
Zabbix мониторинг usb подключений
Мониторинг был и остается важнейшей частью системного и сетевого администрирования. Но если для маленькой локальной сети зачастую достаточно время от времени смотреть логи, то в случае крупных систем приходится использовать специализированные средства. Об одном из них — Zabbix и поговорим сегодня.
Начнем с архитектуры. Система мониторинга Zabbix состоит из нескольких подсистем, причем все они могут размещаться на разных машинах:
- сервер мониторинга, который периодически получает и обрабатывает данные, анализирует их и производит в зависимости от ситуации определенные действия, в основном оповещение администратора;
- база данных — в качестве таковой могут использоваться SQLite, MySQL, PostgreSQL и Oracle;
- веб-интерфейс на PHP, который отвечает за управление мониторингом и действиями, а также за визуализацию;
- агент Zabbix, запускается на той машине/устройстве, с которой необходимо снимать данные. Его наличие хоть и желательно, но, если установить его на устройство невозможно, можно обойтись SNMP;
- Zabbix proxy — используется в основном в тех случаях, когда необходимо мониторить сотни и тысячи устройств для снижения нагрузки на собственно сервер мониторинга.
Логическая единица мониторинга — узел. Каждому узлу присваивается описание и адрес — в качестве адреса можно использовать как доменное имя, так и IP. Узлы могут объединяться в группы, к примеру группа роутеров, для удобства наблюдения. Каждому серверу соответствует несколько элементов данных, то есть отслеживаемых параметров. Поскольку для каждого сервера настраивать параметры, за которыми нужно следить, неудобно (особенно это верно для больших сетей), можно создавать узлы-шаблоны и каждому серверу или группе серверов будет соответствовать несколько шаблонов.
В статье будут рассмотрены интересные сценарии использования Zabbix, но сначала опишем установку этого решения на RHEL-подобные системы с MySQL в качестве БД.
Перво-наперво надо подключить репозиторий EPEL:
Затем поставить нужные пакеты:
И конечно же, надо произвести начальную настройку MySQL.
Затем заходим в консоль MySQL и создаем БД и пользователя:
Теперь импортируем базы данных:
Редактируем файл конфигурации сервера Zabbix ( /etc/zabbix_server.conf ):
Слегка подкрутим конфигурацию PHP ( /etc/php.ini ):
Наконец, запускаем оставшиеся службы:
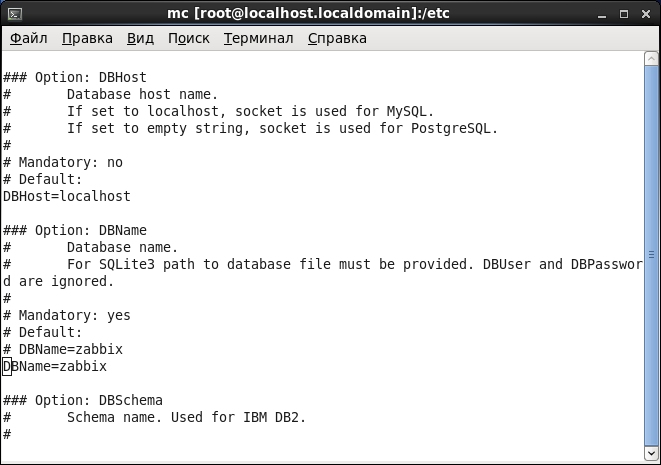
Конфигурационный файл Zabbix-сервера

Другие статьи в выпуске:
Начальная страница настройки веб-интерфейса Zabbix Примерно так выглядит начальная страница в первый раз после захода на нее
Для мониторинга nginx можно, разумеется, использовать самописные скрипты. Но в некоторых случаях, когда времени катастрофически не хватает, хочется найти что-нибудь готовое. В случае с nginx таким готовым решением будет набор питоновских скриптов ZTC. Для их установки сперва нужно установить некоторые пакеты:
Затем используй следующие команды:
Опция --nodeps нужна по причине того, что пакет требует версию Zabbix 1.8, но ничто не мешает попробовать ZTC и на последних его версиях.
Теперь добавим еще один конфиг nginx ( /etc/nginx/conf.d/nginx_status.conf ):
И поправим конфиг nginx в ZTC ( /etc/ztc/nginx.conf ):
Проверим работу скрипта ZTC:
Если все нормально, настраиваем Zabbix-agent на нужной машине ( /etc/zabbix-agentd.conf ):
Теперь нужно настроить веб-интерфейс. Для этого необходимо импортировать шаблон Template_app_nginx.xml , что лежит в /opt/ztc/templates/ . Замечу, что лежит он именно на том компьютере, где установлен ZTC, так что если у тебя на сервере нет GUI, то файл придется копировать на машину, на которой установлен браузер и с которой собственно и ведется мониторинг.
Не стоит забывать, что в этом наборе скриптов кроме мониторинга nginx есть еще мониторинг и других приложений, таких, например, как MongoDB. Настраивается он аналогично, поэтому рассматривать его смысла нет.
А вот для memcache среди этих скриптов нет ничего, так что придется нам его написать самим. Проверим его работо- и дееспособность:
В ответ должны посыпаться статистические данные. Теперь пишем скрипт-однострочник /etc/zabbix/scripts/memcache.sh (при этом не забываем сделать его исполняемым):
Как и в случае с nginx, правим конфиг Zabbix-agent ( /etc/zabbix-agentd.conf ) и не забываем его рестартовать:
Берем шаблон отсюда и импортируем его в веб-интерфейс.
Для сети средних размеров (когда нужно мониторить около десятка устройств) достаточно разместить сервер мониторинга, веб-интерфейс и БД на одной системе, а Zabbix-агенты — на узлах, требующих присмотра.
В основном Zabbix используется для мониторинга серверов, но помимо собственно серверов есть еще множество других устройств, которые также нуждаются в мониторинге. Далее будет описана настройка Zabbix для мониторинга некоторых из них.
В большинстве сетей среднего и крупного размера имеется гремучая смесь всевозможного железа, которая досталась нынешнему админу со времен развертывания (и, скорее всего, это развертывание происходило еще при царе Горохе). По счастью, абсолютное большинство сетевого (да и не только) оборудования поддерживает открытый протокол SNMP, с помощью которого можно как получать о нем информацию, так и управлять параметрами. В данном случае нас интересует первое. Вкратце опишу нужные действия:
- включить поддержку SNMP на устройствах. Не забывай о безопасности — по возможности используй третью версию протокола, устанавливай авторизацию и изменяй имена community;
- добавить нужные элементы в Zabbix. Одному параметру SNMP соответствует один элемент; также нужно указать OID (идентификатор параметра) версию SNMP и, в зависимости от нее, параметры авторизации;
- добавить триггеры на нежелательное изменение параметров.
У каждой железки могут быть десятки отслеживаемых параметров, и вручную их добавлять замучаешься. Но в Сети можно найти множество шаблонов, которые уже содержат в себе все необходимые элементы, триггеры и графики, — остается только их импортировать и подключить нужные хосты. Также существуют стандартные OID, которые описаны в RFC. К таковым относится, например, uptime с OID .1.3.6.1.2.1.1.3.0 или — для коммутаторов — статус порта с OID .1.3.6.1.2.1.2.2.1.8.X, где X — номер порта.
Существует онлайн-генератор шаблонов, который генерирует их на основе стандартных OID. В основном он предназначен для железа от Cisco, но ничто не мешает его использовать для другого оборудования.
Zabbix также поддерживает и карту сети. К сожалению, ее нужно составлять вручную. Есть возможность поставить над соединительными линиями скорость — для этого требуется добавить в подпись нужный элемент в фигурных скобках. Помимо этого, в случае падения соединения можно раскрашивать соединительные линии красным цветом.
Тот же человек, что написал упомянутый генератор шаблонов, написал также и дополнение к фронтенду, которое отображает в удобном виде статус порта (скрипт для второго Zabbix лежит здесь). Установка его, как его автор сам и признает, достаточно заморочена — скрипт писался в первую очередь для внутреннего применения.
Протокол SNMP, помимо пассивного получения данных устройства, поддерживает также и активную их рассылку со стороны устройства. В англоязычной документации это именуется SNMP Trap, в русскоязычной же используется термин SNMP-трап. Трапы удобны, когда нужно срочно уведомить систему мониторинга об изменении какого-либо параметра. Для отлова трапов в Zabbix имеется три способа (во всех трех случаях нужен еще и демон snmptrapd):
- с помощью SNMPTT (SNMP Trap Translator);
- используя скрипт на Perl;
- используя скрипт на bash.
Далее описан первый вариант. Прежде всего, не забываем разрешить 161-й порт UDP и по необходимости временно отключить SELinux. Затем ставим нужные пакеты (предполагается, что репозиторий EPEL у тебя подключен):
Настраиваем snmptrapd ( /etc/snmp/snmptrapd.conf ):
Первая строчка отключает проверки доступа, что, в общем-то, крайне не рекомендуется делать в условиях промышленного использования (здесь она исключительно для простоты конфигурации), вторая указывает обработчик всех поступивших трапов, коим и является snmptthandler.
Затем настраиваем snmptt ( /etc/snmp/snmptt.ini ):
Теперь нужно настроить шаблоны для маппинга трапов на Zabbix SNMP. Ниже будет приведен пример такого шаблона для двух видов трапов — coldStart и всех остальных ( /etc/snmp/snmptt.conf ).
Первые две строчки описывают любые трапы, а вторая пара — конкретный трап с OID. Замечу, что для того, чтобы Zabbix ловил эти трапы, они должны быть именно в формате «ZBXTRAP адрес».
Включаем нужные службы:
Посылаем тестовые трапы и смотрим логи:
Если все нормально, переходим к конфигурированию Zabbix. В файле /etc/zabbix_server.conf укажем местонахождение лога и включим встроенный SNMPTrapper:
После этого нужно зайти в веб-интерфейс Zabbix, по необходимости добавить в узле сети интерфейс SNMP и добавить элемент для трапа. Ставим все необходимые действия, если это нужно, и проверяем, для чего точно так же создаем тестовый трап.
Шаблоны для маппинга SNMP-трапов Настройка трапов в веб-интерфейсе
Масштабирование в Zabbix работает достаточно хорошо — при должной настройке он выдерживает 6000 узлов.
Возникла необходимость мониторинга загрузки кучи туннелей VPN на цисках. Все хорошо, SNMP как на циске, так и на Zabbix настроен, но есть одна загвоздка — OID для каждого соединения формируются динамически, как и их списки. Это связано с особенностями протокола IPsec, в которые я вдаваться не буду — скажу лишь, что это связано с процедурой установления соединения. Алгоритм извлечения нужных счетчиков, таким образом, настолько замудрен, что реализовать его встроенными средствами Zabbix не представляется возможным.
По счастью, имеется скрипт, который это делает сам. Его нужно скачать и закинуть в каталог ExternalScripts (в моем случае это был /var/lib/zabbixsrv/externalscripts ). Проверим его работоспособность:
Если проверка прошла успешно, применим комбинацию LLD с этим скриптом. Создаем шаблон с правилом обнаружения (OID 1.3.6.1.4.1.9.9.171.1.2.3.1.7) и двумя элементами данных с внешней проверкой и ключами 'queryasalan2lan.pl["COMMUNITY>", "", "ASA", "get, "RX", ""]' и 'queryasalan2lan.pl["COMMUNITY>", "", "ASA", "get", "TX", ""]', назвав их соответственно "Incoming traffic in tunnel to " и "Outgoing traffic in tunnel to ". После этого применяем шаблон к нужным узлам и ждем автообнаружения.
К сожалению, LLD сейчас не поддерживает объединение графиков из нескольких прототипов данных, так что приходится добавлять нужные элементы ручками. По окончании этой работы любуемся графиками.
Сам по себе Zabbix не поддерживает MIB (Management Information Base), а готовые шаблоны есть отнюдь не для всех устройств. Конечно, все OID можно добавить и вручную (с помощью snmpwalk), но это работает, только если их у тебя не очень много. Однако существует плагин для веб-интерфейса Zabbix под названием SNMP Builder, который позволяет конвертировать MIB-файлы в шаблоны и уже эти шаблоны допиливать под свои нужды. Берем его из Git-репозитория:
Накладываем патч (в твоем случае, разумеется, имена каталогов могут быть другими, и подразумевается, что ты находишься в каталоге, где размещен фронтенд Zabbix — в случае с RHEL-based системами это /usr/share/zabbix ):
Копируем недостающие файлы и распаковываем картинки:
Теперь можно уже использовать.
Прежде всего нужно найти MIB-файлы для твоего железа. Некоторые производители их скрывают, некоторые — нет. После того как ты их нашел, эти файлы нужно поместить в папку, которую ты указал в вышеуказанной переменной. В отдельных случаях могут возникнуть зависимости — в подобной ситуации нужно найти соответствующий MIB-файл, чтобы их разрешить. Итак, выбери шаблон, MIB-файл и укажи адрес устройства. Если все нормально, ты увидишь список OID, которые нужно затем выбрать для добавления к шаблону. После выбора нужно нажать кнопку «Сохранить». Добавленные элементы появятся в указанном шаблоне.
В отдельных ситуациях нужно отредактировать новодобавленные элементы, поскольку по дефолту интервал обновления 60 секунд, что в случае, например, с именем хоста не имеет особого смысла — лучше в подобных ситуациях ставить его равным 86 400 секунд (24 часа). Для счетчиков же нужно изменить формат хранения на «Дельта в секунду». Кроме того, с некоторыми элементами нужно настроить еще и преобразование их значений в удобочитаемый вид. Для этого перейди в «Администрирование -> Общие» и в выпадающем меню выбери «Преобразование значений», а там уже добавляй его.
В общем-то, модуль мы настроили — все остальное ты уже настраивай самостоятельно.
Итого
Стоит ли заморачиваться на Zabbix, если у вас 20 машин и 1-2 сервера, да ещё и инфраструктура Windows?
Как можно понять из вышеизложенного, работы будет много. Я даже рискну предположить, что объёмы работ и уровень квалификации для них сравнимы с решением "свелосипедить своё с нуля по-быстрому на коленке".
Не стоит рассматривать Zabbix как панацею или серебряную пулю.
Тем не менее, использование уже готового и популярного продукта имеет свои преимущества — в первую очередь, это релевантный опыт для интересных работодателей.
А красивые графики дают усладу глазам и часто — новое видение процессов в динамике.
Если захочется внедрить, то могу пообещать, как минимум — скучно не будет! ;)
Zabbix Devices Output
Скрипт для Zabbix, который позволяет автоматически выводить информацию сетевого оборудования различных вендоров в удобном для чтения формате:
- Состояние интерфейсов;
- Системная информация;
- MAC-адреса на портах;
- Диагностика кабелей;
- VLAN на портах;
- Логи.
Дополнительный модуль, для поиска строки в описании порта и отображения карты VLAN'ов


Список поддерживаемых устройств и функционал
| VENDOR | interfaces | MAC | sys-info | vlans | cable-diag | Logs |
|---|---|---|---|---|---|---|
| Cisco | ✅ | ✅ | ✅ | ✅ | - | ✅ |
| Huawei | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| D-Link | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Eltex | ✅ | ✅ | ✅ | ✅ | - | - |
| Edge-Core | ✅ | ✅ | ✅ | ✅ | - | - |
| Extreme | ✅ | ✅ | ✅ | ✅ | - | - |
| Q-Tech | ✅ | ✅ | ✅ | ✅ | - | - |
| ZTE | ✅ | ✅ | ✅ | ✅ | - | ✅ |
| ProCurve | ✅ | - | ✅ | - | - | ✅ |
| Alcatel | ✅ | - | - | - | - | - |
| Lynksys | ✅ | - | - | - | - | - |
| Juniper | ✅ | - | - | - | - | - |
Интеграция с Zabbix
Для работы скрипта, на сетевом оборудовании должен быть открыт telnet или ssh и создан пользователь для подключения по удаленному терминалу
В файл auth.yaml добавляем новую группу авторизации SomeGroup в раздел GROUPS , где указываем требуемые логин и пароль пользователя
Добавляем макрос к узлу сети, который соответствует группе авторизации

Добавляем глобальный скрипт в Zabbix
Указываем полный путь до скрипта, а в качестве переменных необходимые макросы


Автоматический сбор данных
Чтобы автоматизировать процесс сбора данных, для начало необходимо добавить в базу данных /db/database.db интересующие нас устройства

Обязательные для заполнения поля: IP, device_name, auth_group, default_protocol
Воспользуемся следующей командой:
Данная команда позволяет добавить в базу данных все узлы сети, которые находятся в указанных группах: Zabbix-group1 , Zabbix-group2 .
Указываем данные Zabbix-API в файле конфигурации!
С помощью ключа --data-gather реализуем автоматический сбор данных interfaces , sys-info или vlan со всех устройств
Данные сохраняются в yaml-файл /data//interfaces.yaml :
После того как данные интерфейсов собраны, с помощью скрипта find_description.py можно осуществлять поиск по описанию портов, которые хранятся в файлах /data//interfaces.yaml

После того как данные vlan'ов собраны, с помощью скрипта vlan_traceroute.py можно осуществлять трассировку vlan'ов, которые хранятся в файлах /data//vlan.yaml

Для успешной трассировки vlan'ов, необходимо, чтобы в описании порта было указано имя следующего узла сети
Иногда в описаниях портов может быть неполное имя узла сети, либо с небольшими синтаксическими отличиями. Для таких случаев существует файл /vlan_traceroute/name_format.yaml
В нем указывается слово, которое требуется заменить и на что
В файле /vlan_traceroute/vlan_name.yaml можно указать vlan и его описание
Рассмотрим работу скрипта
- ip - обязательный параметр
- device_name - опциональный (по умолчанию пустая строка)
После создания экземпляра класса необходимо указать тип авторизации для устройства
1. Авторизация по умолчанию
Если не передавать никакие аргументы, то будет произведена попытка авторизироваться как admin/admin
2. Авторизация с помощью логина и пароля
3. Авторизация с помощью группы:
- mode - указывает тип авторизации: group, default, mixed, auto (по умолчанию default)
- auth_file - путь к файлу с авторизацией (по умолчанию ./auth.yaml)
- auth_group - имя группы, которая находится в файле, указанном в параметре auth_file (указывается, если выбран mode='group')
4. Авторизация вперемешку
Использует для авторизации несколько логинов и паролей, соответственно, и несколько попыток, которые указаны в файле авторизации auth_file (по умолчанию ./auth.yaml) в разделе MIXED
Если необходимо использовать другие пары логин/пароль, котороые не указаны в файле, то можно явно передать их с помощью списка
Если длина списков различается, то обрезается по меньшему
5. Автоматическая авторизация
В данном случае логин и пароль будут выбраны автоматически, если ip либо device_name принадлежат какой-либо группе в файле авторизации
Файл авторизации имеет формат YAML
В нем имеются два раздела:
Необходим для определения пользовательских групп. Каждая группа должна иметь логин и пароль. Если при авторизации указать группу, в которой они отсутствуют, то будут выбраны логин и пароль по умолчанию (admin, admin)
В разделе devices_by_ip необходимо указать IP адреса устройств, к которым будет применяться правило выбора логина/пароля при указании автоматической авторизации. Также возможно автоопределять группу по имени устройства в разделе devices_by_name
Можно указывать диапазоны IP адресов используя следующие конструкции:
Данный раздел содержит в себе несколько логинов и паролей для авторизации вперемешку
Далее подключаемся к оборудованию
При успешном подключении возвращает True, в случае неудачи False
Пример работы программы
Нахождение «флэшки» и её исполняемого файла
После установки проверяем какой именно файл будет отдавать нам метрики
$./hid-query /dev/hidraw4 0x01 0x80 0x33 0x01 0x00 0x00 0x00 0x00
Device /dev/hidraw4: 413d:2107 interface 1: (null) (null)
Writing data (9 bytes):
00 01 80 33 01 00 00 00 00
Response from device (8 bytes):
80 80 0a 21 4e 20 00 00
Файл находится по адресу /dev/hidraw4
Настройка работы датчика
Теперь напишем скриптик что ты получить значения температуры в читаемом формате. Скрипт я закинул в папку с Zabbix.
$ cd /etc/zabbix/scripts
$ nano TEMPered
Задаем права на выполнение
$ chmod +x TEMPered
И проверяем работу скрипта
$ ./TEMPered
Что видно сразу, без настроек?
Сразу видно, что Zabbix заточен под другое :) Но и об обычных рабочих станциях в конфигурации "из коробки" можно узнать много: идёт мониторинг оперативной памяти и SWAP, места на жёстких дисках, загрузки ЦП и сетевых адаптеров; будут предупреждения о том, что клиент давно не подключался или недавно перезагружен; агент автоматически создаёт список служб и параметров их работы, и сгенерирует оповещение о "необычном" поведении. Практически из коробки (со скачиванием доп. template'ов с офсайта и небольшой донастройкой) работает всё, что по SNMP: принтеры и МФУ, управляемые свитчи, всякая специфическая мелочь. Иметь алерты по тем же офисным принтерам в едином окне очень удобно.
В общем-то, очень неплохо, но.
Версии протокола SNMP
Существует несколько версий SNMP. Первая версия появилась в 1988 году и на данный момент, хоть и считается устаревшей, все еще очень популярна. Версия 2 (фактически сейчас под ней подразумевают версию 2c) появилась в апреле 1993 года. Она была несовместима с первой версией. Основные новшества второй версии протокола заключались в обмене информацией между управляющими компьютерами. Кроме того, появилась команда получения сразу нескольких переменных (GetBulk).
Несмотря на то что настраивать SNMPv3 сложнее, крайне рекомендуется использовать именно его, а остальные версии протокола отключать.
В данной статье я рассмотрел интересные возможности системы мониторинга Zabbix. Полагаю, если ты хороший админ, то эти возможности можешь применить с пользой для себя. Но не стоит забывать, что мониторинг не вещь в себе — его нужно применять в комплексе с организационными мерами.
Все началось с того что в серверной неожиданно накрылась система кондиционирования и соответственно на серверах накрылись пара куллеров. После это было принято решение настроить мониторинг температур на серверах и серверной в общем.
Поиск

С температурой серверов, благодаря Хабру, проблем не было, а вот с мониторингом самой серверной, пришлось что то выдумывать. Посидев на E-bay и на Alliexpress я нашел 2 варианта:
2 Channels LAN Interface Ethernet Thermometer Temperature Sensor Network APP POE

и
TEMPER USB
Выбор
Идеалом всего было бы взять сетевой термометр 2 Channels LAN Interface Ethernet Thermometer Temperature Sensor Network APP POE на 2 датчика для более масштабного мониторинга температуры + привязки к Zabbix по SNMP (проще, надежней и дороже). Понимания настройки TEMPer USB на Убунту у меня не было, да и полномасштабного знания Линукс тоже. Но как то из серфинга на Хабре, я увидел что кто то, когда то подобное делал тут. Если это кто то сделал, то сделаю и я.
Начальство, посмотрев на цену первого, сказало — «Настроишь TEMPer USB за 5 баксов» (у новых погрешность 2-3 градуса, о старых народ говорит что может быть и 8 градусов, но есть софтинка которая позволяет откалибровать датчик).
Решение

У нас Zabbix сервер установлен на отдельную железку и все это крутится на Ubuntu 18.04 lts.
И конечно же хотелось вставить через USB удлинитель и что бы все заработало, но нет — этот датчик работает из-под винды.
Поиск решений в Гугле особых результатов не дал, кроме нерабочих ссылок десятилетней давности. Но логика осталась прежней.
Добавление на вэб-интерфейс Zabbix

Создадим новый элемент данных (в нашем случае напрямую на сервере с Zabbix):

Проверим поступление данных

Добавим тригер:
И график, для наглядности:
Вывод
Знание того что у некоторых серверов Dell и HP есть встроенные датчики температуры среды, нас как админов немного балуют. И я совсем не о температуре говорю, такие задачи дают нам возможность взбодриться, вытянуть из закромов все знания и техники которые у нас есть.

Вот так, при помощи нехитрых манипуляций, можно смотреть красивые графики про десяток машин и один сервер. Но зачем.
Для тех, кто задумался и сомневается, я решил описать кое-что из своего опыта.
Мониторинг вообще штука полезная, бесспорно. У меня лично в какой-то период возникло сразу несколько задач:
Круглосуточно и непрерывно мониторить одну специфическую железку по ряду параметров;
Мониторить у рабочих станций информацию о температурах, ЦП в первую очередь;
Всякие мелочи в связи с широким внедрением удалёнки: количество подключений по VPN, общее состояние дополнительных виртуальных машин.
Надо было оценить и наглядно представить данные об интернет-канале. Канал на тот момент представлял собой 4G-роутер Huawei. Это устройство было последним, но далеко не первым в огромном количестве плясок с бубном в попытках избавиться от разного рода нестабильностей. Забегая вперёд: забирать с него данные напрямую о качестве сигнала более-менее стандартными средствами оказалось невозможно, и даже добраться до этих данных — отдельный квест. Пришлось городить дендрофекальную конструкцию, которая, на удивление стабильно, и стала в итоге поставлять данные. Данные в динамике и в графическом представлении оказались настолько неутешительными, что позволили убедить всех причастных таки поменять канал, даже и на более дорогой;
Данные о температуре процессора дают сразу несколько линий: можно обнаружить шифровальщик в процессе работы, наглядно сделать вывод о недостаточной мощности рабочей станции, найти повод провести плановую чистку, узнать о нарушении условий эксплуатации. Последний пункт особенно хорош: множество отказов оборудования и BSOD'ов в итоге нашли причину в "я ставлю обогреватель под стол, ну и свой баул, ну да, прям к этой решётке. А что? А я канпуктер развернула, а то неудобно";
Интерфейс того же OpenVPN. ну, он в общем даже и не интерфейс и оставляет желать любого другого. Отдельная история.
Как большой любитель велосипедить всё подряд, сначала я решил свелосипедить и это. Уже валялись под рукой всякие скрипты по сбору статистки, и html проекты с графиками на js, и какие-то тестовые БД. Но тут сработала жадность (и лень, чоужтам). А чего это, подумал я, самому опять корячиться, если в том же Zabbix уже куча всяких шаблонов, и помимо задач из списка можно будет видеть много чего ещё? Да и он бесплатный к тому же. Всего-то делов, виртуалку поднять да клиенты централизованно расставить. Потренируюсь с ним, опять же, он много где используется.
Итак, нам понадобятся:
Виртуальная машина или физический хост. Zabbix нетребователен к ресурсам при небольшом количестве хостов на мониторинге: мне хватило одного виртуального процессора на 2ГГц и 4 Гб RAM за глаза;
Любой инструмент для автоматического раскидывания zabbix-agent. При некотором скилле это можно делать даже через оригинальный WSUS, или просто батником с psexec, вариантов много. Также желательно запилить предварительно сконфигурированный инсталлятор агента — об этом ниже;
Много желания пилить напильником. Скажу честно и сразу: из первоначального списка 3 из 3 реализовывалось руками на местности. Zabbix стандартной комплектации в такое не может.
У Zabbix много вариантов установки. В моём случае (я начинал с 4 LTS) сработала только установка руками в чистую, из собственного образа, OC в виртуальной машине на Hyper-V. Так что, коли не получится с первого раза, — не сдавайтесь, пробуйте. Саму процедуру подробнее описывать не буду, есть куча статей и хороший официальный мануал.
Про формирование инсталлятора агента: один из самых простых способов — использовать утилиты наподобие 7zfx Builder . Нужно будет подготовить:
файлы сторонних приложений и скриптов, используемых в userParameters (об этом ниже) ;
скрипт инсталлятора с кодом наподобие этого:
Кстати, об IP. Адрес в Zabbix является уникальным идентификатором, так что при "свободном" DHCP нужно будет настроить привязки. Впрочем, это и так хорошая практика.
Также могу порекомендовать добавить в инсталлятор следующий код:
Как и многие сервисы, Zabbix agent под Windows при загрузке ОС стартует раньше, чем некоторые сетевые адаптеры. Из-за этого агент не может увидеть IP, к которому должен быть привязан, и останавливает службу. В оригинальном дистрибутиве при установке настроек перезапуска нет.
После этого добавляем хосты. Не забудьте выбрать Template – OS Windows. Если сервер не видит клиента — проверяем:
файрвол на клиенте;
работу службы на клиенте — смотрим zabbix_agentd.log, он вполне информативный.
По моему опыту, сервер и агенты Zabbix очень стабильны. На сервере, возможно, придётся расширить пул памяти по active checks (уведомление о необходимости такого действия появляется в дашборде), на клиентах донастроить упомянутые выше нюансы с запуском службы, а также, при наличии UserParameters, донастроить параметр timeout (пример будет ниже).
About
Скрипт для автоматического вывода в Zabbix информации сетевого оборудования различных вендоров в удобном для чтения формате
Zabbix в примерах
Zabbix. Получение и первичная настройка.
Zabbix можно получить по ссылке:
Системные требования: 2 ядра CPU / 2ГБ
Далее предполагается, что вы скачали с официального сайта образ виртуальной машины, либо ISO-файл и установили его в Ubuntu Server 16.04 LTS.
По умолчанию доступ к веб-интерфейсу разрешен отовсюду.
Инсталляция готового решения Zabbix имеет следующие пароли:
SSH доступ логин.пароль:
Используйте “sudo su” команду вместе с паролем от “appliance” пользователя для получения привилегированных root прав.
Создание своего пользователя. adduser имя_пользователя
После того, как пользователь создан, добавляем его в группу sudo.
usermod -a -G sudo имя_пользователя Не забудьте отключить пользователя по умолчанию
passwd appliance –l
На все вопросы по работе сервера и клиента вам с удовольствием ответят логи. Логи сервера лежат по пути:
tail -f /путь/к/файлу
поможет в прямом эфире отслеживать, что же происходит.
На картинке пример просмотра логов агента.
Zabbix добавление узла сети вручную
Для того, чтобы добавить узел сети, необходимо перейти в меню настройка, подменю узлы сети и выбрить создать узел сети.
Присваиваем узлу сети имя, вводим его видимое имя, добавляем в существующую или создаем новую группу, задаем интерфейс, посредством которого будет осуществляться мониторинг.
Для получения информации по узлу сети необходимо добавить к нему шаблон(ы). Делается это так: выбираем узел сети, переходим на вкладку шаблоны, нажимаем кнопку выбрать, в открывшемся окне выбираем необходимый шаблон или шаблоны и нажимаем выбрать. Когда шаблоны выбраны, нажимаем на главной странице добавить и обновить. В результате получаемые с узла данные будут доступны в меню мониторинг, подменю последние данные.
Обнаружение узлов в сети.
Для того, чтобы не создавать все узлы сети вручную, полезно использовать функцию обнаружения. Она позволяет находить узлы и производить с ними различные действия: добавлять в определенные группы узлов привязывать шаблоны прочее. Чтобы создать правило обнаружения необходимо перейти в раздел обнаружение и выбрать пункт создать правило обнаружения. Дальнейшие действия будем производить на примере принтеров. Предполагается, что нам известен диапазон их адресов.
Установка Zabbix agent в CentOS 7
yum install zabbix-agent
По умолчанию в CentOS сервис не запускается автоматически при перезагрузке! Убеждаемся в этом: systemctl status zabbix-agent
И добавляем его в автозагрузку: systemctl enable zabbix-agent
Запускаем сервис: systemctl start zabbix-agent Проверяем, все ли в порядк: systemctl status zabbix-agent
Установка Zabbix agent в Ubuntu 16.04 LTS
dpkg -i zabbix-release_3.4-1+trusty_all.deb
apt-get install zabbix-agent
Установка Zabbix agent в Windows 7/8/2012 32-x/64-x
- Открыть в файерволе TCP порт 10050, по которому агент общается с сервером
netsh advfirewall firewall add rule name="Zabbix Agent" dir=out protocol=tcp localport=10050 action=allow
netsh advfirewall firewall add rule name="Zabbix Agent" dir=in protocol=tcp localport=10050 action=allow
Переименовать папку в zabbix_agent
c:\zabbix_agent\bin\win64\zabbix_agentd.exe --config c:\zabbix_agent \conf\zabbix_agentd.conf --install
Где: c:\zabbix_agent\bin\win64\zabbix_agentd.exe – путь к исполняемому файлу тебуемой разрядности;
--config c:\zabbix_agent\conf\zabbix_agentd.conf – путь к конфигурационному файлу;
--install – команда для установки сервиса с указанными выше параметрами.
На 64-битных системах требуется 64-битная версия Zabbix агента, чтобы все проверки связанные с запущенными 64-битными процессами корректно работали.
Или возьмите готовое у меня:
Для облегчения задачи я написал скрипт, который автоматически создает конфигурационный файл, открывает порты и устанавливает сервис требуемой разрядности. Полный комплект (zabbix_agent) лежит на яндекс диске в папке soft Скрипт требует настройки SET String=%computername%.%userdomain%.local – заменяем на постфикс вашего домена (ru/loc/net) SET Zabbix=192.168.10.31 – заменяем на адрес вашего сервера Zabbix.
Настройка Zabbix agent (универсальная)
Zabbix agent хранит свои настройки в файле zabbix_agentd.conf . В ОС UNIX он хранится по пути /etc/zabbix/zabbix_agentd.conf В ОС Windows он хранится по пути zabbix_agent\conf\zabbix_agentd.conf Ниже приведена минимальная необходимая для работы конфигурация.
Server=192.168.10.31 – адрес сервера Zabbix
ServerActive=192.168.10.31 – адрес сервера Zabbix
Hostname=001-0036.et.local – полное имя хоста, в таком виде, каким его видит сервер.
ListenPort=10050 - порт, на котором будет работать агент.
LogFile=c:\zabbix_agent\zabbix_agentd.log - расположение файла журнала в Windows
LogFile=/var/log/zabbix/zabbix_agentd.log - расположение файла журнала в UNIX
LogFileSize=10 – размер файла журнала в мегабайтах.
Подробнее про настройку можно почитать тут: для Windows
Получение данных от агента.
В целях отладки очень удобно получать данные от агента в консоли. За это отвечает утилита zabbix_get. Синтаксис у нее такой: zabbix_get -s -p -k ключ Где: -s - адрес узла -p - порт, на котором слушает агент -k ключ – ключ, значение которого необходимо получить
В примере выше мы запросили у узла 192.168.10.30, агент у которого работает на порту 10050 значение ключа sip.status. .
Мониторинг журналов событий Windows
Для того, чтобы работать с журналом событий, достаточно создать элемент данных следующего вида: Тип: Zabbix агент (активный) Ключ: eventlog[System,,"Error|Information","^Zabbix test event$"] Тип информации: Журнал (лог) Затем создаем триггер с текстом <имя.хоста:eventlog[Application,,"Warning|Error|Failure". ].logseverity()>>1 and < имя.хоста:eventlog[Application,,"Warning|Error|Failure". ].nodata(60)><>1
Чтобы упростить себе мониторинг журналов Система и Приложения достаточно импортировать на сервер шаблон YandexDisk\soft\zabbix_templates\zbx_eventlog_template.xml Настройки-Шаблоны-Импорт
Затем выбираем файл и нажимаем импорт
После того, как шаблон добавлен, необходимо прикрепить его к нужному узлу сети. Проверить работу можно, зайдя в Мониторинг-Последние данные
Выбираем узел сети, или группу узлов и видим, какие ошибки и предупреждения поступали.
Мониторинг нестандартных журналов событий Windows
Тип - активный, Ключ eventlog[Microsoft-Windows-Hyper-V-VMMS-Admin,,"Error|Critical". 100,skip] тип информации: лог
Ищем ошибки, относящиеся к работе Windows Scheduler:
eventlog[Microsoft-Windows-TaskScheduler/Operational,,"Error|Critical". 100,skip] Основная проблема - что указать в качестве первого параметра ключа eventlog. Делаем так: открываем родной виндовый Event Viewer (например, right-click на MyComputer -> Manage, затем открываем System Tools -> Event Viewer); в Event Viewer-е находим нужный лог (например, в данном случае: Application and Services Logs -> Microsoft -> Windows -> TaskScheduler -> Operational), на нём RightClick -> Properties; в свойствах находим поле "Full Name" (самое первое), его содержимое и копипастим в качестве первого параметра ключа.
Мониторинг необходимости перезагрузки Windows.
Бывает полезно знать, каким серверам требуется перезагрузка, а когда их много, то удобно об этом узнавать, не заходя на сервер. Для мониторинга нам понадобится клиент, настроенный для активных проверок и соответствующий скрипт. Скрипт берем в галерее технета по ссылке ниже. https://gallery.technet.microsoft.com/scriptcenter/Get-PendingReboot-Query-bdb79542/view/Discussions set-executionpolicy remotesigned Полученный скрипт определяем в папку \zabbix_agent\scripts на клиенте, в конфигурации пишем: UserParameter=Reboot.IsNedeed,powershell -NoProfile -ExecutionPolicy Bypass -command "$ErrorActionPreference = 'silentlycontinue'; $eval = get-pendingreboot; if ($eval.RebootPending) < Write-Host '1'; >else < Write-Host '0' >; На стороне Zabbix создаем элемент данных: Zabbix (активный) ключ: Reboot.IsNedeed
Мониторинг Asterisk на примере Elastix (CentOS 7 x64)
Подразумевается, что агент у вас уже установлен. Если это не так – смотрите соответствующий раздел руководства. Для того, чтобы настроить мониторинг нам нужно сделать несколько вещей: 0 добавить пользователю zabbix от чьего имени работает zabbix agent право запускать программы баз ввода пароля, 1 добавить в конфигурационный файл агента нужные параметры 3 скачать, импортировать и применить к нужному узлу шаблон. Приступим. Открываем файл sudo nano /etc/sudoers И в самый конец допишем: zabbix ALL=(ALL) NOPASSWD:ALL Теперь создадим отдельный файл настроек для работы с Asterisk
nano /etc/zabbix/zabbix_agentd.d/asterisk.conf ```UserParameter=ast.pid,sudo -u zabbix sudo cat /var/run/asterisk/asterisk.pid
UserParameter=ast.uptime,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'core show uptime' | grep uptime | cut -f2 -d: | sed 's/ //g'
UserParameter=ast.reloadtime,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'core show uptime' | grep reload | cut -f2 -d: | sed 's/ //g'
UserParameter=ast.version,sudo -u zabbix sudo /usr/sbin/asterisk -V | cut -f2 -d' '
INFO: Active Calls is Buggy yet.
UserParameter=ast.callsdone,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'core show calls'| grep -i 'processed' | awk ''
UserParameter=iax.status,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'iax2 show registry'|grep Registered |wc -l
UserParameter=sip.status,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'sip show registry'|grep Registered |wc -l
UserParameter=sip.peersonline,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'sip show peers'|grep --text -i 'sip peers'|awk ''
UserParameter=sip.peersoffline,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'sip show peers'|grep --text -i 'sip peers'|awk ''
UserParameter=sip.peers,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'sip show peers'|grep --text -i 'sip peers'|awk ''
UserParameter=dns.status,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'dnsmgr status' | grep 'DNS Manager' | awk ''
UserParameter=dns.entries,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'dnsmgr status' | grep 'Number of entries' | awk ''
UserParameter=fax.sessions,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'fax show stats' | grep 'Current Sessions' | awk ''
UserParameter=fax.transmits,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'fax show stats' | grep 'Transmit Attempts' | awk ''
UserParameter=fax.receive,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'fax show stats' | grep 'Receive Attempts' | awk ''
UserParameter=fax.done,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'fax show stats' | grep 'Completed' | awk ''
UserParameter=fax.fail,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'fax show stats' | grep 'Failed' | awk ''
UserParameter=ast.parkedcalls,sudo -u zabbix sudo /usr/sbin/asterisk -rvvvvvx 'parkedcalls show' | grep 'parked calls in total' | awk ''
Version Info -- Edit this part for your own loss
UserParameter=ast.tribily.ver,sudo -u zabbix sudo echo $
Мониторинг доступности телефонов на примере аппаратов Yealink.
Поскольку SNMP доступен не для всех телефонов, а получать с них информацию необходимость есть, мы воспользуемся функцией Zabbix, которая называется Веб мониторинг. Создаем узел сети с произвольным именем, без указания адреса, он нам нужен только для привязки к нему сценария. После создания кликаем по пункту веб Далее выбираем создать веб сценарий
Даём ему имя, например, «Доступность», потом переходим на вкладку шаги, и нажимаем на кнопку добавить. Вводим название шага, url, по которому необходимо проследовать, строку, которая там должна быть и код ответа. Нажимаем добавить, и еще раз добавить на основной страничке.
Называем триггер, далее нажимаем добавить, и в появившемся окошке из элементов данных выбираем ошибку проверки, а в значении функции Последнее значение NOT N, и нажимаем вставить. Выбираем высокую важность и нажимаем добавить.
Триггер означает, что, если проверка не удалась, и вернула любой код ответа, отличный от N (200, как мы его задали), это будет означать событие высокой важности с немедленным уведомлением заинтересованных лиц.
Настройка оповещений по Email на примере почты от yandex.
Переходим в раздел Администрирование(1)->Способы оповещений(2)->Email(3)
Мониторинг хоста Hyper-V
Для работы нам потребуется пакет freeipmi
'sudo apt-get install freeipmi'
/usr/sbin/ipmi-sensors -D LAN2_0 -h 192.168.10.36 -u пользователь_в_iLO -p пароль -l USER -W discretereading --no-header-output --quiet-cache --sdr-cache-recreate --comma-separated-output --entity-sensor-names
3 копируем скрипты в папку External scripts cp ilo_discovery.pl ipmi_proliant.pl /usr/lib/zabbix/externalscripts/ 4 Делаем их исполняемыми chmod +x /usr/lib/zabbix/externalscripts/ilo_discovery.pl chmod +x /usr/lib/zabbix/externalscripts/ipmi_proliant.pl и даем пользователю заббикс все права на них chown zabbix:zabbix /usr/lib/zabbix/externalscripts/ilo_discovery.pl chown zabbix:zabbix /usr/lib/zabbix/externalscripts/ipmi_proliant.pl 5 Создаем узел сети, в настройках интерфейса ничего не пишем, к нему применяем шаблон из архива, и во вкладке макросы ставим макрос равны IP интерфейса iLO
Мониторинг S.M.A.R.T. в Windows x64
Мониторим время окончания оплаты домена с помощью Zabbix
Для мониторинга нам понадобится скрипт и шаблон.
Скрипт кладем в каталог по умолчанию для внешних скриптов, который указан в конфигурации сервера zabbix, вот строчка по умолчанию в zabbix-server.conf
Подготовка
Установка драйверов и библиотек у кого нет (коллеги всегда нужно смотреть в документацию по Вашей ОС) нам нужно будет: libusb, libhidapi-dev и libusb-dev в Убунту все просто:
$sudo apt-get install libusb
$sudo apt-get install libusb-dev
$sudo apt-get install libhidapi-dev
Установка софта
После этого нам нужно установить необходимый софт и распихать его по папкам, для удобства работать будем из-под Рута ( sudo -i ):
О локальных задачах
Всё, что не встроено в Zabbix agent, реализуется через механизм Zabbix agent (active). Суть проста: пишем скрипт, который будет выдавать нужные нам данные. Прописываем наш скрипт в conf:
если хотите получать в Zabbix строку на кириллице из cmd — не надо. Только powershell;
если параметр специфический – для имени нужно будет придумать и сформулировать дерево параметров, наподобие "hardware.huawei.modem.link.speed" ;
отладка и стабильность таких параметров — вопрос и скрипта, и самого Zabbix. Об этом дальше.
Хотелка №1: температуры процессоров рабочих станций
В качестве примера реализуем хотелку "темература ЦП рабочей станции". Вам может встретиться вариант наподобие:
но это не работает (вернее, работает не всегда и не везде).
Самый простой способ, что я нашёл — воспользоваться проектом OpenHardwareMonitor. Он свои результаты выгружает прямо в тот же WMI, так что температуру получим так:
Конечно, при условии, что OHM запущен. В текущем релизе OHM не умеет работать в качестве Windows service. Так что придётся либо смущать пользователей очередной иконкой в трее, либо снова городить свой инсталлятор и запихивать OHM в сервисы принудительно. Я выбрал поcледнее, создав инсталляционный cmd для всё того же 7zfx Builder наподобие:
NSSM — простая и достаточно надёжная утилита с многолетней историей. Применяется как раз в случаях, когда ПО не имеет режима работы "сервис", а надо. Во вредоносности утилита не замечена;
Обратите внимание на "intelcpu" в скрипте получения температуры от OHM. Т.к. речь идёт о внедрении в малом офисе, можно рассчитывать на единообразие парка техники. Более того, таким образом лично у меня получилось извлечь и температуру ЦП от AMD. Но тем не менее этот пункт требует особого внимания. Возможно, придётся модифицировать и усложнять инсталлятор для большей универсальности.
Работает более чем надёжно, проблем не замечено.
Хотелка № 2: получаем и мониторим температуру чего угодно
Понадобятся нам две вещи:
Штука от братского китайского народа: стандартный цифровой термометр DS18B20, совмещённый с USB-UART контроллером. Стоит не сказать что бюджетно, но приемлемо;
Хотелка № 4: спецжелезка 1
Для большого количества специфического оборудования существуют написанные энтузиастами Template'ы. Обычно они используют и реализуют функционал, уже имеющийся в утилитах к этим железкам.
Боли лирическое отступление
установив один из таких темплейтов, я узнал, что "нормальная рабочая" температура чипа RAID-контроллера в серваке — 65+ градусов. Это, в свою очередь, побудило внимательнее посмотреть и на контроллер, и на сервер в целом. Были найдены косяки и выражены "фи":
Apaptec'у – за игольчатый радиатор из неизвестного крашеного силумина высотой чуть более чем нихрена, поток воздуха к которому закрыт резервной батарейкой с высотой больше, чем радиатор. Особенно мне понравилось потом читать у Adaptec того же "ну, это его нормальная рабочая температура. Не волнуйтесь". Ответственно заявляю: при такой "нормальной рабочей температуре" контроллер безбожно и непредсказуемо-предсказуемо глючил;
Одному отечественному сборщику серверов. "Берём толстый жгут проводов. Скрепляем его, чтобы он был толстым, плотным, надёжным. Вешаем это прямо перед забором воздуха вентиляторами продува серверного корпуса. Идеально!". На "полу" сервера было дофига места, длины кабелей тоже хватало, но сделали почему-то так.
Также был замечен интересный нюанс поведения, связанный с Zabbix. Со старым RAID контроллером при наличии в системном логе специфичных репортов, отваливался мониторинг температуры контроллера в Zabbix, но! при запуске руками в консоли скрипта или спец. утилиты температура выводилась корректно и без задержек.

Можно видеть, какой HDD и даже SSD стоит перед отсеком с БП сервера и хуже охлаждается
Оригинальный репозиторий, вероятно, заброшен, как это довольно часто бывает.
Хотелка № 5, на десерт: спецжелезка 2
Как и обещал, делюсь опытом вырывания данных из беспроводной железки Huawei. Речь о 4G роутере серии B*. Внутри себя железка имеет ПО на ASP, а данные о качестве сигнала — RSSI, SINR и прочее — в пользовательском пространстве показывать не хочет совсем. Смотри, мол, картинку с уровнем сигнала и всё, остальное не твоего юзерского ума дело. К счастью, в ПО остались какие-то хвосты, выводящие нужное в plain JSON. К сожалению, взять да скачать это wget-ом не получается никак: мало того, что авторизация, так ещё и перед генерацией plain json требуется исполнение JS на клиенте. К счастью, существует проект phantomjs. Кроме того, нам понадобится перенесённая руками кука из браузера, где мы единожды авторизовались в веб-интерфейсе, вручную. Кука живёт около полугода, можно было и скрипт написать, но я поленился.
Алгоритм действий и примеры кода:
вызываем phantomjs с кукой и сценарием:
Конструкция запускается из планировщика задач. В Zabbix-агенте производится лишь чтение соответствующих файлов:

Особое внимание на SINR. Он должен быть 10+. Ну, иногда и правда был. Около 4-5 утра обычно
Требует постоянного присмотра, ручных прибиваний и перезапусков процессов, обновления кук. Но для такого шаткого нагромождения фекалий и палок работает достаточно стабильно.
Что доделывать?
Оооо. Ну, хотел повелосипедить, так это всегда пожалуйста. Прежде всего, нет алертов на события типа "критические" из системного лога Windows, при том, что механизм доступа к логам Windows встроенный, а не внешний, как Zabbix agent active. Странно, ну штош. Всё придётся добавлять руками.
для записи и оповещения по событию "Система перезагрузилась, завершив работу с ошибками" (Microsoft-Windows-Kernel-Power, коды 41, 1001) нужно создать Item c типом Zabbix agent (active) и кодом в поле Key:
По этому же принципу создаём оповещения на другие коды. Странно, но готового template я не нашёл.
Cистема автоматизированной генерации по службам генерирует целую тучу спама. Часть служб в Windows предполагает в качестве нормального поведения тип запуска "авто" и остановку впоследствии. Zabbix в такое не может и будет с упорством пьяного сообщать "а BITS-то остановился!". Есть широко рекомендуемый способ избавления от такого поведения — добавление набора служб в фильтр-лист: нужно добавить в Template "Module Windows services by Zabbix agent", в разделе Macros, в фильтре имя службы в формате RegExp. Получается список наподобие:
И он не работает работает с задержкой в 30 дней.

После добавления служб в фильтр триггеры будут висеть ещё 30 дней. Этот срок, впрочем, тоже можно настроить
Про службы, автоматически генерируемые в Windows 10, я вообще промолчу.
Нет никаких температур (но это, если подумать, ладно уж), нет SMART и его алертов (тоже отдельная история, конечно). Нет моих любимых UPS.
Некоторые устройства генерируют данные и алерты, работу с которыми надо выстраивать. В частности, например, управляемый свитч Tp-Link генерирует интересный алерт "скорость на порту понизилась". Почти всегда это означает, что рабочая станция просто выключена в штатном режиме (ушла в S3), но сама постановка вопроса заставляет задуматься: сведения, вообще, полезные — м.б. и драйвер глючит, железо дохнет, время странное.
Некоторые встроенные алерты требуют переработки и перенастройки. Часть из них не закрывается в "ручном" режиме по принципу "знаю, не ори, так надо" и создаёт нагромождение информации на дашборде.
Короче говоря, многое требует допиливания напильником под местные реалии и задачи.

После допиливания – примерно так
Обнаружение «гаджета»
С начала нам нужно узнать видит ли сервер флешку:
$lsusb
У меня код вендора и ИД устройства:
Bus 001 Device 005: ID 413d:2107
Также нам нужно узнать исполняемые файлы «флэшки»
$dmesg
У меня оказался /dev/hidraw4, позже мы к нему обратимся.
Версии протокола SNMP
Существует несколько версий SNMP. Первая версия появилась в 1988 году и на данный момент, хоть и считается устаревшей, все еще очень популярна. Версия 2 (фактически сейчас под ней подразумевают версию 2c) появилась в апреле 1993 года. Она была несовместима с первой версией. Основные новшества второй версии протокола заключались в обмене информацией между управляющими компьютерами. Кроме того, появилась команда получения сразу нескольких переменных (GetBulk).
Несмотря на то что настраивать SNMPv3 сложнее, крайне рекомендуется использовать именно его, а остальные версии протокола отключать.
В данной статье я рассмотрел интересные возможности системы мониторинга Zabbix. Полагаю, если ты хороший админ, то эти возможности можешь применить с пользой для себя. Но не стоит забывать, что мониторинг не вещь в себе — его нужно применять в комплексе с организационными мерами.
Все началось с того что в серверной неожиданно накрылась система кондиционирования и соответственно на серверах накрылись пара куллеров. После это было принято решение настроить мониторинг температур на серверах и серверной в общем.
Поиск
С температурой серверов, благодаря Хабру, проблем не было, а вот с мониторингом самой серверной, пришлось что то выдумывать. Посидев на E-bay и на Alliexpress я нашел 2 варианта:
2 Channels LAN Interface Ethernet Thermometer Temperature Sensor Network APP POE
и
TEMPER USB
Выбор
Идеалом всего было бы взять сетевой термометр 2 Channels LAN Interface Ethernet Thermometer Temperature Sensor Network APP POE на 2 датчика для более масштабного мониторинга температуры + привязки к Zabbix по SNMP (проще, надежней и дороже). Понимания настройки TEMPer USB на Убунту у меня не было, да и полномасштабного знания Линукс тоже. Но как то из серфинга на Хабре, я увидел что кто то, когда то подобное делал тут. Если это кто то сделал, то сделаю и я.
Начальство, посмотрев на цену первого, сказало — «Настроишь TEMPer USB за 5 баксов» (у новых погрешность 2-3 градуса, о старых народ говорит что может быть и 8 градусов, но есть софтинка которая позволяет откалибровать датчик).
Решение
У нас Zabbix сервер установлен на отдельную железку и все это крутится на Ubuntu 18.04 lts.
И конечно же хотелось вставить через USB удлинитель и что бы все заработало, но нет — этот датчик работает из-под винды.
Поиск решений в Гугле особых результатов не дал, кроме нерабочих ссылок десятилетней давности. Но логика осталась прежней.
Подготовка Zabbix
При добавлении в Zabbix самому агенту не хватало прав на выполнение. Поигравшись с правами мы так и не пришли к желаемому результату и сделали проще. Выполняем скрипт из под рута и записываем это все в текстовый файл (TEMPer.txt), для автоматизации используем КРОН.
Проверка записи:
$ ./TEMPered > /tmp/TEMPer.txt
19.04
Заходим в cron
$ nano /etc/crontab
Вносим запись на выполнение каждую минуту
Правим конфиг мониторинга
$nano /etc/zabbix/zabbix_agentd.conf
Читайте также: