
Чтение файла с диска
Класс FileStream представляет возможности по считыванию из файла и записи в файл. Он позволяет работать как с текстовыми файлами, так и с бинарными.
Самый быстрый способ чтения файлов
В интернете люди спрашивают: «Какой самый быстрый способ чтения файлов?» Давайте усложним задачу для этого рецепта: какой самый быстрый и переносимый способ чтения двоичных файлов?
Подготовка
Для этого рецепта требуются базовые знания C++ и std::fstream.
Как это делается.
Техника из этого рецепта широко используется приложениями, чувствительными к производительности ввода-вывода. Это самый быстрый способ чтения файлов.
-
Нам нужно подключить два заголовка из библиотеки Boost.Interprocess:
Как это работает.
Все популярные операционные системы имеют возможность отображать файл в адресное пространство процессов. После того как такое отображение было выполнено, процесс может работать с этими адресами так же, как с обычной памятью. Операционная система сама заботится обо всех файловых операциях, таких как кеширование и упреждающее чтение.
Почему это быстрее, чем традиционные операции чтения и записи? Это связано с тем, что в большинстве случаев чтение и запись реализуются как отображение в память и копирование данных в указанный пользователем буфер. Таким образом, чтение обычно делает немного больше, чем отображение.
Как и в случае с std::fstream из стандартной библиотеки, мы должны передать режим открытия файла. См. этап 2, где мы предоставили режим boost::interprocess::read_only.
См. этап 3, где мы отобразили весь файл сразу. Эта операция действительно очень быстрая, потому что ОС не читает все данные с диска, а сразу возвращает нам управление и ожидает запросов к части отображаемой области. После запроса ОС загружает запрошенную часть файла с диска в память. Как мы видим, операции отображения в память являются ленивыми, а размер отображаемой области не влияет на производительность.
Однако 32-разрядная ОС не может отображать в память большие файлы, поэтому вам придется отображать их по частям. Операционные системы POSIX (Linux) требуют определения макроса _FILE_OFFSET_ BITS=64 для всего проекта, чтобы работать с большими файлами на 32-битной платформе. В противном случае ОС не сможет отобразить части файла, размер находится за границей первых 4 ГБ.
Теперь пришло время измерить производительность:
Как и ожидалось, отображенные в память файлы немного быстрее по сравнению с традиционными операциями чтения. Также видно, что чистые методы C имеют такую же производительность, что и класс C++ std::ifstream, поэтому по возможности не используйте FILE* функции в C++. Они предназначены только для C, а не для C++!
Для обеспечения оптимальной производительности std::ifstream не забудьте открыть файлы в двоичном режиме и читать данные блоками:
Дополнительно.
К сожалению, классы для отображения файлов в память не являются частью C++20, и, похоже, их не будет и в C++23.
Запись в области с отображением в память также является очень быстрой операцией. Операционная система кеширует записи и не сбрасывает изменения на диск немедленно. Существует разница между кешированием данных в ОС и std::ofstream. В случае std::ofstream данные кешируются приложением, и если работа приложения аварийно завершается, закешированные данные могут быть потеряны. Когда данные кешируются ОС, завершение работы приложения не приводит к их потере. Сбои питания и сбои ОС приводят к потере данных в обоих случаях.
Если несколько процессов отображают один файл и один из процессов изменяет отображаемую область, то изменения сразу видны другим процессам (даже без фактической записи данных на диск! Современные ОС очень умные! Только не забывайте про синхронизацию доступа).
См. также
macOS и Windows имеют массу отличий, одно из главных — файловая система. И если на Mac NTFS-диски можно хотя бы читать, то Windows диски, отформатированные в HFS+, не видит вообще. Но если вам очень надо, то есть несколько обходных путей.
Ситуации, когда это может понадобиться, бывают разными. Самая распространённая — это доступ к вашим файлам из Windows, установленной через Boot Camp (по умолчанию доступно только чтение файлов). В таких случаях либо ставят драйвер HFS+, добавляющий поддержку файловой системы Apple в Windows, либо используют специальные утилиты, которые уже умеют работать с HFS+. Мы рассмотрим оба варианта плюс ещё один, бонусный.
Создание FileStream
Для создания объекта FileStream можно использовать как конструкторы этого класса, так и статические методы класса File. Конструктор FileStream имеет множество перегруженных версий, из которых отмечу лишь одну, самую простую и используемую:
Здесь в конструктор передается два параметра: путь к файлу и перечисление FileMode . Данное перечисление указывает на режим доступа к файлу и может принимать следующие значения:
Append : если файл существует, то текст добавляется в конец файл. Если файла нет, то он создается. Файл открывается только для записи.
Create : создается новый файл. Если такой файл уже существует, то он перезаписывается
CreateNew : создается новый файл. Если такой файл уже существует, то приложение выбрасывает ошибку
Open : открывает файл. Если файл не существует, выбрасывается исключение
OpenOrCreate : если файл существует, он открывается, если нет - создается новый
Truncate : если файл существует, то он перезаписывается. Файл открывается только для записи.
Другой способ создания объекта FileStream представляют статические методы класса File:
Первый метод открывает файл с учетом объекта FileMode и возвращает файловой поток FileStream. У этого метода также есть несколько перегруженных версий. Второй метод открывает поток для чтения, а третий открывает поток для записи.
SSD диск
По сути обе программы различались наличием или отсутствием ActionBlock для ScenarioAsyncWithMaxParallelCount32 (с ограничением), в итоге получилось, что чтение лучше не ограничивать, тогда будет использоваться больше памяти (в моем случае в 1,5 раза), а ограничение будет просто на уровне стандартных настроек (т.к. Thread Pool зависит от числа ядер и т.д.)
Минимальный размер файла (байты): 1001, максимальный размер (байты): 25720320, средний размер (байты): 42907.8608
| Сценарий | Время |
| ScenarioAsyncWithMaxParallelCount4 | 00:00:00.4070000 |
| ScenarioAsyncWithMaxParallelCount8 | 00:00:00.2210000 |
| ScenarioAsyncWithMaxParallelCount16 | 00:00:00.1240000 |
| ScenarioAsyncWithMaxParallelCount24 | 00:00:00.2430000 |
| ScenarioAsyncWithMaxParallelCount32 | 00:00:00.3180000 |
| ScenarioAsyncWithMaxParallelCount64 | 00:00:00.5100000 |
| ScenarioAsyncWithMaxParallelCount128 | 00:00:00.7270000 |
| ScenarioAsyncWithMaxParallelCount256 | 00:00:00.8190000 |
| ScenarioSyncAsParallel | 00:00:00.7590000 |
| ScenarioReadAllAsParallel | 00:00:00.3120000 |
| ScenarioAsync | 00:00:00.5080000 |
| ScenarioAsync2 | 00:00:00.0670000 |
| ScenarioNewThread | 00:00:00.6090000 |
Увеличив минимальный размер файла, я получил:
- В лидерах остался запуск программы с числом потоков, близким к числу ядер процессоров.
- В ряде тестов один из потоков постоянно ждал освобождение блокировки (см. Performance Counter «Concurrent Queue Length»).
- Синхронный способ чтение с диска все еще в аутсайдерах.
- Если не ограничивать число потоков, то время чтения становится ближе к синхронным операциям
- Ограничивать уже желательнее как (число ядер) * [2.5 — 5.5]
HDD диск
Если с SSD все было более-менее хорошо, здесь у меня участились падения, так что часть результатов с упавшими программами я исключил.
Минимальный размер файла (байты): 1001, максимальный размер (байты): 54989002, средний размер (байты): 210818,0652
| Сценарий | Время |
| ScenarioAsyncWithMaxParallelCount4 | 00:00:00.3410000 |
| ScenarioAsyncWithMaxParallelCount8 | 00:00:00.3050000 |
| ScenarioAsyncWithMaxParallelCount16 | 00:00:00.2470000 |
| ScenarioAsyncWithMaxParallelCount24 | 00:00:00.1290000 |
| ScenarioAsyncWithMaxParallelCount32 | 00:00:00.1810000 |
| ScenarioAsyncWithMaxParallelCount64 | 00:00:00.1940000 |
| ScenarioAsyncWithMaxParallelCount128 | 00:00:00.4010000 |
| ScenarioAsyncWithMaxParallelCount256 | 00:00:00.5170000 |
| ScenarioSyncAsParallel | 00:00:00.3120000 |
| ScenarioReadAllAsParallel | 00:00:00.5190000 |
| ScenarioAsync | 00:00:00.4370000 |
| ScenarioAsync2 | 00:00:00.5990000 |
| ScenarioNewThread | 00:00:00.5300000 |
Для мелких файлов в лидерах опять асинхронное чтение. Однако и синхронная работа тоже показала неплохой результат. Ответ кроется в нагрузке на диск, а именно — в ограничении параллельных чтений. При попытке принудительно начать читать во много потоков система упирается в большую очередь на чтение. В итоге вместо параллельной работы время тратится на попытки параллельно обслужить много запросов.
Минимальный размер файла (байты): 1001, максимальный размер (байты): 54989002, средний размер (байты): 208913,2665
| Сценарий | Время |
| ScenarioAsyncWithMaxParallelCount4 | 00:00:00.6880000 |
| ScenarioAsyncWithMaxParallelCount8 | 00:00:00.2160000 |
| ScenarioAsyncWithMaxParallelCount16 | 00:00:00.5870000 |
| ScenarioAsyncWithMaxParallelCount32 | 00:00:00.5700000 |
| ScenarioAsyncWithMaxParallelCount64 | 00:00:00.5070000 |
| ScenarioAsyncWithMaxParallelCount128 | 00:00:00.4060000 |
| ScenarioAsyncWithMaxParallelCount256 | 00:00:00.4800000 |
| ScenarioSyncAsParallel | 00:00:00.4680000 |
| ScenarioReadAllAsParallel | 00:00:00.4680000 |
| ScenarioAsync | 00:00:00.3780000 |
| ScenarioAsync2 | 00:00:00.5390000 |
| ScenarioNewThread | 00:00:00.6730000 |
Для среднего размера файлов асинхронное чтение продолжало показывать лучший результат, разве что число потоков желательно ограничивать еще меньшим значением.
Минимальный размер файла (байты): 10008, максимальный размер (байты): 138634176, средний размер (байты): 429888,6019
| Сценарий | Время |
| ScenarioAsyncWithMaxParallelCount4 | 00:00:00.5230000 |
| ScenarioAsyncWithMaxParallelCount8 | 00:00:00.4110000 |
| ScenarioAsyncWithMaxParallelCount16 | 00:00:00.4790000 |
| ScenarioAsyncWithMaxParallelCount24 | 00:00:00.3870000 |
| ScenarioAsyncWithMaxParallelCount32 | 00:00:00.4530000 |
| ScenarioAsyncWithMaxParallelCount64 | 00:00:00.5060000 |
| ScenarioAsyncWithMaxParallelCount128 | 00:00:00.5810000 |
| ScenarioAsyncWithMaxParallelCount256 | 00:00:00.5540000 |
| ScenarioReadAllAsParallel | 00:00:00.5850000 |
| ScenarioAsync | 00:00:00.5530000 |
| ScenarioAsync2 | 00:00:00.4440000 |
Опять в лидерах асинхронное чтение с ограничением на число параллельных операций. Причем, рекомендуемое число потоков стало еще меньше. А параллельное синхронное чтение стабильно стало показывать Out Of Memory.
При большем увеличении размера файла сценарии без ограничения на число параллельных чтений чаще падали с Out Of Memory. Так как результат не был стабильным от запуска к запуску, подобное тестирование я уже счел нецелесообразным.
Какой же результат можно почерпнуть из этих тестов?
-
Почти во всех случаях асинхронное чтение, по сравнению с синхронным, давало лучший результат по скорости.

Привет! Я время от времени рассказываю на Хабре о решениях распространённых задач на C++ и вообще люблю делиться опытом. Поэтому даже написал целую книгу, которая называется «Разработка приложений на С++ с использованием Boost». Она может быть интересна разработчикам, которые уже немного знакомы со стандартной библиотекой языка, хотят глубже изучить Boost, упростить и повысить качество разработки приложений. Уверен, что информация, которую я собрал в книге, будет полезна — всё больше библиотек Boost становятся частью стандарта. Сегодня предлагаю прочитать главу, посвящённую работе с файлами. В ней я рассказываю о перечислении файлов в каталоге, стирании и создании файлов и каталогов, а также о самом быстром способе чтения. Надеюсь, будет интересно. И, пожалуйста, не забывайте делиться впечатлениями в комментариях.
UPD: добавил в конец поста бонус для читателей Хабра.
MacDrive
Более мощный драйвер с дополнительными возможностями. MacDrive умеет всё то же, что и драйвер от Paragon, но при этом позволяет открывать резервные копии Time Machine и копировать файлы из них на Windows-диски. Также драйвер работает в виртуальных машинах и позволяет монтировать Mac-диски в режиме Target Disk Mode для загрузки на других компьютерах.
MacDrive стоит дороже — целых 50 долларов. Пробная версия тоже есть, но на 5 дней.
Результаты
Как я уже написал в шапке, результаты есть на Github: SSD, HDD.
Свойства и методы FileStream
Рассмотрим наиболее важные свойства класса FileStream :
Свойство Length : возвращает длину потока в байтах
Свойство Position : возвращает текущую позицию в потоке
Свойство Name : возвращает абсолютный путь к файлу, открытому в FileStream
Для чтения/записи файлов можно применять следующие методы класса FileStream :
void CopyTo(Stream destination) : копирует данные из текущего потока в поток destination
Task CopyToAsync(Stream destination) : асинхронная версия метода CopyTo
void Flush() : сбрасывает содержимое буфера в файл
Task FlushAsync() : асинхронная версия метода Flush
int Read(byte[] array, int offset, int count) : считывает данные из файла в массив байтов и возвращает количество успешно считанных байтов. Принимает три параметра:
array - массив байтов, куда будут помещены считываемые из файла данные
offset представляет смещение в байтах в массиве array, в который считанные байты будут помещены
count - максимальное число байтов, предназначенных для чтения. Если в файле находится меньшее количество байтов, то все они будут считаны.
Task ReadAsync(byte[] array, int offset, int count) : асинхронная версия метода Read
long Seek(long offset, SeekOrigin origin) : устанавливает позицию в потоке со смещением на количество байт, указанных в параметре offset.
void Write(byte[] array, int offset, int count) : записывает в файл данные из массива байтов. Принимает три параметра:
array - массив байтов, откуда данные будут записываться в файл
offset - смещение в байтах в массиве array, откуда начинается запись байтов в поток
count - максимальное число байтов, предназначенных для записи
Способ 2. Работаем с HFS+ через утилиты
Работа с Mac-дисками через специальные приложения предоставляет более ограниченную поддержку HFS+. Доступ к файловой системе при этом будет возможен только в них, а в «Проводнике» диски даже не будут отображаться. Обычно приложения позволяют только просматривать и копировать файлы, но не записывать.
Утилиты для работы с HFS+ стоят гораздо дешевле, причём встречаются даже бесплатные. Этот способ подойдёт тем, кому нужно только чтение файлов. Кроме того, с помощью не требующих установки утилит можно просматривать файлы с Mac-дисков на компьютерах, где нельзя установить драйвер или стороннее ПО.
Создание FileStream
Для создания объекта FileStream можно использовать как конструкторы этого класса, так и статические методы класса File. Конструктор FileStream имеет множество перегруженных версий, из которых отмечу лишь одну, самую простую и используемую:
Здесь в конструктор передается два параметра: путь к файлу и перечисление FileMode . Данное перечисление указывает на режим доступа к файлу и может принимать следующие значения:
Append : если файл существует, то текст добавляется в конец файл. Если файла нет, то он создается. Файл открывается только для записи.
Create : создается новый файл. Если такой файл уже существует, то он перезаписывается
CreateNew : создается новый файл. Если такой файл уже существует, то приложение выбрасывает ошибку
Open : открывает файл. Если файл не существует, выбрасывается исключение
OpenOrCreate : если файл существует, он открывается, если нет - создается новый
Truncate : если файл существует, то он перезаписывается. Файл открывается только для записи.
Другой способ создания объекта FileStream представляют статические методы класса File:
Первый метод открывает файл с учетом объекта FileMode и возвращает файловой поток FileStream. У этого метода также есть несколько перегруженных версий. Второй метод открывает поток для чтения, а третий открывает поток для записи.
Стирание и создание файлов и каталогов
Давайте рассмотрим следующие строки кода:
В этих строках мы пытаемся записать что-то в файл file.txt в каталоге dir/ subdir. Если такой директории нет, эта попытка будет неудачной.
Давайте посмотрим, как можно сделать это элегантно, используя Boost.
Подготовка
Для этого рецепта требуются базовые знания C++ и класса std::ofstream.
Boost.Filesystem не является библиотекой header-only, поэтому код в этом ре-
цепте требуется линковать с библиотеками boost_system и boost_filesystem.
Как это делается.
Мы продолжаем работать с переносимыми обертками для файловой системы и в этом рецепте посмотрим, как изменить содержимое каталога.
-
Как всегда, нам нужно подключить несколько заголовочных файлов:
Как это работает.
boost::system::error_code может хранить информацию об ошибках и широко используется во всех библиотеках Boost.
Если вы не предоставите экземпляр boost::system::error_code для функций Boost.Filesystem, код будет компилироваться. В этом случае при возникновении ошибки будет выброшено исключение boost::filesystem::filesystem_error.
Внимательно посмотрите на этап 3. Мы использовали функцию boost::filesystem::create_directories вместо boost::filesystem::create_directory, потому что последняя не может создавать вложенные подкаталоги. Та же самая история с boost::filesystem::remove_all и boost::filesystem::remove. Первая удаляет каталоги, которые могут содержать файлы и подкаталоги. Вторая удаляет один файл.
Остальные шаги просты для понимания и не должны вызывать проблем.
Дополнительно.
Класс boost::system::error_code является частью C++11. Его можно найти в заголовочном файле в пространстве имен std. Классы Boost.Filesystem являются частью C++17.
Наконец, небольшая рекомендация для тех, кто собирается использовать Boost.Filesystem. Когда ошибки при работе с файловой системой являются частым явлением, или приложение требует высокой отзывчивости/производительности, используйте класс boost::system::error_codes. В противном случае для обработки ошибок перехват исключений будет предпочтительнее и надежнее.
См. также
Произвольный доступ к файлам
Нередко бинарные файлы представляют определенную структуру. И, зная эту структуру, мы можем взять из файла нужную порцию информации или наоброт записать в определенном месте файла определенный набор байтов. Например, в wav-файлах непосредственно звуковые данные начинаются с 44 байта, а до 44 байта идут различные метаданные - количество каналов аудио, частота дискретизации и т.д.
С помощью метода Seek() мы можем управлять положением курсора потока, начиная с которого производится считывание или запись в файл. Этот метод принимает два параметра: offset (смещение) и позиция в файле. Позиция в файле описывается тремя значениями:
SeekOrigin.Begin : начало файла
SeekOrigin.End : конец файла
SeekOrigin.Current : текущая позиция в файле
Курсор потока, с которого начинается чтение или запись, смещается вперед на значение offset относительно позиции, указанной в качестве второго параметра. Смещение может быть отрицательным, тогда курсор сдвигается назад, если положительное - то вперед.
Рассмотрим простой пример:
Вначале записываем в файл текст "hello world". Затем снова обращаемся к файла для считывания. Сначала перемещаем курсор на пять символов назад относительно конца файлового потока:
То есть после выполнения этого вызова курсор будет стоять на позиции символа "w".
После этого считываем пять байт начиная с символа "w". В кодировке по умолчанию 1 символ будет представлять 1 байт. Поэтому чтение 5 байт будет эквивалентно чтению пяти сиволов: "world".
Соответственно мы получим следующий консольный вывод:
Рассмотрим чуть более сложный пример - с записью начиная с некоторой позиции:
Здесь также вначале записываем в файл строку "hello world". Затем также открываем файл и опять же перемещаемся в конец файла, не доходя до конца пять символов (то есть опять же с позиции символа "w"), и осуществляем запись строки "house". Таким образом, строка "house" заменяет строку "world".
В пятой части нашей серии статей мы показали, как можно использовать прерывания BIOS'а после перехода в защищенный режим, и в качестве примера определили размер оперативной памяти. Сегодня мы разовьем этот успех и реализуем полноценную поддержку работы с дисками с файловой системой FAT16 и FAT32. Работу с файлами на диске можно разбить на 2 части: работа с файловой системой и работа с диском на уровне чтения/записи секторов. Можно сказать, что для этого нам нужно написать «драйвер» файловой системы и «драйвер» диска.
Работа с диском на уровне чтения/записи секторов
Для начала научимся работать с диском.
Итак, мы можем вызывать прерывания BIOS'а. Помимо прочих возможностей, BIOS предоставляет интерфейс для работы с диском, а именно — прерывание int 0x13. Со списком сервисов, предоставляемых прерыванием, можно ознакомиться на википедии. Нас интересуют сервисы чтения и записи дисков.
Существует два способа адресации сектора на диске, с которыми работает BIOS – CHS(cylinder-head-sector) и LBA(logical block addressing). Адресация CHS основана на использовании геометрии диска, и адресом сектора является совокупность трех координат: цилиндр, головка, сектор. Способ позволяет адресовать до 8Гб. Прерывание int0x13 предоставляет возможность читать и писать на диск с использованием этой адресации.
Понятно, что 8Гб — это очень мало, и данный способ адресации является устаревшим, а все современные (и не очень) контроллеры жестких дисков поддерживают адресацию LBA. Адресация LBA абстрагируется от геометрии диска и присваивает каждому сектору собственный номер. Нумерация секторов начинается с нуля. LBA для задания номера блока использует 48 бит, что позволяет адресовать 128 ПиБ, с учетом размера сектора в 512 байт. Прерывание int0x13 предоставляет два сервиса для чтения и записи секторов на диск с использованием LBA. Их мы и будем использовать. Для чтения сектора прерывание in0x13 ожидает следующие параметры:


Прерывание возвращает следующие значения:

Один из параметров – номер диска. Нужно как-то узнать номер диска, с которым мы собрались работать. Нумерация происходит следующим образом: флоппи-диски (fdd), и все, что эмулируется как флоппи, нумеруются с нуля, а жесткие диски (hdd), и все, что эмулируется как они(usb-флешки, например), нумеруются с 0x80. Этот номер никак не связан с последовательностью загрузки в настройках BIOS’а. В нашем случае, диск, с которым мы собираемся работать, является тем диском, с которого мы загрузились.
Когда BIOS передает управление MBR, он загружает его по адресу 0000h:7C00h, а в регистре DL передает нужный нам номер загрузочного устройства. Это является частью интерфейса взаимодействия между BIOS и MBR. Таким образом, этот номер попадает в GRUB, где далее используется для работы с диском. GRUB, в свою очередь, передает этот номер ОС как часть структуры Multiboot information.
Сразу после передачи управления от GRUB’а к ОС в регистре EBX находится указатель на эту структуру. Первое поле структуры – это flags, и если в нем выставлен 2-й бит, то поле boot_device корректно. Это поле так же принадлежит структуре Multiboot information и в его старшем байте (размер поля – 4 байта) хранится нужный нам номер диска, который понимает прерывание int0x13. Таким образом, используя GRUB, мы получили недостающий параметр для чтения/записи секторов на диск.
Мы научились читать и писать сектора на диск, это, безусловно, важно. Но файловая система привязана не к целому диску, а только к его части – разделу. Для работы с файловой системой нужно найти сектор, с которого начинается раздел, на котором она располагается. Информация об имеющихся на диске секторах хранится в первом секторе диска, там же, где располагается MBR. Существует много различных форматов MBR, но для всех них верна следующая структура:

Информация о разделах хранится в таблице разделов. На диске может быть только 4 первичных раздела, с которых можно загрузиться. На запись о разделе приходится 8 байт. Первый байт — это флаги, если его значение 0x80, то раздел загрузочный. Код MBR в процессе своей работы пробегает по этим 4-м разделам в поиске загрузочного раздела. После его обнаружения, MBR копирует содержимое первого сектора этого раздела на адрес 0000h:7C00h и передает туда управление. Нас интересует LBA адрес первого сектора загрузочного раздела, так как именно на нем располагается наше ядро, и присутствует файловая система, которую мы собираемся читать. Для того чтобы получить этот адрес, нужно прочитать первый сектор диска, найти на нем таблицу разделов, в таблице разделов найти загрузочный раздел, а из его записи прочитать нужное поле.
Итак, у нас есть механизм для чтения сектора с диска и знание о расположении нужного нам раздела на диске. Осталось научиться работать с файловой системой на этом разделе.
Работа с файловой системой
Для работы с файловой системой мы будем использовать библиотеку fat_io_lib. Библиотека доступна под лицензией GPL. Она предоставляет интерфейс для работы с файлами и директориями, аналогичный имеющемуся в libc. Реализованы такие функции, как fopen(), fgets(), fputc(), fread(), fwrite() и т.д. Библиотека для своей работы требует всего лишь две функции: записать сектор и прочитать сектор, причем первая является необязательной. Функции имеют следующий прототип:
Библиотека написана на чистом С, что опять-таки нам на руку. Для использования в своей мини-ОС нам не придется менять в ней ни строчки. Библиотека ожидает, что чтение секторов происходит в рамках раздела с файловой системой.
Итак, у нас есть функции чтения/записи сектора на раздел и есть библиотека для работы с FAT16/32, которая использует эти функции. Осталось собрать все воедино и продемонстрировать результат. Но прежде чем перейти к коду, хотелось бы показать, что подход, который мы собираемся использовать, вполне применим в реальной жизни. Ниже представлена небольшая часть VBR windows 7, в которой происходит чтение сектора диска посредством прерывания int0x13. Этот код многократно вызывается в процессе загрузки системы, вплоть до момента отрисовки загрузочной анимации.

Для вызова этого кода, Windows 7, подобно тому, как это делаем мы, переходит из защищенного режима в реальный, и обратно. Это несложно проверить, запустив Windows 7 в QEMU. QEMU должен ожидать подключения отладчика. После подключения отладчика (gdb) ставим breakpoint на адрес (0x7c00 + 0x11d). Срабатывание breakpoint’а будет означать вызов этой функции. Кстати в Windows XP этот механизм отсутствует, для вызова прерываний BIOS'а там переходят в режим VM86.
! ВАЖНО! Все дальнейшие действия могут успешно осуществляться только после успешного прохождения всех шагов из пятой части нашей серии статей
Шаг 1. Изменим основную логику в kernel.c
1. Добавим в файле kernel.c следующие объявления:
Код, печатающий размер оперативной памяти
заменим на следующий код:
Память под переменные mbd и magic зарезервирована в файле loader.s, так что их можно использовать аналогично глобальным переменным из кода на С. Переменная magic содержит сигнатуру, подтверждающую, что для загрузки использовался стандарт Multiboot, эталонной реализацией которого является GRUB. Переменная mbd указывает на структуру multiboot_info_t, которая объявлена в multiboot.h. Номер загрузочного диска определяется следующим выражением — p_multiboot_info->boot_device >> 24. Функция InitBootMedia запоминает номер диска и ищет первый сектор файловой системы, чтобы затем все смещения считать от него.
Библиотека fat_io_lib для инициализации требует вызова двух функций: fl_init и fl_attach_media. Первая функция обнуляет внутренние структуры библиотеки, а вторая получает в качестве параметров функции чтения и записи секторов на диск, которые затем используются для обращения к файлам. Далее идет демонстрация работы с библиотекой: выводится список файлов в папке /boot/grub и распечатывается содержимое файла menu.lst.
2. Добавляем файл multiboot.h в папку include. Содержимое файла берем с сайта спецификации предыдущей версии.
Шаг 2. Добавим функции для работы с диском
1. В файл include\callrealmode.h добавим прототипы следующих функций:
2. В файле include\callrealmode_asm.h добавим в enum callrealmode_Func новое значение так, чтобы получилось следующее:
Добавим в union внутри структуры callrealmode_Data только что объявленную структуру callrealmode_read_disk. Должно получиться следующее:
3. В файл include\string.h добавим функции strncmp и strncpy, используемые в библиотеке fat_io_lib.
4. Добавим в файл callrealmode.c следующие объявления:
И несколько функций:
Функции ReadBootMedia и WriteBootMedia используются библиотекой fat_io_lib для чтения/записи секторов. Функция WriteBootMedia не обязательная и является заглушкой, так как в данном примере нет записи на диск. Ее реализация выглядела бы аналогично функции ReadBootMedia. Функция ReadBootMedia похожа на функцию GetRamsize из прошлой статьи с точностью до типа param.func, а вместо param.getsysmemmap используется param.readdisk. Функция InitBootMedia должна быть вызвана раньше двух остальных, так как она инициализирует значения g_BootPartitionStart и g_BootDeviceInt13Num.
5. Изменим callrealmode_asm.s. Добавим еще один тип CALLREALMODE_FUNC_READ_DISK вызываемых функций, должно получиться следующее:
Далее добавим еще одну проверку на тип функции и непосредственно код, читающий с диска. Должно получиться следующее:
Метка readdisk указывает на код, который формирует структуру DAP из структуры callrealmode_Data и вызывает int0x13. В коде после метки callrealmode_switch добавилось 2 инструкции, проверяющие, не нужно ли вызывать readdisk.
6. Добавим файл include\mbr.h, содержащий определения для работы с MBR. Его содержимое:
Структура MBRSector используется в функции InitBootMedia.
Шаг 3. Добавим библиотеку fat_io_lib и запустим
1. Скачаем архив fat_io_lib.zip и распакуем его в папку fat_io_lib в корне проекта.
2. Добавим пустые файлы assert.h и stdlib.h в папку include. Они нужны, что бы библиотека скомпилировалась.
3. Исправим Makefile. Добавим файлы из библиотеки в список целей для компиляции. Должно получиться следующее:
Теперь размер образа равен 10Mb. Это делается для того, чтобы команда mkdosfs отформатировала раздел в FAT16 вместо FAT12. FAT12 не поддерживается библиотекой fat_io_lib.
С этим дефайном библиотека не будет включать stdio.h, но будет использовать готовый прототип функции printf, который совпадает с нашим, и который уже реализован.
4. Пересоберем проект
sudo make image
Должно получиться следующее:
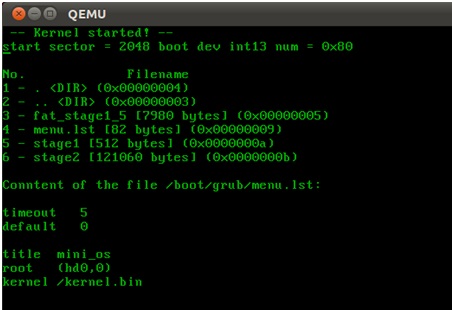
Как и в предыдущих частях, можно сделать dd образа hdd.img на флешку и проверить код на реальном железе, загрузившись с нее.
В результате мы реализовали работу с файловыми системами FAT16 и FAT32. Мы немного схитрили, использовав готовую библиотеку, но разбираться в устройстве FAT'а было бы менее интересно, да и вряд ли бы мы тогда уложились в 1 статью. Надеюсь, вам было интересно читать. Пишите в комментариях, если у вас возникнут проблемы в прохождении описанных шагов!

В интернете я не нашел подобных сравнений (если не считать тюнинга под определенные конфигурации).
Результаты можно посмотреть на Github: SSD, HDD.
Paragon HFS+ for Windows
Самый популярный драйвер с полной поддержкой HFS+ на дисках любого типа (GPT и MBR) и набором дополнительных утилит. Отличается высокой производительностью при передаче файлов большого объёма по различным интерфейсам, включая SATA и USB. Совместим с Windows 10.
Лицензия стоит относительно недорого — 790 рублей. При этом есть 10-дневная пробная версия.
Бонус
Если вы не хотите тратиться и заморачиваться с установкой драйверов или дополнительных утилит, можно поступить по-другому: воспользоваться Live-USB-дистрибутивом Linux. Загрузившись с него, вы получите доступ ко всем вашим дискам, включая HFS+ и NTFS, а затем сможете просмотреть или скопировать любые файлы на них. Так умеет, например, Ubuntu.
Установочный образ обычно имеет и Live USB, поэтому всё, что вам останется сделать, — это скачать образ и записать его на флешку.
Чтение и запись файлов
FileStream представляет доступ к файлам на уровне байтов, поэтому, например, если вам надо считать или записать одну или несколько строк в текстовый файл, то массив байтов надо преобразовать в строки, используя специальные методы. Поэтому для работы с текстовыми файлами применяются другие классы.
В то же время при работе с различными бинарными файлами, имеющими определенную структуру, FileStream может быть очень даже полезен для извлечения определенных порций информации и ее обработки.
Посмотрим на примере считывания-записи в текстовый файл:
Разберем этот пример. Вначале определяем путь к файлу и текст для записи в файл.
И при чтении, и при записи для создания и удаления объекта FileStream используется конструкция using , по завершению которой у созданного объекта FileStream автоматически вызывается метод Dispose , и, таким образом, объект уничтожается.
Поскольку операции с файлами могут занимать продолжительное время и являются узким местом в работе программы, рекомендуется использовать асинхронные версии методов FileStream. И при записи, и при чтении применяется объект кодировки Encoding.Default из пространства имен System.Text . В данном случае мы используем два его метода: GetBytes для получения массива байтов из строки и GetString для получения строки из массива байтов.
В итоге введенная нами строка записывается в файл note.txt . И мы получим следующий консольный вывод:
Записанный файл по сути представляет бинарный файл (не текстовый), хотя если мы в него запишем только строку, то сможем посмотреть в удобочитаемом виде этот файл, открыв его в текстовом редакторе. Однако если мы в него запишем случайные байты, например:
То у нас могут возникнуть проблемы с его пониманием. Поэтому для работы непосредственно с текстовыми файлами предназначены отдельные классы - StreamReader и StreamWriter.
TransMac
Как и HFSExplorer, TransMac не устанавливает драйверы в систему, а открывает доступ к дискам HFS+ внутри своего окна. Более того, приложение вообще не нужно инсталлировать, благодаря чему его можно использовать на рабочем компьютере или в гостях. При этом доступны не только чтение, но и запись данных. Есть даже поддержка изменения и форматирования разделов на дисках HFS+.
Утилита будет полезна всем, кто по каким-либо причинам не хочет (или не может) установить драйверы, но нуждается в полноценной поддержке HFS+.
Стоимость лицензии — 59 долларов, ознакомительный период — 15 дней.
Перечисление файлов в каталоге
Существуют функции и классы стандартной библиотеки для чтения и записи данных в файлы. Но до появления C++17 в ней не было функций для вывода списка файлов в каталоге, получения типа файла или получения прав доступа к файлу.
Знание основ C++ более чем достаточно для использования этого рецепта. Этот рецепт требует линковки с библиотеками boost_system и boost_filesystem.
Как это делается.
Этот и последующий рецепты посвящены переносимым оберткам для работы с файловой системой.
-
Нам нужно подключить следующие два заголовочных файла:
FILE W "./main.o"
FILE W "./listing_files"
DIRECTORY W "./some_directory"
FILE W "./Makefile"
Как это работает.
Функции и классы Boost.Filesystem просто оборачивают системные вызовы для работы с файлами.
Обратите внимание на использование знака "./" на этапе 2. Системы POSIX используют косую черту для указания путей; Windows по умолчанию использует обратную косую черту. Тем не менее Windows также понимает косую черту, а даже если бы не понимала, то библиотека Boost позаботилась бы о неявном преобразовании формата пути.
Посмотрите на этап 3, где мы вызываем конструктор по умолчанию для класса boost::filesystem::directory_iterator. Этот конструктор работает по аналогии с конструктором по умолчанию класса std::istream_iterator, – создает итератор конца диапазона.
Этап 4 сложен не потому, что эту функцию трудно понять, а из-за того, что происходит много преобразований. Разыменование итератора begin возвращает boost::filesystem::directory_entry, который неявно преобразуется в boost::filesystem::path, использующийся в качестве параметра для функции boost::filesystem::status. На самом деле можно написать намного лучше:
Совет:
Внимательно прочитайте справочную документацию, чтобы избежать ненужных неявных преобразований.
Этап 5 очевиден, поэтому мы переходим к этапу 6, где неявное преобразование в boost::filesystem::path происходит снова. Более явное решение выглядит так:
Здесь begin->path() возвращает константную ссылку на переменную
boost::filesystem::path, которая содержится в boost::filesystem::directory_entry.
Дополнительно.
Boost.Filesystem является частью C++17. Все содержимое в C++17 находится в одном заголовочном файле в пространстве имен std::filesystem. Версия стандартной библиотеки несколько отличается от Boost-версии, в основном за счет использования перечислений с областью видимости (enum class) там, где Boost.Filesystem использовала просто перечисление без области видимости.
Совет:
Есть класс directory_entry, который обеспечивает кеширование информации о файловой системе. Так что если вы много работаете с файловой системой и запрашиваете различную информацию, попробуйте использовать directory_entry для лучшей производительности.
Как и в случае с другими библиотеками Boost, Boost.Filesystem работает с компиляторами для стандарта, предшествующего C++17, и даже с компиляторами для стандарта, предшествующего C++11.
См. также
HFSExplorer
Простая и, что немаловажно, бесплатная утилита, которая позволит просматривать файлы с дисков HFS+ в среде Windows. HFSExplorer открывает содержимое Mac-дисков в виде дерева каталогов, где можно выбрать нужные файлы. Для просмотра их нужно скопировать на диск Windows. Также есть возможность создания образов дисков HFS+ для последующей работы уже с ними.
Утилита HFSExplorer не так удобна, как драйверы, и умеет только просматривать файлы, зато не стоит ни копейки.
Закрытие потока
Класс FileStream для освобождения всех реусрсов, связанных с файлом, реализует интерфейс IDisposable. Соответственно после завершения работы с FileStream необходимо освободить связанный с ним файл вызовом метода Dispose. Для корректного закрытия можно вызвать метод Close() , который вызывает метод Dispose:
Либо можно использовать конструкцию using, которая автоматически освободит все связанные с FileStream ресурсы:
Способы чтения и алгоритм тестирования
Есть несколько основных способов:
Проект можно посмотреть здесь, он представляет собой один главный исполняемый файл TestsHost и кучу проектов с названиями Scenario*. Каждый тест это:
-
Запуск exe-файла, который посчитает чистое время.
-
Определяемся с размером файлов и с их числом (я выбрал такие, чтобы суммарный объем был больше, чем объем RAM, чтобы подавить влияние дискового кеша);
-
Программа выдаст код возврата 0 только в случае, если все файлы были прочитаны.
-
Компиляция — в режиме Release в MSVS. Запуск идет как отдельное приложение, без отладчика и пр. Нет какого-то тюнинга, ведь суть проверок именно в том — как в обыкновенном ПО читать файлы быстрее.
Способ 1. Работаем с HFS+ через драйверы
Драйверы хороши тем, что добавляют поддержку HFS+ на системном уровне, а значит, Mac-диски будут отображаться в «Проводнике» и других приложениях. Драйвер загружается при старте Windows, и разница между файловыми системами попросту перестаёт существовать: вы можете работать с дисками любых форматов.
Главное преимущество драйверов — это поддержка как чтения, так и записи файлов. Кроме того, этот способ обеспечивает максимально возможную скорость передачи данных. В качестве минуса можно упомянуть высокую цену: все популярные драйверы, обеспечивающие стабильную работу, довольно дороги.
Читайте также: