
Python прочитать файл doc
Независимо от того, какое приложение вы используете, гарантировано, что в процессе его работы будет задействован ввод или вывод данных. В этом руководстве кратко описываются форматы, которые может обрабатывать Python. Затем мы рассмотрим, как открывать, считывать и записать текстовый файл в Python 3.
Чтение параграфов
С помощью объекта класса Document и пути к файлу можно получить доступ ко всем абзацам документа с помощью атрибута paragraphs. Пустая строка также читается как абзац.
Извлечем все абзацы из файла my_word_file.docx и затем отобразим общее количество абзацев документа:
Теперь поочередно выведем все абзацы, присутствующие в файле my_word_file.docx:
Вывод демонстрирует все абзацы, присутствующие в файле my_word_file.docx.
Также можно получить доступ к определенному абзацу, индексируя свойство paragraphs как массив. Давайте выведем пятый абзац в файле:
Атрибуты объекта Run
Отдельные фрагменты текста, представленные объектами Run , могут подвергаться дополнительному форматированию с помощью атрибутов. Для каждого из этих атрибутов может быть задано одно из трех значений: True (атрибут активизирован), False (атрибут отключен) и None (применяется стиль, установленный для данного объекта Run ).
- bold — Полужирное начертание
- underline — Подчеркнутый текст
- italic — Курсивное начертание
- strike — Зачеркнутый текст
Изменим стили для всех параграфов нашего документа:
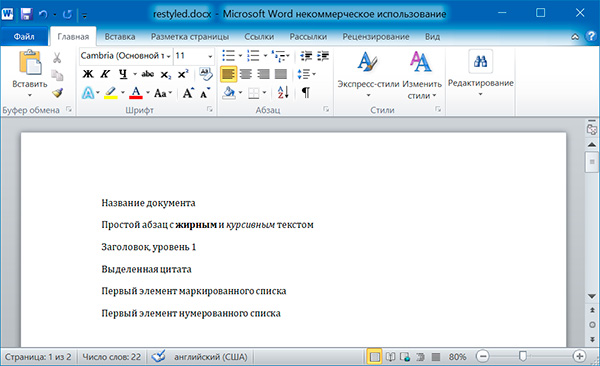
А теперь восстановим все как было:
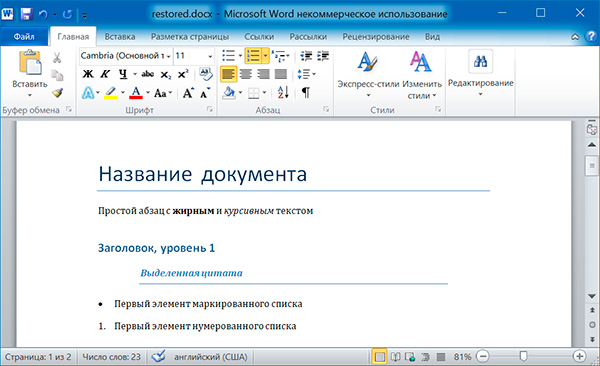
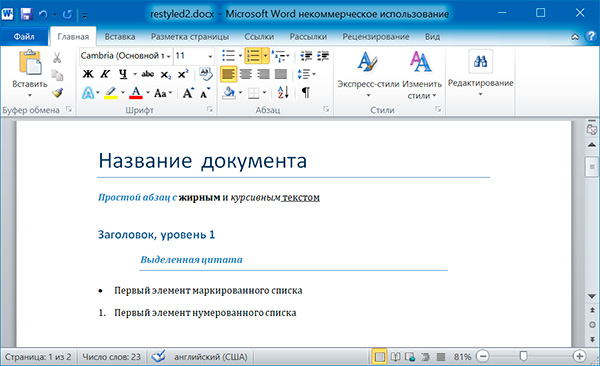
Изменим форматирвание объектов Run второго абзаца:
15 Answers 15
Use the native Python docx module. Here's how to extract all the text from a doc:
Also check out Textract which pulls out tables etc.
Parsing XML with regexs invokes cthulu. Don't do it!
opendocx is not in the module (perhaps it was in 2009). Documents are opened through the Document class, e.g. import docx; document = docx.Document('Hello world.docx') .
This code resulted in an error for me: paragraph.text.encode('utf-8') for paragraph in document.paragraphs TypeError: sequence item 0: expected str instance, bytes found
You could make a subprocess call to antiword. Antiword is a linux commandline utility for dumping text out of a word doc. Works pretty well for simple documents (obviously it loses formatting). It's available through apt, and probably as RPM, or you could compile it yourself.
benjamin's answer is a pretty good one. I have just consolidated.
I should reiterate this only works for docx (Word 2007 or later). For .doc files wvware is your best bet. Depending on your environment it can be a pain to setup, but it does do a very nice job.
To remove XML entities like from 'text': >>>from xml.sax.saxutils import unescape >>>text=unescape(cleaned)
content = docx.read('word/document.xml').decode('utf-8') otherwise you will get error while cleaning: TypeError: cannot use a string pattern on a bytes-like object
Since OOo can load most MS Word files flawlessly, I'd say that's your best bet.
As flawless as MS Word N+1 opens MS Words N files, and way better than MS Word N+1 opens MS Words N-1 files, IMHO
I know this is an old question, but I was recently trying to find a way to extract text from MS word files, and the best solution by far I found was with wvLib:
After installing the library, using it in Python is pretty easy:
And that's it. Pretty much, what we're doing is using the commands.getouput function to run a couple of shell scripts, namely wvText (which extracts text from a Word document, and cat to read the file output). After that, the entire text from the Word document will be in the out variable, ready to use.
Hopefully this will help anyone having similar issues in the future.
Take a look at how the doc format works and create word document using PHP in linux. The former is especially useful. Abiword is my recommended tool. There are limitations though:
However, if the document has complicated tables, text boxes, embedded spreadsheets, and so forth, then it might not work as expected. Developing good MS Word filters is a very difficult process, so please bear with us as we work on getting Word documents to open correctly. If you have a Word document which fails to load, please open a Bug and include the document so we can improve the importer.
Not just that though! Even the most basic text saved in the Word 97 format is nearly impossible to get at easily without relying on word to do it for you (COM). Most word documents are not HTML!
Abiword doesn't assume that it's a HTML document, and considering how extensive the tool is. I don't think it was "easy" to implement it. Abiword is a tool that helps you to read MS Word files. and since the author is concerned with text retrieval, this suffices.
Ah, I'd always thought that abiword was just another word processor! Man, that would have saved me some headaches awhile back.
(Note: I posted this on this question as well, but it seems relevant here, so please excuse the repost.)
Now, this is pretty ugly and pretty hacky, but it seems to work for me for basic text extraction. Obviously to use this in a Qt program you'd have to spawn a process for it etc, but the command line I've hacked together is:
unzip -p file.docx: -p == "unzip to stdout"
grep ': Grab just the lines containing ' is the Word 2007 XML element for "text", as far as I can tell)
sed 's/>//g'*: Remove everything inside tags
grep -v '^[[:space:]]$'*: Remove blank lines
There is likely a more efficient way to do this, but it seems to work for me on the few docs I've tested it with.
As far as I'm aware, unzip, grep and sed all have ports for Windows and any of the Unixes, so it should be reasonably cross-platform. Despit being a bit of an ugly hack ;)
If your intention is to use purely python modules without calling a subprocess, you can use the zipfile python modude.
Your content string however needs to be cleaned up, one way of doing this is:
But there is surely a more elegant way to clean up the string, probably using the re module. Hope this helps.
To remove XML entities like from 'text': >>>from xml.sax.saxutils import unescape >>>text=unescape(content)
To read Word 2007 and later files, including .docx files, you can use the python-docx package:
To read .doc files from Word 2003 and earlier, make a subprocess call to antiword. You need to install antiword first:
Then just call it from your python script:
If you have LibreOffice installed, you can simply call it from the command line to convert the file to text, then load the text into Python.
Ah Philip! I was just looking for a way to reject the trivial edits of style you made to another post of mine. I tried to contact you directly. Would you please state more clearly what you are suggesting here? This answer I gave here is in answer to the question. Isn't that good enough?
Re. your edits of style and grammar: I preferred my own style and grammar, thank you. A good editor doesn't impose his own style. And really, none of us have enough spare time to be doing trivial spell and grammer checking, do we? I think you may find it is a little over-bearing.
I'm not sure if you're going to have much luck without using COM. The .doc format is ridiculously complex, and is often called a "memory dump" of Word at the time of saving!
At Swati, that's in HTML, which is fine and dandy, but most word documents aren't so nice!
Is this an old question? I believe that such thing does not exist. There are only answered and unanswered ones. This one is pretty unanswered, or half answered if you wish. Well, methods for reading *.docx (MS Word 2007 and later) documents without using COM interop are all covered. But methods for extracting text from *.doc (MS Word 97-2000), using Python only, lacks. Is this complicated? To do: not really, to understand: well, that's another thing.
When I didn't find any finished code, I read some format specifications and dug out some proposed algorithms in other languages.
MS Word (*.doc) file is an OLE2 compound file. Not to bother you with a lot of unnecessary details, think of it as a file-system stored in a file. It actually uses FAT structure, so the definition holds. (Hm, maybe you can loop-mount it in Linux. ) In this way, you can store more files within a file, like pictures etc. The same is done in *.docx by using ZIP archive instead. There are packages available on PyPI that can read OLE files. Like (olefile, compoundfiles, . ) I used compoundfiles package to open *.doc file. However, in MS Word 97-2000, internal subfiles are not XML or HTML, but binary files. And as this is not enough, each contains an information about other one, so you have to read at least two of them and unravel stored info accordingly. To understand fully, read the PDF document from which I took the algorithm.
Code below is very hastily composed and tested on small number of files. As far as I can see, it works as intended. Sometimes some gibberish appears at the start, and almost always at the end of text. And there can be some odd characters in-between as well.
Those of you who just wish to search for text will be happy. Still, I urge anyone who can help to improve this code to do so.
При установке модуля надо вводить python-docx , а не docx (это другой модуль). В то же время при импортировании модуля python-docx следует использовать import docx , а не import python-docx .
Запись в файл Python
Чтобы записать данные в файл в Python, нужно открыть его в режиме 'w', 'a' или 'x'. Но будьте осторожны с режимом 'w'. Он перезаписывает файл, если то уже существует. Все данные в этом случае стираются.
Запись строки или последовательности байтов (для бинарных файлов) осуществляется методом write(). Он возвращает количество символов, записанных в файл.
Эта программа создаст новый файл 'test.txt'. Если он существует, данные файла будут перезаписаны. При этом нужно добавлять символы новой строки самостоятельно, чтобы разделять строки.
Запись заголовков
В файлы MS Word также можно добавлять заголовки. Для этого нужно вызвать метод add_heading(). Первым параметром метода add_heading() является текстовая строка для заголовка, а вторым – размер заголовка.
Приведенный ниже скрипт добавляет в файл my_written_file.docx три заголовка уровня 0, 1 и 2:
Стилевое оформление
В документах MS Word применяются два типа стилей: стили абзацев, которые могут применяться к объектам Paragraph , стили символов, которые могут применяться к объектам Run . Как объектам Paragraph , так и объектам Run можно назначать стили, присваивая их атрибутам style значение в виде строки. Этой строкой должно быть имя стиля. Если для стиля задано значение None , то у объекта Paragraph или Run не будет связанного с ним стиля.
Стили абзацев
- Normal
- Body Text
- Body Text 2
- Body Text 3
- Caption
- Heading 1
- Heading 2
- Heading 3
- Heading 4
- Heading 5
- Heading 6
- Heading 7
- Heading 8
- Heading 9
- Intense Quote
- List
- List 2
- List 3
- List Bullet
- List Bullet 2
- List Bullet 3
- List Continue
- List Continue 2
- List Continue 3
- List Number
- List Number 2
- List Number 3
- List Paragraph
- Macro Text
- No Spacing
- Quote
- Subtitle
- TOCHeading
- Title
Стили символов
- Emphasis
- Strong
- Book Title
- Default Paragraph Font
- Intense Emphasis
- Subtle Emphasis
- Intense Reference
- Subtle Reference
Написание файлов MS Word с помощью модуля Python-Docx
Чтобы записать файлы MS Word, создайте объект класса Document с пустым конструктором.
Добавление изображений
Чтобы добавить в файлы MS Word изображения, используется метод add_picture(). Путь к изображению передается как параметр метода add_picture(). Также можно указать ширину и высоту изображения с помощью атрибута docx.shared.Inches().
Приведенный ниже скрипт добавляет изображение из локальной файловой системы в файл my_written_file.docx. Ширина и высота изображения будут 5 и 7 дюймов:
После выполнения всех скриптов, рассмотренных в этой статье, окончательный файл my_written_file.docx должен выглядеть следующим образом:

Он должен содержать три абзаца, три заголовка и одно изображение.
Как закрыть файл в Python?
Закрытие освободит ресурсы, которые были связаны с файлом. Это делается с помощью метода close(), встроенного в язык программирования Python.
В Python есть сборщик мусора, предназначенный для очистки ненужных объектов, Но нельзя полагаться на него при закрытии файлов.
Этот метод не полностью безопасен. Если при операции возникает исключение, выполнение будет прервано без закрытия файла.
Более безопасный способ – использование блока try. finally.
Это гарантирует правильное закрытие файла даже после возникновения исключения, прерывающего выполнения программы.
Также для закрытия файла можно использовать конструкцию with. Оно гарантирует, что файл будет закрыт при выходе из блока with. При этом не нужно явно вызывать метод close(). Это будет сделано автоматически.
Добавление заголовков
Вызов метода add_heading() приводит к добавлению абзаца, отформатированного в соответствии с одним из возможных стилей заголовков:
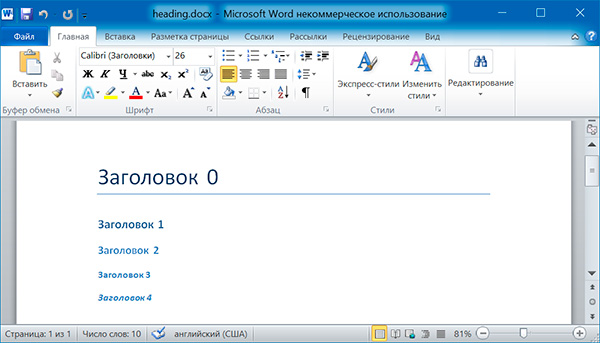
Аргументами метода add_heading() являются строка текста и целое число от 0 до 4. Значению 0 соответствует стиль заголовка Title .
Запись прогонов
Вы также можете записать прогоны с помощью модуля python-docx. Для этого нужно создать дескриптор абзаца, к которому хотите добавить прогон:
В приведенном выше скрипте записывается абзац с помощью метода add_paragraph()объекта mydoc класса Document. Метод add_paragraph() возвращает дескриптор для вновь добавленного пункта.
Чтобы добавить прогон к новому абзацу, необходимо вызвать метод add_run() для дескриптора абзаца. Текст прогона передается в виде строки в метод add_run(). Затем необходимо вызвать метод save() для создания фактического файла.
Шаг 1 - Создание текстового файла
Сначала нужно подготовить файл для работы. Для этого мы откроем любой текстовый редактор для python и создадим новый txt-файл, назовем его days.txt.
В этом файле необходимо ввести несколько строк. В приведенном ниже примере мы перечислим дни недели:
Затем сохраните файл. В нашем примере пользователь sammy сохранил файл здесь: /users/sammy/days.txt . Это будет важно на последующих этапах, когда откроем файл в Python.
Чтение прогонов
Прогон в текстовом документе представляет собой непрерывную последовательность слов, имеющих схожие свойства. Например, одинаковые размеры шрифта, формы шрифта и стили шрифта.
Чтобы получить все прогоны в абзаце, можно использовать свойство run атрибута paragraphобъекта doc.
Считаем все прогоны из абзаца №5 (четвертый указатель) в тексте:
Аналогичным образом приведенный ниже скрипт выводит все прогоны из 6-го абзаца файла my_word_file.docx:
Добавление изображений
Метод add_picture() объекта Document позволяет добавлять изображения в конце документа. Например, добавим в конец документа изображение kitten.jpg шириной 10 сантиметров:
Именованные аргументы width и height задают ширину и высоту изображения. Если их опустить, то значения этих аргументов будут определяться размерами самого изображения.
В этой статье вы узнаете, как в Python считывать и записывать файлы MS Word.
Шаг 4 - Запись файла
На этом этапе мы запишем новый файл, который включает в себя название «Days of the Week», и дни недели. Сначала создадим переменную title.
Также нужно сохранить дни недели в строковой переменной days . Открываем файл в режиме чтения, считываем файл и сохраняем вывод в новую переменную days .
Теперь, когда у нас есть переменные для названия и дней недели, запишем их в новый файл. Сначала нужно указать расположение файла. Мы будем использовать каталог /users/sammy/ . Также нужно указать новый файл, который мы хотим создать. Фактический путь будет /users/sammy/new_days.txt . Мы записываем его в переменную new_path . Затем открываем новый файл в режиме записи, используя функцию open() с режимом w .
Если файл new_days.txt уже существовал до открытия, его содержимое будет удалено, поэтому будьте осторожны при использовании режима «w».
Когда новый файл будет открыт, поместим в него данные, используя .write(). Операция write принимает один параметр, который должен быть строкой, и записывает эту строку в файл.
Если хотите записать новую строку в файл, нужно указать символ новой строки. Мы записываем в файл заголовок, за которым следуют дни недели.
Всякий раз, когда мы заканчиваем работу с файлом, нужно его закрыть. Мы покажем это в заключительном шаге.
Работа с файлами питон - что такое файл Python?
Файл – это именованная область диска, предназначенная для длительного хранения данных в постоянной памяти (например, на жёстком диске).
Чтобы прочитать или записать данные в файл, сначала нужно его открыть. После окончания работы файл необходимо закрыть, чтобы освободить связанные с ним ресурсы.
Поэтому в Python операции с файлами выполняются в следующем порядке:
- Открытие файла Python.
- Чтение из файла Python или запись в файл Python (выполнение операции).
- Закрытие файла Python.
Чтение документов MS Word
Файлы с расширением .docx обладают развитой внутренней структурой. В модуле python-docx эта структура представлена тремя различными типами данных. На самом верхнем уровне объект Document представляет собой весь документ. Объект Document содержит список объектов Paragraph , которые представляют собой абзацы документа. Каждый из абзацев содержит список, состоящий из одного или нескольких объектов Run , представляющих собой фрагменты текста с различными стилями форматирования.

Получаем весь текст из документа:
Шаг 2 - Открытие файла
Прежде чем написать программу, нужно создать файл для кода Python. С помощью текстового редактора создадим файл files.py. Чтобы упростить задачу, сохраните его в том же каталоге, что и файл days.txt:
Чтобы открыть файл, сначала нужно каким-то образом связать его с переменной в Python. Этот процесс называется открытием файла. Сначала мы укажем Python, где находится файл.
Чтобы Python мог открыть файл, ему требуется путь к нему: days.txt -/users/sammy/days.txt . Затем создаем строковую переменную для хранения этой информации. В нашем скрипте files.py мы создадим переменную path и установим для нее значение days.txt .
Затем используем функцию Python open(), чтобы открыть файл days.txt . В качестве первого аргумента она принимает путь к файлу.
Эта функция также позволяет использовать многие другие параметры. Но наиболее важным является параметр, определяющий режим открытия файла. Он зависит от того, что вы хотите сделать с файлом.
Вот некоторые из существующих режимов:
- 'r': использовать для чтения;
- 'w': использовать для записи;
- 'x': использование для создания и записи в новый файл;
- 'a': использование для добавления к файлу;
- 'r +': использовать для чтения и записи в тот же файл.
В текущем примере нужно только считать данные из файла, поэтому будем использовать режим «r». Применим функцию open() , чтобы открыть файл days.txt и назначить его переменной days_file .
После открытия файла мы сможем прочитать его, что сделаем на следующем шаге.
Работа с текстовыми файлами Python 3 -исходные ресурсы
Для этого руководства нужно установить Python 3. Также на вашем компьютере должна быть установлена локальная среда программирования.
Запись докуменов MS Word
Добавление абзацев осуществляется вызовом метода add_paragraph() объекта Document . Для добавления текста в конец существующего абзаца, надо вызвать метод add_run() объекта Paragraph :
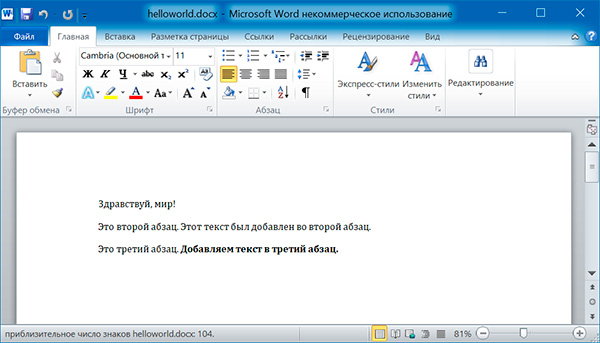
Оба метода, add_paragraph() и add_run() принимают необязательный второй аргумент, содержащий строку стиля, например:
Основа
Python может с относительной легкостью обрабатывать различные форматы файлов:
| Тип файла | Описание |
| Txt | Обычный текстовый файл хранит данные, которые представляют собой только символы (или строки) и не включает в себя структурированные метаданные. |
| CSV | Файл со значениями,для разделения которых используются запятые (или другие разделители). Что позволяет сохранять данные в формате таблицы. |
| HTML | HTML-файл хранит структурированные данные и используется большинством сайтов |
| JSON | JavaScript Object Notation - простой и эффективный формат, что делает его одним из часто используемых для хранения и передачи данных. |
В этой статье основное внимание будет уделено формату txt.
Заключение
В этой статье мы рассказали, как работать с простыми текстовыми файлами в Python 3. Теперь вы сможете открывать, считывать, записывать и закрывать файлы в Python.
Дайте знать, что вы думаете по данной теме материала в комментариях. За комментарии, дизлайки, лайки, отклики, подписки огромное вам спасибо!
Пожалуйста, оставьте свои отзывы по текущей теме материала. Мы крайне благодарны вам за ваши комментарии, дизлайки, отклики, подписки, лайки!
for working with MS word files in python, there is python win32 extensions, which can be used in windows. How do I do the same in linux? Is there any library?
Установка библиотеки Python-Docx
Существует несколько библиотек, которые можно использовать для чтения и записи в Python файлов MS Word. Мы будем использовать модуль python-docx .
Выполните приведенную ниже pip команду в терминале, чтобы загрузить модуль python-docx:
Добавление разрывов строк и страниц
Чтобы добавить разрыв строки (а не добавлять новый абзац), нужно вызвать метод add_break() объекта Run . Если же требуется добавить разрыв страницы, то методу add_break() надо передать значение docx.enum.text.WD_BREAK.PAGE в качестве единственного аргумента:
Открытие файла Python
Не знаете как открыть файл в питоне? В Python есть встроенная функция open(), предназначенная для открытия файла. Она возвращает объект, который используется для чтения или изменения файла.
При этом можно указать необходимый режим открытия файла: 'r'- для чтения,'w' - для записи,'a' - для изменения. Мы также можем указать, хотим ли открыть файл в текстовом или в бинарном формате.
По умолчанию файл открывается для чтения в текстовом режиме. При чтении файла в этом режиме мы получаем строки.
В бинарном формате мы получим байты. Этот режим используется для чтения не текстовых файлов, таких как изображения или exe-файлы.
| Открытие файла Python- возможные режимы | |
| Режим | Описание |
| 'r' | Открытие файла для чтения. Режим используется по умолчанию. |
| 'w' | Открытие файла для записи. Режим создаёт новый файл, если он не существует, или стирает содержимое существующего. |
| 'x' | Открытие файла для записи. Если файл существует, операция заканчивается неудачей (исключением). |
| 'a' | Открытие файла для добавления данных в конец файла без очистки его содержимого. Этот режим создаёт новый файл, если он не существует. |
| 't' | Открытие файла в текстовом формате. Этот режим используется по умолчанию. |
| 'b' | Открытие файла в бинарном формате. |
| '+' | Открытие файла для обновления (чтения и записи). |
В отличие от других языков программирования, в Python символ 'a' не подразумевает число 97, если оно не закодировано в ASCII (или другой эквивалентной кодировке).
Кодировка по умолчанию зависит от платформы. В Windows – это 'cp1252', а в Linux 'utf-8'.
Поэтому мы не должны полагаться на кодировку по умолчанию. При работе с файлами в текстовом формате рекомендуется указывать тип кодировки.
Заключение
И этой статьи вы узнали, как читать и записывать файлы MS Word с помощью модуля python-docx.
Пожалуйста, опубликуйте ваши мнения по текущей теме материала. За комментарии, отклики, лайки, дизлайки, подписки низкий вам поклон!
В этой статье мы рассмотрим операции с файлами в Python. Открытие файла Python. Чтение из файла Python. Запись в файл Python, закрытие файла. А также методы, предназначенные для работы с файлами.
Python работа с файлами - основные методы
Ниже приводится полный список методов для работы с файлами в текстовом режиме.
| Python работа с файлами - методы | |
| Метод | Описание |
| close() | Закрытие файла. Не делает ничего, если файл закрыт. |
| detach() | Отделяет бинарный буфер от TextIOBase и возвращает его. |
| fileno() | Возвращает целочисленный дескриптор файла. |
| flush() | Вызывает сброс данных (запись на диск) из буфера записи файлового потока. |
| isatty() | Возвращает значение True, если файловый поток интерактивный. |
| read(n) | Читает максимум n символов из файла. Читает до конца файла, если значение отрицательное или None. |
| readable() | Возвращает значение True, если из файлового потока можно осуществить чтение. |
| readline(n=-1) | Читает и возвращает одну строку из файла. Читает максимум n байт, если указано соответствующее значение. |
| readlines(n=-1) | Читает и возвращает список строк из файла. Читает максимум n байт/символов, если указано соответствующее значение. |
| seek(offset,from=SEEK_SET) | Изменяет позицию курсора. |
| seekable() | Возвращает значение True, если файловый поток поддерживает случайный доступ. |
| tell() | Возвращает текущую позицию курсора в файле. |
| truncate(size=None) | Изменяет размер файлового потока до size байт. Если значение size не указано, размер изменяется до текущего положения курсора. |
| writable() | Возвращает значение True, если в файловый поток может производиться запись. |
| write(s) | Записывает строки s в файл и возвращает количество записанных символов. |
| writelines(lines) | Записывает список строк lines в файл. |
Дайте знать, что вы думаете по данной теме статьи в комментариях. За комментарии, отклики, лайки, подписки, дизлайки огромное вам спасибо!
Дайте знать, что вы думаете по данной теме материала в комментариях. Мы очень благодарим вас за ваши комментарии, подписки, лайки, отклики, дизлайки!
Шаг 3 - Чтение файла
Файл был открыт, и мы можем работать с ним через переменную, которую мы ему присвоили. Python предоставляет три связанные операции для чтения информации из файла. Покажем, как использовать каждую из них.
Первая операция .read() возвращает все содержимое файла как одну строку.
Вторая операция .readline() возвращает следующую строку файла (текст до следующего символа новой строки, включая сам символ). Проще говоря, эта операция считывает файл по частям.
Поэтому, когда вы прочтете строку с помощью readline, она перейдет к следующей строке. Если вы снова вызовете эту операцию, она вернет следующую строку, прочитанную в файле.
Последняя операция, .readlines() , возвращает список строк в файле. При этом каждый элемент списка представляет собой одну строку.
Как только файл был прочитан с использованием одной из операций, его нельзя прочитать снова. Например, если вы запустите days_file.read() , за которой следует days_file.readlines() , вторая операция вернет пустую строку. Поэтому, когда вы захотите прочитать содержимое файла, вам нужно будет сначала открыть новую файловую переменную.
Чтение из файла Python
Чтобы осуществить чтение из файла Python, нужно открыть его в режиме чтения. Для этого можно использовать метод read(size), чтобы прочитать из файла данные в количестве, указанном в параметре size. Если параметр size не указан, метод читает и возвращает данные до конца файла.
Метод read() возвращает новые строки как 'n'. Когда будет достигнут конец файла, при дальнейших попытках чтения мы получим пустые строки.
Чтобы изменить позицию курсора в текущем файле, используется метод seek(). Метод tell() возвращает текущую позицию курсора (в виде количества байтов).
Мы можем прочитать файл построчно в цикле for.
Извлекаемые из файла строки включают в себя символ новой строки 'n'. Чтобы избежать вывода, используем пустой параметр end метода print(),.
Также можно использовать метод readline(), чтобы извлекать отдельные строки. Он читает файл до символа новой строки.
Метод readlines() возвращает список оставшихся строк. Все эти методы чтения возвращают пустую строку, когда достигается конец файла.
Чтение файлов MS Word с помощью модуля Python-Docx
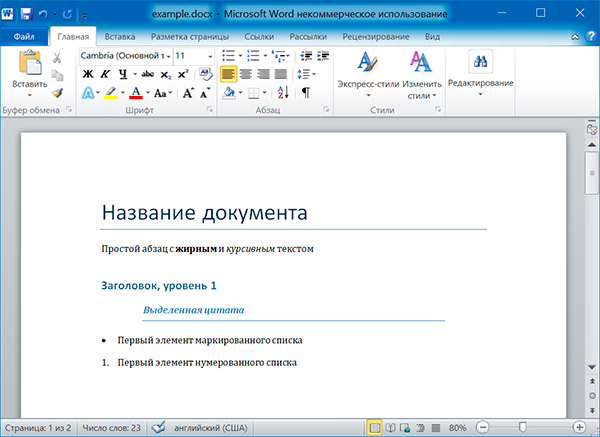
Создайте новый файл MS Word и переименуйте его в my_word_file.docx. Я сохранил файл в корне диска E. Файл my_word_file.docx должен иметь следующее содержимое

Чтобы считать указанный файл, импортируйте модуль docx, а затем создайте объект класса Document из модуля docx. Затем передайте путь к файлу my_word_file.docx в конструктор класса Document:
Объект doc класса Document теперь можно использовать для чтения содержимого файла my_word_file.docx.
Шаг 5 - Закрытие файла
Закрытие файла деактивирует соединение между файлом, сохраненным на жестком диске, и файловой переменной. Закрытие файлов также гарантирует, что другие программы смогут получить к ним доступ и безопасно сохранить данные. Закроем все наши файлы, используя функцию .close() .
Мы закончили обработку файлов в Python и можем перейти к просмотру кода.
Шаг 6 - Проверка кода
Конечный результат должен выглядеть примерно так:
После сохранения кода откройте терминал и запустите свой Python- скрипт, например:
python files.py
Результат должен выглядеть так:
Теперь проверим код полностью, открыв файл new_days.txt . Если все пройдет хорошо, когда мы откроем этот файл, его содержимое должно выглядеть следующим образом:
Запись абзацев
Для записи абзацев используйте метод add_paragraph() объекта класса Document. После добавления абзаца нужно вызвать метод save(). Путь к файлу, в который нужно записать абзац, передается в качестве параметра методу save(). Если файл не существует, то будет создан новый файл. Иначе абзац будет добавлен в конец существующего файла MS Word.
Приведенный ниже скрипт записывает простой абзац во вновь созданный файл my_written_file.docx.
После выполнения этого скрипта вы должны увидеть новый файл my_written_file.docx в каталоге, который указали в методе save(). Внутри файла должен быть один абзац, который гласит: «This is first paragraph of a MS Word file.».
Добавим в файл my_written_file.docx еще один абзац:
Этот абзац будет добавлен в конец файла my_written_file.docx.
Читайте также: