
С помощью какого метода можно получить файл из интернета
Обратите внимание, fetch спецификация отличается от jQuery.ajax() в основном в двух пунктах:
25 августа 2017 г. в спецификации изменилось значение по умолчанию свойства credentials на same-origin . Firefox применяет это изменение с версии 61.0b13.
Базовый запрос на получение данных действительно прост в настройке. Взгляните на следующий код:
Здесь мы забираем JSON файл по сети и выводим его содержимое в консоль. Самый простой способ использования fetch() заключается в вызове этой функии с одним аргументом — строкой, содержащей путь к ресурсу, который вы хотите получить — которая возвращает promise, содержащее ответ (объект Response ).
Примечание: Миксин Body имеет подобные методы для извлечения других типов контента; см. раздел Тело.
Fetch-запросы контролируются посредством директивы connect-src (Content Security Policy), а не директивой извлекаемых ресурсов.
В чем проблема?
Первоначальная загрузка страницы в Интернете была простой - вы отправляли запрос на сервер web-сайта, и если всё работает, как и должно, то вся необходимая информация о странице будет загружена и отображена на вашем компьютере.

Проблема с этой моделью заключается в том, что всякий раз, когда вы хотите обновить любую часть страницы, например, чтобы отобразить новый набор продуктов или загрузить новую страницу, вам нужно снова загрузить всю страницу. Это очень расточительно и приводит к плохому пользовательскому опыту, особенно по мере того, как страницы становятся все более сложными.
На стороне сервера: получение данных
Пример: Чистый PHP

Пример: Python
Этот пример показывает, как вы можете использовать Python для решения той же задачи — отобразить отправленные данные на странице. В этом примере используется Flask framework для визуализации шаблонов, поддерживающих форму отправки данных (смотри python-example.py).
Два шаблона из коде выше взаимодействуют так:
-
: Та же форма, что и выше The POST method , только с использованием action к > . (Это Jinja2 шаблон, который изначально HTML, но может содержать вызовы Python кода в фигурных скобках, которые запустятся веб-сервером. url_for('hello') буквально говорит: после отправки данных переадресуй их в /hello .) : Этот шаблон просто содержит строку, которая отображает два бита данных, переданных ему при отображении. Это сделано с помощью функции hello() , указанной выше, которая выполняется, когда запрос направляется в /hello URL.
Примечание: Опять же, этот код не будет работать, если вы просто попробуете загрузить его прямо в браузер. Python работает немного иначе, чем PHP — чтобы запустить этот код, нужно установить Python/PIP, потом установить Flask используя команду: pip3 install flask . После этого, вы сможете запустить файл из примера, используя команду: python3 python-example.py , потом открыть localhost:5000 в своём браузере.
Другие языки и фреймворки
-
для Python (немного тяжеловеснее, чем Flask, но больше инструментов и опций) для Node.js для PHP для Ruby для Elixir
Стоит отметить, что использование фреймворков и работа с формами - это не всегда легко. Но это намного легче, чем пытаться написать аналогичную функциональность с нуля, и это определённо сэкономит время.
Примечание: Обучению фреймворкам и работе с серверами не входит в рамки этой статьи. Если хотите узнать больше, ссылки ниже помогут в этом.
Функция обнаружения
Поддержка Fetch API может быть обнаружена путём проверки наличия Headers (en-US), Request , Response или fetch() (en-US) в области видимости Window или Worker . Для примера:
Fetch
Давайте преобразуем последний пример, чтобы использовать Fetch!
Сделайте копию своего предыдущего готового каталога примеров. (Если вы не работали над предыдущим упражнением, создайте новый каталог и внутри него создайте копии xhr-basic.html и четырёх текстовых файлов — verse1.txt, verse2.txt, verse3.txt и verse4.txt.)
Внутри функции updateDisplay() найдите код XHR:
Замените весь XHR-код следующим:
Загрузите пример в свой браузер (запустите его через веб-сервер), и он должен работать так же, как и версия XHR, при условии, что вы используете современный браузер.
Итак, что происходит в коде Fetch?
Прежде всего, мы вызываем метод fetch() , передавая ему URL-адрес ресурса, который мы хотим получить. Это современный эквивалент request.open() в XHR, плюс вам не нужен эквивалент .send() .
После этого вы можете увидеть метод .then() , прикреплённый в конец fetch() - этот метод является частью Promises - современная функция JavaScript для выполнения асинхронных операций. fetch() возвращает промис, который разрешает ответ, отправленный обратно с сервера, - мы используем .then() для запуска некоторого последующего кода после того, как промис будет разрешено, что является функцией, которую мы определили внутри неё. Это эквивалент обработчика события onload в XHR-версии.
Эта функция автоматически передаёт ответ от сервера в качестве параметра, когда обещает fetch() . Внутри функции мы берём ответ и запускаем его метод text() (en-US), который в основном возвращает ответ как необработанный текст. Это эквивалент request.responseType = 'text' в версии XHR.
Вы увидите, что text() также возвращает промис, поэтому мы привязываем к нему другой .then() , внутри которого мы определяем функцию для получения необработанного текста, который выполняет text() .
Внутри функции внутреннего промиса мы делаем то же самое, что и в версии XHR, - устанавливаем текстовое содержимое в текстовое значение.
Какой механизм следует использовать?
Это действительно зависит от того, над каким проектом вы работаете. XHR существует уже давно и имеет отличную кросс-браузерную поддержку. Fetch and Promises, с другой стороны, являются более поздним дополнением к веб-платформе, хотя они хорошо поддерживаются в браузере, за исключением Internet Explorer и Safari (которые на момент написания Fetch были доступны в своём предварительный просмотр технологии).
Если вам необходимо поддерживать старые браузеры, тогда может быть предпочтительным решение XHR. Если, однако, вы работаете над более прогрессивным проектом и не так обеспокоены старыми браузерами, то Fetch может быть хорошим выбором.
Вам действительно нужно учиться - Fetch станет более популярным, так как Internet Explorer отказывается от использования (IE больше не разрабатывается, в пользу нового браузера Microsoft Edge), но вам может понадобиться XHR ещё некоторое время.
Заголовки
Интерфейс Headers (en-US) позволяет вам создать ваш собственный объект заголовков через конструктор Headers() (en-US). Объект заголовков - простая мультикарта имён-значений:
То же может быть достигнуто путём передачи массива массивов или литерального объекта конструктору:
Содержимое может быть запрошено и извлечено:
Некоторые из этих операций могут быть использованы только в ServiceWorkers (en-US), но они предоставляют более удобный API для манипуляции заголовками.
Все методы Headers выбрасывают TypeError , если имя используемого заголовка не является валидным именем HTTP Header. Операции мутации выбросят TypeError если есть защита от мутации (смотрите ниже) (прим.пер.: "if there is an immutable guard"). В противном случае они прерываются молча. Например:
Хорошим вариантом использования заголовков является проверка корректности типа контента перед его обработкой. Например:
Отправка данных в формате JSON
При помощи fetch() (en-US) можно отправлять POST-запросы в формате JSON.
XSS "Межсайтовый скриптинг" и CSRF "Подделка межсайтовых запросов"
Межсайтовый скриптинг (XSS "Cross Site Request Forgery") и подделка межсайтовых запросов (CSRF "Cross-Site Scripting") - это распространённые типы атак, которые происходят при отображении данных после ответа сервера или другого пользователя.
Межсайтовый скриптинг (XSS "Cross Site Request Forgery") позволяет злоумышленникам внедрить клиентский скрипт в веб-страницы, просматриваемые другими пользователями. Подделка межсайтовых запросов (CSRF "Cross-Site Scripting") может использоваться злоумышленниками для обхода средств контроля доступа, таких как одна и та же политика происхождения. Последствие от этих атак может варьироваться от мелких неудобств до значительного риска безопасности.
CSRF-атаки аналогичны XSS-атакам в том, что они начинаются одинаково - с внедрения клиентского скрипта в веб-страницы - но их конечные цели разные. Злоумышленники CSRF пытаются назначить права пользователям с более высоким уровнем прав доступа(например, администратору сайта), чтобы выполнить действие, которое они не должны выполнять (например, отправка данных ненадёжному пользователю). Атаки XSS используют доверие пользователя к веб-сайту, в то время как атаки CSRF используют доверие веб-сайта к пользователю.
Чтобы предотвратить эти атаки, вы всегда должны проверять данные, которые пользователь отправляет на ваш сервер, и (если вам нужно отобразить их) стараться не отображать HTML-контент, предоставленный пользователем. Вместо этого вы должны обработать предоставленные пользователем данные, чтобы не отображать их слово в слово. Сегодня почти все платформы на рынке реализуют минимальный "фильтр", который удаляет элементы HTML , (en-US) и (en-US) полученных от любого пользователя. Это помогает снизить риск, но не исключает его полностью.
Проблемы безопасности
Каждый раз, когда вы отправляете данные на сервер, вы должны учитывать безопасность. HTML-формы являются наиболее распространёнными векторами атак на серверы(места, где могут происходить атаки). Проблемы вытекают не из самих форм HTML, а из-за того, как сервер обрабатывает данные из этих форм.
В зависимости от того, что вы делаете, вы можете столкнуться с некоторыми очень известными проблемами безопасности:
Проверка успешности запроса
В методе fetch() (en-US) promise будет отклонён (reject) с TypeError , когда случится ошибка сети или не будет сконфигурирован CORS на стороне запрашиваемого сервера, хотя обычно это означает проблемы доступа или аналогичные — для примера, 404 не является сетевой ошибкой. Для достоверной проверки успешности fetch() будет включать проверку того, что promise успешен (resolved), затем проверку того, что значение свойства Response.ok (en-US) является true. Код будет выглядеть примерно так:
Метод GET
Рассмотрим следующую форму:

Данные добавляются в URL как последовательность пар имя / значение. После того, как URL веб-адрес закончился, мы добавляем знак вопроса ( ? ), за которым следуют пары имя / значение, каждая из которых разделена амперсандом ( & ). В этом случае мы передаём две части данных на сервер:
- say , со значением Hi
- to , со значением Mom
Примечание: вы можете найти этот пример на GitHub — смотрите get-method.html (see it live also).
Резюме
Это завершает нашу статью по извлечению данных с сервера. К этому моменту вы должны иметь представление о том, как начать работать как с XHR, так и с Fetch.
Метод POST
Давайте рассмотрим пример — это та же самая форма, которую мы рассматривали в разделе GET выше, но с атрибутом method , установленным в post .
Заголовок Content-Length указывает размер тела, а заголовок Content-Type указывает тип данных, отправляемых на сервер. Мы обсудим эти заголовки позже.
Примечание: вы можете найти этот пример на GitHub — смотрите post-method.html (see it live also).
- Нажмите F12
- Выберите Network
- Выберите "All"
- Выберите "foo.com" во вкладке "Name"
- Выберите "Headers"
Затем вы можете получить данные формы, как показано на рисунке ниже.

Единственное, что отображается пользователю — вызываемый URL. Как упоминалось раннее, запрос с методом GET позволит пользователю увидеть информацию из запроса в URL, а запрос с методом POST не позволит. Две причины, почему это может быть важно:
Смотрите также
Однако в этой статье обсуждается много разных тем, которые только поцарапали поверхность. Для получения более подробной информации по этим темам, попробуйте следующие статьи:
В этой статье рассматривается, что происходит, когда пользователь отправляет форму - куда передаются данные и как мы их обрабатываем, когда они туда попадают? Мы также рассмотрим некоторые проблемы безопасности, связанные с отправкой данных формы.
| Предварительные знания: | Базовая компьютерная грамотность, понимание HTML и базовые знания по HTTP и программированию на стороне сервера. |
|---|---|
| Задача: | Понять, что происходит при отправке данных формы, в том числе получить представление о том, как данные обрабатываются на стороне сервера. |
Будьте параноиком: никогда не доверяйте вашим пользователям
Как вы боретесь с такими угрозами? Этот вопрос выходит далеко за рамки данной статьи, но есть несколько общих правил, которые следует всегда соблюдать. Самое важное из них - никогда не доверяйте вашим пользователям, в том числе себе; даже проверенный пользователь может быть атакован.
Все данные, поступающие на ваш сервер, необходимо проверять и санитизировать. Все и всегда. Без исключений.
- Избегайте потенциально опасных символов. Конкретные символы, с которыми следует соблюдать осторожность, зависят от контекста, в котором используются данные, а также от используемой платформы. Однако, все языки на стороне сервера имеют соответствующие функции для обеспечения такой защиты.
- Ограничьте входящий объем данных для поступления только реально необходимых данных.
- Помещайте загруженные файлы в песочницу (храните их на другом сервере и предоставляйте доступ к фалам только через отдельный поддомен или даже через совершенно другое доменное имя).
Соблюдая эти три правила, вы сможете избежать многих/большинства проблем. При этом следует помнить, что периодически необходимо проводить анализ защищённости, желательно квалифицированной сторонней организацией. Не считайте, что вы уже сталкивались со всеми возможными угрозами.
Примечание: В статье Безопасность веб-сайта нашего раздела серверного обучения приведено подробное обсуждение упомянутых угроз и возможных способов их устранения.
Загрузка файла на сервер
На сервер можно загрузить файл, используя комбинацию HTML-элемента , FormData() и fetch() .
Составление своего объекта запроса
Вместо передачи пути ресурса, который вы хотите запросить вызовом fetch() , вы можете создать объект запроса, используя конструктор Request() (en-US), и передать его в fetch() аргументом:
Конструктор Request() принимает точно такие же параметры, как и метод fetch() . Вы даже можете передать существующий объект запроса для создания его копии:
Довольно удобно, когда тела запроса и ответа используются единожды (прим.пер.: "are one use only"). Создание копии как показано позволяет вам использовать запрос/ответ повторно, при изменении опций init , при желании. Копия должна быть сделана до прочтения тела, а чтение тела в копии также пометит его прочитанным в исходном запросе.
Примечание: Также есть метод clone() (en-US), создающий копии. Оба метода создания копии прекратят работу с ошибкой если тело оригинального запроса или ответа уже было прочитано, но чтение тела клонированного ответа или запроса не приведёт к маркировке оригинального.
Основной запрос Ajax
Этот набор файлов будет действовать как наша поддельная база данных; в реальном приложении мы с большей вероятностью будем использовать серверный язык, такой как PHP, Python или Node, чтобы запрашивать наши данные из базы данных. Здесь, однако, мы хотим сохранить его простым и сосредоточиться на стороне клиента.
Чтобы начать этот пример, создайте локальную копию ajax-start.html и четырёх текстовых файлов - verse1.txt, verse2.txt, verse3.txt и verse4.txt - в новом каталоге на вашем компьютере. В этом примере мы загрузим другое стихотворение (который вы вполне можете распознать) через XHR, когда он будет выбран в выпадающем меню.
Внутри элемента добавьте следующий код. В нем хранится ссылка на элементы и в переменных и определяется onchange обработчика событий, так что, когда значение select изменяется, его значение передаётся вызываемой функции updateDisplay() в качестве параметра.
Давайте определим нашу функцию updateDisplay() . Прежде всего, поставьте следующее ниже своего предыдущего блока кода - это пустая оболочка функции:
Тем не менее, веб-серверы, как правило, чувствительны к регистру, и имя файла не имеет символа "пробела". Чтобы преобразовать «Verse 1» в «verse1.txt», нам нужно преобразовать V в нижний регистр, удалить пробел и добавить .txt в конец. Это можно сделать с помощью replace () , toLowerCase () и простой конкатенации строк. Добавьте следующие строки внутри функции updateDisplay() :
Затем мы зададим тип ожидаемого ответа, который определяется как свойство responseType - как text . Здесь это не является абсолютно необходимым - XHR возвращает текст по умолчанию - но это хорошая идея, чтобы привыкнуть к настройке этого, если вы хотите получить другие типы данных в будущем. Добавьте следующее:
Получение ресурса из сети - это asynchronous операция, означающая, что вам нужно дождаться завершения этой операции (например, ресурс возвращается из сети), прежде чем вы сможете сделать что-либо с этим ответом, иначе будет выброшена ошибка. XHR позволяет вам обрабатывать это, используя обработчик события onload - он запускается при возникновении события load (en-US) (когда ответ вернулся). Когда это произойдёт, данные ответа будут доступны в свойстве response (ответ) объекта запроса XHR.
Добавьте следующее ниже вашего последнего дополнения. Вы увидите, что внутри обработчика события onload мы устанавливаем textContent poemDisplay (элемент ) в значение request. response .
Вышеприведённая конфигурация запроса XHR фактически не будет выполняться до тех пор, пока мы не вызовем метод send() . Добавьте следующее ниже вашего предыдущего дополнения для вызова функции:
10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
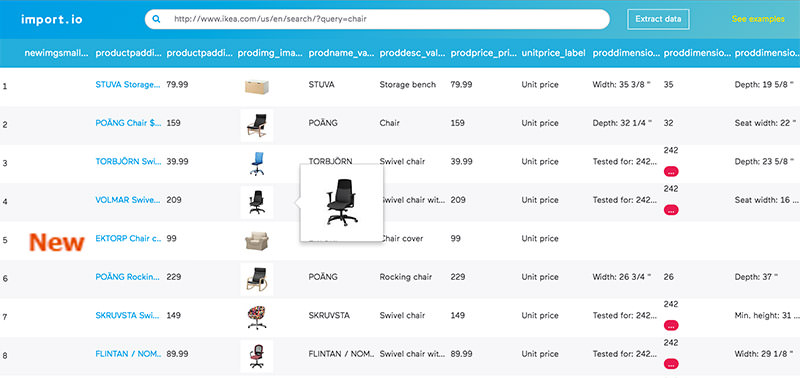
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.

Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.

Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.

ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
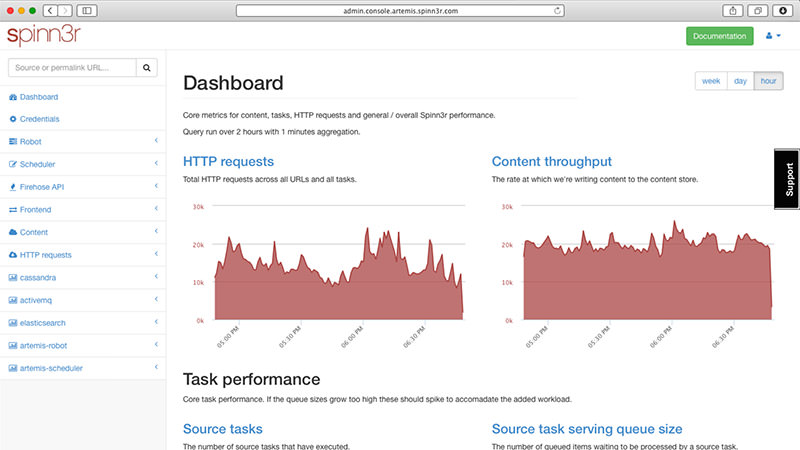
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.

Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
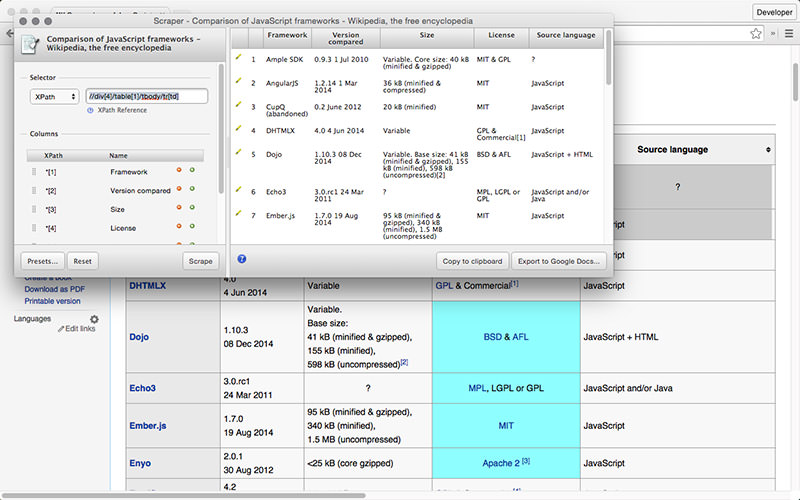
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
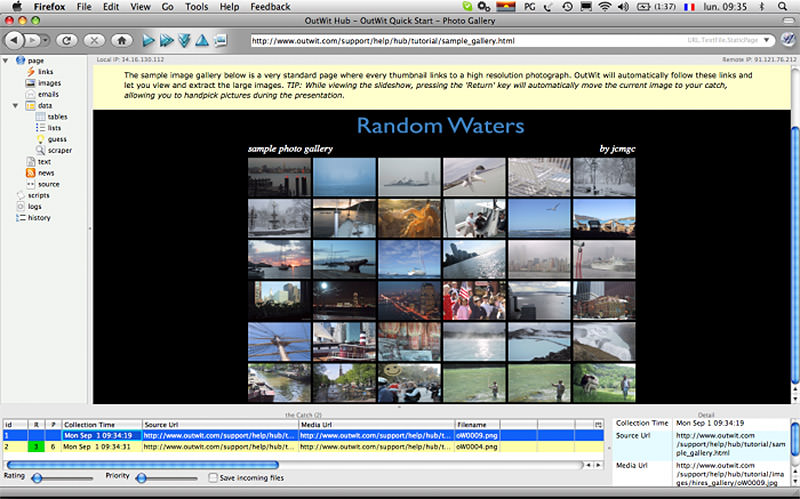
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Куда отправляются данные?
Здесь мы обсудим, что происходит с данными при отправке формы.
Обслуживание вашего примера с сервера
Некоторые браузеры (включая Chrome) не будут запускать запросы XHR, если вы просто запускаете пример из локального файла. Это связано с ограничениями безопасности (для получения дополнительной информации о безопасности в Интернете, ознакомьтесь с Website security).
Чтобы обойти это, нам нужно протестировать пример, запустив его через локальный веб-сервер. Чтобы узнать, как это сделать, прочитайте Как настроить локальный тестовый сервер?
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
| Необходимые условия: | Основы JavaScript (см. первые шаги, структурные элементы, объекты JavaScript), основы клиентских API |
|---|---|
| Задача: | Узнать, как извлекать данные с сервера и использовать их для обновления содержимого веб-страницы. |
Смотрите также
Если вы хотите узнать больше об обеспечении безопасности веб-приложений, вы можете использовать следующие источники информации:
Отправка запроса с учётными данными
Чтобы браузеры могли отправлять запрос с учётными данными (даже для cross-origin запросов), добавьте credentials: 'include' в объект init , передаваемый вами в метод fetch() :
Если вы хотите отправлять запрос с учётными данными только если URL принадлежит одному источнику (origin) что и вызывающий его скрипт, добавьте credentials: 'same-origin' .
Напротив, чтобы быть уверенным, что учётные данные не передаются с запросом, используйте credentials: 'omit' :
Обработка текстового файла построчно
Фрагменты данных, получаемые из ответа, не разбиваются на строки автоматически (по крайней мере с достаточной точностью) и представляют собой не строки, а объекты Uint8Array . Если вы хотите загрузить текстовый файл и обрабатывать его по мере загрузки построчно, то на вас самих ложится груз ответственности за обработку всех упомянутых моментов. Как пример, далее представлен один из способов подобной обработки с помощью создания построчного итератора (для простоты приняты следующие допущения: текст приходит в кодировке UTF-8 и ошибки получения не обрабатываются).
Установка параметров запроса
Метод fetch() может принимать второй параметр - объект init , который позволяет вам контролировать различные настройки:
С подробным описанием функции и полным списком параметров вы можете ознакомиться на странице fetch() (en-US).
Установка параметров запроса
Метод fetch() может принимать второй параметр - объект init , который позволяет вам контролировать различные настройки:
С подробным описанием функции и полным списком параметров вы можете ознакомиться на странице fetch() (en-US).
Помимо промисов
Промисы немного запутывают первый раз, когда вы их встречаете, но не беспокойтесь об этом слишком долго. Через некоторое время вы привыкнете к ним, особенно, когда вы узнаете больше о современных JavaScript-API. Большинство из них в большей степени основаны на промисах.
Давайте посмотрим на структуру промисов сверху, чтобы увидеть, можем ли мы ещё немного понять это:
Фактически, функция, переданная в then() , представляет собой кусок кода, который не запускается немедленно - вместо этого он будет работать в какой-то момент в будущем, когда ответ будет возвращён. Обратите внимание, что вы также можете сохранить своё промис в переменной и цепочку .then() вместо этого. Ниже код будет делать то же самое:
Но имеет смысл называть параметр тем, что описывает его содержимое!
Теперь давайте сосредоточимся только на функции:
Объект ответа имеет метод text() (en-US), который берёт необработанные данные, содержащиеся в теле ответа, и превращает его в обычный текст, который является форматом, который мы хотим в нем А также возвращает промис (который разрешает полученную текстовую строку), поэтому здесь мы используем другой .then() , внутри которого мы определяем другую функцию, которая диктует что мы хотим сделать с этой текстовой строкой. Мы просто устанавливаем свойство textContent элемента нашего стихотворения равным текстовой строке, так что это получается довольно просто.
Также стоит отметить, что вы можете напрямую связывать несколько блоков промисов ( .then() , но есть и другие типы) на конце друг друга, передавая результат каждого блока следующему блоку по мере продвижения по цепочке , Это делает промисы очень мощными.
Следующий блок делает то же самое, что и наш оригинальный пример, но написан в другом стиле:
Многие разработчики любят этот стиль больше, поскольку он более плоский и, возможно, легче читать для более длинных цепочек промисов - каждое последующее промис приходит после предыдущего, а не внутри предыдущего (что может стать громоздким). Единственное отличие состоит в том, что мы должны были включить оператор return перед response.text() , чтобы заставить его передать результат в следующую ссылку в цепочке.
Загрузка нескольких файлов на сервер
На сервер можно загрузить несколько файлов, используя комбинацию HTML-элемента , FormData() и fetch() .
Более сложный пример
Чтобы завершить статью, мы рассмотрим несколько более сложный пример, который показывает более интересные применения Fetch. Мы создали образец сайта под названием The Can Store - это вымышленный супермаркет, который продаёт только консервы. Вы можете найти этот пример в прямом эфире на GitHub и посмотреть исходный код.

По умолчанию на сайте отображаются все продукты, но вы можете использовать элементы управления формы в столбце слева, чтобы отфильтровать их по категориям, поисковому запросу или и тому и другому.
Существует довольно много сложного кода, который включает фильтрацию продуктов по категориям и поисковым запросам, манипулирование строками, чтобы данные отображались правильно в пользовательском интерфейсе и т.д. Мы не будем обсуждать все это в статье, но вы можете найти обширные комментарии в коде (см. can-script.js).
Однако мы объясним код Fetch.
Первый блок, который использует Fetch, можно найти в начале JavaScript:
Это похоже на то, что мы видели раньше, за исключением того, что второй промис находится в условном выражении. В этом случае мы проверяем, был ли возвращённый ответ успешным - свойство response.ok (en-US) содержит логическое значение, которое true , если ответ был в порядке (например, 200 meaning "OK") или false , если он не увенчался успехом.
Если ответ был успешным, мы выполняем второй промис - на этот раз мы используем json() (en-US), а не text() (en-US), так как мы хотим вернуть наш ответ как структурированные данные JSON, а не обычный текст.
Вы можете проверить сам случай отказа:
Второй блок Fetch можно найти внутри функции fetchBlob() :
Это работает во многом так же, как и предыдущий, за исключением того, что вместо использования json() (en-US) мы используем blob() (en-US) - в этом случае мы хотим вернуть наш ответ в виде файла изображения, а формат данных, который мы используем для этого - Blob - этот термин является аббревиатурой от« Binary Large Object »и может в основном использоваться для представляют собой большие файловые объекты, такие как изображения или видеофайлы.
После того как мы успешно получили наш blob, мы создаём URL-адрес объекта, используя createObjectURL() . Это возвращает временный внутренний URL-адрес, указывающий на объект, указанный в браузере. Они не очень читаемы, но вы можете видеть, как выглядит, открывая приложение Can Store, Ctrl-/щёлкнуть правой кнопкой мыши по изображению и выбрать опцию «Просмотр изображения» (которая может немного отличаться в зависимости от того, какой браузер вы ). URL-адрес объекта будет отображаться внутри адресной строки и должен выглядеть примерно так:
Атрибут enctype
Этот атрибут позволяет конкретизировать значение в Content-Type HTTP заголовок, включённый в запрос, при генерировании отправки формы. Этот заголовок очень важен, потому что указывает серверу, какой тип данных отправляется. По умолчанию это: application/x-www-form-urlencoded . На человеческом это значит: "Это форма с данными, которые были закодированы в URL параметры."
- Указать method атрибут POST , поскольку содержимое файла, как и сам файл, не могут быть отображены в URL параметрах.
- Установить в enctype значение multipart/form-data , потому что данные будут разбиты на несколько частей: одна часть на файл (две части на два файла), и одна часть на текстовые данные (при условии, если форма содержит поле для получения тестовых данных).
- Подключите один или более File picker виджетов, чтобы позволить своим пользователям выбрать, какие и сколько файлов будут загружены.
Предупреждение: Многие сервера имеют заданные ограничения на размер загружаемых файлов и запросы от пользователей, чтобы защититься от возможных злоупотреблений. Важно проверять эти ограничения у администратора сервера, прежде чем загружать файлы.
О клиентской/серверной архитектуре
Примечание: Для получения более полного представления о том, как работают клиент-серверные архитектуры, ознакомьтесь с модулем «Первые шаги в программировании на стороне сервера».
Объекты ответа
Как вы видели выше, экземпляр Response будет возвращён когда fetch() промис будет исполнен.
Свойства объекта-ответа которые чаще всего используются:
Они так же могут быть созданы с помощью JavaScript, но реальная польза от этого есть только при использовании сервис-воркеров (en-US), когда вы предоставляете собственный ответ на запрос с помощью метода respondWith() (en-US):
Конструктор Response() принимает два необязательных аргумента — тело для ответа и объект init (аналогичный тому, который принимает Request() (en-US))
Примечание: Метод error() (en-US) просто возвращает ответ об ошибке. Аналогично, redirect() (en-US) возвращает ответ, приводящий к перенаправлению на указанный URL. Они также относятся только к Service Workers.
Запрос и ответ могут содержать данные тела. Тело является экземпляром любого из следующих типов:
Body примесь определяет следующие методы для извлечения тела (реализованы как для Request так и для Response ). Все они возвращают promise, который в конечном итоге исполняется и выводит содержимое.
Это делает использование нетекстовых данных более лёгким, чем при XMR.
В запросе можно установить параметры для отправки тела запроса:
Параметры request и response (and by extension the fetch() function), по возможности возвращают корректные типы данных. Параметр request также автоматически установит Content-Type в заголовок, если он не был установлен из словаря.
На стороне клиента: определение способа отправки данных
Атрибут action
Этот атрибут определяет, куда отправляются данные. Его значение должно быть действительным URL. Если этот атрибут не указан, данные будут отправлены на URL-адрес страницы, содержащей форму.
Здесь мы используем относительный URL - данные отправляются на другой URL на сервере:
Многие старые страницы используют следующий синтаксис, чтобы указать, что данные должны быть отправлены на ту же страницу, которая содержит форму; это было необходимо, потому что до появления HTML5 атрибут action был обязательным. Это больше не нужно.
Атрибут method
Особый случай: отправка файлов
Вызов: XHR версия the Can Store
Мы хотели бы, чтобы вы решили преобразовать версию приложения Fetch для использования XHR в качестве полезной части практики. Возьмите копию ZIP файла и попробуйте изменить JavaScript, если это необходимо.
Некоторые полезные советы:
Примечание: Если у вас есть проблемы с этим, не стесняйтесь сравнить свой код с готовой версией на GitHub (см. исходник здесь, а также см. это в действии).
Заключение
Как мы увидели, отправлять формы просто, однако защитить приложение может быть довольно трудно. Просто помните, что фронтенд разработчики не должны задавать модель безопасности для приложения. Да, как мы увидим далее, мы можем проверить данные на стороне клиента, однако сервер не может доверять этой проверке, потому что он никогда не может по-настоящему узнать что происходит на стороне клиента.
Защита
С тех пор как заголовки могут передаваться в запросе, приниматься в ответе и имеют различные ограничения в отношении того, какая информация может и должна быть изменена, заголовки имеют свойство guard. Это не распространяется на Web, но влияет на то, какие операции мутации доступны для объекта заголовков.
- none : по умолчанию.
- request : защита объекта заголовков, полученного по запросу ( Request.headers (en-US)).
- request-no-cors : защита объекта заголовков, полученного по запросу созданного с Request.mode no-cors .
- response : защита Headers полученных от ответа ( Response.headers (en-US)).
- immutable : в основном, используется в ServiceWorkers; делает объект заголовков read-only.
Появление Ajax
Это привело к созданию технологий, позволяющих веб-страницам запрашивать небольшие фрагменты данных (например, HTML, XML, JSON или обычный текст) и отображать их только при необходимости, помогая решать проблему, описанную выше.

Модель Ajax предполагает использование веб-API в качестве прокси для более разумного запроса данных, а не просто для того, чтобы браузер перезагружал всю страницу. Давайте подумаем о значении этого:
- Перейдите на один из ваших любимых сайтов, богатых информацией, таких как Amazon, YouTube, CNN и т.д., и загрузите его.
- Теперь найдите что-нибудь, например, новый продукт. Основной контент изменится, но большая часть информации, подобной заголовку, нижнему колонтитулу, навигационному меню и т. д., останется неизменной.
Это действительно хорошо, потому что:
- Обновления страницы намного быстрее, и вам не нужно ждать перезагрузки страницы, а это означает, что сайт работает быстрее и воспринимается более отзывчивым.
- Меньше данных загружается при каждом обновлении, что означает меньшее потребление пропускной способности. Это не может быть такой большой проблемой на рабочем столе в широкополосном подключении, но это серьёзная проблема на мобильных устройствах и в развивающихся странах, которые не имеют повсеместного быстрого интернет-сервиса.
Чтобы ускорить работу, некоторые сайты также сохраняют необходимые файлы и данные на компьютере пользователя при первом обращении к сайту, а это означает, что при последующих посещениях они используют локальные версии вместо загрузки свежих копий, как при первой загрузке страницы. Содержимое загружается с сервера только при его обновлении.

Полифил
Для того, чтобы использовать Fetch в неподдерживаемых браузерах, существует Fetch Polyfill , который воссоздаёт функциональность для не поддерживающих браузеров.
В предыдущей статье мы рассмотрели основные понятия и термины в рамках технологии Data Mining. Сегодня более детально остановимся на Web Mining и подходах к извлечению данных из веб-ресурсов.
- Анализ DOM дерева, использование XPath.
- Парсинг строк.
- Использование регулярных выражений.
- XML парсинг.
- Визуальный подход.
Анализ DOM дерева
Этот подход основывается на анализе DOM дерева. Используя этот подход, данные можно получить напрямую по идентификатору, имени или других атрибутов элемента дерева (таким элементом может служить параграф, таблица, блок и т.д.). Кроме того, если элемент не обозначен каким-либо идентификатором, то к нему можно добраться по некоему уникальному пути, спускаясь вниз по DOM дереву, например:
body -> p[10] -> a[1] -> текст ссылки
или пройтись по коллекции однотипных элементов, например:
body -> links -> 5 элемент -> текст ссылки
- можно получить данные любого типа и любого уровня сложности
- зная расположение элемента, можно получить его значение, прописав путь к нему
- различные HTML / JavaScript движки по-разному генерируют DOM дерево, поэтому нужно привязываться к конкретному движку
- путь элемента может измениться, поэтому, как правило, такие парсеры рассчитаны на кратковременный период сбора данных
- DOM-путь может быть сложный и не всегда однозначный
Data Extracting SDK использует Microsoft.mshtml для анализа DOM дерева, но является «надстройкой» над библиотекой для удобства работы:
UriHtmlProcessor proc = new UriHtmlProcessor( new Uri ( "http://habrahabr.ru/new/page1/" ));
proc.Initialize();
* This source code was highlighted with Source Code Highlighter .
Следующим эволюционным этапом анализа DOM дерева является использования XPath — т.е. путей, которые широко используются при парсинге XML данных. Суть данного подхода в том, чтобы с помощью некоторого простого синтаксиса описывать путь к элементу без необходимости постепенного движения вниз по DOM дереву. Данный подход использует всеми известная библиотека jQuery и библиотека HtmlAgilityPack:
HtmlDocument doc = new HtmlDocument();
doc.Load( "file.htm" );
foreach (HtmlNode link in doc.DocumentElement.SelectNodes( "//a[@href" ])
HtmlAttribute att = link[ "href" ];
att.Value = FixLink(att);
>
doc.Save( "file.htm" );
* This source code was highlighted with Source Code Highlighter .
Парсинг строк
Несмотря на то, что этот подход нельзя применять для написания серьезных парсеров, я о нем немного расскажу.
Иногда данные отображаются с помощью некоторого шаблона (например, таблица характеристик мобильного телефона), когда значения параметров стандартные, а меняются только их значения. В таком случае данные могут быть получены без анализа DOM дерева, а путем парсинга строк, например, как это сделано в Data Extracting SDK:
Компания: Microsoft
Штаб-квартира: Редмонд
string data = "Компания: Microsoft
Штаб-квартира: Редмонд
" ;
string company = data.GetHtmlString( "Компания: " , "" );
string location = data.GetHtmlString( "Штаб-квартира: " , "" );
// output
// company = "Microsoft"
// location = "Редмонт"
* This source code was highlighted with Source Code Highlighter .
Использование набора методов для анализа строк иногда (чаще — простых шаблонных случаях) более эффективный чем анализ DOM дерева или XPath.
Регулярные выражения и парсинг XML
Очень часто видел, когда HTML полностью парсили с помощью регулярных выражений. Это в корне неверный подход, так как таким образом можно получить больше проблем, чем пользы.
Регулярные выражения необходимо использоваться только для извлечения данных, которые имеют строгий формат — электронные адреса, телефоны и т.д., в редких случаях — адреса, шаблонные данные.
Еще одним неэффективным подходом является рассматривать HTML как XML данные. Причина в том, что HTML редко бывает валидным, т.е. таким, что его можно рассматривать как XML данные. Библиотеки, реализовавшие такой подход, больше времени уделяли преобразованию HTML в XML и уже потом непосредственно парсингу данных. Поэтому лучше избегайте этот подход.
Визуальный подход
В данный момент визуальный подход находится на начальной стадии развития. Суть подхода в том, чтобы пользователь мог без использования программного языка или API «настроить» систему для получения нужных данных любой сложности и вложенности. О чем-то похожем (правда применимым в другой области) — методах анализа веб-страниц на уровне информационных блоков, я уже писал. Думаю, что парсеры будущего будут именно визуальными.
Проблемы и общие рекомендации
Проблемы при парсинге HTML данных — использование JavaScript / AJAX / асинхронных загрузок очень усложняют написание парсеров; различные движки для рендеринга HTML могут выдавать разные DOM дерева (кроме того, движки могут иметь баги, которые потом влияют на результаты работы парсеров); большие объемы данных требуют писать распределенные парсеры, что влечет за собой дополнительные затраты на синхронизацию.
Нельзя однозначно выделить подход, который будет 100% применим во всех случаях, поэтому современные библиотеки для парсинга HTML данных, как правило, комбинируют, разные подходы. Например, HtmlAgilityPack позволяет анализировать DOM дерево (использовать XPath), а также с недавних пор поддерживается технология Linq to XML. Data Extracting SDK использует анализ DOM дерева, содержит набор дополнительных методов для парсинга строк, а аткже позволяет использовать технологию Linq для запросов в DOM модели страницы.
На сегодня абсолютным лидером для парсинга HTML данных для дотнетчиков является библиотека HtmlAgilityPack, но ради интереса можно посмотреть и на другие библиотеки.

Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.

SQL - вброс
SQL -вброс представляет собой тип атак, при которых осуществляется попытка выполнения действия с базой данных, используемой целевым веб-сайтом. В этих случаях обычно осуществляется отправка SQL-запроса в надежде, что сервер выполнит этот запрос (обычно при попытке сервера приложения сохранить данные, отправляемые пользователем). Данный вид атак является одним из самых направленных атак на веб-сайты.
Последствия могут быть ужасающими, начиная от потери данных и заканчивая утратой контроля над всей инфраструктурой веб-сайта за счёт повышения привилегий. Это очень серьёзная угроза, поэтому никогда не сохраняйте данные, отправляемые пользователем, без выполнения фильтрации данных (например, с помощью mysqli_real_escape_string() .
Такие атаки являются самыми незаметными, но при этом могут превратить ваш сервер в зомби.
Читайте также: