
При рассмотрении времени работы t m и памяти m n что нас интересует
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
1 contributor
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n 3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n . Тогда говорят, что временная сложность этого алгоритма равна О(n 3 ) , т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n) .
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
Users who have contributed to this file
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Потоки и паросочетания
ограничение по времени на тест: 5 секунд
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Дана система из узлов и труб, по которым может течь вода. Для каждой трубы известна наибольшая скорость, с которой вода может протекать через нее. Известно, что вода течет по трубам таким образом, что за единицу времени в каждый узел (за исключением двух — источника и стока) втекает ровно столько воды, сколько из него вытекает.
Ваша задача — найти наибольшее количество воды, которое за единицу времени может протекать между источником и стоком, а также скорость течения воды по каждой из труб.
Трубы являются двусторонними, то есть вода в них может течь в любом направлении. Между любой парой узлов может быть более одной трубы.
В первой строке записано натуральное число N — количество узлов в системе (2 ≤ N ≤ 100). Известно, что источник имеет номер 1, а сток номер N. Во второй строке записано натуральное M (1 ≤ M ≤ 5000) — количество труб в системе. Далее в M строках идет описание труб. Каждая труба задается тройкой целых чисел Ai, Bi, Ci, где Ai, Bi — номера узлов, которые соединяет данная труба (Ai ≠ Bi), а Ci (0 ≤ Ci ≤ 104) — наибольшая допустимая скорость течения воды через данную трубу.
В первой строке выведите наибольшее количество воды, которое протекает между источником и стоком за единицу времени. Далее выведите M строк, в каждой из которых выведите скорость течения воды по соответствующей трубе. Если направление не совпадает с порядком узлов, заданным во входных данных, то выводите скорость со знаком минус. Числа выводите с точностью 10^(-3).
входные данные
выходные данные
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Найдите минимальный разрез между вершинами 1 и n в заданном неориентированном графе.
На первой строке входного файла содержится n (2 ≤ n ≤ 100) — число вершин в графе и m (0 ≤ m ≤ 400) — количество ребер. На следующих m строках входного файла содержится описание ребер. Ребро описывается номерами вершин, которые оно соединяет, и его пропускной способностью (положительное целое число, не превосходящее 10 000 000), при этом никакие две вершины не соединяются более чем одним ребром.
На первой строке выходного файла должны содержаться количество ребер в минимальном разрезе и их суммарная пропускная способность. На следующей строке выведите возрастающую последовательность номеров ребер (ребра нумеруются в том порядке, в каком они были заданы во входном файле).
входные данные
выходные данные
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Две улиточки Маша и Петя сейчас находятся в на лужайке с абрикосами и хотят добраться до своего домика. Лужайки пронумерованы числами от 1 до n и соединены дорожками (может быть несколько дорожек соединяющих две лужайки, могут быть дорожки, соединяющие лужайку с собой же). В виду соображений гигиены, если по дорожке проползла улиточка, то вторая по той же дорожке уже ползти не может. Помогите Пете и Маше добраться до домика.
В первой строке файла записаны четыре целых числа — n, m, s и t (количество лужаек, количество дорог, номер лужайки с абрикосами и номер домика). В следующих m строках записаны пары чисел. Пара чисел (x, y) означает, что есть дорожка с лужайки x до лужайки y (из-за особенностей улиток и местности дорожки односторонние). Ограничения: 2 ≤ n ≤ 10^5, 0 ≤ m ≤ 10^5, s_≠_t .
Если существует решение, то выведите YES и на двух отдельных строчках сначала последовательность лужаек для Машеньки (дам нужно пропускать вперед), затем путь для Пети. Если решения не существует, выведите NO. Если решений несколько, выведите любое.
входные данные
выходные данные
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Двудольным графом называется неориентированный граф (V, E),E ⊆ V × V такой, что его множество вершин V можно разбить на два множества A и B, для которых ∀(e1, e2) ∈ E e1 ∈ A, e2 ∈ B и A ∪ B = V,A ⋂ B = ∅ .
Паросочетанием в двудольном графе называется любой набор его несмежных рёбер, то есть такой набор S ⊆ E , что для любых двух рёбер e1 = (u1, v1), e2 = (u2, v2) из S u1 ≠ u2 и v1 ≠ v2.
Ваша задача — найти максимальное паросочетание в двудольном графе, то есть паросочетание с максимально возможным числом рёбер.
В первой строке записаны два целых числа n и m (1 ≤ n, m ≤ 250), где n — число вершин в множестве A, а m — число вершин в B.
Далее следуют n строк с описаниями рёбер — i-я вершина из A описана в (i + 1)-й строке файла. Каждая из этих строк содержит номера вершин из B, соединённых с i-й вершиной A. Гарантируется, что в графе нет кратных ребер. Вершины в A и B нумеруются независимо (с единицы). Список завершается числом 0.
Первая строка выходного файла должна содержать одно целое число l — количество рёбер в максимальном паросочетании. Далее следуют l строк, в каждой из которых должны быть два целых числа uj и vj — концы рёбер паросочетания в A и B соотвественно.
входные данные
выходные данные
E. Шахматная доска
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Вася любит играть в необычные шахматы. Его братишка Коля был еще очень маленький. Как-то раз, когда Вася вернулся из школы, он увидел, что его любимую шахматную доску кто-то перекрасил. Вася не сильно разозлился на Колю, потому что очень любил своего брата. Так как у них дома были только черная и белая краски, каждая клетка доски была покрашена в один из этих двух цветов.
Вам предстоит помочь Васе. Задано испорченное Колей шахматное поле. Вам необходимо определить, за какое минимальное количество действий Вася сможет перекрасить доску так, чтобы она стала шахматной.
В первой строке входного файла записаны два целых числа: n и m (1 ≤ n, m ≤ 100) — количество строчек и количество столбцов шахматного поля соответственно.
В следующих n строках записано поле, в каждой строке по m символов. Каждая строка входного файла описывает одну строку шахматного поля. W соответствует белой клетке, B — черной.
В выходной файл нужно вывести число p, количество действий, которое потребуется Васе, чтобы его доска снова стала шахматной. В следующих p строках описаны действия. Каждое действие описано тремя параметрами: тип диагонали, координаты клетки и цвет. Тип диагонали — это число 1 или 2. Координаты клетки — это два целых числа: строка и столбец одной из клеток, которую покрасили этим действием. Цвет — это символ W или B, белый и черный соответственно.
входные данные
выходные данные
входные данные
выходные данные
входные данные
выходные данные
F. Двигаем предметы
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
На плоскости расположены n предметов, их нужно переместить в заданные n позиций. При этом не важно, какой предмет какую из них займет. Для каждого предмета известна максимальная скорость, с которой его можно перемещать, при этом перемещать все предметы можно одновременно.
Найдите минимальное время, за которое можно переместить предметы на заданные места.
В первой строке записано число n (1 ≤ n ≤ 50), в следующих n строках содержатся описания предметов, в i-ой из которых, находится три числа координаты xi, yi (1 ≤ xi, yi ≤ 1000) и максимальная скорость vi (1 ≤ vi ≤ 10) i-ого предмета соответственно. В следующих n строках содержатся описания финальных позиций, в i-ой из которых, заданы координаты ai, bi (1 ≤ ai, bi ≤ 1000) i-ой финальной позиции.
Выведите одно число — минимальное время, за которое можно переместить предметы. Погрешность не более 10^(-4).
входные данные
выходные данные
входные данные
выходные данные
входные данные
выходные данные
входные данные
выходные данные
G. Великая стена
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
У короля Людовика двое сыновей. Они ненавидят друг друга, и король боится, что после его смерти страна будет уничтожена страшными войнами. Поэтому Людовик решил разделить свою страну на две части, в каждой из которых будет властвовать один из его сыновей. Он посадил их на трон в города A и B, и хочет построить минимально возможное количество фрагментов стены таким образом, чтобы не существовало пути из города A в город B.
Страну, в которой властвует Людовик, можно упрощенно представить в виде прямоугольника m × n. В некоторых клетках этого прямоугольника расположены горы, по остальным же можно свободно перемещаться. Кроме этого, ландшафт в некоторых клетках удобен для строительства стены, в остальных же строительство невозможно.
При поездках по стране можно перемещаться из клетки в соседнюю по стороне, только если ни одна из этих клеток не содержит горы или построенного фрагмента стены.
В первой строке выходного файла должно быть выведено минимальное количество фрагментов стены F, которые необходимо построить. Далее нужно вывести карту в том же формате, как во входном файле. Клетки со стеной обозначьте символом «+».
Если невозможно произвести требуемую застройку, то выведите в выходной файл единственное число -1.
входные данные
выходные данные
входные данные
выходные данные
входные данные
выходные данные
H. Космические перевозки
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: bring.in
вывод: bring.out
К 3141 году человеческая цивилизация распространилась по всей галактике. Для перехода от одной звездной системы к другой используются специальные гипертуннели. Чтобы использовать гипертуннель, нужно прилететь в специальное место рядом с исходной звездой используя ваш космический корабль, активировать гипердрайв, пролететь через гипертуннель, выйти рядом со звездой назначения и лететь на нужную вам планету. Весь процесс занимает ровно один день. Небольшой недостаток системы состоит в том, что по каждому туннелю может пролететь только один космический корабль в день.
Вы работаете в транспортном отделе компании «Intergalaxy Business Machines». Сегодня утром ваш начальник дал вам новую задачу. Чтобы запустить чемпионат по программированию IBM, нужно доставить K суперкомпьютеров от Земли, где находится штаб-квартира компании на планету Эйсиэм.
Поскольку суперкомпьютеры очень большие, нужно, для перевозки одного нужен целый космический корабль. Вас попросили найти план доставки суперкомпьютеров, который позволит доставить все компьютеры за минимальное число дней. Поскольку IBM является очень мощной корпорацией, можете считать, что каждый раз, когда вам нужен какой-то гипертуннель, он к вашим услугам. Однако вы все равно можно использовать каждый туннель только один раз в день.
Первая строка входного файла содержит N — число звездных систем в галактике, M — число туннелей, K — число суперкомпьютеров для доставки, S — номер солнечной системы, где находится планета Земля и T — номер звездной системы, где находится Планета Эйсиэм (N ≤ 50>, M ≤ 200>, K ≤ 50>, S, T ≤ N>, S ≠ T>)
Следующие M строк содержат по два разных целых числа и описывают туннели. Для каждого туннеля даются номера звездных систем, которые он соединяет. По туннелю можно путешествовать в обоих направлениях, но помните, что каждый день только один корабль может использовать туннель. В частности, два судна не могут одновременно проходить через один и тот же туннель в противоположных направлениях. Ни один туннель не соединяет звезду с самим собой и две звезды связаны не более чем одним туннелем.
В первой строке выходного файла выведите L — наименьшее число дней, необходимых для доставки K суперкомпьютеров от звездной системы S до звездной системы T с использованием гипертуннелей.
Следующие L строк должны описывать процесс. Каждая строка должна начинаться с Ci — числа кораблей, которые отправляются из одной системы в другую в этот день. Далее должны следовать Ci пар целых чисел, пара A, B означает, что корабль номер A перемещается из текущей звездной системы в звездную систему B.
входные данные
выходные данные
I. Групповой турнир
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
В нашем капиталистическом и меркантильном мире всё решают деньги, и даже спорт не стал исключением. Все команды-участницы уже купили себе нужное количество очков в следующем сезоне, и местной федерации хоккея осталось только распределить результаты предстоящих игр. Однако, некоторые команды не поскупились и помимо покупки очков также купили ещё и результаты некоторых игр. Поначалу в федерации думали, что это им только упростит задачу: чем для большего числа игр результаты уже определены, тем меньше работы остаётся им. Но позже они поняли, что ошиблись. Они попросили вас стать участником их коррупционной схемы и помочь с распределением результатов игр предстоящего сезона.
Местный хоккейный турнир проходит по круговой системе: в турнире участвуют N команд и каждая команда играет с каждой ровно одно игру. За игру команды получают очки по следующим правилам:
Если победителя удалось выявить в основное время матча, то ему достаётся 3 очка, а проигравшему — 0. Если основное время закончилось вничью и для выявления победителя понадобилось дополнительное время (овертайм), то победителю дают 2 очка, а проигравшему — 1 очко. Овертайм не ограничен во времени и длится до тех пор, пока одна из команд не забьёт гол. По итогам турнира очки команды определяются как сумма её очков по всем сыгранным играм.
В первой строке входного файла содержится целое число N — количество участников турнира (2 ≤ N ≤ 100). Команды занумерованы числами от 1 до N.
Следующие N строк файла содержат по N символов и представляют собой турнирную таблицу на данный момент. Символ aij в строке i (1 ≤ i ≤ N) на позиции j (1 ≤ j ≤ N) означает результат игры команды номер i с командой номер j и может быть одним из:
В выходной файл выведите полностью заполненную турнирную таблицу в формате, аналогичном формату входного файла.
Гарантируется, что решение существует. Если решений несколько, то можно вывести любое из них.
входные данные
выходные данные
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Несколько чистоплотных тараканьих семей хотят поселиться в однокомнатной квартире. Квартира состоит из большой комнаты и кухни, соединѐнных узким коридором. Тараканов совершенно не интересует коридор сам по себе, однако они хотят иметь доступ и к кухне, и к комнате. Для того чтобы тараканья семья имела такой доступ, ей нужен индивидуальный транспортный путь через коридор. Тараканы — умные насекомые, поэтому они решили составить план коридора и определить, какое максимальное количество транспортных путей можно проложить через коридор.
В тараканьем плане коридор представляется бесконечной в обе стороны полосой шириной W сантиметров. Тараканы начертили прямоугольную систему координат, ось X которой параллельна направлению коридора. Хозяева квартиры расставили в коридоре некоторое количество массивных предметов. Каждый предмет является прямоугольником со сторонами, параллельными осям координат, и вершинами с целыми координатами в сантиметрах. Границы коридора задаются уравнениями y = 0 и y = W. На координатной плоскости тараканы нарисовали квадратную сетку со стороной одной клетки, равной 1 см, начиная от границы коридора.
Тараканы договорились, что каждый транспортный путь является бесконечной в обе стороны цепью квадратных клеток. Цивилизованные тараканы никогда не прыгают, поэтому две подряд идущие клетки в этой цепи должны быть соседними по стороне. Цивилизованные тараканы всегда бегают по полу, поэтому никакая клетка цепи не может пересекаться с хозяйской вещью или выходить за пределы коридора. Тараканы не любят бегать по кругу, поэтому все клетки цепи различны. Тараканы не хотят давки в час пик, поэтому они требуют, чтобы различные транспортные пути не пересекались, то есть не имели общих клеток. Транспортный путь должен соединять кухню и комнату, поэтому разные концы цепи должны уходить в разные стороны коридора.
Ваша задача — определить максимальное количество транспортных путей, которые можно проложить через коридор.
В первой строке входного файла записано два целых числа N и W. N — количество предметов в коридоре, W — ширина коридора в сантиметрах (0 ≤ N ≤ 5000, 0 < W ≤ 10^9).
Каждая из последующих N строк описывает одну из хозяйских вещей. Она содержит четыре целых числа X1, Y1, X2, Y2 — координаты двух противоположных углов прямоугольника ( -10^9 ≤ X1 < X2 ≤ 10^9, 0 ≤ Y1 < Y2 ≤ W). Предметы, расставленные в коридоре, могут пересекаться.-
В выходной файл нужно вывести одно целое число — максимально возможное количество транспортных путей.
Правильные ответы выделены зелёным цветом.
Все ответы: В курсе рассматриваются базовые алгоритмы и структуры данных, включая хешировани, сложность и модели вычислений, деревья поиска, B-деревья, задачи геометрического поиска, динамическую связность в графах и другое.
Пусть известна последовательность из n ключей, представленная массивом A. Что называется k-ой порядковой статистикой?
Какие свойства должны быть выполнены для любой вершины v , чтобы дерево являлось бинарным деревом поиска?
Считается ли компьютерная память важным ресурсом, учитывающимся при разработке эффективного алгоритма?
В представленном ниже псевдокоде алгоритма поиска порядковой статистики что находится на пропущенном месте? Random-select(A, k) задать λ . если k <= |A1|: вернуть Random-select(A1, k) иначе: вернуть Random-select(A2, k - |A1|)
В какой позиции достигается минимум на отрезке [i, j] в последовательности A (декартово дерево с индексами i = 1. n)?
Если откладывать одномерные интервалы [l, r] на двумерной плоскости, то в какой области будут находиться интервалы, пересекаемые с точкой x ?
(1) если от точки (x, x) провести лучи вверх и вправо, то справа сверху будет находиться искомая область
(2) если от точки (x, x) провести лучи вверх и влево, то слева сверху будет находиться искомая область
(4) если от точки (x, x) провести лучи вниз и вправо, то справа внизу будет находиться искомая область
Если T - время работы алгоритма, N - размер входных данных, что отображает функция max T(I) для N(I) = N?
(1) для нового неупорядоченного элемента в правой части множества итеративно выбирается место среди уже упорядоченных ключей
(2) итеративно выбирается место среди оставшихся неупорядоченных ключей, найденный минимум или максимум вынимается из текущего множества в ответ
Какие существуют особенности для алгоритма, который ищет k-ую порядковую статистику за линейное время в худшем случае?
(3) если ячейка с вставляемым хэш-ключем уже занята, то пробуют вставить в следующую, пока не найдут для нее место
(4) для поиска места для вставляемого ключа ячейки таблицы просматриваются последовательно, но с некоторым шагом k
(4) если существуют вершины-потомки, ключи которых больше ключей родителей, если в остальных вершинах это свойство не нарушено
По каким критериям выбирается разделитель, делящий на левые и правые поддеревья в приоритетном дереве поиска (priority search tree)?
Если при оценивании фиксированного алгоритма оценки сверху и снизу совпали, то какие действия предпринимаются?
Какая сложность у процедуры слияния для алгоритма сортировки слияием (MergeSort) для массива длины L?
(4) любая структура данных, представленная в виде дерева, хранящая в себе ключи и связанные с ними значения
Какие действия предпринимают для сохранения свойств красного черного дерева, если при операции вставки вершины x , x и y оказались красными, если y - родитель x , y - корень?
При использовании подхода Bottom-up для алгоритма сортировки слиянием, на блоки какого размера разбивается массив размера n на k-ом шаге?
Какое предположение должно быть выполнено, чтобы была справедлива гипотеза простого равномерного хэширования?
(1) значение хеш-функции от ключа k является случайной величиной, равномерно распределенной на множестве
(1) вычисляются все наименьшие общие предки для всех пар вершин дерева T во время предобработки, чтобы потом бытро выводить ответ на запрос
(2) во время предобработки анализируется структура дерева T, а затем быстро вычисляются наименьшие общие предки для заданных пар вершин
В чём состоит идея оптимизации в структуре двумерное дерево отрезков для задачи поиска в квадратичной области, позволяющая достичь времени работы O(log N) ?
(2) пересчет результатов бинарного поиска для списков нижнего уровня с помощью сохранения позиций, в которые перемещаются точки со списков верхнего уровня
В чем состоит отличие в работе алгоритма для модели "разрешающие деревья" от RAM - модели и модели машины Тьюринга?
(1) для нового неупорядоченного элемента в правой части множества итеративно выбирается место среди уже упорядоченных ключей
(2) массив делится рекурсивно на две части, элементы массива переставляются так, чтобы в левой части оказались элементы, которые не больше чем элементы в правой части
(3) итеративно выбирается место среди оставшихся неупорядоченных ключей, найденный минимум или максимум вынимается из текущего множества в ответ
(4) исходная пследовательность A делится на две одинаковые по размеру части A1 и A2, которые рекурсивно сортируются

Какой тип вращения сплэй-дерева изображен на рисунке?
У структуры данных дерево отрезков рассмотрим произвольную вершину v и относящийся к ней отрезок [l, r]. Если l ≠ r, каких сыновей имеет эта вершина?
Как можно добиться, чтобы логарифмическая оценка для алгоритма быстрой сортировки была справедлива не в среднем, а в худшем случае?
(3) в качестве разделителя использовать медиану из трех элементов последовательности: левой границы, правой границы и середины
(3) каждая вершина является листом или имеет ровно два сына, листья могут находиться на соседних уровнях
В случае универсального хэширования чему равно среднее время успешного поиска ключа для хэш-функции H: k -> <0. N-1>, если k1, . kn - все ключи, присутствующие в хеш-таблице?
Если в splay-дереве есть операция, работающая за O(глубина вершины) , можно ли ее ускорить до учетного логарифма, если да то как это сделать?
Сколько памяти потребуется для предварительного построения таблицы минимумов (RMQ) для отрезков [i, j], где j это степень двойки, какое время будет для запроса после такой предобработки?
Какие указатели должны быть в дереве отрезков, работающим за O(log N) по принципу Fractional cascading?
(2) первые указатели показывают куда точки перемещаются при распределении между списками, вторые указатели показывают следующую точку другого типа в верхнем списке
(3) указатель на ответ для следующего уровня и точный указатель на предыдущий ответ в текущем отрезке
Пусть на вход алгоритма быстрой сортировки поступает N различных ключей. Тогда каким будет матожидание времени его работы при случайном равномерном и независимом выборе разделителяя?
(3) применить операцию MakeHeap для второй половины элементов, затем восстановить свойства кучи только для этой половины элементов
Какой будет учетная стоимость zig-шага для операции splay ? Если r - ранг, r' - новый ранг, v - вращаемая вершина, u - корень в начале операции
Какие действия должна уметь выполнять структура данных для задачи о динамической связности в графах? Для полностью динамического случая
Пусть имеется двоичный счетчик, то есть вектор, состоящий из битов, представляющий двоичное число. Изначально все биты равны 0. Пусть есть операция Increment, какова ее сложность в худшем случае?
Как зависит размер памяти, необходимый для реализании метода совершенного хэширования от количества ключей n?
Какой тип имеет задача о динамической связности в графе, если ответы на все запросы про связность будут получены после обработки всех операций, а не по мере их поступления?
По какому принципу выбирается размер reallocation для аддитивного метода? Если C - старый размер массива.
(2) все блоки входного массива считываются в оперативную память одновременно и каждый блок сортируется с помощью merge-sort, затем происходит слияние по одному блоку
(4) последовательное чтение с диска работает эффективнее, чем случайное, поэтому Merge-sort хорошо подходит для работы с диском
Для оценки сложности цепочки инкрементов, пусть 1 у.е. компьютер требует за 1 элементарную операцию. Пусть записано некоторое двоичное число 010111, над каждой 1 лежит по 1 у.е., сколько потребуется элементарных действий для операции Increment?
Какие существуют стандартные операции для интерфейса множества с ошибками, например для фильтра Блюма?
(2) вызыватся split(T, x) , получаются деревья T1, T2 . Если x∈T , удалить вершину с ключем x из T1 , выполнить Merge(T1, T2)
Какой обход является конкатенацией двух исходных обходов в операциях со списками для структуры Rope, реализующей динамически связный граф?
Для библиотеки std::vector, реализующей массив на C++, что происходит, когда нужно добавить еще один элемент в конец массива, если массив полностью заполнен?
(2) переопределение размера(realocatioon), все элементы копируются в новый массив увеличенного размера, элемент добавляется в конец
(5) для добавляемого элемента создается дополнительный пустой массив, который затем прибавляется к заполненному
Как можно проверить, попадает ли ключ k в хэш-таблицу T фильтра Блюма, заданного хэш-функциями h1. hs: k -> [0, m-1] или нет?
(1) вычислить логическое ИЛИ по всем значениям T[hi(k)]. Если оно равно 0 то не попадает, если 1, то попадает
(2) вычислить логическое И по всем значениям T[hi(k)]. Если оно равно 0 то не попадает, если 1, то попадает
При реализации структуры приближенного множества (Lossy Map) с помощью более блюмового фильтра, как будет работать операция Get(k)?
(1) выдает по некоторому ключу значение и с большой вероятностью это значение удовлетворяет нашим требованиям
(2) может выдать правильное значение, если функция определена в этой точке или если функция неопределена в этой точке, то выдать случайное значение. Или выдает Null, если функция неопределена в этой точке
(3) выдает значение, если функция определена в этой точке, либо выдает Null, если функция неопределена в этой точке
Если до вставки нового ребра E его вершины u и v находились в разных компонентах связности, какие действия предпринимают, чтобы сохранить структуру динамически связного графа?
Выберите, чем характеризуется подход для освобождения памяти для persistent stack, называемый подсчет ссылок (ref-counting)?
Какая основная идея применяется для решения задач, связанных с интервалами, с помощью статической структуры данных?
Какое математическое ожидание времени работы у алгоритма поиска k-ой порядковой статистики (Random-варианта)?
Для декартова дерева с вершинами (key = N, prior = aN), если k = lca(i, j), то чем будет являться вершина ak?
Какой прием можнно использовать, чтобы эффективнее искать интервалы, пересекающие заданную точку с помощью статической структуры данных?
(3) Разделить интервалы на дерево групп, для более быстрого доступа к соответствующей группе или интервалу
Считается ли процессорное время важным ресурсом, учитывающимся при разработке эффективного алгоритма?
В представленном ниже псевдокоде алгоритма поиска порядковой статистики что находится на пропущенном месте? Random-select(A, k) задать λ разделить (A, λ) -> (A1, A2) . вернуть Random-select(A1, k) иначе: вернуть Random-select(A2, k - |A1|)
Какой обход дерева нужно использовать, чтобы ключи двоичного дерева поиска были выведены в порядке неубывания?
Какая структура данных может искать точки в "колодце"(двустороннее ограничение по одной координате и одностороннее ограничение по другой координате)?
Для приведенного псевдокода поиска k-ой порядковой статистики, выберите строки, которых не хватает для корректной работы алгоритма: Select (A, k) . partition(A, λ) -> (A1, A2) if k 1| then: return Select(A1, k) else: return Select(A2, k - |A1|)
(2) нужно для начала определиться, нас интересует оценка на фиксированный алгоритм или на задачу и выполнять оценку исходя из этого
Для алгоритма сортировки слиянием merge-sort при каком количестве элементов в последовательности рекурсивное деление должно прерываться, в стандартном виде?
Какие действия предпринимают для сохранения свойств красного черного дерева после операции вставки вершины x в следующей ситуации. Если A - родитель x , B - родитель A ; B - черная вершина; A , C - красные; C - дядя x
Если корень приоритетного дерева поиска выбирается по минимальной r координате отрезка [l, r] , то по каким параметрам происходит деление на левые и правые поддеревья?
Какие из перечисленных ниже утверждений относятся к параметру машинное слово w в стандартной модели оперативной памяти (RAM - model)?
Пусть мы выполняем запрос Get для некоторого ключа k и пусть перед этим в структуру были вставлены некоторые ключи k1. kn. Для каждого ключа ki обозначим через Xi,j случайную величину, равную 1, если h(ki)=h(kj), и 0 в противном случае. Какая будет длина цепочки с индексом i?
(3) сплэй-деревья не поддерживают баланс постоянно, вместо этого они остаются сбалансированными в среднем
(2) первая, максимально удаленная от корня точка пересечения путей от вершин u и v вверх по дереву до корня
(2) вспомогательные структуры, которые позволяют получить ответ для части, когда известен ответ для целого
(3) в левую часть помещаются ключи, делящиеся на цело на λ, в правую часть помещаются ключи, не делящиеся на цело на λ
В предположении гипотезы простого равномерного хэширования, чему равно среднее время безуспешного поиска ключа для хэш-функции H: k -> <0. N-1>?
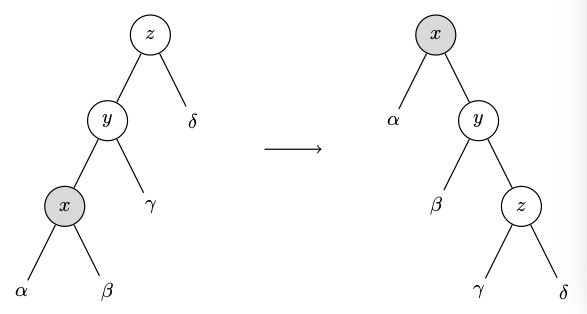
Какой тип вращения сплэй-дерева изображен на рисунке?
Какое время поиска у структуры данных двумерное дерево отрезков, работающей с квадратной области поиска [x1, x2] x [y1, y2] ?
(3) если взять полное бинарное дерево и убрать на последнем уровне часть сыновей, начиная справа, то получится почти полное бинарное дерево
Если использовать универсальное семейство хэш-функций для хранения n ключей, то при размере хэш-таблицы M = n 2 , какова будет вероятность получить хотя бы одну коллизию?
(1) нужно предобработать списки с помощью указателей за разумное время, так, чтобы быстро выводить минимальный элемент для каждого списка
(2) нужно предобработать списки с помощью указателей за разумное время, так, чтобы быстро выводить первый минимальный элемент, больше или равный X для каждого списка
(3) нужно предобработать списки с помощью указателей за разумное время, так, чтобы быстро выводить первый максимальный элемент, больше или равный X для каждого списка
(4) нужно предобработать списки с помощью указателей за разумное время, так, чтобы быстро выводить сумму элементов каждого списка
Пусть на вход алгоритма быстрой сортировки поступает N различных ключей. Тогда каким будет матожидание глубины рекурсии?
Какой будет учетная стоимость zigzig-шага для операции splay ? Если r - ранг, r' - новый ранг, v - вращаемая вершина, u - корень в начале операции
В алгоритме ±1-RMQ после разделения исходной последовательности на блоки, на какие части разделяется отрезок запроса?
(1) на три части: конечный отрезок некоторого блока; второй составлен из целого числа подряд идущих блоков; начальный отрезок некоторого блока
Какие действия должна уметь выполнять структура данных для задачи о динамической связности в графах? Для инкрементальной связности
Пусть имеется двоичный счетчик, то есть вектор, состоящий из битов, представляющий двоичное число. Изначально все биты равны 0. Для M операций Increment, какова их сложность в худшем случае?
За какое в среднем количество проб можно обнаружить хэш-функцию, не дающую коллизий для второго уровня схемы совершенного хэширования?
Какой тип имеет задача о динамической связности в графе, если ответы выдаются сразу после выполнения различных действий с графом и поступления запроса о связности?
По какому принципу выбирается размер reallocation для мультипликативного метода? Если C - старый размер массива.
Отметьте утверждения, характерные для алгоритма сортировки слиянием (Merge-sort), работающего с памятью на диске
Для фильтра Блюма как изменяется вероятность ложного срабатывания с увеличением размера хранимого множества (числа вставленных элементов)?
(4) для T1 (α - левое поддерево, β - правое поддерево) с корнем u , T2 ( γ - левое поддерево, δ - правое поддерево) с корнем v , p(u) < p(v) , то при слиянии корнем нового дерева будет u , левым поддеревом α , правым результат Merge(β, T2)
Если построить Эйлеров обход дерева и для каждой вершины отложить ее глубину, то чему будет равен LCA двух вершин?
Пусть 1 у.е. компьютер требует за 1 элементарную операцию. Пусть записано некоторое двоичное число, начиная справа имеем k единиц до 0. При текущем балансе -(k+1) (credit: k, debit: 1), если k единиц снять со структуры, 1 положить, сколько нужно попросить у клиента, чтобы выйти в 0?
Каким будет оптимальный порядок бинарного слияния всех отрезков L1. Ln различной длины в алгоритме сортировки слиянием?
(1) сначала нужно сливать отрезки наименьшей длины, затем прибавлять к полученному отрезку следующий по длине отрезок и так далее
(2) использовать n-ичное дерево Хаффмана для определения порядка слияния для каждого Li, n зависит от количества отрезков и разброса их длин
(3) использовать бинарное дерево кодирования Хаффмана для определения порядка слияния для каждого Li, на нижнем уровне дерева будут находиться отрезки наименьшей длины, на верхнем уровне - отрезки наибольшей длины
(4) использовать бинарное дерево кодирования Хаффмана для определения порядка слияния для каждого Li, на верхнем уровне дерева будут находиться отрезки наименьшей длины, на нижнем - уровне отрезки наибольшей длины
Для любого программиста важно знать основы теории алгоритмов, так как именно эта наука изучает общие характеристики алгоритмов и формальные модели их представления. Ещё с уроков информатики нас учат составлять блок-схемы, что, в последствии, помогает при написании более сложных задач, чем в школе. Также не секрет, что практически всегда существует несколько способов решения той или иной задачи: одни предполагают затратить много времени, другие ресурсов, а третьи помогают лишь приближённо найти решение.
Всегда следует искать оптимум в соответствии с поставленной задачей, в частности, при разработке алгоритмов решения класса задач.
Важно также оценивать, как будет вести себя алгоритм при начальных значениях разного объёма и количества, какие ресурсы ему потребуются и сколько времени уйдёт на вывод конечного результата.
Этим занимается раздел теории алгоритмов – теория асимптотического анализа алгоритмов.
Предлагаю в этой статье описать основные критерии оценки и привести пример оценки простейшего алгоритма. На Хабрахабре уже есть статья про методы оценки алгоритмов, но она ориентирована, в основном, на учащихся лицеев. Данную публикацию можно считать углублением той статьи.
Определения
Основным показателем сложности алгоритма является время, необходимое для решения задачи и объём требуемой памяти.
Также при анализе сложности для класса задач определяется некоторое число, характеризующее некоторый объём данных – размер входа.
Итак, можем сделать вывод, что сложность алгоритма – функция размера входа.
Сложность алгоритма может быть различной при одном и том же размере входа, но различных входных данных.
Существуют понятия сложности в худшем, среднем или лучшем случае. Обычно, оценивают сложность в худшем случае.
Временная сложность в худшем случае – функция размера входа, равная максимальному количеству операций, выполненных в ходе работы алгоритма при решении задачи данного размера.
Ёмкостная сложность в худшем случае – функция размера входа, равная максимальному количеству ячеек памяти, к которым было обращение при решении задач данного размера.
Порядок роста сложности алгоритмов
Порядок роста сложности (или аксиоматическая сложность) описывает приблизительное поведение функции сложности алгоритма при большом размере входа. Из этого следует, что при оценке временной сложности нет необходимости рассматривать элементарные операции, достаточно рассматривать шаги алгоритма.
Шаг алгоритма – совокупность последовательно-расположенных элементарных операций, время выполнения которых не зависит от размера входа, то есть ограничена сверху некоторой константой.
Виды асимптотических оценок
O – оценка для худшего случая
Рассмотрим сложность f(n) > 0, функцию того же порядка g(n) > 0, размер входа n > 0.
Если f(n) = O(g(n)) и существуют константы c > 0, n0 > 0, то
0 < f(n) < c*g(n),
для n > n0.

Функция g(n) в данном случае асимптотически-точная оценка f(n). Если f(n) – функция сложности алгоритма, то порядок сложности определяется как f(n) – O(g(n)).
Данное выражение определяет класс функций, которые растут не быстрее, чем g(n) с точностью до константного множителя.
Примеры асимптотических функций
| f(n) | g(n) |
|---|---|
| 2n 2 + 7n — 3 | n 2 |
| 98n*ln(n) | n*ln(n) |
| 5n + 2 | n |
| 8 | 1 |
Ω – оценка для лучшего случая
Определение схоже с определением оценки для худшего случая, однако
f(n) = Ω(g(n)), если
0 < c*g(n) < f(n)

Ω(g(n)) определяет класс функций, которые растут не медленнее, чем функция g(n) с точностью до константного множителя.
Θ – оценка для среднего случая
Стоит лишь упомянуть, что в данном случае функция f(n) при n > n0 всюду находится между c1*g(n) и c2*g(n), где c – константный множитель.
Например, при f(n) = n 2 + n; g(n) = n 2 .
Критерии оценки сложности алгоритмов

Равномерный весовой критерий (РВК) предполагает, что каждый шаг алгоритма выполняется за одну единицу времени, а ячейка памяти за одну единицу объёма (с точностью до константы).
Логарифмический весовой критерий (ЛВК) учитывает размер операнда, который обрабатывается той или иной операцией и значения, хранимого в ячейке памяти.
Временная сложность при ЛВК определяется значением l(Op), где Op – величина операнда.
Ёмкостная сложность при ЛВК определяется значением l(M), где M – величина ячейки памяти.
Пример оценки сложности при вычислении факториала
Необходимо проанализировать сложность алгоритма вычисление факториала. Для этого напишем на псевдокоде языка С данную задачу:
Временная сложность при равномерном весовом критерии
Достаточно просто определить, что размер входа данной задачи – n.
Количество шагов – (n — 1).
Таким образом, временная сложность при РВК равна O(n).
Временная сложность при логарифмическом весовом критерии
В данном пункте следует выделить операции, которые необходимо оценить. Во-первых, это операции сравнения. Во-вторых, операции изменения переменных (сложение, умножение). Операции присваивания не учитываются, так как предполагается, что она происходят мгновенно.
Итак, в данной задаче выделяется три операции:
1) i
2) i = i + 1

На i-м шаге получится log(i).
Таким образом, получается сумма .
3) result = result * i

На i-м шаге получится log((i-1)!).
Таким образом, получается сумма .

Если сложить все получившиеся значения и отбросить слагаемые, которые заведомо растут медленнее с увеличением n, получим конечное выражение .
Ёмкостная сложность при равномерном весовом критерии
Здесь всё просто. Необходимо подсчитать количество переменных. Если в задаче используются массивы, за переменную считается каждая ячейка массива.
Так как количество переменных не зависит от размера входа, сложность будет равна O(1).
Ёмкостная сложность при логарифмическом весовом критерии
В данном случае следует учитывать максимальное значение, которое может находиться в ячейке памяти. Если значение не определено (например, при операнде i > 10), то считается, что существует какое-то предельное значение Vmax.
В данной задаче существует переменная, значение которой не превосходит n (i), и переменная, значение которой не превышает n! (result). Таким образом, оценка равна O(log(n!)).
Выводы
Изучение сложности алгоритмов довольно увлекательная задача. На данный момент анализ простейших алгоритмов входит в учебные планы технических специальностей (если быть точным, обобщённого направления «Информатика и вычислительная техника»), занимающихся информатикой и прикладной математикой в сфере IT.
На основе сложности выделяются разные классы задач: P, NP, NPC. Но это уже не проблема теории асимптотического анализа алгоритмов.
Наверняка вы не раз сталкивались с обозначениями вроде O(log n) или слышали фразы типа «логарифмическая вычислительная сложность» в адрес каких-либо алгоритмов. И если вы хотите стать хорошим программистом, но так и не понимаете, что это значит, — данная статья для вас.
Users who have contributed to this file
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Потоки и паросочетания
ограничение по времени на тест: 5 секунд
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Дана система из узлов и труб, по которым может течь вода. Для каждой трубы известна наибольшая скорость, с которой вода может протекать через нее. Известно, что вода течет по трубам таким образом, что за единицу времени в каждый узел (за исключением двух — источника и стока) втекает ровно столько воды, сколько из него вытекает.
Ваша задача — найти наибольшее количество воды, которое за единицу времени может протекать между источником и стоком, а также скорость течения воды по каждой из труб.
Трубы являются двусторонними, то есть вода в них может течь в любом направлении. Между любой парой узлов может быть более одной трубы.
В первой строке записано натуральное число N — количество узлов в системе (2 ≤ N ≤ 100). Известно, что источник имеет номер 1, а сток номер N. Во второй строке записано натуральное M (1 ≤ M ≤ 5000) — количество труб в системе. Далее в M строках идет описание труб. Каждая труба задается тройкой целых чисел Ai, Bi, Ci, где Ai, Bi — номера узлов, которые соединяет данная труба (Ai ≠ Bi), а Ci (0 ≤ Ci ≤ 104) — наибольшая допустимая скорость течения воды через данную трубу.
В первой строке выведите наибольшее количество воды, которое протекает между источником и стоком за единицу времени. Далее выведите M строк, в каждой из которых выведите скорость течения воды по соответствующей трубе. Если направление не совпадает с порядком узлов, заданным во входных данных, то выводите скорость со знаком минус. Числа выводите с точностью 10^(-3).
входные данные
выходные данные
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Найдите минимальный разрез между вершинами 1 и n в заданном неориентированном графе.
На первой строке входного файла содержится n (2 ≤ n ≤ 100) — число вершин в графе и m (0 ≤ m ≤ 400) — количество ребер. На следующих m строках входного файла содержится описание ребер. Ребро описывается номерами вершин, которые оно соединяет, и его пропускной способностью (положительное целое число, не превосходящее 10 000 000), при этом никакие две вершины не соединяются более чем одним ребром.
На первой строке выходного файла должны содержаться количество ребер в минимальном разрезе и их суммарная пропускная способность. На следующей строке выведите возрастающую последовательность номеров ребер (ребра нумеруются в том порядке, в каком они были заданы во входном файле).
входные данные
выходные данные
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Две улиточки Маша и Петя сейчас находятся в на лужайке с абрикосами и хотят добраться до своего домика. Лужайки пронумерованы числами от 1 до n и соединены дорожками (может быть несколько дорожек соединяющих две лужайки, могут быть дорожки, соединяющие лужайку с собой же). В виду соображений гигиены, если по дорожке проползла улиточка, то вторая по той же дорожке уже ползти не может. Помогите Пете и Маше добраться до домика.
В первой строке файла записаны четыре целых числа — n, m, s и t (количество лужаек, количество дорог, номер лужайки с абрикосами и номер домика). В следующих m строках записаны пары чисел. Пара чисел (x, y) означает, что есть дорожка с лужайки x до лужайки y (из-за особенностей улиток и местности дорожки односторонние). Ограничения: 2 ≤ n ≤ 10^5, 0 ≤ m ≤ 10^5, s_≠_t .
Если существует решение, то выведите YES и на двух отдельных строчках сначала последовательность лужаек для Машеньки (дам нужно пропускать вперед), затем путь для Пети. Если решения не существует, выведите NO. Если решений несколько, выведите любое.
входные данные
выходные данные
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Двудольным графом называется неориентированный граф (V, E),E ⊆ V × V такой, что его множество вершин V можно разбить на два множества A и B, для которых ∀(e1, e2) ∈ E e1 ∈ A, e2 ∈ B и A ∪ B = V,A ⋂ B = ∅ .
Паросочетанием в двудольном графе называется любой набор его несмежных рёбер, то есть такой набор S ⊆ E , что для любых двух рёбер e1 = (u1, v1), e2 = (u2, v2) из S u1 ≠ u2 и v1 ≠ v2.
Ваша задача — найти максимальное паросочетание в двудольном графе, то есть паросочетание с максимально возможным числом рёбер.
В первой строке записаны два целых числа n и m (1 ≤ n, m ≤ 250), где n — число вершин в множестве A, а m — число вершин в B.
Далее следуют n строк с описаниями рёбер — i-я вершина из A описана в (i + 1)-й строке файла. Каждая из этих строк содержит номера вершин из B, соединённых с i-й вершиной A. Гарантируется, что в графе нет кратных ребер. Вершины в A и B нумеруются независимо (с единицы). Список завершается числом 0.
Первая строка выходного файла должна содержать одно целое число l — количество рёбер в максимальном паросочетании. Далее следуют l строк, в каждой из которых должны быть два целых числа uj и vj — концы рёбер паросочетания в A и B соотвественно.
входные данные
выходные данные
E. Шахматная доска
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Вася любит играть в необычные шахматы. Его братишка Коля был еще очень маленький. Как-то раз, когда Вася вернулся из школы, он увидел, что его любимую шахматную доску кто-то перекрасил. Вася не сильно разозлился на Колю, потому что очень любил своего брата. Так как у них дома были только черная и белая краски, каждая клетка доски была покрашена в один из этих двух цветов.
Вам предстоит помочь Васе. Задано испорченное Колей шахматное поле. Вам необходимо определить, за какое минимальное количество действий Вася сможет перекрасить доску так, чтобы она стала шахматной.
В первой строке входного файла записаны два целых числа: n и m (1 ≤ n, m ≤ 100) — количество строчек и количество столбцов шахматного поля соответственно.
В следующих n строках записано поле, в каждой строке по m символов. Каждая строка входного файла описывает одну строку шахматного поля. W соответствует белой клетке, B — черной.
В выходной файл нужно вывести число p, количество действий, которое потребуется Васе, чтобы его доска снова стала шахматной. В следующих p строках описаны действия. Каждое действие описано тремя параметрами: тип диагонали, координаты клетки и цвет. Тип диагонали — это число 1 или 2. Координаты клетки — это два целых числа: строка и столбец одной из клеток, которую покрасили этим действием. Цвет — это символ W или B, белый и черный соответственно.
входные данные
выходные данные
входные данные
выходные данные
входные данные
выходные данные
F. Двигаем предметы
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
На плоскости расположены n предметов, их нужно переместить в заданные n позиций. При этом не важно, какой предмет какую из них займет. Для каждого предмета известна максимальная скорость, с которой его можно перемещать, при этом перемещать все предметы можно одновременно.
Найдите минимальное время, за которое можно переместить предметы на заданные места.
В первой строке записано число n (1 ≤ n ≤ 50), в следующих n строках содержатся описания предметов, в i-ой из которых, находится три числа координаты xi, yi (1 ≤ xi, yi ≤ 1000) и максимальная скорость vi (1 ≤ vi ≤ 10) i-ого предмета соответственно. В следующих n строках содержатся описания финальных позиций, в i-ой из которых, заданы координаты ai, bi (1 ≤ ai, bi ≤ 1000) i-ой финальной позиции.
Выведите одно число — минимальное время, за которое можно переместить предметы. Погрешность не более 10^(-4).
входные данные
выходные данные
входные данные
выходные данные
входные данные
выходные данные
входные данные
выходные данные
G. Великая стена
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
У короля Людовика двое сыновей. Они ненавидят друг друга, и король боится, что после его смерти страна будет уничтожена страшными войнами. Поэтому Людовик решил разделить свою страну на две части, в каждой из которых будет властвовать один из его сыновей. Он посадил их на трон в города A и B, и хочет построить минимально возможное количество фрагментов стены таким образом, чтобы не существовало пути из города A в город B.
Страну, в которой властвует Людовик, можно упрощенно представить в виде прямоугольника m × n. В некоторых клетках этого прямоугольника расположены горы, по остальным же можно свободно перемещаться. Кроме этого, ландшафт в некоторых клетках удобен для строительства стены, в остальных же строительство невозможно.
При поездках по стране можно перемещаться из клетки в соседнюю по стороне, только если ни одна из этих клеток не содержит горы или построенного фрагмента стены.
В первой строке выходного файла должно быть выведено минимальное количество фрагментов стены F, которые необходимо построить. Далее нужно вывести карту в том же формате, как во входном файле. Клетки со стеной обозначьте символом «+».
Если невозможно произвести требуемую застройку, то выведите в выходной файл единственное число -1.
входные данные
выходные данные
входные данные
выходные данные
входные данные
выходные данные
H. Космические перевозки
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: bring.in
вывод: bring.out
К 3141 году человеческая цивилизация распространилась по всей галактике. Для перехода от одной звездной системы к другой используются специальные гипертуннели. Чтобы использовать гипертуннель, нужно прилететь в специальное место рядом с исходной звездой используя ваш космический корабль, активировать гипердрайв, пролететь через гипертуннель, выйти рядом со звездой назначения и лететь на нужную вам планету. Весь процесс занимает ровно один день. Небольшой недостаток системы состоит в том, что по каждому туннелю может пролететь только один космический корабль в день.
Вы работаете в транспортном отделе компании «Intergalaxy Business Machines». Сегодня утром ваш начальник дал вам новую задачу. Чтобы запустить чемпионат по программированию IBM, нужно доставить K суперкомпьютеров от Земли, где находится штаб-квартира компании на планету Эйсиэм.
Поскольку суперкомпьютеры очень большие, нужно, для перевозки одного нужен целый космический корабль. Вас попросили найти план доставки суперкомпьютеров, который позволит доставить все компьютеры за минимальное число дней. Поскольку IBM является очень мощной корпорацией, можете считать, что каждый раз, когда вам нужен какой-то гипертуннель, он к вашим услугам. Однако вы все равно можно использовать каждый туннель только один раз в день.
Первая строка входного файла содержит N — число звездных систем в галактике, M — число туннелей, K — число суперкомпьютеров для доставки, S — номер солнечной системы, где находится планета Земля и T — номер звездной системы, где находится Планета Эйсиэм (N ≤ 50>, M ≤ 200>, K ≤ 50>, S, T ≤ N>, S ≠ T>)
Следующие M строк содержат по два разных целых числа и описывают туннели. Для каждого туннеля даются номера звездных систем, которые он соединяет. По туннелю можно путешествовать в обоих направлениях, но помните, что каждый день только один корабль может использовать туннель. В частности, два судна не могут одновременно проходить через один и тот же туннель в противоположных направлениях. Ни один туннель не соединяет звезду с самим собой и две звезды связаны не более чем одним туннелем.
В первой строке выходного файла выведите L — наименьшее число дней, необходимых для доставки K суперкомпьютеров от звездной системы S до звездной системы T с использованием гипертуннелей.
Следующие L строк должны описывать процесс. Каждая строка должна начинаться с Ci — числа кораблей, которые отправляются из одной системы в другую в этот день. Далее должны следовать Ci пар целых чисел, пара A, B означает, что корабль номер A перемещается из текущей звездной системы в звездную систему B.
входные данные
выходные данные
I. Групповой турнир
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
В нашем капиталистическом и меркантильном мире всё решают деньги, и даже спорт не стал исключением. Все команды-участницы уже купили себе нужное количество очков в следующем сезоне, и местной федерации хоккея осталось только распределить результаты предстоящих игр. Однако, некоторые команды не поскупились и помимо покупки очков также купили ещё и результаты некоторых игр. Поначалу в федерации думали, что это им только упростит задачу: чем для большего числа игр результаты уже определены, тем меньше работы остаётся им. Но позже они поняли, что ошиблись. Они попросили вас стать участником их коррупционной схемы и помочь с распределением результатов игр предстоящего сезона.
Местный хоккейный турнир проходит по круговой системе: в турнире участвуют N команд и каждая команда играет с каждой ровно одно игру. За игру команды получают очки по следующим правилам:
Если победителя удалось выявить в основное время матча, то ему достаётся 3 очка, а проигравшему — 0. Если основное время закончилось вничью и для выявления победителя понадобилось дополнительное время (овертайм), то победителю дают 2 очка, а проигравшему — 1 очко. Овертайм не ограничен во времени и длится до тех пор, пока одна из команд не забьёт гол. По итогам турнира очки команды определяются как сумма её очков по всем сыгранным играм.
В первой строке входного файла содержится целое число N — количество участников турнира (2 ≤ N ≤ 100). Команды занумерованы числами от 1 до N.
Следующие N строк файла содержат по N символов и представляют собой турнирную таблицу на данный момент. Символ aij в строке i (1 ≤ i ≤ N) на позиции j (1 ≤ j ≤ N) означает результат игры команды номер i с командой номер j и может быть одним из:
В выходной файл выведите полностью заполненную турнирную таблицу в формате, аналогичном формату входного файла.
Гарантируется, что решение существует. Если решений несколько, то можно вывести любое из них.
входные данные
выходные данные
ограничение по времени на тест: 2 секунды
ограничение по памяти на тест: 256 мегабайт
ввод: стандартный ввод
вывод: стандартный вывод
Несколько чистоплотных тараканьих семей хотят поселиться в однокомнатной квартире. Квартира состоит из большой комнаты и кухни, соединѐнных узким коридором. Тараканов совершенно не интересует коридор сам по себе, однако они хотят иметь доступ и к кухне, и к комнате. Для того чтобы тараканья семья имела такой доступ, ей нужен индивидуальный транспортный путь через коридор. Тараканы — умные насекомые, поэтому они решили составить план коридора и определить, какое максимальное количество транспортных путей можно проложить через коридор.
В тараканьем плане коридор представляется бесконечной в обе стороны полосой шириной W сантиметров. Тараканы начертили прямоугольную систему координат, ось X которой параллельна направлению коридора. Хозяева квартиры расставили в коридоре некоторое количество массивных предметов. Каждый предмет является прямоугольником со сторонами, параллельными осям координат, и вершинами с целыми координатами в сантиметрах. Границы коридора задаются уравнениями y = 0 и y = W. На координатной плоскости тараканы нарисовали квадратную сетку со стороной одной клетки, равной 1 см, начиная от границы коридора.
Тараканы договорились, что каждый транспортный путь является бесконечной в обе стороны цепью квадратных клеток. Цивилизованные тараканы никогда не прыгают, поэтому две подряд идущие клетки в этой цепи должны быть соседними по стороне. Цивилизованные тараканы всегда бегают по полу, поэтому никакая клетка цепи не может пересекаться с хозяйской вещью или выходить за пределы коридора. Тараканы не любят бегать по кругу, поэтому все клетки цепи различны. Тараканы не хотят давки в час пик, поэтому они требуют, чтобы различные транспортные пути не пересекались, то есть не имели общих клеток. Транспортный путь должен соединять кухню и комнату, поэтому разные концы цепи должны уходить в разные стороны коридора.
Ваша задача — определить максимальное количество транспортных путей, которые можно проложить через коридор.
В первой строке входного файла записано два целых числа N и W. N — количество предметов в коридоре, W — ширина коридора в сантиметрах (0 ≤ N ≤ 5000, 0 < W ≤ 10^9).
Каждая из последующих N строк описывает одну из хозяйских вещей. Она содержит четыре целых числа X1, Y1, X2, Y2 — координаты двух противоположных углов прямоугольника ( -10^9 ≤ X1 < X2 ≤ 10^9, 0 ≤ Y1 < Y2 ≤ W). Предметы, расставленные в коридоре, могут пересекаться.-
В выходной файл нужно вывести одно целое число — максимально возможное количество транспортных путей.
Правильные ответы выделены зелёным цветом.
Все ответы: В курсе рассматриваются базовые алгоритмы и структуры данных, включая хешировани, сложность и модели вычислений, деревья поиска, B-деревья, задачи геометрического поиска, динамическую связность в графах и другое.
Пусть известна последовательность из n ключей, представленная массивом A. Что называется k-ой порядковой статистикой?
Какие свойства должны быть выполнены для любой вершины v , чтобы дерево являлось бинарным деревом поиска?
Считается ли компьютерная память важным ресурсом, учитывающимся при разработке эффективного алгоритма?
В представленном ниже псевдокоде алгоритма поиска порядковой статистики что находится на пропущенном месте? Random-select(A, k) задать λ . если k <= |A1|: вернуть Random-select(A1, k) иначе: вернуть Random-select(A2, k - |A1|)
В какой позиции достигается минимум на отрезке [i, j] в последовательности A (декартово дерево с индексами i = 1. n)?
Если откладывать одномерные интервалы [l, r] на двумерной плоскости, то в какой области будут находиться интервалы, пересекаемые с точкой x ?
(1) если от точки (x, x) провести лучи вверх и вправо, то справа сверху будет находиться искомая область
(2) если от точки (x, x) провести лучи вверх и влево, то слева сверху будет находиться искомая область
(4) если от точки (x, x) провести лучи вниз и вправо, то справа внизу будет находиться искомая область
Если T - время работы алгоритма, N - размер входных данных, что отображает функция max T(I) для N(I) = N?
(1) для нового неупорядоченного элемента в правой части множества итеративно выбирается место среди уже упорядоченных ключей
(2) итеративно выбирается место среди оставшихся неупорядоченных ключей, найденный минимум или максимум вынимается из текущего множества в ответ
Какие существуют особенности для алгоритма, который ищет k-ую порядковую статистику за линейное время в худшем случае?
(3) если ячейка с вставляемым хэш-ключем уже занята, то пробуют вставить в следующую, пока не найдут для нее место
(4) для поиска места для вставляемого ключа ячейки таблицы просматриваются последовательно, но с некоторым шагом k
(4) если существуют вершины-потомки, ключи которых больше ключей родителей, если в остальных вершинах это свойство не нарушено
По каким критериям выбирается разделитель, делящий на левые и правые поддеревья в приоритетном дереве поиска (priority search tree)?
Если при оценивании фиксированного алгоритма оценки сверху и снизу совпали, то какие действия предпринимаются?
Какая сложность у процедуры слияния для алгоритма сортировки слияием (MergeSort) для массива длины L?
(4) любая структура данных, представленная в виде дерева, хранящая в себе ключи и связанные с ними значения
Какие действия предпринимают для сохранения свойств красного черного дерева, если при операции вставки вершины x , x и y оказались красными, если y - родитель x , y - корень?
При использовании подхода Bottom-up для алгоритма сортировки слиянием, на блоки какого размера разбивается массив размера n на k-ом шаге?
Какое предположение должно быть выполнено, чтобы была справедлива гипотеза простого равномерного хэширования?
(1) значение хеш-функции от ключа k является случайной величиной, равномерно распределенной на множестве
(1) вычисляются все наименьшие общие предки для всех пар вершин дерева T во время предобработки, чтобы потом бытро выводить ответ на запрос
(2) во время предобработки анализируется структура дерева T, а затем быстро вычисляются наименьшие общие предки для заданных пар вершин
В чём состоит идея оптимизации в структуре двумерное дерево отрезков для задачи поиска в квадратичной области, позволяющая достичь времени работы O(log N) ?
(2) пересчет результатов бинарного поиска для списков нижнего уровня с помощью сохранения позиций, в которые перемещаются точки со списков верхнего уровня
В чем состоит отличие в работе алгоритма для модели "разрешающие деревья" от RAM - модели и модели машины Тьюринга?
(1) для нового неупорядоченного элемента в правой части множества итеративно выбирается место среди уже упорядоченных ключей
(2) массив делится рекурсивно на две части, элементы массива переставляются так, чтобы в левой части оказались элементы, которые не больше чем элементы в правой части
(3) итеративно выбирается место среди оставшихся неупорядоченных ключей, найденный минимум или максимум вынимается из текущего множества в ответ
(4) исходная пследовательность A делится на две одинаковые по размеру части A1 и A2, которые рекурсивно сортируются
Какой тип вращения сплэй-дерева изображен на рисунке?
У структуры данных дерево отрезков рассмотрим произвольную вершину v и относящийся к ней отрезок [l, r]. Если l ≠ r, каких сыновей имеет эта вершина?
Как можно добиться, чтобы логарифмическая оценка для алгоритма быстрой сортировки была справедлива не в среднем, а в худшем случае?
(3) в качестве разделителя использовать медиану из трех элементов последовательности: левой границы, правой границы и середины
(3) каждая вершина является листом или имеет ровно два сына, листья могут находиться на соседних уровнях
В случае универсального хэширования чему равно среднее время успешного поиска ключа для хэш-функции H: k -> <0. N-1>, если k1, . kn - все ключи, присутствующие в хеш-таблице?
Если в splay-дереве есть операция, работающая за O(глубина вершины) , можно ли ее ускорить до учетного логарифма, если да то как это сделать?
Сколько памяти потребуется для предварительного построения таблицы минимумов (RMQ) для отрезков [i, j], где j это степень двойки, какое время будет для запроса после такой предобработки?
Какие указатели должны быть в дереве отрезков, работающим за O(log N) по принципу Fractional cascading?
(2) первые указатели показывают куда точки перемещаются при распределении между списками, вторые указатели показывают следующую точку другого типа в верхнем списке
(3) указатель на ответ для следующего уровня и точный указатель на предыдущий ответ в текущем отрезке
Пусть на вход алгоритма быстрой сортировки поступает N различных ключей. Тогда каким будет матожидание времени его работы при случайном равномерном и независимом выборе разделителяя?
(3) применить операцию MakeHeap для второй половины элементов, затем восстановить свойства кучи только для этой половины элементов
Какой будет учетная стоимость zig-шага для операции splay ? Если r - ранг, r' - новый ранг, v - вращаемая вершина, u - корень в начале операции
Какие действия должна уметь выполнять структура данных для задачи о динамической связности в графах? Для полностью динамического случая
Пусть имеется двоичный счетчик, то есть вектор, состоящий из битов, представляющий двоичное число. Изначально все биты равны 0. Пусть есть операция Increment, какова ее сложность в худшем случае?
Как зависит размер памяти, необходимый для реализании метода совершенного хэширования от количества ключей n?
Какой тип имеет задача о динамической связности в графе, если ответы на все запросы про связность будут получены после обработки всех операций, а не по мере их поступления?
По какому принципу выбирается размер reallocation для аддитивного метода? Если C - старый размер массива.
(2) все блоки входного массива считываются в оперативную память одновременно и каждый блок сортируется с помощью merge-sort, затем происходит слияние по одному блоку
(4) последовательное чтение с диска работает эффективнее, чем случайное, поэтому Merge-sort хорошо подходит для работы с диском
Для оценки сложности цепочки инкрементов, пусть 1 у.е. компьютер требует за 1 элементарную операцию. Пусть записано некоторое двоичное число 010111, над каждой 1 лежит по 1 у.е., сколько потребуется элементарных действий для операции Increment?
Какие существуют стандартные операции для интерфейса множества с ошибками, например для фильтра Блюма?
(2) вызыватся split(T, x) , получаются деревья T1, T2 . Если x∈T , удалить вершину с ключем x из T1 , выполнить Merge(T1, T2)
Какой обход является конкатенацией двух исходных обходов в операциях со списками для структуры Rope, реализующей динамически связный граф?
Для библиотеки std::vector, реализующей массив на C++, что происходит, когда нужно добавить еще один элемент в конец массива, если массив полностью заполнен?
(2) переопределение размера(realocatioon), все элементы копируются в новый массив увеличенного размера, элемент добавляется в конец
(5) для добавляемого элемента создается дополнительный пустой массив, который затем прибавляется к заполненному
Как можно проверить, попадает ли ключ k в хэш-таблицу T фильтра Блюма, заданного хэш-функциями h1. hs: k -> [0, m-1] или нет?
(1) вычислить логическое ИЛИ по всем значениям T[hi(k)]. Если оно равно 0 то не попадает, если 1, то попадает
(2) вычислить логическое И по всем значениям T[hi(k)]. Если оно равно 0 то не попадает, если 1, то попадает
При реализации структуры приближенного множества (Lossy Map) с помощью более блюмового фильтра, как будет работать операция Get(k)?
(1) выдает по некоторому ключу значение и с большой вероятностью это значение удовлетворяет нашим требованиям
(2) может выдать правильное значение, если функция определена в этой точке или если функция неопределена в этой точке, то выдать случайное значение. Или выдает Null, если функция неопределена в этой точке
(3) выдает значение, если функция определена в этой точке, либо выдает Null, если функция неопределена в этой точке
Если до вставки нового ребра E его вершины u и v находились в разных компонентах связности, какие действия предпринимают, чтобы сохранить структуру динамически связного графа?
Выберите, чем характеризуется подход для освобождения памяти для persistent stack, называемый подсчет ссылок (ref-counting)?
Какая основная идея применяется для решения задач, связанных с интервалами, с помощью статической структуры данных?
Какое математическое ожидание времени работы у алгоритма поиска k-ой порядковой статистики (Random-варианта)?
Для декартова дерева с вершинами (key = N, prior = aN), если k = lca(i, j), то чем будет являться вершина ak?
Какой прием можнно использовать, чтобы эффективнее искать интервалы, пересекающие заданную точку с помощью статической структуры данных?
(3) Разделить интервалы на дерево групп, для более быстрого доступа к соответствующей группе или интервалу
Считается ли процессорное время важным ресурсом, учитывающимся при разработке эффективного алгоритма?
В представленном ниже псевдокоде алгоритма поиска порядковой статистики что находится на пропущенном месте? Random-select(A, k) задать λ разделить (A, λ) -> (A1, A2) . вернуть Random-select(A1, k) иначе: вернуть Random-select(A2, k - |A1|)
Какой обход дерева нужно использовать, чтобы ключи двоичного дерева поиска были выведены в порядке неубывания?
Какая структура данных может искать точки в "колодце"(двустороннее ограничение по одной координате и одностороннее ограничение по другой координате)?
Для приведенного псевдокода поиска k-ой порядковой статистики, выберите строки, которых не хватает для корректной работы алгоритма: Select (A, k) . partition(A, λ) -> (A1, A2) if k 1| then: return Select(A1, k) else: return Select(A2, k - |A1|)
(2) нужно для начала определиться, нас интересует оценка на фиксированный алгоритм или на задачу и выполнять оценку исходя из этого
Для алгоритма сортировки слиянием merge-sort при каком количестве элементов в последовательности рекурсивное деление должно прерываться, в стандартном виде?
Какие действия предпринимают для сохранения свойств красного черного дерева после операции вставки вершины x в следующей ситуации. Если A - родитель x , B - родитель A ; B - черная вершина; A , C - красные; C - дядя x
Если корень приоритетного дерева поиска выбирается по минимальной r координате отрезка [l, r] , то по каким параметрам происходит деление на левые и правые поддеревья?
Какие из перечисленных ниже утверждений относятся к параметру машинное слово w в стандартной модели оперативной памяти (RAM - model)?
Пусть мы выполняем запрос Get для некоторого ключа k и пусть перед этим в структуру были вставлены некоторые ключи k1. kn. Для каждого ключа ki обозначим через Xi,j случайную величину, равную 1, если h(ki)=h(kj), и 0 в противном случае. Какая будет длина цепочки с индексом i?
(3) сплэй-деревья не поддерживают баланс постоянно, вместо этого они остаются сбалансированными в среднем
(2) первая, максимально удаленная от корня точка пересечения путей от вершин u и v вверх по дереву до корня
(2) вспомогательные структуры, которые позволяют получить ответ для части, когда известен ответ для целого
(3) в левую часть помещаются ключи, делящиеся на цело на λ, в правую часть помещаются ключи, не делящиеся на цело на λ
В предположении гипотезы простого равномерного хэширования, чему равно среднее время безуспешного поиска ключа для хэш-функции H: k -> <0. N-1>?
Какой тип вращения сплэй-дерева изображен на рисунке?
Какое время поиска у структуры данных двумерное дерево отрезков, работающей с квадратной области поиска [x1, x2] x [y1, y2] ?
(3) если взять полное бинарное дерево и убрать на последнем уровне часть сыновей, начиная справа, то получится почти полное бинарное дерево
Если использовать универсальное семейство хэш-функций для хранения n ключей, то при размере хэш-таблицы M = n 2 , какова будет вероятность получить хотя бы одну коллизию?
(1) нужно предобработать списки с помощью указателей за разумное время, так, чтобы быстро выводить минимальный элемент для каждого списка
(2) нужно предобработать списки с помощью указателей за разумное время, так, чтобы быстро выводить первый минимальный элемент, больше или равный X для каждого списка
(3) нужно предобработать списки с помощью указателей за разумное время, так, чтобы быстро выводить первый максимальный элемент, больше или равный X для каждого списка
(4) нужно предобработать списки с помощью указателей за разумное время, так, чтобы быстро выводить сумму элементов каждого списка
Пусть на вход алгоритма быстрой сортировки поступает N различных ключей. Тогда каким будет матожидание глубины рекурсии?
Какой будет учетная стоимость zigzig-шага для операции splay ? Если r - ранг, r' - новый ранг, v - вращаемая вершина, u - корень в начале операции
В алгоритме ±1-RMQ после разделения исходной последовательности на блоки, на какие части разделяется отрезок запроса?
(1) на три части: конечный отрезок некоторого блока; второй составлен из целого числа подряд идущих блоков; начальный отрезок некоторого блока
Какие действия должна уметь выполнять структура данных для задачи о динамической связности в графах? Для инкрементальной связности
Пусть имеется двоичный счетчик, то есть вектор, состоящий из битов, представляющий двоичное число. Изначально все биты равны 0. Для M операций Increment, какова их сложность в худшем случае?
За какое в среднем количество проб можно обнаружить хэш-функцию, не дающую коллизий для второго уровня схемы совершенного хэширования?
Какой тип имеет задача о динамической связности в графе, если ответы выдаются сразу после выполнения различных действий с графом и поступления запроса о связности?
По какому принципу выбирается размер reallocation для мультипликативного метода? Если C - старый размер массива.
Отметьте утверждения, характерные для алгоритма сортировки слиянием (Merge-sort), работающего с памятью на диске
Для фильтра Блюма как изменяется вероятность ложного срабатывания с увеличением размера хранимого множества (числа вставленных элементов)?
(4) для T1 (α - левое поддерево, β - правое поддерево) с корнем u , T2 ( γ - левое поддерево, δ - правое поддерево) с корнем v , p(u) < p(v) , то при слиянии корнем нового дерева будет u , левым поддеревом α , правым результат Merge(β, T2)
Если построить Эйлеров обход дерева и для каждой вершины отложить ее глубину, то чему будет равен LCA двух вершин?
Пусть 1 у.е. компьютер требует за 1 элементарную операцию. Пусть записано некоторое двоичное число, начиная справа имеем k единиц до 0. При текущем балансе -(k+1) (credit: k, debit: 1), если k единиц снять со структуры, 1 положить, сколько нужно попросить у клиента, чтобы выйти в 0?
Каким будет оптимальный порядок бинарного слияния всех отрезков L1. Ln различной длины в алгоритме сортировки слиянием?
(1) сначала нужно сливать отрезки наименьшей длины, затем прибавлять к полученному отрезку следующий по длине отрезок и так далее
(2) использовать n-ичное дерево Хаффмана для определения порядка слияния для каждого Li, n зависит от количества отрезков и разброса их длин
(3) использовать бинарное дерево кодирования Хаффмана для определения порядка слияния для каждого Li, на нижнем уровне дерева будут находиться отрезки наименьшей длины, на верхнем уровне - отрезки наибольшей длины
(4) использовать бинарное дерево кодирования Хаффмана для определения порядка слияния для каждого Li, на верхнем уровне дерева будут находиться отрезки наименьшей длины, на нижнем - уровне отрезки наибольшей длины
Для любого программиста важно знать основы теории алгоритмов, так как именно эта наука изучает общие характеристики алгоритмов и формальные модели их представления. Ещё с уроков информатики нас учат составлять блок-схемы, что, в последствии, помогает при написании более сложных задач, чем в школе. Также не секрет, что практически всегда существует несколько способов решения той или иной задачи: одни предполагают затратить много времени, другие ресурсов, а третьи помогают лишь приближённо найти решение.
Всегда следует искать оптимум в соответствии с поставленной задачей, в частности, при разработке алгоритмов решения класса задач.
Важно также оценивать, как будет вести себя алгоритм при начальных значениях разного объёма и количества, какие ресурсы ему потребуются и сколько времени уйдёт на вывод конечного результата.
Этим занимается раздел теории алгоритмов – теория асимптотического анализа алгоритмов.
Предлагаю в этой статье описать основные критерии оценки и привести пример оценки простейшего алгоритма. На Хабрахабре уже есть статья про методы оценки алгоритмов, но она ориентирована, в основном, на учащихся лицеев. Данную публикацию можно считать углублением той статьи.
Определения
Основным показателем сложности алгоритма является время, необходимое для решения задачи и объём требуемой памяти.
Также при анализе сложности для класса задач определяется некоторое число, характеризующее некоторый объём данных – размер входа.
Итак, можем сделать вывод, что сложность алгоритма – функция размера входа.
Сложность алгоритма может быть различной при одном и том же размере входа, но различных входных данных.
Существуют понятия сложности в худшем, среднем или лучшем случае. Обычно, оценивают сложность в худшем случае.
Временная сложность в худшем случае – функция размера входа, равная максимальному количеству операций, выполненных в ходе работы алгоритма при решении задачи данного размера.
Ёмкостная сложность в худшем случае – функция размера входа, равная максимальному количеству ячеек памяти, к которым было обращение при решении задач данного размера.
Порядок роста сложности алгоритмов
Порядок роста сложности (или аксиоматическая сложность) описывает приблизительное поведение функции сложности алгоритма при большом размере входа. Из этого следует, что при оценке временной сложности нет необходимости рассматривать элементарные операции, достаточно рассматривать шаги алгоритма.
Шаг алгоритма – совокупность последовательно-расположенных элементарных операций, время выполнения которых не зависит от размера входа, то есть ограничена сверху некоторой константой.
Виды асимптотических оценок
O – оценка для худшего случая
Рассмотрим сложность f(n) > 0, функцию того же порядка g(n) > 0, размер входа n > 0.
Если f(n) = O(g(n)) и существуют константы c > 0, n0 > 0, то
0 < f(n) < c*g(n),
для n > n0.
Функция g(n) в данном случае асимптотически-точная оценка f(n). Если f(n) – функция сложности алгоритма, то порядок сложности определяется как f(n) – O(g(n)).
Данное выражение определяет класс функций, которые растут не быстрее, чем g(n) с точностью до константного множителя.
Примеры асимптотических функций
| f(n) | g(n) |
|---|---|
| 2n 2 + 7n — 3 | n 2 |
| 98n*ln(n) | n*ln(n) |
| 5n + 2 | n |
| 8 | 1 |
Ω – оценка для лучшего случая
Определение схоже с определением оценки для худшего случая, однако
f(n) = Ω(g(n)), если
0 < c*g(n) < f(n)
Ω(g(n)) определяет класс функций, которые растут не медленнее, чем функция g(n) с точностью до константного множителя.
Θ – оценка для среднего случая
Стоит лишь упомянуть, что в данном случае функция f(n) при n > n0 всюду находится между c1*g(n) и c2*g(n), где c – константный множитель.
Например, при f(n) = n 2 + n; g(n) = n 2 .
Критерии оценки сложности алгоритмов
Равномерный весовой критерий (РВК) предполагает, что каждый шаг алгоритма выполняется за одну единицу времени, а ячейка памяти за одну единицу объёма (с точностью до константы).
Логарифмический весовой критерий (ЛВК) учитывает размер операнда, который обрабатывается той или иной операцией и значения, хранимого в ячейке памяти.
Временная сложность при ЛВК определяется значением l(Op), где Op – величина операнда.
Ёмкостная сложность при ЛВК определяется значением l(M), где M – величина ячейки памяти.
Пример оценки сложности при вычислении факториала
Необходимо проанализировать сложность алгоритма вычисление факториала. Для этого напишем на псевдокоде языка С данную задачу:
Временная сложность при равномерном весовом критерии
Достаточно просто определить, что размер входа данной задачи – n.
Количество шагов – (n — 1).
Таким образом, временная сложность при РВК равна O(n).
Временная сложность при логарифмическом весовом критерии
В данном пункте следует выделить операции, которые необходимо оценить. Во-первых, это операции сравнения. Во-вторых, операции изменения переменных (сложение, умножение). Операции присваивания не учитываются, так как предполагается, что она происходят мгновенно.
Итак, в данной задаче выделяется три операции:
1) i
2) i = i + 1
На i-м шаге получится log(i).
Таким образом, получается сумма .
3) result = result * i
На i-м шаге получится log((i-1)!).
Таким образом, получается сумма .
Если сложить все получившиеся значения и отбросить слагаемые, которые заведомо растут медленнее с увеличением n, получим конечное выражение .
Ёмкостная сложность при равномерном весовом критерии
Здесь всё просто. Необходимо подсчитать количество переменных. Если в задаче используются массивы, за переменную считается каждая ячейка массива.
Так как количество переменных не зависит от размера входа, сложность будет равна O(1).
Ёмкостная сложность при логарифмическом весовом критерии
В данном случае следует учитывать максимальное значение, которое может находиться в ячейке памяти. Если значение не определено (например, при операнде i > 10), то считается, что существует какое-то предельное значение Vmax.
В данной задаче существует переменная, значение которой не превосходит n (i), и переменная, значение которой не превышает n! (result). Таким образом, оценка равна O(log(n!)).
Выводы
Изучение сложности алгоритмов довольно увлекательная задача. На данный момент анализ простейших алгоритмов входит в учебные планы технических специальностей (если быть точным, обобщённого направления «Информатика и вычислительная техника»), занимающихся информатикой и прикладной математикой в сфере IT.
На основе сложности выделяются разные классы задач: P, NP, NPC. Но это уже не проблема теории асимптотического анализа алгоритмов.
Наверняка вы не раз сталкивались с обозначениями вроде O(log n) или слышали фразы типа «логарифмическая вычислительная сложность» в адрес каких-либо алгоритмов. И если вы хотите стать хорошим программистом, но так и не понимаете, что это значит, — данная статья для вас.
Примеры
O(n 2 ) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n , т. е. n 2 .
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Алгоритм - формально описанная вычислительная процедура, получающая исходные данные (input), называемые так же входом алгоритма или его аргументом, и выдающая результат вычисления на выход (output).
Структура данных - программная еденица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных.
- добавление данных
- изменение данных
- удаление данных
- поиск данных
Обзор основных алгоритмов и структур данных
- Стандартные операции с массивом
- Доступ к элементам по индексу. Изменение элементов.
- Линейный (последовательный) поиск.
- Бинарный поиск.
- Сортировка массива
- Сортировка вставками, сортировка пузырьком, сортировка выбором.
- Сортировка слиянием.
- Быстрая сортировка.
- Пирамидальная сортировка.
- Поразрядные сортировки.
- TimSort
- Базовые структуры данных
- СД "Динамический массив"
- СД "Однонаправленный список" и "Двунаправленный список"
- СД "Стек"
- СД "Очередь"
- СД "Дек"
- СД "Двоичная куча"
- АТД "Очередь с приоритетом"
- Деревья
- СД "Двоичное дерево"
- Алгоритмы обхода дерева в ширину и в глубину
- СД "Дерево поиска". Сбалансированные деревья.
- СД "Декартово дерево"
- СД "АВЛ дерево"
- СД "Красно-черное дерево"
- СД "Сплей дерево"
- АТД "Ассоциативный массив"
- СД "Дерево отрезков"
- СД "В-дерево"
- Хеширование
- Алгоритмы вычисления хеш-функций
- Хеш-функция для строк.
- СД "Хэш-таблица"
- Реализация хеш-таблицы методом цепочек.
- Реализация хеш-таблицы методом открытой адресации.
- Блюм-фильтр
- Графы
- Обходы в ширину и глубину
- Топологическая сортировка
- Поиск сильносвязанных компонент
- Поиск кратчайших путей между вершинами
- Поиск Эйлерова пути
- Поиск Гамильтонова пути минимального веса. Задача коммивояджера.
- Нахождение основного дерева минимального веса.
- Вычисление максимального потока в сети.
- Нахождение наибольшего паросочетания в двудольном графе.
- Вычисление хроматического числа графа.
- Строки
- Потск подстрок
- Алгоритм Кнута-Морриса-Пратта
- Алгоритм Ахо-Карасик
- Индексирование текста
- Бор
- Суффиксный массив
- Суффиксное дерево
- Суффиксный автомат
- Ренгулярные выражения
- Вычисление редакторского расстояния между строками
- Вычислительная геометрия
- Теория игр
- Полиномы и быстрое преобразование Фурье
- Матрицы
- Алгоритмы сжатия
- Численные методы решения уравнений
- Машинное обучение
Эффективность алгоритма определяется:
- Временем работы
- Объемом дополнительно используемой памяти
- Другими характеристиками. Например, количеством операций сравнения (сортировка) или количеством обращений к диску (например в БД)
Характеристика данных - число n или несколько чисел. Время работы - T(n) Объем дополнительной памяти - M(n)
Пример 1. Сортировка массива слиянием. T(n) ≈ n * log n - Можно сказать, что T(n) - функция, которая принадлежит O(n * log n), Ø(n * log n) M(n) ≈ n - принадлежит классу O(n), Ø(n)
Для обозначения асимптотического поведения времени работы алгоритма (или объема памяти) используются Θ, O и Ω – обозначения. Определение. Для функции g(n) записи Θ(g(n)), O(g(n)) и Ω(g(n)) означают следующие множества функций:
Пояснение к формулам O(g(n)) означает множество функций f, для каждой из которых существует (своя) константа c, такая что начиная с некоторого n0 выполняется: f(n) неотрицательна и ограничена сверху c⋅g(n). Аналогично Ω(g(n)) – класс функций, ограниченных снизу, Θ(g(n)) – класс функций, ограниченных и снизу, и сверху.
Обозначение. Вместо записи «T(n)∈Θ(g(n))» часто используют запись «T(n)=Θ(g(n))».
По простому: O - верхняя граница (меньше или равно), т.е. данная функция не может расти быстрее с точностью до константы. Θ - точная граница (равно), т.е. данная функция растёт точно так же с точностью до константы. Ω - нижняя граница (больше или равно), т.е. данная функция растёт не медленнее с точностью до константы.
Ссылки по теме
Задача: Найти n-ое число Фибоначи
Рекурсивный подход int fibonachi (int n) < if (n == 0 || n == 1) < return 1; >return fibonachi (n - 1) + fibonachi (n - 2); >
Сложность: Время работы - T(n) = Ω(золотое сечение^n) Объем дополнительной памяти - M(n) = O(n) - максимальная глубина рекурсии
Нерекурсивный алгоритм int fibonachi (int n) < if (n == 1) < return 1; >int prev = 1; // F(0) int current = 1; // F(1) for (int i=2; i return current; >
Сложность: Время работы - T(n) = O(n) - количество итераций в цикле Объем дополнительной памяти - M(n) = O(1)
Проверка числа на простоту
Задача. Является ли натуральное число n простым? Варианты решения:
Можем быстро определять, делится ли одно натуральное число (n) на другое (k). Проверять остаток от деления - n % k == 0 Будем проверять все числа n и если условие не выполняется, то n - простое число.
Можно перебирать только от 1 до √n n = a * b Если мы найдем такое a ≥ √n, то b ≤ √n
Время работы - T(n) = O(√n) потому что количество итераций цикла у нас √n Объем дополнительной памяти - M(n) = O(1)
Определение 1. Массив - набор однотипных компонентов (элементов), расположенных в памяти непосредственно друг за другом, доступ к которым осуществляется по индексу. Определение 2. Размерность массива - количество индексов, необходимое для однозначного доступа к элементу массива.
В С и С++ для передачи массива в функцию можно передать указатель на начало массива и количество элементов.
Массивы. Линейный поиск.
Задача 1. Проверить есть ли заданный элемент в массиве (или найти его). Решение. Последовательно проверяем все элементы массива, пока не найдем заданный элемент, либо пока не закончится массив. Сложность: T(n) = O(n) Решение на С++
bool HasElement (const double* arr, int count, double element) < for (int i=0; i> return false; >
Задача 2. Найти максимальный элемент в массиве. Вернуть его значение. Решение. Последовательно проверяем все элементы массива, заполняем текущее значение максимума. Сложность: T(n) = O(n) Решение на С++
double MaxElement (const double* arr, int count) < // число элементов должно быть больше 0 assert (count >0) double curentMax = arr [0]; for (int i=0; i currentMax) < currentMax = arr[i]; >> return currentMax; >
Массивы. Бинарный поиск.
Определение. Упорядоченный по возрастанию массив - массив А, элементы которого сравнимы, и для любых индексов k и l, k < l; A[k] < A[l]. Упорядоченный по убыванию массив определяется аналогично.
Задача. Проверить есть ли заданный элемент в упорядоченном массиве. Если есть, то вернуть позицию его первого вхождения. Если нет, то вернуть -1. Решение. (Бинарный поиск = Двоичный поиск) Шаг. Сравниваем эдемент в середине массива (медиану) с заданным элементом. Выбираем нужную половину массива в зависимости от результатов сравнения. Повторяем этот шаг до тех пор, пока размер массива не уменьшиться до 1.
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
Читайте также: