
Архитектура процессора pentium pro какой способ обработки данных противоречит принципам фон неймана
Одной из главных особенностей шестого поколения микропроцессоров архитектуры IA32 является динамическое (спекулятивное) исполнение . Под этим термином подразумевается следующая совокупность возможностей:
- Глубокое предсказание ветвлений (с вероятностью >90% можно предсказать 10-15 ближайших переходов).
- Анализ потока данных (на 20-30 шагов вперед просмотреть программу и определить зависимость команд по данным или ресурсам).
- Опережающее исполнение команд (МП P6 может выполнять команды в порядке, отличном от их следования в программе).
Внутренняя организация МП P6 соответствует архитектуре RISC , поэтому блок выборки команд, считав поток инструкций IA-32 из L1 кэша инструкций, декодирует их в серию микроопераций. Поток микроопераций попадает в буфер переупорядочивания ( пул инструкций). В нем содержатся как не выполненные пока микрооперации , так и уже выполненные, но еще не повлиявшие на состояние процессора. Для декодирования инструкций предназначены три параллельных дешифратора: два для простых и один для сложных инструкций. Каждая инструкция IA-32 декодируется в 1-4 микрооперации . Микрооперации выполняются пятью параллельными исполнительными устройствами: два для целочисленной арифметики, два для вещественной арифметики и блок интерфейса с памятью. Таким образом, возможно выполнение до пяти микроопераций за такт.
Блок исполнительных устройств способен выбирать инструкции из пула в любом порядке. При этом благодаря блоку предсказания ветвлений возможно выполнение инструкций, следующих за условными переходами. Блок резервирования постоянно отслеживает в пуле инструкций те микрооперации , которые готовы к исполнению (исходные данные не зависят от результата других невыполненных инструкций) и направляет их на свободное исполнительное устройство соответствующего типа. Одно из целочисленных исполнительных устройств дополнительно занимается проверкой правильности предсказания переходов. При обнаружении неправильно предсказанного перехода все микрооперации , следующие за переходом, удаляются из пула и производится заполнение конвейера команд инструкциями по новому адресу.
Взаимная зависимость команд от значения регистров архитектуры IA-32 может требовать ожидания освобождения регистров. Для решения этой проблемы предназначены 40 внутренних регистров общего назначения, используемых в реальных вычислениях.
Блок удаления отслеживает результат спекулятивно выполненных микроопераций. Если микрооперация более не зависит от других микроопераций, ее результат переносится на состояние процессора, и она удаляется из буфера переупорядочивания. Блок удаления подтверждает выполнение инструкций (до трех микроопераций за такт) в порядке их следования в программе, принимая во внимание прерывания, исключения, точки останова и промахи предсказания переходов.
Одной из главных особенностей шестого поколения микропроцессоров архитектуры IA32 является динамическое (спекулятивное) исполнение . Под этим термином подразумевается следующая совокупность возможностей:
- Глубокое предсказание ветвлений (с вероятностью >90% можно предсказать 10-15 ближайших переходов).
- Анализ потока данных (на 20-30 шагов вперед просмотреть программу и определить зависимость команд по данным или ресурсам).
- Опережающее исполнение команд (МП P6 может выполнять команды в порядке, отличном от их следования в программе).
Внутренняя организация МП P6 соответствует архитектуре RISC , поэтому блок выборки команд, считав поток инструкций IA-32 из L1 кэша инструкций, декодирует их в серию микроопераций. Поток микроопераций попадает в буфер переупорядочивания ( пул инструкций). В нем содержатся как не выполненные пока микрооперации , так и уже выполненные, но еще не повлиявшие на состояние процессора. Для декодирования инструкций предназначены три параллельных дешифратора: два для простых и один для сложных инструкций. Каждая инструкция IA-32 декодируется в 1-4 микрооперации . Микрооперации выполняются пятью параллельными исполнительными устройствами: два для целочисленной арифметики, два для вещественной арифметики и блок интерфейса с памятью. Таким образом, возможно выполнение до пяти микроопераций за такт.
Блок исполнительных устройств способен выбирать инструкции из пула в любом порядке. При этом благодаря блоку предсказания ветвлений возможно выполнение инструкций, следующих за условными переходами. Блок резервирования постоянно отслеживает в пуле инструкций те микрооперации , которые готовы к исполнению (исходные данные не зависят от результата других невыполненных инструкций) и направляет их на свободное исполнительное устройство соответствующего типа. Одно из целочисленных исполнительных устройств дополнительно занимается проверкой правильности предсказания переходов. При обнаружении неправильно предсказанного перехода все микрооперации , следующие за переходом, удаляются из пула и производится заполнение конвейера команд инструкциями по новому адресу.
Взаимная зависимость команд от значения регистров архитектуры IA-32 может требовать ожидания освобождения регистров. Для решения этой проблемы предназначены 40 внутренних регистров общего назначения, используемых в реальных вычислениях.
Блок удаления отслеживает результат спекулятивно выполненных микроопераций. Если микрооперация более не зависит от других микроопераций, ее результат переносится на состояние процессора, и она удаляется из буфера переупорядочивания. Блок удаления подтверждает выполнение инструкций (до трех микроопераций за такт) в порядке их следования в программе, принимая во внимание прерывания, исключения, точки останова и промахи предсказания переходов.
Одной из главных особенностей шестого поколения микропроцессоров архитектуры IA32 является динамическое (спекулятивное) исполнение . Под этим термином подразумевается следующая совокупность возможностей:
- Глубокое предсказание ветвлений (с вероятностью >90% можно предсказать 10-15 ближайших переходов).
- Анализ потока данных (на 20-30 шагов вперед просмотреть программу и определить зависимость команд по данным или ресурсам).
- Опережающее исполнение команд (МП P6 может выполнять команды в порядке, отличном от их следования в программе).
Внутренняя организация МП P6 соответствует архитектуре RISC , поэтому блок выборки команд, считав поток инструкций IA-32 из L1 кэша инструкций, декодирует их в серию микроопераций. Поток микроопераций попадает в буфер переупорядочивания ( пул инструкций). В нем содержатся как не выполненные пока микрооперации , так и уже выполненные, но еще не повлиявшие на состояние процессора. Для декодирования инструкций предназначены три параллельных дешифратора: два для простых и один для сложных инструкций. Каждая инструкция IA-32 декодируется в 1-4 микрооперации . Микрооперации выполняются пятью параллельными исполнительными устройствами: два для целочисленной арифметики, два для вещественной арифметики и блок интерфейса с памятью. Таким образом, возможно выполнение до пяти микроопераций за такт.
Блок исполнительных устройств способен выбирать инструкции из пула в любом порядке. При этом благодаря блоку предсказания ветвлений возможно выполнение инструкций, следующих за условными переходами. Блок резервирования постоянно отслеживает в пуле инструкций те микрооперации , которые готовы к исполнению (исходные данные не зависят от результата других невыполненных инструкций) и направляет их на свободное исполнительное устройство соответствующего типа. Одно из целочисленных исполнительных устройств дополнительно занимается проверкой правильности предсказания переходов. При обнаружении неправильно предсказанного перехода все микрооперации , следующие за переходом, удаляются из пула и производится заполнение конвейера команд инструкциями по новому адресу.
Взаимная зависимость команд от значения регистров архитектуры IA-32 может требовать ожидания освобождения регистров. Для решения этой проблемы предназначены 40 внутренних регистров общего назначения, используемых в реальных вычислениях.
Блок удаления отслеживает результат спекулятивно выполненных микроопераций. Если микрооперация более не зависит от других микроопераций, ее результат переносится на состояние процессора, и она удаляется из буфера переупорядочивания. Блок удаления подтверждает выполнение инструкций (до трех микроопераций за такт) в порядке их следования в программе, принимая во внимание прерывания, исключения, точки останова и промахи предсказания переходов.
За последние тридцать лет компьютеры настолько стали популярны, что успели изменить многие процессы в жизни человека и соответственно общества. С каждым годом, согласно закону Мура, они приобретают все больше вычислительных способностей, что позволяет им решать все более сложные задачи. Уже сегодня компьютеры столкнулись с рядом ограничений, которые не позволяют нам решать задачи из фильмов про будущее. Так ли будет и дальше, есть ли предел у современной архитектуры и что нам делать, если такой стремительный рост в дальнейшем невозможен?

На изображении отладочная плата с расположенными чипами Loihi.
Компьютер фон Неймана все так же будет обрабатывать задачи, связанные с реляционными базами данных (про BigData не уверен), численными методами, интернетом и тд. В общем он так и будет заниматься всем тем, для чего он был создан, но уже не будет такого быстрого прироста вычислительных способностей, а для решения задач обработки сигналов “реального мира” будет использоваться другой архитектурный подход. Оба архитектурных подхода будут использоваться на одной печатной плате, а со временем и в одном чипе.
Эта статья является вступлением для статьи Neuromorphic inspired computing и описывает проблематику вопроса, решения предлагаются во второй статье.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Потребление электроэнергии и размер суперкомпьютеров
В современном мире, когда мобильный телефон обладает вычислительными способностями компьютера пятилетней давности и при этом работает от аккумулятора, нам кажется, что мы почти достигли предела в уменьшении потребления энергии компьютерами. Но, если мы сравним вычислительные способности суперкомпьютера IBM Summit, его размеры и потребляемые им объемы энергии с мозгом мыши, окажется, что он неимоверно большой и очень неэффективный.

Рис 4. IBM Power System AC922, IBM POWER9 22C 3.07GHz, NVIDIA Volta GV100, Dual-rail Mellanox
EDR InfiniBand, 2.41 million cores, 148.6 petaflops
Пиковая потребляемая мощность: 13 000 000 W
Размеры: 4,608 nodes * 0.2 m^3 = 920 m^3
Мозг мыши способен обрабатывать куда более сложные задачи при потреблении всего 1-5 ватт.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Физические ограничения материалов
Согласно закону Мура, количество транзисторов удваивается примерно каждые два года при уменьшении стоимости их производства. Реализуется этот факт посредством уменьшения размера транзистора. Уменьшение размеров транзистора приводит нас к еще одному ограничению: их размеры обусловлены физическими свойствами материалов из которых они производятся.
Реалии представляются таким образом, что этот закон начинает испытывать давление со стороны “законов физики микромира”.

Рис. 2. Уменьшение размеров транзистора приводит к ошибкам в его производстве
Тут мы сталкиваемся сразу с несколькими сложностями:
- Во-первых, при уменьшении размеров электрический разряд начинает “пробивать” затвор и затвор перестает выполнять свою роль.
- Во-вторых, усложняется задача отведения тепла от такого транзистора.
- В-третьих, при уменьшении размера транзистора брак при их производстве возрастает, так как меньшее количество вещества на молекулярном уровне формирует сам транзистор.
Классическая архитектура фон Неймана
“Бутылочное горлышко” архитектуры фон Неймана.
Все классические компьютеры обладают так называемой архитектурой фон Неймана.
Рис. 1. The decline of von Neumanns architecture
Недостатком такой архитектуры является тот факт, что данные из области памяти цикл за циклом должны передаваться в область вычислительного юнита и обратно. Интерфейс, связывающий вычислительный юнит и память компьютера, ограничен в своей пропускной способности. Даже тот факт, что современные процессоры имеют несколько уровней кэша непосредственно в вычислительном юните, не решает проблему. Данный подход усугубляется необходимостью аккумулировать и структурировать данные для полного заполнения буфера вычисляемых операций. Можно привести метафору с поездом: пока все пассажиры не займут именно свои места в поезде, поезд никуда не поедет.
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Классическая архитектура фон Неймана
“Бутылочное горлышко” архитектуры фон Неймана.
Все классические компьютеры обладают так называемой архитектурой фон Неймана.
Рис. 1. The decline of von Neumanns architecture
Недостатком такой архитектуры является тот факт, что данные из области памяти цикл за циклом должны передаваться в область вычислительного юнита и обратно. Интерфейс, связывающий вычислительный юнит и память компьютера, ограничен в своей пропускной способности. Даже тот факт, что современные процессоры имеют несколько уровней кэша непосредственно в вычислительном юните, не решает проблему. Данный подход усугубляется необходимостью аккумулировать и структурировать данные для полного заполнения буфера вычисляемых операций. Можно привести метафору с поездом: пока все пассажиры не займут именно свои места в поезде, поезд никуда не поедет.
Online learning and continuous-flow
Тут хочется сказать больше об алгоритмах, нежели об архитектуре, хотя в данном контексте алгоритмы продиктованы архитектурой. Современный компьютер хорошо справляется с дискретными данными, когда есть, пускай и большое количество, но все же порционных, конечных, желательно целочисленных данных, тут он может себя проявить очень хорошо. Но вот, когда речь заходит о последовательностях, непрерывности, бесконечно малых или бесконечно больших значениях, тут мы пытаемся найти некое приближение. В результате мы интерпретируем наши данные в последовательность дискретных кадров, дробим, разделяем и обрабатываем каждый фрейм как нечто статическое и конечное.
Да, сейчас существуют различные подходы bi-directional soft attention (см. BERT) для того, чтобы связывать эти самые кадры в работе с языковыми моделями. Также современные подходы машинного обучения лишены возможности обучаться непосредственно в процессе решения поставленной задачи. Это все еще две различные задачи.
Прерывания
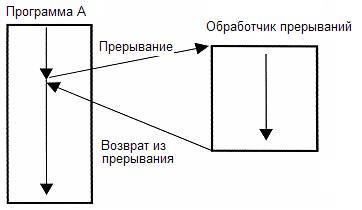
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Параллелизм и масштабируемость
Возвращаясь к архитектуре фон Неймана, мы видим, что весь поток данных проходит через некий вычислительный центр, то есть по сути еще одно узкое горлышко. Количество ядер в современных чипах растет, но вслед за этим возникает и новая проблема: сперва данные нужно распараллелить, а после синхронизировать результаты. То есть, если у вас множество независимых входных сигналов и они не связаны между собой ни во времени, ни в контексте, множество ядер процессоров и ядер видеокарт хорошо справляются с этой задачей. Но в том случае, если у вас большой входной сигнал, то задача параллелизма вычислений, синхронизации результатов может занять большую часть этих самых вычислений.
Оригинал статьи
В следующей статье я рассказываю как решают все перечисленные сложности по средствам Neuromorphic архитектуры.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Отказоустойчивость и брак в производстве
Задумывались ли вы, как производят младшие модели процессоров и чипов для видеокарт? Вы наверное подумаете, что есть специально выделенные команды, которые разрабатывают каждый год новый упрощенный чип. На самом деле процесс выглядит по-другому. Компания разрабатывает один максимально мощный чип. Его устройство выглядит, как некая повторяющаяся архитектура. Обратите внимание на то, что практически все элементы дублируются, как и в авиации.

Рис. 3. Блок схема процессора Xeon
Подход хороший, но он требует отключения очень больших блоков: в случае отказа нескольких транзисторов, которых в одном ядре может быть семьсот миллионов. То есть отказ 0.000000001% транзисторов приводит к потере 10% и более производительности устройства.
Если предположить, что мы можем создавать блоки, основанные на ста транзисторах при количестве этих самых блоков более миллиона мы бы получили значительный прирост отказоустойчивости в чипе. Это значит, что при выходе из строя небольшого количества транзисторов мы бы теряли очень маленький процент блоков от их общего числа. Этот подход сильно бы удешевил стоимость производства, и топовый чип стоил бы уже не, как малолитражный автомобиль, а как хорошая рубашка.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Читайте также: