
Сколько байтов в памяти занимает строка hello
Если вы знаете английский, то рекомендую к ознакомлению следующие статьи: Understanding Intel Instruction Sizes (обязательно) и X86-64 Instruction Encoding (по желанию).
И да, вот ещё. Из справки: Домашние задания надо выполнять самостоятельно. Если у вас возник вопрос по домашнему заданию, не просите его сделать за вас. Задайте конкретный вопрос о проблеме, которую вы не можете решить. Программирование — это то, в чём надо разбираться самому, либо не заниматься им вовсе. Если для вас программирование — лишний предмет в учебной программе, есть сайты и люди на этих сайтах, выполняющие задания за материальное вознаграждение. Здесь предлагать выполнить работу за вас и наоборот — моветон.
У вас в листинге сначала идет номер строки, потом 4 цифры (16-ричных) адрес, потом группы по 2 цифры - байты команд, потом сами команды. Для примера строка: 4 0100 EB 05 90 begin: JMP main , в ней команда занимает 3 байта. Также можно определить сколько строка занимает байт по изменению адреса, например 010D - 010B = 2 (в шестнадцатеричной системе).
С ассемблером дела никогда не имел. У нас была только одна лекция, учусь я на заочке. Задание сделать и не прошу, там задание на 7 листов, которые я сделал сам. Не смог ответить только на один вопрос, который и задал здесь. Программировал только в далеком детстве на Basic и Pascal, 20 лет этим не занимался и не собираюсь.
"Для примера строка: 4 0100 EB 05 90 begin: JMP main, в ней команда занимает 3 байта". Не понял как считать.
9 ответы
Одиночные кавычки обозначают символы, двойные кавычки обозначают строки в стиле C с невидимым ограничителем NUL.
\n (разрыв строки) - это только один символ, как и \\ (обратная косая черта). \\n это просто обратная косая черта, за которой следует n.
Я бы поставил тебе +1, если бы ты изменился std::endl в '\n' . - Робᵩ
@ Роб: Поскольку '\n' уже входит в состав задания, я не хотел излишне запутывать Моше. - фредоверфлоу
Веская причина использовать std::endl что я не считал. +1 - Робᵩ
- 'n' : не строка, это буквальный символ, один байт, код символа для буквы n.
- "n" : строка, два байта, один для n и один для нулевого символа в конце каждой строки.
- "\n" : два байта как \ n обозначают «новую строку», которая занимает один байт плюс один байт для нулевого символа.
- '\n' : то же самое, что и первый, буквальный символ, а не строка, один байт.
- "\\n" : три байта .. один для, один для новой строки и нулевого символа
- "" : один байт, только нулевой символ.
Детально проработать «струну» (строка C? std::string ? Строковый литерал?) Для ясности побеждает. - Гонки легкости на орбите
- A char по определению занимает один байт.
- Литералы, использующие ' являются символьными литералами; литералы, использующие " являются строковыми литералами.
- Строковый литерал неявно завершается нулем, поэтому он займет на один байт больше, чем наблюдаемое количество символов в литерале.
- \ это escape-символ и \n является символом новой строки.
Сложите их вместе, и вы сможете понять это.
Следующее займет x последовательных символов в памяти:
изменить: форматирование исправлено
edit2: Я написал кое-что очень глупое, спасибо Mooing Duck за указание на это.
На самом деле sizeof ("n") должно быть равно 2. Тип "n" - не a const char* , но это const char[2] , что составляет два байта. - Мычание утки
Количество байтов, которые занимает строка, равно количеству символов в строке плюс 1 (терминатор), умноженному на количество байтов на символ. Количество байтов на символ может быть разным. Это 1 байт для обычного char тип.
Все ваши примеры состоят из одного символа, за исключением предпоследнего, равного двум, и последнего, равного нулю. (Некоторые относятся к типу char и определить только один символ.)

Количество байтов на char это 1. Всегда. Пожалуйста, отредактируйте ответ. - Лучиан Григоре
char по определению 1 байт, однако байт не может быть 8 бит. - Пабби
@Joe: Стандарт C проясняет: 1 байт должен быть как минимум 8 бит, но можно и больше. - Ильдьярн
'n' -> Один char . char всегда 1 байт. Это не строка.
"n" -> Строковый литерал, содержащий один n и один завершающий NULL char . Итак 2 байта.
'\n' -> Один char , char всегда 1 байт. Это не строка.
"\n" -> Строковый литерал, содержащий один \n и один завершающий NULL char . Итак 2 байта.
"\\n" -> Строковый литерал, содержащий один \ , один '\ n' и один завершающий NULL char . Итак 3 байта.
"" -> Строковый литерал, содержащий один завершающий NULL char . Итак, 1 байт.
Похоже, вы имеете в виду строковые константы. И отличая их от символьных констант.
A char - это один байт на всех архитектурах. Символьная константа использует разделитель одинарных кавычек ' .
Строка - это непрерывная последовательность символов с завершающим символом NUL для обозначения конца строки. В строке используются символы двойных кавычек '"'.
Кроме того, вы вводите синтаксис константного выражения строки C, в котором для обозначения специальных символов используются черные косые черты. \n - это один символ в строковой константе.
Итак, для примеров 'n', "n", '\n', "\n" :
'n' один персонаж
"n" это строка с одним символом, но она занимает два символа хранения (один для буквы n и один для NUL
'\n' - это один символ, новая строка (ctrl-J в системах на основе ASCII)
"\n" один символ плюс NUL.
Все типы данных, которые используются в исходных кодах, могут различаться размером в зависимости от архитектуры целевой машины, на которой компилируют программный код (см. заголовок О РАЗМЕРЕ ТИПОВ ДАННЫХ)
О РАЗМЕРЕ ТИПОВ ДАННЫХ
В данной статье предполагается, что машина, на которой компилируется исходный код и запускается программа на языке Си, поддерживает тип данных long int с размером ровно 4 байта, тип int - размером 4 байта и тип char - ровно 1 байт. Указатели имеют размер 4 байта. Тип long long int имеет размер 8 байт. Размер типа данных, используемых в настоящей статье, зависят от реализации и архитектуры платформ. За подробностями, следует ознакомиться с соответствующей документацией. Минимальный допустимый диапазон значений типов данных, который должна поддерживать реализация, указана в стандарте ISO\IEC 9899 в редакциях от 1990, 1999, 2011 а также 2018 года, в пункте 5.2.4.2.1 в которой перечислены основные имена констант, и их значения. Эти константы определены в заголовочном файле
Неправильное использование символа конца строки (нулевого символа '\0')
Рассмотрим следующий код:
В данном коде мы получим следующие результаты
Т.к. маркер конца строки помещён между подстроками "Hello " и "world!\n" , а большинство библиотечных функций используют для проверки достижения конца строки равенство просматриваемого символа с нулевым символом, т. е. :
то после прочтения пробела и достижения символа '\0' функция strlen вернёт значение равное 6. Она не учитывает нулевой символ. Аналогично, функция printf будет подставлять вместо %s символы строки str в стандартный поток вывода до тех пор, пока не прочтёт нулевой символ.
Решением данной проблемы будет использование библиотечной функции memcpy которая имеет следующий вид:
Данная функция копирует ровно первые n-байтов из места, указанные через указатель source, в начало блока, указанное адресом dest.
Наконец, с помощью printf, выводим содержимое переменных l2 и c2. Нетрудно убедиться, что мы получим на выводе следующие строки
Отметим одно важное ограничение на функцию memcpy: блоки данных, на которые указывают первые два параметра функции, НЕ ДОЛЖНЫ ПЕРЕКРЫВАТЬСЯ. Это значит, что если они указывают на один и тот же блок ячеек памяти, то возможны ошибки.
Попытка изменить содержимое строки, которая была создана с помощью указателя и строчного литерала.
Рассмотрим следующий код:
При выполнении третьей строчки кода мы получим Segmentation Fault. Причина же этого в том, что память под mystr была выделена в сегменте данных. Данный сегмент доступен только для чтения и это вполне очевидно поскольку при выполнении машинных инструкции, которые содержатся в части .text данного сегмента, никто не должен менять сегмент с целью изменения машинных команд. Поэтому содержимое, которое хранится по адресу, который записан в переменной mystr , доступно только для чтения.
Для решения данной проблемы можно было воспользоваться массивом или функцией malloc, которая бы выделила память в динамической изменяемой куче, где данные доступны и для чтения и для записи. Единственное ограничение - это количество выделяемой памяти, как для массива, так и для блока ячеек данных в куче. В приведенном выше примере для строки mystr потребуется 19 байт.
Неправильное освобождение памяти через функцию free
При выделении памяти в куче с помощью функций malloc или calloc необходимо позаботиться об освобождении ресурсов, т.е. выделенной памяти, после того, как работа с выделенными блоками была завершена. Когда была выполнена последняя команда в функции main, или была вызвана одна из функции семейства exit то процесс автоматически известит ядро системы о завершении работы, а ядро позаботится о том, чтобы освободить память, которую процесс больше не использует, а также закроет все открытые файлы данным процессом, (если, конечно, не была вызвана функция _exit, которая не закрывает файловые дескрипторы, открытые процессом).
Но что если мы больше не используем данные блоки, а работа программы ещё не окончена? Конечно, размер блока может быть небольшим, но он также может быть и достаточно великим, чтобы просто так занимать память процесса. С помощью функции free мы можем освободить блок памяти, передав указатель (т.е. адрес начала блока) ей следующим образом:
Данный код работает правильно, несмотря на изменения функцией process с указателем s1. Функции process передаётся копия значения, т.е. адрес начала блока из 255 байтов, на который указывает переменная s1. Эта копия сохранится в локальной переменной функции s1, которая является также её формальным параметром. Описание же функции process выглядит так:
Конечно, внутри тела функции process можно вызвать любую функцию, которая создаст побочный эффект, т. е. изменит значение переменной s1 извне. Но в данном примере, предположим, что она написана правильно.
Чтобы вызвать ошибку, достаточно перед функции free добавить следующую строчку:
Данная инструкция сохранит новый адрес в переменную s1, который является лишь смещением относительно адреса, хранимого в s1 на 1 байт. Это приведёт к ошибке при вызове free, поскольку теперь s1 указывает не на начало блока ячеек данных, а на вторую ячейку блока.
Конечно, никто так явно не сделает. Но, допустим, что вы используете указатели для итерации, которые хранят текущий элемент из блока. Например, пусть вы хотите вывести все символы строки, на которую ссылается указатель sptr:
Здесь, функция strcpy копирует содержимое второй строки в начало блока ячеек, на который указывает указатель sptr. Но она не копирует нулевой символ. Функция выделения памяти в куче calloc выделяет память с указанным количеством ячеек указанного размера. Её первый аргумент указывает на число элементов в блоке, а второй - на размер ячейки в блоке. Кроме того, функция calloc дополнительно вызывает функцию memset, которая заполнит все ячейки блока нулями (т.е. в конце строки в любом случае окажется нулевой символ, если, конечно, мы его не затрём чем-нибудь другим). Функция memset принимает три параметра: адрес блока ячеек памяти, значение, которое надо присвоить ячейкам данного блока, и число ячеек, которые необходимо заполнить данным значением.
После выполнения цикла while, указатель будет ссылаться на последнюю ячейку в блоке. И мы получим вышеописанную ошибку. Конечно, если знать, что функция free должна принимать адрес начала блока, то проблем можно легко избежать. Всего-навсего, надо лишь сохранить адрес начала блока выделенной памяти в другую переменную, и работать с ней. А исходную переменную не трогать, её-то и надо будет передать функции free, после того как работа с блоком будет завершена.
В предыдущем куске кода, для этого надо сделать две вещи:
1) Добавить строчку кода перед циклом while
2) Заменить имя переменной sptr на sptr_p во всех выражениях и инструкциях, где изменяется адрес sptr (то есть содержимое переменной sptr).
Совет: всегда проверяйте, что указатели, переданные функции free, указывают на НАЧАЛО БЛОКА. И всегда сохраняйте адрес начала блока выделенной памяти.
Использование локальных переменных функции за её пределами после завершения работы функции
Предположим, что мы используем локальные переменные, для которых память была выделена в кадре стека функции, следующим образом:
Структура Person, адрес которой и передаётся данной функции может выглядеть следующим образом:
Предположим, что в коде функции main, выполняется следующий код, который создаёт новую переменную типа Person, и инициирует её имя (name) через функцию process_person:
В коде функции main, выделяется память под переменную типа структуры Person в кадре стека, соответствующему вызову функции main. Далее вызывается функция process_person, которая получает адрес, где хранится структура. Далее, в стеке создаётся новый кадр, который соответствует вызову функции process_person. В данном кадре выделяется память под переменную массива символов name. Далее адрес начала (первой ячейки массива) копируется в поле структуры name, и выводится содержимое данного поля структуры. После того, как завершится работа функции process_person, происходит приостановка выполнения следующей строчки кода, на 2 сек. (вызов функции sleep). Функция sleep определена в заголовочных файлах или или в других файлах в зависимости от целевой платформы и операционной системы. Для приложений, работающих с операционной системой Windows следует подключать заголовок , если же вы работаете с Linux, то надо подключать . Прототипы (заголовки) функции отличаются. Ниже приведён прототип функции из заголовочного файла .
После 2 секунд, выполняется последняя строчка кода, которая должна вывести содержимое поля структуры, хранимой в переменной p1. Но т.к. память может быть уже очищена, то в данном поле ничего не будет. В итоге мы можем получить следующий вывод:
Вторая двойная кавычка и всё, что за ней следует, не появилось в стандартном выводе, так как после очистки памяти из-за удаления кадра стека функции process_person поле структуры p1.name приняло значение по умолчанию, равное нулевому символу \'0' .
Стоит отметить, что данное поведение неопределенно, поскольку память может не успеть очиститься, и мы можем получить что-то вроде такого:
Чтобы избежать подобных ситуации, рекомендую придерживаться принципа Тараса Бульбы:
Т.е. выделять и освобождать один и тот же ресурс необходимо на одном уровне. Т.е. если выделили память внутри функции f, то освободить её надо именно в пределах (внутри) функции f. Внутри, значит в её теле. Причём, если мы вызываем другую функцию g внутри f, и g освобождает память, выделенную в f, то мы не можем считать, что мы освободили ресурс на одном уровне, поскольку выделение происходит в функции f, а освобождение в функции g.
Конечно, при возникновении ошибок, возможны ситуации смена управляющего потока кода, т.е. переход из тела одной функции в тело другой. В данном случае, при подобных ситуациях, можно использовать глобальные переменные с глобальными функциями.
Отсутствие проверок на NULL при работе с указателями.
Наконец, разберём последний тип ошибок, отсутствие проверок на NULL. Вообще говоря, это распространенная ошибка любого языка программирования, допускающего ссылочный тип и выражающего отсутствие значения такого типа (т. е. ссылки) в виде литерала null. Все вышеприведённые куски кода, в которых использовались указатели подвержены данной ошибке. Вообще говоря, у компьютера не бесконечная память. Попытка выделить память под новую переменную динамически с помощью функций, таких как malloc, calloc, realloc может обернуться неудачей. В этом случае, указанные функции вернут нулевой адрес, который является недопустимым для обращения и использования в системе. Нулевой адрес представлен литералом NULL, который может быть оформлен в следующем виде:
Причины, по которым не удалось выделить память могут быть разнообразны. Самая простая - это нехватка памяти. Что касается нехватки памяти, то вы её можете исчерпать как динамически (т.е. в куче), так и статически (переполнение стека, либо заполнение всего адресного пространства одиночного кадра стека). Что касается стека, то на некоторых платформах можно расширить кадр стека (через функцию alloca, которая вызывается аналогично malloc), но лишь на некоторых, а не на всех.
P.S. В данном посте были рассмотрены лишь 5 типа ошибок. Существуют и другие ошибочные ситуации, которые могут возникать чаще, чем вышеописанные.
Кроме того, в данных исходниках использовались зависимые от платформы (системы и архитектуры ЭВМ) типы данных. Используя их, вы создаёте непереносимый код. Конечно, если вы пишете код, который будет работать строго на одной машине с одним определённым типом процессора и определённой операционной системой, то, зная, тонкости данной платформы и её окружения, вы можете НЕ использовать другие типы данных, которые независимы от платформ, или зависят от них в самой меньшей степени.
Размещение сквозной ссылки
Первые шаги в низкоуровневом программировании
Бытует мнение, что программирование на низком уровне – чрезвычайно сложное занятие. Доля правды здесь есть, однако не стоит этого опасаться – всему можно научиться, стоит только начать. Для тех, кто изучает Delphi, но хочет приобщиться и к "низкоуровневым изысканиям" и предназначена эта статья.
Могучая процедура Move
Move - любопытная стандартная процедура, доставшаяся нам в наследство ещё от старого, доброго Turbo Pascal'я. Она, наверное, по какой-то ошибке попала в язык программирования высокого уровня, однако изрядно добавила мощности и упростила жизнь (а мы только и рады ). Вроде бы ничего особенного: procedure Move(const Source; var Dest; Count: Integer); Перемещает из Source в Dest участок памяти, равный Count байтам. Причем, как вы заметили (если заметили), Source/Dest – не указатели, а непосредственно переменные, и за точку отсчета Move берет первый байт, занимаемый переменной. Посмотрите на примеры:
var
b : array[0..80] of byte;
c : array[4..67] of char;
w : array[8..670] of word;
procedure SomeProc;
begin
MessageBox(0, 'hello!', nil, 0);
end;
begin
move (b, c[4], 20); //копирует 20 байт из начала массива b в массив с, начиная с 4-ой позиции.
move (b, w, SizeOf(b)); //копирует весь массив b в начало массива w (обратите внимание на несоответствие размеров типов!)
move (w[4], w[50], SizeOf(word)*100); //"отодвигает" 100 значений с 4-ой на 50-ю позицию внутри одного массива(обратите внимание – участки памяти Source и Dest перекрываются!)
move (SomeProc, b, SizeOf(b)); //копирует код процедуры SomeProc в массив b
.
Теоретически, просто побайтно копируются куски памяти, невзирая на типы данных и их размеры. Замечательно также то, что процедура корректно работает в случае, когда данные на новом месте "задевают" исходные. В примерах мы определяем размер массива с помощью функции SizeOf. Она возвращает размер в байтах либо структуры данных, либо типа данных. Замечу, что в реализации Move не предусмотрено никакой проверки на выход за границы переменных, что является поводом как для большей осторожности при её использовании, так и для всевозможных низкоуровневых трюков. Четвертый пример как раз из таких. Он сегодня для нас является ключевым, итак.
Четвертый пример
Логически, загруженная в память и работающая программа состоит из кода – инструкций для процессора ("глаголов"), и данных, которые этими инструкциями обрабатываются ("существительных"). Хранятся в памяти компьютера и те, и другие одним способом – как последовательности байтов. И поэтому код иногда можно рассматривать как данные. Будь я профессором, сказал бы, что в таком случае жизнь проводится "принцип фон-Неймана". В различных специфических программах (компиляторах, паковщиках исполняемых файлов, всевозможных защитах и т.д.) без него не обойтись. Подобные методы справедливо считаются прерогативой языков низкого уровня (в первую очередь, ассемблера), однако и с Delphi можно провести некоторые любопытные эксперименты такого сорта.
Теперь, ближе к нашему примеру. Массив b заполнится представлением процедуры SomeProc в памяти компьютера. Причем, нам не известно, сколько байт она занимает – скорее всего, исходя из её миниатюрности, в конце массива будет мусор – кусок либо другой процедуры, либо данных. Но будь процедура побольше, то могла бы и не поместиться в отведенные 80 байт. Как видите: сплошная неизвестность, но мы попробуем пролить на ситуацию немного света. Первое, что приходит в голову – посмотреть, что же таки записалось в наш массив. Вполне резонно! Вы, наверное, уже написали что-то вроде
Те, кто не написал, поскорей набирайте, а я же не упущу возможности кое-что пояснить. Паскаль дает возможность задавать любые границы индексации массивов (что есть признак "высокоуровневости" языка – например, в языке Си все массивы индексируются с нуля). В Delphi пошли дальше и ввели функции Low и High, которые определяют нижний и верхний индексы массива, соответственно. Это действительно удобно, так что рекомендую повсеместно в ваших программах использовать их, избавляясь от малозначащих констант.
Итак, колонка чисел. Ничего, вроде, интересного. Но я предлагаю выводить не только код, но еще и символьное представление байта. В итоге, пишем следующее:
Обратите внимание - теперь используется функция IntToHex вместо IntToStr. Она переводит число в его строковое представление в шестнадцатеричной системе счисления. Первым аргументом подается само число, вторым – нужное нам количество знаков в искомом представлении. Профессиональные программисты очень любят использовать шестнадцатеричную систему счисления. Во-первых, в ней для описания значения одного байта достаточно только 2-х символов. А во-вторых, байты имеют обыкновение группироваться в слова (2 байта), и двойные слова (4 байта), для возможности представления чисел, больших 255. И теперь, перед нами стоит задача: определить, какое число определяет машинное слово, состоящее из 2-x байтов <28, 86>(порядок имеет значение!). Нужно вычислять: 28*256 + 86 = 7254. А вот если использовать 16- чную (не хочу уже повторять этот "длиннючее" слово ) систему, то искомое число получится простым "склеиванием". Т.е. в данном случае = 1C56! Еще явственней её преимущества проявляются, когда число надо наоборот, "расчленить" на байты.
Итак, опять возвращаемся к нашим бананам. Запустите программку и внимательно изучите полученный результат. В байтах с 14-го по 19-ый (изъясняюсь в 16-чной, извините-с ) расположилась наша строчка 'hello!'. Уже теплее. Причем, обратите внимание, она завершается байтом с кодом нуль, так называемым "нуль-терминатором". Так устроены строки в Си-программах. Компилятор увидел, что вызывается функция (MessageBox), аргументом которой является строка в стиле Си (в терминологии Delphi ей соответствует тип PChar). И, поэтому, вместо достаточно сложной во внутреннем представлении "паскалевской", сформировал нужную "сишную".
Идем дальше, копаем глубже. Как же все-таки определить, сколько байт занимает наша SomeProc? Для этого её нужно немного изменить:
В Delphi есть удобная возможность вставлять в код нашей программы куски, целиком написанные на ассемблере. Инструкции записываются между ключевыми словами asm и end и вставляются компилятором в нужное место объектного кода без изменений. Нам понадобилась всего одна ассемблерная инструкция - nop (аббревиатура от “No OPeration"), главная задача которой – ничего не делать, а преспокойно занимать собой один байт памяти (скажу вам по секрету, с кодом 90. ). Кое-кто уже, наверное, догадался, что к чему. Мы поставили эту инструкцию дважды в начало и в конец нашей процедурки. Теперь, мы точно сможем сказать, что все, что расположено между двумя парами байт с кодом 90 и есть наша SomeProc! По две же инструкции – для надежности, чтоб отделить свои nop'ы от чужих. Конечно, компилятору нет нужды просто так вставлять в код ничего не делающую инструкцию, однако еще более нет нужды вставлять её дважды .
Итак, барабанная дробь, запускаем нашу программу. Так-так. Два раза по девяносто в самом начале – значит, мы попали, куда надо. Уже хорошо. Идем дальше. Под номером, или как говорят программисты, по смещению 1B видим вторую пару, итак, найдено, наша процедура занимает 19 байтов! Только, что за чертовщина? Строки 'hello!' в этих границах нет! Но ведь строка-то находится внутри процедуры, почему же в итоге она оказалась снаружи? Вот она, как и полагается, сдвинулась на четыре байта относительно предыдущей позиции (мы же добавили в общей сложности 4 nop'a), но она снаружи! Отсюда стоит сделать важный вывод: несмотря на то, что в исходном коде программы данные и инструкции находятся рядом, в выполняемой программе они разнесены, каждый в свое место (мухи отдельно, котлеты, сами понимаете. ).
Теперь, давайте проведем эксперимент: не позволим компилятору самовольно выделять место под строку, а сделаем это сами и посмотрим, что произойдет. SomeProc станет такой:
Запускаем программу, и что мы видим? Строка исчезла с насиженного места в неизвестном направлении! Делаем ещё один вывод: Данные хранятся в разных местах, и места эти зависят от того, кто поместил туда их – компилятор, или сам программист. Разговоры разговорами, а целая строка куда-то делась средь бела дня. Её непременно надо найти!
В поисках Немо
Память компьютера состоит из ячеек (байтов), пронумерованных целыми числами, начиная с нуля. Номер первого байта любой структуры данных называется адресом этой структуры. Таким образом, у всех "жителей" памяти есть адреса. И у нашей потерявшейся строки – тоже. Адрес (или, как еще говорят, указатель) занимает 4 байта. Как нетрудно подсчитать, таким способом можно адресовать FFFFFFFF - целых четыре гигабайта! Что называется, "с запасом".
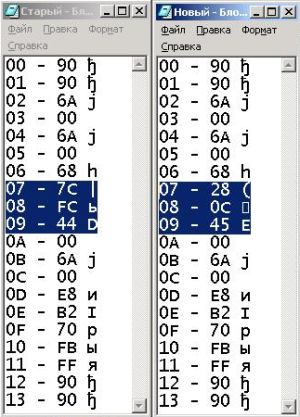
А теперь рассмотрим, как происходит вызов функции MessageBox и передача ей параметра-строки. Мы в программе вызываем функцию по её имени, но как вы могли убедиться, никакого имени непосредственно в код функции не записано. Функция вызывается по адресу, и параметром служит не сама строка, а её адрес – указатель на первый символ. Сплошные адреса! Вот почему в коде SomeProc не оказалось нашей строки, её отправили на хранение в укромное место, а вместо - подставили её адрес. Задача уже кажется разрешимой! Изменилось местоположение строки – значит, изменился её адрес. Дело за малым – определить, где находится тот самый указатель.
Итак, что же делать? Предлагаю вернуться к предыдущей версии SomeProc и скопировать её представление в текстовый файл – пригодится! Теперь, переходим к новой версии, и копируем её представление в другой файл. Осталось только найти отличия! Ведь, кроме адреса строки, ничего не изменилось. Даже невооруженным взглядом можно найти различия трёх подряд идущих байтов. Но, почему трёх? Ведь указатель занимает четыре. Значит, нам не повезло. Один из байтов не изменился. Теперь, вопрос состоит в том, верхний (68), или нижний (00) относиться к адресу. Как видите, круг подозреваемых сузился. Строка почти найдена. Итак, возможные её адреса – либо 00450C28, либо 450C2868 (обратите внимание, байты в программе записаны в обратном порядке).
Теперь вопрос можно решить, просто посмотрев, что находится в памяти по этим адресам у работающей программы. Как это сделать? Есть несколько способов, предлагаю использовать для этого шестнадцатеричный редактор с функцией редактирования памяти. Рекомендую WinHex, как мощный, и в то же время весьма удобный редактор (доступен на сайте www.winhex.com). Запускаем его, заходим в меню Tools -> RAM Editor. Выбираем в списке работающих программ нашу, раскрываем дерево, выбираем “Entire memory" (“Вся память"). Жмем ОК.

Появилась таблица из трех колонок, чем-то напоминающая наши с вами недавно изучаемые. Данные представлены в средней и в правой – как шестнадцатеричные коды, и как символы, соответственно. А в левой колонке показаны смещения.
Нажимаем Alt+G, чтобы перейти к нужному смещению. Итак, вводим первое - 00450C28, и сразу же – удача! Строка найдена. Кстати, оказалось что смещение 450C2868 вообще не принадлежит нашей программе (проверьте). Отлично, коллега, вот мы и распутали это дело.
Эпилог
Вот, пожалуй, и закончено наше занимательное (надеюсь ), повествование, которое (опять же, надеюсь) помогло вам посмотреть на программирование в другом ракурсе и возбудило желание продолжить "низкоуровневые изыскания". Что ж, если так, то пишите мне о том, что вас интересует, и, я надеюсь, вскоре у него появится продолжение. Будьте здоровы!
2 ответа 2
Если считать по изменению адреса, то получается: команда MOV = 4 байта, команда RET = 1 байт, весь сегмент = 15 байт, директива процедуры ENDP = 0 байт.
В целом, как работать с листингом.
Берем строку листинга:
- 9 - номер строки
- 0107 - смещение (адрес) текущей строки
- 8A 26 0103r - байты (машинный код), полученные после трансляции команды
- MOV AH,byte ptr flddb - сама команда
В данном случае для меня проще сразу посмотреть количество байт: 8A 26 0103r - это 8 шестнадцатеричных цифр ( r не считается), делим на 2 (по две цифры на байт), получаем 4 (1 байт - 8 бит, 1 шестнадцатеричная цифра кодирует 4 бита, отсюда 2 цифры на байт).
Другой способ - смотрим разницу смещений соседних строк. Пример:
Разница 010B - 0107 = 4 , что соответствует тому что мы получили выше, просто посчитав байты. Я считаю, что посчитать байты (если их немного) все-таки проще, чем в уме считать в шестнадцатеричной системе. Но не всегда в листинге присутствует колонка с машинным представлением команд, в таких случаях приходится считать разницу смещений.
Отдельно можно заметить, что первоначально смещение 0000 , а потом вдруг становится 0100 . Это не означает, что какая-то строка занимает 100h (256) байт, просто директива ORG 100H принудительно указывает, что после нее смещение должно стать равно 100h . Сама по себе директива org не занимает в объектном файле нисколько, просто в нем прописывается, что начальное смещение равно 100h .
За эту неделю появилось сразу две статьи на хабре и одна в блоге, где авторы соревновались в написании минимально возможной программы мигания светодиодом для микроконтроллеров AVR.
В самой последней статье автор предложил программу длиной всего в 4 байта (!)
Ну как тут можно устоять перед брошенным вызовом?!
И в этой статье я предлагаю программу мигания светодиодом с частотой, заметной на глаз и размером всего в 2 байта.
2 байта – это минимально возможная длина программы, поскольку размер адресуемой ячейки программной памяти в микроконтроллерах AVR составляет 16 бит или 2 байта. Таким образом, программа, а точнее одна инструкция (которая может располагаться по абсолютно любому адресу) будет занимать одну ячейку программной памяти.
Но, к сожалению, предложенная мной программа будет работать далеко не во всех микроконтроллерах AVR, а только лишь в некоторых моделях из семейств Tiny и Mega.
Секрет программы состоит в том, что некоторых микроконтроллерах семейств Tiny и Mega есть примечательная фича, которая позволяет всего одной командой инвертировать состояние разрядов регистров PORTА, PORTB и PORTD. Такую интересную фичу реализует команда sbi A,b
Команда sbi A,b предназначена для установки бита регистров ввода/вывода, которые имеют адреса от 0 до 31.
Эта команда в двоичном виде выглядит следующим образом:
1001 1010 AAAA Abbb
Первые восемь бит 1001 1010 являются кодом операции – это постоянная составляющая команды.
В битах ААААА записывается адрес регистра ввода/вывода в адресном пространстве ввода/вывода. Для адреса отводится 5 бит и именно поэтому, команда имеет ограничение по адресам (0..31).
В младших трех битах bbb располагается номер изменяемого бита (0..7).
Теперь вернемся к той самой примечательной фиче, которая позволяет инвертировать состояние разрядов регистров PORTB и PORTD.
Давайте заглянем в даташит на микроконтроллер ATtiny2313:

Такая возможность точно присутствует в микроконтроллерах ATtiny2313, ATtiny13, ATtiny24/44/84 .
В микроконтроллерах из семейства mega такая удобная функция есть в ATmega48A/PA/88A/PA/168A/PA/328/P. А вот в ATmega8A/16A/32A эта функция отсутствует.
А про остальные микроконтроллеры с уверенностью сказать не могу.
Для того что бы узнать, присутствует ли такая функция в микроконтроллере, можно поискать в даташите словосочетание Toggling the Pin.
Таким образом, прописав, к примеру, команду sbi PINB,0 можно проинвертировать состояние нулевого разряда регистра PORTB.
А что нам это даст?
А это нам дает включение/отключение подтягивающего резистора в нулевом разряде порта B (не забывайте, что после сброса все регистры ввода/вывода обнуляются, поэтому порты B и D настроены на вход). Сопротивление встроенного резистора составляет 30..50 кОм. Однако, даже такого сопротивления вполне хватит, чтобы зажечь низко потребляющие синие, красные и белые светодиоды. А вот на зеленые светодиоды тока уже будет не хватать.
Лично я такой способ запитки светодиодов использую довольно часто. Красные и синие светодиоды типоразмера 0805 и 0603 горят вполне сносно при напряжении питания 5 В.
То есть, для того, чтобы зажечь светодиод, его надо включить между выводом порта и общим проводом (без внешнего токоограничивающего резистора!) и включить внутренний подтягивающий резистор. В такой схеме включения экономится еще и внешний токоограничивающий резистор.

Итак, управлять светодиодом при помощи одной команды мы научились.
Теперь, если эту команду записать в программную память микроконтроллера, например по адресу 0х0000, то микроконтроллер будет работать следующим образом:
По нулевому адресу будет встречена команда sbi PINB,0 и после ее выполнения установиться в единицу нулевой разряд PORTB, включится подтягивающий резистор и зажгет светодиод. А далее, до конца программной памяти, микроконтроллер будет встречать только 0xFFFF. Такие инструкции микроконтроллеру неизвестны, поэтому микроконтроллер просто будет пропускать их, затрачивая на каждую один такт и увеличивая на единицу программный счетчик.
После того как программный счетчик досчитает до конца памяти, он переполниться и сбросится в ноль, то есть произойдет переход на адрес 0х0000, где вновь будет выполнена команда sbi PINB,0. После выполнения команды нулевой разряд PORTB сбросится в ноль, отключится подтягивающий резистор и светодиод погаснет.
Теперь давайте посчитаем, с какой частотой будет мигать светодиод. В качестве микроконтроллера выберем, к примеру, ATtiny2313. В этом микроконтроллере программная память составляет 2048 байт. Каждая ячейка программной памяти занимает 2 байта. Адресное пространство программной памяти представлено адресами от 0 до 1023. То есть всего 1024 адреса. После подачи питания микроконтроллер начнет выполнение программы с адреса 0х0000. Когда микроконтроллер дойдет до адреса 1023, то на следующий такт произойдет обнуление программного счетчика. То есть произойдет переход на адрес 0х0000.
Все команды в нашей программе выполняются за один такт. Поэтому, светодиод будет переключаться в противоположное состояние один раз за 1024 тактов. Допустим, микроконтроллер работает на частоте 1 МГц. На этой частоте один такт составляет 1 мкс. Таким образом, переключение светодиода будет происходить каждые 1024 мкс. Как известно частота – это обратная величина периода. А период одного мигания составляет удвоенное время между переключениями светодиода 1024 мкс * 2 = 2048 мкс. Откуда получаем частоту мигания светодиода 1/(2048 мкс) = 488 Гц.
Многовато получилось. Человеческий глаз на такой частоте мигания не заметит. Чтобы частота мигания была заметна на глаз, нужно будет понизить частоту. Для этого можно затактировать микроконтроллер от тактового генератора watchdog таймера, частота которого составляет около 128 кГц. Но в реальности частота может отличаться на 3..4 кГц, так как таймер не предназначен для точных отсчетов времени.
128 кГц – это в 8 раз ниже 1 МГц. Поэтому и частота мигания будет в 8 раз ниже 488 Гц / 8 = 61 Гц. То же много. На глаз мигание заметно не будет.
Чтобы еще понизить частоту, следует включить fuse-бит CKDIV8, отвечающий за деление частоты на 8. Тогда тактовая частота составит 128 кГц/8 = 16 кГц, а частота мигания уменьшится еще в 8 раз и составит 61 Гц / 8 = 7,6 Гц. А вот такая частота уже вполне будет заметна на глаз.
Но будьте очень аккуратны при понижении частоты до таких значений!
Помните важное правило: если вы программируете микроконтроллер последовательным внутрисхемным программатором (программирование через SPI), то тактовая частота микроконтроллера должна быть, по крайней мере, в 4 раза выше, чем частота программирования.
То есть, при тактовой частоте микроконтроллера 128 кГц частота работы программатора (частота SPI) должна быть ниже
128 кГц/4 = 32 кГц.
А при тактовой частоте 16 кГц частота программирования должна быть ниже
Прежде чем понижать тактовую частоту до 16 кГц, убедитесь, что ваш последовательный программатор способен программировать на частоте ниже 4 кГц.
А иначе вы рискуете «заблокировать» микроконтроллер!
К параллельным программаторам это ограничение не относится.
Теперь давайте, наконец, напишем нашу программу.
Писать программу будем в блокноте и сразу в машинных кодах.
Мы уже знаем, как выглядит команда sbi A,b
1001 1010 AAAA Abbb
Осталось подставить нужные биты.
Зажигать будем светодиод, который подключен к нулевому разряду порта В. В микроконтроллере ATtiny2313 адрес PINB = 0x16. В двоичном виде 0x16 = 0b10110.
Изменять будем нулевой бит, поэтому bbb = 000.
Подставляем биты и получаем: 1001 1010 1011 0000 или 0x9AB0
Теперь создадим HEX файл для прошивки микроконтроллера.
Состав HEX файла выглядит следующим образом:

Наш HEX-файл будет состоять из двух строк: в первой строке будет прописана двухбайтная инструкция 0x9AB0, а вторая строка будет указывать на окончание HEX-файла.
В качестве адреса, где будет расположена наша команда, выберем нулевой адрес. Хотя, можно выбрать абсолютно любой адрес из всего адресного пространства.
Контрольная сумма вычисляется вычитанием из нуля всех байт строки. Младший байт получившегося значения как раз и является контрольной суммой.
То есть, для нашего случая 0x00 — 0x02 — 0xB0 — 0x9A. Младший байт получается равным 0xB4. Его и вписываем в конец строки.
Последняя строка должна указывать на окончание HEX файла и должна выглядеть следующим образом:
И так же нужно помнить, что в HEX-файле байты команд поменяны местами. То есть сначала записываем младший байт 0xB0, затем старший байт 0x9A.
Итоговый HEX файл будет вот таким:
:02000000B09AB4
:00000001FF
Записываем получившиеся строки в блокнот и сохраняем с расширением .hex (впрочем, сохранить можно с любым расширением).
Теперь осталось зашить эту прошивку в микроконтроллер, установить тактирование от генератора watchdog таймера и включить деление на 8.
Вот пример настройки fuse-бит в среде Atmel Studio 6

Получаем результат в виде мигающего светодиода. Проверено в железе. Исправно мигает.
Таким образом, самая простая программа состоит из двух байт, а самая простая схема – из элемента питания, микроконтроллера и светодиода.
Я делаю обзор своего класса C ++ в первом семестре и думаю, что что-то упустил. Сколько байтов занимает строка? Чарльз?
Приведены примеры, некоторые из которых являются символьными литералами, а некоторые - строками:
Меня особенно смущает использование там новых строк.
задан 21 фев '12, 16:02

Под "строкой" вы имеете в виду std::string или завершенный нулем char* ? - Luchian Grigore
Читайте также: