Круглый Робин (RR) Планирование
- Планирование многоуровневых очередей
Эти алгоритмы являются либо не вытесняющими, ни вытесняющими . Непрерывающие алгоритмы разработаны таким образом, что, как только процесс входит в рабочее состояние, он не может быть прерван до тех пор, пока не завершит свое выделенное время, тогда как упреждающее планирование основано на приоритете, когда планировщик может выгрузить процесс с низким приоритетом в любое время, когда высокий приоритет процесс переходит в состояние готовности.
Кратчайшая работа следующая (SJN)
Это также называется первой короткой работой , или SJF
Это не упреждающий, упреждающий алгоритм планирования.
Лучший подход для минимизации времени ожидания.
Легко реализовать в пакетных системах, где необходимое время процессора известно заранее.
Невозможно реализовать в интерактивных системах, где необходимое время ЦП неизвестно.
Процессор должен заранее знать, сколько времени займет процесс.
Это также называется первой короткой работой , или SJF
Это не упреждающий, упреждающий алгоритм планирования.
Лучший подход для минимизации времени ожидания.
Легко реализовать в пакетных системах, где необходимое время процессора известно заранее.
Невозможно реализовать в интерактивных системах, где необходимое время ЦП неизвестно.
Процессор должен заранее знать, сколько времени займет процесс.
Дано: таблица процессов и время их прибытия, время выполнения
| Процесс | Время прибытия | Время исполнения | Время обслуживания |
|---|---|---|---|
| P0 | 0 | 5 | 0 |
| P1 | 1 | 3 | 5 |
| P2 | 2 | 8 | 14 |
| P3 | 3 | 6 | 8 |

Время ожидания каждого процесса выглядит следующим образом –
| Процесс | Время ожидания |
|---|---|
| P0 | 0 – 0 = 0 |
| P1 | 5 – 1 = 4 |
| P2 | 14 – 2 = 12 |
| P3 | 8 – 3 = 5 |
Среднее время ожидания: (0 + 4 + 12 + 5) / 4 = 21/4 = 5,25
▍Core Scheduling
Как же работает Core Scheduling? Всё очень просто! Каждому процессу назначается метка — cookie , по которому его можно идентифицировать. Так же свой уникальный cookie можно назначить каждому пользователю. Тем самым ядро разрешает совместное использование процессора только в случае, если у двух процессов совпадает cookie . Как говорится, всё гениальное просто!

Для управления процессами или потоками используется системный вызов prctl:
В случае с Core Scheduling системный вызов принимает вид:
Где PR_SCHED_CORE говорит, что это операция с Core Scheduling, command это команда которую надо выполнить, pid process id — цифровой идентификатор процесса, pid_type тип pid, cookie — беззнаковое 32 битное число метки.
Для работы с Core Scheduling существует 4 команды:
- PR_SCHED_CORE_CREATE — говорит ядру создать новый cookie и назначить его процессу с pid . С помощью параметра pid_type мы можем управлять шириной назначения cookie. Если значение равно PIDTYPE_PID , то cookie устанавливается для конкретного процесса с pid , а при PIDTYPE_TGID всей группе потоков. cookie не должен быть равен NULL .
- PR_SCHED_CORE_GET — получает cookie для указанного pid , и сохраняет его в переменной cookie . Вы могли обратить внимание, что системному вызову передается не само значение cookie, а указатель на место в памяти где находится значение переменной cookie , тем самым системный вызов свободно может читать и писать значения по этому адресу. Полезность данной команды заключается только в получении cookie двух процессов и их сравнения. Большей ценности данная команда не имеет.
- PR_SCHED_CORE_SHARE_TO — процесс который вызвал prctl может поделится своим cookie с процессом pid которого был передан. В остальном команда полностью повторяет параметры PR_SCHED_CORE_CREATE.
- PR_SCHED_CORE_SHARE_FROM — извлекает cookie у процесса с pid , и назначает вызвавшему prctl .
Включить Core Scheduling можно при сборке ядра: General setup --> [*] Core Scheduling for SMT . Так же вы можете прочитать мою статью LTO оптимизация ядра Linux .
Так вот, если в системе включен Core Scheduling, то когда планировщик берет новую задачу с наивысшим приоритетом из списка, то он отправляет прерывание на родственные процессоры, на что каждый из них должен проверить cookie новой задачи и ответить есть ли задачи на нём с таким же cookie . Таким образом, при совпадении cookie , процессор уже имеющий задачу с таким же cookie , начинает выполнение этой новой задачи. Если же в системе нет процессов имеющий одинаковый cookie , то процессор будет бездействовать, пока такие процессы не появятся. Чтобы предотвратить простой процессора, планировщик будет переносить процессы между ядрами.
К сожалению первые версии Core Scheduling имели большой недостаток — высокие накладные расходы, падала производительность системы т.к. в некоторые моменты времени Core Scheduling заставлял процессор бездействовать, что в итоге стало ещё хуже чем отключение Intel HT и AMD SMT. Но со временем удалось улучшить алгоритм и решать большую часть проблем, но всё же не бесплатно. Поэтому Core Scheduling не подходит каждому т.к. немного снижает производительность системы, а только тем, кому очень важна безопасность, например облачным провайдерам. Так же Core Scheduling не подходит задачам которым важна скорость реакции, так называемые Real Time задачи, для них вовсе рекомендуется отключить Intel Hyper-Threading(Intel HT) и AMD SMT.
Моя прошлая статья LTO оптимизация ядра Linux вызвала у читателей много вопросов. Было много доброжелателей, которые мне писали лично и благодарили. Были и такие которые писали, чтобы поругаться и даже катали жалобы на мои проекты. Конечно же доброжелателей было значительно больше. Поэтому дам краткий ответ на частые вопросы:
- Насколько LTO ядро быстрее? Ответ с бенчмарками есть по ссылке Squeezing More Performance Out Of The Linux Kernel With Clang + LTO
- Для кого подходит LTO Оптимизация ядра? В первую очередь это разработчикам мобильных устройств, которым очень важна производительность и быстрый отклик. Изначально LTO оптимизация появилась для ядра Linux мобильных устройств, но показала свою высокую эффективность и была перенесена на x86_64 . Поэтому LTO Оптимизация ядра Linux подходит всем, кому важна более высокая производительность и быстрый отклик от системы. Например сервера, которым важна скорость обработки и отдачи контента. За месяцы тестов не было выявлено ни одного побочного эффекта от применения LTO Оптимизации. Так же в статье LTO оптимизация ядра Linux был дан ответ почему всё работает хорошо и почему именно выбран clang+llvm .
- Несколько читателей хабра мне написали и попросили сделать репозиторий для моих измененных пакетов arch-packages. Один из них, поработал какое-то время с моими пакетами, и вышел с предложением разместить репозиторий у него на сервере. Так появился Arch Linux Club. Теперь все легко могут протестировать, как влияют измененные пакеты на производительность. Через какое-то время мой проект заметили разработчики одного Linux дистрибутива(форка Arch Linux), связались со мной и написали восторженные отзывы.
- В чем различие моих пакетов от официальных Arch Linux? Основное различие больше патчей и багфиксов. После того, как начал переделывать пакеты, был поражен, что майнтенейры не всегда понимают, что у них в сборочных скриптах, и часто забивают на исправления ошибок и совсем не читают багрепорты в апстриме. Например, не редко было, что некоторые программы у меня при работе крешились, а мейнтейнеры ничего не делали. В этом разработчики RedHat, Gentoo, Suse просто на две головы выше.
Это заставило меня ещё больше переделать пакетов и добавить патчи. Возможно мое начинание даже перейдет в свой дистрибутив. Основной упор в пакетах на безопасность и производительность где возможно включены -z,relro,-z,now и -fstack-protector-strong -fstack-clash-protection -fPIE . Подробнее что это даёт можно прочесть на сайте RedHat.
Первый пришел первый обслужен
First Come First Serve – это полная форма FCFS. Это самый простой и самый простой алгоритм планирования процессора. В этом типе алгоритма процесс, который запрашивает ЦП, сначала выделяет ЦП. Этим методом планирования можно управлять с помощью очереди FIFO.
Когда процесс входит в готовую очередь, его печатная плата (блок управления процессом) связана с хвостом очереди. Таким образом, когда процессор освобождается, он должен быть назначен процессу в начале очереди.
Планирование многоуровневых очередей
Многоуровневые очереди не являются независимым алгоритмом планирования. Они используют другие существующие алгоритмы для группировки и планирования заданий с общими характеристиками.
- Для процессов с общими характеристиками поддерживается несколько очередей.
- Каждая очередь может иметь свои собственные алгоритмы планирования.
- Приоритеты присваиваются каждой очереди.
Например, задания, связанные с процессором, могут планироваться в одной очереди, а все задания, связанные с вводом / выводом, – в другой очереди. Затем планировщик процессов поочередно выбирает задания из каждой очереди и назначает их ЦПУ на основе алгоритма, назначенного очереди.

Не за горами выход новой версии ядра Linux 5.14. За последние несколько лет это обновление ядра является самым многообещающим и одно из самых крупных. Была улучшена производительность, исправлены ошибки, добавлен новый функционал. Одной из новых функций ядра стал Core Scheduling, которому посвящена наша статья. Это нововведение горячо обсуждали в интернете последние несколько лет, и наконец-то оно было принято в ядро Linux 5.14.
Если вы работаете с Linux или занимаетесь информационной безопасностью, вам интересны новые технологии, то добро пожаловать под кат.
Читайте также: