
Raid spare что это
Как начинается процесс восстановления поврежденного диска RAID
Если у вас в системе есть назначенные Global Hot Spare и Dedicated Hot Spare и они полностью отвечает требованиям восстановления поврежденного диска RAID, восстановление начнется автоматически. Hot Spare диски должны быть запланированы до начала восстановления и должны соответствовать всем требованиям для виртуального диска. Если вы удалите виртуальный диск, то Dedicated Hot Spare станет Global Hot Spare.
В: Что такое RAID и зачем он нужен? Какой RAID лучше использовать?
О: Ответу на этот вопрос посвящен раздел [ RAID ].
В: Можно ли использовать в RAID массиве диски разного размера?
О: Да. можно. Но, при этом, используемая емкость у ВСЕХ дисков будет равна емкости наименьшего диска.
Из этого следует, что добавлять в уже существующий RAID массив можно только диски такого же или большего размера.
В: Можно ли использовать в RAID массиве диски разных производителей?
О: Да, можно. Но при этом надо иметь ввиду, что точные размеры дисков одинаковой емкости (36/73/146. ГБ) у разных производителей могут отличаться на несколько килобайт. Когда вы создаете новый RAID массив, на это можно не обращать внимание, но если вы добавляете диски к уже существующему массиву (например, меняете вышедший из строя диск), то важно, чтобы новый диск был больше чем старые, или точно такого же размера.
В: Что такое Write Through и Write Back?
О: Это способ записи данных, полученных RAID контроллером, на дисковый массив. По другому эти способы еще называются так: прямая запись ( Write Through ) и отложенная запись ( Write Back ). Какой из этих способов будет использоваться определяется в BIOS-е контроллера (либо при создании массива, либо позднее).
- Write Through - данные записываются непосредственно на дисковый массив. Т.е. как только данные получены, они сразу же записываются на диски и после этого контроллер подает сигнал управляющей ОС о завершении операции.
- Write Back - данные записываются сначала в кэш , и только потом (либо по мере заполнения кэш -а, либо в моменты минимальной загрузки дисковой системы) из кэш -а на диски. При этом, сигнал о завершении операции записи передается управляющей ОС сразу же по получении данных кэш -ем контроллера.
Избежать описанной проблемы можно или с помощью установки на RAID контроллер BBU (см. ниже), или посредством подключения всего сервера через источник бесперебойного питания (UPS) с функцией программируемого выключения.
Кстати, некоторые RAID контроллеры не позволяют включить функцию Write Back без установленного BBU .
В: Что такое BBU и зачем он нужен?
О: BBU (Battery Backup Unit ) необходим для предотвращения потери данных находящихся в кэш -е RAID контроллера и еще не записанных на диск (отложенная запись - "write-back caching"), в случае аварийного выключения компьютерной системы.
Существуют три разновидности BBU :
- Просто BBU : это аккумулятор, который обеспечивает резервное питание кэша через RAID контроллер.
- Переносимые (Transportable) BBU (tBBU): это аккумулятор, который размещен непосредственно на модуле кэш и питает его независимо от RAID контроллера. В случае выхода из строя RAID контроллера, это позволяет перенести данные, сохраненные в кэш -е, на резервный контроллер и уже на нем завершить операцию записи данных. : основная идея заключается в следующем: в случае сбоя питания RAID контроллер копирует содержимое кэш -а в энергонезависимую память (например, в случае с технологией Adaptec »Zero-Maintenance Cache Protection - на NAND флэш накопитель). Питание, необходимое для завершения этого процесса, обеспечивается встроенным супер-конденсатором. После восстановления питания, данные из флэш памяти копируются обратно в кэш контроллера.
В: Что такое Hot Spare (Hotspare)?
О: Hot Spare - (Резервная Замена Дисководов ("Горячее резервирование")) - Одна из наиболее важных особенностей, которую обеспечивает RAID контроллер, с целью достичь безостановочное обслуживание с высокой степенью отказоустойчивости. В случае выхода из строя диска, восстанавливающая операция будет выполнена RAID контроллером автоматически, если выполняются оба из следующих условий:
- Имеется "резервный" диск идентичного объема, подключенный к тому же контроллеру и назначенный в качестве резервного, именно он и называется Hotspare ;
- Отказавший диск входит в состав избыточной дисковой системы, например RAID 1 , RAID 3 , RAID 5 или RAID 0+1 .
Обратите внимание: резервирование позволяет восстановить данные, находившиеся на неисправном диске, если все диски подключены к одному и тому же RAID контроллеру.
"Резервный" диск может быть создан одним из двух способов:
- Когда пользователь выполняет утилиту разметки, все диски, которые подключены к контроллеру, но не сконфигурированы в любую из групп дисководов, будут автоматически помечены как "резервные" ( Hotspare ) диски (автоматический способ поддерживается далеко не всеми контроллерами).
- Диск может также быть помечен как резервный ( Hotspare ), при помощи соответствующей утилиты RAID контроллера.
В течение процесса автоматического восстановления система продолжает нормально функционировать, однако производительность системы может слегка ухудшиться.
Для того, что бы использовать восстанавливающую особенность резервирования, Вы должны всегда иметь резервный диск ( Hotspare ) в вашей системе. В случае сбоя дисковода, резервный дисковод автоматически заменит неисправный диск, и данные будут восстановлены. После этого, системный администратор может отключить и удалить неисправный диск, заменить его новым диском и сделать этот новый диск резервным.
В этом разделе использованы материалы с сайта "3dnews".
В: Что такое Copyback Hot Spare?
О: Copyback Hot Spare это функция RAID контроллера, которая позволяет пользователям закрепить физическое расположение диска "горячего резерва" ( Hot Spare ), что позволяет улучшить управляемость системы.
В: Что такое JBOD?
О: JBOD (Just a Bunch of Disks) это способ подключить диски к RAID контроллеру не создавая на них никакого RAID . Каждый из дисков доступен так же, как если бы он был подключен к обычному адаптеру. Эта конфигурация применяется когда необходимо иметь несколько независимых дисков, но не обеспечивает ни повышения скорости, ни отказоустойчивости.
В: Что такое размер страйпа (stripe size)?
О: размер страйпа ( stripe size ) определяет объем данных записываемых за одну операцию ввода/вывода. размер страйпа задается в момент конфигурирования RAID массива и не может быть изменен позднее без переинициализации всего массива. Больший размер страйпа обеспечивает прирост производительности при работе с большими последовательными файлами (например, видео), меньший - обеспечивает большую эффективность в случае работы с большим количеством небольших файлов.
В: Нужно ли заниматься архивированием данных в случае использования RAID?
О: Конечно да! RAID это вовсе не замена архивированию, основное его назначение это повышение скорости и надежности доступа к данным в нормальном режиме работы. Но только регулярное архивирование данных гарантировано обеспечит их сохранность при любых отказах оборудования, пожарах, потопах и прочих неприятностях.

Что такое Write Through и Write Back?
Это способ записи данных, полученных RAID контроллером, на дисковый массив. По другому эти способы еще называются так: прямая запись (Write Through) и отложенная запись (Write Back). Какой из этих способов будет использоваться определяется в BIOS-е контроллера (либо при создании массива, либо позднее).
- Write Through - данные записываются непосредственно на дисковый массив. Т.е. как только данные получены, они сразу же записываются на диски и после этого контроллер подает сигнал управляющей ОС о завершении операции.
- Write Back - данные записываются сначала в кэш, и только потом (либо по мере заполнения кэш-а, либо в моменты минимальной загрузки дисковой системы) из кэш-а на диски. При этом, сигнал о завершении операции записи передается управляющей ОС сразу же по получении данных кэш-ем контроллера.
Избежать описанной проблемы можно или с помощью установки на RAID контроллер BBU (см. ниже), или посредством подключения всего сервера через источник бесперебойного питания (UPS) с функцией программируемого выключения.
Кстати, некоторые RAID контроллеры не позволяют включить функцию Write Back без установленного BBU.
RAID 0+1
Под RAID 0+1 может подразумеваться в основном два варианта:
- два RAID 0 объединяются в RAID 1;
- в массив объединяются три и более диска, и каждый блок данных записывается на два диска данного массива; таким образом, при таком подходе, как и в «чистом» RAID 1, полезный объём массива составляет половину от суммарного объёма всех дисков (если это диски одинаковой ёмкости).
Что такое Copyback Hot Spare?
Copyback Hot Spare это функция RAID контроллера, которая позволяет пользователям закрепить физическое расположение диска "горячего резерва" (Hot Spare), что позволяет улучшить управляемость системы.
RAID 60
объединение двух массивов RAID6 в страйп. Скорость записи повышается примерно в два раза, относительно скорости записи в RAID6. Минимальное количество дисков для создания такого массива - 8. Информация не теряется при отказе двух дисков из каждого RAID 6 массива
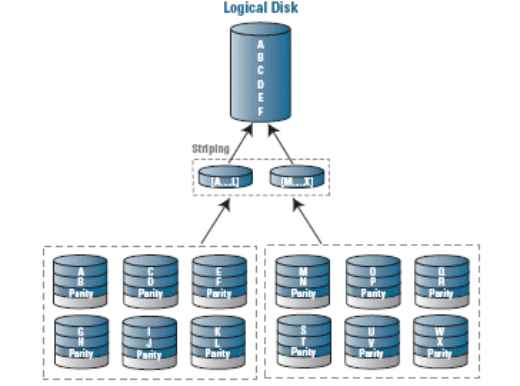
RAID 5
Основным недостатком уровней RAID от 2-го до 4-го является невозможность производить параллельные операции записи, так как для хранения информации о чётности используется отдельный контрольный диск. RAID 5 не имеет этого недостатка. Блоки данных и контрольные суммы циклически записываются на все диски массива, нет асимметричности конфигурации дисков. Под контрольными суммами подразумевается результат операции XOR (исключающее или). Xor обладает особенностью, которая даёт возможность заменить любой операнд результатом, и, применив алгоритм xor, получить в результате недостающий операнд. Например: a xor b = c (где a, b, c — три диска рейд-массива), в случае если a откажет, мы можем получить его, поставив на его место c и проведя xor между c и b: c xor b = a. Это применимо вне зависимости от количества операндов: a xor b xor c xor d = e. Если отказывает c тогда e встаёт на его место и проведя xor в результате получаем c: a xor b xor e xor d = c. Этот метод по сути обеспечивает отказоустойчивость 5 версии. Для хранения результата xor требуется всего 1 диск, размер которого равен размеру любого другого диска в raid.
Достоинства
RAID5 получил широкое распространение, в первую очередь, благодаря своей экономичности. Объём дискового массива RAID5 рассчитывается по формуле (n-1)*hddsize, где n — число дисков в массиве, а hddsize — размер наименьшего диска. Например, для массива из четырех дисков по 80 гигабайт общий объём будет (4 — 1) * 80 = 240 гигабайт. На запись информации на том RAID 5 тратятся дополнительные ресурсы и падает производительность, так как требуются дополнительные вычисления и операции записи, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких дисков массива могут обрабатываться параллельно.
Производительность RAID 5 заметно ниже, в особенности на операциях типа Random Write (записи в произвольном порядке), при которых производительность падает на 10-25% от производительности RAID 0 (или RAID 10), так как требует большего количества операций с дисками (каждая операция записи, за исключением так называемых full-stripe write-ов, сервера заменяется на контроллере RAID на четыре — две операции чтения и две операции записи). Недостатки RAID 5 проявляются при выходе из строя одного из дисков — весь том переходит в критический режим (degrade), все операции записи и чтения сопровождаются дополнительными манипуляциями, резко падает производительность. При этом уровень надежности снижается до надежности RAID-0 с соответствующим количеством дисков (то есть в n раз ниже надежности одиночного диска). Если до полного восстановления массива произойдет выход из строя, или возникнет невосстановимая ошибка чтения хотя бы на еще одном диске, то массив разрушается, и данные на нем восстановлению обычными методами не подлежат. Следует также принять во внимание, что процесс RAID Reconstruction (восстановления данных RAID за счет избыточности) после выхода из строя диска вызывает интенсивную нагрузку чтения с дисков на протяжении многих часов непрерывно, что может спровоцировать выход какого-либо из оставшихся дисков из строя в этот наименее защищенный период работы RAID, а также выявить ранее не обнаруженные сбои чтения в массивах cold data (данных, к которым не обращаются при обычной работе массива, архивные и малоактивные данные), что повышает риск сбоя при восстановлении данных.
Минимальное количество используемых дисков равно трём.
Что применяется первым из Global Hot Spare и Dedicated Hot Spare
Предположим, что у вас есть два виртуальных диска, для каждого из них есть по одному Dedicated Hot Spare и два общих Global Hot Spare, если выходит из строя один из дисков виртуального массива, вопрос, куда буду переноситься данные? Правильный ответ:
- В первую очередь будет использован "Выделенный горячий резерв (Dedicated Hot Spare)"
- Потом уже будет использоваться глобальный диск резервного назначения (Global Hot Spare)
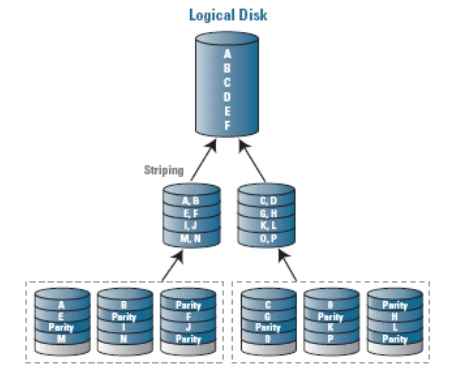
RAID 50
объединение двух(или более, но это крайне редко применяется) массивов RAID5 в страйп, т.е. комбинация RAID5 и RAID0, частично исправляющая главный недостаток RAID5 - низкую скорость записи данных за счёт параллельного использования нескольких таких массивов. Общая ёмкость массива уменьшается на ёмкость двух дисков, но, в отличие от RAID6, без потери данных такой массив переносит отказ лишь одного диска, а минимально необходимое число дисков для создания массива RAID50 равно 6. Наряду с RAID10, это наиболее рекомендуемый уровень RAID для использования в приложениях, где требуется высокая производительность в сочетании приемлемой надёжностью.
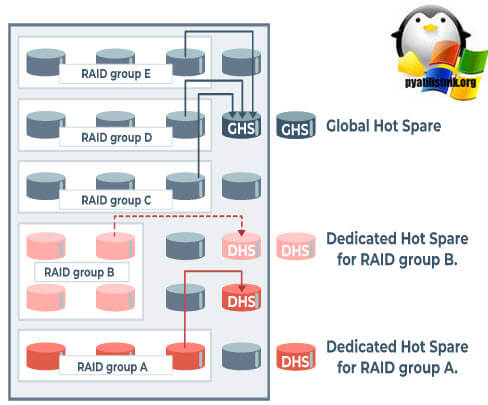
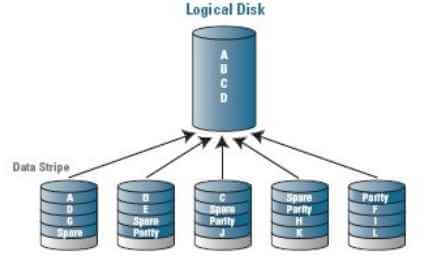
Что такое Global Hot Spare и Dedicated Hot Spare
Если вы хоть раз настраивали сервер, то наверняка задавались вопросом его отказоустойчивости, которая может быть на разных уровнях, например два блока питания или дисковая подсистема, которая для сервера очень важна. Потеря данных просто неприемлема в современной модели бизнеса. Для этого существует технология RAID, где за счет избыточности достигается некий баланс безопасности и денег.
Существует много видов RAID массивов и у каждого свое количество дисков которое может выйти, прежде чем весь массив развалится. Для дополнительной защиты принято выделять один или несколько запасных дисков горячей замены, которые должны успеть подменить выходящий из строя диск, до момента его замены. Существует два вида дисков горячей замены, это Global Hot Spare и Dedicated Hot Spare.
Global Hot Spare - Глобальный диск горячего резервирования позволяет не потерять данные при выходе из строя одного из дисков массива. Это неиспользуемый резервный диск в группе дисков. Данный диск находятся в режиме ожидания и будет активирован на любом из виртуальных дисков, когда возникает сбой физического или повреждение диска, на то он и глобальный. Диск горячего резервирования автоматически активируется только в случае повреждения диска массива. Когда диск горячего резерва активирован, он восстанавливает данные для всех резервных виртуальных дисков, в которых использовался неисправный физический диск. Затем, после замены диска, данные отправляются обратно на новый диск с резервного диска. Следует помнить, что Global Hot Spare диск и физический диск массива должны использовать одну и ту же дисковую технологию и размер (размер может быть больше, но не меньше).
Dedicated Hot Spare - В ыделенный горячий резервный диск - это диск "горячего" резерва, который может использоваться только для одного резервного виртуального диска. Также возможно назначить выделенный Dedicated Hot Spare для защиты более чем одного логического диска; это называется резервным пулом (pool reserve). Прежде чем вы сможете назначить выделенный резервный диск для защиты массива, вы должны создать логический диск.
Из схемы видно, что выделенные диски будут являться резервными только для группы A и B, а вот глобальный Hot Spare для всех массивов.
RAID 5EE
массив, аналогичный RAID5, однако кроме распределенного хранения кодов четности используется распределение резервных областей - фактически задействуется жесткий диск, который можно добавить в массив RAID5 в качестве запасного (такие массивы называют 5+ или 5+spare). В RAID 5 массиве резервный диск простаивает до тех пор, пока не выйдет из строя один из основных жестких дисков, в то время как в RAID 5EE массиве этот диск используется совместно с остальными HDD все время, что положительно сказывается на производительность массива. К примеру, массив RAID5EE из 5 HDD сможет выполнить на 25% больше операций ввода/вывода за секунду, чем RAID5 массив из 4 основных и одного резервного HDD. Минимальное количество дисков для такого массива - 4.
RAID 1E
Похожий на RAID10 вариант распределения данных по дискам, допускающий использование нечётного числа дисков (минимальное количество - 3)
Что такое RAID и зачем он нужен?
Акроним RAID (Reudant Array of Independed Disks) избыточный массив независимых дисков, впервые был использован в 1988 году исследователями из института Беркли Паттерсоном (Patterson), Гибсоном (Gibson) и Кацем (Katz). Они описали конфигурацию массива из нескольких недорогих дисков, обеспечивающих высокие показатели по отказоустойчивости и производительности.
Наиболее "слабой" в смысле отказоустойчивости частью компьютерных систем всегда являлись жесткие диски, поскольку они, чуть ли не единственные из составляющих компьютера, имеют механические части. Данные записанные на жесткий диск доступны только пока доступен жесткий диск, и вопрос заключается не в том, откажет ли этот жесткий диск когда-нибудь, а в том, когда он откажет.
RAID обеспечивает метод доступа к нескольким жестким дискам, как если бы имелся один большой диск (SLED - single large expensive disk), распределяя информацию и доступ к ней по нескольким дискам, обеспечивая снижение риска потери данных, в случае отказа одного из винчестеров, и увеличивая скорость доступа к ним.
Обычно RAID используется в больших файл серверах или серверах приложений, когда важна, высока скорость и надежность доступа к данным. Сегодня RAID находит применение так же в настольных системах, работающих с CAD, мультимедийными задачами и когда требуется обеспечить высокую производительность дисковой системы.
Что такое Hot Spare (Hotspare)?
Hot Spare - (Резервная Замена Дисководов ("Горячее резервирование")) - Одна из наиболее важных особенностей, которую обеспечивает RAID контроллер, с целью достичь безостановочное обслуживание с высокой степенью отказоустойчивости. В случае выхода из строя диска, восстанавливающая операция будет выполнена RAID контроллером автоматически, если выполняются оба из следующих условий:
- Имеется "резервный" диск идентичного объема, подключенный к тому же контроллеру и назначенный в качестве резервного, именно он и называется Hotspare ;
- Отказавший диск входит в состав избыточной дисковой системы, например RAID 1, RAID 3, RAID 5 или RAID 0+1.
Обратите внимание: резервирование позволяет восстановить данные, находившиеся на неисправном диске, если все диски подключены к одному и тому же RAID контроллеру.
"Резервный" диск может быть создан одним из двух способов:
- Когда пользователь выполняет утилиту разметки, все диски, которые подключены к контроллеру, но не сконфигурированы в любую из групп дисководов, будут автоматически помечены как "резервные" ( Hotspare ) диски (автоматический способ поддерживается далеко не всеми контроллерами).
- Диск может также быть помечен как резервный ( Hotspare ), при помощи соответствующей утилиты RAID контроллера.
В течение процесса автоматического восстановления система продолжает нормально функционировать, однако производительность системы может слегка ухудшиться.
Для того, что бы использовать восстанавливающую особенность резервирования, Вы должны всегда иметь резервный диск ( Hotspare ) в вашей системе. В случае сбоя дисковода, резервный дисковод автоматически заменит неисправный диск, и данные будут восстановлены. После этого, системный администратор может отключить и удалить неисправный диск, заменить его новым диском и сделать этот новый диск резервным.
RAID 5EE
массив, аналогичный RAID5, однако кроме распределенного хранения кодов четности используется распределение резервных областей - фактически задействуется жесткий диск, который можно добавить в массив RAID5 в качестве запасного (такие массивы называют 5+ или 5+spare). В RAID 5 массиве резервный диск простаивает до тех пор, пока не выйдет из строя один из основных жестких дисков, в то время как в RAID 5EE массиве этот диск используется совместно с остальными HDD все время, что положительно сказывается на производительность массива. К примеру, массив RAID5EE из 5 HDD сможет выполнить на 25% больше операций ввода/вывода за секунду, чем RAID5 массив из 4 основных и одного резервного HDD. Минимальное количество дисков для такого массива - 4.
RAID 2, 3, 4
различные варианты распределенного хранения данных с дисками, выделенными под коды четности и различными размерами блока. В настоящее время практически не используются из-за невысокой производительности и необходимости выделять много дисковой емкости под хранение кодов ЕСС и/или четности.
Что такое Hotswap?
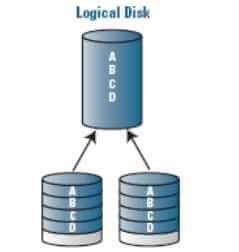
RAID 1 (mirroring — «зеркалирование»)
массив из двух дисков, являющихся полными копиями друг друга. Не следует путать с массивами RAID 1+0, RAID 0+1 и RAID 10, в которых используется более двух дисков и более сложные механизмы зеркалирования.
Обеспечивает приемлемую скорость записи и выигрыш по скорости чтения при распараллеливании запросов.
Имеет высокую надёжность — работает до тех пор, пока функционирует хотя бы один диск в массиве. Вероятность выхода из строя сразу двух дисков равна произведению вероятностей отказа каждого диска, т.е. значительно ниже вероятности выхода из строя отдельного диска. На практике при выходе из строя одного из дисков следует срочно принимать меры — вновь восстанавливать избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва.
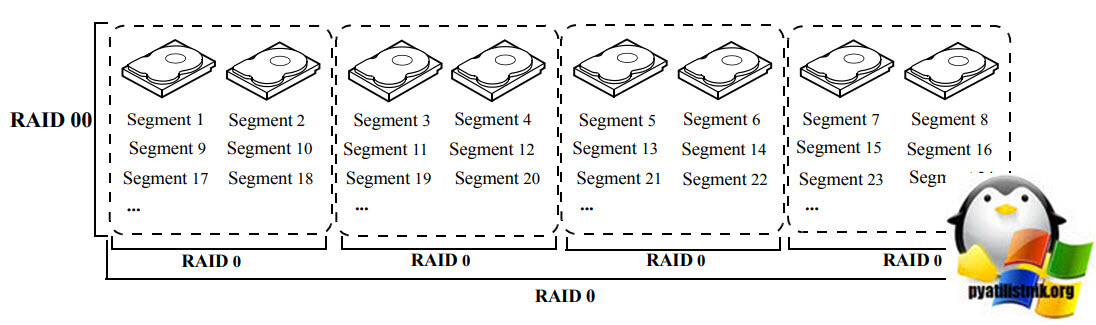
RAID 00
RAID 00 встречается весьма редко, я с ним познакомился на контроллерах LSI. Группа дисков RAID 00 - это составная группа дисков, которая создает чередующийся набор из серии
дисковых массивов RAID 0. RAID 00 не обеспечивает избыточности данных, но наряду с RAID 0, предлагает лучшую производительность любого уровня RAID. RAID 00 разбивает данные на меньшие сегменты, а затем чередует сегменты данных на каждом диске в сторадж группе. Размер каждого сегмента данных определяется размером полосы. RAID 00 предлагает высокая пропускная способность. Уровень RAID 00 не является отказоустойчивым. Если диск в группе дисков RAID 0 выходит из строя, весь
виртуальный диск (все диски, связанные с виртуальным диском) выйдет из строя. Разбивая большой файл на более мелкие сегменты, контроллер RAID может использовать оба SAS
контроллера для чтения или записи файла быстрее. RAID 00 не предполагает четности расчеты усложняют операции записи. Это делает RAID 00 идеальным для
приложения, которые требуют высокой пропускной способности, но не требуют отказоустойчивости. Может состоять от 2 до 256 дисков.
RAID 10 (1+0)
RAID 10 — зеркалированный массив, данные в котором записываются последовательно на несколько дисков, как вRAID 0. Эта архитектура представляет собой массив типа RAID 0, сегментами которого вместо отдельных дисков являются массивы RAID 1. Соответственно, массив этого уровня должен содержать как минимум 4 диска (и всегда чётное количество). RAID 10 объединяет в себе высокую отказоустойчивость и производительность.
Утверждение, что RAID 10 является самым надёжным вариантом для хранения данных вполне обосновано тем, что массив будет выведен из строя после выхода из строя всех накопителей в одном и том же массиве. При одном вышедшем из строя накопителе, шанс выхода из строя второго в одном и том же массиве равен 1/3*100=33%. RAID 0+1 выйдет из строя при двух накопителях, вышедших из строя в разных массивах. Шанс выхода из строя накопителя в соседнем массиве равен 2/3*100=66%, однако так как накопитель в массиве с уже вышедшим из строя накопителем уже не используется, то шанс того, что следующий накопитель выведет из строя массив целиком равен 2/2*100=100%
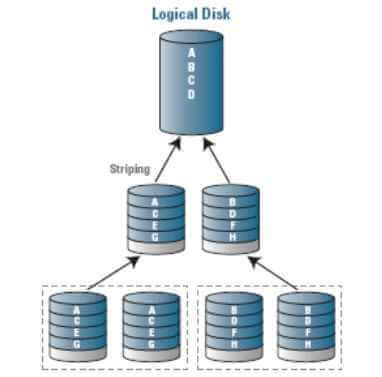
Что быстрее RAID 0 или RAID 00?
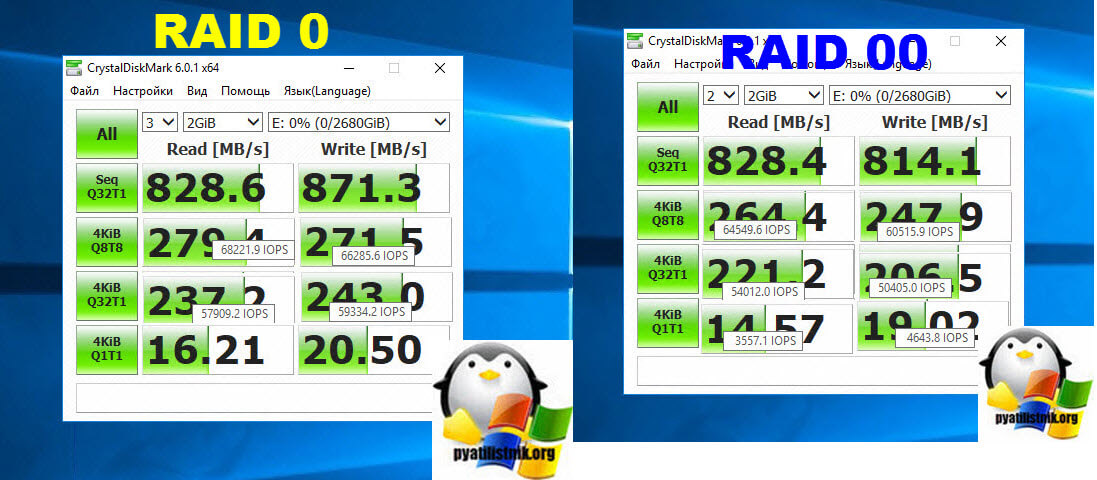
Я провел свое тестирование описанное в статье про оптимизацию скорости твердотельных дисков на LSI контроллерах и получил вот такие вот цифры на массивах из 6-ти SSD
Конспект вебинара HonorCup E=DC2 для сдачи HCNA Storage.
Что/зачем
RAID (Redundant Array of Independent Disks) – объединение дисков (не только жестких, можно и SSD) в один массив.
Основные решаемые задачи:
- отказоустойчивость (не RAID 0) – дублирование и/или восстановление данных посредством контроля четности, горячая замена дисков. НО везде подчеркивается, что RAID не является альтернативой или заменой решений по backup, он защищает только от довольно узкого кейса отказа диска/ов.
- повышение производительности – параллельный доступ к нескольким дискам

Контроллер
Бывают программные и аппаратные RAID контроллеры:
-
аппаратный: отдельная плата с собственными CPU/RAM, в случае PCI-e SSD контроллер встроен в плату PCI-e SSD
- В массиве не обязательно должно быть четное количество дисков (попарно)
- В массиве не обязательно диски одинакового размера. Чаще всего в таком случае мы просто теряем полезную емкость больших дисков (выравнивание объема по меньшему) и использовать его невозможно под другие задачи. Есть режим JBOD (Just buch of disks), в котором можно использовать всю емкость, но это не RAID.
- В массиве не обязательно диски должны иметь одну скорость, но производительность массива определяется по минимальной скорости.
- Обычно используется один тип дисков.
- Обычно в RAID можно на лету добавить еще диски.
- Традиционным способом защиты данных в кэше контроллера является BBU (Battery Backup Unit) модуль (батарея), обеспечивающий питание ОЗУ контроллера в течение некоторого времени после сбоя при помощи литий-ионного аккумулятора. При запуске сервера после восстановления питания контроллер сбрасывает сохранившееся содержимое кэша на дисковый массив. У BBU есть ряд существенных недостатков, связанных с наличием аккумулятора: ограниченное время защиты после сбоя (обычно не более 72 часов), ограниченный срок службы аккумуляторов (1-2 года), необходимость планирования закупок новых BBU модулей и утилизации вышедших из строя.
- В современных контроллерах используется другой способ защиты RAID кэша — при помощи модуля с флэш-памятью и питанием через суперконденсаторы (ионисторы). При возникновении сбоя батарея ионисторов питает модуль защиты кэша только на время копирования содержимого ОЗУ на флэш-память модуля.
- Батареи + служебное пространство 4 дисков (2×2 coffer диска в RAID1) на СХД Huawei
- NVDIMM (non-volatile-DIMM: DIMM + батарейка + флешка) на BigData СХД OceanStor 9000
- Stripe unit или chunk size – минимальная единица данных, записываемая на один диск, перед записью на другой диск.
- Strip (лента) – один или несколько последовательных секторов на диске (логическая группировка chunk).
- Stripe (полоса) – сектора на одном месте (или с одним номером Stripe) на нескольких ЖД в RAID.
- Stripe width/depth (ширина ленты) – суммарная емкость секторов на одной ленте: количество данных в chunk одного stripe * количество дисков под данные в RAID.
- когда вход одинаков – результат ложь (1×1, 0x0 -> 1)
- когда вход отличается – результат истина (0x1, 1×0 -> 0)
- RAID 0 — дисковый массив повышенной производительности с чередованием, без отказоустойчивости;
- RAID 1 — зеркальный дисковый массив;
- RAID 2 зарезервирован для массивов, которые применяют код Хемминга;
- RAID 3 и 4 — дисковые массивы с чередованием и выделенным диском чётности;
- RAID 5 — дисковый массив с чередованием и «невыделенным диском чётности»;
- RAID 6 — дисковый массив с чередованием, использующий две контрольные суммы, вычисляемые двумя независимыми способами;
- RAID 10 — массив RAID 0, построенный из массивов RAID 1;
- RAID 50 — массив RAID 0, построенный из массивов RAID 5;
- RAID 60 — массив RAID 0, построенный из массивов RAID 6.
- Просто BBU: это аккумулятор, который обеспечивает резервное питание кэша через RAID контроллер.
- Переносимые (Transportable) BBU (tBBU): это аккумулятор, который размещен непосредственно на модуле кэш и питает его независимо от RAID контроллера. В случае выхода из строя RAID контроллера, это позволяет перенести данные, сохраненные вкэш-е, на резервный контроллер и уже на нем завершить операцию записи данных.
- Flash BBU: основная идея заключается в следующем: в случае сбоя питания RAID контроллер копирует содержимое кэш-а в энергонезависимую память (например, в случае с технологией Adaptec » Zero-Maintenance Cache Protection - на NAND флэш накопитель). Питание, необходимое для завершения этого процесса, обеспечивается встроенным супер-конденсатором. После восстановления питания, данные из флэш памяти копируются обратно в кэш контроллера.
-
+ производительность, – стоимость
-
– производительность, + стоимость
Обычно на контроллере реализуется только один тип интерфейса под ЖД: SAS/SCSI/SATA. В общем случае на один контроллер цепляется до 8 дисков, но на практике зачастую используется экспандер – может позволить до х3 подключить.
Пример софтового контроллера рядом с нами 🙂 – Windows имеет встроенный программный RAID – может объединить диски в RAID 0, RAID 1 или RAID 5.

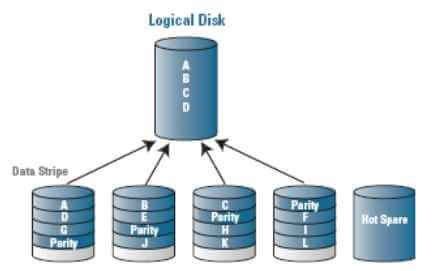
Hot Spare диски
В крупный RAID всегда должен быть включен HotSpare (горячий резерв) диск, на который пойдет автоматический ребилд при падении какого-то из дисков. Hot Spare бывают двух видов: глобальный (резерв под любой массив в системе хранения) и выделенный (выделенный диск под конкретный RAID в системе хранения).
К примеру, конфиг системы хранения: 20 дисков, разбитые на 5 рейдов и 1 диск как hot spare на все.

Политика по количеству hot spare исходя из количества дисков в домене – чем больше дисков, тем больше должно быть в резерве (логично, не правда ли :)).

Статусы работы RAID

1) Создание массива
При создании массива диски записываются нулевыми данными.
Все зависит от массива/контроллера, но в общем случае:
2) Корректная работа массива – все ок
Следующие три статуса работы при отказе одного или несколько из дисков в массиве. Отказ определяется контроллером при попытке записи/чтения с диска.
3) Реконструкция массива (RAID rebuilding/reconstruction)
Реконструкция – в наличии hot spare диск/и, утерянные данные восстанавливаются на hot spare.
Для RAID 10/1 операция не требует расчетов на основе четности, на остальных рейдах требует. Для восстановления данные считываются с “выживших” дисков, происходит расчет XOR и восстановление данных на основе операции. Время восстановления прямо пропорционально количеству потерянных данных – чем больше данных потерялось, тем больше времени восстанавливать. В момент восстановления производительность может заметно падать (при двух дисках) т.к. операция копирования идет с меньшим приоритетом, чем запросы от приложений и приостанавливается при запросе данных приложениями -> в результате восстановление RAID на активно-работающем сервере может занять долгое время

Так же реконструкция происходит, когда добавляется новый диск в RAID. Зависит от контроллера (в основном можно) можно ли добавлять на лету диск в рейд.

4) Деградация массива
Деградация – отказ члена/ов массива (в том числе диска четности) при отсутствии hot spare для запуска реконструкции. Процедура восстановления не может запустится из-за отсутствия носителя.
5) Авария массива
Аварией массива считается ситуация, когда отказало одновременно больше дисков, чем позволяет RAID технология.
За что еще отвечают контроллеры
Сохранение данных кэша при отключении питания
Кеш RAID/СХД контроллера обычно хранится в ОЗУ, а не ПЗУ (HDD/SSD). Поэтому при пропадании питания данные кэша могут быть потеряны.
Есть и другие варианты сохранения данных:
Анализ состояния дисков (SMART analysis, Bad sector detection/repair)
Данные SMART постоянно анализируются RAID/СХД-контроллерами. Контроллер обнаруживает bad sector’а при операциях read/write и восстанавливает информацию, которая была на этом секторе используя технологию восстановления, применяемую в настроенном RAID.


pre-copy на hot-spare
В случае обнаружения плохого SMART/сбойный блок на диске, контроллер RAID/СХД копирует данные с потенциально сбойного диска на hot-spare. После замены потенциально сбойного диска данные с hot-spare копируются на новый диск.


Такой подход считается лучше Data reconstruction в случае выхода из строя диска полностью т.к. он более быстрый, меньше влияет на производительность RAID/СХД и более надежен.

ОБЪЕКТЫ ДАННЫХ RAID (Strip, Stripe, LUN)
Контроллер RAID оперирует объектами данных:

В общем случае RAID-контроллер не знает что такое файловая система (не говоря про бюджетные варианты), а создает LUN.
LUN (Logical Unit, Logical Volume) – логический объект, состоящий из физических секторов (или логических структуры, которые полагаются на сектора). Чаще всего системы хранения/рейд контроллеры предоставляют ОС LUN в виде неформатированного диска (raw capacity), а уже ОС определяет какая файловая система будет использоваться для этого LUN. Новые контроллеры могут создавать несколько LUN на базе одного RAID.


Восстановление данных
Восстановление данных в RAID основывается на replication (mirroring) в случае RAID 1 (и его производных) или на базе булевой функции сложения по модулю (XOR) в случае RAID 3, 5, 6.
Таблица истинности XOR:


Пример с одним контрольным битом: при использовании трех ЖД на одном ЖД хранится один набор бит, на втором – другой, а на третьем (специальный parity disk) хранится результат XOR от первых двух. В результате при выходе любого из ЖД используя тот же XOR можно восстановить данные этого диска.
ЗАПИСЬ НА RAID
Зеркалирование (Mirroring) – RAID контроллер дублирует блок данных. RAID 1, 10, 01.
Страйпинг (Striping) – первый блок данных контроллер кладет на первый диск, второй блок – на второй, третий – на первый и т.д. Таким образом нагрузка при последовательной записи распределяется между дисками. RAID 3, 5, 6, 50, 10, 01.
Уровни RAID

Сравнение уровней, есть так же в куче мест: wiki, огромная дока (не только сравнение), небольшая статья на nix. При выборе защиты нужно всегда помнить, что методы защищающие от отказа одного ЖД (RAID 3/5) хороши, но всегда надо учитывать, что вероятность отказа двух дисков (второго диска в момент rebuilding после отказа первого) выше вероятности отказа одного т.к. после отказа одного нагрузка на RAID увеличивается и увеличивается вероятность отказа.

Чаще всего используемые массивы:
RAID 0 (чисто он сейчас используется редко, если только в связке с резервной копией или если данные не важны – являются копией, например работа с графикой). RAID 0 предоставляет максимальную скорость чтения/записи, но без отказоустойчивости и чем больше дисков, тем больше риск сбоя всего рейда (в случае сбоя только попытка восстановления, но это всегда), причем нет возможности даже использовать диски горячей замены, в отличии от других RAID! Дисков не обязательно два, можно больше.


RAID 1 (может использоваться для БД и других важных данных, но чаще для них используется RAID 10) – зеркалирование дисков. Все диски являются копиями всех – контроллер дублирует данные при записи. Чаще всего в RAID 1 находятся всего 2 диска из-за роста стоимости решения без фактического роста объема. Общий объем данных не должен превышать объем одного диска. Скорость считывания увеличивается за счет того, что контроллер может забирать данные с разных дисков. В случае выхода из строя диска и замены диска на новый диск происходит копия с выжившего ЖД на новый.


RAID 3 (чаще всего вместо него используется RAID 5, может быть даже не реализован на новых контроллерах) – массив дисков с использованием выделенного диска четности. Данные контроллером записываются последовательно на диски в основной массив дисков, а данные о контрольной сумме от данных по XOR записываются на диск четности. При чтении осуществляется операция read только с дисков данных, четность не проверяется. Компьютеру не будет доступна емкость диска четности (n-1 полезная емкость). При этом коэффициент полезного объема повышается с увеличением количества дисков. Производительность всего RAID может иметь узким местом диск четности т.к. на него невозможно “распараллелить” запись. В случае поломки данных, после замены, восстановление данных происходит с помощью диска четности и данных с других (выживших) дисков. Отказ диска четности не критичен, но в случае отказа любых двух дисков (четности или нечетности – не важно) данные потеряны, защита только от отказа одного диска в один момент.


RAID 5 (часто используется, например в файловых/почтовых серверах, обычно до 12 дисков) – частая ошибка что в RAID 5 максимум 5 дисков, по факту в RAID 5 можно включить минимум 3 диска (можно и 4). Данные по четности равномерно распределены между всеми дисками (на первый диск четность по первому stripe, на второй диск четность по второму stripe, etc; блоки четности равномерно распределяются по массиву). Плюс по сравнению с RAID 3 – отсутствие расхода всего диска под четность, нет завязки на производительность диска четности. Достоинства – хорошая скорость считывания данных (как параллельного, так и последовательного). Недостатки – низкая скорость случайной записи и чем больше дисков, тем большее время восстановления, поэтому RAID 5 чаще всего состоит максимум из 10-12 дисков. По аналогии с RAID3 в случае отказа любых двух дисков данные потеряны, защита только от отказа одного диска в один момент.


RAID 6 (при необходимости большой надежности в сравнении с R3/R5; в файловых/почтовых серверах, встречается, но не часто) – RAID 6 похож на RAID 3 и RAID 5 с той разницей что используется две контрольные суммы четности вместо одной. Повышается надежность (защита от отказа до двух дисков одновременно) и производительность, но записываются две суммы на диски. Минимум 4 диска и потеря полезной емкости 2 дисков из них гарантирована. RAID 6 работает немного медленнее RAID 5 из-за необходимости расчета и записи двух контрольных сумм при записи и rebuild. Используется не на очень объемных дисках из-за долго rebuild (не более 1ТБ).

У вендоров существует две основных технологии реализации RAID 6:
RAID 6 DP (double parity) (NetAPP) – похож на RAID 3. Используется двойная контрольная сумма (две суммы, обе рассчитаны используя xor). Первая контрольная сумма рассчитывается по stripe и кладется на основной диск четности, вторая контрольная сумма рассчитывается на основе данных о четности блоков данных разных stripes, включая четность основного диска четности (диагональная четность) и кладется на второй диск четности.

RAID 6 P+Q (Huawei, HDS) – похож на RAID 5. Вычисляются две контрольных суммы (xor + вторая через коды Рида-Соломона) и обе суммы для одного stripe кладутся на все ЖД последовательно.

RAID 2.0+ – проприетарный RAID на СХД Huawei, подробнее в статье про технологии СХД Huawei.
Комбинации
Если в наименовании две цифры (RAID 10/50) – значит происходит одновременное использование нескольких RAID методов:
RAID 01 (редко) – минимум 4 диска. Состоит из stripe, поверх которых осуществляется mirror (массив RAID1 из массивов RAID0). В общем случае не делается больше 2 групп зеркал.
RAID 10 (часто используется, особенно для БД и других важных данных) – минимум 4 диска и общее количество должно быть четным. Состоит из зеркал, поверх которых осуществляется striping (массив RAID0 из массивов RAID1). Частично заимствует скоростные преимущества RAID0 и преимущество надежности RAID1. При этом частично сохраняется основной недостаток RAID1 – высокая стоимость дискового массива. В общем случае в группе зеркал по два диска – они дублируют друг друга, а запись проходит последовательно на несколько групп зеркал. При отказе двух дисков в RAID 10 в разных Disk Mirror групп данные восстанавливаются от соседей выживших Mirror групп. В случае отказа двух дисков в одной Mirror группе – RAID ломается.

RAID 50 (редко) – минимум 6 дисков. Состоит из групп RAID 5 поверх которых осуществляется striping. Лучше RAID 5 при большом количестве дисков. Проще восстановление и лучше скорость доступа.
Нужно ли заниматься архивированием данных в случае использования RAID?
О: Конечно да! RAID это вовсе не замена архивированию, основное его назначение это повышение скорости и надежности доступа к данным в нормальном режиме работы. Но только регулярное архивирование данных гарантировано обеспечит их сохранность при любых отказах оборудования, пожарах, потопах и прочих неприятностях.

Виды RAID и их характеристики
Что такое RAID мы рассмотрели в первой статье. Теперь посмотрим какие есть виды и чем они отличаются.
Калифорнийский университет в Беркли представил следующие уровни спецификации RAID, которые были приняты как стандарт де-факто:
Виды RAID и их характеристики
Аппаратный RAID-контроллер может поддерживать несколько разных RAID-массивов одновременно, суммарное количество жёстких дисков которых не превышает количество разъёмов для них. При этом контроллер, встроенный в материнскую плату, в настройках BIOS имеет всего два состояния (включён или отключён), поэтому новый жёсткий диск, подключённый в незадействованный разъём контроллера при активированном режиме RAID, может игнорироваться системой, пока он не будет ассоциирован как ещё один RAID-массив типа JBOD (spanned), состоящий из одного диска.
Что такое BBU и зачем он нужен?
BBU (Battery Backup Unit) необходим для предотвращения потери данных находящихся в кэш-е RAID контроллера и еще не записанных на диск (отложенная запись - "write-back caching"), в случае аварийного выключения компьютерной системы.
Существуют три разновидности BBU:
Что такое JBOD?
JBOD (Just a Bunch of Disks) это способ подключить диски к RAID контроллеру не создавая на них никакого RAID. Каждый из дисков доступен так же, как если бы он был подключен к обычному адаптеру. Эта конфигурация применяется когда необходимо иметь несколько независимых дисков, но не обеспечивает ни повышения скорости, ни отказоустойчивости.
Что такое размер страйпа (stripe size)?
размер страйпа (stripe size) определяет объем данных записываемых за одну операцию ввода/вывода. размер страйпа задается в момент конфигурирования RAID массива и не может быть изменен позднее без переинициализации всего массива. Больший размер страйпа обеспечивает прирост производительности при работе с большими последовательными файлами (например, видео), меньший - обеспечивает большую эффективность в случае работы с большим количеством небольших файлов.
Можно ли использовать в RAID массиве диски разного размера?
Да. можно. Но, при этом, используемая емкость у ВСЕХ дисков будет равна емкости наименьшего диска.
Из этого следует, что добавлять в уже существующий RAID массив можно только диски такого же или большего размера
Можно ли использовать в RAID массиве диски разных производителей?
Да, можно. Но при этом надо иметь ввиду, что точные размеры дисков одинаковой емкости (36/73/146. ГБ) у разных производителей могут отличаться на несколько килобайт. Когда вы создаете новый RAID массив, на это можно не обращать внимание, но если вы добавляете диски к уже существующему массиву (например, меняете вышедший из строя диск), то важно, чтобы новый диск был больше чем старые, или точно такого же размера.
RAID 6
RAID 6 — похож на RAID 5, но имеет более высокую степень надёжности — под контрольные суммы выделяется ёмкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. Требует более мощный RAID-контроллер. Обеспечивает работоспособность после одновременного выхода из строя двух дисков — защита от кратного отказа. Для организации массива требуется минимум 4 диска. Обычно использование RAID-6 вызывает примерно 10-15% падение производительности дисковой группы, относительно RAID 5, что вызвано большим объёмом обработки для контроллера (необходимость рассчитывать вторую контрольную сумму, а также читать и перезаписывать больше дисковых блоков при записи каждого блока).
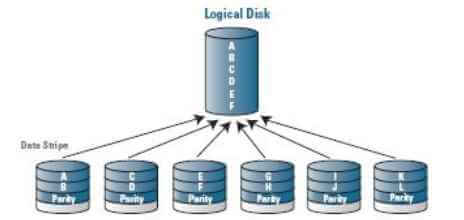
RAID 0 (striping — «чередование»)
Режим, при использовании которого достигается максимальная производительность. Данные равномерно распределяются по дискам массива, дискиобъединяются в один, который может быть размечен на несколько. Распределенные операции чтения и записи позволяют значительно увеличить скорость работы, поскольку несколько дисков одновременно читают/записывают свою порцию данных. Пользователю доступен весь объем дисков, но это снижает надежность хранения данных, поскольку при отказе одного из дисков массив обычно разрушается и восстановить данные практически невозможно. Область применения - приложения, требующие высоких скоростей обмена с диском, например видеозахват, видеомонтаж. Рекомендуется использовать с высоконадежными дисками.
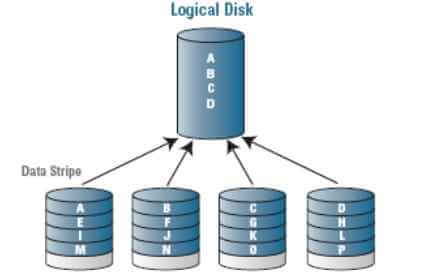
RAID 0 (striping — «чередование»)
Читайте также: