
При открытии файла rtf иероглифы что делать
Что ж продолжим наши изыскания на предмет получения текста из различных форматов данных. Не так давно мы с вами научились вытаскивать текст из zipped-xml-based файлов (odt и docx), а также, в начале этой недели, из pdf. Сегодня мы продолжим с обещанным rtf.
Rich Text Format (он же rtf), вы могли бы подумать, достаточно забытый, хотя и не очень сложный формат представления текстовых данных. Что ж, относительно несложный для получения текста, но за свою историю: от своей первой версии до текущей 1.9.1 — он приобрёл под 300 страниц официально документации и огромное количество надстроек, которые в большей степени нам будут мешать при получении plain text'а. Попробуем их обойти.
А что там внутри?
Как уж повелось давайте заглянем вовнутрь rtf-файла и посмотрим, что там внутри:
Будем считать, что rtf состоит из управляющих слов, которые могут быть сгруппированы во вложенные множества. Управляющие слово начинается на обратный слэш ( \ ), группа обёрнута в фигурные скобки ( < и >).
Управляющие слово состоит из последовательности букв английского алфавита (от a до z ) и может быть завершено численным параметром (возможно отрицательным). Как вариант, слово может содержать один не цифро-буквенный ascii-символ. Всё, что не подпадает под эти правила, не является частью управляющего слова. Таким образом, последовательность вида \rtf1\ansi\ansicpg1251 без проблем делится на три слова rtf с параметром 1 (major-версия формата), ansi (текущая кодировка) и ansicpg с параметром 1251 (текущая кодовая страница под номером 1251 — т.е. Windows-1251).
Группированные множества определяют область действия управляющих слов. Таким образом, управляющие слова описанные внутри фигурных скобок работают только внутри них и всех дочерних подмножеств. Для того, чтобы правильно отработать какие слова имеют место сейчас — требуется вести стек управляющих слов. При открытии фигурной скобки создавать новый элемент-массив в стеке, в который сразу же добавлять данные предыдущего слоя стека, при закрытии скобки — удалять самый верхний слой.
Ещё стоит отметить, что некоторые управляющие слова могут быть закрыты с помощью добавления параметра ноль, а не создания новой подгруппы. Например, следующие варианты эквивалентны: This is text , This is \b bold \b0 text = This is bold text .
Откуда брать текст?
С устройством нового для нас формата мы познакомились, теперь зададимся вопросом, а где брать текст. Тут всё не так сложно, как может показаться — текст надо брать там, где текущая последовательность не идентифицируется, как управляющее слово. С парой исключений, естественно.
Во-первых, стоит отметить, что исходная кодировка rtf-файла — это ANSI, поэтому без всякий изысков сохранится только, английский текст. Нас же интересует, как минимум, русский текст, а ещё лучше Unicode, не так ли? Что правда, то правда — rtf хоть и старый формат, но сгодится на сохранение и того и другого.
Итак, в rtf'е есть возможность использования второй половины таблицы ASCII, та что от 128 и выше. С учётом текущей кодировки (выше управляющее слово \ansicpg ), конечно же. Для этого в RTF была введена последовательность вида \'hh , где hh — это двоичный hex-код символа из таблицы ASCII.
Ну и второй, более интересный вариант, это unicode-кодированные данные. Для них в формат включено лаконично короткое ключевое слово \uABCD с цифровым параметром ABCD. ABCD в данном случае код unicode-символа в десятичной системе счисления. Всё опять просто, как вы могли заметить.
Просто, да не очень. В rtf существует ещё одно ключевое слово \ucN , которое тесно связано с Unicode. Дело в том, что формат RTF очень рьяно поддерживает совместимость со старыми устройствами, на которых возможно придётся открывать данный файл. Как вариант, подобное устройство (ну например компьютер с Windows 3.11 :) не сможет прочитать Unicode, что ему делать? Для этого после каждого unicode-символа, шифрованного ключевым словом \u может быть указано от нуля до нескольких символов, которые должны быть отображены в случае, если rtf-viewer не способен отобразить или разобрать текущие данные (по документации, если просмотрщик не может отобразить верно данные, он должен их пропустить).
В связи с этим, большинство современных редакторов после unicode-управляющего слова ставят символ вопроса, как знак, что требуется показать вместо текущего символа. Но возможны и варианты, например: Lab\u915GValue . Зададимся вопросом — сколько символов требуется отобразить, если нет возможности показать Unicode. Всё опять же не очень сложно — указанное выше ключевое слово \ucN в качестве параметра N как раз и предоставляет это значение. Т.е. перед Unicode-данными обязательно появится что-то типа \uc1 , что скажет нам пропустить один символ после unicode'а.
Давайте почитаем!
Похоже, что накопленных нами данных будет достаточно, чтобы прочитать наши первые rtf-файлы. Поехали:
Код с комментариями вы можете получить на GitHub'е.
Заключение
Что мы имеем в итоге? Данный код справится верно с большинством rtf-файлов, но есть несколько способов его улучшить. Во-первых, стоит добавить дополнительные отсечения на нетекстовые данные — у меня отсекаются только шрифты, цветовая палитра, тема оформления, бинарные данные, а также всё, что помечено, как «не читай меня, если не можешь» ( \* ). Во-вторых же, стоит ещё распарсить кодировку и кодовую страницу, для того чтобы вернее отобразить ключевые слова вида \'hh .
Что дальше? Дальше я бы хотел затронуть форматы электронных книг, такие как fb2, epub и подобные им. В связи с этим, я хотел бы обратиться за помощью к читателям: во-первых, какие ещё форматы электронных книг стоит посмотреть, а во-вторых, где можно найти побольше файлов, указанных вами форматов. Заранее спасибо :)
Наверное, каждый пользователь ПК сталкивался с подобной проблемой: открываешь интернет-страничку или документ Microsoft Word — а вместо текста видишь иероглифы (различные «крякозабры», незнакомые буквы, цифры и т.д. (как на картинке слева…)).
Хорошо, если вам этот документ (с иероглифами) не особо важен, а если нужно обязательно его прочитать?! Довольно часто подобные вопросы и просьбы помочь с открытием подобных текстов задают и мне. В этой небольшой статье я хочу рассмотреть самые популярные причины появления иероглифов (разумеется, и устранить их).
Иероглифы в текстовых файлах (.txt)
Самая популярная проблема. Дело в том, что текстовый файл (обычно в формате txt, но так же ими являются форматы: php, css, info и т.д.) может быть сохранен в различных кодировках .
Чаще всего происходит одна вещь: документ открывается просто не в той кодировке из-за чего происходит путаница, и вместо кода одних символов, будут вызваны другие. На экране появляются различные непонятные символы (см. рис. 1)…
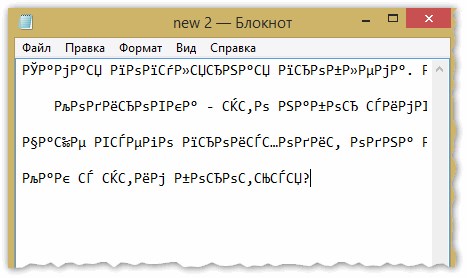
Рис. 1. Блокнот — проблема с кодировкой
Как с этим бороться?
На мой взгляд лучший вариант — это установить продвинутый блокнот, например Notepad++ или Bred 3. Рассмотрим более подробно каждую из них.
Notepad++
Один из лучших блокнотов как для начинающих пользователей, так и для профессионалов. Плюсы: бесплатная программа, поддерживает русский язык, работает очень быстро, подсветка кода, открытие всех распространенных форматов файлов, огромное количество опций позволяют подстроить ее под себя.
В плане кодировок здесь вообще полный порядок: есть отдельный раздел «Кодировки» (см. рис. 2). Просто попробуйте сменить ANSI на UTF-8 (например).
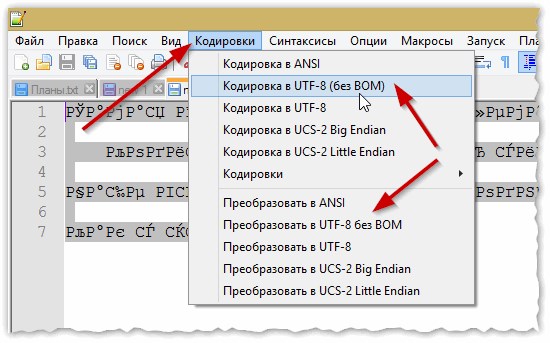
Рис. 2. Смена кодировки в Notepad++
После смены кодировки мой текстовый документ стал нормальным и читаемым — иероглифы пропали (см. рис. 3)!

Рис. 3. Текст стал читаемый… Notepad++
Bred 3
Еще одна замечательная программа, призванная полностью заменить стандартный блокнот в Windows. Она так же «легко» работает со множеством кодировок, легко их меняет, поддерживает огромное число форматов файлов, поддерживает новые ОС Windows (8, 10).
Кстати, Bred 3 очень помогает при работе со «старыми» файлами, сохраненных в MS DOS форматах. Когда другие программы показывают только иероглифы — Bred 3 легко их открывает и позволяет спокойно работать с ними (см. рис. 4).
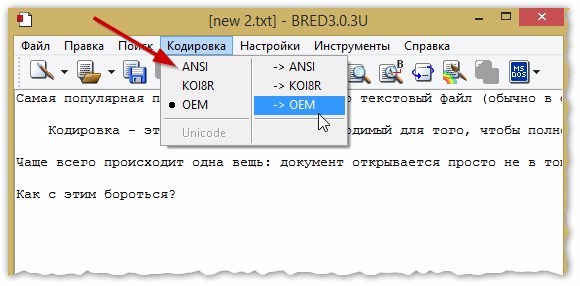
Если вместо текста иероглифы в Microsoft Word
Самое первое, на что нужно обратить внимание — это на формат файла. Дело в том, что начиная с Word 2007 появился новый формат — « docx » (раньше был просто « doc «). Обычно, в «старом» Word нельзя открыть новые форматы файлов, но случается иногда так, что эти «новые» файлы открываются в старой программе.
Просто откройте свойства файла, а затем посмотрите вкладку « Подробно » (как на рис. 5). Так вы узнаете формат файла (на рис. 5 — формат файла «txt»).
Если формат файла docx — а у вас старый Word (ниже 2007 версии) — то просто обновите Word до 2007 или выше (2010, 2013, 2016).
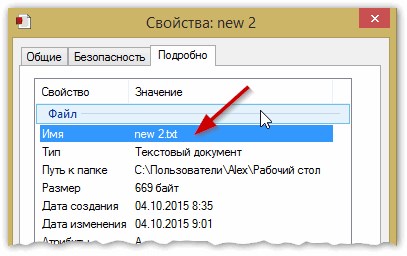
Рис. 5. Свойства файла
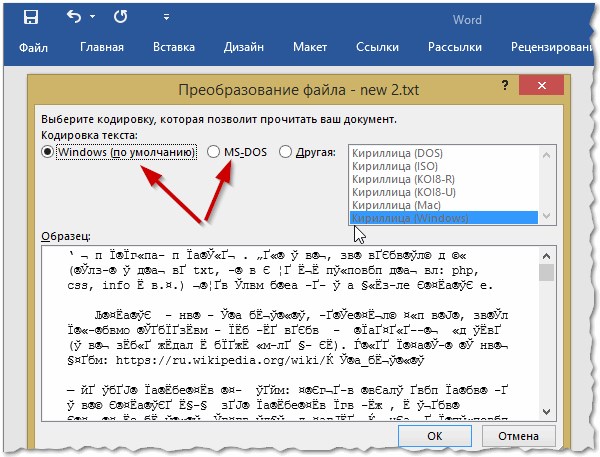
Рис. 6. Word — преобразование файла
Чаще всего Word определяет сам автоматически нужную кодировку, но не всегда текст получается читаемым. Вам нужно установить ползунок на нужную кодировку, когда текст станет читаемым. Иногда, приходится буквально угадывать, в как был сохранен файл, чтобы его прочитать.
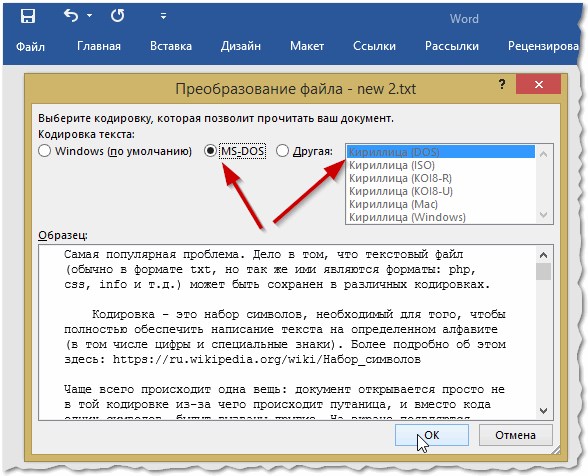
Рис. 7. Word — файл в норме (кодировка выбрана верно)!
Смена кодировки в браузере
Когда браузер ошибочно определяет кодировку интернет-странички — вы увидите точно такие же иероглифы (см. рис 8).

Рис. 8. браузер определил неверно кодировку
- Google chrome: параметры (значок в правом верхнем углу)/дополнительные параметры/кодировка/Windows-1251 (или UTF-8);
- Firefox: левая кнопка ALT (если у вас выключена верхняя панелька), затем вид/кодировка страницы/выбрать нужную (чаще всего Windows-1251 или UTF-8) ;
- Opera: Opera (красный значок в верхнем левом углу)/страница/кодировка/выбрать нужное.
PS
Таким образом в этой статье были разобраны самые частые случаи появления иероглифов, связанных с неправильно определенной кодировкой. При помощи выше приведенных способов — можно решить все основные проблемы с неверной кодировкой.
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
Как открыть файл формата PDF в Word?
- Выберите Файл> Открыть.
- Найдите файл PDF и откройте его (для этого вам может потребоваться нажать кнопку «Обзор» и найти файл в папке).
- Появится предупреждение о том, что копия файла PDF будет создана и преобразована в поддерживаемый формат. Это не меняет исходный файл PDF. Щелкните ОК.
Как изменить формат текста в ворде?
Форматирование текста в Microsoft Word
- Выделите текст, который хотите выделить.
- На вкладке Главная щелкните стрелку Цвет выделения текста. Появится раскрывающееся меню с возможными вариантами цвета.
- Укажите желаемый цвет выделения. Выбранный текст в документе будет выделен.
В этой статье
Почему при копировании текста из PDF иероглифы?
Это все равно, что пытаться скопировать текст с обычного фото, сделанного на вашем смартфоне. В этом случае текст должен распознаваться специальной программой, например ABBYY FineReader.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке "Кириллица (Windows)" знаку "Й" соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка "Кириллица (Windows)", компьютер считывает число 201 и выводит на экран знак "Й".
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка "Западноевропейская (Windows)", знак "Й" из исходного текстового файла на основе кириллицы будет отображен как "É", поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Исправляем иероглифы на текст
Первый способ изменения кодировки в «Word»
Шаг 1. Запустите текстовый документ и откройте вкладку «Файл».
Шаг 2. Перейдите в меню настроек «Параметры».
Шаг 3. Выберите пункт «Дополнительно» и перейдите в раздел «Общие».
Шаг 4. Активируйте настройку в столбце «Подтверждать преобразование формата файла при открытии», щелкнув соответствующую область».
Шаг 5. Сохраните изменения и закройте текстовый документ.
Шаг 6. Снова запустите нужный файл. Перед пользователем появится окно «Преобразование файла», в котором необходимо выбрать пункт «Закодированный текст» и сохранить изменения, нажав «ОК».
Шаг 7. Появится еще одна область, в которой нужно выбрать пункт кодировки «Другая» и выбрать подходящую из списка. Поле «Пример» поможет пользователю выбрать необходимую кодировку, изменения отображены в тексте. Выбрав подходящий, сохраняем изменения кнопкой «ОК».
Как поменять кодировку в Word
Когда человек работает с программой MS Word, ему редко приходится вникать в нюансы кодирования. Но как только вам нужно поделиться документом с коллегами, есть вероятность, что отправленный пользователем файл может просто не быть прочитан получателем. Происходит это из-за несовпадения настроек и особенно кодировок в разных версиях программы.
Как включить кириллицу в Windows 10?
Нажмите клавиши Win + R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра и с правой стороны прокрутите до конца этого раздела. Дважды щелкните параметр ACP, установите значение 1251 (кодовая страница кириллицы), нажмите кнопку ОК и закройте редактор реестра.
Как изменить код текста в ворде?
Затем для шифрования пользователь должен открыть нужный файл Word, перейти на вкладку «Файл», в разделе «Информация» выбрать пункт «Безопасность документа» и подпункт «Зашифровать с помощью пароля». Далее в появившемся окне нужно ввести пароль, затем подтвердить его.
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально).
📌 Могу дать несколько рекомендаций:
- Русификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельцы делают русификаторы. Скорее всего, на вашей системе — данный русификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки "Start" перевод "начать" ?
- Если у вас раньше текст отображался нормально, а сейчас нет — попробуйте 👉 восстановить Windows, если, конечно, у вас есть точки восстановления;
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них (👇).
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R ;
- введите intl.cpl , нажмите Enter.
intl.cpl - язык и регион. стандарты
Проверьте чтобы во вкладке "Форматы" стояло "Русский (Россия) / Использовать язык интерфейса Windows (рекомендуется)" (пример на скрине ниже 👇).
Формат - русский / Россия
Во вкладке "Местоположение" — укажите "Россия" .
И во вкладке "Дополнительно" установите язык системы "Русский (Россия)" .
После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
Текущий язык программ
PS
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF.
Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2016+ и Adobe Reader для примера выше).
Вместо текста, иероглифов, квадратов и крякозабры (в браузере, Word, тексте, окне Windows). Это происходит потому, что текст на странице написан в той же кодировке (подробнее об этом из Википедии) и браузер пытается открыть его в другом.

">
Как изменить Юникод в Windows 10?
Просмотр региональных настроек для Windows
- Щелкните Пуск, затем щелкните Панель управления
- Нажмите Часы, язык и регион
- Windows 10, Windows 8: щелкните Регион …
- Щелкните вкладку Администрирование …
- В разделе «Язык для программ, не поддерживающих Юникод» щелкните «Изменить язык системы» и выберите нужный язык.
- Нажмите ОК
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо.
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные "крякозабры" (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из Википедии ), а браузер пытается открыть его в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.

BAT-файлы (скрипты)
Для начала простой пример о чем идет речь. 👇
На скрине видно, что вместо русского текста отображаются различные квадратики, буквы "г" перевернутые, и пр. иероглифы.

Как выглядит русский текст при выполнении BAT-файла
- в начало BAT-файла добавить код @chcp 1251 ;
- установить программу Notepad++ и в меню выбрать OEM-866: "Кодировки/Кодировки/Кириллица/OEM-866" ;
- установить программу Akelpad, в разделе "Кодировки" выбрать "Сохранить в DOS-866" .
Почему документ Word открывается иероглифами?
Чаще всего Word автоматически определяет нужную кодировку, но текст не всегда читается. Word - файл в порядке (кодировка правильная)! Изменение кодировки в браузере Когда браузер неправильно определяет кодировку веб-страницы, вы увидите точно такие же иероглифы (см.
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке "Китайская традиционная (Big5)". В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке "Кириллица (Windows)", текст на иврите не отобразится, а если сохранить его в кодировке "Иврит (Windows)", то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Документы MS WORD
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx . Дело в том, что с 2007 года в Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
📌 Есть неск. путей решения:
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы (с 2020г. дополнение с офиц. сайта удалено) . Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично) ;
- использовать 👉 аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии (2019+);
- если речь идет о документы TXT — открыть его в Notepad++.
Так же при открытии любого документа в Word (в кодировке которого он "сомневается"), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая.
Переключение кодировки в Word при открытии документа
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может значительно отличаться. Чтобы понять кодировку, вам необходимо знать, что информация в текстовом документе хранится в виде некоторых числовых значений. Персональный компьютер автономно преобразует числа в текст, используя алгоритм единственного кодирования. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, например, Западной Европы, используется «Западная Европа (Windows)». Если текстовый документ был сохранен в кириллической кодировке и открыт в западноевропейском формате, символы будут отображаться совершенно некорректно, представляя бессмысленный набор символов.
Чтобы избежать недоразумений и облегчить работу, разработчики ввели специальную уникальную кодировку для всех алфавитов - «Unicode». Этот общепринятый стандарт кодирования содержит почти все символы большинства письменных языков нашей планеты. Более того, он преобладает в Интернете, где такое объединение так необходимо для охвата большего числа пользователей и удовлетворения их потребностей.
«Word 2013» работает только на основе Unicode, что позволяет обмениваться текстовыми файлами без использования сторонних программ и правильных кодировок в настройках. Но часто пользователи сталкиваются с ситуацией, когда при открытии, казалось бы, простого файла вместо текста отображаются только символы. В этом случае Word неправильно определил существующую исходную кодировку текста.
Ссылка! Некоторые кодировки применимы к определенным языкам. Кодировка «Shift JIS» была разработана специально для японского, «EUC-KR» для корейского и «ISO-2022» и «EUC» для китайского».
Изменение кодировки текста в «Word 2013»
Браузер
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, 👉 современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) — довольно неплохо определяют кодировку, и ошибаются очень редко. 👌
Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для "ручной" настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек.
Итак, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже 👇).

Вместо текста одни лишь крякозабры // Браузер выставил кодировку неверно!
👉 Кстати!
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
Поэтому, я рекомендую в ручном режиме попробовать их обе. Для этого нам понадобиться браузер MX5 (ссылка на офиц. сайт). Он один из немногих позволяет в ручном режиме выбирать кодировку (при необходимости):
- необходимо открыть нужный сайт;
- далее зайти в меню "Инструменты / кодировка" ;
- выбрать вручную UTF 8 или "Авто-определение" ;
- перезагрузить страницу. И, ву-а-ля, — иероглифы на страничке сразу же стали обычным текстом (скрин ниже 👇) !
👉 В помощь!
Если у вас иероглифы в браузере Chrome — ознакомьтесь с этим
Браузер MX5 — выбор кодировки UTF8 или авто-определение

Теперь отображается русский текст норм.
📌 Еще один совет : если вы в своем браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера — вообще нереально!), я рекомендую попробовать открыть страничку в другом браузере (например, в MX5). Очень часто другая программа открывает страницу так, как нужно!
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например, при чтении Readme в какой-нибудь программе прошлого века (скажем, к играм) .
Разумеется, что многие современные блокноты просто не могут прочитать DOS'овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
Попробуйте открыть в Bred 3 свой тексто вый документ (с которым наблюдаются проблемы) . Пример показан у меня на скрине ниже. 👇
Иероглифы при открытии текстового документа
Далее в Bred 3 есть кнопка для смены кодировки: просто попробуйте поменять ANSI на OEM — и старый текстовый файл станет читаемым за 1 сек.!
Исправление иероглифов на текст
👉 Для работы с текстовыми файлами различных кодировок также подойдет еще один блокнот — Notepad++. Вообще, конечно, он больше подходит для программирования, т.к. поддерживает различные подсветки, для более удобного чтения кода.
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
Смена кодировки в блокноте Notepad++
Штирлиц
Сайт разработчика: http://www.shtirlitz.ru/
Эта программа специализируется на "расшифровке" текстов, написанных в разных кодировках: Win-1251, KOI-8r, DOS, ISO-8859-5, MAC и др.
Причем, программа нормально работает даже с текстами со смешанной кодировкой (что не могут др. аналоги). Пример см. на скрине ниже. 👇

Пример работы ПО "Штирлиц"
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Какую выбрать кириллицу в ворде?
После открытия файла в Word (или в Word) выберите меню «Файл»; Нажмите «Сохранить как. » и укажите, где разместить документ с правильной кодировкой; Введите имя и нажмите кнопку «Сохранить»; В открывшемся окне атрибутов установите необходимую кодировку (наиболее универсальная - «Юникод»).
Как изменить иероглифы в ворде?
Чтобы изменить кодировку документа Word, когда никакой метод не помогает, вам необходимо сделать следующее: откройте этот документ, затем Файл - Сохранить как - Тип файла (в этом поле выберите формат Обычный текст * .Txt и нажмите Сохранить, тогда откроется окно с кодировкой.
Как убрать кодировку текста в ворде?
вы можете указать кодировку, которая будет использоваться для просмотра (декодирования) текста.
- Щелкните вкладку Файл.
- Щелкните кнопку Параметры.
- Щелкните кнопку Advanced.
- Перейдите в раздел Общие и установите флажок Подтверждать преобразование формата файла при открытии. …
- Закройте и снова откройте файл.
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Выполните одно из указанных ниже действий.
В Windows 7
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Как поменять кириллицу на латиницу в ворде?
В текстовом поле введите русский текст, выберите нужные параметры и нажмите кнопку «Перевести на латынь». Чтобы отменить последнее действие, используйте кнопку «Отменить передачу».
Читайте также: