
Пишем javascript парсер при помощи google chrome extension
Большой интерес пользователей к статье Учимся парсить сайты с библиотекой PHP Simple HTML DOM Parser показал, что тема парсеров очень актуальна. В продолжении темы, хочу рассказать, как можно парсить сайты используя JavaScript и всю мощь библиотеки jQuery, взамен Simple HTML DOM Parser.
Нет, мы не будем использовать для обработки js, какой-нибудь серверный интерпретатор, весь парсинг и обработка данных будет происходить на Вашей машине, в Вашем браузере. Браузером будет Google Chrome, а парсер мы реализуем в виде расширения Google Chrome Extension.
Почему Google Chrome, трудно сказать, самым верным ответом наверное будет: "А почему бы и нет?!". Не сомневаюсь, что тоже самое можно будет сделать и для Opera. Однако, эта статья не про написание расширений для браузера( хотя возможно Вы почерпнете для себя и здесь, что-то новое), а про то, как писать client-side парсеры на JavaScript.
Также хочу рассказать про преимущества, которые дает такой подход к написанию парсера.
Во первых: jQuery и JavaScript в целом обладает фантастическим набором методов для работы с DOM документа, Simple HTML DOM Parser тихо курит в сторонке. Навигация по дереву DOM браузер априори обрабатывает очень быстро, это собственно его нативный функционал.
Второе: по планете давным давно шагает WEB 2.0. Для тех кто в танке: веб второй версии подразумевает динамически меняющийся контент сайта. AJAX или просто замена определенного участка страницы через JS сводит на нет работу любого php парсера. Проиллюстрирую на примере:
Полагаю Вы догадываетесь, что увидит написанный на php парсер, загрузивший данную страницу, и тупо проверяющий содержание тега body.
Использование браузера в качестве парсер-машины позволяет, обмануть сайт, и выполнить подобные скрипты, получив результирующую страницу.
Итак для начала напишем расширение для Chrome типа Hello World. а затем будем наращивать его функционал. Далее я буду называть наше расширение - приложением, так как расширение увеличивает функционал самого браузера, либо добавляет какие-то фичи к сайту, мы же пишем настоящее приложение, которое работает на базе браузера.
Создайте пустую папку с каким-нибудь внятным названием на латинице. Я назвал парсер xdParser, так обзовем и папку.
В ней создадим два файла main.html и manifest.json, такого содержания:
Самым интересным параметром для нашего парсера здесь будет permissions, дело в том, что по умолчанию ajax не позволяет cross-domain запросы. Прописав нужный домен в массив permissions, мы сообщаем Google Chrome'у, о том что наш ajax будет использовать кросс-доменные запросы. Если же в массив добавить "", то ajax-запросы будут разрешены для любого домена.
Чтобы новое приложение не затерялось в безликой толпе, закиньте в созданную папку набор каких-нибудь иконок, к примеру эти. Иконки должны быть png, иначе они работают не везде. Наверно глюк.

Теперь приложение надо установить, кликаем на панели браузера по иконке с гаечным ключем(Настройки и управление Google Chrome), затем Инструменты -> Расширения, ставим в самом верху галку Режим разработчика
Далее кликаем Загрузить распакованное расширение. и указываем путь к вышеназванной папке. Если manifest.json валиден, то приложение установится и мы увидим его среди прочих.
Открываем новую вкладку, в ней переходим на слайд Приложения, и видим там свое.
С Hello World разобрались, теперь напишем наш первый парсер JavaScript на Google Chrome Extensions.
Как видно из кода, необходимо создать две подпапки js и css. В js закинуть два файла jquery-1.7.2.min.js и main.js
Теперь сделаем что-нибудь посложнее. Возьмем мой пример с парсингом фото из Яндекса при попмощи Simple HTML DOM
не забывайте перезагружать Ваше приложение в расширениях Google Chrome, там же где Вы его устанавливали. Под каждым расширением, в том числе и Вашем есть ссылка Перезагрузить
Иначе изменения внесенные в manifest.json не вступят в силу.
Далее изменим parserGo
Как видите я ввел еще одну функцию requrs:
где fs это экземпляр класса fileStorage для работы с файловой системой. Для его инициализации Вам понадобится файл fileStorage.js и в самом начале main.js прописать создание экземпляра этого класса:
То, как он работает, это тема отдельной статьи, отмечу лишь одни грабли в его использовании: запись следующего файла на диск должна производится только после завершения записи предыдущего. Это очень важно учитывать в асинхронных приложениях, коим и является наш парсер. Поэтому метод loadRemoteFile , одним из своих параметров принимает callback функцию, которая выполняется только по окончании записи файла на диск, и рекурсивно вызывает requrs.
По работе с файлами рекомендую почитать цикл статей по работе с файловой системой в JavaScript Работа с файлами в JavaScript, Часть 1: Основы
В результате файлы с картинками будут аккуратно сложены в папку виртуальной файловой системы Хрома, у меня это папка лежит тут: C:\Users\Leroy\AppData\Local\Google\Chrome\User Data\Default\File System, ее название может быть разным и создается самим Хромом. Повторюсь, что это лишь виртуальная файловая система, и картинок с расширением *.jpg Вы здесь не найдете. Все файлы лежат с восьмизначными числовыми именами, начиная от 00000000, без расширения. Но если открыть их какой-нибудь программой для просмотра изображений, они прекрасно откроются. А в браузере на вкладке с нашим приложением мы увидим прекрассную Джессику:
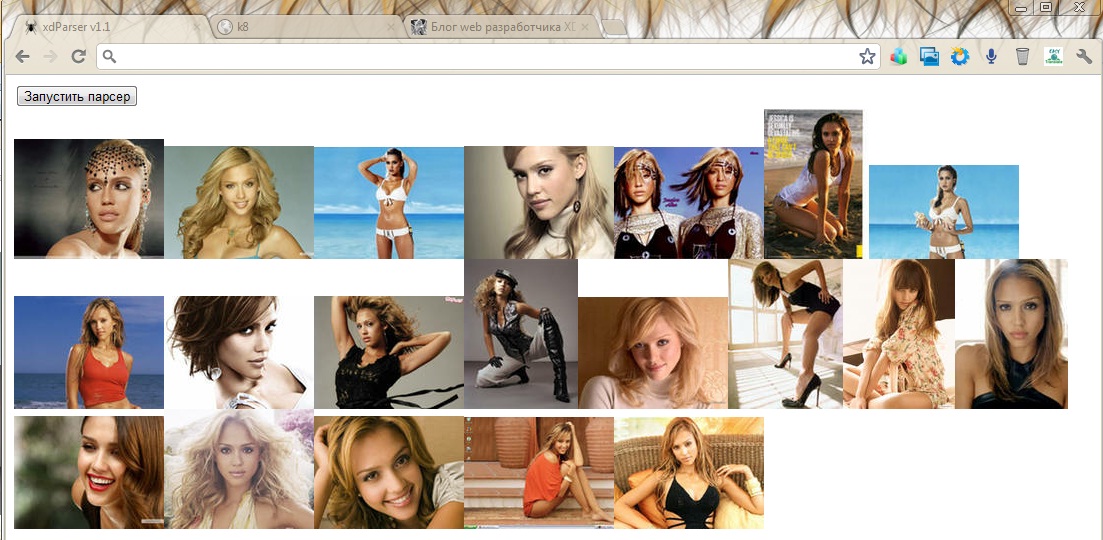
остальные примеры из парсинг фото из Яндекса при попмощи Simple HTML DOM переделайте сами, это не сложно. Мы же рассмотрим более реальный пример парсера.
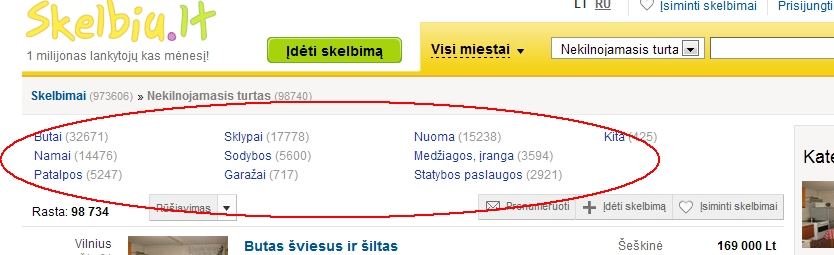
DOM Inspector Google Chrome показывает нам, что все ссылки находятся так:
Также выясняется, что страницы работают без ЧПУ и у каждой подкатегории есть числовой идентификатор, он нам понадобится поэтому получим его из href найденной ссылки при помощи регулярного выражения var cat = $last.attr('href').match(/(5+)\?&category_id=(8+)&orderBy=4+/);
Итак у нас есть id категории cat[2] и общее количество страниц maxpage. Теперь перебираем их все с 1 до maxpage. Делать это циклом используя асинхронные запросы нецелесообразно, поэтому используем рекурсивную функцию function requrs(catid,fullCount,tik,url), где catid - это id категории, fullCount - общее количество страниц в категории, tik - текущий номер страницы, url - ЧПУ адрес подкатегории.
Результат мы увидим в консоли JavaScript, увидеть которую можно нажав ctrl+shift+j
Большой интерес пользователей к статье Учимся парсить сайты с библиотекой PHP Simple HTML DOM Parser показал, что тема парсеров очень актуальна. В продолжении темы, хочу рассказать, как можно парсить сайты используя JavaScript и всю мощь библиотеки jQuery, взамен Simple HTML DOM Parser.
Нет, мы не будем использовать для обработки js, какой-нибудь серверный интерпретатор, весь парсинг и обработка данных будет происходить на Вашей машине, в Вашем браузере. Браузером будет Google Chrome, а парсер мы реализуем в виде расширения Google Chrome Extension.
Почему Google Chrome, трудно сказать, самым верным ответом наверное будет: "А почему бы и нет?!". Не сомневаюсь, что тоже самое можно будет сделать и для Opera. Однако, эта статья не про написание расширений для браузера( хотя возможно Вы почерпнете для себя и здесь, что-то новое), а про то, как писать client-side парсеры на JavaScript.
Также хочу рассказать про преимущества, которые дает такой подход к написанию парсера.
Во первых: jQuery и JavaScript в целом обладает фантастическим набором методов для работы с DOM документа, Simple HTML DOM Parser тихо курит в сторонке. Навигация по дереву DOM браузер априори обрабатывает очень быстро, это собственно его нативный функционал.
Второе: по планете давным давно шагает WEB 2.0. Для тех кто в танке: веб второй версии подразумевает динамически меняющийся контент сайта. AJAX или просто замена определенного участка страницы через JS сводит на нет работу любого php парсера. Проиллюстрирую на примере:
Полагаю Вы догадываетесь, что увидит написанный на php парсер, загрузивший данную страницу, и тупо проверяющий содержание тега body.
Использование браузера в качестве парсер-машины позволяет, обмануть сайт, и выполнить подобные скрипты, получив результирующую страницу.
Итак для начала напишем расширение для Chrome типа Hello World. а затем будем наращивать его функционал. Далее я буду называть наше расширение - приложением, так как расширение увеличивает функционал самого браузера, либо добавляет какие-то фичи к сайту, мы же пишем настоящее приложение, которое работает на базе браузера.
Создайте пустую папку с каким-нибудь внятным названием на латинице. Я назвал парсер xdParser, так обзовем и папку.
В ней создадим два файла main.html и manifest.json, такого содержания:
Самым интересным параметром для нашего парсера здесь будет permissions, дело в том, что по умолчанию ajax не позволяет cross-domain запросы. Прописав нужный домен в массив permissions, мы сообщаем Google Chrome'у, о том что наш ajax будет использовать кросс-доменные запросы. Если же в массив добавить "", то ajax-запросы будут разрешены для любого домена.
Чтобы новое приложение не затерялось в безликой толпе, закиньте в созданную папку набор каких-нибудь иконок, к примеру эти. Иконки должны быть png, иначе они работают не везде. Наверно глюк.
Теперь приложение надо установить, кликаем на панели браузера по иконке с гаечным ключем(Настройки и управление Google Chrome), затем Инструменты -> Расширения, ставим в самом верху галку Режим разработчика
Далее кликаем Загрузить распакованное расширение. и указываем путь к вышеназванной папке. Если manifest.json валиден, то приложение установится и мы увидим его среди прочих.
Открываем новую вкладку, в ней переходим на слайд Приложения, и видим там свое.
С Hello World разобрались, теперь напишем наш первый парсер JavaScript на Google Chrome Extensions.
Как видно из кода, необходимо создать две подпапки js и css. В js закинуть два файла jquery-1.7.2.min.js и main.js
Теперь сделаем что-нибудь посложнее. Возьмем мой пример с парсингом фото из Яндекса при попмощи Simple HTML DOM
не забывайте перезагружать Ваше приложение в расширениях Google Chrome, там же где Вы его устанавливали. Под каждым расширением, в том числе и Вашем есть ссылка Перезагрузить
Иначе изменения внесенные в manifest.json не вступят в силу.
Далее изменим parserGo
Как видите я ввел еще одну функцию requrs:
где fs это экземпляр класса fileStorage для работы с файловой системой. Для его инициализации Вам понадобится файл fileStorage.js и в самом начале main.js прописать создание экземпляра этого класса:
То, как он работает, это тема отдельной статьи, отмечу лишь одни грабли в его использовании: запись следующего файла на диск должна производится только после завершения записи предыдущего. Это очень важно учитывать в асинхронных приложениях, коим и является наш парсер. Поэтому метод loadRemoteFile , одним из своих параметров принимает callback функцию, которая выполняется только по окончании записи файла на диск, и рекурсивно вызывает requrs.
По работе с файлами рекомендую почитать цикл статей по работе с файловой системой в JavaScript Работа с файлами в JavaScript, Часть 1: Основы
В результате файлы с картинками будут аккуратно сложены в папку виртуальной файловой системы Хрома, у меня это папка лежит тут: C:\Users\Leroy\AppData\Local\Google\Chrome\User Data\Default\File System, ее название может быть разным и создается самим Хромом. Повторюсь, что это лишь виртуальная файловая система, и картинок с расширением *.jpg Вы здесь не найдете. Все файлы лежат с восьмизначными числовыми именами, начиная от 00000000, без расширения. Но если открыть их какой-нибудь программой для просмотра изображений, они прекрасно откроются. А в браузере на вкладке с нашим приложением мы увидим прекрассную Джессику:
остальные примеры из парсинг фото из Яндекса при попмощи Simple HTML DOM переделайте сами, это не сложно. Мы же рассмотрим более реальный пример парсера.
DOM Inspector Google Chrome показывает нам, что все ссылки находятся так:
Также выясняется, что страницы работают без ЧПУ и у каждой подкатегории есть числовой идентификатор, он нам понадобится поэтому получим его из href найденной ссылки при помощи регулярного выражения var cat = $last.attr('href').match(/(9+)\?&category_id=(1+)&orderBy=5+/);
Итак у нас есть id категории cat[2] и общее количество страниц maxpage. Теперь перебираем их все с 1 до maxpage. Делать это циклом используя асинхронные запросы нецелесообразно, поэтому используем рекурсивную функцию function requrs(catid,fullCount,tik,url), где catid - это id категории, fullCount - общее количество страниц в категории, tik - текущий номер страницы, url - ЧПУ адрес подкатегории.
Результат мы увидим в консоли JavaScript, увидеть которую можно нажав ctrl+shift+j
Большой интерес пользователей к статье Учимся парсить сайты с библиотекой PHP Simple HTML DOM Parser показал, что тема парсеров очень актуальна. В продолжении темы, хочу рассказать, как можно парсить сайты используя JavaScript и всю мощь библиотеки jQuery, взамен Simple HTML DOM Parser.
Нет, мы не будем использовать для обработки js, какой-нибудь серверный интерпретатор, весь парсинг и обработка данных будет происходить на Вашей машине, в Вашем браузере. Браузером будет Google Chrome, а парсер мы реализуем в виде расширения Google Chrome Extension.
Почему Google Chrome, трудно сказать, самым верным ответом наверное будет: "А почему бы и нет?!". Не сомневаюсь, что тоже самое можно будет сделать и для Opera. Однако, эта статья не про написание расширений для браузера( хотя возможно Вы почерпнете для себя и здесь, что-то новое), а про то, как писать client-side парсеры на JavaScript.
Также хочу рассказать про преимущества, которые дает такой подход к написанию парсера.
Во первых: jQuery и JavaScript в целом обладает фантастическим набором методов для работы с DOM документа, Simple HTML DOM Parser тихо курит в сторонке. Навигация по дереву DOM браузер априори обрабатывает очень быстро, это собственно его нативный функционал.
Второе: по планете давным давно шагает WEB 2.0. Для тех кто в танке: веб второй версии подразумевает динамически меняющийся контент сайта. AJAX или просто замена определенного участка страницы через JS сводит на нет работу любого php парсера. Проиллюстрирую на примере:
Полагаю Вы догадываетесь, что увидит написанный на php парсер, загрузивший данную страницу, и тупо проверяющий содержание тега body.
Использование браузера в качестве парсер-машины позволяет, обмануть сайт, и выполнить подобные скрипты, получив результирующую страницу.
Итак для начала напишем расширение для Chrome типа Hello World. а затем будем наращивать его функционал. Далее я буду называть наше расширение - приложением, так как расширение увеличивает функционал самого браузера, либо добавляет какие-то фичи к сайту, мы же пишем настоящее приложение, которое работает на базе браузера.
Создайте пустую папку с каким-нибудь внятным названием на латинице. Я назвал парсер xdParser, так обзовем и папку.
В ней создадим два файла main.html и manifest.json, такого содержания:
Самым интересным параметром для нашего парсера здесь будет permissions, дело в том, что по умолчанию ajax не позволяет cross-domain запросы. Прописав нужный домен в массив permissions, мы сообщаем Google Chrome'у, о том что наш ajax будет использовать кросс-доменные запросы. Если же в массив добавить "", то ajax-запросы будут разрешены для любого домена.
Чтобы новое приложение не затерялось в безликой толпе, закиньте в созданную папку набор каких-нибудь иконок, к примеру эти. Иконки должны быть png, иначе они работают не везде. Наверно глюк.
Теперь приложение надо установить, кликаем на панели браузера по иконке с гаечным ключем(Настройки и управление Google Chrome), затем Инструменты -> Расширения, ставим в самом верху галку Режим разработчика
Далее кликаем Загрузить распакованное расширение. и указываем путь к вышеназванной папке. Если manifest.json валиден, то приложение установится и мы увидим его среди прочих.
Открываем новую вкладку, в ней переходим на слайд Приложения, и видим там свое.
С Hello World разобрались, теперь напишем наш первый парсер JavaScript на Google Chrome Extensions.
Как видно из кода, необходимо создать две подпапки js и css. В js закинуть два файла jquery-1.7.2.min.js и main.js
Теперь сделаем что-нибудь посложнее. Возьмем мой пример с парсингом фото из Яндекса при попмощи Simple HTML DOM
не забывайте перезагружать Ваше приложение в расширениях Google Chrome, там же где Вы его устанавливали. Под каждым расширением, в том числе и Вашем есть ссылка Перезагрузить
Иначе изменения внесенные в manifest.json не вступят в силу.
Далее изменим parserGo
Как видите я ввел еще одну функцию requrs:
где fs это экземпляр класса fileStorage для работы с файловой системой. Для его инициализации Вам понадобится файл fileStorage.js и в самом начале main.js прописать создание экземпляра этого класса:
То, как он работает, это тема отдельной статьи, отмечу лишь одни грабли в его использовании: запись следующего файла на диск должна производится только после завершения записи предыдущего. Это очень важно учитывать в асинхронных приложениях, коим и является наш парсер. Поэтому метод loadRemoteFile , одним из своих параметров принимает callback функцию, которая выполняется только по окончании записи файла на диск, и рекурсивно вызывает requrs.
По работе с файлами рекомендую почитать цикл статей по работе с файловой системой в JavaScript Работа с файлами в JavaScript, Часть 1: Основы
В результате файлы с картинками будут аккуратно сложены в папку виртуальной файловой системы Хрома, у меня это папка лежит тут: C:\Users\Leroy\AppData\Local\Google\Chrome\User Data\Default\File System, ее название может быть разным и создается самим Хромом. Повторюсь, что это лишь виртуальная файловая система, и картинок с расширением *.jpg Вы здесь не найдете. Все файлы лежат с восьмизначными числовыми именами, начиная от 00000000, без расширения. Но если открыть их какой-нибудь программой для просмотра изображений, они прекрасно откроются. А в браузере на вкладке с нашим приложением мы увидим прекрассную Джессику:
остальные примеры из парсинг фото из Яндекса при попмощи Simple HTML DOM переделайте сами, это не сложно. Мы же рассмотрим более реальный пример парсера.
DOM Inspector Google Chrome показывает нам, что все ссылки находятся так:
Также выясняется, что страницы работают без ЧПУ и у каждой подкатегории есть числовой идентификатор, он нам понадобится поэтому получим его из href найденной ссылки при помощи регулярного выражения var cat = $last.attr('href').match(/(7+)\?&category_id=(9+)&orderBy=3+/);
Итак у нас есть id категории cat[2] и общее количество страниц maxpage. Теперь перебираем их все с 1 до maxpage. Делать это циклом используя асинхронные запросы нецелесообразно, поэтому используем рекурсивную функцию function requrs(catid,fullCount,tik,url), где catid - это id категории, fullCount - общее количество страниц в категории, tik - текущий номер страницы, url - ЧПУ адрес подкатегории.
Результат мы увидим в консоли JavaScript, увидеть которую можно нажав ctrl+shift+j

Хотите написать расширение для Chrome, но не знаете, с чего начать? Читайте это руководство с нуля до подготовки к публикации скрипта содержимого. Здесь применяются фреймворк CSS TailWind и универсальный упаковщик Parcel.js, решаются проблемы переопределения стиля страницы и перезагрузки расширения. Весь код вы найдёте в конце.
Написать расширение для Chrome непросто. Это не то же самое, что разработка веб-приложения: не хочется перегружать браузер оверхедом JS, ведь расширения работают одновременно с сайтами. Более того, у нас нет инструментов упаковки или отладки из привычных фреймворков.
Когда я решил заняться созданием расширения для Chrome, то обнаружил: блог-постов и статей об этом довольно мало. И информации оказывается даже ещё меньше, если вам захочется использовать новые инструменты, например TailwindCSS.
В этом руководстве мы напишем расширение для Сhrome с помощью Parcel.js для упаковки и просмотра результатов, а также TailwindCSS для оформления. Кроме того, мы отделим стилизацию расширения от веб-сайта, чтобы избежать конфликта CSS.
Есть несколько типов расширений для Chrome, достойных упоминания:
- Скрипты содержимого. Наиболее распространённый тип. Они запускаются в контексте веб-страницы и могут изменять её. Именно такое расширение мы и будем создавать.
- Выпадающее окно (popup). Использует иконку справа от адресной строки, чтобы открыть окно с каким-то HTML.
- UI с опциями. Пользовательский интерфейс для настройки параметров в качестве расширения. Получить доступ к нему можно, щелкнув правой кнопкой мыши по значку расширения и выбрав пункт “Параметры” или перейдя на страницу расширения из списка расширений Chrome: chrome://extensions .
- Расширение DevTools. Добавляет функциональность в инструменты разработчика. Оно может добавлять новые панели интерфейса, взаимодействовать с проверяемой страницей, получать информацию о сетевых запросах и многое другое — документация Google Chrome.
В этом руководстве мы напишем расширение, используя исключительно скрипты содержимого, отображая содержимое на веб-странице и взаимодействуя с DOM.
Content Security Policy
Для Chrome расширений, действует так называемое Content Security Policy — это набор строгих правил, которые необходимы для того чтобы сделать расширения безопасней и контролировать контент который может быть загружен и выполнен в расширении.
По умолчанию, если использовать манифест 2 версии то в расширении будут такие ограничения:
- Запрещено использовать eval и схожие функции
- Inline джаваскрипт выполняться не будет
- Возможность загружать только локальные скрипты и ресурсы
Также можно разрешить использование eval функции.
Разрешить нельзя использование только инлайн скриптов.
Разрабатывая хром расширения, получить доступ к методам и возможностям браузера можно с помощью специального Chrome Javascript API’s. Большинство методов асинхронные, о чем нужно помнить разрабатывая расширение.


Так как background страница в другой области видимости чем например контент скрипт который выполняется в контексте веб-страницы, нужен какой то способ коммуникации между Content Scripts и Background scripts.

Два описанных метода коммуникации в Chrome расширениях используют для background страниц или отдельных окон расширения с content script-ами и наоборот. Content scripts выполняються в своей песочнице и это вызывает проблему с доступом к странице и области видимости скриптов.

К сожалению Chrome браузер не предоставляет нормальных способов для решения этой проблемы. Непосредственно с контент скрипта, доступиться к функциям или переменной страницы в данный момент невозможно. Но для этого можно использовать Web Accessible Resources.
Как я уже отмечал ранее, с content script-а мы можем модифицировать DOM, а именно создать например новый тег script, в атрибуте src задать ему путь к скрипту который открыт для внешнего использования, и добавить этот тег в DOM.
Таким способом подключать можно только те которые описаны в массиве web_accessible_resources в manifest.json файле.
С использованием такого подхода вы получаете полный доступ к вашей странице, но конечно тут возникают другие проблемы о которых мы поговорим с Вами в другой части этой статьи.
Добавляем манифест
Прежде чем углубиться в детали работы расширения Chrome, установим и настроим TailwindCSS.
TailwindCSS — это CSS-фреймворк, применяющий служебные классы низкого уровня для создания переиспользуемых и настраиваемых компонентов интерфейса. Tailwind устанавливается двумя способами, самый распространённый — установка с помощью NPM. Кроме того, сразу же стоит добавить autoprefixer и postcss-import :
Они нужны, чтобы добавить префиксы поставщиков к стилям и иметь возможность писать конструкции @import "tailwindcss/base" , импортируя файлы Tailwind прямо из node_modules .
Теперь, когда всё установлено, давайте создадим файл postcss.config.js в корневом каталоге. Этот файл — конфигурация для PostCSS. Вставим в него такой код:
Порядок плагинов здесь имеет значение! Это всё, что нужно, чтобы начать использовать TailwindCSS в вашем расширении. Начинаем. Создадим файл style.css в папке src и импортируем в него стили Tailwind:
Очищаем CSS с помощью PurgeCSS
Убедимся, что мы импортируем только те стили, которые используем, включив очистку. Создадим конфигурационный файл Tailwind, запустив такую команду:
Теперь у нас есть tailwind.config.js . Чтобы удалить неиспользуемый CSS, добавляем пути ко всем нашим файлам JS в поле конфигурации purge :
Теперь CSS будут очищены, а неиспользуемые стили удалены при сборке для продакшна.
Chrome не перезагружает файлы при внесении изменении, то есть нам нужно нажимать кнопку “Перезагрузить” на странице расширений каждый раз, когда мы хотим посмотреть на результат. К счастью, есть пакет NPM для автоматической перезагрузки:
Чтобы использовать его, создадим файл background.js в папке src и импортируем в этот файл crx-hotreload :
Наконец, добавим указатель на background.js в manifest.json , чтобы он мог работать с нашим расширением: горячая перезагрузка в продакшне отключена по умолчанию:
Достаточно конфигураций. Давайте создадим небольшую форму-скрипт в расширении.
Добавляем скрипт содержимого
Создадим файл content-script.js в папке src . И добавим HTML-форму в только что созданный файл:
Оформление стилей браузерного расширения сложнее, чем кажется. Нужно убедиться, что ваши стили не влияют на стили веб-сайта. Применим Shadow DOM для решения этой проблемы.
Теневой DOM — мощная техника инкапсуляции стилей: область применения стиля ограничивается теневым деревом. Таким образом ничего не просачивается на веб-страницу. Кроме того, внешние стили не переопределяют содержимое дерева, хотя переменные CSS всё ещё доступны.
Теневой хост — это любой элемент DOM, к которому мы хотели бы присоединить теневое дерево. Теневой корень — это то, что возвращается из attachShadow , а его содержимое — то, что визуализируется.
Будьте осторожны: единственный способ стилизовать содержимое теневого дерева — встроить стили. Parcel V2 из коробки есть функция, благодаря которой вы можете импортировать содержимое одного пакета и использовать его в качестве скомпилированного текста внутри ваших файлов JavaScript. Именно это мы и сделали со своим пакетом style.css . Parcel заменит его во время упаковки.
Теперь мы можем автоматически встроить CSS в Shadow DOM во время сборки. Конечно, мы должны сообщить браузеру о файле content-script.js , в котором встраивается style.css . Для этого включаем скрипт содержимого в манифест. Обратите внимание на секцию content-scripts ниже первого блока:
Чтобы обслуживать наше расширение, добавим несколько скриптов к package.json :
Наконец, запускаем yarn watch , переходим в chrome://extensions и убеждаемся, что в правом верхнем углу страницы включен режим разработчика. Нажмите на кнопку “Загрузить распакованный” и выберите папку dist в разделе demo-extension .
Прежде чем углубляться в эту тему, давайте добавим новый скрипт в конфигурацию NPM, который поможет сжать файлы расширения в соответствии с требованиями Chrome.
Если у вас ещё не установлен zip, пожалуйста, выполните команду:
- На MacOS: brew install zip .
- На Linux: sudo apt install zip .
- На Windows: powershell Compress-Archive -Path .\\dist\\ -Destination .\\chrome-extension.zip .
Расширения Chrome, в конечном счёте, не так уж сильно отличаются от веб-приложений. Сегодня мы написали расширение с применением новейших технологий и практик в веб-разработке. Надеюсь, это руководство поможет вам немного ускорить разработку вашего расширения!
Что такое Chrome Extension? Это маленькая программа, которая модифицирует и дополняет функциональность браузера Google Chrome. Для создания полноценного расширения вам понадобиться знание HTML, CSS, JavaScript. После написания, файлы пакуются в специальный файл с расширением .crx, который собой являет zip архив. В таком виде пользователь сможет установить расширение. За счет того что этот пакет содержит все необходимые файлы, chrome расширение не зависит от ресурсов из интернета и способен корректно работать даже в оффлайн режиме.
Любое chrome расширение может иметь такую структуру:

может, так как не все эти части есть обязательные, все зависит от конкретных потребностей и особенностей реализации.
Манифест — главный файл в chrome расширении, поскольку здесь информация о доступах которые нужны, о подключаемых файлах, настройки безопасности и многое другое. Например:
- Manifest_version — Версия манифест файла
- Name — название расширения
- Description — описание расширения
- Version — версия расширения
- Permissions — массив с названиями доступов, которые необходимы для корректной работы расширения, например без пермишина tabs вы не сможете работать с вкладками браузера
- Content_scripts — массив файлов, которые будут подключены как контент скрипты
- Background — описание файла или файлов, которые будут выполнять роль background скрипта и страницы
- Web_accessible_resources — набор файлов, которые имеют открытый доступ извне
- Browser_action — настройка соответствующей кнопки, в тулбаре
- Icons — списки иконок по стандартным размерам 16 48 и 128.
Если взять определение с официальной документации — невидимая страница, которая содержит основную логику расширения. Главной особенностью background страницы есть то, что она запускается и выполняет некую работу в фоновом режиме, как только запускается браузер и держится в оперативной памяти как фоновый процесс на протяжении сессии. Используя комбинацию Shift + Esc Вы можете просмотреть список задач, которые выполняются внутри браузера Google Chrome. Когда установлено много расширений, список задач этом списке также большой. Они занимают часть памяти и возможно других ресурсов, но не выполняют никаких функций, так как непосредственно само расширение не запущено, а в списке вы видите background страницу конкретного расширения.

Чтобы оптимизировать использование ресурсов, в 2012 году была разработана концепция ивент страниц (Event Pages). Она выполняет те же функции что и бэкграунд страница, но призвана решить проблему производительности и ресурсов, которые используются иррационально. Главное отличие этого подхода — вместо непрерывной работы в фоновом режиме, ивент страница запускается только тогда, когда нужно — например чтобы обработать конкретное событие. После чего выгружается, освобождая память до того момента пока конкретное событие не сработает в следующий раз. В плане кода, разницы никакой между этими двумя подходами нет, а единственное что нужно, указать в manifest.json файле это корректное значение проперти persistent. По умолчанию это значение будет стоять в true для стандартных background страниц и false для ивент страниц.
Это обязательные элементы Chrome Extension-а, теперь давайте перейдем к опциональным.
Контент скрипты — это javascript файлы или код, которые выполняються не в отдельном фоновом процессе (как бекграунд скрипты) а в контексте Веб страницы. Контент скрипты используют в ограниченном виде Chrome API. Но при этом они изолированные и не могут использовать, как функции и переменные которые объявлены, например на бекграунд странице так и переменные, функции и тд. со скриптов находящихся на веб странице.

Полноценный доступ есть только через к DOM дереву страницы. С контент скрипта вы можете инициировать ивенты, изменять DOM. Даже можете добавлять script тег в страницу и подключать нужные файлы.

Типы скриптов расширения Chrome
Как уже упоминалось, у расширений Chrome есть несколько типов скриптов:
- Скрипты содержимого — это сценарии, которые выполняются в контексте посещаемой веб-страницы. Вы можете запустить любой код JavaScript, в противном случае доступный на любой обычной веб-странице, включая доступ к DOM и манипулирование им.
- Фоновые скрипты — это место, где вы можете реагировать на события браузера с доступом к API расширения.
Читайте также: