
Прикладной процесс использовать системную часть виртуальной памяти
Обращаем Ваше внимание, что в соответствии с Федеральным законом N 273-ФЗ «Об образовании в Российской Федерации» в организациях, осуществляющих образовательную деятельность, организовывается обучение и воспитание обучающихся с ОВЗ как совместно с другими обучающимися, так и в отдельных классах или группах.
Рабочие листы и материалы для учителей и воспитателей
Более 2 500 дидактических материалов для школьного и домашнего обучения
Столичный центр образовательных технологий г. Москва
Получите квалификацию учитель математики за 2 месяца
от 3 170 руб. 1900 руб.
Количество часов 300 ч. / 600 ч.
Успеть записаться со скидкой
Форма обучения дистанционная
- Онлайн
формат - Диплом
гособразца - Помощь в трудоустройстве
311 лекций для учителей,
воспитателей и психологов
Получите свидетельство
о просмотре прямо сейчас!
Организация виртуальной оперативной памяти.
Необходимым условием для того, чтобы программа могла выполняться, является ее нахождение в оперативной памяти. Только в этом случае процессор может извлекать команды из памяти и интерпретировать их, выполняя заданные действия. Объем оперативной памяти, который имеется в компьютере, существенно сказывается на характере протекания вычислительного процесса. Он ограничивает число одновременно выполняющихся программ и размеры их виртуальных адресных пространств. В некоторых случаях, когда все задачи мультипрограммной смеси являются вычислительными (то есть выполняют относительно мало операций ввода-вывода, разгружающих центральный процессор), для хорошей загрузки процессора может оказаться достаточным всего 3-5 задач. Однако если вычислительная система загружена выполнением интерактивных задач, то для эффективного использования процессора может потребоваться уже несколько десятков, а то и сотен задач. Эти рассуждения хорошо иллюстрирует рис.6, на котором показан график зависимости коэффициента загрузки процессора от числа одновременно выполняемых процессов и доли времени, проводимого этими процессами в состоянии ожидания ввода-вывода.

Рис 6 . Зависимость загрузки процессора от числа задач и интенсивности ввода-вывода
Большое количество задач, необходимое для высокой загрузки процессора, требует большого объема оперативной памяти. В условиях, когда для обеспечения приемлемого уровня мультипрограммирования имеющейся оперативной памяти недостаточно, был предложен метод организации вычислительного процесса, при котором образы некоторых процессов целиком или частично временно выгружаются на диск.
В мультипрограммном режиме помимо активного процесса, то есть процесса, коды которого в настоящий момент интерпретируются процессором, имеются приостановленные процессы, находящиеся в ожидании завершения ввода-вывода или освобождения ресурсов, а также процессы в состоянии готовности, стоящие в очереди к процессору. Образы таких неактивных процессов могут быть временно, до следующего цикла активности, выгружены на диск. Несмотря на то, что коды и данные процесса отсутствуют в оперативной памяти, ОС «знает» о его существовании и в полной мере учитывает это при распределении процессорного времени и других системных ресурсов. К моменту, когда подходит очередь выполнения выгруженного процесса, его образ возвращается с диска в оперативную память. Если при этом обнаруживается, что свободного места в оперативной памяти не хватает, то на диск выгружается другой процесс.
Такая подмена (виртуализация) оперативной памяти дисковой памятью позволяет повысить уровень мультипрограммирования — объем оперативной памяти компьютера теперь не столь жестко ограничивает количество одновременно выполняемых процессов, поскольку суммарный объем памяти, занимаемой образами этих процессов, может существенно превосходить имеющийся объем оперативной памяти. Виртуальным называется ресурс, который пользователю или пользовательской программе представляется обладающим свойствами, которыми он в действительности не обладает. В данном случае в распоряжение прикладного программиста предоставляется виртуальная оперативная память, размер которой намного превосходит всю имеющуюся в системе реальную оперативную память. Пользователь пишет программу, а транслятор, используя виртуальные адреса, переводит ее в машинные коды так, как будто в распоряжении программы имеется однородная оперативная память большого объема. В действительности же все коды и данные, используемые программой, хранятся на дисках и только при необходимости загружаются в реальную оперативную память. Понятно, однако, что работа такой «оперативной памяти» происходит значительно медленнее.
Виртуализация оперативной памяти осуществляется совокупностью программных модулей ОС и аппаратных схем процессора и включает решение следующих задач:
размещение данных в запоминающих устройствах разного типа, например, часть кодов программы — в оперативной памяти, а часть — на диске; выбор образов процессов или их частей для перемещения из оперативной памяти на диск и обратно;
перемещение по мере необходимости данных между памятью и диском; Q преобразование виртуальных адресов в физические.
Очень важно то, что все действия по организации совместного использования диска и оперативной памяти, выделение места для перемещаемых фрагментов, настройка адресов, выбор кандидатов на загрузку и выгрузку, осуществляются операционной системой и аппаратурой процессора автоматически, без участия программиста, и никак не сказываются на логике работы приложений.
Отметим, что уже достаточно давно пользователи столкнулись с проблемой размещения в памяти программы, размер которой превышает имеющуюся в наличии свободную память. Одним из первых решений было разбиение программы на части, называемые оверлеями. Когда первый оверлей заканчивал свое выполнение, он вызывал другой оверлей. Все оверлеи хранились на диске и перемещались между памятью и диском средствами операционной системы на основании явных директив программиста, содержащихся в программе. Этот способ, несмотря на внешнее сходство, имеет принципиальное отличие от виртуальной памяти, заключающееся в том, что разбиение программы на части и планирование их загрузки в оперативную память должны были выполняться заранее программистом во время написания программы.
Виртуализация памяти может быть осуществлена на основе двух различных подходов:
свопинг (swapping) — образы процессов выгружаются на диск и возвращаются в оперативную память целиком;
виртуальная память (virtual memory) — между оперативной памятью и диском перемещаются части (сегменты, страницы и т. п.) образов процессов.
Свопинг представляет собой частный случай виртуальной памяти и, следовательно, более простой в реализации способ совместного использования оперативной памяти и диска. Однако подкачке свойственна избыточность: когда ОС решает активизировать процесс, для его выполнения, как правило, не требуется загружать в оперативную память все его сегменты полностью — достаточно загрузить небольшую часть кодового сегмента с подлежащей выполнению инструкцией и частью сегментов данных, с которыми работает эта инструкция, а также отвести место под сегмент стека.
Аналогично при освобождении памяти для загрузки нового процесса очень часто вовсе не требуется выгружать другой процесс на диск целиком, достаточно вытеснить на диск только часть его образа. Перемещение избыточной информации замедляет работу системы, а также приводит к неэффективному использованию памяти. Кроме того, системы, поддерживающие свопинг, имеют еще один очень существенный недостаток: они не способны загрузить для выполнения процесс, виртуальное адресное пространство которого превышает имеющуюся в наличии свободную память.
В некоторых современных ОС, например, версиях UNIX, основанных на коде SVR4, механизм свопинга используется как дополнительный к виртуальной памяти, включающийся только при серьезных перегрузках системы.
Именно из-за указанных недостатков свопинг как основной механизм управления памятью почти не используется в современных ОС . На смену ему пришел более совершенный механизм виртуальной памяти, который, как уже было сказано, заключается в том, что при нехватке места в оперативной памяти на диск выгружаются только части образов процессов.
Ключевой проблемой виртуальной памяти, возникающей в результате многократного изменения местоположения в оперативной памяти образов процессов или их частей, является преобразование виртуальных адресов в физические. Решение этой проблемы, в свою очередь, зависит от того, какой способ структуризации виртуального адресного пространства принят в данной системе управления памятью. В настоящее время все множество реализаций виртуальной памяти может быть представлено тремя классами.
Страничная виртуальная память организует перемещение данных между памятью и диском страницами — частями виртуального адресного пространства, фиксированного и сравнительно небольшого размера.
Сегментная виртуальная память предусматривает перемещение данных сегментами — частями виртуального адресного пространства произвольного размера, полученными с учетом смыслового значения данных,
Сегментно-страничная виртуальная память использует двухуровневое деление: виртуальное адресное пространство делится на сегменты, а затем сегменты делятся на страницы. Единицей перемещения данных здесь является страница. Этот способ управления памятью объединяет в себе элементы обоих предыдущих подходов.
Для временного хранения сегментов и страниц на диске отводится либо специальная область, либо специальный файл, которые во многих ОС по традиции продолжают называть областью или файлом свопинга, хотя перемещение информации между оперативной памятью и диском осуществляется уже не в форме полного замещения одного процесса другим, а частями. Другое популярное название этой области — страничный файл (page file, или paging file).
Текущий размер страничного файла является важным параметром, оказывающим влияние на возможности операционной системы: чем больше страничный файл, тем больше приложений может одновременно выполнять ОС (при фиксированном размере оперативной памяти). Однако необходимо понимать, что увеличение числа одновременно работающих приложений за счет увеличения размера страничного файла замедляет их работу, так как значительная часть времени при этом тратится на перекачку кодов и данных из оперативной памяти на диск и обратно. Размер страничного файла в современных ОС является настраиваемым параметром, который выбирается администратором системы для достижения компромисса между уровнем мультипрограммирования и быстродействием системы.

При работе такой иерархической организованной памяти необходимо обеспечить непротиворечивость данных на всех уровнях. Кэши разных уровней могут согласовывать данные разными способами. Пусть, например, кэш первого уровня использует сквозную запись, а кэш второго уровня — обратную запись. (Именно такая комбинация алгоритмов согласования применена в процессоре Pentium при одном из возможных вариантов его работы.)
Рис. 5.31. Схема выполнения запроса на чтение в системе с двухуровневым кэшем
На рис. 5.32 приведена схема выполнения запроса на запись в такой системе. При модификации данных необходимо убедиться, что они отсутствуют в кэшах. В этом случае выполняется запись только в оперативную память.
Если данные обнаружены в кэше первого уровня, то вступает в силу алгоритм сквозной записи: выполняется запись в кэш первого уровня и передается запрос на запись в кэш второго уровня, играющий в данном случае роль основной памяти. Запись в кэш второго уровня в соответствии с алгоритмом обратной записи, принятом на данном уровне, сопровождается установкой признака модификации, при этом никакой записи в оперативную память не производится.
Если данные найдены в кэше второго уровня, то, так же как и в предыдущем случае, выполняется запись в этот кэш и устанавливается признак модификации.
Рассмотренные в данном разделе проблемы кэширования охватывают только такой класс систем организации памяти, в котором на каждом уровне имеется одно кэширующее устройство. Существует и другой класс систем памяти, главной отличительной особенностью которого является наличие нескольких кэшей одного уровня. Этот вариант характерен для распределенных систем обработки информации — мультипроцессорных компьютерах и компьютерных сетях.
Рис. 5.32. Схема выполнения запроса на запись в системе с двухуровневым кэшем
Оперативная память является важнейшим ресурсом вычислительной системы, требующим тщательного управления со стороны мультипрограммной операционной системы. Особая роль памяти объясняется тем, что процессор может выполнять инструкции программы только в том случае, если они находятся в памяти.
Память распределяется как между модулями прикладных программ, так и между модулями самой операционной системы.
Функциями ОС по управлению памятью в мультипрограммной системе являются:
отслеживание наличия свободной и занятой памяти;
выделение памяти процессам и освобождение памяти при завершении процессов;
вытеснение кодов и данных процессов из оперативной памяти на диск (полное или частичное), когда размеры основной памяти не достаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место;
настройка адресов программы на конкретную область физической памяти;
защита памяти процессов от взаимного вмешательства.
На разных этапах жизненного цикла программы для представления переменных и кодов требуются три типа адресов: символьные (имена, используемые программистом), виртуальные (условные числа, вырабатываемые компилятором) и физические (адреса фактического размещения в оперативной памяти).
Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Диапазон возможных адресов виртуального пространства у всех процессов является одним и тем же.
Виртуальное адресное пространство может быть плоским (линейным) или структурированным.
Необходимо различать максимально возможное виртуальное адресное пространство процесса, которое определяется только разрядностью виртуального адреса и архитектурой компьютера, и назначенное (выделенное) процессу виртуальное адресное пространство, состоящее из набора виртуальных адресов, действительно нужных процессу для работы.
Виртуальное адресное пространство процесса делится на две непрерывные части: системную и пользовательскую. Системная часть является общей для всех процессов, в ней размещаются коды и данные операционной системы.
Наиболее эффективным способом управления памятью является виртуальная память, вытеснившая в современных ОС методы распределения памяти фиксированными, динамическими или перемещаемыми разделами.
Виртуальная память использует дисковую память для временного хранения не помещающихся в оперативную память данных и кодов выполняемых процессов ОС.
В настоящее время все множество реализаций виртуальной памяти может быть представлено тремя классами:
страничная виртуальная память организует перемещение данных между памятью и диском страницами — частями виртуального адресного пространства фиксированного и сравнительно небольшого размера (достоинства — высокая скорость обмена, низкий уровень фрагментации; недостатки — сложно организовать защиту данных, разделенных на части механически);
сегментная виртуальная память предусматривает перемещение данных сегментами — частями виртуального адресного пространства произвольного размера, полученными с учетом смыслового значения данных (достоинства — «осмысленность» сегментов упрощает их защиту; недостатки — медленное преобразование адреса, высокий уровень фрагментации);
сегментно-страничная виртуальная память сочетает достоинства обоих предыдущих подходов.
Сегменты виртуальной памяти могут быть разделяемыми между несколькими процессами. Разделяемые сегменты используются либо для экономии физической памяти, когда несколько пользователей работают с одним кодовым сегментом приложения, либо в качестве средства обмена данными между процессами.
Для ускорения доступа к данным в вычислительных системах широко используется принцип кэширования. В компьютерах существует иерархия запоминающих устройств, в которой нижний уровень занимают емкая, но относительно медленная дисковая память, затем располагается оперативная память, а верхний уровень составляет сверхоперативная память процессорного кэша. Каждый уровень памяти (кроме нижнего) выполняет роль кэша по отношению к нижележащему.

Каждая запись в кэш-памяти об элементе данных включает в себя:
значение элемента данных;
адрес, который этот элемент данных имеет в основной памяти;
дополнительную информацию, которая используется для реализации алгоритма замещения данных в кэше и обычно включает признак модификации и признак действительности данных.
При кэшировании данных из оперативной памяти широко используются две основные схемы отображения: случайное отображение и детерминированное отображение.
При случайном отображении элемент оперативной памяти может быть размещен в произвольном месте кэш-памяти. Для того чтобы в дальнейшем можно было найти нужные данные в кэше, они помещаются туда вместе со своим адресом оперативной памяти.
Детерминированный (прямой) способ отображения предполагает, что любой элемент основной памяти всегда отображается в одно и то же место кэш-памяти. В этом случае кэш-память разделена на строки, каждая из которых предназначена для хранения одной записи об одном элементе данных и имеет свой номер.
Во многих современных процессорах кэш-память строится на основе сочетания этих двух подходов, что позволяет найти компромисс между сравнительно низкой стоимостью кэша с прямым отображением и интеллектуальностью алгоритмов замещения в кэше со случайным отображением.
Задачи и упражнения
1. Чем ограничивается максимальный размер физической памяти, которую можно установить в компьютере определенной модели?
2. Чем ограничивается максимальный размер виртуального адресного пространства, доступного приложению?
3. Может ли прикладной процесс использовать системную часть виртуальной памяти?
4. Какое из этих двух утверждений верно?
А) все виртуальные адреса заменяются на физические во время загрузки программы в оперативную память;
В) виртуальные адреса заменяются на физические во время выполнения программы в момент обращения по данному виртуальному адресу.
5. В каких случаях транслятор создает объектный код программы не в виртуальных, а в физических адресах?
6. Что такое виртуальная память? Какой из следующих методов распределения памяти может рассматриваться как частный случай виртуальной памяти?
А) распределение фиксированными разделами;
В) распределение динамическими разделами;
С) страничное распределение;
D) сегментное распределение;
Е) сегментно-страничное распределение.
7. Распределение памяти перемещаемыми разделами основано на применении процедуры сжатия. Имеет ли смысл использовать данную процедуру при страничном распределении? А при сегментном?
8. Поясните разные значения термина «свопинг».
9. Как величина файла подкачки влияет на производительность системы?
10. Почему размер страницы выбирается равным степени двойки? Можно ли принять такое же ограничение для сегмента?
11. На что влияет размер страницы? Каковы преимущества и недостатки большого размера страницы?
12. Пусть в некоторой программе, работающей в системе со страничной организацией памяти, произошло обращение по виртуальному адресу 012356s. Преобразуйте этот адрес в физический, учитывая, что размер страницы равен 214 байт и что таблица страниц данного процесса содержит следующий фрагмент:
Номер виртуальной страницы
Номер физической страницы
13. Где хранятся таблицы страниц и таблицы сегментов?
14. Чем определяется количество таблиц сегментов, имеющихся в операционной системе в произвольный момент времени?
15. Какие характеристики содержит таблица сегментов и таблица страниц при сегментно-страничной организации памяти?
16. Пусть ОС реализует выгрузку страниц на основе критерия «выгружается страница, которая не использовалась дольше остальных». Предложите алгоритм вычисления данного критерия, использующий аппаратно- устанавливаемые биты доступа.
17. В кэше хранятся данные, которые наиболее активно используются в последнее время. Каким образом система определяет, какие данные должны быть загружены в кэш?
18. Пусть программа циклически обрабатывает данные, то есть в некотором диапазоне адресов идет последовательное обращение к данным, а затем следует возврат в начало и т. д. В системе имеется кэш, объем которого меньше объема обрабатываемых программой данных. Какой алгоритм вытеснения данных из кэша в данном случае будет эффективнее?
А) выгружаются данные, которые не использовались дольше остальных;
В) выгружаются данные, выбранные случайным образом.
19. Почему загрузка и выгрузка данных из кэш-памяти производится блоками?
20. Как обеспечивается согласование данных в кэше с помощью методов обратной и сквозной записи?
21. Известно, что с помощью программных конвейеров данными могут обмениваться только процессы-родственники. В то же время все процессы в UNIX являются родственниками, так как все они — потомки специального процесса, инициализирующего систему. Почему же механизм программных конвейеров не работает для двух произвольных процессов?

Привет, Хабрахабр!
В предыдущей статье я рассказал про vfork() и пообещал рассказать о реализации вызова fork() как с поддержкой MMU, так и без неё (последняя, само собой, со значительными ограничениями). Но прежде, чем перейти к подробностям, будет логичнее начать с устройства виртуальной памяти.
Конечно, многие слышали про MMU, страничные таблицы и TLB. К сожалению, материалы на эту тему обычно рассматривают аппаратную сторону этого механизма, упоминая механизмы ОС только в общих чертах. Я же хочу разобрать конкретную программную реализацию в проекте Embox. Это лишь один из возможных подходов, и он достаточно лёгок для понимания. Кроме того, это не музейный экспонат, и при желании можно залезть “под капот” ОС и попробовать что-нибудь поменять.
Любая программная система имеет логическую модель памяти. Самая простая из них — совпадающая с физической, когда все программы имеют прямой доступ ко всему адресному пространству.
При таком подходе программы имеют доступ ко всему адресному пространству, не только могут “мешать” друг другу, но и способны привести к сбою работы всей системы — для этого достаточно, например, затереть кусок памяти, в котором располагается код ОС. Кроме того, иногда физической памяти может просто не хватить для того, чтобы все нужные процессы могли работать одновременно. Виртуальная память — один из механизмов, позволяющих решить эти проблемы. В данной статье рассматривается работа с этим механизмом со стороны операционной системы на примере ОС Embox. Все функции и типы данных, упомянутые в статье, вы можете найти в исходном коде нашего проекта.
Будет приведён ряд листингов, и некоторые из них слишком громоздки для размещения в статье в оригинальном виде, поэтому по возможности они будут сокращены и адаптированы. Также в тексте будут возникать отсылки к функциям и структурам, не имеющим прямого отношения к тематике статьи. Для них будет дано краткое описание, а более полную информацию о реализации можно найти на вики проекта.
- Расширение реального адресного пространства. Часть виртуальной памяти может быть вытеснена на жёсткий диск, и это позволяет программам использовать больше оперативной памяти, чем есть на самом деле.
- Создание изолированных адресных пространств для различных процессов, что повышает безопасность системы, а также решает проблему привязанности программы к определённым адресам памяти.
- Задание различных свойств для разных участков участков памяти. Например, может существовать неизменяемый участок памяти, видный нескольким процессам.
Виртуальный адрес
Page Global Directory (далее — PGD) — таблица (здесь и далее — то же самое, что директория) самого высокого уровня, каждая запись в ней — ссылка на Page Middle Directory (PMD), записи которой, в свою очередь, ссылаются на таблицу Page Table Entry (PTE). Записи в PTE ссылаются на реальные физические адреса, а также хранят флаги состояния страницы.

То есть, при трёхуровневой иерархии памяти виртуальный адрес будет выглядеть так:
Значения полей PGD, PMD и PTE — это индексы в соответствующих таблицах (то есть сдвиги от начала этих таблиц), а offset — это смещение адреса от начала страницы.
В зависимости от архитектуры и режима страничной адресации, количество битов, выделяемых для каждого из полей, может отличаться. Кроме того, сама страничная иерархия может иметь число уровней, отличное от трёх: например, на x86 нет PMD.
Для обеспечения переносимости мы задали границы этих полей с помощью констант: MMU_PGD_SHIFT, MMU_PMD_SHIFT, MMU_PTE_SHIFT, которые в приведённой выше схеме равны 24, 18 и 12 соответственно их определение дано в заголовочном файле src/include/hal/mmu.h. В дальнейшем будет рассматриваться именно этот пример.
На основании сдвигов PGD, PMD и PTE вычисляются соответствующие маски адресов.
Эти макросы даны в том же заголовочном файле.
Для работы с виртуальной таблицами виртуальной памяти в некоторой области памяти хранятся указатели на все PGD. При этом каждая задача хранит в себе контекст struct mmu_context, который, по сути, является индексом в этой таблице. Таким образом, к каждой задаче относится одна таблица PGD, которую можно определить с помощью mmu_get_root(ctx).
Программная поддержка
- Выделение физических страниц из некоторого зарезервированного участка памяти
- Внесение соответствующих изменений в таблицы виртуальной памяти
- Сопоставление участков виртуальной памяти с процессами, выделившими их
- Проецирование региона физической памяти на виртуальный адрес
Аппаратная поддержка
Обращение к памяти хорошо описанно в этой хабростатье. Происходит оно следующим образом:
Процессор подаёт на вход MMU виртуальный адрес
Если MMU выключено или если виртуальный адрес попал в нетранслируемую область, то физический адрес просто приравнивается к виртуальному
Если MMU включено и виртуальный адрес попал в транслируемую область, производится трансляция адреса, то есть замена номера виртуальной страницы на номер соответствующей ей физической страницы (смещение внутри страницы одинаковое):
Если запись с нужным номером виртуальной страницы есть в TLB [Translation Lookaside Buffer], то номер физической страницы берётся из нее же
Если нужной записи в TLB нет, то приходится искать ее в таблицах страниц, которые операционная система размещает в нетранслируемой области ОЗУ (чтобы не было промаха TLB при обработке предыдущего промаха). Поиск может быть реализован как аппаратно, так и программно — через обработчик исключения, называемого страничной ошибкой (page fault). Найденная запись добавляется в TLB, после чего команда, вызвавшая промах TLB, выполняется снова.
Таким образом, при обращении программы к тому или иному участку памяти трансляция адресов производится аппаратно. Программная часть работы с MMU — формирование таблиц страниц и работа с ними, распределение участков памяти, установка тех или иных флагов для страниц, а также обработка page fault, ошибки, которая происходит при отсутствии страницы в отображении.
В тексте статьи в основном будет рассматриваться трёхуровневая модель памяти, но это не является принципиальным ограничением: для получения модели с бóльшим количеством уровней можно действовать аналогичным образом, а особенности работы с меньшим количеством уровней (как, например, в архитектуре x86 — там всего два уровня) будут рассмотрены отдельно.
Устройство Page Table Entry
В реализации проекта Embox тип mmu_pte_t — это указатель.
Каждая запись PTE должна ссылаться на некоторую физическую страницу, а каждая физическая страница должна быть адресована какой-то записью PTE. Таким образом, в mmu_pte_t незанятыми остаются MMU_PTE_SHIFT бит, которые можно использовать для сохранения состояния страницы. Конкретный адрес бита, отвечающего за тот или иной флаг, как и набор флагов в целом, зависит от архитектуры.
- MMU_PAGE_WRITABLE — Можно ли менять страницу
- MMU_PAGE_SUPERVISOR — Пространство супер-пользователя/пользователя
- MMU_PAGE_CACHEABLE — Нужно ли кэшировать
- MMU_PAGE_PRESENT — Используется ли данная запись директории
Можно установить сразу несколько флагов:
Здесь vmem_page_flags_t — 32-битное значение, и соответствующие флаги берутся из первых MMU_PTE_SHIFT бит.
Работа с Page Table Entry
Для работы с записей в таблице страниц, а так же с самими таблицами, есть ряд функций:
Эти функции возвращают 1, если у соответствующей структуры установлен бит MMU_PAGE_PRESENT
Трансляция виртуального адреса в физический
Как уже писалось выше, при обращении к памяти трансляция адресов производится аппаратно, однако, явный доступ к физическим адресам может быть полезен в ряде случаев. Принцип поиска нужного участка памяти, конечно, такой же, как и в MMU.
Для того, чтобы получить из виртуального адреса физический, необходимо пройти по цепочке таблиц PGD, PMD и PTE. Функция vmem_translate() и производит эти шаги.
Сначала проверяется, есть ли в PGD указатель на директорию PMD. Если это так, то вычисляется адрес PMD, а затем аналогичным образом находится PTE. После выделения физического адреса страницы из PTE необходимо добавить смещение, и после этого будет получен искомый физический адрес.
Пояснения к коду функции.
mmu_paddr_t — это физический адрес страницы, назначение mmu_ctx_t уже обсуждалось выше в разделе “Виртуальный адрес”.
С помощью функции vmem_get_idx_from_vaddr() находятся сдвиги в таблицах PGD, PMD и PTE.

Page Fault
Page fault — это исключение, возникающее при обращении к странице, которая не загружена в физическую память — или потому, что она была вытеснена, или потому, что не была выделена.
В операционных системах общего назначения при обработке этого исключения происходит поиск нужной странице на внешнем носителе (жёстком диске, к примеру).
В нашей системе все страницы, к которым процесс имеет доступ, считаются присутствующими в оперативной памяти. Так, например, соответствующие сегменты .text, .data, .bss; куча; и так далее отображаются в таблицы при инициализации процесса. Данные, связанные с потоками (например, стэк), отображаются в таблицы процесса при создании потоков.
Выталкивание страниц во внешнюю память и их чтение в случае page fault не реализовано. С одной стороны, это лишает возможности использовать больше физической памяти, чем имеется на самом деле, а с другой — не является актуальной проблемой для встраиваемых систем. Нет никаких ограничений, делающих невозможной реализацию данного механизма, и при желании читатель может попробовать себя в этом деле :)
Для виртуальных страниц и для физических страниц, которые могут быть использованы при работе с виртуальной памятью, статически резервируется некоторое место в оперативной памяти. Тогда при выделении новых страниц и директорий они будут браться именно из этого места.
Исключением является набор указателей на PGD для каждого процесса (MMU-контексты процессов): этот массив хранится отдельно и используется при создании и разрушении процесса.
Выделение страниц
Итак, выделить физическую страницу можно с помощью vmem_alloc_page
Функция page_alloc() ищет участок памяти из N незанятых страниц и возвращает физический адрес начала этого участка, помечая его как занятый. В приведённом коде virt_page_allocator ссылается на участок памяти, резервированной для выделения физических страниц, а 1 — количество необходимых страниц.
Выделение таблиц
Тип таблицы (PGD, PMD, PTE) не имеет значения при аллокации. Более того, выделение таблиц производится также с помощью функции page_alloc(), только с другим аллокатором (virt_table_allocator).
После добавления страниц в соответствующие таблицы нужно уметь сопоставлять участки памяти с процессами, к которым они относятся. У нас в системе процесс представлен структурой task, содержащей всю необходимую информацию для работы ОС с процессом. Все физически доступные участки адресного пространства процесса записываются в специальный репозиторий: task_mmap. Он представляет из себя список дескрипторов этих участков (регионов), которые могут быть отображены на виртуальную память, если включена соответствующая поддержка.
brk — это самый большой из всех физических адресов репозитория, данное значение необходимо для ряда системных вызовов, которые не будут рассматриваться в данной статье.
ctx — это контекст задачи, использование которого обсуждалось в разделе “Виртуальный адрес”.
struct dlist_head — это указатель на начало двусвязного списка, организация которого аналогична организации Linux Linked List.
За каждый выделенный участок памяти отвечает структура marea
Поля данной структуры имеют говорящие имена: адреса начала и конца данного участка памяти, флаги региона памяти. Поле mmap_link нужно для поддержания двусвязного списка, о котором говорилось выше.
Ранее уже рассказывалось о том, как происходит выделение физических страниц, какие данные о виртуальной памяти относятся к задаче, и теперь всё готово для того, чтобы говорить о непосредственном отображении виртуальных участков памяти на физические.
Отображение виртуальных участков памяти на физическую память подразумевает внесение соответствующих изменений в иерархию страничных директорий.
Подразумевается, что некоторый участок физической памяти уже выделен. Для того, чтобы выделить соответствующие виртуальные страницы и привязать их к физическим, используется функция vmem_map_region()
В качестве параметров передаётся контекст задачи, адрес начала физического участка памяти, а также адрес начала виртуального участка. Переменная flags содержит флаги, которые будут установлены у соответствующих записей в PTE.
Основную работу на себя берёт do_map_region(). Она возвращает 0 при удачном выполнении и код ошибки — в ином случае. Если во время маппирования произошла ошибка, то часть страниц, которые успели выделиться, нужно откатить сделанные изменения с помощью функции vmem_unmap_region(), которая будет рассмотрена позднее.
Рассмотрим функцию do_map_region() подробнее.
Макросы GET_PTE и GET_PMD нужны для лучшей читаемости кода. Они делают следующее: если в таблице памяти нужный нам указатель не ссылается на существующую запись, нужно выделить её, если нет — то просто перейти по указателю к следующей записи.
В самом начале необходимо проверить, выровнены ли под размер страницы размер региона, физический и виртуальный адреса. После этого определяется PGD, соответствующая указанному контексту, и извлекаются сдвиги из виртуального адреса (более подробно это уже обсуждалось выше).
Затем последовательно перебираются виртуальные адреса, и в соответствующих записях PTE к ним привязывается нужный физический адрес. Если в таблицах отсутствуют какие-то записи, то они будут автоматически сгенерированы при вызове вышеупомянутых макросов GET_PTE и GET_PMD.
После того, как участок виртуальной памяти был отображён на физическую, рано или поздно её придётся освободить: либо в случае ошибки, либо в случае завершения работы процесса.
Изменения, которые при этом необходимо внести в структуру страничной иерархии памяти, производятся с помощью функции vmem_unmap_region().
Все параметры функции, кроме последнего, должны быть уже знакомы. free_pages отвечает за то, должны ли быть удалены страничные записи из таблиц.
try_free_pte, try_free_pmd, try_free_pgd — это вспомогательные функции. При удалении очередной страницы может выясниться, что директория, её содержащая, могла стать пустой, а значит, её нужно удалить из памяти.
нужны как раз для случая двухуровневой иерархии памяти.
Конечно, данной статьи не достаточно, чтобы с нуля организовать работу с MMU, но, я надеюсь, она хоть немного поможет погрузиться в OSDev тем, кому он кажется слишком сложным.
Управление памятью – центральный аспект в работе операционных систем. Он оказывает основополагающее влияние на сферу программирования и системного администрирования. В нескольких последующих постах я коснусь вопросов, связанных с работой памяти. Упор будет сделан на практические аспекты, однако и детали внутреннего устройства игнорировать не будем. Рассматриваемые концепции являются достаточно общими, но проиллюстрированы в основном на примере Linux и Windows, выполняющихся на x86-32 компьютере. Первый пост описывает организацию памяти пользовательских процессов.
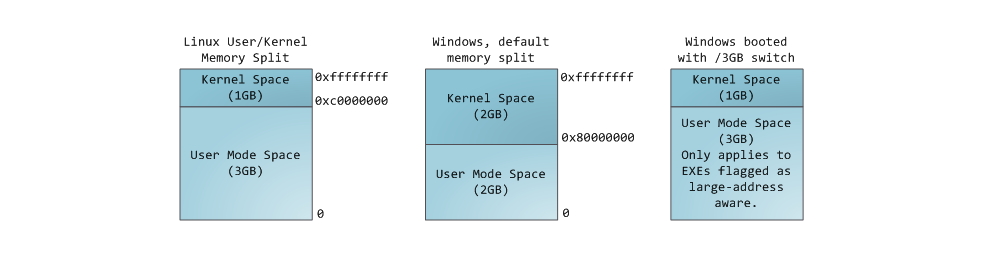
Каждый процесс в многозадачной ОС выполняется в собственной “песочнице”. Эта песочница представляет собой виртуальное адресное пространство, которое в 32-битном защищенном режиме всегда имеет размер равный 4 гигабайтам. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц (page table). Ядро создает и заполняет таблицы, а процессор обращается к ним при необходимости осуществить трансляцию адреса. Каждый процесс работает со своим набором таблиц. Есть один важный момент — концепция виртуальной адресации распространяется на все выполняемое ПО, включая и само ядро. По этой причине для него резервируется часть виртуального адресного пространства (т.н. kernel space).

Синим цветом на рисунке отмечены области виртуального адресного пространства, которым в соответствие поставлены участки физической памяти; белым цветом — еще не использованные области. Как видно, Firefox использовал большую часть своего виртуального адресного пространства. Все мы знаем о легендарной прожорливости этой программы в отношении оперативной памяти. Синие полосы на рисунке — это сегменты памяти программы, такие как куча (heap), стек и так далее. Обратите внимание, что в данном случае под сегментами мы подразумеваем просто непрерывные адресные диапазоны. Это не те сегменты, о которых мы говорим при описании сегментации в Intel процессорах. Так или иначе, вот стандартная схема организации памяти процесса в Linux:

Давным давно, когда компьютерная техника находилась в совсем еще младенческом возрасте, начальные виртуальные адреса сегментов были совершенно одинаковыми почти для всех процессов, выполняемых машиной. Из-за этого значительно упрощалось удаленное эксплуатирование уязвимостей. Эксплойту часто необходимо обращаться к памяти по абсолютным адресам, например по некоторому адресу в стеке, по адресу библиотечной функции, и тому подобное. Хакер, рассчитывающий осуществить удаленную атаку, должен выбирать адреса для обращения в слепую в расчете на то, что размещение сегментов программы в памяти на разных машинах будет идентичным. И когда оно действительно идентичное, случается, что людей хакают. По этой причине, приобрел популярность механизм рандомизации расположения сегментов в адресном пространстве процесса. Linux рандомизирует расположение стека, сегмента для memory mapping, и кучи – их стартовый адрес вычисляется путем добавления смещения. К сожалению, 32-битное пространство не очень-то большое, и эффективность рандомизации в известной степени нивелируется.
В верхней части user mode space расположен стековый сегмент. Большинство языков программирования используют его для хранения локальных переменных и аргументов, переданных в функцию. Вызов функции или метода приводит к помещению в стек т.н. стекового фрейма. Когда функция возвращает управление, стековый фрейм уничтожается. Стек устроен достаточно просто — данные обрабатываются в соответствии с принципом «последним пришёл — первым обслужен» (LIFO). По этой причине, для отслеживания содержания стека не нужно сложных управляющих структур – достаточно всего лишь указателя на верхушку стека. Добавление данных в стек и их удаление – быстрая и четко определенная операция. Более того, многократное использование одних и тех же областей стекового сегмента приводит к тому, что они, как правило, находятся в кеше процессора, что еще более ускоряет доступ. Каждый тред в рамках процесса работает с собственным стеком.
Возможна ситуация, когда пространство, отведенное под стековый сегмент, не может вместить в себя добавляемые данные. В результате, будет сгенерирован page fault, который в Linux обрабатывается функцией expand_stack(). Она, в свою очередь, вызовет другую функцию — acct_stack_growth(), которая отвечает за проверку возможности увеличить стековый сегмент. Если размер стекового сегмента меньше значения константы RLIMIT_STACK (обычно 8 МБ), то он наращивается, и программа продолжает выполняться как ни в чем не бывало. Это стандартный механизм, посредством которого размер стекового сегмента увеличивается в соответствии с потребностями. Однако, если достигнут максимально разрещённый размер стекового сегмента, то происходит переполнение стека (stack overflow), и программе посылается сигнал Segmentation Fault. Стековый сегмент может увеличиваться при необходимости, но никогда не уменьшается, даже если сама стековая структура, содержащаяся в нем, становиться меньше. Подобно федеральному бюджету, стековый сегмент может только расти.
Динамическое наращивание стека – единственная ситуация, когда обращение к «немэппированной» области памяти, может быть расценено как валидная операция. Любое другое обращение приводит к генерации page fault, за которым следует Segmentation Fault. Некоторые используемые области помечены как read-only, и обращение к ним также приводит к Segmentation Fault.
Под стеком располагается сегмент для memory mapping. Ядро использует этот сегмент для мэппирования (отображания в память) содержимого файлов. Любое приложение может воспользоваться данным функционалом посредством системного вызовома mmap() (ссылка на описание реализации вызова mmap) или CreateFileMapping() / MapViewOfFile() в Windows. Отображение файлов в память – удобный и высокопроизводительный метод файлового ввода / вывода, и он используется, например, для загрузки динамических библиотек. Существует возможность осуществить анонимное отображение в память (anonymous memory mapping), в результате чего получим область, в которую не отображен никакой файл, и которая вместо этого используется для размещения разного рода данных, с которыми работает программа. Если в Linux запросить выделение большого блока памяти с помощью malloc(), то вместо того, чтобы выделить память в куче, стандартная библиотека C задействует механизм анонимного отображения. Слово «большой», в данном случае, означает величину в байтах большую, чем значение константы MMAP_THRESHOLD. По умолчанию, это величина равна 128 кБ, и может контролироваться через вызов mallopt().
Если текущий размер кучи позволяет выделить запрошенный объем памяти, то выделение может быть осуществлено средствами одной лишь среды выполнения, без привлечения ядра. В противном случае, функция malloc() задействует системный вызов brk() для необходимого увеличения кучи (ссылка на описание реализации вызова brk). Управление памятью в куче – нетривиальная задача, для решения которой используются сложные алгоритмы. Данные алгоритмы стремятся достичь высокой скорости и эффективности в условиях непредсказуемых и хаотичных пэттернов выделения памяти в наших программах. Время, затрачиваемое на каждый запрос по выделению памяти в куче, может разительно отличаться. Для решения данной проблемы, системы реального времени используют специализированные аллокаторы памяти. Куча также подвержена фрагментированию, что, к примеру, изображено на рисунке:

Наконец, мы добрались до сегментов, расположенных в нижней части адресного пространства процесса: BSS, сегмент данных (data segment) и сегмент кода (text segment). BSS и data сегмент хранят данные, соответствующий static переменным в исходном коде на C. Разница в том, что в BSS хранятся данные, соответствующие неинициализированным переменным, чьи значения явно не указаны в исходном коде (в действительности, там хранятся объекты, при создании которых в декларации переменной либо явно указано нулевое значение, либо значение изначально не указано, и в линкуемых файлах нет таких же common символов, с ненулевым значением. – прим. перевод.). Для сегмента BSS используется анонимное отображение в память, т.е. никакой файл в этот сегмент не мэппируется. Если в исходном файле на C использовать int cntActiveUsers, то место под соответствующий объект будет выделено в BSS.
В отличии от BSS, data cегмент хранит объекты, которым в исходном коде соответствуют декларации static переменных, инициализированных ненулевым значением. Этот сегмент памяти не является анонимным — в него мэппируется часть образа программы. Таким образом, если мы используем static int cntWorkerBees = 10, то место под соответствующий объект будет выделено в data сегменте, и оно будет хранить значение 10. Хотя в data сегмент отображается файл, это т.н. «приватный мэппинг» (private memory mapping). Это значит, что изменения данных в этом сегменте не повлияют на содержание соответствующего файла. Так и должно быть, иначе присвоения значений глобальным переменным привели бы к изменению содержания файла, хранящегося на диске. В данном случае это совсем не нужно!
С указателями все немножко посложнее. В примере из наших диаграмм, содержимое объекта, соответствующего переменной gonzo – это 4-байтовый адрес – размещается в data сегменте. А вот строка, на которую ссылается указатель, не попадет в data сегмент. Строка будет находиться в сегменте кода, который доступен только на чтение и хранит весь Ваш код и такие мелочи, как, например, строковые литералы (в действительности, строка хранится в секции .rodata, которая вместе с другими секциями, содержащими исполняемый код, рассматривается как сегмент, который загружается в память с правами на выполнение кода / чтения данных – прим. перевод.). В сегмент кода также мэппируется часть исполняемого файла. Если Ваша программа попытается осуществить запись в text сегмент, то заработает Segmentation Fault. Это позволяет бороться с «бажными» указателями, хотя самый лучший способ борьбы с ними – это вообще не использовать C. Ниже приведена диаграмма, изображающая сегменты и переменные из наших примеров:
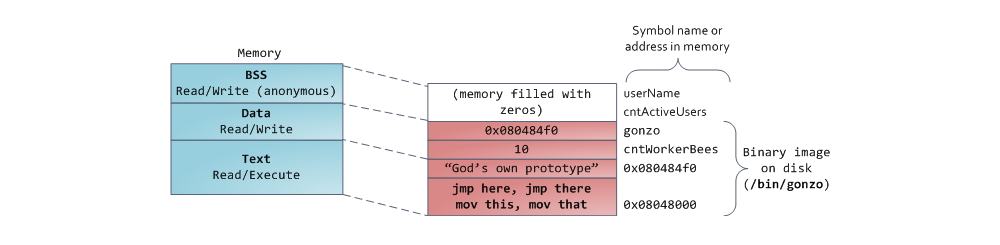
Мы можем посмотреть, как используются области памяти процесса, прочитав содержимое файла /proc/pid_of_process/maps. Обратите внимание, что содержимое самого сегмента может состоять из различных областей. Например, каждой мэппируемой в memory mapping сегмент динамической библиотеке отводится своя область, и в ней можно выделить области для BSS и data сегментов библиотеки. В следующем посте поясним, что конкретно подразумевается под словом “область”. Учтите, что иногда люди говорят “data сегмент”, подразумевая под этим data + BSS + heap.
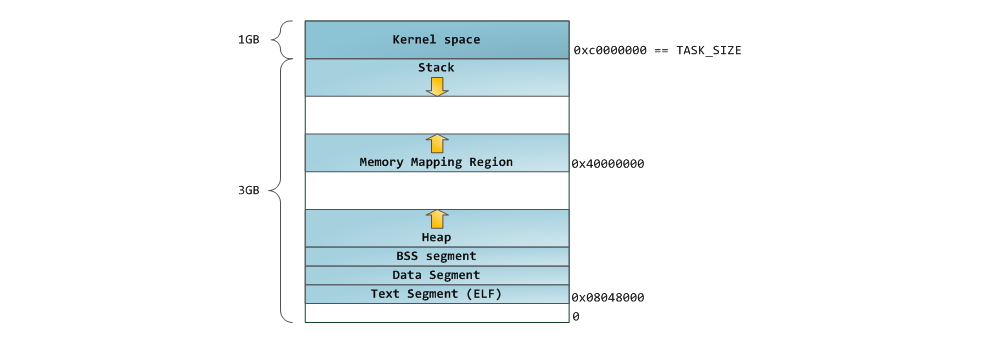
Можно использовать утилиты nm и objdump для просмотра содержимого бинарных исполняемых образов: символов, их адресов, сегментов и т.д. Наконец, то, что описано в этом посте – это так называемая “гибкая” организация памяти процесса (flexible memory layout), которая вот уже несколько лет используется в Linux по умолчанию. Данная схема предполагает, что у нас определено значение константы RLIMIT_STACK. Когда это не так, Linux использует т.н. классическую организации, которая изображена на рисунке:
Ну вот и все. На этом наш разговор об организации памяти процесса завершен. В следующем посте рассмотрим как ядро отслеживает размеры описанных областей памяти. Также коснемся вопроса мэппирования, какое отношение к этому имеет чтение и запись файлов, и что означают цифры, описывающие использование памяти.
Ранее мы увидели как организована виртуальная память процесса. Теперь рассмотрим механизмы, благодаря которым ядро управляет памятью. Обратимся к нашей программе:
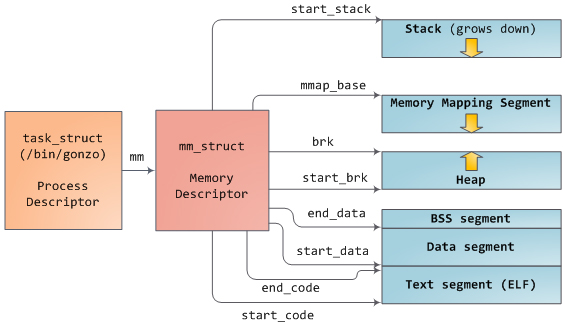
В Linux, процессы реализованы в виде struct-объекта task_struct, который по сути является дескриптором процесса. В поле mm объекта task_struct содержится указатель на т.н. «дескриптор памяти процесса» — struct-объект mm_struct — который содержит исчерпывающую информацию об использовании памяти данным процессом. В дескрипторе памяти процесса хранится информация о начальном и конечном адресе сегментов процесса, как показано на рисунке вверху, число page-фреймов (физических страниц в оперативной памяти), используемых процессом (это RSS или т.н. «резидентный набор страниц»), количество виртуальной памяти, выделенной процессу, и другая мелочь. Дескриптор памяти процесса также указывает на местонахождение дескрипторов VMA (virtual memory area или «область виртуальной памяти») и набора page-таблиц для процесса. Последние две структуры данных — это своего рода «рабочие лошадки», т.к. они задействуются при большинстве операций управления памятью. Области виртуальной памяти для нашей программы указаны на рисунке:

Область виртуальной памяти (VMA) представляет собой непрерывный диапазон виртуальных адресов; области никогда не перекрывают друг друга. Экземпляр struct-объекта vm_area_struct исчерпывающе описывает одну VMA, включая начальный и конечный виртуальный адрес области, флаги, определяющие права и другие особенности доступа к области, поле vm_file с информацией о файле, отображенном в данную область (если таковой файл имеется). Область виртуальной памяти, которая не сопоставлена ни с каким файлом, называется анонимной. Каждому из сегментов программы на вышеприведенном рисунке (куча, стек и т.д.) соответствует своя VMA; исключение в этом отношении состовляет только т.н. «сегмент для мэппирования» (memory mapping segment). Данное положение вещей не является каким-то требованием или чем-то предопределенным, но в случае с платформой x86 это в большинстве случаев именно так. Области виртуальной памяти все равно какому сегменту соответствовать.
Набор VMA для данного процесса описан сразу двумя способами. Во-первых, в дескрипторе памяти процесса (struct-объект mm_struct) имеется указатель mmap на связный список дескрипторов VMA (порядок дескрипторов в списке соответствует порядку следования VMA в виртуальном адресном пространстве). Во-вторых, все в том же дескрипторе памяти имеется указатель mm_rb на структуру, которая представляет собой red-black tree. RB-дерево позволяет ядру быстро устанавливать факт нахождения некоторого виртуального адреса в пределах той или иной виртуальной области. Если посмотреть содержимое файла /proc/pid_of_process/maps в файловой системе proc, то это будет не что иное как информация, полученная ядром в результате «прохода» по связному списку дескрипторов VMA.
В Windows, блок EPROCESS – это, грубо говоря, что-то среднее между структурами task_struct и mm_struct. Аналогом дескриптора области виртуальной памяти является Virtual Address Descriptor или VAD. Информация о VAD дескрипторах храниться в AVL-дереве. Знаете, что самое смешное при сравнении Windows и Linux? Это то, что отличий как раз не так уж и много.

Процессор консультируется с page-таблицами для того, чтобы осуществить преобразование виртуального адреса в физический. У каждого процесса есть свой набор таких page-таблиц; как только происходит переключение процесса (context switch), меняются и page-таблицы для user space-части виртуального адресного пространства. В Linux, указатель на page-таблицы процесса хранится в поле pgd дескриптора памяти процесса. Каждой виртуальной странице соответствует одна запись в page-таблице, и, в случае с классическим x86-пейджингом, это простая 4-байтовая запись, показанная на следующем рисунке:

В ядре Linux есть функции, которые позволяют взвести или обнулить любой флаг в page table записи. Флаг «P» говорит о том, находится ли страница в оперативной памяти или нет. Когда данный флаг установлен в 0, доступ к соответствующей странице вызовет page fault. Нужно учесть, что если данный флаг установлен в 0, то ядро может как угодно использовать оставшиеся биты в page table записи. Флаг «R/W» означает «запись/чтение»; если флаг не установлен, то к странице возможен доступ только на чтение. Флаг «U/S» означает «пользователь/супервайзер»; если флаг не установлен, только код выполняющийся с уровнем привилегий 0 (т.е. ядро) может обратиться к данной странице. Таким образом, данные флаги используются для того, чтобы реализовать концепцию адресного пространства доступного только на запись и пространства, которое доступно только для ядра.
Флаги «D» и «A» означают «dirty» и «accessed». «Dirty-страница» – эта та, в которую была недавно проведена запись, а «accessed»-страница – это страница, к которой было осуществлено обращение (чтение или запись). Оба флага являются «липкими», процессор может их установить, но не будет обнулять – делать это должно ядро. Наконец, page table запись хранит начальный физический адрес страницы в памяти; адрес всегда будет кратным 4 КБ. Это казалось бы безобидное поле является причиной многих проблем, т.к. оно фактически ограничивает размер адресуемой физической памяти 4 гигабайтами. Другие поля page table записи рассмотрим как-нибудь в другой раз, так же как и механизм Physical Address Extension.
Защита памяти осуществляется на постраничной основе, поскольку страница – это самый маленький «кусочек» памяти, для которого можно выставить флаги «U/S» и «R/W». Стоит однако учитывать, что теоретически, две разные виртуальные страницы, имеющие отличающийся набор флагов, могут соответствовать одной и той же физической странице. Заметьте, в формате page table записи не предусмотрены флаги, связанные с запретом на выполнение кода. Иными словами, классический x86-пейджинг никак не препятствует выполнению кода в стеке. Именно поэтому возможно эксплуатирование уязвимостей, в основе которых переполнение буфера в стеке (неисполняемые стеки все равно подвержены уязвимостям; в таком случае используется техника return-to-libc и другие приемы). Отсутсвие no-execute флага также свидетельствует о другом важном аспекте: флаги доступа, содержащиеся в дескрипторе VMA, не всегда имеют прямые соответствия в системе защиты, реализуемой процессором, и соответствуют этой системе лишь в большей или меньшей степени. Образно говоря, ядро делает все, что в его силах, но в конечном счете архитектура процессора накладывает свои ограничения на то, что возможно реализовать.
Конечно же виртуальная память сама по себе ничего не хранит. Виртуальное адресное пространство — это просто абстракция, но оно определенным образом поставлено в соответствие физической памяти. То, как работает адресная шина процессора, вообще говоря, вещь достаточно нетривиальная, но мы сейчас можем от этого абстрагироваться. Будем считать, что процессор работает с диапазоном последовательных адресов от нуля до максимально доступного в системе адреса (в зависимости от количества оперативной памяти) и может при необходимости обратиться к любому байту в этом диапазоне. Физическое адресное пространство рассматривается процессором как последовательность физических страниц (их еще называют page-фреймами). Процессору мало дела до page-фреймов, а вот для ядра они очень важны, т.к. page-фрейм – единица учета и управления физической памятью, которое и осуществляется ядром. 32-битные версии Linux и Windows используют 4-килобайтные page-фреймы; вот пример машины с 2 ГБ оперативной памяти:

Ядро Linux ведет учет каждому page-фрейму с помощью специального дескриптора и нескольких флагов. Взятые вместе, эти дескрипторы описывают всю оперативную память компьютера; в каждый момент времени известно точное состояние любого page-фрейма. В основе управления физической памятью лежит алгоритм Buddy memory allocation. Таким образом, page-фрейм считается свободным, если он доступен для выделения с точки зрения Buddy-алгоритма. Выделенный под использование page-фрейм может быть «анонимным» (в таком случае он содержит данные программы) или он может находиться в т.н. «страничном кэше» (page cache) и хранить порцию данных из некоторого файла или блочного устройства. Существуют и другие, более экзотичные варианты использования page-фреймов, но давайте не будем их сейчас трогать. В Windows также имеется аналогичная структура для учета page-фреймов, и называется она — база данных Page Frame Number.
А теперь, давайте соберем воедино все эти концепции – области виртуальной памяти (VMA), page table-записи и page-фреймы – и посмотрим как это все вместе работает. Далее идет пример кучи в user space области программы:

Прямоугольники с голубым фоном обозначают виртуальные страницы, находящиеся в пределах VMA. Стрелки обозначают page table-записи, с помощью которых виртуальные страницы «мэппируются» в page-фремы (физические страницы). У некоторых виртуальных страниц нет стрелок; это означает, что в соответствующих им page table записях флаг присутствия установлен в 0. Причиной тому может быть то, что данные виртуальные страницы возможно не разу еще не использовались или же потому, что соответствующие им физические страницы были выгружены в своп. В любом случае, попытка доступа к этим страницам приведет к page fault, даже несмотря на то, что виртуальные страницы находятся в пределах некоторой VMA. Может показаться странным, что существует подобного рода разночтение – страницы в пределах VMA и тем не менее доступ к ним является невалидным – но так действительно часто происходит.
VMA представляет собой своего рода «контракт» между программой и ядром. Вы просите ядро выполнить какое-нибудь действие (например, выделить память или замэппировать файл), ядро говорит «без проблем» и создает новую или обновляет существующую VMA. Но ядро при этом не спешит выполнять сами эти действия; вместо этого оно отложит непосредственное выполнение запрошенного действия до того момента, пока не случится page fault. Получается, что ядро – это этакий «ленивый обманщик», и это является основополагающим принципом управления виртуальной памятью. Данный принцип применяется в большинстве ситуаций – некоторые из них могут быть вполне знакомыми, некоторые — неожиданными, но общее правило таково, что VMA лишь фиксирует, то о чем было договорено, в то время как page table-записи отражают то, что непосредственно было сделано ленивым ядром. Эти две структуры вместе учавствуют в управлении памятью программы; обе структуры играют определенную роль при обработке page fault, высвобождении памяти, выгрузке страниц в своп и т.д. Рассмотрим простой случай выделения памяти:

Когда программа запрашивает выделение дополнительной памяти посредством системного вызова brk(), ядро просто напросто обновляет информацию в дескрипторе VMA и на этом считает свою задачу выполненной. В данный момент времени не происходит ни выделение новых page-фреймов, ни размещение их в оперативной памяти. Однако, как только программа попытается обратиться к виртуальной странице, процессор отловит page fault и будет вызван обработчик do_page_fault(). Данная функция осуществит поиск VMA, в пределах которой находится адрес, обращение к которому вызвало page fault. Если такая VMA существует, то дальше прозводится проверка на соответствие между правами доступа к VMA и типом производимого доступа (доступ на чтение или запись). Если же подходящей VMA нет, тогда нет и «контракта», который предусматривал бы возможность обращения к памяти. В последнем случае, процессу посылается сигнал Segmentation Fault, и он завершается.
Допустим, VMA все-таки нашлась. Дальнейшая обработка page fault такая – ядро смотрит на содержимое page table записи и тип VMA. В нашем примере, page table запись свидетельствует о том, что страницы в памяти нет. Более того, наша запись совершенно пустая (состоит из одних нулей), и в Linux это означает, что соответствующая виртуальная страница вообще еще ни разу не была замэппирована. Поскольку мы имеем дело с «анонимной» VMA, то все дальнейшие действия будут связаны только с оперативной памятью, и для обработки данной ситуации вызывается функция do_anonymous_page(). Данная функция производит выделение page-фрейма и мэппирует в него виртуальную страницу путем внесения нужных данных в page table запись.
Дело могли обстоять и иначе. Page table запись для выгруженной в своп страницы, к примеру, имеет флаг присутствия установленный в 0, но остальная часть записи непустая. Остальные биты хранят информацию о нахождении страницы в свопе. Функция do_swap_page() считывает содержимое этой страницы с диска и загружает страницу в оперативную память. Подобного рода page fault называют major fault.
На этом завершим первую часть нашего экскурса в то, как ядро управляет памятью. В следующей статье мы усложним картину, дополнив её работой с файлами — таким образом получим более полное представление об основных концепциях управления памятью, включая и некоторые аспекты производительности.
Размер страницы
В реальных (то есть не в учебных) системах используются страницы от 512 байт до 64 килобайт. Чаще всего размер страницы определяется архитектурой и является фиксированным для всей системы, например — 4 KiB.
С одной стороны, при меньшем размере страницы память меньше фрагментируется. Ведь наименьшая единица виртуальной памяти, которая может быть выделена процессу — это одна страница, а программам очень редко требуется целое число страниц. А значит, в последней странице, которую запросил процесс, скорее всего останется неиспользуемая память, которая, тем не менее, будет выделена, а значит — использована неэффективно.
С другой стороны, чем меньше размер страницы, тем больше размер страничных таблиц. Более того, при отгрузке на HDD и при чтении страниц с HDD быстрее получится записать несколько больших страниц, чем много маленьких такого же суммарного размера.
Отдельного внимания заслуживают так называемые большие страницы: huge pages и large pages [вики] .
| Платформа | Размер обычной страницы | Размер страницы максимально возможного размера |
| x86 | 4KB | 4MB |
| x86_64 | 4KB | 1GB |
| IA-64 | 4KB | 256MB |
| PPC | 4KB | 16GB |
| SPARC | 8KB | 2GB |
| ARMv7 | 4KB | 16MB |
Действительно, при использовании таких страниц накладные расходы памяти повышаются. Тем не менее, прирост производительности программ в некоторых случаях может доходить до 10% [ссылка] , что объясняется меньшим размером страничных директорий и более эффективной работой TLB.
В дальнейшем речь пойдёт о страницах обычного размера.
Читайте также: