
Sli что это в логистике
If there’s one thing every tech company has in common, it’s this: users.
Whether you’re Google’s search engine, serving a billion active monthly users who interact with your service for free, or Salesforce, with 3.75 million paying subscribers, building a technology product means serving people.
And in today’s always-on world, people’s expectations—for free and paid services alike—are high. Speed. Uptime. Useful UX. Today’s user base expects everything to meet a high standard.
Looker trusts Opsgenie to help deliver their service to 200,000 users every day.
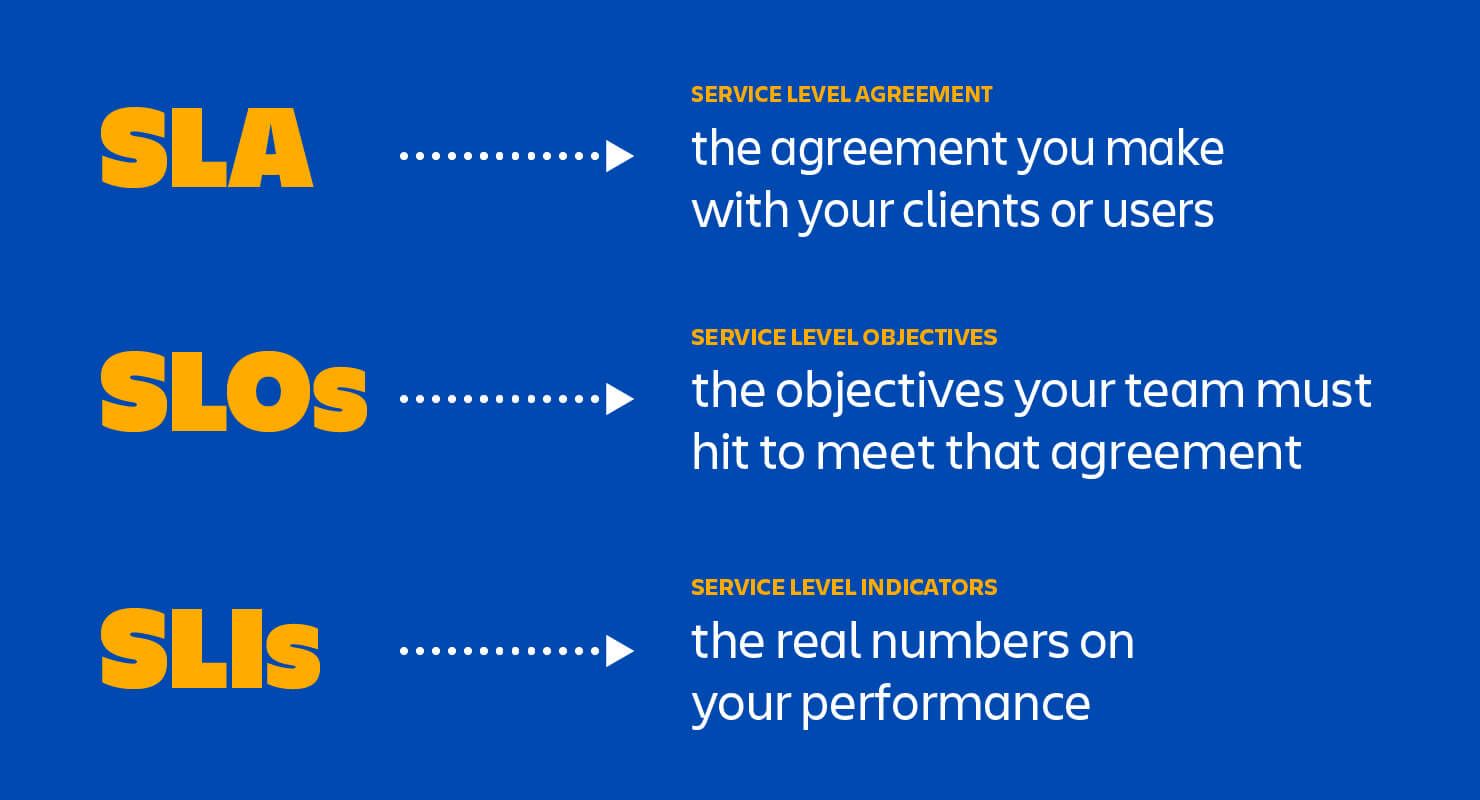
Which is why it’s important for companies to understand and maintain SLAs, SLOs, and SLIs—three initialisms that represent the promises we make to our users, the internal objectives that help us keep those promises, and the trackable measurements that tell us how we’re doing.
The goal of all three things is to get everybody—vendor and client alike—on the same page about system performance. How often will your systems be available? How quickly will your team respond if the system goes down? What kind of promises are you making about speed and functionality? Users want to know—and so you need SLAs, SLOs, and SLIs.
Лучшие практики для SLO и SLI
Когда вы соотносите ваш SLO с вашим SLA, очень важно обратить внимание на следующие пункты:
With SLOs, less is more
Not every metric is vital to client success, which means not every metric should be an SLO. Commit to as few SLOs as possible and focus on the ones that matter most to customers.
SLO: Service Level Objectives
The challenges of SLIs
As with SLOs, the challenge of SLIs is keeping them simple, choosing the right metrics to track, and not overcomplicating IT’s job by tracking too many metrics that don’t actually matter to clients.
Целевые показатели: SLA, SLI, SLO
Одно из главных противоречий между отделом эксплуатации и разработки происходит из разного отношения к надёжности системы. Если для отдела эксплуатации надёжность — это всё, то для разработчиков её ценность не так очевидна.
SRE подход предполагает, что все в компании приходят к общему пониманию. Для этого определяют, что такое надёжность (стабильность, доступность и т. д.) системы, договариваются о показателях и вырабатывают стандарты действий в случае проблем.
Показатели доступности вырабатываются вместе с продакт-оунером и закрепляются в соглашении о целевом уровне обслуживания — Service-Level Objective (SLO). Оно становится гарантом, что в будущем разногласий не возникнет.
Специалисты по SRE рекомендуют указывать настолько низкий показатель доступности, насколько это возможно. «Чем надёжнее система, тем дороже она стоит. Поэтому определите самый низкий уровень надёжности, который может сойти вам с рук, и укажите его в качестве SLO», сказано в рекомендациях Google. Сойти с рук — значит, что пользователи не заметят разницы или заметят, но это не повлияет на их удовлетворенность сервисом.
Чтобы понимание было ясным, соглашение должно содержать конкретные числовые показатели — Service Level Indicator (SLI). Это может быть время ответа, количество ошибок в процентном соотношении, пропускная способность, корректность ответа — что угодно в зависимости от продукта.
SLO и SLI — это внутренние документы, нужные для взаимодействия команды. Обязанности компании перед клиентами закрепляются в в Service Level Agreement (SLA). Это соглашение описывает работоспособность всего сервиса и штрафы за превышение времени простоя или другие нарушения.
Примеры SLA: сервис доступен 99,95% времени в течение года; 99 критических тикетов техподдержки будет закрыто в течение трёх часов за квартал; 85% запросов получат ответы в течение 1,5 секунд каждый месяц.
SLA: Service Level Agreements
Split Frame Rendering
Изображение разбивается на несколько частей, количество которых соответствует количеству видеокарт в связке. Каждая часть изображения обрабатывается одной видеокартой полностью, включая геометрическую и пиксельную составляющие.
Аналог в CrossFire — алгоритм Scissor

Почему никто не стремится к 100% доступности
SRE исходит из предположения, что ошибки и сбои неизбежны. Более того, на них рассчитывают.
Оценивая доступность, говорят о «девятках»:
- две девятки — 99%,
- три девятки — 99,9%,
- четыре девятки — 99,99%,
- пять девяток — 99,999%.
Пять девяток — это чуть больше 5 минут даунтайма в год, две девятки — это 3,5 дня даунтайма.
Стремиться к повышению доступности нормально, однако чем ближе она к 100%, тем выше стоимость и техническая сложность сервиса. В какой-то момент происходит уменьшение ROI — отдача инвестиций снижается.
Например, переход от двух девяток к трём уменьшает даунтайм на три с лишним дня в год. Заметный прогресс! А вот переход с четырёх девяток до пяти уменьшает даунтайм всего на 47 минут. Для бизнеса это может быть не критично. При этом затраты на повышение доступности могут превышать рост выручки.
При постановке целей учитывают также надёжность окружающих компонентов. Пользователь не заметит переход стабильности приложения от 99,99% к 99,999%, если стабильность его смартфона 99%. Грубо говоря, из 10 сбоев приложения 8 приходится на ОС. Пользователь к этому привык, поэтому на один лишний раз в год не обратит внимания.
Что такое индикатор уровня обслуживания (SLI)?
SLI это мера выполнения SLO. Это значит, что без SLI не будет и SLO.
Возвращаясь к примеру онлайн сервиса, — если соглашение между поставщиком и клиентом (SLA) обещает обеспечение 99.95 процентов, тогда ваш SLO также будет 99,95 процентов. Ваш SLI это и есть действительное обеспечение, отправляемое вашей системой.
Если ваш SLI больше 99,95 процентов, это значит, что вы выполнили обязательства перед клиентом. Когда 100 процентов выполнения невозможны, целью становится получить цифру, максимально приближающуюся к 100%.
Одной из сложностей SLI становится выбор актуальной метрики для отслеживания, а также контроль за ее выполнением. Показатели отслеживания существуют в первую очередь для вас, а не для клиента.
Какие выгоды получает команда по техническому обеспечению надежности сайта (SRE) от SLO и SLI?
Обладание точными и конкретными SLO и SLI является основополагающим для бесперебойного перехода от разработок к операциям. SLO помогает команде расставить приоритеты, в то время как SLI указывает на области, где необходимо уделите внимание, чтобы соответствовать ожиданиям клиента.
Теперь вы знаете, что значат SLO и SLI, и теперь мы можем рассмотреть лучшие практики для их применения, чтобы улучшить ваш SRE.
Не каждая метрика это SLO
Ограничив ваш SLO только практическим и необходимым, вы избежите многих проблем. Используйте минимальный SLO, не включайте в него максимум из того, что вы можете, чтобы впечатлить клиента вашими способностями в параметрах измерения.
The challenges of SLOs
SLOs get less hate than SLAs, but they can create just as many problems if they’re vague, overly complicated, or impossible to measure. The key to SLOs that don’t make your engineers want to tear their hair out is simplicity and clarity. Only the most important metrics should qualify for SLO status, the objectives should be spelled out in plain language, and, as with SLAs, they should always account for issues such as client-side delays.
Don’t shoot for the moon
Just because your team can probably maintain 99.99% uptime doesn’t mean that 99.99% should be your SLO number. It’s always better to under-promise and overdeliver. This is especially true for agile teams who want to launch early and often and need an error budget to keep up that quick pace.
Что почитать
В одной статье невозможно рассказать всё об SRE. Вот подборка материалов для тех, кому нужны детали.
SLI AA
Данный алгоритм нацелен на повышение качества изображения. Одна и та же картинка генерируется на всех видеокартах с разными шаблонами сглаживания. Видеокарта производит сглаживание кадра с некоторым шагом относительно изображения другой видеокарты. Затем полученные изображения смешиваются и выводятся. Таким образом достигается максимальные четкость и детализованность изображения. Доступны следующие режимы сглаживания: 8x, 10x, 12x, 14x, 16x и 32x.

Даже после сдачи проекта клиенту работа разработчика программного обеспечения не закончена. Следующей фазой выступает обеспечение надежности оказываемых услуг. В практике проектирование надежности сайта (SRE) есть два ключевых понятия, о которых следует знать инженерам: цель уровня обслуживания (SLO) и индикатор уровня обслуживания (SLI).В этой статье мы рассмотрим важность SLI и SRE и как их применять.
Build in an error budget
Leaving room for failures not only protects the business from SLA violations and hefty consequences, it also leaves room for agility—for the team to make changes quickly and have the space to try innovative new solutions that might fail.
Google actually recommends using leftover error budget for planned downtime, which can help you identify unforeseen issues (e.g. services using servers inappropriately) and maintain appropriate expectations from your clients.
История
В 1998 году компания 3dfx представила графический процессор англ. Scan Line Interleave — чередование строчек), которая предполагала совместную работу двух чипов разрешением 1024x768, что в то время казалось невозможным. Недостатками SLI от 3dfx были высокая цена ($600) и большое тепловыделение, к тому же наблюдались проблемы черезстрочной синхронизации результирующего изображения. Однако вскоре видеокарты переходят с шины AGP-порт. Так как на материнских платах этот порт был только один, то выпуск видеокарт с поддержкой SLI на время прекратился.
В 2000 году с выпуском нового чипа VSA-100 3dfx удалось реализовать SLI на чипа. Однако платы на базе SLI-системы обладали большим энергопотреблением и выходили из строя из-за проблем с электропитанием. На весь мир плат Voodoo5 6000 было продано около 200 штук, причем реально рабочими из них оказались лишь 100.
В 2001 году NVIDIA покупает 3dfx за 110 млн долларов. С введением спецификации PCI-X становится вновь возможным использование нескольких графических карт для обработки изображения. В 2004 году с выходом первых решений на базе новой шины PCI Express NVIDIA объявляет о поддержке в своих продуктах технологии мультичиповой обработки данных SLI, которая расшифровывается уже по-другому — Scalable Link Interface (масштабируемый интерфейс).
В конце 2007 года введена в эксплуатацию технология 3-Way SLI, позволяющая объединять в связке 3 видеокарты
Использовать максимально упрощённый язык
Клиент может и не прочитать документ в вашем присутствии, то есть в тот момент, когда он может попросить вас уточнить или разъяснить какие-либо моменты. Если какая-то часть вашего SLA, которая содержит в себе SLO является двусмысленной, вы и ваш клиент, вероятно, будете иметь разногласия в ожиданиях в будущем.
От DevOps к SRE
Во многих IT-компаниях разработкой и эксплуатацией занимаются разные команды с разными целями. Цель команды разработки — выкатывать новые фичи. Цель команды эксплуатации — обеспечить работу старых и новых фич в продакшене. Разработчики стремятся поставить как можно больше кода, системные администраторы — сохранить надёжность системы.
Цели команд противоречат друг другу. Чтобы разрешить эти противоречия, была создана методология DevOps. Она предполагает уменьшение разрозненности, принятие ошибок, опору на автоматизацию и другие принципы.
Проблема в том, что долгое время не было чёткого понимания, как воплощать принципы DevOps на практике. Редкая конференция по этой методологии обходилась без доклада «Что такое DevOps?». Все соглашались с заложенными идеями, но мало кто понимал, как их реализовать.
Ситуация изменилась в 2016 году, когда Google выпустила книгу «Site Reliability Engineering». В этой книге описывалась конкретная реализация DevOps. С неё и началось распространение SRE-подхода, который сейчас применяется во многих международных IT-компаниях.
DevOps — это философия. SRE — реализация этой философии. Если DevOps — это интерфейс в языке программирования, то SRE — конкретный класс, который реализует DevOps.
Мониторинг и прозрачность
Без мониторинга нельзя понять, вписывается ли команда в бюджет и соблюдает ли критерии, описанные в SLO. Поэтому задача инженера по SRE — настроить мониторинг. Причём настроить его так, чтобы уведомления приходили только тогда, когда требуются действия.
В стандартном случае есть три уровня событий:
- алерты — требуют немедленного действия («чини прямо сейчас!»);
- тикеты — требуют отложенного действия («нужно что-то делать, делать вручную, но не обязательно в течение следующих нескольких минут»);
- логи — не требуют действия, и при хорошем развитии событий никто их не читает («о, на прошлой неделе у нас микросервис отвалился, пойди посмотри в логах, что случилось»).
SRE определяет, какие события требуют действий, а затем описывает, какими эти действия должны быть, и в идеале приходит к автоматизации. Любая автоматизация начинается с реакции на событие.
С мониторингом связан критерий прозрачности (Observability). Это метрика, которая оценивает, как быстро вы можете определить, что именно пошло не так и каким было состояние системы в этот момент.
С точки зрения кода: в какой функции или сервисе произошла ошибка, каким было состояние внутренних переменных, конфигурации. С точки зрения инфраструктуры: в какой зоне доступности произошел сбой, а если у вас стоит какой-нибудь Kubernetes, то в каком поде, каким было его состояние при этом.
Who needs SLIs?
Any company measuring their performance against SLOs needs SLIs in order to make those measurements. You can’t really have SLOs without SLIs.
What is an SLI?
An SLI (service level indicator) measures compliance with an SLO (service level objective). So, for example, if your SLA specifies that your systems will be available 99.95% of the time, your SLO is likely 99.95% uptime and your SLI is the actual measurement of your uptime. Maybe it’s 99.96%. Maybe 99.99%. To stay in compliance with your SLA, the SLI will need to meet or exceed the promises made in that document.
SRE для небольших компаний и компаний без разработки
SRE работает везде, где нужно выкатывать апдейты, менять инфраструктуру, расти и масштабироваться. Инженеры по SRE помогают предсказать и определить возможные проблемы, сопутствующие росту. Поэтому они нужны даже в тех компаниях, где основная деятельность не разработка ПО. Например, в энтерпрайзе.
При этом необязательно нанимать на роль SRE отдельного человека, можно сделать роль переходной, а можно вырастить человека внутри команды. Последний вариант подходит для стартапов. Исключение — жёсткие требования по росту (например, со стороны инвесторов). Когда компания планирует расти в десятки раз, тогда нужен человек, ответственный за то, что при заданном росте ничего не сломается.
Кроме того, для любой компании полезно принять, что ошибки — это нормально, и начать работать с ними. Определить Error budget, стараться тратить его на развитие, а возникающие проблемы разбирать и по результатам разбора внедрять автоматизацию.
What is an SLO?
An SLO (service level objective) is an agreement within an SLA about a specific metric like uptime or response time. So, if the SLA is the formal agreement between you and your customer, SLOs are the individual promises you’re making to that customer. SLOs are what set customer expectations and tell IT and DevOps teams what goals they need to hit and measure themselves against.
Среднее время между сбоями и среднее время восстановления — MTBF и MTTR
Для работы с надёжностью, ошибками и ожиданиями в SRE применяют ещё два показателя: MTBF и MTTR.
MTBF (Mean Time Between Failures) — среднее время между сбоями.
Показатель MTBF зависит от качества кода. Инженер по SRE влияет на него через ревью и возможность сказать «Нет!». Здесь важно понимание команды, что когда SRE блокирует какой-то коммит, он делает это не из вредности, а потому что иначе страдать будут все.
MTTR (Mean Time To Recovery)— среднее время восстановления (сколько прошло от появления ошибки до отката к нормальной работе).
Показатель MTTR рассчитывается на основе SLO. Инженер по SRE влияет на него за счёт автоматизации. Например, в SLO прописан аптайм 99,99% на квартал, значит, у команды есть 13 минут даунтайма на 3 месяца. В таком случае время восстановления никак не может быть больше 13 минут, иначе за один инцидент весь «бюджет» на квартал будет исчерпан, SLO нарушено.
13 минут на реакцию — это очень мало для человека, поэтому здесь нужна автоматизация. Что человек сделает за 7-8 минут, скрипт — за несколько секунд. При автоматизации процессов MTTR очень часто достигает секунд, иногда миллисекунд.
В идеале инженер по SRE должен полностью автоматизировать свою работу, потому что это напрямую влияет на MTTR, на SLO всего сервиса и, как следствие, на прибыль бизнеса.

Обычно при внедрении автоматизации стараются оценивать время на подготовку скрипта и время, которое этот скрипт экономит. По интернету ходит табличка, которая показывает, как долго можно автоматизировать задачу:
Всё это справедливо, но не относится к работе SRE. По факту, практически любая автоматизация от SRE имеет смысл, потому что экономит не только время, но и деньги, и моральные силы сотрудников, уменьшает рутину. Всё это вместе положительно сказывается на работе и на бизнесе, даже если кажется, что с точки зрения временных затрат автоматизация не имеет смысла.
Not every trackable metric should be an SLI
Similarly, tracking performance on 10 components for each of 10 SLOs can get unwieldy very quickly. Instead, strategically choose which metrics actually matter to your core SLOs and put your energy into tracking those effectively.
Чем является цель уровня обслуживания (SLO)?
Цель уровня обслуживания — это соглашение об особых численных показателях качества, таких как продолжительность работы и времени реагирования. Другими словами, SLO — это отдельные обещания поставщика услуг перед клиентом, используемые для того, чтобы определить ожидания от сервиса. SLO также позволяет IT и DevOps командам иметь цель или метрики, чтобы измерить показатели своей работы самостоятельно и понять, насколько хорошо они выполняют свои задачи.
Сервис может иметь более одной SLO, и они могут быть применимы и к оплачивающим, и к не оплачивающим потребителям, и даже к внутренним клиентам этой организации. Например, когда клиентоориентированная команда использует инструментарий, предоставляемый другой командой из этой же организации, эти две команды обязаны иметь четко определенные цели уровня обслуживания, таким образом клиентоориентированная команда сможет удовлетворить обязательства, указанные в договоре.
Для того, чтобы SLO был эффективным, в нем не должно быть размытых, очень запутанных или недостижимых критериев. Только актуальные SLO должны быть указаны в документе и должны быть прописаны простым языком, чтобы обеспечить ясность. Это также необходимо для учета таких проблем, как задержки со стороны клиента.
Цели и задачи SRE-инженера
Инженеры по SRE нужны, когда в компании пытаются внедрить DevOps и разработчики не справляются с возросшей нагрузкой.
В отличие от классического подхода, согласно которому эксплуатацией занимается обособленный отдел, инженер по SRE входит в команду разработки. Иногда его нанимают отдельно, иногда им становится кто-то из разработчиков. Есть подход, где роль SRE переходит от одного разработчика к другому.
Цель инженера по SRE — обеспечить надёжную работу системы. Он занимается тем же, что раньше входило в задачи системного администратора, — решает инфраструктурные проблемы.
Как правило, инженерами SRE становятся опытные разработчики или, реже, администраторы с сильным бэкграундом в разработке. Кто-то скажет: «программист в роли инженера — не лучшее решение». Возможно и так, если речь идёт о новичке. Но в случае SRE мы говорим об опытном разработчике. Это человек, который хорошо знает, что и когда может сломаться. У него есть опыт и внутри компании, и снаружи.
Предпочтение не просто так отдаётся разработчикам. Имея сильный бэкграунд в программировании и зная систему с точки зрения кода, они более склонны к автоматизации, чем к рутинной администраторской работе. Кроме того, они имеют больший багаж знаний и навыков для внедрения автоматизации.
В задачи инженера по SRE входит ревью кода. Нужно, чтобы на каждый деплой SRE сказал: «OK, это не повлияет на надёжность, а если повлияет, то в допустимых пределах». Он следит, чтобы сложность, которая влияет на надёжность работы системы, была необходимой.
- Необходимая — сложность системы повышается в том объёме, которого требуют новые продуктовые фичи.
- Случайная — сложность системы повышается, но продуктовая фича и требования бизнеса напрямую на это не влияют. Тут либо разработчик ошибся, либо алгоритм не оптимален.
Хороший SRE блокирует любой коммит, деплой или пул-реквест, который повышает сложность системы без необходимости. В крайнем случае SRE может наложить вето на изменение кода (и тут неизбежны конфликты, если действовать неправильно).
Во время ревью SRE взаимодействует с оунерами изменений, от продакт-менеджеров до специалистов по безопасности.
Кроме того, инженер по SRE участвует в выборе архитектурных решений. Оценивает, как они повлияют на стабильность всей системы и как соотносятся с бизнес-потребностями. Отсюда уже делает вывод — допустимы нововведения или нет.
Craft SLAs around customer expectations
Every part of your customer agreement should be crafted around what matters to the customer. On the back end, an incident may mean addressing 10 different components. But in the client’s view, all that matters is that the system functions as expected.
Your SLAs and SLOs should reflect this reality. Don’t overcomplicate things by drilling down to a granular level and making individual promises for each of those 10 components. Keep your promises confined to the high-level, user-facing functionality. This will keep clients happier and less confused and simplify the lives of IT pros responsible for making good on your SLA promises.
Принимать во внимание ожидания клиентов
Во время разработки вашего SLA очень важно знать, что ваши заказчики ожидают от вашего сервиса или продукта. Имея понимание, что важно для клиента, ваша команда сможет разрабатывать то, что целесообразно, и с чем клиент сможет работать.
Смотреть что такое "SLI" в других словарях:
slīþa- — *slīþa , *slīþaz, *slīþja , *slīþjaz germ., Adjektiv: Verweis: s. *sleiþa s. sleiþa ; … Germanisches Wörterbuch
SLI — may stand for: Single Line Interface*Scalable Link Interface, NVIDIA s method for connecting 2 or more video cards together to produce a single output. *Scan Line Interleave, 3dfx s method for connecting 2 or more video cards together,… … Wikipedia
SLI — ist die Abkürzung für: Aerolitoral, den ICAO Code einer mexikanischen Fluggesellschaft Scalable Link Interface, eine Technik, die den multiplen Betrieb von PC Grafikkarten des Herstellers NVIDIA ermöglicht Scanline Interleaving, eine Technik, die … Deutsch Wikipedia
slı̏ka — slı̏k|a ž 〈D L slı̏ci, G mn slîkā〉 1. >umjetničko djelo izrađeno u bojama, u dvije dimenzije na plošnoj podlozi (na platnu, papiru, drvu, staklu i sl.) 2. >razg. a. >fotografija [albumi za ∼e] b. >prizor na TV ili… … Veliki rječnik hrvatskoga jezika
slı̏ti — (što, se) svrš. 〈prez. slı̏jēm (se), pril. pr. slîvši (se), prid. trp. slìven〉 1. >(što) a. >uliti kakvu tekućinu u što b. >popiti c. >lijevanjem napraviti ili spojiti 2. >(se) a. >izliti se b.… … Veliki rječnik hrvatskoga jezika
sli — sli·go; sli·mi·cide; … English syllables
slīþja- — *slīþja , *slīþjaz germ., Adjektiv: Verweis: s. *sleiþa s. sleiþa ; … Germanisches Wörterbuch
SLI — SLI, Scan Line Interleave … Universal-Lexikon
slı̏h — m rij. mast koju luči uho; ušna mast, ušna smola … Veliki rječnik hrvatskoga jezika
slı̏na — slı̏n|a ž 〈G mn slînā〉 fiziol. 1. >tekućina koju izlučuje žlijezda slinovnica da bi se održala vlažnost usta te olakšalo žvakanje i gutanje [gutati ∼u, pren. biti uzbuđen; cure mi ∼e, pren. naslađujem se željom za čim] 2. >pljuvačka … Veliki rječnik hrvatskoga jezika
šlı̏c — m 〈N mn šlìcevi〉 reg. prorez na odjeći (sprijeda u visini bedara na hlačama, sprijeda i straga na ženskim suknjama i haljinama); rasporak ✧ >njem … Veliki rječnik hrvatskoga jezika

NVIDIA SLI — технология, позволяющая использовать мощности нескольких видеокарт для обработки трехмерного изображения.
Post mortem вместо поиска виноватых
В SRE придерживаются культуры blameless postmortem, когда при возникновении ошибок не ищут виноватых, а разбирают причины и улучшают процессы.
Предположим, даунтайм в квартал был не 13 минут, а 15. Кто может быть виноват? SRE, потому что допустил плохой коммит или деплой; администратор дата-центра, потому что провел внеплановое обслуживание; технический директор, который подписал договор с ДЦ и не обратил внимания, что его SLA не поддерживает нужный даунтайм. Все понемногу виноваты, значит, нет смысла возлагать вину на кого-то одного. В таком случае организуют постмортемы и правят процессы.
What is an SLA?
An SLA (service level agreement) is an agreement between provider and client about measurable metrics like uptime, responsiveness, and responsibilities.
These agreements are typically drawn up by a company’s new business and legal teams and they represent the promises you’re making to customers—and the consequences if you fail to live up to those promises. Typically, consequences include financial penalties, service credits, or license extensions.
Где поучиться
Одно дело читать о новых практиках, а другое дело — внедрять их. Если вы хотите глубоко погрузиться в тему, приходите на онлайн-интенсив по SRE от Слёрма. Он пройдет 11–13 декабря 2020.
Научим формулировать показатели SLO, SLI, SLA, разрабатывать архитектуру и инфраструктуру, которая их обеспечит, настраивать мониторинг и алёртинг.
На практическом примере рассмотрим внутренние и внешние факторы ухудшения SLO: ошибки разработчиков, отказы инфраструктуры, наплыв посетителей, DoS-атаки. Разберёмся в устойчивости, Error budget, практике тестирования, управлении прерываниями и операционной нагрузкой.
Who needs SLOs?
Where SLAs are only relevant in the case of paying customers, SLOs can be useful for both paid and unpaid accounts, as well as internal and external customers.
Internal systems, such as CRMs, client data repositories, and intranet, can be just as important as external-facing systems. And having SLOs for those internal systems is an important piece of not only meeting business goals but enabling internal teams to meet their own customer-facing goals.
How does this impact SREs?
For those of you following Google’s model and using Site Reliability Engineering (SRE) teams to bridge the gap between development and operations, SLAs, SLOs, and SLIs are foundational to success. SLAs help teams set boundaries and error budgets. SLOs help prioritize work. And SLIs tell SREs when they need to freeze all launches to save an endangered error budget—and when they can loosen up the reins.
Learn incident communication with Statuspage
In this tutorial, we’ll show you how to use incident templates to communicate effectively during outages. Adaptable to many types of service interruption.
The importance of an incident postmortem process
An incident postmortem, also known as a post-incident review, is the best way to work through what happened during an incident and capture lessons learned.
Англо-русский словарь технических аббревиатур . 2011 .
Create a detailed disaster recovery plan
What will you do when downtime strikes? If you don’t already know the answer to that question, the default answer will be “waste precious time figuring out what to do.”
The better your incident response plan, the quicker and more effectively your teams will handle incidents. Which is why the first step of any new incident management program should be process and planning.
Принципы построения и работы
Для построения компьютера на основе SLI необходимо иметь:
-
с двумя и более разъемами PCI Express, поддерживающую технологию SLI (при скорости PCI-E x8 производительность упадет не слишком заметно, 5-7%, в отличие от слота x4)
- качественный блок питания, мощностью минимум 550 Ватт (рекомендуются блоки SLI-Ready); Quadro FX с шиной PCI Express;
- мост, объединяющий видеокарты.
Поддержка чипсетов для работы со SLI осуществляется программно. Видеокарты должны принадлежать к одному классу, при этом версия
SLI-систему можно организовать двумя способами:
- С помощью специального мостика SLI;
- Программным путем.
В последнем случае нагрузка на шину PCIe возрастает, что плохо сказывается на производительности.
Получила распространение система Quad SLI. Она предполагает объединение в SLI-систему двух двухчиповых плат (GeForce 7950GX2, GeForce 9800GX2 или GeForce GTX295). Таким образом, получается, что в построении изображения работают 4 чипа. Примечание: Quad SLI пока корректно работает только в операционной системе Windows Vista, в Windows XP ее нельзя использовать из-за ограничения в ОС.
Используемая память.
Многие производители "двойных" видеокарт предпочитают писать суммарный объем локальной памяти, например (EVGA или Palit). На самом же деле такие видеоадаптеры, фактически являясь SLI-картами, могут использовать только собственную установленную на PCB память. Т.е. в построении изображении, например, видеокарта GeForce GTX295 сможет использовать только 896 Мб памяти. Каждый ее чип имеет в своем распоряжении только половину от заявленной вендором.
Процессорозависимость
Связка из видеокарт SLI изначально является довольно производительным решением, например из пары GeForce GTX260. Но тут возникает проблема процессорозависимости, т.к. многие современные игры очень интенсивно используют ЦП, также как и сам SLI. Поэтому, чтобы связка SLI полностью раскрыла свой потенциал, необходим соответсвующий мощный процессор с высокой тактовой частотой; в противном случае прироста от использования SLI будет намного меньше ожидаемого.
Alternate Frame Rendering
Обработка кадров происходит поочередно: одна видеокарта обрабатывает только четные кадры, а вторая — только нечетные. Однако у этого алгоритма есть недостаток. Дело в том, что один кадр может быть простым, а другой сложным для обработки.
Этот алгоритм, запатентован ATI во время выпуска двухчиповoй видеокарты.
Составьте продуманный план аварийного восстановления
До подтверждения SLO составьте детальный план действий, которые можно будет предпринять, если ваш SLI опуститься ниже вашего SLO. Пропуск этого пункта может привести к нескоординированным ответным мерам, которые только впустую потратят время вашей команды, вместо того, чтобы урегулировать проблему.
Site Reliability Engineering (SRE) — это одна из форм реализации DevOps. SRE-подход возник в Google и стал популярен в среде продуктовых IT-компаний после выхода одноимённой книги в 2016 году.
В статье опишем, как SRE-подход соотносится с DevOps, какие задачи решает инженер по SRE и о каких показателях заботится.

Алгоритмы построения изображений

Содержание
Include factors outside the IT team’s control
What happens when the client is the one slowing down time to resolution? If you aren’t clear on this in your SLA, your team may be held to the impossible standard of resolving client issues without client involvement.
Бюджет на ошибки
Как мы выяснили, пытаться достичь 100% стабильности не самая лучшая идея, потому что это дорого, технически сложно, а часто и бесполезно — скорее всего, пользователь не оценит старания из-за проблем в «соседних» системах.
Поэтому команды всегда принимают некоторую степень риска и прописывают её в SLO. На основе SLO рассчитывается бюджет на ошибки (Error budget).

Бюджет на ошибки помогает разработчикам договариваться с SRE.
Если бюджет на ошибки содержит 43 минуты даунтайма в месяц, и 40 минут из них сервис уже лежал, то очевидно: чтобы оставаться в рамках SLO, надо сократить риски. Как вариант, остановить выпуск фич и сосредоточиться на баг-фиксах.
Если бюджет на ошибки не исчерпан, то у команды остаётся пространство для экспериментов. В рамках SRE подхода Error budget можно тратить буквально на всё:
- релиз фич, которые могут повлиять на производительность,
- обслуживание,
- плановые даунтаймы,
- тестирование в условиях продакшена.
Чтобы не выйти за рамки, Error budget делят на несколько частей в зависимости от задач. Каждая команда должна оставаться в пределах своего бюджета на ошибки.

В ситуации «профицитного» бюджета на ошибки заинтересованы все: и SRE, и разработчики. Для разработчиков такой бюджет сулит возможность заниматься релизами, тестами, экспериментами. Для SRE является показателем хорошей работы.
Эксперименты в продакшене — это важная часть SRE в больших командах. С подачи команды Netflix её называют Chaos Engineering.
В Netflix выпустили несколько утилит для Chaos Engineering: Chaos Monkey подключается к CI/CD пайплайну и роняет случайный сервер в продакшене; Chaos Gorilla полностью выключает одну из зон доступности в AWS. Звучит дико, но в рамках SRE считается, что упавший сервер — это само по себе не плохо, это ожидаемо. И если это входит в бюджет на ошибки, то не вредит бизнесу.
Chaos Engineering помогает:
- Выявить скрытые зависимости, когда не совсем понятно, что на что влияет и от чего зависит (актуально при работе с микросервисами).
- Выловить ошибки в коде, которые нельзя поймать на стейджинге. Любой стейджинг — это не точная симуляция: другой масштаб и паттерн нагрузок, другое оборудование.
- Отловить ошибки в инфраструктуре, которые стейджинг, автотесты, CI/CD-пайплайн никогда не выловят.
Who needs an SLA?
An SLA is an agreement between a vendor and a paying customer. Companies providing a service to users for free are unlikely to want or need an SLA for those free users.
SLA, SLO, and SLI best practices
Use plain language in SLAs
Clients won’t always ask for clarification, so if your SLA language is complicated, you’re probably setting yourself up for some painful misunderstandings down the line. The simpler your language, the less likely client conflict is in your future.
The challenge of SLAs
SLAs are notoriously difficult to measure, report on, and meet. These agreements—generally written by people who aren’t in the tech trenches themselves—often make promises that are difficult for teams to measure, don’t always align with current and ever-evolving business priorities, and don’t account for nuance.
For example, an SLA may promise that teams will resolve reported issues with Product X within 24 hours. But that same SLA doesn’t spell out what happens if the client takes 24 hours to send answers or screenshots to help your team diagnose the problem. Does it mean the team’s 24-hour window been eaten up by client slow-downs or does the clock start and stop based on when clients respond? SLAs need to answer these questions, but they often fail to do so—a fact that has created a lot of animosity toward them from IT managers.
For many experts, the answer to this challenge is, first and foremost, that tech should be involved in the creation of SLAs. The more IT and DevOps collaborate with legal and business development to develop SLAs that address real-world scenarios, the more SLAs will start to reflect key realities, such as clients delaying their own issue resolution.
SLI: Service Level Indicator
Не обещайте луну с неба, если не сможете ее достать
Во время разработки вашего SLO, не нужно обещать клиенту полную мощность. Например, если ваша система может поддерживать продуктивную эксплуатацию в 99,99 процентов, вы не обязаны устанавливать ваш SLO в 99,99 процентов. Лучше иметь пространство для маневров, которые могут понадобиться из-за переоценки или перевыполнения. В этом случае вы сможете позаботиться о непредвиденных проблемах, которые могут повлиять на ваш сервис.
Читайте также: