
Что такое идентификатор процессора
CPU-Z идентифицирует не каждый процессор. Устройства без поддержки инструкции CPUID не определяются. Вы вряд ли встретите несовместимый с командой кристалл. Разберёмся, чем примечательна аббревиатура, что собой представляет. Покажем, как узнать, реализована ли CPUID в процессоре компьютера или ноутбука.
Прерывания
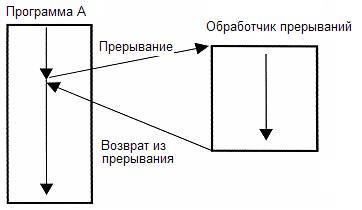
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Что такое CPUID
CPU ID – процессорная инструкция, созданная для сбора и выдачи технической информации о ЦП. Она помогает BIOS, операционной системе и приложениям идентифицировать процессор. Внедряться начала с 1993 года параллельно с выходом на рынок кристаллов Intel 80486 вместе с ещё 75 командами.
Многие из вас думали, что CPUID – это название компании-разработчика?
Перед обращением к процессору в регистр EAX (изредка ECX) помещается значение, указывающее, какие сведения необходимо выдать. В зависимости от входного значения, которое отличается у разных разработчиков и моделей ЦП, получателю отправляются разные данные.
В инструкции два набора команд. Один возвращает основную сводку о CPU, второй – дополнительные сведения.
Последовательность идентификации процессора с помощью CPUID
Исходя из содержимого EAX-регистра, CPUID знает, какие свойства или характеристики нужно выдать.
- EAX = 0 – отправит идентификатор кристалла;
- EAX = 2 – справка о кэше: тип, объем;
- EAX = 3 – идентификатор модели;
- EAX > 3 – выдаст специфические возможности экземпляра, зависят от модели.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Как проверить, поддерживает ли процессор CPUID
Если вашему процессору менее 20 лет, значит он совместим с инструкцией. Не все древние модели, выпущенные в середине 1990-х годов, поддерживают инструкцию. Начиная с линейки Intel486 (80486), кристаллы предоставляют возможность проверить, реализована ли в них команда CPUID. За это отвечает особый флаг (последовательность битов) в регистре EFLAGS. Если значение флага изменяется, команда поддерживается, если недоступно для редактирования – нет.
Для проверки применяется следующий алгоритм (на Ассемблере):
Этот код уже внедрён и в CPU-Z.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
. На различных площадках народ сильно преувеличивает утверждая, будто число опкодов давно перевалило за тысячу. Чтобы-уж наверняка и ради собственного интереса, я скопировал из оглавления указанной доки в блокнот весь перечень, и к своему удивлению на выходе получил всего 632 строки текста, в каждой из которых одна инструкция. Судя по-всему, на данный момент именно такой объём полностью удовлетворяет нашим требованиям, иначе монархи из Intel не упустили-бы возможности записать на свой счёт очередной новый опкод. Из всего этого листа, в данной статье предлагаю рассмотреть одну из интересных инструкций под названием CPUID, которая призвана идентифицировать бортовой процессор CPU.
1. Основная идея
При включении машины, системный BIOS/EFI должен каким-либо образом опознать установленный на материнской плате CPU, чтобы настроить под него чипсет и всё остальное. Нужно сказать, что на первом витке эволюции вплоть до древних 16-битных процессоров i80286 в этом не было необходимости, поскольку архитектура компьютера была примитивной, с довольно устойчивым состоянием. Но тут пришёл 32-битный процессор нового поколения i80386, который мог работать как в 16, так и в 32-битном защищённом режиме. Здесь-то и всплыла проблема. Инженеры Intel с присущим им оптимизмом решили её просто – они жёстко запрограммировали проц, чтобы на старте он возвращал свою "половую" принадлежность в регистровой паре EСX:EDX. Но дальше-больше..
Инструкцию CPUID принёс с собой следующий процессор i80486, когда благодаря механизму PAE (Physical Address Extension, расширение физического адреса) 32-битному CPU стало доступно сразу три ступени памяти, разрядностью 16, 32 и 36-бит. Теперь, биосу требовался паспорт процессора, иначе он просто не мог должным образом настроить ответственные за распределение ОЗУ регистры чипсета. Так возникла необходимость в идентификации CPU, что вынудило Intel включить в набор команд инструкцию CPUID. Первая его спецификация от Intel датируется 1993-годом.
Если говорить об инструкциях в целом, то каждая из них является совокупностью микрокоманд. Когда инструкция простая (типа INC, ADD, SUB и т.д.), для неё достаточно одной микрокоманды, а если сложная – она собирается из нескольких таких команд. На этапе изготовления процессора, производитель зашивает в специально предназначенную для этих целей встроенную ROM-память весь поддерживаемый набор микрокоманд, из которых в конечном счёте и собираются разнообразные инструкции. Блок процессора под названием "микро-секвенсер" (microsequencer) считывает микрокоманды из хранилища ROM, и по-требованию передаёт их в декодер инструкций. Таким образом, чтобы включить в набор команд процессора какую-нибудь новую инструкцию, в большинстве случаях производителю достаточно добавить лишь пару ключевых микрокоманд.
На этапе производства процессора отследить все его ошибки невозможно, что влечёт за собой различные хард-глюки. По этой причине, производитель предусматривает обновление микро-кодов уже при эксплуатации готового продукта. Обновы всегда кратны 2Кб и их можно найти на сайтах Intel и AMD. Включённый в пакет прошивальщик сначала идентифицирует бортовой CPU, и если его модель/степпинг/ревизия совпадает с прошивкой, то заливает обновлённые микро-коды не в ROM процессора, а в системный BIOS, от куда проц потом их и стягивает. Intel давно уже практикует рассылку своих обновлений всем производителям биосов, чтобы они включали их в свой код. В конечном итоге, поддержка биосами современных процессоров определяется в первую очередь наличием соответствующей прошивки.
На уровне-же микроархитектуры CPUID устроена так, что помимо прочего, в постоянную память ROM производитель закладывает порядка 30-ти основных листов с детальной информацией о своём продукте, и некоторое кол-во (под)листов. В документации эти листы назвали "Leaf" , а подлисты "Subleaf" . Перед тем-как вызвать инструкцию CPUID, мы должны предварительно указать номер конкретного листа в регистре EAX, и если этот лист имеет вложенный (под)лист, то его номер занести ещё и в регистр ECX. На программном уровне, запрос каждого из листов представляет собой отдельную функцию, о чём прямым текстом и сообщается в спецификации CPUID.
В таблице ниже я перечислил все доступные мне функции и их назначения. К сожалению, в наличии оказалась только спека от 2012-года, и более свежих данных мне так и не удалось выудить из сети (если кто поделится, буду благодарен). Причём действительна представленная табличка только для процессоров Intel, поскольку у AMD нумерация функций совсем иная. Как по мне, так двум этим гигантам пора-бы уже не выносить нам мозг, а "выпить за мировую", чтобы согласовывать между собой хотя-бы такие элементарные вещи. Ан-нет.. нужно чтобы всё было через известное место. В силу того, что на обеих моих машинах (бук и стационар) установлены процессоры Intel, всё нижесказанное будет относиться исключительно к продуктам Intel.
Обратите внимание, что вложенные подлисты имеют только функции EAX=04,07,0В и 0Dh (выделены красным). Например если мы запросим инструкцию CPUID.EAX=4:ECX=0 , то в регистрах EAX,EBX,ECX,EDX процессор вернёт нам информацию о своём кэше L1. Теперь, чтобы получить характеристики кэша L2, мы должны повторно вызвать CPUID.EAX=4 , только на этот раз сменить номер (под)листа на ECX=1. Соответственно для кэша L3 будет уже EAX=4:ECX=2 , и т.д. в том-же духе. Вне зависимости от разрядности процессора 32 или 64-бит, CPUID всегда возвращает информацию в первые четыре регистра общего назначения EAX,EBX,ECX,EDX. Надеюсь суть вы уловили, и вооружившись спекой можно теперь смело пробираться вглубь.
2. Стандартные функции
Начнём по-порядку и рассмотрим на конкретных примерах, какого рода информацию возвращают все функции CPUID. В некоторых случаях, это поможет осуществить направленные на конкретный процессор атаки, ну или просто идентифицировать его, чтобы пустить код по нужной ветке. К примеру если мы написали приложение с использованием современных инструкций SSE4 или AVX, то это приложение может попасть на платформу, процессор которой вообще не поддерживает данный тип инструкций. Значит перед запуском софта нужно обязательно позвать CPUID и проверить в нём нужные биты. В любом случае знания всегда идут на шаг впереди их отсутствия, а потому профит по-любому будет.
2.0. Функция EAX=0. (Vendor-ID, and Largest Standard Function)
Данная функция возвращает в EAX общее число поддерживаемых процессором стандартных функций, и в остальные три регистра сбрасывает строку с именем производителя. Для Intel и AMD эта строка будет иметь вид "GenuineIntel" и "AuthenticAMD" соответственно. На процессоре своего стационара я получил всего 14 указанных в таблице выше функций, при этом 0x08 и 0x0C находятся в резерве. А вот на буке с 64-битным процессором счётчик показывает уже 25 поддерживаемых функций, но как говорилось выше спеки на него нет. Пример вызова функции выглядит так:
2.1. Функция EAX =1. (Feature Information)
Очередная функция возвращает характерные особенности бортового процессора, где можно будет найти его: Family/Model/Stepping , идентификатор текущего контролёра прерываний APIC, макс.кол-во поддерживаемых ядер (не путать с реальным кол-вом), размер линейки кэш-памяти, и в 64-битах регистровой пары ECX:EDX разнообразные свойства, типа поддержка инструкций SSE4/AVX, гипер-трейдинг HT, x2APIC, RDRAND и многое другое (см.спецификацию). Чтобы вывести все эти 64 типа информации на консоль, придётся чекать их биты по отдельности например инструкцией BT (bit-test), как в примере ниже. Если тестируемый бит взведён, инструкция взводит флаг процессора(CF):
Как видно из листа "FeatureFlags" , мой бородатый проц не знаком с инструкциями SSE4/AVX, а лишь поддерживает макс.SSSE3. Имеет встроенный датчик температуры "TermalMonitor2" (TM2), в режиме энергосбережения может сохранять в специальной область памяти значения всех регистров CPU/FPU (xsave/fxsave соответственно), при переходе в ядро вместо устаревшего SYSCALL использует SYSENTER , способен очищать линейки кэша L1 при помощи инструкции CLFLUSH , и прочее. Описание всех этих аббревиатур имеется в спецификации, так-что курите её.
2.2. Функция EAX =2. (Cache Descriptors)
Каждый дескриптор кэша имеет размер 1-байт, и является закодированным значением определённой строки. На всякий-пожарный, я оформил все эти строки в виде таблички, и сохранил их в инклуд (см.скрепку в подвале статьи). Поскольку результат мы получим в четырёх 4-байтных регистрах EAX,EBX,ECX,EDX, итого получается 4х4=16 байт. Тогда общее кол-во дескрипторов будет 15, без учёта регистра-счётчика(AL). Если дескриптор имеет значение нуль, значит он пустой и не используется.
Теперь, для разбора дескрипторов последовательно перемещаемся от самого старшего байта всех регистров вниз, к младшему их байту (ну или наоборот). Код реализации парсинга дескрипторов и фрагмент таблицы из спецификации представлены ниже:
Однако кроме кэша данных, в процессоре имеется ещё и кэш для хранения адресов страниц виртуальной памяти, к которым он обращался последний раз. Этот кэш назвали TLB, или "Translation Lookaside Buffer" (буфер ассоциативной трансляции). Проблема в том, что для доступа к памяти ОЗУ, транслятор контролёра памяти (в процессоре) сначала должен преобразовать текущий адрес из виртуального в физический, на что может уйти до 100-тактов процессора. По современным меркам, это чистой воды расточительство, поэтому один раз преобразовав вирт.адрес, процессор запоминает его в своём кэше TLB. Как показала практика, такой алго даёт существенный прирост скорости при чтении данных из оперативной памяти.
2.3. Функция EAX=3. (Processor Serial Number)
Если процессор фирменный и благополучно прошёл все надзорные инстанции, производитель может записать в него серийный номер продукта. Но в наше время это скорее исключение, чем правило, и лично мне такие пока не встречались.
2.4. Функция EAX=4. (Deterministic Cache Parameters)
Функция CPUID.EAX=4 имеет подлист, поэтому вызывать её нужно с регистром ECX. Как и функция EAX=2, она возвращает информацию о кэшах процессора L1,2,3, только без кэшей TLB. Индекс в регистре ECX указывает, о каком кэше следует возвращать информацию. Чтобы получить информацию о кэшах всех уровней, мы должны вызывать её в цикле, пока в битах EAX[4:0] не получим нуль. Порядок возврата кэшей не регламентируется и может быть изменен по усмотрению Intel. Это означает, что при вызове функции с ECX=0 мы можем получить инфу например о кэше L3 и т.д. Бонусом, индекс(0) в регистре ECX возвращает ещё и кол-во ядер процессора, в старших битах EAX[31:26].
Вызов этой функции, в регистре EBX возвращает информацию об ассоциативности кэшей, кол-ве блоков "Way", и числу записей "Sets". Используя эти данные можно вычислить и размер кэша, который не возвращает функция CPUID.EAX=4 в явном виде. Спецификация предлагает нам такую формулу для этих целей:
Ниже представлен возможный вариант вывода результата этой функции на консоль. Здесь я при первом вызове получаю кол-во ядер, и дальше в цикле зову эту функцию с инкрементом счётчика в ECX, чтобы получить инфу о кэшах всех уровней:
Здесь стоит отметить, что для хранения информации о кэшах, современные процессоры 64-бит используют только данную функцию CPUID.EAX=4 , полностью игнорируя ранее рассмотренную CPUID.EAX=2 , которая возвращает дескрипторы кэшей. В этом случае, при вызове EAX=2 на выходе получаем 0xFF вместо дескрипторов, что означает см.функцию EAX=4. Вот фрагмент из описания функции CPUID.EAX=2 с дескриптором 0xFF :
3. Расширенные функции
Остальные стандартные функции не представляют особого интереса, и при желании вы можете по-экспериментировать с ними сами. А вот рассмотреть набор расширенных функций CPUID вполне себе стоит. Во времена своего младенчества, Intel и AMD разделили инструкцию CPUID пополам. Чтобы хоть как-то отличаться от Intel, инженеры AMD забрали себе старшую половину функций, начиная с 0x80000000. Однако позже всё утряслось и теперь обоим производителям принадлежит весь диапазон, хотя и нумерация по назначению абсолютно разная.
3.0. Функция EAX=8000_0000h (Largest Extended Function)
Эта функция особо не напрягается, и возвращает в единственный регистр EAX общее число поддерживаемых расширенных функций. На обоих своих процессорах я получаю значение EAX=8.
3.1. Функция EAX=8000_0001h (Extended Feature Bits)
Очередная функция возвращает в регистр EDX флаги расширенных возможностей процессора.
Посмотрим на флаг "XD bit" .
В документации AMD этот бит называется NX, от слова "No eXecution" , а Intel обозвала его XD – "eXecution Disable" . Это самый старший бит(64) в записях виртуальных страниц PTE (Page Table Entry), который предотвращает исполнение данных. Для более детального ознакомления с ним отправляю вас к статье "DEP и ASLR – игра без правил" , где ему была посвящена одна глава. Как видно из скрина, мой древний проц поддерживает и его, и архитектуру Intel-64, хотя в упор не видит гигантских виртуальных страниц размером 1Gb (по-умолчанию 4Кб), и не знаком с современной инструкций генератора рандома RDTSCP . Для перехода в ядро при вызовах API-функций инструкция SYSCALL уже давно не юзается даже процессорами Pentium, и ей на смену пришла свежая SYSENTER .
3.2. Функции EAX=8000_0002/3/4 (Processor Brand String)
Цепочка этих трёх функций возвращает имя процессора, как его окрестил производитель. Под строку брэнда производитель резервирует 48 байт во-встроенной памяти ROM, поэтому чтобы получить её полностью, нужно вызвать эти функции последовательно 3-раза. При каждом запросе в регистры EAX,EBX,ECX,EDX будет возвращаться новая информация, поэтому не забываем сохранять её в выделенный буфер. В примере ниже я поместил счётчик цикла в переменную "count", и на каждой итерации увеличиваю номер функции в EAX:
3.3. Функция EAX=8000_0006h (Extended L2 Cache Features)
Ещё одна функция для сбора информации о кэше, только теперь исключительно об общем L2. Прямым текстом сообщает его размер и длину линейки, и в закодированном виде ассоциативность (мне лень было декодировать). Бьёт без промаха точно в цель на любых процессорах Intel, хоть 32, хоть 64-бит.
3.4. Функция EAX=8000_0008h (Virtual & Physical Address Sizes)
4. Пример кода для сбора информации CPUID
В заключении приведу готовый пример кода, который соберёт всю представленную выше информацию.
Опыты выше показали, что CPUID изначально не способен возвратить некоторую информацию. К примеру в нём нет данных типа: кодовое имя ядра, порог рабочих напряжений, тип сокета, потребляемая мощность, и значение производственного тех.процесса. Судя по всему, софт на подобии CPU-Z хранит это всё в своих таблицах, которые программисты скурпулёзно собирают ручками. Базы подобного рода пишутся исходя из значений "Family/Model/Stepping", предоставляемые нам функцией CPUID.EAX=1 . В любом случае, теперь мы знаем, на что способен "зверь" под названием CPUID, и будем делать соответствующие выводы.
В скрепке можно найти инклуд с описанием дескрипторов кэшей, и исполняемый файл для тестов. Всем удачи, пока!
Какие программы используют инструкцию CPUID
Инструкция CPUID может выполняться не только ядром операционной системы, но и пользовательским программным обеспечение. Это даёт возможность программистам писать приложения для исследования центральных процессоров. Создано много такого софта, предоставляющего сведения о CPU посредством инструкции CPUID.
Из переводящих полученные биты в человеко-понимаемую форму отметим:

Информация о CPU (Central Processing Unit. Центральный процессор) включает в себя подробные сведения о процессоре, такие как архитектура, название производителя, модель, количество ядер, скорость каждого ядра и т.д.
В linux существует довольно много команд для получения подробной информации о CPU.
В этой статье мы рассмотрим некоторые из часто встречающихся команд, которые можно использовать для получения подробной информации о CPU.
1. /proc/cpuinfo
Файл /proc/cpuinfo содержит подробную информацию об отдельных ядрах CPU.
Выведите его содержимое с помощью less или cat .
Каждый процессор или ядро перечислены отдельно, а различные подробности о скорости, размере кэша и названии модели включены в описание.
Чтобы подсчитать количество процессоров, используйте grep с wc
Количество процессоров, показанное в /proc/cpuinfo, может не соответствовать реальному количеству ядер процессора. Например, процессор с 2 ядрами и гиперпоточностью будет показан как процессор с 4 ядрами.
Чтобы получить фактическое количество ядер, проверьте идентификатор ядра на наличие уникальных значений
Соответственно, есть 4 разных идентификатора ядра. Это указывает на то, что существует 4 реальных ядра.
2. lscpu - отображение информации об архитектуре CPU
lscpu - это небольшая и быстрая команда, не требующая никаких опций. Она просто выводит информацию об аппаратном обеспечении CPU в удобном для пользователя формате.
3. hardinfo
Hardinfo - это gui инструмент на базе gtk, который генерирует отчеты о различных аппаратных компонентах. Но он также может запускаться из командной строки, в случае если отсутствует возможность отображения gui (Graphical User Interface — графический интерфейс пользователя).
Он создаст большой отчет о многих аппаратных частях, читая файлы из каталога /proc. Информация о CPU находится в начале отчета. Отчет также может быть записан в текстовый файл.
Hardinfo выполняет несколько эталонных тестов, занимающих несколько минут, прежде чем вывести отчет на экран.
4. lshw
Команда lshw может отобразить ограниченную информацию о CPU. lshw по умолчанию показывает информацию о различных аппаратных частях, а опция ' -class ' может быть использована для сбора информации о конкретной аппаратной части.
Производитель, модель и скорость процессора отображаются правильно. Однако из приведенного выше результата невозможно определить количество ядер в процессоре.
Чтобы узнать больше о команде lshw, ознакомьтесь с этой статьей:
5. nproc
Команда nproc просто выводит количество доступных вычислительных блоков. Обратите внимание, что количество вычислительных блоков не всегда совпадает с количеством ядер.
6. dmidecode
Команда dmidecode отображает некоторую информацию о CPU, которая включает в себя тип сокета, наименование производителя и различные флаги.
7. cpuid
Команда cpuid собирает информацию CPUID о процессорах Intel и AMD x86.
Программа может быть установлена с помощью apt на ubuntu
А вот пример вывода
8. inxi
Inxi - это скрипт, который использует другие программы для создания хорошо структурированного легко читаемого отчета о различных аппаратных компонентах системы. Ознакомьтесь с полным руководством по inxi.
Вывод соответствующей информации о CPU/процессоре
Чтобы узнать больше о команде inxi и ее использовании, ознакомьтесь с этой статьей:
9. Hwinfo
Команда hwinfo - это программа для получения информации об оборудовании, которая может быть использована для сбора подробных сведений о различных аппаратных компонентах в системе Linux.
Она также отображает информацию о процессоре. Вот быстрый пример:
Если не использовать опцию "--short", команда отобразит гораздо больше информации о каждом ядре CPU, например, архитектуру и характеристики процессора.
Чтобы более подробно изучить команду hwinfo, ознакомьтесь с этой статьей:
Заключение
Это были некоторые команды для проверки информации о CPU в системах на базе Linux, таких как Ubuntu, Fedora, Debian, CentOS и др.
Примеры других команд для проверки информации о CPU смотрите в этой статье:
Большинство команд обрабатываются с помощью интерфейса командной строки и выводятся в текстовом формате. Для GUI интерфейса используйте программу Hardinfo.
Она показывает подробности об аппаратном обеспечении различных компонентов в простом для использования GUI интерфейсе.
Если вы знаете какую-либо другую полезную команду, которая может отображать информацию о CPU, сообщите нам об этом в комментариях ниже
В первой части я рассказал о необходимости идентификации расширений, присутствующих на конкретном процессоре. Это нужно для того, чтобы исполняющийся код (операционная система, компилятор или пользовательское приложение) смог надёжно определить, какие возможности аппаратуры он может задействовать. Также в предыдущей статье я сравнил несколько популярных архитектур центральных процессоров общего назначения. Возможности по идентификации между ними сильно разнятся: некоторые предоставляют полную информацию о расширениях ISA, тогда как другие ограничиваются парой чисел для различения вендора и ревизии.
В этой части я расскажу об одной инструкции архитектуры Intel IA-32 — CPUID, введённой специально для перечисления декларируемых процессором расширений. Немного о том, что было до её появления, что она умеет сообщать, какие неожиданности могут поджидать и какой софт позволяет интерпретировать её вывод.

Источник изображения: [1]
История
Как я уже утверждал в первой части, присутствует следующая тенденция: чем более «встраиваемая» природа у процессора, тем меньше возможностей для идентификации заложено в его архитектуру. Создатели встраиваемых систем почему-то не волнуются о переносимости двоичного кода.
Не являлся исключением и Intel 8086 — микропроцессор 1970-х годов, выросший из «калькуляторной» серии 8008, 8080, 8085. Изначально в него не было заложено никаких средств идентификации.
Начиная с 808386 сведения о модели, степпинге и семействе стали сообщаться в регистре EDX сразу после перезагрузки (получения сигнала RESET). Инструкция CPUID, кодируемая байтами 0x0f 0xa2, была введена в процессорах 80486. Наличие CPUID можно было распознать по возможности записи в бит 21 регистра флагов. Для поддержки работы на более старых ЦПУ приходилось идти на очень изощрённые методы для того, чтобы различать процессоры серий от 8086 до 80386.
Перечисленные в оригинальной статье техники были опробованы преимущественно на ЦПУ от Intel. В статье автор признаёт, что они не позволяют надёжно классифицировать клоны x86 других производителей.
Интерфейс
Для системного программиста работа по идентификации некоторого расширения обычно заключается в установке входных значений в регистрах EAX (лист, англ. leaf) и ECX (подлист, англ. subleaf), исполнению CPUID и прочтению результата в четырёх регистрах: EAX, EBX, ECX, EDX. Отдельные битовые поля выходных регистров будут содержать информацию о значениях связанных с ними архитектурных параметров конкретного ядра процессора.
Все валидные сочетания входных листов-подлистов и четвёрок регистров на выходе формируют таблицу CPUID. Для современных процессоров она содержит около двух десятков строк по четыре 32-битных столбца.
Я не буду расписывать детально все официально описанные поля этой таблицы. Интересующиеся всегда могут найти их в Intel SDM [1] (рекомендую запастись терпением — около 40 страниц текста только про CPUID). Болеее того, для уже заявленных, но ещё не выпущенных в физических продуктах расширений ISA соответствующие им новые поля CPUID могут быть найдены в [3]. Вместо этого я классифицирую информацию, которую можно извлечь из вывода этой инструкции. Для обозначения битовых полей таблицы я буду использовать принятую для этого нотацию: CPUID.leaf.subleaf.reg[bitstart:bitend]. Например, CPUID.0.EBX[31:0] — это биты с 0 по 31 выходного регистра EBX после исполнения CPUID, которая на вход получила лист 0 (EAX = 0); подлист (входное значение ECX) игнорируется, поэтому он не указан.
Регионы листов
Неподдерживаемые значения входных EAX и ECX не приводят к возникновению исключений, а вместо этого возвращают нули во всех четырёх регистрах, либо «мусор» (значения другого листа согласно спецификации). Допустимые же сочетания листов и подлистов образуют три непрерывных региона.

- Обычный регион — все листы с номерами, начиная с нулевого и до максимального значения, равного CPUID.0.EAX[31:0]. Номер максимального листа постоянно растёт и уже давно перевалил за десятку.
- Расширенный регион — все листы, начиная с 0x80000000 и до максимального значения, равного CPUID.0x80000000.EAX[31:0]. Довольно долгое время это максимальное значение остаётся равным 0x80000008. Я не нашёл документальных доказательств, но у меня есть чувство, что само появление диапазона расширенных листов связанно с введением компанией AMD 64-битного расширения архитектуры IA-32.
- Диапазон листов 0x40000000-0x4fffffff считается зарезервированным; обещается, что возвращаемые для него CPUID значения всегда будут равны нулю. Однако это не мешает некоторым использовать его для своих нужд. Например, виртуальные машины KVM возвращают в листе 0x40000000 четвёрку чисел [0, 0x4b4d564b, 0x564b4d56, 0x4d].
- CPUID.1.ECX[0] — SSE3 — векторные инструкции.
- CPUID.1.ECX[9] — SSSE3 — другие векторные инструкции.
- CPUID.1.ECX[7] — EIST — Enhanced Intel SpeedStep®, динамическое изменение частоты процессора.
- CPUID.1.EDX[25] — SSE — ещё векторные инструкции.
- CPUID.1.EDX[26] — SSE2 — снова векторные инструкции.
- CPUID.6.EAX[1] — Intel Turbo Boost, оверклокинг «из коробки».
- CPUID.7.0.EBX[4] — Hardware Lock Elision, CPUID.7.0.EBX[11] — Restricted Transactional Memory — два расширения от Intel для поддержки транзакционной памяти.
- CPUID.0x80000001.ECX[5] — LZCNT, инструкция для подсчёта числа старших нулевых бит, похожая (даже слишком) на BSR.
Brand String
Конечно же, ни один вендор не упустит возможности увековечить своё имя в идентификационных данных своего продукта. Причём желательно сделать это не просто в виде числа, а впечатать ASCII-строку (хорошо хоть, что не Unicode).
В IA-32 CPUID текст можно найти минимум в двух группах листов. CPUID.0.EBX, ECX, EDX содержат 12 байт ASCII-строки, специфичной для каждого вендора. Для Intel это, конечно же, «GenuineIntel». А три листа CPUID.0x80000002–0x80000004 предоставляют аж 48 байт для кодирования в ASCII так называемой Brand String. Именно её видно при распечатке cat /proc/cpuinfo в Linux. И, хотя формат её более-менее стандартизован: «вендор марка серия CPU @ частота», я настоятельно не рекомендую по её содержимому принимать решения в программном коде. Слишком значительно её содержимое может варьироваться: частота может быть указана в МГц или в ГГц (а в реальности быть совсем иной из-за динамической подстройки), пробелы могут менять положение, а симулятор или виртуальная машина могут подставить туда вообще что угодно. Вся информация из brand string может быть найдена программно более надёжными способами.
Информация о кэшах, такая как их тип, количество, ёмкость, геометрия, разделяемость между ядрами полезна для тюнинга высокопроизводительного математического софта, например, библиотек BLAS (basic linear algebra system).
Изначально конфигурацию кэшей описывал лист 2. Спроектировали его не очень дальновидно. Формат кодирования информации в нём был выбран не самый гибкий, он не смог в будущем поддержать постоянные изменения в объёме и конфигурации нескольких уровней кэшей. В настоящее время использование информации из листа 2 не рекомендуется, там могут стоять 0xFF-ки.
Судя по тому, что лист 0x80000006 входит в расширенный диапазон (хотя я не уверен, документальных доказательств пока что не нашёл), он был добавлен не Intel. С помощью него была сделана попытка информацию листа 2 дополнить данными о строении кэшей, которые потребовались разработчикам софта. При этом опять же не было намерения предоставить пространство для роста.
Лист 4 — последнее и пока что наиболее гибкое представление данных о кэшах. Цена этому — добавление концепции подлистов, кодируемых в ECX. Каждый подлист описывает один кэш: данных, кода или совмещённый, определяет его уровень, ёмкость и т.д. Хватит ли четвёртого листа надолго — поживём, увидим.
Топология
- SMT — уровень гипер-потока, сущности, содержащей индивидуальное архитектурное состояние (регистры), но потенциально разделяющей исполнительные устройства с другими потоками (в составе одного ядра).
- Ядро (core) — сущность, содержащая индивидуальный набор вычислительных устройств (сумматоров, умножителей и т.д.). Одно ядро может иметь в себе один, два (у ЦПУ с HyperThreading) или четыре (у Xeon Phi) гипер-потока.
- Пакет (пэкадж, package) — собственно железка целиком, покупаемая в магазине и вставляемая в разъём (сокет) на матплате. Имеет на себе как минимум одно ядро. В многопроцессорных серверных системах может быть несколько пэкаджей.
Изменяемые поля
- Бит 18 регистра CR4 влияет на CPUID.1:ECX.OSXSAVE[27], обозначающий поддержку инструкции XSAVE.
- Поля регистра IA32_MISC_ENABLE влияют сразу на несколько полей CPUID: бит 3 — на поля TM1 и TM2, бит 16 — на поле EIST, бит 34 — на поле XD (execution disable) и т.д.
- Включение бита 22 регистра IA32_MISC_ENABLE вообще «отрезает» все листы таблиц CPUID старше третьего (видимо, это было сделано для совместимости с Windows NT4, не зря этот бит так и называется — NT4).
Разное
В этой секции я собрал прочие интересные моменты, связанные с историей и работой команды CPUID.
Processor Serial Number
Во времена Pentium III каждый процессор получил уникальный серийный номер, содержавшийся в CPUID.3.ECX и CPUID.3.EDX [7]. Легко представить, насколько такая фича была бы удобна для нужд защиты ПО от копирования. Однако в 1999 году Европейское сообщество запротестовало, разумно опасаясь, что подобная функциональность повредит приватности пользователей таких систем. Уже в Intel Pentium IV серийный номер был убран, сейчас лист 3 возвращает нули.
Вендоры и CPUID
Очень интересная таблица [5] повествует о том, что хранят (или в прошлом хранили) в разных листах CPUID разные вендоры. Например, описывается некий mystery level 0x8fffffff, в котором процессоры AMD K8 возвращали строку IT'S HAMMER TIME.
Agner Fog о войнах ISA
История появления расширений набора инструкций IA-32 в условиях конкурентной борьбы нескольких компаний [4]. Добавление новых инструкций всегда влияло на CPUID, и не всегда все могли договориться о том, как это сделать правильно.
Они испортили CPUID! IA32_BIOS_SIGN_ID
Инструкция CPUID всегда нравилась мне лаконичностью своего интерфейса и отсутствием неожиданностей в работе: один регистр на входе и четыре на выходе. В её работе нет генерации исключений, нет обращений к памяти, нет чтения/модификации регистра флагов, на неё не влияют префиксы, она работает во всех режимах процессора. По сравнению с зоопарком CISC-команд IA-32 это был почти идеал.
… пока не оказалось, что иногда на вход необходимо подать два регистра для кодирования листа и подлиста. Окей, не так всё хорошо. Ну хотя бы выходные регистры заранее известны и всегда изменяются…
И тут оказалось, что иногда CPUID изменяет ещё один регистр — а именно IA32_BIOS_SIGN_ID, — и сохраняет в нём сигнатуру текущей программы микрокода процессора. Происходит это, если до этого было произведено обновление прошивки процессора. По каким-то причинам информация об этой процедуре была раскидана по мануалу [1] на тысячу страниц, и потому она ускользала от меня очень долго.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Какие данные можно получить при помощи CPUID-инструкции
Благодаря команде утилиты вроде CPU-Z и сама операционная система получают массу подробностей о ЦП. Windows, например, они нужны для идентификации аппаратуры при написании приложений на низкоуровневых языках программирования – операционные системы, компиляторы, драйверы. К получаемым характеристикам относятся:
Читайте также: