
Php прочитать pdf файл
Задача: открыть документ и получить удобоваримый текст.
Опробовано: всё. Действительно всё, у меня весь гугл в сиреневых ссылках и даже контекстная реклама меня уже жалеет и предлагает купить ридер пдф книг.
Помимо PHP готов использовать любую другую технологию которая даст гарантированный результат. Но все же не хотелось бы уходить от родного для проекта языка.
Хардкорный вариант с написанием парсера с нуля по спекам формата не особо желателен в силу запутанности формата и зоопарка версий.
- Вопрос задан более трёх лет назад
- 14842 просмотра
Оценить 1 комментарий
Пока нет ничего что бы работало :(
Как вы себе представляете такое преобразование, если в PDF текст хранится строками с определенными координатами, а не абзацами, например? Также текст может храниться картинкой или векторным форматом. Таблицы хранятся набором кусков текста и линиями. Заголовок — просто строка текста чуть большего размера.
Чтобы восстановить логическую структуру текста, надо систему вроде той, которая используется в продуктах fineReader. Систем эта сложная и на ее разработку у Abbee ушла куча денег, вряд ли вы сможете решить задачу проще. А без этого максимум, что вы можете вытащить из файла — это набор блоков вида «строчка такого-то текста расположена по таким-то координатам». Текст может быть разбит переносами.
Абзацы, конечно, еще можно из этого как-то восстановить, выстроив строчки по возрастанию координат, но переносы останутся, а любые нестандартные вещи, вроде подписи к картинке, будут ломать этот алгоритм.
Резюмируя, выберите другой исходный формат, или откажитесь от мысли преобразовать PDF в осмысленный текст, преобразуйте его в картинку например. Иначе вы всю жизнь будете дописывать костыли, как только кто-то захочет подснуть вашей системе текст, сверстанный другим способом.
Я прекрасно представляю себе формат и информация в нашем случае не храниться картинкой или вектором. Я представляю сложность данной задачи, но что поделать задача есть и её надо решать.
Так получилось, что с месяц назад передо мной выросла совершенно неожиданная задача: сконвертировать PDF в html по имеющемуся шаблону. В том числе необходимо было разбивать все на страницы и выделять в них параграфы. Да и много еще чего. И все бы ничего, и обошелся бы я какой-нибудь левой библиотечкой, но кое-какие специфичные штучки-финтеплюшки, так необходимые мне, в библиотеках не нашлись. И это было печально…
0.Сначала было слово и было это слово: «документация»
1. От слов к делу. Внимание! Задача
В кратчайшие сроки мне нужно было написать приблуду на PHP, которая более или менее экономила бы память, потому что в среднем ожидались PDFки от 6 до 40 Мб. При этом она должна была извлекать содержимое по страницам, разбивать текст на логические блоки (абзацы и заголовки), извлекать картинки и оглавление.
2а. Немного теории. Получаем таблицу объектов.
Для начала немного теории. Вот пример PDF файла открытого в блокноте

Даже не вооруженным глазом можно увидеть что в файле помимо странных кракозябликов есть еще и осмысленный текст и это не может не радовать. Именно он нам и поможет во всем разобраться.
Как оказалось(и помог здесь ISO 3200-1) PDF имеет примерно следующую структуру:
Первой строкой описывается версия PDF. Второй идет таинственная строка в которой я так и не разобрался за ненадобностью. Хотя я допускаю, что в ней скрыта истинная суть нашей вселенной и вообще. Дальше идет описание объектов.
Объекты – универсальные структуры описывающие все данные хранящиеся в PDF и их логические связи. Каждый объект состоит из заголовка вида «N M obj» (без кавычек), где N – номер объекта, M – его версия (чести ради замечу, что я ни разу не встретил объект где M != 0). После заголовка объекта идут его свойства в >. И в заключении опционально идет поток данных окруженный в пару stream, endstream. Все части объекта разделяются переносами строки. Эти элементы я рассмотрю подробнее чуть позже. А пока от объектов перейдем к заключительной части PDF документа
cross-reference table – Некая таблица хранящая в себе адреса каждого объекта в файле. Имеет эта таблица примерно следующую структуру:

Первой строкой идет ключевое слово xref. Второй – два числа, которые обозначают с какого по какой в ней описаны объекты. После чего идет непосредственно сама таблица. Каждая строка вида 0000000032 65535 f описывает объект соответствующего номера. Не забывайте, что в некоторых таблицах нумерация будет начинаться не с первого объекта, а с того, который описан в строке после ключевого слова xref. Первая группа цифр:10 цифр(значение дополняется незначащими нулями слева) обозначающие адрес в файле с которого начинается объект.
UPD: Сасибо, pleax за указание на недочеты. Поправил.
Вторая группа: 5 цифр не более 65535(int) обозначающие номер редакции объекта. и последний символ либо n(для использующихся объектов) либо f для free-объектов(которые были удалены). При удалении объекта номер его редакции(generation) увеличивается на 1, а флаг (n/f) устанавливается в f. Кроме того номер редакции может быть установлен в 65535. Такой объект считается free и никогда больше не используется. Подробнее можно прочитать на странице 40 документации на PDF
Сразу после таблицы идет ключевое слово trailer, после которого можно найти свойства таблицы. Нас будет интересовать только одно: /Prev 321249. Здесь число обозначает адрес в файле с которого начинается предшествующая таблица. Соответственно самая первая таблица такого свойства не имеет.
После свойств таблицы можно найти еще одно ключевое слово startxref, после котрого число, обозначающее адрес начала данной таблицы.
Этих знаний нам хватит, чтобы выгрузить таблицу всех объектов PDF, благодаря чему в дальнейшем нам не придется загружать весь PDF в память. А теперь глотнем пивка и к практике.
2б. Теория на практике. Получаем таблицу объектов.
Нусс. Давайте с места в карьер. Вот немного моего говнокода:
Я думаю, что в целом в коде все понятно: Находим адрес последней таблицы, сохраняем её значения в массив, читаем адрес след таблицы. Последнюю таблицу мы создаем только потому, что в PHP сложно узнать следующий элемент массива. И в моем случае мне легче было хранить лишнюю таблицу, чем каждый раз пробегать весь массив в поисках нужного элемента.
Теперь, когда у нас есть массив RefTable[‘номер объекта’]=’Адрес объекта’ Мы можем использовать простую функцию для чтения файлов пообъектно. Например так:
3а. Еще немного теории. Получаем таблицу страниц.
Вернемся к нашим объектам, а точнее к их свойствам. В PDF существут 9 основных типов данных:
Boolean – True, False;
Numeric – int(623, +17, -98), real(34.5, -3.62)
LiteralString – Набор символов в круглых скобках (abcd)
Hexademical Strings – Строка из шестнадцатеричных значений.
Name — /Prev набор символов поле слэша
Array – [/name 1 /name1 /name2] массив объектов произвольного типа
Dictionary – Набор типа ключ-значение, где ключом всегда является объект типа Name (/Prev), а значение – объект любого типа в том числе и др. словари. Словари всегда окружены в >
Stream – Некоторые данные, которые могут быть закодированы так или иначе.
NULL – Говорит сам за себя
Подробнее смотрите на 14ой странице документации
Так вот свойства объекта хранятся в словарях(Dictionary). И в первую очередь нас будут интересовать свойство /Type в котором, как ни странно, находится тип объекта. Для начала мы найдем два объекта: /Type/Catalog и /Type/Pages в первом, в виде свойств, хранятся ссылки на объекты со служебной информацией и структуры данных, в том числе на /Pages 2 0 R (Это для примера). Здесь видно, что свойству /Pages сопоставляется номер объекта 2 0 R типа /Type/Pages.
Объект /Type/Pages, который мы найдем под номером 2 в нашей таблице ценен тем, что содержит в свойствах массив /Kids[ 3 0 R 29 0 R] с номерами. Объекты, которые мы найдем в этом массиве могут быть как еще одним узлом /Type/Pages со своими /Kids, так и искомыми нами объектами /Type/Page то бишь страницами.
И тут приходит время еще для бутылочки холодного темного.
3б. Вернемся к коду. Получаем таблицу страниц.
Вот функция, которая получит
Далее – вспомогательная функция, которая рекурсивно помогает нам в поиске страниц-детишек.
4а. Теория возвращается. Извлекаем данные из потоков.
Иногда после объектов вы можете найти кучу непонятных символов, а иногда их можно найти в объекта на которые можно найти ссылки в свойстве /Resources объекта. Это закодированные данные. В словаре таких объектов вы найдете свойство /Filter которому может быть присвоено как единственное значение, так и массив (Важно! Вполне может быть, что данные после объекта не будут зашифрованы. В этом случае свойства /Filter не будет. А поток сможет прочитать даже жошкольник). Список всех возможных фильтров вы найдете в документации на странице 22, однако же на одном я остановлюсь. /Filter/FlateDecode – это самый распространённый фильтр и в 99% случаев хватит только его. FlateDecode есть ни что иное, как обычный gzip и все что нам потребуется это gzuncompress($stream). Здесь есть одно но. По стандарту FlateDecode первые 4 бита данных имеют служебный характер и не интерпретируются, но в некоторых PDF эти биты отсутствуют и могут возникать gzuncompress() data error. Могу Вас обрадывать: один мОлодец написал для нас заплатку. Идем сюда и читаем
И вот значит мы молодцы такие взяли да и извлекли данные из потока, а там:
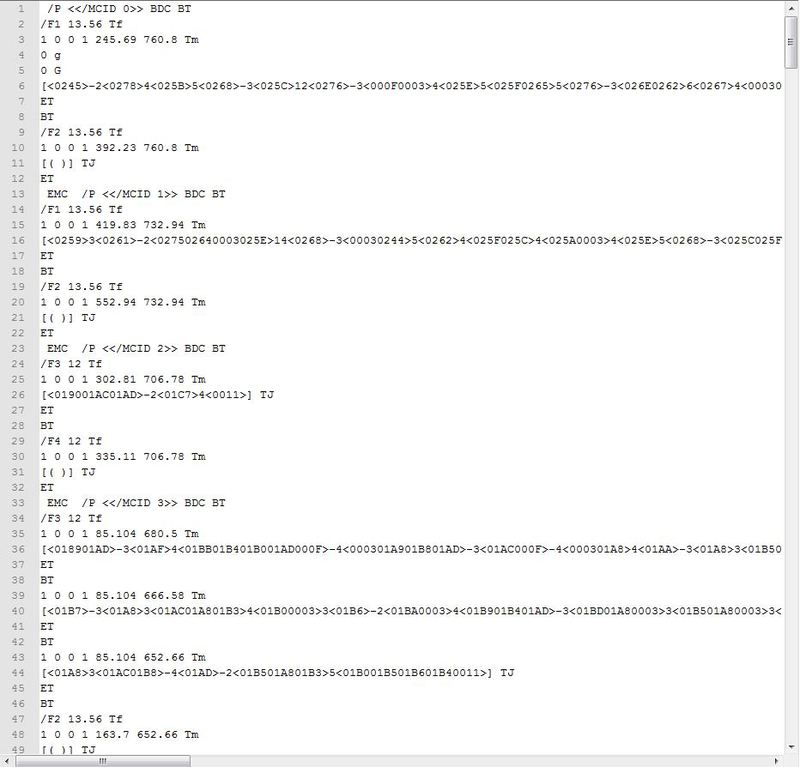
А там текст. Нас пока будут интересовать следующие строки:
Строка которая заканчивается на BT. Вполне может оказаться, что в строке будет только BT
Строка, которая заканчивается на Tf. Она описывает шрифты использующиеся в блоке текста
Строка заканчивающаяся на TJ. В ней мы найдем непосредственно текст(почти).
Ну и закончится все ET
Разберем все подробнее на примере
/P > BDC BT
/F1 13.56 Tf
1 0 0 1 245.69 760.8 Tm
0 g
0 G
[-245-312-3455-36467-3-3] TJ
ET
BT и ET это ни что иное, как begin of text и end of text. Перед BT есть маркер, который собственно помогает выделить логические структуры в тексте(Абзацы и заголовки) В этой статье я не буду подробно на этом останавливаться. Пока можете каждый такой блок >, > итд считать началом параграфа или почитать про них в документации на странице 556 раздел Logical Structure. Если кому интересно будет – могу дополнить статью.
В строке шрифтов нас интересует /F1 и цифирки. /F1 – наименование шрифта, которое понадобится нам для декодирования текста (да, да наши мучения еще не кончились) и получения стилей текста
Перед TJ в [] расположился вожделенный текст. Сейчас нам может повезти и мы увидим текст. Чистый текст всегда находится в круглых скобках. Если же нам не везет, а так и будет, то мы найдем группы цифр в треугольных скобках. Каждые 4 цифры – один символ, шестнадцатеричное значение которого можно найти в таблице соответствия, а таблицу соответствия в объекте шрифта который мы находили ранее, заяц в утке, а утка в яйце… Упс меня понесло…
Найти таблицу кодов символов не сложно: у страницы, которую мы декодировали есть свойство /Resources, а в нем Пока все. Это был лишь общий обзор. Если будет интерес – расскажу подробней как извлекать изображения, каталог, таблицы, стили другие плюшки. Если будут вопросы, you are welcome. И да, прошу не тролить код сильно он не претендует на читстоту он лишь для того, чтоб в целом объяснить суть.
Продолжаем разбирать текстовые форматы на предмет получения текста. Итак, обещанный ранее PDF.
С portable document format'ом не всё так просто, как DOCX или ODT, что мы рассматривали в прошлый раз, но всё же это всё ещё изначально текстовый, а не бинарный формат. Вы удивлены? Тогда давайте посмотрим на то, что там внутри. Дальше действительно много текста.
Как вы могли заметить, перед нами вполне себе «текстовый» документ, с вкраплениями бинарных данных. Конечно, как книгу pdf в блокноте не почитаешь, но понимать, что написано и что в последствии будет отображено на экране, вполне возможно. Заранее отмечу, что целью этой статьи не является описание формата данных, поэтому буду рассказывать по существу: «Где искать текст?» Более подробную информацию по формату PDF вы найдёте по ссылкам в конце этого небольшого руководства.
Типы данных PDF
PDF поддерживает несколько базовых типов данных (если быть точно восемь), часть из которых нам понадобится для работы — это строки (strings), массивы (arrays), словари (distionaries), потоки (streams) и объекты (objects). Остановимся на каждом.
Как результат, на выходе мы получим две строки:
Из-за своей изначальной восьмибитовости в PDF есть несколько способов для вставки текстовых данных, например, в той же кодировке Unicode. Мы можем использовать вставку по восьмеричным кодам символа ( \053 ), с помощью отдельного двухбайтового hex'а ( ) или даже их последовательности ( ). Например, следующие строки эквивалентны:
В строках мы в будущем научимся искать текстовые данные, которые содержит в себе PDF-документ.
Массивы
Массивы в PDF заключаются в квадратные скобки и представляют собой просто последовательность группированных объектов. Например: [(Hello,)10(world!)] . Массивы подчас содержат текстовые строки.
Словари
Это обрамлённые в > пары ключ-значение. Словарь часто используется для наделения объекта, который его содержит, свойствами, что описаны в dictionary. Нам же эти данные помогут определить, как, например, расшифровать поток, узнать его длину или, наоборот, отбросить текущий объект, как неинтересный (если это изображение). Перед вами пример обычного PDF-словаря:
После чтения, мой код представит его в виде:
Потоки
Потоки представляют последовательность восьмибитных данных между ключевыми словами stream и endstream . Любые бинарные данные, будь-то сжатый текст, изображение или внедрённый шрифт, будут представлены в виде потока. Поток всегда находится внутри объекта (чуть ниже) и характеризуется, как минимум, своей длиной (опция /Length N в словаре) и очень часто методом сжатия (например, /Filter /FlateDecode ). PDF поддерживает достаточное количество форматов сжатия (в том числе и формат шифрования /CryptDecode ), нас же будут интересовать лишь три: наиболее часто используемый Flate (gzip-сжатие) и более редкие ASCII Hex (представление данных в виде шестнадцатеричной строки с конечным символом > ) и ASCII 85-based (сжатие, когда подряд идущие 4 символа исходного текста кодируются 5 символами от ! до y в ASCII таблице).
В stream'ах мы будем искать текст, который хотим получить из PDF-документа. Пример потока вы можете найти во второй половине изображения, что вначале данного топика: да-да, те крякозябрики — это оно и есть.
Объекты
Объекты — это наибольшая структура, с которой на предстоит работать. Объект может содержать внутри себя любой другой тип данных от обычного числа до потока, обрамляется ключевыми словами obj и endobj . Объект имеет свой ID внутри документа, по которому можно на него ссылаться. Нам в первую очередь интересны объекты с потоками внутри себя (не забываем об основной подзадаче), которые почти всегда содержат ещё и набор дополнительных опций в виде словаря. Вот обычный пример объекта внутри PDF-файла (с несжатым содержимым потока):
Что ж на этом вводная часть по внутреннему представлению данных закончилась, переходим к «лакомым» штукам — получение текста из потока, а также получения словарей внутренних преобразований символов (реализацию которого я не встречал доселе).
Где искать текст?
Найдём в данном документе какой-нибудь объект и начнём его разбирать. Я немного смухлюю и возьму объект, в котором заведомо есть текстовые данные, но это только для примера — скрипту всё равно с чем работать:
Давайте для начала разберёмся, что перед нами, используя полученные ранее знания о типах данных PDF. Перед нами объект со словарём свойств, которые говорят, что длина потока данных 681 байт ( /Length 681 ), что поток сжат ( /Filter ) в gzip ( /FlateDecode ). Уже достаточно информации, чтобы разжать поток данных — подойдёт gzuncompress :
- Если текст есть в потоке, то он содержится между «маркером» начала текста BT (beginning of text) и конца ET (end of text).
- PDF может отображать текст или не отображать, в зависимости наличия маркета Tj (отобразить текст) или маркера TJ (отобразить текст с учётом индивидуального символьного позиционирования). Данные маркеры стоят после строки текста или массива строк, как в данном случае ( [17101017]TJ ).
- PDF поддерживает индивидуальное позиционирование символов, как я написал выше, это значит, что мы можем задать произвольный и отдельный размер расстояния между каждой парой символов. Об этом подробнее позже
- ПАРУС кодируется, как 01 02 03 04 05
- Белеет — как 06 07 08 0707 09 .
Таблица преобразований
На предыдущем примере бы спасовало бы большинство функций получения текста из PDF, которые вы можете найти в свободном доступе в интернетах. Попробуем разобраться что к чему. Итак, нас интересуют ToUnicode CMaps, о которых рассказывается в подразделе о получении текста описания формата PDF от Adobe. Давайте поищем их в нашем файле. Я опять смухлюю и предложу читателю «заведомо правильный кусочек»:
bfchar
Преобразование, что находится между beginbfchar и endbfchar , самое простое. Оно ставит в соответствие первому коду другой. Например, в примере выше мы узнали, что 01 скрывает за собой код символа П . Но это лишь частный случай работы данного преобразования — есть возможность ставить в соответствие одному коду целую строку до 512 символов длины (т.е. до 128 символов в Unicode).
- — мы работает с диапазоном от 0000 до 005E, каждое значение из которого преобразуется в значения из промежутка 0020 и 007E. Заметили принцип? 0000 преобразуется в 0020, 0001 в 0021, 0002 в 0022 и так далее;
- [ ] — каждое значение из промежутка между 005F и 0061 (т.е. ещё 0060) заменяется на соответствующую последовательность из массива в квадратных скобках: 005F будет заменён на 0066 00 66 (т.е. на ff ), 0060 на fi , а 0061 на ffl .
Алгоритм и код
Используя полученные нами знания мы можем прочитать наш «злополучный» стих о Парусе. Что ж время представить самые интересные куски кода и ссылку на полный исходник:
Код с комментариями вы можете получить на GitHub'е.
Заключение
Что ж этот код не является венцом творения, он не распарсит все предложенные ему pdf-файлы. Есть документы, в которые, к примеру, внедрены русские шрифты, осуществляющие трансформацию из символов английского алфавита в отображение русских букв.
Этот код не работает с индивидуальным позиционированием символов. Задача посильная и не сложная, я возлагаю её решение на плечи читателя.
Этот код не идеален в плане чтения PDF-файла по его внутренним стандартам представления информации: он не ищет страницы, он не будет работать с версиями документа (PDF поддерживает историю изменений), возможно даже, что он не идеально прочитает информацию, которую сможет обработать.
Стоит заметить, что никто не отменял $content = shell_exec('/usr/local/bin/pdftotext '.$filename.' -'); . Но в данном случае стояла задача чтения PDF под любой платформой и на любой площадке.
Надеюсь вас заинтересовала эта статья, цель которой познакомить сообщество с устройством PDF, возможностью его чтения под PHP, а также найти отправные точки для получения данных в сложных случаях.
В зависимости от активности и интереса к проблеме, я либо продолжу рассказ о PDF (внутреннее устройство документа, позиционирование, шрифты, внутренние ссылки), либо вернусь к теме «Текст любой ценой» на примере RTF. Спасибо за внимание!

Порой бывает необходимо извлечь текст из PDF файла средствами PHP и далее я Вам покажу пример скрипта, который решаете данную проблему.
Устанавливаем необходимую библиотеку:
composer require smalot/pdfparser
// подключаем загрузчик
include 'vendor/autoload.php';
// Создаем объект для парсинга PDF
$parser = new \Smalot\PdfParser\Parser();
// парсим PDF файл
$pdf = $parser->parseFile('technic_report.pdf');
// выводим текст из файла
print $pdf -> getText();
Обратите внимание на то, что текст, который Вы получите из pdf файла не будет иметь исходного форматирования документа. Однако это не так уж и важно, чтобы извлечь из текста интересующие Вас данные.
Если в PDF файле несколько страниц, то можно пройтись по каждой странице по отдельности:
// ссылка из PDF
// Извлекаем все страницы из PDF файла
$pages = $pdf->getPages();
// проходимся по каждой странице и получаем текст
foreach ($pages as $page) echo $page->getText();
>
А здесь можно получить метаданные PDF файла:
// извлекаем метаданные из pdf файла
$details = $pdf -> getDetails();
// Проходимся по каждому значению.
foreach ($details as $property => $value) if (is_array($value)) $value = implode(', ', $value);
>
echo $property . ' => ' . $value . "\n";
>
Вот так просто можно, например, автоматизировать обработку большого количества PDF файлов в PHP, извлекая из них необходимые данные.

Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
Она выглядит вот так:
Комментарии ( 8 ):
А можно ли сделать так, чтобы методом post в php скрипт, который вы приводите в статье передавались и сразу же отображались в обозначеном месте?
Можно. $some = $_POST["some"]; Далее эту переменную можете размещать в PDF-файле.
а если pdf документ уже создан отдельно и содержит напечатанную таблицу, можно ли туда в нее вписать?
Читайте документацию по TCPDF.
У Вас опечатка. В Комментариях к коду написано ширина 40мм, а в коде 30
Созданные файлы не открываются FoxitReaderом. Выдаёт ошибку: Format Error: Not a PDF or corrupted. Все другие PDF файлы открываются нормально.
Доброго времени суток! Михаил, подскажите, пожалуйста. Сделал генерацию pdf страницы с помощью tcpdf, на денвере все нормально генерируется, заливаю на хостинг, не хочет, браузер пишет: сервер перенаправляет запрос на этот адрес таким образом, что он никогда не завершится. Заранее благодарю!
Комментарии ( 0 ):

В предыдущей статье я писал про то, как генерировать PDF-файл на PHP с использованием библиотеки PDFLib. Однако, данная библиотека в пакет Denwer не входит. Установить данную библиотеку под Windows и более-менее свежую версию PHP сложно. Так как компилировать через Visual Studio весьма сомнительное и неудобное решение. Вдобавок, в бесплатной версии PDFLib нет возможности редактировать PDF-файл. Поэтому в этой статье я расскажу, как генерировать PDF на PHP с использованием TCPDF.
Теперь привожу код, в котором происходит генерация PDF на PHP с использованием TCPDF:
require_once 'tcpdf/tcpdf.php'; // Подключаем библиотеку
/* Создаём объект TCPDF.
- Книжная ориентация
- Единица измерения - миллиметры
- Формат А4
- Использование unicode
- Кодировка - UTF-8
*/
$pdf = new TCPDF('P', 'mm', 'A4', true, 'UTF-8');
/* Установка отступов
- 20 слева
- 30 справа
- 20 сверху
*/
$pdf->SetMargins(20, 30, 20);
$pdf->AddPage(); // Добавляем страницу
$pdf->SetXY(20, 50); // Установка текущей точки (в мм)
$pdf->SetDrawColor(100, 100, 0); // Установка цвета (RGB)
$pdf->SetTextColor(200, 0, 0); // Установка цвета текста (RGB)
/* Выводим надпись.
- Ширина 30 мм
- Высота 10 мм
- Текст "Hello, World"
*/
$pdf->Cell(30, 10, 'Hello, World!');
$pdf->Output('test.pdf'); // Выводим в браузер
?>
В результате выполнения скрипта у нас откроется PDF-файл, в котором будет надпись "Hello World".
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
Она выглядит вот так:
Читайте также: