
Сколько уровней включает в себя архитектурная модель pci express
Архитектура PCI Express определяется слоями (layers), как показано на рис. 7. Для обеспечения совместимости с существующими приложениями и драйверами сохранена модель адресации PCI. Конфигурация PCI Express использует стандартный механизм PCI Plug-and-Play. Программный уровень генерирует запросы на чтение и запись, которые передаются уровнем транзакций устройствам ввода-вывода с использованием пакетно-ориентированного, с разделяемыми транзакциями (split-transaction) протокола. Уровень «Link” добавляет последовательный номер и CRC код (код контроля ошибок), что обеспечивает высоконадежный механизм передачи. Физический уровень состоит из двух каналов, которые реализованы, как передающая пара и принимающая пара. Начальная скорость в 2.5 Giga transfers/second/direction обеспечивает канал связи с пропускной способностью в 200MB/s, что почти в 2 раза больше, чем у PCI.
«Физический» слой
Основной канал PCI Express сотсоит из двух низковольтных, дифференциальных пар сигналов: передающая пара и принимающая пара (см. рис. 8). Начальная частота в 2.5 Giga transfers/second/direction может быть увеличена до 10 Giga transfers/second/direction (это теоретический предел частоты для медного проводника).
Пропускная способность PCI Express канала может быть линейно увеличена за счет добавления сигнальных пар. «Физический» слой поддерживает x1, x2, x4, x8, x12, x16 и x32 сигнальных пар в одном канале и распределяет байты данных внутри канала, как показано на рис. 9.
В процессе инициализации, каждый из PCI Express каналов автоматически устанавливает частоту и ширину канала в соответствии с возможностями агентов, находящихся на концах канала, при этом не требуется никакого программного обеспечения.
Cлой связи ("Link Layer")
Основное назначение слоя «Link” заключается в обеспечение правильной передачи пакета данных через канал PCI Express . Этот слой отвечает за целостность данных и добавляет к пакету данных порядковый номер и CRC код (код контроля ошибок), см. рисунок 10.
Большинство пакетов инициируются слоем транзакций ("Transaction Layer"), описанным в следующем разделе. Протокол передачи передает пакеты только в том случае, когда приемный буфер свободен, это позволяет избежать повторных передач данных и разгружает шину. Повторная передача поврежденных пакетов, так же обеспечивается Link слоем.
Слой транзакций ("Transaction Layer")
Программный слой ("Software Layer")
Программная совместимость имеет важнейшее значение для третьего поколения шины ввода/вывода. Имеются два аспекта программной совместимости: инициализация и совместимость времени выполнения. PCI имеет отлаженную модель инициализации, с помощью которой, операционная система может обнаружить все имеющиеся дополнительные устройства и оптимальным образом распределить им системные ресурсы (память, прерывания и т.п.). Эта модель сохранена и в PCI Express , как следствие: изменений в операционной системе, для загрузки на PCI Express системах, не требуется. Кроме того, в PCI Express обеспечена поддержка старой (PCI) модели времени выполнения, таким образом, в прикладном ПО изменения так же не требуются. Новое ПО может использовать новые возможности PCI Express .
Программная совместимость с PCI/PCI-X
Программная модель PCI Express совместима с PCI в следующих аспектах:
- обнаружение, нумерация и конфигурирование устройств PCI Express выполняются тем же конфигурационным ПО, что используется в PCI (PCI-X 2.0);
- существующие ОС загружаются без каких-либо модификаций;
- драйверы существующих устройств поддерживаются без каких-либо модификаций;
- конфигурирование и разрешение новых функциональных возможностей PCI Express выполняется по общей идее конфигурирования устройств PCI.
Физический уровень и конструктивы PCI Express
Физический уровень интерфейса допускает как электрическую, так и оптическую реализацию. Базовое соединение электрического интерфейса (1x) состоит из двух дифференциальных низковольтных сигнальных пар — передающей (сигналы PETp0, PETn0) и принимающей (PERp0, PERn0). В интерфейсе применена развязка передатчиков и приемников по постоянному току, что обеспечивает совместимость компонентов независимо от технологии изготовления компонентов и снимает некоторые проблемы передачи сигналов. Для передачи используется самосинхронизирующееся кодирование, что позволяет достигать высоких скоростей передачи. Базовая скорость — 2,5 Гбит/с «сырых» данных (после кодирования 8B/10B) в каждую сторону, в перспективе планируются и более высокие скорости. Для масштабирования пропускной способности возможно агрегирование сигнальных линий (lanes, сигнальных пар в электрическом интерфейсе), по одинаковому числу в обоих направлениях. Спецификация рассматривает варианты соединений из 1, 2, 4, 8, 12, 16 и 32 линий (обозначаются как x1, x2, x4, x8, x12, x16 и x32); передаваемые данные между ними распределяются побайтно. В каждой из линий самосинхронизация выплняется независимо, так что явление переноса (бич параллельных интерфейсов) отсутствует. Таким образом достижима скорость до 32×2,5 = 80 Гбит/с, что примерно соответствует пиковой скорости 8 Гбайт/с. Во время аппаратной инициализации в каждом соединении согласуется число линий и скорость передачи; согласование выполняется на низком уровне без какого-либо программного участия. Согласованные параметры соединения действуют на все время последующей работы.
Обеспечение «горячего» подключение на физическом уровне PCI Express не требует каких-либо дополнительных аппаратных затрат, поскольку двухточечное соединение не затрагивает «лишних» участников. Безопасная коммутация сигналов не требуется, возможности подключаемого устройства никак не влияют на режимы работы остальных устройств.
Малое число сигнальных контактов интерфейса дает большую свободу в выборе конструктивных реализаций PCI Express:
- соединение компонентов в пределах платы;
- слоты и карты расширения в конструктивах PC/AT и ATX;
- внутренние и внешние карты расширения мобильных ПК;
- малогабаритные модули ввода/вывода для серверов и коммуникационной аппаратуры;
- модули для промышленных компьютеров;
- разъемное подключение «дочерних» карт (mezannine interface);
- кабельные соединения блоков.
Для карт расширения в конструктивах PC/AT и ATX предусматриваются разные модификации разъема-слота PCI Express, отличающиеся числом пар сигнальных линий (x1, x4, x8, x16) и, соответственно, размером (см. рисунок ниже). При этом в слоты большего размера можно устанавливать карты с разъемом того же размера или меньшего (это называется Up-plugging). Однако противоположный вариант (Downplugging) — большую карту в меньший слот — механически невозможен (в PCI/PCI-X это возможно). Как было показано выше, самый маленький вариант PCI Express обеспечивает пропускную способность на уровне стандартной шины PCI.
Назначение контактов слотов PCI Express приведено в таблице ниже.
Набор сигналов интерфейса PCI Express невелик:
Питание на карты подается по следующим шинам:
- +3,3V — основное питание +3 В при токе до 9 А;
- +12V — основное питание +12 В при токе до 0,5/2,1/4,4А для слотов x1/x4, x8/x16 соответственно;
- +3,3Vaux — дополнительное питание, ток до 375 мА в системах, способных к пробуждению по сигналу от карты и до 20 мА в непробуждаемых системах.
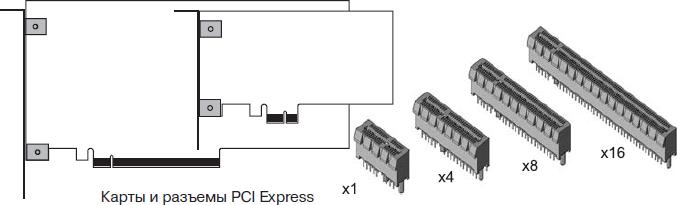
Таблица. Разъемы PCI Express
Для мобильных компьютеров PCMCIA ввела конструктив ExpressCard (см. следующий рисунок), для которого на системный разъем выводится два интерфейса: PCI Express (1x) и USB 2.0. Модули ExpressCard компактнее прежних карт PCMCIA (PC Card и CardBus); предлагается две модификации, различающиеся по ширине: ExpressCard/34 (34×75×5 мм) и ExpressCard/54 (54×75×5 мм). Толщина модулей всего 5 мм, но, если требуется, то более длинные модули могут иметь утолщения в части, выходящие за габариты корпуса компьютера (за пределами 75 мм от края разъема). Как и прежние карты PCIMCIA, карты ExpressCard доступны пользователям и поддерживают «горячее» подключение.


Таблица. Разъемы Mini PCI Express
С интерфейсом PCI Express удобно компонуются модули ввода/вывода и сетевых интерфейсов для серверов и коммуникационных устройств стоечного исполнения. Такие модули могут быть достаточно компактными (высота 2U не вызывает проблем размещения разъема), при этом производительности интерфейса достаточно даже для таких критичных модулей, как Fibre Channel, Gigabit Ethernet (GbE), 10GbE.
Интерфейс PCI Express принимается и для промышленных компьютеров, для чего имеются спецификации PICMG 3.4 (малогабаритные конструктивы для x1, x2 и x4), а также конструктивы в формате Compact PCI.
Интерфейс PCI Express существует и в кабельном исполнении для кабельных соединений блоков, находящихся на небольшом удалении друг от друга. Так, например, по PCI Express можно подключать док-станции к блокнотным ПК. Возможность вывода интерфейса системного уровня за пределы корпуса компьютера из предшественников PCI Express поддерживала только шина ISA, и то только при низких скоростях обмена (на частотах до 5 МГц). Из новых последовательных интерфейсов системного уровня эта возможность имеется и в InfiniBand. Наличие кабельного варианта высокопроизводительного интерфейса системного уровня может позволить отойти от традиционной компоновки компьютера, при которой в системном блоке концентрируются все компоненты, требующие интенсивного обмена с ядром компьютера.
Всё течёт, всё меняется. В сфере компьютерных технологий эта фраза никогда не потеряет актуальности, равно как и девиз «Быстрее! Выше! Сильнее!». И действительно, последние несколько лет можно назвать «временами перемен» компьютерной индустрии. В полной мере это коснулось и такой специфичной области, как шины передачи данных.
Среди наиболее динамично развивающихся областей компьютерной техники стоит отметить сферу технологий передачи данных: в отличие от сферы вычислений, где наблюдается продолжительное и устойчивое развитие параллельных архитектур, в «шинной» 1 сфере, как среди внутренних, так и среди периферийных шин, наблюдается тенденция перехода от синхронных параллельных шин к высокочастотным последовательным. (Заметьте, «последовательные» – не обязательно значит «однобитные», здесь возможны и 2, и 8, и 32 бит ширины при сохранении присущей последовательным шинам пакетной передачи данных, то есть в пакете импульсов данные, адрес, CRC и другая служебная информация разделены на логическом уровне 2 ).
1 Компьютерная шина (магистраль передачи данных между отдельными функциональными блоками компьютера) – совокупность сигнальных линий, объединённых по их назначению (данные, адреса, управление), которые имеют определённые электрические характеристики и протоколы передачи информации. Шины отличаются разрядностью, способом передачи сигнала (последовательные или параллельные), пропускной способностью, количеством и типами поддерживаемых устройств, протоколом работы, назначением (внутренняя, интерфейсная).
Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также могут использовать мультиплексирование (передачу адреса и данных по одним и тем же линиям) и различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами).
2 Основным отличием параллельных шин от последовательных является сам способ передачи данных. В параллельных шинах понятие «ширина шины» соответствует её разрядности – количеству сигнальных линий, или, другими словами, количеству одновременно передаваемых («выставляемых на шину») битов информации. Сигналом для старта и завершения цикла приёма/передачи данных служит внешний синхросигнал. В последовательных же каналах передачи используется одна сигнальная линия (возможно использование двух отдельных каналов для разделения потоков приёма-передачи). Соответственно, информационные биты здесь передаются последовательно. Данные для передачи через последовательную шину облекаются в пакеты (пакет – единица информации, передаваемая как целое между двумя устройствами), в которые, помимо собственно полезных данных, включается некоторое количество служебной информации: старт-биты, заголовки пакетов, синхросигналы, биты чётности или контрольные суммы, стоп-биты и т. п. Но в свете последних достижений в «железной» сфере компьютерной индустрии малое количество сигнальных линий и логически более сложный механизм передачи данных последовательных шин оборачиваются для них существенным преимуществом – возможностью практически безболезненного наращивания рабочих частот в таких пределах, каких никогда не достичь громоздким параллельным шинам с их высокочастотными проблемами ожидания доставки каждого бита к месту назначения. Проблема в том, что каждая линия такой шины имеет свою длину, свою паразитную ёмкость и индуктивность и, соответственно, своё время прохождения сигнала от источника к приёмнику, который вынужден выжидать дополнительное время для гарантии получения данных по всем линиям. Так, к примеру, каждый байт, передаваемый через линк шины PCIExpress, для увеличения помехозащищённости «раздувается» до 10 бит, что, однако, не мешает шине передавать до 0,25 ГБ за секунду по одной паре проводов. Да, ширина последовательной шины на самом деле является количеством одновременно задействованных отдельных последовательных каналов передачи.
Все эти нововведения и смена приоритетов преследуют в конечном итоге одну цель – повышение суммарного быстродействия системы, ибо не все существующие архитектурные решения способны эффективно масштабироваться. Несоответствие пропускной способности шин потребностям обслуживаемых ими устройств приводит к эффекту «бутылочного горлышка» и препятствует росту быстродействия даже при дальнейшем увеличении производительности вычислительных компонентов – процессора, оперативной памяти, видеосистемы и так далее.
Сигнализация прерываний и управление энергопотреблением
Расширенное управление потреблением и бюджетом мощности (PM — power management) означает:
Общая информация
PCI Express — новая архитектура соединения компонентов, введенная под эгидой PCI SIG, известная и под названием 3GIO (3-Generation Input-Output, ввод/вывод 3-го поколения). Здесь шинное соединение устройств с параллельным интерфейсом заменено на двухточечные последовательные соединения с использованием коммутаторов. В этой архитектуре сохраняются многие программные черты шины PCI, что обеспечивает плавность миграции от PCI к PCI Express. В архитектуре появились новые возможности: управление качеством обслуживания (QoS), потреблением и бюджетом связей. Протокол PCI Express отличается малыми накладными расходами и малыми задержками выполнения транзакций.
PCI Express позиционируется как универсальная архитектура ввода/вывода для компьютеров разных классов, телекоммуникационных устройств и встроенных систем. Высокая пропускная способность достигается при цене, соизмеримой с PCI и ниже. Сфера применения — от соединений между микросхемами на плате до межплатных разъемных и кабельных соединений. Высокая пропускная способность на контакт соединения позволяет минимизировать число соединительных контактов. Малое число сигнальных линий позволяет применять малогабаритные конструктивы. Универсальность дает возможность использования единой программной модели для всех форм-факторов. Спецификация PCI Express Base specification Revision 1.0a опубликована в апреле 2003 года.
PCI Express
Элементы и топология соединений PCI Express
Пример топологии средств ввода/вывода, иллюстрирующий архитектуру PCI Express, приведен на рисунке ниже. Центральным элементом архитектуры является корневой комплекс (Root Comlex), соединяющий иерархию ввода/вывода с центром — процессором (одним или несколькими) и памятью. Корневой комплекс может иметь один и более портов PCI Express, каждый из них определяет свой домен иерархии (hierarchy domain). Каждый домен состоит из одной конечной точки (Endpoint) или субиерархии — нескольких конечных точек, связанных коммутаторами. Возможность непосредственных равноранговых коммуникаций между элементами разных доменов обязательной не является, но может присутствовать в конкретных реализациях. Для обеспечения прозрачных равноранговых коммуникаций в корневом комплексе должны присутствовать коммутаторы. Возможность взаимодействия центрального процессора с любым устройством любого домена безусловна, как и возможность обращения любого устройства к памяти. Корневой комплекс должен генерировать запросы к конфигурационному пространству — его роль аналогична главному мосту PCI. Корневой комплекс может генерировать запросы ввода/вывода как запросчик; он может генерировать и блокированные (Locked) запросы, требующие непрерываемого исполнения. Корневой комплекс не должен поддерживать блокированные запросы как исполнитель (Completer) — это предотвращает «заклинивание» ввода/вывода.
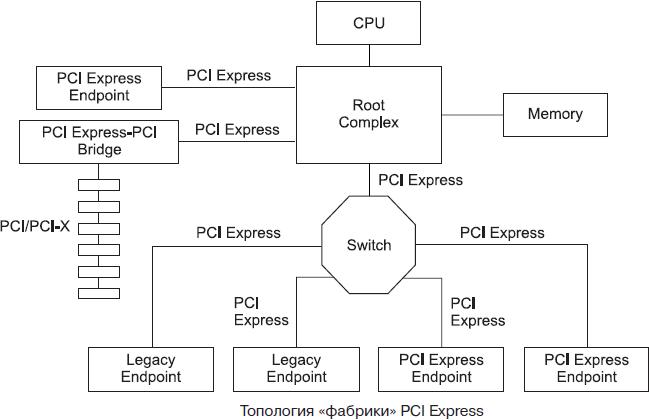
Конечная точка (Endpoint) — это устройство, способное инициировать и/или исполнять транзакции PCI Express от своего имени или от имени устройства не-PCI Express (например, хост контролера USB). Конечная точка должна быть видима в одном из доменов иерархии. Конечная точка должна иметь заголовок конфигурационного пространства типа 0 и отвечать как исполнитель на конфигурационные запросы. В качестве механизма сигнализации прерываний все конечные точки используют MSI. В PCI Express рассматриваются два типа конечных точек: «наследники» (Legacy) и новые точки, построенные по идеологии PCI Express. К «наследным» точкам имеется ряд послаблений:
- в плане адресации памяти они могут и не поддерживать более 4 Гбайт;
- ввод/вывод может не быть абсолютно перемещаемым (из пространства ввода/
вывода в пространство памяти) с помощью регистров базового адреса (BAR), так что могут потребоваться транзакции обращения к пространству ввода/вывода (транзакции к памяти предпочтительнее); - диапазон занимаемых адресов может быть менее 128 байт (требования к границам были жестко сформированы в PCI-X);
- конфигурационное пространство может не быть расширенным (оставаться в пределах 256 байт);
- программная модель может требовать использования блокированных запросов к устройству (но не от него).
Коммутатор (Switch) имеет несколько портов PCI Express. Логически он представляет собой несколько виртуальных мостов PCI-PCI, соединяющих порты коммутатора со своей внутренней локальной шиной. Виртуальный мост PCI описывается конфигурационными регистрами с заголовком типа 1. Порт, ведущий к вершине иерархии, называется восходящим (upstream port) — через него коммутатор конфигурируется как набор мостов PCI. Коммутатор транслирует между портами пакеты всех типов, основываясь на адресной информации, актуальной для пакета данного типа. Коммутатор не распространяет блокированные запросы со своих нисходящих портов. Арбитраж между портами коммутатора может учитывать виртуальные каналы и, соответственно, взвешенно распределять пропускную способность. Коммутатор не имеет права разбивать пакеты на более мелкие (аналог этого права имеется в мостах PCI).
Мост PCI Express–PCI соединяет иерархию шин PCI/PCI-X с «фабрикой» ввода/вывода — корневым комплексом или коммутаторами PCI Express.
Конфигурирование «фабрики» осуществляется либо со 100% совместимостью с конфигурационным механизмом PCI 2.3, либо с использованием расширенного конфигурационного пространства PCI-X. Каждое соединение PCI Express с помощью виртуальных мостов отображается в виде логической шины PCI со своим номером. Логические устройства отображаются в конфигурационном пространстве как устройства PCI, каждое из которых может иметь 1–8 функций со своим набором конфигурационных регистров.
Качество обслуживания и виртуальные каналы
В PCI Express имеется поддержка дифференцированных классов по качеству обслуживания (QoS), обеспечивающая следующие возможности:
- выделять ресурсы соединения для потока каждого класса (виртуальные каналы);
- конфигурировать политику по QoS для каждого компонента;
- указывать QoS для каждого пакета;
- создавать изохронные соединения.
Для поддержки QoS применяется маркировка трафика: каждый пакет TLP имеет трехбитное поле метки класса трафика TC (Traffic Class). Это позволяет различать передаваемые данные по типам, создавать дифференцированные условия передачи трафика для разных классов. Порядок исполнения транзакций соблюдается в пределах одного класса, но не между разными классами. Для дифференцирования условий передачи трафика разных классов в коммутирующих элементах PCI Express могут создаваться виртуальные каналы. Виртуальный канал VC (Virtual Channel) представляет собой физически обособленные наборы буферов и средств маршрутизации пакетов, которые загружаются только обработкой трафика своего виртуального канала. На основе номеров виртуальных каналов и их приоритетов производится арбитраж при маршрутизации входящих пакетов. Каждый порт, поддерживающий виртуальные каналы, выполняет отображение пакетов определенных классов на соответствующие виртуальные каналы. При этом на один канал может отображаться произвольное число классов. По умолчанию весь трафик маркируется нулевым классом (TC0) и передается дежурным каналом (VC0). Виртуальные каналы вводятся по мере необходимости.
Архитектурная модель PCI Express
Архитектура PCI Express разделена на три уровня:
Процессорная шина
Любой процессор архитектуры x86CPU обязательно оснащён процессорной шиной. Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском и так далее. Так, классическая схема организации внешнего интерфейса процессора (используемая, к примеру, компанией Intel в своих процессорах архитектуры х86) предполагает, что параллельная мультиплексированная процессорная шина, которую принято называть FSB (Front Side Bus), соединяет процессор (иногда два процессора или даже больше) и контроллер, обеспечивающий доступ к оперативной памяти и внешним устройствам. Этот контроллер обычно называют северным мостом , он входит в состав набора системной логики ( чипсета ).
Используемая Intel в настоящее время эволюция FSB – QPB , или Quad-Pumped Bus, способна передавать четыре блока данных за такт и два адреса за такт! То есть за каждый такт синхронизации шины по ней может быть передана команда либо четыре порции данных (напомним, что шина FSB–QPB имеет ширину 64 бит, то есть за такт может быть передано до 4х64=256 бит, или 32 байт данных). Итого, скажем, для частоты FSB, равной 200 МГц, эффективная частота передачи адреса для выборки данных будет эквивалентна 400 МГц (2х200 МГц), а самих данных – 800 МГц (4х200 МГц) 3 .
3 Кстати, именно результирующей «учетверённой» частотой передачи данных (как и в случае с «удвоенной» передачей DDR-шины, где данные передаются дважды за такт) хвастаются производители и продавцы, умалчивая тот факт, что для многочисленных мелких запросов, где данные в большинстве своём умещаются в одну 64-байтную порцию (и, соответственно, не используются возможности DDR или QDR/QPB), на чтение/запись важнее именно частота тактирования.
Различия реализации классической архитектуры и АМD-K8
Различия реализации классической архитектуры и АМD-K8
Ещё одним довольно заметным отличием архитектуры К8 является отказ от асинхронности, то есть обеспечение синхронной работы процессорного ядра, ОЗУ и шины HyperTransport, частоты которых привязаны к «шине» тактового генератора (НТТ), которая в этом случае является опорной. Таким образом, для процессора архитектуры К8 частоты ядра и шины HyperTransport задаются множителями по отношению к НТТ, а частота шины памяти выставляется делителем от частоты ядра процессора 4
4 Пример: для системы на базе процессора Athlon 64-3000+ (1,8 ГГц) с установленной памятью DDR-333 стандартная частота ядра (1,8 ГГц) достигается умножением на 9 частоты НТТ, равной 200 МГц, стандартная частота шины HyperTransport (1 ГГц) – умножением НТТ на 5, а частота шины памяти (166 МГц) – делением частоты ядра на 11.
В классической же схеме с шиной FSB и контроллером памяти, вынесенным в северный мост, возможна (и используется) асинхронность шин FSB и ОЗУ, а опорной частотой для процессора выступает частота тактирования 5 (а не передачи данных) шины FSB, частота же тактирования шины памяти может задаваться отдельно. Из наиболее свежих чипсетов возможностью раздельного задания частот FSB и памяти обладает NVIDIA nForce 680i SLI, что делает его отличным выбором для тонкой настройки системы (разгона).
Совсем немного времени осталось до появления новых чипсетов Intel, а вместе с ними придет и новый стандарт – PCI Express. О том, что это, какими преимуществами и недостатками обладает, вы можете узнать из этой статьи.
Любая компьютерная технология проходит свой путь от рождения, триумфа к свалке истории. Все бы ничего, да каждое очередное нововведение, как правило, чревато серьезным перетряхиванием системных блоков и неопределенностью в умах пользователей – пора или еще подождать с апгрейдом? Тем более огромными кажутся все новшества, которые свалятся на головы покупателей в нынешнем году. Такого всестороннего разрушительного действия на основы платформы не было уже давно - сменятся процессорные разъемы (у Intel настанет время Socket 775, у AMD, соответственно, Socket 939); к концу года действительно новой будет называться система лишь с 240-контактными модулями DDR2; вдогонку ко всему этому близится появление новых форм-факторов самих плат – BTX. Но самым радикальным все же станет низвержение старых привычных элементов ландшафта системной платы – разъемов PCI и AGP, которым приходит время сказать последнее "прости-прощай".
Новое поколение технологий приносит новые скорости и новые технологические решения. Правда, на деле случалось не раз, что революционные нововведения оказывались не всегда своевременными и не такими уж полезными, как красиво заявлялось при их выпуске. Традиционно, отдуваться за эксперименты приходится конечному покупателю. Примеров самых передовых, но неоцененных или невостребованных технологий можно привести множество – шина EISA, память RDRAM, слоты AMR/CNR и многое другое.
Не касаясь тупиковых ветвей эволюции ПК, сегодня стоит поговорить о своевременности внедрения новых технологий на примере шины PCI Express. Сегодня можно с уверенностью сказать, что от перехода на этот шинный стандарт никуда не деться. Попробуем рассмотреть ключевые особенности новоявленной шины, ее сходства и отличия от распространенных сейчас PCI и AGP.
Прежде всего, не стоит рассматривать PCI Express как банального наследника традиций PCI. Консорциум разработчиков нового интерфейса, ранее носившего название 3GIO, ставил перед собой цель разработать новую высокоскоростную шину с максимальной масштабируемостью, простой разводкой, низким уровнем паразитных излучений и электромагнитных помех. Это лишь краткий перечень требований к новому интерфейсу, некоторые особенности его реализации в конкретных условиях, как, например, поддержка "горячего" подключения, требуются лишь в определенных специфических приложениях. Сначала -
Немного истории
Первые разработки шины PCI, стартовавшие в начале 90-х годов, были призваны избавиться от множества присутствовавших на тот момент несовместимых шинных интерфейсов – VLB (VESA Local Bus), EISA, ISA и Micro Channel. Наряду с этим преследовалась цель избавиться от тяжкого наследия фрагментированной шины ISA и впервые добиться соединений класса "чип-чип".
На момент появления в 1993 году базовой версии шины Peripheral Component Interconnect (PCI) - IEEE P1386.1, предусматривались революционные усовершенствования: расширение шины данных до 32 бит, поддержка адресации до 4 ГБ данных (32 бита), а также использование режима синхронного обмена данными. По тем временам тактовая частота шины 33 МГц удовлетворяла условиям работы с периферией в настольных и серверных системах, все были довольны. Последовавший за этим резкий скачок тактовых частот процессоров и памяти привел к увеличению тактовой частоты PCI до 66 МГц, хотя, тактовые частоты процессоров за этот же период скакнули с 33 МГц до 3,0+ ГГц. Все последующие варианты PCI – AGP, PCI-X, MiniPCI, CardBus, несмотря на привнесение определенных дополнений, например, иных форм-факторов разъемов, новых сигнальных уровней и даже передачи данных по фронтам импульса (Double Data Rate/ Quadruple Data Rate), тем не менее, несли в себе ограничения, накладываемые самой топологией интерфейса.
Возможности наращивания пропускной способности шины PCI за счет увеличения тактовой частоты без усложнения схем разводки и соответствующего адекватного удорожания к настоящему времени исчерпаны полностью. А ведь на очереди появились такие актуальные интерфейсы, как 1/10 Gigabit Ethernet, IEEE 1394B, которые полностью выбирают пропускную возможность шины одним устройством и даже выходят за эти рамки. PCI душит рост скорости периферии, критичными становятся ограничения по числу сигнальных контактов шины, торможение процессов реального времени и требования по энергосбережению современных ПК. Если вспомнить наиболее производительные версии шины PCI, например, серверную PCI-X и графическую AGP, то в этом случае мы упираемся в укорачивание проводников шины за счет высокой частоты, требование к установке своего контроллера на каждый слот и достаточно высокую стоимость ее реализации.
Грядет тотальное торжество последовательных шин
Итого, параллельные шины себя исчерпали, рано или поздно взоры разработчиков должны были обратиться в сторону последовательных. Так оно и есть, в результате чего практически все современные индустриальные интерфейсы к настоящему времени перебрались на такой принцип обмена данными. Взгляните на приведенную ниже таблицу: речь идет не только о сетевых интерфейсах, которым на роду написано быть последовательными; все остальные ключевые шины уже имеют последовательную природу.
Между прочим, внешние интерфейсы уже давно перебрались на последовательную топологию, и в самых своих свежих реализациях – USB 2.0, IEEE1394b, показывают скорости, которые немыслимы для параллельных соединений. С этой точки зрения шина PCI в наших компьютерах действительно, выглядит своеобразным анахронизмом.
Особенности PCI Express
Основой нового интерфейса, как известно, в общем случае будут являться дифференциальные сигнальные пары контактов, совершающие обмен данными по схеме "точка-точка". Благодаря новой топологии мы сразу получаем массу положительных моментов: удешевление конструкции, снижение габаритов, более простая разводка печатных дорожек с упрощенными требованиями к борьбе с паразитными излучениями, и, главное, возможность работы на гораздо более высоких частотах, с поддержкой "горячей" замены периферийных устройств. Уходит в прошлое такой важный для параллельного интерфейса параметр, как нужда в синхронизации сигнальных линий всей шины.
Архитектуру PCI Express можно рассматривать послойно, в сравнении с адресной моделью PCI. Конфигурация PCI Express является стандартной для устройств, определенных plug-and-play спецификациями PCI: программный уровень генерирует запросы чтения/записи, уровень транзакций транспортирует эти запросы к периферийным устройствам с помощью разделенного пакетного протокола. Для поддержания высокой производительности шины соединительный (link) уровень добавляет пакетам очередность и CRC; базовый физический уровень состоит из двойного симплексного канала, осуществляющего функции приемной и передающей пары. Таким образом, исходная скорость 2,5 Гб/с в каждом направлении позволяет говорить о создании дуплексного коммуникационного канала производительностью до 200 МБ/с, что в четыре раза превышает возможности классической шины PCI.
Рассматривая процессы, протекающие в шине на сигнальном уровне, нельзя не отметить уникальные плюсы PCI Express - значительное снижение затухания в линиях передачи и повышенная чувствительность приемной части интерфейса. Из чего напрашивается вывод о менее критичных требованиях к импедансу входных цепей, а также возможность увеличения длины разводки проводников шины - в нынешней версии стандарта PCI-E они лимитируются 12 дюймами для системных плат, 3,5 дюймами для контроллеров и 15 дюймами для межчиповых соединений. При этом не предъявляется никаких дополнительных требований к технологии разводки печатной платы: могут использоваться как обычные 4-слойные PCB толщиной 0,062 дюйма, так и варианты с шестью и более слоями.
Теоретически, требования, выдвигаемые стандартом PCI Express, с легкостью могут быть адаптированы для нужд устройств любого уровня – от мобильного телефона до сервера уровня предприятия, а также, в перспективе, могут быть переложены для применения других физических типов носителей. Именно такая гибкость и необходима для интерфейса, собирающегося прослужить стандартом ближайшее обозримое будущее.
Использование новых разъемов и других конструктивных возможностей, оговоренных спецификациями нового стандарта, позволяет говорить об увеличении энергопотребления конечных контроллеров до 75 Вт (при токе до 5,5 А)!
Такие мощные контроллеры потребуют дополнительных мер по отводу тепла из корпуса, зато отпадет нужда в подводке разъемов дополнительного питания, которые так характерны для нынешнего поколения видеокарт AGP 8x.
Системы питания компьютеров с поддержкой разных вариантов PCI Express отличаются от привычных нам спецификаций ATX12 и, скорее, схожи с требованиями, предъявляемыми к питанию серверных систем. Так, привычный 20-контактный разъем питания ATX удлиняется и в нем появляются четыре дополнительных контакта, как раз для усиления силовых шин +12 В, 5,0 В и +3,3 В. Соответственно, до 75 Вт повышаются ограничения на питание одного слота в BIOS. При этом нижняя граница мощности для блоков питания устанавливается на уровне примерно 300 Вт. Словом, хотя изменения в цепях питания и не носят такой радикальный характер, как при переходе с AT на ATX, с мыслью о неминуемом апгрейде БП придется свыкнуться.
Варианты PCI Express: их будет много
Версии PCI Express будут внедряться в зависимости от ставящихся перед интерфейсом задач и типом устройства. Например, серверы, где востребована максимальная пропускная способность, будут оборудованы максимальным количеством слотов PCI Express с максимальными показателям. В то же время, для нужд ноутбуков в большинстве случаев будет достаточно архитектуры PCI Express x1. Для настольных ПК и рабочих станций понадобится комбинация из различных вариантов реализации шины.
Совершенно новые требования выдвигаются к механическим показателям PCI Express. Для того, чтобы периферийные платы не имели возможности вывалиться из слота при вибрации или транспортировке, разработаны повышенные требования к защелкам и крепежу разъемов PCI Express.
Несмотря на то, что новый стандарт дает некую свободу конечным производителям при разработке крепежа, жестко оговоренными остаются следующие требования: энергопотребление – не более 75 Вт, вес – не более 350 граммов, высота – не более 115,15 мм.
Конечно, под такими монстрами прозрачно подразумеваются графические карты с интерфейсом PCI Express 16x; во всех других случаях требования к крепежу и другим характеристикам контроллеров значительно скромнее.
Особняком стоит реализация PCI Express для мобильных устройств в виде стандарта ExpressCard. Первыми поддержку модулей этого подстандарта получат ноутбуки и миниатюрные настольные ПК, хотя, уже известны случаи представления концепций серверных плат с разъемом ExpressCard. основное преимущество применения таких модулей - подключение периферии практически без нужды использования крепежного инструмента, а также инсталляции дополнительных драйверов. Технология ExpressCard заменит собой все устаревшие параллельные шины, в результате останутся только три современных интерфейса - PCI Express, USB 2.0 и FireWire.
В настоящее время разработано два форм-фактора модулей ExpressCard – ExpressCard/34 (ширина 34 мм) и ExpressCard/54 (ширина 54). Оба модуля имеют высоту 5 мм, как у стандарта PC Card Type II; длина модулей 75 мм, что на 10,6 мм меньше, чем у PC Card. При этом, модули ExpressCard/34 и ExpressCard/54 обладают одинаковым интерфейсом. Каждый слот под модули ExpressCard может обслуживать шину PCI Express x1.
Преимущества PCI Express
Сравнивая возможности господствовавшей многие годы параллельной шины PCI и архитектуру PCI Express, можно выделить пять наиболее значимых преимуществ последней:
• Высокая производительность – повышение пропускной способности версии x1 как минимум вдвое по сравнению с PCI, возможность линейного наращивания производительности путем линейного расширения шины. Помимо этого, PCI Express является реально дуплексной шиной.
• Упрощение разводки периферии – стандартизация там, где ранее использовались всевозможные варианты PCI - AGP, PCI-X и др.; снижение комплексных затрат на разработку и внедрение систем.
• Уровневая архитектура – основные затраты на развитие PCI Express в дальнейшем ложатся лишь на разработку соответствующей обвязки, можно экономить на возможности работы с прежним программным обеспечением.
Читайте также: