Vmware отключить обрезку страничной памяти
В третьей части мы посмотрим на то, как работает с оперативной памятью гипервизор, а также на техники, которые применяются для высвобождения памяти, когда её становится крайне мало.
Memory Sizing
Стоит внимательно подходить к вопросу выделения оперативной памяти виртуальной машине.
Рекомендуется выделять виртуальной машине достаточное количество оперативной памяти для работы системы и приложений и, одновременно, не стоит выделять значительно больше, чем требуется.
Нужно понимать, что чем больше памяти выделено машине – тем больше накладные расходы гипервиозра на обслуживание данной памяти (overhead). Даже если гипервизор сможет высвободить часть ресурсов из виртуальной машины, уменьшить оверхед уже не получится.
Memory Overcommit Techniques
ESXi использует 5 техник для оптимизации количества потребляемой ОЗУ, в случаях, если ее становится крайне мало.
Чем меньше свободной остается доступной памяти – тем более жесткие техники он начинает применять. Естественно, ни о какой высокой производительности тут не может идти и речи.
Page Sharing – в случае, если участки памяти двух виртуальных машин одинаковы, нет смысла держать два одинаковых участка и занимать двойное пространство ОЗУ, когда можно просто сослать обе машины на один участок памяти, а второй высвободить. До версии 6.0 Page Sharing работал между виртуальными машинами в рамках одного хоста, однако, с 6-й версии, по умолчанию данный метод применяется только внутри виртуальных машин в целях безопасности.
Ballooning – Модуль, который устанавливается в гостевую операционную систему вместе с пакетом VMware Tools, который может «подтолкнуть» гостевую ОС к высвобождению наименее важных страниц памяти.
Memory Compression – Тут все понятно из описания. Сжатие страниц памяти на хосте. Это, конечно, снижает скорость доступа к памяти, но все еще быстрее, чем использование swap файлов.
Swap to Host Cache – Включается своппинг на уровне хоста. Но в данном случае в кэш, если он, конечно, сконфигурирован. Swap to Host Cache позволяет выделить пространство на SSD, доступ к которому будет все еще быстрее, чем доступ к swap на обычном жестком диске.
Regular Host–Level Swapping – Когда нет свободной озу и заканчивается кэш, страницы памяти виртуальных машин начинают попадать в swap файл на хосте. Несложно догадаться, что это самая крайняя мера и до нее лучше не доводить. Доступ виртуальных машин к страницам памяти, располагаемым в swap файлах хоста будет очень медленным, по сравнению с доступом к страницам в оперативной памяти.
Несмотря на все вышеуказанные техники, которые позволяют выделить виртуальным машинам значительно большее количество ресурсов, чем есть на хосте, на котором они располагаются, до этого лучше не доводить.
Если имеется подозрение, что вышеуказанные техники начинают применяться к VM и это сказывается на ее производительности, следует проверить следующее:
- Проверить значения параметра Ballooning у виртуальной машины в меню Monitor – Performance – Advanced в разделе Memory. Нулевое значение данного параметра обычно говорит о том, что у хоста не наблюдается проблем с переподпиской (overcommitment) и ресурсов достаточно для облуживания виртуальной машины. Стоит помнить, что данный параметр имеется только у виртуальных машин с установленным Balloon Driver, который входит в пакет VMware Tools. Небольшое количество balloon memory не всегда говорит о наличии каких-либо проблем;
- Проверить раздел Utilization виртуальной машины. Отличные от нуля значения Swapped и Compressed могут говорить о нехватке памяти гипервизора. Обращение к данным участкам памяти будет замедленно, что скажется на производительности виртуальной машины;
- Стоит проверить активность использования файла подкачки в виртуальной машине. Это может говорить либо об активной процедуре балунинга, либо о недостаточном количестве памяти, выделенной виртуальной машине.
Memory Page Sharing
Как уже было сказано ранее, начиная с версии 6.0, Page sharing работает по умолчанию только в рамках виртуальной машины (intra-VM sharing). При необходимости, его можно включить между виртуальными машинами (inter-VM sharing), если у них выставлено одинаковое значение «salt».
В связи с большой распространенностью страниц памяти размером 2MB (large memory pages), которые не «шарятся», даже если параметр Page Sharing включен, использование дедупликации страниц будет иметь в большинстве случаев незначительный эффект.
В инсталляциях, где используется большое количество мелких страниц памяти (например, VDI, где используется больное количество однотипных машин), Page Sharing может оказаться полезным.
По умолчанию значение «salt» для виртуальной машины это ее uuid, который всегда уникален, что ограничивает Page Sharing рамками данной VM.
Для того, чтобы включить Page Sharing на всех виртуальных машинах хоста, необходимо выставить параметр Mem.ShareForceSalting в значение 0.
Либо, для включения Page Sharing между определенной группой виртуальных машин, можно использовать параметр sched.mem.pshare.salt в конфигурационном параметре VM.
Следует ознакомиться со статьями в базе знаний VMware (1 , 2 )
Memory Swapping Optimizations
Когда ESXi больше не может высвобождать память и оптимизировать ее использование в связи с высокой переподпиской, последней возможностью остается использование файлов подкачки на уровне хоста, что может сильно сказаться на производительности виртуальных машин.
Далее следуют рекомендации, как этого избежать, либо минимизировать негативный эффект:
- Не отключать Ballooning (не забывать устанавливать VMware Tools и следить за их работой в гостевой ОС), Page Sharing и Memory Compression;
- При включении виртуальной машины ESXi создает swap файл для данной VM, который равен размеру памяти машины за вычетом зарезервированной для нее ОЗУ. Следовательно, дисковых ресурсов на хранилище должно быть достаточно для размещения swap файлов машин;
- Если на хосте имеется SSD диск, не будет лишним задействовать его под кэш (Swatp to the Host Cache). Этот кэш доступен всем виртуальным машинам, располагаемым на хосте. Хороший вариант для SSD небольших размеров;
- Хорошим выбором будет размещение swap файлов виртуальных машин на самых скоростных доступных дисках. Лучший выбор – локальный для хоста SSD. Если объема SSD недостаточно для хранения swap файлов машин, лучше его задействовать под Host Cache;
- Если локальных SSD нет, следует размещать файлы на наиболее быстром доступном хранилище, подключенном, например, по Fibre Channel. К примеру, All-Flash массив;
- Независимо от типа используемого хранилища для лучшей производительности и избегания потенциальной ситуации, связанной с нехваткой доступного дискового пространства, не следует размещать файлы подкачки на thin-provisioned хранилище.
По умолчанию swap файл создается там же, где хранится vmx файл виртуальной машины, изменить данный параметр можно в Advanced секции настроек VM.
Уменьшить объем памяти, которая может оказаться в файле подкачки, либо вообще от него избавиться, можно, зарезервировав объем оперативной памяти для виртуальной машины.
Хорошая идея – зарезервировать для виртуальной машины тот объем памяти, с которым она регулярно работает.
В случае, если резерв выставлен во время работы виртуальной машины, эффект от резервирования появится не сразу и будет появляться постепенно. Для мгновенного эффекта стоит выключить и включить виртуальную машину (не перезагрузить из операционной системы, а именно выключить – включить).
Memory Overhead
Стоит понимать, что при использовании системы виртуализации, будут так же появляться и небольшие накладные расходы. Некоторое количество ОЗУ необходимо гипервизору и его службам, а часть ОЗУ для работы виртуальных машин. В целом дополнительно потребляемую память можно поделить на две категории:
- Как уже было сказано часть памяти используется непосредственно гипервизором и его службами (hostd, vpxa и т.п.). ESXi может использовать системный swap файл и уменьшить потребление ОЗУ до 1GB, в ситуациях когда памяти перестает хватать для работы виртуальных машин. Для использования данной возможности необходимо создать swap файл самостоятельно. esxcli sched swap system set -d true -n . Создается файл объемом 1GB на указанном хранилище;
- Дополнительная память используется для каждой запущенной виртуальной машины. Часть памяти резервируется для VMX процесса, часть для процесса VMM. Память резервируется также для виртуальных устройств (мышь, клавиатура, USB). Объем резервируемой оперативной памяти зависит от многих факторов, например, от количества vCPU, сконфигурированного объема памяти, 32-bit или 64-bit гостевая операционная система и т.п.
2MB Large Memory Pages
В дополнение к стандартным размерам страниц памяти в 4KB, ESXi так же может работать со страницами размером в 2MB (Large Pages).
ESXi назначает 2MB страницы гостевой ОС всегда, когда это возможно, даже если гостевая ОС их не запрашивает. Использование Large Pages снижает значения TLB miss, увеличивает производительность многих приложений, особенно, активно работающих с большими объемами памяти, так же уменьшаются служебные затраты ОЗУ на виртуальную машину.
ESXi не использует Page Sharing с большими страницами (скорее всего потому что найти пару двух одинаковых страниц достаточно тяжело). Однако, в случае нехватки оперативной памяти на хосте, большие страницы начинают дробиться на мелкие (4KB), задействуя при этом механизм Page Sharing.
На этом третья часть осмысления заканчивается. В следующей части рассмотрим советы, касающиеся работы с подсистемой хранения.
Виртуальные машины уже прочно заняли свое место среди инструментов, существенно повышающих эффективность использования серверных платформ и персональных компьютеров. Возможность консолидации нескольких виртуальных серверов на одном физическом позволяет организациям различного уровня существенно экономить на аппаратном обеспечении и обслуживании. Пользователи настольных компьютеров применяют виртуальные машины, как в целях обучения, так и в целях создания защищенных и переносных пользовательских сред. В корпоративной среде виртуальные машины на настольных системах применяются также для целей тестирования программного обеспечения в различных конфигурациях, запуска специализированных виртуальных шаблонов и централизованного хранения виртуальных пользовательских десктопов. При массовом использовании виртуальных систем одними из самых важных мероприятий являются обслуживание и оптимизация производительности виртуальных машин. В то время как большинство производителей платформ виртуализации предоставляют пользователям и системным администраторам множество инструментов и средств для поддержания эффективной виртуальной инфраструктуры, оптимизация производительности, как самих платформ, так и виртуальных машин является более тонким моментом. Применение различных техник оптимизации во многом зависит от используемой платформы, вариантов использования виртуальных машин, доступных средств и квалификации персонала.
В России наиболее популярными средствами виртуализации являются продукты компании VMware. И это не случайно: VMware, являясь одним из старейших участников рынка, на данный момент является его лидером и во многом определяет направления развития сферы виртуализации в целом. На сегодняшний день наибольший интерес для пользователей представляют коммерческие платформы VMware Workstation, VMware ESX Server и бесплатная платформа VMware Server. Несмотря на то, что VMware Server является серверной платформой, многие пользователи успешно применяют ее в качестве настольной платформы ввиду ее бесплатности, хотя практически по всем параметрам функциональность продукта VMware Workstation 6 намного выше.
Вопросы оптимизации виртуальных машин и гостевых систем, запущенных в них, возникают как у домашних пользователей продуктов виртуализации, так и компаний, стремящихся максимально полно использовать аппаратные ресурсы. Особенно это актуально для виртуальных серверов, которые должны обладать свойством высокой доступности из внутренней или внешней сети, и серверов, интенсивно использующих какой-либо из аппаратных ресурсов компьютера (например, жесткий диск серверами баз данных).
Сравнительный обзор VMware Server и VMware Workstation
- Доступно при использовании с продуктом Virtual Center (не бесплатен).
- В операционных системах с включенным PAE-режимом.
- Доступно при управлении продуктом Virtual Center (не бесплатен).
- Доступно при использовании VMware Virtual Machine Interface (VMI) 3.0.
- Техническая поддержка не бесплатна, но и не необходима. Пользователи могут купить VMware Gold или Platinum Support and Subscription Services.
Оптимизация производительности VMware Workstation и VMware Server
- правильный выбор аппаратного обеспечения и его оптимизация
- настройка и оптимизация хостовой платформы
- настройка и оптимизация платформы виртуализации и виртуальных машин
- оптимизация гостевой системы
Только при соблюдении рекомендаций VMware по оптимизации производительности с учетом этих компонентов можно получить по-настоящему эффективно и быстро работающие виртуальные системы.
Аппаратное обеспечение
При выборе оборудования для хостовой системы необходимо исследовать среднюю загруженность физической системы, которую необходимо виртуализовать и выбрать так называемый коэффициент виртуализации — количество виртуальных машин, запущенных одновременно на одной физической платформе. Необходимо учитывать не только загруженность процессора, но и всех аппаратных ресурсов, поскольку чрезвычайно интенсивное использование какого-либо ресурса одной виртуальной машины может привести к замедлению работы хоста в целом.
По оценкам экспертов, большинство серверов на данный момент использует приблизительно 10-20 процентов от аппаратных мощностей компьютеров, поэтому, в этом случае, для продукта VMware Server необходимо придерживаться соотношения 2-4 виртуальные машины на ядро процессора, оставив некоторый запас для пиковых нагрузок на какой-либо из серверов. При использовании VMware Workstation пользователи часто создают десятки виртуальных машин, и число одновременно запущенных виртуальных систем может быть различным, в зависимости от применяемых гостевых ОС.
- Память
Оцените количество памяти, используемой виртуальными машинами и приложениями, запущенными в них, прибавьте память, необходимую для хостовой ОС (зависит от выбранной платформы) и поддержки платформы виртуализации (обычно не менее 64 МБ). - Диски
Старайтесь использовать высокопроизводительные SCSI диски и RAID-массивы. Помните, что RAID массивы могут быть различного типа, и от его выбора зависит производительность дисковой системы. Следите за тем, чтобы диски хостовой системы не переполнялись, поскольку это сильно действует на производительность виртуальных машин, в особенности при создании снапшотов или работе с Redo-дисками. Используя SAN или NAS устройства хранения, следите за тем, чтобы на них были включены кэши на чтение и запись и правильно выставлены их размеры. - Сеть
При выборе сетевых адаптеров и устройств коммуникации, учитывайте следующие рекомендации:- используйте коммутаторы («свичи») вместо концентраторов («хабов»)
- при использовании Gigabit Ethernet карт на хостах убедитесь, что вы используете кабели и коммутаторы с соответствующей пропускной способностью
- не используйте большее число физических сетевых интерфейсов, чем необходимо — ненужные адаптеры принимают широковещательные пакеты, что замедляет быстродействие в целом
Хостовая ОС
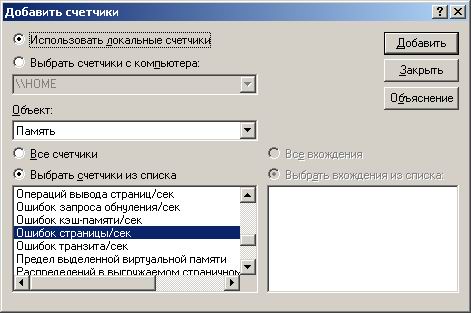
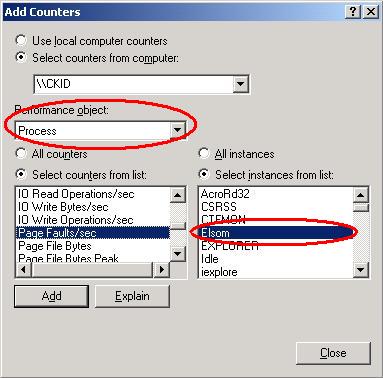
После того, как память для хостовой платформы будет выбрана, необходимо следить за ее использованием процессами, поддерживающими виртуальные машины. Для того чтобы определить, достаточно ли памяти выделено виртуальным машинам, используйте счетчики ошибок страницы (page faults) и число подкачиваемых страниц в секунду (pages/sec counter). В случае если процессы виртуальных машин интенсивно используют виртуальную память, значения этих параметров будут слишком высоки и виртуальным машинам необходимо будет выделить больше физической оперативной памяти. В операционной системе Windows используйте программу perfmon:
нажмите «Пуск»->«Выполнить»->наберите «perfmon», далее нажмите кнопку «добавить»:![Добавление счетчика Ошибок страницы/сек]()
Затем выберите объект «Память» и счетчик «Ошибок страницы/сек» и нажмите кнопку добавить:
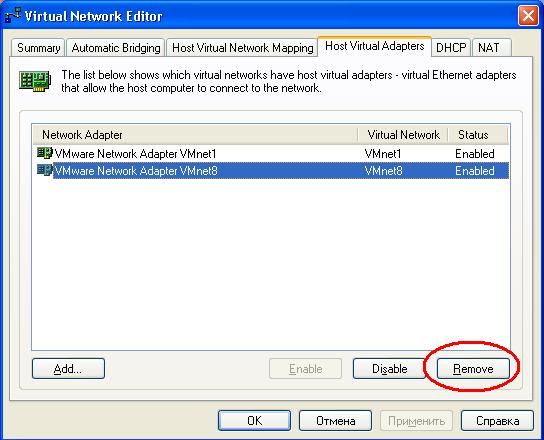
Многие сетевые карты могут работать в различных режимах (100 или 1000 МБит/сек, полудуплексном или дуплексном) — убедитесь, что для сетевого интерфейса выставлен наиболее оптимальный режим. Отключите все неиспользуемые физические сетевые интерфейсы. В случае если быстродействие сети для виртуальных машин вас не устраивает, а вы используете только один тип сетевого взаимодействия (например, bridged), можно отключить неиспользуемые виртуальные сетевые адаптеры:
![Виртуальные сетевые интерфейсы хоста]()
в VMware Workstation или VMware Server в меню «Edit» выберите «Virtual Network Settings», перейдите на вкладку «Host Virtual Adapters» и удалите неиспользуемые адаптеры.
Отключите все ненужные сервисы, которые могут замедлить работу хостовой системы. Для этого в операционной системе Windows в панели управления выберите апплет «Администрирование», затем «Службы» и отключите ненужные сервисы. В хостовой системе Linux используйте команду chkconfig -list для просмотра списка сервисов и команду: chkconfig [on| off| reset], например, chkconfig crond off. Также используйте команду top для просмотра списка запущенных процессов. Уберите также все ненужные вам программы из автозагрузки (в Windows используйте утилиту msconfig.exe).
Платформа виртуализации и виртуальные машины
В случае если ваш процессор использует технологию hyper-threading для представления двух логических процессоров для одного физического, не включайте виртуальный SMP (два виртуальных процессора) в настройках виртуальной машины при ее создании.
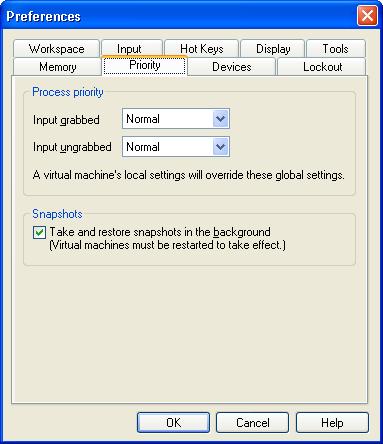
Вы можете также вручную выставить приоритет для процессов виртуальных машин:
![Окно настроек приоритетов виртуальных машин]()
зайдите в меню «Edit», выберите «Preferences», перейдите на вкладку «Priority» и назначьте приоритет активной виртуальной машине (Input grabbed — когда курсор находится внутри виртуальной машины) и остальным виртуальным машинам в фоне (Input ungrabbed).
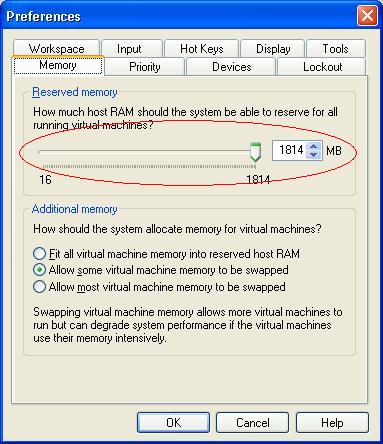
![Настройки памяти для виртуальных машин]()
Если вы используете хостовую ОС не только для запуска виртуальных машин, но и для других задач вы можете задать количество физической оперативной памяти, которое могут использовать виртуальные машины. Для этого зайдите в меню «Edit», выберите «Preferences», перейдите на вкладку «Memory» и выставьте необходимое количество памяти для виртуальных машин.
Здесь вы можете также определить, как виртуальные машины будут использовать файл подкачки. По умолчанию часть памяти виртуальной машины сбрасывается в файл подкачки. Если же выставить параметр «Allow most virtual machine memory to be swapped», это позволит запустить большее число виртуальных машин одновременно, но отрицательно скажется на их быстродействии. Выбор первого параметра повлечет за собой использование только физической памяти хостовой системы, что ускорит быстродействие, однако, соответственно, уменьшит число одновременно запущенных виртуальных машин.
VMware Workstation и VMware Server используют процедуры очистки неиспользуемой памяти (Memory Trimming). Вообще говоря, этот параметр не сильно влияет на производительность, однако его отключение может немного повысить производительность при работе с дисками виртуальной машины. Отключить его можно, добавив в vmx-файл строчку MemTrimRate=0 или в настройках виртуальной машины:
меню «VM», далее «Settings», вкладка «Options», категорию «Advanced», отметить чекбокс «Disable Memory Page Trimming».
По возможности используйте диски виртуальных машин хранящиеся локально. В случае использования сетевых ресурсов, следите за пропускной способностью сети и ее доступностью. По умолчанию VMware Server и VMware Workstation используют эмуляцию SCSI-дисков. Не меняйте этот параметр, поскольку применение виртуальных IDE-дисков снижает быстродействие. Используйте виртуальные диски типа «preallocated», вместо «growable», хотя вторые и выгодны с точки зрения используемого места (растут по мере наполнения), они работают несколько медленнее. Для задания дисков типа «preallocated» при создании виртуальной машины поставьте галку «Allocate all disk space now». Можно также создавать независимые (Independent) диски для виртуальной машины, которые могут быть постоянными (Persistent) и непостоянными (Nonpersistent). Содержимое этих дисков существует независимо от мгновенных снимков виртуальной машины (снапшотов). Непостоянные диски отличаются тем, что их содержимое сбрасывается при выключении виртуальной машины. Диски типа Independent-persistent обладают наилучшим быстродействием и рекомендуются для большинства вариантов использования. Для того чтобы создать такой диск, выберите меню «VM», «Settings», на вкладке «Hardware» выберите диск и нажмите «Advanced», убедитесь, что галки «Independent» и «Persistent» установлены.
-
Отключение режима отладки
Многие забывают, что некоторые старые операционные системы, такие как Windows 98, постоянно проверяют наличие диска в приводе, что приводит к потере быстродействия. Виртуальный CD/DVD-ROM можно отключить в настройках виртуальной машины:
Гостевая ОС и приложения
Оптимизация гостевой системы является наиболее тонким моментом оптимизации виртуальных систем, поскольку многое зависит от того, для каких целей используется виртуальная машина, какие приложения в ней запущены и к каким компонентам системы предъявляются наиболее высокие требования к быстродействию. Самыми значимыми объектами настройки являются: процессор, память, диски, сетевые адаптеры и программное обеспечение виртуальной машины.
![Добавление счетчика производительности к отдельному процессу]()
Внутри виртуальной машины необходимо так же отслеживать интенсивность использования виртуальной памяти, как и для хостовой системы, используя счетчики «Ошибок страницы» и «Ошибок страницы/сек» для того, чтобы определить, достаточно ли памяти выделено виртуальной машине. Чтобы выяснить насколько интенсивно отдельное приложение использует виртуальную память, в программе perfmon добавьте счетчик для объекта «Процесс» и выберите его из списка справа:
- дефрагментация дисков в гостевой системе
- дефрагментация файлов виртуальных дисков средствами VMware
- дефрагментация дисков в хостовой системе
В гостевой и хостовой системах Windows дефрагментацию дисков можно производить либо с помощью встроенной утилиты defrag, либо с помощью программ сторонних производителей. Дефрагментация файлов виртуальных дисков может быть проведена с использованием платформы виртуализации. Выберите меню «VM», «Settings», на вкладке «Hardware» выберите диск и нажмите кнопку «Defragment»:
Убедитесь, что гостевая система использует подходящий драйвер сетевой карты, для этого в Windows посмотрите свойства сетевой карты в диспетчере устройств. При установленных VMware Tools, в качестве драйвера должен быть установлен VMware Accelerated Driver:
- используйте, по возможности, в качестве гостевых и хостовых систем официально поддерживаемые VMware платформы
- попробуйте использовать паравиртуализованные ядра Linux на платформе VMware Workstation, которая, начиная с шестой версии, официально поддерживает техники паравиртуализации
- регулярно обновляйте пакет VMware Tools, который предоставляет наиболее оптимизированные драйвера виртуальных устройств (в шестой версии VMware Workstation есть функция автоматического обновления этого пакета)
- используйте официальные релизы программного обеспечения вместо бет и отладочных версий
Заключение
После того, как все четыре перечисленных мероприятия по оптимизации будут проведены, необходимо постоянное наблюдение за производительностью виртуальных машин, особенно если они работают в качестве виртуальных серверов. Целью оптимизации в этом случае должна стать стабильная одновременная работа нескольких виртуальных систем на одном физическом хосте. Регулярно обновляйте программное обеспечение и платформу виртуализации, и тогда вы сможете максимально эффективно использовать виртуальные машины, как на десктопах, так и в качестве гибких серверных элементов ИТ-инфраструктуры предприятия.
CPU
Предположим, что у нас есть бездействующая ВМ с резервом 2 GHz. В этом случае другие машины могут получить процессорное время, не используемое данной ВМ, несмотря на резерв.
Память
А вот с памятью все иначе.
Если ВМ имеет зарезервированную память, но еще не обращалась ко всему объему резерва, то неиспользованная память может быть отдана другим ВМ. Однако после того, как произошло обращение ко всему объему резерва, ESX сохраняет полный резерв за этой ВМ, даже если ВМ бездействует и не обращается к памяти.
Разъясню чуть более техническим языком – ВМ видит непрерывную vRAM, виртуальную память, часть которой каким-то образом распределена в pRAM, физической памяти сервера. Выделение очередного блока pRAM происходит при первом обращении ВМ к блоку vRAM, поэтому в общем случае объем выделенной pRAM меньше или равен объему vRAM. Т.е. для ВМ с 4 GB памяти фактически может быть выделено 512 MB физической памяти просто потому что к 3.5 GB ВМ ни разу не обращалась. В случае с резервированной памятью все происходит точно так же. Резерв памяти защищает только физическую память, уже выданную ВМ, поэтому даже при резерве в 2 GB фактическое использование может составить лишь 512 MB, а следовательно 1.5 GB физической памяти могут быть выделены другим ВМ. Но как только произойдет обращение к этим 1.5 GB со стороны ВМ с резервом памяти, они будут выделены в pRAM, и далее уже никому другому не будут отданы, даже если не будет ни одного нового обращения.
Зарезервированные 2 GB памяти ни при каких условиях не будут сброшены в своп или выдавлены balloon-драйвером. Однако весь объем памяти ВМ, лежащий выше отметки резерва (т.е. 1 GB для ВМ с 3 GB памяти и резервом в 2 GB), будет рассматриваться сервером ESX на общих основаниях – т.е. и balloon и swap поджидают за углом :)
---
Источник 1Memory management
В полете из солнечной Москвы в прохладный Баку
у меня появилось вдохновение для написания сего текста.
Лично мне он понравился.Вот у нас есть сервер ESX(i), для простоты один. У его есть сколько-то оперативной памяти для виртуальных машин (“Доступная память”), и на нем работает сколько-то виртуальных машин. Этим виртуальным машинам выделено сколько-то памяти (“Показанная память” ), и они сколько-то этой памяти потребляют (“Потребляемая память” ). Что можно рассказать про это?
Несколько общих слов
- Память, которую гипервизор тратит на себя. ESXi создает в памяти RAM диск для своей работы. ESX отрезает 300-800 мегабайт для Service Console. Виртуальным коммутаторам, iSCSI инициатору и прочим компонентам так же нужны ресурсы для своей работы.
- Память, которую гипервизор тратит для создания процесса виртуальной машины. Overhead, говоря в терминах счетчиков нагрузки. Когда мы создаем виртуалку и “показываем” ей гигабайт памяти, гипервизор ей выдает часть или 100% этого гигабайта. И даже в последнем случае еще 100-150 мегабайт тратит на оверхед.
- Еще HA может резервировать сколько-то памяти под свои нужды.
Показанная память – это тот объем памяти, который мы указываем в настройках ВМ, на закладке Hardware. Именно этот объем видит гостевая ОС. Это максимум, который гостевая ОС может использовать. Однако, гипервизор может выделить для ВМ из реальной оперативки и меньший объем, чем “показал” ей памяти. То, что гостю выделено лишь, например, 400 мегабайт из показанного гигабайта изнутри не заметить. По каким причинам гипервизор будет так подло поступать поговорим чуть позже.
Потребляемая память – это сколько реальной оперативной памяти использует виртуальная машина. Или, правильнее сказать, какой объем памяти выделил ей гипервизор. В терминах мониторинга это Consumed.
Memory Overcomitment
Все мы наслышаны про чудесный (без иронии) “Memory Overcomitment”. Что это? Это ситуация, когда “Показанная память” всех ВМ на сервере больше чем “Доступная память”. То есть мы “показали” нашим виртуальным машинам больше памяти, чем есть на сервере. Кстати говоря, и это важно, “Потребляемая память” в такой ситуации может быть как меньше (хороший случай), так и больше чем память “Доступная” (плохой случай).
![image]()
- выделение по запросу;
- transparent memory page sharing:
- balloon driver или его еще можно обозвать vmmemctl;
- memory compression (новинка 4.1);
- vmkernel swap.
Что это? Каково место этих технологий? Насколько они офигенны? Насколько они бесполезны? Давайте поразмышляем.
Вводная к размышлениям
Мы будем рассуждать о потреблении памяти виртуальными машинами, а точнее – гостевыми ОС и приложениями.
Основная идея в чем – “показанная” серверу (тут неважно – физическому или виртуальному) оперативная память никогда не загружена на 100%. Почему? У вас загружена именно так? Значит вы хреново спланировали этот сервер, согласны?
Утверждение 1 – мы должны стремиться к тому. что виртуальные машины не должны все время потреблять 100% от “показанной” им памяти. Таким образом, прочие соображения я буду основывать на том, что у вас именно так. То, что некоторые задачи занимают чем-то всю свободную память – здесь не учитываем, так как разговор идет в общем.
Утверждение 2 – в разное время суток\дни недели наши приложения потребляют память по разному. Большинство задач хотят ресурсов в рабочие часы в будни, с пиками утром или в середине дня или . Однако бывают приложения с нетипичными для нашей инфраструктуры профилем потребления памяти.
Утверждение 3 – в вашей инфраструктуре сделан запас по оперативной памяти серверов, то есть “доступной” памяти. Этот запас делается из следующих соображений:
- архитектор боится промахнуться с необходимым объемом. промахнуться в смысле “продать меньше памяти чем потребуется”;
- как запас на случай отказа сервера (или нескольких);
- как запас на случай роста виртуальных машин или нагрузки на существующие виртуальные машины.
Рискну предположить, что в наших инфраструктурах можно выделить несколько групп виртуалок, по разному потребляющих память.
Попробую предложить классификацию. Она примерна, потому что тут я ее предлагаю лишь для иллюстрации своих размышлений.
- ВМ приложений – сколько памяти вы выделяете (“показываете” в моих определениях тут) своим серверам приложений? При опросах на курсах я слышу цифры 4-8, редко больше. Вернее, для малого числа ВМ больше. Большинство таких приложений потребляет ресурсы в рабочие часы, однако бывают и исключения (например, сервера резервного копирования, работающие по ночам);
- Инфраструктурные ВМ – всякие DNS, DC, и т.п. Обычно гигабайт или два. Потребляют ресурсов мало, пики если вообще есть – в рабочие часы;
- Тестовые ВМ – думаю, гигабайт или два в среднем по больнице, и больше по требованию смотря что тестировать будем. Пики в рабочие часы, где-то бывает куча тестовых виртуалок, простаивающих подавляюще большую часть времени (как крайний случай – кто-то создал и забросил, а удалить виртуалку страшно – вдруг кому нужна).
Выделение по запросу
То, чего нет у других. Ну или я не знаю что есть. (помните, пост про vDiva – “Вы считаете себя нереально крутым спецом по виртуализации, хотя ни разу в жизни не видели Xen, Hyper-V или KVM”).
Виртуальной машине выделили (“показали”) два гигабайта. Виртуальную машину включили. Что происходит дальше?
Этап 2 – гость стартовал все службы, службы начали работать, создавать нагрузку. Но не сто процентов памяти потребляется, см. утверждение 1. Например, 1200 мегабайт из выделенных 2000. То есть гость 800 мегабайт пометил у себя в таблице памяти как “свободная”. По хорошему, гипервизору надо бы ее забрать. Он и забирает, для этого используется механизм balloon(!). Т.е. одна из задач балон-драйвера (подробности о нем см. ниже) – это отбирать ранее выданною, но сейчас ненужную гостю память. Итак, балон раздулся, затем сразу сдулся. Что получилось – гостю 1200 мегабайт нужно, поэтому они балоном или не отнялись, или сразу вернулись обратно. Но больше памяти гостю, обычно, не нужно – и он больше не просит. А раз не просит, гипервизор ему больше и не дает.
Работает этот механизм всегда, когда виртуальная машина потребляет не 100% “показанной” памяти. То есть всегда, кроме первых минут после включения и редких пиков, этот механизм работает, и заметно экономит нам память.
Если виртуальная машина не потребляет всю память часто – механизм очень полезен. Для некоторых тестовых – 100% времени. Для производственных серверов – как минимум ночью. А если часть серверов нагружается в другое время суток чем оставшаяся часть – вообще шоколадно. Для инфраструктурных – иногда бОльшую часть времени.
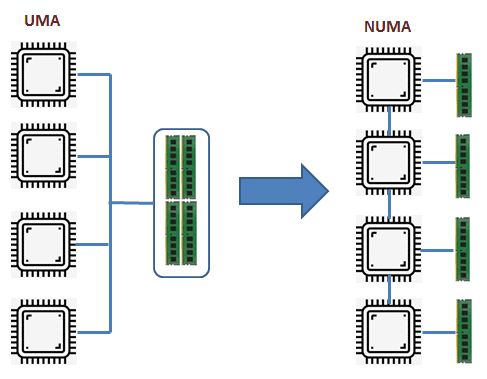
Современные серверные решения на базе архитектуры x86, которые сейчас используются почти во всех программно-аппаратных комплексах, имеют некоторые нюансы. Многопроцессорные сервера, имеющие на материнской плате 2, 4 или даже 8 процессорных сокетов, являются по сути NUMA-архитектурой. NUMA (Non-Uniform Memory Architecture) означает, что каждый процессорный сокет имеет свой пул локальных модулей оперативной памяти и такая связка называется узлом NUMA (рис. 1).
![]()
Рис. 1. UMA и NUMA архитектуры. Все процессорные ядра и вся оперативная память объединены в одну систему, но обращение процессора к своим (локальным) модулям памяти происходит с большей скоростью (или меньшими задержками), чем к памяти соседнего процессора.
Все современные операционные системы и программные решения более высокого уровня (например, виртуальный гипервизор или СУБД) понимают особенности этой архитектуры. В идеале, это понимание позволяет большинство операций выполнять с памятью локального процессора, не ходя в "дальние края" за памятью соседа.
vSphere от VMware тоже прекрасно разбирается в NUMA. При конфигурировании виртуальной машины (если вы не активируете опцию "Enable CPU Hot Add") и при её работе гипервизор будет размещать виртуальные процессорные ядра (vCPU) и память виртуальной машины в один узел NUMA. Причём, эта функция работает по умолчанию, ничего отдельно настраивать не надо.
Это всё прекрасно работает для небольших виртуальных машин, которые занимают гораздо меньше памяти, чем имеется в одном узле NUMA. Для работы большого количества таких относительно небольших виртуальных машин на одном сервере решения виртуализации и были прежде всего разработаны. Но у нас немного другой профиль - SAP системы, которые обычно требуют много ресурсов процессора и памяти.
Хочу на своём примере показать недостаточно корректную настройку размера виртуальных машин, с учётом NUMA архитектуры. На проекте, про который хочу рассказать, были сервера двух типов:
- 4-х сокетный сервер (8 ядер/16 потоков в каждом процессоре) и 384 Гб оперативной памяти,
- 2-х сокетный сервер (8 ядер/16 потоков в каждом процессоре) и 256 Гб оперативной памяти.
Понимая, всю ситуацию с NUMA архитектурой я разместил на серверах первого типа виртуальные машины с характеристиками:
- 16 vCPU + 192 Гб памяти,
- 8 vCPU + 96 Гб памяти.
При конфигурировании такой системы я был очень доволен - ведь я точно попал в узлы NUMA. Большая машина идеально вписывается в 2 узла NUMA. А те, что поменьше идеально вписаны в один узел NUMA, как на первых серверах, так и на вторых.
Но после прокачки своих знаний по VMware, мне открылось, что я совершил ошибку при конфигурации объёмов памяти.
Для мониторинга работы виртуальных машин на узлах ESXi есть команда esxtop (аналог команды top в Linux) (рис. 2). Так вот, для мониторинга работы с памятью и NUMA диагностики, необходимо запустить команду esxtop , нажать "m", перейдя в мониторинг памяти. После этого нажать "f" и добавить к формату вывод статистику по NUMA (рис. 3).
![]()
Рис. 2. Основной экран утилиты esxtop. ![]()
Рис. 3. Активация просмотра статистики по NUMA узлам. После этого на экране появится несколько важных полей:
- NHN - текущий домашний узел для виртуальной машины,
- NMIG - количество NUMA миграций с узла на узел,
- NRMEM (MB) - текущее количество "дальней памяти" (из соседней NUMA), используемой виртуальной машиной,
- NLMEM (MB) - текущее количество локальной памяти, используемой виртуальной машиной,
- N%L - текущий процент запрошенной виртуальной машиной памяти, являющейся локальной.
Последний параметр помогает проанализировать итог работы виртуальной машины на NUMA узлах. Если он равен 100%, значит производительность оптимальна. Если же ниже 100%, значит не всегда в процессе работы на реальных процессорных ядрах для текущей виртуальной машины идёт попадание в память локального узла NUMA.
По моей ситуации. Первые две большие виртуальные машины не всегда попадают в память локального NUMA узла (рис. 4 и 5). Напомню, что обе машины работают на серверах с размером узла NUMA = 16 ядер (с учётом HT) + 96 Гб.
![]()
Рис. 4. Статистика по NUMA виртуальной машины 8 vCPU + 96 Гб. ![]()
Рис. 5. Статистика по NUMA виртуальной машины 16 vCPU + 192 Гб.
Процент попадания в локальный NUMA узел 93% и 92% соответственно. Причём, если посмотреть по другим параметрам статистики: виртуальной машине при работе не хватает всего 6-7 Гб памяти на локальном узле.
"Небольшие" виртуальные машины, работающие на серверах второго типа (с размером узла NUMA = 16 ядер (с учётом HT) + 128 Гб памяти), отлично умещаются в локальных NUMA узлах (рис. 6). Забора "чужой" памяти нет, всё работает оптимально.
![]()
Рис. 6. Статистика по NUMA виртуальной машины, работающей на сервере второго типа. Моя ошибка при конфигурировании размера оперативной памяти больших виртуальных машин в данном случае была в том, что я не учёл накладные расходы гипервизора. Точнее я решил, что накладные расходы общие на весь сервер. А оказалось, что надо учитывать их на каждый узел NUMA. И более оптимально было бы взять не всю память NUMA узла для виртуальной машины, а максимум 90%. Оставив 10% на накладные расходы гипервизора и инфраструктуры VMware.
Максим Мошков рекомендует пользоваться правилом при конфигурировании любых ресурсов в среде VMware - 80% ресурсов можно использовать, а 20% всегда оставлять на запас, накладные расходы и тому подобное.
Если у меня будет возможность, то я переконфигурирую данные виртуальные машины, которые не оптимально попадают в узлы NUMA. И потом поделюсь с вами результатами статистики.
![]()
Немного теории
Оперативная память виртуальных машин берется из памяти сервера, на которых работают ВМ. Это вполне очевидно:). Если оперативной памяти сервера не хватает для всех желающих, ESXi начинает применять техники оптимизации потребления оперативной памяти (memory reclamation techniques). В противном случае операционные системы ВМ падали бы с ошибками доступа к ОЗУ.
Какие техники применять ESXi решает в зависимости от загруженности оперативной памяти:
Состояние памяти Граница Действия High 400% от minFree После достижения верхней границы, большие страницы памяти разбиваются на маленькие (TPS работает в стандартном режиме). Clear 100% от minFree Большие страницы памяти разбиваются на маленькие, TPS работает принудительно. Soft 64% от minFree TPS + Balloon Hard 32% от minFree TPS + Compress + Swap Low 16% от minFree Compress + Swap + Block minFree — это оперативная память, необходимая для работы гипервизора.
До ESXi 4.1 включительно minFree по умолчанию было фиксированным — 6% от объема оперативной памяти сервера (процент можно было поменять через опцию Mem.MinFreePct на ESXi). В более поздних версиях из-за роста объемов памяти на серверах minFree стало рассчитываться исходя из объема памяти хоста, а не как фиксированное процентное значение.
Значение minFree (по умолчанию) считается следующим образом:
Процент памяти, резервируемый для minFree Диапазон памяти 6% 0-4 Гбайт 4% 4-12 Гбайт 2% 12-28 Гбайт 1% Оставшаяся память Например, для сервера со 128 Гбайт RAM значение MinFree будет таким:
MinFree = 245,76 + 327,68 + 327,68 + 1024 = 1925,12 Мбайт = 1,88 Гбайт
Фактическое значение может отличаться на пару сотен МБайт, это зависит от сервера и оперативной памяти.Процент памяти, резервируемый для minFree Диапазон памяти Значение для 128 Гбайт 6% 0-4 Гбайт 245,76 Мбайт 4% 4-12 Гбайт 327,68 Мбайт 2% 12-28 Гбайт 327,68 Мбайт 1% Оставшаяся память (100 Гбайт) 1024 Мбайт Обычно для продуктивных стендов нормальным можно считать только состояние High. Для стендов для тестирования и разработки приемлемыми могут быть состояния Clear/Soft. Если оперативной памяти на хосте осталось менее 64% MinFree, то у ВМ, работающих на нем, точно наблюдаются проблемы с производительностью.
В каждом состоянии применяются определенные memory reclamation techniques начиная с TPS, практически не влияющего на производительность ВМ, заканчивая Swapping’ом. Расскажу про них подробнее.
Transparent Page Sharing (TPS). TPS — это, грубо говоря, дедупликация страниц оперативной памяти виртуальных машин на сервере.
ESXi ищет одинаковые страницы оперативной памяти виртуальных машин, считая и сравнивая hash-сумму страниц, и удаляет дубликаты страниц, заменяя их ссылками на одну и ту же страницу в физической памяти сервера. В результате потребление физической памяти снижается и можно добиться некоторой переподписки по памяти практически без снижения производительности.
![]()
ИсточникПо умолчанию ESXi выделяет память большим страницам. Разбивание больших страниц на маленькие начинается при достижении порога состояния High и происходит принудительно, когда достигается состояние Clear (см. таблицу состояний гипервизора).
Если же вы хотите, чтобы TPS начинал работу, не дожидаясь заполнения оперативной памяти хоста, в Advanced Options ESXi нужно установить значение “Mem.AllocGuestLargePage” в 0 (по умолчанию 1). Тогда выделение больших страниц памяти для виртуальных машин будет отключено.
С декабря 2014 во всех релизах ESXi TPS между ВМ по умолчанию отключен, так как была найдена уязвимость, теоретически позволяющая получить из одной ВМ доступ к оперативной памяти другой ВМ. Подробности тут. Информация про практическую реализацию эксплуатации уязвимости TPS мне не встречалось.
Политика TPS контролируется через advanced option “Mem.ShareForceSalting” на ESXi:
0 — Inter-VM TPS. TPS работает для страниц разных ВМ;
1 – TPS для ВМ с одинаковым значением “sched.mem.pshare.salt” в VMX;
2 (по умолчанию) – Intra-VM TPS. TPS работает для страниц внутри ВМ.Однозначно имеет смысл выключать большие страницы и включать Inter-VM TPS на тестовых стендах. Также это можно использовать для стендов с большим количеством однотипных ВМ. Например, на стендах с VDI экономия физической памяти может достигать десятков процентов.
Memory Ballooning. Ballooning уже не такая безобидная и прозрачная для операционной системы ВМ техника, как TPS. Но при грамотном применении с Ballooning’ом можно жить и даже работать.
Вместе с Vmware Tools на ВМ устанавливается специальный драйвер, называемый Balloon Driver (он же vmmemctl). Когда гипервизору начинает не хватать физической памяти и он переходит в состояние Soft, ESXi просит ВМ вернуть неиспользуемую оперативную память через этот Balloon Driver. Драйвер в свою очередь работает на уровне операционной системы и запрашивает свободную память у нее. Гипервизор видит, какие страницы физической памяти занял Balloon Driver, забирает память у виртуальной машины и возвращает хосту. Проблем с работой ОС не возникает, так как на уровне ОС память занята Balloon Driver’ом. По умолчанию Balloon Driver может забрать до 65% памяти ВМ.
Если на ВМ не установлены VMware Tools или отключен Ballooning (не рекомендую, но есть KB:), гипервизор сразу переходит к более жестким техникам отъема памяти. Вывод: следите, чтобы VMware Tools на ВМ были.
![]()
Работу Balloon Driver’а можно проверить из ОС через VMware Tools.Memory Compression. Данная техника применяется, когда ESXi доходит до состояния Hard. Как следует из названия, ESXi пытается сжать 4 Кбайт страницы оперативной памяти до 2 Кбайт и таким образом освободить немного места в физической памяти сервера. Данная техника значительно увеличивает время доступа к содержимому страниц оперативной памяти ВМ, так как страницу надо предварительно разжать. Иногда не все страницы удается сжать и сам процесс занимает некоторое время. Поэтому данная техника на практике не очень эффективна.
Memory Swapping. После недолгой фазы Memory Compression ESXi практически неизбежно (если ВМ не уехали на другие хосты или не выключились) переходит к Swapping’у. А если памяти осталось совсем мало (состояние Low), то гипервизор также перестает выделять ВМ страницы памяти, что может вызвать проблемы в гостевых ОС ВМ.
Вот как работает Swapping. При включении виртуальной машины для нее создается файл с расширением .vswp. По размеру он равен незарезервированной оперативной памяти ВМ: это разница между сконфигурированной и зарезервированной памятью. При работе Swapping’а ESXi выгружает страницы памяти виртуальной машины в этот файл и начинает работать с ним вместо физической памяти сервера. Разумеется, такая такая “оперативная” память на несколько порядков медленнее настоящей, даже если .vswp лежит на быстром хранилище.
В отличие от Ballooning’а, когда у ВМ отбираются неиспользуемые страницы, при Swapping’e на диск могут переехать страницы, которые активно используются ОС или приложениями внутри ВМ. В результате производительность ВМ падает вплоть до подвисания. ВМ формально работает и ее как минимум можно правильно отключить из ОС. Если вы будете терпеливы ;)
Если ВМ ушли в Swap — это нештатная ситуация, которую по возможности лучше не допускать.
Основные счетчики производительности памяти виртуальной машины
Вот мы и добрались до главного. Для мониторинга состояния памяти в ВМ есть следующие счетчики:
Active — показывает объем оперативной памяти (Кбайт), к которому ВМ получила доступ в предыдущий период измерения.
Usage — то же, что Active, но в процентах от сконфигурированной оперативной памяти ВМ. Рассчитывается по следующей формуле: active ÷ virtual machine configured memory size.
Высокий Usage и Active, соответственно, не всегда является показателем проблем производительности ВМ. Если ВМ агрессивно использует память (как минимум, получает к ней доступ), это не значит, что памяти не хватает. Скорее это повод посмотреть, что происходит в ОС.
Есть стандартный Alarm по Memory Usage для ВМ:![]()
Shared — объем оперативной памяти ВМ, дедуплицированной с помощью TPS (внутри ВМ или между ВМ).
Granted — объем физической памяти хоста (Кбайт), который был отдан ВМ. Включает Shared.
Consumed (Granted — Shared) — объем физической памяти (Кбайт), которую ВМ потребляет с хоста. Не включает Shared.
Если часть памяти ВМ отдается не из физической памяти хоста, а из swap-файла или память отобрана у ВМ через Balloon Driver, данный объем не учитывается в Granted и Consumed.
Высокие значения Granted и Consumed — это совершенно нормально. Операционная система постепенно забирает память у гипервизора и не отдает обратно. Со временем у активно работающей ВМ значения данных счетчиков приближается к объему сконфигурированной памяти, и там остаются.Zero — объем оперативной памяти ВМ (Кбайт), который содержит нули. Такая память считается гипервизором свободной и может быть отдана другим виртуальным машинам. После того, как гостевая ОС получила записала что-либо в зануленную память, она переходит в Consumed и обратно уже не возвращается.
Reserved Overhead — объем оперативной памяти ВМ, (Кбайт) зарезервированный гипервизором для работы ВМ. Это небольшой объем, но он обязательно должен быть в наличии на хосте, иначе ВМ не запустится.
Balloon — объем оперативной памяти (Кбайт), изъятой у ВМ с помощью Balloon Driver.
Compressed — объем оперативной памяти (Кбайт), которую удалось сжать.
Swapped — объем оперативной памяти (Кбайт), которая за неимением физической памяти на сервере переехала на диск.
Balloon и остальные счетчики memory reclamation techniques равны нулю.Вот так выглядит график со счетчиками Memory нормально работающей ВМ со 150 ГБ оперативной памяти.
![]()
На графике ниже у ВМ явные проблемы. Под графиком видно, что для данной ВМ были использованы все описанные техники работы с оперативной памятью. Balloon для данной ВМ сильно больше, чем Consumed. По факту ВМ скорее мертва, чем жива.
![]()
ESXTOP
Как и с CPU, если хотим оперативно оценить ситуацию на хосте, а также ее динамику с интервалом до 2 секунд, стоит воспользоваться ESXTOP.
Экран ESXTOP по Memory вызывается клавишей «m» и выглядит следующим образом (выбраны поля B,D,H,J,K,L,O):
![]()
Интересными для нас будут следующие параметры:
Mem overcommit avg — среднее значение переподписки по памяти на хосте за 1, 5 и 15 минут. Если выше нуля, то это повод посмотреть, что происходит, но не всегда показатель наличия проблем.
В строках PMEM/MB и VMKMEM/MB — информация о физической памяти сервера и памяти доступной VMkernel. Из интересного здесь можно увидеть значение minfree (в МБайт), состояние хоста по памяти (в нашем случае, high).
В строке NUMA/MB можно увидеть распределение оперативной памяти по NUMA-нодам (сокетам). В данном примере распределение неравномерное, что в принципе не очень хорошо.
Далее идет общая статистика по серверу по memory reclamation techniques:
PSHARE/MB — это статистика TPS;
SWAP/MB — статистика использования Swap;
ZIP/MB — статистика компрессии страниц памяти;
MEMCTL/MB — статистика использования Balloon Driver.
По отдельным ВМ нас может заинтересовать следующая информация. Имена ВМ я скрыл, чтобы не смущать аудиторию:). Если метрика ESXTOP аналогична счетчику в vSphere, привожу соответствующий счетчик.
MEMSZ — объем памяти, сконфигурированный на ВМ (МБ).
MEMSZ = GRANT + MCTLSZ + SWCUR + untouched.GRANT — Granted в МБайт.
TCHD — Active в МБайт.
MCTL? — установлен ли на ВМ Balloon Driver.
MCTLSZ — Balloon в МБайт.
MCTLGT — объем оперативной памяти (МБайт), который ESXi хочет изъять у ВМ через Balloon Driver (Memctl Target).
MCTLMAX — максимальный объем оперативной памяти (МБайт), который ESXi может изъять у ВМ через Balloon Driver.
SWCUR — текущий объем оперативной памяти (МБайт), отданный ВМ из Swap-файла.
SWGT — объем оперативной памяти (МБайт), который ESXi хочет отдавать ВМ из Swap-файла (Swap Target).
Также через ESXTOP можно посмотреть более подробную информацию про NUMA-топологию ВМ. Для этого нужно выбрать поля D,G:
![]()
NHN – NUMA узлы, на которых расположена ВМ. Здесь можно сразу заметить wide vm, которые не помещаются на один NUMA узел.
NRMEM – сколько мегабайт памяти ВМ берет с удаленного NUMA узла.
NLMEM – сколько мегабайт памяти ВМ берет с локального NUMA узла.
N%L – процент памяти ВМ на локальном NUMA узле (если меньше 80% — могут возникнуть проблемы с производительностью).
Memory на гипервизоре
Если счетчики CPU по гипервизору обычно не представляют особого интереса, то с памятью ситуация обратная. Высокий Memory Usage на ВМ не всегда говорит о наличие проблемы с производительностью, а вот высокий Memory Usage на гипервизоре, как раз запускает работу техник управления памятью и вызывает проблемы с производительностью ВМ. За алармами Host Memory Usage надо следить и не допускать попадания ВМ в Swap.
![]()
![]()
Unswap
Если ВМ попала в Swap, ее производительность сильно снижается. Следы Ballooning’а и компрессии быстро исчезают после появления свободной оперативной памяти на хосте, а вот возвращаться из Swap в оперативную память сервера виртуальная машина совсем не торопится.
До версии ESXi 6.0 единственным надежным и быстрым способ вывода ВМ из Swap была перезагрузка (если точнее выключение/включение контейнера). Начиная с ESXi 6.0 появился хотя и не совсем официальный, но рабочий и надежный способ вывести ВМ из Swap. На одной из конференций мне удалось пообщаться с одним из инженеров VMware, отвечающим за CPU Scheduler. Он подтвердил, что способ вполне рабочий и безопасный. В нашем опыте проблем с ним также замечено не было.Собственно команды для вывода ВМ из Swap описал Duncan Epping. Не буду повторять подробное описание, просто приведу пример ее использования. Как видно на скриншоте, через некоторое время после выполнения указанной команд Swap на ВМ исчезает.
![]()
Советы по управлению оперативной памятью на ESXi
Напоследок приведу несколько советов, которые помогут вам избежать проблем с производительностью ВМ из-за оперативной памяти:
Читайте также: