
Способы повышения эффективности работы компьютерных сетей в компании
Повышение эффективности информационных систем требует рассмотрения ее как аппаратно-программной системы, устойчиво функционирующей в процессе поддержки приложений в соответствии с требованиями заказчика. Определение необходимых изменений ИС основывается на данных о ее текущем состоянии и перспективных будущих состояниях, связанных с изменением эффективности. Эти состояния, во-первых, зависят от отраслевых особенностей сложных систем, для которых она является надстройкой, а, во-вторых, подлежат интерпретации с учетом человеческого фактора - предпочтений всех заинтересованных лиц.
Содержание работы
Введение …………………………………………………. ……….……………..3
1 Информационные сети и системы в логистике………….….…….…………. 4
2 Внедрение информационных систем………………………………………… 8
2.1 Общая характеристика проектов внедрения информационных систем …………………………………………………………………………….8
2.2 Назначение и состав методологий внедрения……………………. 10
3 Оценка эффективности информационных систем ………………………….14
3.2 Методы оценки прямого результата ………………………………. 16
3.3 Методики, основанные на идеальности процесса ………………….17
3.4 Квалиметрические методы………………………………………….. 18
3.5 Выбор метода оценки общесистемного и офисного ПО …………..19
3.6 Пример расчета эффективности использования ИС методом TEI.. 22
3.6.1 Методика расчета ТСО ……………………………………. 23
3.6.2 Методика выбора …………………………….………………25
4.0 Пример внедрения ИС в крупное предприятие и его последствия. ……..30
4.1 Передовые технологии ……………………………..……….………..30
4.2 Выбор программных решений ………………….…..………………30
4.3 Выбор системы NX был сделан с учетом нескольких факторов. 31
4.4 Процесс внедрения ………………………………………. …………32
4.5 Инженерные расчеты на предприятии ………………….…..………32
4.6 Итоги внедрения новых технологий………………….……..……. 33
4.7 Результат ……………………………………………….………..……33
Вывод …………………………………………………………..………………. 34
Список литературы …………………………….………….……………………37
Файлы: 1 файл
3.2 Методы оценки прямого результата
Потребительский индекс (Customer index). Этот метод предполагает оценку результатов внедрения ПО в виде совокупности индексов, отражающих положительные изменения в работе компании (увеличение доходов, снижение затрат, увеличение оборотов, увеличение клиентской базы и т.п.).
Applied information economics (AIE – прикладная информационная экономика) – методика аналогична потребительскому индексу, но в отличии от нее также предполагает оценку различных субъективных показателей, например, простота работы с системой, удовлетворенность клиентов и т.п.
Economic value sourced (EVS – источник экономической стоимости). Представляет собой оценку того, какую пользу ПО приносит компании при его использовании, оценивается по четырем показателям: увеличение доходов, повышение производительности труда, сокращение времени выпуска продуктов, снижение рисков.
Economic value added (EVA – экономическая добавленная стоимость). Данная методика предполагает определение эффекта как фактическую прибыль от использования ПО, которая равна чистой операционной прибыли за минусом стоимости капитала. Применительно к ИТ проектам EVA означает, что:
- при использовании капитала в ИТ проектах, необходимо учитывать его стоимость, за него необходимо платить также, как и за труд работников;
- предполагается, что ИТ-специалисты продают свои услуги другим подразделениям по рыночным расценкам.
Это позволяет рассматривать ИТ как центр прибыли, а не затрат, при этом четко отображая, как увеличиваются доходы.
Оптимизация сети
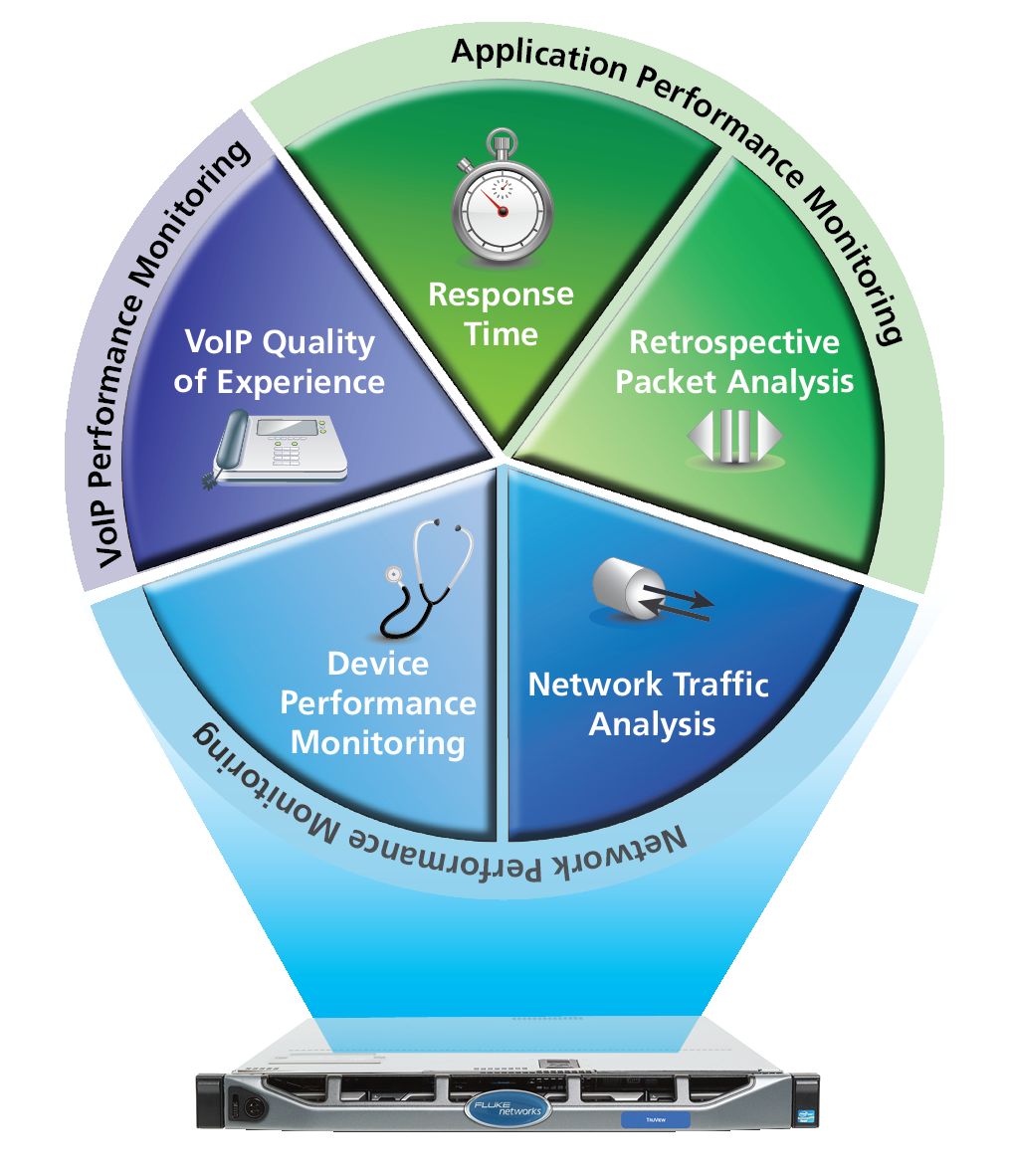
Решение для мониторинга производительности сети и приложений предоставляет инженерам сведения, необходимые для документирования и аудита состояния корпоративной сети. Оно также позволяет им определить замедления в работе приложений и определить, в каких точках работа приложений или серверов замедлена, чтобы внести необходимые изменения. Полученная информация может использоваться для определения приоритетности проектов, таких как обновление серверов и обоснования необходимых изменений. Она также может помочь при установке нового оборудования и приложений, так как инженеры смогут проверить, какие решения сработали, и убедиться, что они не повлияли на производительность других компонентов. Данные также могут подтвердить влияние изменений сети, таких как виртуализация, оптимизация WAN или консолидация центра обработки данных.
Новый подход к решению проблем

Необходимо комплексное решение для анализа производительности сети и приложений, которое захватывает все данные в сети и выполняет интеллектуальный анализ, чтобы инженеры могли быстрее изолировать причину проблемы или определить, находится ли она за пределами сети. Оно должно собирать, объединять, коррелировать и передавать всю информацию, включая потоки, данные SNMP и информацию, собранную от других устройств со степенью детализации до одной миллисекунды. Данные должны отображаться на одной настраиваемой информационной панели, где можно применять рабочие процессы для быстрой изоляции основной причины проблемы. Если устранить догадки и позволить пользователю следовать логическому процессу для определения и устранения неполадок, можно снизить среднее время диагностики и повысить эффективность сетевых инженеров.
Решение для анализа производительности сети и приложений реализует все этапы процесса устранения неполадок и обеспечивает видимость, необходимую для оптимизации сети.
Пример готовой дипломной работы по предмету: Информационные технологии
ШАГ ВТОРОЙ: ИССЛЕДОВАНИЕ
Теперь сетевому инженеру необходимо изучить масштаб проблемы. Для проведения быстрого и точного исследования решение должно собирать все соответствующие сведения, например данные SNMP, потоки, пакеты, время реагирования конечных пользователей и т. д., и сохранять их для последующего анализа. Решение мониторинга производительности сети и приложений также позволяет в реальном времени определять маршрут от клиента до службы или приложения, значительно уменьшая время для анализа. После этого можно выявить канал между двумя устройствами для мониторинга проблем во внутренних и внешних сетях, а также в устройствах в них. Результаты отображаются в графическом формате, что позволяет упростить интерпретацию и ускорить анализ основных причин.
Для оптимальной эффективности система должна поддерживать интерфейсы со скоростями 1 Гбит/с и 10 Гбит/с, а также захват данных на скорости канала. Некоторые решения могут проследить маршрут в сети от клиента до сервера, обнаруживая устройства 2 и 3 уровня и предоставляя детализированные сведения для определения источника проблемы.
Если неполадки вызваны клиентом или группой клиентов, инженер должен выполнить тест производительности или реагирования приложений, чтобы определить, вызвана ли проблема проблемой проводной или беспроводной сетью. Предоставляя инструменты для анализа проводной и беспроводной сети, интегрированные в единый пользовательский интерфейс, система мониторинга сети и приложений позволяет с помощью одного теста выявить источник проблемы.
Список использованной литературы
ШАГ ПЕРВЫЙ: МОНИТОРИНГ И ОПОВЕЩЕНИЕ
Первый необходимый компонент при анализе и устранении проблем сети — система, которая своевременно оповещает о возникновении проблемы. В худшем случае это звонок от пользователя, при этом инженер уже оказывается в невыгодном положении. Многие инструменты управления сетью необходимо настроить вручную для каждой сети, чтобы система обнаруживала все устройства в каждом широковещательном домене. Однако при использовании непрерывно работающего решения анализа производительности сети и приложений автоматическое обнаружение и удобные рабочие процессы позволяют легко понять, что и с чем связано. Это существенно уменьшает время, необходимое для настройки и мониторинга.
Данные производительности непрерывно собираются и сохраняются в базе данных и отображаются на панели мониторинга производительности, которую пользователь может настроить с учетом собственных потребностей. Производительность отслеживается на основе базовых показателей, заданных пользователем (например, соглашения об уровне обслуживания), и любые тревожные события немедленно отображаются в системе. Затем пользователь может изучить проблемы с различной степенью детализации на стадии анализа.
Системы мониторинга производительности сети и приложений также могут быть интегрированы с существующими системами управления сетями, такими как HP OpenView или Tivoli Netcool, и могут передавать данные и оповещения решениям для управления службами и панелям мониторинга.
Содержание
1. НАЗНАЧЕНИЕ, КЛАССИФИКАЦИЯ И ОСНОВНЫЕ ПАРАМЕТРЫ ЛОКАЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СЕТЕЙ (ЛВС) 5
1.1 Назначение ЛВС 5
1.2 Классификация и основные параметры ЛВС 6
2. АППАРАТНОЕ ОБЕСПЕЧЕНИЕ СЕТЕЙ 16
2.1 Анализ коммутационного оборудования 16
2.2 Анализ физической среды передачи данных 20
2.3 Методы доступа к передающей среде 27
3. ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ ФУНКЦИОНИРОВАНИЯ КОМПЬЮТЕРНЫХ СЕТЕЙ 45
3.1 Обзор существующей ЛВС предприятия 45
3.2 Расчет характеристик ЛВС шинной структуры со случайным и маркерным доступом 45
3.4 Расчет характеристик ЛВС кольцевой структуры с тактированным доступом 54
3.5 Сравнительная оценка характеристик ЛВС 56
3.6 Построение конфигурации сети 58
3.7 Расчет сметной стоимости ЛВС 60
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ 66
Где проблемы прячутся в сети

Разрыв между инструментами — системы NMS без подробной информации о сети и сложными инструментами захвата пакетов — увеличивает среднее время устранения проблемы. Неявные, периодически проявляющиеся проблемы могут «прятаться» в сети, ухудшая производительность и репутацию ИТ-отдела.
Для быстрого анализа и устранения проблем с производительностью необходимо полное представление о всей сети: специализированное решение для автоматического анализа сетей и приложений, которое восполняет недостатки традиционных NMS и инструментов захвата пакетов.
Задачи, которые необходимо решить:
- Неуправляемое оборудование, которое приобрели из-за низкой цены, но при возникновении проблем диагностика обходится дороже, так как оно не дает сведений о состоянии каждого сегмента сети и уровнях использования. Например, при наличии управляемого коммутатора сетевой инженер может рассмотреть любой его порт, изучить ошибки, оценить загрузку порта и узнать, кто к нему подключен.
- Недокументированные сети — это вечная проблема, ведь сетевая конфигурация изменяется так часто, что любая документация быстро становится устаревшей. Физическая трассировка каналов займет много времени, но без точной документации инженер просто не будет знать, какие пакеты и куда поступают. Сетевым специалистам необходимы средства обнаружения реального времени во всей сети.
- Данных слишком много, хотя проблема может заключаться всего в нескольких пакетах. Диагностика будет проходить гораздо быстрее при использовании автоматизированного метода просеивания захваченных пакетов для поиска проблемы, а именно ориентированного на подход анализа «сверху вниз».
- Проблемы, возникшие в прошлом, которые попадаются инженеру на глаза после того, как они произошли. Необходимы средства для захвата и анализа больших объемов данных за длительные периода времени, скажем, за 24 часа, чтобы обнаруживать кратковременные проблемы.
- Новая технология, которая еще не контролируется, например Ethernet 10 Гбит/с или Wi-Fi стандарта 802.11n. Многие организации не приобрели инструменты для таких технологий, потому что считают, что существенное увеличение ресурсов поможет решить любые проблемы.
- Беспроводные устройства — инженеру нужен способ для выявления и мониторинга устройств Wi-Fi, в том числе личных устройств пользователей, а также для обнаружения помех, вызванных оборудованием Wi-Fi, устройствами Bluetooth, беспроводными телефонами, микроволновыми печами и т. д. с помощью спектрального анализа.
- Проблемы за пределами сети: инженеру необходимо выявить и устранить их, а также предоставить вспомогательные данные другим ИТ-группам или внешним поставщикам услуг для дальнейшего анализа и быстрого устранения.
3.1 Затратные методы оценки
Котловой метод. Метод основан на определении соотношения объемов вложений в программное обеспечение, включая внедрение и сопровождение, с размерами предприятия и направлениями его бизнеса. Часто данное соотношение задается в виде максимально-допустимого объема вложений по отношению к годовому обороту компании, например не более 1% для небольших компаний и не более 3% для крупных.
Метод функциональной точки. Данный метод используется для приблизительной оценки стоимости создания и внедрения информационной системы (ИС) в зависимости от требований пользователя. Каждое такое требование оценивается как по шкале трудности (легкие, средние и трудные), так и по шкале важности для пользователя. Требования представляются в виде вектора (функциональной точки) в многомерном пространстве. Далее в соответствии с гипотезой «компактности» предполагается, что чем ближе функциональные точки проектов друг к другу в пространстве требований, тем их параметры, включая и эффективность, более схожи. Соответственно в базе ранее внедренных проектов находится такой, чья функциональная точка ближе всего находится к проектируемой ИС, и предполагается, что их эффективности максимально близки.
Total cost of ownership (ТСО – совокупная стоимость владения). Данный метод предполагает количественную оценку на внедрение и сопровождение программного обеспечения, рассчитываемую по формуле: ,
где – оценка интегрированных затрат по проекту в момент ; Е – норма дисконтирования, отражающая временной характер финансовых ресурсов; – дисконтированная сумма фактически произведенных интегральных затрат на момент ; Т – период жизненного цикла системы; - оценка интегральных затрат на проект в периоде t.
Модель ТСО позволяет разобраться в структуре расходов, связанных с ИС, и открывает широкие перспективы для их сокращения, также способствует выявлению текущих проблем, обеспечивает постоянную обратную связь в управлении затратами.
Список использованной литературы
1. Афанасьев, Н.В., Акчурин, Э.А., Лазарев, В.А., Лихтциндер, Б.Я. Локальные вычислительные сети [Текст]: Учебник для вузов связи. – М.: Радио и связь, 1996. – 317с.
2. Олифер, В.Г., Олифер, Н.А. Компьютерные сети. Принципы, технологии, протоколы [Текст].
– СпБ.: Питер, 2011 – 348с.
3. Лазарев, В.А. Основы проектирования локальных вычислительных сетей [Текст]: Учебное пособие для вузов связи. – М.: Радио и связь, 1994. – 177с.
4. СТО СГАУ 02068410-004-2007. Общие требования к учебным текстовым документам. – Самара: СГАУ, 2007. – 30 с.
5. Олифер "Компьютерные сети. Принципы, технологии, протоколы. " СПб.: BHV-СПб, 2003. – 612 стр.Феер К. Беспроводная цифровая связь. Пер. с англ. – М.: Радио и связь, 2000 -520с.
6. Столлингс В. Компьютерные системы передачи данных, 6 –ое издание.: Пер. с англ.– М. : Издательский дом «Вильямс», 2002. – 928 с.
7. Кульгин М.Н. Компьютерные сети. Практика построения. СПб.: Питер, 2000. – 402стр.
8. Иванов В. И., Гордиенко В. Н., Попов Г. Н. Цифровые и аналоговые системы передачи М: Горячая линия-Телеком, 232 с.
9. Дансмор, Брэд, Скандьер, Тоби. Справочник по телекоммуникационным технологиям.: Пер. с англ. – М.: Издательский дом «Вильямс», 2004. – 640 с.
Введение
В современных корпоративных сетях становится все сложнее найти основную причину проблем с сетью и приложениями. Виртуализация распространяется из центра обработки данных на настольные компьютеры, набирают популярность облачные службы, а личные устройства на работе (BYOD) уже стали нормой. Проблемы могут возникнуть из-за растущего числа устройств Wi-Fi, чрезмерного использования полосы пропускания неавторизованными приложениями, ошибок конфигурации, плохой инфраструктуры доставки приложений и многих других причин. Увеличивающееся включение голоса и видео добавляет ещё больше сложностей и приводит к тому, что полоса пропускания подходит к своим пределам.
На исправление проблем с производительностью уходит все больше усилий и времени, так как специалисты пытаются решить, кто ими должен заняться.
КУРСОВИК ПО ЛОГИСТИКЕ.docx
Значительная часть проблем проектов внедрения обусловлена довольно типичными ошибками, которые известны, но тем не менее часто повторяются:
- проектирование систем без учета стратегии развития бизнеса — необходимо представлять структуру и масштабы бизнеса в перспективе как минимум на 3 года .
- нарушение принципа построения системы «сверху-вниз» и, как следствие, отсутствие информационной поддержки принятия управленческих решений на верхних уровнях управления;
- чрезмерное увлечение реинжинирингом бизнес-процессов и порой неоправданное их подчинение требованиям стандартной функциональности базовой ERP-системы;
- кардинальная переработка базовой функциональности ERP-системы;
- нереалистичные ожидания вследствие неверной оценки экономической эффективности внедрения ERP-системы.
В то же время накопленный опыт внедрения информационных систем свидетельствует о наличии устойчивой группы факторов успеха таких проектов и, как следствие, о возможности формирования технологии успешного управления проектом внедрения с учетом этих факторов (рис. 2). Рациональная организация проектов внедрения информационных систем описывается в стандартах (международных, государственных, корпоративных), которые часто называют методологиями внедрения.
Рис. 2 Факторы успеха проекта внедрения
Выдержка из текста
Актуальность темы данной работы обуславливается тем, что локальные вычислительные сети за последнее пятилетие получили широкое распространение в самых различных областях науки, техники и производства. Особенно широко ЛВС применяются при разработке коллективных проектов, например сложных программных комплексов. На базе ЛВС можно создавать системы автоматизированного проектирования. Это позволяет реализовывать новые технологии проектирования изделий машиностроения, радиоэлектроники и вычислительной техники. В условиях развития рыночной экономики появляется возможность создавать конкурентоспособную продукцию, быстро модернизировать ее, обеспечивая реализацию экономической стратегии предприятия. ЛВС позволяют также реализовывать новые информационные технологии в системах организационно-экономического управления. В учебных лабораториях университетов ЛВС позволяют повысить качество обучения и внедрять современные интеллектуальные технологии обучения. [1]
Цель работы – анализ эффективности функционирования компьютерных сетей и пути ее повышения
- анализ понятия и классификации компьютерных сетей
- характеристика аппаратного обеспечения сетей
- программное обеспечение сетей
- анализ путей повышения эффективности функционирования компьютерных сетей
Предмет исследования – компьютерная сеть предприятия.
Объект исследования – пути повышения эффективности функционирования компьютерной сети предприятия.
Теоретической и методологической базой при написании данной работы послужили труды отечественных авторов в области информационных технологий, таких как: Афанасьев В.Г., Гупалов В.К., Пшенко А.В. Стенюков М.В., Трахтенгерц Э.А.и др.
Практическая значимость работы: разработанные мероприятия позволят повысить эффективности функционирования существующей компьютерной сети предприятия.
3.3 Методики, основанные на идеальности процесса
Данные методы основаны на сравнении результатов внедрения ПО с уже существующими хорошими (идеальными) примерами. И предполагается, чем ближе мы приближаемся к этим примерам, тем выше эффективность внедряемого ПО. К таким методам относятся:
Производительность компьютерной сети – это ее свойство, определяющее время на передачу и обработку информации в сети. Производительность сети зависит от быстродействия всех ее компонентов, участвующих в передаче и обработке информации. Вопросы производительности играют важную роль в КС. Процессы взаимодействия многих компонентов сети отличаются сложностью и многообразием, что может привести к непредсказуемым последствиям, сопровождаемым снижением производительности КС.
Глобальные вопросы производительности сети в целом решаются на транспортном уровне модели OSI.
К ключевым вопросам производительности сети относятся следующие:
- установление причин снижения производительности сети (выявление «узких мест» в сети);
- методы и средства измерения производительности;
- проектирование сети, удовлетворяющей требованиям по производительности;
- обеспечение быстрой обработки информационных модулей, т.е. единиц информации, которыми осуществляется обмен на транспортном уровне;
- разработка протоколов управления обменом данными для перспективных высокопроизводительных сетей.
Рассмотрим кратко существо этих вопросов.
Выявление узких мест. Узкими называются места, ограничивающие пропускную способность или производительность всей сети. Пропускная способность всей сети определяется пропускной способностью наименее быстродействующего компонента.
Наиболее характерными причинами снижения производительности сети являются следующие.
1. Временное отсутствие свободных ресурсов. Например, перезагрузка маршрутизатора, вызванная большим входным трафиком, превышающим возможности маршрутизатора. Образуемый затор приводит к снижению производительности сети.
2. Структурный дисбаланс ресурсов. Например, подсоединение маломощного компьютера к гигабитной линии связи. В этом случае компьютер не справляется с обработкой приходящих пакетов, что чревато потерей некоторых пакетов, которые рано или поздно будут переданы повторно. Это приводит к неэффективному использованию пропускной способности линии связи и снижению общей производительности сети.
4. Неверная системная настройка. Например, компьютер имеет мощный центральный процессор и большую оперативную память, но под буфер выделено недостаточно памяти. В этом случае буфер будет переполняться и часть поступающих пакетов потеряется.
5. Неверная установка значений таймеров ожиданий. При отправке информационного модуля обычно включается таймер на случай потери этого модуля. Выбор слишком короткого интервала ожидания подтверждения приводит к излишним повторным передачам модулей, а слишком большого – к увеличению задержки в случае потери модуля. В обоих случаях это негативно сказывается на производительности сети.
Измерение производительности сети. Измерения следует производить разными способами и во многих местах. Один из наиболее распространенных способов измерения состоит в том, что таймер включается во время начала какой-либо активности и измерение продолжается до окончания этой активности. Например, ключевым измерением является измерение интервала времени, необходимого для получения отправителем подтверждения в ответ на отправку информационного модуля.
Не следует ограничиваться единственным измерением какого-нибудь параметра, например времени на передачу одного информационного модуля. Измерение необходимо повторить многократно, а затем вычислить среднее значение. Более того, всю последовательность измерений следует повторить в различное время суток и в разные дни недели, чтобы заметить влияние различной загруженности сети на измеряемые параметры.
Результаты некоторых измерений (например, измерения времени чтения удаленного файла) зависят от конфигурации сети, операционной системы клиента и сервера, аппаратного интерфейса сетевых карт, их драйверов и других факторов. Такие измерения будут пригодны только для данной совокупности факторов.
Инструментальные средства измерения производительности сети рассматриваются ниже.
Проектирование производительных сетей. С помощью измерения и настройки можно улучшить производительность уже спроектированной сети, но только до определенного уровня. Для дальнейшего повышения производительности необходима переделка проекта. Существуют несколько эмпирических правил по проектированию производительных сетей, основанных на опыте работы со многими сетями. Наиболее существенные из них состоят в следующем.
1. Производительность хоста важнее пропускной способности канала. Многочисленные эксперименты показали, что почти во всех сетях временные затраты на работу операционной системы хоста и протокола составляют основное время задержки сетевой операции. При работе с гигабитной линией связи основная задача заключается в обеспечении достаточно быстрой передачи битов из буфера хоста (компьютера пользователя) в линию, а также в том, чтобы на приемной стороне обработка информации осуществлялась с той скоростью, с которой она приходит. Можно утверждать, что удвоение производительности процессора компьютера пользователя может привести к почти удвоению пропускной способности канала связи. Однако удвоение пропускной способности канала часто не дает никакого эффекта, так как узким миром обычно являются хосты.
2. Для уменьшения программных накладных расходов необходимо уменьшить число пакетов в фиксированном объеме передаваемой информации.
Решение вопроса о размере пакета связано с необходимостью не только учета накладных расходов на обработку заголовков (т.е. программных накладных расходов), но и учета накладных расходов нижних уровней. Прибытие каждого пакета вызывает прерывание, сопровождающееся нарушением работы процессорного конвейера, снижением эффективности функционирования кэш-памяти, необходимостью сохранения в стеке значительного числа регистров процессора. Следовательно, уменьшение числа посылаемых пакетов дает соответствующее снижение числа прерываний и накладных расходов.
3. Необходимо минимизировать число операций копирования поступающих пакетов. Часто полученный пакет копируется три или четыре раза, прежде чем содержащиеся в нем данные доставляются по назначению. На каждое копирование затрачивается время работы процессора. Грамотно разработанные операционные системы компьютера позволяют сократить число операций копирования и в конечном счете повысить эффективность функционирования компьютера.
4. Сокращение времени задержки в линии связи важнее повышения ее пропускной способности. Более высокая пропускная способность может быть обеспечена использованием более качественной передающей среды или прокладкой дополнительного кабеля. Но от этого времени задержки меньше не станет. Для ее снижения потребуется улучшение программного обеспечения протоколов, операционной системы или сетевого интерфейса.
5. Лучше избегать перегрузки в сети, чем бороться с уже возникшей перегрузкой. При возникновении перегрузки образуется затор, пакеты теряются, пропускная способность линии связи растрачивается впустую, увеличиваются издержки и т.п. Процесс восстановления после перегрузки связан с потерей времени. Более эффективной стратегией является предотвращение перегрузки.
6. Необходимо минимизировать количество тайм-аутов. Каждое срабатывание таймера обычно сопровождается повторением какого-либо действия. Но это повторение действительно должно быть необходимым. Период ожидания следует устанавливать с небольшим запасом. Таймер, срабатывающий слишком поздно, увеличивает задержку в случае потери пакета. Преждевременно срабатывающий таймер растрачивает попусту время процессора, пропускную способность линии связи и увеличивает нагрузку на маршрутизаторы.
Обеспечение быстрой обработки информационных модулей. На пути повышения производительности сетей основным препятствием является программное обеспечение протоколов. Некоторые способы преодоления этого препятствия рассмотрены в специальной литературе, где обращено внимание на способы сокращения затрат времени на обработку заголовков пакетов и на обработку каждого байта в пакете. Рассматриваются также две другие области, в которых возможны основные улучшения производительности сети, - это управление буферами и управление таймерами.
Разработка протоколов для высокопроизводительных (гигабитных) сетей. Гигабитные сети появились в начале 90-х годов XX- го века. Попытки применить к ним старые протоколы натолкнулись на ряд проблем. Наиболее важные из них следующие.
1. Ограниченность адресного пространства старых протоколов. В них используются 32-разрядные порядковые номера. Для типичной скорости выделенных линий между маршрутизаторами, равной 56 Кбит/с, количество номеров 232 вполне достаточно, так как хосту, при постоянной выдаче в сеть данных потребовалось бы больше недели на то, чтобы у него закончились порядковые номера. Это вполне приемлемо, если учесть, что максимальное время жизни пакета в сети Internet равно 120 с. Однако ситуация резко изменяется в гигабитных сетях. Если, например, сеть Ethernet выдает в Internet данные со скоростью 1 Гбит/с, порядковые номера закончатся примерно через 34 с, что существенно меньше времени жизни пакета. Это означает, что отправителю, посылающему достаточно много пакетов, придется повторять их порядковые номера в то время, как старые пакеты все еще будут блуждать по сети.
Следовательно, предположение разработчиков протоколов, что время цикла пространства порядковых номеров значительно превосходит максимальное время жизни пакетов, оказалось неприемлемым для гигабитных сетей.
2. Более быстрый рост скорости передачи данных, чем скорости обработки данных. Это обстоятельство вынуждает разработчиков протоколов управления обменом данными и обработки данных искать приемлемые решения.
3. В длинных гигабитных линиях главным ограничивающим фактором является не пропускная способность, а задержка. Этим гигабитные линии принципиально отличаются от мегабитных. В гигабитных линиях время на передачу фиксированного объема информации с возрастанием скорости передачи уменьшается, но только до определенного предела. При дальнейшем увеличении скорости передачи время на передачу почти не изменяется, главным ограничивающим фактором становится задержка. Такая зависимость демонстрирует ограничения старых сетевых протоколов. Например, протоколы с ожиданием подтверждений, такие как удаленный вызов процедуры, имеют врожденное ограничение на производительность.
4. Появление новых гигабитных мультимедийных приложений, для которых постоянство времени передачи пакета так же важно, как и среднее значение времени задержки. Постоянная скорость доставки, даже если она низкая, часто предпочтительнее высокой, но непостоянной. Эта проблема связана уже не с протоколами или технологиями.
Некоторые методы решения указанных проблем рассматриваются ниже.
Главный принцип, которым должны руководствоваться разработчики гигабитных сетей, формулируется так: при проектировании таких сетей следует стремиться увеличивать скорость обработки пакетов, а не пропускную способность линий связи. В гигабитных сетях нет смысла экономить пропускную способность, так как ее более чем достаточно. Необходимо при разработке протоколов минимизировать время обработки.
Попытки ускорить работу сетей за счет создания быстрых сетевых интерфейсов на аппаратном уровне обычно не приводят к положительным результатам, так как такой интерфейс представляет собой дополнительный сопроцессор со своей программой. Если его сделать быстрым, то он будет очень дорогим, если медленным, то центральный процессор будет ждать, пока сопроцессор закончит свою работу. Более того, для взаимодействия двух процессоров общего назначения потребуются тщательно продуманные протоколы, обеспечивающие их корректную синхронизацию. Как правило, лучшим решением является создание простых протоколов, реализацию которых возложить на центральный процессор.
В гигабитных сетях крайне важен формат пакета. В заголовке должно быть как можно меньше полей, а сами поля должны быть достаточно большими, чтобы нести в себе как можно больше необходимой служебной информации. Все это позволит сократить время обработки заголовков.
Контрольные суммы заголовка и данных лучше подсчитывать раздельно. Это дает возможность определять контрольные суммы быстрее и, кроме того, позволяет убедиться в правильности заголовка, прежде чем начать копировать данные в пространство получателя. Контрольную сумму данных лучше проверять во время копирования данных.
Размер поля данных в пакете должен быть достаточно большим. Это уменьшает общую сумму заголовков в потоке передаваемых данных (т.е. снижает накладные расходы на их обработку) и, кроме того, обеспечивает возможность эффективной работы сети даже при наличии больших задержек.
В гигабитных сетях линии связи, как правило, являются высококачественными, ошибки в них появляются очень редко. Поэтому разработчик этих сетей должен в первую очередь минимизировать время обработки для нормального режима работы, когда ошибки отсутствуют. Минимизация времени обработки в случае наличия ошибок на линии связи должна быть на втором месте.

Сеть — это фундамент большинства предприятий, который поддерживает важные бизнес-приложения, предоставляя данные для принятия решений и позволяя общаться с клиентами, партнерами, поставщиками и сотрудниками. Сегодня сеть играет важнейшую стратегическую роль, и любой простой или снижение производительности сети или приложений напрямую влияют на работу организации. Для предоставления уровней обслуживания необходимо решить две задачи: использовать профилактические меры для оптимизации производительности и устранять любые проблемы как можно быстрее для сокращения времени простоя. Данная методология решения проблем с производительностью сети и приложений описывает подход, который поможет быстро выявлять первопричины всех проблем.
ШАГ ТРЕТИЙ: ИЗОЛЯЦИЯ
На этом этапе проблема изолирована в одном сегменте сети, коммутаторе, маршрутизаторе, сервере или приложении, при этом определены маршрут и все затронутые устройства и порты. Теперь необходимо проанализировать маршрут, чтобы получить статистику по трафику для каждого канала и выяснить, вызваны ли неполадки неисправным устройством, кабелем, помехами или перегрузкой трафика.
Одно из величайших преимуществ протокола SNMP — это возможность изолировать неисправный участок. Используя SNMP, можно опросить каждую точку подключения, чтобы определить, вызвано ли замедление узким местом при передаче трафика. Это просто, если устройства в маршруте управляемые, а у инженера есть пароли или строки доступа для опроса устройств. В противном случае потребуется подключить инструмент к каждому каналу без нарушения целостности сети для просмотра пакетов и статистики трафика. Для этого может потребоваться очень много времени, если каналов много и они находятся в масштабной географической области, и множество инструментов на различных объектах.
Автоматизированная проверка состояния сетевой инфраструктуры с помощью инструмента мониторинга производительности сети и приложений позволяет контролировать все поддерживаемые SNMP-устройства, анализируя потоки приложений с потерей пакетов или высокой загруженностью, регулярно опрашивая базы MIB SNMP в маршрутизаторах. Процесс будет простым и быстрым даже для десятков и сотен коммутаторов в сети.
Некоторые проблемы проявляются только в конкретной точке. Для их обнаружения требуется портативное устройство с широкими возможностями тестирования и нужным интерфейсом для подключения к проблемной точке, будь то клиент или канал 10 Гбит/с в центре обработки данных. Сейчас многие работают удаленно, поэтому инструмент, который обеспечит такую видимость, просто незаменим, а с ростом числа личных устройств на работе он станет еще более важным компонентом.
Если нет перегруженных каналов или ошибок кадров, проблема не в сети. Но подтвердить это можно, только если инженер проанализировал каналы в течение соответствующего периода времени, а проблема по-прежнему существует. Для этого система мониторинга производительности сети и приложений должна записывать данные в течение длительного времени.
Работа выполнена на
7. листах и включает в себя введение, основную часть, состоящую из 3 глав, заключение и список литературы.
ШАГ ЧЕТВЕРТЫЙ: АНАЛИЗ ПРИЧИН ВОЗНИКНОВЕНИЯ ПРОБЛЕМЫ И ЕЕ УСТРАНЕНИЕ
На данном этапе инженер подтверждает причину проблемы, разрабатывает, применяет и проверяет решение. Если проблема не заключается в сети, скорости реагирования сервера или перегрузки ресурсов, требуется получить более подробную информацию за счет захвата и анализа пакетов. Сначала важно изолировать канал или проблему между сервером, сетью и приложением, так как для анализа пакетов требуется очень много времени и богатый опыт.
Чтобы быстрее добраться до основной причины лучше всего начинать с уровня приложений. Например, если сетевой тракт в порядке, но время отклика — нет, значит проблема может заключаться в виртуализированном сервере, приложении, которое работает на нескольких уровнях или в ошибке приложения.
Один из вариантов — использовать анализатор пакетов, который показывает данные на уровне приложений и многоступенчатые схемы пакетов. Протяженные или зеркальные ответвленные соединения легко настроить, но они могут терять пакеты при интенсивном трафике, и для них не отображаются ошибки 1 уровня, так как они блокируются коммутатором 2 уровня. Пассивные разветвители являются лучшими, но при их подключении разрывается соединение, а пользователи лишаются доступа к соответствующим службам. Если производительность падает, это обычно не вызывает проблем, но может повлиять на тех, кто использует этот канал для подключения к другим службам.
Лучшим решением будет сеть с уже готовыми ответвлениями трафика, размещенными перед стойками серверов, центрами обработки данных, маршрутизаторами внешних каналов и в ядре сети. Это позволяет захватывать пакеты без нарушения работы сети. Если это невозможно инженеру может потребоваться использовать зеркалирование диапазонов или портов, принимая во внимание сопутствующие проблемы и неточности.
Решение для мониторинга производительности сети и приложений предоставляет автоматизированный метод просеивания захваченных пакетов для поиска проблемных. Оно использует ориентированный на приложения подход с пользовательским интерфейсом, в котором отображается каждый поток данных с визуальным индикатором проблем. Инженер может просто щелкнуть его, чтобы просмотреть подробные сведения и узнать, в каких пакетах возникли проблемы. Для более точного анализа можно захватить пакеты в нескольких точках инфраструктуры, чтобы определить, где возникает проблема. Для этого требуется возможность для многосегментного анализа, одновременного сбора данных в нескольких точках и объединения результатов для получения полной картины.
Эффективный анализ основных причин может осуществляться в центре обработки данных или на удаленных площадках, чтобы узнать, связаны ли проблемы с серверами или приложениями. Некоторые инструменты могут извлечь данные об управлении из физических или виртуальных серверов, чтобы установить причины с производительностью или дефицитом ресурсов.
Собирая и анализируя детализированные исторические данные, система мониторинга производительности сети и приложений также позволяет инженеру вернуться назад во времени для изучения симптомов, которые проявились, когда проблема возникла впервые, чтобы выявлять и устранять кратковременные проблемы.
10. Столлингс В. Современные компьютерные сети. – СПб: Питер, 2003, – 783 с.
12. Абрамов С.М., Котельников В.П., Пономаре в А.Ю., Шевчук Ю.В. О построении высокоскоростная оптической магистрали городской компьютерной сети с учетом особенностей электропитания в районных центрах России
13. Галкин В. А., Григорьев Ю. А. Телекоммуникации и сети СПб.: BHV-СПб, 2000. – 462 стр.
14. Дымарский Я. С., Крутякова Н. П., Яновский Г. Г. Управление сетями связи: принципы, протоколы, прикладные задачи. СПб.: BHV-СПб, 2002. – 346 стр.
15. Ирвин Дж., Харль Д. Передача данных в сетях: инженерный подход. М.: Диасофт, 1998. – 335 стр.
16. Камер Д. Сети TCP/IP, том. 1. – М.: Вильямс, 2003. – 453 стр.
17. Поляк-Брагинский А.В. Сеть своими руками. Самоучитель. Киев.: BHV-Kиeв, 2002. – 264 стр.
18. Столлингс В. Современные компьютерные сети. М.: Символ-Плюс, 2002. – 439 стр.
19. Таненбаум Э. Компьютерные сети СПб.: BHV-СПб, 1998. – 345 стр.
20. Холмогоров В.П. Компьютерная сеть своими руками. Самоучитель. СПб.: Питер, 2001. – 895 стр.
21. Абросимов Л.И. Анализ и проектирование вычислительных сетей: Учеб. пособие — М. Изд-во МЭИ. 2000. — 52 с.
22. Стандарты по локальным вычислительным сетям: Справочник / В.К. Щербо, В.М.Киреичев, С.И.Самойленко; под ред.С.И.Самойленко. — М.: Радио и связь, 2004, 304 с
23. Брискер А.С., Гусев Ю.М., Ильин В.В. и другие. Спектральное уплотнение волоконно-оптических линий ГТС//Электросвязь, 1997, № 1, с41-42.
25. Рудов Ю.К., Зингеренко Ю.А., Оробинский С.П., Миронов С.А.. Применение оптических циркуляторов в волоконно-оптических системах передачи//Электросвязь, 1999, № 6, с 36-37.
26. Черемискин И.В., Чехлова Т.К.. Волноводные оптические системы спектрального мультиплексирования / демультиплексирования //Электросвязь, 2000, № 2, с23-29.
27. М.М. Бутусов, С.М. Верник, С.Л. Балкин и другие. Волоконно-оптические системы передачи. -М.: Радио и связь, 1998 – 416 с.
28. Заславский К.Е.Учебное пособие. Волоконно-оптические системы передачи. Часть 3.-Н.:СибГАТИ, 1997 – 61с.
29. Лазерная безопасность. Общие требования безопасности при разработке и эксплуатации лазерных изделий. -М.:Издательство стандартов, 1995 – 20 с.
30. Оптические системы передачи: Учебник для ВУЗов. Под ред. В.И. Иванова. –М.: Радио и связь, 1994.
31. Строительство и техническая эксплуатация волоконно-оптических линий связи. Под ред. Б.В. Попова. –М.: Радио и связь, 1995.
32. Синенко О., Куцевич Н., Леньшин В., журнал, "Промышленные контроллеры и АСУ", Москва, № 10, 2012г.
33. Стенюков М.В. «Документы. Делопроизводство». – М.: ПРИОР, 2013г. 137с.
34. Трахтенгерц Э.А. «Компьютерная поддержка принятия решений»: Научно-практическое издание. Серия «Информатизация России на пороге ХХI века». – М.: СИНТЕГ, 2010г. – 376с.
35. Автоматизированные информационные технологии в экономике: Учебник/ под ред. проф. Г.А. Титоренко. – М.: Компьютер, ЮНИТИ, 2012. – 400с.
36. «Автоматизированные информационные технологии в экономике». Учебник / Семенов М.И., Трубилин И.Т., Лойло В.И., Барановская Т.П. // Под общ.ред. И.Т.Трубилина. – М.: Финансы и статистика, 2011г. – 268с.
37. Баженова И.Ю. VisualFoxPro 6.0. – М.: Диалог – МИФИ, 2012. – 390 с.
38. Уткин Э. «Инновации в управлении человеческими ресурсами предприятия». Издательство Теис, 2012г. – 304с.
39. Щёголев А.Г., Ерохина Е.А. «Основы информатики и вычислительной техники», Учеб.пособие для ВУЗов. М.: Просвещение, 2009г. – 274с.
40. Янковая В.Ф. «Терминология документационного обеспечения управления». – М.: Делопроизводство. 2012г., № 1 66с.
41. Учет основных средств. Методические рекомендации. Амортизация. Нормы. – М.: Издательство «Ось-89», 2013. – 208 с.
2.2 Назначение и состав методологий внедрения
Методологии внедрения обычно разрабатываются ведущими производителями информационных систем с учетом особенностей их программных продуктов, а также сферы внедрения. Положительная сторона таких стандартов — их практическая направленность. Они представляют собой глубоко проработанные, проверенные, многократно апробированные рабочие инструкции и шаблоны проектных документов. Такие стандарты обычно далеки от теоретических абстракций, ориентированы на особенности конкретных систем, содержат наилучший опыт. Но у стандартов есть и отрицательные стороны: даже методологии, предназначенные для систем, близких по классу, не взаимозаменяемы. Например, методология внедрения системы Microsoft Axapta направлена во многом на управление настройками модулей и доработками; а при внедрении функционально подобных модулей SAP или ORACLE EBS превалирует идеология бизнес-реинжиниринга, при котором организации предлагается изменять свои бизнес-процессы, адаптируя их под «лучший опыт», зафиксированный в системе. В качестве наиболее известных примеров методологий можно привести следующий, далеко не исчерпывающий перечень:
- разработки компании Microsoft — методологии «OnTarget», «MSF (Microsoft Solutions Framework)», «Business Solutions Partner Methodology»;
- разработки компании SAP — методологии «Процедурная модель SAP», «ASAP (Accelerated SAP)»;
- разработки компании Oracle — комплекс методологий «Oracle Method».
Такое разнообразие стандартов позволяет организациям выбрать на их основе рациональную стратегию и сформировать собственные процедуры внедрения, т. е. не «изобретать велосипед» и в то же время обеспечить конкурентные преимущества. Адаптация методологий к нуждам конкретного предприятия заключается не столько в переводе текстов и шаблонов документов на русский язык, сколько в корректировке подходов с учетом российских условий. При этом обычно пересматриваются рекомендуемые стандартами сроки и последовательность задач, создаются методики сбора, верификации и преобразования исходных данных, разрабатываются решения по интеграции с унаследованными системами.
Для Заказчика информационной системы основными результатами использования методологии являются:
- создание решения, оптимально соответствующего требованиям клиента;
- максимально эффективное использование ресурсов проекта;
- минимизация сроков и затрат на внедрение;
- уменьшение рисков проекта.
В то же время организация работы в соответствии с документально зафиксированной методологией оказывается полезной и для разработчика системы:
- появляется методическая база для обучения новых сотрудников стандартным методам внедрения;
- сокращаются внутренние расходы на организацию и реализацию проектов;
- улучшается взаимодействие и взаимопонимание между членами проектной группы;
- повышается эффективность совместного использования ресурсов между проектами, командами.
Несмотря на разнообразие существующих методологий, их содержание включает в себя следующие стандартные компоненты: описание состава и структуры комплекса работ проекта внедрения, правила управления таким проектом, организационную структуру команды внедрения.
Структурирование комплекса работ заключается прежде всего в выделении фаз (этапов) проекта. Разбиение проекта на фазы (длительностью 3-4 месяца) обусловлено высокой сложностью проектов и значительными затратами времени на внедрение информационных систем, позволяет получить значимые результаты в более сжатые сроки и реализовать следующие преимущества в организации проекта:
- данные проектной документации не устаревают;
- после выполнения каждой фазы проекта появляется возможность уточнить или скорректировать задачи к решению на последующих фазах;
- снижаются проектные риски, обусловленные организационными изменениями на предприятии Заказчика в ходе проекта;
- оптимизируются бюджет проекта и график платежей.
Состав этапов проекта и распределение работ по этапам зависит от конкретной методологии, однако можно выделить типовой состав этапов, которые в той или иной степени присутствуют во всех методологиях и определяются самой логикой внедрения. Это этапы определения проекта, обследования объекта автоматизации, анализа результатов обследования и разработки дизайна системы, создания (настройки) системы, запуска системы в эксплуатацию, сопровождения системы.
Следующим шагом является выделение процессов (комплексов работ), выполняемых на различных этапах проектов. Состав и последовательность исполнения процессов определяются конкретной методологией и служат основой для планирования проекта — для построения иерархической структуры работ .
Таким образом, методология внедрения строится как пересечение двух различных областей знаний: специфической технологии создания продукта — информационной системы — и достаточно универсальной технологии управления проектной деятельностью (рис.3).
Технология создания продукта
Технология управления проектом
Корпоративная методология внедрения
Рис. 3 Составляющие методологии внедрения
Исходя из этого внедрение информационных процессов достаточно сложный и трудоемкий процесс требующий постоянной модернизации обслуживания. Состоящий из множества факторов и аспектов игнорируя которые можно нарушить структуру всего производства и привести если не к разорению предприятия то как минимум к ненужным затратам.
3. Оценка эффективности информационных систем
Одной из проблем определения эффективности общесистемного и офисного программного обеспечения (ПО) является выбор методики оценки. В классической литературе, посвященной вопросу оценки эффективности, она рассчитывается по формуле: ,
Затраты – совокупные затраты на приобретение, установку и конфигурирование, сопровождение и поддержку, а также затраты связанные с простоем оборудования во время техническое обслуживание или устранения неисправностей.
Эффект – эффект, достигаемый при внедрении ПО. Однако из-за специфики использования общесистемного и офисного ПО определить прямой эффект от их внедрения (во временных или финансовых показателях) затруднительно. Вследствие этого возникает задача выбора метода оценки, все множество которых можно разделить на:
- Затратные методы. Оценка производится не на основе измерения конечного продукта или результата, а на основе затраченных ресурсов или сил.
- Методы оценки прямого результата. Методика оценивает прямой измеримый результат, например, снижение стоимости владения, повышение функциональности системы, снижение трудозатрат или появление побочного продукта основного трудопроизводства.
- Методы, основанные на оценке идеальности процесса. Такие методики базируются на статических или динамических сравнительных алгоритмах. Базовым показателем выбирается объект рассматриваемой системы, тогда идеальной считается информационная система с лучшими для отрасли показателями затрат на единицу выхода. Популярны также подходы на базе сравнения с альтернативным решением.
- Квалиметрические подходы. Такие методики комплексно рассматривают информационную систему, организуют ее измерение и обрабатывают полученные результаты статистическими, социологическими и/или экспертными методами.
Процесс устранения проблем с производительностью сети
Чтобы выяснить основную причину проблем с производительностью сети, используется процесс из четырех шагов.

Рисунок 1. Рабочий процесс устранения проблем.
Доступные инструменты для решения проблем делятся на две категории: системы управления сетью (NMS) и инструменты захвата и анализа пакетов.
NMS, в основном, используется на этапе мониторинга и оповещения, отслеживая работу маршрутизаторов и серверов компании. Однако некоторые NMS очень сложно правильно настроить, в результате чего они следят только за устройствами 3 уровня, а коммутаторы на 2 уровне остаются вне области мониторинга. Данные опроса устройств обобщаются за долгий период, что скрывает влияние пиков нагрузки. К тому же из-за того что система NMS расположена в центре, измерения, сделанные для анализа времени реакции конечных пользователей, оказываются неточными, потому что в тесте используются различные части сети для связи с оцениваемыми устройствами.
В процессе устранения неполадок полезность NMS уменьшается, так как она не предоставляет подробные сведения, необходимые для полного анализа проблем с производительностью.
Согласно данным опроса 3 000 сетевых специалистов, проведенного компанией NETSCOUT, 82 % респондентов считают низкую производительность сети и приложений критической проблемой, а 52 % считают, что возможностей NMS в большинстве случаев недостаточно для поиска причин снижения производительности. Кроме того, 51 % респондентов сообщили, что в большинстве случаев они вынуждены покидать свое рабочее место, чтобы устранить неполадку.
Чтобы получить более подробную информацию, сетевому инженеру необходимо использовать бесплатные или коммерческие инструменты захвата и анализа пакетов. Их роль на этапе оповещения ограничена, так как они рассматривают только одну точки в сети, но на стадии анализа причин они проявляют себя во всей красе. Для использования сложных инструментов анализа пакетов требуются квалифицированные опытные инженеры. При этом процесс отнимает много времени, а его результатом могут стать миллионы пакетов, которые нужно изучить в различных пользовательских интерфейсах. Все это делает процесс устранения неполадок гораздо более сложным и трудоемким.
Читайте также: