
Заданные файловые документы что это
О сложности и жуткости вордовских файлов давно ходили легенды. Известно было, что формат этот крайне запутанный, а к тому же еще и полностью засекреченный, так что о половине тамошних полей можно было только догадываться.
Не скрою, что и меня эти файлы интересовали, но дальше первой страницы описания я так продвинуться и не смог. Однако незакрытый гештальт остался.
А теперь вот жизнь заставила (или подкинула возможность) все-таки разобраться во внутренностях всем хорошо известных документов, тем более, что в Штирлица теперь играть не обязательно, достаточно скачать с сайта «Майкрософта» официальные спецификации.
Что тут можно сказать? Невольно вспоминается старый пошлый анекдот: ну ужас. Ну просто ужас, но ведь не ужас-ужас-ужас.
Слава богу, что я разбирал эти файлы на Перле, а не на каком-нибудь автокоде Си. Высокий уровень языка и куча готовых библиотек (например, для чтения разных кодовых страниц) — это дар божий.
Так что работа в совокупности заняла неделю, и самым сложным было понять внутренний формат. Конечно, понимание это не совсем полное, потому что моей задачей было вытащить из документа одни тексты без всякого форматирования, но уж это я сделал тщательно.
Итак, как же устроены вордовские файлы?
Контейнер
Начнем с того, что это совсем не вордовские файлы, а некий универсальный контейнер, в который упакованы собственно документы. В такой контейнер засунуты все файлы Офиса, а, может быть, и еще что-нибудь.
Формат контейнера называется по-разному — docfile, ole storage, compound document file. Уже сам разнобой в названиях намекает на то, что он не сильно-то и нужен, поскольку действительно полезная вещь обычно имеет одно и четкое название. Основная его идея — иметь возможность запихать в один файл несколько других. Самым разумным было бы (как и сделали в OpenOffice) упаковать все в архив ZIP (можно без архивации, если она не нужна). Формат известен огромному множеству программ, компактен, легко разбирается. Но в «Майкрософте», очевидно, процветает синдром «Not invented here». Главное — изобрести велосипед, пусть и трехколесный, но собственный.
В принципе, формат OLE Storage достаточно разумен и не производит впечатление чего-то совсем идиотского. Но… он совершенно не нужен. Фактически, это что-то типа файловой системы FAT16, засунутой внутрь отдельного файла. Это не то что стрельба из пушки по воробьям, а истребление этих самых воробьев ядерными торпедами. В документе, внутри которого лежит несколько файлов, не нужна файловая система, находящаяся не менее чем на уровне ФС времен ДОС.
Итак, файлы CDF (как их называет юниксовская утилитка file) начинаются с заголовка. В заголовке отведено место под первую сотню записей ТРФ (таблицы размещения файлов, в просторечии — ФАТ). ФАТ там самый натуральный, очень похож на то, что можно найти на досовских дискетках. Остальные записи ТРФ лежат в отдельных секторах, соединенных связанным списком. Дополнительные сектора бывают только в больших (>7мб) файлах.
По табличке ФАТ/ТРФ можно собрать содержимое любого внутреннего файла (в терминологии МС он называется потоком, но это только запутывает дело), если знать, с какого блока он начинается. Начальные блоки разных структур написаны, естественно, в заголовке. Дальше из таблицы можно вытянуть всю цепочку секторов, в котором записано содержимое этого псевдофайла.
В частности, у CDF есть корневой каталог, физически размазанный по куче секторов. Это самый настоящий каталог, опять-таки, очень напоминающий старый досовский. Правда, для эффективности (или для выпендрежа) он выполнен не просто линейным списком, а сбалансированным двоичным деревом. Это значит, что в него без потери эффективности поиска можно записывать десятки тысяч отдельных записей. Зачем это нужно в файле, в котором записей бывает обычно штук пять, ну иногда, двадцать, ну максимум сто штук (презентация с огромным количество картинок) — знают только в Редмонде. Кстати, имена файлов в каталоге хранятся в UTF16 — тоже на всякий случай.
По каталогу можно определить начальный сектор любого файла и с помощью ТРФ вытянуть всю его цепочку размещения.
Но это еще не все.
Поскольку размер блока немаленький (обычно 512 байт, по спецификации возможно также 4096), то при хранении мелких псевдофайлов, теоретически можно потерять много свободного места. Поэтому существует отдельное хранилище, поделенное на блочки по 64 байта. Хранилище опять-таки вытягивается по цепочке ФАТ.
Чтобы указать, какие блочки какому файлу принадлежат, существует отдельная табличка ФАТ или, вернее сказать, миниФАТ.
Итак, чтобы добраться до вордовского документа, надо сделать следующее:
1. Прочитать заголовок CDF
2. Загрузить в память ФАТ — таблицу размещения файлов, собрав ее по цепочке секторов.
3. Загрузить табличку МиниФАТ, собрав ее по цепочке ТРФ
4. Загрузить хранилище блочков, собрав ее по цепочке ТРФ
5. Загрузить корневой каталог, собрав ее по цепочке ТРФ
6. Разобрать каталог и преобразовать его во что-то читаемое
7. Найти в каталоге запись WordDocument
8. Если это маленький файл, то собрать его с помощью миниТРФ из хранилища для блочков.
9. Если большой, то вытянуть с диска сектора по цепочке ТРФ.
Каждый шаг сам по себе не особенно сложен, но в совокупности они вызывают исключительно недоумение. Зачем такие сложности? Почему нельзя было разместить после заголовка обыкновенный линейный каталог, а после него непрерывно, друг за другом записывать внутренние файлы?
Единственное, что можно предположить — все это сделано для того, чтобы была возможность дописывать подфайлы, не трогая начало основного файла. Надо заметить, что, во-первых, это не сильно востребованная операция, поскольку все программы обычно записывают документы от начала до конца в один проход. Исключение составляет только MS Word и то только в пресловутом режиме быстрого сохранения, проклятом пользователями. А во-вторых, даже в этих условиях все равно не получится не трогать начало основного файла, поскольку надо обновлять каталоги, ТРФ и заголовки.
В общем, «Майкрософт» в своем амплуа. Зачем делать просто, если можно сложно и запутанно?
WordDocument
Формат CDF при всей своей монструозности хотя бы логичен и не очень сложен (если сравнивать с остальным содержимым вордовского документа). Его описание занимает всего каких-то двадцать страниц — тьфу по сравнению с 300 страницами формата Ворда.
Формат документа сложно даже назвать форматом, гораздо больше к нему подойдет определение каменной летописи. Представьте себе такой каменный обрыв, на котором отпечаталось пятьдесят миллионов лет истории планеты. Вот мезозойский слой, вот кайнозойский, вот отпечаток крыла птеродактиля, а сверху уже третичные отложения. Примерно так же выглядит и документ изнутри.
Достаточно посмотреть на заголовок, который занимает чуть ли не треть файла. Заголовков целых три. Сначала идет один небольшой, в котором половина записей зияет дырами «Reserved» или «Not used». Раньше, в мезозое, там явно что-то лежало, но потом было выкинуто на свалку истории. Здесь же имеется версия записавшей программы, по которой в коде, похоже, выполняется огромный switch/case.
Затем идет второй заголовок, состоящий из шестнадцатибитовых слов. В нем нет вообще ничего полезного. В его начале прописан размер явно с таким расчетом, что здесь будут в будущем откладываться панцири простейших.
После этого идет третий заголовок, на этот раз современный, из длинных слов (32 бита). Он немерянной длины, в начале тоже указывает количество записей с прицелом на дальнейшее расширение, и в основном представляет собой список, где искать различные таблицы и куски файла — пары начало/размер. Сами таблицы, кстати, лежат не здесь, а в отдельном псевдофайле CDF под названием 0Table или 1Table (возможны варианты).
В первом заголовке написана длина самого текста и его начало. Очевидно, что во времена царя Гороха именно так его и можно было прочитать. Текст лежал одним большим куском. Забавно, что можно читать его так и сейчас, но… не всегда! На десять читаемых файлов найдется такой, у которого в середине окажутся невразумительные куски, в конце — сноски, которых там быть не должно, а в самом начале — большой кусок текста, который стерли в прошлом году. Кроме того, половина файла окажется написана китайскими иероглифами. Прискорбно заметить, что известная утилита catdoc Витуса Вагнера в некоторых случаях именно такие результаты и дает, из чего можно сделать вывод, что формат она разбирает недокорректно.
Жизнь на самом деле гораздо сложнее. Когда-то в файлах действительно был только текст, однако со временем под давлением пользователей и маркетинга накапливались различные «фичи». Под них отвели отдельные потоки — под простые сноски, под сноски концевые, под колонтитулы, под какие-то textbox (то еще извращение — на вид текст, но не текст. Назначение толком не ясно).
Начала этих потоков указаны в специальных местах заголовка, но самый первый заголовок почему-то показывает общую длину — не самого текста, а текста плюс все этих извращений. Вот и первая причина, почему в вывод многих утилит попадают надписи типа Page 1.
Где-то в архее в редактор добавили быстрое сохранение. Смысл его в том, что файл целиком не переписывается, а добавления и изменения просто дописываются в его конец, что теоретически должно быть быстрее. Предполагалось радовать этим пользователей, но фактически они остались недовольны. Особой разницы в скорости записи при этом не получается, но в файле образуется много мусора, причем из кусков, которые теоретически уже стерты. Если там была какая-нибудь секретная информация, то простым просмотром дампа файла ее можно легко обнаружить.
Для поддержки быстрого сохранения была заведена особая таблица огрызков (piece table), в которую записывается начало каждого куска и его адрес в файле. Длины нет, но ее можно высчитать, вычтя начало текущего куска из начала следующего. Однако тут тоже надо быть осторожным, поскольку огрызки перечисляются из всех потоков. Слава богу, что они идут в определенном порядке, поэтому, зная общую длину текста, легко вовремя остановиться.
Теоретически, этот сложный формат задействован только, если в заголовке установлен специальный флажок fComplex. Но… Вот на этом очередном «но» тоже прокалываются многие конверторы.
Уже в наше время в документы добавили возможность записи в Юникоде. При этом встала проблема (как по мне, надуманная): а ведь файлы получаются ровно в два раза длиннее. Поскольку ПО разрабатывают американцы, которые в душе вообще не верят в существование других азбук, и тайно считают, что всякие странные буквы бывают только в диссертациях про Древнюю Грецию, да и там встречаются только иногда, первое, что пришло им на ум — отделить чистые символы ASCII от грязных юникодовских. Первые писать по байту на символ, вторые — как получится.
Из этой идеи возникла, например, элегантная кодировка UTF-8, где двухбайтовые символы кодируются хитрыми последовательностями в духе кодирования Хаффмана. В «Майкрософте» сделали то же самое, только не так красиво. Раз уж у нас есть таблица огрызков, то запишем туда заодно и какие куски текста написаны в чистом ASCII (на самом деле сp1252), а какие — на всякого рода невразумительных алфавитах, требующих Юникода и, соответственно два байта на символ. Поэтому нынешние файлы всегда нужно разбирать с помощью таблицы кусков, невзирая на всякие там флажки. Юникодовские фрагменты там берутся как есть, только надо учитывать, что количество читаемых байтов должно быть в два раза больше количества читаемых символов. Однобайтовые фрагменты отмечаются в адресе установленным вторым слева старшим битом (почему не первым?). Чтобы узнать настоящий адрес, нужно этот бит сбросить, а адрес разделить на два (!).
Если учесть, что сама эта таблица огрызков тоже занимает место, а еще больше места в файле занимают разные двоичные деревья и таблички цепочек секторов от формата CDF, то размеры экономии текста на символах Юникода не поразят воображения даже в древнегреческих диссертациях. О файлах на великом и могучем языке и говорить нечего. Положили бы все в UTF-16 и не страдали. Ну заархивировали бы поток, раз уж так жаба давит.
После героических усилий по чтению текста, в нем самом, как ни странно, нет ничего сложного. Обычный текст (с поправкой на кодировку), кое-какие коды ниже пробела играют служебную роль. Например, 0х9 обозначает, как и положено, табуляцию, 0хА — конец страницы, 0х7 — конец ячейки таблицы и т.д. Единственная тонкость связана с полями. Начало содержимого поля обозначается как 0х13, конец поля — 0х15, имя и параметры поля отделяются символом 0х14 от того, что, собственно, видно в тексте пользователю. Но… Вторая часть может иметь в себе вложенное поле, чего многие программы не учитывают. В результате в тексте остаются огрызки вроде INCLUDEPICTURE или PAGEREF *.
Впрочем, есть еще одна мелкая пакость. Некоторые символы могут означать что-нибудь совсем другое, вроде текущей даты. Чтобы понять, простой это символ или нет, надо разбирать таблицы свойств символов, о которых ниже. Каюсь, я просто вырезал все символы с кодом ниже пробела, что не совсем достаточно, но дешево, быстро и практично.
Выдрав текст, дальше в формат я углубляться не стал. Это уже занятие для молодых и сильных духом — разобрать все эти таблицы с такими многообещающими названиями как CHP, PAPX, SHST, PLCF и все в том же духе. Занятие совсем уже для титанов — вопроизвести форматирование в точности, как это делает сам Ворд.
Кратко изложу только, что все хранится в специальных таблицах, входом в которые служит адрес символа с начала потока. Стили лежат в длинных списках, изменения в стилях — в специальных списках исключений. Локальные изменения стиля, например, при редактировании абзаца или символа хранятся в таблицах как специальные команды по изменению родительских таблиц стилей. Сами команды очень напоминают команды виртуальной машины от типичной игры-квеста.
Осталось только подвести мораль, а она банальна: что один человек придумал, то другой завсегда поломать может. Что не делает формат Ворда менее позорным, уродливым и совершенно неприспособленным для задач массового обмена информацией в гетерогенных системах.
Думаю, что «Майкрософт» столько лет его не открывала не потому, что боялась конкуренции, а просто потому что было… стыдно.
Назначение: восстановление информации при повреждении файловой системы, удалении файлов, удалении или пересоздании разделов, переустановки ОС, сборка и восстановление данных с массивов RAID-0, RAID-5, RAID-6, JBOD, виртуальных дисков платформ виртуализации (VMware, VirtualBox, QEMU).
Поддерживаемых файловые системы: FAT12, FAT16, FAT32, NTFS, NTFS5 (созданная и используемая в Windows 2000 /XP/2003/Vista/7, exFAT, ReFS (новая файловая система, представленная Microsoft в Windows 2012 Server), Ext2/3/4FS (созданные в Linux или другой ОС), HFS, HFS+, HFSX, and UFS1, UFS2, UFS BigEndian (используемые в ОС FreeBSD, OpenBSD, и NetBSD).
Пример практического использования R-Studio
Рассмотрим как восстановить данные на конкретном примере.
Дано: USB-flash SanDisk Ultra 32GB.
Симптом: Windows при попытке открыть диск просит его отформатировать, ниже снимок экрана.


Важно заметить, что сама флешка исправна, но повреждён раздел. Раздел или том — понятия исключительно логические, том — более широкое понятие, может состоять из нескольких физических носителей, но, тем не менее, видится, как единое пространство.
И так, запускаем программу. В примере используется Demo-версия с ограничением по размеру восстанавливаемых файлов.
В среде Windows Vista и старше программу нужно запускать от имени администратора даже, если ваша учётная запись имеет права администратора.
В окне Drives слева видим список устройств и разделов. Справа, в Properties, свойства выбранного устройства или раздела. Сканировать на предмет поиска файловых систем и данных можно как всё устройство, так и существующие разделы или можно задать область сканирования вручную.



- Simple – выводит только индикатор прогресса сканирования
- Detailed – информация о найденных загрузочных секторах, файловых системах, файлах документов, если включена Extra search
- None – никакой уточняющей информации о сканировании не выводится.

Процесс пошёл. На карте расположения информации на диске цветом показано какие найдены структуры данных. Ниже, под картой приводится расшифровка. Для полного восстановления данных необходимо просканировать всю поверхность накопителя. В данном примере информации на флешке мало, она располагается в первой половине флеш-памяти и дальше сканировать смысла нет, поэтому был нажат Stop. После предварительной обработки, откроется результат сканирования.

- Зелёный — найдена файловая система и boot-сектор — самый лучший вариант
- Оранжевый — найдена файловая система, но нет загрузочного сектора, присутствует часто в нескольких вариантах, отличающихся количеством восстановимых данных
- Красный — найден только загрузочный сектор без файловой системы, причём их может быть много, как правило интереса не представляют.



Теперь остаётся только переписать найденную информацию на другой носитель. Для этого нужно отметить нужные файлы и папки или выделить всё, поставив галочку около Root-элемента. И в контекстном меню выбрать Recover marked.


Output folder – нужно указать, куда сохранять данные. Остальное можно оставить как есть.
Внимание! Никогда не сохраняйте данные на тот же диск с которого Вы их восстанавливаете. Иначе восстановленные файлы будут записываться на место восстанавливаемых файлов, что приведёт к их необратимому повреждению.

Некоторые параметра стоит изменить во вкладке Advanced.
- prompt – спрашивать на каждом случае повтора
- rename – переименовывать автоматически
- overwrite – перезаписывать
- skip – пропускать (стоит выбрать, чтоб не увеличивать объём данных).
- prompt – спрашивать каждый раз
- rename and change invalid symbols to – переименовывать, заменяя недопустимые символы на заданный символ
- skip – просто пропускать (выбрать, часто при первавильном имени содержимое тоже повреждено).
- prompt – спрашивать каждый раз
- remove – удалять (выбрать).
Не всегда сканирование даёт такой превосходный результат, как в данном примере. Чтобы показать, какой может быть результат сканирования, откроем другой, отмеченный красным, вариант восстановления и увидим следующее.

Как видно на иллюстрации, большинство папок отмечено красным знаком вопроса. То, что не отмечено им внутри пустые, а окно с логом переполнено ошибками. Данный результат не содержит практически полезной информации.
R-Studio как пользоваться правильно, чтобы не усложнить наверно и без того сложную ситуацию, в которую вы попали. Пожалуйста прослушайте небольшой курс молодого бойца по работе с подобными программами, без этого вы можете наделать много ошибок и вместо того, чтобы вернуть свои удалённые данные, вы ещё хуже затрёте их.
Что такое форматы файлов и расширения файлов. В чем разница?
Отметим, что расширение файла и формат – это понятия близкие, но не взаимозаменяемые. Их не следует путать. Файлы одинакового формата могут иметь различные расширения.
Изучая форматы файлов, операционная система распознает их содержимое, а также подбирает соответствующее приложение, чтобы обеспечить взаимодействие с выбранным материалом. Существует множество форматов: графические, офисные, установочные, архивные, музыкальные, системные, служебные и другие. Расширение в имени файла находится по правую сторону от точки – это всего несколько латинских букв. Операционная система благодаря этим данным, определяет программу, которой будет открыт выбранный файл.
Немного практики. Один формат — разные расширения
Описанную выше теорию подкрепим простым примером. Часто на практике мы встречаемся с файлами, которые содержат в себе различную документацию, рассказы, схемы и списки. В данном случае, речь идет о текстовом формате, он взаимодействует с различными офисными программами, поэтому его также можно назвать офисным. При этом, мы сами можем создать документы, используя редактор Word либо стандартное приложение «Блокнот». Полученный в результате файл будет обладать различным расширением. Таким образом, мы на практике доказали, что расширение файлов в Windows и форматы – это разные понятия. Не следует их путать в будущем.
Как поменять расширение файла и настройка его видимости
Если вы знаете, какое расширение имеют файлы, при необходимости вы можете его сменить. Иногда недостаточно внести правки в имя файла для такого преобразования, а требуются особые программы – конвертеры.
К примеру, вы решили разместить в Интернете видеоролик, однако он имеет формат .avi и отличается большим объемом. Для сжатия можно применить конвертер. В итоге, мы получим куда более меньший файл, расширение которого изменится, например, на .3gp.
Если ваша операционная система настроена таким образом, что возле каждого файла видно расширение, его можно скрыть. Для этого в настройках системы существует специальный раздел «Параметры папок».
Здесь нам необходимо обратить внимание на вторую вкладку. В ней содержаться различные дополнительные параметры. Среди них есть и функция, которая позволяет выбрать скрывать или отображать расширения файлов в их именах.
Коротко о типах расширений
Список из 10 расширений файлов, которые используются чаще всего выглядит следующим образом:
Некоторые из них мы обсудим отдельно.
Открываем файл с определенным расширением нужным приложением
Файлы различных форматов обладают расширениями, которые служат указателями для приложений. Но не все так просто, поскольку одинаковое расширение может быть открыто различными программами. К примеру, пользователь может одновременно установить на компьютер целый ряд видеоплееров. AVI – это наиболее распространенное расширение файлов видео, поэтому его откроет любое из этих приложений. Но если просто запустить видеоролик, он будет открыт той программой, которая указана «по умолчанию». Этот параметр можно настроить в ручном режиме. Для этого нажимаем на необходимый нам файл правой кнопкой мыши. В возникшем меню используем пункт «Свойства». Открывается окно, в котором нас интересует строка «Приложение». Именно здесь можно узнать программу, которая взаимодействует с данным типом файлов. При необходимости можно использовать функцию «Изменить», и подобрать более подходящее приложение. Кроме предложенных системой вариантов, программу можно указать самостоятельно, посредством кнопки «Обзор». Если файл отказывается взаимодействовать с выбранным приложением, снова повторяем описанную процедуру и указываем более подходящую программу.
↑ Полный поиск и восстановление удалённых файлов
Для поиска и восстановления других удалённых данных, воспользуемся функцией полного сканирования диска (Scan).
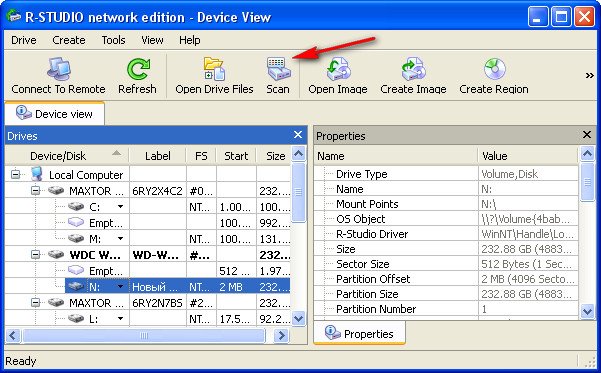
В данном окне ставим галочку Поиск известных типов файлов, и выбираем Детализированное сканирование и жмём Scan .

Наберёмся терпения, операция довольно продолжительная, в правом окне в виде разноцветных квадратиков, отображён ход процесса, на данный момент просканировано всего 13%.




В окне программы, приведённом ниже, можно увидеть распознанные программой файловые системы и соответственно сведения или данные, которые можно восстановить.
Recognized 0 или Recognized 1 , Recognized 2 – помеченные зелёным цветом, здесь находятся данные, которые можно восстановить практически на 100%.
Extra Found Files – помеченные жёлтым и красным цветом, данные, которые программа не смогла распознать и сопоставить какой-либо файловой системе, восстановить их скорее всего не удасться, а если что и восстановится, будет не читаемо, что бы выудить из таких файлов информацию, нужен hex-редактор, но это уже другая тема, требующая не одной, а нескольких больших статей.
Так же мало шансов на восстановление у Recognized 0 , помеченного жёлтым цветом.
В последней папке Recognized 2 , я нашёл почти все файлы, которые были нужны, двойным щелчком левой кнопкой мыши заходим в папку.



Смотрим и удивляемся, чего тут только нет, вот бы ещё восстановить всё это, ставим галочки на нужных файлах и нажимаем Recover , указываем куда и ОК , настройки восстановления оставляем по умолчанию.


Возникает знакомое окно, с предложением убрать у восстанавливаемых файлов атрибут скрытый, соглашаемся, далее возникает окно с предложением заменить или пропустить системный файл Thumbs, пропускаем, жмём Skip ..

Ожидаем окончания процесса восстановления, он тоже довольно продолжителен, после его окончания идем в Мои документы-личная папка R-Studio, напомню R-TT и просматриваем файлы, подавляющее большинство фотографий без искажений, у видеофайлов 5% с незначительными дефектами, почти все текстовые файлы открываются.

Под конец хочу сказать, то, что мы проделали, лишь небольшая часть возможностей программы R-Studio , вы можете применить её для восстановления RAID-массивов и поиска информации внутри локальной сети. Так же вы можете использовать поиск удалённых данных по маске и по различным атрибутам, создавать образ падающего винчестера и пользоваться встроенным Универсальным Шестнадцатиричным Просмотрщиком/Редактором.
Если вы системный администратор или считаете себя продвинутым пользователем, вы обязаны иметь R-Studio у себя.
Файлы… что вообще может быть проще? Мы все привыкли создавать, удалять, редактировать, перекидываться файлами.
Но можем ли мы заглянуть внутрь каждого файла и понять как он устроен? Конечно можем, поэтому сегодня мы немного покопаемся в бинарном коде и пощупаем метаданные.
Заодно узнаем, почему iPhone зависает от SMS и распотрошим PowerPoint.
Почему форматов файлов так много?
Если бы мы просто могли взглянуть на сырые данные, которые хранятся внутри жесткого диска или SSD, то мы бы не увидели никаких файлов: мы бы увидели только нолики и единички. Потому как, в любом случае, в памяти компьютера всё хранится в виде сплошного потока двоичного кода.
Но как же тогда понять, где заканчивается один файл и начинается другой?
Поначалу эту проблему человечество решало брутально. Люди записывали один файл на один жесткий диск, чтобы уж точно не ошибиться. Поэтому раньше словом файл называли не отдельную область на жестком диске, а прям целое устройство. К примеру IBM 305.

CTSS (Compatible Time-Sharing System)
Но потом, люди придумали файловые системы. Если очень упростить, это такое оглавление в котором указано имя файла, где он начинается и его длина. А также всякие метаданные, типа время создания, изменения, и можно ли его перезаписывать.

Но для того чтобы прочитать файл, знать его местоположение и границы на жестком диске недостаточно, ведь нам нужно как-то расшифровать бинарный код.
Для этого и существуют различные форматы файлов. В большинстве операционных систем форматы файлов указываются в виде расширения, которое отделяется точкой от имени файла. А если вы не видите расширения, это нормально. Потому что, по умолчанию, современные ОС их скрывают, но можно поставить галочку в настройках.
Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано. Например, увидев файл droider.jpg операционная система и мы, люди, сразу понимаем, что это картинка в формате JPEG.
Естественно, для типов данных и разных задач оптимальной будет разная структура файла. Поэтому и форматов файлов существует огромная масса.
Поэтому давайте разберем, как устроены наиболее популярные форматы файлов от более простых к более сложным.
Один из самый простых форматов — это TXT. Это текстовый формат. Знаменитое приложение «Блокнот» в Windows работает как раз с этим форматом.
TXT — формат незамысловатый. Он может хранить в себе только простой неформатированный текст, то есть в нем нет никаких выделений, подчеркиваний, курсивов, отступов, разных шрифтов. Только голый текст, а точнее просто символы.
Каждый символ в TXT-формате хранится в виде бинарного кода.
То что мы с вами видим как осмысленный текст, операционная система видит вот так:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Каждые 8 цифр, то есть 8 бит этого кода — это отдельный символ.
Например, 01001000 — это “H”, 01100101 — это “e”, и так далее.
Подобрав правильную кодировку остается дело техники. Система сопоставляет бинарный код с таблицей кодировки UTF-8 и готово! Но что будет если система подберет кодировку неправильно? Вариантов не много, скорее всего мы увидим крякозябры:
И такое часто случается, так как TXT-файл не содержит никакой дополнительной информации о кодировке. И это большой недостаток формата.
И вдобавок, эту таблицу нужно было загрузить в оперативную память при загрузке компьютера, а у типового ПК в начале 80-х годов редко было больше 640 килобайт оперативки. А использовать 16-битные таблицы (65536 вариантов) было просто невозможно, такая таблица просто не влезла бы в память.
Но мощность компьютеров росла и проблема ушла. К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый. Поэтому текст на русском занимает в два раза больше памяти, при том же количестве символов.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111000 11010001 10000000 00100001
11010000 10011111 — П
11010001 10000000 — р
10111000 11010000 — и
11010000 10110010 — в
Старики помнят лайфхак, если писать SMS на латинице, то влезет в два раза больше текста. Всё это как раз из-за кодировки.
Так вот, чтобы у операционной системы не было проблем с пониманием как прочитать файл. Помимо самих данных, в разные форматы стали добавлять данные о данных. То есть метаданные, которые хранятся прямо внутри файла и содержат дополнительную информацию о том, как этот файл прочитать.
Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV.

Первые 44 байта классического WAV-файла содержат заголовок, к котором указывается полезнейшая информация:
- количество аудио каналов;
- частота дискретизации;
- битовая глубина;
- и многое другое.
Открытые и проприетарные форматы
Структура WAV хорошо известна и наверное такой файл сможет прочитать практически любой плеер. Всё потому, что WAV-файл — это пример открытого формата.
Есть и другие открытые форматы, которыми вы ежедневно пользуетесь. Например:
- язык разметки web-страниц — HTML;
- картинки — PNG;
- аудио в формате — OGG;
- архива — ZIP;
- видео — MKV;
- электронной книги — EPUB;
- и другие.
Проприетарные форматы всем прекрасны, но в отдельных случаях они препятствуют конкуренции в сфере программного обеспечения, так как приводят к замыканию на поставщике. Есть даже такой термин Vendor lock-in.
Старый офис
Например, раньше такая ситуация была с форматами Microsoft Office: DOC, XLS, PPT.
Мало того, что это были проприетарные форматы компании Microsoft и работали только с фирменным ПО. Так еще Microsoft постоянно меняли свою структуру файлов от одной версии MS Office к другой. И в результате? при выходе новой версии офисного пакета? файлы из старого редактора уже не читались новым, а наоборот — и подавно.
Такая ситуация не очень нравилась Европейскому Союзу. Поэтому, ЕС взъелся на тему ограничения конкуренции. В итоге, форматы файлов опубличили, и все научились хотя бы их читать, но для записи в старые форматы, по-прежнему, нужна лицензия Microsoft. И параллельно этому начали разрабатываться открытые форматы.
ODF и OOXML
1 мая 2006 года на свет появился формат формат ODF, что буквально расшифровывается как открытый формат документов для офисных приложений. Он был разработан консорциумом OASIS и Sun Microsystems.
- ODF — Open Document Format for Office Application.
- OASIS — Organization for the Advancement of Structured Information Standards.

Microsoft тоже не спал. Под давлением Европейского суда они объединились с рядом компаний в ассоциацию ECMA и разработали свой открытый формат Office Open XML, который появился на свет чуть позже в 2006 году.
OOXML стандартизирован European Computer Manufacturers Association. Standard ECMA-376
К привычным форматом конце добавилась буква X и мы получили: DOCX, XLSX, PPTX.
OOXML — Office Open XML (DOCX, XLSX, PPTX)
OOXML, в целом, очень похож на ODF. Он также основан на XML-разметке и также представляет из себя ZIP-архив. Поэтому вы также можете заглянуть внутрь офисных файлов при помощи любого архиватора. Можно даже вытащить картинки и даже подменить их, что бывает особенно удобно при работе с презентациями или когда вам присылают текстовый документ с картинками внутри файла.

Несмотря на кажущуюся простоту, формат реально сложный. Только основная документация — это 5 тысяч страниц. И это практически без картинок.
Тем не менее, кто-то всё таки смог прочитать всю эту документацию и поэтому на свет появились классные офисные пакеты, например МойОфис, которые умеют работать и ODF форматом, и с Office Open XML, и даже с устаревшими форматами типа DOC.
Но есть важная ремарка про старые форматы. Как правило, современный софт умеет их только читать, но не записывать, потому как это действие требует приобретение лицензии Microsoft. Впрочем, в наше время это действие, мягко говоря, бессмысленно.
Итого

Что мы в итоге узнали? Файлы бывают нескольких типов:
Самые базовые — бинарные. Такие форматы любят придумывать компании, чтобы никто не понял, как их программы хранят данные.
Более открытый вариант — xml-контейнеры. К счастью, большинство популярных офисных форматов сейчас такие. Если хотите работать со всеми этими файлами хоть дома, хоть на бегу, скачивайте программы МойОфис! На этом у нас сегодня всё.

Жесткий диск персонального компьютера наполнен различными данными. Поэтому следует разобраться, какие бывают форматы файлов, и для каких целей они используются. Знание основных расширений существенно облегчает поиск информации на ПК, а также процесс очистки его от ненужной информации. В зависимости от того, какое файл имеет расширение, его можно открыть и отредактировать, либо стандартными средствами ОС Windows, либо сторонними программными продуктами, которые потребуется сперва отыскать и установить. Расширение файла можно сделать видимым, либо скрыть.
↑ Программа для восстановления файлов R-Studio: как пользоваться
Первая ошибка, это волнение, которое сопровождается вытекающими отсюда последствиями, например необдуманными действиями, успокойтесь, дочитайте статью до конца, спокойно всё обдумайте, а затем действуйте. Кстати, если вы случайно удалили с вашего жёсткого диска фотографии, то у нас есть очень простая статья, которая я уверен вам поможет "Как восстановить удалённые фотографии". Ещё вам могут пригодиться статьи о восстановлении бесплатными программами: DMDE , R.saver и Recuva и платными - Ontrack EasyRecovery Professional, GetDataBack for NTFS .
Когда мы с вами, Дорогие мои, случайно удаляем файл, без которого наше дальнейшее существование на планете Земля, будет нам не в радость, знайте, что физически с жёсткого диска он не удалился, но навсегда потерять его можно, записав любую информацию поверх него. Поэтому, даже если вы читали как пользоваться R-Studio, но опыта как такового у вас нет, сразу выключаем компьютер и лучше в аварийном порядке. Больше никаких действий с вашим жёстким диском не производим, тогда наши шансы на благополучный успех увеличиваются.
- Примечание: много раз ко мне обращались люди с подобными проблемами и не могли вспомнить, какие действия они предпринимали до того, как обратиться в технический сервис. Они даже толком не могли назвать точное название программы, которой пытались спасти свои данные, а самое главное, после удаления своих файлов, например мимо корзины, они активно пользовались компьютером (иногда несколько дней), что категорически делать нельзя, только потом всё-таки шли в сервис и требовали чуда.
После того как мы выключили компьютер, берём системный блок и идём к профессионалам, ваши данные 90% будут спасены, естественно с вас возьмут немного денежки, сколько, лучше узнать сразу, но, если денежки попросят очень много, читаем дальше.
Сейчас я пишу эту статью, а передо мной стоит системный блок, в нём находится жёсткий диск, его случайно форматировали, то есть удалили всё что на нём находилось, давайте попробуем восстановить потерянные файлы с помощью R-Studio , а заодно научимся пользоваться этой хорошей программой.
В первую очередь нам с вами нужно эвакуировать пострадавшего, другими словами, снять форматированный винчестер и подсоединить к моему компьютеру, я делаю так всегда, потому что нельзя сохранять восстанавливаемую информацию на тот же носитель, с которого были удалены файлы.

Если для вас это трудно, тогда хотя бы не восстанавливайте файлы на тот раздел жёсткого диска, с которого они были удалены.
Примечание: Друзья, самое главное правило при восстановлении информации звучит так: число обращений к жёсткому диску с удалёнными данными должно быть сведено к минимуму. А значит, перед работой с R-Studio желательно сделать образ жёсткого диска с потерянными данными и восстанавливать информацию уже с образа. Как сделать посекторный образ жёсткого диска и восстановить с него информацию написано в этой нашей статье.
Итак начнём, на нашем пострадавшем от форматирования винчестере пропало очень много папок с семейными фотографиями и видео, нам нужно их вернуть.
Запускаем R-Studio , у программы интуитивно понятный англоязычный интерфейс, но нам не привыкать, я уверен, что, попользовавшись ей один раз, вы запомните её навсегда.
Главное окно программы Device View "Просмотр дисков" в левой его части показаны практически все накопители, находящиеся в системе: жёсткие диски, разбитые на логические разделы, USB-накопители, DVD-диски, флеш-карты, правое окно предоставляет полнейшую информацию о выбранном нам накопителе, начиная с названия и заканчивая размером кластеров.
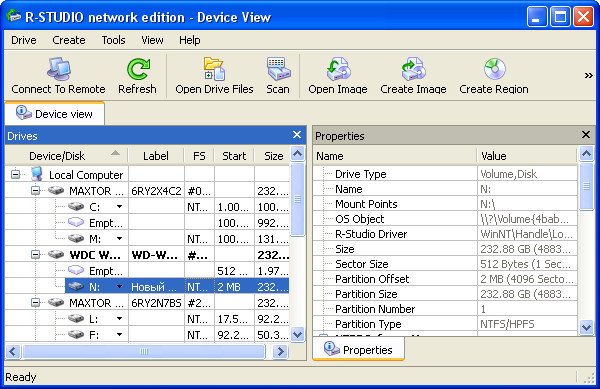
Выбираем наш диск (N:) и жмём Open Drive Files (Открыть файлы диска),
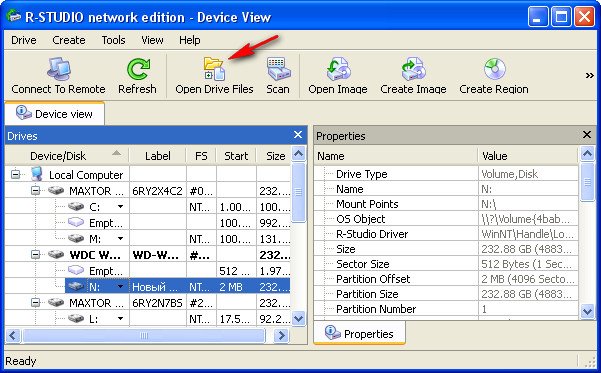
сейчас мы с вами используем самый простой способ восстановления удалённых файлов, перед нами открывается несколько папок, имеющих древовидную структуру, раскрываем все начиная с первой, предупреждаю, не ждите обычных названий ваших файлов, в нашем случае Фото сынишки и т.д. Можно сказать нам повезло, в окне присутствуют папки перечёркнутые красным крестиком, это значит они были удалены, смотрим названия: Глава 01, 02 и т.д,, это нужные нам папки с лекциями Университетского профессора, дело в том что перед подобными операциями восстановления, я внимательно расспрашиваю людей о названиях удалённых файлов и их расширениях, это нужно в особых запущенных случаях для поиска по маске и т.д. Вы можете не забивать себе голову на первый раз, в конце статьи мы воспользуемся методом расширенного сканирования ( Scan ) и восстановим всё что было на винчестере, это конечно займёт времени по сравнению с простым способом в десять раз больше. А сейчас ставим везде галочки и далее Recover ,
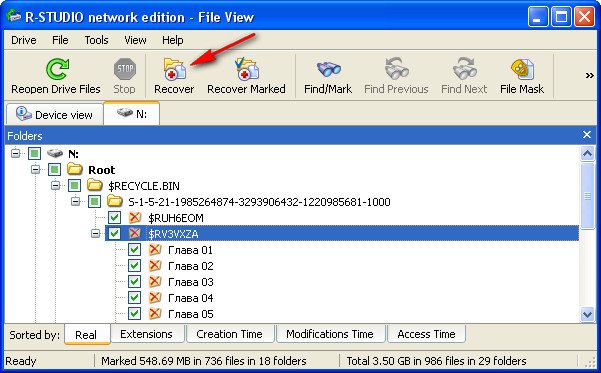
выбираем куда восстанавливать, по умолчанию в личную папку R-Studio в Моих документах и предложение изменить настройки восстановления по умолчанию, оставляем всё как есть нажимаем ОК .


Может возникнуть такое окно, содержание которого я вам перевёл в фотошопе, думаю мне за это ничего не будет, окно с предупреждением, что какой-либо из восстанавливаемых файлов имеет атрибут скрытый, R-Studio предложит убрать этот атрибут со всех подобных файлов, соглашаемся, ставим галочку, где надо и Продолжить .

После окончания процесса восстановления, идём в папку Мои документы, далее личная папка R-Studio , она называется R-TT и смотрим результат, восстановились папки с очень нужным видео Глава 01, 02, а так же, несколько папок с личными фотографиями, уже не плохо, но такой результат нас не устраивает.

Читайте также: