
В каком файле хранится конфигурация для компиляции
Когда возникает необходимость создания мощной и надёжной системы на основе Linux (будь то обслуживание технологических процессов, веб-хостинга и т. д.), то очень часто приходится настраивать системное ядро таким образом, чтобы вся система работала более эффективно и надёжно. Ядро Linux хоть и является универсальным, однако бывают ситуации, когда его необходимо «подтюнинговать» по объективным причинам. Да и сама архитектура ядра это предполагает благодаря своей открытости. Таким образом, системные администраторы Linux – это те люди, которым важно знать и понимать некоторые общие аспекты конфигурирования ядра Linux.
Внутри Make-файла
В первой строке рассматриваемого Make-файла описывается переменная RM , значением которой является полный путь к бинарному файлу утилиты rm , которая используется для удаления файлов. Для того, чтобы получить значение переменной RM и использовать его в рамках вашего Make-файла, вам придется использовать нотацию $(RM) . Мы поговорим о переменных более подробно в следующем разделе.
В строке 3 описывается цель program , имеющая пять зависимостей, причем тремя ее зависимостями являются другие цели ( file2.o , file3.o и file4.o ), а остальными двумя - файл исходного кода на языке C++ и соответствующий заголовочный файл. Цель program имеет лишь одну ассоциированную команду, которая приведена в строке 4. Однако, как становится очевидно при рассмотрении цели clean (также из приведенного выше Make-файла), с любой целью может ассоциироваться более одной команды. В строках с 6 по 10 приведены инструкции по созданию объектных файлов на основе трех классов из файлов с исходным кодом на языке С++ с именами file2.cpp , file3.cpp и file4.cpp соответственно. Последнее правило предназначено для удаления всех временных файлов - использование цели clean является обычной практикой для Make-файлов, так как подобная цель, осуществляющая удаление всех временных файлов без какой-либо модификации основных файлов проекта, позволяет осуществлять полную пересборку проекта.
Параметр -с компилятора из набора GCC используется главным образом для обработки файлов, которые не содержат реализации функции main() , так как он сообщает компилятору C++ из состава GCC о том, что нужно осуществлять лишь предварительную обработку, компиляцию и ассемблирование исходного кода. Параметр -o , используемый в рамках цели program сообщает g++ и gcc о необходимости сохранения результирующего бинарного файла под именем . Если вы попытаетесь задействуете цель, соответствующую файлам в актуальном состоянии, вы получите аналогичный вывод:
В первой части Make-файла описывается множество переменных, которые будут использоваться далее в файле и могут быть разделены на два вида. Некоторые переменные используются для хранения путей к бинарным файлам команд (это позволяет переносить Make-файлы на другие операционные системы). Например:
Другие переменные используются для формирования имен новых файлов на основе различных параметров, таких, как дата и путь к резервной копии файла. Например:
Несложно заметить, что имеется возможность комбинирования множества переменных в рамках одной инструкции для генерации уникальных имен файлов и директорий.
Рассматриваемый Make-файл содержит переменную, хранящую номер версии вашей программы. Значение этой переменной может изменяться либо с помощью параметра командной строки, либо путем редактирования самого Make-файла. Если вы желаете использовать значение переменной, отличное от объявленного в Make-файле (в данном случае это переменная VERSION), вы можете осуществить аналогичный вызов GNU Make:
Однако, данная возможность должна использоваться с особой осторожностью особенно при работе с номерами версий или другими важными параметрами сборки проектов, так как вы в конце концов можете запутаться в версиях своей программы и потерять важные изменения кода.
Переменные GNU Make также называются макросами. Следующее правило является реализацией цели make all :
Это простая цель, которая позволяет создать программный продукт на основе его исходного кода путем передачи управления другому правилу ( executable ). Все программы проекта GNU должны в обязательном порядке поддерживать цель all .
Следующее правило реализует команду make clean , позволяющую удалить все файлы, которые были сгенерированы при предыдущих сборках проекта:
Это очень простое правило, удаляющее все файлы, сгенерированные при предыдущих сборках проекта. Символ @ сообщает GNU Make о том, что в процессе исполнения команды ее вывод не должен отображаться с помощью терминала.
Правило install просто копирует скомпилированные файлы в нужное место. Его реализация выглядит следующим образом:
Цель target должна зависеть от цели executable , так как при отсутствии исполняемого файла вы не сможете установить его в систему!
Для копирования файла в директорию, расположенную за пределами домашней директории, обычно требуются особые привилегии. Директория /tmp является исключением из данного правила; однако, директория /tmp обычно очищается после перезагрузки системы. Если вам нужно установить бинарный файл в директорию /usr/local/bin , которая обычно используется для хранения исполняемых файлов, вам придется выполнить команду make install либо от лица пользователя root, либо с помощью утилиты sudo .
Следующие команды реализуют команду make backup , генерируя архив с резервной копией файлов проекта, уникально идентифицируемый с помощью времени и даты создания:
Хранение резервной копии файлов проекта за пределами его директории является разумной практикой. В приведенном выше Make-файле файл архива сохраняется в директории /tmp , но вы можете использовать вместо нее любую другую директорию.
Другой переменной, практически всегда используемой в процессе компиляции кода на языках C и C++, является переменная CFLAGS , которая хранит флаги, используемые в процессе компиляции. Например, вы можете активировать режим вывода всех предупреждений компилятора и включить информацию о символах в результирующий бинарный файл для упрощения процесса отладки с помощью следующих флагов:
Вы можете изменить значение переменной CFLAGS для активации поддержки отладчиков, механизмов оптимизации кода или генерации машинного кода для отличной архитектуры центрального процессора.
Для того, чтобы избавить разработчиков от создания огромного количества аналогичных правил в make была добавлена поддержка шаблонов. Например, символ % соответствует любой последовательности символов. Этот механизм может пригодится, к примеру, в том случае, если вам понадобится скомпилировать все файлы с исходным кодом на языке C и сохранить объектный код в файлах с соответствующими именами:
В данном случае вам также следует обратить внимание на типичный пример использования переменной CFLAGS . Вы должны самостоятельно принять решение о том, обоснованно ли написание отдельных правил для генерации объектных файлов в ручном режиме или проще воспользоваться соответствующим шаблоном. Вообще говоря, подход с использованием шаблонов является предпочтительным тогда, когда приходится обрабатывать большое количество файлов. Конечно же, в случае использования шаблона вам придется также изменить вашу реализацию команды make clean на аналогичную приведенной ниже:
Следующая цель позволяет вывести список значений всех переменных Make-файла:
Список значений будет достаточно длинным, так как в него также будут включены все значения переменных командной оболочки. Но, несмотря на это, данная цель является достаточно полезной для отладки Make-файла.
Вы можете сделать вывод данной цели чуть более простым с помощью фильтра, ограничивающего объем выводимых данных. Например, если вам нужно получить список значений всех переменных с именами, начинающимися с буквы A, вы можете использовать следующую версию цели, задействующую механизм шаблонов и регулярное выражение:
Несложно заметить, что Make-файл становится достаточно сложным для чтения после добавления целей, правил, зависимостей и переменных, практически таким же, как файл с исходным кодом проекта. По этой причине вы должны стараться структурировать его содержимое и при необходимости добавлять в него комментарии, которые должны начинаться с символа решетки.

Make масштабируется практически до любого уровня сложности проекта. Даже исходный код ядра Linux содержит Make-файлы
Несмотря на то, что основным предназначением утилиты make является автоматизация процесса сборки программных проектов, администраторы Unux-систем, а также их обычные пользователи могут использовать ее и для своих целей. Вы можете использовать данную утилиту для создания резервных копий файлов конфигурации после их обновления, установки новых версий сценариев командной оболочки, генерации новых таблиц поиска Postfix с последующим перезапуском соответствующей службы, создания заданной структуры директорий для каждого из новых пользователей системы, генерации документации и выполнения других подобных действий - ее возможности безграничны; конечно же, вы также можете выработать новые методики использования утилиты GNU Make.
Поехали!
Обычно при использовании программы make придерживаются некоторых соглашений. Например, таких как:
make без аргументов производит просто компиляцию и не выполняет установки программы.
make install компилирует программу (правда не всегда), и инсталлирует необходимые файлы в нужное место в файловой системе. Некоторые файлы не всегда корректно инсталлируются (man, info), но их можно скопировать вручную. Иногда команду make install необходимо запускать несколько раз в подкаталогах. Обычно это случается с модулями, разработанными третьими лицами.
make clean удаляет все временные файлы, создающиеся при компиляции, а также, в большинстве случаев, исполняемые файлы.
На первой стадии необходимо скомпилировать программу, для этого нужно набрать: (нереальный пример):
Замечательно, допустим что все бинарники правильно откомпилировались. Мы готовы для перехода на следующую стадию, на которой будут инсталлироваться файлы пакета (бинарные файлы, файлы с данными и т.д). Смотрите раздел “Инсталляция”.
Различные полезные параметры утилиты make
Если вам понадобится использовать Make-файл с именем, отличающимся от makefile или Makefile , вы можете воспользоваться параметром -f , передав после него имя этого файла. Параметры --file=ИМЯ_ФАЙЛА и --makefile=ИМЯ_ФАЙЛА полностью эквивалентны параметру -f . Параметр -k сообщает утилите make о необходимости осуществления сборки проекта так долго, как это возможно вне зависимости от обнаруженных ошибок. Параметр -t позволяет изменить метки времени модификации файлов вместо выполнения команд для сборки проекта; данный режим работы предназначен для симуляции полной пересборки проекта, что соответствующим образом отразится на результате последующего запуска утилиты make . Параметр --trace позволяет получить информацию о том, почему заданная цель требует пересборки проекта и какие команды будут выполнены в ходе этой операции. Параметр --trace также может использоваться для отладки файлов GNU Make.
Вы можете без каких-либо сложностей прочитать или изменить значение существующей переменной окружения, объявив ее в рамках своего Make-файла. Если вы захотите отключить данный механизм, вы можете просто вызвать утилиту make , передав ей параметр -e .

Пример вывода утилиты GNU Make с параметрами -n, -p и -d, которые используются главным образом для целей отладки Make-файлов
Установка (инсталляция) ядра
Способы конфигурации ядра Linux
За время развития Linux постепенно сложились четыре основных способа для конфигурирования её ядра:
- модификация настраиваемых параметров ядра;
- сборка ядра из исходных кодов с внесением нужных изменений и/или дополнений в тексты исходных кодов ядра;
- динамическое подключение новых компонентов (функциональных модулей, драйверов) к существующей сборке ядра;
- передача специальных инструкций ядру во время начальной загрузки и/или используя загрузчик (например GRUB).
В зависимости от конкретной ситуации следует использовать тот или иной способ. Но сразу необходимо отметить, что на самом деле самым простым является первый — настройка параметров ядра. Самым же сложным является компиляция ядра из исходных кодов.
Настраиваемые параметры ядра
Системное ядро Linux разрабатывалось таким образом, чтобы всегда была возможность его максимально гибко (впрочем, как и всё в системах UNIX и Linux) настроить, адаптируя его к требуемым условиям эксплуатации и аппаратному окружению. Причём так, чтобы это было возможно динамически на готовой сборке ядра. Другими словами, системные администраторы могут в любой момент времени вносить корректирующие параметры, влияющие на работу как самого ядра, так и его отдельных компонентов.
Для реализации этой задачи между ядром и программами пользовательского уровня существует специальный интерфейс, основанный на информационных каналах. Через эти каналы и направляются инструкции, задающие значения для параметров ядра.
Но как и всё в системах UNIX и Linux, настройка параметров ядра по информационным каналам завязана на файловой системе. Чтобы просматривать конфигурацию ядра и управлять ею, в файловой системе в каталоге /proc/sys существуют специальные файлы. Это обычные файлы, но они играют роль посредников в предоставления интерфейса для динамического взаимодействия с ядром. Однако документация, касающаяся этого аспекта, в частности об описании конкретных параметров и их значений довольно скудна. Одним из источников, из которого можно почерпнуть некоторые сведения по этой теме, является подкаталог Documentation/sysent в каталоге с исходными кодами ядра.
Для наглядности стоит рассмотреть небольшой пример, показывающий, как через параметр ядра настроить максимальное число одновременно открытых файлов в системе:
Как можно видеть, к такому приёму можно довольно быстро привыкнуть и это не будет казаться чем-то очень сложным. Такой метод хоть и удобен, однако изменения не сохраняются после перезапуска системы.
Также можно использовать специализированную утилиту sysctl. Она позволяет получить значения переменных прямо из командной строки, либо список пар вида переменная=значение из файла. На этапе начальной загрузки утилита считывает начальные значения некоторых параметров, которые заданы в файле /etc/sysctl.conf. Более подробную информацию об утилите sysctl можно найти на страницах man-руководства.
В следующей таблице приводятся некоторые настраиваемые параметры ядра:
Условные обозначения: F — /proc/sys/fs, N — /proc/sys/net/ipv4, К — /proc/sys/kernel, С — /proc/sys/dev/cdrom.
В результате выполнения этой команды будет отключено перенаправление IP-пакетов. Есть одна особенность для синтаксиса этой команды: символы точки в «net.ipv4.ip_forward» заменяют символы косой черты в пути к файлу ip_forward.
Золотые правила разработки Make-файлов
При разработке нового Make-файла в первую очередь следует описать все макросы (переменные), которые должны содержать полные пути ко всем используемым бинарным файлам системных команд. Это объясняется тем, что вы должны четко знать, какие команды исполняются в процессе сборки проекта, а не полагаться на наличие путей к директориям с необходимыми бинарными файлами системных команд в значении переменной окружения PATH .
Лучше всего начать работу с создания небольшого корректно работающего Make-файла и постепенно добавлять в него новые правила и зависимости. После добавления каждой инструкции вы должны тестировать корректность работы Make-файла, а не продолжать его модификацию. Таким образом вы будете точно знать, какая модификация Make-файла повлекла за собой появление ошибки. Пожалуйста помните о том, что команды из состава правила будут исполняться лишь при модификации целевых файлов, а не всех файлов с исходным кодом проекта.
Не пытайтесь использовать утилиту GNU Make в рамках крупного проекта, если вы все еще изучаете ее возможности; попробуйте внедрить ее в проекты меньшего масштаба перед тем, как начинать работу с более сложными проектами. И наконец, уясните, что переменные полезны и могут существенно сэкономить ваше время, поэтому вам определенно стоит использовать их всегда, когда это возможно.

А это пример практического использования сложного Make-файла в рамках программного проекта на языке C
Скачиваем исходный код ядра
Теперь нужно скачать исходный код ядра. Мы будем скачивать ядро для Ubuntu. Вы можете скачать определенную версию ядра, например, ту, которую вы в данный момент используете или же скачать самую последнюю версию. Для того, чтобы определить версию ядра Linux, которую вы используете, выполните команду uname с параметром -r :
Вывод команды будет примерно следующим:
Имя пакета, содержащего исходные коды ядра обычно имеет следующий вид: linux-source-Версия. Например, для ядра версии 2.6.24: linux-source-2.6.24. Самая последняя версия ядра в репозиториях Ubuntu называется просто linux-source, без указания версии на конце. Для установки исходных кодов последней версии ядра Ubuntu Linux, выполните команду:
Эта команда скачивает исходники ядра и размещает их в директории /usr/src . На момент написания заметки последняя версия ядра, которая была скачана — 2.6.27, ее мы и будем использовать. Если мы теперь перейдем в директорию /usr/src и выполним команду ls , то увидим, что среди файлов присутствует файл linux-source-2.6.27.tar.bz2. Это и есть исходные коды ядра Linux (ядра Ubuntu).
Установка утилит
Для настройки и сборки ядра Linux вам потребуется установить несколько пакетов, которые понадобятся для сборки и настройки ядра: kernel-package , build-essential , libncurses-dev . Сделать это можно командой:
Подсказка
После того, как вы скопируете файл .config в домашний каталог root, как было описано ранее, вызовите командочку make mrproper. В этом случае будет гарантия того, что от старой конфигурации ядра не осталось ничего лишнего и вы получите чистенькое ядро.
Далее, настал черед компиляции.
| Пред. | Уровень выше | След. |
| Конфигурирование Ядра | Начало | Компиляция Ядра и Модулей, Установка Бестии |
linux samba mail postfix FreeBSD Unix doc linux howto ALTLinux PHP faq bind sendmail apache iptables firewall kernel rpm apt-get Slackware openssh Cisco debian vmware GNU oracle sun awk /etc/ passwd linux установка учебник книга скачать
Теперь, когда программное обеспечение правильно сконфигурировано, остается только его откомпилировать. Этот этап прост и не должен вызывать каких либо серьезных проблем.
Конфигурирование параметров ядра
Конфигурация для будущей сборки ядра Linux хранится в файле .config. Мало кто занимается ручным созданием и редактированием этого файла, поскольку, во-первых: это сложный синтаксис, который далеко не самый «человекопонятный», и во-вторых: существуют способы для автоматической генерации конфигурации сборки ядра с удобным графическим (или псевдографическим) интерфейсом. Список основных команд для конфигурирования сборки ядра:
- make xconfig – рекомендуется, если используется графическая среда KDE. Весьма удобный инструмент;
- make gconfig – лучший вариант для использования в графической среде GNOME;
- make menuconfig – данную утилиту следует использовать в псевдографическом режиме. Она не так удобна, как две предыдущие, однако со своими функциями справляется достойно;
- make config – самый неудобный «консольный» вариант, выводящий запросы на задание значений каждого параметра ядра. Не позволяет изменить уже заданные параметры.
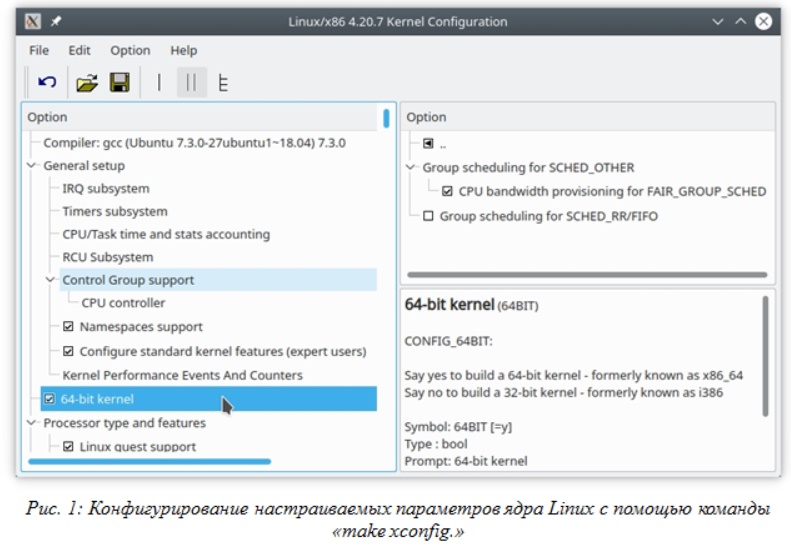
Практически все варианты (за исключением последнего) позволяют получать краткую справку по каждому параметру, производить поиск нужного параметра (или конфигурационного раздела), добавлять в конфигурацию дополнительные компоненты, драйверы, а также показывают, каким образом конкретный компонент может быть сконфигурирован — как компонент, встроенный в ядро или как загружаемый модуль, а также поддерживает ли он вообще вариант компиляции в качестве загружаемого модуля.

Очень полезной может оказаться команда make oldconfig, предназначенная для переноса существующей конфигурации с другой версии (сборки) ядра в новый билд. Эта команда читает конфигурацию из перенесенного из другой сборки файла .config со старой сборкой, определяет, какие новые параметры доступны для актуальной сборки и предлагает их включить или оставить как есть.
Для выполнения конфигурации сборки ядра Linux нужно перейти в каталог с исходными кодами и запустить одну из команд генерации конфигурации.
В результате работы вышеуказанных команд будет сгенерирован файл .conf, фрагмент содержимого из которого может быть следующим:
Как можно видеть, в данном коде нет ничего привлекательного для ручного редактирования, о чём даже упоминает запись комментария в начале файла .config. Символ «y» в конце какой-либо из строк указывает, что соответствующий компонент будет скомпилирован в составе ядра, «m» — как подключаемый модуль. Расшифровки или описания о каждом компоненте или параметре в файле .config не содержится — по этим вопросам следует изучать соответствующую документацию.
А что если. все это не работает?
Не паникуйте, это может случится с любым. Чаще всего это могут быть следующие ошибки:
glloq.c:16: decl.h: No such file or directory
Компилятор не может найти соответствующий заголовочный файл. Вообще-то эту ошибку должна была предвидеть программа конфигурации. Но эта проблема решаема:
Проверьте, действительно ли существует данный файл в следующих каталогах: /usr/include, /usr/local/include, /usr/X11R6/include или в каком-нибудь из подкаталогов. Если там нет, поищите по всему диску (с помощью утилит find или locate) и, если вы все же не можете найти этот файл, проверьте, действительно ли вы установили библиотеку, в которую входит этот заголовочный файл. Примеры использования утилит find и locate вы можете найти в соответствующих страничках руководства (man find; man locate).
Проверьте, действительно ли этот файл доступен для чтения (для проверки этого введите less /.h )
Если это каталог типа /usr/local/include или /usr/X11R6/include, вам прийдется добавить новый аргумент компилятору. Откройте соответствующий Makefile (будьте внимательны: нужный файл находится в каталоге, в котором произошла ошибка компиляции [32] ) в вашем любимом текстовом редакторе (Emacs, Vi, и т.д.). Перейдите на строку, в которой содержится ошибка, и добавьте строку -I - где это путь к каталогу, в котором вы отыскали недостающий заголовочный файл. Эти опции нужно добавить в конце строки, в которой вызывается компилятор (gcc, или $(CC)). Если вы не знаете куда добавить эти опции, допишите их в конце строк CFLAGS= или CC= , которые расположены в начале файла.
Запустите снова make и, если это опять не работает, перепроверьте снова то, что эти опции (смотрите предыдущий пункт) действительно были добавлены и получены компилятором.
Если это опять не работает, обращаетесь за помощью к вашему местному гуру, или к сообществу свободного программного обеспечения (смотрите раздел “Техническая поддержка”).
glloq.c:28: `struct foo' undeclared (first use this function)
Структуры - это такие специальные формы представления данных, которые используются при написании любых программ. Многие из них определяются системой в заголовочных файлах. Обычно эта проблема вызвана тем, что нет какого-то заголовочного файла или он неверен. Правильной процедурой для решения этой проблемы будут следующие действия:
Попробуйте найти где определяется эта самая структура (в программе или ее определяет система). Для этого используется утилита grep, с помощью которой выясняется определена ли эта структура в каком либо заголовочном файле.
Станьте root-ом и выполните следующую команду:
В результате может получиться очень много строк (потому что вы найдете все случаи, когда эта структура используется). Если структура все-таки существует, найдите заголовочный файл, в котором она определяется.
Определение структуры выглядит так:
Проверьте, соответствует ли это тому, что имеется у вас. Если да, то это значит, что заголовочный файл не включен в .c файл, содержащий ошибку. Для устранения этого дефекта есть два способа:
скопируйте определение этой структуры в начало .c файла (на самом деле это не очень правильно, зато обычно помогает).
Если эта структура не находится, попробуйте выяснить в какой библиотеке (то есть это набор функций, структур и т.д., содержащихся в отдельном пакете) оно должно содержатся (просмотрите файлы INSTALL или README на предмет того, какие библиотеки использует данная программа и какие версии библиотек необходимы). Если требуемые программой версии библиотек не соответствуют тем, что установлены в вашей системе - вам прийдется установить требуемые версии этих библиотек.
Если все же это не работает, уточните, может ли работать эта программа в Linux (некоторые программы могут не работать корректно во всех UNIX). Проверьте также, правильно ли переданы все опции команде configure. Особенно, нет ли каких-то дополнительных опций для вашей конкретной архитектуры.
Ошибки синтаксического анализа (parse error)
это значит, что тип данных glloq_t не определен. Для решения этой проблемы нужно предпринять действия, аналогичные тем, что были описаны для решения предыдущей проблемы.
Отладка Make-файлов
Make-файл может содержать синтаксические или логические ошибки, препятствующие его корректному функционированию. Наиболее полезным в плане отладки Make-файлов параметром утилиты make является параметр -n , который позволяет утилите просто выводить предназначенные для исполнения команды, но не исполнять их. Еще одним полезным параметром является параметр -d , который позволяет утилите выводить большой объем отладочной информации в процессе обычной обработки файла (хотя эта информация и может показаться интересной, она не всегда является полезной).
Последним полезным параметром для отладки Make-файлов является параметр -p , который позволяет утилите make выводить содержимое базы данных, а именно, все правила и значения переменных, извлеченные из Make-файла, перед выполнением необходимых пользователю действий. Если вы хотите получить содержимое базы данных без обработки каких-либо правил и файлов, вам придется воспользоваться следующей командой:

Это наглядная иллюстрация процесса обработки Make-файла, благодаря которой изящность технического решения, положенного в основу утилиты make, становится вполне очевидной
Объяснения
Если вы достаточно любопытны, чтобы заглянуть в файл Makefile, то вы найдете там известные команды (rm, mv, cp, и т.д.) и, кроме того, странные строки вроде этой $(CFLAGS).
Это переменные , которые обычно расположены в начале файла Makefile и связанные с ними значения. Это удобно в случае, когда вам нужно использовать несколько раз одно и тоже значение в нескольких местах.
Например, для того чтобы напечатать строку “ foo ” при выполнении цели make all, можно сделать следующее:
Обычно определены следующие переменные:
CC: Это компилятор. Обычно это cc, который присутствует в большинстве свободных систем, также это может быть его аналог gcc. Если у вас возникают сомнения, ставьте gcc.
LD: это программа, которая используется на конечной стадии компилирования (см. раздел “Четыре шага компиляции”). По умолчанию это программа ld.
CFLAGS: это дополнительные опции компилятору, которые используются компилятором на первой стадии компиляции. Среди них:
-I : указывает компилятору где искать дополнительные заголовочные файлы (к примеру: -I/usr/X11R6/include разрешает компилятору использовать файлы header, расположенные в allows /usr/X11R6/include).
-D : определяет дополнительные символы, которые могут быть необходимы для программ, компиляция которых зависит от определения таких символов (к примеру: использовать заголовочный файл string.h в случае, если определено HAVE_STRING_H).
Строка для компиляции обычно выглядит следующим образом:
LDFLAGS (или LFLAGS): Этот аргумент используется во время конечной стадии компиляции. Среди них:
-L : Определяет дополнительные пути поиска библиотек (например: -L/usr/X11R6/lib).
-l : Определяет дополнительные библиотеки, которые будут использоваться в конечном этапе компиляции.
make
Общество свободного программного обеспечения считает утилиту make излюбленным инструментом для компиляции исходных кодов. Это дает следующие преимущества:
Разработчик экономит время, потому что у него есть возможность эффективно управлять процессом компиляции своего проекта.
Конечный пользователь может откомпилировать и установить программное обеспечения, введя всего несколько командных строк, даже в том случае, если он ничего не понимает в программировании.
Действия, которые необходимо выполнить для получения откомпилированной версии исходных кодов, обычно хранятся в файле с названием Makefile или (реже) в файле GNUMakefile. На самом деле, при вызове команды make читается этот файл из текущего каталога. Возможно явное указание этого файла для команды make с помощью опции -f.
Замечание
еще может быть parse error в старых библиотеках curses, если мне не изменяет память.
no space left on device (на диске кончилось место)
Эту проблему легко решить: недостаточно места на диске для того, чтобы создать бинарник из исходника. Решение состоит в расчистке места на том разделе, на котором находится каталог инсталляции (удалите временные файлы или исходники, деинсталлируйте программы, которые вы не используете). Если вы развернули его в /tmp, а не в /usr/local/src, это зря, потому что он напрасно занимает место на разделе /tmp. Проверьте, нет ли на диске файлов core>. Если найдутся, удаляйте их или заставьте их удалиться, если они принадлежат другому пользователю.
/usr/bin/ld: cannot open -lglloq: No such file or directory
Это означает, что программа ld (используемая gcc во время последнего шага компиляции) не может найти библиотеку. Для того чтобы ее включить, ld ищет файл, чье имя является аргументом типа -l . Это файл lib.so. Если ld не находит его, получается ошибка. Для решения проблемы делайте следующее:
Проверьте, есть ли файл на диске с помощью команды locate. Графические библиотеки обычно находятся в /usr/X11R6/lib. Например:
Если поиск ничего не принес, вы можете попытаться поискать с помощью команды find command (то есть: find /usr -name libglloq.so*). Если и это ничего не дало, вам прийдется установить его.
Как только библиотека будет размещена, проверьте ее на доступность для ld: файл /etc/ld.so.conf определяет, где искать библиотеки. Добавьте каталог-виновник в его конец (возможно, вам прийдется перегрузить компьютер, чтобы изменения вступили в силу). Кроме того, вы можете добавить этот каталог путем изменения содержимого переменной окружения LD_LIBRARY_PATH. Например, если каталог такой /usr/X11R6/lib, напишите:
(если ваша shell это bash).
Если до сих пор не работает, убедитесь что формат библиотеки это выполняемый файл (или ELF) командой file. Если он является символической ссылкой, проверьте что ссылка правильная и не указывает на несуществующий файл (например, так nm libglloq.so). Права файла тоже могут быть неверными (если вы используете аккаунт, отличный от root, и если библиотека защищена от чтения, например).
glloq.c(.text+0x34): undefined reference to `glloq_init'
Это проблема с символом, которая не была решена во время последнего шага компиляции. Обычно это проблема библиотеки. Может возникать по нескольким причинам:
первое, что необходимо выяснить, это предполагалось ли наличие символа в библиотеке. Например, если символ в начале это gtk, он принадлежит библиотеке gtk. Если имя библиотеки легко определимо, (frobnicate_foobar), вы можете вывести список символов библиотеки командой nm. Например,
Добавив параметр -o к nm, вы получите вывод имени библиотеки в каждой строке, что облегчит поиск. Давайте предположим, что мы ищем символ bulgroz_max, сырое решение поиска выглядит так:
Замечательно! Символ bulgroz_max определен в библиотеке frobnicate (большая буква T стоит перед ее именем). Теперь вам только нужно добавить строку -lfrobnicate в строку компиляции, отредактировав файл Makefile : добавьте ее в конец строки, где определены LDFLAGS или LFGLAGS (или, на худой конец, CC) , или в строку, соответствующую созданию конечного бинарного файла.
компиляция производится с версией библиотеки, которая не подходит для данного программного обеспечения. Читайте README или INSTALL чтобы узнать, какая версия должна использоваться.
не все объектные файлы поставки были корректно слинкованы. Файл, в котором определена функция, отсутствует. Напишите nm -o *.o чтобы узнать что это за файл и добавить соответствующий файл .o в строку компиляции, если его не хватает.
Segmentation fault (core dumped)
no space on /tmp
Компиляции необходимо временное рабочее пространство во время ее различных шагов; если ей не хватит места на диске, она упадет. Поэтому вы можете почистить свои разделы диска, но будьте осторожны с некоторыми программами, которые выполняются (X, сервер, каналы и т.д.), так как они могут упасть, если некоторые файлы будут удалены. Вы должны знать что делаете! Если раздел /tmp является частью раздела, который содержит не только его (например, root), поищите и, по возможности, удалите несколько core файлов.
make/configure в бесконечном рекурсивном цикле
Часто это проблема со временем в вашей системе. Действительно, make нужно знать дату в компьютере и дату файлов для проверки. Она сравнивает даты и использует результат для того, чтобы определить насколько цель отличается по времени создания от зависимостей.
Проблемы с датой могут заставить make бесконечно пересоздавать саму себя (или формировать снова и снова поддерево в бесконечном цикле рекурсии). В таком случае проблема решается обычно использованием команды touch (которая здесь используется для установки файлам по запросу текущего времени).
или так (грубо, но эффективно):
linux samba mail postfix FreeBSD Unix doc linux howto ALTLinux PHP faq bind sendmail apache iptables firewall kernel rpm apt-get Slackware openssh Cisco debian vmware GNU oracle sun awk /etc/ passwd linux установка учебник книга скачать
Пересборка ядра Linux дело очень интересное и почему-то часто отпугивает новичков. Но ничего сложного в этом нет, и скомпилировать ядро Linux бывает не сложнее, чем собрать (скомпилировать) любую другую программу из исходников. Пересборка ядра может понадобиться, когда вам требуются какие-нибудь функции, не включенные в текущее ядро, или же, наоборот, вы хотите что-то отключить. Все дальнейшие действия мы будем выполнять в Ubuntu Linux.
Когда нужно собирать новую версию ядра?
В настоящее время ядро Linux развивается очень быстро и бурно. Зачастую производители дистрибутивов не успевают внедрять в свои системы новые версии ядер. Как правило все новомодные «фишки» больше понадобятся любителям экзотики, энтузиастам, обладателям новинок устройств и оборудования и просто любопытствующим — т. е. преимущественно тем, в чьём распоряжении имеется обычный пользовательский компьютер.
Для серверных машин, однако, мода вряд ли имеет какое-то значение, а новые технологии внедряются только после того как на практике доказали свою надёжность и эффективность на тестовых стендах или даже платформах. Каждый опытный системный администратор знает, что гораздо надёжнее один раз настроить то, что может и должно хорошо и безотказно работать, чем пытаться бесконечно модернизировать систему. Ведь для этого необходимы многие часы работы (ведь приходится собирать ядро из исходных кодов, что довольно сложно) и обслуживания, что довольно дорогостоящее занятие, поскольку, вдобавок ко всему прочему требует глубокого резервирования — сервера не должны останавливаться без организации «горячего» (а уж тем более без «холодного») резерва.
Поэтому всегда стоит взвешивать все факторы и оценить, стоит ли вообще обновляться ради несущественных заплат, не влияющих на работу системы или внедрённых новых драйверов для устройств, коих в данный момент в системе нет и нескоро предвидится.
Запуск системы с новым ядром
Проверим работоспособность системы с новым ядром. Перезагрузите компьютер. В меню загрузчика GRUB вы должны будете увидеть новый пункт, соответствующей вашему новому ядру, которое должно загрузиться по умолчанию. Если все пройдет успешно, то система запустится с новым ядром.
Оригинал: GNU Make: Manage Your Software Builds
Автор: Mihalis Tsoukalos
Дата публикации: 14 декабря 2016 г.
Перевод: А.Панин
Дата перевода: 30 января 2017 г.
Компилируете программное обеспечение из исходного кода? Если это так, вам просто необходимо разобраться с Make-файлами.
Для чего это нужно?
- Вы сэкономите время, автоматизировав процесс сборки своих программных проектов с помощью Make.
- После создания корректного Make-файла для своего программного проекта, вы едва ли сможете допустить ошибки в процессе его сборки.
Make является мощной системой для автоматизации процесса сборки программного обеспечения, разработанной Стюартом Фельдманом из Bell Labs в апреле 1976 года. GNU Make является стандартной реализацией Make, используемой в Linux и Mac OS X с множеством улучшений, которая, в том числе, необходима для компиляции ядра Linux. Ее основной задачей является автоматическое выявление модифицированных файлов исходного кода сложных приложений и исполнение команд, направленных на их повторную компиляцию.
Для конфигурации make используются так называемые Make-файлы, которые позволяют сохранить группы команд для их последующего исполнения. Давайте рассмотрим содержимое Make-файла более подробно. Но перед этим вы должны принять к сведению тот факт, что GNU Make трактует отступы различных форматах по-разному, то есть, в представлении данного инструмента символ табуляции отличается от 4 или 8 последовательных символов пробела, следовательно, вам придется отнестись к форматированию рассматриваемых файлов с особым вниманием. Это особенно важно, так как каждая строка Make-файла с новой командой должна начинаться с символа табуляции.
Make-файлы могут управлять процессом компиляции программного обеспечения благодаря наличию зависимостей, целей и правил. Правила сообщают GNU Make о том, когда, почему и как нужно исполнять заданные последовательности команд для генерации результирующих файлов на основе файлов исходного кода. Целями являются файлы, которые должны генерироваться с участием GNU Make, причем их имена располагаются слева от символов двоеточий в описаниях правил. Чаще всего каждое из правил имеет по одной цели; однако, в рамках одного правила допускается использование сразу нескольких целей. Зависимости располагаются справа от символов двоеточий в описаниях правил и указывают на то, какие файлы или другие цели могут инициировать исполнение команд, описанных в рамках правила, по причине модификаций.
Впоследствии вы можете переместиться в данную директорию и просто выполнить в ней команду make .
Распаковываем исходный код ядра
Перейдем в директорию /usr/src и разархивируем ядро. Для этого выполните следующие команды:
Для удобства мы создали символьную ссылку с именем linux , которая указывает на директорию с исходниками.
Компиляция ядра
Самое сложное в компиляции ядра Linux – это создание конфигурации сборки, поскольку нужно знать, какие компоненты подключать. Хотя использование команд make xconfig, make gconfig, make menuconfig и обеспечивает задание стандартной рабочей конфигурации, с которой система будет работать на большинстве аппаратных платформ и конфигураций. Вопрос лишь в том, чтобы грамотно задать конфигурацию ядра без ненужных и занимающих лишние ресурсы компонентов при его работе.
Итак, для успешного конфигурирования и компиляции ядра нужно выполнить следующие действия:
Далее остаётся протестировать загрузку и работу нового ядра. В случае проблем обычно подбираются нужные параметры для системных загрузчиков.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Компиляция ядра
Пришло время скомпилировать ядро с теми изменениями, которые мы внесли на предыдущем шаге. Для начала выполним команду, которая удалит файлы (если они имеются), оставшиеся от предыдущей компиляции:
Наконец, чтобы запустить компиляцию ядра, выполним команду:
Ключ -append-to-version используется, чтобы добавить к имени файла образа ядра, который мы получим после компиляции, строку -mykernel , чтобы было проще идентифицировать свое ядро. Вместо -mykernel вы можете использовать любой префикс.
Компиляция ядра занимает довольно много времени и может длиться от нескольких десятков минут до нескольких часов, в зависимости от мощности вашего компьютера.
Сохранение Файлов Конфигурации Ядра для Повторного Использования
Настройки ядра хранятся в файле /usr/src/linux/.config. Очень рекомендуется делать резервную копию этого файла, например в каталоге /root, для того чтобы иметь возможность использовать в последствии, причем сохранять с разными именами.
Один из возможных вариантов именования файлов конфигурации - по версии ядра. Так, при изменении версии ядра как было показано в “Конфигурирование Ядра”, вы делаете следующее:
Если вы решитесь (для примера) обновить ядро до версии 2.4.12, вы можете использовать повторно этот файл, а различия в конфигурации этих двух ядер будет очень маленькими. Просто используйте резервную копию:
Но копирование этого файла обратно все же не подразумевает того, что ядро готово к компиляции. Вы снова должны вызвать команду make menuconfig (или другую команду, которую вы хотите использовать), для того чтобы были созданы (или изменены) некоторые файлы, необходимые для компиляции.
Однако, во время механической работы по повторному прохождению всех меню, вы можете не заметить какую-то новую интересную опцию. Чтобы избежать такой неприятности, мы советуем использовать make oldconfig. В этом имеются два преимущества:
если в файле конфигурации ядра появится новая опция, которой не было ранее, то при выборе этого способа процесс остановится на ней и будет ждать вашего выбора..
Правила
Программа make действует согласно системным зависимостям (dependencies), так для компиляции бинарного файла (“ цели (target) ”) требуется прохождение через несколько стадий (“зависимостей (dependencies)”). Например, для того чтобы создать (мнимый) бинарный файл glloq, сначала нужно откомпилировать объектные файлы main.o и init.o (это промежуточные файлы в процессе компиляции), а потом их нужно слинковать в готовый бинарный файл. Эти объектные файлы также являются целями, а зависимостями для них будут файлы исходных текстов.
Этот текст является только маленьким введением, инструкцией по выживанию в сложном мире make. Для того, чтобы узнать больше, мы советуем вам отправится на сайт APRIL , где размещена более подробная документация о make. [31] Для получения исчерпывающей информации обратитесь ко второму изданию O'Reilly Managing Projects with Make Andrew Oram и Steve Talbott .
Что же должно случиться?
Теперь вы готовы к исполнению команды make . В случае исполнения команды make program вы должны увидеть аналогичный вывод:
Приведенный в конце вывод утилиты ls позволяет убедиться в том, что все работает в точности так, как ожидалось и был получен желаемый результат.
В случае исполнения команды make clean , позволяющей удалить сгенерированные файлы, должен быть получен аналогичный вывод:
Реализация функции main() находится в файле исходного кода file1.cpp ; исходя из этого, последними компилируемыми файлами должны быть файлы file1.cpp и file1.h . Рассматриваемый проект является настолько простым, что каждый файл с расширением .cpp , за исключением файла file1.cpp , содержит реализацию лишь одного класса, описанного в рамках соответствующего файла с расширением .h , которая используется в рамках файла file1.cpp . Это обстоятельство обуславливает наличие зависимостей, которые описываются в рамках Make-файла.
Важная информация: утилита Make не исследует содержимое файлов проекта для принятия решения о том, стоит ли осуществлять их повторную компиляцию - она всего лишь проверяет метки времени модификации этих файлов.
Конфигурация ядра
Теперь перейдем к конфигурированию ядра. Чтобы не создавать конфигурацию с нуля, возьмем за основу конфигурацию ядра, которая в данный момент используется. Получить текущую конфигурацию можно выполнив команду make oldconfig . Выполните в терминале:
В результате выполнения команды make oldconfig создастся файл .config , содержащий параметры конфигурации ядра.
Получить справку по всем параметрам make для ядра Linux вы можете, выполнив команду make help .
Для изменения конфигурации ядра мы воспользуемся консольной утилитой menuconfig . Для ее запуска выполните:
Перед вами появится интерфейс, в котором вы можете включать или отключать определенные опции ядра:

Для примера я включу опцию «NTFS write support». Для этого, нажимая кнопку Вниз , найдите пункт «File systems» и нажмите Enter .

Вы окажетесь в меню настройки файловых систем. Найдите в этом списке пункт «DOS/FAT/NT Filesystems» и нажмите Enter .

Перейдите к пункту «NTFS write support» и нажмите Пробел , рядом с пунктом появится звездочка, означающая, что данная опция будет включена в ядро.

Читайте также: