
Частота ошибок позиционирования жесткого диска
| Конфигурация компьютера | |
| Процессор: Intel Core 2 Duo E8400, 3000 MHz | |
| Материнская плата: Gigabyte GA-EP35-DS3 | |
| Память: OCZ2P800LP1 1+1Gb | |
| HDD: MAXTOR STM3500320AS, WDC WD1002FAEX-00Z3A0 | |
| Видеокарта: XFX 4890ZSFC | |
| Звук: Нет | |
| Блок питания: Thermaltake 700W W0106RE | |
| CD/DVD: Нет | |
| Монитор: SyncMaster T200N | |
| ОС: Windows 7 Ultimate x86 | |
| Прочее: Нет |
Проблема в том что ему 2-е суток как работает а прога HDDlife 2.9, бьет тревогу о его производительности. Купил, поставил, установил винду, дрова, и енту прогу, полтора суток без проблем, пока был пуст писала 90% потом немного забил софтом, а другие разделы всякой ерундой, гигов на 100 стало 65% а через час посля, сразу тревога и 17%. Подскажите в чем дело.
Ниже некоторая тестовая информация.
dilja,
Seek Error Rate
Частота появления ошибок позиционирования БМГ
Частота появления ошибок позиционирования БМГ. В случае сбоя в механической системе позиционирования, повреждения сервометок (servo), сильного термического расширения дисков и т.п, возникают ошибки позиционирования, Чем их больше, тем хуже механики и/или поверхности жесткого диска.
Raw Read Error Rate
Частота появления ошибок при чтении данных с диска.
Данный параметр показывает частоту появления ошибок при операциях чтения с поверхности диска по вине аппаратной части накопителя.
Hardware ECC Recovered - общее количество ошибок чтения, восстановленных с применением ECC - для Seagate это нормально
У моего винчестера Seagate в полях S.M.A.R.T. “Raw Read Error Rate”, “Seek Error Rate”, “Hardware ECC Recovered” совершенно дикие значения, в то время как у накопителей иных производителей там нули. Это нормально?
Огромные числа в этих полях обусловлены тем, что жёсткие диски Seagate по-другому считают значения этих параметров. При работе современного винчестера всегда возникают ошибки такого рода и он восстанавливает их самостоятельно, это нормально, просто другие производители не считают нужным указывать количество этих ошибок.
Для отключения данного рекламного блока вам необходимо зарегистрироваться или войти с учетной записью социальной сети.
| Конфигурация компьютера | |
| Процессор: Intel Core 2 Duo E8400, 3000 MHz | |
| Материнская плата: Gigabyte GA-EP35-DS3 | |
| Память: OCZ2P800LP1 1+1Gb | |
| HDD: MAXTOR STM3500320AS, WDC WD1002FAEX-00Z3A0 | |
| Видеокарта: XFX 4890ZSFC | |
| Звук: Нет | |
| Блок питания: Thermaltake 700W W0106RE | |
| CD/DVD: Нет | |
| Монитор: SyncMaster T200N | |
| ОС: Windows 7 Ultimate x86 | |
| Прочее: Нет |
Значит с винтом все в порядке? Я правильно понял? В принципе визуально я потерю производительности не увидел да и тест Everestа тоже, судя по его данным, скорости считывания и записи и т.п.
-------
Ненавижу, когда все шагают строем - одинаково стриженые, одинаково одетые, с одинаковыми мыслями в одинаково пустых головах. (С) Кий
| Конфигурация компьютера | |
| Процессор: Intel Core 2 Duo E8400, 3000 MHz | |
| Материнская плата: Gigabyte GA-EP35-DS3 | |
| Память: OCZ2P800LP1 1+1Gb | |
| HDD: MAXTOR STM3500320AS, WDC WD1002FAEX-00Z3A0 | |
| Видеокарта: XFX 4890ZSFC | |
| Звук: Нет | |
| Блок питания: Thermaltake 700W W0106RE | |
| CD/DVD: Нет | |
| Монитор: SyncMaster T200N | |
| ОС: Windows 7 Ultimate x86 | |
| Прочее: Нет |
Подождем, посмотрим, Только сколько винтов у меня было и есть, такая фигня только с ентим приключилась. У меня все Сигейты 80, 160, IDE. 120 SATA. И HDDlife ничего такого им не пророчила. Всегда писала не ниже 55%.
Недавно слышал мнение, что даже на новых SATA дисках имеются кластеры с большим временем доступа. И якобы это компенсируется большой скоростью вращения и буфером. Сам это не проверял, но выглядит правдоподобно.
И естественно, что программа не будет прогнозировать таким дискам высокий процент.
-------
Ненавижу, когда все шагают строем - одинаково стриженые, одинаково одетые, с одинаковыми мыслями в одинаково пустых головах. (С) Кий
| Конфигурация компьютера | |
| Процессор: Intel Core 2 Duo E8400, 3000 MHz | |
| Материнская плата: Gigabyte GA-EP35-DS3 | |
| Память: OCZ2P800LP1 1+1Gb | |
| HDD: MAXTOR STM3500320AS, WDC WD1002FAEX-00Z3A0 | |
| Видеокарта: XFX 4890ZSFC | |
| Звук: Нет | |
| Блок питания: Thermaltake 700W W0106RE | |
| CD/DVD: Нет | |
| Монитор: SyncMaster T200N | |
| ОС: Windows 7 Ultimate x86 | |
| Прочее: Нет |
Я первым делом проверяю кластеры, сразу после установки винта в системник, MHDD-дой. У меня все в порядке. Был забавный касяк со 160-й, поставил в системник начал тестить поверхность MHDD, и сразу 2 битых сектора прочем почти в самом начале, гдето около гига после начала, отнес, сразу поменяли, хотя брал в запечатанной упаковке. Забавно? А в январе купил Samsung 400g j3 месяц проработал, и smart считывать перестал, пошол вернули деньги. теперь купил ST320. И опять косяк. Это злой рок. какойто.
| Конфигурация компьютера | |
| Процессор: Intel Core 2 Duo E8400, 3000 MHz | |
| Материнская плата: Gigabyte GA-EP35-DS3 | |
| Память: OCZ2P800LP1 1+1Gb | |
| HDD: MAXTOR STM3500320AS, WDC WD1002FAEX-00Z3A0 | |
| Видеокарта: XFX 4890ZSFC | |
| Звук: Нет | |
| Блок питания: Thermaltake 700W W0106RE | |
| CD/DVD: Нет | |
| Монитор: SyncMaster T200N | |
| ОС: Windows 7 Ultimate x86 | |
| Прочее: Нет |
Добавлено:
Проверил материнку (IDE каналы) и интерфейсный IDE-кабель другими IDE-hdd/кабелями - они в порядке. Менял инт. кабеля у этого hdd - на всех +6/+2 =(
Добавлено:
На SATA каналах два винта Seagate ST380013AS Barracuda тоже плюсуют эти значения параметров оО
Материнку и кабеля проверял, всё работает, на третьем hdd (western digital) ничего не плюсуется!
Разница в sata hdd (первом и втором - "одинаковыми") только в firmware на +\- 0,1 (т.е. 3.18 и 3.19) и тот, что 3.18 с бедами :P
Последний раз редактировалось ZeLiK, 17-01-2010 в 08:12 . Причина: Добавление информации x2
Сегодня, хотелось бы чуточку подробнее поговорить о вскользь упомянутой в предыдущей статье о критериях выбора винчестера технологии SMART, а также выяснить вопрос о появлении плохих секторов при проверке поверхности специальными программами и исчерпании резервной поверхности для их переназначения - вопросу, поднятому на форуме из прошлой статьи.
Для начала как всегда краткий исторический экскурс. Надежность жесткого диска (и любого устройства хранения в самом общем случае) всегда придается огромное значение. И дело отнюдь не в его стоимости, а в ценности той информации, которую он уносит с собой в мир иной, уходя из жизни сам, и в потерях прибыли, связанных с простоями при выходе из строя винчестеров, если речь идет о бизнес-пользователях, даже в том случае, если информация осталась. И вполне естественно, что о таких неприятных моментах хочется знать заранее. Даже обычные рассуждения на бытовом уровне подсказывают, что наблюдение за состоянием прибора в работе, может подсказать такие моменты. Осталось только каким-то образом реализовать это наблюдение в винчестере.
Впервые над этой задачей задумались инженеры голубого гиганта (IBM то бишь). И в 1995 году они предложили технологию, отслеживающую несколько критически важных параметров накопителя, и делающую попытки на основании собранных данных предсказать выход его из строя - Predictive Failure Analysis (PFA). Идею подхватила Compaq, которая чуть позже создала свою технологию - IntelliSafe. В разработке Compaq также поучаствовали Seagate, Quantum и Conner. Созданная ими технология также отслеживала ряд рабочих характеристик диска, сравнивала их с допустимым значением и рапортовала хост-системе в случае наличия опасности. Это был огромный шаг вперед если и не в повышении надежности винчестеров, то хотя бы в уменьшении риска потери информации при их использовании. Первые попытки оказались удачными, и показали необходимость дальнейшего развития технологии. Уже в объединении всех крупных производителей жестких дисков появилась технология S.M.A.R.T (Self Monitoring Analysing and Reporting Technology), базирующаяся на технологиях IntelliSafe и PFA (кстати говоря, PFA существует и поныне, как набор технологий для наблюдения и анализа за различными подсистемами серверов IBM, в том числе и дисковой подсистемой, причем наблюдение за последней базируется именно на технологии SMART).
Итак, SMART - это технология внутренней оценки состояния диска, и механизм предсказания возможного выхода из строя жесткого диска. Важно отметить то, что технология в принципе не решает возникающих проблем (основные из них показаны на рисунке чуть ниже), она способна лишь предупредить об уже возникшей проблеме либо об ожидающейся в ближайшем времени.
При этом нужно также сказать, что технология не в состоянии предсказать абсолютно все возможные проблемы и это логично: выход электроники в результате скачка напряжения, порча головок и поверхности в результате удара и т.п. никакая технология предсказать не в силах. Предсказуемы лишь те проблемы, которые связаны с постепенным ухудшением каких-либо характеристик, равномерной деградацией каких либо компонент.
Этапы развития технологии
В своем развитии технология SMART прошла три этапа. В первом поколении было реализовано наблюдение небольшого числа параметров. Никаких самостоятельных действий накопителя не предусматривалось. Запуск осуществлялся только командами по интерфейсу. Спецификации описывающей стандарт полностью нет, и, следовательно, не было и нет и четкого предначертания, о том, какие именно параметры надлежит контролировать. Более того, их определение и определение допустимого уровня их снижения целиком и полностью предоставлялся производителям винчестеров (что естественно в силу того, что производителю виднее что именно надлежит контролировать данном его винчестере, ибо все винчестеры слишком различны). И программное обеспечение, по этой причине, написанное, как правило, сторонними фирмами, не было универсальным, и могло ошибочно рапортовать о предстоящем сбое (путаница возникала из-за того, что под одним и тем же идентификатором различные производители хранили значения различных параметров). Имело место большое число жалоб на то, что число случаев обнаружения пред сбойного состояния чрезвычайно мало (особенности человеческой природы: получать хочется все и сразу, жаловаться на внезапные отказы дисков до внедрения SAMRT в голову как-то никому не приходило). Ситуация усугубилась еще и тем, что в большинстве случаев не были выполнены минимально необходимые требования для функционирования SMART (об этом поговорим позже). Статистика говорит о том, что число предсказываемых сбоев было менее 20%. Технология на этом этапе была далека от совершенства, но являлась революционным шагом вперед.
О втором этапе развития SMART - SMART II известно также не много. В основном наблюдались те же проблемы, что и с первой. Нововведениями являлись возможность фоновой проверки поверхности, выполняемая диском в автоматическом режиме при простоях и ведение журналов ошибок, расширился список контролируемых параметров (снова же в зависимости от модели и производителя). Статистика говорит о том, что число предсказываемых сбоев достигло 50%.
Современный этап представлен технологией SMART III. На ней остановимся подробней, попытаемся разобраться в общих чертах как она работает, что и зачем в ней нужно.
Нам уже известно, что SMART производит наблюдение за основными характеристиками накопителя. Эти параметры называются атрибутами. Необходимые к мониторингу параметры определяются производителем. Каждый атрибут имеет какую-то величину - Value. Обычно изменяется в диапазоне от 0 до 100 (хотя может быть в диапазоне до 200 или до 255), ее величина - это надежность конкретного атрибута относительно некоторого его эталонного значения (определяется производителем). Высокое значение говорит об отсутствии изменений данного параметра или, в зависимости от значения, его медленном ухудшении. Низкое значение говорит о быстрой деградации или о возможном скором сбое, т.е. чем выше значение Value атрибута, тем лучше. Некоторыми программами мониторинга выводится значение Raw или Raw Value - это значение атрибута во внутреннем формате (который так же различен у дисков разных моделей и разных производителей), в том, в котором он хранится в накопителе. Для простого пользователя он малоинформативен, больший интерес представляет посчитанное из него значение Value. Для каждого атрибута производителем определяется минимальное возможное значение, при котором гарантируется безотказная работа накопителя - Threshold. При значении атрибута ниже величины Threshold очень вероятен сбой в работе или полный отказ. Осталось только добавить, что атрибуты бывают критически важными и некритически. Выход критически важного параметра за пределы Threshold фактический означает выход из строя, выход за переделы допустимых значений некритически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность (хотя, возможно, с некоторым ухудшением некоторых характеристик: производительности например).
К наиболее часто наблюдаемым критически важным характеристикам относятся: Raw Read Error Rate - частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time - время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся немаксимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например блок питания подкачал.
Spin Up Retry Count - число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно немаксимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate - частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count - число операций переназначения секторов. SMART в современных способен произвести анализ сектора на стабильность работы "на лету" и в случае признания его сбойным произвести его переназначение. Ниже мы поговорим об этом подробнее.
Все происходящие ошибки и изменения параметров фиксируются в журналах SMART. Эта возможность появилась уже в SMART II. Все параметры журналов - назначение, размер, их число определяются изготовителем винчестера. Нас с вами в настоящий момент интересует только факт их наличия. Без подробностей. Информация хранящаяся в журналах используется для анализа состояния и составления прогнозов.
Если не вдаваться в подробности, то работа SMART проста - при работе накопителя просто отслеживаются все возникающие ошибки и подозрительные явления, которые находят отражение в соответствующих атрибутах. Кроме того начиная так же со SMART II у многих накопителей появились функции самодиагностики. Запуск тестов SMART возможен в двух режимах, off-line - тест выполняется фактически в фоновом режиме, так как накопитель в любое время готов принять и выполнить команду, и монопольном при котором при поступлении команды, выполнение теста завершается.
Документировано существует три типа тестов самодиагностики: фоновый сбор данных (Off-line collection), сокращенный тест (Short Self-test), расширенный тест (Extended Self-test). Два последних способны выполняться как в фоновом, так и в монопольном режимах. Набор тестов в них входящих не стандартизирован.
Продолжительность их выполнения может быть от секунд до минут и часов. Если вы вдруг не обращаетесь к диску, а он при этом издатет звуки как и при рабочей нагрузке - он просто похоже занимается самоанализом. Все данные собранне в результате таких тестов будут также сохранены в журналах и аттрибутах.
Немного про состояние SSD
SSD также имеют S.M.A.R.T., но их принцип работы сильно отличается, поэтому о том, как узнать состояние SSD, читайте в следующей статье.
Дополнительная полезная информация
Перед тем, как ознакомиться с данным пунктом, настоятельно рекомендуется узнать о базовых принципах работы жесткого диска из Википедии или других источников.
Пункт техсостояние показывает общую усредненную оценку состояния жесткого диска; если мы хотим узнать более подробные сведения о работе диска, то нужно разобраться в основных показателях работы нашего диска. Для этого разберем все строки из таблицы программы. У каждого диска есть предельное значение и фактическое значение. Чтобы было более наглядно, выполните действия как на картинке ниже, установив другое отображение для RAW данных.

Теперь рассмотрим основные колонки данной таблицы.

- Левые голубые и желтые кружочки обозначают оценку программы жесткого диска,
- Атрибут - в ней указывается название параметра,
- Текущее - состояние параметра на данный момент
- Наихудшее - наихудшее значение параметра Текущее за все время.
- Порог - пороговое значение параметра, установленное заводом изготовителем данного диска.
- Raw-значения - самый главный показатель, который нужно сравнивать с полем "Порог"
Н иже вы увидите список, где указан каждый параметр и как он считается; жирным шрифтом в нём отмечены самые важные параметры, которые показывают состояние жесткого диска. Чтобы оценить состояние, нужно каждый параметр из графы "Raw-значения" сравнивать с числом в графе "Порог". Если число из колонки "Raw-значения" больше числа в графе "Порог", то смотрите описание в списке ниже, чтобы оценить состояние диска.
Ох уж эти плохие сектора.
Теперь вернемся к вопросу бэд-секторов, с которых все началось. В SMART III появилась функция, позволяющая прозрачно для пользователя переназначать BAD сектора. Работает механизм достаточно просто, при неустойчивом чтении сектора, или же ошибки его чтения, SMART заносит его в список нестабильных и увеличит их счетчик (Current Pending Sector Count). Если при повторном обращении сектор будет прочитан без проблем, он будет выброшен из этого списка. Если же нет, то при предоставившейся возможности - при отсутствии обращений к диску, диск начнет самостоятельную проверку поверхности, в первую очередь подозрительных секторов. Если сектор будет признан сбойным, то он будет переназначен на сектор из резервной поверхности (соответственно RSC увеличиться). Такое фоновое переназначение приводит к тому, что на современных винчестерах сбойные секторы практически никогда не видны при проверке поверхности сервисными программами. В тоже время, при большом числе плохих секторов их переназначение не может происходить до бесконечности. Первый ограничитель очевиден - это объем резервной поверхности. Именно этот случай я имел ввиду. Второй не столь очевиден - дело в том, что у современных винчестеров есть два дефект-листа P-list (Primary, заводской) и G-list (Growth, формируется непосредственно во время эксплуатации). И при большом числе переназначений может оказаться так, что в G-list не оказывается места для записи о новом переназначении. Эта ситуация может быть выявлена по высокому показателю переназначенных секторов в SMART. В этом случае еще не все потеряно, но это выходит за рамки данной статьи.
Итак, используя данные SMART даже не нося диск в мастерскую можно довольно точно сказать, что с ним происходит. Существуют различные технологии-надстройки над SMART, которые позволяют определить состояние диска еще более точно и практически достоверно причину его неисправности. Об этих технологиях мы поговорим в отдельной статье.
Нужно знать, что приобретения накопителя со SMART не достаточно, для того, что бы быть в курсе всех происходящих с диском проблем. Диск, конечно, может следить за своим состоянием и без посторонней помощи, но он не сможет сам предупредить в случае приближающейся опасности. Нужно что-то, что позволит на основании данных SMART выдать предупреждение. (обычная цепочка приведена на рисунке чуть ниже).
Как вариант возможен BIOS, который при загрузке при включенной соответствующей опции проверяет состояние SMART накопителей. А если же вам хочется вести постоянный контроль за состоянием диска, необходимо использовать какую-то программу мониторинга. Тогда вы сможете видеть информацию в подробном и удобном виде.
SmartMonitor из HDD Speed работающий под DOS
SIGuiardian, работающая из Windows
Об этих программах мы также поговорим в отдельной статье. Именно это я имел ввиду, когда говорил о том, что по началу не выполнялись необходимые требования при эксплуатации жестких дисков с SMART .
Бида! Бида!
Приобрел три винчестера и каждый отработал на сегодняшний день 44-240 часов.
После просмотра SMART данных возникло ощущение, что их надо сдавать обратно.
Указанные ниже параметры – это нормально для новых винчестеров или мне это так повезло.
Проблема №1 самая большая.
Hitachi HTS547550A9 – 500Gb 20часов работы.
1.1. Тест поверхности “S.M.A.R.T. Vision 4.1» обнаружил около 50 зон со скоростью доступа «>500ms». По мере прохождения теста – счетчик «197 Текущее количество нестабильных секторов» то увеличивался, то вдруг обнулялся, хотя при повторном тесте поверхности общее количество секторов «>500ms» - осталось.
Вопрос. Почему программа вначале добавила эти сектора в список подозрительных, а потом убрала? Та же картина наблюдалась и в программе «Victoria 446f» которая была запущена параллельно, чтобы посмотреть как идет учет в ней.
1.2. Та же проблема наблюдается с параметрами «191 | G-Sense Error Rate | 99 | 0 | 99 | 65537 |» которые то опускаются до 99 с RAW 65537, то вдруг снова восстанавливаются до 100 и RAW 0.
Вопрос. Почему постоянно обнуляются SMART данные которые по идее должны вроде как накапливается?
1.3. Разные программы S.M.A.R.T. Vision 4.1 и «Victoria 446f» выдают совершенно разные результат в один и тот же промежуток времени.
Hitachi 500Gb S.M.A.R.T. Vision 4.1
-------------------------------------------------------------------------
ID Name Value| Worst| Tresh| Raw| Health
-------------------------------------------------------------------------
1 Raw read error rate 100| 100| 62| 0| •••••
2 Throughput perfomance 100| 100| 40| 0| •••••
3 Spin-up time 176 | 100 | 33| 73014444033 | •••••
4 Number of spin-up times 100| 100| 0| 21| •••••
5 Reallocated sector count 100| 100| 5| 0| •••••
7 Seek error rate 100| 100| 67| 0| •••••
8 Seek time perfomance 100| 100| 40| 0| •••••
9 Power-on time 100| 100| 0| 44| •••••
10 Spin-up retries 100| 100| 60| 0| •••••
12 Power cycle count 100| 100| 0| 19| •••••
191 G-SENSOR shock counter 100| 96 | 0| 0 | •••••
192 Power-off retract count 100| 100| 0| 4| •••••
193 Load/unload cycle count 100| 100| 0| 585| •••••
194 HDA Temperature 176| 142| 0| 34°C/93°F| ••••
194 Minimum temperature 90| 142| 0| 18°C/64°F| -
194 Maximum temperature 90| 142| 0| 42°C/107°F| -
195 Hardware ECC recovered 100| 84| 0| 0| •••••
196 Reallocated event count 100| 100| 0| 0| •••••
197 Current pending sectors 100| 100| 0| 0| •••••
198 Offline scan UNC sectors 100| 100| 0| 0| •••••
199 Ultra DMA CRC errors 200| 200| 0| 0| •••••
211 Spin running current 153| 100| 0| 131213| •••••
212 SSM errors count 100| 100| 0| 0| •••••
218 FlashROM ECC corr. count 100| 100| 0| 0| •••••
220 Disk shift 1| 1 | 0| 15759 | •
222 Loaded hours 100| 100| 0| 32| •••••
223 Load retry count 100| 100| 0| 0| •••••
226 Load-in time 143| 100| 40| 429503283202| •••••
Особо смущает строка:
220 Disk shift 1| - 1 | - 0| - 15759 | - •
Которая есть в программе Victoria 446f но отсутствует в других программах – частности S.M.A.R.T. Vision 4.1
И особо смущает
| 191 | G-Sense Error Rate | 99 | 0 | 99 | 65537 |
191 G-SENSOR shock counter 100| - 96 | - 0| - 0| - •••••
Параметр которые в разных программах хоть и имеют разное значение – но то прогрессирует то обнуляется, а потом снова прогрессирует при отсутствии каких либо толчков.
Ну и подозрительна скрость шпенделя.
Вопрос. Ваше мнение про данный винчестер и про причуды SMART?
Добавлено через 8 минут
Время работы всего 76 часов.
Но:
| 7 | Частота ошибок позиционирования | 67 | 30 | 60 | 6036900 |
Слишком подозрительно большая. Нежилец?
Добавлено через 19 минут
P.S. Только что обратил внимание.
ST3500630AS 5QG28DHP S.M.A.R.T.:
Как это понимать?
Бида №3
Hitachi 1Tb
Время работы данного винчестера 240 часов.
Но
Вопрос насколько это критично тоже?
Вопрос насколько это критично тоже?
Винт №1 купил для ноутбука.
Винт №2 Для внешнего хранения данных.
Винт №3 для стационарного компа.
Несмотря на важность таких критериев, как скорость работы или шумность диска, самым главным качеством HDD остаётся надёжность. И естественно, она тоже должна как-то измеряться и оцениваться. Уже почти 20 лет в качестве основного диагностического стандарта используется технология S.M.A.R.T. Как пишут в Википедии, S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Общее состояние вашего жесткого диска
Итак, как же узнать, в каком состоянии находится ваш жесткий диск? Вскрывать его и смотреть его внутреннее состояние нельзя. да и незачем. Для оценки его текущего состояния придумали специальную технологию — "S.M.A.R.T.". Эта технология встроена в каждый жесткий диск любого производителя и формата, и позволяет судить о его состоянии, оценивая множество параметров его работы. Просмотреть эту информацию можно разными способами: запустить специальную программу в Windows или использовать специальный загрузчик, который работает напрямую с диска или флешки, и позволяет отобразить эту информацию с жесткого диска. Вторым методом можно воспользоваться, если не работает операционная система, и есть подозрения в неисправности жесткого диска. Мы же воспользуемся первым способом, как наиболее простым и легким.

Одним из преимуществ данной программы является перевод всех показателей жесткого диска.
Выбираем в верхней панели один из жестких дисков:

Первое, на что нужно обратить внимание, так это общий статус диска (левый верхний угол, под надписью "Техсостояние"). Если там написано "Хорошо" или "Отлично", то с вашим диском все в порядке.
В случае, если написано "Тревога", то нужно задуматься о смене диска, и скопировать всю важную информацию на другой диск. Ниже представлен пример скриншота программы для диска на WD 500GB 2008 г. производства. Т.е. на момент написания статьи ему уже 9 лет. Такой диск точно требует замены.

Н еобходимо обращать внимание на температуру диска, она должна быть не выше 45-50 градусов. Если температура превышает данные значения, нужно задуматься об охлаждении вашего диска.
Косвенно о состоянии вашего жесткого диска можно судить по времени его работы. На сайте изготовителе вашего жесткого диска можно найти время наработки на отказ, однако даже если этот порог будет превышен, то это не значит, что жесткий диск не пригоден для использования. Это лишь сигнал к тому, что нужно иногда проверять его состояние.
Сравнение S.M.A.R.T. различных дисков и описание проблем. Примеры оценки.
Диск 1. SeaGate 200 Гб. 2003 г. выпуска

На диске странные значения по Raw-данным, но их появление связано с возрастом диска. На момент написания статьи ему 14 лет.
Диск 2. WesternDigital 500 Гб. 2008 г. выпуска

На диске много переназначенных и нестабильных, значительно превышающих порог — это значит, что размер диска уже уменьшился и идет его деградация.
Диск 3. WesternDigital 250 Гб. 2007 г. выпуска

Диск в полном порядке, однако присутствует странное время раскрутки шпинделя. Диск полностью исправен.
Диск 4. WesternDigital 640 Гб. 2008 г. выпуска

Огромное количество ошибок чтения-записи и нестабильные сектора. Диск на замену.
Функции S.M.A.R.T. - известные и предполагаемые
Поскольку производители тщательно скрывают информацию о структуре программ, составляющих систему S.M.A.R.T., доподлинно известной информации о работе этой подсистемы не так много, как хотелось бы.
Перечень функций, о которых можно сказать, что они присутствуют во всех HDD всех фирм, выглядит следующим образом:
- Сбор информации о состоянии диска, ведение журналов ошибок.
- Ведение счетчиков событий (количества включений, парковок, повторных запусков, срабатываний датчика удара и пр.)
- Тестирование систем накопителя и поверхности магнитных пластин.
Однако на основании опыта специалистов по восстановлению данных есть все основания полагать, что у современных жёстких дисков S.M.A.R.T. не просто подсистема, а основа управляющей программы диска, которая умеет не только вести мониторинг состояния и тестировать HDD, но и, основываясь на собранных данных, предпринимать активные действия по приведению параметров устройства к допустимым значениям.
Возможно, что относительно долгой работой HDD (при современной-то плотности записи), мы обязаны именно технологии S.M.A.R.T, которая выступает в качестве настройщика, который подгоняет параметры чтения/записи под постоянно изменяющееся состояние среды, в которой работает устройство.
Жесткий диск является одним из важнейших компонентов любого ПК. Он хранит в себе всю информацию, которой вы пользуетесь на вашем ПК. Именно поэтому нужно следить за состоянием этого компонента, как и впрочем любого другого, но в случае возникновения проблем с вашим жестким диском, вы можете потерять всю информацию на нём.
Прежде чем перейти к оценке состояния жесткого диска или SSD, необходимо запомнить важное правило:
Всегда делайте копии важных фалов и документов, ведь каким бы надежным и дорогим не был ваш накопитель, от сбоев в его работе никто не застрахован.
Атрибуты S.M.A.R.T.
Атрибуты S.M.A.R.T. - это характеристики, которые используются при анализе состояния и запаса «живучести» накопителя.
Атрибуты вводятся производителем накопителя на основании собственного опыта производства и эксплуатации HDD. Предполагается, что с помощью этих атрибутов, можно предсказывать ухудшение рабочих характеристик накопителя или определить его дефектность. Каждый производитель имеет свой характерный набор атрибутов, и вносит изменения в этот набор в соответствии со своими собственными соображениями, никого об этом не уведомляя. Конечному пользователю остается только доверять мнению производителя. Значения атрибутов (value) используются для представления надежности отдельного показателя, относительно его эталонного значения. Каждый атрибут имеет собственное пороговое значение (threshold), оно необходимо для сравнения со значением атрибута и указывает на ухудшение рабочих характеристик или дефектность накопителя. Допустимое значение атрибута - относительное, и судить о его величине можно лишь сравнивая его с threshold. Высокое значение атрибута говорит о том, что параметр в порядке и имеет низкую вероятность ухудшения и выхода накопителя из строя. Соответственно, низкое значение атрибута говорит о том, что результат анализа параметра указывает на высокую вероятность его ухудшения или выхода накопителя из строя.
Производитель определяет числовое значение порогового атрибута анализируя результаты испытаний на надежность. Пороговое значение каждого атрибута указывает на нижнюю допустимую границу значения атрибута, до которой накопитель можно считать надежным.
Атрибут Worst - наихудшее значение атрибута за всю историю работы HDD - читается из логов S.M.A.R.T. и помогает понять, в каких условиях работал накопитель.
Атрибут Raw является текущим значением измеряемого параметра. Его размерность, в зависимости от типа параметра, может быть в «разах» (к примеру, количество парковок), градусах, часах и в других величинах (частота ошибок чтения и т.д.).
Продвинутый читатель может заметить, что мы привели не так уж много примеров атрибутов в статье. Это так. Многие программы отображают больше атрибутов, но хотим заверить вас, если изменится значение атрибута, к примеру, «Disk Shift» (смещение пакета дисков относительно оси шпинделя), то ваш диск - труп, и его нужно нести в сервис по восстановлению данных или выбрасывать. Все атрибуты используют только в специальных подразделениях компаний-производителей HDD, так называемых «Failure Analysis», где специалисты исследуют причины отказов дисков. Представленного же в этой статье набора атрибутов вполне достаточно для оценки состояния жесткого диска.
Режимы сбора данных в S.M.A.R.T.
Сбор текущих данных S.M.A.R.T. (on-line-режим): Сбор текущих данных S.M.A.R.T. не должен мешать нормальной работе устройства. Данные S.M.A.R.T., которые в настоящий момент собираются, или методы, которыми пользуется технология для сбора данных, могут отличаться от методов, используемых для хранения данных S.M.A.R.T. (типы таблиц и т.п.), и могут также отличаться от устройства к устройству.
On-line режим означает, что HDD производит сбор информации о параметрах чтения/записи во время обработки запросов операционной системы, дискретно записывая полученную статистику в таблицы S.M.A.R.T. Это не сказывается на скорости обработки команд накопителем.
Сбор данных в режиме off-line (накопитель активен, но не выполняет никаких действий по интерфейсу) Устройство может использовать режим off-line для сбора данных и проведения самотестирования. Такой режим работы S.M.A.R.T. может меняться от устройства к устройству. Собранные данные или методики сбора данных в этом режиме могут отличаться от методик, используемых при сборе текущих данных (режим on-line) для любого устройства и могут варьировать от устройства к устройству.
Off-line режим представляет собой самотестирование HDD, при котором устройство производит сканирование определенных областей магнитных пластин, оценивает работу механических частей, тестирует оперативную память и канал чтения/записи. Если вы слышите, как ваш жёсткий диск активно жужжит, в момент, когда у операционной системы нет активных задач - скорее всего, это означает идущее off-line сканирование.
Основные параметры S.M.A.R.T.
- Ошибки чтения (Raw Read Error Rate) - атрибут показывает количество ошибок чтения с пластин жесткого диска. На дисках WD, Samsung до SpinPoint F1 (не включительно), Hitachi большое значение параметра указывает на аппаратные проблемы с диском. На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания. Смотреть число в графе Raw-значения.
- Время раскрутки (Spin-Up Time) - время раскрутки шпинделя с "блинами", значение не влияет на состояние диска.
- Запуски/Остановки шпинделя (Number of Spin-Up Times (Start/Stop Count)) - количество запусков и остановок шпинделя, не влияет на состояние диска.
- Переназначенные сектора (Reallocated Sector Count) - Очень важный параметр для оценки состояния диска. Сама суть параметра: при работе диска через какое-то время появляются битые сектора, которые неправильно записываются или читаются. Диск их помечает и заменяет на другие, которые были заранее зарезервированы производителем. Это параметр показывает количество таких переназначений. Если число в графе "Raw-значения" больше числа в графе "Порог", то у диска закончились резервные сектора и начинаются ошибки в работе. При превышении значения "порог" более чем на 10%, желательна замена диска.
- Ошибки позиционирования (Seek Error Rate) - частота ошибки позиционирования головок на "блинах" жесткого диска. Не влияет на состояние диска.
- Часы работы (Power On Hours Count (Power-on Time)) - значение показывает количество часов работы диска. Ничего не говорит о его состоянии.
- Повторные попытки раскрутки (Spin Retry Count) - количество повторных попыток раскрутить шпиндель жесткого диска с "блинами". Чаще всего ничего не говорит о здоровье диска, но значительное увеличение этого параметра указывает на плохой контакт проводов питания или нестабильную работу блока питания компьютера.
- Повторы рекалибровки (Calibration Retry Count (Recalibration Retries)) - показывает количество попыток жесткого диска установки головки считывания на нулевую дорожку. Ненулевое, а особенно растущее значение параметра, может означать проблемы с диском.
- Включения/Отключения (Power Cycle Count) - количество полных циклов «включение-отключение» диска. Не связан с состоянием диска.
- End-to-End ошибки - ошибка четности при передаче данных между кэшем и хостом. При увеличении параметра вероятны проблемы с диском.
- Отказы отключения питания (Power Off Retract Count (Emergency Retry Count)) - количество суммарных циклов включения, отключения диска. Не влияет на состояние диска.
- Циклы загрузки/выгрузки (Load/Unload Cycle Count) - количество циклов парковки и распарковки головок. Не влияет на состояние диска.
- Температура (Temperature (HDA Temperature, HDD Temperature)) - показывает температуру диска. На разных дисках датчик температуры находиться в разных местах. Не влияет на состояние диска, но при превышении 55-60 градусов стоит задуматься о его охлаждении.
- События переназначения (Reallocated Event Count) - количество операций переназначения секторов. Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
- Нестабильные сектора ( Current Pending Sector Count ) - количество нестабильных секторов, которые когда то диск посчитал испорченными, каждый раз перед записью в такой сектор, диск проверяет этот сектор на стабильность и в зависимости от его состояния, либо заменяет его на резервный либо помечает как битый. Ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
- Неисправимые ошибки секторов (Offline Uncorrectable Sector Count (Uncorrectable Sector Count)) - обозначает тоже самое что и в предыдущем пункте, но эти данные диск получает в режиме самотестирования в простое.Ненулевое значение говорит о неполадках на диске.
- CRC-ошибки UltraDMA (UltraDMA CRC Error Count) - количество ошибок при передаче данных между жестким диском и материнской платой. Увеличения значения свидетельствует о некачественном кабеле, на здоровье диска не влияет.
- Ошибки записи (Write Error Rate (MultiZone Error Rate)) - частота возникновения ошибок записи. Ненулевое значение говорит о проблемах с диском, а именно о износе магнитных головок.
- Ошибки адресации данных (Data Address Mark Error) - содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо.
История S.M.A.R.T.
Появление технологии мониторинга состояния накопителей на жёстких магнитных дисках стало естественным ответом на возрастающие требования к их надёжности. Первая разработка в этой области была выпущена компанией IBM в 1992 году, и называлась PFA (Predictive Failure Analysis).
В 1994 году компаниями Compaq, Seagate, Quantum и Conner была разработана технология IntelliSafe, а уже в 1995 году на её основе появился стандарт технологии S.M.A.R.T.: Self-Monitoring, Analysis and Reporting Technology - "Технология самодиагностики, анализа и отчёта".
После этого их уже поддержали такие компании как IBM, Maxtor и Samsung. Hitachi приняла участие в развитии технологии S.M.A.R.T. уже на стадии разработки SMART II, первыми предложив методику полной самодиагностики накопителя (extended self-test). Сущность технологии описана в стандарте, называющемся «Information Technology - AT Attachment … - ATA/ATAPI Command Set» (Информационная технология - в приложении… - набор команд ATA/ATAPI). Вместо многоточия ставится номер стандарта. Наиболее новая ревизия стандарта-8, является только продолжением и дополнением стандартов 2, 4, 6 и 7. Раздел о S.M.A.R.T. есть в каждом из них.
Этот стандарт описывает принципы, на которых общаются между собой HDD и компьютер. В стандарте описаны только общие правила функционирования S.M.A.R.T., необходимые для совместимости всех жестких дисков со всеми компьютерами - остальные же функции в общедоступной документации не представлены, являются разработками компаний-производителей HDD (вендоров) и охраняются как коммерческая тайна.
Стандарты S.M.A.R.T.
Разберём, как трактует технологию S.M.A.R.T. стандарт АТА-АТАРI (далее курсивом выделены цитаты из стандарта ATA-ATAPI-8):
Назначением технологии S.M.A.R.T. является защита данных пользователя и минимизация вероятности их потери посредством предсказания деградации и/или выхода из строя устройства. Контролируя и сохраняя критические рабочие и калибровочные параметры, SMART устанавливает устройству возможность предсказания ближайшего времени деградации или отказа устройства.
Таким образом, S.M.A.R.T. обеспечивает компьютеру (хосту) возможность узнать о низкой надежности устройства, и предупреждает пользователя об этом, чтобы уменьшить риск потери данных.
Поддержка технологии S.M.A.R.T. указывается в ответе устройства на команду, подаваемую BIOS при опросе подключенных HDD.
Однако устройства, которые поддерживают пакетные команды (это, к примеру, DVD-ROM) не поддерживают S.M.A.R.T. так, как это делают HDD (пакетные устройства общаются с хостом посредством АТА команд, но как бы «обернутых» в оболочку из команд SCSI).
Устройства, поддерживающие пакетные команды, поддерживают S.M.A.R.T. в виде, определённом для таких устройств, с использованием пакетных команд.
Структура данных S.M.A.R.T.-устройства: функция S.M.A.R.T. - устанавливать информацию о надежности и состоянии устройства и хранить эту информацию в специализированных S.M.A.R.T.-структурах устройства. Набор хранимых устройством S.M.A.R.T.-данных может быть использован при запуске команды S.M.A.R.T. EXECUTE OFF-LINE IMMEDIATE (Смарт: немедленно перейти в режим off-line), если эта команда поддерживается устройством.
Такую команду может подавать BIOS (если включена опция отслеживания SMART в BIOS) при считывании информации о состоянии HDD из структуры SMART при запуске компьютера. Следует отметить, что, на самом деле, атрибутов SMART очень много, и они различны у разных вендоров. Пользователю доступна лишь относительно небольшая часть собранной HDD информации, которой, в прочем, вполне достаточно.
Лог S.M.A.R.T.
Узнать о проблемах в диском можно при загрузке компьютера. Функция контроля состояния S.M.A.R.T. встроена во все современные BIOS – ведь именно для этого и создавалась технология.
Однако BIOS лишь пишет bad или good. Выяснить, в чём именно проблема можно только с помощью специальной программы анализа атрибутов.
Приведём пример лога S.M.A.R.T. типичного, вполне исправного, HDD WD3200AAKS-00L9A0, открытого в программе Smart Vision от Ace Lab:
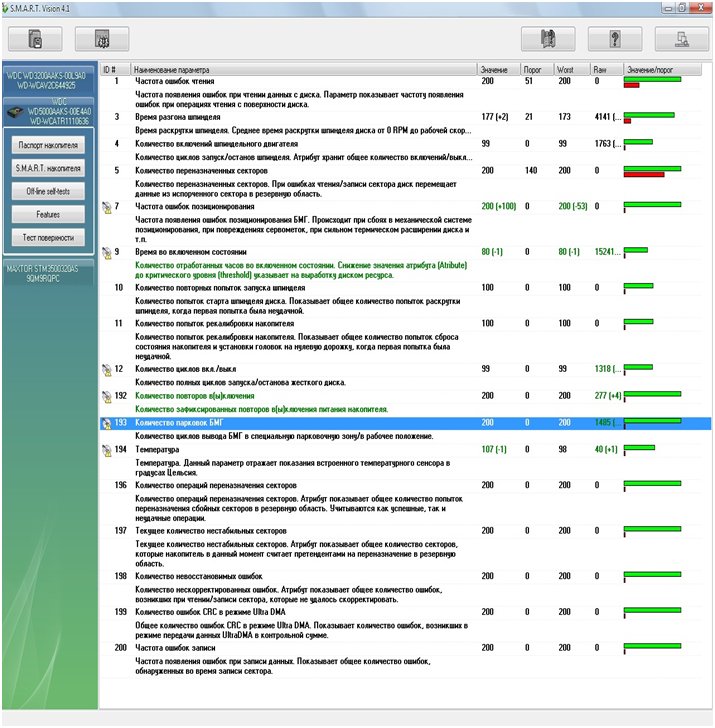
Как видим, здесь приведены наиболее критичные для надежности HDD атрибуты. Это пример S.M.A.R.T. уже «повидавшего жизнь» диска. Его надежность на удовлетворительном уровне (не превышены атрибуты «1» и «5»), но подумать о неспешной замене стоит.
Рассмотрим каждый атрибут подробнее.
- Частота ошибок чтения: насколько часто возникают ошибки при чтении секторов. Ухудшение значения этого атрибута может свидетельствовать о разрушении магнитного слоя, износе механических составляющих диска, о существенном превышении температуры.
- Время раскрутки шпинделя: если двигатель медленно раскручивает пакет с магнитными пластинами, это может означать потерю мощности двигателя (следовательно, угрозу обрыва провода в обмотке) или увеличение сопротивления в гидродинамическом подшипнике (возникновение заусенца внутри корпуса подшипника, к примеру).
- Количество включений шпиндельного двигателя: счетчик, по нему можно косвенно определить время и режим работы диска.
- Количество переназначенных секторов: критически важный атрибут. Если ошибка чтения часто обратима, и может быть обусловлена условиями работы диска, то ухудшение атрибута «количество переназначенных секторов» явно свидетельствует о повреждении поверхности дисков. Переполнение таблиц дефектов – одна из наиболее часто встречающихся неисправностей HDD.
- Частота ошибок позиционирования: ухудшение этого атрибута может указывать на превышение температуры или износ механических частей.
- Время во включенном состоянии: время работы диска.
- Количество повторных попыток запуска шпинделя: ухудшение атрибута может свидетельствовать об ухудшении состояния двигателя, механики или поверхности магнитных дисков.
Этапы развития технологии
В своем развитии технология SMART прошла три этапа. В первом поколении было реализовано наблюдение небольшого числа параметров. Никаких самостоятельных действий накопителя не предусматривалось. Запуск осуществлялся только командами по интерфейсу. Спецификации описывающей стандарт полностью нет, и, следовательно, не было и нет и четкого предначертания, о том, какие именно параметры надлежит контролировать. Более того, их определение и определение допустимого уровня их снижения целиком и полностью предоставлялся производителям винчестеров (что естественно в силу того, что производителю виднее что именно надлежит контролировать данном его винчестере, ибо все винчестеры слишком различны). И программное обеспечение, по этой причине, написанное, как правило, сторонними фирмами, не было универсальным, и могло ошибочно рапортовать о предстоящем сбое (путаница возникала из-за того, что под одним и тем же идентификатором различные производители хранили значения различных параметров). Имело место большое число жалоб на то, что число случаев обнаружения пред сбойного состояния чрезвычайно мало (особенности человеческой природы: получать хочется все и сразу, жаловаться на внезапные отказы дисков до внедрения SAMRT в голову как-то никому не приходило). Ситуация усугубилась еще и тем, что в большинстве случаев не были выполнены минимально необходимые требования для функционирования SMART (об этом поговорим позже). Статистика говорит о том, что число предсказываемых сбоев было менее 20%. Технология на этом этапе была далека от совершенства, но являлась революционным шагом вперед.
О втором этапе развития SMART - SMART II известно также не много. В основном наблюдались те же проблемы, что и с первой. Нововведениями являлись возможность фоновой проверки поверхности, выполняемая диском в автоматическом режиме при простоях и ведение журналов ошибок, расширился список контролируемых параметров (снова же в зависимости от модели и производителя). Статистика говорит о том, что число предсказываемых сбоев достигло 50%.
Современный этап представлен технологией SMART III. На ней остановимся подробней, попытаемся разобраться в общих чертах как она работает, что и зачем в ней нужно.
Нам уже известно, что SMART производит наблюдение за основными характеристиками накопителя. Эти параметры называются атрибутами. Необходимые к мониторингу параметры определяются производителем. Каждый атрибут имеет какую-то величину - Value. Обычно изменяется в диапазоне от 0 до 100 (хотя может быть в диапазоне до 200 или до 255), ее величина - это надежность конкретного атрибута относительно некоторого его эталонного значения (определяется производителем). Высокое значение говорит об отсутствии изменений данного параметра или, в зависимости от значения, его медленном ухудшении. Низкое значение говорит о быстрой деградации или о возможном скором сбое, т.е. чем выше значение Value атрибута, тем лучше. Некоторыми программами мониторинга выводится значение Raw или Raw Value - это значение атрибута во внутреннем формате (который так же различен у дисков разных моделей и разных производителей), в том, в котором он хранится в накопителе. Для простого пользователя он малоинформативен, больший интерес представляет посчитанное из него значение Value. Для каждого атрибута производителем определяется минимальное возможное значение, при котором гарантируется безотказная работа накопителя - Threshold. При значении атрибута ниже величины Threshold очень вероятен сбой в работе или полный отказ. Осталось только добавить, что атрибуты бывают критически важными и некритически. Выход критически важного параметра за пределы Threshold фактический означает выход из строя, выход за переделы допустимых значений некритически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность (хотя, возможно, с некоторым ухудшением некоторых характеристик: производительности например).
К наиболее часто наблюдаемым критически важным характеристикам относятся: Raw Read Error Rate - частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time - время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся немаксимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например блок питания подкачал.
Spin Up Retry Count - число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно немаксимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate - частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count - число операций переназначения секторов. SMART в современных способен произвести анализ сектора на стабильность работы "на лету" и в случае признания его сбойным произвести его переназначение. Ниже мы поговорим об этом подробнее.
Все происходящие ошибки и изменения параметров фиксируются в журналах SMART. Эта возможность появилась уже в SMART II. Все параметры журналов - назначение, размер, их число определяются изготовителем винчестера. Нас с вами в настоящий момент интересует только факт их наличия. Без подробностей. Информация хранящаяся в журналах используется для анализа состояния и составления прогнозов.
Если не вдаваться в подробности, то работа SMART проста - при работе накопителя просто отслеживаются все возникающие ошибки и подозрительные явления, которые находят отражение в соответствующих атрибутах. Кроме того начиная так же со SMART II у многих накопителей появились функции самодиагностики. Запуск тестов SMART возможен в двух режимах, off-line - тест выполняется фактически в фоновом режиме, так как накопитель в любое время готов принять и выполнить команду, и монопольном при котором при поступлении команды, выполнение теста завершается.
Документировано существует три типа тестов самодиагностики: фоновый сбор данных (Off-line collection), сокращенный тест (Short Self-test), расширенный тест (Extended Self-test). Два последних способны выполняться как в фоновом, так и в монопольном режимах. Набор тестов в них входящих не стандартизирован.
Продолжительность их выполнения может быть от секунд до минут и часов. Если вы вдруг не обращаетесь к диску, а он при этом издатет звуки как и при рабочей нагрузке - он просто похоже занимается самоанализом. Все данные собранне в результате таких тестов будут также сохранены в журналах и аттрибутах.
Читайте также: