
Технология файл сервер не является распределенной
Файловый сервер – это, как правило, центральный сервер в компьютерной сети, который обеспечивает подключение пользователей к сетевой системе хранения данных (СХД).
Этот термин может означать как оборудование, так и программное обеспечение, необходимое для выполнения функций файлового сервера.
Пользователи, получив необходимые права на доступ к определенным файлам в сетевой СХД, могут их открывать и редактировать, а также удалять файлы и папки точно так же, как если бы они работали на собственном компьютере.
На файловом сервере каждому авторизованному пользователю предоставляется определенное пространство для хранения рабочих файлов. Другие пользователи могут также их открывать, читать и редактировать, в соответствии с их правами доступа. Эти права устанавливаются администратором файлового сервера. Он определяет, кто какие файлы и в каких папках может открывать и просматривать, а также (если это разрешено) редактировать, удалять или добавлять новые файлы.

Расположение файлового сервера в компьютерной сети предприятия
Кроме того, файловый сервер может иметь подключение к интернету, и, при соответствующей конфигурации прав доступа, пользователи могут получать доступ к ресурсам интернет, если доступ к ним разрешен сетевым администратором. В некоторых организациях может административно устанавливаться запрет на доступ к определенным ресурсам по тем или иным критериям. Например, может быть закрыт доступ к видеохостингу Youtube, сайтам с развлекательным контентом и пр. Кроме того, подключение файлового сервера к интернету обеспечивает удаленный доступ пользователей к своим рабочим папкам на файловом сервере, если они находятся не на рабочем месте.
Для файлового сервера могут подойти любые современные операционные системы Windows, Linux или macOS, хотя надо иметь в виду, что сетевые устройства должны быть с ними совместимы.
Также надо принять во внимание, что файловые серверы часто используются не только для хранения и обработки файлов, но также и как репозиторий для программ, которые доступны пользователям корпоративной сети, а также в качестве сервера резервирования.
Как работает файловый сервер
Для надежной работы файлового сервера необходимо выбрать соответствующее оборудование. Это прежде всего процессор достаточной мощности для обслуживания заданного числа пользователей, а также дисковые накопители, которые обладают емкостью, достаточной для размещения необходимых программ и операционной системы и другого программного обеспечения для обслуживания пользователей корпоративной сети. Немаловажное значение для быстродействия системы имеет объем оперативной памяти (ОЗУ), в которой размещаются модули запущенных для работы программ. Если объем ОЗУ будет недостаточен, то работа системы сильно замедлится, и не поможет даже самый мощный и высокоскоростной процессор.
Определяющим фактором для выбора параметров файлового сервера является число пользователей корпоративной сети. Для связи пользователей с файловым сервером используются специальные протоколы, например, протокол SMB (Server Message Block) разработанный IBM. Он может использоваться в локальных сетях как на устройствах Windows, так и macOS. В качестве протокола сетевой операционной системы часто используется NFS (Network File System). Если файловый сервер работает под ОС Unix, то чтобы совместить оба типа протоколов в одной сети, как клиенты, так и файловые серверы, должны быть оснащены программами, которые позволяют выполнять протокол SMB в этих системах. Это может быть, например, программная платформа Samba.
Интерфейс сервера директорий
Обеспечивает операции создания и удаления директорий, именования и переименования файлов, перемещение файлов из одной директории в другую. Определяет алфавит и синтаксис имен. Для спецификации типа информации в файле используется часть имени (расширение) либо явный атрибут.
Какие бывают файловые сервера?
- Прежде всего нужно понять, что файловый сервер — это, в первую очередь, средство для хранения файлов и получения доступа к этим файлам по сети.
• Выделенный сервер, на который системный администратор разворачивает операционную систему (Windows или UNIX) и настраивает роль файлового сервера. Это самый дорогой вариант, но он лишен каких-либо ограничений.
• Решение под ключ. Представляет из себя оборудование, на котором уже установлена своя система с настроенным сервисом хранения данных. Удобен тем, что его можно достать из коробки и начать пользоваться после 10 минут настройки. Минус в достаточно высокой стоимости и некоторых ограничениях (система позволит настроить только то, что предусмотрено разработчиками)
• Внешний жесткий диск с сетевым интерфейсом. Да, в некоторых случаях так тоже можно организовать общее хранилище файлов. А если купить дисковый бокс с возможностью организации RAID, решение еще и будет достаточно надёжным.
• Любой компьютер пользователя в сети компании. Самый худший вариант, так как при перезагрузке или выключении компьютера пропадает доступ к данным. Более того, пользовательские операционные системы хуже всего рассчитаны на организацию серверов, но это самый простой и дешевый метод, поэтому он имеет место быть.
Оборудование для организации файлового сервера
Для файлового сервера организаций небольших и средних размеров подойдут бюджетные решения крупнейших вендоров – HPE, Dell, Fujitsu.
ИТ: 7. Технология «Файл-Сервер», «Клиент-Сервер». Модели взаимодействия «Клиент-Сервер».
Реализация распределенных файловых систем
Использование файлов Приступая к реализации очень важно понимать, как система будет использоваться. Приведем результаты некоторых исследований использования файлов (статических и динамических) в университетах. Очень важно оценивать представительность исследуемых данных. большинство файлов имеют размер менее 10К (следует перекачивать целиком). чтение встречается гораздо чаще записи (кэширование). чтение и запись последовательны, произвольный доступ редок (упреждающее кэширование, чтение с запасом, выталкивание после записи следует группировать). большинство файлов имеют короткое время жизни (создавать файл в клиенте и держать его там до уничтожения). мало файлов разделяются (кэширование в клиенте и семантика сессий). существуют различные классы файлов с разными свойствами (следует иметь в системе разные механизмы для разных классов).
Основные преимущества файлового сервера:
- Легкая организация и инвентаризация корпоративных ресурсов.
- Прозрачность и легкость нахождения нужной информации.
- Удобство коллективной работы с документами.
- Отсутствие конфликтов версионности.
- Отсутствие ресурсных ограничений персональных машин пользователей.
- Возможность удаленного доступа к файлам и работы на выезде.
- Высокая степень защиты и безопасности данных.
Файл-серверная и клиент-серверная технологии информационных систем
Системы, применяемые в туристском бизнесе, относятся к классу информационно-управляющих систем (ИУС).
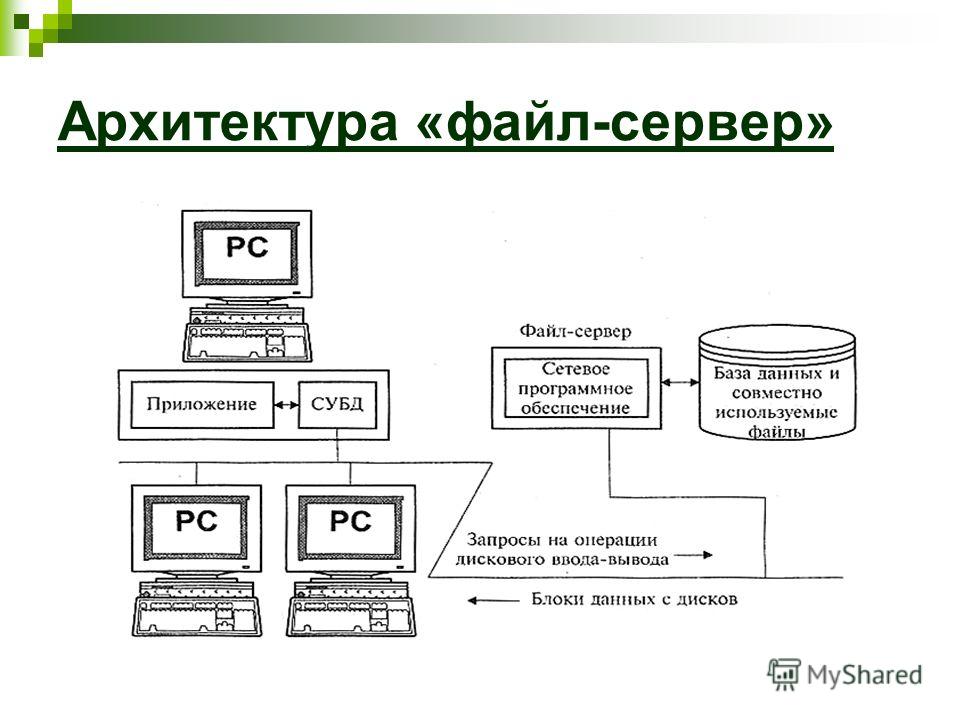
При файл-серверной реализации ИУС база данных располагается в виде файлов на винчестерском диске одного из компьютеров сети. Серверы, разделяемым ресурсом которых является дисковая память (или, говоря иначе, файлы, хранящиеся на винчестерском диске), называются файл-серверами.
Программы пользователей работают на рабочих станциях и при необходимости обращаются к файлам сервера, в которых хранится база данных системы. При этом возникает немало проблем.
Файловый сервер обрабатывает огромное количество запросов на обслуживание файлов, это требует значительного времени. Пользователю приходится ждать.
При одновременном обращении нескольких пользователей к одному файлу (например, к базе данных туров) могут возникнуть проблемы с надежностью хранения информации, так как файловый сервер производит чтение/запись блоков данных, не контролируя их содержимое.
Соответственно, некорректная работа клиентского приложения может легко разрушить базу данных системы.

Каждый клиент обращается к БД - что и как этот клиент выполняет, полностью зависит от него и от надежности всей системы.
Эта технология хороша тем, что между базой данных и клиентом становится посредник - SQL-сервер. Применительно к информационным системам это означает, что

работа с базой данных реализуется с помощью SQL-сервера.
Технология «клиент-сервер», получает все большее распространение, но реализация технологии в конкретных программных продуктах существенно различается.
Один из основных принципов технологии «клиент-сервер», заключается в разделении операций обработки данных на три группы, имеющие различную природу.
- Ввод и отображение данных.
- Прикладные операции обработки данных, характерные для решения задач данной предметной области.
- Операции хранения и управления данными (базами данных или файловыми системами).
Согласно этой классификации в любом техпроцессе можно выделить программы трех видов:
· программы представления, реализующие операции первой группы;
• прикладные программы, поддерживающие операции второй группы;
• программы доступа к информационным ресурсам, реализующие операции третьей группы.
В соответствии с этим выделяют три модели реализации технологии «клиент — сервер»:
1. модель доступа к удаленным данным (Remote Data Access — RDA);
2. модель сервера базы данных (DateBase Server — DBS);
3. модель сервера приложений (Application Server — AS).
В RDA-модели программы представления и прикладные программы объединены и выполняются на компьютере-клиенте, который поддерживает как операции ввода и отображения данных, так и прикладные операции. Доступ к информационным ресурсам обеспечивается или операторами языка SQL, если речь идет о базах данных, или вызовами функций специальной библиотеки. Запросы к информационным ресурсам направляются по сети удаленному компьютеру, например серверу БД, который обрабатывает запросы и возвращает клиенту необходимые для обработки блоки данных (рис. 4.4).

DBS-модель строится в предположении, что программы, выполняемые на компьютере-клиенте, ограничиваются вводом и отображением, а прикладные программы реализованы в процедурах базы данных и хранятся непосредственно на компьютере-сервере базы данных вместе с программами, управляющими и доступом к данным - ядру СУБД (рис. 4.5).

На практике часто используются смешанные модели, когда поддержка целостности базы данных и простейшие операции обработки данных поддерживаются хранимыми процедурами (DBS-модель), а более сложные операции выполняются непосредственно прикладной программой, которая выполняется на компьютере-клиенте (RDA-модель).
В AS-модели программа, выполняемая на компьютере-клиенте, решает задачу ввода и отображения данных, т. е. реализует операции первой группы. Прикладные программы выполняются одним либо группой серверов приложений (удаленный компьютер или несколько компьютеров). Доступ к информационным ресурсам, необходимым для решения прикладных задач, обеспечивается так же, как и в RDA-модели. Прикладные программы обеспечивают доступ к ресурсам различных типов — базам данных, индексированным файлам, очередям и др. RDA- и DBS-модели опираются на двухзвенную схему разделений операций. В AS-модели реализована трехзвенная схема разделения операций, где прикладная программа выделена как важнейшая (рис. 4.6).

Главное преимущество RDA-модели состоит в том, что она представляет множество инструментальных средств, которые обеспечивают быстрое создание приложений, работающих с SQL-ориентированными СУБД. Иными словами, основное достоинство RDA-модели заключается в унификации и широком выборе средств разработки приложений. Подавляющее большинство этих средств разработки на языках четвертого поколения, включая и средства автоматизации программирования, обеспечивает разработку прикладных программ и операций представления.
Несмотря на широкое распространение, RDA-модель постепенно уступает место более технологичной DBS-модели. Последняя реализована в некоторых реляционных СУБД (Ingres, SyBase, Oracle).
В DBS-модели приложение является распределенным. Программы представления выполняются на компьютере-клиенте, в то время как прикладные программы решения задач оформлены как набор хранимых процедур и функционируют на компьютере-сервере БД. Преимущества DBS-модели перед RDA-моделью оче-видны: это и возможность централизованного администрирования решения экономических задач, и снижение напряженности, и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов ПК за счет использования однажды созданного плана выполнения процедуры.
Основным элементом принятой в AS-модели трехзвенной схемы является сервер приложения. Он реализует несколько прикладных функций, каждая из которых оформлена как служба и предоставляет услуги всем программам, которые желают и могут ими воспользоваться. Серверов приложений может быть несколько, и каждый из них предоставляет определенный набор услуг. Любая программа, которая пользуется ими, рассматривается как клиент приложения. Детали реализации прикладных программ в сервере приложений полностью скрыты от клиента приложения.
AS-модель имеет универсальный характер. Четкое разграничение логических компонентов и рациональный выбор программных средств для их реализации обеспечивают модели такой уровень гибкости и открытости, который пока недостижим в RDA- и DBS-моделях. Именно AS-модель используется в качестве фундамента относительно нового вида программного обеспечения — мониторов транзакций.
Прикладные программы управления данными представляют собой необходимый инструмент для распределенной обработки.
Архитектура клиент-сервера сети позволяет различным прикладным программам одновременно использовать общую базу данных. Совершенно очевидно, что перенос программ управления данными с рабочих станций на сервер способствует высвобождению ресурсов рабочих станций, предоставляет возможность увеличить число частных, локально решаемых задач. Данная архитектура позволяет также централизовать ряд самых важных функций управления данными, такие, как защита информации баз данных, обеспечение целостности данных, управление совместным использованием ресурсов.
Одним из важных преимуществ архитектуры клиент-сервера в сетевой обработке данных является возможность сокращения времени реализации запроса. В подтверждение этому рассмотрим две базовые технологии обработки информации в архитектуре клиент-сервера сети и технологии использования традиционного файлового сервера.
Допустим, что прикладная программа базы данных загружена на рабочую станцию и пользователю необходимо получить все записи, удовлетворяющие некоторым поисковым условиям. В среде традиционного файлового сервера программа управления данными, которая выполняется на рабочей станции, должна осуществить запрос к серверу каждой записи базы данных (рис.9.5,а). Программа управления данными на рабочей станции может определить, удовлетворяет ли запись поисковым условиям, лишь после того, как она будет передана на рабочую станцию. Очевидно, что данный технологический вариант обработки информации имеет наибольшее суммарное время передачи данных по каналам сети.
В среде клиент-сервера, напротив, рабочая станция посылает запрос высокого уровня серверу базы данных. Сервер базы данных осуществляет поиск записей на диске и анализирует их. Записи, удовлетворяющие условиям, могут быть накоплены на сервере. После того, как запрос целиком обработан, пользователю на рабочую станцию передаются все записи, которые удовлетворяют поисковым условиям (рис. 9.5,б).
Данная технология позволяет снизить сетевой трафик и повысить пропускную способность сети. Более того, за счет выполнения операции доступа к диску и обработки данных в одной системе сервер может осуществить поиск и обрабатывать запросы быстрее, чем если бы эти запросы обрабатывались на рабочей станции.

| Файл–сервер | Рабочая станция |

Рис. 9.5. Технологии обработки запросов по базовым вариантам: а – типовая среда обработки запросов в сетях ЭВМ; б – распределенная среда обработки запросов в сетях ЭВМ
Прикладные программы баз данных клиент-сервера поддерживаются программными продуктами:
· NetWare Btrieve – программой управления записями с индексацией по ключу (выполняется на сервере);
· NetWare SQL – ядром реляционных баз данных, предназначенным для обеспечения системы защиты и целостности данных.
Службы баз данных NetWare Btrieve и NetWare SQL фирмы Novell позволяют разработчикам создавать надежные прикладные программы баз данных без необходимости написания собственных программ управления записями, что обеспечивает удобный перенос прикладных программ в среду клиент-сервера.
В настоящее время разработаны десятки тысяч прикладных автономных и многозадачных программ, ориентированных на клиента версий NetWare Btrieve, NetWare SQL, которые могут быть использованы организациями, создающими или имеющими сеть ЭВМ. Более того, версии NetWare Btrieve и NetWare SQL фирмы Novell для клиентов имеют согласованные API, что упрощает перенос программ из среды одного клиента в среду другого.
По степени изменчивости все базы данных (БД) можно разделить на два класса:
· А – условно-постоянные (в основном для справочных систем);
· Б – сильно динамичные (для банковских, биржевых систем и т.п.).
Для ведения баз данных первого и второго классов используются системы управления базами данных (СУБД), которые в значительной степени отличаются друг от друга как по функциональным возможностям, так и по эксплуатационным характеристикам.
Например, для условно-постоянных БД наиболее важными показателями являются показатели скорости отработки запросов и скорости формирования выходных отчетов по БД, а такие показатели, как скорость отработки транзакций и контроль целостности БД при отработке транзакций не столь критичны; для сильнодинамичных БД, на первый план выходят такие показатели, как скорость отработки транзакций, возможность контроля целостности, скорость формирования отчетов, согласованность по чтению и транзакциям. Менее критичны здесь скорости отработки запросов.

Поэтому любая СУБД не может одинаково успешно применяться при работе с БД разных классов. Такие системы, как CLIPPER, FOXPRO, ориентированы на первый класс БД – А, и здесь имеются неплохие результаты, а такие СУБД , как Informix, Ingres, SyBase, создавались для второго класса – Б.
Исходя из вышесказанного, напрашивается вывод: найти «золотую середину», которая удовлетворяла бы требованиям обоих классов А и Б. Решением этой противоречивой задачи является использование дифференциальной организации файлов базы данных, или дифференциальных файлов (ДФ).
В последнее время разработчики СУБД ведущих фирм подошли к использованию идеи ДФ. Причинами явились следующие факты:
• значительное расширение класса решаемых на IBM PC задач, так что термин «персональный компьютер» уже не соответствует действительности;
• широкое распространение локальных вычислительных систем (ЛВС);
• разработка многопользовательских и многозадачных систем;
• стремительное развитие технической базы ЭВМ (в большей степени дисковой памяти).
Остановимся на сути ДФ применительно к БД в ЛВС. Реализация идеи ЛВС в различных СУБД значительно отличается.
Идея ДФ включает положения:
• основной файл БД остается неизменным при любых обновлениях базы данных, т.е., любые изменения БД последовательно накапливаются в специальном файле изменений (не путать с журналом транзакций) – ДФ;
• никакие индексы для него не создаются и не поддерживаются.
Когда ДФ достигает значительных размеров (примерно 25 – 40 % от размеров БД), администратор вносит все изменения в основной файл БД в удобный момент времени в пакетном режиме.
В качестве примера сравним книгу, где наблюдаются опечатки в страницах, и базу данных с ДФ. Нет необходимости переиздания книги из-за нескольких опечаток или незначительных изменений. Если это количество имеет тенденцию к значительному росту и достигло предельного значения, то становятся оправданными затраты на переиздание книги, куда должны быть включены все накопленные изменения.
Достоинства ДФ относятся к обеспечению высокой надежности, целостности БД и скорости отработки транзакций.
Вопрос, какие скорости отработки транзакций можно обеспечить при использовании ДФ, является довольно важным. Очевидно, что скорость отработки транзакций при такой организации БД возрастет в десятки раз. При этом сервер базы данных практически напоминает обычный файл-сервер.
Что касается индексов, то проблемы их поддержания не существует (скорости добавления, удаления, модификации записей БД находятся на самом высоком уровне). Внесение добавлений в БД не отличается от добавлений в обычный последовательный файл. Время обновления записей БД не зависит ни от размеров БД, ни от длины ключей, ни от их числа. Временные затраты на блокировку (как одно из узких мест для БД и ЛВС) сведены к минимуму.
Для того чтобы обеспечить согласованность данных по чтению, нет необходимости блокировать целиком таблицу, что имеет место в ряде СУБД, т.е., когда запрос (или формируемый отчет) начинает выполняться, СУБД «запоминает» старший адрес в ДФ (моментальный снимок). При этом пользователь, инициализирующий свой запрос, не обязан ждать «своего момента». Он «не видит» никого из пользователей и получает снимок БД именно в этот момент времени. Далее, по мере выполнения запроса (даже очень быстрого) часть записей-целей могла быть или изменена, или удалена. Это отразится только на старших адресах ДФ, а поэтому СУБД просто проигнорирует любые изменения данных, случившиеся после начала выполнения запроса. Гарантируется корректировка сложных и длительных запросов к БД, т.е. обеспечение согласованности по чтению и транзакциям.
А, как в этом случае ведется поиск в БД? По ассоциатору находится множество записей-целей: число и список их адресов в основной БД, после чего производится считывание ассоциатора ДФ и производится корректировка этого списка. За счет этой корректировки время поиска увеличивается, причем величина этого увеличения зависит от размеров ДФ. Своевременность обновления БД должна быть в компетенции администратора БД. Чтобы исключить существенные издержки, связанные с ДФ, можно накапливать изменения БД для их пакетной обработки и при поиске ДФ не учитывать. В ряде систем, таких как банковские, допускается потеря некоторой точности в период между циклами обновления – контролируемое запаздывание.
Помимо всего прочего использование ДФ обеспечивает:
• возможность администратору восстанавливать случайно удаленные записи;
• возможность (при необходимости) хранить индексные файлы на самих рабочих станциях;
• возможность создания распределенных БД;
• одновременное выполнение транзакций.
Непротиворечивость данных может обеспечиваться механизмом захвата на уровне записи – откат транзакций любой доступной вложенности.
Выделились несколько самостоятельных технологий распределенной обработки данных [14]:
Реальные распределенные информационные системы, как правило, построены на основе сочетания этих технологий.
Системы на основе технологии клиент-сервер развились из первых централизованных многопользовательских информационных систем на основе мэйнфреймов и получили наиболее широкое распространение в корпоративных информационных системах.
При реализации данной технологии отступают от одного из основных принципов создания распределенных систем — отсутствия центрального узла [14].
Принцип централизации хранения и обработки данных является базовым принципом технологии клиент-сервер.
Можно выделить следующие идеи, лежащие в основе технологии клиент-сервер [14]:
• общие для всех пользователей данные, расположенные на одном или нескольких серверах;
• множество пользователей, осуществляющих доступ к общим данным.
Важное значение в технологии клиент-сервер имеют понятия сервера и клиента.
Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем процессора, файлами и т. д.). Клиентом называется любая система, процесс, компьютер, пользователь, делающие запрос к серверу на использование ресурса [14].
Настольные (локальные) СУБД, в случае их использования несколькими пользователями в компьютерной сети, функционируют на основе технологии файл-сервер, которая появилась раньше технологии клиент-сервер. Дело в том, что настольные СУБД не содержат специальных сервисов, управляющих данными, а используют для этой цели файловые сервисы операционной системы. Поэтому вся обработка данных в таких СУВД осуществляется в клиентском приложении. При выполнении запросов все данные (даже те, которые не удовлетворяют запросу, а это могут быть сразу несколько таблиц) должны быть доставлены клиентскому приложению. Это приводит к перегрузке сети при увеличении числа пользователей и объема БД, а также грозит нарушением целостности данных.
Одним из важнейших преимуществ архитектуры клиент-сервер является снижение сетевого трафика при выполнении запросов. Клиент посылает запрос серверу на выборку данных, запрос обрабатывается сервером, и клиенту передается не вся таблица (как было бы в технологии файл-сервер), а только результат обработки запроса.
Вторым преимуществом архитектуры клиент-сервер является возможность хранения так называемой бизнес-логики (например, правил ссылочной целостности или ограничений на значения данных) на сервере, что дозволяет избежать дублирования кода в различных клиентских приложениях, использующих общую базу данных.
Во многих случаях узким местом клиент-серверных ИС является недостаточно высокая производительность из-за необходимости передачи по сети все-таки большого количества данных.
Построение быстродействующих информационных систем обеспечивают технологии репликации данных.
Репликой называют копию БД, размещенную на другом компьютере сети для автономной работы пользователей. Основная идея репликации заключается в том, что пользователи работают автономно с общими данными, растиражированными по локальным базам данных. Производительность работы системы повышается из-за отсутствия необходимости обмена данными по сети. Для реализации технологии репликации программное обеспечение СУБД дополняется функциями тиражирования данных, их структуры, системной информации, информации о конфигурировании распределенной системы [14].
При этом, однако, возникают две проблемы реализации одного из принципов функционирования распределенных систем — принципа непрерывности согласованного состояния данных [14]:
• обеспечение согласованного состояния данных во всех репликах БД;
• обеспечение согласованного состояния структуры данных во всех репликах БД.
Обеспечение согласованного состояния данных, в свою очередь, основывается на реализации одного из двух принципов [14]:
• принципа непрерывного размножения обновлений;
• принципа отложенных обновлений (обновления реплик могут быть отложены до специальной команды или ситуации).
Принцип непрерывного размножения обновлений является основополагающим при построении так называемых систем реального времени (например, систем управления воздушным движением, систем бронирования билетов пассажирского транспорта и др.), где требуется непрерывное и точное соответствие реплик во всех узлах и компонентах распределенных систем в любой момент времени. Реализация этого принципа заключается в том, что любая транзакция считается успешно завершенной, если она успешно завершена на всех репликах системы.
В ряде предметных областей режим реального времени с точки зрения непрерывности согласования данных не требуется. Такого рода информационные системы можно строить на основе принципа отложенных обновлений. Накопленные в какой-либо реплике изменения данных передаются командой пользователя для обновления всех остальных реплик системы. Такая операция называется синхронизацией реплик.
Унификация взаимодействия прикладных компонентов с ядром информационных систем в виде SQL-серверов, наработанная для клиент-серверных систем, позволила выработать аналогичные решения и по интегрированию разрозненных локальных баз данных под управлением настольных СУБД. Такая технология получила название объектного связывания данных [14].
Технология объектного связывания данных решает задачу обеспечения доступа из одной локальной БД, открытой одним пользователем, к данным другой локальной БД, возможно, находящейся на другом компьютере, открытой другим пользователем. Решение этой задачи основывается на поддержке современными настольными СУБД технологии объектов доступа к данным — DAO (Data Access Objects). Под объектом понимается интеграция данных и методов их обработки в одно целое, на чем, как известно, основываются технологии объектно-ориентированного программирования [14].
Технология объектного связывания данных основана на протоколе ODBC (Open Database Connectivity), который является стандартом доступа к данным БД клиент-серверных систем (посредством SQL-запросов), а также к любым данным, находящимся под управлением реляционных СУБД.
Подобный принцип построения распределенных систем при больших объемах данных в связанных таблицах приводит к существенному увеличению сетевого трафика, так как по сети постоянно передаются страницы файлов баз данных. Другой проблемой является отсутствие надежных механизмов безопасности данных и обеспечение ограничений целостности. Так же как и в технологии файл-сервер, совместная работа нескольких пользователей с одними и теми же данными обеспечивается только функциями операционной системы по одновременному доступу к файлу нескольких приложений [14].
Контрольные вопросы
1. Дайте понятие распределенной БД.
2. Охарактеризуйте принципы распределенной БД, сформулированные К. Дейтом.
3. В чем состоит сущность технологии клиент-сервер?
4. Назовите преимущества технологии клиент-сервер по сравнению с технологией файл-сервер.
Файл-сервер – это выделенный сервер, оптимизированный для выполнения файловых операций ввода-вывода. Предназначен для хранения файлов любого типа. Как правило, обладает большим объемом дискового пространства.
Файловый сервер оборудован RAID – контроллером для обеспечения надежности сохранности данных.
Файл-серверные приложения – приложения, схожие по своей структуре с локальными приложениями и использующие сетевой ресурс для хранения программы и данных.
Функции сервера: хранения данных и кода программы. Функции клиента: обработка данных происходит исключительно на стороне клиента. Количество клиентов ограничено десятками.
Плюсы: низкая стоимость разработки; высокая скорость разработки; невысокая стоимость обновления и изменения ПО.
Минусы: низкая производительность (хотя это зависит еще и от производительности сети, сервера и клиента); плохая возможность подключения новых клиентов; ненадежная система.

Узел вычислительной сети, реализующий начальный уровень архитектуры клиент-сервер. Обычно файловый сервер работает под управлением серверной операционной системы. Основной задачей файл-серверов является надежное хранение и быстрый доступ к данным находящимся на общем дисковом пространстве, при котором обеспечивается управление доступом к файлам и базам данных;
Данная серия специально спроектирована для решения задач по хранению и быстрому доступу к данным, как отдельных пользователей, так и всего предприятия в целом. Для достижения полной сохранности Ваших данных, в серверах используются RAID-контроллеры с технологиями зеркалирования данных, для коррекции ошибок, используется память FBDIMM ECC, а в старших моделях реализовано резервирование питания с технологией HOT-SWAP, что позволяет уберечь сервер от остановки даже при выходе из строя одного блока питания. Опционально данные серверы могут монтироваться в 19 дюймовую стойку.

FTP (File Transfer Protocol - Протокол передачи файлов) позволяет передавать файлы между двумя компьютерами, соединенными средствами Internet. Для доступа к FTP вам нужна программа-клиент для соединения с машиной, содержащей файлы (сервером) Если в вашей системе есть FTP-клиент и вы соединены с Internet, вы можете получить доступ к очень большому количеству файлов, доступных на FTP-серверах. Если у вас нет прямого доступа к FTP, вам следует обратить свое внимание на серверы, позволяющие получить доступ к FTP средствами E-mail.
Большое количество серверов в Internet предоставляют доступ к файлам средствами так называемого Anonymous FTP. Это значит, что вы можете получить доступ к машине не являясь ее официальным пользователем. Эти сервера содержат программное обеспечение, документы различного рода, картинки, тексты песен и тому подобное. Гигантский объем информации на таких серверах доступен любому.
Что бы соединится с сервером просто наберите команду ftp, а затем имя системы, с которой хотите соединиться, например, ftp ftp.lipetsk.su
Через несколько секунд появится запрос login: Если вы не являетесь официальным пользователем системы, введите Anonymous. Затем появится запрос Password: Что вы введете в общем-то не имеет значения, но согласно неписанным правилам, вы должны ввести свой E-mail адрес, поскольку операторы серверов были бы не прочь узнать, кто использует их сервер. После этого вы увидите приглашение сервера (обычно ftp>) Вы в системе. Вы можете посмотреть список директорий, набрав команду dir. Если сервер использует Unix и dir не работает, попробуйте ls -l. Обычно сервер имеет файл с именем README или 00-index.txt, содержащий в себе краткое описание сервера и местонахождения файлов. Надо отметить, что FTP-клиенты, встроенные в Web-browser'ы выполняют всю процедуру соединения автоматически. Так же поступают и специализированные FTP-клиенты типа CuteFTP, команды FTP.
Все команды FTP используются для получения файлов. Некоторые команды одинаковы для всех серверов, некоторые нет. Также, некоторые серверы поддерживают свои собственные команды, например, получение целой директории одной командой, поиск по директориям, etc. Прочтите содержащийся почти на каждом сервера файл README для получения информации о таких командах. Обычно FTP-сервер выдает список команд в ответ на команду help или? Итак, основные команды:
ASCII - переключение в ASCII режим. Этот режим является стандартным для передачи текстов.
Binary - переключение в двоичный режим. Для передачи архивов, картинок,
Cd - cмена директории на сервере.
Dir - список файлов в текущей директории сервера.
Get - копирует файл с сервера на ваш компьютер.
Help - список доступных команд.
LCD - cмена директории на вашем компьютере.
Lpwd - показывает текущую директорию вашего компьютера
Mget - получение сразу нескольких файлов по маске
Pwd - показывает текущую директорию на сервере.
Итак, вы в системе. Вы можете осмотреться, выбрать интересующие вас файлы и получить их (большинство серверов не позволяет пользователям самим посылать файлы) Обычно все самое интересное находится в директории /pub. Помните, что в Unix-системах вместо обратной дроби (\) используется прямая (/). Некоторые сервера содержат файлы типа ls-lR, которые содержат полный список имеющихся на сервере файлов. Если такового не имеется, вы можете набрать ls -lR и получить такой список. Однако помните, что это может занять много времени (списки размером 10 Mb не являются редкостью)
При приеме нетекстовых файлов вы должны использовать двоичный режим. Перед получением файла наберите команду binary. Обычно файлы хранятся в сжатом виде. Чаще всего в Unix-системах используется программа compress, результатом работы которой являются файлы с расширением.Z. Встречаются также Arc, Zoo, Arj, Lzh, Gz, Zip, в соответствии с используемой программой компрессии. Проблемой может стать получение файлов вида filename.tar.gz. MS-DOS не воспринимает подобные имена файлов, поэтому для получения такого файла используйте следующую схему:
get filename.tar.Z filename.tz Затем используйте последовательно compress и tar для распаковки файла. Многие сервера поддерживают режим on-line распаковки файлов на лету (на тот случай, если у вас нет утилит для декомпрессии файлов) Используйте следующую схему: get filename.z filename Вы получите распакованный файл. Помните, что передача такого файла займет больше времени, чем передача сжатого.
Распределенная система обычно имеет два существенно отличающихся компонента - непосредственно файловый сервис и сервис директорий.
Интерфейс файлового сервера
Для любой файловой системы первый фундаментальный вопрос - что такое файл. Во многих системах, таких как UNIX и MS-DOS, файл - не интерпретируемая последовательность байтов. На многих централизованных ЭВМ (IBM/370) файл представляется последовательность записей, которую можно специфицировать ее номером или содержимым некоторого поля (ключом). Так, как большинство распределенных систем базируются на использовании среды UNIX и MS-DOS, то они используют первый вариант понятия файла.
Файл может иметь атрибуты (информация о файле, не являющаяся его частью). Типичные атрибуты - владелец, размер, дата создания и права доступа. Важный аспект файловой модели - могут ли файлы модифицироваться после создания. Обычно могут, но есть системы с неизменяемыми файлами. Такие файлы освобождают разработчиков от многих проблем при кэшировании и размножении.
Защита обеспечивается теми же механизмами, что и в однопроцессорных ЭВМ - мандатами и списками прав доступа. Мандат - своего рода билет, выданный пользователю для каждого файла с указанием прав доступа. Список прав доступа задает для каждого файла список пользователей с их правами. Простейшая схема с правами доступа - UNIX схема, в которой различают три типа доступа (чтение, запись, выполнение), и три типа пользователей (владелец, члены его группы, и прочие).
Файловый сервис может базироваться на одной из двух моделей - модели загрузки/разгрузки и модели удаленного доступа. В первом случае файл передается между клиентом (памятью или дисками) и сервером целиком, а во втором файл сервис обеспечивает множество операций (открытие, закрытие, чтение и запись части файла, сдвиг указателя, проверку и изменение атрибутов, и т.п.). Первый подход требует большого объема памяти у клиента, затрат на перемещение ненужных частей файла. При втором подходе файловая система функционирует на сервере, клиент может не иметь дисков и большого объема памяти.
Какие могут быть файловые серверы: способы организации
- Компьютер пользователя. В самом простом варианте, если в корпоративной сети немного пользователей (порядка 10-15), то в качестве файлового сервера может быть использован любой компьютер пользователя в сети компании. Это, конечно, далеко не лучший вариант, поскольку при перезагрузке или выключении этого компьютера сеть оказывается без файлового сервера. Кроме того, пользовательские операционные системы мало подходят для работы в качестве сервера.
- Выделенный серверс установленной ОС (Windows Server или Unix), на котором системный администратор настраивает роль файлового сервера. Это самый дорогой вариант, но и самый универсальный, поскольку все настройки можно сделать точно в соответствии с требованиями.
- Выделенный сервер без предустановленной ОС, например файловый сервер FreeNAS. Этот программный сервер предназначен только для системы файлового хранения. Такой метод дает возможность самостоятельно выбрать оборудование, но разворачивание займет больше времени.
- Решение под ключ. Представляет собой сервер, на котором производителем или поставщиком предустановлена система с настроенным сервисом хранения данных. Такой вариант удобен тем, что он требует не более 10 минут настройки для последующей работы. Это также недешевый вариант и имеющий некоторые ограничения, поскольку все настройки предусмотрены разработчиками.
Преимущества файлового сервера
Для многих компаний решающим критерием при использовании файлового сервера в корпоративной сети является возможность централизованного управления и разграничения прав доступа между пользователями различных подразделений. Кроме того, легко можно обеспечить возможность коллективной работы над документами, исключив при этом проблему использования разных версий одного документа разными пользователями.
Другое преимущество файлового сервера — это устранение ресурсных ограничений для пользователей. За исключением личных файлов все рабочие документы и их резервные копии могут быть размещены на общем сервере. При правильной организации структуры папок и директорий пользователи получают единообразное представление всех доступных документов в организации в соответствии со своими правам доступа.
Если файловый сервер сконфигурирован для работы через интернет, то файлы так же доступны для удаленной работы, как и при работе в локальной сети. Но, в отличие от облачного решения, компания продолжает сохранять контроль над файлами и их безопасностью. Это явное преимущество перед сторонними решениями по хранению корпоративной информации.
Проблемы файловых серверов
Несмотря на явные преимущества, перечисленные выше, проблемы у файловых серверов тоже есть.
Компании часто недооценивают объем работы по установке, настройке и обслуживанию такого оборудования и ПО, как файловый сервер. Иногда к этой работе подходят без должного планирования. В результате не только аппаратные ресурсы быстро подходят к своим пределам использования, но также и многие потенциальные преимущества файлового сервера не могут проявиться в полной мере. Например, при отсутствии четких принципов распределения прав доступа пользователи часто не могут соответствующим образом выполнить свои обязанности, т. к. не могут получить необходимые данные. Проблемы могут возникнуть также из-за беспорядочного и бессистемного построения иерархии папок и каталогов, если вообще такой иерархии кто-то придерживается.
Эти аспекты необходимо продумать с самого начала, перед покупкой и установкой файлового сервера. Также предварительной проработки требуют вопросы защиты данных и информационной безопасности, особенно, если файловый сервер предназначен для удаленной работы через интернет. Установка и правильная конфигурация программ информационной безопасности так же критична, как и обучение сотрудников, которые получают доступ к серверу. Требуется четкое понимание персоналом того, где и как хранить свои рабочие файлы на сервере, чтобы исключить ситуации информационного хаоса.
Читайте также: