
Прямой способ отображения кэша
Алгоритм поиска и алгоритм замещения данных в кэше непосредственно зависят от того, каким образом основная память отображается на кэш-память. Принцип прозрачности требует, чтобы правило отображения основной памяти на кэш-память не зависело от работы программ и пользователей. При кэшировании данных из оперативной памяти широко используются две основные схемы отображения: случайное отображение и детерминированное отображение.
При случайном отображении элемент оперативной памяти в общем случае может быть размещен в произвольном месте кэш-памяти. Для того чтобы в дальнейшем можно было найти нужные данные в кэше, они помещаются туда вместе со своим адресом, то есть тем адресом, который данные имеют в оперативной памяти. При каждом запросе к оперативной памяти выполняется поиск в кэше, причем критерием поиска выступает адрес оперативной памяти из запроса. Очевидная схема простого перебора для поиска нужных данных в случае кэша оказывается непригодной из-за недопустимо больших временных затрат.
Для кэшей со случайным отображением используется так называемый ассоциативный поиск, при котором сравнение выполняется не последовательно с каждой записью кэша, а параллельно со всеми его записями (рис. 5.26). Признак, по которому выполняется сравнение, называется тегом (tag). В данном случае тегом является адрес данных в оперативной памяти. Электронная реализация такой схемы приводит к удорожанию памяти, причем стоимость существенно возрастает с увеличением объема запоминающего устройства. Поэтому ассоциативная кэш-память используется в тех случаях, когда для обеспечения высокого процента попадания достаточно небольшого объема памяти.
В кэшах, построенных на основе случайного отображения, вытеснение старых данных происходит только в том случае, когда вся кэш-память заполнена и нет свободного места. Выбор данных на выгрузку осуществляется среди всех записей кэша. Обычно этот выбор основывается на тех же приемах, что и в алгоритмах замещения страниц, например выгрузка данных, к которым дольше всего не было обращений, или данных, к которым было меньше всего обращений.
Второй, детерминированный способ отображения предполагает, что любой элемент основной памяти всегда отображается в одно и то же место кэш-памяти. В этом случае кэш-память разделена на строки, каждая из которых предназначена для хранения одной записи об одном элементе данных* и имеет свой номер. Между номерами строк кэш-памяти и адресами оперативной памяти устанавливается соответствие «один ко многим»: одному номеру строки соответствует несколько (обычно достаточно много) адресов оперативной памяти.
В качестве отображающей функции может использоваться простое выделение нескольких разрядов из адреса оперативной памяти, которые интерпретируются как номер строки кэш-памяти (такое отображение называется прямым). Например, пусть в кэш-памяти может храниться 1024 записи, то есть кэш имеет 1024 строки, пронумерованные от 0 до 1023. Тогда любой адрес оперативной памяти может быть отображен на адрес кэш-памяти простым отделением 10 двоичных разрядов (рис. 5.27).
' В действительности запись в кэше обычно содержит несколько элементов данных.
При поиске данных в кэше используется быстрый прямой доступ к записи по номеру строки, полученному путем обработки адреса оперативной памяти из запроса. Однако поскольку в найденной строке могут находиться данные из любой ячейки оперативной памяти, младшие разряды адреса которой совпадают с номером строки, необходимо выполнить дополнительную проверку. Для этих целей каждая строка кэш-памяти дополняется тегом, содержащим старшую часть адреса данных в оперативной памяти. При совпадении тега с соответствующей частью адреса из запроса констатируется кэш-попадание.
Если же произошел кэш-промах, то данные считываются из оперативной памяти и копируются в кэш. Если строка кэш-памяти, в которую должен быть скопирован элемент данных из оперативной памяти, содержит другие данные, то последние вытесняются из кэша Заметим, что процесс замещения данных в кэш-памяти на основе прямого отображения существенно отличается от процесса замещения данных в кэш-памяти со случайным отображением. Во-первых, вытеснение данных происходит не только в случае отсутствия свободного места в кэше, во-вторых, никакого выбора данных на замещение не существует.

Во многих современных процессорах кэш-память строится на основе сочетания этих двух подходов, что позволяет найти компромисс между сравнительно низкой стоимостью кэша с прямым отображением и интеллектуальностью алгоритмов замещения в кэше со случайным отображением. При смешанном подходе произвольный адрес оперативной памяти отображается не на один адрес кэш-памяти (как это характерно для прямого отображения) и не на любой адрес кэш-памяти (как это делается при случайном отображении), а на некоторую группу адресов. Все группы пронумерованы. Поиск в кэше осуществляется вначале по номеру группы, полученному из адреса оперативной памяти из запроса, а затем в пределах группы путем ассоциативного просмотра всех записей в группе на предмет совпадения старших частей адресов оперативной памяти (рис. 5.28).
При промахе данные копируются по любому свободному адресу из однозначно заданной группы. Если свободных адресов в группе нет, то выполняется вытеснение данных. Поскольку кандидатов на выгрузку несколько — все записи из данной группы — алгоритм замещения может учесть интенсивность обращений к данным и тем самым повысить вероятность попаданий в будущем. Таким образом в данном способе комбинируется прямое отображение на группу и случайное отображение в пределах группы.
В соответствии с описанной логикой работы кэш-памяти следует, что при возникновении запроса сначала просматривается кэш, а затем, если произошел промах, выполняется обращение к основной памяти. Однако часто реализуется и другая схема работы кэша: поиск в кэше и в основной памяти начинается одновременно, а затем, в зависимости от результата просмотра кэша, операция в основной памяти либо продолжается, либо прерывается.
При выполнении запросов к оперативной памяти до многих вычислительных системах используется двухуровневое кэширование (рис. 5.30). Кэш первого уровня имеет меньший объем и более высокое быстродействие, чем кэш второго уровня. Кэш второго уровня играет роль основной памяти по отношению к кэшу первого уровня.
На рис. 5.31 показана схема выполнения запроса на чтение в системе с двухуровневым кэшем. Сначала делается попытка обнаружить данные в кэше первого уровня. Если произошел промах, поиск продолжается в кэше второго уровня. Если же нужные данные отсутствуют и здесь, тогда происходит считывание данных из основной памяти. Понятно, что время доступа к данным оказывается минимальным, когда кэш-попадание происходит уже на первом уровне, несколько большим — при обнаружении данных на втором уровне и обычным временем доступа к оперативной памяти, если нужных данных нет ни в том, ни в другом кэше. При считывании данных из оперативной памяти происходит их копирование в кэш второго уровня, а если данные считываются из кэша второго уровня, то они копируются в кэш первого уровня.
Вопросы для самопроверки
109. На какие классы принято разделять алгоритмы распределения памяти?
110. Какие подходы используются для виртуализации памяти в современных ОС?
111. Как называют область жесткого диска, которая отводится ОС для временного хранения страниц или сегментов виртуальной памяти?
112. Возможна ли организация разделяемой памяти при страничном распределении ОП?
Контрольные вопросы
113. Возможна ли ситуация, когда при динамическом способе распределения памяти ОС не принимает процесс на выполнение?
114. Что такое фрагментация ОП?
115. В чем суть процедуры сжатия ОП?
116. Укажите основной недостаток свопинга.
117. Укажите классы структуризации виртуальной памяти.
118. Чем отличается страничное распределение памяти от свопинга?
119. Какая информация содержится в дескрипторе страницы?
120. В какой информационной структуре хранятся адреса таблицы страниц?
121. Какой критерий используется ОС для определения выгружаемой из ОП страницы?
122. Почему в современных ОС предпочтительно сегментное распределение памяти, а не страничное?
123. Какая характеристика ПК определяет максимально возможный размер виртуального адресного пространства?
124. Если несколько процессов использует один и тот же сегмент памяти (общий), то как поступает ОС в этом случае?
За счет чего же мы наблюдаем постоянный рост производительности однопоточных программ? В данный момент мы находимся на той ступени развития микропроцессорных технологий, когда прирост скорости работы однопоточных приложений зависит только от памяти. Количество ядер растет, но частота зафиксировалась в пределах 4 ГГц и не дает прироста производительности.
Скорость и частота работы памяти — это то основное за счет чего мы получаем «свой кусок бесплатного торта» (ссылка). Именно поэтому важно использовать память, настолько эффективно, насколько мы можем это делать, а тем более такую быструю как кэш. Для оптимизации программы под конкретный компьютер, полезно знать характеристики кэш-памяти процессора: количество уровней, размер, длину строки. Особенно это важно в высокопроизводительном коде — ядра систем, математические библиотеки.
Как же определить характеристики кэша автоматический? (естественно cpuinfo распарсить не считается, хотя-бы потому-что в конечном итоге мы бы хотели получить алгоритм, который можно без труда реализовать в других ОС. Удобно, не правда ли? ) Именно этим мы сейчас и займемся.
Немного теории
В данный момент существуют и широко используются три разновидности кэш-памяти: кэш с прямым отображением, ассоциативный кэш и множественно-ассоциативный кэш.
Кэш с прямым отображением (direct mapping cache)
— данная строка ОЗУ может быть отображена в единственную строку кэша, но в каждую строку кэша может быть отображено много возможных строк ОЗУ.

Ассоциативный кэш (fully associative cache)
— любая строка ОЗУ может быть отображена в любую строку кэша.

Множественно-ассоциативный кэш
— кэш-память делится на несколько «банков», каждый из которых функционирует как кэш с прямым отображением, таким образом строка ОЗУ может быть отображена не в единственную возможную запись кэша (как было бы в случае прямого отображения), а в один из нескольких банков; выбор банка осуществляется на основе LRU или иного механизма для каждой размещаемой в кэше строки.

LRU — вытеснение самой «долго не использованной» строки, кэш памяти.
Чтобы определить количество уровней кэша нужно рассмотреть порядок обращений к памяти, на котором будет четко виден переход. Разные уровни кэша отличаются прежде всего скоростью отклика памяти. В случае «кэш-промаха» для кэша L1 будет произведен поиск данных в следующих уровнях памяти, при этом если размер данных больше L1 и меньше L2 — то скоростью отклика памяти будет скорость отклика L2. Предыдущее утверждение так же верно в общем случаи.
Ясно что нужно подобрать тест на котором, мы будем четко видеть кэш промахи и протестировать его на различных размерах данных.
Зная логику множественно-ассоциативных кэшей, работающих по алгоритму LRU не трудно придумать алгоритм на котором кэш «валится», ничего хитрого — проход по строке. Критерием эффективности будем считать время одного обращения к памяти. Естественно нужно последовательно обращаться ко всем элементам строки, повторяя многократно для усреднения результата. К примеру возможны случаи, когда строка умещается в кэше но для первого прохода мы грузим строку из оперативной памяти и потому получаем совсем неадекватное время.
Хочется увидеть что-то подобное ступенькам, проходя по строкам разной длины. Для определения характера ступенек рассмотрим пример прохода по строке для прямого и ассоциативного кэша, случай с множественно-ассоциативным кэшем будет среднем между кэшем с прямым отображением и ассоциативным кэшем.
Как только размер данных превышает размер кэш-памяти,
полностью ассоциативный кэш «промахивается» при каждом обращении к памяти.

Рассмотрим разные размеры строк. — показывает максимальное количество промахов, которое потратит процессор для доступа к элементам массива при следующем проходе по строке.

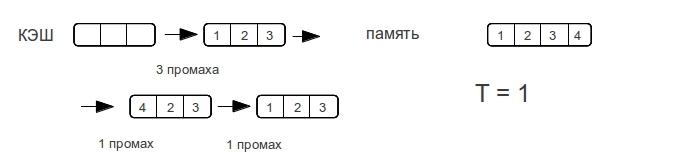
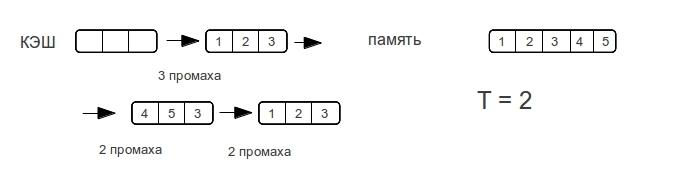
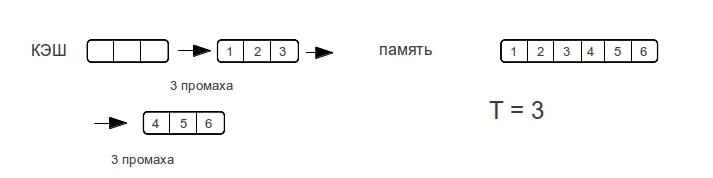
Как видно время доступа к памяти возрастает не резко, а по мере увеличения объема данных. Как только размер данных превысит размер кэша, то промахи будут при каждом обращении к памяти.
Потому у ассоциативного кэша ступенька будет вертикальной, а у прямого — плавно возрастать вплоть до двойного размера кэша. Множественно ассоциативный кэш будет средним случаем, «бугорком», хотя бы потому, что время-доступа не может быть лучше прямого.
Если-же говорить о памяти — то самая быстрая это кэш, следом идет оперативная, самая медленная это swap, про него мы в дальнейшем говорить не будем. В свою очередь у разных уровней кэша (как правило сегодня процессоры имеют 2-3 уровня кэша) разная скорость отклика памяти: чем больше уровень, тем меньше скорость отклика. И поэтому, если строка помещается в первый уровень кэша, (который кстати полностью ассоциативный) время отклика будет меньше, чем у строки значительно превышающей размеры кэша первого уровня. По-этому на графике времени отклика памяти от размеров строки будет несколько плато — плато* отклика памяти, и плато вызванные различными уровнями кэша.
Приступим к реализации
Для реализации будем использовать Си (ANSI C99).
Быстро написан код, обычный проход по строкам разной длины, меньше 10мб, выполняющийся многократно. (Будем приводить небольшие куски программы, несущие смысловую нагрузку).

Очевидно что это может происходить по двум причинам: либо в процессоре нет кэш памяти, либо процессор так хорошо угадывает обращения к памяти. Поскольку первый вариант ближе к фантастике причина всему хорошее предсказание обращений.
Дело в том, что сегодня далеко не топовые процессоры, помимо принципа пространственной локальности, предсказывают также и арифметическую прогрессию в порядке обращения к памяти. Поэтому нужно рандомизовать обращения к памяти.
Длина рандомизованного массива должна быть сопоставимой с длиной основной строки, чтобы избавиться от большой гранулярности обращений, так же длина массива не должна быть степенью двойки, из-за этого происходили «наложения» — следствием чего могут — быть выбросы. Лучше всего задать гранулярность константно, в том числе, если гранулярность простое число, то можно избежать эффектов наложений. А длина рандомиованого массива — функция от длинны строки.
После чего мы удивили столь долгожданную «картинку», о которой говорили в начале.


Программа разбита на 2 части — тест и обработка данных. Написать скрипт в 3 строки для запуска или 2 раза запустить ручками решайте сами.
Листинг файла size.с Linux
Листинг файла size.с Windows
В общем- то думаю все понятно, но хотелось бы оговорить несколько моментов.
Массив A объявлен как volatile — эта директива гарантирует нам что к массиву A всегда будут обращения, то-есть их не «вырежут» ни оптимизатор, ни компилятор. Так-же стоит оговорить то что вся вычислительная нагрузка выполняется до замера времени, что позволяет нам, уменьшить фоновое влияние.
Файл переведен в ассемблер на Ubuntu 12.04 и компилятором gcc 4.6 — циклы сохраняются.
Обработка данных
Для обработки данных логично использовать производные. И несмотря на то что с повышением порядка дифференцирования шумы возрастают, будет использована вторая производная и её свойства. Как бы не была зашумлена вторая производная, нас интересует лишь знак второй производной.
Находим все точки, в которых вторая производная больше нуля (с некоторой погрешностью потому-что вторая производная, помимо того что считается численно, — сильно зашумлена ). Задаем функцию зависимости знака второй производной функции от размера кэша. Функция принимает значение 1 в точках, где знак второй производной больше нуля, и ноль, если знак второй производной меньше или равен нулю.
Точки «взлетов» — начало каждой ступеньки. Также перед обработкой данных нужно убрать одиночные выбросы, которые не меняют смысловой нагрузки данных, но создают ощутимый шум.
Листинг файла data_pr.с
Тесты
CPU/ОС/версия ядра/компилятор/ключи компиляции — будут указаны для каждого теста.
Intel Pentium CPU P6100 @2.00GHz / Ubuntu 12.04 / 3.2.0-27-generic / gcc -Wall -O3 size.c -lrt
Давайте поговорим о «граблях»
Грабля обнаружилась при обработке данных на серверном процессоре Intel Xeon 2.4/L2 = 512 кб/Windows Server 2008

Проблема заключается в маленьком количестве точек, попадающих на интервал выхода на плато, — соответственно, скачок второй производной незаметен и принимается за шум.
Можно решить эту проблему методом наименьших квадратов, либо прогонять тесты в по ходу определения зон плато.

Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
Пример 1: доступ к памяти и производительность
Как вы думаете, насколько второй цикл быстрее первого?
int [] arr = new int [64 * 1024 * 1024];
Первый цикл умножает все значения массива на 3, второй цикл только каждое шестнадцатое значение. Второй цикл совершает только 6% работы первого цикла, но на современных машинах оба цикла выполняются примерно за равное время: 80 мс и 78 мс соответственно (на моей машине).
Разгадка проста — доступ к памяти. Скорость работы этих циклов в первую очередь определяется скоростью работы подсистемы памяти, а не скоростью целочисленного умножения. Как мы увидим в следующем примере, количество обращений к оперативной памяти одинаково и в первом и во втором случае.
Пример 2: влияние строк кэша
Копнём глубже — попробуем другие значения шага, не только 1 и 16:
Вот время работы этого цикла для различных значений шага K:

Обратите внимание, при значениях шага от 1 до 16 время работы практически не изменяется. Но при значениях больше 16, время работы уменьшается примерно вдвое каждый раз когда мы увеличиваем шаг в два раза. Это не означает, что цикл каким-то магическим образом начинает работать быстрее, просто количество итераций при этом так же уменьшается. Ключевой момент — одинаковое время работы при значениях шага от 1 до 16.
Причина этого в том, что современные процессоры осуществляют доступ к памяти не побайтно, а небольшими блоками, которые называют строками кэша. Обычно размер строки составляет 64 байта. Когда вы читаете какое-либо значение из памяти, в кэш попадает как минимум одна строка кэша. Последующий доступ к какому-либо значению из этой строки происходит очень быстро.
Из-за того, что 16 значений типа int занимают 64 байта, циклы с шагами от 1 до 16 обращаются к одинаковому количеству строк кэша, точнее говоря, ко всем строкам кэша массива. При шаге 32, обращение происходит к каждой второй строке, при шаге 64, к каждой четвёртой.
Понимание этого очень важно для некоторых способов оптимизации. От места расположения данных в памяти зависит число обращений к ней. Например, из-за невыровненных данных может потребоваться два обращения к оперативной памяти, вместо одного. Как мы выяснили выше, скорость работы при этом будет в два раза ниже.
Пример 3: размеры кэшей первого и второго уровня (L1 и L2)
Современные процессоры, как правило, имеют два или три уровня кэшей, обычно их называют L1, L2 и L3. Для того, чтобы узнать размеры кэшей различных уровней, можно воспользоваться утилитой CoreInfo или функцией Windows API GetLogicalProcessorInfo. Оба способа так же предоставляют информацию о размере строки кэша для каждого уровня.
На моей машине CoreInfo сообщает о кэшах данных L1 объёмом по 32 Кбайт, кэшах инструкций L1 объёмом по 32 Кбайт и кэшах данных L2 объёмом по 4 Мбайт. Каждое ядро имеет свои персональные кэши L1, кэши L2 общие для каждой пары ядер:
Проверим эту информацию экспериментально. Для этого, пройдёмся по нашему массиву инкрементируя каждое 16-ое значение — простой способ изменить данные в каждой строке кэша. При достижении конца, возвращаемся к началу. Проверим различные размеры массива, мы должны увидеть падение производительности когда массив перестаёт помещаться в кэши разных уровней.
int steps = 64 * 1024 * 1024; // количество итераций
int lengthMod = arr.Length - 1; // размер массива -- степень двойки

На моей машине заметны падения производительности после 32 Кбайт и 4 Мбайт — это и есть размеры кэшей L1 и L2.
Пример 4: параллелизм инструкций
Теперь давайте взглянем на кое-что другое. По вашему мнению, какой из этих двух циклов выполнится быстрее?
int steps = 256 * 1024 * 1024;
int [] a = new int [2];
// первый
for ( int i = 0; i
// второй
for ( int i = 0; i
Оказывается, второй цикл выполняется почти в два раза быстрее, по крайней мере, на всех протестированных мной машинах. Почему? Потому, что команды внутри циклов имеют разные зависимости по данным. Команды первого имеют следующую цепочку зависимостей:

Во втором цикле зависимости такие:

Функциональные части современных процессоров способны выполнять определённое число некоторых операций одновременно, как правило, не очень большое число. Например, возможен параллельный доступ к данным из кэша L1 по двум адресам, так же возможно одновременное выполнение двух простых арифметических команд. В первом цикле процессор не может задействовать эти возможности, но может во втором.
Пример 5: ассоциативность кэша
-
Кэш прямого отображения, данные каждой строки кэша в оперативной памяти хранятся только в одной заранее определённой ячейке кэша. Простейший способ вычисления отображения: индекс_строки_в_памяти % количество_ячеек_кэша. Две строки, отображённые на одну и ту же ячейку, не могут находится в кэше одновременно.
К примеру, на моей машине кэш L2 размером в 4 Мбайт является 16-входовым частично-ассоциативным кэшем. Вся оперативная память разделена на множества строк по младшим битам их индексов, строки из каждого множества соревнуются за одну группу из 16 ячеек кэша L2.
Так как кэш L2 имеет 65 536 ячеек (4 * 2 20 / 64) и каждая группа состоит из 16 ячеек, всего мы имеем 4 096 групп. Таким образом, младшие 12 битов индекса строки определяют к какой группе относится эта строка (2 12 = 4 096). В результате, строки с адресами кратными 262 144 (4 096 * 64) разделяют одну и ту же группу из 16-ти ячеек и соревнуются за место в ней.
Чтобы эффекты ассоциативности проявили себя, нам необходимо постоянно обращаться к большому количеству строк из одной группы, например, используя следующий код:
public static long UpdateEveryKthByte( byte [] arr, int K)
const int rep = 1024 * 1024; // количество итераций
Stopwatch sw = Stopwatch.StartNew();
int p = 0;
for ( int i = 0; i < rep; i++)
arr[p]++;
p += K; if (p >= arr.Length) p = 0;
>
Метод инкрементирует каждый K-ый элемент массива. По достижении конца, начинаем заново. После довольно большого количества итераций (2 20 ), останавливаемся. Я сделал прогоны для различных размеров массива и значений шага K. Результаты (синий — большое время работы, белый — маленькое):

Синим областям соответствуют те случаи, когда при постоянном изменении данных кэш не в состоянии вместить все требуемые данные одновременно. Яркий синий цвет говорит о времени работы порядка 80 мс, почти белый — 10 мс.
-
Почему появляются вертикальные линии? Вертикальные линии соответствуют значениям шага при которых осуществляется доступ к слишком большому числу строк (больше 16-ти) из одной группы. Для таких значений, 16-входовый кэш моей машины не может вместить все необходимые данные.
Некоторые из плохих значений шага — степени двойки: 256 и 512. Для примера рассмотрим шаг 512 и массив в 8 Мбайт. При этом шаге, в массиве имеются 32 участка (8 * 2 20 / 262 144), которые ведут борьбу друг с другом за ячейки в 512-ти группах кэша (262 144 / 512). Участка 32, а ячеек в кэше под каждую группу только 16, поэтому места на всех не хватает.
Другие значения шага, не являющиеся степенями двойки, просто невезучие, что вызывает большое количество обращений к одинаковым группам кэша, а так же приводит к появлению вертикальных синих линий на рисунке. На этом месте любителям теории чисел предлагается задуматься.
Даже если бы кэш был полностью ассоциативным, это не позволило бы сохранить в нём 8 Мбайт данных. Заметьте, что в уже рассмотренном примере с шагом 512 и размером массива 8 Мбайт, нам необходим только 1 Мбайт кэша, чтобы сохранить все нужные данные, но это невозможно сделать из-за недостаточной ассоциативности кэша.
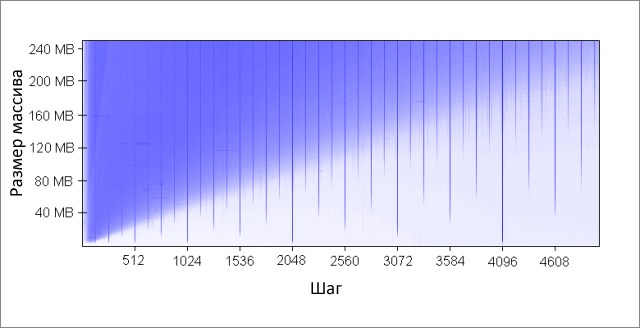
Ассоциативность кэша — интересная штука, которая может проявить себя при определённых условиях. В отличие от остальных рассмотренных в этой статье проблем, она не является настолько серьёзной. Определённо, это не то, что требует постоянного внимания при написании программ.
Пример 6: ложное разделение кэша
На многоядерных машинах можно столкнуться с другой проблемой — согласование кэшей. Ядра процессора имеют частично или полностью раздельные кэши. На моей машине кэши L1 раздельны (как и обычно), так же имеются два кэша L2, общие для каждой пары ядер. Детали могут различаться, но в целом современные многоядерные процессоры имеют многоуровневые иерархические кэши. Причём самые быстрые, но и самые маленькие кэши, принадлежат индивидуальным ядрам.
Когда одно из ядер модифицирует значение в своём кэше, другие ядра больше не могут использовать старое значение. Значение в кэшах других ядер должно быть обновлено. Более того, должна быть обновлена полностью вся строка кэша, так как кэши оперируют данными на уровне строк.
Продемонстрируем эту проблему на следующем коде:
private static int [] s_counter = new int [1024];
private void UpdateCounter( int position)
for ( int j = 0; j < 100000000; j++)
s_counter[position] = s_counter[position] + 3;
>
>
Если на своей четырёхядерной машине я вызову этот метод с параметрами 0, 1, 2, 3 одновременно из четырёх потоков, то время работы составит 4.3 секунды. Но если я вызову метод с параметрами 16, 32, 48, 64, то время работы составит только 0.28 секунды.
Почему? В первом случае, все четыре значения, обрабатываемые потоками в каждый момент времени, с большой вероятностью попадают в одну строку кэша. Каждый раз когда одно ядро увеличивает очередное значение, оно помечает ячейки кэша, содержащие это значение в других ядрах, как невалидные. После этой операции, все остальные ядра должны будут закэшировать строку заново. Это делает механизм кэширования неработоспособным, убивая производительность.
Пример 7: сложность железа
Даже теперь, когда принципы работы кэшей для вас не секрет, железо по-прежнему будет преподносить вам сюрпризы. Процессоры отличаются друг от друга методами оптимизации, эвристиками и прочими тонкостями реализации.
Кэш L1 некоторых процессоров может осуществлять параллельный доступ к двум ячейкам, если они относятся к разным группам, но если они относятся к одной, только последовательно. Насколько мне известно, некоторые даже могут осуществлять параллельный доступ к разным четвертинкам одной ячейки.
Процессоры могут удивить вас хитрыми оптимизациями. Например, код из предыдущего примера про ложное разделение кэша не работает на моём домашнем компьютере так, как задумывалось — в простейших случаях процессор может оптимизировать работу и уменьшить негативные эффекты. Если код немного модифицировать, всё встаёт на свои места.
Вот другой пример странных причуд железа:
private static int A, B, C, D, E, F, G;
Если вместо подставить три разных варианта, можно получить следующие результаты:

Инкрементирование полей A, B, C, D занимает больше времени, чем инкрементирование полей A, C, E, G. Что ещё страннее, инкрементирование полей A и C занимает больше времени, чем полей A, C и E, G. Не знаю точно каковы причины этого, но возможно они связаны с банками памяти (да-да, с обычными трёхлитровыми сберегательными банками памяти, а не то, что вы подумали). Имеющих соображения на этот счёт, прошу высказываться в комментариях.
У меня на машине вышеописанного не наблюдается, тем не менее, иногда бывают аномально плохие результаты — скорее всего, планировщик задач вносит свои «коррективы».
Из этого примера можно вынести следующий урок: очень сложно полностью предсказать поведение железа. Да, можно предсказать многое, но необходимо постоянно подтверждать свои предсказания с помощью измерений и тестирования.
Заключение
Надеюсь, что всё рассмотренное помогло вам понять устройство кэшей процессоров. Теперь вы можете использовать полученные знания на практике для оптимизации своего кода.
На днях решил систематизировать знания, касающиеся принципов отображения оперативной памяти на кэш память процессора. В результате чего и родилась данная статья.
Кэш память процессора используется для уменьшения времени простоя процессора при обращении к RAM.
Основная идея кэширования опирается на свойство локальности данных и инструкций: если происходит обращение по некоторому адресу, то велика вероятность, что в ближайшее время произойдет обращение к памяти по тому же адресу либо по соседним адресам.
Логически кэш-память представляет собой набор кэш-линий. Каждая кэш-линия хранит блок данных определенного размера и дополнительную информацию. Под размером кэш-линии понимают обычно размер блока данных, который в ней хранится. Для архитектуры x86 размер кэш линии составляет 64 байта.
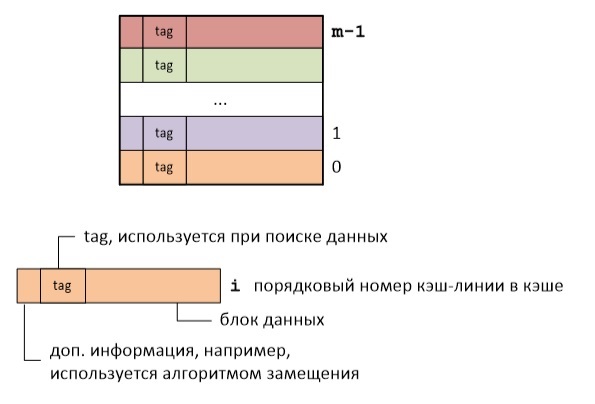
Так вот суть кэширования состоит в разбиении RAM на кэш-линии и отображении их на кэш-линии кэш-памяти. Возможно несколько вариантов такого отображения.
DIRECT MAPPING
Основная идея прямого отображения (direct mapping) RAM на кэш-память состоит в следующем: RAM делится на сегменты, причем размер каждого сегмента равен размеру кэша, а каждый сегмент в свою очередь делится на блоки, размер каждого блока равен размеру кэш-линии.

Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на одну и ту же кэш-линию кэша:
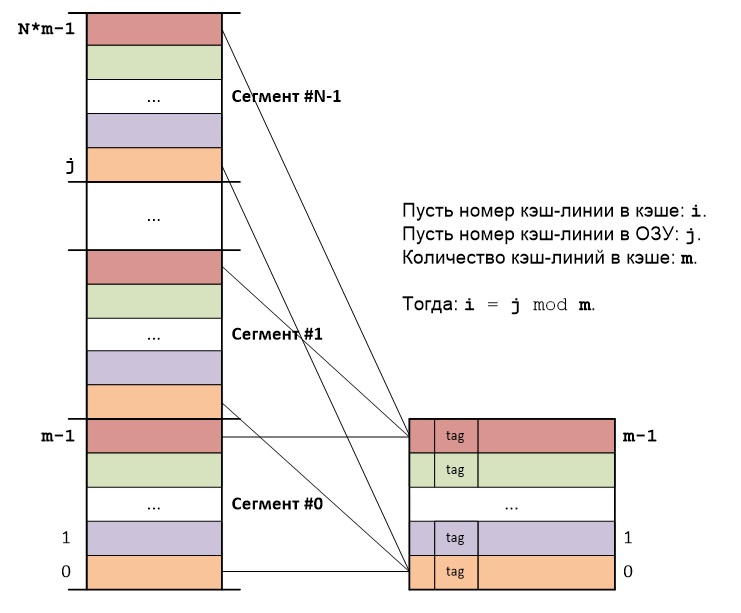
Адрес каждого байта представляет собой сумму порядкового номера сегмента, порядкового номера кэш-линии внутри сегмента и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера сегментов, а порядковые номера кэш-линий внутри сегментов и порядковые номера байт внутри кэш-линий — повторяются.
Таким образом нет необходимости хранить полный адрес кэш-линии, достаточно сохранить только старшую часть адреса. Тэг (tag) каждой кэш-линии как раз и хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий в кэше.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий внутри каждого сегмента потребуется: log2m бит.
m = Объем кэш-памяти/Размер кэш линии.
Для адресации N сегментов RAM: log2N бит.
N = Объем RAM/Размер сегмента.
Для адресации байта потребуется: log2N + log2m + log2b бит.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер кэш-линии в кэше.
2. Тэг кэш-линии с данным номером сравнивается со старшей частью адреса (log2N).
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
FULLY ASSOCIATIVE MAPPING
Основная идея полностью ассоциативного отображения (fully associative mapping) RAM на кэш-память состоит в следующем: RAM делится на блоки, размер которых равен размеру кэш-линий, а каждый блок RAM может сохраняться в любой кэш-линии кэша:
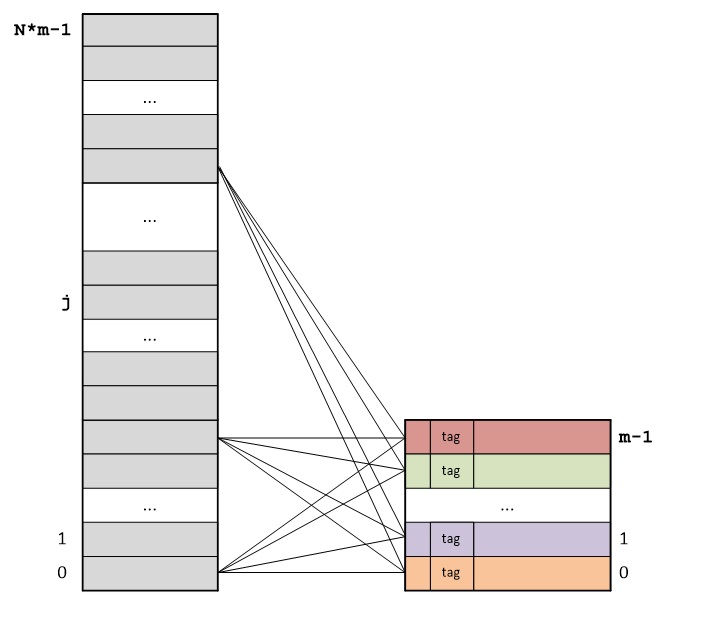
Адрес каждого байта представляет собой сумму порядкового номера кэш-линии и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера кэш-линий. Порядковые номера байт внутри кэш-линий повторяются.
Тэг (tag) каждой кэш-линии хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий, умещающихся в RAM.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий: log2m бит.
m = Размер RAM/Размер кэш-линии.
Для адресации байта потребуется: log2m + log2b бит.
Этапы поиска в кэше:
1. Тэги всех кэш-линий сравниваются со старшей частью адреса одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
SET ASSOCIATIVE MAPPING
Основная идея наборно ассоциативного отображения (set associative mapping) RAM на кэш-память состоит в следующем: RAM делится также как и в прямом отображении, а сам кэш состоит из k кэшей (k каналов), использующих прямое отображение.
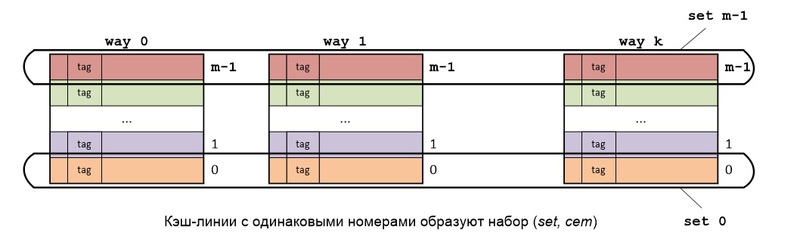
Кэш-линии, имеющие одинаковые номера во всех каналах, образуют set (набор, сэт). Каждый set представляет собой кэш, в котором используется полностью ассоциативное отображение.
Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на один и тот же set кэша. Если в данном сете есть свободные кэш-линии, то считываемый из RAM блок будет сохраняться в свободную кэш-линию, если же все кэш-линии сета заняты, то кэш-линия выбирается согласно используемому алгоритму замещения.
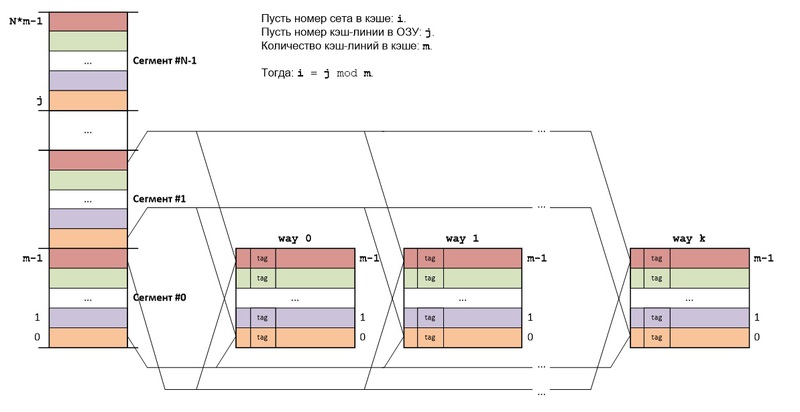
Структура адреса байта в точности такая же, как и в прямом отображении: log2N + log2m + log2b бит, но т.к. set представляет собой k различных кэш-линий, то поиск в кэше немного отличается.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер сэта в кэше.
2. Тэги всех кэш-линий данного сета сравниваются со старшей частью адреса (log2N) одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
Т.о количество каналов кэша определяет количество одновременно сравниваемых тэгов.
Кэш прямого отображения (direct mapped) наиболее дешевый и простой по организации.
Область оперативной памяти разбивается на блоки. На такие же блоки разбивается кэш память. Количество блоков в кэш значительно меньше, чем количество блоков в ОЗУ. Каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти.
При записи данных в кэш каждый блок оперативной памяти может претендовать только на определенный блок кэш памяти. Например, на месте первого блока кэш памяти, состоящей из четырех блоков прямого отображения (рис. 1.), может размещаться первый блок ОЗУ, пятый, девятый и т.д. На место второго блока в кэш претендуют блоки 2-ой, 6-ой, 10-ый и т.д. Как видим, на одну и ту же область кэш претендует несколько блоков ОЗУ, что может привести к конфликтам.

Рис. 1. Кэш прямого отображения
Кроме того, даже если конфликты разрешаются схемой управления, то при последовательном обращении к блокам, претендующим на одно и то же место в кэш, происходит постоянная замена блоков и кэш память теряет смысл, т.к. не увеличивает скорость обмена данными между процессором и оперативной памятью.
Полностью ассоциативный кэш
Полностью ассоциативный кэш реализуется аппаратно. Поиск информации как и в ассоциативной памяти производится по ключевому слову. Особенность такой организации кэш в том, что любой блок оперативной памяти может занимать любое место в кэш памяти. Такой способ адресации не требует внешнего описания памяти. Информация о том, какой именно блок занимает данную строку, и каково состояние строки (действительная или пустая) называется тегом (tag) и хранится в связанной с данной строкой ячейке специальной памяти тегов (tag RAM). Поиск данных производится параллельно во всех блоках кэш. При операции записи или считывания контроллер кэш проверяет нет ли записи в кэш и фиксирует частоту обращения к каждому блоку кэш. Такая реализация требует больших аппаратных затрат. Для персональных компьютеров этот способ реализации кэш слишком дорог.
Читайте также: