
Сколько занимает одна ячейка памяти
Не могу найти убедительного ответа на следующий вопрос.
Нужно узнать, как много места занимает для хранения значение типа данных NUMBER(p) .
Например: NUMBER(1) , NUMBER(3) , NUMBER(8) , NUMBER(10) и т.д..
Получается, независимо от точности, требуется 22 байта. Это действительно так?
Решение
Я более чем уверен, что ошибаюсь в деталях, но общий приницп верен
Планка памяти имеет единицу обращения, равную, например, 4 байтам (или 8). Есть шина, соединяющая память и контроллер памяти, она будет иметь размер в 32 (или 64) бита. Таким образом за одно обращение в память можно либо только прочитать 4 байта, либо только записать 4 байта. При этом адреса должны быть только выравненными, а точнее, младшие 2 (или 3 бита) адреса попросту откидываются, т.к. они всегда нулевые. Когда процессору нужно прочитать кусок в 4 байта по адресу 11, а контроллер памяти работает только по адресам, выровненным на 4, то в реальности в память будет два обращения: сначала прочитаем 4 байта по адресу 8 (из них процессор выцепит только байт с адреса 11), а затем прочитаем 4 байта по адресу 12 (из них процессор выцепит только байты с адреса 12, 13, 14), а потом склеит 4-байтное значение из двух кусков. Т.е. на самом деле планка памяти работает как бы с 32-битными (или 64-битными) байтами и ничего не знает про то, что в человеческом понимании адресуемая единица равна 8 битам. Точно так же для планки памяти не существует младших двух битов байтового адреса
В реальности путь от процессора до памяти - это сложный конвейер, начинающийся от исполнительного устройства, проходящий через нескольку уровней кэша, контроллер памяти и заканчивающийся на планке памяти. Возможно, там есть что-то ещё, о чём я и не ведаю. Взаимодействия между разными участками конвейера построено по тем принципам, которые описаны выше, только на разных стадиях единица обмена данными имеет разный размер. В реальности планка памяти имеет единицу обмена с размером, равным размеру кэшлайна, а единицы размером в 4 или 8 байт находятся уже в самом начале этого конвейера (т.е. близко к исполнительным устройствам процессора)
Когда процессору нужно прочитать кусок в 4 байта по адресу 11, а контроллер памяти работает только по адресам, выровненным на 4, то в реальности в память будет два обращения: сначала прочитаем 4 байта по адресу 8 (из них процессор выцепит только байт с адреса 11), а затем прочитаем 4 байта по адресу 12 (из них процессор выцепит только байты с адреса 12, 13, 14)
Вот именно об этом я и подумал когда написал что "допёр"
Добавлено через 6 минут
Это более менее логичный вариант, начинать чтение с ближайшего выровненного адреса, который расположен до запрошенного адреса

Фиксированный размер ячеек
Имеется форма регистрации: <center><strong>Авторизация</strong> </center> <center><form.
Размер ячеек таблицы
Хочу увеличить расстояние между 1/2 и 2/3 ячейками. Писал и cellspacing и border radius. Толку 0.
Stringgrid размер ячеек
Здравствуйте. Есть StringGrid, на котором количество строк и столбцов устанавливается в работающем.
TChart, размер ячеек сетки
Как получить ширину и высоту одной ячейки сетки в пикселях?
при работе программы, программа использует оперативную память, а после завершения работы программы она освобождает ту память которую занимала? ? и еще вопрос, что собственно из себя представляют ячейки памяти? ) пока не представлю не пойму что значит "сдвиг значения а на k битов вправо или влево". в моем больном представлении это выглядит как какой то ветктор ячеек с нулями и единицами.. .
то блин это единица счисления, то это состояние того, что проходит ток или нет, уже голова болит).
и еще вопрос такой, почему у тип "byte" от диапозон от 0. 255 это еще понятно, но почему тип булеан занимает тоже 1 байт, хотя может принимать всего 2 значения, либо тру или ложь.

Ячейка памяти - маленький кусочек чипа. :)
Можешь представлять ее себе в виде цифры на электрическом счетчике - она всегда там есть, она всегда что-то показывает (говорят, что в ней это что-то записано) . Например, в ячейке в 1 байт может храниться значение от 0 до 255, всего 256 значений.
Занятая и свободная память - условности. Где-то в памяти ОС хранит таблицу - какие участки памяти сейчас используются разными программами, какие - нет. Программа в начале работы сообщает ОС, сколько ей нужно памяти, и ОС отмечает, что память занята, а в конце работы программы ОС помечает, что память уже не используется.
Сдвиг в десятичной системе - очень просто: берем число 1234, сдвигаем на 1 разряд влево - выходит 12340, вправо - выходит 123 (один знак потерялся) . А комьютерные чипы работают в 2-ичной системе (1 знак - 1 бит) , вот и выходит.. .
1 бит - это единица информации, которая в каждом отдельном случае может принимать разные формы: есть ток - нет тока, положительное напряжение - отрицательное напряжение, горит лампочка - не горит лампочка, стоит галочка - не стоит галочка.. . Главное - это одно из 2-х (равновероятных, но про это позднее) значений.
Вот тебе схема.. . ну, почти что ячейки памяти (точнее, сдвигового регистра, но сейчас не важно) :
4 элемента (триггера) , каждый может быть в 2-х состояниях (ток на одном из 2-х выходов).
Ты всё правильно представляешь. . Там Нолики и Единички.. . Есть еще и буковки, если 16-тиричная прога. . Ячейка памяти. . это: "Ячейки памяти, построенные на полупроводниковых технологиях, могут быть статическими (SRAM), то есть не требующими регулярного обновления, и динамическими (DRAM), требующими периодической перезаписи для сохранения данных. Как правило, при помощи статических ячеек организуются кэши, при помощи динамических — ОЗУ. "
8 бит=1 байт
16=2 байта
Ячейки памяти могут иметь разную ёмкость (число разрядов, длину) . Современные запоминающие устройства обычно имеют размер ячейки памяти равным одной из степеней двойки: 8 бит, 16 бит, 32 бита, 64 бита.
1 ответ 1
Все чиселовые значения хранятся в виде поля переменной длины от 0 до 22 байт. Размер занимаемый для хранения зависит от фактического числового значения, а также от точности и количества знаков после запятой.
Oracle Database stores numeric data in variable-length format. Each value is stored in scientific notation, with 1 byte used to store the exponent. The database uses up to 20 bytes to store the mantissa, which is the part of a floating-point number that contains its significant digits. Oracle Database does not store leading and trailing zeros.
Более интересно о хранении числовых значений повествуется в книге Expert Oracle Database Architecture (один из авторов: Томас Кайт). Цитирую (источник: блог Томаса Кайта):
It is interesting and useful to note that the NUMBER type is in fact a varying length data type on disk and will consume between 0 and 22 bytes of storage. Many times, programmers consider a numeric datatype to be a fixed length type and that is what they typically see when programming with 2 or 4 byte integers and 4 or 8 byte floats. The Oracle NUMBER type is similar to a varying length character string.
Можно посмотреть, что происходит с числами, содержащими разное количество значащих цифр. Создадим таблицу с двумя столбцами чисел и заполним первый столбец числами, содержащими 2, 4, 6, . 38 значащих цифр. Затем, просто добавим 1 к каждому из них:
Стандартная функция VSIZE покажет, сколько места в байтах занимает значение в столбце:
При добавлении значащих цифр, требуемый объем памяти занимает все больше места. Каждые 2 цифры увеличивают объем памяти еще на один байт. Но если прибавить к этому значению единицу, что увеличит длину ещё на один знак, то занимаемое место постоянно 2 байта. БД пытается для сохранения числа выделить как можно меньше места. Для этого сохраняются значащие цифры, экспонента, используемая для десятичной точки, и знак числа (положительный или отрицательный).
Таким образом, чем больше значащих цифр содержит число, тем больше места для хранения оно требует.
Полезно знать, что числа хранятся в полях переменной длины. При попытке определить размер таблицы, например, чтобы оценить, какой объем памяти на диске потребуется для хранения 1.000.000 строк в таблице. Будут ли числа занимать 2 байта или 20 байт? Точно оценить размер таблицы без репрезентативных тестовых данных очень сложно.

Новый Год – приятный, светлый праздник, в который мы все подводим итоги год ушедшего, смотрим с надеждой в будущее и дарим подарки. В этой связи мне хотелось бы поблагодарить всех хабра-жителей за поддержку, помощь и интерес, проявленный к моим статьям (1, 2, 3, 4). Если бы Вы когда-то не поддержали первую, не было и последующих (уже 5 статей)! Спасибо! И, конечно же, я хочу сделать подарок в виде научно-популярно-познавательной статьи о том, как можно весело, интересно и с пользой (как личной, так и общественной) применять довольно суровое на первый взгляд аналитическое оборудование. Сегодня под Новый Год на праздничном операционном столе лежат: USB-Flash накопитель от A-Data и модуль SO-DIMM SDRAM от Samsung.
Теоретическая часть
Постараюсь быть предельно краток, чтобы все мы успели приготовить салат оливье с запасом к праздничному столу, поэтому часть материала будет в виде ссылок: захотите – почитаете на досуге…
Какая память бывает?
На настоящий момент есть множество вариантов хранения информации, какие-то из них требуют постоянной подпитки электричеством (RAM), какие-то навсегда «вшиты» в управляющие микросхемы окружающей нас техники (ROM), а какие-то сочетают в себе качества и тех, и других (Hybrid). К последним, в частности, и принадлежит flash. Вроде бы и энергонезависимая память, но законы физики отменить сложно, и периодически на флешках перезаписывать информацию всё-таки приходится.
Тут можно подробнее ознакомиться с ниже приведённой схемой и сравнением характеристик различных типов «твердотельной памяти». Или тут – жаль, что я был ещё ребёнком в 2003 году, в таком проекте не дали поучаствовать…

Современные типы «твердотельной памяти». Источник
Единственное, что, пожалуй, может объединять все эти типы памяти – более-менее одинаковый принцип работы. Есть некоторая двумерная или трёхмерная матрица, которая заполняется 0 и 1 примерно таким образом и из которой мы впоследствии можем эти значения либо считать, либо заменить, т.е. всё это прямой аналог предшественника – памяти на ферритовых кольцах.
Что такое flash-память и какой она бывает (NOR и NAND)?
Начнём с flash-памяти. Когда-то давно на небезызвестном ixbt была опубликована довольно подробная статья о том, что представляет собой Flash, и какие 2 основных сорта данного вида памяти бывают. В частности, есть NOR (логическое не-или) и NAND (логическое не-и) Flash-память (тут тоже всё очень подробно описано), которые несколько отличаются по своей организации (например, NOR – двумерная, NAND может быть и трехмерной), но имеют один общий элемент – транзистор с плавающим затвором.
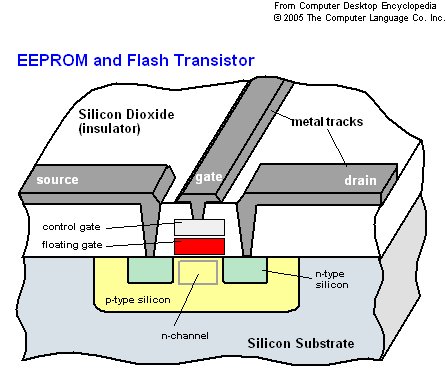
Схематическое представление транзистора с плавающим затвором. Источник
Итак, как же это чудо инженерной мысли работает? Вместе с некоторыми физическими формулами это описано тут. Если вкратце, то между управляющим затвором и каналом, по которому ток течёт от истока к стоку, мы помещаем тот самый плавающий затвор, окружённый тонким слоем диэлектрика. В результате, при протекании тока через такой «модифицированный» полевой транзистор часть электронов с высокой энергией туннелируют сквозь диэлектрик и оказываются внутри плавающего затвора. Понятно, что пока электроны туннелировали, бродили внутри этого затвора, они потеряли часть энергии и назад практически вернуться не могут.
NB: «практически» — ключевое слово, ведь без перезаписи, без обновления ячеек хотя бы раз в несколько лет Flash «обнуляется» так же, как оперативная память, после выключения компьютера.
Там же, на ixbt, есть ещё одна статья, которая посвящена возможности записи на один транзистор с плавающим затвором нескольких бит информации, что существенно увеличивает плотность записи.
В случае рассматриваемой нами флешки память будет, естественно, NAND и, скорее всего, multi-level cell (MLC).
Если интересно продолжить знакомиться с технологиями Flash-памяти, то тут представлен взгляд из 2004 года на данную проблематику. А здесь (1, 2, 3) некоторые лабораторные решения для памяти нового поколения. Не думаю, что эти идеи и технологии удалось реализовать на практике, но, может быть, кто-то знает лучше меня?!
Что такое DRAM?
Если кто-то забыл, что такое DRAM, то милости просим сюда.
Опять мы имеем двумерный массив, который необходимо заполнить 0 и 1. Так как на накопление заряда на плавающем затворе уходит довольно продолжительное время, то в случае RAM применяется иное решение. Ячейка памяти состоит из конденсатора и обычного полевого транзистора. При этом сам конденсатор имеет, с одной стороны, примитивное физическое устройство, но, с другой стороны, нетривиально реализован в железе:
Устройство ячейки RAM. Источник
Опять-таки на ixbt есть неплохая статья, посвящённая DRAM и SDRAM памяти. Она, конечно, не так свежа, но принципиальные моменты описаны очень хорошо.
Единственный вопрос, который меня мучает: а может ли DRAM иметь, как flash, multi-level cell? Вроде да, но всё-таки…
Часть практическая
Flash
Те, кто пользуется флешками довольно давно, наверное, уже видели «голый» накопитель, без корпуса. Но я всё-таки кратко упомяну основные части USB-Flash-накопителя:

Основные элементы USB-Flash накопителя: 1. USB-коннектор, 2. контроллер, 3. PCB-многослойная печатная плата, 4. модуль NAND памяти, 5. кварцевый генератор опорной частоты, 6. LED-индикатор (сейчас, правда, на многих флешках его нет), 7. переключатель защиты от записи (аналогично, на многих флешках отсутствует), 8. место для дополнительной микросхемы памяти. Источник
Пойдём от простого к сложному. Кварцевый генератор (подробнее о принципе работы тут). К моему глубокому сожалению, за время полировки сама кварцевая пластинка исчезла, поэтому нам остаётся любоваться только корпусом.

Корпус кварцевого генератора
Случайно, между делом, нашёл-таки, как выглядит армирующее волокно внутри текстолита и шарики, из которых в массе своей и состоит текстолит. Кстати, а волокна всё-таки уложены со скруткой, это хорошо видно на верхнем изображении:

Армирующее волокно внутри текстолита (красными стрелками указаны волокна, перпендикулярные срезу), из которого и состоит основная масса текстолита
А вот и первая важная деталь флешки – контроллер:

Контроллер. Верхнее изображение получено объединением нескольких СЭМ-микрофотографий
Признаюсь честно, не совсем понял задумку инженеров, которые в самой заливке чипа поместили ещё какие-то дополнительные проводники. Может быть, это с точки зрения технологического процесса проще и дешевле сделать.
После обработки этой картинки я кричал: «Яяяяязь!» и бегал по комнате. Итак, Вашему вниманию представляет техпроцесс 500 нм во всей свой красе с отлично прорисованными границами стока, истока, управляющего затвора и даже контакты сохранились в относительной целостности:

«Язь!» микроэлектроники – техпроцесс 500 нм контроллера с прекрасно прорисованными отдельными стоками (Drain), истоками (Source) и управляющими затворами (Gate)
Теперь приступим к десерту – чипам памяти. Начнём с контактов, которые эту память в прямом смысле этого слова питают. Помимо основного (на рисунке самого «толстого» контакта) есть ещё и множество мелких. Кстати, «толстый» < 2 диаметров человеческого волоса, так что всё в мире относительно:

СЭМ-изображения контактов, питающих чип памяти
Если говорить о самой памяти, то тут нас тоже ждёт успех. Удалось отснять отдельные блоки, границы которых выделены стрелочками. Глядя на изображение с максимальным увеличением, постарайтесь напрячь взгляд, этот контраст реально трудно различим, но он есть на изображении (для наглядности я отметил отдельную ячейку линиями):
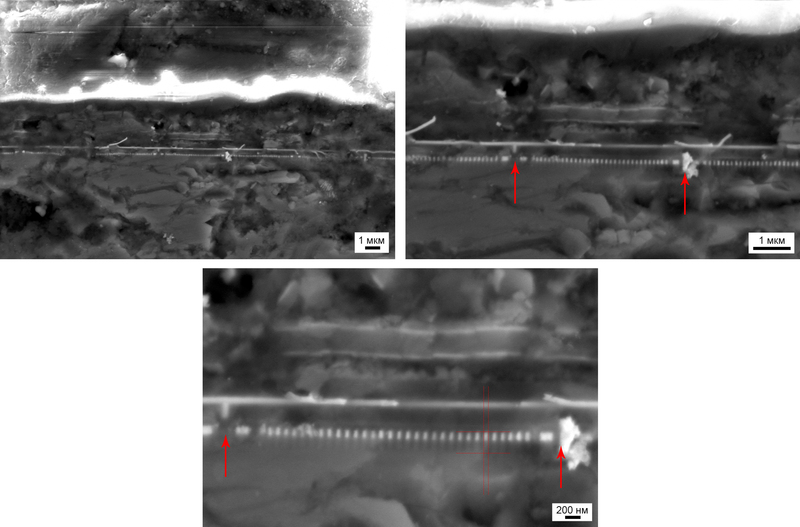
Ячейки памяти 1. Границы блоков выделены стрелочками. Линиями обозначены отдельные ячейки
Мне самому сначала это показалось как артефакт изображения, но обработав все фото дома, я понял, что это либо вытянутые по вертикальной оси управляющие затворы при SLC-ячейке, либо это несколько ячеек, собранных в MLC. Хоть я и упомянул MLC выше, но всё-таки это вопрос. Для справки, «толщина» ячейки (т.е. расстояние между двумя светлыми точками на нижнем изображении) около 60 нм.
Чтобы не лукавить – вот аналогичные фото с другой половинки флешки. Полностью аналогичная картина:

Ячейки памяти 2. Границы блоков выделены стрелочками. Линиями обозначены отдельные ячейки
Конечно, сам чип – это не просто набор таких ячеек памяти, внутри него есть ещё какие-то структуры, принадлежность которых мне определить не удалось:

Другие структуры внутри чипов NAND памяти
Всю плату SO-DIMM от Samsung я, конечно же, не стал распиливать, лишь с помощью строительного фена «отсоединил» один из модулей памяти. Стоит отметить, что тут пригодился один из советов, предложенных ещё после первой публикации – распилить под углом. Поэтому, для детального погружения в увиденное необходимо учитывать этот факт, тем более что распил под 45 градусов позволил ещё получить как бы «томографические» срезы конденсатора.
Однако по традиции начнём с контактов. Приятно было увидеть, как выглядит «скол» BGA и что собой представляет сама пайка:

«Скол» BGA-пайки
А вот и второй раз пора кричать: «Язь!», так как удалось увидеть отдельные твердотельные конденсаторы – концентрические круги на изображении, отмеченные стрелочками. Именно они хранят наши данные во время работы компьютера в виде заряда на своих обкладках. Судя по фотографиям размеры такого конденсатора составляют около 300 нм в ширину и около 100 нм в толщину.
Из-за того, что чип разрезан под углом, одни конденсаторы рассечены аккуратно по середине, у других же срезаны только «бока»:

DRAM память во всей красе
Если кто-то сомневается в том, что эти структуры и есть конденсаторы, то тут можно посмотреть более «профессиональное» фото (правда без масштабной метки).
Единственный момент, который меня смутил, что конденсаторы расположены в 2 ряда (левое нижнее фото), т.е. получается, что на 1 ячейку приходится 2 бита информации. Как уже было сказано выше, информация по мультибитовой записи имеется, но насколько эта технология применима и используется в современной промышленности – остаётся для меня под вопросом.
Конечно, кроме самих ячеек памяти внутри модуля есть ещё и какие-то вспомогательные структуры, о предназначении которых я могу только догадываться:
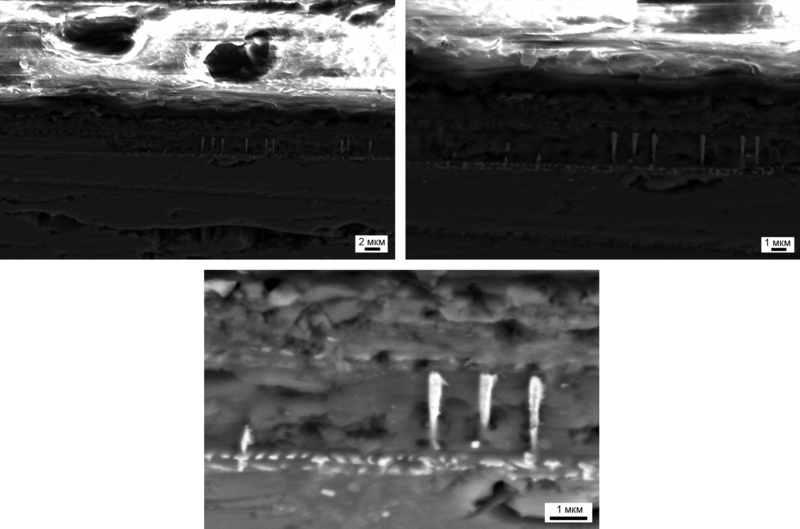
Другие структуры внутри чипа DRAM-памяти
Послесловие
Помимо тех ссылок, что раскиданы по тексту, на мой взгляд, довольно интересен данный обзор (пусть и от 1997 года), сам сайт (и фотогалерея, и chip-art, и патенты, и много-много всего) и данная контора, которая фактически занимается реверс-инжинирингом.
К сожалению, большого количества видео на тему производства Flash и RAM найти не удалось, поэтому довольствоваться придётся лишь сборкой USB-Flash-накопителей:
P.S.: Ещё раз всех с наступающим Новым Годом чёрного водяного дракона.
Странно получается: статью про Flash хотел написать одной из первых, но судьба распорядилась иначе. Скрестив пальцы, будем надеяться, что последующие, как минимум 2, статьи (про биообъекты и дисплеи) увидят свет в начале 2012 года. А пока затравка — углеродный скотч:

Углеродный скотч, на котором были закреплены исследуемые образцы. Думаю, что и обычный скотч выглядит похожим образом
Во-первых, полный список опубликованных статей на Хабре:
В-третьих, если тебе, дорогой читатель, понравилась статья или ты хочешь простимулировать написание новых, то действуй согласно следующей максиме: «pay what you want»
Yandex.Money 41001234893231
WebMoney (R296920395341 или Z333281944680)
Иногда кратко, а иногда не очень о новостях науки и технологий можно почитать на моём Телеграм-канале — милости просим;)
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес --> Линейный (виртуальный)--> Физический

Все линейное адресное пространство разбито на сегменты. Адресное пространство каждого процесса имеет по крайней мере три сегмента:
Сегмент кода. (содержит команды из нашей программы, которые будут исполнятся.)
Сегмент данных. (Содержит данные, то бишь переменные)
Сегмент стека, про который я писал выше.
Линейный адрес вычисляется по формуле:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Базовый адрес сегмента кода берется из регистра CS. Значение смещения для сегмента кода берется из регистра EIP, в котором хранится адрес инструкции, после исполнения которой, значение EIP увеличивается на размер этой команды. Если команда занимает 4 байта, то значение EIP увеличивается на 4 байта и будет указывать уже на следующую инструкцию. Все это делается автоматически без участия программиста.
Сегментов кода может быть несколько в нашей памяти. В нашем случае он один.
Сегмент данных
Данные загружаются в регистры DS, ES, FS, GS
Это значит что сегментов данных может быть до 4х. На нашей картинке он один.
Смещение внутри сегмента данных задается как операнд команды. По дефолту используется сегмент на который указывает регистр DS. Для того чтобы войти в другой сегмент надо это непосредственно указать в команде префикса замены сегмента.
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес.
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке:
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
В зависимости от 55 G-бита(гранулярити), предел может измеряться в байтах при нулевом значении бита и тогда максимальный предел составит 1 мб, или в значении 1, предел измеряется страницами, каждая из которых равна 4кб. и максимальный размер такого сегмента будет 4Гб.
Для сегмента стека предел будет в интервале:
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.
Каков размер ячеек памяти? Вычитал, что одна ячейка равна одному байту. Но тут возник вопрос:
Предположим, в памяти хранится int равный четырем байтам
[1-ый байт][2-ой байт][3-ий байт][4-ый байт]
Как я понимаю, 32 битный процессор может за одну операцию чтения прочитать 4 байта
За одну операцию он считывает 4 байта при условии, что адрес начала считываемых данных кратен четырем
Но такое утверждение приводит к мысли, одна ячейка для 32 битных архитектур должна быть равна 4 байтам
Иначе какой смысл в выравнивании, если можно просто выставить указатель на начало читаемых данных и считать те же четыре байта независимо от выравнивания
Так как все устроено на самом деле?
Изменить размер нижних ячеек, не меняя размера верхних ячеек
Вообщем вопрос, как сделать чтобы в первых 15 строках таблицы ячейки были одной длины и высоты, А с.
Записать дополнительный код содержимого 16 ячеек памяти, начиная с адреса 910. Результаты занести в ячейки памяти, н
Записать дополнительный код содержимого 16 ячеек памяти, начиная с адреса 910. Результаты занести в.
Размер ячеек
Просьба сильно не пинать за ламерство. я только начинаю. Вот такой вопрос возникает в каких.
Ага. А из за чего быстрее, если одна ячейка 1 байт а начинать чтение можно с любой позиции
Добавлено через 1 минуту
Я читал что при выравнивании приходится обходить меньше ячеек для чтения
Но узнав что одна ячейка равноа одному байту все перемешалось (перестал видеть смысл)
Добавлено через 23 минуты
Всё, допёр.
Глупый был вопрос.
Читайте также: