
2 какие команды может осуществить процессор
Заказать трехфазный двигатель в Новосибирске с доставкой по городу.
Система команд процессора
Хранение информации — регистры и память
Как говорилось ранее, процессор выполняет поступающие на него команды. Команды в большинстве случаев работают с данными, которые могут быть промежуточными, входными или выходными. Все эти данные вместе с инструкциями сохраняются в регистрах и памяти.
Принцип работы процессора.
Процессор является одним из тех устройств, которые все время должен работать. Процессор ПК не может быть выключен. Даже если на наш взгляд процессор ничего не делает, все равно выполняется какая-то программа.
Процессор работает, по сравнению с другими устройствами компьютера, с наибольшей скоростью. И самыми медленными по сравнению с ним являются внешние устройства, в том числе и человек. Так, например, работая с клавиатурой, человек отправляет в компьютер в среднем один байт в секунду (нажимает на одну клавишу в секунду). Процессор обрабатывает такую и формацию за 0,000001 секунды. А что же делает процессор в остальное время, если он не может выключаться? А в остальное время он может получать сигналы от мыши, от других компьютеров, от гибких и жестких дисков. Он успевает несколько раз в течение секунды подзарядить оперативную память, обслужить внутренние часы компьютера, отдать распоряжение, как правильно отображать информацию на экране, и выполнить множество прочих дел.
Команды (инструкции)
Команды — это фактические действия, которые компьютер должен выполнять. Они бывают нескольких типов:
- Арифметические: сложение, вычитание, умножение и т. д.
- Логические: И (логическое умножение/конъюнкция), ИЛИ (логическое суммирование/дизъюнкция), отрицание и т. д.
- Информационные: move , input , outptut , load и store .
- Команды перехода: goto , if . goto , call и return .
- Команда останова: halt .
Прим. перев. На самом деле все арифметические операции в АЛУ могут быть созданы на основе всего двух: сложение и сдвиг. Однако чем больше базовых операций поддерживает АЛУ, тем оно быстрее.
Инструкции предоставляются компьютеру на языке ассемблера или генерируются компилятором высокоуровневых языков.
В процессоре инструкции реализуются на аппаратном уровне. За один такт одноядерный процессор может выполнить одну элементарную (базовую) инструкцию.
Группу инструкций принято называть набором команд (англ. instruction set).
Устройство управления
Устройство управления (УУ) помогает процессору контролировать и выполнять инструкции. УУ сообщает компонентам, что именно нужно делать. В соответствии с инструкциями он координирует работу с другими частями компьютера, включая второй основной компонент — арифметико-логическое устройство (АЛУ). Все инструкции вначале поступают именно на устройство управления.
Существует два типа реализации УУ:
- УУ на жёсткой логике (англ. hardwired control units). Характер работы определяется внутренним электрическим строением — устройством печатной платы или кристалла. Соответственно, модификация такого УУ без физического вмешательства невозможна.
- УУ с микропрограммным управлением (англ. microprogrammable control units). Может быть запрограммирован для тех или иных целей. Программная часть сохраняется в памяти УУ.
УУ на жёсткой логике быстрее, но УУ с микропрограммным управлением обладает более гибкой функциональностью.
Система прерываний процессора.
Каким образом, в таком ритме работы, процессор узнает, откуда приходят данные — от клавиатуры или от мыши, от монитора или от принтера? А может быть от микроволновой печи? И как с такими данными работать?
Для этого используются прерывания, которых существует 256 видов. Прерывания прерывают работу процессора над текущим заданием и направляют его на выполнение другой программы.
Предположим, мы решили подключить к компьютеру микроволновую печь. Выберем для нее какое-нибудь прерывание, не используемое другим устройством, например «103». Когда микроволновая печь захочет обратить на себя внимание процессора, она пошлет к нему сигнал и число 103. Процессор получит число и заглянет в специальную область памяти- вектор прерываний, где найдет адрес руководства по работе с микроволновой печью и начнет работать с этим устройством.
Новые сигналы прерываний могут временно приостановить работу текущей программы, и вернуться к ней по окончании работы с пришедшим прерыванием. Что было бы, если бы процессор работал не со скоростью сотни миллионов байтов в секунду, а в привычном для человека ритме. Как часто получал бы он сигналы?
- Сигналы от клавиатуры он получал бы один раз в десять лет. Обработка слова «компьютер» занимала бы почти 100 лет.
- Данные от мыши — один раз в год. Перемещение указателя мыши из одного угла экрана в другой заняло бы тысячелетие.
- Данные, поступившие по телефонным проводам через модем, — один раз в сутки. Прием и обработка одной страницы текста занимали бы 5-7 лет.
- Данные от гибкого диска — один символ в несколько часов.
- Данные от жесткого или лазерного диска — один байт в час.
Память (ОЗУ)
ОЗУ (оперативное запоминающее устройство, англ. RAM) — это большая группа этих самых регистров, соединённых вместе. Память у такого хранилища непостоянная и данные оттуда пропадают при отключении питания. ОЗУ принимает адрес ячейки памяти, в которую нужно поместить данные, сами данные и флаг записи/чтения, который приводит в действие триггеры.
Прим. перев. Оперативная память бывает статической и динамической — SRAM и DRAM соответственно. В статической памяти ячейками являются триггеры, а в динамической — конденсаторы. SRAM быстрее, а DRAM дешевле.
Система команд процессора.
Процессор обрабатывает информацию, выполняя определенные команды. Таких команд может быть более тысячи. У каждой команды есть свой код (номер). Например, есть команда 000, 001, 002 и т.д. Коды всех команд процессора записаны в двоичной форме в специальном документе, который называется системой команд процессора.
У каждого процессора своя система команд, поэтому один и тот же код для, разных процессоров может обозначать разные команды. Если же процессоры имеют ограниченную совместимость, то их рассматривают как семейство. Примером семейства процессоров являются все процессоры Intel. Их родоначальником был процессор Intel 8086, на базе которого был сделан первый IBM PC. Процессоры семейства совместимы «сверху вниз», т.е. новый процессор понимает» все команды своих предшественников, но не наоборот.
Таблица прерываний AMD Atlon 64 X2:
| Прерывание | Вид | Описание |
|---|---|---|
| DMA 02 | Исключительный | Стандартный контроллер гибких дисков |
| DMA 04 | Исключительный | Контроллер прямого доступа к памяти |
| IRQ 00 | Исключительный | Высокоточный таймер событий |
| IRQ 01 | Исключительный | Стандартная (101/102 клавиши) или клавиатура PS/2 Microsoft Natural |
| IRQ 03 | Общий | Ethernet-контроллер |
| IRQ 04 | Общий | Прочее устройство моста PCI |
| IRQ 06 | Исключительный | Последовательный порт (COM1) |
| IRQ 08 | Исключительный | Стандартный контроллер гибких дисков |
| IRQ 09 | Исключительный | Высокоточный таймер событий |
| IRQ 11 | Общий | Microsoft ACPI-совместимая система |
| IRQ 13 | Общий | SM контроллер шины |
| IRQ 11 | Исключительный | Процессор числовых данных |
| IRQ 17 | Общий | Realtek RTL8139 Family PCI Fast Ethernet NIC |
| IRQ 17 | Общий | NVIDIA GeForce 7600 GT |
| IRQ 18 | Общий | Стандартный OpenHCD USB хост-контроллер |
| IRQ 22 | Общий | Стандартный двухканальный контроллер PCI IDE |
| IRQ 22 | Общий | Стандартный расширенный PCI — USB хост-контроллер |
| IRQ 23 | Общий | Стандартный двухканальный контроллер PCI IDE |
| IRQ 23 | Общий | Стандартный контроллер гибких дисков |
Всю таблицу выписывать нет смысла, так, как она очень обьемная. Посмотреть свою таблицу прерываний вы можите через программу EVEREST, заходим во вкладку Устройства, и выбираем Ресурсы устройств.
Все процессоры можно разделить на:
- Процессоры с расширенной системой команд (CISC — процессоры).
- Процессоры с сокращенной системой команд (RISC — процессоры).
Первый тип процессоров характеризуется небольшим числом регистров, но большим количеством команд, более длинным форматом их записи в байтах и, соответственно, более медленной работой. Такие процессоры используются в универсальных вычислительных системах и являются стандартом для микрокомпьютеров.
Второй тип процессоров характеризуется меньшим количеством команд и, соответственно, более высоким быстродействием. Но сложные операции в этом случае приходится разбивать на последовательность простейших команд, что не всегда эффективно. Поэтому такие процессоры используются в специализированных вычислительных системах, ориентированных на выполнение однообразных операций.
Инструмент проще, чем машина. Зачастую инструментом работают руками, а машину приводит в действие паровая сила или животное.
Компьютер тоже можно назвать машиной, только вместо паровой силы здесь электричество. Но программирование сделало компьютер таким же простым, как любой инструмент.
Процессор — это сердце/мозг любого компьютера. Его основное назначение — арифметические и логические операции, и прежде чем погрузиться в дебри процессора, нужно разобраться в его основных компонентах и принципах их работы.
Арифметические команды
Минимальный набор арифметических команд очень мал. Это (например):
- сложение — ADD;
- инвертирование — COM / NOT (такая ЭВМ действительно была: PDP-8 (DEC));
- прибавление "единицы" — INC.
Все остальное можно сделать, комбинируя эти команды.
Однако в современном микропроцессоре арифметических команд обычно больше:
- SUB — вычитание;
- CMP — сравнение операндов. Эта команда выполняет вычитание операндов, по результату изменяет флаги, после чего результат теряется (команда предназначена для проверки условий);
- NEG — смена знака операнда;
- ASR, ASL, SAR, SAL — арифметические сдвиги операнда (Arithmetic Shift to Right/Left);
- INC, DEC — увеличение или уменьшение операнда на 1;
- ADC, SBC/SBB - операции с переносом C (carry-bit) — для выполнения действий с повышенной точностью, когда операнд занимает несколько слов;
- SXT, SEX, CBW, CWD, CDQ — расширение знака (преобразование в формат с повышенной разрядностью);
- MUL, DIV — умножение и деление беззнаковых и знаковых чисел.
- Набор операций с плавающей точкой, включающий обычно значительное количество команд (несколько десятков), в которые часто входят команды вычисления элементарных функций — Sin, Cos, Log, Exp и т.п.
Команды пересылки
Пересылки общего назначения
Пересылки общего назначения MOV, L**, LD*, LOD* (от Load — загрузить), ST* (от Store — сохранить). Передают слово/байт данных из одной части ЭВМ в другую без изменения. Иногда в эту группу включают также и команды ввода-вывода для ЭВМ у которых область адресов внешних устройств включена в общее адресное пространство.
Пересылки из/в стек
Пересылки из/в стек: PUSH (втолкнуть), POP (вынуть). Обычно отличаются тем, что используют стековую адресацию (задаваемую неявно.
Пересылки двоичных слов
Пересылки двоичных слов, представляющих собой адреса операндов или части (компоненты) адресов. Для операций с адресами нередко в процессор вводят специальные команды. Это связано с тем, что разрядность адреса в процессоре не всегда совпадает с разрядностью АЛУ и регистров.
Пересылки между элементами вычислительного ядра
Пересылки между элементами вычислительного ядра (регистры процессора, элементы памяти) и периферийными устройствами. Хотя эти команды выполняют простую передачу двоичного слова, соответствующая группа команд (называемая командами ввода-вывода) обычно рассматривается отдельно.
Арифметико-логическое устройство
Это устройство, как ни странно, выполняет все арифметические и логические операции, например сложение, вычитание, логическое ИЛИ и т. п. АЛУ состоит из логических элементов, которые и выполняют эти операции.

Большинство логических элементов имеют два входа и один выход.
Ниже приведена схема полусумматора, у которой два входа и два выхода. A и B здесь являются входами, S — выходом, C — переносом (в старший разряд).
Схема арифметического полусумматора
Проверки и передача управления
Эти команды позволяют реализовать конструкции:
IF . THEN . ELSE
REPEAT . UNTIL
WHILE . DO
FOR . DO
GOTO .
Для выполнения этих функций в каждом процессоре есть регистр флагов (регистр состояния), разряды которого устанавливаются или сбрасываются в зависимости от свойств результата предыдущей операции. Анализируются:
- равенство нулю;
- знак;
- перенос;
- арифметическое переполнение;
- перенос между тетрадами и др.
Команды проверки
- TEST — проверка отдельных битов (логическим умножением).
- CMP — сравнение операндов.
Кроме того, признаки устанавливаются после выполнения многих команд. Обратите внимание на то, что нет единых правил поведения признаков. (В процессорах фирмы Motorola при пересылке флаги "нуля" и "знака" изменяются, а в процессорах Intel — нет).
Команды ветвления по условию
B** / J*** от слов ( branch / jump). Их может быть 10. 30 штук. (например, BNE — переход, если не равно 0). Набор команд ветвления обсуждается при рассмотрении системы команд процессоров х86.
Адресация в командах ветвления может быть разного типа:
- а) полный адрес перехода;
- б) относительная (смещение);
- в) пропуск команды.
Но чаще всего — короткая относительная. Короткая, потому что участки, которые надо обходить, имеют не очень большую длину. Если необходимо перейти далеко, то надо комбинировать условный переход с безусловным JMP.
Команда безусловной передачи управления
JMP Адресация делается такой, чтобы можно было "прыгнуть" в любое место программной памяти ("длинная" адресация).
Команда организации цикла
Позволяет организовать в программе структуры FOR . DO более простым способом, чем с помощью команд ветвления.
LOOP*
Команда обращения к подпрограмме (вызов процедуры)
JSR, JMS, CALL
Для экономии памяти, занимаемой программой, предоставляют возможность записать эту последовательность команд только в одном месте памяти и передавать управление к ней из разных мест вызывающей программы.
При обращении / возврате надо обеспечить:
- а) передачу управления в любое место памяти, поэтому "длинная" адресация;
- б) возврат в то место, откуда был вызов (т.е. место вызова должно автоматически запоминаться);
- в) запоминание промежуточных результатов, имеющихся к моменту вызова (содержимое регистров процессора, а, при рекурсивном вызове, процедуры, — надо запоминать и промежуточные результаты работы самой процедуры). Для запоминания чаще всего используется стек (участок ОЗУ или специальное ОЗУ со стековой адресацией). Часть вышеперечисленной информации запоминается автоматически при выполнении команды CALL, а сохранение оставшегося — дело программиста.
Система команд процессора
Хотя наборы команд, реализованных в разных процессорах, различаются по количеству и перечню команд, по способам кодирования, по длине команд и по времени их выполнения, в системах команд разных процессоров есть весьма много общего. Знание этих общих свойств помогает быстрее освоить программирование нового процессора.
Разработчики процессора стремятся включить в систему команд прежде всего те действия, которые чаще требуются программистам. При этом наиболее часто требуемые действия стремятся реализовать в более коротких и быстрых командах. Перечень и свойства операций, выполняемых процессорными командами, тесно связаны со свойствами разных видов данных, которые обрабатываются на ЭВМ. Общего в разных системах команд достаточно много. Далее будем рассматривать главным образом это общее, часто упоминая, чем вызваны те или иные различия.
Для описания команд и их действия будем использовать мнемоники, принятые в языке Ассемблера. Язык Ассемблера специфичен для каждого типа процессора, так как включает в себя совокупность символических обозначений процессорных команд и способов адресации. Несмотря на специфичность, в языках Ассемблера для разных процессоров достаточно много общего, как в форме (в синтаксисе) так и в содержании отображаемых конструкциями языка понятий, поскольку и в различных процессорах также имеется много одинаковых, либо похожих свойств.
Примечание!
- Собственно синтаксис Ассемблера, мнемоники команд процессора и способов адресации.
- Управление процессом трансляции (директивы Ассемблера), позволяющее программисту получить программу с нужными свойствами, например, задать требуемое расположение частей программы в памяти и т.п.
- Изучение набора и свойств сервисов используемой операционной системы (стандартных подпрограмм ОС, доступных прикладному программисту).
Для облегчения понимания кратко опишем основные правила записи команд на Ассемблере (они справедливы для многих известных автору Ассемблеров).
1) Как правило, ассемблерная строка однозначно соответствует одной процессорной команде.
2) Команда языка Ассемблера имеет следующую структуру:
Меткаl: КОП Оп1,Оп2,… ;Комментарий
Вот пример команды на языке ассемблера
Пояснение: Данный оператор содержит команду пересылки, которая загружает константу 12A9h в регистр процессора r1. Константа задана программистом в виде шестнадцатиричного числа.
Оператор включает в свой состав следующие поля:
- Метка — это символическое обозначение адреса. В мнемонике команды, приведенной выше, метка обозначает адрес, начиная с которого байты данной команды будут расположены в ОЗУ после загрузки программы в память. Имя метки часто используется как операнд в командах переходов. (Замечание 1: метки могут обозначать любой адрес, в том числе и тот, с которого расположен операнд. Замечание 2: конкретное значение физического адреса, соответствующего метке будет определено только после загрузки оттранслированной программы в память. При разных запусках этот физический адрес может получиться различным, если программист не принимает специальных мер по заданию определенного значения для этого адреса.).
- КОП — мнемоническое обозначение кода операции, выполняемой данной командой, например mov — переслать
- Оп1, Оп2,… — символические обозначения операндов, обычно они разделяются запятыми (хотя в некоторых Ассемблерах для разделения операндов используется пробел). Количество операндов в команде может быть различным, в большинстве современных процессоров — от 0 до 3. Если операндов больше, чем один, некоторые из них являются "источниками", а некоторые другие — "приемниками". Например, команда сложения
содержит указания на два операнда-приемника (слагаемые) — op1 и op2, а также указание на элемент данных (sum), куда команде следует поместить результат.
Количество операндов, которые программист может указать в команде, определено отдельно для каждой команды конкретного процессора его разработчиками. Для многих команд делают допустимым несколько форматов (см., например, команду целочисленного умножения imul для процессоров семейства х86).
В Ассемблерах процессоров фирмы Intel, по большей части, операнды-источники записываются левее операндов-приемников. В Ассемблерах других фирм это может быть наоборот. В качестве операнда можно использовать метку, в этом случае метка будет обозначать адрес, с которого располагается в памяти соответствующий операнд.
- Комментарий позволяет программисту записать пояснение к строке, и, как правило, игнорируется транслятором.
3) Хотя каждый процессор имеет свой Ассемблер (соответствующий его системе команд), многие мнемонические обозначения в разных Ассемблерах одинаковы для одинаковых операций. Этот факт сильно облегчает изучение следующего Ассемблера (и процессора), после того, как хотя бы один уже изучен.
4) При записи обозначений операндов используются условные обозначения выбранного программистом способа адресации. Обозначения различных способов адресации в разных ассемблерах также имеют много общего. Мы познакомимся с конкретными обозначениями при рассмотрении способов адресации.
Количество команд для разных типов ЭВМ колеблется от малых десятков до сотен. В таком множестве разобраться достаточно трудно, поэтому для рассмотрения разобьем все команды на группы (проклассифицируем). В разных книгах эта классификация тоже сделана по-разному. Выделяют от 3 до более 10 групп. (Наиболее обозримой для человека является классификация, содержащая на нижележащем уровне от 3 до 8 подклассов).
Два основных компонента процессора
Команды ввода — вывода (обмена с периферийными устройствами)
Фактически команды ввода-вывода — это тоже команды пересылки. Основное отличие между пересылками "регистр-память" и пересылками из/в периферийное устройство ПУ состоит в том, что скорость функционирования ПУ может существенно отличаться от скорости работы процессора и поэтому ПУ далеко не всегда бывает готово к обмену.
- Устройств ввода-вывода (УВВ) много, надо как-то рбеспечить адресацию.
- Устройства ввода-вывода разные, надо как-то унифицировать правила обмена.
- Скорость работы УВВ отличается от скорости работы процессора, надо как-то синхронизировать работу процессора и УВВ.
Варианты структуры взаимодействия процессора и УВВ:
- а) УВВ имеют свою систему нумерации (адресации), и в системе команд есть отдельные команды I/O, (как в IBM PC):
•IN — команда ввода из ВНУ;
•OUT — команда вывода на ВНУ.
В этом случае в формате команды УВВ предусматривается своя система адресации.
- б) Обращение к УВВ такое же, как к памяти, часть адресов использована для ВНУ (ввод / вывод, отображенный на память).
Достоинства: можно использовать для обмена с ВНУ всю систему команд, в том числе, команды обработки, что сокращает программу.
Предположим, что вы — рабочая группа, которой необходимо как можно быстрее решить некоторую задачу. Вы должны работать в помещении 1, а условие задачи, исходные данные и этапы решения находятся в помещении 2, причем выдача необходимой информации происходит достаточно медленно. В помещение 2 может ходить только 1 человек.
Ваша работа должна выполняться по следующему плану:
- Человек идет в помещение 2 за порцией данных, необходимых для решения задачи.
- Приносит их в помещение 1.
- Рабочая группа быстро обрабатывает данные и посылает за следующей порцией информации. При этом она бездействует в ее ожидании.
- Человек идете в помещение 2 за следующей порцией информации.
- Приносит их в помещение 1.
- Рабочая группа быстро обрабатывает данные и посылает за следующей порцией информации. При этом она бездействует в ее ожидании.
- И т.д., до тех пор, пока задача не будет решена.
Подумайте и скажите, каким образом можно ускорить этот процесс, если Вы обрабатываете информацию быстрее, чем вам ее вам дают в помещении 2, в результате чего вы теряете много времени.
Возникают следующие вопросы:
- Можно ли поручить решение задачи более «умной» рабочей группе, которая решит ее быстрее?
- Можно ли информацию из помещения 2 частично сразу перенести в Помещение 1?
- Можно ли посылать за информацией в помещение 2 не одного человека, а нескольких?
Только что, вы смоделировали процесс ускорения работы процессора. Помещение 1 — это процессор, а помещение 2 — это оперативная память. Главная задача ученых и инженеров — сделать процессоры более производительными.
Достигается это за счет:
- Повышения тактовой частоты (более «умная» рабочая группа). Это самый очевидный путь повышения производительности.
- Повышения разрядности процессора (поручить приносить информацию из помещения 2 более чем одному человеку). Чем выше разрядность процессора ( количество человек), тем больше байтов (больше информации) он может обработать за один такт.
- Кэширования памяти. Процессор по отношению, например, к оперативной памяти является более быстрым устройством, поэтому он вынужден постоянно простаивать, ожидая медленно работающую память. Поэтому, чтобы процессор реже обращался к оперативной памяти, внутри него создают небольшой участок памяти размерим 256 или 512 Кбайт. Эта «сверхоперативная» память получила название кэш. В кэш-память процессор записывает те данные, которые получил из оперативной памяти, и если это данные понадобятся еще раз, он возьмет их из кэш. Таким образом, работа процессора происходит быстрее.
Сдвиги
Операция сдвига состоит в одновременном перемещении содержимого операнда в разрядной сетке. Существует 3 разновидности операции сдвигов, которые различаются тем, что происходит с битами, выходящими за пределы разрядной сетки с одного "конца" операнда, и с освобождающимися позициями на другом его "конце".
- ROR, ROL, RCR, RCL — циклические сдвиги. При циклическом сдвиге то, что выходит за границу разрядной сетки, помещается в освобождающуюся позицию на другом конце операнда.
- ASR, ASL/SAR, SAL — арифметические сдвиги. Эта разновидность сдвига осуществляется таким образом, что результат оказывается эквивалентен умножению (при сдвиге влево) или делению (при сдвиге вправо) операнда на основание системы счисления, т.е. на 2. Сравните: если "сдвинуть" цифры в десятичном числе на разряд влево, результат будет эквивалентен исходному числу, умноженному на 10 (12 и 120 после сдвига). Более подробно особенности арифметического сдвига обсуждаются при рассмотрении системы команд процессоров х86.
- SHL, SHR — логические сдвиги. При выполнении логических сдвигов биты, "выдвигаемые" из разрядной сетки, теряются, а противоположный конец операнда заполняется "нулями".
Каждая из упомянутых разновидностей может также иметь варианты.
Например, в составе системы команд х86 различают пять видов сдвигов.
Регистры
Регистр — минимальная ячейка памяти данных. Регистры состоят из триггеров (англ. latches/flip-flops). Триггеры, в свою очередь, состоят из логических элементов и могут хранить в себе 1 бит информации.
Прим. перев. Триггеры могут быть синхронные и асинхронные. Асинхронные могут менять своё состояние в любой момент, а синхронные только во время положительного/отрицательного перепада на входе синхронизации.
По функциональному назначению триггеры делятся на несколько групп:
- RS-триггер: сохраняет своё состояние при нулевых уровнях на обоих входах и изменяет его при установке единице на одном из входов (Reset/Set — Сброс/Установка).
- JK-триггер: идентичен RS-триггеру за исключением того, что при подаче единиц сразу на два входа триггер меняет своё состояние на противоположное (счётный режим).
- T-триггер: меняет своё состояние на противоположное при каждом такте на его единственном входе.
- D-триггер: запоминает состояние на входе в момент синхронизации. Асинхронные D-триггеры смысла не имеют.
Для хранения промежуточных данных ОЗУ не подходит, т. к. это замедлит работу процессора. Промежуточные данные отсылаются в регистры по шине. В них могут храниться команды, выходные данные и даже адреса ячеек памяти.
Принцип действия RS-триггера
Выполнение инструкций
Инструкции хранятся в ОЗУ в последовательном порядке. Для гипотетического процессора инструкция состоит из кода операции и адреса памяти/регистра. Внутри управляющего устройства есть два регистра инструкций, в которые загружается код команды и адрес текущей исполняемой команды. Ещё в процессоре есть дополнительные регистры, которые хранят в себе последние 4 бита выполненных инструкций.
Ниже рассмотрен пример набора команд, который суммирует два числа:
- LOAD_A 8 . Это команда сохраняет в ОЗУ данные, скажем, . Первые 4 бита — код операции. Именно он определяет инструкцию. Эти данные помещаются в регистры инструкций УУ. Команда декодируется в инструкцию load_A — поместить данные 1000 (последние 4 бита команды) в регистр A .
- LOAD_B 2 . Ситуация, аналогичная прошлой. Здесь помещается число 2 ( 0010 ) в регистр B .
- ADD B A . Команда суммирует два числа (точнее прибавляет значение регистра B в регистр A ). УУ сообщает АЛУ, что нужно выполнить операцию суммирования и поместить результат обратно в регистр A .
- STORE_A 23 . Сохраняем значение регистра A в ячейку памяти с адресом 23 .
Вот такие операции нужны, чтобы сложить два числа.
Все данные между процессором, регистрами, памятью и I/O-устройствами (устройствами ввода-вывода) передаются по шинам. Чтобы загрузить в память только что обработанные данные, процессор помещает адрес в шину адреса и данные в шину данных. Потом нужно дать разрешение на запись на шине управления.

У процессора есть механизм сохранения инструкций в кэш. Как мы выяснили ранее, за секунду процессор может выполнить миллиарды инструкций. Поэтому если бы каждая инструкция хранилась в ОЗУ, то её изъятие оттуда занимало бы больше времени, чем её обработка. Поэтому для ускорения работы процессор хранит часть инструкций и данных в кэше.
Если данные в кэше и памяти не совпадают, то они помечаются грязными битами (англ. dirty bit).
Тактирование процессора
Быстродействие компьютера определяется тактовой частотой его процессора. Тактовая частота — количество тактов (соответственно и исполняемых команд) за секунду.
Частота нынешних процессоров измеряется в ГГц (Гигагерцы). 1 ГГц = 10⁹ Гц — миллиард операций в секунду.
Чтобы уменьшить время выполнения программы, нужно либо оптимизировать (уменьшить) её, либо увеличить тактовую частоту. У части процессоров есть возможность увеличить частоту (разогнать процессор), однако такие действия физически влияют на процессор и нередко вызывают перегрев и выход из строя.
Команды обработки
Поток инструкций
Современные процессоры могут параллельно обрабатывать несколько команд. Пока одна инструкция находится в стадии декодирования, процессор может успеть получить другую инструкцию.

Однако такое решение подходит только для тех инструкций, которые не зависят друг от друга.
Если процессор многоядерный, это означает, что фактически в нём находятся несколько отдельных процессоров с некоторыми общими ресурсами, например кэшем.
Двухбитное поле Масштаб (Scale) кодирует значение масштабного множителя (1, 2, 4, 8), который указывает размер элементов массива при использовании индексной адресации.
6.3 Аппаратная организация защиты в процессорах Pentium
Современные ВМ поддерживают многопрограммный (мультипрограммный) и многозадачный (мультизадачный) режимы работы /1/.
Многопрограммный режимпредполагает одновременное выполнение процессором нескольких программ, переключаясь между ними. Естественно, в каждый конкретный момент времени процессор может выполнять команды только определённой программы.
Многозадачностью называется способ организации работы компьютера, при котором в его оперативной памяти содержатся программы и данные для одновременного выполнения нескольких процессов обработки информации (задач). Один из способов реализации многозадачности, называемый разделением времени, заключается в предоставлении каждой задаче некоторого интервала времени (кванта обслуживания), в течение которого процессор выполняет команды соответствующей программы. Если по истечении выделенного кванта времени обработка программы не заканчивается, она прерывается и становится в очередь программ, ожидающих обработки. При реализации многозадачности необходимо обеспечить взаимную защиту программ и данных, относящихся к различным задачам.
Для обнаружения и идентификации ошибок современные процессоры, в т.ч., и процессоры Intel, сконструированы со встроенным механизмом защиты. Этой цели способствует организация памяти, которая предусматривает взаимное разделение адресных пространств различных задач с помощью сегментов. Система привилегий жёстко регламентирует взаимоотношения задач с памятью, операционной системой (ОС) и друг с другом. Для эффективного управления всей системой ОС разрешён доступ к памяти всех программ, а пользовательским программам обеспечивается доступ к программам ОС только в разрешённых точках входа. Для поддержки указанных функций в систему команд процессоров Intel введены некоторые привилегированные команды, которые могут выполняться только ОС. Кроме того, в структуре процессора имеется ряд регистров, к которым закрыт доступ со стороны пользовательских программ.
Основной единицей защиты является сегмент. При каждом обращении к сегменту проверяется ряд параметров защиты, задаваемых в дескрипторе, в т. ч., предел, тип сегмента, права, уровень привилегий.
Специальное поле предел определяет границы сегмента. С его помощью процессор обнаруживает такие распространённые ошибки, как переполнение стека, неверные указатели и индексы массивов, неправильные адреса вызовов и переходов. Ошибки нарушения границы обнаруживаются в момент их возникновения, что существенно облегчает поиск их причины. Остальные параметры защиты хранятся в байте доступа (Access Rights) дескриптора, структура которого представлена на рисунке 6.1.
Рисунок 6.1 – Формат байта доступа дескриптора
Специальный бит присутствия Р указывает, где размещён искомый сегмент – в основной памяти ВМ (Р=1) или на диске (Р=0).
Бит доступа А фиксирует каждое обращение к сегменту.
Бит S кодирует назначение и способ использования дескриптора. При S=0 дескрипторы являются системными. Они используются для обращения к системным сегментам TSS, LDT или являются шлюзами для задания разрешённых точек входа в защищённые программы ОС. Дескрипторы несистемных сегментов кода, данных и стека имеют бит S=1.
Поле TYPE доопределяет тип дескриптора. Проверка типа обнаруживать ошибки при использовании сегмента не по назначении. Например, в сегмент кода нельзя записывать, а с сегментом таблицы LDT нельзя явно производить операции считывания, записи и выполнения.

Права, которыми может быть помечен несистемный дескриптор, ограничивают множество операций, которые можно производить с его сегментом. Права указываются также в поле TYPE несистемных дескрипторов. Например, исполняемый сегмент кода дополнительно может быть помечен как читаемый.
Поле привилегий DPL (Descriptor Privilege Level) задаёт разрешённый уровень привилегий для доступа к сегменту. Привилегии – это свойство, которое определяет, какие программы можно выполнять и к каким данным возможен доступ в каждый конкретный момент времени. В целом уровень привилегий программы определяет конкретное подмножество сегментов адресного пространства, к которому программа может обращаться. Привилегии устанавливаются программами ОС в байте доступа дескриптора сегмента при заполнении дескрипторных таблиц. Попытка задачи использовать сегмент с более высоким уровнем привилегий приводит к особому случаю защиты.
Уровни привилегий (PL) удобно представить в виде колец защиты: уровень привилегий PL=0 отводится для ядра ОС, PL=1 – утилитам ОС, PL=2 – служебным программам ОС, системам управления базами данных и др., PL=3 – пользовательским программам.
При любом межсегментном взаимодействии всегда участвуют два сегмента – текущий сегмент кода и сегмент, к которому происходит обращение (сегмент назначения). Обратиться к данным сегмента назначения можно в том случае, если уровень его привилегий равен или меньше уровня привилегий текущего сегмента кода. При межсегментных передачах управления (доступе к другому сегменту кода) переход возможен, если уровень привилегий сегмента назначения равен уровню привилегий текущего сегмента кода (т.е., сегменты кода находятся в пределах одного кольца защиты). Варианты возможных межсегментных взаимодействий наглядно демонстрирует рисунок 6.2 /1/.
Рисунок 6.2 – Обращения в пределах колец защиты и между ними
Последовательность проверок при всех межсегментных обращениях следующая. Перед тем как обратиться к операнду в памяти, программа загружает селектор в один из сегментных регистров, и аппаратным путём выполняется проверка возможности к адресуемому операнду. Сначала процессор сравнивает формируемое внутрисегментное смещение со значением поля предела сегмента и определяет правильность адреса (в случае выхода за границы сегмента процессор формирует прерывание общей защиты). Затем процессор выполняет проверку привилегий сегмента, к которому происходит обращение (такая проверка зависит от типа сегмента назначения). Непосредственно перед каждым обращением к операндам, в т.ч. и внутрисегментном, дополнительно аппаратным путём проверяется ещё ряд параметров защиты. Нарушение любого из них приводит к обработке особого случая и предотвращает обращение к операнду.
Передача управления в защищённом режиме осуществляется командами CALL, JMP, INT, RET, IRET, а также механизмами исключений и прерываний. При выполнении внутрисегментного перехода осуществляется только проверка границы перехода. При исполнении команд межсегментного перехода выполняется проверка привилегированности кодового сегмента назначения. Если межсегментный переход осуществляется в пределах одного кольца защиты, то доступ к вызываемому сегменту разрешён.
Реализуя защиту, процессор запрещает пользовательским программам выполнять те операции, которые выполняются программами ОС. Однако в любой системе есть некоторые стандартные процедуры, которые желательно выполнять на любом уровне привилегий, например, доступ пользовательских программ к утилитам ОС (они имеют PL=1). Это приводит к наличию исключений в общих правилах защиты. Процессоры Pentium обеспечивают 2 способа реализации межсегментных передач управления из менее привилегированного сегмента в более привилегированный: обращение к согласованному сегменту и использование шлюзов вызова.
Согласованный сегмент – это сегмент, у которого отсутствует защита по привилегиям. Выделение согласованного сегмента осуществляется с помощью специального бита подчинения С в поле TYPE байта доступа сегмента кода. Процедуры, размещённые в согласованном сегменте кода, можно вызывать из программ с любым уровнем привилегий. Наличие согласованных сегментов удобно для организации системных библиотек, программы которых должны быть доступны всем задачам.
Шлюзы вызова – это специальные дескрипторы, которые определяют разрешённые точки входа в защищённые процедуры более высокого уровня. Благодаря шлюзам вызова, пользовательские программы получают от ОС только те обслуживания, которые ОС разрешает оказывать пользовательским программам. По существу, шлюзы вызова не являются дескрипторами, но их удобно размещать в дескрипторных таблицах. При использовании шлюзов вызова передача управления всегда осуществляется косвенно. Вызывающая программа обращается к шлюзу вызова, а он определяет точку входа в вызываемой процедуре. 32-разрядный дескриптор шлюза вызова имеет следующий формат: байт доступа, счётчик слов (1 байт), селектор сегмента назначения (1 байт) и смещение (1 байт).
Селектор сегмента назначения содержит адрес дескриптора кодового сегмента назначения, который (дескриптор) также хранится в дескрипторной таблице. Селектор и смещение задают полный адрес перехода, который определяет вход в защищённую процедуру только в разрешённой точке.
При передаче управления более защищённой программе может потребоваться копирование параметров из стека вызывающей программы в стек вызываемой. Для этого в шлюзе вызова предусмотрено поле – счётчик слов, в котором указывается число копируемых параметров.
Доступ к шлюзу вызова контролируется механизмом защиты. Селекторы шлюзов вызова можно загружать только в сегментный регистр кода CS. При доступе к шлюзу действуют такие же ограничения, как и при обращении к данным (см. рисунок 6.2).
6.4 Аппаратные средства поддержки многозадачности
В структуре процессоров Pentium имеются средства поддержки многозадачного режима, с помощью которых реализуется защита и быстрое переключение задач /1/: специальная структура данных, организованная в виде сегмента состояния задачи TSS, дескриптор сегмента TSS, дескриптор шлюза задачи, 16-разрядный регистр TR (Task Register) и связанный с ним программно недоступный теневой 64-разрядный регистр TRт.
Переключение задачи сходно с вызовом процедуры, но требует сохранения большего количества информации о состоянии процессора. Содержимое регистров процессора, участвующих в выполнении задачи, называетсясредой задачи. Для каждой задачи создаётся собственный сегмент TSS, который фактически характеризует состояние виртуального процессора задачи в многозадачной системе. Выполнение задач процессора осуществляется в соответствии с планом и в порядке, определяемым ОС. При переключении задач среда выполняемой задачи переписывается в сегмент TSS этой задачи (на этот сегмент указывает регистр текущей задачи TRт) – (стрелка 1 на рисунке 6.3). После этого в регистр TR помещается селектор нового сегмента TSS (стрелки 2), и в регистры процессора из сегмента TSS вызываемой задачи загружается содержимое её среды (стрелка 3). Выполнение программы новой задачи продолжается с команды, адрес которой указан в регистре EIP новой задачи, а не с самого начала. Указанные операции реализуются автоматически с помощью аппаратных средств процессора. При этом в стеке, в отличие от вызова подпрограмм, никакой информации не сохраняется, управление передаётся полностью в среду выполняемой задачи. Схема переключения задач представлена на рисунке 6.3 /19/.
Длительность процедуры переключения задач составляет 200 тактов.
Если переключение задач осуществляется на одном уровне привилегий (внутри одного кольца защиты), то используется прямое переключение задач, когда селектор указывает на дескриптор задачи. Для вызова задач в более привилегированном кольце используются шлюзы задач, т.е. выполняется косвенное переключение задач, когда селектор указывает на шлюз задачи.
Основным назначением механизма переключения задач является организация очередных переходов между выполняемыми программами. Переключение программ может производиться командами JMP и CALL типа FAR (межсегментные переходы), командами вызова прерываний (INT n) или командой IRET, а также аппаратными прерываниями и ловушками.
Рисунок 6.3 – Схема переключения задач
При выполнении межсегментных переходов в защищённом режиме в регистре EIP содержится смещение (адрес команды внутри сегмента), а в регистре CS может находиться адрес или дескриптора сегмента, или шлюза дескриптора сегмента, или дескриптора TSS, или дескриптора шлюза TSS.
Сегмент TSS определяется одноимённым сегментным дескриптором, который может находиться только в глобальной дескрипторной таблице GDT. Этот дескриптор помимо адреса содержит ещё указание размера и уровня привилегий сегмента TSS. Выбор дескриптора TSS текущей задачи в таблице GDT осуществляется с помощью селектора, загружаемого в программно доступный регистр TR. Для уменьшения времени обращения к операндам сегмента TSS дескриптор TSS текущей задачи после выборки из таблицы GDT запоминается в программно недоступном регистре TRт. Содержимое этого регистра автоматически обновляется процессором при смене задачи. При инициализации системы с помощью специальной команды LTR в регистр TR загружается селектор исходной задачи, а в процессе работы его содержимое может изменяться.
С сегментом TSS нельзя явно проводить операции записи, чтения и выполнения. Для этого используются дополнительные сегменты данных с разрешённой записью, которые имеют тот же базовый адрес и предел, что и программно недоступный системный сегмент.
6.5 Перспективы развития процессоров
Согласно /1/, самым существенным фактором, влияющим на архитектурные решения современных процессоров, является постоянное совершенствование технологии производства ИС. Как следствие,- рост уровня интеграции, уменьшение задержек в вентилях и связях, снижение энергопотребления при переключении вентиля. В целом с ростом уровня интеграции увеличиваются ресурсы на кристалле и повышается тактовая частота работы микросхем, что позволяет повышать производительность процессоров. Первое направление связано с увеличением объёма внутренней кэш-памяти и совершенствованием способов её организации. Второе направление связано с реализацией в процессорах принципов конвейеризации и параллельной обработки в нескольких конвейерах на разных стадиях выборки и выполнения команд.
Практически все накопленные в процессе конкуренции различных фирм архитектурные решения находят своё воплощение в новых архитектурах. По этой причине в архитектуре современных процессоров различных производителей много общего, и ставится вопрос об унификации архитектур. На сегодняшний день можно выделить следующие основные тенденции развития архитектур современных процессоров:
1) Применение суперскалярной обработки с динамическим параллелизмом в процессорах с чисто аппаратным механизмом выборки несвязанных команд программы из памяти и параллельном запуске их на исполнение (например, процессоры Pentium, PowerPC, Alpha, SPARC и др.).
2) Развитие суперскалярной обработки со статическим параллелизмом, при котором выявление скрытого параллелизма и определение возможности параллельного исполнения команд возлагается на оптимизирующий компилятор (например, процессоры Itanium, Crusoe и др.).
3) Использование аппаратных средств, обеспечивающих векторную обработку данных.
Современный процессор – это 64-разрядный суперконвейерный, суперскалярный процессор с RISC-операционным ядром и большим числом дополнительных блоков, реализующий динамическое исполнение команд. Для эффективной обработки данных мультимедиа и графики система команд современных процессоров расширяется за счёт специализированных команд мультимедийной обработки: например, команд расширений MMX, SSE, SSE2 в процессорах компании Intel; ActiVec – IBM, Motorola; VIS – SPARC; 3DNow! – AMD.
Для унификации структур обработки данных в структуры некоторых современных процессоров включают специальные преобразователи исходных кодов команд во внутренние машинные команды «исполнительного процессора» (например, сложных CISC-команд в RISC-команды в процессорах Pentium, AMD или VLIW-команды в процессоре Crusoe).
Как уже упоминалось ранее, масштабные исследования ведутся по созданию процессорных элементов и компьютеров в целом с использованием принципиально иной элементной базы: биполярных молекул, молекул ДНК, квантовых кубитов и света.
Разнообразие типов данных, форм их представления и действий, которые необходимы для обработки информации и управления ходом вычислений, порождает необходимость использования различных команд — набора команд. Каждый процессор имеет собственный вполне определенный набор команд, называемый системой команд процессора. Система команд должна обладать двумя свойствами — функциональной полнотой и эффективностью.
Функциональная полнота — это достаточность системы команд для описания любого алгоритма. Требование функциональной полноты не является слишком жестким. Доказано, что свойством функциональной полноты обладает система, включающая всего три команды (система Поста): присвоение О, присвоение 1, проверка на 0. Однако составление программ в такой системе команд крайне неэффективно.
Эффективность системы команд — степень соответствия системы команд назначению ЭВМ, т. е. классу алгоритмов, для выполнения которых предназначается ЭВМ, а также требованиям к производительности ЭВМ. Очевидно, что реализация развитой системы команд связана с большими затратами оборудования и, следовательно, с высокой стоимостью процессора. В то же время ограниченный набор команд приводит к снижению производительности и повышенным требованиям к памяти для размещения программы. Даже простые и дешевые современные микропроцессоры поддерживают систему команд, содержащую несколько десятков (а с модификациями — сотен) команд.
Система команд процессора характеризуется тремя аспектами: форматами, способами адресации и системой операций.
Под форматом команды следует понимать длину команды, количество, размер, положение, назначение и способ кодировки ее полей.
Команды, как и любая информация в ЭВМ, кодируются двоичными словами, которые должны содержать в себе следующие виды информации:
□ тип операции, которую следует реализовать в данной команде (КОП);
□ место в памяти, откуда следует взять первый операнд (А1);
□ место в памяти, откуда следует взять второй операнд (А2);
□ место в памяти, куда следует поместить результат (A3).
Каждому из этих видов информации соответствует своя часть двоичного слова — поле, а совокупность полей (их длины, расположение в командном слове, способ кодирования информации) называется форматом команды. В свою очередь, некоторые поля команды могут делиться на подполя. Формат команды, поля которого перечислены выше, называетсятрехадресным (рис. 2.1, а).
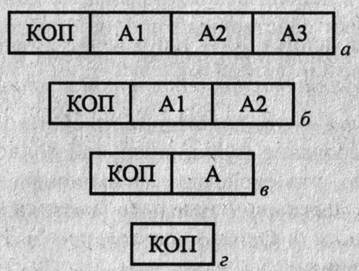
. Форматы команд: а — трехадресный; б — двухадресный; в — одноадресный;
г — безадресный
Команды трехадресного формата занимают много места в памяти, в то же время далеко не всегда поля адресов используются в командах эффективно. [Действительно, наряду с двухместными операциями (сложение, деление, Конъюнкция и др.) встречаются и одноместные (инверсия, сдвиг, инкремент др.), для которых третий адрес не нужен. При выполнении цепочки вычис-ний часто результат предыдущей операции используется в качестве опе-да для следующей. Более того, нередко встречаются команды, для кото-операнды не определены (СТОП) или подразумеваются самим кодом раций (DAA, десятичная коррекция аккумулятора).
ому в системах команд реальных ЭВМ трехадресные команды встреча-я редко. Чаще используются двухадресные команды (рис. 2.1,6), в этом "ае в бинарных операциях результат помещается на место одного из опе-ов.
реализации одноадресных форматов (рис. 2.1, в) в процессоре преду-ивают специальную ячейку— аккумулятор. Первый операнд и резуль-всегда размещаются в аккумуляторе, а второй операнд адресуется по-А.
ьная система команд обычно имеет команды нескольких форматов, при-тип формата определяется в поле КОП.
12. Способы адресации
особ адресации определяет, каким образом следует использовать инфор-ию, размещенную в поле адреса команды.
Не следует думать, что во всех случаях в поле адреса команды помещается адрес операнда. Существует пять основных способов адресации операндов в командах.
□ Прямая — в этом случае в адресном поле располагается адрес операнда. Разновидность — прямая регистровая адресация, адресующая не ячейку памяти, а РОН. Поле адреса регистра имеет в команде значительно меньшую длину, чем поле адреса памяти.
□ Непосредственная — в поле адреса команды располагается не адрес операнда, а сам операнд. Такой способ удобно использовать в командах с константами.
□ Косвенная — в поле адреса команды располагается адрес ячейки памяти, в которой хранится адрес операнда ("адрес адреса"). Такой способ позволяет оперировать адресами как данными, что облегчает организацию циклов, обработку массивов данных и др. Его основной недостаток — потеря времени на двойное обращение к памяти — сначала за адресом, потом — за операндом. Разновидность — косвенно-регистровая адресация, при которой в поле команды размещается адрес РОН, хранящего адрес операнда. Этот способ, помимо преимущества обычной косвенной адресации, позволяет обращаться к большой памяти с помощью коротких команд и не требует двойного обращения к памяти (обращение к регистру занимает гораздо меньше времени, чем к памяти).
□ Относительная— адрес формируется как сумма двух слагаемых: базы, хранящейся в специальном регистре или в одном из РОН, и смещения, извлекаемого из поля адреса команды. Этот способ позволяет сократить длину команды (смещение может быть укороченным, правда в этом случае не вся память доступна в команде) и/или перемещать адресуемые массивы информации по памяти (изменяя базу). Разновидности— индексная и базово-индексная адресации. Индексная адресация предполагает наличие индексного регистра вместо базового. При каждом обращении содержимое индексного регистра автоматически модифицируется (обычно увеличивается или уменьшается на 1). Базово-индексная адресация формирует адрес операнда как сумму трех слагаемых: базы, индекса и смещения.
□ Безадресная — поле адреса в команде отсутствует, а адрес операнда или не имеет смысла для данной команды, или подразумевается по умолчанию. Часто безадресные команды подразумевают действия над содержимым аккумулятора. Характерно, что безадресные команды нельзя применить к другим регистрам или ячейкам памяти.
Одной из разновидностей безадресного обращения является использование т. н. магазинной памяти или стека. Обращение к такой памяти напоминает обращение с магазином стрелкового оружия. Имеется фиксированная ячейка, называемая верхушкой стека. При чтении слово извлекается из верхушки, а все остальное содержимое "поднимается вверх" подобно патронам в магазине, так что в верхушке оказывается следующее по порядку слово. Одно слово нельзя прочитать из стека дважды. При записи новое слово помещается в верхушку стека, а все остальное содержимое "опускается вниз" на одну позицию. Таким образом, слово, помещенное в стек первым, будет прочитано последним. Говорят, что стек поддерживает дисциплину LIFO — Last In First Out (последний пришел — первый ушел). Реже используется безадресная память типа очередь с дисциплиной FIFO — First In First Out (первый пришел — первый ушел).
Логические команды
Логические команды — это команды побитовой обработки.
- OR — поразрядное логическое сложение. Фактически это команда побитовой установки (т.е. записи "единицы" в заданные биты операнда). Пример:
or opr, 0Ch ;Установка в 1 битов в позициях 2 и 3 в операнде al
Если исходно в al содержался, например, операнд 1101 10012, то после выполнения команды в al будет содержаться: 1101 11 01 (отмечены установленные биты). Второй операнд — обычно константа, задавая которую, программист указывает, какие биты следует установить (он на жаргоне программистов носит название "маска").
Можно описать действие команды OR следующим образом: команда безусловно устанавливает в "единицу" биты в тех позициях первого операнда, которые отмечены "единицами" во втором операнде (в маске), оставляя прочие биты первого операнда неизменными.
- AND — поразрядное логическое умножение. Это команда побитового сброса (записи в заданные биты "нулей"). Пример:
and bh, 0Fh ;Сброс старшей тетрады (старшего ниббла) в байтовом операнде.
Если, например, исходно в регистре bh содержался операнд 1101 10012, то после выполнения команды в регистре bh будет содержаться 0000 10012 (отмечены очищенные биты). Действие команды AND можно описать следующим образом: команда безусловно сбрасывает в 0 биты в тех позициях первого операнда, которые отмечены "нулями" в маске, оставляя прочие биты первого операнда неизменными.
- XOR — поразрядное исключающее ИЛИ, eXclusive OR (иногда на русском эту операцию называют "ЛИБО"). Эта двухоперандная команда фактически выполняет выборочное инвертирование битов. Например:
xor cl,0F0h ;Инвертирование битов старшей тетрады
Если исходно в cl содержалось 1101 10012, то после выполнения команды в cl будет содержаться 0010 10012 (отмечены проинвертированные биты). Действие команды xor можно описать так: команда инвертирует в первом операнде биты в позициях, которые отмечены в маске "единицами", оставляя прочие биты неизменными.
- TEST — проверка битовых полей. Команда чаще всего двухоперандная, выполняет поразрядное логическое умножение операндов и по результату операции изменяет состояние флагов "нуля" zf и "знака" sf, после чего результат операции теряется.
- NOT, COM — инвертирование операнда (замена значения каждого бита на противоположное). Это однооперандная команда.
Читайте также: