
Python не находит файл read csv
CSV-файл в Python означает «значения, разделенные запятыми» и определяется как простой формат файла, использующий определенную структуру для упорядочивания табличных данных. Он хранит табличные данные, такие как электронная таблица или база данных, в виде обычного текста и имеет общий формат для обмена данными. Файл csv открывается на листе Excel, а данные строк и столбцов определяют стандартный формат.
Узнаем, как осуществляется чтение и запись CSV-файлов в Python.
Запись CSV в словарь
Мы также можем использовать класс DictWriter для записи файла CSV непосредственно в словарь.
Файл с именем python.csv содержит следующие данные:
Parker, Accounting, November
Smith, IT, October
18 Answers 18
(If the file name has quotes)
The first suggestion should work if you tweak it to include the reference to the root directory, i.e.: pd.read_csv("/Users/alekseinabatov/Documents/Python/FBI-CRIME11.csv") . The file name should not have quotation symbols in it.
the following code worked: pd.read_csv("/Users/alekseinabatov/Documents/Python/FBI-CRIME11.csv"). Thank you so much!
@AlekseiNabatov A pythonic way is declare a constant containing the path: PATH = 'Users/alekseinabatov/Documents/Python/' and then pd.read_csv(PATH + 'FBI-CRIME11.csv') . If this path will be shared across projects, you can use an environment variable containing the path ;-)
in my case changed ev = pd.read_csv(join(sub,'evaluation.csv')) -> ev = pd.read_csv(join(sub,"evaluation.csv"))
Just referring to the filename like
generally only works if the file is in the same directory as the script.
If you are using windows, make sure you specify the path to the file as follows:
Using Mac actually. I was wondering how to set this directory as default one so I do not have to write the whole path every time I do input/output operations.
Had an issue with the path, it turns out that you need to specify the first '/' to get it to work! I am using VSCode/Python on macOS
I also experienced the same problem I solved as follows:
Being on jupyter notebook it works for me including the relative path only. For example:
But, for example, in vscode I have to put the complete path:
You are missing '/' before Users. I assume that you are using a MAC guessing from the file path names. You root directory is '/'.
I had the same issue, but it was happening because my file was called "geo_data.csv.csv" - new laptop wasn't showing file extensions, so the name issue was invisible in Windows Explorer. Very silly, I know, but if this solution doesn't work for you, try that :-)
Just change the CSV file name. Once I changed it for me, it worked fine. Previously I gave data.csv then I changed it to CNC_1.csv .
What worked for me:
Make sure your source file is saved in .csv format. I tried all the steps of adding the full path to the file, including and deleting the header=0, adding skiprows=0 but nothing works as I saved the excel file(data file) in workbook format and not in CSV format. so keep in mind to first check your file extension.
Adnane's answer helped me.
Here's my full code on mac, hope this helps someone. All my csv files are saved in /Users/lionelyu/Documents/Python/Python Projects/
Run "pwd" command first in cli to find out what is your current project's direction and then add the name of the file to your path!
In my case I just removed .csv from the end. I am using ubuntu.
If you get this type of Error
Then fix the path of the directory
Sometimes we ignore a little bit issue which is not a Python or IDE fault its logical error We assumed a file .csv which is not a .csv file its a Excell Worksheet file have a look


When you try to open that file using Import compiler will through the error have a look
1. Определим путь к файлу
После загрузки файла на компьютер, необходимо определить путь к этому файлу. Предлагаю воспользоваться универсальным способом и указать путь к файлу относительно рабочей директории. Кстати, давайте уточним путь к Вашей рабочей директории! Для этого исполним код:
Теперь путь к рабочей директории находится в переменной work_path. Поэтому вывести на экран адрес рабочего каталога, в котором по умолчанию хранятся скрипты, можно при помощи строки:
Предлагаю создать в рабочей директории папку «datasets» и загрузить в нее .csv файл со скачанными данными (предварительно распакуйте скачанный архив так, чтобы файл 'ks-projects-201801.csv' находился непосредственно в папке «datasets»). В этом случае путь к .csv файлу будет выглядеть так:
4. Вывод данных из прочитанного csv файла в Python
Предлагаю вывести 10 первых строк на экран. Для этого вызовем функцию head() и передадим ей в качестве аргументов желаемое для вывода число строк:
Взгляните на результат работы функции head(10):
Давайте рассмотрим выведенную таблицу. По умолчанию, строки пронумерованы, каждый столбец таблицы имеет заголовок. Установив значения аргументов функции read_csv() желаемым образом, вы можете прочитать csv-файл без заголовков, пропустить некоторые строки, а также определить вид разделителя. Давайте рассмотрим, как это сделать.
Чтение csv файла в Python при помощи Pandas.
Файлы с расширением «.CSV» — верные хранители табличных данных, ставшие популярными не случайно: с ними довольно просто работать, кроме того, большинство программ для обработки табличных данных могут использовать формат «.CSV». А в любимом для большинства специалистов по Data Science языке Python, существует целая библиотека, упрощающая работу с табличными данными. Имя этой библиотеки Pandas! Реализуем чтение csv файла в Python при помощи Pandas на примере ниже. Но прежде..
— Краткий ликбез для тех, кто спешит —

Чтение CSV файлов
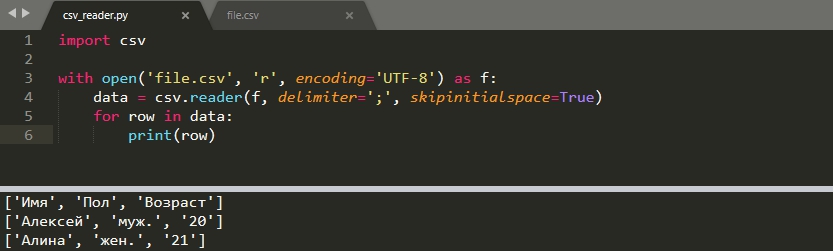
Как уже говорилось, основной модуль уже установлен вместе с Python. Для чтения файлов используется функция 'reader()', которая возвращает объект для итерации. Так мы можем открыть файл в большинстве случаев:
Для каких-то ОС может понадобится открывать файл с указанием разделителя новой строки, т.е. так:
Начальные пробелы
Со скриншота выше видно, что пробелы, в начале строки, не обрабатываются должным образом. Что бы убрать пробелы нужно указать параметр 'skipinitialspace':
Запись словаря
Аналогично чтению мы можем выполнить конвертацию словаря в CSV. Для этого есть класс 'DictWriter'. Запись словаря, от его чтения, отличается параметром 'fieldnames' в котором указываются заголовки колонок. Пример такой записи:
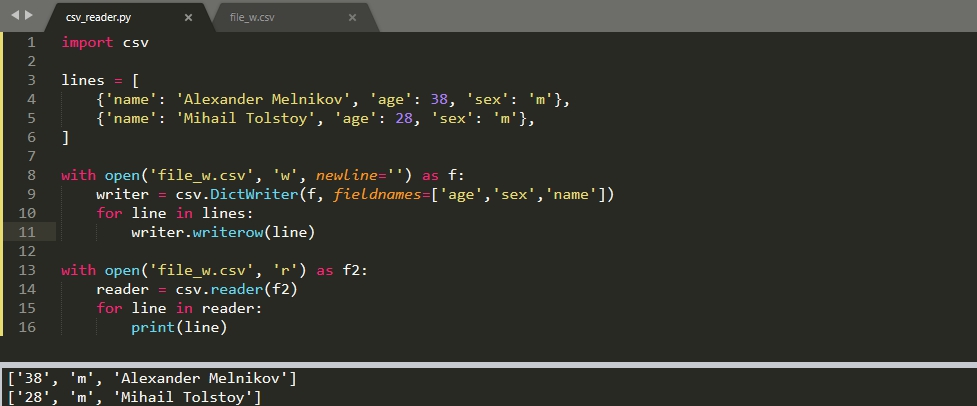
Параметры, переданные в 'DictWriter', могут быть такими же что и в 'writer'.
Указание разделителя
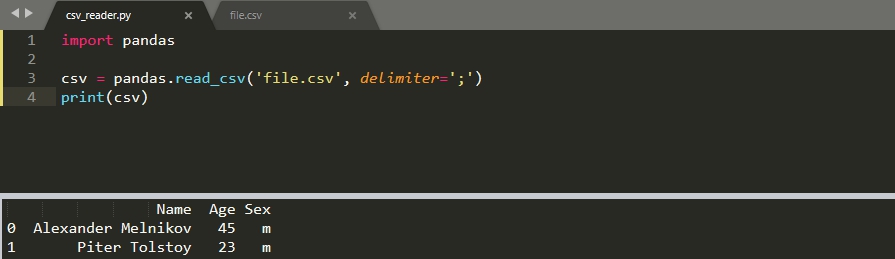
По умолчанию считается, что вы используете запятую в качестве делимитра. В моем файле, в качестве разделителя, стоит ';', а файл содержит кириллицу (кириллица имеет значение на Windows). В этом случае файл читается следующим образом:
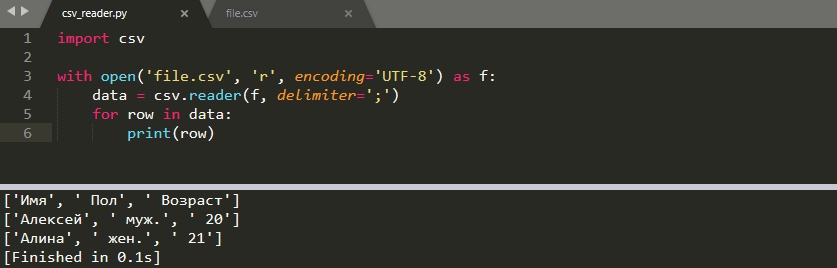
В случае Windows по умолчанию используется кодировка 'cp1251' и, если вы не укажете 'UTF-8', то может появится ошибка:
- UnicodeDecodeError: 'charmap' codec can't decode byte 0x98 in position 1: character maps to
Открываем файл .csv в Python при помощи Pandas
Если Вы желаете вывести данные без наименований столбцов, или же с другими особыми пожеланиями, переходите к разделу этой статьи «Настраиваем аргументы функции read_csv()».
Чтение CSV в словаре
Мы также можем использовать функцию DictReader() для чтения файла CSV непосредственно в словаре, а не для работы со списком отдельных строковых элементов.
Автоматическое определение параметров CSV файла
Если используются разные файлы CSV и в каждом из них разные параметры для чтения, мы можем определить их автоматически с классом 'Sniffer'. Результат работы этого класса мы можем передать как диалект:
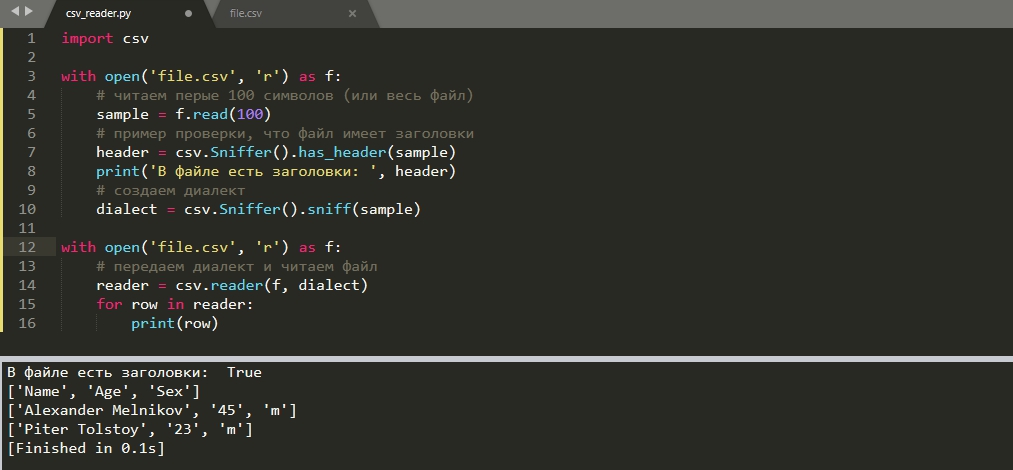
Метод 'has_header()' проверяет есть ли в файле заголовки. Аналогично этому методу могут быть использованы и другие методы проверяющие кавычки, делимитры и т.д.
Функции модуля Python CSV
Модуль CSV используется для обработки файлов CSV для чтения / записи и получения данных из указанных столбцов. Существуют следующие типы функций CSV:
Диалекты
Они определяются как конструкция, которая позволяет создавать, хранить и повторно использовать различные параметры форматирования. Диалект поддерживает несколько атрибутов; наиболее часто используются:
- Dialect.delimiter: этот атрибут используется как разделительный символ между полями. Значение по умолчанию – запятая(,).
- Dialect.quotechar: этот атрибут используется для выделения полей, содержащих специальные символы, в кавычки.
- Dialect.lineterminator: используется для создания новых строк, значение по умолчанию – ‘\r\n’.
Запишем следующие данные в файл CSV.
Он возвращает файл с именем Python.csv, который содержит следующие данные:
Создание шаблона диалекта
Если у вас используется множество разных параметров и идет нарушение принципов DRY (dont repeat yorself), то вы можете использовать диалект (или просто шаблон). В примере мы регистрируем параметры под общим названием 'myDialect' и передаем в функцию или класс:
Запись данных в CSV
Для записи данных есть функция 'writer()'. В эту функцию мы можем передать все те же параметры, что в случае чтения. Базовая запись данных будет выглядеть следующим образом:
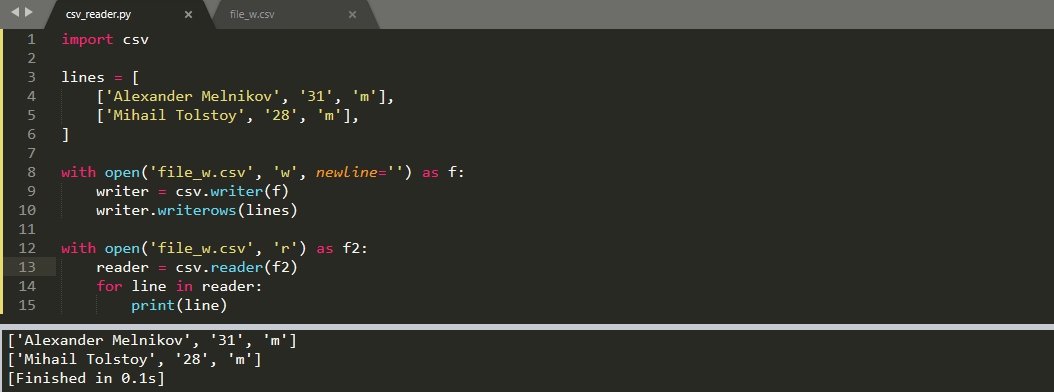
Как и понятно с примера выше:
- writerow - записывает каждый список построчно;
- writerows - записывает список списков в файл целиком.
Надобность в 'newline' так же может отличаться в разных ОС. Вы можете указать в функции 'writer' параметр 'lineterminator' со значением '\n', который обозначает символ переноса новой строки. По умолчанию он равен '\r\n':
Аналогично 'lineterminator' могут передаваться следующие параметры:
- quotechar - символ для экранирования значений попадающие под условия указанные в 'quoting'. По умолчанию этот символ равен двойным кавычкам;
- quoting - какие значения должны быть экранированы: csv.QUOTE_MINIMAL (если в значении есть делимитер или сам символ экранирования), csv.QUOTE_ALL (все символы), csv.QUOTE_NONNUMERIC (оборачивает в кавычки все нечисловые значения), csv.QUOTE_NONE (не использует кавычки и, если в значениях используется символ делимитера, экранирует его в 'escapechar');
- escapechar - если поведение с кавычками не установлено, то символы разделителя в значениях экранируются в этот символ.
Чтение с конвертацией в словарь
Если первая строка у вас содержит заголовки колонок, то вы ее можно преобразовать в ключи словаря. Что бы это сделать, вместо метода 'reader()' используется класс 'DictReader()':
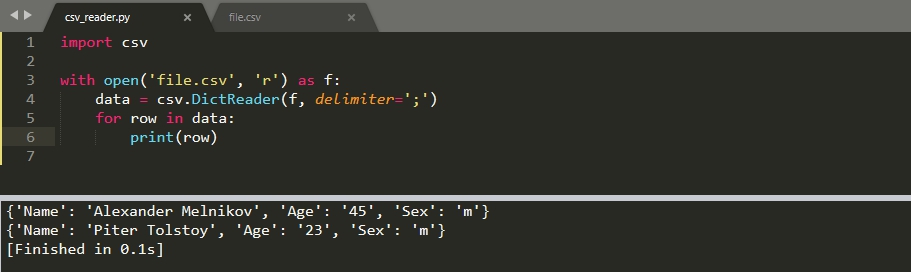
Тип словаря зависит от версии Python. Если вы используете версию ниже 3.8, то вернется 'OrderedDict', который можно преобразовать в обычный с 'dict()'. В версиях 3.8 и старше возвращается обычный тип словаря.
Параметры у класса аналогичны методу 'reader()'. Мы так же можем определять кавычки и символы экранирования.
To Resolve the issue
open your Target file into Microsoft Excell and save that file in .csv format it is important to note that Encoding is important because it will help you to open the file when you try to open it with

So you are set to go now Try to open your file as this

Here is the Output
Запись файлов CSV
Мы также можем не только читать, но и писать любые новые и существующие файлы CSV. Запись файлов на Python осуществляется с помощью модуля csv.writer(). Он похож на модуль csv.reader() и также имеет два метода, то есть функцию записи или класс Dict Writer.
Он представляет две функции: writerow() и writerows(). Функция writerow() записывает только одну строку, а функция writerows() записывает более одной строки.
Запись с pandas
Что бы сохранить данные с pandas мы сначала должны выполнить конвертацию в 'DataFrame':
Кавычки
CSV файл может содержать кавычки в произвольных местах:
Убрать их можно используя параметр 'quoting':
А теперь обо всем с подробностями да на живом примере!
Файл загружен! Переходим к написанию кода. Кстати, работать будем как настоящие профессионалы по четкому плану:
- Определим путь к файлу
- Импортируем Pandas
- Загрузим данные из csv файла в переменную data
- Выведем часть данных на экран, чтобы убедиться в том, что файл был успешно прочитан
- Реализуем самые смелые пожелания в рамках вида прочитанных данных (удалим названия колонок, оставим названия колонок и т.д.)
Итак, следуя плану, приступим к реализации первого пункта:
Как устроен формат CSV
Основное отличие формата CSV от обычного текста в его структуре, которая проявляется в разделителе. Именно из-за этого этот формат расшифровывается как 'comma separated values' (значения разделенные запятыми). Разделитель не всегда обязан быть в виде запятой, он может принимать и другие виды, например ';'. Разделители так же могут называться делимитер (delimiter). Пример того, как может выглядеть файл:
Первая строка может содержать название заголовки колонок, но это не обязательно. Так же видно, что разделители разделяют значения и из-за этого они не используются в конце строки.
Из-за простого формата CSV вам не обязательно импортировать модули. Вы можете использовать существующий функционал, который создаст данные в формате CSV, например так:
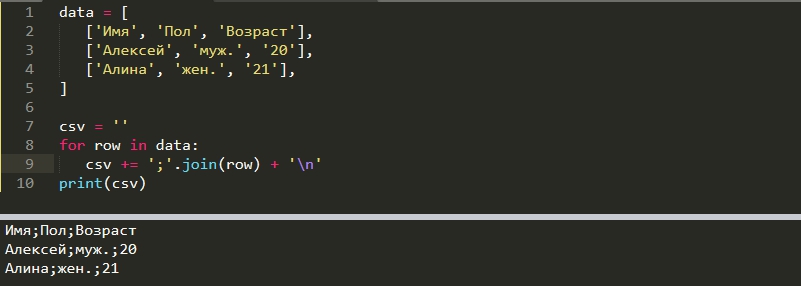
Тем не менее в модулях реализованы дополнительные возможности по анализу таких данных. Например преобразование в словарь или определение форматов (диалекта).
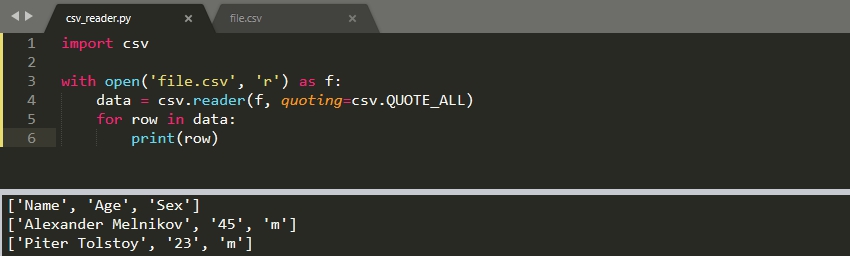
По умолчанию ищется двойная кавычка. Если вы хотите ее переопределить, то нужно использовать параметр 'quotechar'.
Поиска этой кавычки зависит от того, что указано в параметр 'quoting'. Так значение 'csv.QUOTE_ALL' говорит, что все значения находятся внутри кавычек. Параметр может принимать другие значения:
- csv.QUOTE_MINIMAL - используется по умолчанию. Кавычки используются в местах содержащие специальные символы (например двойная кавычка из quotechar или сам дилиметр);
- csv.QUOTE_NONNUMERIC - кавычки используются в нечисловых значениях. Если кавычек в значении не присутствует оно будет преобразовано во float;
- csv.QUOTE_NONE - кавычки, вокруг значений, не используются.
Если вы установили 'csv.QUOTE_NONE', а в файле все равно экранируются специальные символы, то можно использовать параметр 'escapechar' указывающий на символ экранирования.
Чтение с помощью Pandas
Pandas определяется как библиотека с открытым исходным кодом, которая построена на основе библиотеки NumPy. Он обеспечивает быстрый анализ, очистку данных и подготовку данных для пользователя.
Чтение файла csv в pandas DataFrame выполняется быстро и просто. Нам не нужно писать достаточно строк кода, чтобы открывать, анализировать и читать файл csv в pandas, и он хранит данные в DataFrame.
Здесь мы берем для чтения немного более сложный файл под названием hrdata.csv, который содержит данные сотрудников компании.
В приведенном выше коде трех строк достаточно для чтения файла, и только одна из них выполняет фактическую работу, то есть pandas.read_csv()
Чтение файлов CSV
Python предоставляет различные функции для чтения файла CSV. Опишем несколько методов для чтения.
В Python модуль csv.reader() используется для чтения файла csv. Он берет каждую строку файла и составляет список всех столбцов.
Мы взяли текстовый файл с именем python.txt, в котором есть разделитель по умолчанию(,) со следующими данными:
В приведенном выше коде мы открыли python.csv с помощью функции open(). Мы использовали функцию csv.reader() для чтения файла, который возвращает итеративный объект чтения. Объект чтения состоял из данных, и мы повторили цикл, используя цикл for, чтобы распечатать содержимое каждой строки.
2. Импортируем Pandas
1. Прежде всего, импортируем библиотеку Pandas в проект. Сделать это можно, добавив строку «import pandas as pd» в начале скрипта:
Теперь обращаться к функциям из Pandas будем, предваряя название функции префиксом «pd.».
3. Загрузим данные из csv-файла в переменную data
Для того, чтобы осуществить чтение csv файла в Python, вызовем функцию read_csv() из библиотеки Pandas и передадим в качестве аргумента адрес, по которому располагается csv файл:
После прочтения csv файла в Python все содержимое файла хранится в переменной data. Предлагаю убедиться в том, что файл был успешно прочитан и вывести данные на экран.
С помощью Pandas
Это так же просто, как прочитать файл CSV с помощью pandas. Вам необходимо создать DataFrame, который представляет собой двумерную неоднородную табличную структуру данных и состоит из трех основных компонентов: данных, столбцов и строк. Здесь мы берем для чтения немного более сложный файл под названием hrdata.csv, который содержит данные о сотрудниках компании.
I am currently learning Pandas for data analysis and having some issues reading a csv file in Atom editor.
When I am running the following code:
I get an error message, which ends with
OSError: File b'FBI-CRIME11.csv' does not exist
Here is the directory to the file: /Users/alekseinabatov/Documents/Python/"FBI-CRIME11.csv".
When i try to run it this way:
I get another error:
NameError: name 'Users' is not defined
I have also put this directory into the "Project Home" field in the editor settings, though I am not quite sure if it makes any difference.
I bet there is an easy way to get it to work. I would really appreciate your help!
5. Настраиваем аргументы функции read_csv()
Рассмотрим некоторые из аргументов функции read_csv(), которые могут Вам помочь в работе:
1) Работаем с именами столбцов:
Параметр header содержит номер строки, в которой прописаны имена столбцов. Обычно это нулевая строка, и по-умолчанию параметр header имеет нулевое значение, т. е. header=0.
Строка: data = pd.read_csv(data_path, header=0) равносильна строке: data = pd.read_csv(data_path)
Давайте изменим значение header на header=2. В итоге вторая строка станет заголовком, и далее файл будет прочитан начиная с 3-й строки (т.е. 3-я строка сместится на нулевую позицию). Для сравнения рассмотрим, как выглядит одна и та же таблица при header=0 и header=2:
header = 0
Иногда бывает так, что в исходном файле отсутствуют названия столбцов. В данном случае, чтобы строка с информативными данными не превратилась в заголовки столбцов, нужно определить значение header как None:
У рассматриваемой выше таблицы, нулевая строка содержит заголовки столбцов, поэтому значение header=None только «спутает всю малину»:
2) Читаем только часть файла:
Аргумент nrows позволяет считать заданное количество строк. Например, если nnows=3, то функция read_csv() прочитает только 3 строки:
Аргумент sciprows позволяет пропустить указанное количество строк при чтении. Например:
- Если skiprows = 5, чтение файла начнется с 5 строки, при этом имена колонок, если не указано другое, также будут прочитаны.
- Если skiprows = [3, 5, 8], то строки под номерами 3, 5, 8 не будут прочитаны,
- При skiprows = range(4, 7) из чтения будут исключены строки 4,5,6.
3) Устанавливаем вид разделителя:
Чтобы задать вид разделителя, нужно в функции read_csv() определить аргумент sep. Например, требуется прочитать файл вида:
В представленном выше файле данные разделены символом «|». Поэтому, для прочтения этого файла в функции read_csv нужно определить аргумент sep = «|»:
Мы рассмотрели только некоторые возможные аргументы функции read_csv(), которая используется для csv файла в Python. С полным списком аргументов можно ознакомиться в официальной документации.
Время прочтения: 4 мин.
EmptyDataError… Звучит знакомо? В этой статье рассмотрим несколько советов, дабы избежать ошибок при загрузке файлов CSV с помощью Pandas DataFrame.
Данные находятся в центре конвейера машинного обучения. Чтобы использовать полную мощность алгоритма, данные должны быть сначала правильно очищены и обработаны.
Первый шаг очистки/обработки данных — загрузка файла и последующее установление соединения по пути к файлу. Существуют файлы с различными типами разделителей:
- разделители-табуляция;
- разделители-запятые;
- разделители из нескольких символов и другие.
Импорт файла в фрейм данных Pandas часто вызывает ошибки. Например, EmptyDataError говорит о том, что нет столбцов для синтаксического анализа из файла. Возникает ошибка в основном из-за того, что:
- неверно указан путь к файлу;
- неверно указаны типы разделителей данных;
- неверно указан каталог файлов;
- файловое соединение не установлено.
Специалисты по обработке данных не могут позволить себе тратить много времени на трудоемкий этап. Поэтому при загрузке файла необходимо выполнять определенные шаги, которые позволят сэкономить время и избавят от хлопот, связанных с просмотром большого количества информации, чтобы найти решение вашей конкретной проблемы.
Чтение и импорт файла CSV не так прост, как можно предположить. Вот несколько советов, которые помогут загрузить файл данных для построения модели машинного обучения.
Для Windows
- Зайдите в Панель управления;
- Нажмите на региональные и языковые параметры;
- Перейдите на вкладку «Региональные параметры»;
- Нажмите Настроить/Дополнительные настройки;
- Введите запятую в поле «Разделитель списка» (,);
- Дважды нажмите «ОК», чтобы подтвердить изменение.
Примечание: работает, только если «десятичный символ» также не является запятой.
Для MacOS
- Зайдите в Системные настройки;
- Щелкните «Язык и регион», а затем перейдите к параметру «Дополнительно»;
- Измените «Десятичный разделитель» на один из следующих сценариев: если десятичным разделителем является точка, то разделителем CSV будет запятая, если десятичным разделителем является запятая, то разделителем CSV будет точка с запятой.
2. Воспользуйтесь предварительным просмотром данных (в блокноте Jupyter, либо в Microsoft Excel) для проверки способа разделения данных.
3. Правильно укажите все аргументы.
От правильности заполнения аргументов функции pd.read_csv напрямую зависит правильность чтения вашего CSV файла. Рассмотрим список всех аргументов:

Нас больше всего интересует следующий аргумент: sep — определяет тип разделения между значениями данных. По умолчанию ‘,’. Наиболее распространенные типы разделителей: запятая, табуляция и двоеточие. Следовательно, они должны быть указаны, как sep = ‘,’, sep = », sep = ‘;’ соответственно. Это сообщит pandas DataFrame, как распределять данные по столбцам.
Если после корректного указания аргументов проблема не устранена, воспользуемся следующим пунктом.
4. Проверьте путь к файлу.
Местоположение файла должно быть указано правильно. Чаще всего люди не знают рабочий каталог и в конечном итоге указывают неправильный путь к файлу. В этом случае мы должны проверить рабочий каталог, чтобы убедиться, что указанный путь к файлу написан правильно. Напишите приведенный ниже код, чтобы проверить рабочий каталог.
Мы также можем изменить рабочий каталог, используя приведенную ниже строку кода. После указания нового каталога мы должны указать путь.
5. Отметьте разделитель, используемый для указания местоположения файла.
Часто ошибка возникает и при изменении рабочего каталога. Это происходит из-за того, что разделитель не написан в соответствии с правильным синтаксисом.

Прежде всего проверьте разделитель, используя команду ниже.
Затем используйте разделитель только в начале расположения каталога, а не в конце. Пожалуйста, обратите внимание, что эта спецификация синтаксиса разделителя (/) верна для MacOS и может быть неверна для Windows.
Если ваш файл находится в рабочем каталоге, упомяните только имя файла, как показано ниже.
Но если ваш файл находится в какой-либо другой папке, вы можете указать следующие папки после рабочего каталога, например, ваш рабочий каталог — «/Users/username», а ваш файл находится в папке с именем «files» в «документах», тогда используйте следующий код:
6. Убедитесь, что файл находится по пути:
Теперь проверьте, присутствует ли ваш файл по описанному пути, используя приведенный ниже код. Мы получим ответ либо «True», либо «False».
7. Распечатайте данные файла для перекрестной проверки:
Теперь мы можем проверить, правильно ли загружен наш файл данных, используя приведенный ниже код.

Эти советы помогут вам больше не сталкиваться с проблемами при загрузке файла CSV с помощью Pandas DataFrame.

Один из самых популярных форматов данных является CSV. Для работы с CSV в Python есть несколько библиотек и модулей. С помощью их вы сможете обрабатывать эти данные конвертируя их в словари и списки, создавать файлы и читать их. Основной модуль называется CSV и большинство задач разберем на его примере.
Навигация по посту
Чтение в pandas
В библиотеке для анализа данных pandas так же есть возможность прочитать CSV файл. Эта библиотека устанавливается отдельно:
Читайте также: