
Распределительный способ обработки данных предполагает локальные компьютеры
Персональные компьютеры стоят на рабочих местах, т.е. на местах возникновения и использования информации. Они соединены каналами связи. Это дало возможность распределить их ресурсы по отдельным функциональным сферам деятельности и изменить технологию обработки данных в направлении децентрализации.
Распределенная обработка данных заключается в том, что пользователь и его прикладные программы (приложения) получают возможность работать со средствами, расположенными в рассредоточенных узлах сетевой системы.
Системы, имеющие программы распределенной среды, включают компьютеры, называемые серверами и клиентами. Каждый сервер имеет свою группу клиентов.
Программное обеспечение сетевой среды обслуживается и поддерживается сетевыми операционными системами. В роли сервера выступает главный, более мощный компьютер.
Распределенная среда требует организации распределенной базы данных и такого инструментария, как распределенная система управления базой данных (РСУБД).
Распределенная обработка данных позволила повысить эффективность удовлетворения изменяющейся информационной потребности информационного работника и тем самым обеспечить гибкость принимаемых им решений.
Преимущества распределенной обработки данных:
■ большое число взаимодействующих между собой пользователей, выполняющих функции сбора, регистрации, хранения, передачи и выдачи информации;
■ снятие пиковых нагрузок с централизованной базы путем распределения обработки и хранения локальных баз данных на разных ЭВМ;
■ обеспечение доступа информационного работника к вычислительным ресурсам сети ЭВМ;
■ обеспечение симметричного обмена данными между удаленными пользователями.
Введение классификации моделей представления данных на иерархические, сетевые и реляционные отразилось на архитектуре систем управления базами данных и технологии их обработки. Архитектура СУБД описывает ее функционирование как взаимодействие процессов двух типов: клиента и сервера.
Распределенная обработка и распределенная база данных не синонимы.
Если при распределенной обработке производится работа с базой, то подразумевается, что представление данных, их содержательная обработка, работа с базой на логическом уровне выполняются на персональном компьютере клиента, а поддержание базы в актуальном состоянии — на сервере.
В случае использования распределенной базы данных последняя размещается на нескольких серверах. Работа с ней осуществляется на тех же персональных компьютерах или на других, и для доступа к удаленным данным надо использовать сетевую СУБД.
Организация обработки данных зависит от способа их распределения. Существуют централизованный, децентрализованный и смешанный способы распределения данных.
Централизованная организация данных. На одном сервере находится единственная копия базы данных. Все операции с базой данных обеспечиваются этим сервером. Доступ к данным выполняется с помощью удаленного запроса или удаленной транзакции.
Достоинством такого способа является легкая поддержка базы данных в актуальном состоянии, а недостатком — то, что размер базы ограничен размером внешней памяти; все запросы направляются к единственному серверу с соответствующими затратами на стоимость связи и временную задержку. Отсюда - ограничение на параллельную обработку.

Централизованная организация данных
Децентрализованная организация данных предполагает разбиение информационной базы на несколько физически распределенных.
Каждый клиент пользуется своей базой данных, которая может быть либо частью об-щей информационной базы (Рис. 2), либо копией информационной базы в целом (Рис. 2), что приводит к ее дублированию для каждого клиента.
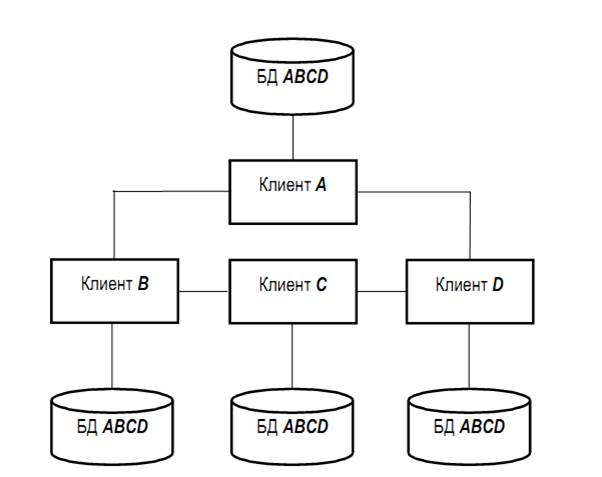
Децентрализованная обработка данных
При распределении данных на основе разбиения база данных размещается на нескольких серверах. Существование копий отдельных частей недопустимо.
Достоинства этого метода: большинство запросов удовлетворяются локальными базами, что сокращает время ответа; увеличиваются доступность данных и надежность их хранения; стоимость запросов на выборку и обновление снижается по сравнению с централизованным распределением; система останется частично работоспособной, если выйдет из строя один сервер.
Имеются и недостатки: часть удаленных запросов или транзакций может потребовать доступ ко всем серверам, что увеличивает время ожидания и цену обслуживания; необходимо иметь сведения о размещении данных в различных БД. Однако доступность и надежность увеличатся.

Расчлененные базы данных наиболее подходят к случаю совместного использования локальных и глобальных сетей ЭВМ.
Способ дублирования заключается в том, что в каждом сервере сети ЭВМ размещается полная база данных. Это обеспечивает наибольшую надежность хранения данных. Недостатки способа: повышенные требования к объему внешней памяти; усложнение корректировки баз, так как требуется синхронизация в целях согласования копий. Достоинства — все запросы выполняются локально, что обеспечивает быстрый доступ. Данный способ используется, когда фактор надежности является критическим, база небольшая, интенсивность обновления невелика.
Смешанная организация хранения данных. Возможна и смешанная организация хранения данных, которая объединяет два способа распределения: разбиение и дублирование (Рис. 3), приобретая при этом и преимущества, и недостатки обоих способов.
Появляется необходимость хранить информацию о том, где находятся данные в сети. При этом достигается компромисс между объемом памяти под базу в целом и под базу в каждом сервере, чтобы обеспечить надежность и эффективность ее работы; легко реализуется параллельная обработка, т.е. обслуживание распределенного запроса, или транзакции.
Несмотря на гибкость смешанного способа организации данных, остается проблема взаимозависимости факторов, влияющих на производительность системы, проблема ее надежности и выполнения требований к памяти. Смешанный способ организации данных можно использовать лишь при наличии сетевой СУБД.
В базах данных коллективного пользования центральным технологическим звеном становятся серверы баз данных.

Смешанная система обработки данных
Программные средства серверов баз данных обеспечивают реализацию многопользовательских приложений, централизованное хранение, целостность и безопасность данных.
Производительность серверов баз данных на порядок выше по сравнению с файл-серверами, которые используются в локальных сетях.
Локальные вычислительные сети создавались для совместного использования дорогостоящего периферийного оборудования. Использование сервера баз данных обеспечило доступ многих пользователей к одним и тем же файлам. Это и стало предпосылкой создания сетевых СУБД.
Мощность сетевых СУБД, основанных на файл-сервере, в настоящее время недостаточна. В нагруженной сети неизбежно падает производительность, нарушаются безопасность и целостность данных. Проблема производительности возникла не потому, что процессоры 386нс обладают достаточной мощностью, а потому что файл-серверы реализуют принцип «все или ничего». Полные копии файлов базы перемещаются взад-вперед по сети. Проблемы с безопасностью, целостностью возникли из-за того, что с самого начала файл-серверы не были сконструированы с учетом сохранения целостности данных и их восстановления в случае аварии.
Технологии «клиент-сервер»
Характеристика технологии «клиент-сервер». «Клиент-сервер» - это модель взаимодействия компьютеров в сети.
Как правило, компьютеры в такой конфигурации не являются равноправными. Каждый из них имеет свое, отличное от других, назначение, играет свою роль.
Некоторые компьютеры в сети владеют и распоряжаются информационно- вычислительными ресурсами, такими, как процессоры, файловая система, почтовая служба, служба печати, базы данных. Другие же компьютеры имеют возможность обращаться к этим службам, пользуясь услугами первых.
Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, желающий им воспользоваться — клиентом (Рис. 4.).

Конкретный сервер определяется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого - обслуживать запросы клиентов, связанные с обработкой данных в базах; если ресурс - файловая система, то говорят о файловом сервере, или файл-сервере, и т.д.
В сети один и тот же компьютер может выполнять роль как клиента, так и сервера (Рис. 5.). Например, в информационной системе, включающей персональные компьютеры, большую ЭВМ и мини-компьютер, последний может выступать как в качестве сервера базы данных, обслуживая запросы от клиентов - персональных компьютеров, так и в качестве клиента, направляя запросы большой ЭВМ.
Этот же принцип распространяется и на взаимодействие программ. Если одна из них выполняет некоторые функции, предоставляя другим соответствующий набор услуг, то такая программа выступает в качестве сервера. Программы, которые пользуются этими услугами, принято называть клиентами.
Обработка информации данных строится на использовании технологии баз и банков данных. В базе информация организована по определенным правилам и представляет собой интегрированную совокупность взаимосвязанных данных. Такая технология обеспечивает увеличение скорости их обработки при больших объемах.
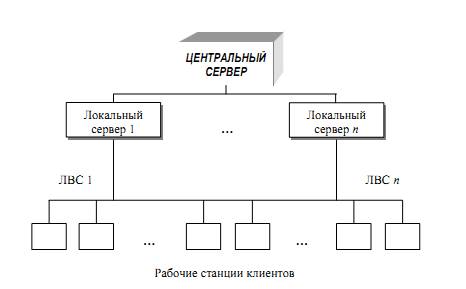
Рис. 5. Трехуровневая модель «клиент-сервер»
Обработка данных на внутримашинном уровне представляет собой процесс выполнения последовательности операций, задаваемых алгоритмом. Технология обработки прошла длинный путь развития.
Сегодня обработка данных осуществляется компьютерами или их системами. Данные обрабатываются прикладными программами пользователей.
Первостепенное значение в системах управления организациями имеет обработка данных для нужд пользователей, и в первую очередь для пользователей верхнего уровня.
В процессе эволюции информационных технологий заметно стремление упростить и удешевить для пользователей компьютеры, их программное оснащение и процессы, выполняемые на них.
Одновременно с этим пользователи получают все более широкий и сложный сервис со стороны вычислительных систем и сетей, что приводит к появлению технологий, получивших название клиент-сервер.
Ограничение числа сложных абонентских систем в локальной сети приводит к появлению компьютеров в роли сервера и клиента.
Реализация технологий «клиент-сервер» может иметь различия в эффективности и стоимости информационно-вычислительных процессов, а также в уровнях программного и технического обеспечения, в механизме связей компонентов, в оперативности доступа к информации, ее многообразии и т.д.
Получение разнообразного и сложного сервиса, организованного в сервере, делает работу пользователей более производительной и стоит пользователям дешевле, чем сложное программно-техническое оснащение многих компьютеров-клиентов.
Технология клиент-сервер, как более мощная, заменила технологию файл-сервер. Она позволила совместить достоинства однопользовательских систем (высокий уровень диалоговой поддержки, дружественный интерфейс, низкая цена) с достоинствами более крупных компьютерных систем (поддержка целостности, защита данных, многозадачность).
В классическом понимании СУБД представляет собой набор программ, позволяющих создавать и поддерживать базу данных в актуальном состоянии. Функционально СУБД состоит из трех частей: ядра (базы данных), языка и инструментальных средств программирования.
Инструментальные средства программирования относятся к интерфейсу клиента, или внешнему интерфейсу. Они могут включать процессор обработки данных на языке запросов. Язык — это совокупность процедурных и непроцедурных команд, поддерживаемых СУБД. Наиболее употребительными языками являются SQL и QBE. Ядро выполняет все остальные функции, которые, включены в понятие «обработка базы данных».
Основная идея технологии клиент-сервер заключается в том, чтобы серверы расположить на мощных машинах, а приложения клиентов, использующих язык, — на менее мощных машинах. Тем самым будут задействованы ресурсы более мощного сервера и менее мощных машин клиентов.
Ввод-вывод к базе основан не на физическом дроблении данных, а на логическом, т.е. сервер отправляет клиентам не полную копию базы, а только логически необходимые порции, тем самым сокращая трафик сети.
Сервер обрабатывает запросы клиентов, выбирает необходимые данные из базы данных, посылает их клиентам по сети, производит обновление информации, обеспечивает целостность и сохранность данных.
Основные достоинства систем «клиент-сервер» состоят в следующем:
■ низкая нагрузка на сеть (рабочая станция посылает серверу базы данных запрос на поиск определенных данных, сервер сам осуществляет поиск и возвращает по сети только результат обработки запроса, т.е. одну или несколько записей);
■ высокая надежность (СУБД, основанные на технологии «клиент-сервер», поддерживают целостность транзакций и автоматическое восстановление при сбое);
■ гибкая настройка уровня прав пользователей (одним пользователям можно назначить только просмотр данных, другим просмотр и редактирование, третьи вообще не увидят каких-либо данных);
■ поддержка полей больших размеров (поддерживаются типы данных размер которых может измеряться сотнями килобайт и мегабайт).
Однако системам «клиент-сервер» присущи также и недостатки:
■ трудность администрирования, вследствие территориальной разобщенности и неоднородности компьютеров на рабочих местах;
■ недостаточная степень защиты информации от несанкционированных действий;
■ закрытый протокол для общения клиентов и сервера, специфичный для данной информационной системы.
Для устранения указанных недостатков используется архитектура систем Интранет, сконцентрировавших и объединивших в себе лучшие качества централизованных систем и традиционных систем «клиент-сервер».
1. Централизованный - обрабатывает данные в одном месте, используя мощный компьютер и сложное программное обеспечение, установленное только на нем. Терминалы пользователей и автоматизированные устройства ввода первичных документов посылают данные на центральную ЭВМ для обработки, которая, если необходимо, предоставляет на терминалы обработанные данные. Преимуществами такого подхода являются меньшие затраты, лучший контроль за данными и программами (поскольку они находятся в одном месте), большая безопасность. Среди недостатков - большая сложность эксплуатации, высокие затраты на коммуникации (при большой удаленности терминалов).

2. Децентрализованный -системы,в которых данные хранятся и обрабатываются независимо в разных местах. При этом на каждом компьютере хранится какое-то подмножество всех данных компании, а часть данных находится в нескольких местах.
3. Распределительный – способ, при котором все подразделения компании, находящиеся в разных местах, соединены в единую сеть. Каждое из них имеет средства и возможности самостоятельно обрабатывать свои данные, поэтому пользуется преимуществами децентрализованной обработки. В то же время локальные компьютеры из разных мест могут посылать данные на центральную ЭВМ для подведения итогов и пользоваться общими данными компании, находящимися на ней, поэтому распределенная обработка дает и преимущества централизованной системы. В результате получается система, ориентированная как на нужды пользователей, так и на нужды руководства компании.

Преимущества распределенной обработки:
· Поскольку пользователи контролируют каждую локальную систему, они имеют возможность подогнать ее под свои нужды и тем самым улучшить качество производимой информации.
· Распределенная обработка данных позволяет быстрее и точнее вводить и корректировать данные, быстрее получать ответы на запросы.
· Уменьшаются затраты на коммуникации, т.к. обработка производится локально.
· Поскольку данные и другие ресурсы находятся в разных местах и частично дублируются, компьютеры как бы страхуют друг друга, уменьшая вероятность катастрофических потерь.
· Каждая локальная система может рассматриваться как модуль общей системы, который может быть добавлен, модифицирован или удален из системы без необходимости изменять другие модули.
Недостатки распределительной обработки:
· Распределенные системы более дороги, чем централизованные.
· Намного усложняются задачи обслуживания оборудования, программного обеспечения, поддержания данных в необходимом состоянии.
· Поскольку данные принадлежат разным подразделениям, неизбежно их дублирование со всеми вытекающими последствиями от использования такой информации, поэтому возникает необходимость специальных процедур по согласованию содержимого общих частей баз данных.
· Поскольку неизбежно распределение полномочий и зон ответственности в такой системе, намного усложняется процесс документирования и контроля.
· Разбросанность частей системы в пространстве и наличие коммуникаций снижают возможности обеспечения безопасности.
· Уменьшается информационная насыщенность каждой отдельной локальной системы, поскольку вся информация, которая присуща централизованным системам, не может быть продублирована на всех компьютерах.
4. Интегрированный - способ обработки информации. Он предусматривает создание информационной модели управляемого объекта, то есть создание распределенной базы данных. Такой способ обеспечивает максимальное удобство для пользователя.
Различаются следующие способы обработки данных: централизованные, децентрализованные, распределенные и интегрированные.
Централизованная обработка предполагает наличие вычислительного центра (ВЦ). При этом способе пользователь доставляет на ВЦ исходную информацию и получают результаты обработки в виде результативных документов. Особенностью такого способа обработки являются сложность и трудоемкость налаживания быстрой, бесперебойной связи, большая загруженность ВЦ информацией (т.к. велик ее объем), регламентацией сроков выполнения операций, организация безопасности системы от возможного несанкционированного доступа.
Децентрализованная обработка. Этот способ связан с появлением ПЭВМ, дающих возможность автоматизировать конкретное рабочие место. В настоящие время банковской системе существуют три вида технологий децентрализованной обработки данных. Первая основывается на персональных компьютерах, не объединенных в локальную сеть.(данные хранятся в отдельных файлах и на отдельных дисках). Для получения показателей производится перезапись информации на компьютер. Недостатки: отсутствие взаимной увязки задач, невозможность обработки больших объемов информации, низкая зашита от несанкционированного доступа. Второй: ПК объединенные в локальную сеть, что ведет к созданию единых файлов данных (но он не рассчитан на большие объемы информации).Третий: ПК объединенные в локальную сеть, в которую включаются специальные серверы (с режимом “клиент-банк”).
Распределенный способ обработки данных основан на распределении функций обработки между различными ЭВМ, включенными в сеть. Этот способ может быть реализован двумя путями: первый предполагает установку ЭВМ в каждом узле сети (или на каждом уровне системы), при этом обработка данных осуществляется одной или несколькими ЭВМ в зависимости от реальных возможностей системы и ее потребностей на текущий момент времени. Второй путь - размещение большого числа различных процессоров внутри одной системы. Такой путь применяется в системах обработки банковской и финансовой информации, там, где необходима сеть обработки данных (филиалы, отделения и т.д.).
Преимущества распределенного способа: возможность обрабатывать в заданные сроки любой объем данных; высокая степень надежности, так как при отказе одного технического средства есть возможность моментальной замены его на другой.; сокращение времени и затрат на передачу данных; повышение гибкости систем, упрощение разработки и эксплуатации программного обеспечения и т.д. Распределенный способ основывается на комплексе специализированных процессоров, т.е. каждая ЭВМ предназначена для решения определенных задач, или задач своего уровня.
Следующий способ обработки данных - интегрированный. Он предусматривает создание информационной модели управляемого объекта, то есть создание распределенной базы данных. Такой способ обеспечивает максимальное удобство для пользователя. С одной стороны, базы данных предусматривают коллективное пользование и централизованное управление. С другой стороны, объем информации, разнообразие решаемых задач требуют распределения базы данных. Технология интегрированной обработки информации позволяет улучшить качество, достоверность и скорость обработки, т.к. обработка производится на основе единого информационного массива, однократно введенного в ЭВМ. Особенностью этого способа является отделение технологически и по времени процедуры обработки от процедур сбора, подготовки и ввода данных.
Тема 4. Программное обеспечение АРМ менеджера
Одной из важнейших и динамично развивающихся сетевых технологий являются технологии распределенной обработки данных. Использование этих технологий позволяет существенно улучшить информационное обеспечение территориально распределенного производства. При этом для администрации фирмы безразлично, где именно находится производство: в этом же здании, за 100 м или за 10 000 км. Появляются совсем другие проблемы, такие как межконтинентальное снабжение, поясное время и т.д.
Персональные компьютеры стоят на рабочих местах, т.е. в местах возникновения и использования информации (например, в иногороднем филиале фирмы, в пункте обмена валют коммерческого банка и т.д.). Они соединены каналами связи. Использование технологии распределенной обработки данных дает возможность распределить ресурсы всех компьютеров такой корпоративной (региональной) компьютерной сети по отдельным функциональным сферам деятельности и изменить технологию обработки данных в направлении децентрализации.
Преимущества распределенной обработки данных:
- большое число взаимодействующих между собой пользователей, выполняющих функции сбора, регистрации, хранения, передачи и выдачи информации;
- снятие пиковых нагрузок с централизованной базы путем распределения обработки и хранения локальных баз данных на разных ЭВМ;
- обеспечение доступа каждого работника к вычислительным ресурсам сети ЭВМ;
- обеспечение симметричного обмена данными между удаленными пользователями.
Распределенная обработка и распределенная база данных не синонимы. Если при распределенной обработке производится работа с базой, то подразумевается, что представление данных, их содержательная обработка, работа с базой на логическом уровне выполняются на персональном компьютере клиента, а поддержание базы в актуальном состоянии (состоянии, соответствующем состоянию реальной системы) — на сервере. В случае использования распределенной базы данных последняя размещается на нескольких серверах. Работа с ней осуществляется на тех же персональных компьютерах либо на других, и для доступа к удаленным данным надо использовать сетевую СУБД.
В системе распределенной обработки клиент может послать запрос как к собственной локальной базе данных, так и к удаленной. Удаленный запрос — единичный запрос к одному серверу. Несколько удаленных запросов к одному серверу объединяются в удаленную транзакцию. Если отдельные запросы транзакции обрабатываются различными серверами, то транзакция называется распределенной. При этом один запрос транзакции обрабатывается одним сервером. Распределенная же СУБД позволяет обрабатывать один запрос несколькими серверами. Такой запрос называется распределенным. Только обработка распределенного запроса поддерживает концепцию распределенной базы данных.
Организация обработки данных зависит от способа их распределения. Существуют централизованный, децентрализованный и смешанный способы распределения данных
Централизованная организация данных является самой простой для реализации (рис. 3.2.). На одном сервере находится единственная копия базы данных. Все операции с базой данных обеспечиваются этим сервером. Отсюда — ограничение на параллельную обработку. Доступ к данным выполняется с помощью удаленного запроса или удаленной транзакции. Достоинством такого способа являлся легкая поддержка базы данных в актуальном состояние а недостатками — то, что размер базы ограничен размером внешней памяти сервера; все запросы направляются к единственному серверу с соответствующими затратами на стоимость связи и временную задержку. Кроме того, база может стать полностью недоступной для удаленных пользователей при появлении ошибок связи или при отказе центрального сервера.
Децентрализованная организация данных предполагает разбиение информационной базы на несколько физически распределенных. Каждый клиент пользуется своей базой данных, которая может быть либо частью общей информационной базы (рис. 3.3), либо копией информационной базы в целом (рис. 3.4), что приводит к ее дублированию для каждого клиента.
При распределении данных на основе разбиения база данных размещается на нескольких серверах. Существование копий отдельных частей недопустимо. Достоинства этого метода: большинство запросов удовлетворяются локальными серверами, что сокращает время получения ответа и снижает стоимость обработки запроса; система остается частично работоспособной при выходе из строя одного из серверов. Имеются и недостатки: часть удаленных запросов или транзакций может потребовать доступ к нескольким или даже всем серверам, что увеличит время ожидания; постоянно необходимо иметь сведения о размещении данных в различных БД. Расчленение базы данных наиболее подходит в случае совместного использования локальных и глобальных сетевых коммуникаций, поскольку обеспечивает безопасное использование внутрикорпоративных данных.

Способ дублирования заключается в том, что на каждом сервере сети размещается полная база данных (рис. 3.4). Это обеспечивает наибольшую надежность хранения данных. Недостатки способа: повышенные требования к объему внешней памяти клиентских компьютеров; усложнение корректировки баз, так как требуется синхронизация в целях согласования копий. Достоинства — все запросы выполняются локально, что обеспечивает быстрый доступ. Данный способ используется, когда фактор надежности является критическим, база небольшая, интенсивность обновления невелика.
Возможна и смешанная организация хранения данных, которая объединяет два способа распределения: разбиение и дублирование (рис. 3.5), приобретая при этом и преимущества, и недостатки обоих способов.
Появляется необходимость хранить информацию о том, где находятся данные в сети. При этом достигается компромисс между объемом памяти под базу в целом и под базу на каждом сервере, чтобы обеспечить надежность и эффективность работы сети; легко реализуется параллельная обработка. Смешанный способ организации данных можно использовать лишь при наличии сетевой СУБД.
В базах данных коллективного пользования центральным технологическим звеном становятся серверы баз данных. Программные средства серверов баз данных обеспечивают реализацию многопользовательских приложений, централизованное хранение, целостность и безопасность данных. Производительность серверов баз данных на порядок выше по сравнению с файл-серверами, которые используются в локальных сетях.
Серверы баз данных рассчитаны на поддержку большого числа различных типов приложений. Для реализации интерфейса с сервером базы данных можно использовать объектно-ориентированные средства, электронные таблицы, текстовые процессоры, графические пакеты, настольные издательские системы и другие информационные технологии.
Недостаток технологии клиент-сервер заключается в повышении требований к производительности ЭВМ-сервера, в усложнении управления вычислительной сетью, а при отсутствии сетевой СУБД — в сложности организации распределенной обработки.
Концепция построения сети
До появления компьютерных сетей каждый пользователь должен был иметь свой принтер, плоттер и другие периферийные устройства. Чтобы совместно использовать принтер, существовал единственный способ - пересесть за компьютер, подключенный к этому принтеру. Сети позволяют целому ряду пользователей одновременно «владеть» данными на носителях прямого доступа и периферийными устройствами. Если нескольким пользователям надо распечатать документ, все они могут обратиться к сетевому принтеру.
Самая простая сеть состоит как минимум из двух компьютеров, соединенных друг с другом кабелем. Это позволяет им использовать данные совместно. Все сети (независимо от сложности) основываются именно на этом простом принципе. Рождение компьютерных сетей было вызвано практической потребностью - иметь возможность для совместного использования данных. Персональный компьютер - прекрасный инструмент для создания документа, подготовки таблиц, графических данных и других видов информации, но при этом Вы не можете быстро поделиться своей информацией с другими. Когда не было сетей, приходилось распечатывать каждый документ, чтобы другие пользователи могли работать с ним, или в лучшем случае - копировать информацию на дискеты. Одновременная обработка документа несколькими пользователями исключалась. Подобная схема работы называется работой в автономной среде.
Сетью называется группа соединенных компьютеров и других устройств. А концепция соединенных и совместно использующих ресурсы компьютеров носит название сетевого взаимодействия. Компьютеры, входящие в сеть, могут совместно использовать:
Данный список постоянно пополняется, так как возникают новые способы совместного использования ресурсов.
Первоначально компьютерные сети были небольшими и объединяли до десяти компьютеров и один принтер. Технология передачи данных ограничивала размеры сети, в том числе количество компьютеров в сети и ее физическую длину. Например, в начале 1980-х годов наиболее популярный тип сетей состоял не более чем из 30 компьютеров, а длина кабеля не превышала 185 м (600 футов). Такие сети легко располагались в пределах одного этажа здания или небольшой организации. Для маленьких фирм подобная конфигурация подходит и сегодня. Эти сети называются локальными вычислительными сетями [ЛВС (LAN)].
Локальные сети не совсем соответствуют потребностям крупных предприятий, офисы которых обычно территориально расположены в различных местах. Этот факт поставил задачу расширения сетей. Так на основе небольших локальных сетей возникли более крупные системы. В настоящее время миллионы ЛВС объединены в глобальную вычислительную сеть ГВС (WAN), а количество компьютеров в сети достигает нескольких тысяч.
В настоящее время большинство организаций хранит и совместно использует в сетевой среде огромные объемы жизненно важных данных. Вот почему сети сейчас так же необходимы, как еще совсем недавно были необходимы пишущие машинки и картотеки.
Два типа ЛВС - одноранговые сети и сети с выделенным сервером
Все сети имеют некоторые общие компоненты, функции и характеристики:
· серверы (server) - компьютеры, предоставляющие свои ресурсы сетевым пользователям;
· клиенты (client) - компьютеры, осуществляющие доступ к сетевым ресурсам, предоставляемым сервером;
· среда (media) - способ соединения компьютеров;
· совместно используемые данные - файлы, предоставляемые серверами по сети;
· совместно используемые периферийные устройства, например принтеры, библиотек CD-ROM и т.д.,
· ресурсы, предоставляемые серверами;
· ресурсы - файлы, принтеры и другие элементы, используемые в сети.
· Несмотря на определенные сходства, сети разделяются на два типа:
· на основе сервера (server based).
Различия между одноранговыми сетями и сетями на основе сервера имеют принципиальное значение, поскольку определяют разные возможности этих сетей. Выбор типа сети зависит от многих факторов:
· необходимого уровня безопасности;
· уровня доступности административной поддержки;
· объема сетевого трафика;
· потребностей сетевых пользователей;
Распределенная обработка данных
Распределенная обработка данных - методика выполнения прикладных программ группой систем. При этом пользователь получает возможность работать с сетевыми службами и прикладными процессами, расположенными в нескольких взаимосвязанных абонентских системах.
В современном бизнесе очень часто возникает необходимость предоставить доступ к одним и тем же данным группам пользователей, территориально удаленным друг от друга. В качестве примера можно привести банк, имеющий несколько отделений. Эти отделения могут находиться в разных городах, странах или даже на разных континентах, тем не менее необходимо организовать обработку финансовых транзакций (перемещение денег по счетам) между отделениями. Результаты финансовых операций должны быть видны одновременно во всех отделениях.
Существуют два подхода к организации обработки распределенных данных.
1. технология распределенной базы данных. Такая база включает фрагменты данных, расположенные на различных узлах сети. С точки зрения пользователей она выглядит так, как будто все данные хранятся в одном месте. Естественно, такая схема предъявляет жесткие требования к производительности и надежности каналов связи.
2. технология тиражирования. В этом случае в каждом узле сети дублируются данные всех компьютеров. При этом:
o передаются только операции изменения данных, а не сами данные
o передача может быть асинхронной (неодновременной для разных узлов)
o данные располагаются там, где обрабатываются.
Это позволяет снизить требования к пропускной способности каналов связи, более того при выходе из строя линии связи какого-либо компьютера, пользователи других узлов могут продолжать работу. Однако при этом допускается неодинаковое состояние базы данных для различных пользователей в один и тот же момент времени. Следовательно, невозможно исключить конфликты между двумя копиями одной и той же записи.
Достоинствами распределенной обработки информации является:
o большое число взаимодействующих между собой пользователей;
o устранение пиковых нагрузок с централизованной базы данных за счет распределения обработки и хранения локальных баз данных на разных ЭВМ;
o возможность доступа пользователя к вычислительным ресурсам сети ЭВМ;
o обеспечение обмена данными между удаленными пользователями.
При распределенной обработке производится работа с базой, т.е. представление данных, их обработка, работа с базой на логическом уровне осуществляется на компьютере клиента, а поддержание базы в актуальном состоянии - на сервере. При наличии распределенной базы данных база размещается на нескольких серверах. В настоящее время созданы базы данных по всем направлениям человеческой деятельности: экономической, финансовой, кредитной, статистической, научно-технической, маркетинга, патентной информации, электронной документации и т.д.
Читайте также: