
Установка zfs на raid
ZFS is a combined file system and logical volume manager designed by Sun Microsystems. Starting with Proxmox VE 3.4, the native Linux kernel port of the ZFS file system is introduced as optional file system and also as an additional selection for the root file system. There is no need for manually compile ZFS modules - all packages are included.
By using ZFS, its possible to achieve maximum enterprise features with low budget hardware, but also high performance systems by leveraging SSD caching or even SSD only setups. ZFS can replace cost intense hardware raid cards by moderate CPU and memory load combined with easy management.
Easy configuration and management with Proxmox VE GUI and CLI.
Protection against data corruption
Data compression on file system level
Various raid levels: RAID0, RAID1, RAID10, RAIDZ-1, RAIDZ-2 and RAIDZ-3
Can use SSD for cache
Continuous integrity checking
Designed for high storage capacities
Asynchronous replication over network
ZFS RAID Level Considerations
There are a few factors to take into consideration when choosing the layout of a ZFS pool. The basic building block of a ZFS pool is the virtual device, or vdev . All vdevs in a pool are used equally and the data is striped among them (RAID0). Check the zpool(8) manpage for more details on vdevs.
Проверяем состояние пула
Проверить состояние всех пулов можно так:
Вот так выглядит zpool status когда умер один диск:
Как заменить диск в zfs пуле
Если случилась беда и умер один диск в пуле с резервированием, то его можно легко заменить. Процедура аналогична замене диска в RAID-массиве.
Вот пример из жизни когда в zfs-RAID10 массиве сломался один диск:
Здесь видим, что sdf приказал долго жить и требует замены. В данном случае - это железный сервер и пул построен на целых дисках. Находим нужный диск в железном сервере, и “на горячую” меняем старый диск на новый, такого же размера. В dmesg можно увидеть как определяется новый диск. В моем примере, я вынул /dev/sdf из сервера, вставил новый диск, и он определился в системе с таким же именем.
Теперь меняем диск в пуле. Мы говорим заменить диск, который именовался в пуле как sdf на диск, который в системе именуется /dev/sdf (так же как и старый):

В данной статье публикуются результаты замеров скорости доступа к файловой системе внутри гипервизора в различных вариантах установки ZFS. Всем кому интересно прошу под кат, предупреждаю о наличии большого количества изображений под спойлерами (оптимизированы).
Всем привет! В сети довольно много материалов, посвященных файловой системе (далее ФС) ZFS, ее развитию в Linux'е и практическому применению. Меня данная ФС очень заинтересовала в контексте совершенствования моего домашнего сервера виртуализации ( а также благодаря посту пользователя kvaps), однако я не смог найти в интернете (может быть плохо искал?) сравнительных тестов производительности виртуализированных машин. Поэтому решил собрать тестовую платформу для проведения своего сравнительного исследования.
Моя статья не претендует на какие-либо научные открытия, вряд ли поможет профессионалам, которые давно работают с ZFS, и знают все ее возможности, однако поможет новичкам приблизительно оценить «цену» каждого гигабайта поделенного на производительность.

Суть эксперимента заключалась в следующем: на машину устанавливалась (каждый раз с загрузочного диска) ОС Proxmox VE 5.2. Во время установки выбирался Один из вариантов XFS/ZFS. После этого создавалась виртуальная машина, на которую производилась установка Windows Server 2008 R2, после чего запускалась популярная утилита CrystalDiskMark 5.2.2 и проводились тесты на объемах 1, 4, 32 GiB (в связи с потерей изображений с результатами 32 GiB тестов нельзя воспользоваться при выборе решения, имеющиеся данные приводятся для массовки).
Тест на ФС XFS использовался для измерения эталонной скорости работы одного ЖД (возможно это и неправильно, но других вариантов ее оценить я не придумал).
Тесты ZFS RAID 0, RAID 1 проводились на двух случайно выбранных дисках, ZFS RaidZ1 на 3 дисках, ZFS RAID 10, RaidZ2 на 4 дисках. Тесты с ZFS RaidZ3 не проводились по причине отсутствия желания купить еще один крайне экономически нецелесообразный HDD на 500GB.
Под спойлером кратко приведу описания каждого из видов ZFS RAID с моим примером получаемого объема «коммерческих» гигабайтов:
- ZFS RAID 0 — чередование (Striped), объем 2 * DiskSize = 1000ГБ.
- ZFS RAID 1 — зеркалирование (Mirror), объем 1 * DiskSize = 500ГБ.
- ZFS RaidZ1 — он же ZFS RaidZ, аналог RAID5, объем (N — 1) * DiskSize = 1000ГБ.
- ZFS RAID 10 — зеркалирование с чередованием (Striped Mirrored), объем 2 * DiskSize = 1000ГБ.
- ZFS RaidZ2 — аналог RAID6, объем (N — 2) * DiskSize = 1000ГБ.
- при этом, я такой тест не проводил, но ZFS RaidZ1 при 4 дисках = 1500ГБ.
Хочется отметить, что помимо различной скорости доступа файловой системы, еще нужно учитывать общий объем получаемого массива, и надежность сохранности данных, в случаях выхода из строя жестких дисков.
Технические характеристики платформы, (возможно) влияющие на результаты тестирования:
- Материнская плата: Intel Desktop Board DS67SQ-B3;
- Процессор: Intel Pentium G630 2.7GHz;
- Оперативная память: 2 x 4096Mb Hynix PC3-10700;
- Жесткие диски: 3 x WD 5000AZRX 500GB SATA 64MB Cache, 1 x WD 5000AZRZ 500GB SATA 64MB Cache, SSD SATA Goldenfir T650-8GB;
- Блок питания: DeepCool DA500N 500W.

Для систем, установленных на ZFS выполнялось 2 теста, во втором в качестве кэш-диска подключался SSD.
Все результаты представлены в виде скриншотов ниже. Если у кого-нибудь возникнет желание оцифровать данные результаты — буду благодарен и включу результаты работы в статью.



























Спасибо всем кто уделил внимание, надеюсь для кого-то данная выборка окажется, как и для меня, полезной.
P.S. по непонятным мне причинам часть изображений куда-то пропали, замеры проводились в конце весны, тестовую платформу уже не собрать в том виде, к счастью все они приходятся на тесты с 32 GiB.
Ребята, подскажите мануал, как ставить ZFS и программный RAID1.
Машина такая:
Материнка: ASUS P8Z77-V LX2
Процессор: Intel Core i7-377 3.4GHz
8 ядер.
16 Гб оперативки.
2 SATA-диска по 1 терабайту.
AMD64 соответственно.
Можно настроить RAID и в биосе, но я слышал, что такие рэйды фейковые, и предпочтительно настраивать программный рэйд в FreeBSD.
Что сначала, что потом: RAID или ZFS?
Ребята, подскажите мануал, как ставить ZFS и программный RAID1.
Машина такая:
Материнка: ASUS P8Z77-V LX2
Процессор: Intel Core i7-377 3.4GHz
8 ядер.
16 Гб оперативки.
2 SATA-диска по 1 терабайту.
AMD64 соответственно.
Можно настроить RAID и в биосе, но я слышал, что такие рэйды фейковые, и предпочтительно настраивать программный рэйд в FreeBSD.
Что сначала, что потом: RAID или ZFS?
давайте так, мухи - RAID, отдельно, котлеты - ZFS, тоже.
RAID - не имеет отношения к FS (filesystems)
ZFS - файловая система, это если рассматривать ее верхний уровень.
RAID'ы бывают: программные (soft-raid), аппаратные - hw-raid.
Рейды в hardware исполнении можно разделить: ATA/PATA и SAS/SCSI
Fake-RAID - это дешевые рейды, с уровнем не более чем 0,1,0+1
Что есть Fake-RAID: это полу-программный или полу-хардверный рейд, первый вариант
более правильный по названию.
В чем смысл, в том что для Fake-RAID, можно создавать RAID0,1,0+1 через BIOS
контроллера, только создавать - это означает что в специальной области диска
создаются метаданные описывающие RAID, а все остальное делает драйвер.
Вывод - fake-raid это полупрограммный, более правильно программный рейд.
Во FreeBSD поддерживаются Fake-RAID'ы только на ATA/PATA контроллерах, и то
не все:
- посредством ataraid и утилиты atacontrol (устаревшая конструкция)
- посредством graid (на базе GEOM, взамен ataraid)
отдельно для программных рейдов на базе GEOM, существуют реализации:
- gconcat (а-ля JBOD)
- gstripe (а-ля RAID0)
- gmirror (RAID1)
- graid3
Еще несколько слов о FAKE-RAID'ах, ataraid/graid поддерживают НЕ все известные
в "природе" рейды, мало того, часть fake-raid'ов поддерживается только на READ
- без возможности управления из OS, часть на READ-WRITE - с возможностью
управления из OS.
Для того чтобы программный рейд (в случае FAKE: 0/1) управлялся из OS, его
следует создавать в OS, и ни в коем случае не из BIOS контроллера FAKE-RAID'а.
Во FreeBSD НЕ ПОДДЕРЖИВАЮТСЯ SCSI Fake-RAID'ы
Есть и другие, но уже устаревшие средства создания программных рейдов.
Для поддержки HARDWARE RAID ничего не нужно, за исключением утилит управления,
таких во FreeBSD не много, а значит, реорганизовать HW-RAID на ходу без таких
утилит невозможно! Только из BIOS HW-RAID'а, что означает ПРОСТОЙ сервера,
точнее OSю
ZFS - как было сказано, это мощная файловая система, которую СТРОГО не советуют
использовать поверх каких бы то ни было RAID'ов, в силу конструктива.
Одна из первых рекомендаций - использование HBA контроллеров для direct access HDD.
В ZFS имеются могучие встроенные средства реализации разных уровней RAID, кеширования
и журналирования, ведение снапшотов и тд и тп.
Другая важна рекомендация - чем больше RAM, тем быстрей и оптимальней работает ZFS,
вот почему в ZFS есть несколько уровней кеширования и для отдельных из них
советуют использовать SSD (это еще одна отдельная тема: какие и почему), аналогично
и для журнала - тоже советуют использовать SSD (еще одна тема).
При создании различных RAID'ов поддерживаемых ZFS - необходимо изучить, какие
есть ограничения и рекомендации по кол-ву используемых дисков, группировке их
и какие есть ограничения, не смешивать разные виды рейдов в одном пуле и тд и тп.
Как минимум, ZFS это и создание/управление пулом ("томами") + файловая система с массой
встроенных современных достижений: кеширование, журналирование, снимки.
Ключевые слова: ARC,L2ARC,кеширование, уровни, HBA контроллеры, дедупликация и
zpool, mirror, raidz, raidz2 и тд и тп.
Руководство по ZFS на русском или английском на Oracle и другие полезные
FAQ и Recomendation в сети.
К сожалению, книг по ZFS нет и даже нет книг с хорошими главами по ZFS.
Старайтесь структуризировать знания и опыт по мере работы, иначе это будут просто
сваленные в кучу кирпичи, в отличие от тех из которых выстраивается здание:
свалили - построили, свалили - построили и тд и тп.
Create a new zpool
To create a new pool, at least one disk is needed. The ashift should have the same sector-size (2 power of ashift ) or larger as the underlying disk.
Подвернулась мне задача — запустить Proxmox и несколько виртуалок на сервере всего с 2 дисками. При этом требовалось обеспечить ну хоть какую-то надежность и простоту исправления проблем связанных с выходом из строя одного из дисков. Далее в заметке подробное описание тестирования решения на стенде.
Вводная
Я считаю что читатель данной заметки может самостоятельно установить Proxmox на ноду и не буду рассматривать установку и настройку самого гипервизора. Рассмотрим только настройки касающиеся ZFS RAID1 и тестирование ситуации сбоя одного из дисков.
Железо на котором предстояло развернуть проект представляло из себя ноду Supermicro, видимо в исполнении 2 node in 1U с псевдо-рейдом интегрированном в чипсет от Intel который не поддерживается в Proxmox. В связи с этим попробуем испытать решение предлагаемое «из коробки» в версии 4.0. Хоть убейте — я не помню был-ли такой вариант установки в Proxmox 3.6, может и был, но не отложилось в памяти из-за невостребованности такой конфигурации. В тестовой стойке у нас отыскался аналогичный сервер и я принялся за проверку решения, предоставляемого ребятами из Proxmox Server Solutions.
Установка
Как и предупреждал — не буду показывать установку полностью, заострю внимание только на важных моментах.
Выбираем zfs RAID1:
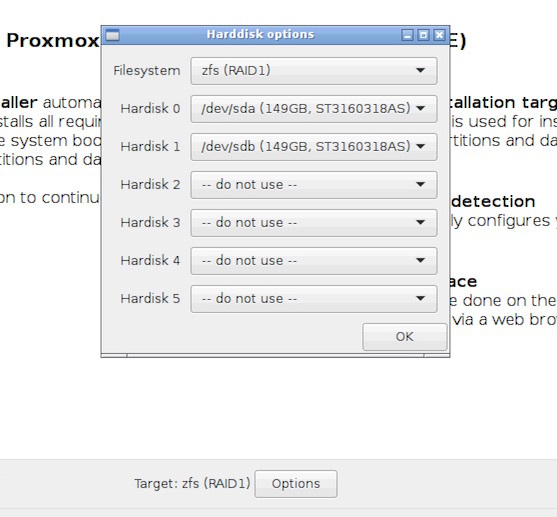
Сервер тестовый и нет подписки на коммерческий репозиторий. В /etc/apt/sources.list подключаем бесплатный:
В /etc/apt/sources.list.d/pve-enterprise.list закомментируем коммерческий.
Ну и вдруг забудете:
Смотрим что нам нарезал инсталлятор на дисках (привожу только часть вывода):
Глянем на наш массив:
По умолчанию инсталлятор Proxmox установил загрузчик на оба раздела — отлично!
Тестирование
Имитируем отказ жесткого диска следующим образом:
— выключаем сервер;
— выдергиваем одну из корзин;
— включаем сервер.
Сервер прекрасно грузится на любом из оставшихся дисков, массив работает в режиме DEGRADED и любезно подсказывает какой диск нам надо сменить и как это сделать:
Если вернуть извлеченный диск на место — он прекрасно «встает» обратно в зеркало:
Инсценируем замену диска на новый. Я просто взял другую корзину с таким-же диском из старого сервера. Ставим корзину на горячую для большей правдоподобности:
Условно неисправный диск у нас /dev/sdb и учитывая одинаковую емкость и геометрию копируем таблицу разделов 1:1 с исправного диска /dev/sda
Генерируем уникальные UUID для /dev/sdb
Ставим загрузчик на замененный диск и обновляем GRUB:
Осталось только заменить сбойный диск в массиве на свежеустановленный, но тут всплывает одна проблема, порожденная методом адресации дисков в массиве примененной в инсталляторе. А именно — диски включены в массив по физическому адресу и команда zpool replace rpool /dev/sdb2 покажет нам вот такую фигу:
Что совершенно логично, нельзя сменить сбойный диск на /dev/sdb2 так как сбойный диск и есть /dev/sdb2, а зачем нам повторять недоработку инсталлятора? Привяжем диск по UUID, я вообще уже забыл то время когда диски прибивались гвоздями вида /dev/sdХХ — UUID наше все:
Нас предупредили о необходимости дождаться окончания синхронизации прежде чем перезагружаться. Проверим статус массива:
Для общего порядку включим и sda2 в массив используя UUID:
Пока я копипастил предыдущие 2 команды из консоли в редактор массив уже синхронизировался:
Вывод
Когда нет аппаратного Raid-контроллера вполне удобно применить размещение корневого раздела на доступном в Proxmox 4.0 «из коробки» zfs RAID1. Конечно-же всегда остается вариант переноса /boot и корня на зеркала созданные средствами mdadm, что тоже неоднократно было использовано мной и до сих пор работает не нескольких серверах, но рассмотренный вариант проще и предлагается разработчиками продукта «из коробки».
Дополнение
Было несколько вопросов, пока руки дошли только до проверки работоспособности autoexpand. Тестовые диски на 160Gb были заменены на 500Gb.
После замены первого диска:
После замены второго:
Все манипуляции происходят онлайн, без перезагрузки сервера и остановки виртуальных машин.
Сделал инструкцию по классической установке Proxmox на soft raid1, таких инструкций много, но в 4-й версии есть свои мелкие детали. Кому интересно — читаем

ZFS - это файловая система на стероидах. С помощью ZFS можно собрать подобие RAID-массивов, но с дополнительными функциями, которые могут быть полезны в хозяйстве. Здесь покажу как установить zfs и собрать аналог RAID-10 массива на примере Ubuntu 18.04
ZFS Administration
This section gives you some usage examples for common tasks. ZFS itself is really powerful and provides many options. The main commands to manage ZFS are zfs and zpool . Both commands come with great manual pages, which can be read with:
Аналог RAID1 и RAID10
Выше мы создавали пул, аналогичный RAID0(stripe), без какого-либо резервирования данных. Если умрет хотя бы один диск из пула, то развалится весь пул. Чтобы повысить отказоустойчивость - создадим зеркалированный пул.
Вот так можно создать RAID1(mirror) с помощью zfs:
Создание RAID10 из шести (sdb, sdc, sdd, sde, sdf, sdg) дисков выглядит так:
Installation as Root File System
When you install using the Proxmox VE installer, you can choose ZFS for the root file system. You need to select the RAID type at installation time:
Also called “striping”. The capacity of such volume is the sum of the capacities of all disks. But RAID0 does not add any redundancy, so the failure of a single drive makes the volume unusable.
Also called “mirroring”. Data is written identically to all disks. This mode requires at least 2 disks with the same size. The resulting capacity is that of a single disk.
A combination of RAID0 and RAID1. Requires at least 4 disks.
A variation on RAID-5, single parity. Requires at least 3 disks.
A variation on RAID-5, double parity. Requires at least 4 disks.
A variation on RAID-5, triple parity. Requires at least 5 disks.
The installer automatically partitions the disks, creates a ZFS pool called rpool , and installs the root file system on the ZFS subvolume rpool/ROOT/pve-1 .
Another subvolume called rpool/data is created to store VM images. In order to use that with the Proxmox VE tools, the installer creates the following configuration entry in /etc/pve/storage.cfg :
After installation, you can view your ZFS pool status using the zpool command:
The zfs command is used configure and manage your ZFS file systems. The following command lists all file systems after installation:
Hardware
ZFS depends heavily on memory, so you need at least 8GB to start. In practice, use as much as you can get for your hardware/budget. To prevent data corruption, we recommend the use of high quality ECC RAM.
If you use a dedicated cache and/or log disk, you should use an enterprise class SSD (e.g. Intel SSD DC S3700 Series). This can increase the overall performance significantly.
| Do not use ZFS on top of a hardware RAID controller which has its own cache management. ZFS needs to communicate directly with the disks. An HBA adapter or something like an LSI controller flashed in “IT” mode is more appropriate. |
If you are experimenting with an installation of Proxmox VE inside a VM (Nested Virtualization), don’t use virtio for disks of that VM, as they are not supported by ZFS. Use IDE or SCSI instead (also works with the virtio SCSI controller type).
Size, Space usage and Redundancy
While a pool made of mirror vdevs will have the best performance characteristics, the usable space will be 50% of the disks available. Less if a mirror vdev consists of more than 2 disks, for example in a 3-way mirror. At least one healthy disk per mirror is needed for the pool to stay functional.
The usable space of a RAIDZ type vdev of N disks is roughly N-P, with P being the RAIDZ-level. The RAIDZ-level indicates how many arbitrary disks can fail without losing data. A special case is a 4 disk pool with RAIDZ2. In this situation it is usually better to use 2 mirror vdevs for the better performance as the usable space will be the same.
Another important factor when using any RAIDZ level is how ZVOL datasets, which are used for VM disks, behave. For each data block the pool needs parity data which is at least the size of the minimum block size defined by the ashift value of the pool. With an ashift of 12 the block size of the pool is 4k. The default block size for a ZVOL is 8k. Therefore, in a RAIDZ2 each 8k block written will cause two additional 4k parity blocks to be written, 8k + 4k + 4k = 16k. This is of course a simplified approach and the real situation will be slightly different with metadata, compression and such not being accounted for in this example.
This behavior can be observed when checking the following properties of the ZVOL:
refreservation (if the pool is not thin provisioned)
used (if the pool is thin provisioned and without snapshots present)
volsize is the size of the disk as it is presented to the VM, while refreservation shows the reserved space on the pool which includes the expected space needed for the parity data. If the pool is thin provisioned, the refreservation will be set to 0. Another way to observe the behavior is to compare the used disk space within the VM and the used property. Be aware that snapshots will skew the value.
There are a few options to counter the increased use of space:
Increase the volblocksize to improve the data to parity ratio
Use mirror vdevs instead of RAIDZ
Use ashift=9 (block size of 512 bytes)
The volblocksize property can only be set when creating a ZVOL. The default value can be changed in the storage configuration. When doing this, the guest needs to be tuned accordingly and depending on the use case, the problem of write amplification if just moved from the ZFS layer up to the guest.
Using ashift=9 when creating the pool can lead to bad performance, depending on the disks underneath, and cannot be changed later on.
Mirror vdevs (RAID1, RAID10) have favorable behavior for VM workloads. Use them, unless your environment has specific needs and characteristics where RAIDZ performance characteristics are acceptable.
Установка zfs
Изначально ZFS была доступна только в Solaris, но с помощью модулей ядра можно установить и в Linux.
На последних версиях Ubuntu установка абсолютно элементарная:
Автоматически устанавливаются модули ядра, а также тулзы для создания разделов.
В терминах zfs - сначала создается pool из разделов или дисков, потом на этот pool накатывается файловая система. Все как и в случае с raid-ами.
Создание pool-а
Пока никаких пулов не создано:
Создаем пул из сырых дисков. Пул можно также создавать из разделов диска (/dev/sdb1, /dev/sdc2 etc.):
Эта команда создала пул аналогичный RAID0(stripe) - без резервирования. Автоматически на этот пул накатывается ФС.
Смотрим созданные в системе пулы:
После создания пула, просиходит его автомаунт в /
Bootloader
Proxmox VE uses proxmox-boot-tool to manage the bootloader configuration. See the chapter on Proxmox VE host bootloaders for details.
Performance
Each vdev type has different performance behaviors. The two parameters of interest are the IOPS (Input/Output Operations per Second) and the bandwidth with which data can be written or read.
A mirror vdev (RAID1) will approximately behave like a single disk in regards to both parameters when writing data. When reading data if will behave like the number of disks in the mirror.
A common situation is to have 4 disks. When setting it up as 2 mirror vdevs (RAID10) the pool will have the write characteristics as two single disks in regard of IOPS and bandwidth. For read operations it will resemble 4 single disks.
A RAIDZ of any redundancy level will approximately behave like a single disk in regard of IOPS with a lot of bandwidth. How much bandwidth depends on the size of the RAIDZ vdev and the redundancy level.
For running VMs, IOPS is the more important metric in most situations.
Читайте также: