
Undo log oracle что это
For a default installation, Oracle Database automatically manages undo. There is typically no need for DBA intervention. However, if your installation uses Oracle Flashback operations, you may need to perform some undo management tasks to ensure the success of these operations.
Oracle Database creates and manages information that is used to roll back, or undo, changes to the database. Such information consists of records of the actions of transactions, primarily before they are committed. These records are collectively referred to as undo .
Oracle Database can manage undo information and space automatically.
You specify the minimum undo retention period (in seconds) by setting the UNDO_RETENTION initialization parameter.
Automatic tuning of undo retention typically achieves better results with a fixed-size undo tablespace. If you decide to use a fixed-size undo tablespace, then the Undo Advisor can help you estimate needed capacity.
You manage undo tablespaces by completing tasks such as creating, altering, and dropping them. You can also switch undo tablespaces and establish user quotas for undo space.
If you are currently using rollback segments to manage undo space, Oracle strongly recommends that you migrate your database to automatic undo management.
By default, undo records for temporary tables are stored in the undo tablespace and are logged in the redo, which is the same way undo is managed for persistent tables. However, you can use the TEMP_UNDO_ENABLED initialization parameter to separate undo for temporary tables from undo for persistent tables. When this parameter is set to TRUE , the undo for temporary tables is called temporary undo .
You can query a set of views for information about undo space in the automatic undo management mode.
Using Oracle Managed Files for information about creating an undo tablespace whose data files are both created and managed by Oracle Database.
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
16.1 What Is Undo?
Oracle Database creates and manages information that is used to roll back, or undo, changes to the database. Such information consists of records of the actions of transactions, primarily before they are committed. These records are collectively referred to as undo .
Undo records are used to:
Roll back transactions when a ROLLBACK statement is issued
Recover the database
Provide read consistency
Analyze data as of an earlier point in time by using Oracle Flashback Query
Recover from logical corruptions using Oracle Flashback features
When a ROLLBACK statement is issued, undo records are used to undo changes that were made to the database by the uncommitted transaction. During database recovery, undo records are used to undo any uncommitted changes applied from the redo log to the data files. Undo records provide read consistency by maintaining the before image of the data for users who are accessing the data at the same time that another user is changing it.
Parent topic: Managing Undo
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
14.6.7 Undo Logs
An undo log is a collection of undo log records associated with a single read-write transaction. An undo log record contains information about how to undo the latest change by a transaction to a clustered index record. If another transaction needs to see the original data as part of a consistent read operation, the unmodified data is retrieved from undo log records. Undo logs exist within undo log segments, which are contained within rollback segments. Rollback segments reside in the system tablespace, in undo tablespaces, and in the temporary tablespace.
Undo logs that reside in the temporary tablespace are used for transactions that modify data in user-defined temporary tables. These undo logs are not redo-logged, as they are not required for crash recovery. They are used only for rollback while the server is running. This type of undo log benefits performance by avoiding redo logging I/O.
InnoDB supports a maximum of 128 rollback segments, 32 of which are allocated to the temporary tablespace. This leaves 96 rollback segments that can be assigned to transactions that modify data in regular tables. The innodb_rollback_segments variable defines the number of rollback segments used by InnoDB .
The number of transactions that a rollback segment supports depends on the number of undo slots in the rollback segment and the number of undo logs required by each transaction. The number of undo slots in a rollback segment differs according to InnoDB page size.
| InnoDB Page Size | Number of Undo Slots in a Rollback Segment (InnoDB Page Size / 16) |
|---|---|
| 4096 (4KB) | 256 |
| 8192 (8KB) | 512 |
| 16384 (16KB) | 1024 |
| 32768 (32KB) | 2048 |
| 65536 (64KB) | 4096 |
A transaction is assigned up to four undo logs, one for each of the following operation types:
INSERT operations on user-defined tables
UPDATE and DELETE operations on user-defined tables
INSERT operations on user-defined temporary tables
UPDATE and DELETE operations on user-defined temporary tables
Undo logs are assigned as needed. For example, a transaction that performs INSERT , UPDATE , and DELETE operations on regular and temporary tables requires a full assignment of four undo logs. A transaction that performs only INSERT operations on regular tables requires a single undo log.
A transaction that performs operations on regular tables is assigned undo logs from an assigned system tablespace or undo tablespace rollback segment. A transaction that performs operations on temporary tables is assigned undo logs from an assigned temporary tablespace rollback segment.
An undo log assigned to a transaction remains attached to the transaction for its duration. For example, an undo log assigned to a transaction for an INSERT operation on a regular table is used for all INSERT operations on regular tables performed by that transaction.
Given the factors described above, the following formulas can be used to estimate the number of concurrent read-write transactions that InnoDB is capable of supporting.
It is possible to encounter a concurrent transaction limit error before reaching the number of concurrent read-write transactions that InnoDB is capable of supporting. This occurs when the rollback segment assigned to a transaction runs out of undo slots. In such cases, try rerunning the transaction.
When transactions perform operations on temporary tables, the number of concurrent read-write transactions that InnoDB is capable of supporting is constrained by the number of rollback segments allocated to the temporary tablespace, which is 32.
If each transaction performs either an INSERT or an UPDATE or DELETE operation, the number of concurrent read-write transactions that InnoDB is capable of supporting is:
If each transaction performs an INSERT and an UPDATE or DELETE operation, the number of concurrent read-write transactions that InnoDB is capable of supporting is:
If each transaction performs an INSERT operation on a temporary table, the number of concurrent read-write transactions that InnoDB is capable of supporting is:
If each transaction performs an INSERT and an UPDATE or DELETE operation on a temporary table, the number of concurrent read-write transactions that InnoDB is capable of supporting is:
Предполагается, что вы инсталлировали базу данных, согласно документа.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
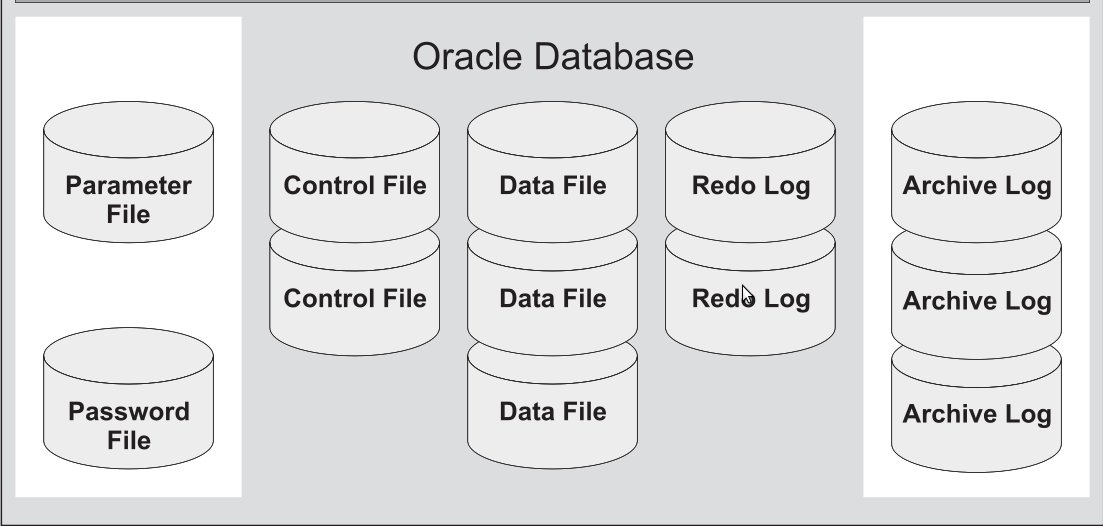
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
16.1 What Is Undo?
Oracle Database creates and manages information that is used to roll back, or undo, changes to the database. Such information consists of records of the actions of transactions, primarily before they are committed. These records are collectively referred to as undo .
Undo records are used to:
Roll back transactions when a ROLLBACK statement is issued
Recover the database
Provide read consistency
Analyze data as of an earlier point in time by using Oracle Flashback Query
Recover from logical corruptions using Oracle Flashback features
When a ROLLBACK statement is issued, undo records are used to undo changes that were made to the database by the uncommitted transaction. During database recovery, undo records are used to undo any uncommitted changes applied from the redo log to the data files. Undo records provide read consistency by maintaining the before image of the data for users who are accessing the data at the same time that another user is changing it.
Parent topic: Managing Undo
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
16.2 Introduction to Automatic Undo Management
Oracle Database can manage undo information and space automatically.
Oracle provides a fully automated mechanism, referred to as automatic undo management, for managing undo information and space. With automatic undo management, the database manages undo segments in an undo tablespace.
The undo retention period is the minimum amount of time that Oracle Database attempts to retain old undo information before overwriting it.
Parent topic: Managing Undo
16.2.1 Overview of Automatic Undo Management
Oracle provides a fully automated mechanism, referred to as automatic undo management, for managing undo information and space. With automatic undo management, the database manages undo segments in an undo tablespace.
Automatic undo management is the default mode for a newly installed database. An auto-extending undo tablespace named UNDOTBS1 is automatically created when you create the database with Database Configuration Assistant (DBCA).
You can also create an undo tablespace explicitly. The methods of creating an undo tablespace are explained in "Creating an Undo Tablespace" .
When the database instance starts, the database automatically selects the first available undo tablespace. If no undo tablespace is available, then the instance starts without an undo tablespace and stores undo records in the SYSTEM tablespace. This is not recommended, and an alert message is written to the alert log file to warn that the system is running without an undo tablespace.
If the database contains multiple undo tablespaces, then you can optionally specify at startup that you want to use a specific undo tablespace. This is done by setting the UNDO_TABLESPACE initialization parameter, as shown in this example:
If the tablespace specified in the initialization parameter does not exist, the STARTUP command fails. The UNDO_TABLESPACE parameter can be used to assign a specific undo tablespace to an instance in an Oracle Real Application Clusters environment.
The database can also run in manual undo management mode . In this mode, undo space is managed through rollback segments, and no undo tablespace is used.
Space management for rollback segments is complex. Oracle strongly recommends leaving the database in automatic undo management mode.
The following is a summary of the initialization parameters for undo management:
If AUTO or null, enables automatic undo management. If MANUAL , sets manual undo management mode. The default is AUTO .
Optional, and valid only in automatic undo management mode. Specifies the name of an undo tablespace. Use only when the database has multiple undo tablespaces and you want to direct the database instance to use a particular undo tablespace.
When automatic undo management is enabled, if the initialization parameter file contains parameters relating to manual undo management, they are ignored.
Earlier releases of Oracle Database default to manual undo management mode. To change to automatic undo management, you must first create an undo tablespace and then change the UNDO_MANAGEMENT initialization parameter to AUTO . If your Oracle Database is Oracle9 i or later and you want to change to automatic undo management, see Oracle Database Upgrade Guide for instructions.
A null UNDO_MANAGEMENT initialization parameter defaults to automatic undo management mode in Oracle Database 11 g and later, but defaults to manual undo management mode in earlier releases. You must therefore use caution when upgrading a previous release to the current release. Oracle Database Upgrade Guide describes the correct method of migrating to automatic undo management mode, including information on how to size the undo tablespace.
16.2.2 The Undo Retention Period
The undo retention period is the minimum amount of time that Oracle Database attempts to retain old undo information before overwriting it.
When automatic undo management is enabled, there is always a current undo retention period , which is the minimum amount of time that Oracle Database attempts to retain old undo information before overwriting it.
Oracle Database automatically tunes the undo retention period based on how the undo tablespace is configured.
To guarantee the success of long-running queries or Oracle Flashback operations, you can enable retention guarantee.
For a fixed-size undo tablespace, the database calculates the best possible retention based on database statistics and on the size of the undo tablespace.
You can determine the current retention period by querying the TUNED_UNDORETENTION column of the V$UNDOSTAT view.
16.2.2.1 About the Undo Retention Period
When automatic undo management is enabled, there is always a current undo retention period , which is the minimum amount of time that Oracle Database attempts to retain old undo information before overwriting it.
After a transaction is committed, undo data is no longer needed for rollback or transaction recovery purposes. However, for consistent read purposes, long-running queries may require this old undo information for producing older images of data blocks. Furthermore, the success of several Oracle Flashback features can also depend upon the availability of older undo information. For these reasons, it is desirable to retain the old undo information for as long as possible.
Old (committed) undo information that is older than the current undo retention period is said to be expired and its space is available to be overwritten by new transactions. Old undo information with an age that is less than the current undo retention period is said to be unexpired and is retained for consistent read and Oracle Flashback operations.
Oracle Database automatically tunes the undo retention period based on undo tablespace size and system activity. You can optionally specify a minimum undo retention period (in seconds) by setting the UNDO_RETENTION initialization parameter. The exact impact this parameter on undo retention is as follows:
The UNDO_RETENTION parameter is ignored for a fixed size undo tablespace. The database always tunes the undo retention period for the best possible retention, based on system activity and undo tablespace size. See "Automatic Tuning of Undo Retention" for more information.
For an undo tablespace with the AUTOEXTEND option enabled, the database attempts to honor the minimum retention period specified by UNDO_RETENTION . When space is low, instead of overwriting unexpired undo information, the tablespace auto-extends. If the MAXSIZE clause is specified for an auto-extending undo tablespace, when the maximum size is reached, the database may begin to overwrite unexpired undo information. The UNDOTBS1 tablespace that is automatically created by DBCA is auto-extending.
16.2.2.2 Automatic Tuning of Undo Retention
Oracle Database automatically tunes the undo retention period based on how the undo tablespace is configured.
If the undo tablespace is configured with the AUTOEXTEND option, the database dynamically tunes the undo retention period to be somewhat longer than the longest-running active query on the system. However, this retention period may be insufficient to accommodate Oracle Flashback operations. Oracle Flashback operations resulting in snapshot too old errors are the indicator that you must intervene to ensure that sufficient undo data is retained to support these operations. To better accommodate Oracle Flashback features, you can either set the UNDO_RETENTION parameter to a value equal to the longest expected Oracle Flashback operation, or you can change the undo tablespace to fixed size.
If the undo tablespace is fixed size, the database dynamically tunes the undo retention period for the best possible retention for that tablespace size and the current system load. This best possible retention time is typically significantly greater than the duration of the longest-running active query.
If you decide to change the undo tablespace to fixed-size, you must choose a tablespace size that is sufficiently large. If you choose an undo tablespace size that is too small, the following two errors could occur:
DML could fail because there is not enough space to accommodate undo for new transactions.
Long-running queries could fail with a snapshot too old error, which means that there was insufficient undo data for read consistency.
Automatic tuning of undo retention is not supported for LOBs. This is because undo information for LOBs is stored in the segment itself and not in the undo tablespace. For LOBs, the database attempts to honor the minimum undo retention period specified by UNDO_RETENTION . However, if space becomes low, unexpired LOB undo information may be overwritten.
Не так давно в моём рассказе про опыт миграции одной SAP системы я упоминал о ситуации, когда онлайн журнальные файлы (r edo log files ) Oracle оказались узким местом при импорте данных. Решением стало пересоздание данных файлов намного большего размера. Давайте поговорим об этом более детально.
Про журнальные файлы Oracle я рассказывал в этом посте. Существует два вида данных журналов - онлайн и оффлайн. Вторые являются копией первых при активации режима работы базы данных - ARCHIVELOG MODE . Именно про этот режим в большей степени был мой прошлый пост. Сегодняшний же рассказ про первый вид - online redo log files .
В утилите BR*Tools перейти по меню "2 - Space management -> 7 - Additional space functions -> 3 - Show redolog files -> cont, cont, cont" (рис. 2).
Первый запрос изменяет формат экрана для удобного просмотра результатов работы второго. А второй собирает информацию из двух системных представлений (Oracle Views) V$LOGFILE и V$LOG . Результатом будет список онлайн журналов с размером и статусом (рис. 3).
Как видно из снимков экранов в данном случае в системе 4 группы онлайн журнальных файлов, в каждой группе по 2 копии файлов, а размер каждого файла 200 Мб. Данные журналы используются по кругу, предыдущая информация каждый раз перезаписывается. В текущий момент времени запись может производиться только в одну группу. На снимках экранов это четвёртая группа файлов, она имеет статус CURRENT . Те журнальные файлы, записи в которых уже были внесены в дата-файлы, имеют статус INACTIVE . То есть система помечает, что их можно перезаписать. И существует еще статус ACTIVE, когда указатель переключился на следующий журнал, но перезаписывать журнал ещё нельзя. Так как СУБД ещё не зафиксировала данные изменения в дата-файлах.
Задача пересоздания онлайн журналов может возникнуть по разным причинам. Например, для решения проблемы с производительностью, когда в системном журнале Oracle наблюдаются ошибки вида 'Chekpoint not complete' (SAP note 79341 - Checkpoint not complete) и рекомендуется увеличить размер журнальных файлов. Или как в моей истории при импорте большого объёма данных в систему. Иногда бывает необходимо перенести файлы журналов в другое место, изменить состав групп или решить другие подобные административные задачи.
Пересоздать отдельную группу онлайн журнальных файлов можно на живую, при работающей системе. Единственное условие - группа не должна использоваться, то есть должна находиться в статусе INACTIVE . Для выполнения операции придётся использовать SQLPlus . В BR*Tools такой функциональности не предусмотрено. Ну и, как вы поймёте из описания процедуры, необходимо выбрать период с минимальной нагрузкой на систему. Нам необходимо чтобы во время проведения операции переключение между группами журналов происходило как можно реже.
Итак, перейдём к процедуре и инструментарию (набору SQL-запросов и команд). Для примера увеличим размер online redo log files до 250 Мб .
Для начала необходимо просмотреть информацию о текущем состоянии онлайн журнальных файлов, выполнив 2 SQL-запроса из списка выше (пункт 3) (рис. 4).
После этого выбираем первую неактивную группу онлайн журнальных файлов для удаления. В данном случае это группа 1 (G11). Удаление группы производится SQL-запросом вида:
Открыть еще один терминал операционной системы и в нём удалить файлы только что удалённой группы онлайн журналов. Для этого использовать команды вида:
Для удаления файлов необходимо иметь достаточные полномочия: суперпользователя root , пользователя < ora >sid (Oracle до версии 11g) либо пользователя oracle (при использовании базы данных Oracle 12c и выше) (рис. 6).
Вернуться в терминал с SQLPlus и создать удалённую группу онлайн журнальных файлов Oracle заново SQL-запросом вида:
После этого данная группа должна появиться в списке. Статус UNUSED означает что база данных эти журналы еще ни разу не использовала (рис. 7).
 |
| Рис. 7. Процесс пересоздания онлайн журнальных файлов - 4. |
Если необходимо создать группу онлайн журнальных файлов с одним файлом, без зеркалирования, то в SQL-запросе в скобках указываем только один файл.
Повторить шаги, описанные в пунктах 3-5, для следующих групп онлайн журнальных файлов имеющих статус INACTIVE .
Для того, чтобы выполнить операцию удаления и создания для группы, файлы которой находятся в статусе ACTIVE или CURRENT , можно выбрать 2 способа. В первом случае просто подождать. Рано или поздно система заполнит текущий журнальный файл и переключится на следующий.
Во втором же случае можно выполнить следующие SQL-запросы:
ALTER SYSTEM CHECKPOINT;
Первый запрос принудительно переключает текущий журнал Oracle на следующий, а второй инициирует принудительное выполнение контрольной точки базы данных (Checkpoint). В этом случае все записи из журнала фиксируются в дата-файлах и журнал освобождается (рис. 8).
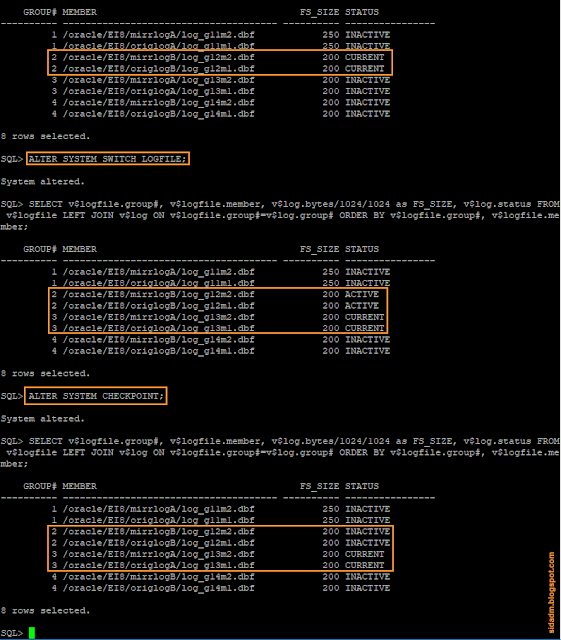 |
| Рис. 8. Пример переключения текущего журнального файла. |
В итоге после пересоздания всех групп журнальных файлов у вас должна получиться требуемая вам картина (рис. 9).
Подытожим. Онлайн журнальные файлы можно пересоздавать онлайн. Но для проведения операции необходимо выбирать период минимальной нагрузки на систему. Лучше предварительно создать всю последовательность команд в текстовом файле, чтобы провести операцию в максимально короткие сроки, не ловя моменты освобождения журнальных файлов нужной группы.
В начале хочу сразу обозначить, что я не являюсь супер бизоном, который знает Oracle вдоль и поперёк. С базами данных Oracle мне приходится иметь дело только с позиции SAP Basis консультанта, для которого база данных это лишь одна из компонент большой инфраструктуры. Да и мои взгляды на вопросы установки, мониторинга и администрирования сформированы через призму документации компании SAP.
Поэтому этот пост прошу воспринимать не как попытку показать какой я умный, а как попытку упорядочить картину прежде всего у себя в голове. Знаете же выражение: пока объяснял, сам понял. :)

Представим базовую часть СУБД Oracle в виде схемы, изображённой на рисунке 1. Предупреждаю сразу: тут далеко не все части и процессы Oracle. Я отобразил только те процессы и компоненты, которые важны в рамках механизмов, которые я буду описывать далее.
- инстанция базы данных, состоящая из процессов и общих областей памяти (System Global Area или SGA ),
- файлы базы данных на уровне файловой системы.
Как вы скорее всего уже знаете, при использовании базы данных Oracle в SAP системах в качестве клиентов базы данных выступают рабочие процессы SAP инстанций ( SAP WPs ). Каждому такому процессу соответствует один рабочий процесс со стороны инстанции Oracle ( shadow process ).
Самая маленькая логическая единица, которую Oracle использует при операциях с данными - это data block . При создании базы данных его размер можно выбрать, но в SAP инсталляциях размер data block всегда 8 Кб (8 192 байт).
Все данные базы данных Oracle содержатся в дата-файлах ( data files ), которые хранятся на дисковом хранилище. Однако обработка данных никогда не производится напрямую в файлах. При операциях чтения соответствующий процесс базы данных ( shadow process ) сначала копирует данные из дата-файлов в Database buffer cache (конечно, если этих данных еще нет в кэше). И только после этого передаёт данные пользователю, то есть рабочему процессу SAP. Так как все подключенные к инстанции Oracle пользователи могут совместно использовать одни и те же, скопированные из дата-файлов в Database buffer cache , данные, то данный механизм существенно ускоряет последующие операции чтения.
Размер Database buffer cache инстанции Oracle имеет ограниченный размер, так как оперативная память сервера не безгранична. Поэтому в кэше хранятся только последние прочитанные блоки данных. А перезапись блоков кэша происходит по алгоритму LRU («наиболее давно используемый»).
Любые изменения данных в базе данных (операции INSERT , UPDATE или DELETE ) также всегда производятся в Database buffer cache . При этом изменённые блоки кэша помечаются как « dirty blocks ». При копировании данных в кэш такие блоки ( dirty buffers ) не могут быть перезаписаны shadow процессами, до тех пор пока эти изменённые блоки не будут скопированы в дата-файлы. Записью « dirty blocks » занимается не shadow процесс, а специальный фоновый процесс инстанции Oracle - DBW0 (database writer).
- перед тем, как скопировать данные в кэш, shadow процесс сканирует области Database buffer cache на наличие не изменённых блоков, которые можно перезаписать. И если количество сканированных блоков достигает определённого порогового значения, то shadow процесс сигнализирует DBW0 , чтобы он записал часть « dirty blocks » на диск. DBW0 копирует часть « dirty blocks » в дата-файлы, используя алгоритм LSU (Least Number of Stream Used). После этого эти блоки в кэше становятся доступными для shadow процессов.
- в момент Checkpoint , когда DBW0 записывает все « dirty blocks » из Database buffer cache в файлы на дисках. Событие Checkpoint инициируется фоновым процессом CKPT . Детали будут чуть ниже.
Использование механизма отложенной записи повышает быстродействие. Во-первых, во многих случаях, прежде чем DBW0 скопирует блок на диск, данные в блоке могут несколько раз измениться. Во-вторых, повышается эффективность операций ввода-вывода, так как DBW0 часто выполняет запись сразу нескольких блоков параллельно.
Почти всегда можно руководствоваться правилом: чем больше данный кэш, тем быстрее работает база данных. Вспомните мой старый пост про это.
Но основанный на отложенной записи механизм должен избегать потери данных и обеспечивать консистентность базы данных, даже в случае сбоя любого компонента системы. А сбой может быть как аппаратным (например, сбой дискового хранилища), так и программным - сбой инстанции Oracle.
Как я уже рассказывал здесь, транзакция базы данных - это LUW (logical unit of work) сервера базы данных. Так как LUW всегда атомарная, то изменения из LUW должны быть или выполнены полностью, или полностью отменены. Для достижения консистентности данных (и консистентности чтения данных) в рамках концепции LUW СУБД Oracle использует Redo-записи для отката или восстановления (например, после сбоя) и Undo-записи для отката неподтверждённых (uncommitted) транзакций.
Redo-записи
Redo-записи содержат информацию необходимую и достаточную для того, чтобы реконструировать, восстановить или откатить, внесенные в базу данных с помощью SQL-запросов данные прежде всего в подтверждённых (commit) транзакциях.
Параллельно с изменением блоков данных в Database buffer cache , shadow процесс записывает Redo-записи в Redo log buffer . Это круговой буфер, находящийся в SGA , в который временно записываются все завершённые и незавершённые изменения данных. Фоновый процесс LGWR (log writer) периодически записывает порции записей из Redo log buffer последовательно на диск - в Online redo log file .
Oracle redo log file имеет заранее заданный фиксированный размер и не растёт динамически, как обычный файл. Поэтому, когда текущий Online redo log file заполняется, процесс LGWR закрывает файл и начинает запись в следующий. В SAP инсталляциях по умолчанию используется 4 группы Online redo log files по 2 копии файлов в каждой. Online redo log file , в который LGWR пишет в данный момент, называется CURRENT. А процедура переключения файлов называется log switch .
Так как количество Online redo log files также заранее ограничено, Oracle перезаписывает старые Redo-записи новыми, используя эти файлы по кругу.
Каждый log switch СУБД увеличивает LSN (log sequence number). С помощью LSN Oracle автоматически создаёт последовательные номера для Redo log files .
- при подтверждении (commit) любой транзакции,
- каждые 3 секунды,
- когда Redo log buffer полон на одну треть,
- когда DBW0 собирается записать изменённые блоки из Database buffer cache на диск, а некоторые соответствующие Redo-записи еще не были записаны в Online redo log files . Таким образом предотвращается попытка записи с опережением журналирования (write-ahead logging).
Этого достаточно для того, чтобы всегда иметь место для новых Redo-записей в Redo log buffer . При этом по умолчанию размер этого буфера при установке в SAP системах небольшой (1 - 8 Мб).
Дополнительно когда пользователь (рабочий процесс SAP) подтверждает завершение (commit) транзакции, транзакции присваивается SCN (system change number) базы данных. Oracle записывает SCN , вместе с Redo-записями транзакции в Redo log buffer . При этом DBW0 нет необходимости записывать блоки данных в момент подтверждения (commit) транзакции. Потому что в СУБД Oracle используется журналирование с опережением записи.
Новые значения модифицированных данных, которые хранятся в Redo-записях, называются «after images».
Undo-записи содержат информацию необходимую для отмены или отката любых изменений в блоках данных, которые были выполнены в результате неподтверждённых (uncommitted) транзакций .
Oracle хранит Undo-записи в специальных Undo сегментах, которые хранятся в специальном пространстве - Undo space. При этом Undo space может быть реализовано двумя способами:
- Automatic Undo Management ( AUM ),
- Manual Undo Management.
При AUM администратор должен лишь создать специальное табличное пространство - Undo tablespace ( PSAPUNDO ) достаточного размера и настроить пару параметров Oracle. Управление Undo сегментами СУБД осуществляет сама.
При ручном управлении необходимо создать и настроить некоторое количество Rollback segments , у которых необходимо тщательно рассчитать размер и параметры. Данные сегменты также располагаются в отдельном табличном пространстве ( PSAPROLL ). Про проблемы с данными сегментами у меня был отдельный пост.
Таким образом Undo-записи хранят информацию для транзакций, сохраняя её в Undo space, как минимум, до завершения транзакции. Так как данные записи используются для отката транзакций, то Undo-записи могут быть перезаписаны только после того, как транзакция будет подтверждена (commit) или сброшена (rollback).
Стоит отметить, что Oracle может использовать Undo-записи и для других целей. Например, для консистентного чтения из snapshots. В этом случае данные читаются из «before images». В то время, как происходит изменение этих же данных в ещё неподтверждённых (uncommitted) транзакциях.
Каждая база данных Oracle имеет свой контрольный файл ( control file ). Это маленький бинарный файл, необходимый как в момент старта базы данных, так и в процессе работы. Следовательно данный файл должен быть всегда доступен на запись.
Control file содержит записи, которые определяют физическую структуру и состояние базы данных. Например, в нём хранится информация о табличных пространствах, именах и положении дата-файлов и Online redo log files , а также текущий LSN .
Oracle control file очень важен для работы базы данных. Поэтому несколько копий могут быть сохранены в разных местах, а СУБД обновляет их одновременно. В SAP системах по умолчанию сконфигурировано 3 копии control files .
Checkpoint
Checkpoint это момент времени, в котором файлы базы данных находятся в консистентном состоянии. Достигается это состояние тем, что в этот момент DBW0 сбрасывает все текущие изменённые блоки из Database buffer cache в дата-файлы. За инициацию события Checkpoint отвечает специальный фоновый процесс CKPT , который и даёт команду процессу DBW0 начать запись блоков. Одновременно Checkpoint обозначает специальную позицию в Redo log .
- DBW0 активируется, получая сигнал в определённые моменты времени от фонового процесса CKTP .
- DBW0 копирует все текущие « dirty blocks » на диск. Причём, пока DBW0 закончит выполнять запись, другие блоки в кэше могут быть изменены, но они уже не записываются.
- Когда событие Checkpoint закончится (то есть будут записаны все выбранные блоки), самый старый буфер из « dirty blocks » в Database buffer cache будет обозначать точку в Redo log , после которой может быть начато восстановление в случае сбоя. Это позиция журнала и называется Checkpoint position .
- записывает информацию о Checkpoint в заголовок каждого дата-файла,
- записывает информацию о Checkpoint position в Online redo log file в контрольный файл Oracle ( control file ).
Информация о позиции Checkpoint в Online redo log file в контрольном файле необходима в процессе восстановления инстанции. Позиция Checkpoint сообщает инстанции Oracle, что все Redo-записи, которые были записаны до этого момента, не нуждаются в восстановлении. Так как эти данные уже записаны в дата-файлы.
Частота Checkpoints один из важных факторов, который напрямую влияет на время необходимое для восстановления инстанции в случае сбоя. Чем реже будут в системе происходить Checkpoints , тем большее времени будет необходимо инстанции для восстановления в случае сбоя.
Хотя частоту Checkpoint можно настроить через параметры Oracle, при разворачивании SAP систем эти параметры не используются. А Checkpoint всегда возникает только в моменты переключения Online redo log files ( log switch ).
Теперь основываясь на всех механизмах, которые были описаны выше, разберём как происходит восстановление базы данных.
Речь пойдёт не о восстановлении из резервной копии базы данных, которую должен выполнять администратор. А речь пойдёт об автоматическом восстановлении базы данных, которое СУБД производит в момент старта. Так называемое instance recovery. Оно необходимо, если предыдущий останов базы данных был выполнен не чисто, например, с опцией IMMEDIATE или ABORT. Или произошёл сбой работы сервера базы данных по аппаратной или программной причине.
- В control file находится последний Checkpoint . После этого, начиная с позиции Checkpoint , читаются Redo-записи из Online redo log files и заново проводятся все транзакции, указанные в журнале. Происходит процесс roll forward. Заметьте, что этот шаг всегда включает и проведение изменений для Undo space, то есть восстанавливаются «before images».
- Для всех заново применённых транзакций, которые не были подтверждены (commit) до сбоя или были отменены прямо перед сбоем (поэтому для них нет подтверждения в Redo log), выполняется откат. Для отката используется образ «before images» из Undo space. СУБД уверена, что это всегда возможно, потому что Undo-записи незавершённых транзакций из Undo space никогда не удаляются и не перезаписываются.
В результате после открытия консистентная база данных содержит только те изменения, которые были подтверждены (commit) перед сбоем.
Из процесса восстановления базы данных видно, что Online redo log files это одна из критически важных частей сервера Oracle. А если вспомнить, что в SAP установках Checkpoint наступает только в момент log switch , то при автоматическом восстановлении СУБД всегда нужен последний Online redo log file целиком. И если он будет потерян во время сбоя, то полное восстановление (complete recovery of database) будет невозможно. В результате чего данные будут потеряны, а база данных может оказаться в неконсистентном состоянии.
Поэтому-то Online redo log files должны храниться минимум в двух копиях, каждая из которых расположена на отдельном диске. Так же в продуктивной системе база данных должна работать в ARCHIVELOG режиме. В этом режиме фоновый процесс ARC0 (archiver) копирует каждый только что записанный Online redo log file в Offline redo log file . Offline redo log file в своём имени содержит LSN . Понятно, что копирование возможно начать только после переключения ( log switch ) и необходимо закончить до повторного возвращения процесса LGWR к этому файлу. Так как в таком режиме перезапись старых Redo-записей в Online redo log files не разрешается до тех пор, пока эти записи не скопированы в Offline redo log files .
Ну и должно соблюдаться ещё одно ограничение: могут быть перезаписаны только те Redo-записи, которые расположены до позиции Checkpoint в Redo log . То есть соответствующие им изменения уже записаны в дата-файлы. Это гарант возможности автоматического восстановления инстанции в случае сбоя.
Если хотите разобраться в вопросах администрирования базы данных Oracle на практике, то можете приобрести мой обучающий курс SAPADM 2.0. Этой теме в курсе полностью посвящён третий пакет заданий.
MySQL 5.7 Reference Manual Including MySQL NDB Cluster 7.5 and NDB Cluster 7.6
Обязательные файлы:
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Читайте также: