
Raid tp что это
За последние двадцать лет мощность процессоров выросла почти в 580 раз, пропускная способность каналов — в 1000 раз, а вот производительность СХД — только в 20 раз. Хранение данных стало «слабым местом», которое тормозит развитие всех IT-систем. Положение дел заметно улучшилось благодаря распространению СХД на SSD-накопителях. К таким системам относится Huawei OceanStor Dorado V3 — СХД высокой доступности (99,9999%). В этом посте мы без громких эпитетов расскажем о технологиях, на которые стоит обратить внимание, оценивая нашу новинку.
All-flash СХД Huawei OceanStor Dorado V3 рассчитана для использования в ИТ-системах, где скорость и надёжность систем хранения становятся критически важны. Это, к примеру, обработка транзакций в реальном времени (OLTP), оперативная аналитическая обработка (OLAP) крупных баз данных, высокопроизводительные вычисления (HPC), инфраструктура виртуального рабочего стола (VDI). В них потенциал нашей СХД основан на разработках в трех областях — это оригинальные SSD, функциональная ОС и широкие возможности интеграции.

Основа Dorado V3 — собственные накопители Huawei SSD, работа с которыми оптимизирована на уровне операционной системы. В зависимости от модели СХД, в нее можно установить до 200, 800 или 2400 накопителей.
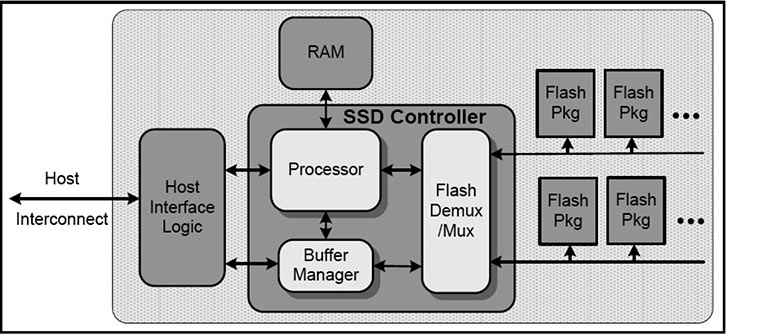
Контроллер накопителя основан на SoC Cortex-A9, поддерживает DDR4, 18 каналов NAND-флэш, 12 Гбит/с SAS и 8 GT/s PCIe. Непосредственно на SSD реализовано несколько функций, обеспечивающих необходимые для систем высокой доступности пропускную способность и надёжность.

Чтобы снизить количество ошибок, данные проверяются на каждом этапе. Многоступенчатая проверка процесса позволяет получить частоту битовых ошибок (BER) равную 10 -17 . На уровне DDR для предотвращения ошибок данных используются ECC (error correction code) и CRC (cyclic redundancy check). На уровне NAND-флеш используются LDPC (low density parity check code) и CRC. И непосредственно на уровне DIE алгоритм XOR.

Read Retry попробует прочитать данные, изменяя напряжение flash-накопителя. В разумных пределах, разумеется. Чтобы устранить задержку при последовательном переборе нескольких уровней напряжения, Read Retry учитывает частоту использования блока, продолжительности хранения данных.
Read Retry использует только предустановленные уровни напряжения, поэтому дополнительно применяется технология Read Offset. На SSD компании Huawei сохраняются таблицы калибровки напряжения. При возникновении ошибки Huawei Enterprise SSD запрашивает таблицу на основе состояния блока и выбирает наиболее подходящее напряжение.
Из-за ограниченного срока службы SSD считают слабым местом all-flash СХД. Мы постарались сбалансировать нагрузку так, чтобы износ не стал проблемой. Наш основной инструмент здесь — регулирование износа SSD.
Но при достижении высокого показателя выработки (>80%) такой подход может привести к одновременному выходу из строя всех дисков. А наш RAID готов только к трём одновременным отказам. Поэтому, когда жизненный цикл SSD близится к концу, включается обратная функция — Anti-Wear Leveling. Система выбирает SSD с самым большим износом и начинает писать данные на него, а пользователю тем временем советует его заменить.
Особенность работы NAND-флэш такова, что для записи новых данных на страницу — минимальную единицу в местной терминологии — нужно очистить весь блок в который она входит. Поэтому если в блоке есть полезные данные, их нужно перенести, что требует дополнительных операций.

Чтобы локализовать данные, к которым обращаются чаще всего, их на уровне SSD разделяют на «горячие» и «холодные». Данным с разной частотой использования добавляются соответствующие метки. SSD сохраняют данные с теми же ярлыками в один и тот же блок. Таким образом, «горячие» и «холодные» данные хранятся в разных блоках, уменьшая объем данных, с которым приходится работать системе.

Программная архитектура OceanStor Dorado V3 (BDM — управление блоками данных, DSW — сетевой коммутатор)
СХД семейства OceanStore работают под управлением одноименной ОС. Самое интересное в этой операционке — это набор утилит FlashLink для управления и оптимизации записи на SSD. FlashLink охватывает I/O-модули ПО контроллера с драйверами SSD дисков. Симбиоз на двух уровнях СХД позволяет увеличить IOPS и обеспечить задержку не более 0,5 мс. Функции FlashLink можно разложить по трем слоям.
Базовый уровень — виртуализация дисков. RAID 2.0 со знаком «плюс» стирает границы между RAID-массивами. Это позволяет одновременно и лучше распределять нагрузку, и ускорять работу. А при необходимости и восстановление информации. RAID-TP застрахует от проблем с данными даже если из строя выйдут сразу три диска.
На уровень распределения данных идет взаимодействие с накопителями. Разделение на горячие и холодные данные, выравнивание износа, цельнострайповая последовательная запись (full-stripe sequential write) — FlashLink управляет этими функциями, благодаря которым SSD живут долго, счастливо и не умирают неожиданно.
Уровень обслуживания данных: здесь происходит объединение все записей в один страйп, распределение по дискам раздаются приоритеты по распределению ресурсов.
Чтобы эффективно распределять нагрузку на дисковые массивы, нужно обеспечивать быструю запись на несколько дисков сразу. Чтобы сократить задержки используется цельнострайповая последовательная запись: новые и измененные данные объединяются в полный страйп и пишутся в свободное место на SSD. Благодаря тому, что здесь произвольная запись становится последовательной, мы избегаем задержек на чтение/очистку/запись, характерных для NAND:
При записи новых данных система объединяет данные LUN 1 и LUN 2 в страйп, а затем записывает данные на диски, как показано в левой части рисунка.
При изменении данных, пользователь изменяет 1B на 1b в LUN 1, записывает новые данные 3A и 3B в LUN 3, а новые данные 4A — LUN 4. Система объединяет 1b, 2B, 2C, 3A, 3B и 4A в качестве нового страйпа, а затем записывает данные на SSD. Блок 1B отмечается на удаление.
Глобальная очистка проводится после того, как все нужные данные были скопированы и сохранены в новом месте
При накоплении большого числа мусорных данных используется глобальная очистка. Таким образом освобождается пространство для записи целых страйпов.

Приведем аналогию. Вы поехали с большой компанией друзей на рыбалку. Поехали недалеко, потому что собрать столько народу надолго не получилось. Закинули удочки, сидите. Вдруг у вас в камышах запутывается леска. Капитально запуталась — нужно лезть в заросли, и неизвестно, распутаете ли вообще. У вашего друга рядом такая же история. Вместо того, чтобы долго распутывать снасти (перезаписывать данные) вы просто обрезаете леску и быстро натягиваете все заново — крючок, поплавок, грузило (записываете данные на пустое пространство). Когда рыбалка подойдет к концу, самый молодой и ловкий залезет в заросли и вытащит все сразу, с листьями и узлами, которые можно распутать по пути домой (в контексте СХД — проведет глобальную очистку).
Защита с помощью технологии RAID очень важна для СХД для обеспечения баланса между высокой доступностью и производительностью. Тем не менее надежность защиты с точки зрения RAID ставится под сомнение из-за плохо контролируемого времени восстановления (на ИТ-жаргоне - ребилдинга), особено в случае требований большого дискового пространства.
Кроме того, из своего личного опыта могу назвать случаи, когда в ходе восстановления массива с RAID 5, из-за возрастающей нагрузки на оставшиеся рабочие диски, выходил из строя еще один из них и массив окончательно рассыпался. Иногда его удавалось собрать, но только после обращение в специализированные фирмы и с очень большими финансовыми затратами.
Поэтому компания Huawei предложила на рынке технологию RAID-TP, обеспечивающую оптимальный компромисс между доступностью и производительностью, надежностью и использованием дискового пространства.

Рисунок 1 – Сравнение традиционного RAID и RAID-TP
Сравнение традиционного алгоритма RAID и алгоритма динамического RAID от Huawei
Алгоритм традиционного RAID
Когда диск в традиционном RAID допускает сбой, он помечается как сбойный, данные с оставшихся дисков восстанавливаются на резервном (hot-spare) диске.

Рисунок 2 – Восстановление традиционного RAID

Рисунок 3 – Восстановление динамического RAID
СХД Huawei Dorado V 3 storage использует динамический RAID и RAID - TP
RAID Triple-parity (TP) – это специализированный режим массива RAID. RAID-TP означает RAID c тройной четностью, что означает его устойчивость к потере до 3-х дисков, что является наилучшим значением среди других режимов RAID (включая двойную четность. Использование RAID-TP в СХД Huawei Dorado V3, благодаря оптимизированному алгоритму Huawei FlexEC , предоставляет пользователям лучшую утилизацию при росте объема дискового пространства.
Как это работает
Данные четности распределены по разным чанкам. Данные четности для каждой группы чанков занимают пространство из 3-х чанков. RAID-TP устойчив к потере всех 3-х, но не более. В типичной системе с режимом RAID6 (4+2 означает, что на каждые 6 дисков приходится 2 диска четности) обычно утилизация составляет 67%, но это показатель для Dorado v3 c RAID-TP при объеме в 26 дисков улучшает этот показатель на 20% .

Рисунок 4 – Работа RAID-TP
Можно сказать, что RAID TP — это схема создания страйпов с тройным резервным копированием. Это реализуется благодаря тому, что в цельнострайповой последовательной записи в массив RAID добавляется дополнительный диск с информацией для исправления ошибок. Благодаря этому сохранность данных обеспечивается даже при выходе из строя 3-х дисков, и при этом не происходит потери производительности. Таким образом, Dorado V3 поддерживает 23+3 (23 основных диска и 3 четности) конфигурацию RAID, более надежную по сравнению с 23+2.
Представленные на рынке системы хранения данных, в основной своей массе, мало чем отличаются друг от друга, ведь многие вендоры заказывают оборудование едва ли не у одних и тех же ODM-производителей. У нас же почти все свое, начиная от шасси и заканчивая контроллерами, технологиями типа RAID 2.0+ и софтом.

Под катом немного деталей про то, что такого необычного может быть в каждом из узлов системы хранения данных.
Полупроводниковые тонкости
Важные компоненты СХД мы дублируем: если что-то выйдет из строя – всегда есть подстраховка. К примеру, модули питания у младших моделей работают по схеме 1+1, у более солидных – 2+1 и даже 3+1.

Контроллеры, которых в системе хранения как минимум два (одноконтроллерные системы мы не поставляем) тоже резервируются. В СХД 6800-й и более старших серий резервирование производится по схеме 3+1, в младших моделях – 1+1.
Зарезервирован даже модуль управления (management board), который непосредственно на работу системы не влияет, а нужен только для изменения конфигурации и мониторинга. Кроме того, любые интерфейсные платы расширения для СХД у нас продаются только парами, чтобы у клиента имелся резерв.
Все компоненты — БП, вентиляторы, контроллеры, менеджмент-модули и т.п. — оснащены микроконтроллерами, способными реагировать на определенные ситуации. Например, если вентилятор начинает сам по себе сбавлять обороты, на управляющий модуль посылается сигнал тревоги. В результате заказчик имеет полную картину состояния СХД – и может при необходимости заменить некоторые компоненты самостоятельно, не дожидаясь прибытия нашего сервисного инженера. А если политика безопасности заказчика позволяет, мы настраиваем контроллеры так, чтобы они передавали информацию о состоянии железа в нашу техподдержку.
Что интересного на уровне модуля
Конструкционно все современные СХД от любого производителя выглядят одинаково: во фронтальную часть стального коробчатого шасси устанавливаются контроллеры, в тыльную — интерфейсные модули. Есть еще блоки питания и вентиляции. Казалось бы, все привычно и стандартно. Но на самом деле мы внедрили в эту парадигму много всего интересного.

Начнем с монтажа элементов системы хранения в шасси. Магнитных 3,5-дюймовых дисков в СХД становится меньше, начинают преобладать гибридные системы и all-flash. Но даже несколько дисковых накопителей с частотой вращения шпинделя до 15 тысяч оборотов в минуту создают вибрацию, которую нельзя не учитывать. У нас на этот случай выработан целый свод рекомендаций – как распределять по дисковым полкам магнитные накопители с различными параметрами.
Пусть даже на какие-то доли процентов, но на надежность это влияет. А в масштабе крупного ЦОДа доли процентов на один накопитель превращаются в ощутимые показатели отказов и сбоев. Чтобы вибрация отдельных дисков в меньшей степени передавалась через жесткую конструкцию шасси, салазки под диски мы оборудуем резиновыми или металлическими демпферами. Чтобы нейтрализовать еще один источник вибрации в СХД – модули вентиляции – ставим двунаправленные вентиляторы, а все вращающиеся элементы изолируем от корпуса шасси.
Для шпиндельных накопителей минимальная тряска — уже проблема: головки начинают сбиваться, производительность существенно падает. SSD – другое дело, вибрации они не боятся. Но надежная фиксация компонентов по-прежнему важна. Взять процесс доставки: ящик могут уронить или небрежно швырнуть, поставить боком или вверх тормашками. Поэтому у нас все компоненты СХД закрепляются строго в трех измерениях. Это исключает возможность их смещения при транспортировке, предохраняет разъемы от выскакивания из гнезд при случайном ударе.

Когда-то давно мы начинали с разработки вычислительной техники для телеком-индустрии, где стандарты работоспособности по температуре и влажности традиционно высоки. И мы перенесли их и на другие направления: металлические детали СХД не окисляются даже при повышенной влажности – за счет применения никелирования и оцинковки.
Тепловой дизайн наших СХД разрабатывался с упором на равномерность распределения температуры по шасси – чтобы не допустить ни перегрева, ни слишком сильного охлаждения какого-либо угла дисковой полки. Иначе не избежать физической деформации – пусть даже незначительной, но все-таки нарушающей геометрию и способной привести к сокращению срока работы оборудования. Таким образом выигрываются какие-то доли процента, но на общую надежность системы это все-таки влияет.
RAID 2.0+

Отказоустойчивый дизайн в СХД мы продумали и на уровне системы. Наша технология Smart Matrix представляет собой надстройку поверх PCIe – эта шина, на основе которой реализованы межконтроллерные соединения, особенно хорошо подходит для SSD.
Smart Matrix обеспечивает, в частности, 4-контроллерный full mesh в нашем СХД Ocean Store 6800 v5. Для того чтобы каждый контроллер имел доступ ко всем дискам в системе, мы разработали особый SAS-бэкэнд. Кэш, естественно, зеркалируется между всеми активными в данный момент контроллерами.

Когда происходит сбой контроллера, сервисы с него быстро переключаются на контроллер зеркала, а оставшиеся контроллеры восстанавливают взаимосвязь, чтобы зазеркалить друг друга. В то же время данные, записанные в кэш-память, имеют зеркальный резерв для обеспечения надежности системы.

Система выдерживает отказ трех контроллеров. Как показано на рисунке, при отказе элемента управления A данные кэша контроллера B будут выбирать контроллер C или D для зеркального отображения кэша. Когда выходит из строя контроллер D, контроллеры B и C делают зеркальное отображение кэша.

Система распределения данных RAID 2.0 – стандарт для наших СХД: виртуализация на уровне дисков давно пришла на смену безыскусному поблоковому копированию содержимого с одного носителя на другой. Все диски группируются в блоки, те объединяются в более крупные конгломераты двухуровневой структуры, а уже поверх ее верхнего уровня строятся логические тома, из которых составляются RAID-массивы.

Основное преимущество такого подхода – сокращенное время перестроения массива (rebuild). Кроме того, в случае выхода из строя диска перестроение производится не на стоявший все это время «под паром» (hot spare) диск, а на свободное место во всех используемых дисках. На рисунке ниже в качестве примера показаны девять жестких дисков RAID5. Когда жесткий диск 1 вышел из строя, данные CKG0 и CKG1 повреждены. Система выбирает CK для реконструкции случайным образом.


Нормальная скорость восстановления RAID составляет 30 МБ / с, поэтому для восстановления данных объемом 1 ТБ требуется 10 часов. RAID 2.0+ сокращает это время до 30 минут.
Нашим разработчикам удалось добиться равномерного распределения нагрузки между всеми шпиндельными накопителями и SSD в составе системы. Это позволяет раскрыть потенциал гибридных СХД гораздо лучше, чем привычное использование твердотельных накопителей в роли кэша.

В системах класса Dorado мы реализовали так называемся RAID-TP, массив с тройной четностью. Такая система продолжит работать при одновременном выходе из строя любых трех дисков. Это повышает надежность по сравнению с RAID 6 на два десятичных порядка, с RAID 5 — на три.

RAID-TP мы рекомендуем для особо критичных данных, тем более что благодаря RAID 2.0 и высокоскоростным flash-накопителям на производительность это особого влияния не оказывает. Просто нужно больше свободного пространства для резервирования.

Как правило, системы all-flash используют для СУБД с маленькими блоками данных и высоким IOPS. Последнее не очень хорошо для SSD: быстро исчерпывается запас прочности ячеек памяти NAND. В нашей реализации система сперва собирает в кэше накопителя сравнительно крупный блок данных, а затем целиком записывает его в ячейки. Это позволяет снизить нагрузку на диски, а также в более щадящем режиме вести «сборку мусора» и высвобождение места на SSD.
Свои чипы лучше и понятнее
Мы – единственная компания, разрабатывающая собственные процессоры, чипы и контроллеры твердотельных накопителей для своих СХД.

Так, в некоторых моделях в качестве основного процессора системы хранения (Storage Controller Chip) мы используем не классический Intel x86, а ARM-процессор HiSilicon, нашего дочернего предприятия. Дело в том, что ARM-архитектура в СХД – для расчета тех же RAID и дедупликации – показывает себя лучше, чем стандартная х86-я.
Наша особая гордость — чипы для SSD-контроллеров. И если серверы у нас могут комплектоваться полупроводниковыми накопителями сторонних производителей (Intel, Samsung, Toshiba и др.), то в системы хранения данных мы устанавливаем только SSD собственной разработки.

Микроконтроллер модуля ввода-вывода (smart I/O чип) в системах хранения – тоже разработка HiSilicon, как и Smart Management Chip для удаленного управления хранилищами. Использование собственных микросхем помогает нам лучше понимать, что происходит в каждый момент времени с каждой ячейкой памяти. Именно это позволило нам свести к минимуму задержки при обращении к данным в тех же СХД Dorado.

Для магнитных дисков с точки зрения надежности чрезвычайно важен постоянный мониторинг. В наших СХД поддерживается система DHA (Disk Health Analyzer): диск сам непрерывно фиксирует, что с ним происходит, насколько хорошо он себя чувствует. Благодаря накоплению статистики и построению умных предиктивных моделей удается предсказать переход накопителя в критическое состояние за 2-3 месяца, а не за 5-10 дней. Диск еще «живой», данные на нем в полной безопасности – но заказчик уже готов его заменить при первых признаках возможного сбоя.
Шесть девяток

Перечисленное выше позволяет говорить об отказоустойчивости наших систем на уровне всего решения. Проверка реализуется на уровне приложения (например, СУБД Oracle), операционной системы, адаптера, СХД – и так вплоть до диска. Такой подход гарантирует, что ровно тот блок данных, который пришел на внешние порты, безо всяких повреждений и потерь будет записан на внутренние диски системы. Это подразумевает enterprise-уровень.

Для надежного хранения данных, их защиты и восстановления, а также быстрого доступа к ним мы разработали целый ряд фирменных технологий.

HyperMetro – наверное, самая интересная разработка последних полутора лет. Готовое решение на базе наших систем хранения для построения отказоустойчивого метро-кластера внедряется на уровне контроллера, никаких дополнительных шлюзов или серверов, кроме арбитра, оно не требует. Реализуется просто лицензией: две CХД Huawei плюс лицензия – и это работает.

Технология HyperSnap обеспечивает непрерывную защиту данных без потери производительности. Система поддерживает RoW. Для предотвращения потери данных на СХД в каждый конкретный момент используется множество технологий: различные снэпшоты, клоны, копии.

На основе наших СХД разработано и проверено на практике как минимум четыре решения для аварийного восстановления данных.

Еще у нас есть решение для трех дата-центров 3DC Ring DR Solution: два ЦОДа в кластере, на третий идет репликация. Можем организовать организована асинхронную репликацию или миграцию со сторонних массивов. Имеется лицензия smart virtualization, благодаря чему можно использовать тома с большинства стандартных массивов с доступом по FC: Hitachi, DELL EMC, HPE и т.д. Решение реально отработанное, аналоги на рынке встречаются, но стоят дороже. Есть примеры использования в России.
В итоге на уровне всего решения можно получить надежность шесть девяток, а на уровне локальной СХД — пять девяток. В общем, мы старались.
Автор: Владимир Свинаренко, старший менеджер по IT-решениям Huawei Enterprise в России
RAID 01 (RAID 0+1)

RAID 0+1 (называется также RAID 01) - RAID уровень, сочетающий в себе одновременно два базовых массива. Основной целью "гибридизации" двух базовых уровней является сочетание их преимуществ в целях создания более совершенной системы обработки, хранения и чтения информации.
Минимальное количество дисков, требуемое для организации данной системы - 3, но наиболее часто в данных системах применяется 4 диска.
В чем разница между RAID 0+1 и RAID 1+0?
Ключевая разница между RAID 0+1 и RAID 1+0 состоит в локации каждой RAID-системы: RAID 0+1 - это зеркальная система полос, где два RAID 0 объединяются в RAID 1, тогда как RAID 1+0 представляет собой сочетание двух RAID 1, объединенных в RAID 0.
Некоторые производители более не используют RAID 0+1, заменив его на RAID 1+0, поскольку он обеспечивает более корректную и безопасную работу системы.
Производительность системы RAID 0+1 представляет собой формулу:
(N/2) * Smin,
где N - общее число дисков, а Smin - производительность самого меньшего из дисков в массиве данных.
На практике
Комбинация RAID 0+1 в плане надежности оказывается хуже, чем RAID5. В то время, когда для восстановления данных RAID 0+1 потребуется 4 диска, для RAID 5 потребуется всего 3.
Пример работы RAID 0+1
Диски 11+12+13+14+15+16+17+18+19+20 = RAID 0 (Полоса B)
Согласно схеме мы видим, что две полосы зеркальны. Если, скажем, в полосе A один из дисков будет иметь ошибку (например, 5), то вся остальная цепочка тоже будет неработоспособна. Но в случае с гибридом RAID 0+1 работоспособность сохранится благодаря полосе B. Таким образом, многое зависит от того, где именно возникла ошибка - в начале или в конце полосы. При выходе из строя, скажем, 17-го диска, пользователь сможет работать с 7-ым диском. Следовательно, теоретически, RAID 0+1 и RAID 1+0 имеют равную устойчивость к ошибкам и сбоям. Большинство контроллеров не имеют таких внушительных показателей надежности.
ООО "Альтербит", 197183, Санкт-Петербург, Комендантский проспект, 2 схема проезда
Телефон: (812) 309-2602 ← Звони если хочешь купить сервер, схд, компьютер
RAID 10 (RAID 1+0)

RAID 1+0 (называемый также RAID 10) - схожий с RAID 01 массив независимых дисков, с той лишь разницей, что уровни, используемые в данной системе, реверсивны и представляют собой полоску зеркал. Диски вложенного массива объединены парами в "зеркала" RAID 1. Затем эти зеркальные пары трансформируются в общий массив, используя чередование RAID 0.
Восстановление данных
Каждый диск с массива RAID 1 может быть поврежден без потери данных. Однако, минус системы в том, что поврежденные диски незаменяемы, и в случае возникновения ошибки в работе системы, пользователь будет вынужден использовать оставшиеся ресурсы системы. Некоторые системы RAID 10 имеют так называемый специальный диск "hot spare", который автоматически заменяет вышедший из строя диск в массиве.
Производительность и скорость
Согласно отзывам производителей и спецификациям устройств, в большинстве случаев RAID 10 предлагает лучшую пропускную способность и меньшее время ожидания, чем все остальные RAID уровни, за исключением RAID 0 (лучшая пропускная способность). Это один из самых предпочтительных уровней для работы "тяжелых" приложений, требующих высокую работоспособность системы.
RAID 10 дает возможность объединить лишь четное количество дисков.
- Минимальное количество дисков – 4,
- Максимальное количество дисков – 16.
В чем разница между RAIN 1+0 и RAID 0+1?

Ключевая разница между гибридами RAID 0+1 и RAID 1+0 состоит в локации каждой RAID-системы: RAID 0+1 - это зеркальная система полос, где два RAID 0 объединяются в RAID 1, тогда как RAID 1+0 представляет собой сочетание двух RAID 1, объединенных в RAID 0. "Снаружи", визуально, RAID 0+1 представляет собой тот же RAID 10.
Некоторые производители используют RAID 1+0, сменив им RAID 0+1, поскольку он обеспечивает более корректную и безопасную работу системы.
Теоретически, RAID 0+1 и RAID 1+0 имеют равную устойчивость к ошибкам и сбоям. Большинство контроллеров не имеют таких внушительных показателей надежности.
Достоинства системы
"Зеркало" RAID 1 обеспечивает системе надежность, массив RAID 0 увеличивает производительность.
Недостатки системы
Минусы у уровня RAID 10 такие же, как и у уровня RAID 0. Пользователю рекомендуется включать в массив диски горячего резерва из расчета 1 резервный на 5 рабочих.
Пример работы RAID 1+0:
- Диски 1+2 = RAID 1 (Зеркальный сэт A)
- Диски 3+4 = RAID 1 (Зеркальный сэт B)
- Диски 5+6 = RAID 1 (Зеркальный сэт C)
- Диски 7+8 = RAID 1 (Зеркальный сэт D)
- Диски 9+10 = RAID 1 (Зеркальный сэт E)
- Диски 11+12 = RAID 1 (Зеркальный сэт F)
- Диски 13+14 = RAID 1 (Зеркальный сэт G)
- Диски 15+16 = RAID 1 (Зеркальный сэт H)
- Диски 17+18 = RAID 1 (Зеркальный сэт I)
- Диски 19+20 = RAID 1 (Зеркальный сэт J)
В данном случае, мы сможем внедрить полосу RAID 0 поперек всех сэтов: с A по J. Предположим, если в 5 диске обнаружена ошибка, единственным зеркальным сэтом будет являться сэт C. Он также имеет диск 6 в связке, но этот диск не прекратит свое функционирование и будет работать дальше.
ООО "Альтербит", 197183, Санкт-Петербург, Комендантский проспект, 2 схема проезда
Телефон: (812) 309-2602 ← Звони если хочешь купить сервер, схд, компьютер
Читайте также: