
Размер адресной памяти узнать
Когда процессор считывает или записывает данные в расположение памяти, он использует виртуальный адрес. В рамках операции чтения или записи процессор преобразует виртуальный адрес в физический адрес.
Доступ к памяти через виртуальный адрес имеет следующие преимущества:
Программа может использовать непрерывный диапазон виртуальных адресов для доступа к большому буферу памяти, который не является непрерывным в физической памяти.
Программа может использовать диапазон виртуальных адресов для доступа к буферу памяти, который больше доступной физической памяти. По мере уменьшения объема физической памяти диспетчер памяти сохраняет страницы физической памяти (обычно 4 килобайта) в файл диска. При необходимости страницы данных или кода перемещаются между физической памятью и диском.
Виртуальные адреса, используемые различными процессами, изолированы друг от друга. Код в одном процессе не может изменить физическую память, используемую другим процессом или операционной системой.
Диапазон виртуальных адресов, доступных процессу, называется виртуальным адресным пространством для процесса. Каждый процесс пользовательского режима имеет собственное частное виртуальное адресное пространство.
Для 32-разрядного процесса виртуальное адресное пространство обычно представляет собой 2-гигабайтовый диапазон 0x00000000 через 0x7FFFFFFF.
Диапазон виртуальных адресов иногда называется диапазоном виртуальной памяти. Дополнительные сведения см. в разделе "Ограничения памяти и адресного пространства".
На этой схеме показаны некоторые ключевые функции виртуальных адресных пространств.

На схеме показаны виртуальные адресные пространства для двух 64-разрядных процессов: Notepad.exe и MyApp.exe. Каждый процесс имеет собственное виртуальное адресное пространство, которое переходит от 0x000 0000000 до 0x7FF'FFFFFFFF. Каждый затененных блок представляет одну страницу (размер 4 килобайта) виртуальной или физической памяти. Обратите внимание, что в процессе Блокнот используются три смежных страницы виртуальных адресов, начиная с 0x7F7'93950000. Но эти три смежных страницы виртуальных адресов сопоставляются с неконтентными страницами в физической памяти. Обратите внимание, что оба процесса используют страницу виртуальной памяти, начиная с 0x7F7'93950000, но эти виртуальные страницы сопоставляются с разными страницами физической памяти.
виртуальное адресное пространство для 32-разрядного Windows с 4GT
Если включена Настройка 4 гигабайта (4GT), диапазон памяти для каждой секции выглядит следующим образом.
| Диапазон памяти | Использование |
|---|---|
| С низким 3 ГБ (0x00000000 до 0xBFFFFFFF) | Используется процессом. |
| Высокий 1 ГБ (0xC0000000 до 0xFFFFFFFF) | Используется системой. |
После включения 4GT процесс, имеющий установленный в заголовке изображения флаг с большим количеством _ файлов _ _ _ изображений , будет иметь доступ к дополнительному объему памяти (1 ГБ), превышающему младшие 2 ГБ.
Разграждаемый пул и непагированный пул
В пользовательском пространстве все страницы физической памяти можно вывести на диск при необходимости. В системном пространстве некоторые физические страницы можно вывести, а другие — невозможно. Системное пространство содержит два региона для динамического выделения памяти: разбиение на страницы пула и непагированного пула.
Память, выделенная в пуле страниц, можно вывести на дисковый файл по мере необходимости. Память, выделенная в непакованном пуле, никогда не может быть выгружается в файл диска.
Виртуальным адресным пространством для процесса является набор адресов виртуальной памяти, который можно использовать. Адресное пространство для каждого процесса является закрытым и не может быть доступно другим процессам, если он не является общим.
Виртуальный адрес не представляет фактическое физическое расположение объекта в памяти; Вместо этого система ведет таблицу страниц для каждого процесса, который представляет собой внутреннюю структуру данных, используемую для преобразования виртуальных адресов в соответствующие физические адреса. Каждый раз, когда поток ссылается на адрес, система преобразует виртуальный адрес в физический адрес.
виртуальное адресное пространство для 32-разрядного Windows имеет размер 4 гигабайта (гб) и делится на две секции: одна для использования процессом, а другая зарезервирована для использования системой. дополнительные сведения о пространстве виртуальных адресов в 64-битном Windows см. в разделе виртуальное адресное пространство в 64-разрядной Windows.
Дополнительные сведения о виртуальной памяти см. в следующих разделах:
Пространство пользователя и системное пространство
Такие процессы, как Notepad.exe и MyApp.exe выполняются в пользовательском режиме. Основные компоненты операционной системы и многие драйверы выполняются в более привилегированном режиме ядра. Дополнительные сведения о режимах процессора см. в разделе "Режим пользователя" и "Режим ядра".
Каждый процесс пользовательского режима имеет собственное частное виртуальное адресное пространство, но весь код, который выполняется в режиме ядра, использует одно виртуальное адресное пространство, называемое системным пространством. Виртуальное адресное пространство для процесса в пользовательском режиме называется пространством пользователя.
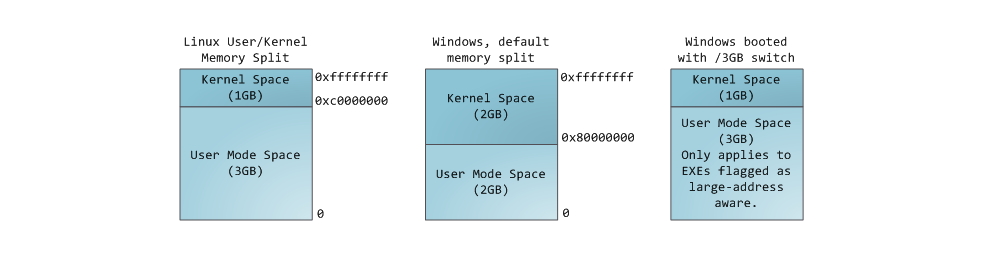
В 32-разрядном Windows общее доступное виртуальное адресное пространство составляет 2^32 байта (4 гигабайта). Обычно для пространства пользователя используются нижние 2 гигабайта, а верхние 2 гигабайта используются для системного пространства.

В 32-разрядной Windows вы можете указать (во время загрузки), что для пользовательского пространства доступно более 2 гигабайта. Следствием является то, что для системного пространства доступно меньше виртуальных адресов. Размер пространства пользователя можно увеличить до 3 гигабайт, в этом случае для системного пространства доступно только 1 гигабайт. Чтобы увеличить размер пользовательского пространства, используйте BCDEdit /set increaseuserva.
В 64-разрядной Windows теоретический объем виртуального адресного пространства составляет 2^64 байта (16 exabytes), но фактически используется только небольшая часть диапазона 16-exabyte.
Код, выполняемый в пользовательском режиме, имеет доступ к пространству пользователя, но не имеет доступа к системным пространствам. Это ограничение предотвращает чтение или изменение защищенных структур данных операционной системы в пользовательском режиме. Код, выполняемый в режиме ядра, имеет доступ как к пространству пользователя, так и к системным пространствам. То есть код, выполняющийся в режиме ядра, имеет доступ к системным пространствам и виртуальному адресном пространству текущего процесса пользовательского режима.
Драйверы, которые выполняются в режиме ядра, должны быть очень осторожны при непосредственном чтении или записи в адреса в пользовательском пространстве. В этом сценарии показано, почему.
Программа пользовательского режима инициирует запрос на чтение некоторых данных с устройства. Программа предоставляет начальный адрес буфера для получения данных.
Подпрограмма драйвера устройства, запущенная в режиме ядра, запускает операцию чтения и возвращает управление вызывающей программе.
Позже устройство прерывает работу любого потока, чтобы сказать, что операция чтения завершена. Прерывание обрабатывается подпрограммами драйвера в режиме ядра, выполняемыми в этом произвольном потоке, который принадлежит произвольному процессу.
На этом этапе драйвер не должен записывать данные в начальный адрес, предоставленный программой пользовательского режима на шаге 1. Этот адрес находится в виртуальном адресном пространстве процесса, который инициировал запрос, который, скорее всего, не совпадает с текущим процессом.
Виртуальное адресное пространство по умолчанию для 32-разрядного Windows
В следующей таблице показан диапазон памяти по умолчанию для каждой секции.
| Диапазон памяти | Использование |
|---|---|
| Низкая 2 ГБ (от 0x00000000 до 0x7FFFFFFF) | Используется процессом. |
| Высокий 2 ГБ (от 0x80000000 до 0xFFFFFFFF) | Используется системой. |
Настройка виртуального адресного пространства для 32-разрядного Windows
Можно использовать следующую команду, чтобы задать параметр записи загрузки, который настраивает размер раздела, который может использоваться процессом, в диапазоне от 2048 (2 ГБ) до 3072 (3 ГБ):
BCDEdit/Set инкреасеусерва мегабайт
После установки параметра загрузочной записи диапазон памяти для каждой секции выглядит следующим образом.
| Диапазон памяти | Использование |
|---|---|
| Низкая (0x00000000 до мегабайт) | Используется процессом. |
| Высокий (в мегабайтах+ 1 – 0xFFFFFFFF) | Используется системой. |
Windows Server 2003: Задайте для параметра /USERVA в boot.ini значение от 2048 до 3072.
Часто возникает необходимость понять, почему база данных 1С занимает много места. Особенно если это новый клиент\проект.
1. Увеличилось количество вводимых данных.
2. Хранение детальной аналитики предыдущих лет.
Здесь тоже все просто. Компания работает на рынке 5-10 лет и сверткой информационной базы никто не занимался. База потихоньку росла, и в какой-то момент размер стал сказываться на производительности. Обработка по свертке информационной базы нам поможет.
3. Активное использования хранилища дополнительной информации.
Именно для оценки данного параметра и написана текущая обработка.
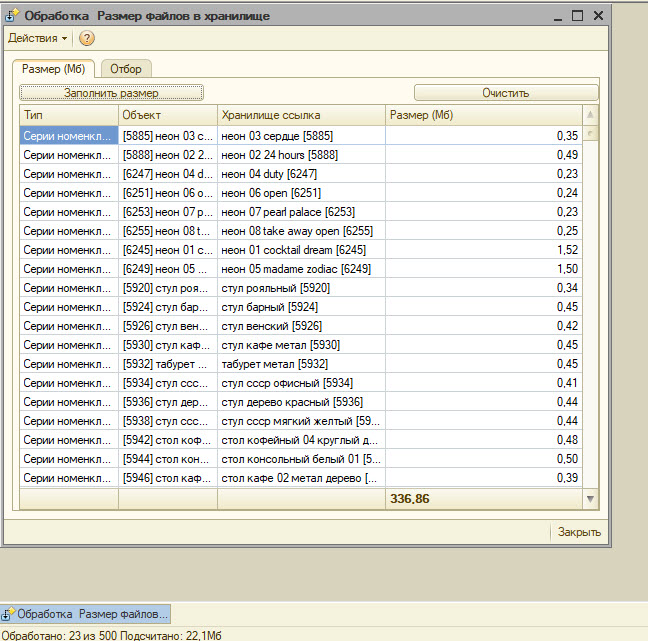
Сама функция расчета занимаемого места взята отсюда:
для 32-битной системы — 2гб
для 64-разрядной — 4 гб
Для того чтобы увеличить размер адресной памяти, необходимо:
Запустить командную строку: «Пуск — Выполнить» — введите CMD и нажмите enter.
Введите в командной строке «bcdedit /set increaseuserva 3072″, где 3072 — размер желаемой адресной памяти.
Перезагрузите компьютер.
Попробуйте выполнить действие в 1С 8, которое не получалось ранее.
Если всё получилось и операция повторяется не так часто, рекомендуется вернуть размер адресной памяти к значению по умолчанию с помощью команды «bcdedit /deletevalue increaseuserva».
При открытии обработки заполняется поле для отбора, где можно просмотреть наиболее используемые типы данных.
Нужно установить отбор по выбранным типам объектов.

Или отметить необходимое количество объектов для оценки.
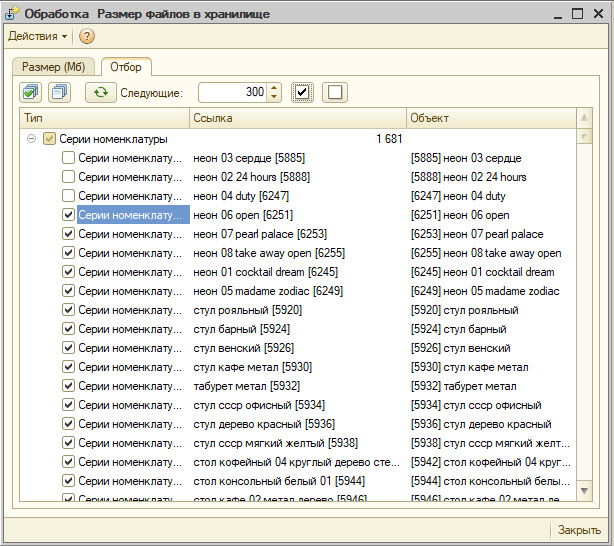
После выбора необходимых данных. На вкладке размер жмем кнопку "Заполнить размер".
Также можно остановить расчет Ctrl+Break (ОбработкаПрерыванияПользователя())
Обработка проверялась на работоспособность в конфигурации:
Управление торговым предприятием для Украины редакция 1.2.51.2
Но должна работать во всех типовых конфигурациях, где есть справочник "Хранилище дополнительной информации".
Управление памятью – одна из главных задач ОС. Она критична как для программирования, так и для системного администрирования. Я постараюсь объяснить, как ОС работает с памятью. Концепции будут общего характера, а примеры я возьму из Linux и Windows на 32-bit x86. Сначала я опишу, как программы располагаются в памяти.
Каждый процесс в многозадачной ОС работает в своей «песочнице» в памяти. Это виртуальное адресное пространство, которое в 32-битном режиме представляет собою 4Гб блок адресов. Эти виртуальные адреса ставятся в соответствие (mapping) физической памяти таблицами страниц, которые поддерживает ядро ОС. У каждого процесса есть свой набор таблиц. Но если мы начинаем использовать виртуальную адресацию, приходится использовать её для всех программ, работающих на компьютере – включая и само ядро. Поэтому часть пространства виртуальных адресов необходимо резервировать под ядро.


Это не значит, что ядро использует так много физической памяти – просто у него в распоряжении находится часть адресного пространства, которое можно поставить в соответствие необходимому количеству физической памяти. Пространство памяти для ядра отмечено в таблицах страниц как эксклюзивно используемое привилегированным кодом, поэтому если какая-то программа пытается получить в него доступ, случается page fault. В Linux пространство памяти для ядра присутствует постоянно, и ставит в соответствие одну и ту же часть физической памяти у всех процессов. Код ядра и данные всегда имеют адреса, и готовы обрабатывать прерывания и системные вызовы в любой момент. Для пользовательских программ, напротив, соответствие виртуальных адресов реальной памяти меняется, когда происходит переключение процессов:
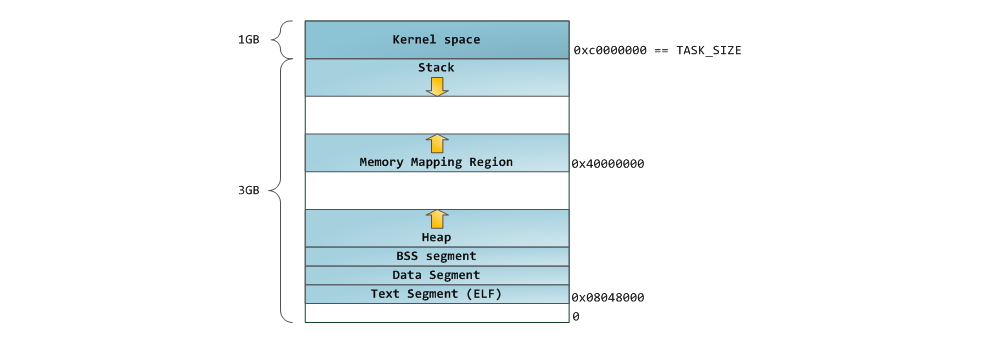
Голубым отмечены виртуальные адреса, соответствующие физической памяти. Белым – пространство, которому не назначены адреса. В нашем примере Firefox использует гораздо больше места в виртуальной памяти из-за своей легендарной прожорливости. Полоски в адресном пространстве соответствуют сегментам памяти таким, как куча, стек и проч. Эти сегменты – всего лишь интервалы адресов памяти, и не имеют ничего общего с сегментами от Intel. Вот стандартная схема сегментов у процесса под Linux:

Когда программирование было белым и пушистым, начальные виртуальные адреса сегментов были одинаковыми для всех процессов. Это позволяло легко удалённо эксплуатировать уязвимости в безопасности. Зловредной программе часто необходимо обращаться к памяти по абсолютным адресам – адресу стека, адресу библиотечной функции, и т.п. Удаленные атаки приходилось делать вслепую, рассчитывая на то, что все адресные пространства остаются на постоянных адресах. В связи с этим получила популярность система выбора случайных адресов. Linux делает случайными стек, сегмент отображения в память и кучу, добавляя смещения к их начальным адресам. К сожалению, в 32-битном адресном пространстве особо не развернёшься, и для назначения случайных адресов остаётся мало места, что делает эту систему не слишком эффективной.
Самый верхний сегмент в адресном пространстве процесса – это стек, в большинстве языков хранящий локальные переменные и аргументы функций. Вызов метода или функции добавляет новый кадр стека (stack frame) к существующему стеку. После возврата из функции кадр уничтожается. Эта простая схема приводит к тому, что для отслеживания содержимого стека не требуется никакой сложной структуры – достаточно всего лишь указателя на начало стека. Добавление и удаление данных становится простым и однозначным процессом. Постоянное повторное использование районов памяти для стека приводит к кэшированию этих частей в CPU, что добавляет скорости. Каждый поток выполнения (thread) в процессе получает свой собственный стек.
Можно прийти к такой ситуации, в которой память, отведённая под стек, заканчивается. Это приводит к ошибке page fault, которая в Linux обрабатывается функцией expand_stack(), которая, в свою очередь, вызывает acct_stack_growth(), чтобы проверить, можно ли ещё нарастить стек. Если его размер не превышает RLIMIT_STACK (обычно это 8 Мб), то стек увеличивается и программа продолжает исполнение, как ни в чём не бывало. Но если максимальный размер стека достигнут, мы получаем переполнение стека (stack overflow) и программе приходит ошибка Segmentation Fault (ошибка сегментации). При этом стек умеет только увеличиваться – подобно государственному бюджету, он не уменьшается обратно.
Динамический рост стека – единственная ситуация, в которой может осуществляться доступ к свободной памяти, которая показана белым на схеме. Все другие попытки доступа к этой памяти вызывают ошибку page fault, приводящую к Segmentation Fault. А некоторые занятые области памяти служат только для чтения, поэтому попытки записи в эти области также приводят к Segmentation Fault.
После стека идёт сегмент отображения в память. Тут ядро размещает содержимое файлов напрямую в памяти. Любое приложение может запросить сделать это через системный вызов mmap() в Linux или CreateFileMapping() / MapViewOfFile() в Windows. Это удобный и быстрый способ организации операций ввода и вывода в файлы, поэтому он используется для подгрузки динамических библиотек. Также возможно создать анонимное место в памяти, не связанное с файлами, которое будет использоваться для данных программы. Если вы сделаете в Linux запрос на большой объём памяти через malloc(), библиотека C создаст такую анонимное отображение вместо использования памяти из кучи. Под «большим» подразумевается объём больший, чем MMAP_THRESHOLD (128 kB по умолчанию, он настраивается через mallopt().)
Если в куче оказывается недостаточно места для выполнения запроса, эту проблему может обработать сама программа без вмешательства ядра. В ином случае куча увеличивается системным вызовом brk(). Управление кучей – дело сложное, оно требует хитроумных алгоритмов, которые стремятся работать быстро и эффективно, чтобы угодить хаотичному методу размещению данных, которым пользуется программа. Время на обработку запроса к куче может варьироваться в широких пределах. В системах реального времени есть специальные инструменты для работы с ней. Кучи тоже бывают фрагментированными:

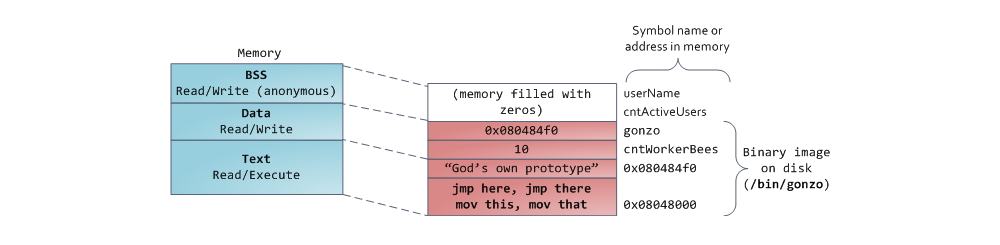
И вот мы добрались до самой нижней части схемы – BSS, данные и текст программы. BSS и данные хранят статичные (глобальные) переменные в С. Разница в том, что BSS хранит содержимое непроинициализированных статичных переменных, чьи значения не были заданы программистом. Кроме этого, область BSS анонимна, она не соответствует никакому файлу. Если вы пишете static int cntActiveUsers , то содержимое cntActiveUsers живёт в BSS.
Сегмент данных, наоборот, содержит те переменные, которые были проинициализированы в коде. Эта часть памяти соответствует бинарному образу программы, содержащему начальные статические значения, заданные в коде. Если вы пишете static int cntWorkerBees = 10 , то содержимое cntWorkerBees живёт в сегменте данных, и начинает свою жизнь как 10. Но, хотя сегмент данных соответствует файлу программы, это приватное отображение в память (private memory mapping) – а это значит, что обновления памяти не отражаются в соответствующем файле. Иначе изменения значения переменных отражались бы в файле, хранящемся на диске.
Пример данных на диаграмме будет немного сложнее, поскольку он использует указатель. В этом случае содержимое указателя, 4-байтный адрес памяти, живёт в сегменте данных. А строка, на которую он показывает, живёт в сегменте текста, который предназначен только для чтения. Там хранится весь код и разные другие детали, включая строковые литералы. Также он хранит ваш бинарник в памяти. Попытки записи в этот сегмент оканчиваются ошибкой Segmentation Fault. Это предотвращает ошибки, связанные с указателями (хотя не так эффективно, как если бы вы вообще не использовали язык С). На диаграмме показаны эти сегменты и примеры переменных:

Изучить области памяти Linux-процесса можно, прочитав файл /proc/pid_of_process/maps. Учтите, что один сегмент может содержать много областей. К примеру, у каждого файла, сдублированного в память, есть своя область в сегменте mmap, а у динамических библиотек – дополнительные области, напоминающие BSS и данные. Кстати, иногда, когда люди говорят «сегмент данных», они имеют в виду данные + bss + кучу.
Бинарные образы можно изучать при помощи команд nm и objdump – вы увидите символы, их адреса, сегменты, и т.п. Схема виртуальных адресов, описанная в этой статье – это т.н. «гибкая» схема, которая по умолчанию используется уже несколько лет. Она подразумевает, что переменной RLIMIT_STACK присвоено какое-то значение. В противном случае Linux использует «классическую» схему:
Управление памятью – центральный аспект в работе операционных систем. Он оказывает основополагающее влияние на сферу программирования и системного администрирования. В нескольких последующих постах я коснусь вопросов, связанных с работой памяти. Упор будет сделан на практические аспекты, однако и детали внутреннего устройства игнорировать не будем. Рассматриваемые концепции являются достаточно общими, но проиллюстрированы в основном на примере Linux и Windows, выполняющихся на x86-32 компьютере. Первый пост описывает организацию памяти пользовательских процессов.
Каждый процесс в многозадачной ОС выполняется в собственной “песочнице”. Эта песочница представляет собой виртуальное адресное пространство, которое в 32-битном защищенном режиме всегда имеет размер равный 4 гигабайтам. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц (page table). Ядро создает и заполняет таблицы, а процессор обращается к ним при необходимости осуществить трансляцию адреса. Каждый процесс работает со своим набором таблиц. Есть один важный момент — концепция виртуальной адресации распространяется на все выполняемое ПО, включая и само ядро. По этой причине для него резервируется часть виртуального адресного пространства (т.н. kernel space).

Синим цветом на рисунке отмечены области виртуального адресного пространства, которым в соответствие поставлены участки физической памяти; белым цветом — еще не использованные области. Как видно, Firefox использовал большую часть своего виртуального адресного пространства. Все мы знаем о легендарной прожорливости этой программы в отношении оперативной памяти. Синие полосы на рисунке — это сегменты памяти программы, такие как куча (heap), стек и так далее. Обратите внимание, что в данном случае под сегментами мы подразумеваем просто непрерывные адресные диапазоны. Это не те сегменты, о которых мы говорим при описании сегментации в Intel процессорах. Так или иначе, вот стандартная схема организации памяти процесса в Linux:

Давным давно, когда компьютерная техника находилась в совсем еще младенческом возрасте, начальные виртуальные адреса сегментов были совершенно одинаковыми почти для всех процессов, выполняемых машиной. Из-за этого значительно упрощалось удаленное эксплуатирование уязвимостей. Эксплойту часто необходимо обращаться к памяти по абсолютным адресам, например по некоторому адресу в стеке, по адресу библиотечной функции, и тому подобное. Хакер, рассчитывающий осуществить удаленную атаку, должен выбирать адреса для обращения в слепую в расчете на то, что размещение сегментов программы в памяти на разных машинах будет идентичным. И когда оно действительно идентичное, случается, что людей хакают. По этой причине, приобрел популярность механизм рандомизации расположения сегментов в адресном пространстве процесса. Linux рандомизирует расположение стека, сегмента для memory mapping, и кучи – их стартовый адрес вычисляется путем добавления смещения. К сожалению, 32-битное пространство не очень-то большое, и эффективность рандомизации в известной степени нивелируется.
В верхней части user mode space расположен стековый сегмент. Большинство языков программирования используют его для хранения локальных переменных и аргументов, переданных в функцию. Вызов функции или метода приводит к помещению в стек т.н. стекового фрейма. Когда функция возвращает управление, стековый фрейм уничтожается. Стек устроен достаточно просто — данные обрабатываются в соответствии с принципом «последним пришёл — первым обслужен» (LIFO). По этой причине, для отслеживания содержания стека не нужно сложных управляющих структур – достаточно всего лишь указателя на верхушку стека. Добавление данных в стек и их удаление – быстрая и четко определенная операция. Более того, многократное использование одних и тех же областей стекового сегмента приводит к тому, что они, как правило, находятся в кеше процессора, что еще более ускоряет доступ. Каждый тред в рамках процесса работает с собственным стеком.
Возможна ситуация, когда пространство, отведенное под стековый сегмент, не может вместить в себя добавляемые данные. В результате, будет сгенерирован page fault, который в Linux обрабатывается функцией expand_stack(). Она, в свою очередь, вызовет другую функцию — acct_stack_growth(), которая отвечает за проверку возможности увеличить стековый сегмент. Если размер стекового сегмента меньше значения константы RLIMIT_STACK (обычно 8 МБ), то он наращивается, и программа продолжает выполняться как ни в чем не бывало. Это стандартный механизм, посредством которого размер стекового сегмента увеличивается в соответствии с потребностями. Однако, если достигнут максимально разрещённый размер стекового сегмента, то происходит переполнение стека (stack overflow), и программе посылается сигнал Segmentation Fault. Стековый сегмент может увеличиваться при необходимости, но никогда не уменьшается, даже если сама стековая структура, содержащаяся в нем, становиться меньше. Подобно федеральному бюджету, стековый сегмент может только расти.
Динамическое наращивание стека – единственная ситуация, когда обращение к «немэппированной» области памяти, может быть расценено как валидная операция. Любое другое обращение приводит к генерации page fault, за которым следует Segmentation Fault. Некоторые используемые области помечены как read-only, и обращение к ним также приводит к Segmentation Fault.
Под стеком располагается сегмент для memory mapping. Ядро использует этот сегмент для мэппирования (отображания в память) содержимого файлов. Любое приложение может воспользоваться данным функционалом посредством системного вызовома mmap() (ссылка на описание реализации вызова mmap) или CreateFileMapping() / MapViewOfFile() в Windows. Отображение файлов в память – удобный и высокопроизводительный метод файлового ввода / вывода, и он используется, например, для загрузки динамических библиотек. Существует возможность осуществить анонимное отображение в память (anonymous memory mapping), в результате чего получим область, в которую не отображен никакой файл, и которая вместо этого используется для размещения разного рода данных, с которыми работает программа. Если в Linux запросить выделение большого блока памяти с помощью malloc(), то вместо того, чтобы выделить память в куче, стандартная библиотека C задействует механизм анонимного отображения. Слово «большой», в данном случае, означает величину в байтах большую, чем значение константы MMAP_THRESHOLD. По умолчанию, это величина равна 128 кБ, и может контролироваться через вызов mallopt().
Если текущий размер кучи позволяет выделить запрошенный объем памяти, то выделение может быть осуществлено средствами одной лишь среды выполнения, без привлечения ядра. В противном случае, функция malloc() задействует системный вызов brk() для необходимого увеличения кучи (ссылка на описание реализации вызова brk). Управление памятью в куче – нетривиальная задача, для решения которой используются сложные алгоритмы. Данные алгоритмы стремятся достичь высокой скорости и эффективности в условиях непредсказуемых и хаотичных пэттернов выделения памяти в наших программах. Время, затрачиваемое на каждый запрос по выделению памяти в куче, может разительно отличаться. Для решения данной проблемы, системы реального времени используют специализированные аллокаторы памяти. Куча также подвержена фрагментированию, что, к примеру, изображено на рисунке:

Наконец, мы добрались до сегментов, расположенных в нижней части адресного пространства процесса: BSS, сегмент данных (data segment) и сегмент кода (text segment). BSS и data сегмент хранят данные, соответствующий static переменным в исходном коде на C. Разница в том, что в BSS хранятся данные, соответствующие неинициализированным переменным, чьи значения явно не указаны в исходном коде (в действительности, там хранятся объекты, при создании которых в декларации переменной либо явно указано нулевое значение, либо значение изначально не указано, и в линкуемых файлах нет таких же common символов, с ненулевым значением. – прим. перевод.). Для сегмента BSS используется анонимное отображение в память, т.е. никакой файл в этот сегмент не мэппируется. Если в исходном файле на C использовать int cntActiveUsers, то место под соответствующий объект будет выделено в BSS.
В отличии от BSS, data cегмент хранит объекты, которым в исходном коде соответствуют декларации static переменных, инициализированных ненулевым значением. Этот сегмент памяти не является анонимным — в него мэппируется часть образа программы. Таким образом, если мы используем static int cntWorkerBees = 10, то место под соответствующий объект будет выделено в data сегменте, и оно будет хранить значение 10. Хотя в data сегмент отображается файл, это т.н. «приватный мэппинг» (private memory mapping). Это значит, что изменения данных в этом сегменте не повлияют на содержание соответствующего файла. Так и должно быть, иначе присвоения значений глобальным переменным привели бы к изменению содержания файла, хранящегося на диске. В данном случае это совсем не нужно!
С указателями все немножко посложнее. В примере из наших диаграмм, содержимое объекта, соответствующего переменной gonzo – это 4-байтовый адрес – размещается в data сегменте. А вот строка, на которую ссылается указатель, не попадет в data сегмент. Строка будет находиться в сегменте кода, который доступен только на чтение и хранит весь Ваш код и такие мелочи, как, например, строковые литералы (в действительности, строка хранится в секции .rodata, которая вместе с другими секциями, содержащими исполняемый код, рассматривается как сегмент, который загружается в память с правами на выполнение кода / чтения данных – прим. перевод.). В сегмент кода также мэппируется часть исполняемого файла. Если Ваша программа попытается осуществить запись в text сегмент, то заработает Segmentation Fault. Это позволяет бороться с «бажными» указателями, хотя самый лучший способ борьбы с ними – это вообще не использовать C. Ниже приведена диаграмма, изображающая сегменты и переменные из наших примеров:
Мы можем посмотреть, как используются области памяти процесса, прочитав содержимое файла /proc/pid_of_process/maps. Обратите внимание, что содержимое самого сегмента может состоять из различных областей. Например, каждой мэппируемой в memory mapping сегмент динамической библиотеке отводится своя область, и в ней можно выделить области для BSS и data сегментов библиотеки. В следующем посте поясним, что конкретно подразумевается под словом “область”. Учтите, что иногда люди говорят “data сегмент”, подразумевая под этим data + BSS + heap.
Можно использовать утилиты nm и objdump для просмотра содержимого бинарных исполняемых образов: символов, их адресов, сегментов и т.д. Наконец, то, что описано в этом посте – это так называемая “гибкая” организация памяти процесса (flexible memory layout), которая вот уже несколько лет используется в Linux по умолчанию. Данная схема предполагает, что у нас определено значение константы RLIMIT_STACK. Когда это не так, Linux использует т.н. классическую организации, которая изображена на рисунке:
Ну вот и все. На этом наш разговор об организации памяти процесса завершен. В следующем посте рассмотрим как ядро отслеживает размеры описанных областей памяти. Также коснемся вопроса мэппирования, какое отношение к этому имеет чтение и запись файлов, и что означают цифры, описывающие использование памяти.
Читайте также: