
Проблема когерентности кэшей заключается в том что
Требования, предъявляемые современными процессорами к полосе пропускания памяти можно существенно сократить путем применения больших многоуровневых кэшей. Тогда, если эти требования снижаются, то несколько процессоров смогут разделять доступ к одной и той же памяти. Начиная с 1980 года эта идея, подкрепленная широким распространением микропроцессоров, стимулировала многих разработчиков на создание небольших мультипроцессоров, в которых несколько процессоров разделяют одну физическую память, соединенную с ними с помощью разделяемой шины. Из-за малого размера процессоров и заметного сокращения требуемой полосы пропускания шины, достигнутого за счет возможности реализации достаточно большой кэш-памяти, такие машины стали исключительно эффективными по стоимости. В первых разработках подобного рода машин удавалось разместить весь процессор и кэш на одной плате, которая затем вставлялась в заднюю панель, с помощью которой реализовывалась шинная архитектура. Современные конструкции позволяют разместить до четырех процессоров на одной плате. На рисунке 5.40 показана схема именно такой машины.
В такой машине кэши могут содержать как разделяемые, так и частные данные. Частные данные - это данные, которые используются одним процессором, в то время как разделяемые данные используются многими процессорами, по существу обеспечивая обмен между ними. Когда кэшируется элемент частных данных, их значение переносится в кэш для сокращения среднего времени доступа, а также требуемой полосы пропускания. Поскольку никакой другой процессор не использует эти данные, этот процесс идентичен процессу для однопроцессорной машины с кэш-памятью. Если кэшируются разделяемые данные, то разделяемое значение реплицируется и может содержаться в нескольких кэшах. Кроме сокращения задержки доступа и требуемой полосы пропускания такая репликация данных способствует также общему сокращению количества обменов. Однако кэширование разделяемых данных вызывает новую проблему: когерентность кэш-памяти.
Рис. 5.40. Типовая архитектура мультипроцессорной системы с общей памятью
Мультипроцессорная когерентность кэш-памяти
Проблема, о которой идет речь, возникает из-за того, что значение элемента данных в памяти, хранящееся в двух разных процессорах, доступно этим процессорам только через их индивидуальные кэши. На рисунке 5.41 показан простой пример, иллюстрирующий эту проблему.
Рис. 5.41. Иллюстрация проблемы когерентности кэш-памяти
- Протоколы на основе справочника (directory based). Информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы).
- Протоколы наблюдения (snooping). Каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии. Централизованная система записей отсутствует. Обычно кэши расположены на общей (разделяемой) шине и контроллеры всех кэшей наблюдают за шиной (просматривают ее) для определения того, не содержат ли они копию соответствующего блока.
В мультипроцессорных системах, использующих микропроцессоры с кэш-памятью, подсоединенные к централизованной общей памяти, протоколы наблюдения приобрели популярность, поскольку для опроса состояния кэшей они могут использовать заранее существующее физическое соединение - шину памяти.
Неформально, проблема когерентности памяти состоит в необходимости гарантировать, что любое считывание элемента данных возвращает последнее по времени записанное в него значение. Это определение не совсем корректно, поскольку невозможно требовать, чтобы операция считывания мгновенно видела значение, записанное в этот элемент данных некоторым другим процессором. Если, например, операция записи на одном процессоре предшествует операции чтения той же ячейки на другом процессоре в пределах очень короткого интервала времени, то невозможно гарантировать, что чтение вернет записанное значение данных, поскольку в этот момент времени записываемые данные могут даже не покинуть процессор. Вопрос о том, когда точно записываемое значение должно быть доступно процессору, выполняющему чтение, определяется выбранной моделью согласованного (непротиворечивого) состояния памяти и связан с реализацией синхронизации параллельных вычислений. Поэтому с целью упрощения предположим, что мы требуем только, чтобы записанное операцией записи значение было доступно операции чтения, возникшей немного позже записи и что операции записи данного процессора всегда видны в порядке их выполнения.
- Операция чтения ячейки памяти одним процессором, которая следует за операцией записи в ту же ячейку памяти другим процессором получит записанное значение, если операции чтения и записи достаточно отделены друг от друга по времени.
- Операции записи в одну и ту же ячейку памяти выполняются строго последовательно (иногда говорят, что они сериализованы): это означает, что две подряд идущие операции записи в одну и ту же ячейку памяти будут наблюдаться другими процессорами именно в том порядке, в котором они появляются в программе процессора, выполняющего эти операции записи.
Первое свойство очевидно связано с определением когерентного (согласованного) состояния памяти: если бы процессор всегда бы считывал только старое значение данных, мы сказали бы, что память некогерентна.
Необходимость строго последовательного выполнения операций записи является более тонким, но также очень важным свойством. Представим себе, что строго последовательное выполнение операций записи не соблюдается. Тогда процессор P1 может записать данные в ячейку, а затем в эту ячейку выполнит запись процессор P2. Строго последовательное выполнение операций записи гарантирует два важных следствия для этой последовательности операций записи. Во-первых, оно гарантирует, что каждый процессор в машине в некоторый момент времени будет наблюдать запись, выполняемую процессором P2. Если последовательность операций записи не соблюдается, то может возникнуть ситуация, когда какой-нибудь процессор будет наблюдать сначала операцию записи процессора P2, а затем операцию записи процессора P1, и будет хранить это записанное P1 значение неограниченно долго. Более тонкая проблема возникает с поддержанием разумной модели порядка выполнения программ и когерентности памяти для пользователя: представьте, что третий процессор постоянно читает ту же самую ячейку памяти, в которую записывают процессоры P1 и P2; он должен наблюдать сначала значение, записанное P1, а затем значение, записанное P2. Возможно он никогда не сможет увидеть значения, записанного P1, поскольку запись от P2 возникла раньше чтения. Если он даже видит значение, записанное P1, он должен видеть значение, записанное P2, при последующем чтении. Подобным образом любой другой процессор, который может наблюдать за значениями, записываемыми как P1, так и P2, должен наблюдать идентичное поведение. Простейший способ добиться таких свойств заключается в строгом соблюдении порядка операций записи, чтобы все записи в одну и ту же ячейку могли наблюдаться в том же самом порядке. Это свойство называется последовательным выполнением (сериализацией) операций записи (write serialization). Вопрос о том, когда процессор должен увидеть значение, записанное другим процессором достаточно сложен и имеет заметное воздействие на производительность, особенно в больших машинах.
Альтернативные протоколы
Имеются две методики поддержания описанной выше когерентности. Один из методов заключается в том, чтобы гарантировать, что процессор должен получить исключительные права доступа к элементу данных перед выполнением записи в этот элемент данных. Этот тип протоколов называется протоколом записи с аннулированием (write ivalidate protocol), поскольку при выполнении записи он аннулирует другие копии. Это наиболее часто используемый протокол как в схемах на основе справочников, так и в схемах наблюдения. Исключительное право доступа гарантирует, что во время выполнения записи не существует никаких других копий элемента данных, в которые можно писать или из которых можно читать: все другие кэшированные копии элемента данных аннулированы. Чтобы увидеть, как такой протокол обеспечивает когерентность, рассмотрим операцию записи, вслед за которой следует операция чтения другим процессором. Поскольку запись требует исключительного права доступа, любая копия, поддерживаемая читающим процессором должна быть аннулирована (в соответствии с названием протокола). Таким образом, когда возникает операция чтения, произойдет промах кэш-памяти, который вынуждает выполнить выборку новой копии данных. Для выполнения операции записи мы можем потребовать, чтобы процессор имел достоверную (valid) копию данных в своей кэш-памяти прежде, чем выполнять в нее запись. Таким образом, если оба процессора попытаются записать в один и тот же элемент данных одновременно, один из них выиграет состязание у второго (мы вскоре увидим, как принять решение, кто из них выиграет) и вызывает аннулирование его копии. Другой процессор для завершения своей операции записи должен сначала получить новую копию данных, которая теперь уже должна содержать обновленное значение.
Альтернативой протоколу записи с аннулированием является обновление всех копий элемента данных в случае записи в этот элемент данных. Этот тип протокола называется протоколом записи с обновлением (write update protocol) или протоколом записи с трансляцией (write broadcast protocol). Обычно в этом протоколе для снижения требований к полосе пропускания полезно отслеживать, является ли слово в кэш-памяти разделяемым объектом, или нет, а именно, содержится ли оно в других кэшах. Если нет, то нет никакой необходимости обновлять другой кэш или транслировать в него обновленные данные.
- Несколько последовательных операций записи в одно и то же слово, не перемежающихся операциями чтения, требуют нескольких операций трансляции при использовании протокола записи с обновлением, но только одной начальной операции аннулирования при использовании протокола записи с аннулированием.
- При наличии многословных блоков в кэш-памяти каждое слово, записываемое в блок кэша, требует трансляции при использовании протокола записи с обновлением, в то время как только первая запись в любое слово блока нуждается в генерации операции аннулирования при использовании протокола записи с аннулированием. Протокол записи с аннулированием работает на уровне блоков кэш-памяти, в то время как протокол записи с обновлением должен работать на уровне отдельных слов (или байтов, если выполняется запись байта).
- Задержка между записью слова в одном процессоре и чтением записанного значения другим процессором обычно меньше при использовании схемы записи с обновлением, поскольку записанные данные немедленно транслируются в процессор, выполняющий чтение (предполагается, что этот процессор имеет копию данных). Для сравнения, при использовании протокола записи с аннулированием в процессоре, выполняющим чтение, сначала произойдет аннулирование его копии, затем будет производиться чтение данных и его приостановка до тех пор, пока обновленная копия блока не станет доступной и не вернется в процессор.
Эти две схемы во многом похожи на схемы работы кэш-памяти со сквозной записью и с записью с обратным копированием. Также как и схема задержанной записи с обратным копированием требует меньшей полосы пропускания памяти, так как она использует преимущества операций над целым блоком, протокол записи с аннулированием обычно требует менее тяжелого трафика, чем протокол записи с обновлением, поскольку несколько записей в один и тот же блок кэш-памяти не требуют трансляции каждой записи. При сквозной записи память обновляется почти мгновенно после записи (возможно с некоторой задержкой в буфере записи). Подобным образом при использовании протокола записи с обновлением другие копии обновляются так быстро, насколько это возможно. Наиболее важное отличие в производительности протоколов записи с аннулированием и с обновлением связано с характеристиками прикладных программ и с выбором размера блока.
Основы реализации
Ключевым моментом реализации в многопроцессорных системах с небольшим числом процессоров как схемы записи с аннулированием, так и схемы записи с обновлением данных, является использование для выполнения этих операций механизма шины. Для выполнения операции обновления или аннулирования процессор просто захватывает шину и транслирует по ней адрес, по которому должно производиться обновление или аннулирование данных. Все процессоры непрерывно наблюдают за шиной, контролируя появляющиеся на ней адреса. Процессоры проверяют не находится ли в их кэш-памяти адрес, появившийся на шине. Если это так, то соответствующие данные в кэше либо аннулируются, либо обновляются в зависимости от используемого протокола. Последовательный порядок обращений, присущий шине, обеспечивает также строго последовательное выполнение операций записи, поскольку когда два процессора конкурируют за выполнение записи в одну и ту же ячейку, один из них должен получить доступ к шине раньше другого. Один процессор, получив доступ к шине, вызовет необходимость обновления или аннулирования копий в других процессорах. В любом случае, все записи будут выполняться строго последовательно. Один из выводов, который следует сделать из анализа этой схемы заключается в том, что запись в разделяемый элемент данных не может закончиться до тех пор, пока она не захватит доступ к шине.
В дополнение к аннулированию или обновлению соответствующих копий блока кэш-памяти, в который производилась запись, мы должны также разместить элемент данных, если при записи происходит промах кэш-памяти. В кэш-памяти со сквозной записью последнее значение элемента данных найти легко, поскольку все записываемые данные всегда посылаются также и в память, из которой последнее записанное значение элемента данных может быть выбрано (наличие буферов записи может привести к некоторому усложнению).
Однако для кэш-памяти с обратным копированием задача нахождения последнего значения элемента данных сложнее, поскольку это значение скорее всего находится в кэше, а не в памяти. В этом случае используется та же самая схема наблюдения, что и при записи: каждый процессор наблюдает и контролирует адреса, помещаемые на шину. Если процессор обнаруживает, что он имеет модифицированную ("грязную") копию блока кэш-памяти, то именно он должен обеспечить пересылку этого блока в ответ на запрос чтения и вызвать отмену обращения к основной памяти. Поскольку кэши с обратным копированием предъявляют меньшие требования к полосе пропускания памяти, они намного предпочтительнее в мультипроцессорах, несмотря на некоторое увеличение сложности. Поэтому далее мы рассмотрим вопросы реализации кэш-памяти с обратным копированием.
Для реализации процесса наблюдения могут быть использованы обычные теги кэша. Более того, упоминавшийся ранее бит достоверности (valid bit), позволяет легко реализовать аннулирование. Промахи операций чтения, вызванные либо аннулированием, либо каким-нибудь другим событием, также не сложны для понимания, поскольку они просто основаны на возможности наблюдения. Для операций записи мы хотели бы также знать, имеются ли другие кэшированные копии блока, поскольку в случае отсутствия таких копий, запись можно не посылать на шину, что сокращает время на выполнение записи, а также требуемую полосу пропускания.
Чтобы отследить, является ли блок разделяемым, мы можем ввести дополнительный бит состояния (shared), связанный с каждым блоком, точно также как это делалось для битов достоверности (valid) и модификации (modified или dirty) блока. Добавив бит состояния, определяющий является ли блок разделяемым, мы можем решить вопрос о том, должна ли запись генерировать операцию аннулирования в протоколе с аннулированием, или операцию трансляции при использовании протокола с обновлением. Если происходит запись в блок, находящийся в состоянии "разделяемый" при использовании протокола записи с аннулированием, кэш формирует на шине операцию аннулирования и помечает блок как частный (private). Никаких последующих операций аннулирования этого блока данный процессор посылать больше не будет. Процессор с исключительной (exclusive) копией блока кэш-памяти обычно называется "владельцем" (owner) блока кэш-памяти.
При использовании протокола записи с обновлением, если блок находится в состоянии "разделяемый", то каждая запись в этот блок должна транслироваться. В случае протокола с аннулированием, когда посылается операция аннулирования, состояние блока меняется с "разделяемый" на "неразделяемый" (или "частный"). Позже, если другой процессор запросит этот блок, состояние снова должно измениться на "разделяемый". Поскольку наш наблюдающий кэш видит также все промахи, он знает, когда этот блок кэша запрашивается другим процессором, и его состояние должно стать "разделяемый".
Рис. 5.42. Примеры протоколов наблюдения
Если процессор использует многоуровневый кэш со свойствами охвата, тогда каждая строка в основном кэше имеется и во вторичном кэше. Таким образом, активность по наблюдению может быть связана с кэшем второго уровня, в то время как большинство активностей процессора могут быть связаны с первичным кэшем. Если механизм наблюдения получает попадание во вторичный кэш, тогда он должен выполнять арбитраж за первичный кэш, чтобы обновить состояние и возможно найти данные, что обычно будет приводить к приостановке процессора. Такое решение было принято во многих современных системах, поскольку многоуровневый кэш позволяет существенно снизить требований к полосе пропускания. Иногда может быть даже полезно дублировать теги во вторичном кэше, чтобы еще больше сократить количество конфликтов между активностями процессора и механизма наблюдения.
В реальных системах существует много вариаций схем когерентности кэша, в зависимости от того используется ли схема на основе аннулирования или обновления, построена ли кэш-память на принципах сквозной или обратной записи, когда происходит обновление, а также имеет ли место состояние "владения" и как оно реализуется. На рисунке 5.42 представлены несколько протоколов с наблюдением и некоторые машины , которые используют эти протоколы.
В свое время это тема показалась мне очень интересной, поэтому я решил поделиться своими скромными знаниями с вами. Данная статья не претендует на полное детальное описание, скорее это краткий обзор.
Введение
Ни для кого не секрет, что в современных компьютерах доступ к памяти могут одновременно иметь несколько независимых процессоров (ядер, трэдов). Каждый из них имеет свои приватные кэши, в которых хранятся копии необходимых линий, а некоторые из них при этом локально модифицированы. Встает вопрос, а что если одна и та же линия одновременно понадобится нескольким процессорам. Не сложно сделать вывод, что для корректной работы системы необходимо обеспечить единое пространство памяти для всех процессоров.
Для обеспечения этого были придуманы специальные протоколы когерентности. Когерентность кэша — свойства кэш-памяти, означающее целостность данных, хранящихся в локальных кэшах, разделяемой системы. Каждая ячейка кэша имеет флаги, описывающие, как ее состояние соотносится с состоянием ячейки с таким же адресом в других процессорах системы.
Было придумано множество протоколов когерентности, отличающиеся алгоритмами, количеством состояний и, как следствие скоростью работы и масштабируемостью. Большинство современных протоколов когерентности представляют вариации протокола MESI [1]. По этой причине мы его и рассмотрим.
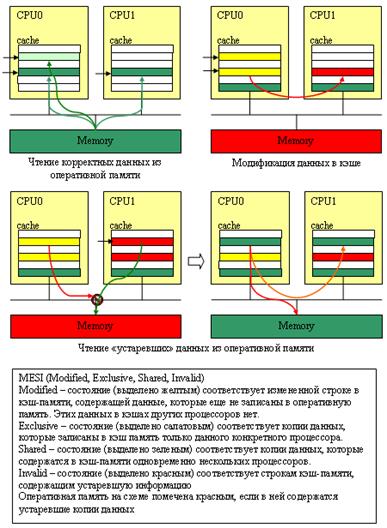
В данной схеме каждая линию кэша может находиться в одном из четырех состояний:
- Модифицированная (M) англ. modified. Таким флагом может быть помечена только линия в одном кэше. Данное состояние означает, что данная линия была изменена, но до памяти эти изменения еще не дошли. Хозяин такой линии может спокойно читать и писать в нее без опроса остальных.
- Эксклюзивная (E) англ. exclusive. Обозначенная таким флагом линия, так же, как и M-линия может находиться только в одном кэше. Содержащиеся в ней данные полностью идентичны данным в оперативной памяти. Записывать и читать из нее можно без внешних запросов, так как она хранится только в одном кэше. После записи такая строка должна быть помечена, как модифицированная.
- Разделяемая (S) англ. shared. Линия может одновременно содержаться в кэшах нескольких устройств и использоваться совместно. Запросы на запись в такую линию всегда идут на общую шину, что привод к тому, что все линии с таким адресов в остальных кэшах помечаются как недействительные. При этом содержание основной памяти также обновляется. Чтение же из такой линии, не требует ни каких внешних запросов.
- Недействительная (I) англ. invalid. Такая линия считается невалидной и попытка прочитать приведет к кэш-промаху. Линия помечается недействительной в случае если она пусти или содержит устаревшую информацию.
Диаграмма переходов протокола MESI. Доступ являет местным, если он был инициирован процессоров данного кэша, удаленным — если его вызвал любой другой.

Также хочу рассмотреть одну из оптимизаций протокола MESI
MOESI
Для данного протокола флаги состояния были расширены еще одним значением «Владелец» (O) англ. owner. Данное состояние является комбинацией состояний «Модифицированная» и «Разделяемая». Такое состояние позволяет избежать необходимости записи измененной линии в память, тем самым снижая трафик направленный в память. Кэш линия в такой состоянии содержит наиболее свежие данные. Описанное состояние похоже на Shared тем, что и другие процессоры тоже могут иметь наиболее более свежие по отношению к ОЗУ данные у себя в кэш-памяти. Однако в отличие от него такое состояние обозначает, что данные в памяти устарели. Только одна линия с определенным адресом может иметь такое состояние, при этом на все запросы о чтении по данному адресу отвечать будет именно она, а не память.
Это все, про что я хотел рассказать сегодня, надеюсь, что моя статья окажется кому-нибудь интересна.
Дополнительную информацию на эту тему можно найти в источниках обозначенных ниже.
Литература
[1] Обзор существующих протоколов, с диаграммами перехода
[2] Г.С. Речистов, Е.А. Юлюгин, А.А. Иванов, П.Л. Шишпор, Н.Н. Щелкунов «Основы программного моделирования ЭВМ» URL
[3]Ulrich Drepper «What Every Programmer Should Know About Memory» URL
Да, текущие двухъядерные процессоры AMD и Intel не имеют «общей» кэш-памяти, используя которую одно ядро могло бы увеличивать свою производительность за счёт другого. Можно даже встретить мнение, что, мол, ничего принципиально интересного поэтому в двухъядерниках AMD нету. Но процессоры архитектуры K8 способны эффективно «лазить» в кэш-память своих соседей, не обращая внимания на то, что кэши у них раздельные! Просто нужно обратить внимание на скромную строчку в перечне характеристик кэша – где в графе «протокол поддержания когерентности кэшей» у процессоров AMD записано «MOESI».
 |
Что вообще такое «протокол поддержания когерентности кэшей»? Пусть, например, у нас процессор CPU0 произвел какие-то вычисления и записал полученный результат в оперативную память. Поскольку у CPU0, разумеется, есть «своя», персональная кэш-память (хотя бы первого уровня), то запись данных производится не в «тормозную» оперативную память, а в кэш. В случае однопроцессорных систем эта схема замечательно работает… но что будет, если в многопроцессорной системе та же самая ячейка памяти, которую изменил процессор CPU0, для каких-то целей понадобится и процессору CPU1? В «лучшем» случае CPU1 прочитает эту ячейку из оперативной памяти, куда, если повезет, процессор CPU0 уже успеет сохранить её новое значение. В худшем – эта ячейка (с устаревшими данными) окажется в его кэше и CPU1 даже не будет пытаться выяснить, изменилось ли что-нибудь с тех пор, как он в последний раз эту ячейку из оперативной памяти прочитал. Всё вместе называется «проблемой когерентности кэшей», а методы её решения – как раз и называют соответствующими «протоколами».
 |
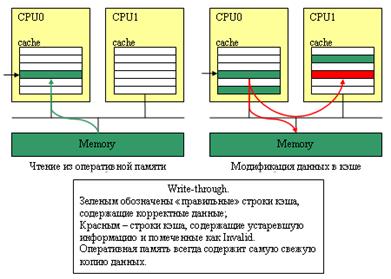
Как эту проблему решают? Простейший протокол поддержания когерентности – это так называемый Write-Through, когда любые изменения сразу же записываются (write through cache) не только в кэш-память, но и в оперативную память компьютера; причем остальные процессоры как-то об этом знаменательном событии информируются. Например, если используется общая шина, то другие процессоры просто «подслушивают» (snoop), что текущий «владелец» шины по ней пересылает и, зарегистрировав, что CPU0 выполняет операцию записи в память, обновляют «свои» записи в кэше. Обычно, чтобы сэкономить время - просто помечают, что соответствующие строки в кэше отныне «неправильные» (Invalid) и при обращении к ним данные необходимо брать не из кэша, а из оперативной памяти. Схема достаточно простая. но неэффективная: запись данных в оперативную память – далеко не быстрый процесс.
 |
Но зачем разбазаривать зря ресурсы компьютера (пропускную способность шины и оперативной памяти), сохраняя малейшие изменения в медленной оперативной памяти, если вся эта «обновленная» информация может еще десять раз обновиться, прежде чем она понадобится кому-то кроме «владеющего» этой информацией процессора? А ведь если поразмыслить, то работа нескольких процессоров одновременно с одним и тем же участком оперативной памяти – явление исключительное: в подавляющем большинстве случаев каждый процессор занимается обработкой «своего» участка и лишь изредка – обращается к участку «чужому»2. Именно эта идея положена в основу протокола MESI. Использующий его процессор, четко различает кэш-строки, которых заведомо нет в кэшах других процессоров (они помечаются как Exclusive) и «общие», присутствующие более чем в одном кэше (они помечаются как Shared). Если изменяется Shared-строка, то «соседям» по компьютеру передается сигнал-требование проверить свои кэши и, если что, сделать напротив своих записей в кэшах пометку «неправильно» (Invalid); если изменяется Exclusive-строка (а как уже говорилось, вероятность этого события очень велика), то делать эту достаточно трудоемкую операцию нет необходимости. В любом случае строка помечается как Modified, но попыток эту самую строку немедленно записать в оперативную память не предпринимается. Зато все процессоры бдительно наблюдают за всеми операциями чтения данных из памяти и если один из процессоров замечает, что его сосед пытается прочитать строчку памяти, которая в его кэше помечена, как «Modified», то он прерывает эту операцию, сохраняет изменения в оперативной памяти, снимает со «своей» кэш-строки «галочку» Modified и только после этого разрешает вызвавшему «проблему» процессору завершить операцию чтения. В итоге «типовые» операции с кэш-памятью в MESI происходят практически с той же скоростью, что и в single-системе.

 |
А что же AMD? AMD использует всё тот же MESI, но только доработанный таким образом, чтобы процессоры могли эффективно использовать данные из кэш-памяти друг друга. В MESI процессоры почти не используют кэши своих соседей: в лучшем случае, чтение обновленных данных из памяти производится при выгрузке этих данных в память «соседом». В протоколе же MOESI любая операция чтения сопровождается проверкой кэшей соседей – если нужные данные находятся в одном из них, то и читаются они прямо оттуда; причем сохранение этих данных в оперативную память при этом не производится. Просто «владелец» этой памяти делает у себя «зарубку» Owner3 напротив соответствующей строки кэш-памяти. Мы убиваем двух зайцев одним выстрелом: не производим ненужных записей в оперативную память и эффективно используем память «соседа». В итоге в двухядерных процессорах кэш-память первого и второго уровней «соседнего ядра» может работать как кэш-память третьего уровня (L3); а кэш-память «чужих» процессоров в многопроцессорной системе – как кэши четвертого уровня. Конечно, это не «полноценный» кэш L3/L4 и уж точно – не полноценный разделяемый L2 (поскольку самостоятельно загрузить «соседа» своими данными ядро процессора не может – оно может только надеяться, что «сосед» тоже эти данные будет использовать), однако свою прибавку к производительности, безусловно, MOESI должен обеспечивать. Только не следует думать, что в Intel не могут реализовать аналог протокола, предложенного еще аж в 1986 году (и определенные варианты таки присутствует в Itanium-системах и некоторых других ядрах) – просто для систем с общей системной шиной никаких преимуществ по сравнению с MESI он не предоставляет. Что просто перебросить по этой медленной общей шине данные от одного процессора к другому, что эти данные заодно и в оперативную память записать – разницы почти никакой. А вот для процессоров AMD, у которых ядра и процессоры связаны между собой интерфейсами, работающими гораздо быстрее обычной оперативной памяти, разница есть и порой она становится весьма ощутимой.
 |
| Система на основе Pentium 4 supporting Hyper-Threading |
Чтобы всё не выглядело настолько неприглядно для Intel, заметим, что у этой корпорации тоже есть очень сильный козырь в кармане – и называется он Hyper-Threading. Технология виртуальной многопоточности (когда одно физическое ядро изображает из себя несколько «виртуальных») позволяет гораздо эффективнее загрузить исполнительные блоки этих процессоров работой. Мало кто знает, что IPC (количество инструкций, которые можно выполнить за один такт) для этих процессоров в устоявшемся режиме может доходить до четырех. Это не просто много: это очень много даже по современным меркам. Для сравнения, процессоры AMD архитектур K7 и K8 выполняют по 3 (в пике – до 6) инструкций за такт, то есть теоретическая эффективность в пересчете на один мегагерц у Pentium 4 должна быть выше, чем у Athlon 64 и Opteron. Почему КПД архитектуры NetBurst в ряде приложений получается «очень скромным» - вопрос для немаленькой отдельной статьи (да и написано по этому поводу уже очень много), отметим только, что сверхвысокие IPC для Pentium 4 вполне можно увидеть на практике – на тщательно оптимизированных приложениях и тестах типа Linpack-а или Prime 95. Главное – это то, что Hyper-Threading позволяет существующий КПД процессора на 10-25% увеличить: подобная прибавка вполне способна перекрыть и выигрыш от более быстрой подсистемы памяти, и от более быстрой шины и от «более продвинутого» протокола MOESI.
Впрочем, по утверждениям самой Intel, двухъядерность будет значительно эффективнее на тех же задачах, где имеется прирост от использования Hyper-Threading. И это легко понять, если взглянуть на следующие блок-схемы протекания процессов в двуядерной системе и одноядерной системе с Hyper-Threading.
| Блок-схемы Hyper-Threading vs Dual Core |
 |
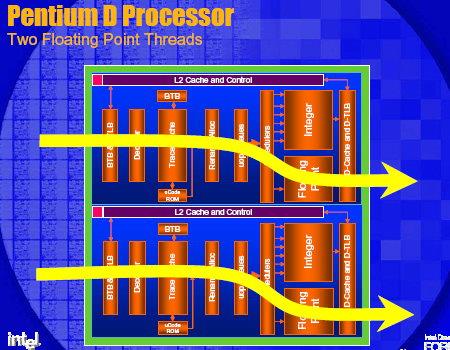 |
 |
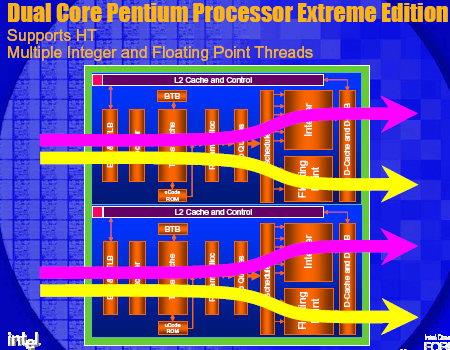 |
Тем не менее, для процессора Intel Pentium Extreme Edition, имеющего обе эти «фичи» и видимого в операционной системе как четыре логических процессора, определенные сомнения в эффективности совместного использования двухъядерности и Hyper-Threading могут возникнуть, хотя профессиональные приложения, показывающие мощный прирост и в этом случае, все же существуют (например, Cinema 4D и другой 3D-рендеринг).
Двуядерные процессоры AMD и Intel не имеют общей кэш-памяти, используя которую, одно ядро могло бы увеличивать свою производительность за счёт другого. Но процессоры архитектуры K8 способны эффективно «лазить» в кэш-память своих соседей, не обращая внимания на то, что кэш у них раздельные. Просто нужно обратить внимание на скромную строчку в перечне характеристик кэш, где в графе «протокол поддержания когерентности кэш-памяти» у процессоров AMD записано «MOESI».
 |
Что же такое «протокол поддержания когерентности кэш»? Пусть, например, у нас процессор CPU0 произвел какие-то вычисления и записал полученный результат в оперативную память. Поскольку у CPU0, разумеется, есть «своя», персональная кэш-память (хотя бы первого уровня), то запись данных производится не в «медленную» оперативную память, а в кэш.
 |
В случае однопроцессорных систем эта схема хорошо работает, но что будет, если в многопроцессорной системе та же самая ячейка памяти, которую изменил процессор CPU0, для каких-то целей понадобится и процессору CPU1? В «лучшем» случае CPU1 прочитает эту ячейку из оперативной памяти, куда, если повезет, процессор CPU0 уже успеет сохранить её новое значение. В худшем – эта ячейка (с устаревшими данными) окажется в его кэш, и CPU1 даже не будет пытаться выяснить, изменилось ли что-нибудь с тех пор, как он в последний раз эту ячейку из оперативной памяти прочитал. Всё вместе называется «проблемой когерентности кэш-памяти», а методы её решения – как раз и называют соответствующими протоколами.
Простейший протокол поддержания когерентности – это так называемый Write-Through, когда любые изменения сразу же записываются (write through cache) не только в кэш-память, но и в оперативную память компьютера; причем остальные процессоры об этом событии информируются. Например, если используется общая шина, то другие процессоры просто «подслушивают» (snoop), что текущий «владелец» шины по ней пересылает и, зарегистрировав, что CPU0 выполняет операцию записи в память, обновляют «свои» записи в кэш. Обычно, чтобы сэкономить время - просто помечают, что соответствующие строки в кэш отныне «неправильные» (Invalid) и при обращении к ним данные необходимо брать не из кэш, а из оперативной памяти. Схема достаточно простая, но неэффективная: запись данных в оперативную память – далеко не быстрый процесс.
 |
Но зачем тратить зря ресурсы компьютера (пропускную способность шины и оперативной памяти), сохраняя малейшие изменения в медленной оперативной памяти, если вся эта «обновленная» информация может еще десять раз обновиться, прежде чем она понадобится кому-то кроме «владеющего» этой информацией процессора? Работа нескольких процессоров одновременно с одним и тем же участком оперативной памяти – явление исключительное: в подавляющем большинстве случаев каждый процессор занимается обработкой «своего» участка и лишь изредка – обращается к участку «чужому».
Именно эта идея положена в основу протокола MESI. Использующий его процессор четко различает кэш-строки, которых заведомо нет в кэш других процессоров (они помечаются как Exclusive), и «общие», присутствующие более чем в одном кэш (они помечаются как Shared). Если изменяется Shared-строка, то «соседям» по компьютеру передается сигнал-требование проверить свои кэш и, если требуется, сделать напротив своих записей в кэш пометку «неправильно» (Invalid). Если изменяется Exclusive-строка (а как уже говорилось, вероятность этого события очень велика), то делать эту достаточно трудоемкую операцию нет необходимости. В любом случае строка помечается как Modified, но попыток эту самую строку немедленно записать в оперативную память не предпринимается. Зато все процессоры бдительно наблюдают за всеми операциями чтения данных из памяти, и если один из процессоров замечает, что его сосед пытается прочитать строчку памяти, которая в его кэш помечена как «Modified», то он прерывает эту операцию, сохраняет изменения в оперативной памяти, снимает со «своей» кэш-строки «галочку» Modified и только после этого разрешает вызвавшему «проблему» процессору завершить операцию чтения. В итоге «типовые» операции с кэш-памятью в MESI происходят практически с той же скоростью, что и в single-системе.
AMD использует всё тот же протокол MESI, но только доработанный таким образом, чтобы процессоры могли эффективно использовать данные из кэш-памяти друг друга. В MESI процессоры почти не используют кэш своих соседей: в лучшем случае чтение обновленных данных из памяти производится при выгрузке этих данных в память «соседом». В протоколе же MOESI любая операция чтения сопровождается проверкой кэш соседей – если нужные данные находятся в одном из них, то и читаются они прямо оттуда; причем сохранение этих данных в оперативную память при этом не производится. Просто «владелец» этой памяти ставит у себя метку Owner3 напротив соответствующей строки кэш-памяти. Это позволяет не производить ненужных записей в оперативную память и эффективно использовать память «соседа». В итоге в двуядерных процессорах кэш-память первого и второго уровней «соседнего ядра» может работать как кэш-память третьего уровня (L3); а кэш-память «чужих» процессоров в многопроцессорной системе – как кэш четвертого уровня. Конечно, это не «полноценный» кэш L3/L4 и уж точно – не полноценный разделяемый L2 (поскольку самостоятельно загрузить «соседа» своими данными ядро процессора не может – оно может только надеяться, что «сосед» тоже эти данные будет использовать), однако свою прибавку к производительности, безусловно, MOESI должен обеспечивать. Это не означает, что в Intel не могут реализовать аналог протокола, предложенного в 1986 году (и определенные варианты присутствует в Itanium-системах и некоторых других ядрах) – просто для систем с общей системной шиной никаких преимуществ по сравнению с MESI он не предоставляет. Что просто перебросить по этой медленной общей шине данные от одного процессора к другому, что эти данные заодно и в оперативную память записать – разницы почти никакой. А вот для процессоров AMD, у которых ядра и процессоры связаны между собой интерфейсами, работающими гораздо быстрее обычной оперативной памяти, разница есть, и порой она становится весьма ощутимой.
| Система на основе Pentium 4 supporting Hyper-Threading |
Чтобы отметить преимущества подхода Intel, заметим, что у этой корпорации тоже есть эффективная технология Hyper-Threading. Технология виртуальной многопоточности (когда одно физическое ядро изображает из себя несколько «виртуальных») позволяет гораздо эффективнее загрузить исполнительные блоки этих процессоров работой. Параметр IPC (количество инструкций, которые можно выполнить за один такт) для этих процессоров в устоявшемся режиме может доходить до четырех. Это не просто много: это очень много даже по современным меркам. Для сравнения: процессоры AMD архитектур K7 и K8 выполняют по 3 (в пике – до 6) инструкций за такт, то есть теоретическая эффективность в пересчете на один мегагерц у Pentium 4 должна быть выше, чем у Athlon 64 и Opteron. Причина низкого КПД архитектуры NetBurst в ряде приложений – предмет отдельного анализа: отметим только, что сверхвысокие IPC для Pentium 4 вполне можно увидеть на практике – на тщательно оптимизированных приложениях. Главное – это то, что Hyper-Threading позволяет существующий КПД процессора на 10-25% увеличить: подобная прибавка вполне способна перекрыть и выигрыш от более быстрой подсистемы памяти, и от более быстрой шины, и от «более продвинутого» протокола MOESI.
По утверждениям Intel, двуядерность будет значительно эффективнее на тех же задачах, где имеется прирост от использования Hyper-Threading. И это легко понять, если взглянуть на следующие блок-схемы протекания процессов в двуядерной системе и одноядерной системе с Hyper-Threading.
Для процессора Intel Pentium Extreme Edition, имеющего обе эти особенности и видимого в операционной системе как четыре логических процессора, определенные сомнения в эффективности совместного использования двуядерности и Hyper-Threading могут возникнуть, хотя профессиональные приложения, показывающие мощный прирост и в этом случае, все же существуют (например, Cinema 4D и другой 3D-рендеринг).
Основная задача кэш-памяти – согласование работы быстрого процессора и медленной основной памяти. Кэш-память исполняет роль буфера между ОП и процессором (рис. 9.1). Использование кэш-памяти базируется на «принципе локальности ссылок».
Это означает, что следующее обращение к памяти в программе с большой вероятностью произойдет к тому же блоку данных, который находится в данный момент в кэш-памяти.
Кэш-память разбивается на строки по 32 байта, соответствующие одному стандартному пакетному циклу обращения к динамической памяти. На такие же строки условно разделяются и страницы основной памяти. Обмен информацией между ними осуществляется строками, даже если необходимо передать только один байт.
Процессор, выполняя команду, запрашивает операнд по некоторому адресу в адресном пространстве. Кэш-контроллер проверяет, есть ли в кэш-памяти строка данных, соответствующая запрашиваемому адресу. В случае наличия такой строки ситуация называется кэш-попадание. Если строки в кэш-памяти нет, то происходит кэш-промах, и кэш-контроллер инициирует обращение к основной памяти ОП для переписи из нее нужной строки в кэш-память.
Рис. 9.1. Двухуровневая кэш-память в компьютере
В связи с этим возникает проблема замены какой-либо строки в кэше на новую строку из ОП. Для этого используют специальные дисциплины замещения строк. Эти функции выполняет кэш-контроллер.
В современных вычислительных системах используются три типа организации кэш-памяти:
с прямым отображением;
Кэш-память с прямым отображением. Каждая строка кэш-памяти может содержать строку основной памяти только из определенного подмножества адресов, причем эти подмножества не пересекаются. Поиск состоит из следующих шагов:
определение, в какое из подмножеств адресов основной памяти попадает адрес строки, выработанный процессором;
обращение к единственной соответствующей строке и сравнение ее тега с адресом от центрального процессора для определения, является ли эта строка искомой.
На рис. 9.2 приведен пример структуры кэш-памяти с прямым отображением. Для простоты дана структура ОП, содержащей 16 строк данных, и кэш-память объемом в четыре строки.
Рис.9.2. Кэш-память с прямым отображением
Все строки основной памяти, имеющие S одинаковых младших разрядов , объединяются в подмножества, которые могут отображаться в кэше в строке с индексом, равным коду этих разрядов. В нашем примере индекс образуют два младших разряда адреса ОП. Следовательно, например, строки 1, 5, 9 и 13 могут находиться только в строке кэша с индексом 01 и ни в какой другой. В общем случае если разрядность адреса ОП равна N, а разрядность индекса – n, то адресные теги содержат оставшиеся N-n разрядов адреса строки.
Преимущество описываемой кэш-памяти состоит в простоте организации и низкой стоимости. Основной недостаток – ограниченное число комбинаций строк в кэше, что приводит к увеличению процента кэш-промахов. Например, строки 5 и 9 не могут одновременно находиться в кэш-памяти, даже если есть свободные места для других индексов.
Полностью ассоциативная кэш-память. В такой памяти любая строка ОП может находиться в любом месте кэш-памяти, причем в любой комбинации с другими строками. Комбинационные схемы сравнения СС1-СС4 (рис. 9.3) одновременно анализируют все теги строк, находящихся в кэше в данный момент, и сравнивают их с адресом, поступившим с шины адреса от процессора.
При кэш-попадании строка считывается в шину данных (ШД). При кэш-промахе происходит замещение строки в кэш-памяти на требуемую строку из ОП.
При кэш-попадании строка считывается в шину данных (ШД). При кэш-промахе происходит замещение строки в кэш-памяти на требуемую строку из ОП.
Преимущество данной памяти состоит в высокой скорости считывания. Недостаток – в сложности аппаратной реализации.
Множественно-ассоциативная кэш-память. Этот вид памяти является промежуточным между двумя рассмотренными выше. В нем сочетаются простота кэша с прямым отображением и скорость ассоциативного поиска.
Рис. 9.3. Полностью ассоциативная кэш-память
Кэш-память делится на непересекающиеся подмножества (блоки) строк. Каждая строка основной памяти может попадать только в одно подмножество кэша. Для поиска блоков используется прямое отображение, а для поиска внутри подмножества – полностью ассоциативный поиск. Число строк в подмножестве кэша определяет число входов (портов) самого кэша.
Если 2 n строк кэша разбивается на 2 s непересекающихся подмножеств, то S младших разрядов оперативной памяти показывают, в каком из подмножеств (индексов) должен вестись ассоциативный поиск. Старшие n-s разрядов адреса основной памяти являются тегами.
Если S=0, то получим одно подмножество, что соответствует полностью ассоциативной кэш-памяти. Если S=n, то получим 2 n подмножеств (то есть одна строка – одно подмножество). Это кэш-память с прямым отображением. Если 1£ S £ n-1, то имеем множественно-ассоциативную кэш-память.
На рис. 9.4 приведен пример кэша, где S=1, то есть имеются два подмножества кэш-памяти. Это двухвходовая множественно-ассоциативная кэш-память.
Физический адрес 1011, выработанный процессором, разделяется на индекс 1, равный младшему разряду, и тег 101. По индексу выбирается второе подмножество строк в кэш-памяти, а затем происходит ассоциативный поиск среди тегов строк выбранного подмножества. Найденная строка 11 с тегом 101 передается в шину данных (ШД). Ассоциативный поиск производится одновременно по всем тегам с помощью комбинационных схем сравнения СС1 и СС2.
Особенности записи и замещения информации
в кэш-памяти. Когерентность кэш-памяти
Обращение по чтению можно начинать сразу и к кэш, и к оперативной памяти. Тогда, если информация отсутствует в кэше, к моменту установления этого факта будет уже выполнена часть цикла обращения к ОЗУ, что может повысить производительность. Если информация имеется в кэше, то обращение к оперативной памяти можно остановить.
При обращении по записи используется два метода: запись производится только в кэш или сразу и в кэш, и в ОЗУ. Эти методы получили название алгоритмов обратной WB (Write Back) и сквозной записи WT (Write Through) соответственно. Второй из них более простой, но и более медленный, хотя и гарантирует, что копии одной и той же информации в кэше и оперативной памяти всегда совпадают. Большинство ранних процессоров Intel используют именно этот алгоритм.
Рис. 9.4. Множественно-ассоциативная кэш-память
Алгоритм обратной записи WB более быстрый. Передача информации в ОЗУ производится только тогда, когда на место данной строки кэша передается строка из другой страницы ОП, или при выполнении команды обновления содержимого кэша. Этот алгоритм требует более аккуратного управления, поскольку существуют моменты, когда копии одной и той же информации различны в кэше и ОП. Кроме того, не каждая строка изменяется за время своего пребывания в кэше. Если изменения не было, то нет необходимости переписывать строку обратно в оперативную память. Обычно используют флаг M (modified – изменена) в памяти тэгов. Он сбрасывается в «0» при первоначальной загрузке строки в кэш и устанавливается в «1» при записи в нее информации. При выгрузке строки из кэша запись в ОП выполняется только при единичном значении флага M.
При возникновении промаха контроллер кэш-памяти должен выбрать подлежащую замещению строку. Для прямого отображения аппаратные решения наиболее простые. На попадание проверяется только одна строка, и только эта строка может быть замещена. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько строк, из которых надо выбрать кандидата в случае промаха. Для решения этой задачи используют следующие специальные правила, называемые алгоритмами замещения:
FIFO (First In First Out – первый пришедший – первым выбывает);
LRU (Least Recently Used – дольше других неиспользуемый);
LFU (Least Frequently Used – реже других используемый);
Первый и последний методы являются самыми простыми в реализации, но они не учитывают, насколько часто используется та или иная строка кэш-памяти. При этом может быть удалена строка, к которой в самом ближайшем будущем будет обращение. Вероятность ошибки для указанных методов гораздо выше, чем у второго и третьего.
В алгоритме FIFO для замещения выбирается строка, первой попавшая в кэш. Каждая вновь размещаемая в кэше строка добавляется в хвост этой очереди. Алгоритм не учитывает фактическое ее использование. Например, первые загруженные строки могут содержать данные, требующиеся на протяжении всей работы. Это приводит к немедленному возвращению к только что замещенной строке.
Алгоритм LRU предусматривает, что для удаления следует выбирать ту строку, которая не использовалась дольше других. При каждом обращении к строке ее временная метка обновляется. Это может быть сопряжено с существенными издержками. Однако алгоритм LRU наиболее часто используется на практике. Недостаток его заключается в том, что если программа проходит большой цикл, охватывающий множество строк, может случиться так, что строка, к которой дольше всего не было обращений, в действительности станет следующей используемой.
Одним из близких к LRU является алгоритм LFU, согласно которому удаляется наименее часто использовавшаяся строка. При этом необходимо подсчитывать количество обращений к каждой строке и контролировать его. Может оказаться, что наименее интенсивно используется та строка, которая только что записана в кэш-память и к которой успели обратиться только один раз (в то время как к другим строкам обращались больше). Она может быть удалена, что является недостатком алгоритма LFU.
Содержимое кэш-памяти меняется под управлением процессора. При этом основная память может оставаться неизменной. С другой стороны, внешние устройства могут изменять данные в ОП в режиме прямого доступа. При этом кэш-память не меняет своих данных. Еще сложнее ситуация в мультипроцессорных системах, когда несколько процессоров обращаются к общей памяти. Возникает проблема когерентности кэш-памяти.
Вычислительная система имеет когерентную память, если каждая операция чтения по адресу, выполненная каким-либо устройством, возвращает значение последней копии по этому адресу независимо от того, какое из них производило запись последним. Проблема когерентности является наиболее важной для систем с обратным копированием
Читайте также: