
Redo log oracle что это
The most crucial structure for recovery operations is the redo log , which consists of two or more preallocated files that store all changes made to the database as they occur. Every instance of an Oracle Database has an associated redo log to protect the database in case of an instance failure.
Повреждение онлайнового журнала повторного выполнения
Включение параметра инициализации DB_BLOCK_CHECKSUM гарантирует проверку Oracle журналов повторного выполнения перед их архивированием. Если онлайновые журналы повторного выполнения повреждены, файл не может быть архивирован, и единственным решением может быть лишь их удаление и воссоздание заново. Но если есть только две группы журналов, вы не сможете этого сделать, поскольку Oracle требует постоянного наличия минимум двух групп файлов онлайновых журналов повторного выполнения. В этом случае можно создать новую (третью) группу журнала повторного выполнения и удалить текущую.
Также не удастся удалить файл онлайнового журнала повторного выполнения, если этот файл является частью текущей группы. В этом случае стратегия должна состоять в повторной инициализации файла журнала с помощью следующей команды:
Если группы журналов еще не были архивированы, можно применить следующий оператор:
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
Clusterware. CRS.
На данном уровне необходимо обеспечить координацию и совместную работу узлов кластера, т.е. clusterware слой: где-то между самим экземпляром базы данных и дисковым хранилищем:
CRS (Cluster-Ready Services) – набор сервисов, обеспечивающий совместную работу узлов, отказоустойчивость, высокую доступность системы, восстановление системы после сбоя. CRS выглядит как «мини-экземпляр» БД (ПО) устанавливаемый на каждый узел кластера. Устанавливать CRS – в обязательном порядке для построения Oracle RAC. Кроме того, CRS можно интегрировать с решениями clusterware от сторонних производителей, таких как HP или Sun.
Опять немного «терминологии»…
- CSSD – Cluster Synchronization Service Daemon
- CRSD – Cluster Ready Services Daemon
- EVMD – Event Monitor Daemon
Как уже стало ясно из таблички, самым главным процессом, «самым могущественным демоном», является CRSD (Cluster Ready Services Daemon). В его обязанности входит: запуск, остановка узла, генерация failure logs, реконфигурация кластера в случае падения узла, он также отвечает за восстановление после сбоев и поддержку файла профилей OCR. Если демон падает, то узел целиком перезагружается. CRS управляет ресурсами OCR: Global Service Daemon (GSD), ONS Daemon, Virtual Internet Protocol (VIP), listeners, databases, instances, and services.
- Node Membership (NM).Каждую секунду проверяет heartbeat между узлами. NM также показывает остальным узлам, что он имеет доступ к так называемому voting disk (если их несколько, то хотя бы к большинству), делая регулярно туда записи. Если узел не отвечает на heartbeat или не оставляет запись на voting disk в течение нескольких секунд (10 для Linux, 12 для Solaris), то master узел исключает его из кластера.
- Group Membership (GM). Функция отвечает за своевременное оповещение при добавлении / удалении / выпадении узла из кластера, для последующей реконфигурации кластера.
Информатором в кластере выступает EVMD (Event Manager Daemon), который оповещает узлы о событиях: о том, что узел запущен, потерял связь, восстанавливается. Он выступает связующим звеном между CRSD и CSSD. Оповещения также направляются в ONS (Oracle Notification Services), универсальный шлюз Oracle, через который оповещения можно рассылать, например, в виде SMS или e-mail.
Стартует кластер примерно по следующей схеме: CSSD читает из общего хранилища OCR, откуда считывает кластерную конфигурацию, чтобы опознать, где расположен voting disk, читает voting disk, чтобы узнать сколько узлов (поднялось) в кластере и их имена, устанавливает соединения с соседними узлами по протоколу IPC. Обмениваясь heartbeat, проверяет, все ли соседние узлы поднялись, и выясняет, кто в текущей конфигурации определился как master. Ведущим (master) узлом становится первый запустившийся узел. После старта, все запущенные узлы регистрируются у master, и впоследствии будут предоставлять ему информацию о своих ресурсах.
Уровнем выше CRS на узлах установлены экземпляры базы данных.
Друг с другом узлы общаются по private сети – Cluster Interconnect, по протоколу IPC (Interprocess Communication). К ней предъявляются требования: высокая ширина пропускной способности и малые задержки. Она может строиться на основе высокоскоростных версий Ethernet, решений сторонних поставщиков (HP, Veritas, Sun), или же набирающего популярность InfiniBand. Последний кроме высокой пропускной способности пишет и читает непосредственно из буфера приложения, без необходимости в осуществлении вызовов уровня ядра. Поверх IP Oracle рекомендует использовать UDP для Linux, и TCP для среды Windows. Также при передаче пакетов по interconnect Oracle рекомендует укладываться в рамки 6-15 ms для задержек.
В начале хочу сразу обозначить, что я не являюсь супер бизоном, который знает Oracle вдоль и поперёк. С базами данных Oracle мне приходится иметь дело только с позиции SAP Basis консультанта, для которого база данных это лишь одна из компонент большой инфраструктуры. Да и мои взгляды на вопросы установки, мониторинга и администрирования сформированы через призму документации компании SAP.
Поэтому этот пост прошу воспринимать не как попытку показать какой я умный, а как попытку упорядочить картину прежде всего у себя в голове. Знаете же выражение: пока объяснял, сам понял. :)

Представим базовую часть СУБД Oracle в виде схемы, изображённой на рисунке 1. Предупреждаю сразу: тут далеко не все части и процессы Oracle. Я отобразил только те процессы и компоненты, которые важны в рамках механизмов, которые я буду описывать далее.
- инстанция базы данных, состоящая из процессов и общих областей памяти (System Global Area или SGA ),
- файлы базы данных на уровне файловой системы.
Как вы скорее всего уже знаете, при использовании базы данных Oracle в SAP системах в качестве клиентов базы данных выступают рабочие процессы SAP инстанций ( SAP WPs ). Каждому такому процессу соответствует один рабочий процесс со стороны инстанции Oracle ( shadow process ).
Самая маленькая логическая единица, которую Oracle использует при операциях с данными - это data block . При создании базы данных его размер можно выбрать, но в SAP инсталляциях размер data block всегда 8 Кб (8 192 байт).
Все данные базы данных Oracle содержатся в дата-файлах ( data files ), которые хранятся на дисковом хранилище. Однако обработка данных никогда не производится напрямую в файлах. При операциях чтения соответствующий процесс базы данных ( shadow process ) сначала копирует данные из дата-файлов в Database buffer cache (конечно, если этих данных еще нет в кэше). И только после этого передаёт данные пользователю, то есть рабочему процессу SAP. Так как все подключенные к инстанции Oracle пользователи могут совместно использовать одни и те же, скопированные из дата-файлов в Database buffer cache , данные, то данный механизм существенно ускоряет последующие операции чтения.
Размер Database buffer cache инстанции Oracle имеет ограниченный размер, так как оперативная память сервера не безгранична. Поэтому в кэше хранятся только последние прочитанные блоки данных. А перезапись блоков кэша происходит по алгоритму LRU («наиболее давно используемый»).
Любые изменения данных в базе данных (операции INSERT , UPDATE или DELETE ) также всегда производятся в Database buffer cache . При этом изменённые блоки кэша помечаются как « dirty blocks ». При копировании данных в кэш такие блоки ( dirty buffers ) не могут быть перезаписаны shadow процессами, до тех пор пока эти изменённые блоки не будут скопированы в дата-файлы. Записью « dirty blocks » занимается не shadow процесс, а специальный фоновый процесс инстанции Oracle - DBW0 (database writer).
- перед тем, как скопировать данные в кэш, shadow процесс сканирует области Database buffer cache на наличие не изменённых блоков, которые можно перезаписать. И если количество сканированных блоков достигает определённого порогового значения, то shadow процесс сигнализирует DBW0 , чтобы он записал часть « dirty blocks » на диск. DBW0 копирует часть « dirty blocks » в дата-файлы, используя алгоритм LSU (Least Number of Stream Used). После этого эти блоки в кэше становятся доступными для shadow процессов.
- в момент Checkpoint , когда DBW0 записывает все « dirty blocks » из Database buffer cache в файлы на дисках. Событие Checkpoint инициируется фоновым процессом CKPT . Детали будут чуть ниже.
Использование механизма отложенной записи повышает быстродействие. Во-первых, во многих случаях, прежде чем DBW0 скопирует блок на диск, данные в блоке могут несколько раз измениться. Во-вторых, повышается эффективность операций ввода-вывода, так как DBW0 часто выполняет запись сразу нескольких блоков параллельно.
Почти всегда можно руководствоваться правилом: чем больше данный кэш, тем быстрее работает база данных. Вспомните мой старый пост про это.
Но основанный на отложенной записи механизм должен избегать потери данных и обеспечивать консистентность базы данных, даже в случае сбоя любого компонента системы. А сбой может быть как аппаратным (например, сбой дискового хранилища), так и программным - сбой инстанции Oracle.
Как я уже рассказывал здесь, транзакция базы данных - это LUW (logical unit of work) сервера базы данных. Так как LUW всегда атомарная, то изменения из LUW должны быть или выполнены полностью, или полностью отменены. Для достижения консистентности данных (и консистентности чтения данных) в рамках концепции LUW СУБД Oracle использует Redo-записи для отката или восстановления (например, после сбоя) и Undo-записи для отката неподтверждённых (uncommitted) транзакций.
Redo-записи
Redo-записи содержат информацию необходимую и достаточную для того, чтобы реконструировать, восстановить или откатить, внесенные в базу данных с помощью SQL-запросов данные прежде всего в подтверждённых (commit) транзакциях.
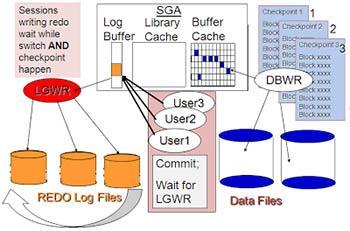
Параллельно с изменением блоков данных в Database buffer cache , shadow процесс записывает Redo-записи в Redo log buffer . Это круговой буфер, находящийся в SGA , в который временно записываются все завершённые и незавершённые изменения данных. Фоновый процесс LGWR (log writer) периодически записывает порции записей из Redo log buffer последовательно на диск - в Online redo log file .
Oracle redo log file имеет заранее заданный фиксированный размер и не растёт динамически, как обычный файл. Поэтому, когда текущий Online redo log file заполняется, процесс LGWR закрывает файл и начинает запись в следующий. В SAP инсталляциях по умолчанию используется 4 группы Online redo log files по 2 копии файлов в каждой. Online redo log file , в который LGWR пишет в данный момент, называется CURRENT. А процедура переключения файлов называется log switch .
Так как количество Online redo log files также заранее ограничено, Oracle перезаписывает старые Redo-записи новыми, используя эти файлы по кругу.
Каждый log switch СУБД увеличивает LSN (log sequence number). С помощью LSN Oracle автоматически создаёт последовательные номера для Redo log files .
- при подтверждении (commit) любой транзакции,
- каждые 3 секунды,
- когда Redo log buffer полон на одну треть,
- когда DBW0 собирается записать изменённые блоки из Database buffer cache на диск, а некоторые соответствующие Redo-записи еще не были записаны в Online redo log files . Таким образом предотвращается попытка записи с опережением журналирования (write-ahead logging).
Этого достаточно для того, чтобы всегда иметь место для новых Redo-записей в Redo log buffer . При этом по умолчанию размер этого буфера при установке в SAP системах небольшой (1 - 8 Мб).
Дополнительно когда пользователь (рабочий процесс SAP) подтверждает завершение (commit) транзакции, транзакции присваивается SCN (system change number) базы данных. Oracle записывает SCN , вместе с Redo-записями транзакции в Redo log buffer . При этом DBW0 нет необходимости записывать блоки данных в момент подтверждения (commit) транзакции. Потому что в СУБД Oracle используется журналирование с опережением записи.
Новые значения модифицированных данных, которые хранятся в Redo-записях, называются «after images».
Undo-записи содержат информацию необходимую для отмены или отката любых изменений в блоках данных, которые были выполнены в результате неподтверждённых (uncommitted) транзакций .
Oracle хранит Undo-записи в специальных Undo сегментах, которые хранятся в специальном пространстве - Undo space. При этом Undo space может быть реализовано двумя способами:
- Automatic Undo Management ( AUM ),
- Manual Undo Management.
При AUM администратор должен лишь создать специальное табличное пространство - Undo tablespace ( PSAPUNDO ) достаточного размера и настроить пару параметров Oracle. Управление Undo сегментами СУБД осуществляет сама.
При ручном управлении необходимо создать и настроить некоторое количество Rollback segments , у которых необходимо тщательно рассчитать размер и параметры. Данные сегменты также располагаются в отдельном табличном пространстве ( PSAPROLL ). Про проблемы с данными сегментами у меня был отдельный пост.
Таким образом Undo-записи хранят информацию для транзакций, сохраняя её в Undo space, как минимум, до завершения транзакции. Так как данные записи используются для отката транзакций, то Undo-записи могут быть перезаписаны только после того, как транзакция будет подтверждена (commit) или сброшена (rollback).
Стоит отметить, что Oracle может использовать Undo-записи и для других целей. Например, для консистентного чтения из snapshots. В этом случае данные читаются из «before images». В то время, как происходит изменение этих же данных в ещё неподтверждённых (uncommitted) транзакциях.
Каждая база данных Oracle имеет свой контрольный файл ( control file ). Это маленький бинарный файл, необходимый как в момент старта базы данных, так и в процессе работы. Следовательно данный файл должен быть всегда доступен на запись.
Control file содержит записи, которые определяют физическую структуру и состояние базы данных. Например, в нём хранится информация о табличных пространствах, именах и положении дата-файлов и Online redo log files , а также текущий LSN .
Oracle control file очень важен для работы базы данных. Поэтому несколько копий могут быть сохранены в разных местах, а СУБД обновляет их одновременно. В SAP системах по умолчанию сконфигурировано 3 копии control files .
Checkpoint
Checkpoint это момент времени, в котором файлы базы данных находятся в консистентном состоянии. Достигается это состояние тем, что в этот момент DBW0 сбрасывает все текущие изменённые блоки из Database buffer cache в дата-файлы. За инициацию события Checkpoint отвечает специальный фоновый процесс CKPT , который и даёт команду процессу DBW0 начать запись блоков. Одновременно Checkpoint обозначает специальную позицию в Redo log .
- DBW0 активируется, получая сигнал в определённые моменты времени от фонового процесса CKTP .
- DBW0 копирует все текущие « dirty blocks » на диск. Причём, пока DBW0 закончит выполнять запись, другие блоки в кэше могут быть изменены, но они уже не записываются.
- Когда событие Checkpoint закончится (то есть будут записаны все выбранные блоки), самый старый буфер из « dirty blocks » в Database buffer cache будет обозначать точку в Redo log , после которой может быть начато восстановление в случае сбоя. Это позиция журнала и называется Checkpoint position .
- записывает информацию о Checkpoint в заголовок каждого дата-файла,
- записывает информацию о Checkpoint position в Online redo log file в контрольный файл Oracle ( control file ).
Информация о позиции Checkpoint в Online redo log file в контрольном файле необходима в процессе восстановления инстанции. Позиция Checkpoint сообщает инстанции Oracle, что все Redo-записи, которые были записаны до этого момента, не нуждаются в восстановлении. Так как эти данные уже записаны в дата-файлы.
Частота Checkpoints один из важных факторов, который напрямую влияет на время необходимое для восстановления инстанции в случае сбоя. Чем реже будут в системе происходить Checkpoints , тем большее времени будет необходимо инстанции для восстановления в случае сбоя.
Хотя частоту Checkpoint можно настроить через параметры Oracle, при разворачивании SAP систем эти параметры не используются. А Checkpoint всегда возникает только в моменты переключения Online redo log files ( log switch ).
Теперь основываясь на всех механизмах, которые были описаны выше, разберём как происходит восстановление базы данных.
Речь пойдёт не о восстановлении из резервной копии базы данных, которую должен выполнять администратор. А речь пойдёт об автоматическом восстановлении базы данных, которое СУБД производит в момент старта. Так называемое instance recovery. Оно необходимо, если предыдущий останов базы данных был выполнен не чисто, например, с опцией IMMEDIATE или ABORT. Или произошёл сбой работы сервера базы данных по аппаратной или программной причине.
- В control file находится последний Checkpoint . После этого, начиная с позиции Checkpoint , читаются Redo-записи из Online redo log files и заново проводятся все транзакции, указанные в журнале. Происходит процесс roll forward. Заметьте, что этот шаг всегда включает и проведение изменений для Undo space, то есть восстанавливаются «before images».
- Для всех заново применённых транзакций, которые не были подтверждены (commit) до сбоя или были отменены прямо перед сбоем (поэтому для них нет подтверждения в Redo log), выполняется откат. Для отката используется образ «before images» из Undo space. СУБД уверена, что это всегда возможно, потому что Undo-записи незавершённых транзакций из Undo space никогда не удаляются и не перезаписываются.
В результате после открытия консистентная база данных содержит только те изменения, которые были подтверждены (commit) перед сбоем.
Из процесса восстановления базы данных видно, что Online redo log files это одна из критически важных частей сервера Oracle. А если вспомнить, что в SAP установках Checkpoint наступает только в момент log switch , то при автоматическом восстановлении СУБД всегда нужен последний Online redo log file целиком. И если он будет потерян во время сбоя, то полное восстановление (complete recovery of database) будет невозможно. В результате чего данные будут потеряны, а база данных может оказаться в неконсистентном состоянии.
Поэтому-то Online redo log files должны храниться минимум в двух копиях, каждая из которых расположена на отдельном диске. Так же в продуктивной системе база данных должна работать в ARCHIVELOG режиме. В этом режиме фоновый процесс ARC0 (archiver) копирует каждый только что записанный Online redo log file в Offline redo log file . Offline redo log file в своём имени содержит LSN . Понятно, что копирование возможно начать только после переключения ( log switch ) и необходимо закончить до повторного возвращения процесса LGWR к этому файлу. Так как в таком режиме перезапись старых Redo-записей в Online redo log files не разрешается до тех пор, пока эти записи не скопированы в Offline redo log files .
Ну и должно соблюдаться ещё одно ограничение: могут быть перезаписаны только те Redo-записи, которые расположены до позиции Checkpoint в Redo log . То есть соответствующие им изменения уже записаны в дата-файлы. Это гарант возможности автоматического восстановления инстанции в случае сбоя.
Если хотите разобраться в вопросах администрирования базы данных Oracle на практике, то можете приобрести мой обучающий курс SAPADM 2.0. Этой теме в курсе полностью посвящён третий пакет заданий.
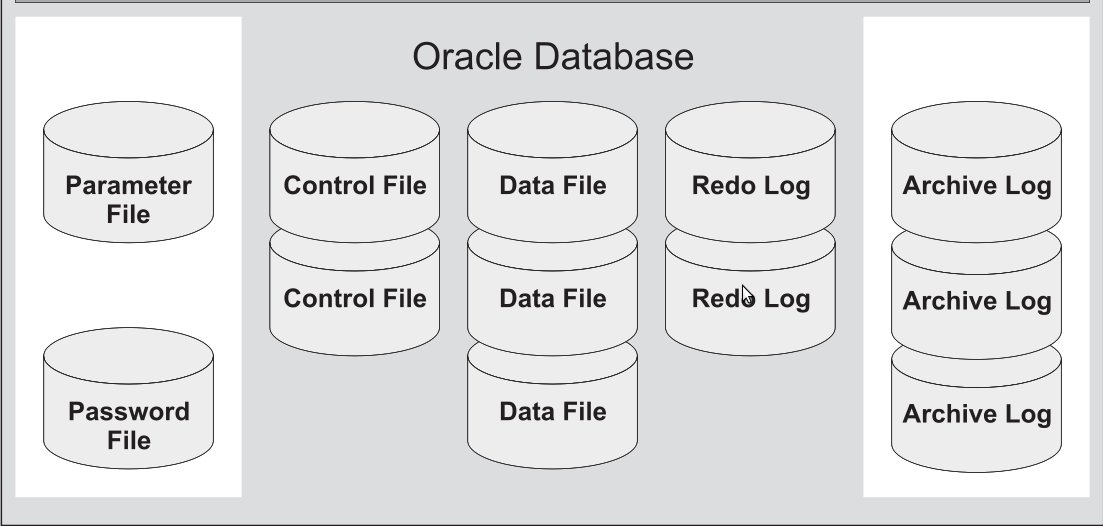
Предполагается, что вы инсталлировали базу данных, согласно документа.
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Мониторинг журналов повторного выполнения
Для мониторинга журналов повторного выполнения применяются два ключевых динамических представления — V$LOG и V$LOGFILE.
Представление V$LOGFILE содержит полные имена файлов журналов повторного выполнения, их состояние и тип, как показано ниже:
Представление V$LOG выдает детальную информацию о размерах и состоянии журналов повторного выполнения, а также показывает, были ли журналы архивированы:

Высоконагруженные сайты, доступность «5 nines». На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g – означает «grid», распределенные вычисления. В основе распределенных вычислений «как ни крути» лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл – просто дать представление о технологии RAC.
Статью хотелось написать как можно доступнее, чтобы прочесть ее было интересно даже человеку, мало знакомому с СУБД Oracle. Поэтому рискну начать описание с аспектов наиболее часто встречаемой конфигурации БД – single-instance, когда на одном физическом сервере располагается одна база данных (RDBMS) Oracle. Это не имеет непосредственного отношения к кластеру, но основные требования и принципы работы будут одинаковы.
Группы онлайнового журнала повторного выполнения
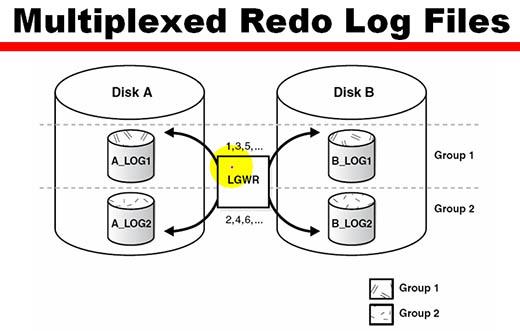
В случае мультиплексирования журнала повторного выполнения поддерживаются идентичные копии одних и тех же файлов. Предположим, что вы создаете две копии файла журнала повторного выполнения. Понадобится создать группу журналов повторного выполнения, которая будет включать эти два идентичных файла, именуемых членами группы. В любой заданный момент времени процесс LGWR будет писать в одну группу файлов онлайнового журнала повторного выполнения, и члены этой группы будут называться текущими.
Ниже описаны некоторые базовые условия для групп журнала повторного выполнения Oracle.
- Все файлы журнала повторного выполнения в группе должны иметь одинаковый размер.
- Хотя можно разместить оба члена группы онлайнового журнала повторного выполнения на одном физическом диске, разумнее разнести их по разным дискам, чтобы идентичные копии страховали друг друга на случай сбоя диска; в такой ситуации пострадает только один из членов группы. Oracle продолжит писать в уцелевшие члены группы онлайнового журнала повторного выполнения, когда один член окажется недоступным для записи (возможно, из-за проблем с дисковым приводом).
Active (Current) and Inactive Redo Log Files
Oracle Database uses only one redo log files at a time to store redo records written from the redo log buffer. The redo log file that LGWR is actively writing to is called the current redo log file.
Redo log files that are required for instance recovery are called active redo log files. Redo log files that are no longer required for instance recovery are called inactive redo log files.
If you have enabled archiving (the database is in ARCHIVELOG mode), then the database cannot reuse or overwrite an active online log file until one of the archiver background processes (ARC n ) has archived its contents. If archiving is disabled (the database is in NOARCHIVELOG mode), then when the last redo log file is full, LGWR continues by overwriting the first available active file.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
Удаление онлайновых журналов повторного выполнения
С помощью следующей команды можно уничтожить всю группу журнала повторного выполнения:
Для удаления единственного члена группы служит такая команда:
Если файл онлайнового журнала повторного выполнения, который планируется удалить, активен или является текущим, Oracle не позволит это сделать. В этом случае сначала нужно с помощью следующей команды переключить файл журнала, после чего можно будет удалить его:
Обязательные файлы:
Redo Threads
When speaking in the context of multiple database instances, the redo log for each database instance is also referred to as a redo thread . In typical configurations, only one database instance accesses an Oracle Database, so only one thread is present. In an Oracle Real Application Clusters environment, however, two or more instances concurrently access a single database and each instance has its own thread of redo. A separate redo thread for each instance avoids contention for a single set of redo log files, thereby eliminating a potential performance bottleneck.
This chapter describes how to configure and manage the redo log on a standard single-instance Oracle Database. The thread number can be assumed to be 1 in all discussions and examples of statements. For information about redo log groups in an Oracle Real Application Clusters environment, please refer to Oracle Real Application Clusters Administration and Deployment Guide .
Создание групп онлайнового журнала повторного выполнения
Введение. Single-instance.
- область хранения данных, т.е. физические файлы на диске (datastorage) (сама БД)
- экземпляр БД (получающая и обрабатывающая эти данные в оперативной памяти) (СУБД)

Во всех современных реляционных БД данные хранятся в таблицах. Таблицы, индексы и другие объекты в Oracle хранятся в логических контейнерах – табличных пространствах (tablespace). Физически же tablespace располагаются в одном или нескольких файлах на диске. Хранятся они следующим образом:
Каждый объект БД (таблицы, индексы, сегменты отката и.т.п.) хранится в отдельном сегменте – области диска, которая может занимать пространство в одном или нескольких файлах. Сегменты в свою очередь, состоят из одного или нескольких экстентов. Экстент – это непрерывный фрагмента пространства в файле. Экстенты состоят из блоков. Блок – наименьшая единица выделения пространства в Oracle, по умолчанию равная 8K. В блоках хранятся строки данных, индексов или промежуточные результаты блокировок. Именно блоками сервер Oracle обычно выполняет чтение и запись на диск. Блоки имеют адрес, так называемый DBA (Database Block Address).

При любом обращении DML (Data Manipulation Language) к базе данных, Oracle подгружает соответствующие блоки с диска в оперативную память, а именно в буферный кэш. Хотя возможно, что они уже там присутствуют, и тогда к диску обращаться не нужно. Если запрос изменял данные (update, insert, delete), то изменения блоков происходят непосредственно в буферном кэше, и они помечаются как dirty (грязные). Но блоки не сразу сбрасываются на диск. Ведь диск – самое узкое место любой базы данных, поэтому Oracle старается как можно меньше к нему обращаться. Грязные блоки будут сброшены на диск автоматически фоновым процессом DBWn при прохождении контрольной точки (checkpoint) или при переключении журнала.

- Что будет, если Oracle упадет где-то на середине длинной транзакции (если бы она вносила изменения)?
- Какие же данные прочтет первая транзакция, когда в кэше у нее «под носом» другая транзакция изменила блок?
- журнал повтора (redo log)
- сегмент отмены (undo)

Когда в базу данных поступает запрос на изменение, то Oracle применяет его в буферном кэше, параллельно внося информацию, достаточную для повторения этого действия, в буфер повторного изменения (redo log buffer), находящийся в оперативной памяти. Как только транзакция завершается, происходит ее подтверждение (commit), и сервер сбрасывает содержимое redo buffer log на диск в redo log в режиме append-write и фиксирует транзакцию. Такой подход гораздо менее затратен, чем запись на диск непосредственно измененного блока. При сбое сервера кэш и все изменения в нем потеряются, но файлы redo log останутся. При включении Oracle начнет с того, что заглянет в них и повторно выполнит изменения таблиц (транзакции), которые не были отражены в datafiles. Это называется «накатить» изменения из redo, roll-forward. Online redo log сбрасывается на диск (LGWR) при подтверждении транзакции, при прохождении checkpoint или каждые 3 секунды (default).
С undo немного посложнее. С каждой таблицей в соседнем сегменте хранится ассоциированный с ней сегмент отмены. При запросе DML вместе с блоками таблицы обязательно подгружаются данные из сегмента отката и хранятся также в буферном кэше. Когда данные в таблице изменяются в кэше, в кэше так же происходит изменение данных undo, туда вносятся «противодействия». То есть, если в таблицу был внесен insert, то в сегмент отката вносится delete, delete – insert, update – вносится предыдущее значение строки. Блоки (и соответствующие данные undo) помечаются как грязные и переходят в redo log buffer. Да-да, в redo журнал записываются не только инструкции, какие изменения стоит внести (redo), но и какие у них противодействия (undo). Так как LGWR сбрасывает redo log buffer каждые 3 секунды, то при неудачном выполнении длительной транзакции (на пару минут), когда после минуты сервер упал, в redo будут записи не завершенные commit. Oracle, как проснется, накатит их (roll-forward), и по восстановленным (из redo log) в памяти сегментам отката данных отменит (roll-back) все незафиксированные транзакции. Справедливость восстановлена.
Кратко стоит упомянуть еще одно неоспоримое преимущество undo сегмента. По второму сценарию (из схемы) когда select дойдет до чтения блока (DBA) 500, он вдруг обнаружит что этот блок в кэше уже был изменен (пометка грязный), и поэтому обратится к сегменту отката, для того чтобы получить соответствующее предыдущее состояние блока. Если такого предыдущего состояния (flashback) в кэше не присутствовало, он прочитает его с диска, и продолжит выполнение select. Таким образом, даже при длительном «select count(money) from bookkeeping» дебет с кредитом сойдется. Согласованно по чтению (CR).
Отвлеклись. Пора искать подступы к кластерной конфигурации. =)
Log Switches and Log Sequence Numbers
A log switch is the point at which the database stops writing to one redo log file and begins writing to another. Normally, a log switch occurs when the current redo log file is completely filled and writing must continue to the next redo log file. However, you can configure log switches to occur at regular intervals, regardless of whether the current redo log file is completely filled. You can also force log switches manually.
Oracle Database assigns each redo log file a new log sequence number every time a log switch occurs and LGWR begins writing to it. When the database archives redo log files, the archived log retains its log sequence number. A redo log file that is cycled back for use is given the next available log sequence number.
Each online or archived redo log file is uniquely identified by its log sequence number. During crash, instance, or media recovery, the database properly applies redo log files in ascending order by using the log sequence number of the necessary archived and redo log files.

Онлайновые журналы повторного выполнения (redo logs) — это средства Oracle, благодаря которым гарантируется, что все изменения, проведенные пользователями, будут зафиксированы в журналах на случай, если произойдет сбой между моментом проведения изменений и моментом записи их в постоянное хранилище. Таким образом, журналы повторного выполнения — основа процесса восстановления.
Oracle организует свои файлы журналов повторного выполнения в группы журналов, и нужно иметь как минимум две разных группы журналов повторного выполнения и, минимум, по одному члену в каждом. Потребуется, самое меньшее, две группы, потому что когда один журнал повторного выполнения архивируется, процесс писатель журнала должен иметь возможность продолжать писать в активный журнал повторного выполнения.
Хотя база данных Oracle будет достаточно хорошо работать и с только одним членом в каждой группе журналов повторного выполнения, в Oracle настоятельно рекомендуют мультиплексировать онлайновые журналы повторного выполнения. Мультиплексирование означает просто то, что необходимо поддерживать более одного члена в каждой из групп журналов повторного выполнения. Все члены такой группы идентичны — мультиплексирование предназначено для защиты от потери одной из копий файла журнала. При мультиплексировании онлайновых журналов повторного выполнения процесс-писатель журналов выполняет запись параллельно во все файлы члены группы.
Совет. Всегда мультиплексируйте онлайновый журнал повторного выполнения, поскольку вы можете потерять данные, если случится сбой в онлайновом журнале повторного выполнения из-за проблем с диском. Мультиплексированные журналы повторного выполнения в идеале должны располагаться на разных дисковых приводах под управлением разных дисковых контроллеров.
Переименование файлов журнала повторного выполнения
Для переименования файла журнала повторного выполнения выполните следующие шаги.
- Остановите базу данных и запустите ее в смонтированном режиме:
- Переместите файлы в новое местоположение командой операционной системы:
- Воспользуйтесь командой ALTER DATABASE RENAME datafile TO для переименования этого файла внутри управляющего файла:
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Сравнение аппаратного зеркального отображения и мультиплексирования Oracle
Зеркальное отображение защитит данные от дисковых сбоев, но не защитит от непреднамеренного удаления файлов. Мультиплексирование гарантирует защиту файлов от подобного рода ошибок.
Если вы потеряете онлайновый журнал повторного выполнения, то можете утратить важные данные, поэтому при мультиплексированной системе журналов повторного выполнения фоновый процесс LGWR, который отвечает за запись данных из буфера журнала повторного выполнения, пишет одновременно во все (идентичные) файлы-члены мультиплексированной группы. Если возникнут проблемы записи в один из членов мультиплексированной группы журналов повторного выполнения, запись в другие члены группы пройдет беспрепятственно.
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Уровень доступа к данным. ASM.

Хранилищем (datastorage) в больших БД почти всегда выступает SAN (Storage Area Network), который предоставляет прозрачный интерфейс серверам к дисковым массивам.
Сторонние производители (Hitachi, HP, Sun, Veritas) предлагают комплексные решения по организации таких SAN на базе ряда протоколов (самым распространенным является Fibre Channel), с дополнительными функциональными возможностями: зеркалирование, распределение нагрузки, подключение дисков на лету, распределение пространства между разделами и.т.п.
Позиция корпорации Oracle в вопросе построения базы данных любого масштаба сводится к тому, что Вам нужно только соответствующее ПО от Oracle (с соответствующими лицензиями), а выбранное оборудование – по возможности (если средства останутся после покупки Oracle :). Таким образом, для построения высоконагруженной БД можно обойтись без дорогостоящих SPARC серверов и фаршированных SAN, используя сервера на бесплатном Linux и дешевые RAID-массивы.
На уровне доступа к данным и дискам Oracle предлагает свое решение – ASM (Automatic Storage Management). Это отдельно устанавливаемый на каждый узел кластера мини-экземпляр Oracle (INSTANCE_TYPE = ASM), предоставляющий сервисы работы с дисками.
Oracle старается избегать обращений к диску, т.к. это является, пожалуй, основным bottleneck любой БД. Oracle выполняет функции кэширования данных, но ведь и файловые системы так же буферизуют запись на диск. А зачем дважды буферизировать данные? Причем, если Oracle подтвердил транзакцию и получил уведомления том, что изменения в файлы внесены, желательно, чтобы они уже находились там, а не в кэше, на случай «падения» БД. Поэтому рекомендуется использовать RAW devices (диски без файловой системы), что делает ASM.
- отсутствие необходимости в отдельном ПО для управления разделами дисков
- нет необходимости в файловой системе
- Зеркалирование данных:
как правило, 2-х или 3-х ступенчатое, т.е. данные одновременно записываются на 2 или 3 диска. Для зеркалирования диску указываются не более 8 дисков-партнеров, на которые будут распределяться копии данных. - Автоматическая балансировка нагрузки на диски (обеспечение высокой доступности):
если данные tablespace разместить на 10 дисках и, в некоторый момент времени, чтение данных из определенных дисков будет «зашкаливать», ASM сам обратится к таким же экстентам, но находящимся на зеркалированных дисках. - Автоматическая ребалансировка:
При удалении диска, ASM на лету продублирует экстенты, которые он содержал, на другие оставшиеся в группе диски. При добавлении в группу диска, переместит экстенты в группе так, что на каждом диске окажется приблизительно равное число экстентов.
Таким образом, кластер теперь может хранить и читать данные с общего файлового хранилища.
Пора на уровень повыше.
Redo Log Contents
Redo log files are filled with redo records . A redo record, also called a redo entry , is made up of a group of change vectors , each of which is a description of a change made to a single block in the database. For example, if you change a salary value in an employee table, you generate a redo record containing change vectors that describe changes to the data segment block for the table, the undo segment data block, and the transaction table of the undo segments.
Redo entries record data that you can use to reconstruct all changes made to the database, including the undo segments. Therefore, the redo log also protects rollback data. When you recover the database using redo data, the database reads the change vectors in the redo records and applies the changes to the relevant blocks.
Redo records are buffered in a circular fashion in the redo log buffer of the SGA (see "How Oracle Database Writes to the Redo Log") and are written to one of the redo log files by the Log Writer (LGWR) database background process. Whenever a transaction is committed, LGWR writes the transaction redo records from the redo log buffer of the SGA to a redo log file, and assigns a system change number (SCN) to identify the redo records for each committed transaction. Only when all redo records associated with a given transaction are safely on disk in the online logs is the user process notified that the transaction has been committed.
Redo records can also be written to a redo log file before the corresponding transaction is committed. If the redo log buffer fills, or another transaction commits, LGWR flushes all of the redo log entries in the redo log buffer to a redo log file, even though some redo records may not be committed. If necessary, the database can roll back these changes.
How Oracle Database Writes to the Redo Log
The redo log of a database consists of two or more redo log files. The database requires a minimum of two files to guarantee that one is always available for writing while the other is being archived (if the database is in ARCHIVELOG mode). See "Managing Archived Redo Logs" for more information.
LGWR writes to redo log files in a circular fashion. When the current redo log file fills, LGWR begins writing to the next available redo log file. When the last available redo log file is filled, LGWR returns to the first redo log file and writes to it, starting the cycle again. Figure 12-1 illustrates the circular writing of the redo log file. The numbers next to each line indicate the sequence in which LGWR writes to each redo log file.
Filled redo log files are available to LGWR for reuse depending on whether archiving is enabled.
If archiving is disabled (the database is in NOARCHIVELOG mode), a filled redo log file is available after the changes recorded in it have been written to the datafiles.
If archiving is enabled (the database is in ARCHIVELOG mode), a filled redo log file is available to LGWR after the changes recorded in it have been written to the datafiles and the file has been archived.
Figure 12-1 Reuse of Redo Log Files by LGWR
Добавление групп журнала повторного выполнения
Хотя необходимо иметь минимум две группы онлайнового журнала повторного выполнения, идеальное количество таких групп для базы данных зависит только от интенсивности транзакций.
Совет. Начните с трех групп онлайнового журнала повторного выполнения и следите за журналом предупреждающих сигналов на предмет появления в нем любых ошибок журнала повторного выполнения. Если журнал сигналов часто показывает ожидание процесса-писателя журналов возможности записи в журнал, значит, следует увеличить количество групп журнала повторного выполнения.
Следующий оператор, который использует синтаксис ADD LOGFILE GROUP, добавляет новую группу журнала повторного выполнения в базу данных. Обратите внимание, что эта группа дублирована; в ней создается два файла журнала повторного выполнения, а не один:
В примере из предыдущего раздела были созданы три группы онлайнового журнала повторного выполнения, но каждая из них включала только по одному члену. Чтобы продублировать эти группы с целью повышения безопасности, потребуется добавить по одному члену в каждую группу. Для добавления одного члена в существующую группу используется оператор ADD LOGFILE MEMBER:
Как видите, размер нового члена группы журнала повторного выполнения, добавляемого в группу 2, специфицировать не понадобилось. Размер нового члена будет просто установлен равным размерам существующих членов группы.
Читайте также: