
Принцип локальности в компьютерах
Основная задача кэш-памяти – согласование работы быстрого процессора и медленной основной памяти. Кэш-память исполняет роль буфера между ОП и процессором (рис. 9.1). Использование кэш-памяти базируется на «принципе локальности ссылок».
Это означает, что следующее обращение к памяти в программе с большой вероятностью произойдет к тому же блоку данных, который находится в данный момент в кэш-памяти.
Кэш-память разбивается на строки по 32 байта, соответствующие одному стандартному пакетному циклу обращения к динамической памяти. На такие же строки условно разделяются и страницы основной памяти. Обмен информацией между ними осуществляется строками, даже если необходимо передать только один байт.
Процессор, выполняя команду, запрашивает операнд по некоторому адресу в адресном пространстве. Кэш-контроллер проверяет, есть ли в кэш-памяти строка данных, соответствующая запрашиваемому адресу. В случае наличия такой строки ситуация называется кэш-попадание. Если строки в кэш-памяти нет, то происходит кэш-промах, и кэш-контроллер инициирует обращение к основной памяти ОП для переписи из нее нужной строки в кэш-память.
Рис. 9.1. Двухуровневая кэш-память в компьютере
В связи с этим возникает проблема замены какой-либо строки в кэше на новую строку из ОП. Для этого используют специальные дисциплины замещения строк. Эти функции выполняет кэш-контроллер.
В современных вычислительных системах используются три типа организации кэш-памяти:
с прямым отображением;
Кэш-память с прямым отображением. Каждая строка кэш-памяти может содержать строку основной памяти только из определенного подмножества адресов, причем эти подмножества не пересекаются. Поиск состоит из следующих шагов:
определение, в какое из подмножеств адресов основной памяти попадает адрес строки, выработанный процессором;
обращение к единственной соответствующей строке и сравнение ее тега с адресом от центрального процессора для определения, является ли эта строка искомой.
На рис. 9.2 приведен пример структуры кэш-памяти с прямым отображением. Для простоты дана структура ОП, содержащей 16 строк данных, и кэш-память объемом в четыре строки.
Рис.9.2. Кэш-память с прямым отображением
Все строки основной памяти, имеющие S одинаковых младших разрядов , объединяются в подмножества, которые могут отображаться в кэше в строке с индексом, равным коду этих разрядов. В нашем примере индекс образуют два младших разряда адреса ОП. Следовательно, например, строки 1, 5, 9 и 13 могут находиться только в строке кэша с индексом 01 и ни в какой другой. В общем случае если разрядность адреса ОП равна N, а разрядность индекса – n, то адресные теги содержат оставшиеся N-n разрядов адреса строки.
Преимущество описываемой кэш-памяти состоит в простоте организации и низкой стоимости. Основной недостаток – ограниченное число комбинаций строк в кэше, что приводит к увеличению процента кэш-промахов. Например, строки 5 и 9 не могут одновременно находиться в кэш-памяти, даже если есть свободные места для других индексов.
Полностью ассоциативная кэш-память. В такой памяти любая строка ОП может находиться в любом месте кэш-памяти, причем в любой комбинации с другими строками. Комбинационные схемы сравнения СС1-СС4 (рис. 9.3) одновременно анализируют все теги строк, находящихся в кэше в данный момент, и сравнивают их с адресом, поступившим с шины адреса от процессора.
При кэш-попадании строка считывается в шину данных (ШД). При кэш-промахе происходит замещение строки в кэш-памяти на требуемую строку из ОП.
При кэш-попадании строка считывается в шину данных (ШД). При кэш-промахе происходит замещение строки в кэш-памяти на требуемую строку из ОП.
Преимущество данной памяти состоит в высокой скорости считывания. Недостаток – в сложности аппаратной реализации.
Множественно-ассоциативная кэш-память. Этот вид памяти является промежуточным между двумя рассмотренными выше. В нем сочетаются простота кэша с прямым отображением и скорость ассоциативного поиска.
Рис. 9.3. Полностью ассоциативная кэш-память
Кэш-память делится на непересекающиеся подмножества (блоки) строк. Каждая строка основной памяти может попадать только в одно подмножество кэша. Для поиска блоков используется прямое отображение, а для поиска внутри подмножества – полностью ассоциативный поиск. Число строк в подмножестве кэша определяет число входов (портов) самого кэша.

Если 2 n строк кэша разбивается на 2 s непересекающихся подмножеств, то S младших разрядов оперативной памяти показывают, в каком из подмножеств (индексов) должен вестись ассоциативный поиск. Старшие n-s разрядов адреса основной памяти являются тегами.
Если S=0, то получим одно подмножество, что соответствует полностью ассоциативной кэш-памяти. Если S=n, то получим 2 n подмножеств (то есть одна строка – одно подмножество). Это кэш-память с прямым отображением. Если 1£ S £ n-1, то имеем множественно-ассоциативную кэш-память.
На рис. 9.4 приведен пример кэша, где S=1, то есть имеются два подмножества кэш-памяти. Это двухвходовая множественно-ассоциативная кэш-память.
Физический адрес 1011, выработанный процессором, разделяется на индекс 1, равный младшему разряду, и тег 101. По индексу выбирается второе подмножество строк в кэш-памяти, а затем происходит ассоциативный поиск среди тегов строк выбранного подмножества. Найденная строка 11 с тегом 101 передается в шину данных (ШД). Ассоциативный поиск производится одновременно по всем тегам с помощью комбинационных схем сравнения СС1 и СС2.
Особенности записи и замещения информации
в кэш-памяти. Когерентность кэш-памяти
Обращение по чтению можно начинать сразу и к кэш, и к оперативной памяти. Тогда, если информация отсутствует в кэше, к моменту установления этого факта будет уже выполнена часть цикла обращения к ОЗУ, что может повысить производительность. Если информация имеется в кэше, то обращение к оперативной памяти можно остановить.
При обращении по записи используется два метода: запись производится только в кэш или сразу и в кэш, и в ОЗУ. Эти методы получили название алгоритмов обратной WB (Write Back) и сквозной записи WT (Write Through) соответственно. Второй из них более простой, но и более медленный, хотя и гарантирует, что копии одной и той же информации в кэше и оперативной памяти всегда совпадают. Большинство ранних процессоров Intel используют именно этот алгоритм.
Рис. 9.4. Множественно-ассоциативная кэш-память
Алгоритм обратной записи WB более быстрый. Передача информации в ОЗУ производится только тогда, когда на место данной строки кэша передается строка из другой страницы ОП, или при выполнении команды обновления содержимого кэша. Этот алгоритм требует более аккуратного управления, поскольку существуют моменты, когда копии одной и той же информации различны в кэше и ОП. Кроме того, не каждая строка изменяется за время своего пребывания в кэше. Если изменения не было, то нет необходимости переписывать строку обратно в оперативную память. Обычно используют флаг M (modified – изменена) в памяти тэгов. Он сбрасывается в «0» при первоначальной загрузке строки в кэш и устанавливается в «1» при записи в нее информации. При выгрузке строки из кэша запись в ОП выполняется только при единичном значении флага M.
При возникновении промаха контроллер кэш-памяти должен выбрать подлежащую замещению строку. Для прямого отображения аппаратные решения наиболее простые. На попадание проверяется только одна строка, и только эта строка может быть замещена. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько строк, из которых надо выбрать кандидата в случае промаха. Для решения этой задачи используют следующие специальные правила, называемые алгоритмами замещения:
FIFO (First In First Out – первый пришедший – первым выбывает);
LRU (Least Recently Used – дольше других неиспользуемый);
LFU (Least Frequently Used – реже других используемый);
Первый и последний методы являются самыми простыми в реализации, но они не учитывают, насколько часто используется та или иная строка кэш-памяти. При этом может быть удалена строка, к которой в самом ближайшем будущем будет обращение. Вероятность ошибки для указанных методов гораздо выше, чем у второго и третьего.
В алгоритме FIFO для замещения выбирается строка, первой попавшая в кэш. Каждая вновь размещаемая в кэше строка добавляется в хвост этой очереди. Алгоритм не учитывает фактическое ее использование. Например, первые загруженные строки могут содержать данные, требующиеся на протяжении всей работы. Это приводит к немедленному возвращению к только что замещенной строке.
Алгоритм LRU предусматривает, что для удаления следует выбирать ту строку, которая не использовалась дольше других. При каждом обращении к строке ее временная метка обновляется. Это может быть сопряжено с существенными издержками. Однако алгоритм LRU наиболее часто используется на практике. Недостаток его заключается в том, что если программа проходит большой цикл, охватывающий множество строк, может случиться так, что строка, к которой дольше всего не было обращений, в действительности станет следующей используемой.
Одним из близких к LRU является алгоритм LFU, согласно которому удаляется наименее часто использовавшаяся строка. При этом необходимо подсчитывать количество обращений к каждой строке и контролировать его. Может оказаться, что наименее интенсивно используется та строка, которая только что записана в кэш-память и к которой успели обратиться только один раз (в то время как к другим строкам обращались больше). Она может быть удалена, что является недостатком алгоритма LFU.
Содержимое кэш-памяти меняется под управлением процессора. При этом основная память может оставаться неизменной. С другой стороны, внешние устройства могут изменять данные в ОП в режиме прямого доступа. При этом кэш-память не меняет своих данных. Еще сложнее ситуация в мультипроцессорных системах, когда несколько процессоров обращаются к общей памяти. Возникает проблема когерентности кэш-памяти.
Вычислительная система имеет когерентную память, если каждая операция чтения по адресу, выполненная каким-либо устройством, возвращает значение последней копии по этому адресу независимо от того, какое из них производило запись последним. Проблема когерентности является наиболее важной для систем с обратным копированием
Аннотация: В настоящей лекции рассматриваются простейшие способы управления памятью в ОС. Физическая память компьютера имеет иерархическую структуру. Программа представляет собой набор сегментов в логическом адресном пространстве. ОС осуществляет связывание логических и физических адресных пространств.
Введение
Главная задача компьютерной системы – выполнять программы. Программы вместе с данными, к которым они имеют доступ , в процессе выполнения должны (по крайней мере частично) находиться в оперативной памяти . Операционной системе приходится решать задачу распределения памяти между пользовательскими процессами и компонентами ОС. Эта деятельность называется управлением памятью. Таким образом, память ( storage , memory ) является важнейшим ресурсом, требующим тщательного управления. В недавнем прошлом память была самым дорогим ресурсом.
Часть ОС, которая отвечает за управление памятью , называется менеджером памяти.
Физическая организация памяти компьютера
Запоминающие устройства компьютера разделяют, как минимум, на два уровня: основную (главную, оперативную , физическую ) и вторичную (внешнюю) память.
Основная память представляет собой упорядоченный массив однобайтовых ячеек, каждая из которых имеет свой уникальный адрес (номер). Процессор извлекает команду из основной памяти , декодирует и выполняет ее. Для выполнения команды могут потребоваться обращения еще к нескольким ячейкам основной памяти . Обычно основная память изготавливается с применением полупроводниковых технологий и теряет свое содержимое при отключении питания.
Вторичную память (это главным образом диски) также можно рассматривать как одномерное линейное адресное пространство , состоящее из последовательности байтов. В отличие от оперативной памяти , она является энергонезависимой, имеет существенно большую емкость и используется в качестве расширения основной памяти .
Эту схему можно дополнить еще несколькими промежуточными уровнями, как показано на рис. 8.1. Разновидности памяти могут быть объединены в иерархию по убыванию времени доступа, возрастанию цены и увеличению емкости.
Многоуровневую схему используют следующим образом. Информация, которая находится в памяти верхнего уровня, обычно хранится также на уровнях с большими номерами. Если процессор не обнаруживает нужную информацию на i-м уровне, он начинает искать ее на следующих уровнях. Когда нужная информация найдена, она переносится в более быстрые уровни.
Локальность
Оказывается, при таком способе организации по мере снижения скорости доступа к уровню памяти снижается также и частота обращений к нему.
Ключевую роль здесь играет свойство реальных программ, в течение ограниченного отрезка времени способных работать с небольшим набором адресов памяти. Это эмпирически наблюдаемое свойство известно как принцип локальности или локализации обращений.
Свойство локальности (соседние в пространстве и времени объекты характеризуются похожими свойствами) присуще не только функционированию ОС, но и природе вообще. В случае ОС свойство локальности объяснимо, если учесть, как пишутся программы и как хранятся данные, то есть обычно в течение какого-то отрезка времени ограниченный фрагмент кода работает с ограниченным набором данных. Эту часть кода и данных удается разместить в памяти с быстрым доступом. В результате реальное время доступа к памяти определяется временем доступа к верхним уровням, что и обусловливает эффективность использования иерархической схемы. Надо сказать, что описываемая организация вычислительной системы во многом имитирует деятельность человеческого мозга при переработке информации. Действительно, решая конкретную проблему, человек работает с небольшим объемом информации, храня не относящиеся к делу сведения в своей памяти или во внешней памяти (например, в книгах).
Кэш процессора обычно является частью аппаратуры, поэтому менеджер памяти ОС занимается распределением информации главным образом в основной и внешней памяти компьютера. В некоторых схемах потоки между оперативной и внешней памятью регулируются программистом (см. например, далее оверлейные структуры ), однако это связано с затратами времени программиста, так что подобную деятельность стараются возложить на ОС.
Адреса в основной памяти , характеризующие реальное расположение данных в физической памяти , называются физическими адресами. Набор физических адресов, с которым работает программа, называют физическим адресным пространством .
Логическая память
Аппаратная организация памяти в виде линейного набора ячеек не соответствует представлениям программиста о том, как организовано хранение программ и данных. Большинство программ представляет собой набор модулей, созданных независимо друг от друга. Иногда все модули, входящие в состав процесса, располагаются в памяти один за другим, образуя линейное пространство адресов. Однако чаще модули помещаются в разные области памяти и используются по-разному.
Схема управления памятью, поддерживающая этот взгляд пользователя на то, как хранятся программы и данные, называется сегментацией. Сегмент – область памяти определенного назначения, внутри которой поддерживается линейная адресация. Сегменты содержат процедуры, массивы, стек или скалярные величины , но обычно не содержат информацию смешанного типа.
По-видимому, вначале сегменты памяти появились в связи с необходимостью обобществления процессами фрагментов программного кода (текстовый редактор, тригонометрические библиотеки и т. д.), без чего каждый процесс должен был хранить в своем адресном пространстве дублирующую информацию. Эти отдельные участки памяти, хранящие информацию, которую система отображает в память нескольких процессов, получили название сегментов . Память, таким образом, перестала быть линейной и превратилась в двумерную. Адрес состоит из двух компонентов: номер сегмента , смещение внутри сегмента . Далее оказалось удобным размещать в разных сегментах различные компоненты процесса (код программы, данные, стек и т. д.). Попутно выяснилось, что можно контролировать характер работы с конкретным сегментом , приписав ему атрибуты, например права доступа или типы операций, которые разрешается производить с данными, хранящимися в сегменте .
Некоторые сегменты , описывающие адресное пространство процесса, показаны на рис. 8.2. Более подробная информация о типах сегментов имеется в лекции 10.
Большинство современных ОС поддерживают сегментную организацию памяти. В некоторых архитектурах (Intel, например) сегментация поддерживается оборудованием.
Адреса, к которым обращается процесс, таким образом, отличаются от адресов, реально существующих в оперативной памяти . В каждом конкретном случае используемые программой адреса могут быть представлены различными способами. Например, адреса в исходных текстах обычно символические. Компилятор связывает эти символические адреса с перемещаемыми адресами (такими, как n байт от начала модуля). Подобный адрес, сгенерированный программой, обычно называют логическим (в системах с виртуальной памятью он часто называется виртуальным) адресом. Совокупность всех логических адресов называется логическим (виртуальным) адресным пространством .
Связывание адресов
Итак логические и физические адресные пространства ни по организации, ни по размеру не соответствуют друг другу. Максимальный размер логического адресного пространства обычно определяется разрядностью процессора (например, 2 32 ) и в современных системах значительно превышает размер физического адресного пространства . Следовательно, процессор и ОС должны быть способны отобразить ссылки в коде программы в реальные физические адреса, соответствующие текущему расположению программы в основной памяти . Такое отображение адресов называют трансляцией (привязкой) адреса или связыванием адресов (см. рис. 8.3).
Связывание логического адреса, порожденного оператором программы, с физическим должно быть осуществлено до начала выполнения оператора или в момент его выполнения. Таким образом, привязка инструкций и данных к памяти в принципе может быть сделана на следующих шагах [Silberschatz, 2002].
Аннотация: В настоящей лекции рассматриваются простейшие способы управления памятью в ОС. Физическая память компьютера имеет иерархическую структуру. Программа представляет собой набор сегментов в логическом адресном пространстве. ОС осуществляет связывание логических и физических адресных пространств.
Введение
Главная задача компьютерной системы – выполнять программы. Программы вместе с данными, к которым они имеют доступ , в процессе выполнения должны (по крайней мере частично) находиться в оперативной памяти . Операционной системе приходится решать задачу распределения памяти между пользовательскими процессами и компонентами ОС. Эта деятельность называется управлением памятью. Таким образом, память ( storage , memory ) является важнейшим ресурсом, требующим тщательного управления. В недавнем прошлом память была самым дорогим ресурсом.
Часть ОС, которая отвечает за управление памятью , называется менеджером памяти.
Физическая организация памяти компьютера
Запоминающие устройства компьютера разделяют, как минимум, на два уровня: основную (главную, оперативную , физическую ) и вторичную (внешнюю) память.
Основная память представляет собой упорядоченный массив однобайтовых ячеек, каждая из которых имеет свой уникальный адрес (номер). Процессор извлекает команду из основной памяти , декодирует и выполняет ее. Для выполнения команды могут потребоваться обращения еще к нескольким ячейкам основной памяти . Обычно основная память изготавливается с применением полупроводниковых технологий и теряет свое содержимое при отключении питания.
Вторичную память (это главным образом диски) также можно рассматривать как одномерное линейное адресное пространство , состоящее из последовательности байтов. В отличие от оперативной памяти , она является энергонезависимой, имеет существенно большую емкость и используется в качестве расширения основной памяти .
Эту схему можно дополнить еще несколькими промежуточными уровнями, как показано на рис. 8.1. Разновидности памяти могут быть объединены в иерархию по убыванию времени доступа, возрастанию цены и увеличению емкости.
Многоуровневую схему используют следующим образом. Информация, которая находится в памяти верхнего уровня, обычно хранится также на уровнях с большими номерами. Если процессор не обнаруживает нужную информацию на i-м уровне, он начинает искать ее на следующих уровнях. Когда нужная информация найдена, она переносится в более быстрые уровни.
Локальность
Оказывается, при таком способе организации по мере снижения скорости доступа к уровню памяти снижается также и частота обращений к нему.
Ключевую роль здесь играет свойство реальных программ, в течение ограниченного отрезка времени способных работать с небольшим набором адресов памяти. Это эмпирически наблюдаемое свойство известно как принцип локальности или локализации обращений.
Свойство локальности (соседние в пространстве и времени объекты характеризуются похожими свойствами) присуще не только функционированию ОС, но и природе вообще. В случае ОС свойство локальности объяснимо, если учесть, как пишутся программы и как хранятся данные, то есть обычно в течение какого-то отрезка времени ограниченный фрагмент кода работает с ограниченным набором данных. Эту часть кода и данных удается разместить в памяти с быстрым доступом. В результате реальное время доступа к памяти определяется временем доступа к верхним уровням, что и обусловливает эффективность использования иерархической схемы. Надо сказать, что описываемая организация вычислительной системы во многом имитирует деятельность человеческого мозга при переработке информации. Действительно, решая конкретную проблему, человек работает с небольшим объемом информации, храня не относящиеся к делу сведения в своей памяти или во внешней памяти (например, в книгах).
Кэш процессора обычно является частью аппаратуры, поэтому менеджер памяти ОС занимается распределением информации главным образом в основной и внешней памяти компьютера. В некоторых схемах потоки между оперативной и внешней памятью регулируются программистом (см. например, далее оверлейные структуры ), однако это связано с затратами времени программиста, так что подобную деятельность стараются возложить на ОС.
Адреса в основной памяти , характеризующие реальное расположение данных в физической памяти , называются физическими адресами. Набор физических адресов, с которым работает программа, называют физическим адресным пространством .
Логическая память
Аппаратная организация памяти в виде линейного набора ячеек не соответствует представлениям программиста о том, как организовано хранение программ и данных. Большинство программ представляет собой набор модулей, созданных независимо друг от друга. Иногда все модули, входящие в состав процесса, располагаются в памяти один за другим, образуя линейное пространство адресов. Однако чаще модули помещаются в разные области памяти и используются по-разному.
Схема управления памятью, поддерживающая этот взгляд пользователя на то, как хранятся программы и данные, называется сегментацией. Сегмент – область памяти определенного назначения, внутри которой поддерживается линейная адресация. Сегменты содержат процедуры, массивы, стек или скалярные величины , но обычно не содержат информацию смешанного типа.
По-видимому, вначале сегменты памяти появились в связи с необходимостью обобществления процессами фрагментов программного кода (текстовый редактор, тригонометрические библиотеки и т. д.), без чего каждый процесс должен был хранить в своем адресном пространстве дублирующую информацию. Эти отдельные участки памяти, хранящие информацию, которую система отображает в память нескольких процессов, получили название сегментов . Память, таким образом, перестала быть линейной и превратилась в двумерную. Адрес состоит из двух компонентов: номер сегмента , смещение внутри сегмента . Далее оказалось удобным размещать в разных сегментах различные компоненты процесса (код программы, данные, стек и т. д.). Попутно выяснилось, что можно контролировать характер работы с конкретным сегментом , приписав ему атрибуты, например права доступа или типы операций, которые разрешается производить с данными, хранящимися в сегменте .
Некоторые сегменты , описывающие адресное пространство процесса, показаны на рис. 8.2. Более подробная информация о типах сегментов имеется в лекции 10.
Большинство современных ОС поддерживают сегментную организацию памяти. В некоторых архитектурах (Intel, например) сегментация поддерживается оборудованием.
Адреса, к которым обращается процесс, таким образом, отличаются от адресов, реально существующих в оперативной памяти . В каждом конкретном случае используемые программой адреса могут быть представлены различными способами. Например, адреса в исходных текстах обычно символические. Компилятор связывает эти символические адреса с перемещаемыми адресами (такими, как n байт от начала модуля). Подобный адрес, сгенерированный программой, обычно называют логическим (в системах с виртуальной памятью он часто называется виртуальным) адресом. Совокупность всех логических адресов называется логическим (виртуальным) адресным пространством .
Связывание адресов
Итак логические и физические адресные пространства ни по организации, ни по размеру не соответствуют друг другу. Максимальный размер логического адресного пространства обычно определяется разрядностью процессора (например, 2 32 ) и в современных системах значительно превышает размер физического адресного пространства . Следовательно, процессор и ОС должны быть способны отобразить ссылки в коде программы в реальные физические адреса, соответствующие текущему расположению программы в основной памяти . Такое отображение адресов называют трансляцией (привязкой) адреса или связыванием адресов (см. рис. 8.3).
Связывание логического адреса, порожденного оператором программы, с физическим должно быть осуществлено до начала выполнения оператора или в момент его выполнения. Таким образом, привязка инструкций и данных к памяти в принципе может быть сделана на следующих шагах [Silberschatz, 2002].
Аннотация: В настоящей лекции рассматриваются простейшие способы управления памятью в ОС. Физическая память компьютера имеет иерархическую структуру. Программа представляет собой набор сегментов в логическом адресном пространстве. ОС осуществляет связывание логических и физических адресных пространств.
Введение
Главная задача компьютерной системы – выполнять программы. Программы вместе с данными, к которым они имеют доступ , в процессе выполнения должны (по крайней мере частично) находиться в оперативной памяти . Операционной системе приходится решать задачу распределения памяти между пользовательскими процессами и компонентами ОС. Эта деятельность называется управлением памятью. Таким образом, память ( storage , memory ) является важнейшим ресурсом, требующим тщательного управления. В недавнем прошлом память была самым дорогим ресурсом.
Часть ОС, которая отвечает за управление памятью , называется менеджером памяти.
Физическая организация памяти компьютера
Запоминающие устройства компьютера разделяют, как минимум, на два уровня: основную (главную, оперативную , физическую ) и вторичную (внешнюю) память.
Основная память представляет собой упорядоченный массив однобайтовых ячеек, каждая из которых имеет свой уникальный адрес (номер). Процессор извлекает команду из основной памяти , декодирует и выполняет ее. Для выполнения команды могут потребоваться обращения еще к нескольким ячейкам основной памяти . Обычно основная память изготавливается с применением полупроводниковых технологий и теряет свое содержимое при отключении питания.
Вторичную память (это главным образом диски) также можно рассматривать как одномерное линейное адресное пространство , состоящее из последовательности байтов. В отличие от оперативной памяти , она является энергонезависимой, имеет существенно большую емкость и используется в качестве расширения основной памяти .
Эту схему можно дополнить еще несколькими промежуточными уровнями, как показано на рис. 8.1. Разновидности памяти могут быть объединены в иерархию по убыванию времени доступа, возрастанию цены и увеличению емкости.
Многоуровневую схему используют следующим образом. Информация, которая находится в памяти верхнего уровня, обычно хранится также на уровнях с большими номерами. Если процессор не обнаруживает нужную информацию на i-м уровне, он начинает искать ее на следующих уровнях. Когда нужная информация найдена, она переносится в более быстрые уровни.
Локальность
Оказывается, при таком способе организации по мере снижения скорости доступа к уровню памяти снижается также и частота обращений к нему.
Ключевую роль здесь играет свойство реальных программ, в течение ограниченного отрезка времени способных работать с небольшим набором адресов памяти. Это эмпирически наблюдаемое свойство известно как принцип локальности или локализации обращений.
Свойство локальности (соседние в пространстве и времени объекты характеризуются похожими свойствами) присуще не только функционированию ОС, но и природе вообще. В случае ОС свойство локальности объяснимо, если учесть, как пишутся программы и как хранятся данные, то есть обычно в течение какого-то отрезка времени ограниченный фрагмент кода работает с ограниченным набором данных. Эту часть кода и данных удается разместить в памяти с быстрым доступом. В результате реальное время доступа к памяти определяется временем доступа к верхним уровням, что и обусловливает эффективность использования иерархической схемы. Надо сказать, что описываемая организация вычислительной системы во многом имитирует деятельность человеческого мозга при переработке информации. Действительно, решая конкретную проблему, человек работает с небольшим объемом информации, храня не относящиеся к делу сведения в своей памяти или во внешней памяти (например, в книгах).
Кэш процессора обычно является частью аппаратуры, поэтому менеджер памяти ОС занимается распределением информации главным образом в основной и внешней памяти компьютера. В некоторых схемах потоки между оперативной и внешней памятью регулируются программистом (см. например, далее оверлейные структуры ), однако это связано с затратами времени программиста, так что подобную деятельность стараются возложить на ОС.
Адреса в основной памяти , характеризующие реальное расположение данных в физической памяти , называются физическими адресами. Набор физических адресов, с которым работает программа, называют физическим адресным пространством .
Логическая память
Аппаратная организация памяти в виде линейного набора ячеек не соответствует представлениям программиста о том, как организовано хранение программ и данных. Большинство программ представляет собой набор модулей, созданных независимо друг от друга. Иногда все модули, входящие в состав процесса, располагаются в памяти один за другим, образуя линейное пространство адресов. Однако чаще модули помещаются в разные области памяти и используются по-разному.
Схема управления памятью, поддерживающая этот взгляд пользователя на то, как хранятся программы и данные, называется сегментацией. Сегмент – область памяти определенного назначения, внутри которой поддерживается линейная адресация. Сегменты содержат процедуры, массивы, стек или скалярные величины , но обычно не содержат информацию смешанного типа.
По-видимому, вначале сегменты памяти появились в связи с необходимостью обобществления процессами фрагментов программного кода (текстовый редактор, тригонометрические библиотеки и т. д.), без чего каждый процесс должен был хранить в своем адресном пространстве дублирующую информацию. Эти отдельные участки памяти, хранящие информацию, которую система отображает в память нескольких процессов, получили название сегментов . Память, таким образом, перестала быть линейной и превратилась в двумерную. Адрес состоит из двух компонентов: номер сегмента , смещение внутри сегмента . Далее оказалось удобным размещать в разных сегментах различные компоненты процесса (код программы, данные, стек и т. д.). Попутно выяснилось, что можно контролировать характер работы с конкретным сегментом , приписав ему атрибуты, например права доступа или типы операций, которые разрешается производить с данными, хранящимися в сегменте .
Некоторые сегменты , описывающие адресное пространство процесса, показаны на рис. 8.2. Более подробная информация о типах сегментов имеется в лекции 10.
Большинство современных ОС поддерживают сегментную организацию памяти. В некоторых архитектурах (Intel, например) сегментация поддерживается оборудованием.
Адреса, к которым обращается процесс, таким образом, отличаются от адресов, реально существующих в оперативной памяти . В каждом конкретном случае используемые программой адреса могут быть представлены различными способами. Например, адреса в исходных текстах обычно символические. Компилятор связывает эти символические адреса с перемещаемыми адресами (такими, как n байт от начала модуля). Подобный адрес, сгенерированный программой, обычно называют логическим (в системах с виртуальной памятью он часто называется виртуальным) адресом. Совокупность всех логических адресов называется логическим (виртуальным) адресным пространством .
Связывание адресов
Итак логические и физические адресные пространства ни по организации, ни по размеру не соответствуют друг другу. Максимальный размер логического адресного пространства обычно определяется разрядностью процессора (например, 2 32 ) и в современных системах значительно превышает размер физического адресного пространства . Следовательно, процессор и ОС должны быть способны отобразить ссылки в коде программы в реальные физические адреса, соответствующие текущему расположению программы в основной памяти . Такое отображение адресов называют трансляцией (привязкой) адреса или связыванием адресов (см. рис. 8.3).
Связывание логического адреса, порожденного оператором программы, с физическим должно быть осуществлено до начала выполнения оператора или в момент его выполнения. Таким образом, привязка инструкций и данных к памяти в принципе может быть сделана на следующих шагах [Silberschatz, 2002].
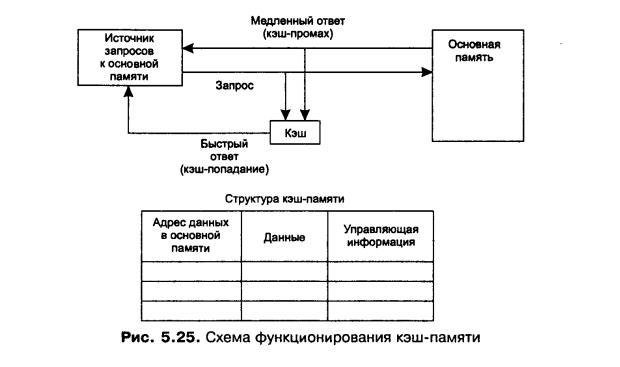
Рассмотрим одну из возможных схем работы кэш-памяти для понимания принципов ее работы:
В кэш памяти содержатся ЗАПИСИ обо всех загруженных в нее элементах.
Каждая запись включает:
17. Адрес этих данных в основной памяти
18. Дополнительная инфа (признак модификации, признак действительности данных)
Процесс обращается к основной памяти:
19. ОС просматривает содержимое КЭШа, нет ли нужных данных там.
20. КЭШ-память не адресуема, поиск идет по адресу данных в оперативной памяти
1) Если данные есть – кэш попадание, данные считываются из КЭШа и передаются запросившему.
2) Если данных нет – кэш-промах, ОС идет в основную память и добывает данные оттуда.
При оценке эффективности кэш-памяти обычно используют следующие характеристики:
• коэффициент попаданий (hit rate) — отношение числа обращений к памяти, при которых произошло попадание, к общему числу обращений к ЗУ данного уровня иерархии;
• коэффициент промахов (miss rate) — отношение числа обращений к памяти, при
которых имел место промах; к общему числу обращений к ЗУ данного уровня иерархии;
• время обращения при попадании (hit time) — время, необходимое для поиска
нужной информации в памяти верхнего уровня (включая выяснение, является ли обращение попаданием), плюс время на фактическое считывание данных;
• потери на промах (miss penalty) — время, требуемое для замены блока в памяти более высокого уровня на блок с нужными данными, расположенный в ЗУ следующего (более низкого) уровня. Потери на промах включают в себя:
a. время доступа (access time) — время обращения к первому слову блока при промахе
b. время пересылки (transfer time) — дополнительное время для пересылки оставшихся слов блока.
Время доступа обусловлено задержкой памяти более низкого уровня, в то время как время пересылки связано с полосой пропускания канала между ЗУ двух смежных уровней.
От чего зависит эффективность кэширования? От вероятности попаданий в кэш.
Использование кэш-памяти имеет смысл только при высокой вероятности кэш-попаданий, т.к. иначе это только дополнительные расходы времени на поиск в КЭШе.
Вероятность кэш-попаданий зависит от:
- объема кэшируемой памяти
- алгоритма замещения данных в КЭШе
- особенностей выполняемой программы
- времени ее работы
Но в большинстве реализаций процент кэш-попаданий высокий, более 90%. Круть.
Это достигается за счет того, что данные обладают свойствами пространственной и временной локальности.
21. Временная локальность – если произошло обращение к какому-то адресу, то с большой вероятностью скоро по нему снова обратятся
22. Пространственная локальность – если произошло обращение к какому-то адресу, то скоро произойдет обращение по соседним адресам.
В соответствии с принципом временной локальности, в Кэше сохраняют недавно просмотренные данные, а в соответствии с принципом пространственной локальности, в кэш считывается не один элемент информации, а целый блок данных или целый массив, если идет обработка массива.
Читайте также: