
С помощью компьютерных технологий можно абсолютно точно закодировать
Одно из основных достоинств компьютера связано с тем, что это удивительно универсальная машина. Каждый, кто хоть когда-нибудь с ним сталкивался, знает, что занятие арифметическими подсчетами составляет совсем не главный метод использования компьютера. Компьютеры прекрасно воспроизводят музыку и видеофильмы, с их помощью можно организовывать речевые и видеоконференции в Интернете, создавать и обрабатывать графические изображения и и.д
Одна и та же запись может нести разную смысловую нагрузку. Например, набор цифр 251299 может обозначать: массу объекта; длину объекта; расстояние между объектами; номер телефона; запись даты 25 декабря 1999 года.
Для представления информации могут использоваться разные коды и, соответственно, надо знать определенные правила - законы записи этих кодов, т.е. уметь кодировать.
Код - набор условных обозначений для представления информации.
Кодирование - процесс представления информации в виде кода.
Для общения друг с другом мы используем код - русский язык. При разговоре этот код передается звуками, при письме - буквами. Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора. Таким образом, кодирование сводиться к использованию совокупности символов по строго определенным правилам.
Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы.
Способ кодирования (форма представления) информации зависит от цели, ради которой осуществляется кодирование. Такими целями могут быть сокращение записи, засекречивание (шифровка) информации, удобство обработки и т. п.
Чаще всего применяют следующие способы кодирования информации:
1) графический - с помощью рисунков или значков;
2) числовой - с помощью чисел:
3) символьный с помощью символов того же алфавита, что и исходный текст.
Переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки, также называют кодированием .
Действия по восстановлению первоначальной формы представления информации принято называть декодированием . Для декодирования надо знать код.
История шифрования
Шифрование берет своё начало ещё из древних времен. Примерно 1300 лет до нашей эры был создан один из первых методов шифрования – Атбаш. Принцип шифрования заключается в простой подставке символов по формуле:, где:
n – количество символов в алфавите
i – порядковый номер символа.
Шифр получил своё название в честь первой, последней, второй и предпоследней буквы Еврейского алфавита - «алеф», «тав», «бет», «шин» . Такой шифр имеет низку криптографическую стойкость, потому как алгоритм шифрования довольно прост
С тех самых пор шифрование активно развивалось вместе с развитием нашей цивилизации
Первым делом выбирается два случайный простых числа, которые перемножаются друг на друга – именно это и есть открытый ключ.
К слову: Простые числа — это те числа, которые могут делиться без остатка либо на 1, либо на себя.
Длина таких чисел может быть абсолютно любая. К примеру, возьмем два простых числа 223 и 13. Их произведение 2899 – будет являться открытым ключом, который мы и будем передавать по открытому каналу связи. Далее нам необходимо вычислить функцию «Эйлера» для произведения этих чисел.
Функция Эйлера – количество натуральных чисел, меньших чем само число и, которые будут являть взаимно простыми числами с самим числом.
Возможно, звучит непонятно, но давайте это разберем на небольшом примере:
φ (26) [фи от двадцати шести] = какому-то числу чисел, которое всегда будет меньше 26, а сами числа должны иметь только один общий делитель единицу с 26.
1 – подходит всегда, идем дальше;
2 – делится и на 2, и на 1, как и число 26, - не подходит;
3 – делится и на 3, и на 1, а вот число 26 не делится на 3, - подходит;
4 – имеет общие делители 2 и 1 с 26 - не подходит;
5 – только на 1 - подходит;
6 – на 2 и 1 - не подходит;
7 – только на 1 – подходит;
и так далее до 25.
Общее количество таких чисел будет равно 12. А найти это число можно по формуле: φ(n*k) = (n-1)(k-1) в нашем случае 26 можно представить как 2 * 13, тогда получим φ(26) = φ(2 * 13) = (2-1)*(13-1) = 1 * 12 = 12
Теперь, когда мы знаем, что такое функция Эйлера и умеем её вычислять найдем её для нашего открытого ключа – φ(2899) = φ(223 * 13) =(223 – 1)*(13-1) = 222 * 12 = 2664
После чего нам нужно найти открытую экспоненту. Не пугайтесь, тут будет гораздо проще чем с функцией «Эйлера».
Открытая экспонента – это любое простое число, которое не делится на функцию Эйлера. Для примера возьмем 13. 13 не делится нацело на число 2664. Вообще открытую экспоненту лучше выбирать по возрастанию простым перебором, а не просто брать случайную. Так для нашего примера разумнее было бы взять число 5, но давайте рассмотрим на примере 13
Следующий шаг – закрытая экспонента. Вычисляется она банальным перебором по этому равенству: d * e mod φ(n) = 1 , где
φ(n) - функция Эйлера
e – открытая экспонента
mod – остаток отделения
а число d, которое и является закрытой экспонентой, мы должны подобрать перебором, либо попытаться выразить через формулу d = ceil(φ(n) / e) , где ceil – округление в большую сторону.
В обоих случаях у нас получится число 205
T – шифруемый текст
e – открытая экспонента
n – открытый ключ
mod – остаток от деления
92 ^ 13 mod 2899 = 235 . Именно число 235 он нам и отправит.
С – зашифрованный текст
d – закрытая экспонента
n – открытый ключ
mod – остаток от деления
235 ^ 205 mod 2899 = 92.
Но ничто в мире не идеально, в том числе и этот метод.
Его первый недостаток – это подборка пары чисел для открытого ключа. Нам нужно не просто сгенерировать случайно число, но ещё и проверить на то простое ли оно. На сегодняшний нет методов, которые позволяют делать это сверх быстро.
Второй недостаток – так же связан с генерацией ключа. Как мы с вами помним: «ключи должны генерировать независимо от каких-либо факторов», но именно это правило нарушается, когда мы пытается сгенерировать строго простые числа.
Третий недостаток – подбор и перебор чисел для экспонент.
Четвертый – длина ключей. Чем больше длина, тем медленнее идет процесс декодирования, поэтому разработчики пытаются использовать наименьшие по длиннее ключи и экспоненты. Даже я акцентировал на это внимание, когда говорил, что лучше взять число 5, вместо 13 для открытой экспоненты. Именно из-за этого и происходит большая часть взломов и утечек данных
Но не стоит печалиться, ведь как я и говорил: криптография и шифрование развивается вместе с развитием цивилизации. Поэтому довольно скоро все мы будем шифровать свои данные с помощью Квантового шифрование.
Этот метод основывается на принципе квантовой суперпозиции – элементарная частица может сразу находится в нескольких положениях, иметь разную энергию или разное направление вращения одновременно. По такому принципу и работает передача ключей шифрования по протоколу BB-84.

Вернемся к нашему ключу 101001011. Мы случайным образом выбираем направление – обычное или диагональное. Для удобства присвоим обычному номер 1, а диагональному 2.
Давайте отправим ключ – 1(1), 0(2), 1(1), 0(1), 0(1), 1(2), 0(2), 1(1), 1(2). Теперь человеку, которому мы отправляем ключ, нужно точно так же, совершенно случайно, выбрать случайное направление.
Допустим он выбрал направления: 221111212. Поскольку есть всего 2 плоскости отправки: 1 и 2, они же называются: канонический и диагональный базис, то шанс того, что он выбрал правильные направления 50%.

А что, если кто-то перехватит отправку кода? Тогда ему придется точно также подбирать случайным образом базисы, что добавит ещё 25% погрешности при получении кода человеку, которому мы изначально и отправили его. Чтобы проверить это, после отсеивания мы, как отправитель, должны проверить сколько процентов кода оказалось не верным. В нашем 1 случае это (9 – 7)/9 * 100% = 22% , если это число будет больше 50%, то мы начнем повторную отправку ключей, до тех пор, пока погрешность не будет меньше 50%
Задание 2
Закодировать текст Happy Birthday to you!! с помощью кодировочной таблицы ASCII
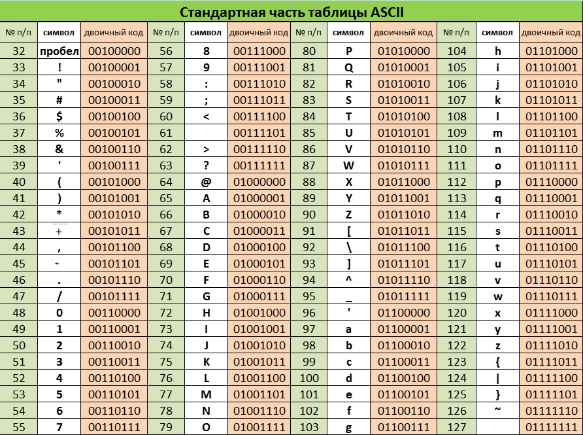
Записать двоичное и шестнадцатеричное представление кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
Кодирование текстовой информации
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Для хранения двоичного кода одного символа выделен 1 байт = 8 бит.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно 28 = 256. Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов. Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т.д.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Кодирование текстовой информации с помощью байтов опирается на несколько различных стандартов, но первоосновой для всех стал стандарт ASCII (American Standart Code for Information Interchange), разработанный в США в Национальном институте ANSI (American National Standarts Institute). В системе ASCII закреплены две таблицы кодирования - базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т.е. в национальных кодировках одному и тому же коду соответствуют различные символы. В настоящее время существует много различных кодовых таблиц для русских букв (КОИ-8, СР1251, СР866, Mac, ISO),поэтому тексты, созданные в одной кодировке , могут не правильно отображаться в другой.
Задание 7
С помощью табличного процессора Excel построить кодировочную таблицу ASCII, в которой символы буду автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).
Справочная информация
Алгоритм Хаффмена. Сжатием информации в памяти компьютера называют такое её преобразование, которое ведёт к сокращению объёма ханимаемой памяти при сохранении закодированного содержания. Рассмотрим один из способов сжатия текстовой информации - алгоритм Хаффмена. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьный кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рисунке приведён пример такого дерева, построенный для алфавита английского языка с учётом частоты встречаемости его букв.
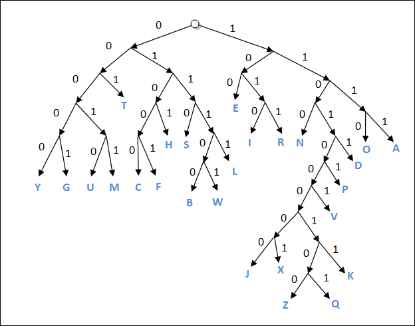
Закодируем с помощью данного дерева слово "hello":
0101 100 01111 01111 1110
При размещении этого кода в памяти побитово он примет вид:
010110001111011111110
Таким образом, текст, занимающий в кодировки ASCII 5 байтов, в кодировке Хаффмена займет 3 байта.
Кодирование графической информации
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек (пикселей). Каждому пикселю присвоен код, хранящий информацию о цвете пикселя.
Для получения черно-белого изображения (без полутонов) пиксель может принимать только два состояния: “белый” или “черный”. Тогда для его кодирования достаточно 1 бита:
Пиксель на цветном дисплее может иметь различную окраску. Поэтому 1 бита на пиксель – недостаточно.
Для кодирования 4-цветного изображения требуется два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов:
00 – черный 10 – зеленый
01 – красный 11 – коричневый
Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего. Из трех цветов можно получить восемь комбинаций:
1 1 0 Коричневый
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.
Шестнадцатицветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно.
В наш век интернет-технологий, когда мы доверяем все свои данные интернет-сервисам, нужно знать и понимать, как они их хранят и обрабатывают.
Но зачем это вообще нужно знать? Чтобы попросту не попасть в ситуацию, когда ваши личные данные, пароли от аккаунтов или банковских карт окажутся в руках мошенников. Как говорится: «Доверяй, но проверяй»
Важные аспекты в хранении данных, будь то на внешних серверах или домашнем компьютере, – это прежде всего кодирования и шифрование. Но чем они отличаются друг от друга? Давайте разбираться!
Ни для кого не секрет, что компьютер может хранить информацию, но он не может хранить её в привычной для нас форме: мы не сможем просто так написать на флешки реферат, не можем нарисовать на жестком диске картинку так, чтобы её мог распознать компьютер. Для этого информацию нужно преобразовать в язык понятный компьютеру, и именно этот процесс называется кодированием. Когда мы нажимаем на кнопку на клавиатуре мы передаем код символа, который может распознать компьютер, а не сам символ.
Заключение
Причитав и разобрав эту статью, мы с вами узнали, чем отличается кодирование от шифрования, их историю с будущим, узнали каким должен быть идеальный шифр и немного поговорили про крипто анализ. Уже с этими знаниями, которые были предоставлены в этой статье, можно спокойно идти и делать какую-нибудь систему авторизации или пытаться взломать какой-то сайт, главное не перебарщивать.
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
Определения и различия
Кодирование – процесс преобразования доступной нам информации в информацию понятную компьютерную.
Шифрование – процесс изменения информации таким образом, чтобы её смогли получить только нужные пользователи.
Шифрование применялось и задолго до создания компьютеров и информатики как таковой. Но зачем? Цели её применения можно было понять из определения, но я опишу их ещё раз более подробно. Главные цели шифрования это:
конфиденциальность – данные скрыты от посторонних
целостность – предотвращение изменения информации
идентифицируемость – возможность определить отправителя данных и невозможность их отправки без отправителя
Оценить стойкость шифра можно с помощью криптографической стойкости.
Криптографическая стойкость – это свойство шифра противостоять криптоанализу, изучению и дешифровки шифра.
Криптостойкость шифра делится на две основные системы: абсолютно стойкие системы и достаточно стойкие системы.
Абсолютно стойкие системы – системы не подверженные криптоанализу. Основные критерии абсолютно стойких систем:
Генерация ключей независима
К сожалению, такие системы не удобны в своём использовании: появляется передача излишней информации, которая требует мощных и сложных устройств. Поэтому на деле применяются достаточно стойкие системы.
Достаточно стойкие системы – системы не могут обеспечить полную защиту данных, но гораздо удобнее абсолютно стойких. Надежность таких систем зависит от возможностей крипто аналитика:
Времени и вычислительных способностей
А также от вычислительной сложности шифра.
Вычислительная сложность – совокупность времени работы шифрующей функции, объема входных данных и количества используемой памяти. Чем она больше, тем сложнее дешифровать шифр.
Задание 8
Используя метод сжатия Хаффмена, закодируйте следующие слова:
а) administrator
б) revolution
в) economy
г) department
1.2 Чередующиеся сигналы

Индеец пингует
В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы "включено/выключено". Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме "точка-тире", что нам даёт букву "A" может звучать и так - "точка-пауза-тире" и тогда это уже две буквы "ET".

Задание 1
Определить, какие символы кодируются таблицей ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
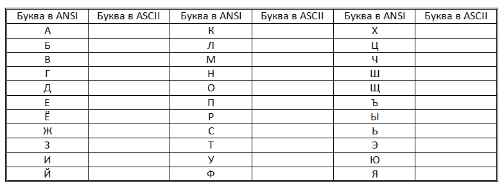
Задание 6
Текстовая информация
Принципиально важно, что текстовая информация уже дискретна — состоит из отдельных знаков. Поэтому возникает лишь технический вопрос — как разместить ее в памяти компьютера.
Напомним о байтовом принципе организации памяти компьютеров, обсуждавшемся в курсе информатики основной школы. Вернемся к рис. 1.5. Каждая клеточка на нем обозначает бит памяти. Восемь подряд расположенных битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера. Именно по адресам процессор обращается к данным, читая или записывая их в память (рис. 1.10).

Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную систему кодировки Unicode, в которой используются многобайтовые коды. Например, если код символа занимает 2 байта, то с его помощью можно закодировать 2 16 = 65 536 различных символов.
Текстовый документ, хранящийся в памяти компьютера, состоит не только из кодов символьного алфавита. В нем также содержатся коды, управляющие форматами текста при его отображении на мониторе или на печати: тип и размер шрифта, положение строк, поля и отступы и пр. Кроме того, текстовые процессоры (например, Microsoft Word) позволяют включать в документ и редактировать такие «нелинейные» объекты, как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и т. д. Всё это также представляется в виде последовательности байтовых кодов.
Задание 9
Используя дерево Хаффмена, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
б) 00010110 01010110 10011001 01101101 01000100 000

С прошлого учебного года моя методическая тема: «Формирование универсальных учебных действий в условиях дифференцированного подхода на уроках физики и информатики как эффективное средство развития самоконтроля учащихся»
Мы хотим представить вашему вниманию материалы, находящиеся в стадии разработки.
Вы знаете, что существует три мотива, стимула, побуждающих учащихся заниматься.
Во – первых, интерес к предмету. «Я изучаю предмет не потому, что преследую какую-то цель, а потому, что сам процесс изучения доставляет мне удовольствие». Высшая степень интереса – это тоже увлечение. Занятия при увлечении порождают сильные положительные эмоции, а невозможность заниматься воспринимается как лишение.
Во – вторых, сознательность. «Занятия по данному предмету мне скучны, но я осознаю их необходимость и усилием воли заставляю себя заниматься».
В – третьих, принуждение. «Я занимаюсь потому, что кто-то заставляет». Это принуждение иногда поддерживается страхом наказания и соблазном награды (отметки, поощрения).
Интерес к предмету – самый сильный стимул к обучению, он в очень высокой степени повышает производительность занятий. При этом материал усваивается легко.
Для того, чтобы подобрать приемы и методы обучения, нужно знать насколько высока мотивации ученика. Наблюдение не всегда дает точный результат, так как мотив – это скрытая внутренняя составляющая личности, поэтому было принято решение провести небольшое психологическое исследование.
При анкетировании учащихся 28 и 39 колонии весной этого года мы выяснили следующее. Методика изучения мотивации учения старшеклассников по Окуневой и Васильевой показала, что 7% школьников имеют очень высокий уровень мотивации, 74,4% - высокий уровень мотивации, 18,6% - средний уровень. Эти уровни показывают, насколько сильным для школьников является личностный смысл учения.
Интерес к уроку можно поддерживать различными приемами обучения.
Нашим учащимся, в отличие от учеников других общеобразовательных школ характерны низкая база знаний, продолжительные пропуски в учебе и т.д., поэтому нам как никому нужно учитывать уровень подготовленности каждого ученика. Исходя из этого, возникла проблема увлечь и подобрать приемы и задания, дифференцированные по уровню сложности, для организации самостоятельной деятельности учащегося.
Контроль и оценивание знаний – важнейший момент в организации учебного процесса.
Проблема контроля учебных достижений всегда очень актуальна, особенно по такому предмету как информатика. Где существует граница между теоретическими знаниями и практическими навыками и умениями учащихся? Учащиеся могут успешно работать за компьютером, но при этом не владеть теоретической частью.
Все мы понимаем, что знания будут усвоены тогда, когда учащиеся смогут пользоваться ими, применить полученные знания на практике в незнакомых ситуациях. Научить применять знания, значит, научить ученика набору умственных действий. Любое усвоение знаний строится на усвоении учеником учебных действий, овладев которыми, ученик смог бы усваивать знания самостоятельно, пользуясь различными источниками информации. Научить учиться, а именно усваивать и должным образом перерабатывать информацию – главный тезис информационно - деятельностного подхода к обучению. Это полностью соответствует требованию формирования УУД в новом образовательном стандарте.
В настоящее время тестовые контрольные работы очень распространены. Их отличие от обычных в том, что они не требуют от учеников письменных изложений, экономны в отношении времени, имеют многоцелевое назначение.
По определению, учебный тест – стандартизированные, краткие, ограниченные во времени испытания, предназначенные для установления количественных и качественных результатов обучения. Несмотря на то, что ведется много споров по поводу использования тестов для контроля и оценки качества знаний, на мой взгляд, именно тестовый контроль подходит для оценки учителем работы учащихся с материалом раздела, особенно теоретическим. Тесты заставляют учащихся мыслить логически, использовать зрительное внимание, укреплять память, что очень проблематично для наших учеников.
Ученикам нравиться работать с тестами в силу их возрастных психологических особенностей.
Тесты и по назначению могут быть разные: входное тестирование, тест – разминка, контрольное тестирование, аттестационное тестирование и т.д.. Задания с выборочным ответом (тезисы) на контролирующем этапе, на котором учитель производит оценку подготовленности учащихся по предмету, направляют усилия учащегося на использование определённого приёма мыслительной деятельности, побуждают учащихся к самооценке и самоконтролю умений, знаний и их комплексного применения на практике.
Основной задачей педагогического использования тестов является определение объема и качества знаний, а также уровня умений и навыков.
В связи с этим выделяют три класса тестов: знаний, умений и навыков. Типы тестовых заданий определяются способами однозначного распознавания ответных действий тестируемого.
Типы тестовых заданий по блоку "знания":
- альтернативные вопросы (требуют ответа "да/нет");
- вопросы с выбором (ответ выбирается из готового набора вариантов);
- информативные вопросы на знание фактов (где, когда, сколько);
- вопросы, ответы на которые можно распознать каким-либо методом однозначно.
Типы тестовых заданий по блоку "навыки" (распознавание деятельности манипуляций с клавиатурой, по конечному результату):
- задания на стандартные алгоритмы (альтернативные "да/нет", выбор из набора вариантов);
- выполнение определенных действий.
Типы тестовых заданий по блоку "умения":
- задания на нестандартные алгоритмы (альтернативные "да/нет", выбор из набора вариантов);
- выполнение определенных действий.
Предложенные тесты и тезисы в большой степени учитывают сложный характер самого предмета изучения – информатики и особенностей её функционирования и развития.
Каким образом можно применять тесты?
На уроках используются различные подходы к организации контроля.
- выборочный – когда «слабым» учащимся выдается упрощенные задания, «средним» – усреднные, а «сильным» – дополнительные
Но при таком подходе закрепляется разделение учащихся на указанные категории, уровень развития затормаживается
- поступательный – контроль предусматривает для всех одинаковый набор заданий, расположенных по возрастанию трудности. Но учащиеся разных уровней выполняют соответственно различное их количество. Здесь уже наблюдается рост способностей учащихся.
- следующий прием – учащимся выдаются одинаковые задания, в требуемом программой объеме, а дифференцируется помощь учителя: слабым – с указаниями по выполнению, средним – достаточно подсказки, сильные выполняют задания самостоятельно. Этот прием позволяет учащимся систематически улучшать свои способности, у них появляется уверенность в своих силах. Достоинства учащихся не ущемляются – задания были одинаковыми, и все с ними справились.
Проблема выбора ученика на уроке также может быть решена: по желанию ученик выбирает задание либо на «3», либо на «4», либо на «5».
Если нет компьютеров –вариант использования тестов в печатном виде. Но когда компьютеры есть, возможность использования тестов гораздо шире.
Конечно, метод тестов – не нов, их используют все. Но часто у учителя возникают затруднения при определении целесообразности выбора вида теста на конкретном этапе урока.
Поэтому мы предлагаем для использования в работе следующую форму – рекомендацию «Примерная таблица по использованию тестовой формы работы в урочной деятельности учителя». В ней предусматриваются следующие моменты:
- звенья процесса обучения и структурные компоненты урока;
- виды тестов, наиболее адекватных конкретной дидактической задаче;
- цели использования данных видов тестов.
Хотелось еще предложить вашему вниманию программу «Информатика» , которую мы часто используем на уроке, учащиеся очень охотно с ней работают. Программа предусматривает тестирование по разделам предмета, по различным уровням и количеству вопросов в тестах. Это может быть и самостоятельный выбор учащегося для изучения пропущенной темы.
Где можно найти помощь в создании различных тестов?
Программы My Test XPro
Центр развития и мышления – «вот задачка»
Большая перемена – всероссийский фестиваль знаний, электронный журнал «Помощник учителя», конкурсы, викторины, педагогическое тестирование, олимпиады
Конкурсы, гранды, премии, фестивали – реклама всевозможных конкурсов для учеников и педагогов
На сайте нашей школы можно найти тесты по всем предметам
Предлагаю внести в решение педсовета рекомендацию по использованию представленных материалов в педагогической деятельности
1.1 Речь, мимика, жесты
Удивительно, но всё это - коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода - улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль - как форма, удобная для непосредственного использования, преобразуется в речь - форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда - человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
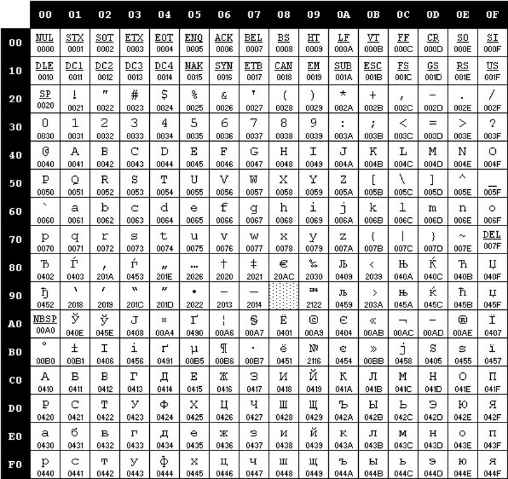
1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной - звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук - череда дискретных значений о звуковом сигнале, видео - череда кадров изображений, текст - череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим - час или даже пара недель.
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
72 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты - бит и байт. Бит, как атом информации, а байт - как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза "ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП".

2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Урок 13. Представление текстовой информации в компьютере. Кодовые таблицы.
Практическая работа № 4. Представление текстов. Сжатие текстов

В этом параграфе обсудим способы компьютерного кодирования текстовой, графической и звуковой информации. С текстовой и графической информацией конструкторы «научили» работать ЭВМ, начиная с третьего поколения (1970-е годы). А работу со звуком «освоили» лишь машины четвертого поколения, современные персональные компьютеры. С этого момента началось распространение технологии мультимедиа.
Что принципиально нового появлялось в устройстве компьютеров с освоением ими новых видов информации? Главным образом, это периферийные устройства для ввода и вывода текстов, графики, видео, звука. Процессор же и оперативная память по своим функциям изменились мало. Существенно возросло их быстродействие, объем памяти. Но как это было на первых поколениях ЭВМ, так и осталось на современных ПК — основным навыком процессора в обработке данных является умение выполнять вычисления с двоичными числами. Обработка текста, графики и звука представляет собой тоже обработку числовых данных. Если сказать еще точнее, то это обработка целых чисел. По этой причине компьютерные технологии называют цифровыми технологиями.
О том, как текст, графика и звук сводятся к целым числам, будет рассказано дальше. Предварительно отметим, что здесь мы снова встретимся с главной формулой информатики:
Смысл входящих в нее величин здесь следующий: i — разрядность ячейки памяти (в битах), N — количество различных целых положительных чисел, которые можно записать в эту ячейку.
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101101 00100000 01010101
01101110 01101001 01110110 01100101 01110010 01110011
01101001 01110100 01111001
Практикум
Практическая работа № 1.4 "Представление текстов. Сжатие текстов"
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики - базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом - не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня - табличка с надписью, знак на дороге, светофоры, и для современного мира - штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
Читайте также: