
Сколько памяти занимает сайт
Конечно, современные браузеры развиваются. Программисты совершенствуют механизмы работы браузеров, но всё же полностью решить задачу порой бывает сложно. Например, когда «слабый» компьютер (4 ГБ или меньше оперативной памяти, недостаточная производительность процессора и/или устройств хранения информации и т.д.).
Так как узнать общий объём занятой памяти ( имеется ввиду оперативной памяти, скрытых процессов, файла подкачки ) браузером и понять действительно ли проблема из-за нехватки памяти или это проблема иного характера?
Рекомендуемые способы использования нового API
Использование памяти веб-страницами зависит от возникновения событий, от действий пользователя, от сборки мусора. Именно поэтому API performance.measureMemory() предназначен для исследования уровня использования памяти в продакшне. Результаты вызова этого API в тестовом окружении менее полезны. Вот примеры вариантов его использования:
- Выявление случаев замедления работы приложения в ходе развёртывания новой версии веб-страницы при обнаружении новых утечек памяти.
- A/B-тестирование новой возможности, направленное на оценку её воздействия на память и на обнаружение утечек памяти.
- Сопоставление использования памяти и длительности сессии для подтверждения наличия или отсутствия утечек памяти.
- Сопоставление использования памяти с метриками, характеризующими пользователя. Это позволяет понять воздействие уровня использования памяти на работу с приложением.
▍Включение поддержки на этапе Origin Trial
API performance.measureMemory() доступен в Chrome 83 по схеме Origin Trial. Ожидается, что эта фаза завершится с выходом Chrome 84.
Программа Origin Trial позволяет разработчикам пользоваться новыми возможностями Chrome и делиться с веб-сообществом отзывами об удобстве, практичности и эффективности этих возможностей. Подробности об этой программе можно почитать здесь. Подписаться на участие в программе можно на странице регистрации.
-
токен для интересующей вас возможности.
Добавьте токен на страницы экспериментального проекта. Существует 2 способа это сделать:
Поддержите нас
Планируете пользоваться performance.measureMemory() ? Если так — расскажите об этом. Такие рассказы помогают команде разработчиков Chrome расставлять приоритеты. Эти рассказы показывают создателям других браузеров важность поддержки новых возможностей. Если хотите — отправьте твит @ChromiumDev и расскажите нам о том, где и как вы пользуетесь новым API.

У многих из нас хороший, скоростной интернет. Поэтому многие вебмастера не задумываются над тем, сколько должен весить сайт. Однако, я часто сталкиваюсь с тем, что в моём распоряжении слабый интернет. Таким примером является то, что живя на достаточном расстоянии от города М, у нас нет 4G, а скорость 3G я совсем не замечаю на своём телефоне. Скорее всего, статья ничего нового вам не раскроет, просто посмотрим сколько «весят» главные страницы популярных сайтов, а так же попытаемся выяснить приемлимые цифры.
Сайты
Будем грузить главные страницы сайта и выяснять, сколько они весят.
Для анализа я взял первые 50 сайтов из статистики liveinternet. Остальные 30 я составил из рейтингов забугорья и личного пользования.
В данной статье не будем разделять сайты по типам, а просто взглянем на общую картину мира.
Браузер и машина
Для снятия показаний был взят Firefox 20 на машине с xUbuntu 12.04. На других машинах и браузерах сайты могут отличаться, но не сильно.
Для автоматизации процесса были взяты аддоны:
Linky — через него я сразу открывал все сайты в новые вкладки
NoScript — для отключения скриптов и анализа размера страниц, собственно, без них
UnMHT — для сохранения всех открытых вкладок с содержимым в отдельные файлы, название которых совпадает с открытым сайтом
Сохранение
MTH сохраняет файлы немного большего размера, но погрешность не слишком высокая, по крайней мере, на моих замерах между UnMTH и сохранялкой Firefox.
Краснопанда была открыта в приватном режиме, чтобы мои кукукесы и остальные штуки не мешали чистому результату. Поэтому, все социальные сети должны весить мало, ввиду того, что никто там не залогинен. Посмотрим, так ли это.
Сайты со всем включённым

Я открыл все вкладки и сохранил их. Под сохранение попали и Flash и HTML5 вещи, что значительно увеличивает размеры сайта.
Получился такой график
Я всё строил в LibreOffice Calc, просто потому что могу.
Средняя получена путем высчитывания среднего арифметического по 4м соседям, просто для наглядности.
Видно, что почти все вкладываются в 3 Мб, а средний вес сайта составляет около 1,4 Мб.
Сайты с отключенными Javascript и Flash/Html5 объектами
Общий график

Выводы
Лучше всего посмотреть что не так с Page Speed.
- Оптимизируйте изображения. Они как правило составляют огромную весовую часть сайта.
- Сжимайте CSS и JS. Иногда получается скукожить раза в два.
- Используйте Ajax, для подзагрузки страниц и элементов, а не перезагрузки
- Кешируйте всё, что сможете. Главное, следите за нагрузкой на сервер.
- Включите Gzip сжатие
- Используйте отложенную загрузку изображений. Я на своих сайтах подключил Lazyload. Рекомендую, особенно на мобильных сайтах или мобильных версиях сайта.
- Css-спрайты. Группируйте картинки. И клиент, и сервер будут рады.
- Убирайте всё лишнее! Не ставьте тяжелые Flash приколюхи, онлайн радио и автоплей видеороликов без необходимости.
Советы, которые я дал выше, ускорят ваш сайт, а пользователям будет комфортнее. Однако, если ваш сайт супер крутой, то никакие мегабайты не смогут остановить пользователя зайти на него. Если же ваш сайт так себе, оптимизация мало чего даст.

Мы уже привыкли к постоянному и безудержному росту объёма информации в сети. Остановить или замедлить этот процесс никому не под силу, да и смысла в этом нет. Все знают, что интернет огромен, как по количеству данных, так и по поголовью сайтов. Но насколько он велик? Можно ли как-то оценить, хотя бы приблизительно, сколько петабайт бегает по кабелям, опутывающим планету? Сколько сайтов ждут посетителей на сотнях тысяч серверов? Этим вопросом задаются многие, в том числе и учёные, которые пытаются разработать подходы к оценке безбрежного моря информации, называемого интернетом.
Всемирная сеть — очень оживлённое место. Согласно сервису Internet Live Stats, каждую секунду в Google делается более 50 000 поисковых запросов, просматривается 120 000 видео на Youtube, отправляется почти 2,5 млн электронных писем. Да, весьма впечатляет, но всё же эти данные не позволяют в полной мере представить себе размеры интернета. В сентябре 2014 года общее количество сайтов перевалило за миллиард, и сегодня их примерно 1,018 млрд. А ведь здесь ещё не подсчитана так называемая «глубокая паутина» (Deep Web), то есть совокупность сайтов, не индексируемых поисковиками. Как указывается на Википедии, это не синоним «тёмной паутины», к которой в первую очередь относятся ресурсы, на которых ведётся всевозможная противоправная деятельность. Тем не менее, контент в «глубокой паутине» может быть как совершенно безобидным (например, онлайновые базы данных), так и совершенно непригодным для глаз законопослушной публики (к примеру, торговые площадки чёрного рынка с доступом только через Tor). Хотя Tor’ом пользуются далеко не только нечистые на руку люди, но и вполне чистые перед законом пользователи, алчущие сетевой анонимности.
Конечно, вышеприведённая оценка численности веб-сайтов является приблизительной. Сайты возникают и исчезают, к тому же размеры глубокой и тёмной паутин определить практически невозможно. Поэтому даже приблизительно оценивать размеры сети по этому критерию весьма непросто. Но одно несомненно — сеть постоянно растёт.
Браузерная совместимость
Сейчас рассматриваемый API поддерживается только в Chrome 83, по схеме Origin Trial. Результаты, возвращаемые API, сильно зависят от реализации, так как разные браузеры используют разные способы представления объектов в памяти и разные способы оценки уровня использования памяти. Браузеры могут исключать из учёта некоторые области памяти в том случае, если полный учёт всей используемой памяти является неоправданно сложной или невыполнимой задачей. В итоге можно сказать, что результаты, выдаваемые этим API в разных браузерах, не поддаются сравнению. Сравнивать имеет смысл лишь результаты, полученные в одном и том же браузере.
▍Проверка возможности использования API
Вызов функции performance.measureMemory() может завершиться неудачно, с выдачей ошибки SecurityError. Это может произойти в том случае, если окружение не удовлетворяет требованиям по безопасности, касающимся утечек информации. В процессе Origin Trial-тестирования в Chrome этот API требует включения возможности Site Isolation. Когда API будет готов к обычному использованию, он будет полагаться на свойство crossOriginIsolated. Веб-страница может работать в таком режиме, установив заголовки COOP и COEP.
Вот пример кода:
Физическое воплощение
Несмотря на восход цифрового века, для многих из нас биты и байты остаются понятиями несколько абстрактными. Ну, раньше память измеряли мегабайтами, теперь гигабайтами. А что если попробовать представить размер интернета в каком-то вещественном воплощении? В 2015 году двое учёных предложили использовать для оценки настоящие бумажные страницы А4. Взяв за основу данные с вышеупомянутого сервиса WorldWideWebSize, они решили считать каждую веб-страницу эквивалентной 30 страницам бумажным. Получили 4,54 х 10 9 х 30 = 1,36 х 10 11 страниц А4. Но с точки зрения человеческого восприятия это ничем не лучше тех же байтов. Поэтому бумагу привязали к… амазонским джунглям. Согласно расчёту авторов, для изготовления вышеуказанного количества бумаги нужно 8 011 765 деревьев, что эквивалентно 113 км 2 джунглей, то есть 0,002% от общей площади амазонских зарослей. Хотя позднее в газете Washington Post предположили, что 30 страниц — слишком много, и одну веб-страницу правильнее приравнять к 6,5 страницам А4. Тогда весь интернет можно распечатать на 305,5 млрд бумажных листов.
Но всё это справедливо лишь для текстовой информации, которая занимает далеко не самую большую долю от общего объёма данных. Согласно Cisco, в 2015 году на одно только видео приходилось 27 500 петабайт в месяц, а совокупный трафик веб-сайтов, электронной почты и «данных» — 7 700 петабайт. Немногим меньше пришлось на передачу файлов — 6 100 петабайт. Если кто забыл, петабайт равен миллиону гигабайт. Так что амазонские джунгли никак не позволят представить объёмы данных в интернете.
В упомянутом выше исследовании от 2011 года предлагалось визуализировать с помощью компакт-дисков. Как утверждают авторы, в 2007 году 94% все информации было представлено в цифровом виде — 277,3 оптимально сжатых эксабайта (термин, обозначающий сжатие данных с помощью наиболее эффективных алгоритмов, доступных в 2007 году). Если записать всё это богатство на DVD (по 4,7 Гб), то получим 59 000 000 000 болванок. Если считать толщину одного диска равной 1,2 мм, то эта стопка будет высотой 70 800 км. Для сравнения, длина экватора равна 40 000 км, а общая протяжённость государственной границы России — 61 000 км. Причём это объём данных по состоянию на 2007 год! Теперь попробуем таким же образом оценить общий объём трафика, который прогнозируется на этот год — 1,1 зеттабайта. Получим стопку DVD-дисков высотой 280 850 км. Тут уже впору переходить на космические сравнения: среднее расстояние до Луны составляет 385 000 км.
Другая аналогия: общая производительность всех вычислительных устройств в 2007 году достигала 6,4 х 10 18 инструкций/сек. Если принять, что в человеческом мозге 100 млрд нейронов, каждый из которых имеет 1000 связей с соседними нейронами и посылает до 1000 импульсов в секунду, то максимальное количество нейронных импульсов в мозге равно 10 17 .

Вы замечали, что мы постоянно скачиваем всё больше и больше информации, при этом она сама становится больше. Что я имею в виду - фильм, который раньше каждый из нас с удовольствием смотрел весил 400-600Мб, сейчас же - качество в 2-4Гб считается не очень, а уж если полноценно смотреть в высококачественном разрешении 4К - то конечно же надо скачивать фильм 20-30Гб по размеру и более. А уже не за горами и разрешение 8К и далее. И так со всеми остальными видами - тексты больше, картинки больше - всё больше.
И всё это радостно накапливается в Интернете … Сколько же сейчас там хранится данных, вот конкретно в нашем 2020м году. Оказывается, существует не только множество исследований, но и множество методик, которые пытаются оценить размер Интернета. Но прежде всего, нам придётся разобраться в единицах измерения - ибо конечно же Гигабайты и Терабайты в этом нам не помогут :)
Йоттабайт это очень много
Итак, как всем прекрасно известно, минимальный размер информации это 1 бит - то есть 0 или 1, 8 бит нам дают 1 байт и вот после этого и начинается прирост размера измерений почти на 1000, точнее на 1024 - связано это с тем, что 1024 это 2 в 10 степени. Отсюда и появляются некруглые итоговые значения. Кстати математики придумали гораздо большее количество названий большим и ОЧЕНЬ большим числам .
В Интернете нас более 4.5 миллиардов
Итак, прежде всего немного статистики - общее количество пользователей Интернета - более 4.5 миллиардов, более 1.5 миллиардов сайтов. Ежедневно мы шлём более 237 миллиардов электронных писем, более 705 миллионов постов в Твиттере, более 6 миллиардов видео просмотрено на YouTube. Живую статистику можно посмотреть прям здесь . А вот сколько именно данных создаёт каждый из нас - можно почитать здесь .
Каков же размер Интернета?
Итак, сколько же действительно данных в Интернете. На текущий размер ежегодный прирост данных в Интернете оценивается примерно в 1,1 Зеттабайт, что как мы помним из таблицы равно около 1,2 миллиарда терабайт данных. В целом же общий размер Интернета можно выразить в диапазоне от 2 до 4 Зеттабайт данных. И в целом если вдруг захочется скачать весь Интернет - то сегодня на хорошей скорости это потребует около 11 миллиардов лет.
А сколько же весит Интернет?
И вот это самый интересный вопрос - оказывается это можно посчитать :) Как мы помним, вся информация состоит из бит - то есть нулей и единиц и если 0 это просто отсутствие чего-то, то единица это фактически заряженный конденсатор - микроскопический и при этом содержит около 40.000 электронов - это очень мало, но они уже что-то весят! Масса электрона составляет 9,11 * 10⁻³¹ кг. Принимая, что примерно 0 и 1 одинаковое количество умножим на общий размер Интернета получаем, что он весит сейчас от 0,0000005 грамм до 0,0000015 грамм - немного не правда ли :)
Чем новый API performance.measureMemory() отличается от старого performance.memory?
Если вы знакомы с существующим нестандартным API performance.memory , то вас, возможно, интересует вопрос о том, чем новый API отличается от старого. Главное отличие заключается в том, что старый API возвращает размер JavaScript-кучи, а новый оценивает использование памяти всей веб-страницей. Это различие оказывается важным в том случае, когда Chrome организует совместное использование кучи несколькими веб-страницами (или несколькими экземплярами одной и той же страницы). В таких случаях результаты, возвращаемые старым API, могут быть искажены. Так как старый API определён в терминах, специфичных для реализации, таких, как «куча», его стандартизация — безнадёжное дело.
Ещё одно отличие заключается в том, что в Chrome новый API производит измерения памяти при сборке мусора. Это уменьшает «шум» в результатах измерений, но может потребовать некоторого времени, необходимого для получения результатов. Обратите внимание на то, что создатели других браузеров могут решить реализовать новый API без привязки к сборке мусора.
Всё дело в данных
Если одних только веб-сайтов более миллиарда, то отдельных страницы гораздо больше. Например, на ресурсе WorldWideWebSize представлена оценка размера интернета именно по количеству страниц. Методика подсчёта разработана Морисом де Кундером (Maurice de Kunder), опубликовавшим её в феврале этого года. Вкратце: сначала система осуществляет поиск в Google и Bing по списку из 50 распространённых английских слов. На основании оценки частоты этих слов в печатных источниках полученные результаты экстраполируются, корректируются, вводится поправка на совпадения результатов по разным поисковикам, и в результате получается некая оценка. На сегодняшний день размер интернета оценивается в 4,58 млрд отдельных веб-страниц. Правда, речь идёт об англоязычном сегменте сети. Для сравнения, там же указан размер голландского сегмента — 225 млн страниц.
Но веб-страница в качестве единицы измерения — вещь слишком абстрактная. Куда интереснее оценить размер интернета с точки зрения объёма информации. Но и здесь есть нюансы. Какую именно информацию считать? Передаваемую или обрабатываемую? Если, к примеру, нас интересует информация передаваемая, то и здесь можно считать по-разному: сколько данных может быть передано за единицу времени, или сколько передано фактически.
Одним из способов оценки циркулирующей в интернете информации является измерение трафика. Согласно данным Cisco, к концу 2016 года по всему миру будет передано 1,1 зеттабайта данных. А в 2019 году объём трафика удвоится, достигнув 2 зеттабайт в год. Да, это ОЧЕНЬ много, но как можно попытаться представить себе 10 21 байт? Как услужливо подсказывается в инфографике от той же Cisco, 1 зеттабайт эквивалентен 36 000 лет HDTV-видео. И понадобится 5 лет для просмотра видео, передаваемого по миру каждую секунду. Правда, там было предсказано, что этот порог трафика мы перейдём в конце 2015, ну ничего, немного не угадали.
В 2011 году было опубликовано исследование, согласно которому, в 2007 году человечество хранило на всех своих цифровых устройствах и носителях примерно 2,4 х 10 21 бит информации, то есть 0,3 зеттабайта. Суммарная вычислительная мощность мирового парка вычислительных устройств «общего назначения» достигала 6,4 х 10 12 MIPS. Любопытно, что 25% от этой величины приходилось на игровые приставки, 6% — на мобильные телефоны, 0,5% — на суперкомпьютеры. При этом суммарная мощность специализированных вычислительных устройств оценивалась в 1,9 х 10 14 MIPS (на два порядка больше), причём 97% приходилось на… видеокарты. Конечно, с тех пор прошло целых 9 лет. Но очень примерно оценить текущее положение дел можно исходя из того, что за период 2000-2007 среднегодовой рост объёмов хранимой информации составил 26%, а вычислительной мощности — 64%. Учитывая развитие и удешевление носителей, а также замедление прироста вычислительной мощности процессоров, предположим, что количество информации на носителях растёт на 30% в год, а вычислительная мощность — на 60%. Тогда объём хранимых данных в 2016 году можно оценить на уровне 1,96 х 10 22 бит = 2,45 зеттабайта, а вычислительную мощность персональных компьютеров, смартфонов, планшетов и приставок на уровне 2,75 х 10 14 MIPS.
В 2012 году появилось любопытное исследование количества используемых на тот момент IPv4-адресов. Изюминка в том, что информация была получена с помощью глобального сканирования интернета силами огромной хакерской ботнет-сети из 420 тыс. узлов.
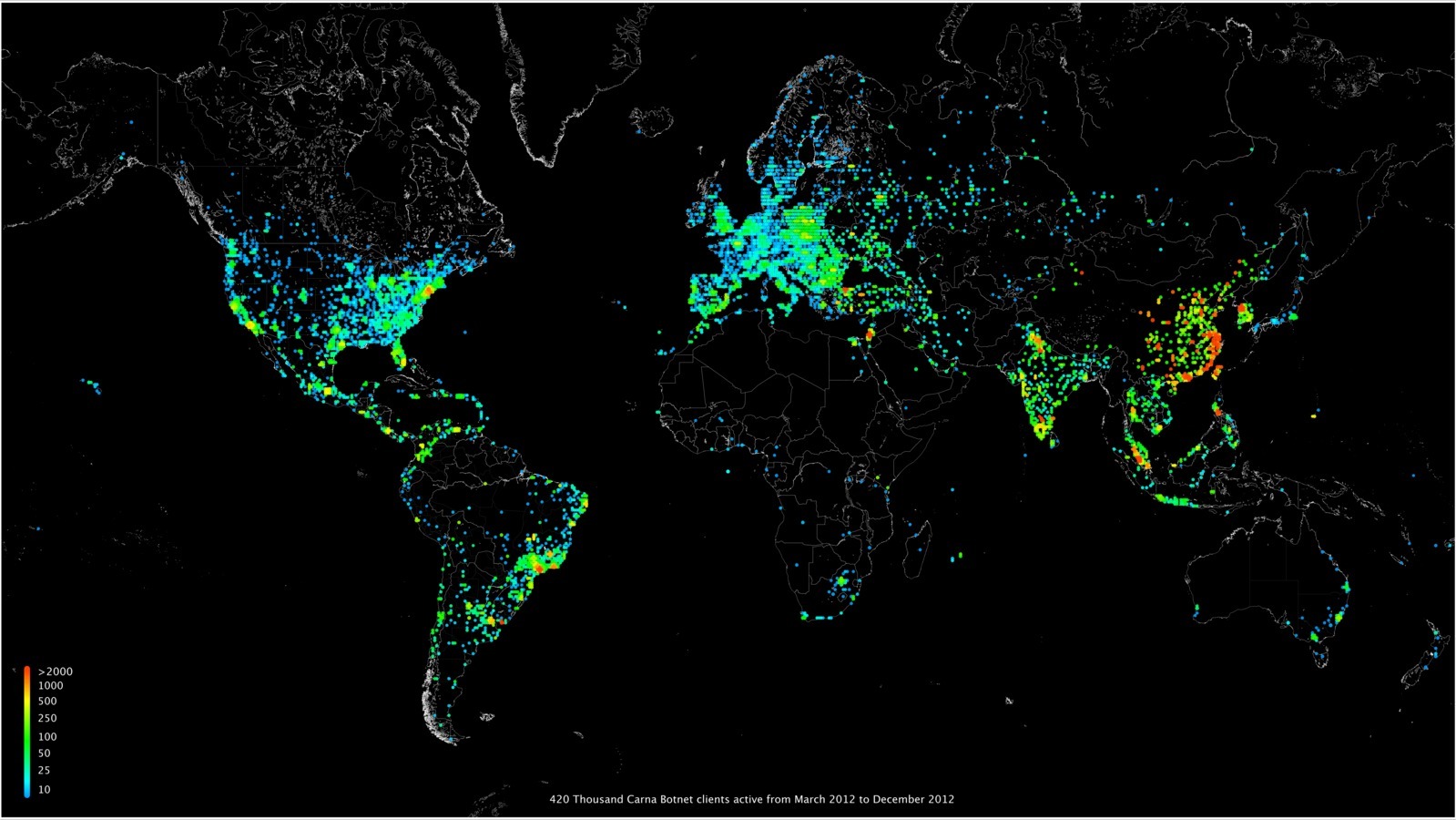
После сбора информации и алгоритмической обработки выяснилось, что одновременно активными были около 1,3 млрд IP-адресов. Ещё 2,3 млрд бездействовали.
Поделитесь с нами своими идеями об устройстве API
Есть ли в этом API что-то такое, что работает не так, как ожидается? Может, в нём не хватает чего-то такого, что нужно вам для реализации вашей идеи? Откройте новую задачу в трекере проекта или прокомментируйте существующую задачу.
Windows
Самый простой способ - это открыть диспетчер задач (для ОС Windows на панели задач нажать правую кнопку мыши, из меню выбрать «Диспетчер задач») и посмотреть объём занимаемой памяти браузером.
Например, на скриншоте открыты два браузера Microsoft Edge и Mozilla Firefox с одинаковым количеством вкладок и одинаковыми сайтами. Firefox занимает в памяти 650 МБ, а Edge - 430 МБ. Но верно ли «Диспетчер задач» показывает занимаемый объём памяти?
В прошлой статье я рассказывал о программе Windows Terminal . Запустим Windows Terminal. По-умолчанию программа запускается с инструментом Windows PowerShell. Скопируйте текст ниже и вставьте в окно Windows Terminal.
Это команда покажет размер в байтах всех процессов браузера Microsoft Edge. Для Microsoft Edge процесс называется msedge. Для Mozilla Firefox - firefox, для Google Chrome - chrome, для Яндекс.Браузера - browser, для Opera - opera и т.д.
Для перевода в мегабайты разделим получившееся число на 1024 (килобайты) и ещё раз на 1024 (мегабайты) и получим 1178,19 МБ или примерно 1,1 ГБ с округлением в меньшую сторону.
Можно использовать такую команду для отображения сразу в мегабайтах.
Почему «Диспетчер задач» показывает 430 МБ, хотя формально браузер использует 1,1 ГБ памяти? Дело в том, что часть процессов браузеров скрыта системой.
▍Локальное тестирование
Chrome выполняет измерение памяти при сборке мусора. Это означает, что обращение к API не приводит к мгновенному разрешению промиса. Для получения результата нужно дождаться следующего сеанса сборки мусора. API принудительно запускает сборку мусора по прошествии определённого тайм-аута, который в настоящее время установлен на 20 секунд. Если запустить Chrome с флагом командной строки --enable-blink-features='ForceEagerMeasureMemory' , то тайм-аут будет снижен до нуля, что полезно для целей локальной отладки и локального тестирования.
Linux
Для пользователей операционных систем Linux я предлагаю (не претендуя на абсолютную правильность) использовать в терминале такую команду:
Как и для Windows необходимо перевести в мегабайты, например, так
и для вывода результата
Таким образом, можно понять достаточно ли вам ОЗУ, размера файла подкачки для работы браузера.
Автор статьи, перевод которой мы сегодня публикуем, рассказывает о том, как мониторить память, выделяемую веб-страницам. Внимательное отношение к памяти страниц, работающих в продакшне, помогает поддерживать производительность веб-проектов на высоком уровне.

Браузеры автоматически управляют памятью, выделяемой веб-страницам. Когда страница создаёт объект, браузер, используя свои внутренние механизмы, выделяет память для хранения этого объекта. Так как память — это не бесконечный ресурс, браузер периодически выполняет процедуру сборки мусора, в ходе которой обнаруживаются ненужные объекты и очищается занимаемая ими память. Процесс обнаружения таких объектов, правда, не идеален. Было доказано, что абсолютно точное и полное выявление таких объектов — неразрешимая задача. В результате браузеры заменяют идею поиска «ненужных объектов» на идею поиска «недостижимых объектов». Если веб-страница не может обратиться к объекту через имеющиеся у неё переменные и поля других объектов, достижимых для неё, это значит, что браузер может безопасно очистить память, занимаемую таким объектом. Разница между «ненужным» и «недостижимым» приводит к утечкам памяти, что проиллюстрировано в следующем примере:
Здесь имеется большой ненужный массив b , но браузер не освобождает занимаемую им память из-за того, что он достижим через свойство объекта object.b в коллбэке. В результате память, занимаемая этим массивом, «утекает».
Утечки памяти — это распространённое явление в веб-разработке. Они очень легко появляются в программах, когда, например, разработчики забывают отменить подписку на прослушиватель событий, когда случайно захватывают объекты в элементе iframe , когда забывают закрыть воркер, когда собирают объекты в массивах. Если на веб-странице есть утечки памяти, это приводит к тому, что со временем растёт потребление памяти страницей. Такая страница кажется пользователям медленной и неповоротливой.
Первый шаг в решении этой проблемы заключается в выполнении измерений. Новый API performance.measureMemory() позволяет разработчикам измерять уровень использования памяти веб-страницами в продакшне и, в результате, выявлять утечки памяти, проскользнувшие через локальные тесты.
Пример
Новый API рекомендуется использовать, определяя глобальный монитор памяти, который измеряет уровень использования памяти всей страницы и отправляет результаты на сервер, где они могут быть агрегированы и проанализированы. Самый простой способ организации работы с этим API заключается в проведении периодических измерений. Например, они могут выполняться каждые M минут. Это, правда, вносит в данные искажения, так как пики в использовании памяти могут приходиться на периоды между измерениями. Следующий пример демонстрирует то, как, с использованием процесса Пуассона, производить измерения, свободные от систематических ошибок. Этот подход гарантирует то, что сеансы измерений могут, с равной вероятностью, прийтись на любой момент времени (вот демонстрация этого подхода, вот — исходный код).
Сначала объявим функцию, которая планирует следующий запуск сеанса измерения объёма потребляемой памяти с использованием функции setTimeout() со случайно задаваемым интервалом. Эта функция должна быть вызвана после загрузки страницы в окно браузера.
Функция measurementInterval() находит случайный интервал, выраженный в миллисекундах, задаваемый таким образом, чтобы одно измерение проводилось бы примерно каждые пять минут. Если вам интересны математические концепции, на которых основана эта функция — почитайте об экспоненциальном распределении.
В итоге асинхронная функция performMeasurement() вызывает наш API, записывает результат и планирует следующее измерение.
Результаты измерений могут выглядеть так:
Оценка общего уровня использования памяти выводится в поле bytes . При выводе этой оценки используются разделители разрядов чисел. Эти значения сильно зависят от реализации. Если они получены для разных браузеров, то сравнивать их нельзя. То, как они получаются, может различаться даже в разных версиях одного и того же браузера. Пока длится программа Origin Trial — в возвращаемые значения входят показатели использования JavaScript-памяти главным окном, показатели использования памяти элементов iframe с того же сайта, и показатели связанных окон. Когда API будет готов, это значение будет представлять собой сведения о памяти, потребляемой JavaScript, DOM, всеми элементами iframe , связанными окнами и веб-воркерами.
Список breakdown даёт более подробную информацию об используемой памяти. Каждая запись описывает некий фрагмент памяти и связывает этот фрагмент с набором окон, элементов iframe или воркеров, идентифицируемых с помощью URL. В поле userAgentSpecificTypes перечисляются типы памяти, определяемые особенностями реализации.
Важно рассматривать эти списки в общем виде и не пытаться, опираясь на особенности некоего браузера, анализировать всё, основываясь на них. Например, некоторые браузеры могут возвращать пустой список breakdown или пустые поля attribution . Другие браузеры могут возвращать в элементе attribution по несколько URL, указывая на то, что они не могут точно определить, какому из этих URL принадлежит память.
Обратная связь
Web Performance Community Group и команда разработчиков Chrome рады будут узнать о том, что вы думаете о performance.measureMemory() , и узнать о вашем опыте использования этого API.
Использование performance.measureMemory()
Текущий ход работ
| Шаг | Состояние |
| 1. Создание пояснений к API | Завершено |
| 2. Создание черновика спецификации | Выполняется |
| 3. Сбор отзывов и доработка проекта | Выполняется |
| 4. Испытания по схеме Origin Trial | Выполняется |
| 5. Запуск | Не начат |
Сообщите о проблеме с реализацией
▍Включение новой возможности через флаги Chrome
Читайте также: