
Способы организации файловых операций
Файловая система ОС должна предоставлять пользователю набор операций для работы с файлами, оформленные в виде системных вызовов. Набор состоит из: создание файла, чтение из файла и т. д.
Какие бы операции не выполнялись над файлом ОС необходимо выполнить ряд универсальных для всех операций действий:
1. по символьному имени файла найти характеристики, которые хранятся в физической системе на диске;
2. скопировать характеристики файла в оперативную память, чтобы программный код мог их использовать;
3. на основании характеристик файла проверить права пользователя на выполнение запрошенной информации;
4. очистить область памяти, отведенную на временное хранение характеристик файлов.
Кроме того, каждая операция включает ряд уникальных действий:
а) чтение определенного набора кластеров диска;
б) удаление файлов и т.д.
ОС может выполнять последовательность действий над файлами двумя способами:
1. для каждой операции выполняется как универсальные, так и уникальные действия, такая схема называется схема без запоминания состояния операции.. он более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от операции предыдущей. Применяется в распределенных сетевых файловых системах.
2. все универсальные действия выполняются в начале и конце последовательности операций, а для промежуточной операции выполняются только уникальные действия, подавляющее большинство файловых систем поддерживает этот метод как более экономный и быстрый.
Стандартные файлы ввода и вывода, перенаправление вывода
Ввод/вывод в операционных системах может быть организован двумя принципиально разными способами. Первый способ- это прямое программирование устройств ввода/вывода (дисковода, экрана, модема, клавиатуры). Он может быть организован на различных уровнях (непосредственное программирование устройств, использование сервисных средств операционной системы, смешанный подход и т.д.), но суть его при этом не меняется. Каждая программа, написанная с использованием этого способа, может работать только с этим устройством и ни с каким другим. В настоящее время используется именно этот способ. Именно с помощью этого подхода (точнее, путем "косвенного" программирования периферийных устройств через драйверы этих устройств) и реализован классический WIMP - интерфейс. Он позволяет создавать красивые и довольно содержательные средства общения с пользователем (меню, окна и тому подобное), а современные технологии позволяют программе при установке автоматически настраиваться на установленное на компьютере оборудование. Но у этих систем есть недостаток: они не могут принять данные с устройств и передать данные устройствам, для работы с которыми они не созданы. Например, нельзя данные вводить с модема, если программа работает только с клавиатурой. Чтобы осуществить это, используют другой способ: ввод/вывод с использованием потоков. В этом случае каждое устройство рассматривается операционной системой как файл, куда можно поместить и откуда можно взять информацию. Так же, как информация, записанная в файл, рассматривается операционной системой как единое целое, не зависимо от способа записи его на диске, так и физическая реализация процесса ввода/вывода информации устройством никак не отражается на работе пользователя.
Как правило, эффект, достигаемый прямым программированием устройств, невозможно реализовать на уровне потоков (нельзя даже поменять цвет символов, не говоря уж о применении графики!) Но выигрыш в унификации процессов иногда оказывается более существенным, например, при работе с текстовой информацией, при автоматическом проведении эксперимента и тому подобное.
Поток, представляет собой некоторый буфер в памяти, куда поступает или откуда выбирается информация. Существуют следующие стандартные потоки:
1. Стандартный поток ввода - это обычно клавиатура.
2. Стандартный поток вывода - это обычно монитор.
Символы переадресации очень удобны, но иногда бывает необходимо организовать последовательность программ, выполняющих обработку информации, причем результат предыдущей программы является исходным для следующей. При этом промежуточные данные желательно никуда не записывать. Чтобы организовать такую обработку, используют знак '|' конвейера. Команды - "цепочки" такой обработки данных просто записываются в одну строку в порядке их вызова для обработки данных, и отделяются одна от другой знаком конвейера '|'. Пример:
В этом примере данные из файла mylist сортируются программой sort и постранично выводятся на экран программой more.
В UNIX тоже возможна переадресация потока с одновременным выводом данных на экран, и даже переадресация на два разных устройства. Для переадресации стандартного вывода в файл с одновременной выдачей информации на экран используется команда tee. Например, команда cat в UNIX позволяет просматривать файл. Следующая конструкция:
cat first | tee second
копирует файл first в файл second, одновременно показывая его на экране.
Для вывода данных на принтер используются конструкции:
в DOS > prn в UNIX lpr
Еще один пример: команда
cat first | tee second | lpr
копирует файл first в файл second, одновременно распечатывая его на принтере.
Командой lpr можно также вывести несколько файлов на печать.
Файловая система ОС должна предоставлять пользователям набор операций для работы с файлами, оформленный в виде системных вызовов. В различных ОС имеются различные наборы файловых операций. Наиболее часто встречающимися системными вызовами для работы с файлами являются [13, 17]:
- Create (создание). Файл создается без данных. Этот системный вызов объявляет о появлении нового файла и позволяет установить некоторые его атрибуты;
- Delete (удаление). Ненужный файл удаляется, чтобы освободить пространство на диске;
- Olien (открытие). До использования файла его нужно открыть. Данный вызов позволяет прочитать атрибуты файла и список дисковых адресов для быстрого доступа к содержимому файла;
- Close (закрытие). После завершения операций с файлом его атрибуты и дисковые адреса не нужны. Файл следует закрыть, чтобы освободить пространство во внутренней таблице;
- Read (чтение). Файл читается с текущей позиции. Процесс, работающий с файлом, должен указать (открыть) буфер и количество читаемых данных;
- Write (запись). Данные записываются в файл в текущую позицию. Если она находится в конце файла, его размер автоматически увеличивается. В противном случае запись производится поверх существующих данных;
- Append (добавление). Это усеченная форма предыдущего вызова. Данные добавляются в конец файла;
- Seek (поиск). Данный системный вызов устанавливает файловый указатель в определенную позицию;
- Get attributes (получение атрибутов). Процессам для работы с файлами бывает необходимо получить их атрибуты;
- Set attributes (установка атрибутов). Этот вызов позволяет установить необходимые атрибуты файлу после его создания;
- Rename (переименование). Этот системный вызов позволяет изменить имя файла. Однако такое действие можно выполнить копированием файла. Поэтому данный системный вызов не является необходимым;
- Execute (выполнить). Используя этот системный вызов, файл можно запустить на выполнение.
Рассмотрим примеры файловых операций в ОС Windows 2000 и UNIX. Как и в других ОС, в Windows 2000 есть свой набор системных вызовов, которые она может выполнять. Однако корпорация Microsoft никогда не публиковала список системных вызовов Windows, кроме того, она постоянно меняет их от одного выпуска к другому [17]. Вместо этого Microsoft определила набор функциональных вызовов, называемый Win 32 API (Win 32 Application Programming Interface). Эти вызовы опубликованы и полностью документированы. Они представляют собой библиотечные процедуры, которые либо обращаются к системным вызовам, чтобы выполнить требуемую работу, либо выполняют ее прямо в пространстве пользователя.
Философия Win 32 API заключается в предоставлении всеобъемлющего интерфейса, с возможностью выполнить одно и то же требование несколькими (тремя-четырьмя) способами. В ОС UNIX все системные вызовы формируют минимальный интерфейс: удаление даже одного из них приведет к снижению функциональности ОС.
Многие вызовы API создают объекты ядра того или иного типа (файлы, процессы, потоки, каналы и т.д.). Каждый вызов, создающий объект, возвращает вызывающему процессу результат, называемый дескриптором (небольшое целое число). Дескриптор используется впоследствии для выполнения операций с объектами. Он не может быть передан другому процессу и использован им. Однако при определенных обстоятельствах дескриптор может быть дублирован и передан другому процессу защищенным способом, что предоставляет второму процессу контролируемый доступ к объекту, принадлежащему первому процессу. С каждым объектом ассоциирован дескриптор безопасности, описывающий, кто и какие действия может, а какие не может выполнять с данным объектом.
Основные функции Win 32 API для файлового ввода-вывода и соответствующие системные вызовы ОС UNIX приведены ниже.
| Функция Win 32 API | Системные вызовы UNIX | Описание |
| CreateFile | open | Создать или открыть файл; вернуть дескриптор файла |
| DeleteFile | unlink | Удалить существующий файл |
| CloseHandle | close | Закрыть файл |
| ReadFile | read | Прочитать данные из файла |
| WriteFile | write | Записать данные в файл |
| SetFilePointer | lseek | Установить указатель в файле в определенную позицию |
| GetFileAttributes | stat | Вернуть атрибуты файла |
| LockFile | fcntl | Заблокировать область файла для обеспечения взаимного исключения |
| UnlockFile | fcntl | Отменить блокировку области файла |
Аналогично файловым операциям обстоит дело с операциями управления каталогами. Основные функции Win 32 API и системные вызовы UNIX для управления каталогами приведены ниже.

| Функция Win 32 API | Системные вызовы UNIX | Описание |
| CreateDirectory | mkdir | Создать новый каталог |
| RemoveDirectory | rmdir | Удалить пустой каталог |
| FindFirstFile | opendir | Инициализация, чтобы начать чтение записей каталога |
| FindNextFile | readdir | Прочитать следующую запись каталога |
| MoveFile | rename | Переместить файл из одного каталога в другой |
| SetCurrentDirectory | chdir | Изменить текущий рабочий каталог |
Способы выполнения файловых операций
Чаще всего с одним и тем же файлом пользователь выполняет не одну, а последовательность операций. Независимо от набора этих операций операционной системе необходимо выполнить ряд постоянных (универсальных) для всех операций действий.
- По символьному имени файла найти его характеристики, которые хранятся в файловой системе на диске.
- Скопировать характеристики в оперативную память, поскольку только в этом случае программный код может их использовать.
- На основании характеристик файла проверить права пользователя на выполнение запрошенной операции.
- Очисть область памяти, отведенную под временное хранение характеристик файла.
Кроме того, каждая операция включает ряд уникальных для нее действий, например, чтение определенного набора кластеров диска, удаление файла, изменение его атрибутов и т.п.
ОС может выполнить последовательность действий над файлами двумя способами (см. рис. рис. 7.22).
- Для каждой операции выполняются как универсальные, так и уникальные действия. Такая схема иногда называется схемой без заполнения состояния операции (stateless).
- Все универсальные действия выполняются в начале и конце последовательности операций, а для каждой промежуточной операции выполняются только уникальные действия.
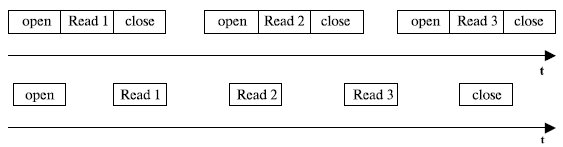
Рис. 7.22. Варианты выполнения последовательности действий над файлами
Подавляющее большинство файловых систем поддерживает второй способ, как более экономичный и быстрый. Однако первый способ более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от результата предыдущей. Поэтому первый способ иногда применяется в распределенных сетевых файловых системах, когда сбои из-за потерь пакетов или отказов одного из сетевых узлов более вероятны, чем при локальном доступе к данным.
При втором способе в ФС вводится два специальных системных вызова: open и close. Первый выполняется перед началом любой последовательности операций с файлом, а второй – после окончания работы с файлом.
Основной задачей вызова open является преобразование символьного имени файла в его уникальное числовое имя, копирование характеристик файла из дисковой области в буфер оперативной памяти и проверка прав пользователя на выполнение запрошенной операции. Вызов close освобождает буфер с характеристиками файла и делает невозможным продолжение операций с файлами без его повторного открытия.
Приведем несколько примеров системных вызовов для работы с файлами. Системный вызов create в ОС UNIX работает с двумя аргументами: символьным именем открываемого файла и режимом защиты. Так команда
fd = create ("abc", mode);
создает файл abc с режимом защиты, указанным в переменной mode. Биты mode определяют круг пользователей, которые могут получить доступ к файлам, и уровень предоставляемого им доступа. Системный вызов create не только создает новый файл, но также открывает его для записи. Чтобы последующие системные вызовы могли получить доступ к файлу, успешный системный вызов create возвращает небольшое неотрицательное целое число – дескриптор файла – fd. Если системный вызов выполняется с существующим файлом, длина этого файла уменьшается до 0, а все содержимое теряется.
Чтобы прочитать данные из существующего файла или записать в него данные, файл сначала нужно открыть с помощью системного вызова open с двумя аргументами: символьным именем файла и режимом открытия файла (для записи, чтения или того т другого), например
fd = open ("file", how);
Для ввода-вывода данных с помощью стандартных потоков в библиотеке Си определены функции:
- getchar ( )/putchar ( ) – ввод-вывод отдельного символа;
- gets ( )/ puts ( ) – ввод-вывод строки;
- scanf ( )/ printf ( ) – ввод-вывод в режиме форматирования данных.
Процесс в любое время может организовать ввод данных из стандартного файла ввода, выполнить символьный вызов:
read (stdin, buffer, nbyts);
Аналогично организуется вывод в стандартный файл вывода
write (stdout, buffer, nbytes).
При работе в Windows 2000 с помощью функции CreateFile можно создать файл и получить дескриптор к нему. Эту же функцию следует применять и для открытия уже существующего файла, так как в Win 32 API нет специальной функции File Open. Параметры функций, как правило, многочисленны, например, функция CreateFile имеет семь параметров:
Небольшие каталоги (small indexes). Если количество файлов в каталоге невелико, то список файлов может быть резидентным в записи в MFT, являющейся каталогом. Для резидентного хранения списка используется единственный атрибут — Index Root. Список файлов содержит значения атрибутов файла. По умолчанию — это имя файла, а также номер записи MTF, содержащей начальную запись файла.
Большие каталоги (large indexes). По мере того как каталог растет, список файлов может потребовать нерезидентной формы хранения. Однако начальная часть списка всегда остается резидентной в корневой записи каталога в таблице MFT. Имена файлов резидентной части списка файлов являются узлами так называемого В-дерева (двоичного дерева). Остальные части списка файлов размещаются вне MFT. Для их поиска используется специальный атрибут Index Allocation, представляющий собой адреса отрезков, хранящих остальные части списка файлов каталога. Одни части списков являются листьями дерева, а другие являются промежуточными узлами, то есть содержат наряду с именами файлов атрибут Index Allocation, указывающий на списки файлов более низких уровней.
Поиск в каталоге уникального имени файла, которым в NTFS является номер основной записи о файле в MFT, по его символьному имени происходит следующим образом. Сначала искомое символьное имя сравнивается с именем первого узла в резидентной части индекса. Если искомое имя меньше, то это означает, что его нужно искать в первой нерезидентной группе, для чего из атрибута Index Allocation извлекается адрес отрезка (VCN,, LCNj, Kj), хранящего имена файлов первой группы. Среди имен этой группы поиск осуществляется прямым перебором имен и сравнением до полного совпадения всех символов искомого имени с хранящимся в каталоге именем. При совпадении из каталога извлекается номер основной записи о файле в MFT и остальные характеристики файла берутся уже оттуда.
Если же искомое имя больше имени первого узла резидентной части индекса, то его сравнивают с именем второго узла, и если искомое имя меньше, то описанная процедура применяется ко второй нерезидентной группе имен, и т. д.
В результате вместо перебора большого количества имен (в худшем случае — всех имен каталога) выполняется сравнение с гораздо меньшим количеством имен узлов и имен в одной из групп каталога.
Файловые операции. Два способа организации файловых операций
Чаще всего с одним и тем же файлом пользователь выполняет не одну операцию, а последовательность операций. Например, при работе текстового редактора с файлом, в котором содержится некоторый документ, пользователь обычно считывает несколько страниц текста, редактирует эти данные и записывает их на место считанных, а затем считывает страницы из другой области файла, и т. п. После большого количества операций чтения и записи пользователь завершает работу с данным файлом и переходит к другому.
Какие бы операции не выполнялись над файлом, ОС необходимо выполнить ряд универсальных для всех операций действий:
1)По символьному имени файла найти его характеристики, которые хранятся в файловой системе на диске.
2)Скопировать характеристики файла в оперативную память, так как только таким образом программный код может их использовать.
3)На основании характеристик файла проверить права пользователя на выполнение запрошенной операции (чтение, запись, удаление, просмотр атрибутов файла).
4)Очистить область памяти, отведенную под временное хранение характеристик файла.
Операционная система может выполнять последовательность действий над файлом двумя способами:
- Для каждой операции выполняются как универсальные, так и уникальные действия. Такая схема иногда называется схемой без запоминания состояния операций (stateless).
- Все универсальные действия выполняются в начале и конце последовательности операций, а для каждой промежуточной операции выполняются только уникальные действия.
Подавляющее большинство файловых систем поддерживает второй способ организации файловых операций как более экономичный и быстрый. Первый способ обладает одним преимуществом — он более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от результата предыдущей. Поэтому первый способ иногда применяется в распределенных сетевых файловых системах (например, в Network File System, NFS компании Sun), когда сбои из-за потерь пакетов или отказов одного из сетевых узлов более вероятны, чем при локальном доступе к файлам.
При втором способе в файловой системе вводятся два специальных системных вызова: open — открытие файла, и close — закрытие файла.
Открытие файла
Системный вызов open в ОС UNIX работает с двумя аргументами: символьным именем открываемого файла и режимом открытия файла. Режим открытия говорит системе, какие операции будут выполняться над файлом в последовательности операций до закрытия файла по системному вызову close, например: только чтение, только запись или чтение и запись.
При открытии файла ОС сначала выполняет преобразование первого аргумента системного вызова, то есть символьного имени файла, в его уникальное числовое имя, которым в традиционных файловых системах UNIX является номер индексного дескриптора.
По номеру индексного дескриптора inode файловая система находит нужную запись на диске и копирует из нее характеристики файла в оперативную память.
Для хранения копии индексного дескриптора используются буферные области системного виртуального пространства. Характеристики индексного дескриптора, перенесенные в оперативную память, помещаются в структуру так называемого виртуального дескриптора vnode (virtual node). Структура vnode включает поля индексного дескриптора файла inode, а также несколько перечисленных ниже дополнительных полей, полезных при выполнении операций с файлом.
- Состояние индексного дескриптора в памяти, отражающее:
o заблокирован ли файл;
o ждет ли снятия блокировки с файла какой-либо процесс;
o отличается ли представление характеристик файла в памяти от своей дисковой копии в результате изменения содержимого индексного дескриптора;
o отличается ли представление файла в памяти от своей дисковой копии в результате изменения содержимого файла;
o является ли файл точкой монтирования.
- Логический номер устройства файловой системы, содержащей файл.
- Номер индексного дескриптора. В дисковом индексном дескрипторе это поле отсутствует, так как номер определяется положением дескриптора относительно начала области индексных дескрипторов.
- Счетчик ссылок на данную структуру vnode.
С одним и тем же файлом в какой-то период времени могут работать различные процессы, но операционная система не создает для каждого процесса отдельную копию структуры vnode, а для каждого файла, с которым в данный момент работает хотя бы один процесс, хранит ровно одну копию виртуального дескриптора. При очередном открытии файла ОС проверяет, имеется ли в системной памяти структура vnode открываемого файла (по номеру логического устройства и номеру индексного дескриптора, которые определяются при преобразовании символьного имени), и если имеется, то счетчик ссылок на нее увеличивается на единицу. При очередном закрытии этого файла счетчик ссылок уменьшается на единицу, и если он становится равным 0, то буфер, хранящий данный vnode, считается свободным.
При каждом открытии процессом файла ОС проверяет права пользовательского процесса на выполнение запрошенной операции с файлом и, если проверка прошла успешно, создает в системной области памяти новую структуру file, которая описывает как открытый файл, так и операции, которые процесс собирается производить с файлом (например, чтение).
Структура file содержит такие поля, как:
- признак режима открытия (только для чтения, для чтения и записи и т. п.);
- указатель на структуру vnode;
- текущее смещение в файле (переменная offset) при операциях чтения/записи;
- счетчик ссылок на данную структуру;
- указатель на структуру, содержащую права процесса, открывшего файл (эта структура находится в дескрипторе процесса);
- указатели на предыдущую и последующую структуры file, связывающие все такие структуры в двойной список.
Переменная offset, хранящаяся в структуре file, позволяет ОС запоминать текущее положение условного указателя в последовательности байт файла
Системный вызов open возвращает в пользовательский процесс дескриптор файла, который представляет собой номер записи в таблице открытых файлов процесса. Дескриптор файла имеет локальное значение только для того процесса, который открыл файл, для разных процессов одно и то же значение дескриптора указывает на разные операции, в общем случае над разными файлами.
После открытия файла его дескриптор используется во всех дальнейших операциях с файлом вплоть до явного закрытия файла. Таким образом, дескриптор файла является временным уникальным именем, но не файла, а определенной последовательности операций с этим файлом.
Для открытия файла /bin/prog 1.ехе в режиме «только для чтения» прикладной программист может использовать следующее выражение на языке С:
fd = open("/bin/progl exe". 0_RDONLY);
Здесь fd — это целочисленная переменная, сохраняющая значение дескриптора открытого файла. Ее значение должно использоваться в операциях обмена данными с файлом /bin/progI.exe. При неудачной попытке открытия файла (нет прав для выполнения затребованной операции, неверное имя файла) переменной fd присваивается значение -1, которое является индикатором ошибки для всех системных вызовов UNIX.
Обмен данными с файлом
Для обмена данными с предварительно открытым файлом в ОС UNIX существуют системные вызовы read и write. В том случае, когда необходимо явным образом указать, с какого байта файла необходимо читать или записывать данные, используется также системный вызов Т seek.
Системный вызов чтения данных из файла read имеет три аргумента:
read(fd buffer nbytes):
Первый аргумент fd является целочисленной переменной, имеющей значение дескриптора открытого файла. Второй аргумент buffer является указателем на область пользовательской памяти, в которую система должна поместить считанные данные.Количество байт этой области памяти задается третьим целочисленным аргументом nbytes. Функция read возвращает действительное количество считанных байт (оно может отличаться от заданного, если, например, была задана область чтения, выходящая за пределы файла) или же код ошибки -1. Начало дисковой области, которую нужно прочитать с помощью вызова read, явно в этом системном вызове не указывается. Чтение начинается с того байта, на который указывает смещение offset в структуре file. На это смещение указывает запись с номером fd в таблице открытых файлов процесса. После выполнения вызова read смещение offset наращивается на количество прочитанных байт. Вид системного вызова записи данных write аналогичен вызову read: wnte(fd buffer.nbytes).
Функция write записывает nbytes из буфера оперативной памяти buffer в файл, описываемый дескриптором fd. Функция write, так же как и read, возвращает вызвавшей ее программе значение реально переданных ею байт или код ошибки.
Рассмотрим пример, в котором прикладная программа работает с файлом, состоящем из записей фиксированной длины в 50 байт:
fd = open("/doc/qwery/base12. txt" 0_RDWR).
read(fd bufferl,50):
read(fd.buffer2, 2500):
Iseek(fd, 150, 0):
write (fd, output, 300):
В приведенном фрагменте программы после открытия файла /doc/query/base12.txt для чтения и записи выполняется чтение первой записи файла, а затем читается область файла, включающая еще 50 записей, начиная со 2 по 51. После обработки считанных записей (эти инструкции опущены) производятся перемещение указателя смещения в файле на начало четвертой записи и запись результатов в шесть последовательных записей, начиная с четвертой. Завершается фрагмент закрытием файла с помощью системного вызова close.
Все описанные системные вызовы являются синхронными, то есть пользовательский процесс переводится в состояние ожидания до тех пор, пока операция ввода-вывода не завершится.
Блокировки файлов
Блокировки файлов и отдельных записей в файлах являются средством синхронизации между работающими в кооперации процессами, пытающимися использовать один и тот же файл одновременно.
Процессы могут иметь соответствующие права доступа к файлу, но одновременное использование этих прав (в особенности права записи) может привести к некорректным результатам. Примером такой ситуации является одновременное редактирование одного и того же документа несколькими пользователями. Если доступ к файлу не управляется блокировками, то каждый пользователь, который имеет право записи в файл, работает со своей копией данных файла.
В обязательном режиме запрет на выполнение операции с заблокированным файлом поддерживает операционная система, поэтому процесс в любом случае не получит доступа к такому файлу. Однако при работе в этом режиме операционная система тратит много усилий и времени на его поддержание, поэтому обычно он не рекомендуется
Файл — это определенное количество информации (программа или данные), имеющее имя и хранящееся в долговременной (внешней) памяти.
Имя файла состоит из двух частей, разделенных точкой: собственно имя файла и расширение, определяющее его тип (программа, данные и т. д.). Собственно имя файлу дает пользователь, а тип файла обычно задается программой автоматически при его создании. Расширение файла — часть имени файла, отделённая самой правой точкой в имени.
1. Разрешается использовать до 255 символов.
2. Разрешается использовать символы национальных алфавитов, в частности русского.
3. Разрешается использовать пробелы и специальные символы, за исключением следующих девяти: /\:*?"<>|.
4. В имени файла можно использовать несколько точек. Расширением имени считаются все символы, стоящие за последней точкой.
Роль расширения имени файла чисто информационная, а не командная. Если файлу с рисунком присвоить расширение имени ТХТ, то содержимое файла от этого не превратится в текст. Его можно просмотреть в программе, предназначенной для работы с текстами, но ничего вразумительного такой просмотр не даст.
Атрибуты файла устанавливаются для каждого файла. Они указывают системе, какие операции можно производить с файлами. Существует четыре атрибута:
- только чтение (R);
Атрибут файла «Только чтение»
Данный атрибут указывает, что файл нельзя изменять. Все попытки изменить файл с атрибутом «только чтение», удалить его или переименовать завершатся неудачно.
Атрибут файла «Скрытый»
Файл с таким атрибутом не отображается в папке. Атрибут можно применять также и к целым папкам. Надо помнить, что в системе предусмотрена возможность отображения скрытых файлов, для этого достаточно в меню Проводника Сервис – Свойства папки – вкладка Вид – Показывать скрытые файлы и папки.
Атрибут файла «Архивный»
Такой атрибут имеют практически все файлы, его включение/отключение практически не имеет никакого смысла. Использовался атрибут программами резервного копирования для определения изменений в файле.
Атрибут файла «Системный»
Этот атрибут устанавливается для файлов, необходимых операционной системе для стабильной работы. Фактически он делает файл скрытым и только для чтения. Самостоятельно выставить системный атрибут для файла невозможно.
В процессе работы на компьютере над файлами чаще всего производятся следующие операции:
· создание (создание файла или папки)
· копирование (копия файла помещается в другой каталог);
· перемещение (сам файл перемещается в другой каталог);
· переименование (изменяется имя файла).
· удаление (запись о файле удаляется из каталога);
Файловая система.
На каждом носителе информации (гибком, жестком или лазерном диске) может храниться большое количество файлов. Порядок хранения файлов на диске определяется установленной файловой системой.
Файловая система - это система хранения файлов и организации каталогов. Она определяет формат физического хранения информации, которую принято группировать в виде файлов. Конкретная файловая система определяет размер имени файла, максимальный возможный размер файла, набор атрибутов файла. Некоторые файловые системы предоставляют сервисные возможности, например, разграничение доступа или шифрование файлов.
Если на диске хранятся сотни и тысячи файлов, то для удобства поиска файлы организуются в многоуровневую иерархическую файловую систему, которая имеет «древовидную» структуру (имеет вид перевернутого дерева).
В таком случае файлы на дисках объединяются в каталоги. Начальный, корневой, каталог содержит вложенные каталоги 1-го уровня, в свою очередь, в каждом из них бывают вложенные каталоги 2-го уровня и т. д. Необходимо отметить, что в каталогах всех уровней могут храниться и файлы. В Windows каталоги называются папками.
По сути, папка - это тоже файл, поэтому имеет похожие свойства. Каждая папка имеет свои свойства. Папки могут быть скрытыми, они могут быть защищены от копирования и изменения. При правом щелчке мыши по папке, выберите обозначение Свойства и получите полную информацию о занимаемом дисковом пространстве папки (количество информации в мегабайтах), количестве вложенных файлов, о том сколько свободного места осталось на диске, о правах доступа к папке (индивидуальные или общий ресурс), а также сможете произвести некоторые изменения в настройках.
Типы файловых систем
Современные файловые системы, в основном, иерархические. Редко встречаются одноуровневые ФС, когда файлы хранятся в единственной «куче», корневом каталоге носителя. Также редко можно встретить реляционные и прочие ФС, обеспечивающие другие методы идентификации данных.
Файловые системы различаются также по устойчивости к сбоям:
Неустойчивые к сбоям как правило представляю собой тривиальные структуры, полная согласованность которых обеспечивается во время работы не всегда. При сбое системы в моменты несогласованности возможна потеря данных, или даже разрушение всей ФС целиком. Восстановление часто требует длительных и нетривиальных действий.
Устойчивые к сбоям системы представляют полностью согласованные структуры в любой момент времени существования файловой системы, таким образом, отсутствуют моменты, когда сбой может привести к потерям данных или разрушению ФС. Как правило это журналируемые ФС, дублирующие все изменения структуры в специальной области — журнале таким образом, что в случае сбоя есть возможность завершить незавершённую операцию или откатить состояние ФС до сбоя.

В многоуровневых иерархических ФС полное имя файла включает путь к файлу, который состоит из имени диска и серии вложенных каталогов (папок):

В операционной системе Windows наибольшее распространение приобрели ФС NTFS и FAT32 (в основном на флешках). Во многих дистрибутивах операционных систем, основанных на ядре Linux, в качестве файловой системы по умолчанию обычно используется ext (Extended File System – расширенная файловая система). Есть несколько версий этой файловой системы — ext2, ext3, ext4.
Буфер обмена
Бу́фер обме́на (англ. clipboard) — промежуточное хранилище данных, предоставляемое программным обеспечением и предназначенное для переноса или копирования между приложениями или частями одного приложения.
Приложение может использовать свой собственный буфер обмена, доступный только в нём, или общий, предоставляемый операционной системой или другой средой через определённый интерфейс.
Буфер обмена некоторых сред позволяет вставлять скопированные данные в различных форматах в зависимости от получающего приложения, элемента интерфейса и других обстоятельств. Например, текст, скопированный из текстового процессора, может быть вставлен с разметкой в поддерживающие её приложения и в виде простого текста в остальные.
Вставить объект из буфера обмена можно сколько угодно раз.
Как правило, при копировании информации в буфер его предыдущее содержимое пропадает. Но, например, Microsoft Office содержит несколько буферов, поэтому может хранить одновременно несколько фрагментов информации. Некоторые среды рабочего стола включают программу для ведения протокола последних значений буфера и извлечения уже перезаписанных.
© 2014-2022 — Студопедия.Нет — Информационный студенческий ресурс. Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав (0.007)
Изучение файловых операций ввода/вывода с использованием библиотеки управления потоками C++. Характеристика и функции основных операторов, которые позволяют читать и записывать данные в файл. Создание программы с использованием операторов ввода/вывода.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 01.12.2009 |
| Размер файла | 22,9 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Волжский Университет им. В.Н, Татищева
Факультет Информатики и Телекоммуникаций
тема: “Файловые операции ввода/вывода в языке C++”
ОГЛАВЛЕНИЕ
Файловые операции ввода/вывода
Общие функции потокового ввода/вывода
Последовательный текстовый поток ввода/вывода
Последовательный двоичный файловый ввод/вывод
Файловый ввод/вывод с прямым доступом
Описание 10-ой лабораторной работы
ФАЙЛОВЫЕ ОПЕРАЦИИ ВВОДА/ВЫВОДА
Этот реферат посвящен файловым операциям ввода/вывода с использованием библиотеки управления потоками C++. Есть две возможности: либо использовать функции файлового ввода/вывода, описанные в заголовочном файле STDIO.H, либо функции stream-библиотеки C++. Каждая из этих библиотек имеет множество мощных и удобных функций. В этом реферате я представлю основные операторы, которые позволяют читать и записывать данные в файл. В данном реферате я затрону следующие темы:
Стандартные функции потоков ввода/вывода
Последовательный ввод/вывод потока с текстовой информацией
Последовательный ввод/вывод двоичных данных
Прямой доступ к потоку двоичных данных
STREAM-БИБЛИОТЕКА C++
Stream-библиотека (известная также как библиотека iostream) выполнена в виде иерархии классов, которые описаны в нескольких заголовочных файлах. Файл IOSTREAM.H, используемый до сих пор, - это только один из них. Другой, который будет интересен в этой главе, - FSTREAM.H. Файл IOSTREAM.H поддерживает основные классы для ввода/вывода потока. Файл FSTREAM.H содержит определения для основных классов файлового ввода/вывода.
Существуют дополнительные файлы библиотеки ввода/вывода, в которых имеются более специализированные функции ввода/вывода.
О бщие функции потокового ввода / выводаВ этом разделе представлены функции-элементы ввода/вывода, являющиеся общими как для последовательного, так и для прямого доступа. Эти функции включают open, close, good и fail в дополнение к операции !. Функция open открывает файловый поток для ввода, вывода, добавления, а также для ввода и вывода. Эта функция позволяет указывать тип данных, с которыми вы собираетесь работать: двоичные или текстовые.
При работе с файловым вводом/выводом очень важно знать различие между текстовым и двоичным режимами. Текстовый режим предназначен для текстовых файлов, в которых имеются строки обычного текста. Двоичный режим используется для любых других и особенно для файлов, которые сохраняются в форматах, неудобных для чтения человеком.
Существуют некоторые особые тонкости, связанные с файлами текстового режима, на которые следует обратить особое внимание и запомнить. Первая из них - символ EOF (26 в коде ASCII или Ctrl+Z) - представляет собой метку (символ) конца файла. В текстовом режиме, где встречается символ EOF, система C++ низкого уровня автоматически продвигается к концу файла; вы ничего не можете прочитать после специального символа. Это может вызвать проблемы, если такой специальный символ окажется в середине файла.
Другая особенность текстового режима заключается в том, как интерпретируются строки текстового файла. Каждая строка заканчивается последовательностью конца строки (EOL). На компьютерах под управлением операционных систем производства Microsoft EOL-последовательность представлена двумя символами кода ASCII: CR (13 в коде ASCII или Ctrl+M) и LF (10 в коде ASCII или Ctrl+J). Эта CRLF-последовательность используется функциями чтения и записи текстовой строки, которые автоматически, вставляют ее в файл или удаляют из него. Заметьте, что на большинстве других, операционных систем (unix-like и Macintosh) EOF просто является символом LF.
ФУНКЦИЯ-КОМПОНЕНТ OPEN
Прототип функции open
void open (const char* filename, int mode, int m = filebuf::openprot);
Параметр filename задает имя открываемого файла. Параметр mode указывает режим ввода/вывода. Далее следует список аргументов для mode, описанных в заголовочном файле FSTREAM.H:
in открыть поток для ввода,
out открыть поток для вывода,
ate установить указатель потока на конец файла,
app открыть поток для добавления,
trunk удалить содержимое файла, если он уже существует (bc++5),
nocreate инициировать ошибку, если уже не существует,
noreplace инициировать ошибку, если файл уже существует,
binary открыть в двоичном режиме.
Пример 1.
// открыть поток для ввода
fstream f;
f.open("simple.txt", ios::in);
// открыть поток для вывода fstream f;
fstream f;
f.open ("simple.txt", ios::out);
// открыть поток ввода/вывода для двоичных данных fstream f;
fstream f;
f.open("simple.txt", ios::in | ios::out | ios::binary);
Функция close закрывает поток и освобождает использовавшиеся ресурсы. Эти ресурсы включают буфер памяти для операции потокового ввода/вывода.
ФУНКЦИЯ-КОМПОНЕНТ CLOSE
Прототип для функции close:
void close();
Пример 2.
fstream f;
// открыть поток
f.open ( "simple.txt", ios::in);
// работа с файлом
// закрыть поток
f.close ();
Stream-библиотека C++ Включает в себя набор основных функций, которые контролируют состояние ошибки потоковой операции. Эти функции включают следующие:
Функция good() возвращает ненулевое значение, если при выполнении потоковой операции не возникает ошибки. Объявление функции good: int good();
Функция fail() возвращает ненулевое значение, если при выполнении потоковой операции возникает ошибка. Объявление функции fail: int fail();
Перегруженная операция ! применяется к экземпляру потока для определения состояния ошибки.
Stream-библиотека C++ предоставляет дополнительные функции для установки и опроса других аспектов и типов ошибок потока.
ПОСЛЕДОВАТЕЛЬНЫЙ ТЕКСТОВЫЙ ПОТОК ВВОДА/ВЫВОДА
Функции и операции последовательного текстового ввода/вывода являются довольно простыми. Эти функции и операции включают:
Операция извлечения из потока
Операция помещения в поток >> читает символы потока.
Функция getline читает строку из потока.
ФУНКЦИЯ-ЭЛЕМЕНТ GETLINE
Прототипы функции-элемента getline:
istream& getline (char* buffer, int size, char delimiter = '\n');
istream& getline (signed char* buffer, int size, char delimiter = '\n');
istream& getline (unsigned char* buffer, int size, char delimiter = '\n');
Параметр buffer - это указатель на строку, принимающую символы из потока. Параметр size задает максимальное число символов для чтения. Параметр delimiter указывает разделяющий символ, который вызывает прекращение ввода строки до того, как будет введено количество символов, указанное в параметре size. По умолчанию параметру delimiter присваивается значение '\n'.
Пример 3.
fstream f;
char textLine[MAX];
f.open("sample.txt", ios::in);
while (!f.eof())
f.getline(textLine, MAX);
f.close();
ПОСЛЕДОВАТЕЛЬНЫЙ ДВОИЧНЫЙ ФАЙЛОВЫЙ ВВОД/ВЫВОД
f.getline(textLine, MAX);
f.close();
ПОСЛЕДОВАТЕЛЬНЫЙ ДВОИЧНЫЙ ФАЙЛОВЫЙ ВВОД/ВЫВОД
Stream-библиотека C++ имеет перегруженные потоковые функции-элементы write и read для последовательного двоичного файлового ввода/вывода. Функция write посылает ряд байт в выходной поток. Эта функция может записывать любую переменную или экземпляр в поток.
ФУНКЦИЯ-ЭЛЕМЕНТ WRITE
Прототип перегруженной функции-элемента:
ostream& write(const char* buff, int num);
ostream& write(const signed char* buff, int num);
ostream& write(const unsigned char* buff, int num);
Параметр buff - это указатель на буфер, содержащий данные, которые будут посылаться в выходной поток. Параметр num указывает число байт в буфере, которые передаются в этот поток.
Пример 4.
const MAX = 80;
char buff[MAX+1] = "Hello World!";
int len = strlen (buff) + 1;
fstream f;
f.open("CALC.DAT", ios::out | ios::binary);
f.write((const unsigned char*) &len, sizeof(len));
f.write((const unsigned char*) buff, len);
f.close();
В этом примере открывается файл CALC.DAT, записывается целое, содержащее число байт в строке и записывается сама строка перед тем, как файл закрывается.
Функция read считывает некоторое количество байт из входного потока. Эта функция может считывать любую переменную или экземпляр из потока.
ФУНКЦИЯ-ЭЛЕМЕНТ READ
Прототип перегруженной функции-элемента read:
ostream& read(char* buff, int num);
ostream& read(signed char* buff, int num);
ostream& read(unsigned char* buff, int num);
Параметр buff - это указатель на буфер, который принимает данные из входного потока. Параметр num указывает число считываемых из потока байт.
Пример 5.
const MAX = 80;
char buff [MAX+1];
int len;
fstream f;
f.open("CALC.DAT", ios::in | ios::binary);
f.read((unsigned char*) &len, sizeof(len));
f.read((unsigned char*) buff, len);
f.close();
В этом примере считывается информация, записанная в предыдущем примере.
ФАЙЛОВЫЙ ВВОД/ВЫВОД С ПРЯМЫМ ДОСТУПОМ
Файловые операции ввода/вывода прямого доступа также используют потоковые функции-элементы read и write, представленные в предыдущем разделе. Stream-библиотека имеет ряд функций, позволяющих передвигать указатель потока в любое необходимое положение. Функция-элемент seekg - одна из таких функций.
ФУНКЦИЯ-ЭЛЕМЕНТ SEEKG
Прототип для перегруженной функции-компонента seekg:
istream& seekg(long pos);
istream& seekg(long offset, seek_dir dir);
Параметр pos в первой версии определяет абсолютное положение байта в потоке. Во второй версии параметр offset определяет относительное смещение, в зависимости от аргумента dir. Аргументы для последнего параметра:
ios::beg С начала файла
ios::cur С текущей позиции файла
ios::end С конца файла
Пример 6.
const BLOCK SIZE = 80
char buff[BLOCK_SIZE] = "Hello World!";
f.open("CALC.DAT", ios::in | ios::out | ios::binary);
f.seekg(3 * BLOCK_SIZE); // продвинутся к блоку 4
f.read((const unsigned char*)buff, BLOCK_SIZE);
fclose ();
ОПИСАНИЕ 10-ОЙ ЛАБОРАТОРНОЙ РАБОТЫ
Задание: Дан файл, содержащий сведения о личной коллекции книголюба. Каждая запись содержит поля - шифр книги, автор, названия, год издания, местоположение (номер стеллажа, шкафа и т. п.). Написать программу, выдающую следующую информацию:
- местоположение книги автора Х названия Y;
- список автора Z, находящихся в коллекции;
- число книг издания ХХ года.
Значения книг Х, Y, Z и год издания вводятся по запросу с терминала.
Листинг программы:
struct books
char id[100];
char author[100];
char title[100];
int dop;
int n_shkafa;
int n_polki;
void add_book()
books buf;
ofstream f("lab_10.dat",ios::app);
char s[100];
memset(&buf,0,sizeof(books));
cin.getline(s,sizeof(s));
cin.getline(s,sizeof(s));
strcpy(buf.id,s);
cin.getline(s,sizeof(s));
strcpy(buf.author,s);
cin.getline(s,sizeof(s));
strcpy(buf.title,s);
cin>>buf.dop;
cin>>buf.n_shkafa;
cin>>buf.n_polki;
f.write((char *)&buf,sizeof(books));
f.close();
void show_book()
books buf;
ifstream f("lab_10.dat");
char author_x[100],title_y[100];
cin.getline(author_x,sizeof(author_x));
cin.getline(author_x,sizeof(author_x));
cin.getline(title_y,sizeof(title_y));
memset(&buf,0,sizeof(books));
f.read((char *)&buf,sizeof(books));
if (f.eof()) break;
if((*buf.author==*author_x) && (*buf.title==*title_y))
f.close();
getch();
void show_author()
books buf;
char author_z[100];
ifstream f("lab_10.dat");
cin.getline(author_z,sizeof(author_z));
cin.getline(author_z,sizeof(author_z));
clrscr();
memset(&buf,0,sizeof(books));
f.read((char *)&buf,sizeof(books));
if(f.eof()) break;
if(*buf.author==*author_z)
f.close();
getch();
void show_num()
books buf;
int dop_xx,k=0;
ifstream f("lab_10.dat");
cin>>dop_xx;
clrscr();
memset(&buf,0,sizeof(books));
f.read((char *)&buf,sizeof(books));
if(f.eof()) break;
if(buf.dop==dop_xx) k++;
f.close();
getch();
void main(void)
int choice,i;
char menu[kol][100]=
"2. Показать месторасположение книги",
"3. Показать список автора",
"4. Показать число книг",
"5. Выход">;
textcolor(10);
clrscr();
for(i=0;i
cin>>choice;
clrscr();
switch(choice)
case 1: add_book();break;
case 2: show_book();break;
case 3: show_author();break;
case 4: show_num();break;
default: ;
while(choice!=5);
В программе описывается структура books, содержащая поля - шифр книги, автор, название, год издания, местоположение (номер шкафа, номер полки). Управление программой происходит из меню. Процедура add_book() открывает файл в режиме добавления, считывает с клавиатуры шифр книги, автора, название, год издания, местоположение. Затем записывает данные в файл. Процедура show_book() открывает файл на чтение, считывает с консоли автора и название книги, и производит поиск в файле. Если находит книгу по заданным условиям то выводит на экран местоположение книги (номер шкафа и номер полки). Процедура show_author() считывает с терминала автора книги и, производя поиск по коллекции, выводит список книг данного автора, находящихся в коллекции. Процедура show_num() подсчитывает число книг введённого года издания.
ЗАКЛЮЧЕНИЕ
Данный реферат представил краткое введение в библиотеку ввода/вывода C++ и вынес на обсуждение следующие вопросы:
Общие функции ввода/вывода, включая open, close, good, fail и оператор !.
Функция open открывает файловый поток ввода/вывода и поддерживает попеременный и множественный режимы ввода/вывода. Функция close закрывает файловый поток. Функции good и fail индицируют успешную или ошибочную, соответственно, потоковую операцию ввода/вывода.
C++ позволяет выполнять последовательный потоковый ввод/вывод для текста с использованием операций < и >, так же как и при помощи потоковой функции getline. Операция < позволяет записать символы и строки (а также и другие предопределенные типы данных). Операция >применяется для получения символов. Функция getline позволяет вашему приложению считывать строки с клавиатуры или из текстового файла.
Последовательный потоковый ввод/вывод двоичных данных использует потоковые функции write или read для записи или считывания данных из переменных любого типа.
Потоковый ввод/вывод прямого доступа для двоичных данных использует функцию seekg в объединении с функциями read и write. Функция seekg позволяет передвигать потоковый указатель либо в абсолютное, либо в относительное положение в потоке.
Подобные документы
cin>>choice;
clrscr();
switch(choice)
case 1: add_book();break;
case 2: show_book();break;
case 3: show_author();break;
case 4: show_num();break;
default: ;
while(choice!=5);
В программе описывается структура books, содержащая поля - шифр книги, автор, название, год издания, местоположение (номер шкафа, номер полки). Управление программой происходит из меню. Процедура add_book() открывает файл в режиме добавления, считывает с клавиатуры шифр книги, автора, название, год издания, местоположение. Затем записывает данные в файл. Процедура show_book() открывает файл на чтение, считывает с консоли автора и название книги, и производит поиск в файле. Если находит книгу по заданным условиям то выводит на экран местоположение книги (номер шкафа и номер полки). Процедура show_author() считывает с терминала автора книги и, производя поиск по коллекции, выводит список книг данного автора, находящихся в коллекции. Процедура show_num() подсчитывает число книг введённого года издания.
ЗАКЛЮЧЕНИЕ
Данный реферат представил краткое введение в библиотеку ввода/вывода C++ и вынес на обсуждение следующие вопросы:
Анализ операторов ввода и вывода, а также характеристика форматов, используемых в этих операторах. Оформление законченной программы с применением этих операторов. Структура программы. Алфавит языка и типы данных. Ввод и вывод информации. Форматный вывод.
лабораторная работа [62,0 K], добавлен 15.07.2010
Организация и назначение консольного ввода-вывода, необходимые для этого функции и их применение. Библиотеки, организующие функционирование потокового ввода-вывода, выполняемые операции. Арифметические операции и математические функции в среде С++.
лабораторная работа [33,8 K], добавлен 15.07.2009
Организация файлов и доступ к ним. Файловые операции. Программирование с использованием встроенных функций ввода-вывода; линейных, разветвляющихся и циклических вычислительных процессов с использованием If-else, оператора выбора Case; массивов и матриц.
курсовая работа [5,8 M], добавлен 24.05.2014
Программирование линейных алгоритмов. Процедуры ввода READ и READLN и вывода WRITE и WRITELN. Примеры решения задач на языке Паскаль. Оператор присваивания и выражения. Основные способы формирования структурных операторов. Операторы вызова процедур.
курсовая работа [44,3 K], добавлен 18.03.2013
Характеристика базовых конструкций языков программирования. Изучение истории их развития и классификации. Определение основных понятий языков программирования. Описание основных операторов, которые используются в языках программирования высокого уровня.
курсовая работа [400,6 K], добавлен 10.11.2016
Обеспечение использования принтера в прикладных пакетах. Приемы управления работой печатающих устройств в MS-DOS. Стандартныe файлы ввода и вывода, пeрeнаправлeниe вывода. Обмен данными с файлом. Проектирование символов для матричных принтеров.
курсовая работа [2,0 M], добавлен 26.06.2011
Использование программой функции ввода-вывода данных для реализации дружественного интерфейса с пользователем. Функции консоли и особенности их применения для обеспечения аккуратного ввода информации и упорядоченного вывода. Обзор стандартных функций.
Читайте также: