
Зависает виртуальная машина vmware

03.05.2021

itpro

VMWare, Windows 10, Виртуализация, Вопросы и ответы

Комментариев пока нет
Заметил одну неприятную особенность в гипервизоре VMWare Workstation. Если вы не используете виртуальную машину в течении некоторого времени, она автоматически приостанавливается функцией Suspend. Чтобы продолжить использование ВМ приходится нажимать кнопку Resume this virtual machine.

Функция автоматической приостановки (Suspend) в VMWare Workstation Player/ Fusion включена по умолчанию. Ее задача – экономия ресурсов хоста, которая автоматически замораживает состояние ВМ, не выключая ее полностью. Чтобы включить замороженную ВМ нужно несколько секунд, но лично мне эта функция мешает. Во-первых, это неудобно, если вы тестируете что-то на ВМ и ожидаете результатов процесса или скрипта; во-вторых, периодический Suspend ВМ и сброс состояния памяти на диск расходует ресурс SSD диска; в-третьих, я не хочу каждый раз ждать по несколько секунд пока VMWare Workstation возобновит работу ВМ.
Гипервизор может включить Suspend автоматически или, когда обнаружит что гостевая ОС переведена в спящее состояние. Например, в Windows 10 по умолчанию компьютер переводится в спящий режим через 30 минут неактивности (Control Panel\Hardware and Sound\Power Options\Edit Plan Settings -> Put the computer to sleep).

К сожалению, полностью отключить функцию Auto Suspend в настройках VMWare Workstation нельзя. Но вы можете в параметрах vmx файла конкретной ВМ запретить гипервизору переводить в состояние suspend.
Совет. Вы можете добавить строку в текстовый vmx файл с помощью следующей PowerShell команды:
Add-Content C:\VHD\win10x64\win10x64.vmx 'suspend.disabled = "TRUE"'
Проверьте, что строка была успешно добавлена в vmx файл ВМ:
get-content C:\VHD\win10x64\win10x64.vmx | Select-String "suspend"
09.10.2019
itpro
VMWare
комментариев 7
Иногда сталкиваюсь с тем, что определенная виртуальная машина на хосте VMWare ESXi зависает и ее нельзя никаким средствами выключить или перезагрузить из веб-интерфейса клиента vSphere. Перезагружать целиком ESXi сервер из-за одной виртуальной машины – не совсем целесообразно (особенно, если у вас всего один ESXi хост, или оставшиеся сервера в DRS кластере не потянут дополнительной нагрузки в виде виртуальных машин с перезагружаемого сервера). Рассмотрим основные способы принудительной остановки зависшей виртуальной машины в VMWare ESXi.
Если процесс виртуальной машины на сервере ESXi завис, она перестает реагировать на команды Reset / Power Off, и на любое действие выдает одну из ошибок:
-
The attempted operation cannot be performed in the current state ;
В таких случаях вы можете вручную остановить процесс виртуальной машины на хосте ESXi из командной строки ESXi Shell или PowerCLI.
Сначала определите на каком ESXi хосте запушена зависшая виртуальная машина. Для этого в интерфейсе vSphere Client найдите ВМ. Имя хоста, на котором она запущена, указано на вкладке Summary в секции Related Object -> Host.

Щёлкните по имени хоста ESXi. Вам нужно разрешить доступ к нему по протоколу SSH. Перейдите в Configure -> Services -> SSH -> Start.

Теперь вы можете подключиться к этому ESXi хосту через SSH с помощью клиента putty.
Выведем список ВМ, запушенных на хосте ESXi:
esxcli vm process list

Скопируйте идентификатор нужной виртуальной машины (World ID).
Чтобы завершить процесс зависшей виртуальной машинына хосте ESXi используется следующая команда:
esxcli vm process kill --type=[soft,hard,force] --world-id=WorldNumber
Как вы видите, есть три типа завершения процесса ВМ:
- Soft – самый безопасный способ завершить VMX процесс (похож на kill -SIGTERM);
- Hard – немедленное завершение процесса ВМ (kill -9);
- Force – самый жесткий режим завершения процесса, должен использоваться в последнюю очередь, если ничего другое не помогает.
Убедитесь, что для ВМ нет активных заданий по созданию снапшотов, бэкапов, и подобных операций, а у ВМ нет статуса Virtual Machine disks consolidation is needed. Иначе вы можете сломать свою ВМ и ее придется восставливать из бэкапа.
Попробуем мягко остановить ВМ с указанным ID:
esxcli vm process kill --type=soft -w=25089429

ВМ должна выключиться.
Вы можете остановить зависшую виртуальную машину с помощью PowerCLI (это удобно, т.к. при подключении к vCenter вам не нужно искать хост, на котором запушена ВМ и включать SSH доступ). Проверим, что ВМ запушена:
get-vm “web2" | select name,PowerStates

Принудительно остановите процесс ВМ командой:
stop-vm -kill "web2" -confirm:$false

Также вы можете остановить зависшую виртуальную машину с помощью утилиты ESXTOP.
В SSH сесиии введите команду esxtop, затем нажмите “c” для отображения ресурсов CPU и shift + V, чтобы отображать только процессы вириальных машин

Затем нажмите “f” (выбрать отображаемы поля), “c” (отобразить поле LWID- Leader World Id) и нажмите Enter.

В столбце Name найдите виртуальную машину, которую нужно остановить, и определите номер ее LWID по соответствующему столбцу.
Затем осталось нажать кнопку «k» (kill) и набрать LWID идентфикатор той виртуальной машины, которую нужно принудительно выключить.
Последний способ жёсткого выключения виртуальной машины – воспользоваться утилитой kill. Такой способ позволит остановить не только ВМ, но и все дочерние процессы.
Получим ID родительского процесса ВМ:
kill -9 24288474

После такого “hard reset”, установленная ОС запустится в режиме восстановления. В случае гостевой Windows, скрин будет выглядеть так.
Предыдущая статья Следующая статья

Как расширить диск виртуальной машины в VMWare
Установка VMware Tools на Debian, Ubuntu и CentOS
Сжимаем тонкий (thin) диск в ESXi 5
Создаем собственные правила файервола в ESXi 5.0
+5 Спасибо, очень помог!
А нет ли лекарства, чтобы виртуалки не зависали таким образом ? На сервере крутится единственная включенная вируталка с win2008r2/sql2008r2. Виснет она строго по ночам, без каких либо выявленных закономерностей: может месяцами не виснуть, может 2 раза за ночь. Достало просыпаться по ночам и перезагружать.
Странно — у меня баг с зависанием виртуальной машиной на ESXi встречался не столько часто…
Возможно стоит для начала обновить версию до последней версию ESXi и VMtools на гостевой ОС.
Если ничего не поможет — придется прикручивать какой-нибудь костыль в виде скрипта, периодически запускающегося на хосте ESXi и проверяющий доступность определенного сервиса на виртуалке (хотя бы тем же telnet-ом). Если сервис не отвечает — выполняем скрипт перезапуска виртуалки (по мотивам этого мануала)
Спасибо за инфу!
У меня были случаи подвисания виртуальных машин с Linux, Windows и FreeBSD — так что решение, похоже, не универсальное. Скорее тут какой-то глюх самого ESXi.
В любом случае по результатам, пожалуйста, отпишитесь…
К сожалению не помогла заплатка. зависания всё равно случаются.
Может память или ядра неправильно распределены?
Я заметил что бывают торможения всех виртуалок и начал оставлять запас по мощности.

13.04.2022
itpro
PowerShell, VMWare, Виртуализация
Комментариев пока нет
На хостах VMware ESXi по-умолчанию отключен удаленный доступ к командной строке (консоли сервера) через SSH. Поэтому при подключении к хосту через sshвы получите ошибку: ssh: connect to host 192.168.13.51 port 22: Connection refused. В этой статье мы рассмотрим все способы включения.
Ошибка VMWare ESXi: Errno 28 — No space left on device
06.09.2021
itpro
VMWare, Виртуализация
Один комментарий
Алгоритм действий и возможные причины зависания
- Первое, что я вам советую сделать, это избавится от ошибки "Vmware Tools is outdated on this virtual machine" путем обновления Vmware Tools. Напоминаю, что это сделать можно из меню "Guest OS - Update Vmware Tools". Потребуется перезагрузка виртуальной машины.
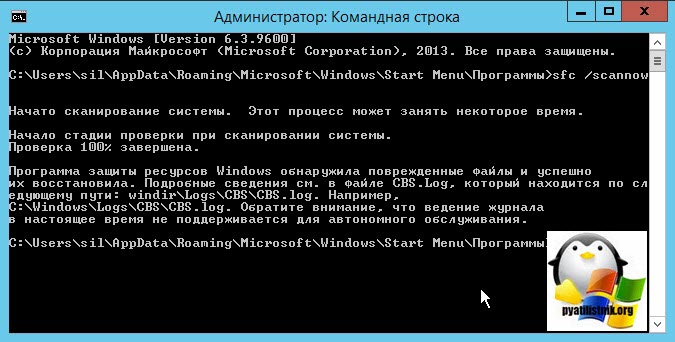
- Следующим пунктом, я вам советую проверить операционную систему на предмет повреждения системных файлов, сделать это просто. Запустите cmd от имени администратора или откройте Power Shell, кому что привычнее и введите команду:
Программа защиты ресурсов Windows обнаружила поврежденные файлы и успешно их восстановила. Подробные сведения см. в файле CBS.Log, который находится по следующему пути: windir\Logs\CBS\CBS.log.
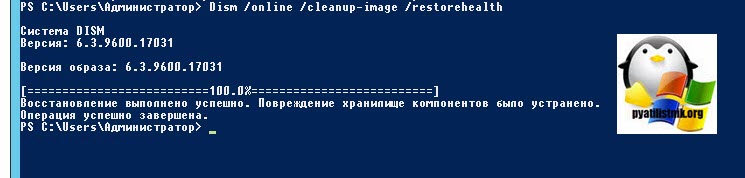
Если ошибки не были устранены, то советую выполнить команду:
Утилита DISM обратится к внешним репозиториям Microsoft и скачает от туда валидные файлы, чтобы восстановить аналогичные в вашей системе. Процесс так же может занимать некоторое время. Как видим:
Восстановление выполнено успешно. Повреждение хранилище компонентов было устранено. Операция успешно завершена.
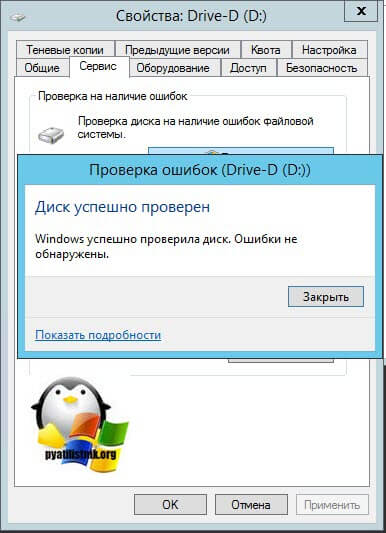
Еще одним пунктом диагностики проблем с ошибками ID 111 и ID 129, я вам советую выполнить сканирование ваших дисков на предмет ошибок. Для этого есть два варианта, старая добрая утилита командной строки ChkDsk и ее графический аналог в свойствах диска "Проверка диска на наличие ошибок файловой системы"
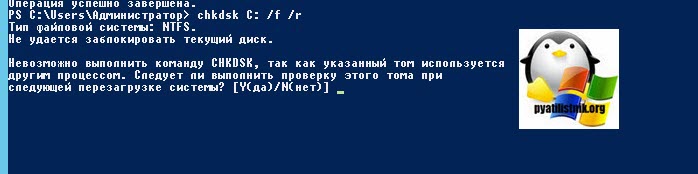
Для проверки локальных дисков через командную строку, вы можете воспользоваться командой:
Ключ /f указывает утилите исправлять ошибки на диске, флаг /R обязывает CHDSK искать на диске повреждённые сектора, и попытаться восстановить данные на них. Если диск системный, то вас попросят перезагрузиться, и проверка диска будет перед загрузкой системы.
Невозможно выполнить команду CHKDSK, так как указанный том используется другим процессом. Следует ли выполнить проверку этого тома при следующей перезагрузке системы? [Y(да)/N(нет)]
То же самое вы можете сделать и в свойствах локального диска, для этого щелкните по нему правым кликом и перейдите в его свойства. Найдите там вкладку "Сервис" и на ней пункт "Проверка диска на наличие ошибок файловой системы". Нажмите проверить.
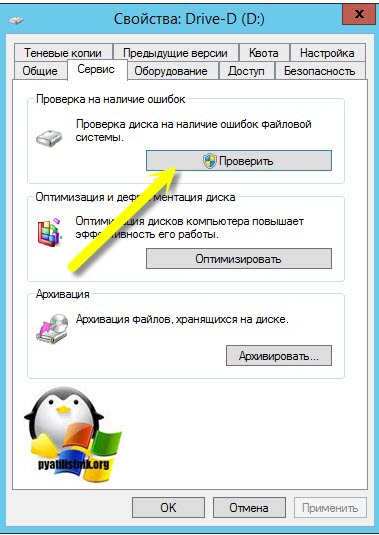
В новом окне нажимаем "Проверить диск".
Будет запущен процесс сканирования диска, обычно он занимает не много времени.
После чего вы получите результат. В моем случае я вижу, что "Диск успешно проверен".
Немного теории

В ESXi за работу каждого vCPU (ядра виртуальной машины) отвечает отдельный процесс – world в терминологии VMware. Также есть служебные процессы, но с точки зрения анализа производительности ВМ они менее интересны.
Процесс в ESXi может находиться в одном из четырех состояний:
- Run – процесс выполняет какую-то полезную работу.
- Wait – процесс не выполняет никакой работы (idle) либо ждет ввода/вывода.
- Costop – состояние, которое возникает в многоядерных виртуальных машинах. Оно возникает, когда планировщик CPU гипервизора (ESXi CPU Scheduler) не может запланировать одновременное исполнение на физических ядрах сервера всех активных ядер виртуальной машины. В физическом мире все ядра процессора работают параллельно, гостевая ОС внутри ВМ рассчитывает на аналогичное поведение, поэтому гипервизору приходится замедлять ядра ВМ, у которых есть возможность закончить такт быстрее. В современных версиях ESXi планировщик CPU использует механизм, который называется relaxed co-scheduling: гипервизор считает разрыв между самым «быстрым» и самым “медленным" ядром виртуальной машины (skew). Если разрыв превышает определенный порог, «быстрое» ядро переходит в состояние costop. Если ядра ВМ проводят много времени в этом состоянии, это может вызвать проблемы с производительностью.
- Ready – процесс переходит в данное состояние, когда у гипервизора нет возможности выделить ресурсы для его исполнения. Высокие значения ready могут вызвать проблемы с производительностью ВМ.
Сброс пароля администратора в HP ILO

10.11.2020
itpro
HP, Linux, VMWare, Windows Server 2016
Один комментарий
В этой статье мы покажем основные способы сброса пароля администратора на плате управления серверами HPE — Integrated Lights Out (ILO) на примере iLO 4 (инструкция применима также к iLO 3 и iLO 4).

Если вы администрируете виртуальную инфраструктуру на базе VMware vSphere (или любого другого стека технологий), то наверняка часто слышите от пользователей жалобы: «Виртуальная машина работает медленно!». В этом цикле статей разберу метрики производительности и расскажу, что и почему «тормозит» и как сделать так, чтобы не «тормозило».
Буду рассматривать следующие аспекты производительности виртуальных машин:
Для анализа производительности нам понадобятся:
Описание проблемной виртуальной машины
Как я и писал выше, виртуальная машина намертво зависла, по RDP или ping она была не доступна. Гостевой операционной системой была Windows Server 2012 R2. Попытавшись запустить Web Console из интерфейса vCenter Server, виртуальная машина ни на что не реагировала.

Подключение iSCSI хранилища (LUN) в VMWare ESXi

27.04.2021
itpro
VMWare, Виртуализация
Комментариев пока нет
В VMware vSphere вы можете использовать iSCSI диски в качестве общего дискового хранилища для ваших ESXi хостов. ESXi хост получает доступ к таким дискам по вашей локальной сети с помощью протокола TCP. В этой статье мы рассмотрим, как подключить iSCSI LUN.
CPU на гипервизоре
В vCenter есть также счетчики производительности CPU для гипервизора, но они не представляют из себя ничего интересного – это просто сумма счетчиков по всем ВМ на сервере.
Удобнее всего смотреть состояние CPU на сервере на вкладке Summary:

Для сервера, как и для виртуальной машины, есть стандартный Alarm:

При высокой нагрузке на CPU сервера у ВМ, работающих на нем, начинаются проблемы с производительностью.
В ESXTOP данные о загрузке CPU сервера представлены в верхней части экрана. Помимо стандартного CPU load, который малоинформативен для гипервизоров, есть еще три метрики:
CORE UTIL(%) – загрузка ядра физического сервера. Данный счетчик показывает, сколько времени за период измерения ядро выполняло работу.
PCPU UTIL(%) – если включен hyper-threading, то на каждое физическое ядро приходится два потока (PCPU). Данная метрика показывает, сколько времени каждый поток выполнял работу.
PCPU USED(%) – то же, что PCPU UTIL(%), но учитывает frequency scaling (либо снижение частоты ядра в целях энергосбережения, либо повышение частоты ядра за счет технологии Turbo Boost) и hyper-threading.
PCPU_USED% = PCPU_UTIL% * эффективную частоту ядра / номинальную частоту ядра.

На этом скриншоте для некоторых ядер из-за работы Turbo Boost’а значение USED больше 100%, так как частота ядра выше номинальной.
Пара слов о том, как учитывается hyper-threading. Если процессы исполняются 100% времени на обоих потоках физического ядра сервера, при этом ядро работает на номинальной частоте, то:
- CORE UTIL для ядра будет 100%,
- PCPU UTIL для обоих потоков будет 100%,
- PCPU USED для обоих потоков будет 50%.
В ESXTOP также есть экран с параметрами энергопотребления CPU сервера. Здесь можно посмотреть, используются ли сервером технологии энергосбережения: C-states и P-states. Вызывается клавишей «p»:

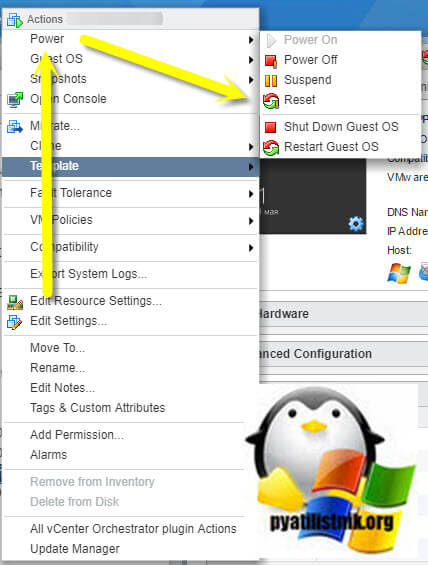
Диагностика зависшей виртуальной машины
Первым делом, чтобы восстановить сервис, вам необходимо принудительно перезагрузить виртуальную машины, для этого щелкните по ней правым кликом мыши и выберите пункт "Power - Reset".
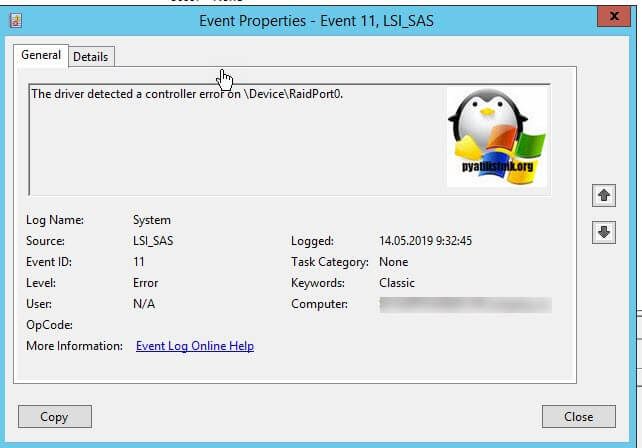
После того, как операционная система в ней загрузится, я вам советую начать изучение логов Windows. Открываем просмотр событий и делаем поиск ошибок и предупреждений. Мне удалось найти два события, которые косвенно говорили, что проблема с зависанием виртуальной машины связана непосредственно с операционной системой и возможными проблемами с поврежденными системными файлами или драйверами Vmware Tools. Первое событие:

Так же можно обнаружить и ошибки вот такого рода, которые так же заставляю виртуальную машину флапать, зависать с черным экраном.
Данное событие связано с сетевым интерфейсом типа E1000, советую его поменять на паравиртуализованный VMXNET3. E1000 кушает больше ресурсов процессорных мощностей и так же более капризный, но за то не требует установки Vmware Tools.

Так же вы можете посмотреть логи самой виртуальной машины на уровне Vmware ESXI 6.5. Я нашел там вот такую выборку:
2019-05-14T11:06:41.739Z| vmx| I125: GuestMsg: Channel 0, Cannot unpost because the previous post is already completed
2019-05-14T11:08:48.012Z| svga| I125: MKSScreenShotMgr: Taking a screenshot
2019-05-14T11:08:53.849Z| mks| I125: SOCKET 1396535 (189) Creating VNC remote connection.
2019-05-14T11:08:53.849Z| mks| I125: MKSControlMgr: New VNC connection 1
2019-05-14T11:08:53.912Z| mks| W115: VNCENCODE 1396535 failed to allocate VNCBlitDetect
2019-05-14T11:08:53.912Z| mks| I125: VNCENCODE 1396535 VNCEncodeChooseRegionEncoder: region encoder adaptive. Resolution: 1024 x 768
2019-05-14T11:08:54.289Z| vmx| I125: Tools_SetGuestResolution: Sending rpcMsg = Resolution_Set 1920 863
2019-05-14T11:08:54.630Z| vcpu-7| I125: VMMouse: CMD Read ID
2019-05-14T11:09:54.289Z| vmx| I125: GuestRpcSendTimedOut: message to toolbox timed out.
2019-05-14T11:10:07.476Z| svga| I125: MKSScreenShotMgr: Taking a screenshot
2019-05-14T11:10:19.546Z| mks| I125: SOCKET 1396535 (189) recv error 0: Success
2019-05-14T11:10:19.546Z| mks| I125: SOCKET 1396535 (189) VNC Remote Disconnect.
2019-05-14T11:10:19.546Z| mks| I125: MKSControlMgr: Remove VNC connection 1
2019-05-14T11:10:31.357Z| vmx| I125: VigorTransportProcessClientPayload: opID=HardPowerOpsResolver-applyOnMultiEntity-5384149-ngc:70276545-fb-c5-9d61 seq=2571570: Receiving Sched.SetResourceGroup request.
2019-05-14T11:10:31.357Z| vmx| I125: VigorTransport_ServerSendResponse opID=HardPowerOpsResolver-applyOnMultiEntity-5384149-ngc:70276545-fb-c5-9d61 seq=2571570: Completed Sched request.
2019-05-14T11:10:31.358Z| vmx| I125: VigorTransportProcessClientPayload: opID=HardPowerOpsResolver-applyOnMultiEntity-5384149-ngc:70276545-fb-c5-9d61 seq=2571571: Receiving PowerState.InitiateReset request.
2019-05-14T11:10:31.358Z| vmx| I125: Vix: [8790361 vmxCommands.c:686]: VMAutomation_Reset. Trying hard reset
2019-05-14T11:10:31.358Z| vmx| W115:
2019-05-14T11:10:31.358Z| vmx| W115+
2019-05-14T11:10:31.358Z| vmx| W115+ VMXRequestReset
2019-05-14T11:10:31.358Z| vmx| I125: Vigor_Reset: Attaching to reset.
2019-05-14T11:10:31.358Z| vmx| I125: Stopping VCPU threads.
2019-05-14T11:10:31.360Z| vcpu-0| I125: VMMon_WaitForExit: vcpu-0: worldID=9507337
2019-05-14T11:10:31.360Z| vcpu-7| I125: VMMon_WaitForExit: vcpu-7: worldID=9507347
2019-05-14T11:10:31.360Z| vcpu-3| I125: VMMon_WaitForExit: vcpu-3: worldID=9507343
2019-05-14T11:10:31.360Z| vcpu-1| I125: VMMon_WaitForExit: vcpu-1: worldID=9507341
2019-05-14T11:10:31.360Z| vcpu-5| I125: VMMon_WaitForExit: vcpu-5: worldID=9507345
2019-05-14T11:10:31.360Z| vcpu-10| I125: VMMon_WaitForExit: vcpu-10: worldID=9507350
2019-05-14T11:10:31.360Z| vcpu-9| I125: VMMon_WaitForExit: vcpu-9: worldID=9507349
2019-05-14T11:10:31.360Z| vcpu-8| I125: VMMon_WaitForExit: vcpu-8: worldID=9507348
2019-05-14T11:10:31.360Z| vcpu-6| I125: VMMon_WaitForExit: vcpu-6: worldID=9507346
2019-05-14T11:10:31.360Z| vcpu-4| I125: VMMon_WaitForExit: vcpu-4: worldID=9507344
2019-05-14T11:10:31.360Z| vcpu-2| I125: VMMon_WaitForExit: vcpu-2: worldID=9507342
2019-05-14T11:10:31.360Z| vcpu-11| I125: VMMon_WaitForExit: vcpu-11: worldID=9507351
2019-05-14T11:10:31.360Z| svga| I125: SVGA thread is exiting
2019-05-14T11:10:31.360Z| vmx| I125: MKS thread is stopped
2019-05-14T11:10:31.361Z| vmx| I125:
2019-05-14T11:10:31.361Z| vmx| I125+ OvhdMem: Final (Power Off) Overheads
Основные счетчики производительности CPU виртуальной машины
CPU Usage, %. Показывает процент использования CPU за заданный период.

Как анализировать? Если ВМ стабильно использует CPU на 90% или есть пики до 100%, то у нас проблемы. Проблемы могут выражаться не только в «медленной» работе приложения внутри ВМ, но и в недоступности ВМ по сети. Если система мониторинга показывает, что ВМ периодически отваливается, обратите внимание на пики на графике CPU Usage.
Есть стандартный Аlarm, который показывает загрузку CPU виртуальной машины:

Что делать? Если у ВМ постоянно зашкаливает CPU Usage, то можно задуматься об увеличении количества vCPU (к сожалению, это не всегда помогает) или переносе ВМ на сервер с более производительными процессорами.
Расширить размер VMFS хранилища в VMWare ESXi
02.06.2021
itpro
VMWare, Виртуализация
комментария 3
В этой статье мы рассмотрим, как увеличить размер VMFS хранилища с помощью веб интерфейса vSphere Client и из командной строки VMWare ESXi.
Стандартные проблемы производительности CPU
Напоследок пробегусь по типичным причинам возникновения проблем с производительностью CPU ВМ и дам короткие советы их решению:
Не хватает тактовой частоты ядра. Если нет возможности перевести ВМ на более производительные ядра, можно попробовать изменить настройки энергопотребления, чтобы Turbo Boost работал эффективнее.
Неправильный сайзинг ВМ (слишком много/мало ядер). Если поставить мало ядер, будет высокая загрузка CPU ВМ. Если много, словите высокий co-stop.
Неправильная NUMA-топология на больших ВМ. NUMA-топология, которую видит ВМ (vNUMA), должна соответствовать NUMA-топологии сервера (pNUMA). Про диагностику и возможные варианты решения данной проблемы написано, например, в книге «VMware vSphere 6.5 Host Resources Deep Dive». Если не хотите углубляться и у вас нет лицензионных ограничений по ОС, установленной на ВМ, делайте на ВМ много виртуальных сокетов по одному ядру. Много не потеряете :)
На этом про CPU у меня все. Задавайте вопросы. В следующей части расскажу про оперативную память.
Обновление VMware ESXi из командной строки

29.11.2021
itpro
VMWare, Виртуализация
Комментариев пока нет
В этой статье мы рассмотрим процесс ручной установки rollup патчей на хост VMware ESXi из командной строки, а также процесс апгрейда версии ESXi (в этом примере разберем обновление с VMware ESXi 6.7 до 7.0). Ручное обновление ESXi из консоль esxcli можно.
Установка Windows 11 на виртуальную машину VMware

22.10.2021
itpro
VMWare, Windows 11, Виртуализация
комментариев 5
Эта статья посвящена особенностям установки Windows 11 на виртуальную машину, запущенную на гипервизорах VMware Workstation ии VMware ESXi. Большинство пользователей при попытке установить Windows 11 в виртуальную машину VMware сталкиваются с ошибкой, сообщающей, что запуск Windows 11 на этом компьютере невозможен.
Ранее установленный софт
Очень часто причиной зависания виртуальной машины на ESXI 6.5 выступает недавняя установка обновлений в системе или различного рода программного обеспечения. Обязательно посмотрите в "Панель управления\Все элементы панели управления\Программы и компоненты" по дате установки, что недавно было проинсталлировано.
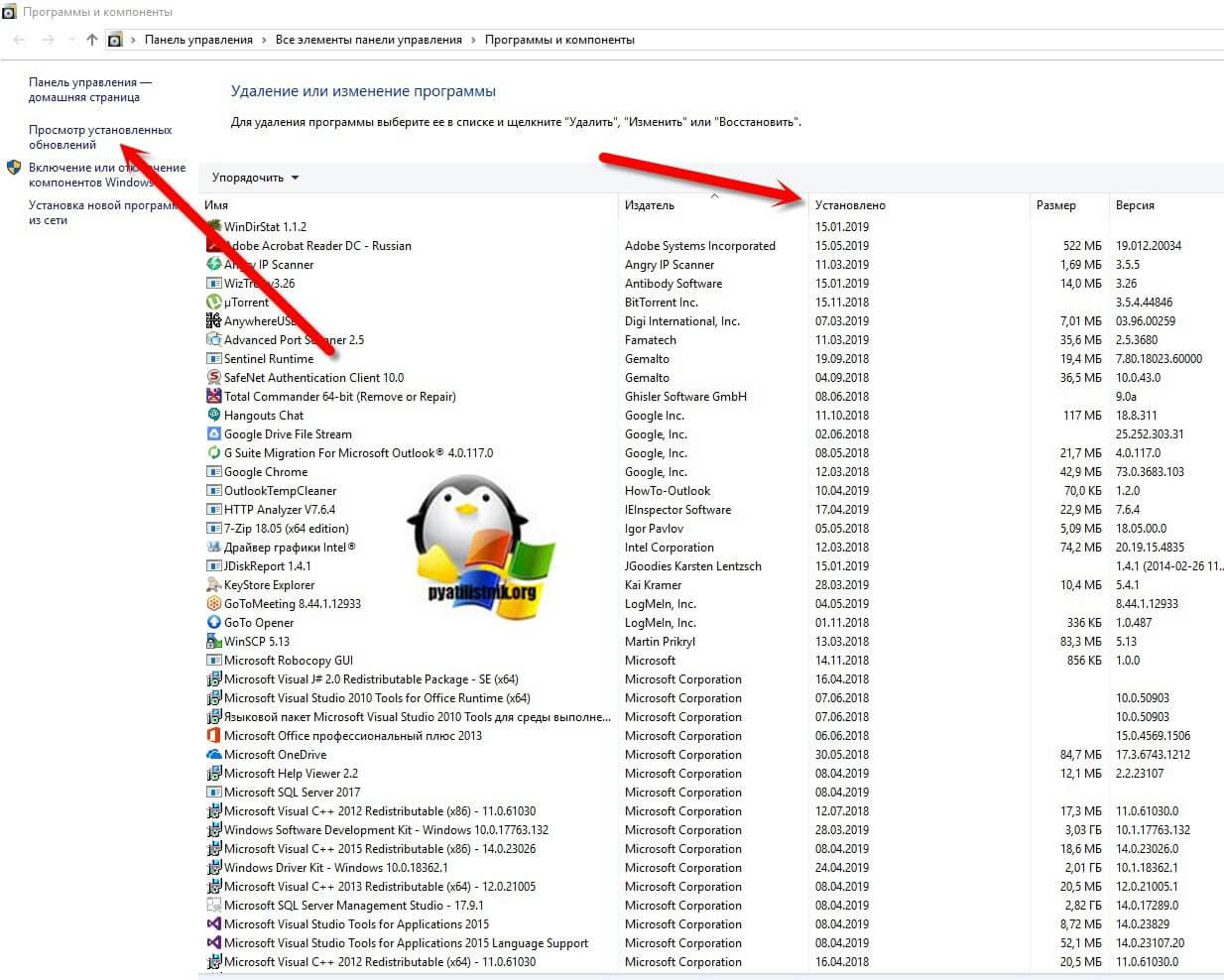
Тут же можно посмотреть установленные обновления. Недавно Microsoft выпустило обновление KB4015553 (Со временем может меняться), которое в Windows Server 2012 R2 стало вызывать зависание. Необходимо удалить KB4015553, kb4019215 и kb4019217, перезагрузить ваш сервер.
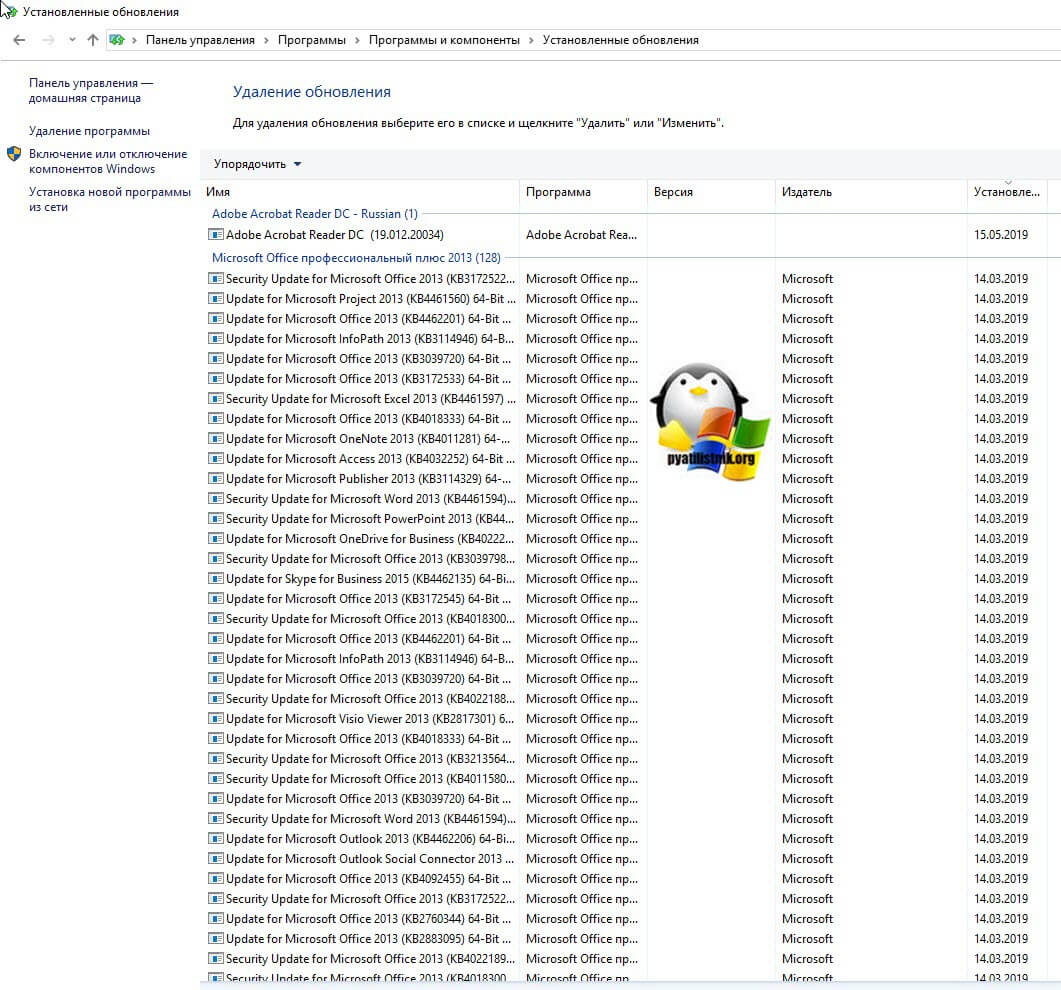
Сама компания Symantec рекомендует в ветке (https://support.symantec.com/en_US/article.TECH236543.html) Исключите из проверки следующий каталог, включая все подкаталоги: путь зависит от вашей версии SEP: "C:\ProgramData\Symantec\Symantec Endpoint Protection\\Data\Definitions". Пример для SEP 14.0 MP1: C:\ProgramData\Symantec\Symantec Endpoint Protection\14.0.2332.0100.105\Data\Definitions. Если вышеуказанное исключение не решает проблему, также исключите следующий каталог: C:\Windows\rescache.
Эти пути могут отличаться в зависимости от сборки продукта или от того, что каталоги ProgramData или Windows были перемещены на другой диск.
Сделать, это можно в "Change Settings - Exception - SONAR Exception" нажимаем кнопку "Add" и выбираем нужные каталоги.
Отключаем автоматическую приостановку (suspend) виртуальной машины в VMWare Workstation/Player

03.05.2021
itpro
VMWare, Windows 10, Виртуализация, Вопросы и ответы
Комментариев пока нет
Заметил одну неприятную особенность в гипервизоре VMWare Workstation. Если вы не используете виртуальную машину в течении некоторого времени, она автоматически приостанавливается функцией Suspend. Чтобы продолжить использование ВМ приходится нажимать кнопку Resume this virtual machine.
Co-stop
Как анализировать? Данный счетчик также имеет тип Summation и переводится в проценты аналогично Ready:
(CPU co-stop summation value / (chart default update interval in seconds * 1000)) * 100 = CPU co-stop %
Здесь также нужно обращать внимание на количество ядер на ВМ и на интервал измерения.
В состоянии сostop ядро не выполняет полезную работу. При правильном подборе размера ВМ и нормальной нагрузке на сервер счетчик со-stop должен быть близок к нулю.

В данном случае нагрузка явно ненормальная:)
Также co-stop вырастет, если для активных ядер одной ВМ используются треды на одном физическом ядре сервера со включенным hyper-treading. Такая ситуация может возникнуть, например, если у ВМ больше ядер, чем физически есть на сервере, где она работает, или если для ВМ включена настройка «preferHT». Про эту настройку можно прочитать здесь.
Чтобы избежать проблем с производительностью ВМ из-за высокого сo-stop, выбирайте размер ВМ в соответствии с рекомендациями производителя ПО, которое работает на этой ВМ, и с возможностями физического сервера, где работает ВМ.
Не добавляйте ядра про запас, это может вызвать проблемы с производительностью не только самой ВМ, но и ее соседей по серверу.
Добавление виртуальной звуковой карты в VMWare ESXi

11.12.2020
itpro
VMWare, Windows 10, Виртуализация
Комментариев пока нет
По умолчанию в виртуальных машинах на VMWare ESXi отсутствуют звуковые устройства. Если вам нужно получить звук с удаленной ВМ с Windows, проще всего воспользоваться возможностью RDP Remote Audio (проброс звуков с удаленного компьютера на аудиоустройство локального компьютера в RDP-клиенте). Однако в.
Другие полезные метрики CPU
Run – сколько времени (мс) за период измерения vCPU находился в состоянии RUN, то есть собственно выполнял полезную работу.
Idle – сколько времени (мс) за период измерения vCPU находился в состоянии бездействия. Высокие значения Idle – это не проблема, просто vCPU было «нечего делать».
Wait – сколько времени (мс) за период измерения vCPU находился в состоянии Wait. Так как в данный счетчик включается IDLE, высокие значения Wait также не говорят о наличии проблемы. А вот если при высоком Wait IDLE низкий, значит ВМ ждала завершения операций ввода/вывода, а это, в свою очередь, может говорить о наличии проблемы с производительностью жесткого диска или каких-либо виртуальных устройств ВМ.
Max limited – сколько времени (мс) за период измерения vCPU находился в состоянии Ready из-за установленного лимита по ресурсам. Если производительность необъяснимо низкая, то полезно проверить значение данного счетчика и лимит по CPU в настройках ВМ. У ВМ действительно могут оказаться выставлены лимиты, о которых вы не знаете. Например, так происходит, когда ВМ была склонирована из шаблона, на котором был установлен лимит по CPU.
Swap wait – сколько времени за период измерения vCPU ждал операции с VMkernel Swap. Если значения данного счетчика выше нуля, то у ВМ точно есть проблемы с производительностью. Подробнее про SWAP поговорим в статье про счетчики оперативной памяти.
Установка VMWare ESXi в виртуальную машину Windows Hyper-V

19.04.2021
itpro
Hyper-V, VMWare, Windows 10, Виртуализация
комментариев 10
Для домашнего стенда мне понадобилось установить гипервизор VMWare ESXi -V в качестве виртуальной машины Hyper-V на Windows 10. Hyper-V и VMWare ESXi поддерживают вложенную виртуализацию (nested virtualization) и в принципе этот сценарий возможен (хотя официально не поддерживается). Однако есть несколько особенностей.
CPU Ready (Readiness)
Если ядро ВМ (vCPU) находится в состоянии Ready, оно не выполняет полезную работу. Такое состояние возникает, когда гипервизор не находит свободное физическое ядро, на которое можно назначить процесс vCPU виртуальной машины.
Как анализировать? Обычно если ядра виртуальной машины находятся в состоянии Ready больше 10% времени, то вы заметите проблемы с производительностью. Проще говоря, больше 10% времени ВМ ждет доступности физических ресурсов.
В vCenter можно посмотреть 2 счетчика, связанных с CPU Ready:
Значения счетчика Ready можно посмотреть также в исторической перспективе. Это полезно для установления закономерностей и для более глубокого анализа проблемы. Например, если у виртуальной машины начинаются проблемы с производительностью в какое-то определенное время, можно сопоставить интервалы повешенного значения CPU Ready с общей нагрузкой на сервер, где данная ВМ работает, и принять меры по снижению нагрузки (если DRS не справился).
Ready в отличие от Readiness показывается не в процентах, а миллисекундах. Это счетчик типа Summation, то есть он показывает, сколько времени за период измерения ядро ВМ находилось в состоянии Ready. Перевести данное значение в проценты можно по несложной формуле:
(CPU ready summation value / (chart default update interval in seconds * 1000)) * 100 = CPU ready %
Например, для ВМ на графике ниже пиковое значение Ready на всю виртуальную машину получится следующим:

При подсчете значения Ready в процентах стоит обращать внимание на два момента:
- Значение Ready по всей ВМ – это сумма Ready по ядрам.
- Интервал измерения. Для Real-time – это 20 секунд, а, например, на дневных графиках – это 300 секунд.
Рассчитаем Ready на основе данных из графика ниже. (324474/(20*1000))*100 = 1622% на всю ВМ. Если смотреть по ядрам получится уже не так страшно: 1622/64 = 25% на ядро. В данном случае обнаружить подвох довольно просто: значение Ready нереалистичное. Но если речь идет о 10–20% на всю ВМ с несколькими ядрами, то по каждому ядру значение может быть в пределах нормы.

Что делать? Высокое значение Ready говорит о том, что серверу не хватает ресурсов процессора для нормальной работы виртуальных машин. В такой ситуации остается только уменьшить переподписку по процессору (vCPU:pCPU). Очевидно, этого можно добиться, уменьшив параметры существующих ВМ или путем миграции части ВМ на другие серверы.
Восстановление удаленного VMFS хранилища в VMware ESXi/vSphere

21.12.2021
itpro
VMWare, Виртуализация
комментария 3
Рассмотрим гипотетическую проблему потери или повреждения VMFS хранилища, подключенное к ESXi хосту/vSphere. Например, из-за человеческой ошибки, когда администратор VMware случайно удалил VMFS хранилище, или когда диск/LUN с VMFS был отключен/потерян из-за ошибок на устройстве хранения/резервного копирования. В этой статье мы покажем.
ESXTOP
Если счетчики производительности в vCenter хороши для анализа исторических данных, то оперативный анализ проблемы лучше производить в ESXTOP. Здесь все значения представлены в готовом виде (не нужно ничего переводить), а минимальный период измерения 2 секунды.
Экран ESXTOP по CPU вызывается клавишей «c» и выглядит следующим образом:
Для удобства можно оставить только процессы виртуальных машин, нажав Shift-V.
Чтобы посмотреть метрики по отдельным ядрам ВМ, нажмите «e» и вбейте GID интересующей ВМ (30919 на скриншоте ниже):

Кратко пройдусь по столбцам, которые представлены по умолчанию. Дополнительные столбцы можно добавить, нажав «f».
NWLD (Number of Worlds) – количество процессов в группе. Чтобы раскрыть группу и увидеть метрики для каждого процесса (например, для каждого ядра многоядерной ВМ), нажмите “e”. Если в группе больше одного процесса, то значения метрик для группы равны сумме метрик для отдельных процессов.
%USED – сколько циклов CPU сервера использует процесс или группа процессов.
%RUN – сколько времени за период измерения процесс находился в состоянии RUN, т.е. выполнял полезную работу. Отличается от %USED тем, что не учитывает hyper-threading, frequency scaling и время, затраченное на системные задачи (%SYS).
%SYS – время, затраченное на системные задачи, например: обработку прерываний, ввода/вывода, работу сети и пр. Значение может быть высоким, если на ВМ большой ввод/вывод.
%OVRLP – сколько времени физическое ядро, на котором выполняется процесс ВМ, потратило на задачи других процессов.
Данные метрики соотносятся между собой следующим образом:
%USED = %RUN + %SYS — %OVRLP.
Обычно метрика %USED является более информативной.
%WAIT – сколько времени за период измерения процесс находился в состоянии Wait. Включает IDLE.
%IDLE – сколько времени за период измерения процесс находился в состоянии IDLE.
%SWPWT – сколько времени за период измерения vCPU ждал операции с VMkernel Swap.
%VMWAIT – сколько времени за период измерения vCPU находилось в состояния ожидания события (обычно ввода/вывода). Аналогичного счетчика нет в vCenter. Высокие значения говорят о проблемах с вводом/выводом на ВМ.
%WAIT = %VMWAIT + %IDLE + %SWPWT.
Если ВМ не использует VMkernel Swap, то при анализе проблем с производительностью целесообразно смотреть на %VMWAIT, так как данная метрика не учитывает время, когда ВМ ничего не делала (%IDLE).
%RDY – сколько времени за период измерения процесс находился в состоянии Ready.
%CSTP – сколько времени за период измерения процесс находился в состоянии сostop.
%MLMTD – сколько времени за период измерения vCPU находился в состоянии Ready из-за установленного лимита по ресурсам.
%WAIT + %RDY + %CSTP + %RUN = 100% – ядро ВМ все время находится в каком-то из этих четырех состояний.
CPU Usage in Mhz
В графиках на vCenter Usage в % можно посмотреть только по всей виртуальной машине, графиков по отдельным ядрам нет (в Esxtop значения в % по ядрам есть). По каждому ядру можно посмотреть Usage in MHz.
Как анализировать? Бывает, что приложение не оптимизировано под многоядерную архитектуру: использует на 100% только одно ядро, а остальные простаивают без нагрузки. Например, при дефолтных настройках бэкапа MS SQL запускает процесс только на одном ядре. В итоге резервное копирование тормозит не из-за медленной скорости дисков (именно на это изначально пожаловался пользователь), а из-за того, что не справляется процессор. Проблема была решена изменением параметров: резервное копирование стало запускаться параллельно в несколько файлов (соответственно, в несколько процессов).

Пример неравномерной нагрузки ядер.
Также бывает ситуация (как на графике выше), когда ядра нагружены неравномерно и на некоторых из них есть пики в 100%. Как и при загрузке только одного ядра, alarm по CPU Usage не сработает (он по всей ВМ), но проблемы с производительностью будут.
Что делать? Если ПО в виртуальной машине нагружает ядра неравномерно (использует только одно ядро или часть ядер), нет смысла увеличивать их количество. В таком случае лучше переместить ВМ на сервер с более производительными процессорами.
Также можно попробовать проверить настройки энергопотребления в BIOS сервера. Многие администраторы включают в BIOS режим High Performance и тем самым отключают технологии энергосбережения C-states и P-states. В современных процессорах Intel используется технология Turbo Boost, которая увеличивает частоту отдельных ядер процессора за счет других ядер. Но она работает только при включенных технологиях энергосбережения. Если мы их отключаем, то процессор не может уменьшить энергопотребление ядер, которые не нагружены.
VMware рекомендует не отключать технологии энергосбережения на серверах, а выбирать режимы, которые максимально отдают управление энергопотреблением гипервизору. При этом в настройках энергопотребления гипервизора нужно выбрать High Performance.
Если у вас в инфраструктуре отдельные ВМ (или ядра ВМ) требуют повышенную частоту CPU, корректная настройка энергопотребления может значительно улучшить их производительность.

Увеличить таймаут неактивности в сессии VMware ESXi и vSphere
17.11.2021
itpro
VMWare, Виртуализация
Комментариев пока нет
В веб интерфейсах управления ESXi Host Client и vShere Web Client по умолчанию настроены таймауты неактивности, благодаря которым сессия пользователя автоматически завершается, если он не открывал вкладку браузера с веб интерфейсом управления VMWare. В этой статье мы покажем, как увеличить или.
Читайте также: