
Проверить sql запрос oracle
Оптимизатор SQL запросов Oracle достиг небывалого уровня сложности. Количество встроенных решений для предопределённых "частных случаев" иногда делает планы выполнения непредсказуемыми. Задача анализа и оптимизации SQL усложняется широким распространением параллельного выполнения и кластеров, "переписыванием" запросов "на лету", динамическим сбором статистики. В этих условиях традиционные методы анализа производительности и выполнения SQL оказываются недостаточными.
Предлагаемая читателю заметка рассказывает о новом средстве проверки выполнения и оптимизации SQL запросов в реальном времени - Active SQL Monitor Report.
Прежде всего мы проанализируем два варианта простого SQL запроса и найдём причину чрезмерного количества чтений блоков данных. Затем, используя Real Time SQL Monitoring, мы проверим наши выводы и посмотрим как можно избежать излишнего выполнения "проблемных" запросов во время анализа.
User guide
- First, Drag and drop your SQL file or copy / paste your request directly into the editor above.
- Finally, you must click on "Check SQL syntax" button to display if there is an syntax error in your code.
You can click on "Format SQL query" to make your query more readable. This simplifies the correction.
Review Existing Objects in the HR Schema
In this topic, you review the existing objects in the hr schema.
Expand the EMPLOYEES table. Notice that the column definitions are listed.
Click the DEPARTMENTS table in the navigator.
Notice that the information in the EMPLOYEES tab was replaced by the DEPARTMENTS table information. If you want the table information in the tab to remain frozen, select the Pin icon to Freeze the pane.
Then click the EMPLOYEES table again in the navigator.
Notice this time you have 2 tabs, one for each of the tables because the DEPARTMENTS table pane is frozen.
You can see the data in the EMPLOYEES table. Click the Data subtab.
The data in the EMPLOYEES table is displayed. You can also enter a SQL statement in the SQL Worksheet. Click the hr_orcl tab.
Enter the following SQL statement and select the Execute SQL Statement icon.
select * from employees
where job_id like '%SA%';
The Query Results are displayed. In the next topic, you run the script you generated in the previous tutorial on Data Modeler.
Оптимизация запроса
После анализа плана выполнения запроса осуществляется его оптимизация.
Оптимизация запроса предполагает удаление причин неэффективности запроса, среди которых наиболее весомыми являются:
- плохая статистика таблиц и индексов, участвующих в запросе (наиболее важный фактор, на который в первую очередь надо обратить внимание);
- проблемы с индексами: отсутствие нужных индексов, неэффективно построенные индексы, неэффективно используемые индексы, большое значение фактора кластеризации;
- проблемы с хинтами: отсутствие хинтов или они неэффективны;
- неэффективная структура запроса (запрос построен не корректно).
Creating a Database Connection
In this topic, you will create a database connection to the HR Schema in SQL Developer:
-
Double click on the SQL Developer icon on the Desktop.
The first time SQL Developer is open, the "Start Page" is displayed. You can deselect the Show on Startup check box to turn it off.
In the Connections tab, right click Connections and select New Connection
Instructions and result (including collapsible image with text file for accessibility):
A New / Update Database Connection dialog opens. Enter the connection details as follows and click Test.
Connection Name: hr_orcl
User Name: hr
Password: (Select the Save Password checkbox)
SID:

Description of this image
Note: In this tutorial the Service Name is specified instead of SID.
The status of your test is 'Success'. Click Connect in the New/ Update Database Connection dialog to create the connection.
Expand the hr_orcl connection. Notice all the object types. Expand Tables. In the next section, you examine the objects currently in the hr schema.
"Плохой" SQL запрос
Заставим Оракл использовать индекс и оценим результат.
В этом случае raw trace файл показывает, что "cr" равен "cost" для обеих строк плана "INDEX FULL SCAN" и "TABLE ACCESS BY INDEX ROWID" - наша сессия читает по одному блоку за раз. Просто для полного прочтения таблицы через индекс нам понадобится один блок для "корня" индекса, 12 блоков для "листьев" индекса и 17 прочтений блоков (смотрите CLUSTERING_FACTOR в начале заметки) для доступа к строкам самой таблицы - итого 30 consistent gets - буферов, прочитанных из buffer cache, равным по размеру 8192 байт каждый.
И чем выше значение CLUSTERING_FACTOR для используемого индекса - тем большее количество обращений к диску или buffer cache будет необходимо для прочтения всей таблицы. В нашем примере индекс PK_SALES_ID имеет почти идеальную структуру и очень низкий CLUSTERING_FACTOR, в реальной ситуации полное прочтение таблицы по индексу потребует значительно больше ресурсов чем простой full table scan.
Также заметьте, что при таком запросе не используется специфический для Exadata "INDEX STORAGE FULL SCAN".
Становится понятным, что показанный выше способ анализа производительности SQL запроса весьма трудоёмок и потребует многократного выполнения запроса, очищения buffer cache, трассировки сессий и прочих специфических приёмов, недопустимых на "живой" системе.
"Хороший" SQL запрос
В этот раз нам надо узнать сколько наименований продуктов купил каждый клиент.
В этот раз результат немного неожиданный - индекс не был использован вообще, поскольку полное чтение всей таблицы требует приблизительно такого же количества чтений блоков из буфера (19 буферов за 7 операций чтения), как и сканирование индекса (17 буферов за 5 операций.).
Также надо заметить что при пустом buffer cache платформа Exadata позволяет операции "TABLE ACCESS STORAGE FULL" использовать в одной сессии два разных способа чтения данных в buffer cache (а не PGA) - "cell single block physical read" для доступа к заголовку сегмента и "cell multiblock physical read" для прочтения "за один раз" всех оставшихся блоков. Если же buffer cache оказывается не пустым, как в этом примере "хорошего" запроса - сессия прочитает все необходимые блоки из памяти SGA (а не PGA), опять же несмотря на способ доступа к таблице "TABLE ACCESS STORAGE FULL".
Возможно ли что Оракл выбрал неоптимальный способ чтения данных и нам надо использовать индекс?
Debugging a Procedure
The procedure created in the earlier section was created with an error. You can locate errors in the code by debugging the code. You have to run a script before you actually start the debug process
Данные для запроса
Создадим таблицу, содержащую абстрактные данные о продажах чего-либо.
Проверим, действительно ли значения нашего primary key монотонно возрастают:
Теперь посмотрим, как близко находятся ("упакованы") записи внутри блоков нашего индекса, отсортированного по столбцу SALEID:
Близость значений CLUSTERING_FACTOR и LEAF_BLOCKS говорит нам о хорошей "упаковке" записей в индексе. Это сделает индекс PK_SALES_ID более "привлекательным" для оптимизатора запросов, что теоретически должно гарантировать нам самый быстрый доступ к данным таблицы.
Проверим это предположение на практике. Для простого теста мы хотим определить количество проданных продуктов в каждой покупке. Исходя из определения primary key для нашей таблицы очевидно, что это значение всегда будет равным единице. Последующий запрос необходимо выполнить как минимум дважды, для полного устранения обрашений к диску.
Получен ожидаемый результат - обращений к таблице не было вообще, все необходимые данные были получены из самого индекса. Изменим запрос так, чтобы использование индекса не было таким привлекательным.
Данные для запроса
Создадим таблицу, содержащую абстрактные данные о продажах чего-либо.
Проверим, действительно ли значения нашего primary key монотонно возрастают:
Теперь посмотрим, как близко находятся ("упакованы") записи внутри блоков нашего индекса, отсортированного по столбцу SALEID:
Близость значений CLUSTERING_FACTOR и LEAF_BLOCKS говорит нам о хорошей "упаковке" записей в индексе. Это сделает индекс PK_SALES_ID более "привлекательным" для оптимизатора запросов, что теоретически должно гарантировать нам самый быстрый доступ к данным таблицы.
Проверим это предположение на практике. Для простого теста мы хотим определить количество проданных продуктов в каждой покупке. Исходя из определения primary key для нашей таблицы очевидно, что это значение всегда будет равным единице. Последующий запрос необходимо выполнить как минимум дважды, для полного устранения обрашений к диску.
Получен ожидаемый результат - обращений к таблице не было вообще, все необходимые данные были получены из самого индекса. Изменим запрос так, чтобы использование индекса не было таким привлекательным.
Типичные неэффективные технологии тестирования
В ходе тестирования программы необходимо определить, какие изменения вносятся в ходе ее работы: возвращаемая функцией строка, обновленная процедурой таблица и т. д. Затем вы заранее формируете прогноз правильного поведения программы для заданного набора входных данных и конфигурации (тестового сценария). После выполнения программы фактические результаты (внесенные программой изменения) сравниваются с прогнозируемыми значениями. Если они совпадают — значит, программа работает. Если что-то отличается — значит, где-то произошел сбой.
Это очень хорошее общее описание процесса тестирования; остается выяснить, как определить все необходимые тестовые сценарии и реализовать тесты. Начнем с весьма типичного (и к сожалению, неэффективного) подхода к тестированию.
Допустим, мы пишем большое приложение, обрабатывающее большое количество строк. В PL/SQL имеется функция SUBSTR , которая возвращает заданную часть строки. Однако ее использование связано с некоторыми проблемами. Дело в том, что эту функцию удобно применять, когда вы знаете начальную позицию и длину строки. Однако очень часто известно лишь местоположение начального (start) и конечного (end) символов, а длину строки приходится вычислять. Но по какой формуле? Чтобы не мучиться с вычислениями (кстати говоря, правильный ответ end — start + 1), мы напишем функцию betwnstr, которая произведет все вычисления за нас:
К сожалению, объем работы весьма велик, а это всего лишь одна из множества написанных программ, которую необходимо протестировать. Мы пишем примитивный «тестовый сценарий» с использованием DBMS_OUTPUT.PUT_LINE и запускаем его:
Работает. надо же! Но одного теста недостаточно. Давайте зададим конечное значение за пределами строки — например, 500. Функция должна вернуть остаток строки, как бы это сделала функция SUBSTR :
Снова работает! Теперь нужно убедиться в том, что функция правильно работает со значениями NULL :
Три из трех! Функция работает правильно, скажете вы? Нет — скорее всего, вы покачаете головой и скажете себе: «Такое тестирование даже в первом приближении не проверяет все возможные сценарии. Оно даже не изменяет значение первого аргумента! К тому же при каждом изменении входных значений предыдущий тест терялся».
И это будет правильно. Вместо того чтобы наугад проверять разные значения аргументов, следует составить список тестовых сценариев, поведение которых мы хотим проверить.
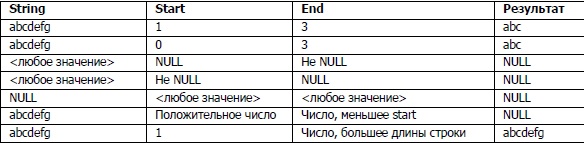
На основании этой таблицы строится простой сценарий следующего вида:
Каждый раз, когда нам потребуется протестировать betwnstr , мы просто выполним этот сценарий и проверим результаты. Для исходной реализации они будут выглядеть так:
«Проверим результаты». Легко сказать, но как это сделать? Как узнать, прошли ли тесты? Нам придется просматривать результаты строку за строкой и проверять их по таблице. К тому же при действительно тщательном тестировании у нас будет более 30 тестовых сценариев (не забыли об отрицательных значениях начальной и конечной позиции?). На просмотр результатов уйдет несколько минут, и это для совершенно тривиального кода. Сама мысль о распространении этой методики на «реальный» код выглядит устрашающе. А теперь представьте, что программа изменяет две таблицы и возвращает два аргумента OUT . Счет тестовых сценариев пойдет на сотни, да еще добавьте к этому проблемы настройки конфигурации и проверку правильности содержимого таблиц.
И все же многие разработчики выбирают этот путь при «тестировании» своего кода. Почти все проводимое тестирование обладает рядом ключевых недостатков:
- Тестовый код пишется вручную, что существенно ограничивает объем тестирования. У кого найдется время на написание всего необходимого кода?
- Неполное тестирование. Будем откровенны: при тестировании мы обычно ограничиваемся несколькими очевидными случаями, чтобы убедиться в том, что программа не имеет очевидных изъянов. Вряд ли это можно назвать полноценным тестированием.
- Одноразовые тесты. Было бы неплохо подумать о будущем и понять, что нам (или кому-то другому) еще неоднократно придется проводить те же тесты.
- Ручная проверка. Если мы будем полагаться только на собственную наблюдательность при проверке результатов, это займет слишком много времени и, скорее всего, приведет к ошибкам.
- Тестирование после разработки. Многие программисты говорят себе: «Вот допишу программу и займусь тестированием». Вроде бы вполне разумный подход, и все же он в корне неверен. Во-первых, наши программы никогда не «дописываются» — исправления вносятся до последней минуты, поэтому времени на тестирование вечно не хватает. Во-вторых, если вы начинаете думать о тестировании только после завершения работы над реализацией, вы подсознательно выбираете тесты, которые имеют наибольшую вероятность успеха, и избегаете тех, которые могут столкнуться с проблемами. Так уж устроено наше сознание.
Если вы хотите, чтобы тестирование было действительно эффективным и тщательным, необходимо действовать иначе. Тесты должны определяться так, чтобы они могли легко сопровождаться с течением времени. Мы должны иметь возможность легко проводить тестирование и, что еще важнее, — без продолжительного анализа определить результат: успех или неудача. При этом выполнение тестов не должно требовать написания больших объемов тестового кода.
Далее я сначала дам несколько советов относительно того, как организовать тестирование вашего кода. Затем будут рассмотрены средства автоматизации тестирования для разработчиков PL/SQL; особое внимание будет уделено utPLSQL и Quest Code Tester for Oracle .
Creating and Running a Unit Test
Now that the Unit Testing Repository has been created, you will create a unit test for the PL/SQL procedure you created earlier in this tutorial. Then you will run the unit test to see if various values will work
Select View > Unit Test.
In the Unit Test navigator, right-click Tests and select Create Test.
In Select Operation, select the hr_orcl connection that you used to create the AWARD_BONUS procedure.
Expand Procedures, select AWARD_BONUS and click Next.
In Specify Test Name window, make sure that AWARD_BONUS is specified for Test Name and that Create with single Dummy implementation is selected, then click Next.
In Specify Startup window, click '+' icon and select Table or Row Copy from the drop down list box.
Enter EMPLOYEES for Source Table and click OK. Note that the table affected by the test will be saved to a temporary table and the query to the table is automatically generated.
Click Next.
In the Specify Parameters window, change the Input string for EMP_ID to 149 and SALES_AMT to 2000 and click Next.
Select the '+' icon to add a validation and select Query returning row(s) from the drop down list.
Specify the following query and click OK. This query will test the results of the change that the unit test performed.
Click Next.
In the Specify Teardown window,click the '+' icon and select Table or Row Restore from the drop down list.
Leave the Row Identifier as Primary Key and click OK.
Click Next.
Click Finish.
Expand Tests. Your test appears in the list.
Select the AWARD_BONUS test in the left navigator. Notice that the test details are displayed on the right panel.
Run the test by clicking the Debug Implementation icon.
The Progress window appears.
When the test completes, the results are displayed. Click Close.


Всем нам нравится создавать что-то новое — собственно, это одна из причин, по которой мы занимаемся программированием. Мы берем интересную задачу и придумываем способ ее реализации на языке PL/SQL.
Однако никому не нравится возиться с тестированием своих программ (и писать документацию для них). Нам приходится это делать, но мы занимаемся этим без особого энтузиазма. На практике разработчики выполняют пару-тройку составленных на скорую руку тестов и решают, что если ошибки не найдены сразу, значит, их в программе нет. Почему это происходит?
- Стремление к успеху. Мы настолько убеждены в том, что наш код будет работать правильно, что предпочитаем держаться подальше от плохих новостей — и даже от самой возможности их появления. Мы проводим поверхностное тестирование, убеждаемся, что в первом приближении все работает, и ждем, пока другие найдут ошибки, если они есть (а они есть, можете не сомневаться!).
- Сроки. Сейчас время Интернета, время выхода на рынок определяет успех. Все должно быть готово немедленно — и мы выпускаем предварительную бета-версию как готовый продукт, а пользователи мучаются с тестированием наших разработок.
- Некомпетентность руководства. Как правило, руководители информационных отделов ничего не смыслят в разработке ПО. И если у вас нет времени на создание полноценного проекта (включая проектирование, написание кода, тестирование, документирование и т. д.), то в результате получится убогая поделка с множеством ошибок.
- Затраты на организацию тестирования. Создание тестовых программ обычно считается пустой тратой времени, ведь всегда найдется более важная работа. Одним из следствий такого подхода является то, что значительная часть обязанностей по тестированию перекладывается на отдел контроля качества (если он есть). Конечно, участие профессионалов в области контроля качества может оказать огромное влияние на результат, однако и разработчики не должны снимать с себя ответственность за модульное тестирование своего кода.
Таким образом, программы почти всегда нуждаются в дополнительном тестировании. Как повысить его эффективность в мире PL/SQL ?
Для начала мы рассмотрим типичный пример неудачного процесса тестирования. Затем будут представлены выводы относительно ключевых проблем ручного тестирования, и мы познакомимся со средствами автоматизированного тестирования кода PL/SQL.
Анализ плана выполнения запроса.
Анализ плана выполнения запроса имеет определенную последовательность действий. Рассмотрим на примере плана выполнения запроса из представление V$SQL_PLAN для ранее приведенного запроса
- При анализе план просматриваетcя снизу вверх. В процессе просмотра в первую очередь обращается внимание на строки с большими Cost, CPU Cost.
- Как видно из плана, резкий скачек этих значений имеется в 4-ой строке. Причиной такого скачка является 5-я строка с INDEX FULL SCAN, указывающая на наличие полного сканирование индекса X_DICTI_NAME таблицы DICTI. С этих строк и надо начинать поиск причины ресурсоемкости запроса. После нахождения строки с большим Cost и CPU Cost продолжается просмотр плана снизу вверх до следующего большого CPU Cost и т.д. При этом, если CPU Cost в строке близок к CPU Cost первой строки (максимальное значение), то найденная строка является определяющей в ресурсоемкости запроса и с ней в первую очередь надо искать причину ресурсоемкости запроса.
- Помимо поиска больших Cost и CPU Cost в строках плана следует просматривать первый столбец Operation плана на предмет наличия в нем HASH JOIN. Соединение по HASH JOIN приводит к соединению таблиц в памяти и, казалось бы, более эффективным, чем вложенные соединения NESTED LOOPS. Вместе с тем, HASH JOIN эффективно при наличии таблиц, хотя бы одна из которых помещаются в память БД или при наличии соединения таблиц с низкоселективными индексами. Недостатком этого соединения является то, что при нехватке памяти для таблицы (таблиц) будут задействованы диски, которые существенно затормозят работу запроса. В связи с чем, при наличии высокоселективных индексов, целесообразно посмотреть, а не улучшит ли план выполнения хинт USE_NL, приводящий к соединению по вложенным циклам NESTED LOOPS. Если план будет лучше, то оставить этот хинт. При этом в хинте USE_NL в скобках обязательно должны перечисляться все алиасы таблиц, входящих во фразу FROM, в противном случае может возникнуть дефектный план соединения. Этот хинт может быть усилен хинтами ORDERED и INDEX. Следует обратить так же внимание на MERGE JOIN. При большом CPU Cost в строке с MERGE JOIN стоит проверить действие хинта USE_NL для улучшения эффективности запроса.
- Особое внимание в плане следует так же уделить строкам в плане с операциями полного сканирования таблиц и индексов в столбец Operation: FULL — для таблиц и FULL SCAN, FAST FULL SCAN , SKIP SCAN — для индексов. Причинами полного сканирования могут быть проблемы с индексами: отсутствие индексов, неэффективность индексов, неправильное их применение. При небольшом количестве строк в таблице полное сканировании таблицы FULL может быть нормальным явлением и эффективнее использования индексов.
- Наличие в столбце Operation операции MERGE JOIN CARTESIAN говорит, что между какими-то таблицами нет полной связки. Эта операция возникает при наличии во фразе From трех и более таблиц, когда отсутствуют связи между какой-то из пар таблиц.
Решением проблемы может быть добавление недостающей связки, иногда помогает использование хинта Ordered.
Проблемы с хинтами в запросе
Проблемы с хинтами могут быть следующие:
- Неэффективный хинт. Он может привести к существенному снижению производительности. Причины возникновения не эффективности хинтов:
— хинт был написан, когда БД работала на 9-ом Oracle, при переходе на Oracle 10g и выше хинт стал тормозом (это могут быть хинты Rule, Leading и др.). Leading –мощный хинт, но при переходе на другую версию Oracle в некоторых случаях приводит в резкому снижению производительности и перед применение этих хинтов необходимо учитывать вероятность изменения со временем статистики системы и ее объектов (таблиц и индексов), используемых в запросе;
— в хинте USE_NL содержится не полный перечень алиасов;
— в составном хинте используется неправильный порядок следования хинтов, в результате чего хинты блокирую эффективную работу друг. Например, хинт Leading полностью игнорируются при использовании двух или более конфликтующих подсказок Leading или при указании в нем более одной таблицы.
— хинт написан давно, после чего была модификация запроса (например, отсутствует или изменился индекс, указанный в хинте). - В запросе отсутствует хинт, который бы повысил эффективность работы запроса. В ряде случаем наличие хинта повышает эффективность запроса и обеспечивает стабилизацию планов выполнения (например, при изменении статистики).
- При создании хинта в запросе есть ряд рекомендаций:
— В хинте INDEX могут быть перечислены несколько индексов. Оптимизатор сам выберет соответствующий индекс. Можно поставить хинт NO_INDEX, если надо заблокировать использование какого-то индекса.
— При наличии Distinct в запросе Distinct ставиться после хинта (т.е. хинт всегда идет после Select).
— Наиболее эффективные и часто используемыми являются хинты: Ordered, Leading, Index , No_Index, Index_FFS, Index_Join, Use_NL, Use_Hash, Use_Merge, First_Rows(n), Parallel, Use_Concat, And_Equal, Hash_Aj и другие. При этом, например, индекс Index_FFS кроме быстрого полного сканирования индекса позволяет ему выполняться параллельно, в силу чего можно получить существенный выигрыш в производительности. Пример такого использования для секционированной таблицы где T-алиас таблицы.
— Изменение параметров инициализации базы данных в пределах запроса позволяет сделать хинт /*+ opt_param('Параметр инициализацци' N) */ , например, /*+ opt_param('optimizer_index_caching' 10) */. Данный хинт используется для проверки производительности работы запроса в случае, когда запрос разрабатывается или тестируется на базе с одним значением параметров инициализации, а работает на базе с другими значениями.
Замечание. В некоторых случаях, когда хинт неэффективный, но заменить его оперативно в запросе не представляется возможным (например, чужая разработка), имеется возможность, не меняя рабочий запрос в программном модуле, заменить хинт (хинты) в запросе, а также в его подзапросах, на эффективный хинт (хинты). Это прием — подмена хинтов (который известен, как использование хранимых шаблонов Stored Outlines). Но такая подмена должна быть временным решением до момента корректировки запроса, поскольку постоянная подмена хинта может привести к некоторому снижению производительности запроса.
Средства автоматизации тестирования программ PL/SQL
В наши дни разработчики PL/SQL могут использовать целый ряд автоматизированных инфраструктур и средств тестирования своего кода:

В этой статье изложен многолетний опыт оптимизации SQL-запросов в процессе работы с базами данных Oracle 9i, 10g и 11g. В качестве рабочего инструмента для получения планов запросов мною используется всем известные программные продукты Toad и PLSQL Developer.
Нередко возникают ситуации, когда запрос работает долго, потребляя значительные ресурсы памяти и дисков. Назовем такие запросы неэффективными или ресурсоемкими.
Причины ресурсоемкости запроса могут быть следующие:
- плохая статистика по таблицам и индексам запроса;
- проблемы с индексами в запросе;
- проблемы с хинтами в запросе;
- неэффективно построенный запрос;
- неправильно настроены параметры инициализации базы данных, отвечающие за производительность запросов.
Программные средства, позволяющие получить планы выполнения запросов, можно разделить на 2 группы:
- средства, позволяющие получить предполагаемый план выполнения запроса;
- средства, позволяющие получить реальный план выполнения запроса;
К средствам, позволяющим получить предполагаемый план выполнения запроса, относятся Toad, SQL Navigator, PL/SQL Developer и др. Это важный момент, поскольку надо учитывать, что реальный план выполнения может отличаться от того, что показывают эти программные средства. Они выдают ряд показателей ресурсоемкости запроса, среди которых основными являются:
Чем больше значение этих показателей, тем менее эффективен запрос.
Ниже приводиться пример плана выполнения запроса:
полученного в Toad
Из плана видно, что наибольшие значения Cost и Cardinality содержатся во 2-й строке, в которой и надо искать основные проблемы производительности запроса.
Вместе с тем, многолетний опыт оптимизации показывает, что качественный анализ эффективности запроса требует, помимо Cost и Cardinality, рассмотрения других дополнительных показателей:
- CPU Cost — процессорная стоимость выполнения;
- IO Cost — стоимость ввода-вывода;
- Temp Space – показатель использования дискового пространства.
Если дисковое пространство используется (при нехватке оперативной памяти для выполнения запроса, как правило, для проведения сортировок, группировок и т.д.), то с большой вероятностью можно говорить о неэффективности запроса. Указанные дополнительные параметры с соответствующей настройкой можно увидеть в PL/SQL Developer и Toad при их соответствующей настройке. Для PL/SQL Developer в окне с планом выполнения надо выбрать изображение гаечного ключа, войти в окно Preferensec добавить дополнительные параметры в Select Column, после чего и нажать OK. В Toad в плане выполнения по правой кнопке мыши выбирается директива Display Mode, а далее Graphic, после чего появляется дерево, в котором по каждому листу нажатием мышки можно увидеть дополнительные параметры: CPU Cost, IO Cost, Cardinality. Структура плана запроса, указанного выше, в виде дерева приведена ниже.
Предполагаемый план выполнения запроса с Cost и Cardinality можно также получить, выполнив после анализируемого запроса другой запрос, формирующий план выполнения:
Дополнительно в плане выполнения запроса выдается значение SQL_ID запроса, который можно использовать для получения реального плана выполнения запроса с набором как основных (Cost, Cardinality), так и дополнительных показателей через запрос:
Реальный план выполнения запроса и указанный выше перечень характеристик для анализа ресурсоемкого запроса дают динамические представления Oracle: V$SQL_PLAN и V$SQL_PLAN_MONITOR (последнее представление появилось в Oracle 11g).
План выполнения запроса получается из представления Oracle по запросу:
где SQL_ID – это уникальный идентификатор запроса, который может быть получен из разных источников, например, из представления V$SQL:
Трассировочный файл — это еще одно средство получение реального плана выполнения. Это довольно сильное средство диагностики и оптимизации запроса. Для получения трассировочного файла ( в Toad или PL/SQL Developer) запускается PL/SQL блок:
где первая, третья и последняя строки являются стандартными, а во второй строке пишется идентификатор (любые символы), который включается в имя трассировочного файла. Так, если в качестве идентификатора напишем M_2013, то имя трассировочного файла будет включать этот идентификатор и будет иметь вид: oraxxx_xxxxxx_ M_2013.trc. Результат пишется в соответствующую директорию сервера, которая находиться из запроса
Трассировочный файл для удобства чтения расшифровывается утилитой Tkprof (при определенном навыке анализировать можно без расшифровки, в этом случае имеем более детальную информацию).
Ещё одним из средств получения реального плана выполнения запроса с получением рекомендаций по его оптимизации является средство Oracle SQLTUNE.
Для анализа запроса запускается PL/SQL блок (например, в Toad или PL/SQL Developer) , в котором имеются стандартные строки и анализируемый запрос. Для рассматриваемого выше запроса блок PL/SQL примет вид:
Все строки (кроме текста запроса) являются стандартными.
Далее запуск запрос, который выдает на экран текст рекомендаций:
Для работы SQLTUNE необходимо как минимум из под SYSTEM выдать права на работу с SQLTUNE схеме, в которой запускается PL/SQL блок. Например, для выдачи прав на схему HIST выдается GRANT ADVISOR TO HIST;
В результате работы SQLTUNE выдает рекомендации (если Oracle посчитает, что есть что рекомендовать). Рекомендациями могут быть: собрать статистику, построить индекс, запустить команду создания нового эффективного плана и т.д.
Неэффективная статистика.
Прежде чем оптимизировать запрос, целесообразно посмотреть статистику таблиц и индексов, участвующих в запросе. Порой достаточно обновить статистику, чтобы запрос стал работать эффективно. Возможные варианты не эффективной статистики, приводящие к ресурсоемкости запроса:
- Устаревшая статистика. Время последнего сбора статистики определяется значением поля Last_Analyzed для таблиц и индексов, которое находиться из Oracle таблиц ALL_TABLES (DBA_TABLES) и ALL_INDEXES (DBA_INDEXES) соответственно. Oracle ежедневно в определенные часы в рабочие дни и в определенные часы в выходные сам собирает статистику по таблицам. Но для этого DML операции с таблицей должны привести к изменению не менее 10% строк таблицы. Однако, мне приходилось сталкиваться с ситуацией, когда в течение дня таблица неоднократно и существенно меняет число строк или таблица столь большая, что 10% изменений наступает через длительное время. В этом случае приходилось обновлять статистику, используя процедуры сбора статистики внутри пакетов, а ряде случае использовать JOB, запускающийся в определенные часы для анализа и обновления статистики.
Статистика по таблице и индексу (на примере таблицы AGREEMENT и индекса X_AGREEMENT в схеме HIST) обновляется соответственно процедурами: - для таблицы:
- для индекса:
где число 10 в процедуре указывает на процент сбора статистики. С учетом времени сбора статистики и числа строк в таблице (индексе) были выработаны рекомендации для таблиц (индексов) по проценту сбора статистики: если число строк более 100 млн. процент сбора устанавливать 2 -5, при числе строк с 10 млн. до 100 млн. процент сбора устанавливать 5-10, менее 10 млн. процент сбора устанавливать 20 -100. При этом, чем выше процент сбора, тем лучше, однако, при этом растет и может быть существенным время сбора статистики.
Для таблиц процент сбора статистики (на примере таблицы AGREEMENT в схеме HIST) вычисляется запросом:
Процент сбора статистики по индексу находиться по запросу
Необходимо пересобрать статистику по таблице или индексу с плохой статистикой.
Замечание. При хорошем значении статистики по таблице может быть неблагополучная статистика по какому-то индексу таблицы, в силу чего целесообразно отслеживать статистику не только таблицы, но и индексов таблицы.
SQL validator online
SQL (Structured Query Language) is a domain-specific language used in relational databases. It is useful in handling structured data.
When working on a large SQL query, it is sometimes difficult to find where a syntax error is.
SQL error checker tool allows to find syntax errors. You can test your SQL query online directly in your browser.
If a syntax error is detected in your request, then the line in error is highlighted (rather useful for large sql requests). Frequent errors: forgetting to close parentheses, typology error of a keyword, omission of a keyword, .
It is not necessarily easy to start in SQL, even for developers (it has nothing to do with programming languages). Even knowing the syntax of SQL, there is still a lot to learn to use the full power of SQL!
It checks the MySQL dialect because it is the most popular database. Mysql shares a significant part of its sql syntax with other databases (But there are of course differences with other databases like postgres, db2, . ). If you think it would be interesting to make it compatible with other databases, let me known via a comment.
Hoping that this little tool will be useful to developers and database administrators. It is a simple but effective tool :)
If you think of new features, do not hesitate to add a comment. I do not have a lot of time but I will do my best.
This tool uses the library SQL parser. This library has been used by phpMyAdmin since version 4.5!
You can report a bug or give feedback by adding a comment (below) or by clicking "Contact me" link (at the top right hand corner of the page).
This tutorial covers how to execute a DDL script, review changes to the database objects, create, execute, test and debug a procedure.
Time to Complete
Approximately 60 minutes
Introduction
Oracle SQL Developer is a free and fully supported graphical tool that enhances productivity and simplifies database development tasks. Using SQL Developer, users can browse, edit and create database objects, run SQL statements, edit and debug PL/SQL statements, build PL/SQL unit tests, run reports, and place files under version control.
In this tutorial, you use SQL Developer Release 4.1 to examine various tasks.
Prerequisites
Before starting this tutorial, you should:
- Have installed Oracle SQL Developer Release 4.1 or above
- Have access to an Oracle Database 11g database that has the sample schema installed.
- Grant HR user DEBUG CONNECT SESSION and DEBUG ANY PROCEDURE privileges.
- Performed the Re-engineering Your Database Using Oracle SQL Developer Data Modeler 4.1 tutorial.
- Downloaded and unzipped the files.zip into your working directory.
Debugging
Now open the AWARD_BONUS procedure you created earlier. Compile the procedure

Description of this image
You can see the error message in the compiler log. It specifies a line number where the error occurred
Modify the code in line 13 by adding a semi colon. Select the Compile icon.

Description of this image
Run the procedure by clicking on Run icon.
The Run PL/SQL dialog window appears. Notice that the values for EMP_ID and SALES_AMT are currently set to 1.
Change the default values to 149 for EMP_ID and 2000 for SALES_AMT and click OK.
Note that the procedure executed successfully and the value for salary was changed. To see how debug works, you create a break point. Click the line number 7.
When a break point is created at line 7, the execution will break at line 7 and allows developer to monitor the data held in different variables. Click the Debug icon.
Click OK to accept the same input values as before.
The debugger is running and has stopped at line 8. Click the Smart Data tab. The Smart Data tab holds the values of variables in the PL/SQL block. These are currently set to NULL.
You can see all the data manipulated in the procedure in the Data tab.

Description of this image
You see that the current values of l_salary and l_commission are NULL.
Click the Step Over icon to move to the next statement in the procedure.
Notice the values for l_salary and l_commission have changed to the existing values in the database, as the execution of select statement is complete, you can see the values from the database are fetched into the variables in the procedure.
Click the Step Over icon again to move to the next statement.As the execution of the update statement completes, you can see the new values of salary and commission in the Data tab
Notice that the debugger moved to the next statement in the procedure. You want to run the rest of the procedure, click the Resume icon.
Procedure execution and debugging is complete. In the next topic, you create a test repository so that you can create and run a unit test.
Creating and Executing a Procedure
In this topic, you create, execute and debug a procedure that determines the commission any employee receives based on a sales amount and the employees commission percentage.
A script with the procedure has already been created so you can open the file. Select File > Open.
Locate the proc.sql and click Open.
Click the Run Script icon to create the AWARD_BONUS procedure.
Select the hr_orcl connection and click OK.
The procedure was created and compiled with an error. To see the error, expand Procedures in the navigator.
Creating a Unit Test Repository
In this topic, you create a database user called UNIT_TEST_REPOS. You create this user to hold the Unit Testing Repository data. You will then create the repository in the schema of the user that you created.
Create a connection for the SYS User. Right-click Connections and select New Connection.
Enter the following information and click Connect.
Connection Name: sys_orcl
Username: sys
Password: oracle
Select Save Password checkbox
Role: SYSDBA
Service Name: pdb1
Your connection was created successfully. Collapse the hr_orcl connection. Expand the sys_orcl connection and right-click Other Users and select Create User.
Enter the following information and select the Granted Roles tab.
Username: unit_test_repos
Password: oracle
Default Tablespace: USERS
Temporary Tablespace: TEMP
Select the Connect and Resource roles and click Apply.
In the Quotas tab, check the Unlimited check box for the USERS tablespace
The unit_test_repos user was created successfully. Click OK.
You now need to create a connection to the unit_test_repos user. This user will hold the unit testing repository data. Right-click Connections and select New Connection.
Enter the following information and click Connect.
Connection Name: unit_test_repos_orcl
Username: unit_test_repos
Password: oracle
Select Save Password checkbox
Service Name: pdb1
The unit_test_repos user and unit_test_repos_orcl connection were created successfully.
Select Tools > Unit Test > Repository, then select Select Current Repository.
Select the unit_test_repos_orcl connection and click OK.
You would like to create a new repository. Click Yes.
This connection does not have the permissions it needs to create the repository. Click OK to show the permissions that will be applied.
Enter oracle for the sys password and click OK.
The grant statement is shown. Click Yes.
The UNIT_TEST_REPOS user needs select access to some required tables. Click OK.
The grant statements are displayed. Click Yes.
The UNIT_TEST_REPOS user does not currently have the ability to manage repository owners. Click OK to see the grant statements that will be executed.
The grant statements are displayed. Click Yes.
Your repository was created successfully. Click OK.
Before you Debug
In order to debug a sub program you should have DEBUG privileges.
To check the privileges you can execute a SQL statement
You can see that the hr user doesn't have DEBUG CONNECT and DEBUG privileges
If you don't have the required DEBUG privileges, a SYSDBA role user has to assign them. Login as a SYSDBA user
Execute the grant commands and ACL(Access Control List) script shown as a SYSDBA user
Now login as hr user, who has a non-sysdba user role
Execute the SQL statement shown to check whether required privileges are granted to hr user
Executing a DDL Script
In this topic, you execute the DDL script you generated in the Data Modeler tutorial. If you did not complete the previous tutorial, you can access the solution using the dm_mods.sql in the files folder.
Select File > Open.
Locate the dm_mods.sql file and click Open.
This SQL file contains all the DDL to change the HR Schema so that it is synchronized with the model changes you made in the previous tutorial. When you execute this script, the PROJECTS and TASKS tables will be created, and the new COST_CENTER column will be added to the DEPARTMENTS table. Scroll down to review the DDL.
Select the hr_orcl connection from the list and click OK.
All the statements in the DDL script executed successfully
Click the Refresh icon to refresh the list of tables.
Notice that the new tables PROJECTS and TASKS are contained in the list. Expand the DEPARTMENTS, PROJECTS and TASKS table nodes and review the results. In the next topic, you create a procedure and run it.
Проблемы с индексами
Проблемы с индексами в плане выполнения проявляются при наличии в столбце Options значений FULL, FULL SCAN, FAST FULL SCAN и SKIP SCAN в силу следующих причин:
- Отсутствие нужного индекса. Требуемое действие — создать новый индекс;
- Индекс имеется, но он неэффективно построен. Причинами неэффективности индекса могут быть:
— Малая селективность столбца, на котором построен индекс, т.е. в столбце много одинаковых значений, мало уникальных значений. Решение в данной ситуации — убрать индекс из таблицы или столбец, на основе которого построен индекс, ввести в составной индекс.
— Столбец селективный, но он входит в составной индекс, в котором этом столбец не является первым (ведущим) в индексе. Решение – сделать этот столбец ведущим или создать новый индекс, где столбец будет ведущим; - Построен эффективный индекс, но он работает не эффективно в силу следующих причин:
— Индекс заблокирован от использования. Блокируют использование индекса следующие операции над столбцом, по которому используется индекс: SUBSTR, NVL, DECODE, TO_CHAR,TRUNC,TRIM, ||конкатенация, + цифра к цифровому полю и т.д.
Решение – модифицировать запрос, освободиться от блокирующих операций или создать индекс по функции, блокирующей индекс.
— Не собрана или неактуальная статистика по индексу. Решение – собрать статистику по индексу запуском процедуры, указанной выше.
— Имеется хинт, блокирующий работу индекса, например NO_INDEX.
— Неэффективно настроены параметры инициализации базы данных БД (особенно отвечающие за эффективную работу индексов, например, optimizer_index_caching и optimizer_index_cost_adj). По моему опыту использования Oracle 10g и 11g эффективность работы индексов повышалась, если optimizer_index_caching=95 и optimizer_index_cost_adj=1. - Имеются сильные индексы, но они соперничают между собой.
Это происходит тогда, когда в условии where имеется строка, в которой столбец одной таблицы равен столбцу другой таблицы. При этом на обоих столбцах построены сильные или уникальные индексы. Например, в условии Where имеется строка AND A.ISN=B.ISN. При этом оба столбца ISN разных таблиц имеют уникальные индексы. Однако, эффективно может работать индекс только одного столбца (левого или правого в равенстве). Индекс другого столбца, в лучшем случае, даст FAST FULL SCAN. В этой ситуации, чтобы эффективно заработали оба индекса, потребуется вести дополнительное условие для одного из столбцов. - Индекс имеет большой фактор кластеризации CLUSTERING_FACTOR.
По каждому индексу Oracle вычисляет фактор кластеризации (ФК), определяющий число перемещений от одного блока к другому в таблице при выборе индексом строк из таблицы. Минимальное значение ФК равно числу блоков таблицы, максимальное — числу строк в таблице. CLUSTERING_FACTOR определяется по запросу:
Фактор кластеризации для индекса считает во время сбора статистики. Он используется оптимизатором при расчете стоимости индексного доступа к данным таблицы. Большой ФК (особенно близкий к числу строк в таблице) говорит о неэффективном индексе. Таким образом, ФК является характеристикой индекса, а не таблицы. Первое решение при большом ФК является убрать существующий индекс как не эффективный. Второе решение, если данный индекс наиболее часто применяется в запросах и он нужен, то перестроить структуру таблицы таким образом, чтобы строки в блоках таблицы были упорядочены в том же порядке, в котором расположена информация по данным строкам в индексе, т.е. сделать кластерными блоки таблицы, уменьшив таким образом число перемещений от одного блока к другому при работе индекса.
Общие рекомендации по тестированию кода PL/SQL
Выбор инструмента тестирования зависит только от вас, но для повышения качества тестирования следует принять во внимание следующие факторы:
- Осознанная необходимость тестирования. Самые важные изменения должны произойти у вас в голове. От позиции «Надеюсь, эта программа сработает» необходимо перейти к позиции «Я должен быть способен доказать, что моя программа работает». Осознав необходимость тестирования, вы начнете писать более модульный код, который проще тестируется. Также вам понадобятся инструменты, позволяющие более эффективно проводить процесс тестирования.
- Продумайте тестовые сценарии до того, как возьметесь за написание программы, — сформулируйте их на листке бумаги или в программе, управляющей процессом тестирования. Очень важно, чтобы ваши представления о том, что же необходимо протестировать, нашли внешнее воплощение; в противном случае вы с большой вероятностью о чем-нибудь забудете. Приступая к работе над программой в понедельник, я легко могу представить 25 разных сценариев (требований), которые необходимо реализовать. Три дня спустя отведенное время заканчивается, я перехожу к тестированию — и как ни удивительно, могу вспомнить всего пять тестовых сценариев (да и то самых очевидных). Если вы составите список известных тестовых сценариев в начале работы, вам будет намного проще запомнить и проверить их.
- Не беспокойтесь о стопроцентном тестовом покрытии. Вряд ли существует хоть одна нетривиальная программа, которая была полностью протестирована. Не ставьте себе цель обеспечить стопроцентное покрытие всех возможных тестовых сценариев. Скорее всего, это нереально, а результат только приведет вас в уныние. Самое важное в тестировании — взяться за него. И что с того, что в фазе 1 было реализовано всего 10% тестовых сценариев? Это на 10% больше, чем было прежде. А когда ваши тестовые сценарии (и связанный с ними код) окажутся на месте, дополнить их новыми возможностями станет проще.
- Интеграция тестирования в разработку. Нельзя откладывать тестирование до того момента, когда вы «закончите» работу над программой. Чем раньше вы начнете думать над ним, тем лучше. Составьте перечень тестовых сценариев, спланируйте тестовый код и запускайте тесты в процессе реализации, отладки и совершенствования программы. При любой возможности снова выполняйте тесты и убеждайтесь в том, что программа действительно двигается вперед. Если вам нужно красивое название (методология), которое убедит вас в ценности такого подхода, изучите широко распространенную (в объектно-ориентированных кругах) методологию разработки через тестирование (TDD, Test-Driven Development).
- Подготовьте регрессионные тесты. Все перечисленные предложения в сочетании с инструментами, о которых рассказано в следующем разделе, помогут вам организовать регрессионное тестирование. Такие тесты должны предотвратить регрессию, то есть нарушение работоспособности ранее работавшего кода при внесении изменений. Ужасно неприятно, когда при выпуске версии 2 продукта половина функций версии 1 вдруг перестает работать. «Как это могло произойти?» — вопрошают пользователи. И что им на это ответить? Честный ответ должен звучать так: «Извините, но у нас не было времени на регрессионные тесты. Когда мы вносим изменения в своем запутанном коде, на самом деле мы понятия не имеем, что при этом могло сломаться». Но после создания нормальных регрессионных тестов вы можете уверенно вносить изменения и выдавать новые версии.
Active SQL Monitor Report
Основное назначение этого отчёта - периодически оценивать степень выплонения длительного SQL запроса. То есть этот отчёт может показывать нам сколько процентов работы уже выполнено параллельными сессиями, и сколько ещё осталось. В дополнение, Active SQL Monitor Report собирает для нас всю использованную выше статистику для уже выполненных SQL запросов длинной более 5 секунд (и для всех параллельных запросов). Это позволяет нам увидеть всю необходимую информацию в одном месте, без блуждания по raw trace файлам - и почти полностью исключает необходимость перезапусков "медленных" запросов. Генерировать этот отчёт надо как можно быстрее - желательно сразу же после завершения "плохого" запроса.
Итак, освежим нашу память - в чём проблема? Предположим, что один из разработчиков "по-старинке" уверен что индекс надо использовать всегда. Наш специалист берёт "хороший" запрос и делает из него "плохой" запрос (см. выше). После попадания этого кода в "живую" систему наши пользователи начинают жаловаться на резкое замедление работы приложения.
Как администраторы баз данных, мы должны найти причину деградации производительности как можно скорее. Мы быстренько генерируем AWR report за последние 15-20 минут и обнаруживаем наш "плохой" запрос на месте лидера по потреблению ресурсов системы. У нас нет времени на подробное "разжёвывание" запроса, как было сделано выше. Нам надо просто как можно быстрее понять, на что же "плохой" запрос тратит время и IO ресурсы. Выплоняем следующий шаг:
Главное, что нам надо записать - SQL_ID и SQL_EXEC_ID, эти два параметра однозначно определяют о каком SQL запросе мы говорим. Найдём соответствующие значения для "плохого" отчёта с индексом.
Итак, все необходимые данные имеются - сгенерируем Active SQL Monitor Report для обоих случаев. Необходимо правильно настроить параметры вывода SQL*Plus и потом вручную отредактировать HTML файлы. Не пропустите самую первую строку "set . " - без неё ваш SQL Monitor Report будет нечитаемым.
Отредактируем оба spool файла так, чтобы в них не было лишних строк внизу и вверху и загрузим их к себе на компьютер. Используйте веб броузер, подключённый к интернету и с полностью включенными Java Script и Plugins. Я всегда пользуюсь Opera.
Открыв файл "bad.sql", на странице "Details / Plan" мы сможем увидеть точное распределение 30-ти "consistent gets" между операциями доступа к таблице по индексу - 13 чтений буферов (в нашем случае и блоков) индекса и 17 чтений таблицы. "Откопать" эту информацию иным способом достаточно сложно и долго. Кроме того, время исполнения запроса указано с точностью до микросекунды. Сравните данные со вторым отчётом "good.sql".
Теперь поэкспериментируйте с другими запросами посложнее и обратите внимание на очень полезную страницу "Activity".
Я уверен что "Active SQL Monitor Report" послужит вам отличным подспорьем в работе.
SQL checker allows to check your SQL query syntax, it focuses on MySQL dialect (MySQL syntax checker). You can valide the syntax of your queries and find the syntax errors easily (the errors are highlighted).
Читайте также: