
Способы преобразования неструктурированных файлов
Термин «неструктурированные данные» подразумевает данные, неупорядоченные и произвольные по форме, однако этот тип информации все же обладает определенной структурой. На сегодняшний день существует большое разнообразие данных и, как следствие, появляется необходимость их интерпретировать. Среди задач интерпретации можно выделить прогнозирование, классификацию, кластеризацию, ассоциацию, поиск последовательностей, визуализацию данных, анализ отклонений. Сложность обработки заключается в том, что сами данные могут различаться не только с точки зрения формата, но и с точки зрения своей структуры. Одной из ключевых задач при работе с неструктурированными данными является поиск и выявление закономерностей с целью их понимания и разработки шаблонов заполнения. В работе проводится анализ правил оформления библиографических источников с целью выявления общих закономерностей. Затрагиваются понятия структурированных и неструктурированных данных. Рассматриваются существующие направления работы с неструктурированными данными и способы их обработки, в частности, правила оформления библиографических списков литературных источников. На основании этих правил сформированы шаблоны, состоящие из смысловых групп, на основе примеров соответствующих списков библиографических источников. При итоговом сравнении полученных шаблонов выявлены как общие черты, объединяющие все рассмотренные шаблоны, так и черты, их разделяющие.
Ключевые слова
Шаблоны Grok
Встроенные шаблоны Grok
Logstash поставляется с более чем 100 встроенными шаблонами для структурирования неструктурированных данных. Вы определенно должны воспользоваться этим преимуществом, когда это возможно для общих системных журналов, таких как apache, linux, haproxy, aws и так далее.
Однако что происходит, когда у вас есть пользовательские журналы, как в приведенном выше примере? Вы должны построить свой собственный шаблон Grok.
Кастомные шаблоны Grok
Нужно пробовать, чтобы построить свой собственный шаблон Grok. Я использовал Grok Debugger и Grok Patterns.
Обратите внимание, что синтаксис шаблонов Grok выглядит следующим образом: %
Первое, что я попытался сделать, это перейти на вкладку Discover в отладчике Grok. Я подумал, что было бы здорово, если бы этот инструмент мог автоматически генерировать шаблон Grok, но это было не слишком полезно, так как он нашел только два совпадения.

Используя это открытие, я начал создавать свой собственный шаблон на отладчике Grok, используя синтаксис, найденный на странице Github Elastic.

Поиграв с разными синтаксисами, я наконец-то смог структурировать данные журнала так, как мне хотелось.

То что получилось в итоге
Имея в руках шаблон Grok и сопоставленные данные, последний шаг — добавить его в Logstash.
Обновление файла конфигурации Logstash.conf
На сервере, на котором вы установили стек ELK, перейдите к конфигурации Logstash:
После сохранения изменений перезапустите Logstash и проверьте его состояние, чтобы убедиться, что он все еще работает.
Наконец, чтобы убедиться, что изменения вступили в силу, обязательно обновите индекс Elasticsearch для Logstash в Kibana!

С Grok ваши данные из логов структурированы!

Как мы видим, на изображении выше, Grok способен автоматически сопоставлять данные журнала с Elasticsearch. Это облегчает управление журналами и быстрый запрос информации. Вместо того чтобы рыться в файлах журналов для отладки, вы можете просто отфильтровать то, что вы ищете, например среду или url-адрес.
Попробуйте дать Grok expressions шанс! Если у вас есть другой способ сделать это или у вас есть какие-либо проблемы с примерами выше, просто напишите комментарий ниже, чтобы сообщить мне об этом.
Спасибо за чтение — и, пожалуйста, следуйте за мной здесь, на Medium, для получения более интересных статей по программной инженерии!
Тема анализа неструктурированных данных сама по себе не нова. Однако в последнее время в эпоху «больших данных» этот вопрос встаёт перед организациями гораздо острее. Многократный рост объёмов хранимых данных в последние годы, его постоянно увеличивающиеся темпы и нарастающее разнообразие хранимой и обрабатываемой информации существенно усложняют задачу управления корпоративными данными. С одной стороны, проблема имеет инфраструктурный характер. Так, по данным IDC, до 60% корпоративных хранилищ занимает информация, не приносящая организации никакой пользы (многочисленные копии одного и того же, разбросанные по разным участкам инфраструктуры хранения данных; информация, к которой никто не обращался несколько нет и уже вряд ли когда-нибудь обратится; прочий «корпоративный мусор»).

С другой стороны, неэффективное управление информацией ведёт к увеличению рисков для бизнеса: хранение персональных данных и прочей конфиденциальной информации на общедоступных информационных ресурсах, появление подозрительных пользовательских зашифрованных архивов, нарушения политик доступа к важной информации и т.д.
В этих обстоятельствах умение качественно анализировать корпоративную информацию и оперативно реагировать на любые несоответствия её хранения политикам и требованиям бизнеса является ключевым показателем зрелости информационной стратегии организации.
Теме аналитики файловых данных посвящён отдельный документ Gartner, вышедший в сентябре 2014 г. под названием «Market Guide for File Analysis Software». В данном документе приводятся следующие типовые сценарии использования аналитического ПО:
-
Оптимизация хранения. Наиболее типичный сценарий. Целью внедрения файловой аналитики является снижение объёма хранимых данных, и, тем самым, повышение эффективности их хранения.
В данной статье будет сделан технический обзор обоих продуктов.
Типичные области применения ECM
I. В центре обработки телефонных звонков заказчиков для ответа на вопросы заказчика надо найти необходимые документы, которых под рукой нет; в таких случаях оператор просит перезвонить. В большинстве случаев заказчик больше не перезванивает; клиент потерян, убытки налицо.
II. Коллектив авторов составлял сложный документ, готовил несколько версий различных частей документа. Наконец, работа закончена, документ передан начальству. Один из авторов уехал (уволился, заболел и т.д.). Неожиданно, понадобилась предыдущая редакция документа. Вряд ли без ECM ее удастся восстановить.
III. В американской компании Enron документы, для которых по закону был установлен срок хранения в несколько лет, были случайно (или намеренно) уничтожены. В результате руководство компании попало под суд. Если бы использовались средства ECM с системой обеспечения регламентов хранения/уничтожения документов, то случайное удаление документов было бы невозможно.
IV. Сегодня все работают с системами электронной почты. Почтовые ящики регулярно переполняются и их надо чистить; из-за этого система часто становится недоступной, а при большом объеме писем она работает медленно. Кроме того, у нас зачастую считается, что корпоративная электронная почта — это собственность и личное дело владельца почтового ящика. Между тем, в переписке содержится много информации, полезной для разных сотрудников компании, которая может пригодиться в будущем. Вот почему во многих западных компаниях электронная почта — это корпоративное имущество. Вся корреспонденция (или, по крайней мере, ее часть) автоматически помещается на хранение в систему ECM, и в будущем при поиске информации на определенную тему будут найдены и документы, и письма, и — возможно — даже результаты телеконференций.
V. В организации создается несколько порталов — внутренний, внешний, тематический и т.д. Часть информации они разделяют. Если нет единой системы управления содержанием, то у каждого портала будет свое хранилище неструктурированных данных, следствием чего станет дублирование информации, ее несогласованность, несвоевременная корректировка и т.д. ECM решает эту проблему.
Об авторах
Томашевская Валерия Сергеевна, кандидат технических наук, доцент кафедры корпоративных информацион-ных систем Института информационных технологий ФГБОУ ВО
119454, Россия, Москва, пр-т Вернадского, д. 78
Яковлев Дмитрий Андреевич, аспирант кафедры корпоративных информационных систем Института информационных технологий ФГБОУ ВО
119454, Россия, Москва, пр-т Вернадского, д. 78
HP Storage Optimizer: анализ данных с целью оптимизации их хранения
HP Storage Optimizer объединяет в себе возможности по анализу метаданных объектов в репозиториях неструктурированной информации и назначению политик их иерархического хранения.
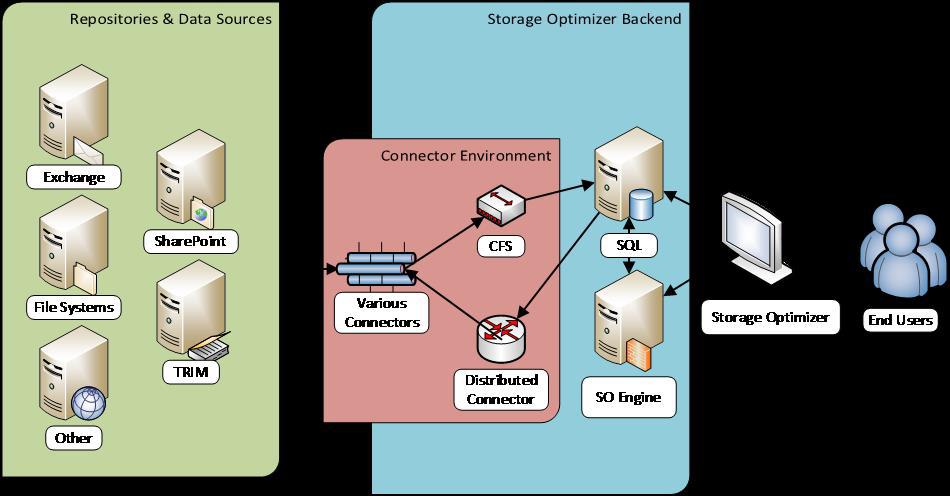
Архитектура HP Storage Optimizer
Источники анализируемой информации в терминологии HP Storage Optimizer называются репозиториями. В качестве репозиториев поддерживаются различные файловые системы, а также MS Exchange, MS SharePoint, Hadoop, Lotus Notes, Documentum и многие другие. Есть также возможность заказать разработку коннектора к репозиторию, который в настоящее время не поддерживается продуктом.
HP Storage Optimizer использует собственные соответствующие коннекторы для обращения к анализируемым репозиториям. Информация с коннекторов поступает в компонент под названием Connector Framework Server (обозначенный как «CFS» на картинке), который, в свою очередь, обогащает её дополнительными метаданными и направляет получившиеся данные на индексирование. Для повышения отказоустойчивости и балансировки нагрузки при взаимодействии приложения с коннекторами используется компонент Distributed Connector.
Метаданные индексируются «движком» HP Storage Optimizer Engine («SO Engine» на первой картинке) и помещаются в БД MS SQL. Для доступа к результатам анализа и назначения политик управления используется веб-приложение HP Storage Optimizer.
Для наглядного отображения информации, потенциально подлежащей оптимизации, в HP Storage Optimizer используются круговые диаграммы (ниже), показывающие дубликаты данных, редковостребованные и «ненужные» данные (ROT analysis: Redundant, Obsolete, Trivial). Критерии «редковостребованности» и «ненужности» можно гибко настроить, в том числе индивидуально для каждого репозитория. Кроме круговых диаграмм, доступны графики, иллюстрирующие разбивку данных по типам, времени и частоте добавления и др. Все элементы визуализации интерактивны, т.е. позволяют переходить в какую-либо категорию диаграммы (или столбец) и получать доступ к соответствующим данным.

Графический анализ данных в HP Storage Optimizer
Перечень метаданных, по которым может быть проведён анализ, необычайно широк и даёт возможность осуществлять высокоточные тематические выборки.

Пример работы с метаданными в HP Storage Optimizer
Хотелось бы заметить, что в состав продуктов HP Storage Optimizer и HP Control Point входит «движок» индексирования и визуализации, позволяющий просматривать более 400 различных форматов данных без установки на сервер соответствующих приложений для предпросмотра. Это значительно упрощает и ускоряет процесс анализа большого количества разноплановой информации.
После того как анализ данных проведён, администратору системы предоставляется возможность назначить политики удаления или перемещения данных. Политики на те или иные выборки данных возможно назначать как вручную, так и автоматически. Мощная ролевая модель управления, реализованная в HP Storage Optimizer и в HP Control Point, даёт возможность выдавать полномочия по работе с репозиториями, анализу данных в них, а также по назначению политик, максимально гибко.
Когда нужна система ECM
В России, говоря о работе с неструктурированными данными, в первую очередь обычно подразумевают систему документооборота. Действительно, на основе ECM можно построить такую систему, но сегодня есть масса самых разных готовых, коробочных систем документооборота. Однако, если в организации надо создать сразу несколько систем для работы с неструктурированными данными — если, к примеру, нужна система документооборота, электронная библиотека, архив документов, порталы, система долгосрочного хранения электронной почты и документов пакетных приложений, система «видео по требованию», система совместной работы с документами и т.д., — то разумнее не внедрять множество разнородных, не связанных между собой систем, а построить их на единой платформе управления содержанием.
Когда-то каждый программист создавал свою собственную информационную систему с нуля, придумывал структуру файлов, пытался встроить средства обеспечения мультидоступа и защиты данных, оптимизировал работу системы и т.д. Каждый делал это заново, по-своему; качество реализации, как правило, было невысоким. Со временем стало ясно, что любой информационной системе нужны стандартные функции для работы с данными. Были разработаны коммерческие СУБД, которые реализовали этот функционал. Системы для работы с неструктурированными данными сейчас проходят тот же путь — от множества доморощенных разнородных систем к единой коммерческой платформе.
Заключение
Как видно из текущего обзора, спектр применения HP Storage Optimizer и HP Control Point для решения задач анализа и управления корпоративными данными весьма широк. Кроме того, возможности анализа документов на разных языках (включая русский), а также масштабируемая архитектура компонентов обоих продуктов позволяет эффективно решать задачи по анализу всего объёма неструктурированных данных в организациях любого масштаба и сложности.
Автор статьи – Максим Луганский, технический консультант, Data Protection & Archiving, HP Big Data
ETL означает извлечение, преобразование и загрузку. Это относится к процессу сбора данных из нескольких источников и подготовки данных для интеграции и загрузки на целевую платформу, такую как хранилище данных или аналитическая среда.
ELT аналогичен, но загружает данные в необработанном формате, оставляя преобразования для людей, чтобы они могли применить их для «самостоятельной аналитики». Оба метода являются типичными примерами развертывания конвейера данных.
Что такое ETL?
ETL (Extract, Transform, Load) — это аббревиатура автоматизированной методологии разработки конвейера данных, с помощью которой данные собираются и подготавливаются для последующего использования в аналитической среде, такой как хранилище данных.
Извлечение данных (Extract)
Извлечение данных — это первый этап процесса ETL, когда данные извлекаются из различных исходных систем. Данные могут быть полностью необработанными, например данные датчиков с устройств, или ,это неструктурированные данные из отсканированных медицинских документов или электронных писем компании. Это могут быть потоковые данные, поступающие из сети социальных сетей или транзакции покупки/продажи на фондовом рынке практически в режиме реального времени, или они могут поступать из существующих корпоративных баз данных и хранилищ данных.
Трансформация (Transform)
На этапе преобразования к данным применяются правила и процессы для их подготовки к загрузке в целевую систему. Обычно это делается в промежуточной рабочей среде, называемой «площадкой подготовки» («staging area» ). Здесь данные очищаются для обеспечения надежности и согласования для обеспечения совместимости с целевой системой. Могут быть применены многие другие преобразования, в том числе:
Очистка: исправление любых ошибок или отсутствующих значений
Фильтрация: выбор только необходимого
Присоединение: объединение разрозненных источников данных
Нормализация: преобразование данных в общепринятые единицы
Структурирование данных: преобразование одного формата данных в другой, например JSON, XML или CSV, в таблицы базы данных.
Разработка функций: создание KPI для информационных панелей или машинного обучения.
Анонимизация и шифрование: обеспечение конфиденциальности и безопасности
Сортировка: упорядочивание данных для повышения эффективности поиска.
Агрегирование: суммирование подробных данных
Нагрузка (Load)
Фаза загрузки заключается в записи преобразованных данных в целевую систему. Система может быть такой же простой, как файл с разделителями-запятыми, который по сути является просто таблицей данных, такой как электронная таблица Excel. Целью также может быть база данных, которая может быть частью гораздо более сложной системы, такой как хранилище данных, витрина данных, озеро данных или какое-либо другое унифицированное централизованное хранилище данных, формирующее основу для анализа, моделирования и обработки данных.
Сценарий использования:
Процесс извлечения получает данные из одного или нескольких источников.
Процесс преобразования преобразует данные в формат, подходящий для их назначения и предполагаемого использования.
Окончательный процесс загрузки принимает преобразованные данные и загружает их в новую среду, готовую к визуализации, исследованию, дальнейшему преобразованию и моделированию.
Что такое ELT?
ELT (Extract, Load, Transform) — это аббревиатура для конкретной методологии проектирования автоматизированных конвейеров данных.
Почему появился ELT?
Решения для облачных вычислений развиваются с огромной скоростью из-за требований больших данных. Они могут легко обрабатывать огромные объемы асинхронных данных, которые могут быть распределены по всему миру. Ресурсы облачных вычислений практически не ограничены и могут масштабироваться. В отличие от традиционного локального оборудования, вы платите только за используемые вычислительные ресурсы.
Таким образом, ELT является гибким вариантом, позволяющим использовать различные приложения из одного и того же источника данных. Поскольку вы работаете с репликой исходных данных, потери информации нет. Многие виды преобразований могут привести к потере информации, и если это происходит где-то выше по потоку в конвейере, может пройти много времени, прежде чем вы сможете удовлетворить запрос на изменение. Что еще хуже, информация может быть навсегда потеряна, если необработанные данные не будут сохранены.
Сценарий использования:
Процесс извлечения получает данные из всех источников и считывает данные, часто асинхронным образом.
Процесс загрузки берет необработанные данные и загружает их в новую среду, где используются аналитические инструменты.
Процесс преобразования для ELT гораздо более динамичен, чем для обычного ETL, так как можно использовать различные приложения для преобразования данных.
Варианты использования процессов ELT обычно относятся к области высокопроизводительных вычислений и больших данных.
Кейсы включают в себя:
устранение значительных колебаний масштаба, связанных с внедрением продуктов для работы с большими данными;
расчет аналитики в режиме реального времени для потоковой передачи больших данных;
Для работы со структурированными данными имеются достаточно развитые методы, однако неструктурированные данные требуют совсем иного подхода. Мало того, в ряде случаев требуется специальная платформа для построения промышленных систем обработки неструктурированных данных предприятия.

Неструктурированные данные нам хорошо знакомы, мы работаем с ними ежедневно, и их объемы огромны. Лавина документов, фильмов, рисунков и другой информации нарастает ежедневно; работать вручную с ними становится невозможно. Бумажные и видеоархивы занимают в организациях огромное пространство. Найти нужный документ часто становится невозможно.
Для работы с неструктурированными данными предприятия появился новый класс информационных систем, называемый ECM (enterprise content management — «управление содержанием предприятия»). Следует обратить внимание на слово «предприятие»: системы данного класса предназначены не только для решения одной локальной задачи работы с документами, не только для небольших объемов информации. Они могут быть платформой для автоматизации всех задач обработки содержания в рамках и мелких, и огромных территориально распределенных организаций.
Неструктурированные данные есть у всех; вот почему продажи систем ECM непрерывно растут. Помимо стремительного роста объемов неструктурированных данных потребность в ECM стимулируется и новыми требованиями бизнеса. Предприятиям важно обеспечить долговременное хранение и своевременное предоставление корпоративной отчетности: увеличивается ответственность за преждевременное уничтожение или потерю документов, появились строгие регламенты, управляющие сроками хранения документов, активно развиваются технологии порталов, основанные на работе с содержанием. Игроков на рынке серьезных систем ECM сегодня не так уж много (Таблица 1).
Неструктурированные данные из логов
Если вы внимательно посмотрите на необработанные данные, то увидите, что они на самом деле состоят из разных частей, каждая из которых разделена пробелом.
Структурированный вид наших данных
- localhost == environment
- GET == method
- /v2/applink/5c2f4bb3e9fda1234edc64d == url
- 400 == response_status
- 46ms == response_time
- 5bc6e716b5d6cb35fc9687c0 == user_id
Как мы видим в структурированных данных, существует порядок для неструктурированных журналов. Следующий шаг – это программная обработка необработанных данных. Вот где Грок сияет.
Архитектура IBM Content Manager
IBM Content Manager состоит из двух основных компонентов, библиотечного сервера и менеджера ресурсов (рис. 1). Они могут размещаться на одном или на разных компьютерах. Метаданные, которые описывают созданные типы документов, папки, связи и т.д., хранятся в библиотечном сервере. Там же хранятся значения атрибутов документов и индексы для полнотекстового поиска.
Библиотечный сервер — это сервер баз данных DB2 с набором дополнительных хранимых процедур. Все запросы на поиск документов преобразуются в SQL-операторы и выполняются на библиотечном сервере.
IBM Content Manager позволяет работать с несколькими менеджерами ресурсов, которые могут располагаться на компьютерах с разными операционными системами. Данные, запрашиваемые с менеджера ресурсов, кэшируются, поэтому повторные обращения выполняются быстрее. Можно настроить систему так, чтобы при сбое одного менеджера она автоматически обращалась к резервному менеджеру, что обеспечивает повышенную надежность.
IBM Content Manager — ядро системы для работы с неструктурированными данными. При необходимости к ядру можно добавить ряд дополнений (Таблица 2). Records Manager обеспечивает соблюдение сроков хранения документов. Content Manager On Demand служит для захвата стандартных документов (чеки, накладные, счета и т.д.). Для работы со сложными составными документами, извещениями пользователей по электронной почте и с чертежами используется DB2 Document Manager, который, в частности, поддерживает документы в форматах AutoCAD, MicroStation, AutoVue, Myriad. Компонент CommonStore, существующий в трех видах (для Lotus Domino, для Microsoft Exchange, для SAP R/3), позволяет автоматически (в соответствии с указанной политикой) или вручную помещать письма, присоединенные файлы, документы на хранение в IBM Content Manager. После этого они становятся доступными для поиска, а размер базы данных в приложении значительно уменьшается. Открыв письмо, пользователь видит ссылку на месте текста или присоединенного файла; нажав на нее, он может открыть текст или присоединенный файл. При архивировании писем атрибуты документа могут браться из полей заголовка письма («от кого», «кому», «тема» и т.д.). Можно настроить систему таким образом, чтобы в IBM Content Manager уходили только старые письма, письма от конкретных адресатов и т.д. Использование CommonStore не только превращает письма в корпоративное имущество, но и упрощает администрирование архива, повышает надежность системы и ее быстродействие. Lotus WorkPlace Web Content Manager позволяет без помощи Web-мастера разрабатывать Web-страницы, описывать потоки документов для создания и публикации Web-содержания.
Рецензия
Для цитирования:
For citation:
Контент доступен под лицензией Creative Commons Attribution 4.0 License.
Поиск ссылок
Послать статью по эл. почте (Необходимо имя пользователя (логин))
Связаться с автором (Необходимо имя пользователя (логин))
В. С. Томашевская
МИРЭА – Российский технологический университет
Россия
Томашевская Валерия Сергеевна, кандидат технических наук, доцент кафедры корпоративных информацион-ных систем Института информационных технологий ФГБОУ ВО
119454, Россия, Москва, пр-т Вернадского, д. 78
Д. А. Яковлев
МИРЭА – Российский технологический университет
Россия
Яковлев Дмитрий Андреевич, аспирант кафедры корпоративных информационных систем Института информационных технологий ФГБОУ ВО
Если вы используете стек Elastic (ELK) и заинтересованы в сопоставлении пользовательских журналов Logstash с Elasticsearch, то этот пост для вас.

Стек ELK – это аббревиатура для трех проектов с открытым исходным кодом: Elasticsearch, Logstash и Kibana. Вместе они образуют платформу управления журналами.
- Elasticsearch – это поисковая и аналитическая система.
- Logstash – это серверный конвейер обработки данных, который принимает данные из нескольких источников одновременно, преобразует их и затем отправляет в “тайник”, например Elasticsearch.
- Kibana позволяет пользователям визуализировать данные с помощью диаграмм и графиков в Elasticsearch.
Beats появился позже и является легким грузоотправителем данных. Введение Beats преобразовало Elk Stack в Elastic Stack, но это не главное.
Эта статья посвящена Grok, которая является функцией в Logstash, которая может преобразовать ваши журналы, прежде чем они будут отправлены в тайник. Для наших целей я буду говорить только об обработке данных из Logstash в Elasticsearch.

Grok-это фильтр внутри Logstash, который используется для разбора неструктурированных данных на что-то структурированное и подлежащее запросу. Он находится поверх регулярного выражения (regex) и использует текстовые шаблоны для сопоставления строк в файлах журналов.
Как мы увидим в следующих разделах, использование Grok имеет большое значение, когда речь заходит об эффективном управлении журналами.
Без Grok ваши данные журнала Неструктурированы

Список литературы
2. Антонов С.И., Редько С.Г. Автоматизация управления неструктурированными данными в рамках системы управления контентом на предприятии. Научно-технические ведомости СПбГПУ. Инноватика. 2009;5:277–282.
4. Дядичев В.В., Ромашка Е.В., Голуб Т.В., Задачи и методы интеллектуального анализа данных. Геополитика и экогеодинамика регионов. 2015;1-11(3):23–29.
5. Амаева Л.А. Сравнительный анализ методов интеллектуального анализа данных. Инновационная наука. 2017;2(1):27–29.
6. Климко Е.Г. Программно-алгоритмические средства интеллектуального анализа данных. Радиоэлектроника и информатика. 2001;3:64–67.
7. Юсков В.С., Баранникова И.В. Сравнительный анализ платформ обработки естественного языка. Горный информационно-аналитический бюллетень. 2017:3:272–278.
8. Цитульский А.М., Иванников А.В., Рогов И.С. Интеллектуальный анализ текста. Научно-образовательный журнал для студентов и преподавателей «StudNet». 2020;6:476–483.
9. Укуев Б.Т. Особенности обработки неструктурированных данных в информационной базе научных исследований ВУЗа. Современная наука: актуальные проблемы теории и практики. Серия: Естественные и технические науки. 2018;03:75–76.
10. Цитульский А.М., Иванников А.В., Рогов И.С. NLP – Обработка естественных языков. Научно-образовательный журнал для студентов и преподавателей «StudNet». 2020;6:467–475.
Одной из ключевых задач при работе с неструктурированными данными является поиск и выявление закономерностей с целью их понимания и разработки шаблонов заполнения. В работе проводится анализ правил оформления библиографических источников с целью выявления общих закономерностей. Рассматриваются существующие направления работы с неструктурированными данными и способы их обработки, в частности, правила оформления библиографических списков литературных источников. На основании этих правил сформированы шаблоны, состоящие из смысловых групп.
HP Control Point: комплексный анализ для снижения бизнес-рисков, связанных с хранением данных
HP Control Point, по сути, представляет собой расширенную версию HP Storage Optimizer и предоставляет инструментарий не только для решения задач по оптимизации хранения, но и для внедрения политик хранения и управления жизненным циклом корпоративной информации.
Продукт позволяет проводить анализ информации не только по метаданным, но и по её содержимому. Кроме того, в нём реализованы дополнительные механизмы анализа данных и назначения политик по работе с ними.
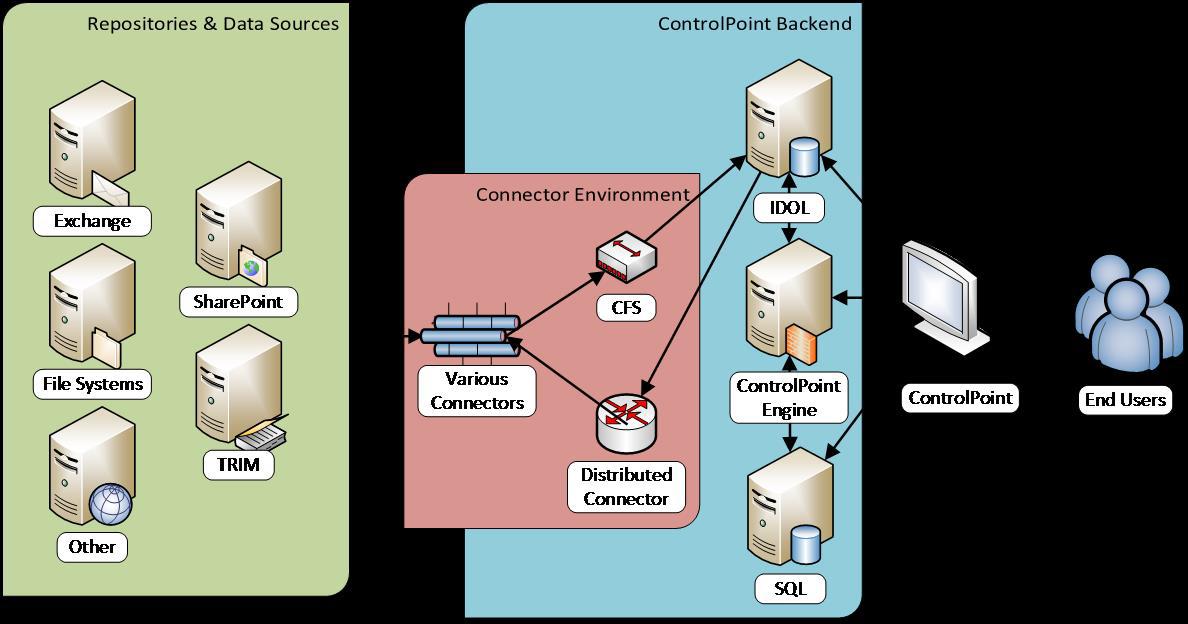
Архитектура HP Control Point
В отличие от HP Storage Optimizer, в HP Control Point широко используются возможности индексирования и смысловой категоризации информации «движка» HP IDOL (Intelligent Data Operating Layer): визуализация, категоризация, тэгирование и др. В его основе лежит возможность определять «смысл» набора анализируемой информации независимо от её формата, языка и т.д.
В частности, в HP Control Point дополнительно доступны два типа визуализации информации: кластерная карта и спектрограф. Кластерная карта представляет собой двухмерное изображение информационных «кластеров». Один кластер объединяет в себе информацию, имеющую схожий смысл. Таким образом, глядя на кластерную карту, можно быстро получить понимание основных смысловых групп этой информации. Кластерные карты интерактивны, т.е. позволяют с помощью кликов на те или иные кластеры получать доступ к информации, содержащейся в них.

Внешний вид кластерной карты в HP Control Point
Спектрограф представляет собой набор информационных кластеров, снятых в различные моменты времени и даёт возможность графически отследить, как менялся смысл информации в анализируемых репозиториях с течением времени.

Внешний вид спектрограммы в HP Control Point
Помимо расширенных возможностей визуализации информации, в HP Control Point доступна возможность категоризации анализируемой информации. Изначально информация категоризируется автоматически – средствами HP IDOL, выдавая пользователю системы массив данных, разбитый на смысловые части. Получив первичное разбиение, аналитик далее может сделать более выверенную категоризацию. Например, использовать какой-либо набор файлов, заведомо для аналитика релевантных той или иной категории, для «тренировки» категории на этот набор файлов, чтобы впоследствии получать более точные результаты категоризации. Для ещё более тонкой настройки можно использовать индивидуальные весовые коэффициенты файлов и даже фраз и отдельных слов внутри файлов, отражающие степень соответствия тех или иных единиц информации «тренируемой» категории. Такая детализация может использоваться, например, для создания подробных правил отнесения анализируемой информации к разряду конфиденциальной.
Что касается политик работы с анализируемой информацией, то в HP Control Point кроме копирования, переноса и удаления доступны также следующие опции:
– «Заморозка» объектов. Позволяет заблокировать доступ к отдельным объектам, не допуская их несанкционированное изменение или удаление.
– Создание рабочего процесса (workflow). Например, информирование или запрос утверждения уполномоченного сотрудника или владельца анализируемых объектов перед их переносом или удалением.
– Безопасный перенос в систему управления корпоративными записями HP Records Manager (например, в случае выявления несанкционированного присутствия конфиденциальных документов на общедоступном файловом сервере). При этом переносимые данные сопровождаются метаданными, которые будут использованы для дальнейшего управления документами в системе HP Records Manager с необходимыми настройками доступа, уровнями секретности и т.п.
IBM Content Manager
Программное обеспечение IBM Content Manager выполняет основные функции работы с неструктурированными данными — ввод или захват данных, хранение, поиск и предоставление. В качестве данных могут выступать:
Для простоты все эти виды неструктурированных данных будем называть документами.
Прежде чем вводить информацию в систему, надо спроектировать типы документов. В типе документа описывается сам документ (он может быть и составным) и его атрибуты, которые используются при поиске. Структура атрибутов может быть достаточно сложной; можно создавать групповые атрибуты, отношения атрибутов «один ко многим», атрибуты со многими значениями и т.д. Проектирование типа документа осуществляется с использованием визуального инструментария и не представляет большого труда.
IBM Content Manager работает практически со всеми промышленными сканерами. Можно выполнять индивидуальное и потоковое сканирование документов, подключать программы распознавания текстов, извлекать из текста атрибуты. Используя систему Kofax, можно на отсканированном изображении типового документа выделить отдельные поля и поставить их в соответствие с атрибутами документа. После этого при сканировании документов система сама определит тип документа, автоматически выберет, преобразует и сформирует значения атрибутов, распознает текст и загрузит все это в IBM Content Manager. Загружаться может изображение документа, распознанный текст или документ в формате pdf. При вводе распознанных текстов они индексируются, поэтому поиск можно осуществлять не только по значениям атрибутов, но и по содержанию документа.
Помимо хранения введенных документов, IBM Content Manager обеспечивает поддержку их блокировки (если кто-то запросил документ для изменений, остальные смогут только его только читать). Поддерживается контроль версий документов и их частей (если требуется хранить пять версий документа, то только при вводе шестой модификации система удалит первую версию; всегда можно запросить любую из этих пяти версий). Обеспечивается аудит действий, выполняемых с документом и возможность репликации данных в другие системы управления содержанием.
Важная особенность решения от IBM — встроенная поддержка системы иерархического хранения на основе Tivoli Storage Manager. Дело в том, что неструктурированных данных всегда очень много — особенно, если это видео, аудио, изображения или архив большой организации. Как правило, ни при создании СУБД, ни при создании систем для работы с неструктурированными данными никто не задумывается о том, как хранить эти данные и сколько это будет стоить — просто создаются файлы на дисках, где и хранятся данные. Встроенная в IBM Content Manager система иерархического хранения позволяет решить эту задачу.
Допустим, требуется, чтобы введенные в IBM Content Manager документы первоначально были легко доступны и хранились на дорогих и быстрых дисках. Через некоторое время, когда отпадет потребность в частом использовании этих данных или когда частота их использования упадет ниже установленного значения, следует автоматически переместить эти документы на более дешевые устройства хранения. Перемещение производится в соответствии с политиками хранения; при этом IBM Content Manager сам взаимодействует с Tivoli Storage Manager для реализации этих политик. В состав IBM Content Manager входят драйверы к самым разным устройствам хранения (дисковым, ленточным, оптическим и т.д.) и можно подобрать подходящее.
В IBM Content Manager реализован механизм WorkFlow, позволяющий описать путь движения документа, которого в дальнейшем будет придерживаться система. К примеру, отсканированный документ сначала поступает на узел проверки качества сканирования; если качество плохое, он уходит на повторное сканирование, а если хорошее, то на утверждение, затем документ публикуется и т.д. Это удобно, в частности, при построении систем документооборота. Каждый пользователь системы, регистрируясь в ней, указывая свое имя и пароль, видит документы, которые он должен обработать, и, обработав, отправляет их по одному из доступных в этой точке путей. Можно задать точки сбора информации; например, пока сюда не попадет один документ типа А и три документа типа Б, пачка дальше не пойдет.
Предусмотрено два варианта реализации WorkFlow — простой и сложный. В простом варианте маршрут описывается в виде таблицы переходов (куда из данного узла могут направляться документы и по каким условиям); более сложный предусматривает использование MQ WorkFlow. В этом случае при проектировании потоков документов используется графический интерфейс, описываются точки принятия решения, точки сбора и подпотоки. Доступны С++ и Java.
Сегодня актуальность приобретает задача хранения и уничтожения документов в соответствии с заданными регламентами; одни документы должны храниться вечно, другие десять лет, третьи уничтожаются каждый год. Средства управления жизненным циклом информации (information lifecycle management, ILM) описывают правила построения таких систем. IBM Content Manager вместе с компонентом Records Manager позволяют реализовать поддержку жизненного цикла информации. Можно разделить документы на классы, для каждого описав политику их хранения и уничтожения. Система будет ее реализовывать, не позволяя удалять документы с действующим сроком хранения, и наоборот, предлагая избавиться от устаревших документов, чтобы освободить место хранения; однако, решение об уничтожении документов в любом случае должен принимать человек.
Предусмотрен комплекс мер защиты документов от несанкционированного доступа: каждый пользователь должен указать имя и пароль для входа в систему; права доступа и возможность выполнения операций с документами регламентируются списками контроля доступа (access control list, ACL), которые можно задавать для пользователей, для типов документов и даже для отдельных узлов потока документов. В конечном счете, действует суперпозиция этих списков, и каждый пользователь с конкретным документом может сделать только то, что ему позволено в данном узле потока.
В состав IBM Content Manager входит три типа клиентских мест: толстый (Windows-клиент), тонкий (Java-программа) и портлеты. Толстый и тонкий клиенты реализуют большую часть функций системы, но имеют стандартный интерфейс. Специальный API позволяет писать любые программы, работающие с IBM Content Manager. В системе есть точки подключения дополнительной обработки, используя которые можно расширять ее функциональность. Портлеты позволяют вставить окна для работы с IBM Content Manager в портал.
Ключевые слова
Читайте также: