
В каких файлах используется самый эффективный способ сжатия графической информации цветное фото
Для уменьшения объема дискового пространства файлы подвергаются компрессии (сжатию). Существует два основных принципа сжатия: сжатие без потерь, когда информация полностью восстанавливается, и сжатие с потерями, когда информация до и после сжатия отличается в определенной и регулируемой степени.
Кодирование с помощью деревьев секущих функций
Кодирование с помощью секущих функций – разработанный авторами алгоритм, позволяющий получать префиксные коды. В основе алгоритма лежит идея построения дерева, каждый узел которого содержит секущую функцию. Чтобы подробнее описать алгоритм, необходимо ввести несколько определений.
Слово – упорядоченная последовательность из m бит (число m называют разрядностью слова).
Литерал секущей – пара вида разряд-значение разряда. Например, литерал (4,1) означает, что 4 бит слова должен быть равен 1. Если условие литерала выполняется, то литерал считается истинным, в противном случае — ложным.
k-разрядной секущей называют множество из k литералов. Если все литералы истинны, то и сама секущая функция истинная, в противном случае она ложная.
Дерево строится так, чтобы каждый узел делил алфавит на максимально близкие части. На Рис. 3 показан пример дерева секущих:

Дерево секущих функций в общем случае не гарантирует оптимального кодирования, но зато обеспечивает крайне высокую скорость работы за счёт простоты операции в узлах.
Кодирование с помощью деревьев Шеннона-Фано
Алгоритм Шеннона-Фано — один из первых разработанных алгоритмов сжатия. В основе алгоритма лежит идея представления более частых символов с помощью более коротких кодов. При этом коды, полученные с помощью алгоритма Шеннона-Фано, обладают свойством префиксности: т.е. ни один код не является началом никакого другого кода. Свойство префиксности гарантирует, что кодирование будет взаимно-однозначным. Алгоритм построения кодов Шеннона-Фано представлен ниже:
1. Разбить алфавит на две части, суммарные вероятности символов в которых максимально близки друг к другу.
2. В префиксный код первой части символов добавить 0, в префиксный код второй части символов добавить 1.
3. Для каждой части (в которой не менее двух символов) рекурсивно выполнить шаги 1-3.
Несмотря на сравнительную простоту, алгоритм Шеннона-Фано не лишён недостатков, самым существенным из которых является неоптимальность кодирования. Хоть разбиение на каждом шаге и является оптимальным, алгоритм не гарантирует оптимального результата в целом. Рассмотрим, например, следующую строку: «ААААБВГДЕЖ». Соответствующее дерево Шеннона-Фано и коды, полученные на его основе, представлены на Рис. 1:

Словарное сжатие (алгоритмы LZ)
Группа словарных алгоритмов, в отличие от алгоритмов группы RLE, кодирует не количество повторов символов, а встречавшиеся ранее последовательности символов. Во время работы рассматриваемых алгоритмов динамически создаётся таблица со списком уже встречавшихся последовательностей и соответствующих им кодов. Эту таблицу часто называют словарём, а соответствующую группу алгоритмов называют словарными.
Например, только что инициализированный словарь для фразы «КУКУШКАКУКУШОНКУКУПИЛАКАПЮШОН» приведён в Табл. 3:


При описании алгоритма намеренно было опущено описание ситуации, когда словарь заполняется полностью. В зависимости от варианта алгоритма возможно различное поведение: полная или частичная очистка словаря, прекращение заполнение словаря или расширение словаря с соответствующим увеличением разрядности кода. Каждый из этих подходов имеет определённые недостатки. Например, прекращение пополнения словаря может привести к ситуации, когда в словаре хранятся последовательности, встречающиеся в начале сжимаемой строки, но не встречающиеся в дальнейшем. В то же время очистка словаря может привести к удалению частых последовательностей. Большинство используемых реализаций при заполнении словаря начинают отслеживать степень сжатия, и при её снижении ниже определённого уровня происходит перестройка словаря. Далее будет рассмотрена простейшая реализация, прекращающая пополнение словаря при его заполнении.
Для начала определим словарь как запись, хранящую не только встречавшиеся подстроки, но и количество хранящихся в словаре подстрок:
- type
- TDictionary = record
- WordCount : byte ;
- Words : array of string ;
- end ;
Встречавшиеся ранее подпоследовательности хранятся в массиве Words, а их кодом являются номера подпоследовательностей в этом массиве.
Также определим функции поиска в словаре и добавления в словарь:
- const
- MAX_DICT_LENGTH = 256 ;
- function FindInDict ( D : TDictionary ; str : ShortString ) : integer ;
- var
- r : integer ;
- i : integer ;
- fl : boolean ;
- begin
- r : = - 1 ;
- if D . WordCount > 0 then
- begin
- i : = D . WordCount ;
- fl : = false ;
- while ( not fl ) and ( i > = 0 ) do
- begin
- i : = i - 1 ;
- fl : = D . Words [ i ] = str ;
- end ;
- end ;
- if fl then
- r : = i ;
- FindInDict : = r ;
- end ;
- procedure AddToDict ( var D : TDictionary ; str : ShortString ) ;
- begin
- if D . WordCount < MAX_DICT_LENGTH then
- begin
- D . WordCount : = D . WordCount + 1 ;
- SetLength ( D . Words , D . WordCount ) ;
- D . Words [ D . WordCount - 1 ] : = str ;
- end ;
- end ;
Используя эти функции, процесс кодирования по описанному алгоритму можно реализовать следующим образом:
- function LZWEncode ( InMsg : ShortString ) : TEncodedString ;
- var
- OutMsg : TEncodedString ;
- tmpstr : ShortString ;
- D : TDictionary ;
- i , N : byte ;
- begin
- SetLength ( OutMsg , length ( InMsg ) ) ;
- N : = 0 ;
- InitDict ( D ) ;
- while length ( InMsg ) > 0 do
- begin
- tmpstr : = InMsg [ 1 ] ;
- while ( FindInDict ( D , tmpstr ) > = 0 ) and ( length ( InMsg ) > length ( tmpstr ) ) do
- tmpstr : = tmpstr + InMsg [ length ( tmpstr ) + 1 ] ;
- if FindInDict ( D , tmpstr ) < 0 then
- delete ( tmpstr , length ( tmpstr ) , 1 ) ;
- OutMsg [ N ] : = FindInDict ( D , tmpstr ) ;
- N : = N + 1 ;
- delete ( InMsg , 1 , length ( tmpstr ) ) ;
- if length ( InMsg ) > 0 then
- AddToDict ( D , tmpstr + InMsg [ 1 ] ) ;
- end ;
- SetLength ( OutMsg , N ) ;
- LZWEncode : = OutMsg ;
- end ;
Результатом кодирования будут номера слов в словаре.
Процесс декодирования сводится к прямой расшифровке кодов, при этом нет необходимости передавать созданный словарь, достаточно, чтобы при декодировании словарь был инициализирован так же, как и при кодировании. Тогда словарь будет полностью восстановлен непосредственно в процессе декодирования путём конкатенации предыдущей подпоследовательности и текущего символа.
Единственная проблема возможна в следующей ситуации: когда необходимо декодировать подпоследовательность, которой ещё нет в словаре. Легко убедиться, что это возможно только в случае, когда необходимо извлечь подстроку, которая должна быть добавлена на текущем шаге. А это значит, что подстрока удовлетворяет шаблону cSc, т.е. начинается и заканчивается одним и тем же символом. При этом cS – это подстрока, добавленная на предыдущем шаге. Рассмотренная ситуация – единственная, когда необходимо декодировать ещё не добавленную строку. Учитывая вышесказанное, можно предложить следующий вариант декодирования сжатой строки:
- function LZWDecode ( InMsg : TEncodedString ) : ShortString ;
- var
- D : TDictionary ;
- OutMsg , tmpstr : ShortString ;
- i : byte ;
- begin
- OutMsg : = '' ;
- tmpstr : = '' ;
- InitDict ( D ) ;
- for i : = 0 to length ( InMsg ) - 1 do
- begin
- if InMsg [ i ] > = D . WordCount then
- tmpstr : = D . Words [ InMsg [ i - 1 ] ] + D . Words [ InMsg [ i - 1 ] ] [ 1 ]
- else
- tmpstr : = D . Words [ InMsg [ i ] ] ;
- OutMsg : = OutMsg + tmpstr ;
- if i > 0 then
- AddToDict ( D , D . Words [ InMsg [ i - 1 ] ] + tmpstr [ 1 ] ) ;
- end ;
- LZWDecode : = OutMsg ;
- end ;
К плюсам словарных алгоритмов относится их большая по сравнению с RLE эффективность сжатия. Тем не менее надо понимать, что реальное использование этих алгоритмов сопряжено с некоторыми трудностями реализации.
Арифметическое кодирование

При декодировании необходимо выполнить аналогичную последовательность действий, только на каждом шаге необходимо дополнительно определять, какой именно символ был закодирован.
Очевидным плюсом арифметического кодирования является его эффективность, а основным (за исключением патентных ограничений) минусом – чрезвычайно высокая сложность процессов кодирования и декодирования.
Обращаем Ваше внимание, что в соответствии с Федеральным законом N 273-ФЗ «Об образовании в Российской Федерации» в организациях, осуществляющих образовательную деятельность, организовывается обучение и воспитание обучающихся с ОВЗ как совместно с другими обучающимися, так и в отдельных классах или группах.
Рабочие листы и материалы для учителей и воспитателей
Более 2 500 дидактических материалов для школьного и домашнего обучения
Столичный центр образовательных технологий г. Москва
Получите квалификацию учитель математики за 2 месяца
от 3 170 руб. 1900 руб.
Количество часов 300 ч. / 600 ч.
Успеть записаться со скидкой
Форма обучения дистанционная
- Онлайн
формат - Диплом
гособразца - Помощь в трудоустройстве
311 лекций для учителей,
воспитателей и психологов
Получите свидетельство
о просмотре прямо сейчас!

«Как закрыть гештальт: практики и упражнения»
Свидетельство и скидка на обучение каждому участнику
JPEG (Joint Photographic Experts Group)
Исследователями визуального восприятия человека отмечено, что далеко не вся информация требуется для того, чтобы адекватно воспринимать цветное изображение. Для реализации этого закона были разработаны алгоритмы с потерей информации, которые обеспечивают выбор уровня компрессии с уровнем качества изображения (рис. 1). Тем самым достигается компромисс между размером и качеством изображений.
Наиболее известным методом компрессии с потерями является JPEG-компрессия. Метод компрессии основан на особенности человеческого восприятия: глаз достаточно четко различает яркость объекта и цветовые контрасты, а плавные изменения в светах и тенях значительно меньше. При записи такой изобразительной информации часть цветовых данных может быть опущена, как предполагается, без заметного ущерба для восприятия.
Рис. 1. Компромисс между качеством и уровнем компрессии
Для этого обработка изображения происходит в несколько этапов. Сначала изображение конвертируется в особое цветовое пространство, напоминающее цветовую модель CIE Lab, в котором один канал сохраняет яркостные характеристики, а в остальных двух цветовых каналах уменьшается разрешение (по методу мозаики).
Замечание: RGB-изображение конвертируется в пространство YUV (иногда называемое также YcrCb), основанное на характеристиках яркости (составляющая Y) и цветности (составляющие U и V).
Затем изображение разбивается на фрагменты квадратной формы со стороной в 8 пикселей. Каждый фрагмент подвергается достаточно сложным математическим преобразованиям. Записывается два типа информации — усредненная информация о блоке и информация о его деталях, далее, в зависимости от выбранной степени сжатия, удаляется то или иное количество дополнительной информации. Чем меньше будет размер файла, тем хуже будет его качество.
Одновременно каждый блок разлагается на составляющие цвета и производится подсчет частоты встречаемости каждого цвета. Информация о частоте позволяет исключить небольшую часть яркостной характеристики и довольно значительную цветовой. Уровень исключения информации как раз и определяется установкой требуемого качества.
Затем информация о яркости и цвете кодируется таким образом, что остаются только различия между соседними блоками. Результатом всего процесса обработки являются последовательности простых чисел, которые в свою очередь легко сжимать каким-либо алгоритмом сжатия без потерь из уже упомянутых, например алгоритмом Хаффмана.
Алгоритмы сжатия с потерями, в частности алгоритм JPEG, не позволяют полностью восстановить изображение до его исходного состояния, а, следовательно, не рекомендуется сжимать изображения несколько раз.
Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит.
Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит.
Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов.
Словарные алгоритмы
Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности.
Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча.
Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом.
Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками.
Рассмотрим пример сжатия алгоритмом. Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.

В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит.
По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются.
Алгоритмы статистического кодирования
Алгоритмы этой серии ставят наиболее частым элементам последовательностей наиболее короткий сжатый код. Т.е. последовательности одинаковой длины кодируются сжатыми кодами различной длины. Причём, чем чаще встречается последовательность, тем короче, соответствующий ей сжатый код.
Алгоритм Хаффмана
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который равен частоте появления символа
- Выбираются два свободных узла дерева с наименьшими весами
- Создается их родитель с весом, равным их суммарному весу
- Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Арифметическое кодирование
Алгоритмы арифметического кодирования кодируют цепочки элементов в дробь. При этом учитывается распределение частот элементов. На данный момент алгоритмы арифметического кодирования защищены патентами, поэтому мы рассмотрим только основную идею.
Пусть наш алфавит состоит из N символов a1,…,aN, а частоты их появления p1,…,pN соответственно. Разобьем полуинтервал [0;1) на N непересекающихся полуинтервалов. Каждый полуинтервал соответствует элементам ai, при этом длина полуинтервала пропорциональна частоте pi.
Кодирующая дробь строится следующим образом: строится система вложенных интервалов так, чтобы каждый последующий полуинтервал занимал в предыдущем место, соответствующее положению элемента в исходном разбиении. После того, как все интервалы вложены друг в друга можно взять любое число из получившегося полуинтервала. Запись этого числа в двоичном коде и будет представлять собой сжатый код.
Декодирование – расшифровка дроби по известному распределению вероятностей. Очевидно, что для декодирования необходимо хранить таблицу частот.
Арифметическое кодирование чрезвычайно эффективно. Коды, получаемые с его помощью, приближаются к теоретическому пределу. Это позволяет утверждать, что по мере истечения сроков патентов, арифметическое кодирование будет становиться всё более и более популярным.
Алгоритмы сжатия с потерями
Не смотря на множество весьма эффективных алгоритмов сжатия без потерь, становится очевидно, что эти алгоритмы не обеспечивают (и не могут обеспечить) достаточной степени сжатия.
Сжатие с потерями (применительно к изображениям) основывается на особенностях человеческого зрения. Мы рассмотрим основные идеи, лежащие в основе алгоритма сжатия изображений JPEG.
Алгоритм сжатия JPEG
JPEG на данный момент один из самых распространенных способов сжатия изображений с потерями. Опишем основные шаги, лежащие в основе этого алгоритма. Будем считать, что на вход алгоритма сжатия поступает изображение с глубиной цвета 24 бита на пиксел (изображение представлено в цветовой модели RGB).
Перевод в цветовое пространство YCbCr
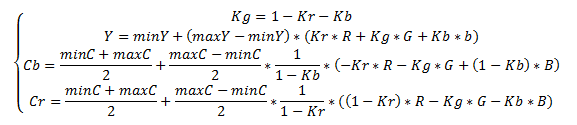
В цветовой модели YCbCr мы представляем изображение в виде яркостной компоненты (Y) и двух цветоразностных компонент (Cb,Cr). Человеческий глаз более восприимчив к яркости, а не к цвету, поэтому алгоритм JPEG вносит по возможности минимальные изменения в яркостную компоненту (Y), а в цветоразностные компоненты могут вноситься значительные изменения. Перевод осуществляется по следующей формуле:
Выбор Kr и Kb зависит от оборудования. Обычно берётся Kb=0.114;Kr=0.299. В последнее время также используется Kb=0.0722;Kr=0.2126, что лучше отражает характеристики современных устройств отображения.
Субдискретизация компонент цветности
- :4:4 – отсутствует субдискретизация;
- 4:2:2 – компоненты цветности меняются через одну по горизонтали;
- 4:2:0 – компоненты цветности меняются через одну строку по горизонтали, при этом по вертикали они меняются через строку.
Дискретное косинусное преобразование
Изображение разбивается на компоненты 8*8 пикселов, к каждой компоненте применятся ДКП. Это приводит к уплотнению энергии в коде. Преобразования применяются к компонентам независимо.
Квантование
Человек практически не способен замечать изменения в высокочастотных составляющих, поэтому коэффициенты, отвечающие за высокие частоты можно хранить с меньшей точностью. Для этого используется покомпонентное умножение (и округление) матриц, полученных в результате ДКП, на матрицу квантования. На данном этапе тоже можно регулировать степень сжатия (чем ближе к нулю компоненты матрицы квантования, тем меньше будет диапазон итоговой матрицы).
Зигзаг-обход матриц

Зигзаг-обход матрицы – это специальное направление обхода, представленное на рисунке:
При этом для большинства реальных изображений в начале будут идти ненулевые коэффициенты, а ближе к концу будут идти нули.
RLE- кодировние
Используется особый вид RLE-кодирования: выводятся пары чисел, причём первое число в паре кодирует количество нулей, а второе – значение после последовательности нулей. Т.е. код для последовательности 0 0 15 42 0 0 0 44 будет следующим (2;15)(0;42)(3;44).
Кодирование методом Хаффмана
Используется описанный выше алгоритм Хаффмана. При кодировании используется заранее определённая таблица.
Алгоритм декодирования заключается в обращении выполненных преобразований.
К достоинствам алгоритма можно отнести высокую степень сжатие (5 и более раз), относительно невысокая сложность (с учётом специальных процессорных инструкций), патентная чистота. Недостаток – артефакты, заметные для человеческого глаза.
5. Какие программы используют для уменьшения объема файлов?
B) программы резервного копирования файлов
6. Что такое архив?
A) набор данных определенной длины, имеющий имя, дату создания, дату изменения и последнего использования
B) инфицированный файл
C) системный файл
D) набор файлов, папок и других данных, сжатых и сохраненных в одном файле *
E) корневой каталог
7. Архивный файл представляет собой …
A) файл, которым долго не пользовались
B) файл, защищенный от копирования
C) файл, упакованный с помощью архиватора*
D) файл, защищенный от несанкционированного доступа
E) файл, который имеет большой размер
8. Сжатый (архивированный) файл отличается от исходного тем, что …
A) доступ к нему занимает меньше времени
B) он легче защищается от вирусов
C) он легче защищается от несанкционированного доступа
D) он занимает меньше места *
E) им нельзя пользоваться
9. Укажите программы-архиваторы.
A) WinZip, WinRar *
B) WordArt, Norton Commander
C) Word, PowerPoint
D) Excel, Internet Explorer
E) DrWeb, Aidstest, AVP
10. Программа WinRar предназначена…
A) для работы папками
B) для работы с файлами
C) для антивирусной обработки
D) для сжатия файлов*
E) для работы с базой данных
11. Программа WinZip предназначена…
A) для работы папками
B) для работы с файлами
C) для антивирусной обработки
D) для сжатия файлов*
E) для работы с базой данных
12. Чтобы архивировать файл или папку, надо …
A) щелкнуть на выбранном объекте правой кнопкой мыши, в контекстном меню выбрать команду Добавить в архив – выбрать нужные параметры – нажать ОК*
B) щелкнуть на выбранном объекте левой кнопкой мыши, в Главном меню выбрать команду Выполнить – заполнить нужные параметры - нажать ОК
C) выделить объект, в меню Файл выбрать команду Добавить в архив – выбрать нужные параметры – нажать ОК
D) выделить объект, в меню Сервис выбрать команду Добавить в архив – выбрать нужные параметры – нажать ОК
E) щелкнуть на выбранном объекте правой кнопкой мыши, в контекстном меню выбрать команду Создать ярлык
13. Какое из названных действий необходимо произвести со сжатым файлом перед началом работы?
B) сделать копию в текущем каталоге
D) запустить на выполнение
14. Чтобы распаковать архив, надо выполнить команду . . .
15. Расширение заархивированных файлов в операционной системе Windows:
16. С использованием архиватора Arj лучше всего сжимаются:
E) игровые программы.
17 . Что не является архиватором ?
18. Самый эффективный способ сжатия графической информации (цветное фото) используется в файлах . . .
19. В тех случаях, когда предполагается передача большого архива на носителях малой емкости, создают
A) Самораспаковывающиеся архивы
B) Структурный архив
C) Программный архив
D) Распределённый архив*
E) Файловый архив
20. Файловый архиватор позволяет
A) упаковать за один прием один-единственный файл – исполняемую программу ЕХЕ-типа
B) чисто программным способом увеличить почти вдвое доступное дисковое пространство
C) упаковывать один или несколько файлов в единый архивный файл*
D) распаковать файлы . GIF, . JPЕG – для графических данных
E) изменить содержания данных с потерей информации
21. Характерными форматами сжатия с потерей информации являются:
A) . JPЕG, . МPG, . МРЗ*
B) . ЕХЕ, . BMP, . DOC
C) . М PG, . МРЗ, . ЕХЕ, . BMP
D) . BMP, . DOC, . BAS, . МРЗ
E) . C R, . JPЕ G, . GIF, . DOC
22. Характерными форматами сжатия без потери информации являются:
A) . GIF, . TIF, . PCX, . AVI*
B) . ЕХЕ, . DOC, . МРЗ
C) . МPG, . МР3, . ЕХЕ, . BMP
D) . BMP, . DOC, . BAS, . МРЗ
E) . C R, . JPЕG, . GIF, . DOC
23. Весь спектр существующих сегодня архиваторов можно разделить на три группы, которые условно называются
A) файловыми, программными и дисковыми*
B) распределёнными, программными, самораспаковывающиеся
C) файловыми, дисковыми, распределёнными
D) самораспаковывающиеся, дисковыми, программными
E) структурными, программными, дисковыми
24. Программные архиваторы позволяют
A) упаковывать один или несколько файлов в единый архивный файл
B) чисто программным способом увеличить почти вдвое доступное дисковое пространство
C) распаковать файлы . GIF, . JPЕG – для графических данных
D) изменить содержания данных с потерей информации
E) упаковать за один прием один-единственный файл – исполняемую программу ЕХЕ-типа*
25. Дисковые архиваторы позволяют
A) упаковать за один прием один-единственный файл – исполняемую программу ЕХЕ-типа
B) упаковывать один или несколько файлов в единый архивный файл
C) чисто программным способом увеличить почти вдвое доступное дисковое пространство*
D) распаковать файлы . GIF, . JPЕG – для графических данных
E) изменить содержания данных с потерей информации
26 . Степень сжатия файла зависит:
A) только от типа файла;
B) только от программы-архиватора;
C) от типа файла и программы-архиватора*;
D) от производительности компьютера;
E) от объема оперативной памяти персонального компьютера, на котором производится архивация файла.
27. В процессе сжатия растровых графических файлов по алгоритму JPЕG его информационный объем обычно уменьшается в…
E) не изменяется
28. Процесс восстановления файлов из архивов точно в таком виде, какой они имели до помещения в архив:
29. Архив, к которому присоединена программа архивации:
30. Непрерывным архивом называют:
A) совокупность нескольких файлов в одном архиве;
B) архивный файл большого объема;
C) архивный файл, содержащий файлы с одинаковыми расширениями*;
D) файл, заархивированный в нескольких архивных файлах;
E) произвольный набор архивных файлов.
31. Метод Хафмана архивации текстовых файлов основан на том, что:
D) в обычном тексте частоты появления разных символов различны*;
32. Метод Лемпеля – Зива архивации текстовых файлов основан на том, что:
D) в обычном тексте частоты появления разных символов различны;
33. В основе методов архивации изображений без потери информации лежит:
A) идея учета того, что частоты появления разных байтов, кодирующих рисунок, различны;
Алгоритмы сжатия с потерями
Описание презентации по отдельным слайдам:
Форматы графических файлов. Векторные и растровые форматы. Методы сжатия графических данных.

Представление графических данных Формат графического файла — способ представления и расположения графических данных на внешнем носителе. В условиях отсутствия стандартов каждый разработчик изобретал новый формат для собственных приложений. Поэтому возникали большие проблемы обмена данными между различными программами (текстовыми процессорами, издательскими системами, пакетами иллюстративной графики, программами САПР и др.)- Но с начала 80-х гг. официальные группы по стандартам начали создавать общие форматы для различных приложений. Единого формата, пригодного для всех приложений, нет и быть не может, но всё же некоторые форматы стали стандартными для целого ряда предметных областей. Пользователю графической программы не требуется знать, как именно в том или ином формате хранится информация о графических данных. Однако умение разбираться в особенностях форматов имеет большое значение для эффективного хранения изображений и организации обмена данными между различными приложениями.

ТIFF (Tagged Image File Format). Формат предназначен для хранения растровых изображений высокого качества (расширение имени файла ТIF). Аппаратно независимый формат ТIFF на сегодняшний день является одним из самых распространенных и надежных, его поддерживают практически все программы на РС и Macintosh ТIFF является лучшим выбором при импорте растровой графики в векторные программы и издательские системы. Доступен весь диапазон цветовых моделей от монохромной до RGB, СМУК

PSD (Photoshop Document) Собственный формат программы Adobe Photoshop. Один из наиболее мощных по возможностям хранения растровой графической информации (до 48 bit, цветоделение, параметры слоев и каналов, маски, степень прозрачности). Основной недостаток - отсутствие эффективного алгоритма сжатия информации приводит к большому объему файлов. Начиная с версии 3.0, используется RLE-компрессия, в 4-й версии файлы становятся еще меньше. PSD понимают некоторые программы.

Windows Bitmap. ВМР (Windows Devise Independent Bitmap). Формат хранения растровых изображений в операционной системе Windows. Формат ВМР является «родным» форматом Windows, он поддерживается всеми графическими редакторами, работающими под его управлением. Способен хранить как индексированный (до 256 цветов), так и RGB-цвет (16млн.оттенков). Возможно применение сжатия по принципу RLE.

JPEG (Joint Photographic Experts Group). Формат предназначен для хранения растровых изображений (расширение имени файла jpg). JPEG называется не формат, а алгоритм сжатия, основанный не на поиске одинаковых элементов, как в RLEи LZW, а на разнице между пикселями. JPEG ищет плавные цветовые переходы. Вместо действительных значений JPEG хранит скорость изменения от пикселя к пикселю. Лишнюю, с его точки зрения, цветовую информацию он отбрасывает, усредняя некоторые значения. Можно задать уровень компрессии. Чем выше уровень компрессии, тем больше данных отбрасывается, тем ниже качество. Используя JPEG, можно получить файл в 10 - 500 раз меньше, чем ВМР. Формат аппаратно независим. JPEG лучше сжимаются растровые картинки фотографического качества, чем логотипы или схемы. В JPEG следует сохранять только конечный вариант работы, потому что каждое пересохранение приводит к всё новым потерям (отбрасыванию) данных.

GIF (Graphics Interchange Format). Растровый формат с 256 количеством цветов и достаточной степенью сжатия. Применяется только в электронных документах. Предназначен для передачи растровых изображений по сетям. Он использует LZW-компрессию, что позволяет хорошо сжимать файлы, в которых много однородных заливок (логотипы, надписи, схемы). В GIF'е можно назначить один или более цветов прозрачными, они станут невидимыми в интернетовских браузерах и некоторых других программах файл GIF может содержать не одну, а несколько растровых картинок, которые интернетовские браузеры могут подгружать одну за другой с указанной в файле частотой. Это называется GIF-анимация. Ограничение формата GIF состоит в том, что цветное изображение может быть записано только в режиме от 2 до 256 цветов. Для полиграфии этого явно недостаточно.

PNG (Portable Network Graphics). Новый Internet - формат, призванный заменить собой GIF. Поддерживаются три типа изображений - цветные с глубиной 8 или 24 бита, вплоть до 48 бит (RGB, для (cравнения, - 24) и черно-белое с градацией 256 оттенков серого. Сжатие информации происходит практически без потерь. Файлы PNG могут делать все основные графические редакторы.

ТGА (Targa) «Targa» - это имя графического адаптера фирмы Тruevision, который впервые использовал TGA-формат. Формат может хранить изображения с глубиной цвета до 32 бит. Наряду со стандартными тремя RGB - каналами, TGA-файл имеет дополнительный альфа-канал для представления информации о прозрачности изображения. Информация может быть сжата. Формат используется программными продуктами многих известных в мире компьютерной графики фирм.

WMF (Windows MetaFile). Формат хранения векторных изображений. Еще один «родной» формат Windows. Служит для передачи векторов через буфер обмена. Понимается практически всеми программами Windows, так или иначе связанными с векторной графикой. Пользоваться форматом стоит только в крайних случаях для передачи «голых» векторов, искажает (!) цвет, не может сохранять ряд параметров, которые могут быть присвоены объектам в различных векторных редакторах.

EPS (Encapsulated PostScript). Формат описания как векторных, так и растровых изображений. Экранное изображение недостаточно точно отображает реальное и требует специальных просмотрщиков.

PDF (Portable Document Format). Универсальный формат документа. Является аппаратно-независимым, т.е. вывод изображений допустим на любых устройствах - от экрана монитора до фотоэкспонирующего устройства. Достаточно высокая степень сжатия при высоком качестве.


Методы сжатия графических данных Метод сжатия RLE (Run Length Encoding) Последовательность повторяющихся величин (в нашем случае — набор бит для представления видеопикселя) заменяется парой — повторяющейся величиной и числом её повторений. Сжатие методом RLE наиболее эффективно для изображений, которые содержат большие области однотонной закраски, и наименее эффективно — для отсканированных фотографий, так как в них нет длинных последовательностей одинаковых видеопикселей.

Методы сжатия графических данных Метод сжатия LZW (назван по первым буквам его разработчиков Lempel, Ziv, Welch) Основан на поиске повторяющихся узоров в изображении. Сильно насыщенные узорами рисунки могут сжиматься до 0,1 их первоначального размера. Метод сжатия LZW применяется для файлов форматов ТIFF и GIF; при этом данные формата GIF сжимаются всегда, а в случае формата ТIFF право выбора возможности сжатия предоставляется пользователю. Из-за различных схем сжатия некоторые версии формата TIFF могут оказаться несовместимыми друг с другом. Это означает, что возможна ситуация, когда файл в формате TIFF не может быть прочитан в некоторой графической программе, хотя она должна «понимать» этот формат. Другими словами, не все форматы TIFF одинаковы. Но, несмотря на эту проблему, TIFF является одним из самых популярных растровых форматов в настоящее время.

Методы сжатия графических данных Метод сжатия JPEG. Обеспечивает высокий коэффициент сжатия для рисунков фотографического качества. Сжатие по методу JPEG сильно уменьшает размер файла с растровым рисунком (возможен коэффициент сжатия 100 : 1). Высокий коэффициент сжатия достигается за счёт потери исходной информации. Человеческий глаз очень чувствителен к изменению яркости, но изменения цвета он замечает хуже. Поэтому при сжатии этим методом запоминается больше информации о разнице между яркостями видеопикселей и меньше — о разнице между их цветами. Пользователю предоставляется возможность контролировать уровень потерь, указывая степень сжатия. Возможность задания коэффициента сжатия позволяет сделать выбор между качеством изображения и экономией памяти. Если сохраняемое изображение — фотография, предназначенная для высокохудожественного издания, то ни о каких потерях не может быть и речи, так как рисунок должен быть воспроизведён как можно точнее. Если же изображение — фотография, которая будет размещена на поздравительной открытке, то потеря части исходной информации не имеет большого значения.
Кодирование с помощью деревьев Хаффмана

Алгоритм LZW
Алгоритм, названный в честь своих создателей Лемпеля, Зива и Велча (Lempel, Ziv и Welch), не требует вычисления вероятностей встречаемости символов или кодов. Основная идея состоит в замене совокупности байтов в исходном файле ссылкой на предыдущее появление той же совокупности.
Процесс сжатия выглядит следующим образом. Последовательно считываются символы входного потока и происходит проверка, существует ли в созданной таблице строк такая строка. Если такая строка существует, считывается следующий символ, а если строка не существует, в поток заносится код для предыдущей найденной строки, строка заносится в таблицу, а поиск начинается снова.
Например, если сжимают байтовые данные (текст), то строк в таблице окажется 256 (от "0" до "255"). Для кода очистки и кода конца информации используются коды 256 и 257. Если используется 10-битный код, то под коды для строк остаются значения в диапазоне от 258 до 1023. Новые строки формируют таблицу последовательно, т. е. можно считать индекс строки ее кодом.
Пусть сжимается последовательность символов АВВСВВВ. Сначала в сжатый документ сохраняется код удаления [256], затем считывается символ "А" и проверяется, существует ли в таблице строка "А". Поскольку при инициализации в таблицу сохраняются все строки длиной в один символ, то строка "А", конечно, существует в таблице.
Далее считывается следующий символ "В" и проверяется, существует ли в таблице строка "АВ". Такая строка в таблице пока отсутствует, поэтому с первым свободным кодом [258] в таблицу вносится строка "АВ", а в документе сохраняется код [А]. Последовательность "АВ" в таблице отсутствует, поэтому в таблицу добавляется код [258] для сочетания "АВ", а в документе сохраняется код [А].
Далее рассматривается последовательность "ВВ", которая отсутствует в таблице, в таблицу заносится код [259] для символов "ВВ", а в документе сохраняется код [В].
Считывается символ "С" и проверяется наличие символов "ВС" в таблице, поскольку такая последовательность отсутствует, то в таблицу заносится кед [260] для последовательности "ВС", а в документ — код [В].
Снова добавляется из исходного файла символ "В" и теперь уже проверяется сочетание "СВ", которое тоже отсутствует. В таблицу записывается код [261] для "СВ", а в документ — код [С].
Затем считывается символ "В" и строка "ВВ", наконец, имеется в таблице, поэтому считывается следующий символ и рассматривается последовательность "ВВВ", которая, конечно, в таблице отсутствует. В таблицу заносится код [262] для "ВВВ", а в документ (внимание!) — код [259].
В результате в документе окажется следующая последовательность кодов [256][А][В][В][С][259], что короче исходной последовательности. К сожалению, последовательность слишком короткая, а алгоритм достатчно сложен, чтобы выгода оказалась реальной. При значительном объеме коэффициент сжатия может достигать несколько сот единиц.
Особенностью рассматриваемого алгоритма LZW является то, что для выполнения обратного процесса ("распаковки") нет необходимости сохранять таблицу в документе (алгоритм позволяет восстановить таблицу строк только из сохраненных в документе кодов).
Этот метод гораздо совершеннее RLE для областей с переходами цветов, однако кодировка в него требует больше системных ресурсов.
Метод LZW включается в некоторые графические форматы, например: TIFF ; GIF .
Алгоритмы сжатия без потерь
В качестве примеров таких алгоритмов сжатия без потерь можно рассмотреть следующие:
Ø кодирование длин серий;
Ø метод Хаффмана;
Кодирование длин серий (Run Length Encoding )
Как известно, все документы (графика, тексты, программы и т. п.) хранятся в компьютере в виде файлов — организованных записей. Изображения хранятся в файлах специальных графических форматов, которых сейчас насчитывается более десятка. Основой для разложения изображения на множество элементов является пиксель. Основа файла — это описание цветов всех пикселей. Описание цвета пикселя (три / четыре числа) является кодом цвета в соответствии с той или иной цветовой моделью. Указание на цветовую модель также включается в файл. Кроме того, записывается размер изображения в пикселях.
Итак, условная структура файла (аналог формата BMP), будет содержать: сведения о цветовой модели; габаритах изображения; и, например, об авторе картинки, включенные в специальный раздел файла, называемый заголовком . После заголовка в файле записываются друг за другом коды цветов (или параметров цветовой модели) отдельных пикселей, слева направо и сверху вниз.
Пиксельное изображение при сохранении фактически вытягивается в цепочку и логично предположить, что встречаются цепочки (последовательности) одинаковых байтов. Самым простым способом, который позволяет уменьшить объем файла, является поиск повторяющихся кодов (символов, цвета и т. п.) — серий одинаковых значений. Каждая такая серия фиксируется двумя числами: первое указывает количество одинаковых значений, а второе — само значение.
Заменим для простоты значения цвета буквами. Если в документе, скажем, имеется такая последовательность "АААААВВВВВВВСССССС", ее можно сжать таким образом: 5А7В6С. В результате вместо 18 символов в документе достаточно хранить всего 6.
Алгоритм рассчитан на деловую или декоративную графику — изображения с большими областями локального (повторяющегося) цвета.
Достоинством такого алгоритма является простота (что очень важно, т. к. позволяет выполнять процедуры компрессии и декомпрессии достаточно быстро), а недостатками — необходимость различать собственно данные и числа повторений, а также возможное увеличение объема файла, если в документе мало повторений (например, серия АВСАВС не уменьшит, а увеличит объем документа, поскольку будет иметь следующий вид: 1А1В1С1А1В1С, т. е. вместо 6 символов получится вдвое больше).
Если система выводит ошибку, возможно программа, считывающая файл ожидает появление данных в ином порядке, чем программа, сохраняющая этот файл на диске. Требуется преобразование в иной формат
Метод RLE включается в некоторые графические форматы, например:
Ø BMP (для 16 и 256 по желанию);
Ø TGA (по желанию);
Краткое описание документа:
Формат графического файла — способ представления и расположения графических данных на внешнем носителе. В условиях отсутствия стандартов каждый разработчик изобретал новый формат для собственных приложений. Поэтому возникали большие проблемы обмена данными между различными программами. Презентация по информатике "Форматы графических файлов" поможет учителю информатики наглядно представить ученикам разные форматы файлов и рассказать об особенностях каждого формата.
Кодирование длин серий
Кодирование длин серий (RLE — Run-Length Encoding) — это один из самых простых и распространённых алгоритмов сжатия данных. В этом алгоритме последовательность повторяющихся символов заменяется символом и количеством его повторов.
Например, строку «ААААА», требующую для хранения 5 байт (при условии, что на хранение одного символа отводится байт), можно заменить на «5А», состоящую из двух байт. Очевидно, что этот алгоритм тем эффективнее, чем длиннее серия повторов.
Основным недостатком этого алгоритма является его крайне низкая эффективность на последовательностях неповторяющихся символов. Например, если рассмотреть последовательность «АБАБАБ» (6 байт), то после применения алгоритма RLE она превратится в «1А1Б1А1Б1А1Б» (12 байт). Для решения проблемы неповторяющихся символов существуют различные методы.
Самым простым методом является следующая модификация: байт, кодирующий количество повторов, должен хранить информацию не только о количестве повторов, но и об их наличии. Если первый бит равен 1, то следующие 7 бит указывают количество повторов соответствующего символа, а если первый бит равен 0, то следующие 7 бит показывают количество символов, которые надо взять без повтора. Если закодировать «АБАБАБ» с использованием данной модификации, то получим «-6АБАБАБ» (7 байт). Очевидно, что предложенная методика позволяет значительно повысить эффективность RLE алгоритма на неповторяющихся последовательностях символов. Реализация предложенного подхода приведена в Листинг 1:
- type
- TRLEEncodedString = array of byte ;
- function RLEEncode ( InMsg : ShortString ) : TRLEEncodedString ;
- var
- MatchFl : boolean ;
- MatchCount : shortint ;
- EncodedString : TRLEEncodedString ;
- N , i : byte ;
- begin
- N : = 0 ;
- SetLength ( EncodedString , 2 * length ( InMsg ) ) ;
- while length ( InMsg ) > = 1 do
- begin
- MatchFl : = ( length ( InMsg ) > 1 ) and ( InMsg [ 1 ] = InMsg [ 2 ] ) ;
- MatchCount : = 1 ;
- while ( MatchCount < = 126 ) and ( MatchCount < length ( InMsg ) ) and ( ( InMsg [ MatchCount ] = InMsg [ MatchCount + 1 ] ) = MatchFl ) do
- MatchCount : = MatchCount + 1 ;
- if MatchFl then
- begin
- N : = N + 2 ;
- EncodedString [ N - 2 ] : = MatchCount + 128 ;
- EncodedString [ N - 1 ] : = ord ( InMsg [ 1 ] ) ;
- end
- else
- begin
- if MatchCount <> length ( InMsg ) then
- MatchCount : = MatchCount - 1 ;
- N : = N + 1 + MatchCount ;
- EncodedString [ N - 1 - MatchCount ] : = - MatchCount + 128 ;
- for i : = 1 to MatchCount do
- EncodedString [ N - 1 - MatchCount + i ] : = ord ( InMsg [ i ] ) ;
- end ;
- delete ( InMsg , 1 , MatchCount ) ;
- end ;
- SetLength ( EncodedString , N ) ;
- RLEEncode : = EncodedString ;
- end ;
- type
- TRLEEncodedString = array of byte ;
- function RLEDecode ( InMsg : TRLEEncodedString ) : ShortString ;
- var
- RepeatCount : shortint ;
- i , j : word ;
- OutMsg : ShortString ;
- begin
- OutMsg : = '' ;
- i : = 0 ;
- while i < length ( InMsg ) do
- begin
- RepeatCount : = InMsg [ i ] - 128 ;
- i : = i + 1 ;
- if RepeatCount < 0 then
- begin
- RepeatCount : = abs ( RepeatCount ) ;
- for j : = i to i + RepeatCount - 1 do
- OutMsg : = OutMsg + chr ( InMsg [ j ] ) ;
- i : = i + RepeatCount ;
- end
- else
- begin
- for j : = 1 to RepeatCount do
- OutMsg : = OutMsg + chr ( InMsg [ i ] ) ;
- i : = i + 1 ;
- end ;
- end ;
- RLEDecode : = OutMsg ;
- end ;
Вторым методом повышения эффективности алгоритма RLE является использование алгоритмов преобразования информации, которые непосредственно не сжимают данные, но приводят их к виду, более удобному для сжатия. В качестве примера такого алгоритма мы рассмотрим BWT-перестановку, названную по фамилиям изобретателей Burrows-Wheeler transform. Эта перестановка не изменяет сами символы, а изменяет только их порядок в строке, при этом повторяющиеся подстроки после применения перестановки собираются в плотные группы, которые гораздо лучше сжимаются с помощью алгоритма RLE. Прямое BWT преобразование сводится к последовательности следующих шагов:
1. Добавление к исходной строке специального символа конца строки, который нигде более не встречается;
2. Получение всех циклических перестановок исходной строки;
3. Сортировка полученных строк в лексикографическом порядке;
4. Возвращение последнего столбца полученной матрицы.
Реализация данного алгоритма приведена в Листинг 3.
- const
- EOMsg = '|' ;
- function BWTEncode ( InMsg : ShortString ) : ShortString ;
- var
- OutMsg : ShortString ;
- ShiftTable : array of ShortString ;
- LastChar : ANSIChar ;
- N , i : word ;
- begin
- InMsg : = InMsg + EOMsg ;
- N : = length ( InMsg ) ;
- SetLength ( ShiftTable , N + 1 ) ;
- ShiftTable [ 1 ] : = InMsg ;
- for i : = 2 to N do
- begin
- LastChar : = InMsg [ N ] ;
- InMsg : = LastChar + copy ( InMsg , 1 , N - 1 ) ;
- ShiftTable [ i ] : = InMsg ;
- end ;
- Sort ( ShiftTable ) ;
- OutMsg : = '' ;
- for i : = 1 to N do
- OutMsg : = OutMsg + ShiftTable [ i ] [ N ] ;
- BWTEncode : = OutMsg ;
- end ;
Проще всего пояснить это преобразование на конкретном примере. Возьмём строку «АНАНАС» и договоримся, что символом конца строки будет символ «|». Все циклические перестановки этой строки и результат их лексикографической сортировки приведены в Табл. 1.

Реализация обратного преобразования на первый взгляд не представляет сложности, и один из вариантов реализации приведён в Листинг 4.
- const
- EOMsg = '|' ;
- function BWTDecode ( InMsg : ShortString ) : ShortString ;
- var
- OutMsg : ShortString ;
- ShiftTable : array of ShortString ;
- N , i , j : word ;
- begin
- OutMsg : = '' ;
- N : = length ( InMsg ) ;
- SetLength ( ShiftTable , N + 1 ) ;
- for i : = 0 to N do
- ShiftTable [ i ] : = '' ;
- for i : = 1 to N do
- begin
- for j : = 1 to N do
- ShiftTable [ j ] : = InMsg [ j ] + ShiftTable [ j ] ;
- Sort ( ShiftTable ) ;
- end ;
- for i : = 1 to N do
- if ShiftTable [ i ] [ N ] = EOMsg then
- OutMsg : = ShiftTable [ i ] ;
- delete ( OutMsg , N , 1 ) ;
- BWTDecode : = OutMsg ;
- end ;
Но на практике эффективность зависит от выбранного алгоритма сортировки. Тривиальные алгоритмы с квадратичной сложностью, очевидно, крайне негативно скажутся на быстродействии, поэтому рекомендуется использовать эффективные алгоритмы.

После сортировки таблицы, полученной на седьмом шаге, необходимо выбрать из таблицы строку, заканчивающуюся символом «|». Легко заметить, что это строка единственная. Т.о. мы на конкретном примере рассмотрели преобразование BWT.
Подводя итог, можно сказать, что основным плюсом группы алгоритмов RLE является простота и скорость работы (в том числе и скорость декодирования), а главным минусом является неэффективность на неповторяющихся наборах символов. Использование специальных перестановок повышает эффективность алгоритма, но также сильно увеличивает время работы (особенно декодирования).
Алгоритм Хаффмана
Алгоритм Хаффмана основан на определенном анализе документа и вычислении частоты встречаемости цветовых значений (или значений других видов информации), а затем этим значениям в соответствии с рангом присваиваются коды сначала с минимальным количеством битов, а затем по мере снижения частоты (уменьшения ранга) используется все большее количество двоичных разрядов. Такой способ кодирования иногда называют алфавитным кодированием.
Заменим также для простоты значения цвета буквами. Например, в следующей последовательности букв ААСАААВАВАВВАВСАСВСАСААССС заметно, что чаще всего встречается символ А (12 раз), затем символ С (9 раз) и, наконец, символ В (5 раз). Следовательно, символ А можно заменять кодом 0, символ С — кодом 1, а символ В — кодом 00. И так далее, если элементов для кодирования больше. В результате, если считать, что каждый символ в нашем примере кодируется 1 битом, то для передачи строки потребуется 208 битов, а в сжатом виде объем информации составит только 31 бит.
Читайте также: