
Пишем свой фреймворк для тестирования
Это седьмая статья в серии, где я описываю свой опыт написания веб-приложения на Python с использованием микрофреймворка Flask.
Цель данного руководства — разработать довольно функциональное приложение-микроблог, которое я за полным отсутствием оригинальности решил назвать microblog.
Краткое повторение
В предыдущих частях этого руководства мы постепенно развивали наш микроблог, шаг за шагом добавляя новые возможности. К этому времени наше приложение умеет использовать базу данных, может регистрировать и авторизовывать пользователей, а также позволяет им редактировать собственные данные в профиле.
Сегодня мы не будем добавлять новых возможностей. Вместо этого мы постараемся сделать уже написанный код более устойчивым, а также создадим свой фреймворк, который в будущем поможет нам предотвратить возможные сбои.
Поиски бага
В конце предыдущей главы я упомянул, что в коде присутствует ошибка. Сейчас я расскажу в чем она заключается и мы увидим, как наше приложение реагирует на подобные вещи.
Проблема заключается в том, что у нас нет никакой возможности обеспечить уникальность ников пользователей. Первоначальный ник выбирается автоматически. Если провайдер OpenID сообщает нам ник, мы используем его. В противном случае в качестве ника будет использована первая часть email пользователя. Если два пользователя с одинаковыми никами попробуют зарегистрироваться, это удастся только первому. Позволив пользователям самостоятельно изменять свои данные, мы сделали только хуже, ведь здесь у нас также нет никакой возможности избегать коллизий.
Прежде, чем мы решим эти проблемы, давайте взглянем на то, как ведёт себя приложение, когда происходит ошибка.
Отладка во Flask
Прежде всего создадим новую базу данных. Если у вас Linux:
- Залогиньтесь, используя первый аккаунт.
- На странице редактирования профиля измените ник на 'dup'
- Выйдите из системы
- Зайдите с помощью второго аккаунта
- На странице редактирования профиля измените ник на 'dup'
Ниже находится трассировка стека этой ошибки, в которой можно не только посмотреть исходный код каждого фрейма, но даже выполнять свой код прямо в браузере!
Описание ошибки весьма однозначно. Ник, который мы пытались присвоить пользователю, уже содержится в базе данных. Обратите внимание, что в модели User поле nickname объявлено как unique=True , именно поэтому возникла такая ситуация.
В дополнение к этой ошибке у нас есть еще одна проблема. Если действия пользователя приводят к ошибке (этой или любой другой), он увидит описание ошибки и весь трейсбэк. Это очень удобно во время разработки, но мы точно не хотели бы, чтобы кто-нибудь кроме нас это видел.
Всё это время наше приложение работало в режиме отдалки. Этот режим активируется при запуске, с помощью аргумента debug=True , переданного методу run . Когда мы будем запускать приложение на боевом сервере, необходимо будет убедиться, что режим отладки выключен. Для этого нам пригодится еще один скрипт (файл runp.py ):
Теперь запустим приложение с помощью этого скрипта
Тем не менее, перед нами стоит еще две задачи. Во-первых, по умолчанию страница ошибки 500 выглядит уродливо. Вторая проблема гораздо более серьезная. Если всё оставить как есть, мы никогда не узнаем как и когда возникают ошибки, так как все ошибки теперь замалчиваются. К счастью, у этих проблем есть весьма простые решения.
Flask позволяет приложениям использовать свои собственные страницы для отображения ошибок. В качестве примера реализуем свои страницы для ошибок 404 и 500, так как они наиболее часто встречаются. Для других ошибок процесс создания собственных страниц будет точно таким же.
Чтобы объявить собственный обработчик ошибок, нам понадобится декоратор errorhandler (файл app/views.py ):
Не думаю, что этот код нуждается в разъяснениях. Единственное выражение, заслуживающее внимания здесь — db.session.rollback() . Эта функция будет вызываться в результате исключения. Если исключение было вызвано ошибкой взаимодействия с базой данных, нам необходимо откатить текущую сессию.
Шаблон для ошибки 404:
А также шаблон для ошибки 500:
Для решения второй проблемы мы настроим две системы отчетов об ошибках приложения. Первая из них будет отправлять нам на почту письмо каждый раз, когда происходит ошибка.
Прежде всего нам необходимо настроить почтовый сервер и список администраторов нашего приложения. (файл config.py ):
Само собой, вам нужно изменить эти значения.
Мы будем отправлять эти письма только в том случае, если выключен режим отладки. Ничего страшного, если у вас нет настроенного почтового сервера. Для наших целей вполне подойдёт отладочный сервер SMTP, который нам предоставляет Python. Чтобы запустить его, введите в консоли (или в командной строке, если вы пользователь Windows):
После этого, все письма, отправленные приложением будут перехватываться и отображаться прямо в консоли. (Прим.пер. Вы также можете воспользоваться крайне удобным SMTP сервером, не требующим специальных знаний для настройки — Mailcatcher. Этот способ значительно удобнее, но при этом требует установки Ruby.)
Запись лога в файл
Процесс настройки очень похож на то, что мы только что делали для почты (файл app/__init__.py ):
Лог будет сохраняться в папке tmp под именем microblog.log . Мы использовали RotatingFileHandler , что позволяет установить лимит на количество хранимых данных. В нашем случае размер файла ограничен одним мегабайтом, при этом сохраняются последние десять файлов.
Чтобы сделать лог более полезным, мы снижаем уровень логгирования как в app.logger , так и в file_handler , это позволит нам записывать не только ошибки, но и другую информацию, которая может оказаться полезной. К примеру, мы будем записывать время запуска приложения. Теперь каждый раз, когда микроблог будет запущен без режима отладки, в лог будет сохраняться это событие.
В настоящее время у нас нет потребности в использовании, однако, если наше приложение будет работать на удалённом веб-сервере, диагностика и отладка будут затруднены. Именно поэтому стоит заранее позаботиться о том, чтобы получать нужную нам информацию без остановки сервера.
Исправление ошибок
Итак, давайте наконец исправим баг с одинаковыми никнеймами.
Как было сказано ранее, у нас есть два проблемных места, где отсутствует проверка дубликатов. Первое — в обработчике after_login , который вызывается когда пользователь авторизуется в системе и нам нужно создать новый объект User. Вот, что мы можем сделать, чтобы избавиться от проблемы: (файл app/views.py ):
Наше решение заключается в том, чтобы поручить классу User создание уникального ника. Вот как это реализуется (файл app/models.py ):
Этот метод просто добавляет счетчик к нику, пока он не станет уникальным. Например, если пользователь «miguel» уже существует, в методе будет предложен вариант «miguel2», затем, если и такой пользователь есть, «miguel3» и так далее. Обратите внимание на декоратор staticmethod, мы применили его, так как эта операция не привязана к конкретному инстансу класса.
Второе место, где проблема дубликатов по прежнему актуальна — страница редактирования профиля. В этом случае всё несколько усложняется тем, что пользователь сам выбирает свой ник. Лучшим решением в данном случае будет проверка на уникальность и в случае неудачи предложение выбрать другой ник. Для этого нам понадобится добавить еще один валидатор для соответствующего поля. Если пользователь введёт существующий ник, форма просто не пройдет валидацию. Чтобы добавить свой валидатор, необходимо перегрузить метод validate (файл app/forms.py ):
Конструктор формы теперь принимает новый аргумент — original_nickname . Метод validate использует его для того, чтобы определить — изменился ник или нет. Если изменился, проводим проверку на уникальность.
Проинициализируем форму новым аргументом:
Также нам нужно выводить все ошибки, возникающие при валидации формы, рядом с полем, в котором обнаружена ошибка. (файл app/templates/edit.html ):
Вот и всё, проблема с дубликатами решена! Правда, у нас всё еще есть потенциальная проблема с одновременным доступом к базе данных из нескольких потоков или процессов, но эта тема будет освещена одной из будущих статей.
Теперь вы можете снова попробовать изменить ник на существующий и убедиться, что проблемы больше нет.
Фреймворк для тестирования
С развитием приложения становится всё сложнее проверять, что изменения в коде не сломают существующий функционал. Именно поэтому так важно автоматизировать процесс тестирования.
Традиционный подход тестированию весьма хорош. Вы пишете тесты для проверки всех возможностей приложения. Периодически в процессе разработки вам нужно будет запускать эти тесты, чтобы убедиться, что всё по прежнему работает стабильно. Чем шире зона охвата тестов, тем больше вы можете быть уверены, что всё в порядке.
Давайте напишем небольшой фреймворк для тестирования с помощью модуля unittest (файл app/tests.py ):
В нашем случае нет необходимости в каких-то сложных действиях до и после теста. В setUp немного изменяется конфигурация приложения. Например, мы используем отдельную базу данных для тестирования. В методе tearDown мы очищаем базу данных.
Тесты реализованы в виде методов, которые должны вызывать какую-либо функцию нашего приложения и сравнивает результат её выполнения с предполагаемым. Если результаты не совпадают, тест считается проваленным.
Итак, у нас есть два теста в нашем фреймворке. Первый проверяет URL аватара, который мы реализовали в прошлой главе. Второй тест проверяет метод make_unique_nickname , который мы только что написали для класса User. Сперва создаётся пользователь с именем 'john'. После того, как он сохранён в базе данных, тестируемый метод должен возвращать ник, отличный от 'john'. Затем мы создаём и сохраняем второго пользователя с предложенным ником и проверяем, что еще один вызов make_unique_nickname вернёт имя, отличное от имён обоих созданных пользователей.
Если при этом будут возникнут какие-либо ошибки, они будут выведены в консоль.
Заключительные слова
На этом заканчивается наше обсуждение отладки, ошибок и тестирования. Надеюсь, вам понравилась эта статья. Как всегда, если у вас есть какие-либо вопросы, задавайте их в комментариях.
Как всегда, виртуальное окружение и база данных отсутствуют. Процесс их создания описан в предыдущих статьях.
Мы продолжаем рассказывать о QA. Руководитель отдела тестирования Дмитрий Рак расскажет об архитектуре фреймворка для автоматизации тестирования.
Последние осенние солнечные деньки подходят к концу, мы лениво подбираемся к нашим лаптопам, перебирая в голове тысячи фотографий с желтой листвой под ногами. Чтобы перестать хандрить от мысли о наступающих промозглых утрах и грязевых ландшафтах вокруг, мы решаем создать что-то светлое, вдохновляющее и обещающее невероятные приключения. Например, новый фреймворк для автоматизации тестирования проекта. И, конечно, мы можем взять прекрасную инструкцию из интернета, но не возьмем потому что:
- Создать-то фреймворк − они создали, но не объяснили, зачем;
- Может быть даже какие-то из компонентов забыли;
- Мы получаем невероятно удовольствие от изобретения очередного колеса через муки и страдания.
Псс, парень. Не хочешь немного системных автотестов?
Хочу рассказать вам о проекте, который разрабатываю я с моим коллегой уже без малого три года, и который совсем недавно мы, неконец, зарелизили. Этот проект посвящен автоматизации тестов, и не абы каких, а системных.
Что такое системные тесты? Если вкратце - это тестирование программы (или набора программ) с учетом окружения, в котором программе предстоит работать.
Представьте, что вы написали приложение-калькулятор. Вы написали для него множество простейших тестов (проверили функции сложения, умножения, деления, и так далее). В сущности, вы написали unit-тесты (или, по-русски, модульные тесты).
Модульные тесты очень хороши, и оченнь многие ответственные программисты пишут достаточно много таких тестов для своих приложений. И это часто даёт им возможность спокойнее спать по ночам, зная, что их программа работает нормально, и хоть прямо сейчас её можно выкатывать довольным заказчикам.
Но так ли это? Ведь ваш калькулятор будет работать не просто так, а в конкретной операционной системе с конкретными настройками. А ещё у него может быть инстяллятор, который должен успешно отрабатывать, несмотря ни на что. А ещё он может зависеть от внешних библиотек, которые не всегда установлены в целевой системе.
И вот получается, что все модули по отдельности вроде бы протестированы, а на самом деле, спокойно спать всё ещё нельзя: ведь если калькулятор устанавливается и работает в Windows XP, то это абсолютно не означает, что он будет так же работать в Windows 7 или Windows 10.
И вот даже в самом простом калькуляторе вы сталкиваетесь с проблемой: как удостовериться, что мой калькулятор успешно устанавливается на Windows XP x32, Windows XP x64, Windows 7 x32, Windows 7 x64. И вот с этого момента вы начинаете, по сути, заниматься системным тестированием.
Системные тесты это замечательная штука, да вот только есть проблема - их очень сложно автоматизировать. Особенно, если вы тестируете приложение с графическим интерфейсом, но даже консольные приложения могут доставлять много боли при системном тестировании. В самом деле, как автоматизировать системные тесты самого элементарного клиент-серверного приложения? Это же надо иметь два компьютера, на один из них надо установить сервер, на другой - клиент, а затем проверить, что они корректно взаимодействуют.
Чаще всего системные тесты проводят вручную. Обычно этим занимаются тестировщики (если они есть). Это проще всего, не требует особого умственного труда, но занимает кучу времени. Для крупных коммерческих проектов один полный прогон системных тестов может занимать несколько месяцев работы целого отдела.
Поэтому часто бывает так: в компании перед релизом проводят один полный прогон системных тестов, в ходе которого вылавливают N багов. Затем разработчики фиксят эти баги, а тесирование проверяет, что баги успешно закрыли. Но на второй полный прогон системных тестов времени уже просто не остаётся, поэтому компания просто надеется, что фиксы найденных багов не затронут другие части системы. Очень надёжно, правда?
Компания и рада бы проводить прогон системных тестов каждый день/неделю, да никаких ресурсов для этого у неё просто нет. Да и представьте сами - если вы написали калькулятор, готовы ли вы каждый раз при новой сборке проверять, что он усатнавливается на все возможные операционные системы?
Именно на решение этой проблемы мы направили свои усилия в своём проекте, который мы решили назвать Testo. В состав этой платформы входит специальный язык тестовый сценариев Testo-lang (да, мы написали целый язык для тестовых сценариев), который позволяет вам писать интуитивно-понятные сценарии для системных тестов.
Вместо тысячи слов - просто посмотрите как с помощью нашего проекта можно автоматизировать установку Dr. Web на Windows 7:
Для создания тестовых сценариев не обязательно иметь навыки программирования - достаточно просто документировать все действия, которые вы делаете руками, тестируя какую-либо программу. Например, тест с Dr. Web выражается вот таким сценарием. Даже если вы не знаете ни одного языка программирования, вы всё равно наверняка сможете понять, что именно тут происходит:

Я не буду в этом посте очень долго распыляться о том, как это работает и устроено. Любители технических подробностей могут найти парочку наших статей на хабре (поиск по слову Testo-lang).
Также у нас есть сайт (тоже легко гуглится по Testo-lang), где вы можете скачать абсолютно бесплатно, без регистрации и СМС нашу платформу и пользоваться её сколько угодно (да, у нас есть платная версия, но она отличается от бесплатной только скоростью работы команды wait).
Больше примеров можно глянуть на Youtube-канале (тоже элементарно гуглится).
Если мы сможем помочь хоть одному пикабушнику, который как раз думает о том "как бы мне автоматизировать вот эту штуку. " - то значит уже три года разработки не прошли даром :)

Суть модульного тестирования заключается в проверке небольших изолированных фрагментов кода. Если тест использует внешний ресурс, например сеть или базу данных, он уже не является модульным.
Фреймворки модульного тестирования описывают тесты в человекочитаемом формате, чтобы те, кто не связан с технической сферой, смогли в них разобраться. Однако даже если вы являетесь представителем технической сферы, тесты в формате BDD могут значительно облегчить поиск проблемы.
Например, чтобы протестировать следующую функцию:
Нужно написать тест jasmine spec:
① Функция describe(string, function) определяет тестовый набор — набор индивидуальных спецификаций теста.
② Функция it(string, function) определяет отдельную спецификацию теста, которая содержит одно или несколько ожиданий теста.
③ Выражение expect(actual) — это фактическое значение в тесте. В сочетании с Matcher он описывает ожидаемый фрагмент поведения в приложении.
④ Выражение matcher(expected) — это Matcher. Он выполняет логическое сравнение ожидаемого значения с фактическим, переданным функции expect. Если они имеют ложное значение, спецификация не выполняется.
В некоторых случаях при тестировании функции необходимо выполнить настройку. Например, создать несколько тестовых объектов. Кроме того, после завершения теста может потребоваться очистка. Например, удаление файлов с жесткого диска.
Эти действия называются setup и teardown (для очистки). В Jasmine есть несколько функций для упрощения этого процесса:
beforeAll вызывается один раз перед запуском всех спецификаций в тестовом наборе.
afterAll вызывается один раз после завершения всех спецификаций в тестовом наборе.
beforeEach вызывается перед каждой спецификацией теста, если функция запущена.
afterEach вызывается после выполнения каждой спецификации теста.
В проекте Node файлы модульного теста определяются в папке test в одной директории с папкой src :
Тест содержит файлы спецификации, которые являются модульными тестами для файлов в папке src. В package.json test находится в разделе script .
Если в командной строке запущен npm run test , тестовый фреймворк jest запустит все файлы спецификации в папке test и отобразит результат в командной строке.
Переходим к созданию собственного тестового фреймворка, который будет работать на Node.
В нашем тестовом фреймворке будет CLI-часть, с помощью которой он будет запускаться из командной строки. Вторая часть — исходный код тестового фреймворка, который будет находиться в папке lib.
Начнем с создания проекта Node:
Устанавливаем зависимость chalk, с помощью которой мы будем раскрашивать результаты тестов: npm i chalk .
Создаем папку lib, в которой будут находиться файлы:
Создаем папку bin, поскольку фреймворк будет использоваться в качестве инструмента CLI Node:
Начнем с создания файла CLI.
Создаем файл kwuo в папке bin и добавляем следующее:
Устанавливаем шебанг с указанием на /usr/bin/env, чтобы запускать этот файл без команды node. Заголовок процесса устанавливаем на “kwuo” и запрашиваем файл “lib/cli/cli”. Эти действия вызывают файл cli.js, который запускает процесс тестирования.
Переходим к установке и заполнению lib/cli/cli.js.
Этот файл находит папку test, получает все файлы из нее и запускает их.
Прежде чем реализовывать “lib/cli/cli.js”, нужно установить глобальные переменные. Функции describe, it, expect, afterEach, beforeEach, afterAll и beforeAll используются в тестовых файлах:
Однако ни одна из них не определена в этих файлах. Каким образом файлы и функции работают без ReferenceError? Причина в том, что тестовый фреймворк реализовывает функции и устанавливает их как global перед запуском тестовых файлов.
Создаем файл index.js в папке lib:
Здесь мы устанавливаем глобальные переменные и реализуем функции describe , it , expect , afterEach , beforeEach , afterAll и beforeAll :
В начале работы мы добавили библиотеку chalk, чтобы обозначить неудачные тесты красным цветом, а пройденные — зеленым. Сокращаем console.log до log.
Затем устанавливаем массивы beforeEachs, afterEachs, afterAlls и beforeAlls. beforeEachs содержит функции, которые вызываются в начале функции it , к которой он прикреплен. afterEachs вызывается в конце it . beforeEachs и afterEachs вызываются в начале и конце describe .
Устанавливаем Totaltests , которая будет содержать количество запущенных тестов. passTests содержит количество пройденных тестов, а failTests - количество неудачных тестов.
stats собирает статистику каждой функции describe, а curDesc обозначает текущую функцию describe, запущенную для сбора данных тестирования. currIt содержит запущенную в данный момент функцию it, выполняющую сбор тестовых данных.
Устанавливаем функции beforeEach, afterEach, beforeAll и afterAll, которые передают аргумент функции в соответствующие массивы: afterAll — в массив afterAlls, beforeEach — в beforeEachs и т. д.
Также у нас есть функция expect. Она выполняет тестирование:
Функция expect принимает аргумент для тестирования и возвращает объект, который содержит функции matcher. В данном случае она возвращает объект с функциями toBe и toEqual с аргументом, который они используют для сопоставления с аргументом значения, предоставляемым функцией expect. toBe использует === для сопоставления аргумента значения с ожидаемым аргументом. toEqual использует == для проверки фактического значения с ожидаемым. Функции увеличивают переменные passedTests и failedTests в зависимости от результатов теста, а также записывают статистику в переменную currIt. Мы используем только две функции matcher, однако их гораздо больше:
Вы также можете реализовать их.
Переходим к функции it . Аргумент desc содержит имя описания теста, а fn - функцию. Сначала он обрабатывает beforeEachs, устанавливает статистику и вызывает функцию fn и afterEachs.
Функция describe выполняет те же действия, что и it , но вызывает beforeAlls и afterAlls в начале и в конце.
Функция showTestsResults анализирует массив stats и печатает пройденные и неудачные тесты на терминале.
Таким образом, мы реализовали и установили все функции в объект global , чтобы тестовые файлы могли вызывать их без ошибок.
Вернемся к “lib/cli/cli.js”:
Сначала он импортирует функцию showTestsResult из "lib/index.js", которая отобразит результат запуска тестовых файлов в терминале. Кроме того, импорт этого файла установит глобальные переменные.
Функция run является главной и запускает весь процесс. Она выполняет поиск папки test с помощью searchTestFolder , получает тестовые файлы в массиве - getTestFiles , а затем просматривает массив тестовых файлов и запускает их с помощью runTestFiles .
runTestFiles принимает файлы в массиве, просматривает их с помощью метода forEach и использует метод require для запуска каждого файла.
Структура папки kwuo выглядит следующим образом:

Попробуем протестировать наш фреймворк с реальным проектом Node.
Создаем папку src и добавляем add.js и sub.js:
Содержимое add.js и sub.js:
Создаем папку test и тестовые файлы:
Файлы спецификации будут проверять функции add и sub в add.js и sub.js:
Теперь воспользуемся “test” в разделе “scripts” в package.json для запуска тестового фреймворка:
Запускаем npm run test в командной строке:
Результат теста будет следующим:

В статистике указано количество пройденных тестов в общей сложности и список тестовых наборов с маркировкой пройден/неудачный. “add Hello + World” возвращает “HelloWorld”, однако ожидалось “Hello”. После исправления и повторного запуска, все тесты будут пройдены.

В современном мире существует множество инструментов, помогающих ускорить достижение цели.
Я подготовил список из 10 лучших инструментов автоматизации, которые помогут справляться с задачами намного быстрее. Они используются в таких областях, как автоматическое/ручное тестирование, модульное тестирование, тестирование производительности, веб, мобильное тестирование и пр.
Самое главное, что все эти инструменты являются бесплатными.
Что ж, приступим!
Selenium использует Web Driver для Chrome, чтобы тестировать команды и обрабатывать веб-страницы для получения нужных данных.
Он совместим практически со всеми языками программирования, предлагая при этом широкий набор команд и опций для управления.

Beautiful Soup — это библиотека Python для извлечения данных из файлов HTML и XML. Она создаёт деревья считывания данных, позволяющие с лёгкостью эти данные получать.
Одни только мощные возможности этого инструмента и простота использования ставят его в число излюбленных мной инструментов.
Robotium — это бесплатный фреймворк для автоматизированного тестирования приложений Android. Он поддерживает множество областей тестирования, включая тестирование серого ящика UI, системное тестирование и пользовательское приемочное тестирование, как для нативных, так и для гибридных приложений Android.
Robotium — это фреймворк для автоматического тестирования, имеющий полную поддержку нативных и гибридных приложений. Он облегчает написание мощных и надёжных автоматических тестов чёрного ящика UI в приложениях Android. С его поддержкой разработчики тестовых случаев могут писать сценарии тестирования функций, системы и пользовательского приемочного тестирования, охватывающие несколько видов активности.

Watir — бесплатная библиотека Ruby, позволяющая выполнять автоматизированное тестирование в виде кликов, заполнения форм и пр.
Ее имя — это акроним, происходящий из Web Application Testing In Ruby.
Информация с официального сайта:
Являясь открытой библиотекой Ruby для автоматических тестов, Watir взаимодействует с браузером, симулируя поведение пользователей: открывает ссылки, заполняет формы и проверяет текст.

Apache JMeter — это бесплатное десктопное Java-приложение, которое в основном используется для нагрузочного тестирования веб-приложений. При этом функциональное и модульное тестирование он поддерживает в ограниченной форме.
У Apache JMeter есть множество опций, вроде динамического отчёта, переносимости и мощной IDE тестирования. Помимо этого, он поддерживает различные типы приложений, скриптов оболочек, Java объектов и баз данных.
Информация с официального сайта:
Приложение Apache JMeter является открытым ПО, 100% чистым Java приложением, спроектированным для нагрузочного тестирования функционального поведения и измерения производительности. Изначально оно было создано для тестирования веб-приложений, но с тех пор было расширено другими функциями тестирования.
Apache JMeter может использоваться для испытания производительности как на статических, так и на динамических ресурсах, веб-динамических приложениях.
Его можно использовать для симуляции сильной нагрузки на сервер, группу серверов, сеть или объект, чтобы протестировать их выносливость или проанализировать общую производительность под различными видами нагрузки.

Katalon — это открытое ПО, предназначенное для автоматизированного тестирования в веб и на мобильных устройствах. Это очень простой кроссплатформенный инструмент, имеющий, помимо прочего, удивительную реализацию JIRA.
Информация с официального сайта:
Katalon помогает вам быстро генерировать автоматизированные кросс-платформенные тесты, а также без усилий интегрировать эти тесты в CI/CD линию сборки. Помимо этого, он предоставляет централизованные отчёты и качественные аналитические данные, формируемые Katalon TestOps.

Maven — это бесплатный инструмент для автоматизированного тестирования проектов Java. Я использую его достаточно часто и должен сказать, что он весьма впечатляет.
Информация с официального сайта:

Это бесплатный фреймворк для автоматизации приложений Android и мобильных сетей. Его главная особенность — поддержка масштабирования и параллельного тестирования.
Информация с официального сайта:
Selendroid является фреймворком для автоматизации тестирования, который работает с UI нативных и гибридных приложений, а также с мобильной сетью. Тесты написаны с использованием клиентского API Selenium 2.

Информация с официального сайта:
Проект тестирования GNU LDTP направлен на создание высококачественного фреймворка для автоматизации тестирования, снаряжённого новейшими инструментами, которые могут использоваться для тестирования и улучшения рабочих столов GNU/Linux или Solaris. Он использует библиотеки доступности, чтобы произвести проверку UI приложения.

Это бесплатный инструмент для тестирования веб, мобильных приложений и API.
Информация с официального сайта:
OpenTest является открытым фреймворком для автоматизации функционального тестирования веб и мобильных приложений, а также API. Он разработан для масштабирования и расширения с акцентом на включение основных методов автоматизации процесса тестирования. OpenTest имеет богатый арсенал инструментов, требует минимум навыков написания кода и может обрабатывать почти любой проект по автоматизации тестирования.

Существует великое множество инструментов, не рассмотренных мной в рамках этой статьи, но, по моему скромному мнению, перечисленные выше являются наилучшими вариантами.
Окей, элементы расписаны. Что дальше?

Из них составляем страницы, из страниц готовим наборы бизнес-шагов, из них − тестовые сценарии.
Как автоматизатор я хочу максимальное время уделять тестированию приложения, а не подготовке тестовых данных.
Если тестовые сценарии написаны с помощью UI-библиотеки, например, Selenium, то со временем вы удивитесь почему один небольшой тест занимает 5-10 минут времени. Проблема в создании тестовых данных. Поэтому чем раньше в вашем фреймворке появится возможность использовать REST API или базу данных приложения, тем лучше. REST Assured и JDBC вам в помощь. Приятным бонусом будет то, что теперь внутри фреймворка можно делать тестовую пирамиду и автоматизировать часть проверок, используя только REST API.
Как автоматизатор я хочу забыть, где объявлен WebDriver, забыть о проблемах с параллелизацией и частыми StaleElementReferenceException.
Ребята из Selenide за последние несколько лет сделали многое для того, чтобы мы писали меньше кода.
- Встроенные ожидания;
- WebDriver не хранится как поле класса, а вызывается методом getWebDriver из любой точки кода. Не конфликтует друг с другом из коробки при параллельном запуске;
- StaleElementReferenceException побежден раз и навсегда за счет «умного» обращения к DOM вашей страницы под капотом Selenide.
Как автоматизатор я хочу запускать тесты не у себя на компьютере.
Словосочетание Continuous Integration и так всем известно. Зачем? Чтобы не пить чай, пока запускаются тесты, а продолжать разрабатывать новые. В это время старые генерируют нам проблемы. Здесь подробный список доступных сейчас CI tools. Из приятных нововведений, появившихся не так давно: CircleCI для Selenium-like фреймворка заводится за несколько минут и предоставляет 240 бесплатных минут в неделю.
Как автоматизатор я хочу понимать, почему мои тесты упали.
Всем привет! В предыдущем посте я начал рассказывать про создание test framework-а с нуля. В нем рассказал про выбор технологий, создание проекта в IDE, структуру и написание feature на языке Gherkin. Далее рассмотри создание Step-ов для реализации тестовой логики.
Итак начнем. Тестовая логика у нас прописана в feature-файлах. Для ее реализации необходимы Step-файлы. Они служат для перевода языка Gherkin, на язык программирования, в моем случае это Java. У IntelliJ IDEA есть замечательная настройка, позволяющая автоматически сгенерировать Step-файл для каждого из ключевых слов теста. На практие это выглядит так:
public void userSendLetterTo(String arg0) throws Throwable
Так как Step не является исполняемым классом, то он расположен в package "java"
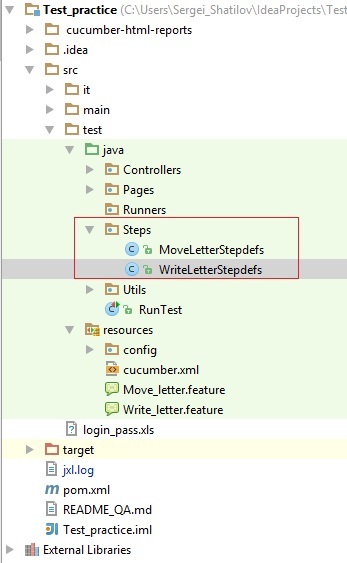
Теперь рассмотрим на примере структуру Step-файла:
На изображении выше видно, что все ключевые слова реализованы уже на Java языке. Причем нужно не забывать, что при написании реализации ключевых слов необходимо четко указывать в скобках точную фразу, написанную в feature, иначе Step просто не подцепится и компиляция и выполнение теста не произойдет.
Так как я изначально использовал методологию Page Object Pattern, то при написании Step-ов мне всего навсего необходимо было проинициализировать page-и, а дальше уже использовать функции, реализованные в самих page-ах. Самым разумным решением, на мой взгляд, это произвети инициализацию в Before-методе используя PageObjectFactory, а объявление page-ов методом "@Autowired @Lazy" (cucumber). @Lazy говорит о том, что применение и инициализация того или иного page-а будет происходить только в момент его вызова, а не при старте теста. Это отчасти облегчает тест и немного увеличивает его скорость прохождения.
Так же необходимо незабывать писать javadoc-и, так как никогда не известно кто в дальнейшем будет поддерживать ваши тесты. Да и вряд ли вы сами после написания 100-200 тестов будете четко помнить что именно реализует тот или иной метод.
Еще одним из основных параметров, которые необходимо прописать в Step-ах - это @ContextConfiguration(locations = "/cucumber.xml"). Данный параметр указывает на то, где расположена конфигурация cucumber-тестов. В данном xml-файле описана основная конфигурация и описаны bean-ы, используемые в тестах. И так как он является конфигурационным файлом, он расположен в package-е resources.
Так же в package-е resources расположен еще один config-файл (target.properties), служащий для конфигурации адреса тестируемого приложения, данных пользователя и других часто используемых параметров.
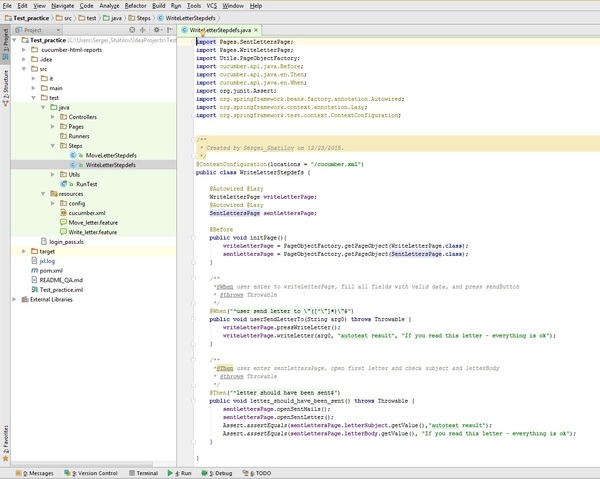
Ну и для закрепления, ниже изображен еще один Step-файл
Итак, подведем итоги. В данном посте были рассмотрены правила и примеры написания Step-файлов, реализующих тестовую логику, прописанную в feature-файлах. Так же были рассмотрены конфигурационные файлы, используемые в тестах.
З.Ы. Всем огромное спасибо за внимание и интерес к моим постам. В следующем посте мы рассмотрим применение Page Object Pattern при описании элементов страниц.
Пусть автор никого не слушает, а публикует, что собирался. По закону Старджона 90% всего на свете - . , так что, этот ресурс точно не проиграет в качестве контента. И, да, на какой-то публичный репозиторий исходники залить - точно не больше времени, чем уже потрачено.
@madtester, вот тебе совет: не делай посты, заведи блог и пиши туда. тут это нахуй никому не упало, а если кто-то заинтересуется, гугл даст ссылку на твой блог.
Реквестирую ссыль на репозиторий с данным проектом)
Мне кажется, что можно было начать с ИДЕ. В случае, если человек не очень дружит в джавой - хоть немного понятно. А так, действительно получается узкоспециализировано.
Почему ява-кодеры такие тугие? Ну не нужны тут такие посты, это видно по их рейтингу.
На хабр не пускают, а посрать в интернетах "гайдами" нулевого уровня хочется?

Зачем автоматизировать тестирование?

Цели создания фреймворка для автоматизации:
- Не хотим писать один и тот же код дважды;
- После создания фреймворка – написание тестов должно свестись к простому составлению последовательности шагов, вытекающих в тестовые сценарии.
Разработчики каждый раз пугаются фразе «создать фреймворк», считая, что это похоже на разработку собственного приложения/библиотеки/модуля. Реальность отличается: фреймворк для автоматизации тестирования − это адаптация нескольких решений, имеющихся на рынке, под нужды конкретного проекта.
Ниже расскажем, из чего может состоять фреймворк и какие цели та или иная его часть может преследовать. Добавим суматохи в ряды автоматизаторов и поговорим в формате User Stories, где каждая будет начинаться с привычных и столь нелюбимых нами: «Как автоматизатор я хочу. ».
Как автоматизатор я хочу иметь возможность расширять решение, добавлять новые возможности и не зависеть от создателей сторонних продуктов.
Вечный выбор между record-replay или языками программирования. Я адепт решений, связанных с языками программирования потому что:
- Готовые решения плохо работают с динамическими данными;
- Готовые решения, в большинстве своем, платные;
- Готовые решения могут менять набор функциональности, доступной для пользователей либо содержать баги, мешающие работе;
- Готовые решения не дают возможности встроить все, что душе заблагорассудится, в их продукт. Необходимо ждать внедрения интеграции от создателей.
Если говорить о выборе языка программирования, то холивары на этот счет никогда не прекращаются в связи с тем, что:
- Бытует миф, что разработчики могут помогать писать автотесты автоматизаторам (на самом деле, нет);
- Говорят, что хранить код продукта вместе с кодом автотестов − это правильно.
Как автоматизатор я хочу иметь возможность легко подключать новые библиотеки и запускать тесты c помощью командной строки.
Далее мы рассмотрим примеры, приближенные к языку программирования Java. Тем не менее, информация ниже применима в любом из языков программирования.
Начнем. Подключаем любой build tool, например, Maven/Ant+Ivy/Gradle и наслаждаемся простотой добавления и широким выбором библиотек, которые можно использовать в проекте. Приятный бонус: запуск тестов из командной строки, что пригодится нам на этапе внедрения в CI, но об этом позже.
Как автоматизатор я хочу иметь возможность запускать тесты в параллели, использовать Asserts и группировку по тест-пакетам.
Для запуска тестов в параллели проще всего использовать xUnit-библиотеки. То есть хватаем JUnit или TestNG, и вуаля. Я фанат TestNG. Возможно, в паре с Hamcrest из-за большего количества функциональности и поддержки от создателей. Говорят, JUnit 5 просто космос. Пишите ваше мнение в комментариях.
Как автоматизатор я хочу описать взаимодействие со всеми элементами в приложении один раз и больше не задумываться о том, как это работает.
Ниже разговор пойдет о фреймворках, так или иначе касающихся взаимодействия с UI-частью приложения через Selenium. И здесь не о библиотеке, а о стандартном подходе в Page Object Model, где в каждом из проектов описаны такие пакеты/модули:
- Elements − взаимодействие с кнопками/инпутами и другими элементами, доступными в приложении. Здесь и ожидания, и логирование, и обработка исключения;
- Pages − описание локаторов и действий с каждым из элементов, используя классы из elements;
- Steps − объединение отдельных действий из разных страниц в так называемые business-scenarios. Ценные для конечного пользователя/описываемые в репортинге. Создатели Serenity прекрасно «переиспользовали» модель у себя во фреймворке, но, к сожалению, пожертвовали гибкостью;
- Tests − из отдельных шагов собирается тестовый сценарий. Из тестов только пробрасывается ввод от конечного пользователя.
Читайте также: