
Способы физической организации файловой системы
Файловая система позволяет программам обходиться набором достаточно простых операций для выполнения действий над некоторым абстрактным объектом, представляющим файл . При этом программистам не нужно иметь дело с деталями действительного расположения данных на диске, буферизацией данных и другими низкоуровневыми проблемами передачи данных с запоминающего устройства. Все эти функции файловая система берет на себя. Файловая система распределяет дисковую память , поддерживает именование файлов, отображает имена файлов в соответствующие адреса во внешней памяти, обеспечивает доступ к данным, поддерживает разделение, защиту и восстановление данных.
Таким образом, файловая система играет роль промежуточного слоя, экранизирующего все сложности физической организации долговременного хранилища данных и создающего для программ более простую логическую модель этого хранилища, а затем предоставляет им набор удобных в использовании команд для манипулирования файлами.
Классическая схема организации программного обеспечения файловой системы представлена на рис. 7.6.
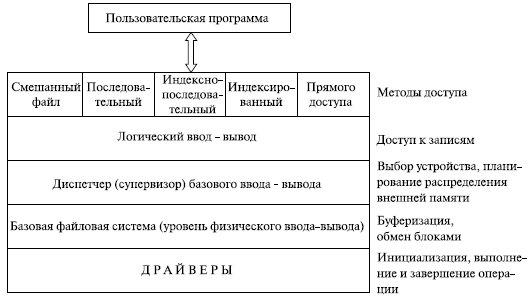
На нижнем уровне драйверы устройств непосредственно связаны с периферийными устройствами или их котроллерами либо каналами. Драйвер устройства отвечает за начальные операции ввода-вывода устройства и за обработку завершения запроса ввода-вывода. При файловых операциях контролируемыми устройствами являются дисководы и стримеры (накопители на МЛ). Драйверы устройств рассматриваются как часть операционной системы.
Следующий уровень называется базовой файловой системой, или уровнем физического ввода-вывода. Это первичный интерфейс с окружением (периферией) компьютерной системы. Он оперирует блоками данных, которыми обменивается с дисками, магнитной лентой и другими устройствами. Поэтому он связан с размещением и буферизацией блоков в оперативной памяти. На этом уровне не выполняется работа с содержимым блоков данных или структурой файлов. Базовая файловая система обычно рассматривается как часть операционной системы (в MS- DOS эти функции выполняет BIOS , не относящийся к ОС).
Диспетчер базового ввода-вывода отвечает за начало и завершение файлового ввода-вывода. На этом уровне поддерживаются управляющие структуры, связанные с устройством ввода-вывода, планированием и статусом файлов. Диспетчер осуществляет выбор устройства, на котором будет выполняться операция файлового ввода-вывода, планирование обращения к устройству (дискам, лентам), назначение буферов ввода-вывода и распределение внешней памяти. Диспетчер базового ввода-вывода является частью ОС.
Логический ввод- вывод предоставляет приложениям и пользователям доступ к записям. Он обеспечивает возможности общего назначения по вводу-выводу записей и поддерживает информацию о файлах. Наиболее близкий к пользователю уровень ФС часто называется методом доступа. Он обеспечивает стандартный интерфейс между приложениями и файловыми системами и устройствами, содержащими данные. Различные методы доступа отражают различные структуры файлов и различные пути доступа и обработки данных.
Файловая система
Одной из основных задач ОС является предоставление удобств пользователю при работе с данными, хранящимися на дисках. Для этого ОС подменяет физическую структуру хранящихся данных некоторой удобной для пользователя логической моделью, которая реализуется в виде дерева каталогов, выводимого на экран такими утилитами, как Norton Commander, Far Manager или Windows Explorer. Базовым элементом этой модели является файл, который так же, как и файловая система в целом, может характеризоваться как логической, так и физической структурой.
Управление файлами
Файл – именованная область внешней памяти, предназначенная для считывания и записи данных.
Файлы хранятся в памяти, не зависящей от энергопитания. Исключением является электронный диск, когда в ОП создается структура, имитирующая файловую систему.
Файловая система (ФС) — это компонент ОС, обеспечивающий организацию создания, хранения и доступа к именованным наборам данных — файлам.
Файловая система включает:Файловая система включает:
- Совокупность всех фалов на диске.
- Наборы структур данных, используемых для управления файлами (каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске).
- Комплекс системных программных средств, реализующих различные операции над файлами: создание, уничтожение, чтение, запись, именование, поиск.
Задачи, решаемые ФС, зависят от способа организации вычислительного процесса в целом. Самый простой тип – это ФС в однопользовательских и однопрограммных ОС. Основные функции в такой ФС нацелены на решение следующих задач:
- Именование файлов.
- Программный интерфейс для приложений.
- Отображения логической модели ФС на физическую организацию хранилища данных.
- Устойчивость ФС к сбоям питания, ошибкам аппаратных и программных средств.
Задачи ФС усложняются в однопользовательских многозадачных ОС, которые предназначены для работы одного пользователя, но дают возможность запускать одновременно несколько процессов. К перечисленным выше задачам добавляется новая задача — совместный доступ к файлу из нескольких процессов.
Файл в этом случае является разделяемым ресурсом, а значит ФС должна решать весь комплекс проблем, связанных с такими ресурсами. В частности: должны быть предусмотрены средства блокировки файла и его частей, согласование копий, предотвращение гонок, исключение тупиков. В многопользовательских системах появляется еще одна задача: Защита файлов одного пользователя от несанкционированного доступа другого пользователя.
Еще более сложными становятся функции ФС, которая работает в составе сетевой ОС ей необходимо организовать защиту файлов одного пользователя от несанкционированного доступа другого пользователя.
Основное назначение файловой системы и соответствующей ей системы управления файлами– организация удобного управления файлами, организованными как файлы: вместо низкоуровневого доступа к данным с указанием конкретных физических адресов нужной нам записи, используется логический доступ с указанием имени файла и записи в нем.
Термины «файловая система» и «система управления файлами» необходимо различать: файловая система определяет, прежде всего, принципы доступа к данным, организованным как файлы. А термин «система управления файлами» следует употреблять по отношению к конкретной реализации файловой системы, т.е. это комплекс программных модулей, обеспечивающих работу с файлами в конкретной ОС.
Пример
Файловая система FAT (file allocation table) имеет множество реализаций как система управления файлами
- Система, разработанная для первых ПК называлась просто FAT (сейчас ее называют просто FAT-12) . Ее разрабатывали для работы с дискетами, и некоторое время она использовалась для работы с жесткими дисками.
- Потом ее усовершенствовали для работы с жесткими дисками большего объема, и эта новая реализация получила название FAT–16. это название используется и по отношению к СУФ самой MS-DOS.
- Реализация СУФ для OS/2 называется super-FAT (основное отличие – возможность поддерживать для каждого файла расширенные атрибуты).
- Есть версия СУФ и для Windows 9x/NT и т.д. (FAT-32).
Физическая и логическая структура диска
Жесткий диск состоит из одной или нескольких стеклянных или металлических пластин, каждая из которых покрыта с одной или двух сторон магнитным материалом. Для записи информации на магнитную поверхность дисков применяется следующий способ: поверхность рассматривается как последовательность точечных позиций, каждая из которых считается битом и может быть установлена в 0 или 1. Так как расположения точечных позиций определяется неточно, то для записи требуются заранее нанесенные метки, которые помогают записывающему устройству находить позиции записи. Процесс нанесения таких меток называется физическим форматированием и является обязательным перед первым использованием накопителя.
Физическое форматирование – это процесс записи на поверхность диска служебной информации, обозначающей сектора на диске (пометка начала и конца дорожки и сектора).
На каждой стороне каждой пластины размечены тонкие концентрические окружности (по ним располагаются синхронизирующиеся метки). Каждая концентрическая окружность называется дорожкой.
Количество дорожек зависит от типа диска. Нумерация дорожек начинается с 0 от внешнего края к центру диска. Когда диск вращается, головка чтения/записи считывает двоичные данные с магнитной дорожки или записывает их на нее. Нумерация сторон начинается с 0.
Группы дорожек (треков) одного радиуса, расположенных на поверхностях магнитных дисков, называются цилиндрами. Номер цилиндра совпадает с номером образующей дорожки. Жесткие диски могут иметь по несколько десятков тысяч цилиндров, на поверхности дискеты, как правило, их восемьдесят. Зная количество рабочих поверхностей, дорожек на одной стороне, размер сектора, можно определить емкость диска.
Для дискет 3.5”: 2 рабочие поверхности, 80 дорожек на каждой стороне, 18 секторов на каждой дорожке, 512 байт – каждый сектор. Тогда, емкость дискеты=21801181512=1 474 560 байтов = 1.44 Мбайт.
Каждая дорожка разбивается на секторы. Сектор – наименьшая адресуемая единица обмена данными дискового устройства с оперативной памятью. Нумерация секторов начинается с 1. Каждый сектор состоит из поля данных и поля служебной информации, ограничивающей и идентифицирующей его.
Для того чтобы контроллер диска мог найти на диске нужный сектор, необходимо задать ему все составляющие адреса сектора: номер цилиндра, номер поверхности, номер сектора ([c-h-s]).
ОС при работе с диском использует, как правило, собственную единицу дискового пространства, называемую кластером.
Кластер (ячейка размещения данных) – объем дискового пространства, участвующий в единичной операции чтения/записи, осуществляемой ОС.
Кластер – это минимальный размер места на диске, которое может быть выделено файловой системой для хранения одного файла.
Пример. Если файл имеет размер 2560 байт, а размер кластера в файловой системе определен в 1024 байта, то файлу будет выделено на диске 3 кластера.
Размер кластера зависит от формата диска и может соответствовать одному сектору или нескольким смежным секторам дорожки.
Размер кластера определяется, как правило, автоматически при логическом форматировании.
Узнать размер кластера можно следующими способами:
- В ОС Windows: Панель управления → Администрирование → Управление компьютером → Дефрагментация диска → Выделить логический диск → Анализ.
- Выбор размера кластера: Format c:/a:size.
- Создать файл небольшого размера, например документ блокнота и вывести свойства файла. Размер фала на диске будет соответствовать размеру кластера.
7.13. Организация файлов и доступ к ним
Типы, именование и атрибуты файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых входят обычные файлы, содержащие информацию произвольного характера (текст, графика , звук и др.), файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и др.
Обычные файлы, или просто файлы, или регулярные файлы, содержат информацию, которую в них заносит пользователь или которая образуется в результате работы системных и пользовательских программ. Большинство ОС не контролируют содержимое и структуру регулярных файлов , которые в основном являются ASCII-файлами либо двоичными файлами. ASCII-фалы состоят из текстовых строк. Они могут отображаться на экране и выводиться на печать без какого-либо преобразования, и могут редактироваться практически любым текстовым редактором. Двоичные файлы имеют определенную внутреннюю структуру, которая известна программе, использующей данный файл . При выводе двоичного файла на принтер получается случайный набор символов.
Каталоги – это системные файлы, обеспечивающие поддержку структуры файловой системы. Они содержат системную справочную информацию о наборе файлов, сгруппированных пользователем по какому-либо неформальному признаку (договоры, рефераты, курсовые проекты и т.п.). Во многих ОС в каталог могут входить другие файлы, в том числе другие каталоги, за счет чего образуется древовидная структура, удобная для поиска требуемого файла. Каталоги устанавливают соответствие между именами файлов и их характеристиками, используемыми файловой системой для управления файлами. В число таких характеристик входят тип файла , права доступа к файлу, его распоряжение на диске, размер, дата и время создания и др.
Специальные файлы – это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к последовательным устройствам ввода-вывода, таким как терминалы, принтеры и др. (например, MS- DOS рассматривает монитор и клавиатуру как файлы со стандартным именем con – консоль , а принтер – как файл prn ). Блочные специальные файлы используются для моделирования дисков.
Именованные конвейеры (каналы) представляют собой циклические буферы, позволяющие выходной файл одной программы соединить со входным файлом другой программы.
Наконец, отображаемые файлы – это обычные файлы, отображенные на адресное пространство процесса по указанному виртуальному адресу.
Файлы относятся к абстрактному механизму. Они предоставляют способ сохранять информацию на запоминающем устройстве и считывать ее позднее снова. При этом от пользователя должны скрываться такие детали, как способ и место хранения информации, а также детали работы устройства.
Во многих операционных системах имя файла состоит из двух частей, разделенных точкой. Часть имени после точки называется расширением файла и обычно означает его тип. Так, в MS- DOS имя файла может содержать от 1 до 8 символов, а расширение от 0 (отсутствует) до 3.
В некоторых ОС, например, Windows , расширение указывает на программу, создавшую файл . Другие ОС, например, UNIX , не принуждают пользователя строго придерживаться расширений. Некоторые типичные расширения файлов приведены ниже.
В иерархически организованных файловых системах обычно используются три типа имен файлов: простые, составные и относительные.
Простое (короткое) символьное имя идентифицирует файл в пределах одного каталога. Несколько файлов могут иметь одно и то же простое имя , если они принадлежат разным каталогам.
Составное (полное) символьное имя представляет собой цепочку, содержащую имя диска и имена всех каталогов, через которые проходит путь от корневого каталога до данного файла.
Относительное имя файла определяется через текущий каталог , т.е. каталог, в котором в данный момент времени работает пользователь . Таким образом, относительных имен у файла может быть достаточно много, и все они являются частью полного имени.
Понятие файла включает не только хранимые им данные и имя, но и информацию, описывающую свойства файла. Эта информация составляет атрибуты файла. Список атрибутов может быть различным в различных ОС. Пример возможных атрибутов приведен ниже.
Пользователь может получить доступ к атрибутам, используя средства, предоставляемые для этой цели файловой системой. Обычно разрешается читать значение любых атрибутов, а изменять – только некоторые.
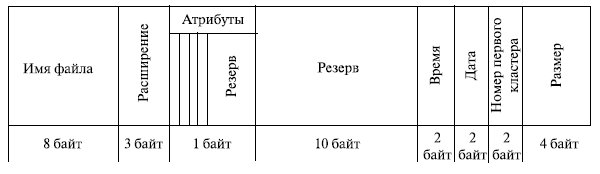
Значения атрибутов файлов могут содержаться в каталогах, как это сделано, например, в MS- DOS (рис. 7.7). Другим вариантом является размещение атрибутов в специальных таблицах, в этом случае в каталогах содержатся ссылки на эти таблицы.
Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура (организация) файла является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть целиком возложено на приложение либо в той или иной степени эту работу может взять на себя файловая система .
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла, целиком относятся к ведению приложения, файл представляется файловой системе неструктурированной последовательностью данных. Приложение формирует запросы к файловой системе на ввод- вывод , используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт , которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой. Следует подчеркнуть, что интерпретация данных никак не связана с действительным способом их хранения в файловой системе.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью байт , стала популярной вместе с ОС UNIX , и теперь широко используется в современных ОС. Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями, поскольку разные приложения могут по -своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл . В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением!
Известно пять фундаментальных способов организации файлов [10]:
- смешанный файл,
- последовательный файл ,
- индексно- последовательный файл ,
- индексируемый файл,
- файл прямого доступа.
При выборе способа организации файла нужно учитывать несколько критериев:
- быстрота доступа,
- легкость обновления,
- экономность хранения,
- простота обслуживания,
- надежность.
Смешанный файл . Это наименее сложная форма организации файла. Данные накапливаются в порядке поступления. Запись состоит из одного пакета данных. Записи могут иметь различные или одинаковые поля, расположенные в различном порядке (рис. 7.8). Каждое поле описывает само себя, включая как имя, так и значение . Длина каждого поля должна быть указана явно либо посредством применения разделителя.

Поскольку смешанный файл не имеет никакой структуры, доступ к записи осуществляется полным перебором всех записей файла. Смешанные файлы применяются в том случае, когда данные накапливаются и сохраняются перед обработкой, или если данные неудобны для организации. Файлы этого типа рационально используют дисковое пространство , хорошо подходят для полного набора. Обновление записей достаточно сложно, так же как и вставка записи.
Последовательный файл . Для записей используется фиксированный формат. Все записи имеют одинаковую длину (но иногда и не одинаковую) и состоят из одинакового количества полей фиксированной длины, организованных в определенном порядке (рис. 7.9). Поскольку длина и позиция каждого поля известны, сохранению подлежат только значения полей. Атрибутами файловой структуры является имя и длина каждого поля.
Одно определенное поле (или несколько полей) называется ключевым. Оно однозначно идентифицирует запись , так как это поле различно для каждой записи. Более того, записи сохраняются в "ключевой" последовательности: в алфавитном порядке для текстового ключа и в числовом – для числового. Последовательные файлы часто используются пакетными приложениями и обычно являются оптимальным вариантом, если эти приложения выполняют обработку всех записей. Удобно и то, что такой файл можно хранить как на ленте, так и на магнитном диске.
Для диалоговых приложений последовательный файл малоэффективен, поскольку для нахождения нужной записи требуется последовательный перебор записи файла. Правда, если в оперативную память загрузить весь файл , возможен более эффективный метод поиска. Дополнения к файлу или изменения в записях создают проблемы.
Обычно последовательный файл сохраняется с последовательной организацией записей внутри блока, т.е. физическая организация файла в точности соответствует логической. Новые записи размещаются в отдельном смешанном файле, называемом журнальным файлом, или файлом транзакции. Периодически в пакетном режиме выполняется слияние основного и журнального файлов в новый файл с корректной последовательностью ключей.
Альтернативной организацией может быть физическая организация в виде списка с использованием указателей. В каждом физическом блоке сохраняется одна или несколько записей, и каждый блок содержит указатель на следующий блок. Для вставки новых записей достаточно изменить указатели, и нет необходимости в том, чтобы новые записи занимали определенную физическую позицию. Это удобство достигается за счет определенных накладных расходов и дополнительной работы. Если в последовательном файле записи имеют одну и ту же длину, то можно вычислить адрес требуемой записи по ее номеру, номеру текущей записи и длине записи. Если записи имеют переменную длину, такой подход невозможен.
Индексно- последовательный файл . Одним из методов преодоления недостатков последовательного файла является индексно-последовательная организация файла. В этом случае файл состоит из трех частей (файлов): главный файл , содержащий записи с последовательно идущими ключами, индексный файл , содержащий индексное поле , и указатель в главный с ключами, файл переполнения (рис. 7.10).
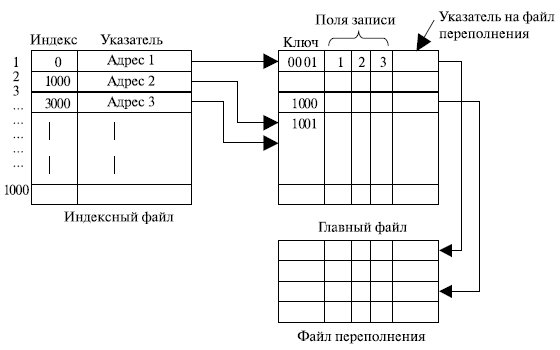
Для поиска нужной записи по ее ключу сначала выполняется поиск в индексном файле. После того как в нем найдено наибольшее значение ключа, которое не превышает искомое, продолжается поиск в главном файле. Например, пусть последовательный файл (главный) содержит 1 млн записей. Для поиска определенного ключевого значения необходимо в среднем 0,5 млн операций доступа к записям. Если создать индексный файл , содержащий 1000 элементов, то потребуется в среднем 500 операций доступа к индексному файлу, после чего еще нужно в среднем 500 операций доступа к главному файлу. В результате средняя длина поиска уменьшилась с 0,5 млн до 1000. Еще лучшего результата можно достичь, используя многоуровневую индексацию. При этом нижний уровень индексного файла рассматривается как последовательный файл , для которого создается индексный файл верхнего уровня.
Дополнения к файлу обрабатываются следующим образом. В каждой записи главного файла содержится дополнительное поле , невидимое для приложения и являющееся указателем на файл переполнения. Если в файле производится вставка новой записи, она добавляется в файл переполнения. Запись в главном файле, непосредственно предшествующая новой записи в логической последовательности, обновляется и указывает на новую запись в файле переполнения. Время от времени выполняется слияние индексно- последовательного файла с файлом переполнения.
Индексированный файл . Индексно- последовательный файл сохраняет одно ограничение последовательного файла : эффективная работа с файлом ограничена работой с ключевым полем. Если необходимо производить поиск записи по какой-либо иной характеристике, отличной от ключевого поля, то оказываются непригодными обе организации последовательного файла , в то время как в некоторых приложениях эта гибкость крайне желательна.
Для достижения гибкости необходимо применение большого количества индексов, по одному для каждого типа поля, которое может быть объектом поиска. В обобщенном индексированном файле доступ к записям осуществляется только по их индексам. В результате в размещении записей нет никаких ограничений до тех пор, пока указатель по крайней мере в одном индексе ссылается на эту запись . Кроме того, в таком файле легко реализуются записи переменной длины.
Используется два типа индексов. Полный индекс содержит по одному элементу для каждого типа записей главного файла. Сам по себе индекс организовывается в виде последовательного файла для облегчения поиска. Частный индекс содержит элементы для записей, в которых имеется интересующее пользователя поле . При добавлении новой записи в главный файл необходимо обновлять все индексные файлы.
Индексированные файлы применяются теми приложениями, в которых время доступа к информации является критической характеристикой и редко требуется обработка всех записей в файле.
Файл прямого доступа. Такой файл использует возможность прямого доступа к блоку с известным адресом при хранении файлов на диске. В каждой записи в этом случае также имеется ключевое поле .
Представление пользователя о файловой системе как об иерархически организованном множестве информационных объектов имеет мало общего с порядком хранения файлов на диске. Файл, имеющий образ цельного, непрерывающегося набора байт, на самом деле очень часто разбросан «кусочками» по всему диску, причем это разбиение никак не связано с логической структурой файла, например, его отдельная логическая запись может быть расположена в несмежных секторах диска. Логически объединенные файлы из одного каталога совсем не обязаны соседствовать на диске. Принципы размещения файлов, каталогов и системной информации на реальном устройстве описываются физической организацией файловой системы. Очевидно, что разные файловые системы имеют разную физическую организацию.
Важным компонентом физической организации файловой системы является физическая организация файла, то есть способ размещения файла на диске. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.

Непрерывное размещение — простейший вариант физической организации (рисунок (а)), при котором файлу предоставляется последовательность кластеров диска, образующих непрерывный участок дисковой памяти.
Следующий способ физической организации — размещение файла в виде связанного списка кластеров дисковой памяти (рисунок (б)). При таком способе в начале каждого кластера содержится указатель на следующий кластер. В этом случае адресная информация минимальна: расположение файла может быть задано одним числом — номером первого кластера.
Популярным способом, применяемым, например, в файловой системе FAT, является использование связанного списка индексов (рисунок ( в)). Этот способ является некоторой модификацией предыдущего. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связывается некоторый элемент — индекс. Индексы располагаются в отдельной области диска.
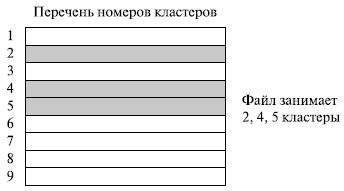
Еще один способ задания физического расположения файла заключается в простом перечислении номеров кластеров, занимаемых этим файлом (рисунок (г)). Этот перечень и служит адресом файла. Недостаток данного способа очевиден: длина адреса зависит от размера файла и для большого файла может составить значительную величину. Достоинством же является высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация, которая исключает просмотр цепочки указателей при поиске адреса произвольного кластера файла. Фрагментация на уровне кластеров в этом способе также отсутствует.
Последний подход с некоторыми модификациями используется в традиционных файловых системах ОС UNIX s5 и ufs. Для сокращения объема адресной информации прямой способ адресации сочетается с косвенным. Ну да хуй с ним.
В этой статье, мы поговорим на такие темы, как организация файлов, затронем тему организации файловой структуры, а также изучим логическую структуру дисков.
Типы файлов
Обычные файлы: содержат информацию произвольного характера, которую заносит в них пользователь или которая образуется в результате работы системных и пользовательских программ. Содержание обычного файла определяется приложением, которое с ним работает.
Обычные файлы могут быть двух типов:
Каталоги – это, с одной стороны, группа файлов, объединенных пользователем исходя из некоторых соображений (например, файлы, содержащие программы игр, или файлы, составляющие один программный пакет), а с другой стороны – это особый тип файлов, которые содержат системную справочную информацию о наборе файлов, сгруппированных пользователями по какому-либо неформальному признаку (тип файла, расположение его на диске, права доступа, дата создания и модификация).
Специальные файлы – это фиктивные файлы, ассоциированные с устройствами ввода/вывода, которые используются для унификации механизма доступа к файлам и внешним устройствам. Специальные файлы позволяют пользователю осуществлять операции ввода/вывода посредством обычных команд записи с файлов или чтения из файлов. Эти команды обрабатываются сначала программами ФС, а затем на некотором этапе выполнения запроса преобразуются ОС в команды управления соответствующим устройством (PRN, LPT1 – для порта принтера (символьные имена, для ОС – это файлы), CON – для клавиатуры).
Пример. Copy con text1 (работа с клавиатурой).
Файловая структура
Файловая структура – вся совокупность файлов на диске и взаимосвязей между ними (порядок хранения файлов на диске).
Виды файловых структур:
- простая, или одноуровневая: каталог представляет собой линейную последовательность файлов.
- иерархическая или многоуровневая: каталог сам может входить в состав другого каталога и содержать внутри себя множество файлов и подкаталогов. Иерархическая структура может быть двух видов: «Дерево» и «Сеть». Каталоги образуют «Дерево», если файлу разрешено входить только в один каталог (ОС MS-DOS, Windows) и «Сеть» – если файл может входить сразу в несколько каталогов (UNIX).
- Файловая структура может быть представлена в виде графа, описывающего иерархию каталогов и файлов:



Типы имен файлов
Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения ОС как на используемые символы, так и на длину имени. В ранних файловых системах эти границы были весьма узкими. Так в популярной файловой системе FATдлина имен ограничивается известной схемой 8.3 (8 символов — собственно имя, 3 символа — расширение имени), а в ОС UNIX System V имя не может содержать более 14 символов.
Однако пользователю гораздо удобнее работать с длинными именами, поскольку они позволяют дать файлу действительно мнемоническое название, по которому даже через достаточно большой промежуток времени можно будет вспомнить, что содержит этот файл. Поэтому современные файловые системы, как правило, поддерживают длинные символьные имена файлов.
Например, Windows NT в своей файловой системе NTFS устанавливает, что имя файла может содержать до 255 символов, не считая завершающего нулевого символа.
При переходе к длинным именам возникает проблема совместимости с ранее созданными приложениями, использующими короткие имена. Чтобы приложения могли обращаться к файлам в соответствии с принятыми ранее соглашениями, файловая система должна уметь предоставлять эквивалентные короткие имена (псевдонимы) файлам, имеющим длинные имена. Таким образом, одной из важных задач становится проблема генерации соответствующих коротких имен.
Символьные имена могут быть трех типов: простые, составные и относительные:
- Простое имя идентифицирует файл в пределах одного каталога, присваивается файлам с учетом номенклатуры символа и длины имени.
- Полное имя представляет собой цепочку простых символьных имен всех каталогов, через которые проходит путь от корня до данного файла, имени диска, имени файла. Таким образом, полное имя является составным, в котором простые имена отделены друг от друга принятым в ОС разделителем.
- Файл может быть идентифицирован также относительным именем. Относительное имя файла определяется через понятие «текущий каталог». В каждый момент времени один из каталогов является текущим, причем этот каталог выбирается самим пользователем по команде ОС. Файловая система фиксирует имя текущего каталога, чтобы затем использовать его как дополнение к относительным именам для образования полного имени файла.
В древовидной файловой структуре между файлом и его полным именем имеется взаимно однозначное соответствие – «один файл — одно полное имя». В сетевой файловой структуре файл может входить в несколько каталогов, а значит может иметь несколько полных имен; здесь справедливо соответствие – «один файл — много полных имен».
Для файла 2.doc определить все три типа имени, при условии, что текущим каталогом является каталог 2008_год.

- Простое имя: 2.doc
- Полное имя: C:\2008_год\Документы\2.doc
- Относительное имя: Документы\2.doc
Атрибуты файлов
Важной характеристикой файла являются атрибуты. Атрибуты – это информация, описывающая свойства файлов. Примеры возможных атрибутов файлов:
- Признак «только для чтения» (Read-Only);
- Признак «скрытый файл» (Hidden);
- Признак «системный файл» (System);
- Признак «архивный файл» (Archive);
- Тип файла (обычный файл, каталог, специальный файл);
- Владелец файла;
- Создатель файла;
- Пароль для доступа к файлу;
- Информация о разрешенных операциях доступа к файлу;
- Время создания, последнего доступа и последнего изменения;
- Текущий размер файла;
- Максимальный размер файла;
- Признак «временный (удалить после завершения процесса)»;
- Признак блокировки.
В файловых системах разного типа для характеристики файлов могут использоваться разные наборы атрибутов (например, в однопользовательской ОС в наборе атрибутов будут отсутствовать характеристики, имеющие отношение к пользователю и защите (создатель файла, пароль для доступа к файлу и т.д.).
Пользователь может получать доступ к атрибутам, используя средства, предоставленные для этих целей файловой системой. Обычно разрешается читать значения любых атрибутов, а изменять – только некоторые, например можно изменить права доступа к файлу, но нельзя изменить дату создания или текущий размер файла.
Права доступа к файлу
Определить права доступа к файлу — значит определить для каждого пользователя набор операций, которые он может применить к данному файлу. В разных файловых системах может быть определен свой список дифференцируемых операций доступа. Этот список может включать следующие операции:
- создание файла.
- уничтожение файла.
- запись в файл.
- открытие файла.
- закрытие файла.
- чтение из файла.
- дополнение файла.
- поиск в файле.
- получение атрибутов файла.
- установление новых значений атрибутов.
- переименование.
- выполнение файла.
- чтение каталога и др.
В самом общем случае права доступа могут быть описаны матрицей прав доступа, в которой столбцы соответствуют всем файлам системы, строки — всем пользователям, а на пересечении строк и столбцов указываются разрешенные операции:

В некоторых системах пользователи могут быть разделены на отдельные категории. Для всех пользователей одной категории определяются единые права доступа, например в системе UNIX все пользователи подразделяются на три категории: владельца файла, членов его группы и всех остальных.
Физическая организация выделяет способ размещения файлов на диске и учет соответствия блоков диска файлам. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Наиболее часто используются следующие схемы размещения файлов:
- непрерывное размещение (непрерывные файлы);
- сводный список блоков (кластеров) файла;
- сводный список индексов блоков (кластеров) файла;
- перечень номеров блоков (кластеров) файла в структурах, называемых i-узлами (index-node – индекс-узел).
Простейший вариант физической организации – непрерывное размещение в наборе соседних кластеров (рис. 7.15a). Достоинство этой схемы – высокая скорость доступа и минимальный объем адресной информации, поскольку достаточно хранить номер первого кластера и объем файла. Размер файла при такой организации не ограничивается.
Однако у этой схемы имеется серьезный недостаток – фрагментация, возрастающая по мере удаления и записи файлов. Кроме того, возникает вопрос, какого размера область нужно выделить файлу, если при каждой модификации он может увеличить свой размер.
И все-таки есть ситуации, в которых непрерывные файлы могут эффективно использоваться и действительно широко применяются – на компакт-дисках. Здесь все размеры файлов заранее известны и не могут меняться.
Второй метод размещения файлов состоит в представлении файла в виде связного списка кластеров дисковой памяти (рис. 7.15б). Первое слово каждого кластера используется как указатель на следующий кластер . В этом случае адресная информация минимальна, поскольку расположение файла задается номером его первого кластера.
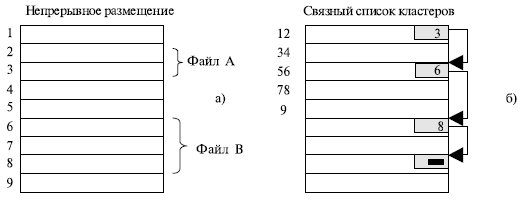
Кроме того, отсутствует фрагментация на уровне кластеров, а файл легко может изменять размер наращиванием или удалением цепочки кластеров. Однако доступ к такому файлу может оказаться медленным, так как для получения доступа к кластеру n операционная система должна прочитать первые n-1 кластеры. Кроме того, размер кластера уменьшается на несколько байтов, требуемых для хранения. Указателю это не очень важно, но многие программы читают и пишут блоками, кратными степени двойки.
Оба недостатка предыдущей схемы организации файлов могут быть устранены, если указатели на следующие кластеры хранить в отдельной таблице, загружаемой в память . Таким образом, образуется связный список не самих блоков (кластеров) файла, а индексов, указывающих на эти блоки (рис. 7.16).
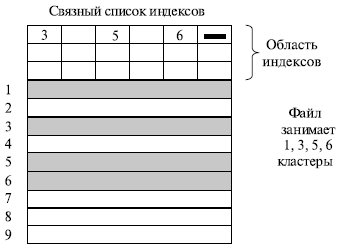
Такая таблица , называемая FAT -таблицей (File Allocation Table ), используется в файловых системах MS- DOS и Windows ( FAT 16 и FAT 32). Файлу выделяется память на диске в виде связного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. С каждым кластером диска связывается индекс . Индексы располагаются в FAT -таблице в отдельной области диска. Когда память свободна, все индексы равны нулю. Если некоторый кластер N назначен файлу, то индекс этого кластера либо становится равным номеру M следующего кластера файла, либо принимает специальное значение , являющееся признаком того, что кластер является последним для файла. Вообще индексы могут содержать следующую информацию о кластере диска (для FAT 32):
- не используется (Unused) – 0000.0000;
- используется файлом (Cluster in use by a file) – значение, отличное от 000.000, FFFF.FFFF и FFFF.FFF7;
- плохой кластер ( Bad cluster ) – FFFF.FFF7;
- последний кластер файла (Last cluster in a file) – FFFF.FFFF.
При такой организации сохраняются все достоинства второго метода организации файлов: отсутствие фрагментации, отсутствие проблем при изменении размера. Кроме того, данный способ обладает дополнительными преимуществами: для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать FAT -таблицу, отсчитать нужное количество кластеров файла по цепочке и определить номера нужного кластера. Во-вторых, данные файла заполняют кластер целиком в объеме, кратном степени двойки.
Еще один способ заключается в простом перечислении номеров кластеров, занимаемых файлом (рис. 7.17). Этот перечень и служит адресом файла. Недостаток такого подхода – длина адреса зависит от размера файла. Достоинства – высокая скорость доступа к произвольному кластеру благодаря прямой адресации, отсутствие внешней фрагментации.
Эффективный метод организации файлов, используемый в Unix -подобных операционных системах, состоит в связывании с каждым файлом структуры данных, называемой i-узлами. Такой узел содержит атрибуты файла и адреса кластеров файла (рис. 7.18). Преимущество такой схемы перед FAT -таблицей заключается в том, что каждый конкретный i-узел должен находиться в памяти только тогда, когда открыт соответствующий ему файл . Если каждый узел занимает n байт , а одновременно может быть открыто k файлов, то массив i-узлов займет в памяти k * n байт , что значительно меньше, чем FAT - таблица .
Это объясняется тем, что размер FAT -таблицы растет линейно с размером диска и даже быстрее, чем линейно, так как с увеличением количества кластеров на диске может потребоваться увеличить разрядность числа для хранения их номеров.
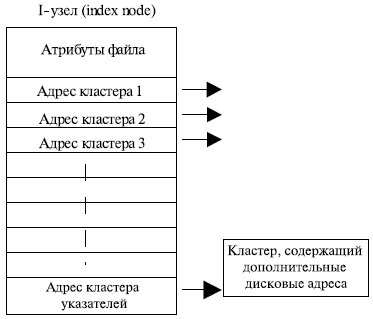
Достоинством i-узлов является также высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация . Фрагментация на уровне кластеров также отсутствует.
Однако с такой схемой связана проблема, заключающаяся в том, что при выделении каждому файлу фиксированного количества адресов кластеров этого количества может не хватить. Выход из этой ситуации может быть в сочетании прямой и косвенной адресации. Такой поход реализован в файловой системе ufs , используемой в ОС UNIX , схема адресации в которой приведена на рис. 7.19.
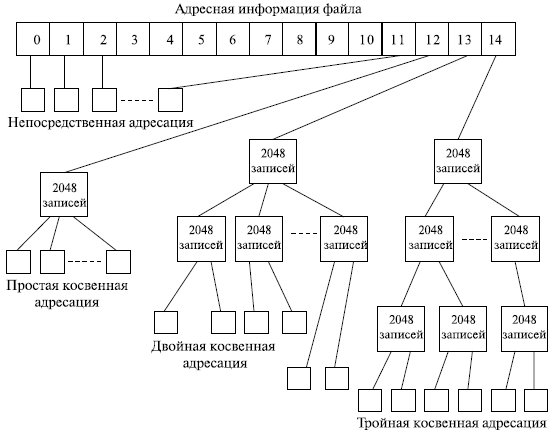
Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт . Если размер файлов меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса. Если кластер имеет размер 8 Кбайт, то можно адресовать файл размеров до 8 Кбайт * 12 = 98304 байт . Если размер кластера превышает 12 кластеров, то следующее 13 поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров, и размер файла может возрасти до 8192 * (12 + 2048) = 16.875.520 байт .
Следующий уровень адресации, обеспечиваемый 14-м полем, позволяет адресовать до 8192 * (12 + 2048 + 20482) = 3,43766*1020 байт . Если и этого недостаточно, используется следующее 15-е поле . В этом случае максимальный размер файла может составить 8192 * (12 + 2048 + 20482 + 20483) = 7,0403*1013 байт .
При этом объеме самой адресной информации составит всего 0,05% от объема адресуемых данных (задачи. ).
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS , применяемой в Windows NT/2000/2003. Для сокращения объема адресной информации в NTFS адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область называется экстентом ( extent ) и описывается двумя числами: номером начального кластера и количеством кластеров.
Структура логического диска

Для организации логического диска каждая ОС разделяет его на две части:
- системная область.
- область данных (Data).
Системная область предназначена для хранения служебной информации и управляет использованием области данных: применяется для регистрации состояния каждого участка диска. Эта область создается при форматировании и обновляется при операциях с файлами.
В системной области находятся:
- Загрузочная запись – начальная область логического диска, содержащая небольшую программу, инициализирующую процесс загрузки ОС. Содержит блок параметров диска (DPB – Disk Parameter Block) и системный загрузчик (SB – System Bootstrap). Загрузочная запись системного диска называется главной загрузочной записью – Master Boot Record.
- Таблица размещения файлов («таблица» — условное обозначение).
- Корневой каталог – встроенное оглавление информации, содержащейся в области данных. Корневой каталог на диске единственный, совпадает с именем соответствующего диска и не может быть удален программными средствами.
Область данных предназначена для регистрации данных, хранящейся на диске. Содержит файлы и каталоги, подчиненные корневому каталогу. С учетом общей структуры логического диска структуру всего дискового пространства, разбитого на несколько разделов, можно представить следующим образом:

Вся информация, необходимая для начальной загрузки компьютера, находится в самом первом секторе жёсткого диска. Эта информация называется главной записью загрузки — MBR (Master Boot Record).
Расширенная таблица разделов состоит из двух элементов: первый элемент расширенной таблицы разделов для первого логического устройства указывает на его загрузочный сектор, второй элемент — на EBR следующего логического устройства (Extended Boot Record, EBR — Расширенная загрузочная запись).
Доброго времени суток уважаемый пользователь, в этой статье речь пойдет о такой теме, как файлы. А именно мы рассмотрим: Управление файлами, типы файлов, файловая структура, атрибуты файла.
7.13. Организация файлов и доступ к ним
Типы, именование и атрибуты файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых входят обычные файлы, содержащие информацию произвольного характера (текст, графика , звук и др.), файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и др.
Обычные файлы, или просто файлы, или регулярные файлы, содержат информацию, которую в них заносит пользователь или которая образуется в результате работы системных и пользовательских программ. Большинство ОС не контролируют содержимое и структуру регулярных файлов , которые в основном являются ASCII-файлами либо двоичными файлами. ASCII-фалы состоят из текстовых строк. Они могут отображаться на экране и выводиться на печать без какого-либо преобразования, и могут редактироваться практически любым текстовым редактором. Двоичные файлы имеют определенную внутреннюю структуру, которая известна программе, использующей данный файл . При выводе двоичного файла на принтер получается случайный набор символов.
Каталоги – это системные файлы, обеспечивающие поддержку структуры файловой системы. Они содержат системную справочную информацию о наборе файлов, сгруппированных пользователем по какому-либо неформальному признаку (договоры, рефераты, курсовые проекты и т.п.). Во многих ОС в каталог могут входить другие файлы, в том числе другие каталоги, за счет чего образуется древовидная структура, удобная для поиска требуемого файла. Каталоги устанавливают соответствие между именами файлов и их характеристиками, используемыми файловой системой для управления файлами. В число таких характеристик входят тип файла , права доступа к файлу, его распоряжение на диске, размер, дата и время создания и др.
Специальные файлы – это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к последовательным устройствам ввода-вывода, таким как терминалы, принтеры и др. (например, MS- DOS рассматривает монитор и клавиатуру как файлы со стандартным именем con – консоль , а принтер – как файл prn ). Блочные специальные файлы используются для моделирования дисков.
Именованные конвейеры (каналы) представляют собой циклические буферы, позволяющие выходной файл одной программы соединить со входным файлом другой программы.
Наконец, отображаемые файлы – это обычные файлы, отображенные на адресное пространство процесса по указанному виртуальному адресу.
Файлы относятся к абстрактному механизму. Они предоставляют способ сохранять информацию на запоминающем устройстве и считывать ее позднее снова. При этом от пользователя должны скрываться такие детали, как способ и место хранения информации, а также детали работы устройства.
Во многих операционных системах имя файла состоит из двух частей, разделенных точкой. Часть имени после точки называется расширением файла и обычно означает его тип. Так, в MS- DOS имя файла может содержать от 1 до 8 символов, а расширение от 0 (отсутствует) до 3.
В некоторых ОС, например, Windows , расширение указывает на программу, создавшую файл . Другие ОС, например, UNIX , не принуждают пользователя строго придерживаться расширений. Некоторые типичные расширения файлов приведены ниже.
В иерархически организованных файловых системах обычно используются три типа имен файлов: простые, составные и относительные.
Простое (короткое) символьное имя идентифицирует файл в пределах одного каталога. Несколько файлов могут иметь одно и то же простое имя , если они принадлежат разным каталогам.
Составное (полное) символьное имя представляет собой цепочку, содержащую имя диска и имена всех каталогов, через которые проходит путь от корневого каталога до данного файла.
Относительное имя файла определяется через текущий каталог , т.е. каталог, в котором в данный момент времени работает пользователь . Таким образом, относительных имен у файла может быть достаточно много, и все они являются частью полного имени.
Понятие файла включает не только хранимые им данные и имя, но и информацию, описывающую свойства файла. Эта информация составляет атрибуты файла. Список атрибутов может быть различным в различных ОС. Пример возможных атрибутов приведен ниже.
Пользователь может получить доступ к атрибутам, используя средства, предоставляемые для этой цели файловой системой. Обычно разрешается читать значение любых атрибутов, а изменять – только некоторые.
Значения атрибутов файлов могут содержаться в каталогах, как это сделано, например, в MS- DOS (рис. 7.7). Другим вариантом является размещение атрибутов в специальных таблицах, в этом случае в каталогах содержатся ссылки на эти таблицы.
Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура (организация) файла является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть целиком возложено на приложение либо в той или иной степени эту работу может взять на себя файловая система .
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла, целиком относятся к ведению приложения, файл представляется файловой системе неструктурированной последовательностью данных. Приложение формирует запросы к файловой системе на ввод- вывод , используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт , которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой. Следует подчеркнуть, что интерпретация данных никак не связана с действительным способом их хранения в файловой системе.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью байт , стала популярной вместе с ОС UNIX , и теперь широко используется в современных ОС. Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями, поскольку разные приложения могут по -своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл . В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением!
Известно пять фундаментальных способов организации файлов [10]:
- смешанный файл,
- последовательный файл ,
- индексно- последовательный файл ,
- индексируемый файл,
- файл прямого доступа.
При выборе способа организации файла нужно учитывать несколько критериев:
- быстрота доступа,
- легкость обновления,
- экономность хранения,
- простота обслуживания,
- надежность.
Смешанный файл . Это наименее сложная форма организации файла. Данные накапливаются в порядке поступления. Запись состоит из одного пакета данных. Записи могут иметь различные или одинаковые поля, расположенные в различном порядке (рис. 7.8). Каждое поле описывает само себя, включая как имя, так и значение . Длина каждого поля должна быть указана явно либо посредством применения разделителя.
Поскольку смешанный файл не имеет никакой структуры, доступ к записи осуществляется полным перебором всех записей файла. Смешанные файлы применяются в том случае, когда данные накапливаются и сохраняются перед обработкой, или если данные неудобны для организации. Файлы этого типа рационально используют дисковое пространство , хорошо подходят для полного набора. Обновление записей достаточно сложно, так же как и вставка записи.
Последовательный файл . Для записей используется фиксированный формат. Все записи имеют одинаковую длину (но иногда и не одинаковую) и состоят из одинакового количества полей фиксированной длины, организованных в определенном порядке (рис. 7.9). Поскольку длина и позиция каждого поля известны, сохранению подлежат только значения полей. Атрибутами файловой структуры является имя и длина каждого поля.
Одно определенное поле (или несколько полей) называется ключевым. Оно однозначно идентифицирует запись , так как это поле различно для каждой записи. Более того, записи сохраняются в "ключевой" последовательности: в алфавитном порядке для текстового ключа и в числовом – для числового. Последовательные файлы часто используются пакетными приложениями и обычно являются оптимальным вариантом, если эти приложения выполняют обработку всех записей. Удобно и то, что такой файл можно хранить как на ленте, так и на магнитном диске.
Для диалоговых приложений последовательный файл малоэффективен, поскольку для нахождения нужной записи требуется последовательный перебор записи файла. Правда, если в оперативную память загрузить весь файл , возможен более эффективный метод поиска. Дополнения к файлу или изменения в записях создают проблемы.
Обычно последовательный файл сохраняется с последовательной организацией записей внутри блока, т.е. физическая организация файла в точности соответствует логической. Новые записи размещаются в отдельном смешанном файле, называемом журнальным файлом, или файлом транзакции. Периодически в пакетном режиме выполняется слияние основного и журнального файлов в новый файл с корректной последовательностью ключей.
Альтернативной организацией может быть физическая организация в виде списка с использованием указателей. В каждом физическом блоке сохраняется одна или несколько записей, и каждый блок содержит указатель на следующий блок. Для вставки новых записей достаточно изменить указатели, и нет необходимости в том, чтобы новые записи занимали определенную физическую позицию. Это удобство достигается за счет определенных накладных расходов и дополнительной работы. Если в последовательном файле записи имеют одну и ту же длину, то можно вычислить адрес требуемой записи по ее номеру, номеру текущей записи и длине записи. Если записи имеют переменную длину, такой подход невозможен.
Индексно- последовательный файл . Одним из методов преодоления недостатков последовательного файла является индексно-последовательная организация файла. В этом случае файл состоит из трех частей (файлов): главный файл , содержащий записи с последовательно идущими ключами, индексный файл , содержащий индексное поле , и указатель в главный с ключами, файл переполнения (рис. 7.10).
Для поиска нужной записи по ее ключу сначала выполняется поиск в индексном файле. После того как в нем найдено наибольшее значение ключа, которое не превышает искомое, продолжается поиск в главном файле. Например, пусть последовательный файл (главный) содержит 1 млн записей. Для поиска определенного ключевого значения необходимо в среднем 0,5 млн операций доступа к записям. Если создать индексный файл , содержащий 1000 элементов, то потребуется в среднем 500 операций доступа к индексному файлу, после чего еще нужно в среднем 500 операций доступа к главному файлу. В результате средняя длина поиска уменьшилась с 0,5 млн до 1000. Еще лучшего результата можно достичь, используя многоуровневую индексацию. При этом нижний уровень индексного файла рассматривается как последовательный файл , для которого создается индексный файл верхнего уровня.
Дополнения к файлу обрабатываются следующим образом. В каждой записи главного файла содержится дополнительное поле , невидимое для приложения и являющееся указателем на файл переполнения. Если в файле производится вставка новой записи, она добавляется в файл переполнения. Запись в главном файле, непосредственно предшествующая новой записи в логической последовательности, обновляется и указывает на новую запись в файле переполнения. Время от времени выполняется слияние индексно- последовательного файла с файлом переполнения.
Индексированный файл . Индексно- последовательный файл сохраняет одно ограничение последовательного файла : эффективная работа с файлом ограничена работой с ключевым полем. Если необходимо производить поиск записи по какой-либо иной характеристике, отличной от ключевого поля, то оказываются непригодными обе организации последовательного файла , в то время как в некоторых приложениях эта гибкость крайне желательна.
Для достижения гибкости необходимо применение большого количества индексов, по одному для каждого типа поля, которое может быть объектом поиска. В обобщенном индексированном файле доступ к записям осуществляется только по их индексам. В результате в размещении записей нет никаких ограничений до тех пор, пока указатель по крайней мере в одном индексе ссылается на эту запись . Кроме того, в таком файле легко реализуются записи переменной длины.
Используется два типа индексов. Полный индекс содержит по одному элементу для каждого типа записей главного файла. Сам по себе индекс организовывается в виде последовательного файла для облегчения поиска. Частный индекс содержит элементы для записей, в которых имеется интересующее пользователя поле . При добавлении новой записи в главный файл необходимо обновлять все индексные файлы.
Индексированные файлы применяются теми приложениями, в которых время доступа к информации является критической характеристикой и редко требуется обработка всех записей в файле.
Файл прямого доступа. Такой файл использует возможность прямого доступа к блоку с известным адресом при хранении файлов на диске. В каждой записи в этом случае также имеется ключевое поле .
Представление пользователя о файловой системе как об иерархически организованном множестве информационных объектов имеет мало общего с порядком хранения файлов на диске. Файл, имеющий образ цельного, непрерывающегося набора байт, на самом деле очень часто разбросан «кусочками» по всему диску, причем это разбиение никак не связано с логической структурой файла, например, его отдельная логическая запись может быть расположена в несмежных секторах диска. Логически объединенные файлы из одного каталога совсем не обязаны соседствовать на диске. Принципы размещения файлов, каталогов и системной информации на реальном устройстве описываются физической организацией файловой системы. Очевидно, что разные файловые системы имеют разную физическую организацию.
Важным компонентом физической организации файловой системы является физическая организация файла, то есть способ размещения файла на диске. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Непрерывное размещение — простейший вариант физической организации (рисунок (а)), при котором файлу предоставляется последовательность кластеров диска, образующих непрерывный участок дисковой памяти.
Следующий способ физической организации — размещение файла в виде связанного списка кластеров дисковой памяти (рисунок (б)). При таком способе в начале каждого кластера содержится указатель на следующий кластер. В этом случае адресная информация минимальна: расположение файла может быть задано одним числом — номером первого кластера.
Популярным способом, применяемым, например, в файловой системе FAT, является использование связанного списка индексов (рисунок ( в)). Этот способ является некоторой модификацией предыдущего. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связывается некоторый элемент — индекс. Индексы располагаются в отдельной области диска.
Еще один способ задания физического расположения файла заключается в простом перечислении номеров кластеров, занимаемых этим файлом (рисунок (г)). Этот перечень и служит адресом файла. Недостаток данного способа очевиден: длина адреса зависит от размера файла и для большого файла может составить значительную величину. Достоинством же является высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация, которая исключает просмотр цепочки указателей при поиске адреса произвольного кластера файла. Фрагментация на уровне кластеров в этом способе также отсутствует.
Последний подход с некоторыми модификациями используется в традиционных файловых системах ОС UNIX s5 и ufs. Для сокращения объема адресной информации прямой способ адресации сочетается с косвенным. Ну да хуй с ним.
В этой статье, мы поговорим на такие темы, как организация файлов, затронем тему организации файловой структуры, а также изучим логическую структуру дисков.
Этапы подготовки диска к записи
Процесс подготовки диска к записи данных разбивается на следующие этапы:
- Форматирование низкого уровня (физическое форматирование).
- Логическое разбиение (только для HDD).
- Логическое форматирование (высокоуровневое).
В результате выполнения процедуры физического форматирования в секторах создаются адресные метки, использующиеся для их идентификации в процессе использования диска (создаются дорожки и секторы).
Низкоуровневый формат диска не зависит от типа ОС, которая этот диск будет использовать.
В результате выполнения процедуры логического разбиения HDD делится на логические разделы (тома) перед форматированием диска под определенную файловую систему.
Раздел – это непрерывная часть физического диска, которую ОС представляет пользователю как логическое устройство (логический диск). Необходимость в разбиении на разделы возникает в следующих случаях:
- если существует ограничение на размер диска со стороны операционной системы.
- если необходимо разграничить дисковое пространство между пользователями.
- для удобства работы с разными видами информации: системный диск, архивный диск, документы и т.д.
- если есть необходимость в нескольких операционных системах или/и файловых системах.

ОС может поддерживать разные статусы разделов, особым образом отмечая разделы, которые могут быть использованы для загрузки модулей ОС, и разделы, в которых можно устанавливать только приложения и хранить файлы данных. Один из разделов диска помечается как загружаемый (основной, первичный, Primary). Именно из этого раздела считывается загрузчик ОС. А другой – как дополнительный (расширенный, Extenshion).
Разметку диска под конкретный тип файловой системы выполняют процедуры высокоуровневого, или логического, форматирования. При высокоуровневом форматировании определяется размер кластера и на диск записывается информация, необходимая для работы файловой системы, в том числе информация о доступном и неиспользуемом пространстве, о границах областей, отведенных под файлы и каталоги, информация о поврежденных областях. Кроме того, на диск записывается загрузчик ОС.
Логическое форматирование – процесс преобразования уже размеченного дискового пространства в соответствии со стандартами конкретной ОС. Единый стандарт разметки границ дискового раздела и разграничения разделов содержится в таблице разделов диска, которая находится в 1-ом секторе диска (цилиндр 0, дорожка 0, сектор 1). Таблица разделов содержит параметры диска, число разделов, размер и расположение каждого раздела и др.
Организация файлов
В общем случае, данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура является базой при разработке программы, предназначенной для обработки этих данных.
Например, чтобы текст мог быть правильно выведен на экран, программа должна иметь возможность выделить отдельные слова, строки, абзацы и т.д. Признаками, отделяющими один структурный элемент от другого, могут служить определенные кодовые последовательности или просто известные программе значения смещений этих структурных элементов, относительно начала файла. Поддержание структуры данных может быть либо целиком возложено на приложения либо в той или иной степени может взять на себя ФС (файловую систему).
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла целиком относятся к ведению приложения. Файл представляется ФС неструктурированной последовательностью данных. Приложение формулирует запросы к ФС на ввод/вывод, используя общие для всех приложений системные средства. Например, указывая смещение от начала файла и количество байт, которые необходимо считать или записать.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью (потоком) байт, стала популярной вместе с ОС UNIX, а теперь она широко используется в большинстве современных ОС (MS-DOS, Windows2000/NT, NetWare).
Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями: разные приложения могут по-своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файлов, которая применялась в ОС OS/360, DEC RSX, VMS, а в настоящее время используется достаточно редко – это структурированный файл. В этом случае поддержание структуры файла поручается ОС. ФС видит файл как упорядоченную последовательность логических записей. Приложение может обращаться к ФС с запросами на ввод-вывод на уровне записей, например, «считать запись 25 из файла FILE.DOC». ФС должна обладать информацией о структуре файла, достаточной для того, чтобы выделить любую запись. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащаяся в этой записи, выполняется приложением. Замечание. Развитием этого подхода стали СУБД.
Способы физической организации файла
Физическая организация файла (ФОФ) – это способ размещения файла на диске. Основные критерии эффективности физической организации файлов:
- Скорость доступа к данным.
- Объем адресной информации файла.
- Степень фрагментированнности дискового пространства.
- Максимально возможно размер файла.
Фрагментация – это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Существует несколько способов физической организации файла. Непрерывное размещение – это простейший вариант ФОФ, при котором файлу предоставляется последовательность кластеров диска, образующих непрерывный участок дисковой памяти:

Достоинства способа: высокая скорость доступа, так как затраты на поиск и считывание кластеров файла минимальны, отсутствие фрагментации на уровне файла, минимален объем адресной информации – достаточно хранить только номер первого кластера и объем файла. Недостатки невозможно сказать, какого размера должна быть непрерывная область, выделяемая файлу, так как файл при каждой модификации может увеличить свой размер, фрагментация на уровне кластеров, из-за которой нельзя выбрать место для размещения файла целиком. Из-за этих недостатков на практике используются другие методы, при которых файл размещается в нескольких, в общем случае несмежных областях диска.
Размещение файла в виде связанного списка кластеров дисковой памяти.
При таком способе в начале каждого кластера содержится указатель на следующий кластер:

Достоинства: Адресная информация минимальна расположение файла может быть задано одним числом – номером первого кластера, фрагментация на уровне кластеров отсутствует, так как каждый кластер может быть присоединен к цепочке кластеров какого-либо файла, файл может изменять свой размер, наращивая число кластеров.
Недостатки: Сложность организации доступа к произвольно заданному месту файла – чтобы прочитать пятый по порядку кластер файла, необходимо последовательно прочитать четыре первых кластера, прослеживая цепочку номеров кластеров, количество данных файла в одном кластере не равно степени двойки (одно слово израсходовано на номер следующего кластера), а многие программы читают данные кластерами, размер которых равен степени двойки, Фрагментация на уровне файлов (файл может разбиваться на несмежные фрагменты).
При отсутствии фрагментации на уровне кластеров на диске все равно имеется определенное количество областей памяти небольшого размера, которые невозможно использовать, то есть фрагментация все же существует. Эти фрагменты представляют собой неиспользуемые части последних кластеров, назначенных файлам, так как объем файла в общем случае не кратен размеру кластера. На каждом файле в среднем теряется половина кластера. Эти потери особенно велики, когда на диске имеется большое количество маленьких файлов, а кластер имеет большой размер.
Использование связанного списка индексов (например, в FAT)
Данный способ является модификацией предыдущего метода. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связан индекс. Индексы располагаются в отдельной области диска – в файловых системах FAT это таблица (File Allocation Table):

Когда память свободна, все индексы имеют нулевое значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого кластера становится равным либо номеру M следующего кластера данного файла, либо принимает специальное значение – признак того, что этот кластер является для файла последним. Индекс же предыдущего кластера файла принимает значение N, указывая на вновь назначенный кластер.
Достоинства: минимальность адресной информации, отсутствие фрагментации на уровне кластеров, отсутствие проблем при изменении размера файла, для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать только секторы диска, содержащие таблицу индексов, отсчитать нужное количество кластеров файла по цепочке и определить номер нужного кластера, данные файла заполняют кластер целиком, следовательно имеют объем, равный степени двойки. Недостатки: Фрагментация на уровне файлов (файл может разбиваться на несмежные фрагменты).
Перечисление номеров кластеров, занимаемых этим файлом.
Достоинства: высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация, которая исключает просмотр цепочки указателей при поиске адреса произвольного кластера файла, отсутствие фрагментации на уровне кластеров. Недостатки: длина адреса зависит от размера файла и для большого файла может составить значительную величину. Данный подход с некоторыми модификациями используется в ОС UNIX.
Организация файловой системы
Файл, имеющий образ цельного, непрерывающегося набора байт, на самом деле разбросан «кусочками» по всему диску, причем это разбиение никак не связано с логической структурой файла: логически объединенные файлы из одного каталога совсем не обязательно должны соседствовать на диске.
Принципы размещения файлов, каталогов и системной информации на реальном устройстве (диске) называются физической организацией файловой системы.
Замечание. Различные файловые системы имеют разную физическую организацию (например, размер кластера). Основным типом устройства, которое используется для хранения файлов, являются дисковые накопители. Эти устройства предназначены для считывания и записи данных на жесткие и гибкие магнитные диски, оптические диски, flash-носители и др.
Читайте также: