
Создание com и exe их структурное отличие на примере сегментов памяти
Ассемблер – это язык программирования низкого уровня и программа, написанная на Ассемблере, должна пройти три этапа обработки на компьютере, как и программа, написанная на любом другом языке программирования.
I этап - преобразование исходного модуля в объектный – ассемблирование. Исходных модулей может быть 1 или несколько.
II этап - с помощью программы редактора связей объектные модули объединяются в загрузочный, исполняемый модуль.
III этап – выполнение программы.
Исходный файл должен занимать только один сегмент памяти (и программа и данные только в одном сегменте). Стек не описывается, создается автоматически. Поскольку данные вместе с программой, то сегмент данных не определяется отдельно. Программа располагается в одном сегменте, все сегментные регистры перед началом выполнения программы в качестве значений содержат адрес блока, который называется префиксом сегмента программы (PSP). Этот блок размером 256 байтов размещается и перед EXE, и перед COM-файлом. Так как адрес первой исполняемой команды оказывается отстоящим на 256 байтов от начала сегмента, то для обхода этого блока используется специальная директива ORG 100h.
Если сравнивать EXE и COM-файлы для одной и той же программы, то вторые файлы меньше как минимум на 512 байт. Но с другой стороны первые файлы могут занимать произвольное количество сегментов в отличие от вторых. Таким образом рекомендуются небольшие программы писать под COM исполнительные файлы.
Отличия exe-файла от com-файла:
В com-файлах отсутствует блок начальной загрузки и следовательно он занимает меньше места, чем exe-файл.
exe-файл может занимать произвольный объем ОП. com-файл может занимать только один сегмент памяти.
Стек создается автоматически ОС, поэтому у пользователя нет необходимости выделять для него место. Данные располагаются там же, где и программа.

Т.к. вся программа содержится в одном сегменте, перед выполнением программы все сегментные регистры содержат в качестве значения адрес префикса программного сегмента – PSP
PSP - 256 байтный блок, который содержится как в exe-файле, так и в com-файле, и т.к. адрес первой исполняемой команды отстоит на 256 (100h) байтов от адреса начала сегмента, то сразу после директивы ASSUME используется специальная директива org 100h, осуществляющая обход префикса программного сегмента
Пример создания com-файла.
TITLE Prog_Сom-файл
Page 60 , 85
СSeg Segment Para ‘Сode’
ASSUME SS:CSeg, DS:CSeg, CS:CSeg
Org 100h
Start: JMP Main
St1 DB ‘String1’, 13, 10, ‘$’
St2 DB ‘String2’, ‘$’
Main Proc
MOV AH, 9
LEA DX, St1
Int 21h
LEA DX, St2
Int 21h
MOV AH, 4CH
Int 21h
Main endp
CSeg ends
End Start
Model tiny
Code
JMP Met
St1 DB ‘String1’, ‘$’
Met: MOV AH, 09h
LEA DX, St1
Int 21h
MOV AH, 4Ch
Int 21h
End Met
Beg Proc
MOV AH, 9
LEA DX, St1
Int 21h
MOV AH, 4Ch
Int 21h
Beg endp
St1 DB ‘String1’, ‘$’
End beg
• Не каждый исходный файл удовлетворяет требованиям com-файла.
• Небольшие по объему программы рекомендуется оформлять как com-файлы.
• Исходный файл, написанный как com-файл, не может быть выполнен как exe-файл.
19) Команды двоичной арифметики: сложение, вычитание, умножение и деление
Сложение (вычитание) беззнаковых чисел выполняется по правилам аналогичным сложению (вычитанию) по модулю 2 k принятым в математике. В информатике, если в результате более k разрядов, то к+1-й пересылается в CF.
X + Y = (X + Y) mod 2 k = X + Y и CF = 0, если X + Y < 2 k
X + Y = (X + Y) mod 2 k = X + Y -2 k и CF = 1, если X + Y >= 2 k
Пример, работая с байтами (k=8), получим:
250 + 10 = (250 + 10) mod 2 8 = 260 mod 256 = 4
260 = 1 0000 01002, CF = 1, результат - 0000 01002 = 4
X - Y = (X - Y) mod 2 k = X – Y и CF = 0, если X >= Y
X - Y = (X - Y) mod 2 k = X + 2 k –Y и CF = 1, если X < Y
1 - 2 = 2 8 + 1 - 2 = 257 – 2 = 255, CF = 1
Сложение (вычитание) знаковых чисел сводится к сложению (вычитанию) с использованием дополнительного кода.
X = 10 n - |X|
В байте: -1 = 256 – 1 = 255 = 111111112
-3 = 256 – 3 = 253 = 111111012
3 + (-1) = ( 3 + (-1)) mod 256 = (3+255) mod 256 = 2
1 + (-3) = (1 + (-3)) mod 256 = 254 = 111111102
Ответ получили в дополнительном коде, следовательно результат получаем в байте по формуле X = 10 n - |X| , т.е.
х = 256 – 254 = |2| и знак минус. Ответ -2.
Переполнение происходит, если есть перенос из старшего цифрового в знаковый, а из знакового нет и наоборот, тогда OF = 1. Программист сам решает какой флажок анализировать OF или CF, зная с какими данными он работает.
Арифметические операции изменяют значение флажков
OF, CF, SF, ZF, AF, PF.
В Ассемблере команда ‘+’
ADD OP1, OP2; (OP1) + (OP2) ® OP1
ADC OP1, OP2; (OP1) + (OP2) + (CF) ® OP1
XADD OP1, OP2; i486 и >
(OP1) « (OP2) (меняет местами), (OP1) + (OP2) ® OP1
INC OP1; (OP1) + 1 ® OP1
В Ассемблере команда ‘-‘
SUB OP1, OP2; (OP1) – (OP2) ® OP1
SBB OP1, OP2; (OP1) – (OP2) – (CF) ® OP1
DEC OP1; (OP1) – 1 ® OP1.
X = 1234AB12h, Y = 5678CD34h, X + Y =
MOV AX, 1234h
MOV BX, 0AB12h
MOV CX, 5678h
MOV DX, 0CD34h
ADD BX, DX
ADC AX, CX
X – Y = SUB BX, DX
SBB AX, CX
В командах сложения и вычитания можно использовать любые способы адресации:
ADD AX, mas[SI]; прямая с индексированием
95h + 82h = 117h 95 = 100101012 82 = 100000102
100101012 + 100000102 = 1 0001 01112, 10010101
CF = 1, OF = 1, SF = 0, ZF = 0, AF = 0, PF = 1. 10000010
Пример2: 1 00010111
MOV AL, 9h
SUB AL, 5h
9h – 5h = 4h 5 = 00000101 -5 = 11111011 9 = 00001001
9 + (-5) = 11111011 + 00001001 = 1 0000 0100
CF = 1, OF = 0, SF = 0, ZF = 0, AF = 1, PF = 0.
Почему человек чувствует себя несчастным?: Для начала определим, что такое несчастье. Несчастьем мы будем считать психологическое состояние.
Как вы ведете себя при стрессе?: Вы можете самостоятельно управлять стрессом! Каждый из нас имеет право и возможность уменьшить его воздействие на нас.
Личность ребенка как объект и субъект в образовательной технологии: В настоящее время в России идет становление новой системы образования, ориентированного на вхождение.

Операционная система MS DOS предъявляет некоторые обязательные требования к структуре ASM-программы, предназначенной для последующего создания EXE-файла:
l Программа может использовать 4 сегмента памяти, начальные адреса которых должны быть загружены в регистры микропроцессора CS, SS, DS и ES, а сами сегменты в явном виде определены в программе в виде операторных скобок: имя_сегмента segment . имя_сегмента ends (версии MS DOS 4.0 и выше допускают более простое указание сегментов в программе: имя_сегмента).
l В программе должно быть указание, какие сегментные регистры закрепляются за используемыми сегментами памяти; при исполнении программы сегментные регистры CS, SS, ES в соответствии с этими указаниями загружаются автоматически.
l Сегмент данных DS в EXE-программе не может быть загружен автоматически, поскольку он используется программным загрузчиком для формирования начального адреса служебной области памяти — префикса программного сегмента (PSP), непосредственно предшествующего любой исполняемой программе EXE. Регистр сегмента данных DS должен быть инициирован принудительно — для этого следует в самом начале ASM-программы записать в стек вектор-адрес возврата к служебной области PSP: содержимое регистра DS и нулевое смещение, а затем в регистр DS загрузить адрес сегмента данных. PSP — это группа служебных слов в оперативной памяти, формируемая для каждой загружаемой программы пользователя и занимающая обычно 256 байтов (100h). При запуске программы пользователя в ОЗУ автоматически формируется PSP, и ее начальный адрес помещается в регистр DS.
Типовая структура ASM-программы включает в себя:
1. Имя программы.
Может присутствовать комментарий назначения программы.
2. Инициализацию стековой памяти в сегменте стека:
STACKSEG segment stack
DW N dup(?) ; меньше 32 слов в стеке обычно задавать не следует
3. Инициализацию всех переменных в сегменте данных:
; задаются имена всех констант и переменных,
; их начальные значения и резервируется память под них
4. Назначение сегментных регистров в сегменте кодов:
Assume CS:codeseg, DS:dataseg, SS:stackseg
5. Организацию главной программной процедуры far:
6. Запись адреса префикса программного сегмента (PSP) в стек:
7. Инициализацию содержимого регистра сегмента данных:
; при указании в команде в качестве операнда символического
; имени сегмента (dataseg) происходит пересылка начального адреса
; этого сегмента — неверно указывать offset dataseg
8. Текст программы пользователя в сегменте кодов:
основной текст программы
9. Восстановление адреса PSP в DS:
10. Тексты процедур; если имеются процедуры near, используемые в данной программе, то записываются тексты этих процедур.
11. Закрытие главной процедуры main, сегмента кодов и выход из программы:
Итак, обобщенная структура программы:
; задание поля памяти для стека
; задание полей памяти для данных и определение всех констант и переменных
assume CS:codeseg, DS:dataseg, SS:stackseg
; основной текст программы
; тексты ближних процедур
Рассмотрим программу расчета сложных процентов.
Капитал Q вкладывается в некоторое мероприятие, обеспечивающее ежегодный прирост капитала D%. Задача: определить текущую величину капитала в течение первых N лет. Вот соответствующая ASM-программа для создания исполняемого EXE-файла.
| TITLE | RASCHET.ASM | ; расчет сложных процентов |
| STACKSG | SEGMENT | STACK 'STACK' |
| DW | 64 DUP(?) | |
| STACKSG | ENDS | |
| DATASG | SEGMENT | 'DATA' ; задание переменных |
| VVQ | DB | ' Введите величину начального капитала (до 64 000)' |
| DB | 10,13,'$' | |
| DB | 10,13,'Введите процент годового прироста' | |
| DB | 10,13,'$' | |
| VVN | DB | 10,13,'Введите количество расчетных лет' |
| DB | 10,13,'$' | |
| Q0 | DW | ? |
| D | DW | ? |
| D1 | DW | ? |
| N | DW | ? |
| I | DW | |
| Q | DW | ? |
| BUF | DB | 5, 0, 0, 0, 0, 0, 0, 0 |
| VIV1 | DB | ' год капитал' |
| DB | 10,13,'$' | |
| SRB | DB | 14 DUP(0), '$' |
| SR | DB | 6 DUP(0), '$' |
| SRK | DB | 10, 13, '$' |
| FT10 | DW | |
| TEN | DW | |
| STO | DW | |
| DATASG | ENDS | |
| CODESG | SEGMENT | 'CODE' |
| MAIN | PROC | FAR |
| ASSUME | CS:CODESG, DS:DATASG, SS:STACKSG | |
| PUSH | DS | |
| SUB | AX, AX | |
| PUSH | AX | |
| MOV | AX, DATASG | |
| MOV | DS, AX | |
| MOV | AH, 9 ; запрос на ввод Q | |
| MOV | DX, offset VVQ | |
| INT | 21H | |
| MOV | AH, 0Ah ; ввод Q | |
| MOV | DX, offset BUF | |
| INT | 21H | |
| CALL | STR2BIN | |
| MOV | Q0, DI | |
| MOV | AH, 9 ; запрос на ввод D | |
| MOV | DX, offset VVD | |
| INT | 21H | |
| MOV | AH, 0AH ; ввод D | |
| MOV | DX, offset BUF | |
| INT | 21H | |
| CALL | STR2BIN | |
| MOV | D, DI | |
| MOV | AH, 9 ; запрос на ввод N | |
| MOV | DX, offset VVN | |
| INT | 21H | |
| MOV | AH, 0AH ; ввод N | |
| MOV | DX, offset BUF | |
| INT | 21H | |
| CALL | STR2BIN | |
| MOV | N, DI | |
| MOV | AX, D | |
| MOV | D1, AX | |
| ADD | D1, 100 ; расчет D1 = (1 + D/100) * 100 | |
| MOV | AX, Q0 ; присвоение Q = Q0 | |
| MOV | Q, AX | |
| MOV | AH, 9 | |
| MOV | DX, offset VIV1 | |
| INT | 21H | |
| RST: | MOV | AX, Q ; расчет Q = Q * D1 |
| MUL | D1 | |
| DIV | STO | |
| MOV | Q, AX | |
| MOV | AX, I | |
| CALL | BIN2STR | |
| MOV | AH, 9 ; вывод года | |
| MOV | DX, offset SR | |
| INT | 21H | |
| MOV | AH, 9 ; вывод пробела | |
| MOV | DX, offset SRB | |
| INT | 21H | |
| MOV | AX, Q ; вывод прибыли | |
| CALL | BIN2STR | |
| MOV | AH, 9 | |
| MOV | DX, offset SR | |
| INT | 21H | |
| MOV | AH, 9 ; перевод строки | |
| MOV | DX, offset SRK | |
| INT | 21H | |
| INC | I ; I = I + 1 | |
| MOV | AX, I ; сравнение I с N | |
| CMP | AX, N | |
| JLE | RST ; условный переход по I | |
| RET | ||
| BIN2STR | PROC | NEAR |
| MOV | SI, offset SR+5 ; процедура перевода двоичного | |
| PR2: | SUB | DX, DX ; кода в код ASCII с предварительным |
| MOV | [SI], DL ; обнулением поля SR | |
| DEC | SI | |
| CMP | SI, offset SR | |
| JA | PR2 | |
| MOV | CX, 10 | |
| MOV | SI, offset SR+5 | |
| PR1: | XOR | DX, DX |
| DIV | CX | |
| OR | DL, 30H | |
| MOV | [SI], DL | |
| DEC | SI | |
| CMP | AX,0 | |
| JNE | PR1 | |
| RET | ||
| BIN2STR | ENDP | |
| STR2BIN | PROC | NEAR ; процедура перевода ASCII-кодов |
| MOV | FT10, 1 ; в двоичный код | |
| XOR | DI, DI | |
| MOV | CX, 10 | |
| LEA | SI, BUF + 1 | |
| XOR | BH, BH | |
| MOV | BL, [BUF + 1] | |
| PR3: | MOV | AL, [SI+BX] |
| AND | AX, 0FH | |
| MUL | FT10 | |
| ADD | DI, AX | |
| MOV | AX, FT10 | |
| MUL | TEN | |
| MOV | FT10, AX | |
| DEC | BX | |
| JNZ | PR3 | |
| RET | ||
| STR2BIN | ENDP | |
| MAIN | ENDP | |
| CODESG | ENDS | |
| END | MAIN |
В качестве иллюстративного примера для сравнения сложности программ на языке ассемблера с программами на языке высокого уровня, ниже приводится без пояснений программа решения этой задачи на языке Basic:
Существует два основных типа загрузочных программ: EXE и COM. Рассмотрим требования к EXE-программам. DOS имеет четыре требования для инициализации ассемблерной EXE-программы: 1) указать ассемблеру, какие сегментные регистры должны соответствовать сегментам, 2) сохранить в стеке адрес, находящийся в регистре DS, когда программа начнет выполнение, 3) записать в стек нулевой адрес и 4) загрузить в регистр DS адрес сегмента данных.
Существуют определенные различия между программой, выполняемой как EXE-файл и программой, выполняемой как COM-файл.
1. Размер программы. EXE-программа может иметь любой размер, в то время как COM-файл ограничен размером одного сегмента и не превышает 64К. COM-файл всегда меньше, чем соответствующий EXE-файл; одна из причин этого - отсутствие в COM-файле 512-байтового начального блока EXE-файла.
2. Сегмент стека. В EXE-программе определяется сегмент стека, в то время как COM-программа генерирует стек автоматически. Таким образом при создании ассемблерной программы, которая будет преобразована в COM-файл, стек должен быть опущен.
3. Сегмент данных. В EXE программе обычно определяется сегмент данных, а регистр DS инициализируется адресом этого сегмента. В COM-программе все данные должны быть определены в сегменте кода.
4. Инициализация. EXE-программа записывает нулевое слово в стек и инициализирует регистр DS. Так как COM-программа не имеет ни стека, ни сегмента данных, то эти шаги отсутствуют. Когда COM-программа начинает работать, все сегментные регистры содержат адрес префикса программного сегмента (PSP),
- 256-байтового (шест. 100) блока, который резервируется операционной системой DOS непосредственно перед COM или EXE программой в памяти. Так как адресация начинается с шест. смещения 100 от начала PSP, то в программе после оператора SEGMENT кодируется директива ORG 100H.
Warning: No STACK Segment
(Предупреждение: Сегмент стека не определен)
ПРИМЕР ПРОГРАММЫ
Программа преобразования двузначного шестнадцатеричного числа в символьном виде в двоичное представление.
Выход: результат преобразования помещается в регистр dl.
data segment para public “data” ;сегмент данных
message db “Введите две 16-теричные цифры, $”
stk segment stack
db 256 dup (“?”) ;сегмент стека
code segment para public “code” ;начало сегмента кода
main proc ;начало процедуры main
mov ax,data ;адрес сегмента данных в регистр ах
mov ds,ax ;ax в ds
mov dx,offset message
xor ax,ax ;очистить регистр ах
mov ah,1h ;1h в регистр ah
int 21h ;генерация прерывания с номером 21h
mov dl,al ;содержимое регистра al в регистр dl
sub dl,30h ;вычитание: (dl)=(dl)-30h
cmp dl,9h ;сравнить (dl) с 9h
jle M1 ;перейти на метку М1, если dl
sub dl,7h ;вычитание: (dl)=(dl)-7h
M1: ;определение метки М1
mov cl,4h ;пересылка 4h в регистр сl
shl dl,cl ;сдвиг содержимого dl на 4 разряда влево
int 21h ;вызов прерывания с номером 21h
sub al,30h ;вычитание: (dl)=(dl)-30h
cmp al,9h ;сравнить (al) c 9h
jle M2 ;перейти на метку М2, если al
sub al,7h ;вычитание: (al)=(al)-7h
M2: ;определение метки М2
add dl,al ;сложение: (dl)=(dl)+(al)
mov ax,4c00h ;пересылка 4с00h в регистр ax
int 21h ;вызов прерывания с номером 21h
main endp ;конец процедуры main
code ends ;конец сегмента кода
end main ;конец программы с точкой входа main
Строки 4-6 описывают сегмент стека, который является просто областью памяти длиной 256 байт, инициализированной символами «”?”». Отличие сегмента стека от сегментов других типов состоит в использовании и адресации памяти. В отличие от сегмента данных (наличие которого необязательно, если программа не работает с данными), сегмент стека желательно определять всегда.

Строка 9 содержит директиву ассемблера, которая связывает сегментные регистры с именами сегментов.
Строки 10-11 выполняют инициализацию сегментного регистра DS.
Строка 15 подготавливает регистр АХ к работе, обнуляя его.
Строки 16-17 обращаются к средствам операционной системы для ввода символа с клавиатуры. Введенный символ операционная система помещает в регистр AL.
Строка 18 пересылает содержимое AL в регистр DL. Это делается для того, чтобы освободить AL для ввода второй цифры.
Строка 19 преобразует символьную цифру в ее двоичный эквивалент путем вычитания 30h, в результате чего в регистре DL будет двоичное значения числа.
В строках 20-21 выясняется, нужно ли корректировать двоичное значение DL. Если оно лежит в диапазоне 0…9, то в DL находится правильный двоичный эквивалент введенного символа шестнадцатеричной цифры. Если значение в DL больше 9, то введенная цифра является одним из символов A,B,C,D,E,F. В первом случае строка 21 передаст управление на метку М1.
В строках 24-25 значение в DL сдвигается на 4 разряда влево, освобождая место в младшей тетраде под младшую шестнадцатеричную цифру.
В строке 26 в регистр AL вводится вторая шестнадцатеричная цифра.
В строках 27-29 выясняется, попадает ли двоичный эквивалент второго символа шестнадцатеричной цифры в диапазон 0…9. Наша вторая цифра не попадает в диапазон, поэтому для получения правильного двоичного эквивалента нужно произвести дополнительную корректировку. Это делается в строке 38.
Строки 33-34 предназначены для завершения программы и возврата управления операционной системе.
СТРУКТУРЫ
Описание типа структуры
Структура - это составной объект, занимающий несколько соседних ячеек памяти. Это тип данных, состоящий из фиксированного числа элементов разного типа. Компоненты структуры называются полями, они могут быть разного типа (размера) - байт, слово и т. д. Поля именуются, доступ к полям осуществляется по именам. Для использования структур в программе необходимо выполнить 3 действия.
1. Задать шаблон структуры. По смыслу это означает определение нового типа данных, который впоследствии можно использовать для определения переменных этого типа.
2. Определить экземпляр структуры. Этот этап подразумевает инициализацию конкретной переменной с заранее определенной структурой.
3. Организовать обращение к элементам структуры.
Существует разница между описанием структуры в программе и ее определением. Описание структуры в программе означает лишь указание компилятору ее схемы или шаблона; память при этом не выделяется. Компилятор извлекает из этого шаблона информацию о расположении полей структуры и их значениях по умолчанию. Определение структуры означает указание транслятору на выделение памяти и присвоение этой области памяти символического имени. Описать структуру можно только один раз, а определить любое количество раз.
Описание шаблона структуры.
Прежде чем использовать структуру, надо описать ее тип - указать, сколько в ней полей, какие имена у полей и т. д. Описание типа структуры выглядит так:
Описание типа открывает директива STRUC, где указывается имя, которое дали типу структуры. Это же имя должно быть в директиве ENDS. Между этими двумя директивами может быть указано любое число директив, описывающих поля структуры.
Например, тип структуры DATE из трех полей Y (год), M(месяц), D(день) можно описать так:
Описание типа структуры носит чисто информационный характер, по нему ассемблер ничего не заносит в машинную программу, поэтому такое описание можно размещать в любом месте программы, но обязательно до описания переменных этого типа.
После того как описан тип структуры, можно определять в программе переменные этого типа, отводить под них память. Такие переменные называются переменными-структурами или просто структурами. Описываются они с помощью директив следующего вида:
Пример описания переменных-структур:
Это директивы особого рода. До этого мы рассматривали директивы, названиями которых были служебные слова, а здесь названием является имя DATE. Каждая такая директива описывает одну переменную, имя которой указывается в начале директивы.
DT2 DATE эквивалентно DT2 DATE
DT3 DATE < , , >эквивалентно DT3 DATE
Одной директивой можно описать сразу несколько структур, т. е. можно описать массив, элементами которого являются структуры. Например по директиве
DTS DATE < , 12, 5 >10 dup (<>)
описывается массив из 11 структур типа DATE, причем поля первой из них будут иметь начальные значения: 2004, 12, 5, а остальные десять структур получают один и тот же набор начальных значений, взятых по умолчанию: 2004, 3, ?.
Описав тип структуры и переменные этого типа, получаем право работать с этими переменными-структурами. Как единое целое структуры обрабатываются редко, обычно они обрабатываются по полям. чтобы сослаться на поле структуры, надо использовать конструкцию вида
Такая конструкция обозначает ту ячейку памяти, которую занимает указанное поле указанной переменной. Встречая эту конструкцию, ассемблер заменяет ее на адрес данной ячейки.
Пример. Если в переменной DT1 хранится мартовская дата, то требуется записать сюда дату следующего дня года.
jne FIN ; не март - FIN
je APRL ; 31 марта - APRL
inc DT1.D ; следующий день в марте
APRL: mov DT1.M, 4 ; замена 31 марта 1 апреля
ОБЪЕДИНЕНИЯ
Объединение - тип данных, позволяющий трактовать одну и ту же область памяти как данные, имеющие разные типы и имена. Описание объединений в программе напоминает описание структур, т. е. сначала указывается шаблон, в котором с помощью директив описания данных перечисляются имена и типы полей:
Отличие объединений от структур состоит в том, что при определении переменной типа объединения память выделяется в соответствии с размером максимального элемента. Обращение к элементам объединения происходит по их именам, но при этом нужно помнить, что все поля в объединении накладываются друг на друга. В качестве элементов объединения можно использовать и структуры.
Как было показано выше, обращение к памяти осуществляется исключительно посредством сегментов - логических образований, накладываемых на любые участки физического адресного пространства. Начальный адрес сегмента, деленный на 16, т.е. без младшей шестнадцатеричной цифры, заносится в один из сегментных регистров; после этого мы получаем доступ к участку памяти, начинающегося с заданного сегментного адреса.
Каким образом понятие сегментов памяти отражается на структуре программы? Следует заметить, что структура программы определяется, с одной стороны, архитектурой процессора (если обращение к памяти возможно только с помощью сегментов, то и программа, видимо, должна состоять из сегментов), а с другой - особенностями той операционной системы, под управлением которой эта программа будет выполняться. Наконец, на структуру программы влияют также и правила работы выбранного транслятора - разные трансляторы предъявляют несколько различающиеся требования к исходному тексту программы. При подготовке этой книги для трансляции и отладки примеров программ использовался пакет TASM 5.0 корпорации Borland International; он удобен, в частности, наличием наглядного многооконного отладчика. Вопрос этот, однако, не принципиален, и читатель может для отладки примеров, приведенных в книге, воспользоваться любым ассемблером, ознакомившись предварительно с его описанием.
В настоящем разделе мы на простом примере рассмотрим особенности сегментной адресации и роль регистров процессора в выполнении прикладной программы. Однако для того, чтобы программа была работоспособна, нам придется включить в нее ряд элементов, не имеющих прямого отношения к рассматриваемым вопросам, но необходимых для ее правильного функционирования. К таким элементам, в частности, относится вызов функций DOS. Приведя полный текст программы, мы дадим краткие пояснения.
Пример 1-1. Простая программа с тремя сегментами
;Укажем соответствие сегментных регистров сегментам
assume CS:code,DS:data
;Опишем сегмент команд
code segment ;Откроем сегмент команд
begin:
mov AX,data ;Настроим DS
mov DS,AX ;на сегмент данных
;Выведем на экран строку текста
mov АН,09h ;Функция DOS вывода на экран
mov DX,offset msg ;Адрес выводимой строки
int 21h ;Вызов DOS
;Завершим программу
mov AX,4C00h ;Функция DOS завершения программы
int 21h ;Вызов DOS
code ends ;Закроем сегмент команд
;Опишем сегмент данных
data segment ;Откроем сегмент данных
msg db "Программа работает!$' ;Выводимая строка
data ends ;Закроем сегмент данных
;Опишем сегмент стека
stk segment stack ;Откроем сегмент стека
db 256 dup (?) ;Отводим под стек 256 байт
stk ends ;Закроем сегмент стека
end begin ;Конец текста с точкой входа
Следует заметить, что при вводе исходного текста программы с клавиатуры можно использовать как прописные, так и строчные буквы; транслятор воспринимает, например, строки MOV AX,DATA и mov ax,data одинаково. Однако с помощью соответствующих ключей можно заставить транслятор различать прописные и строчные буквы в отдельных элементах предложений. В настоящей книге в текстах программ и при описании операторов языка в основном используются строчные буквы, за исключением обозначений регистров, которые для наглядности выделены прописными буквами.
Предложения языка ассемблера могут содержать комментарии, которые отделяются от предложения языка знаком точки с запятой (;). При необходимости комментарий может занимать целую строку (тоже, естественно, начинающуюся со знака ";"). Поскольку в языке ассемблера нет знака завершения комментария, комментарий нельзя вставлять внутрь предложения языка, как это допустимо делать во многих языках высокого уровня. Каждое предложение языка ассемблера, даже самое короткое, должно занимать отдельную строку текста.
В программе 1-1 описаны три сегмента: сегмент команд с именем code, сегмент данных с именем data и сегмент стека с именем stk. Описание каждого сегмента начинается с ключевого слова segment, предваряемого некоторым именем, и заканчивается ключевым словом end, перед которым указывается то же имя, чтобы транслятор знал, какой именно сегмент мы хотим закончить. Имена сегментов выбираются вполне произвольно. Текст программы заканчивается директивой ассемблера end, завершающей трансляцию. В качества операнда этой директивы указывается точка входа в программу; в нашем случае это метка begin.
Порядок описания сегментов в программе, как правило, не имеет значения. Часто программу начинают с сегмента данных, это несколько облегчает чтение программы, и в некоторых случаях устраняет возможные неоднозначности в интерпретации команд, ссылающиеся на данные, которые еще не описаны. Мы в начале программы расположили сегмент команд, за ним - сегмент данных и в конце - сегмент стека; такой порядок предоставляет некоторые удобства при отладке программы. Важно только понимать, что в оперативную память компьютера сегменты попадут в том же порядке, в каком они описаны в программе (если специальными средствами ассемблера не задать иной порядок загрузки сегментов в память).
Сегменты вводятся в программу с помощью директив ассемблера segment и ends. Что такое директива ассемблера? В тексте программы встречаются ключевые слова двух типов: команды процессора (mov, int) и директивы транслятора (в данном случае термины "транслятор" и "ассемблер" являются синонимами, обозначая программу, преобразующую исходный текст, написанный на языке ассемблера, в коды, которые будут при выполнении программы восприниматься процессором). К директивам ассемблера относятся обозначения начала и конца сегментов segment и ends; ключевые слова, описывающие тип используемых данных (db, dup); специальные описатели сегментов вроде stack и т. д. Директивы служат для передачи транслятору служебной информации, которой он пользуется в процессе трансляции программы. Однако в состав выполнимой программы, состоящей из машинных кодов, эти строки не попадут, так как процессору, выполняющему программу, они не нужны. Другими словами, операторы типа segment и ends не транслируются в машинные коды, а используются лишь самим ассемблером на этапе трансляции программы. С этим вопросом мы еще столкнемся при рассмотрении листингов программ.
Еще одна директива ассемблера используется в первом предложении программы:
Здесь устанавливается соответствие сегмента code сегментному регистру CS и сегмента data сегментному регистру DS. Первое объявление говорит о том, что сегмент code является сегментом команд, и встречающиеся в этом сегменте метки принадлежат именно этому сегменту, что помогает ассемблеру правильно транслировать команды переходов. В нашей программе меток нет, и эту часть предложения можно было бы опустить, однако в более сложных программах она необходима (при использовании транслятора MASM эта часть объявления необходима в любой, даже самой простой программе).
Второе объявление помогает транслятору правильно обрабатывать предложения, в которых производится обращение к полям данных сегмента data. Выше уже отмечалось, что для обращения к памяти процессору необходимо иметь две составляющие адреса: сегментный адрес и смещение. Сегментный адрес всегда находится в сегментном регистре. Однако в процессоре два сегментных регистра данных, DS и ES, и для обращения к памяти можно использовать любой из них. Разумеется, процессор при выполнении команды должен знать, из какого именно регистра он должен извлечь сегментный адрес, поэтому команды обращения к памяти через регистры DS или ES кодируются по-разному. Объявляя соответствие сегмента data регистру DS, мы предлагаем транслятору использовать вариант кодирования через регистр DS.
Однако отсюда совсем не следует, что к моменту выполнения команды с обращением к памяти в регистре DS будет содержаться сегментный адрес требуемого сегмента. Более того, можно гарантировать, что нужного адреса в сегментном регистре не будет. Директива assume влияет только на кодирование команд, но отнюдь не на содержимое сегментных регистров. Поэтому практически любая программа должна начинаться с предложений, в которых в сегментный регистр, используемый для адресации к сегменту данных (как правило, это регистр DS) заносится сегментный адрес этого сегмента. Так сделано и в нашем примере с помощью двух команд
mov AX,data ;Настроим DS
mov DS,AX ;на сегмент данных
с которых начинается наша программа. Сначала значение имени data (т.е. адрес сегмента data) загружается командой mov в регистр общего назначения процессора АХ, а затем из регистра АХ переносится в регистр DS. Такая двухступенчатая операция нужна потому, что процессор в силу некоторых особенностей своей архитектуры не может выполнить команду непосредственной загрузки адреса в сегментный регистр. Приходится пользоваться регистром АХ в качестве "перевалочного пункта".
Поместив в регистр DS сегментный адрес сегмента данных, мы получили возможность обращаться к полям этого сегмента. Поскольку в программе может быть несколько сегментов данных, операционная система не может самостоятельно определить требуемое значение DS, и инициализировать его приходится "вручную".
Назначением программы 1-1 предполагается вывод на экран текстовой строки "Программа работает!", описанной в сегменте данных. Следующие предложения программы как раз и выполняют эту операцию. Делается это не непосредственно, а путем обращения к служебным программам операционной системы MS-DOS, которую мы для краткости будем в дальнейшем называть просто DOS. Дело в том, что в составе команд процессора и, соответственно, операторов языка ассемблера нет команд вывода данных на экран (как и команд ввода с клавиатуры, записи в файл на диске и т.д.). Вывод даже одного символа на экран в действительности представляет собой довольно сложную операцию, для выполнения которой требуется длинная последовательность команд процессора. Конечно, эту последовательность команд можно было бы включить в нашу программу, однако гораздо проще обратиться за помощью к операционной системе. В состав DOS входит большое количество программ, осуществляющих стандартные и часто требуемые функции - вывод на экран и ввод с клавиатуры, запись в файл и чтение из файла, чтение или установка текущего времени, выделение или освобождение памяти и многие другие.
Для того, чтобы обратиться к DOS, надо загрузить в регистр общего назначения АН номер требуемой функции, в другие регистры - исходные данные для выполнения этой функции, после чего выполнить команду int 21h (int - от interrupt, прерывание), которая передаст управление DOS. Вывод на экран строки текста можно осуществить функцией 09h, которая требует, чтобы в регистрах DS:DX содержался полный адрес выводимой строки. Регистр DS мы уже инициализировали, осталось поместить в регистр DX относительный адрес строки, который ассоциируется с именем поля данных msg. Длину выводимой строки указывать нет необходимости, так как функция 09h DOS выводит на экран строку от указанного адреса до символа доллара, который мы предусмотрительно включили в выводимую строку. Заполнив все требуемые для конкретной функции регистры, можно выполнить команду int 21h, которая осуществит вызов DOS.
Для того, чтобы выполнить пробный прогон приведенной программы, ее необходимо сначала оттранслировать и скомпоновать. Пусть исходный текст программы хранится в файле с именем P.ASM. Трансляция осуществляется вызовом ассемблера TASM.EXE с помощью следующей команды DOS;
Ключ /z разрешает вывод на экран строк исходного текста программы, в которых ассемблер обнаружил ошибки (без этого ключа поиск ошибок пришлось бы проводить по листингу трансляции).
Ключ /zi управляет включением в объектный файл информации, не требуемой при выполнении программы, но используемой отладчиком.
Ключ /n подавляет вывод в листинг перечня символических обозначений в программе, от чего несколько уменьшается информативность листинга, но сокращается его размер.
Стоящие далее параметры определяют имена файлов: исходного (P.ASM), объектного (P.OBJ) и листинга (P.LST). При желании можно в строке вызова транслятора указать полные имена файлов с их расширениями, однако необходимости в этом нет, так как по умолчанию транслятор использует именно указанные выше расширения.
Строка вызова компоновщика имеет следующий вид:
Ключ /х подавляет образование листинга компоновки, который обычно не нужен.
Ключ /v передает в загрузочный файл информацию, используемую отладчиком. Стоящие далее параметры обозначают имена модулей: объектного (Р.ОBJ) и загрузочного (Р.ЕХЕ).
Поскольку при изучении этой книги вам придется написать и отладить большое количество программ, целесообразно создать командный файл (с именем, например, А.ВАТ), автоматизирующий выполнение однотипных операций трансляции и компоновки. Текст командного файла в простейшем варианте может быть таким (в предположении, что путь к каталогу с пакетом TASM был указан в параметре команды PATH):
tasm /z/zi/n p,p,p
tlink /x/v p,p
Запуск подготовленной программы Р.ЕХЕ осуществляется командой р.ехе
При загрузке программы сегменты размещаются в памяти, как показано на рис. 1.9.
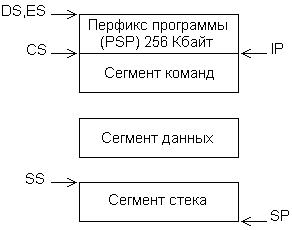
Рис. 1.9. Образ программы в памяти.
Образ программы в памяти начинается с сегмента префикса программы (Program Segment Prefix, PSP), образуемого и заполняемого системой. PSP всегда имеет размер 256 байт; он содержит таблицы и поля данных, используемые системой в процессе выполнения программы. Вслед за PSP располагаются сегменты программы в том порядке, как они объявлены в программе. Сегментные регистры автоматически инициализируются следующим образом: ES и DS указывают на начало PSP (что дает возможность, сохранив их содержимое, обращаться затем в программе к PSP), CS - на начало сегмента команд, a SS - на начало сегмента стека. В указатель команд IP загружается относительный адрес точки входа в программу (из операнда директивы end), а в указатель стека SP - величина, равная объявленному размеру стека, в результате чего указатель стека указывает на конец стека (точнее, на первое слово за его пределами).
Таким образом, после загрузки программы в память адресуемыми оказываются все сегменты, кроме сегмента данных. Инициализация регистра DS в первых строках программы позволяет сделать адресуемым и этот сегмент.
Отсюда следует, что сегмент всегда начинается с адреса, кратного 16, т.е. на границе 16-байтового блока памяти (параграфа). Сегментный адрес можно рассматривать, как номер параграфа, с которого начинается данный сегмент. Размер сегмента определяется объемом содержащихся в нем данных, но никогда не может превышать величину 64 Кб, что определяется максимально возможной величиной смещения.
Сегментный адрес сегмента команд хранится в регистре CS, а смещение к адресуемому байту - в указателе команд IP. Как уже отмечалось, после загрузки программы в IP заносится смещение первой команды программы; процессор, считав ее из памяти, увеличивает содержимое IP точно на длину этой команды (команды процессоров Intel могут иметь длину от 1 до 6 байт), в результате чего IP указывает на вторую команду программы. Выполнив первую команду, процессор считывает из памяти вторую, опять увеличивая значение IP. В результате в IP всегда находится смещение очередной команды, т. е. команды, следующей за выполняемой. Описанный алгоритм нарушается только при выполнении команд переходов, вызовов подпрограмм и обслуживания прерываний.
Сегментный адрес сегмента данных обычно хранится в регистре DS, a смещение может находится в одном из регистров общего назначения, например, в ВХ или SI. Однако в МП 86 два сегментных регистра данных - DS и ES. Дополнительный сегментный регистр ES часто используется для обращения к полям данных, не входящим в программу, например к видеобуферу или системным ячейкам. Однако при необходимости его можно настроить и на один из сегментов программы. В частности, если программа работает с большим объемом данных, для них можно предусмотреть два сегмента и обращаться к одному из них через регистр DS, а к другому - через ES.
Программа на ассемблере представляет собой совокупность блоков памяти, называемых сегментами памяти. Программа может состоять из одного или нескольких таких блоков-сегментов. Каждый сегмент содержит совокупность предложений языка, каждое из которых занимает отдельную строку кода программы.
Предложения ассемблера бывают четырех типов:
- команды или инструкции, представляющие собой символические аналоги машинных команд.
В процессе трансляции инструкции ассемблера преобразуются в соответствующие команды системы команд микропроцессора;

Навигация сайта
Структура COM и EXE файлов
Структура COM файла
В основном COM файлы пишут на языке Ассемблера, но это не обязательно. Нописать файл можно на любом языке, который можно потом компилировать.
.286 ; Устанавливаем тип процессора
mov ah,09h ;Функцию DOS (прерывание 21h) 09h
mov dx,offset message ; Заносим в dx значение переменной message
int 21h ;Устанавливаем прерывание которое должно обработать функцию 09h
mov ah,4Ch ;Функцию DOS (прерывание 21h) 4Ch
int 21h ;Устанавливаем прерывание которое должно обработать функцию 00h
message db "My first COM programms",13,10,"$" ;Придаем значение переменной message
Использую определение прерывания можно сказать как действует эта программа.
mov ah,09h
int 21h
В первой строке в регистр ah заносится значение 09, где h означает, что это число в шестнадцатеричной системе исчисления, во второй строке указывается прерывание, в данном случае это 21, (h тоже самое, что и в первой строке) т.е. прерывание DOS. Получив такую команду, процессор на время перестает выполнять текущие операции и передает управление находящейся в оперативной памяти программе, обработчику функции 09h. После выполнения всех этих операций процессор возвращается к выполнению ранее выполняемой операции.
Ниже приведены два варианта кода COM - файла до "инфицирования" вирусом и после:
.286 ;Задаем тип процессора
code segmen ; Начало сегмента кода программы
org 100h ;Все COM программы начинаются с адреса 100h
jmp coob ; Тело программы начинается с метки coob
mov ah,4Ch
int 21h
coob: ;Начало тела программы
mov ah,09h ; Заносим значение 09h в регистр ah
mov dx,offset message ; В регистре dx указываем адрес строки с текстом
int 21h ; Указываем, что это прерывание DOS 21h
message db "Файл не инфицирован",13,10,"$" ; Строка с текстом для вывода на экран
mov ah,4Ch ;Выходим из программы
int 21h ; Прерывание 21h
ends code ; Конец сегмента кода программы
.286 ;Задаем тип процессора
code segmen ; Начало сегмента кода программы
org 100h ;Все COM программы начинаются с адреса 100h
jmp virus ; JMP изменены таками образом, чтобы вирус получил управление
mov ah,4Ch
int 21h
coob:
mov ah,09h
mov dx,offset message
int 21h
message db "Файл не инфицирован",13,10,"$" ; Строка с текстом для вывода на экран
mov ah,4Ch
int 21h
virus:
mov .
. > Вирус размножается и выполняет свои разрушительные действия
. int 21h
jmp coob
ends code ; Конец сегмента кода программы
Ниже приведена структура инфицированного файла
Хвост COM программы
Тело вируса
Оригинальное начало
COM программы
Структура EXE файла
COM файлы пишут в основном на языке Ассемблера, но они постепенно устаревают и на смену им приходят огромные по своим размерам и сложные по своей структуре EXE файлы.
Состоять EXE файлы могут из нескольких сегментов, следовательно их размер не ограничен 64 кб. По структуре EXE файл сложнее, кроме кода программы в файле также содержется: заголовок файла, таблица настройки адресов, данные и т.п.
Примерная структура EXE файла:
Тело программы
Конец программы
Заголовок EXE файла - содержет данные необходимые для загрузки программы
Тело программы - основная часть программы, выполняющая какие-либо полезные действия
Конец программы - завершающая часть программы, которая сохраняет нужные и удаляет ненужные данные из ОЗУ, закрывает все открытые данной программой файлы и т.п.
Первая и последняя часть программы являются обязательными для всех EXE файлов, а вторая часть вовсе не обязательна. Вы можете просто взять её и пропустить.
Приводить виды "инфицированного" и "не инфицированного" EXE файла я не буду, т.к. в отличие от COM вирусов, у EXE вирусов есть множество способов заражения. Подробно о каждом из них я расскажу Вам в следующих выпусках рассылки, а сейчас только перечислю названия основных из них:
OVERWRITE - вирусы, замещающие программный код
COMPANION - вирусы-спутники
PARASITIC - вирусы, внедряющиеся в программу
метод переименования EXE файла
внедрение способом переноса
внедрение способом сдвига
Стандартный вирус
Не только файлы имеют определенную структуру, но и вирусы для осуществления своей вредоносной деятельности должны соблюдать определенную структуру своего тела и действовать в определенном порядке.
Данная рассылка полна биологических и медицинских терминов, т.к. способы заражения, методы распространения компьютерных вирусов очень схожи с биологическими вирусами. Даже первый вирус создавался по аналогии с биологическими вирусами.
Интересно, а кто создал первый вирус ?
С момента появления вычислительной техники программистов и электронщиков интересовала одна тема: самовопроизводяющиеся и самораспространяющиеся механизмы. Первым кто попробовал осуществить эту идею в 1951 году был Дж. фон Нейман. Но Нейман и не думал использовать эти материалы в каких либо разрушительных целях, но другие люди, воспользовавшись его материалами и знаниями в этой области начали создавать различных вредоносные программы - компьютерные вирусы. Но что же побудило этих людей пойти на это. Ученые считают, что людей побуждают создавать компьютерные вирусы некоторые факторы:
- озорство и одновременное непонимание всех последствий распространения вируса
- стремление навредить кому-либо
- неестественная потребность в совершение преступлений
- желание самоутвердиться
- невозможночть использовать свои знания в правильном русле
Как и у биологических, у компьютерных вирусов есть определенные стадии "развития":
- латентный период - в течение которого вирус себя никак не проявляет (для того, чтобы "замести следы" источника его попадания на "инфицированный" ПК)
- инкубационный период - в рамках которого вирус только размножается
- период проявления - в течение которого вирус выполняет несанкционированные пользователем действия.
Компьютерные вирусы классифицируют по следующим признакам.
- способ обитания
- способ заражения и среды обитания
- способ активизации
- способ проявления
- способ маскировки
Нелепо думать, что компьютерные вирусы могут содержаться везде. Особенно это проявляется на пользователях "чайниках" которые могут часами просиживать перед экраном и с упортством проверять файлы, которые никак не могут содержать вирусы. Ведь вирус - это программа, следовательно имеет смысл внедряться только в другие программы. В связи с этим компьютерные вирусы подразделяют еще на:
- файловые
- загрузочные
- файлово-загрузочные вирусы
ФАЙЛОВЫЕ
Вирусы могут внедряться в следующие компоненты системы:
- файлы с компонентами DOS
- исполняемые файлы COM
- исполняемые файлы EXE
- внешние драйвера устройств (SYS- и BIN-файлы)
- объектные модули (OBJ-файлы)
- файлы программы до их компиляции, в надежде на то, что их когда нибуть компилируют и запустят
- командные файлы (BAT-файлы)
- файлы-библиотеки (LIB, DLL и др.файлы)
- оверлейные файлы (PIF, OV? и др. файлы)
- файлы текстовых процессоров поддерживающих макроcы (DOC, XLS и др.файлы)
С каждым днем этот список растет.
Чаще всего вирусы внедряются в файлы COM, EXE и DOC
ЗАГРУЗОЧНЫЕ
загрузояные вирусы распространяются в BOOT секторах дисков и дискет
- BR - на дискетах
- MBR - на жестком диске
При загрузке этих дискет выполняется программа в BOOT секторе этого диска, а следовательно и сам вирус. Плюс этого типа вирусов в том, что если прочитать этот инфицированный диск, то на нем не окажется ни одного файла.
ФАЙЛОВО-ЗАГРУЗОЧНЫЕ ВИРУСЫ
Вирусы данного типа обладают большей инфицирующей способностью, так как они распространяются в BOOT секторах диска и в файлах на этом диске.
СПОСОБЫ ЗАРАЖЕНИЯ СРЕДЫ ОБИТАНИЯ
Вирусы могут "имплантироваться" в следующие места файлов:
- конец файла
- начало файла
- середина файлов
- хвостовой части файлов (свободной)
Читайте также: