
Открытие файлов слишком много запросов
У меня есть ограничение на большое количество открытых файлов в MySQL.
Я установил open_files_limit на 150000 , но MySQL по-прежнему использует его почти 80% .
Также у меня низкий трафик и максимальное количество одновременных подключений около 30, и ни один запрос не имеет более 4 соединений.
Проверка конкретного запроса в Linux
В Linux вы можете использовать strace (см. Выше) и проверить, какие файлы открываются и как:
Тем временем с другого терминала я запускаю запрос и:
. это файлы, которые использовались в запросе (* не забудьте запустить запрос в MySQL с "холодным запуском", чтобы предотвратить кеширование), и я вижу, что самый высокий назначенный дескриптор файла был 39, поэтому ни разу там не было более 40 открытых файлов.
Эти же файлы можно проверить из / proc / $ PID / fd или из MySQL:
Но счетчик MySQL немного короче, он не учитывает дескрипторы сокетов, файлы журналов и временные файлы.

Устраняем проблемы, связанные с Windows и сторонним софтом
Помимо браузера, на работу сети могут влиять другие программные продукты (экраны, защищающие от «непонятных подключений»). И вирусы. Да и сама Windows может стать проблемой. Почти любой ее компонент. Поэтому надо бы проделать следующее:
- Повторно установитьNET.Framework. Желательно перед этим удалить предыдущую версию.
- Установить какой-нибудь приличный антивирус (а лучше два) и запустить глубокую проверку систему. Возможно, подключению и входу на ресурс мешает вредоносная программа.
- Если у вас уже установлен антивирус, то, наоборот, попробуйте его отключить. Иногда встроенные в них экраны проверки подключений блокируют работу браузера целиком или отдельных страниц. Лучше выдать браузеру больше прав на выполнение своих задач или установить антивирус, который более лояльно относится к установленному на компьютере софту.
- Еще надо поменять параметры брандмауэра. Его можно разыскать в панели управления Windows. Там надо добавить в список исключений ваш браузер. Тогда брандмауэр не будет мешать подключению к запрашиваемому сайту.
- Почистить Windows от программного мусора. Можно пройтись приложением CCleaner.
- Обновить драйверы для сетевых устройств.
- Обновить Windows или просканировать систему на наличие погрешностей в системных компонентах.
Исправляем ошибку 400 Bad Request на стороне клиента
Так как ошибка 400 в 99 случаев из 100 возникает на стороне клиента, начнем с соответствующих методов. Проверим все элементы, участвующие в передаче запроса со стороны клиента (браузера).
Загружаем файл подходящего размера
Если ошибка 400 Bad Request появляется при попытке загрузить на сайт какой-нибудь файл, то стоит попробовать загрузить файл поменьше. Иногда вебмастера ленятся грамотно настроить ресурс, и вместо понятного объяснения вроде «Загружаемые файлы не должны быть размером больше 2 мегабайт» люди получают Bad Request. Остается только гадать, какой там у них лимит.
Заключительные слова

429 слишком много запросов в Google Chrome:
429. Это ошибка.
Сожалеем, но вы недавно отправили нам слишком много запросов. Пожалуйста, повторите попытку позже. Это все, что мы знаем.
Если вы видите эту ошибку, это означает, что вы отправили слишком много запросов за заданный промежуток времени. В течение этого периода сервер не будет выполнять какие-либо запросы или вызовы, которые создаются сразу. Ваша учетная запись будет временно заблокирована устройством с целью уменьшения большого количества запросов к серверу, отправляемых за короткое время.
3 ответа
Файлы, открытые сервером, отображаются в файле performance_schema.
См. Таблицу performance_schema.file_instances.
Что касается отслеживания того, какой запрос открывает какой файл, это не работает из-за кеширования на самом сервере (кеш таблиц, кеш определения таблиц).
Это было бы возможно только путем корректировки исходного кода и добавления ведения журнала на этом уровне.
Альтернативный вариант: запустите тест по этому сценарию:
Вам нужно будет настроить автоматический тест, чтобы это стало возможным:
- Зарегистрируйте свои запросы;
- Создайте сценарий, который предварительно загружает вашу кучу обычным набором данных (иначе вы тестируете пустую память), сделайте снимок количества открытых таблиц;
- Выполнять каждый запрос и делать снимки открытых таблиц; (Оглядываясь назад) Я думаю, вы могли бы сделать это без перезапуска MySQL каждый раз, поэтому просто каждый запрос и записывайте результаты. Отладка - утомительная работа: не невозможная, просто действительно утомительная.
Лично я бы начал с другого:
- Установите плагин cacti и percona cacti
- Зарегистрируйте неделю нормальной нагрузки
- Затем найдите запросы с высокой нагрузкой (медленный журнал> 0,1 секунды, выполните сценарий, чтобы найти повторяющиеся запросы).
- Еще одна неделя мониторинга
- Затем выследите дополнительные запросы с большим количеством повторений: это часто неэффективный код, запускающий большое количество запросов, где можно было бы использовать меньше (например, получение ключей, а затем всех значений для каждого ключа на ключ (одно за другим: бывает много когда программисты используют ORM).
MySQL не должен открывать такое количество файлов, если вы не установили смехотворно большое значение для параметра table_cache (по умолчанию 64, максимум 512 КБ).
Вы можете уменьшить количество открытых файлов, введя команду FLUSH TABLES .
В противном случае соответствующее значение table_cache можно приблизительно оценить (в Linux), запустив strace -c для всех потоков MySQLd. Вы получите что-то вроде:
. и посмотрите, есть ли разумная разница во влиянии вызовов open () и close (); это вызовы, на которые влияет table_cache , и которые влияют на количество открытых файлов в любой момент.
Если влияние open() незначительно, то обязательно уменьшите table_cache . Это в основном необходимо на медленных IOSS, а их осталось немного.
Если вы работаете в Windows, вам придется попробовать использовать ProcMon от SysInternals или аналогичный инструмент.
Как только у вас будет table_cache до управляемых уровней, ваш запрос, который теперь открывает слишком много файлов, просто закроет и снова откроет многие из тех же файлов. Возможно, вы заметите влияние на производительность, которое, по всей вероятности, будет незначительным. Скорее всего, меньший размер кэша таблицы может действительно дать вам результаты быстрее , поскольку выборка элемента из современного быстрого кеша IOSS может быть быстрее, чем поиск его в действительно большом кэше.
Исправляем ошибки в коде и скриптах
Ничего из вышеперечисленного не помогло? Тогда осталось проверить свой код и работающие скрипты. Лучше провести дебаггинг вручную и не надеяться на помощь компьютера. Сделать копию приложения или сайта, потом пошагово проверить каждый отрезок кода в поисках ошибок.
В крайнем случае придется кричать «полундра» и звать на помощь техподдержку хостинга. Возможно, возникли сложности на их стороне. Тогда вообще ничего не надо будет делать. Просто ждать, пока все исправят за вас.
На этом все. Основные причины появления 400 Bad Request разобрали. Как ее лечить — тоже. Теперь дело за вами. Пользуйтесь полученной информацией, чтобы больше не пришлось мучиться в попытках зайти на нужный ресурс.
Для Internet Explorer
Шаг 1: Щелкните значок Настройки значок и выберите Настройки интернета из раскрывающегося меню.
Теперь найдите папку, в которой вы только что открыли Проводник для рассматриваемого сайта. Затем удалите файлы cookie. Затем проверьте, не исчезла ли проблема «слишком большой файл cookie».
Для Google Chrome
Шаг 1: Откройте Google Chrome и нажмите Настройки вариант.
Шаг 2: Перейдите к Конфиденциальность и безопасность часть и щелкните Настройки сайта вариант.
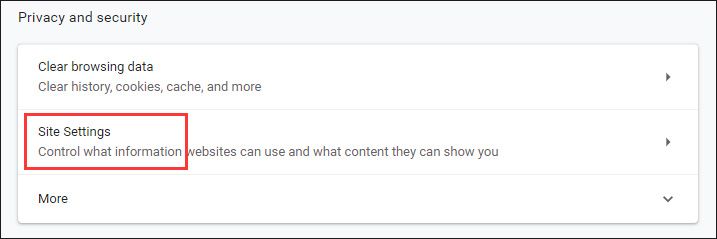
Шаг 3: Нажмите Файлы cookie и данные сайтов и нажмите Просмотреть все файлы cookie и данные сайтов . Затем щелкните значок удалять Все вариант.
Затем вы можете проверить, был ли исправлен «Заголовок запроса или файл cookie слишком большой».
Ищем проблему на стороне сервера
Если что-то происходит на стороне ресурса, то это редко заканчивается ошибкой 400. Но все-таки есть несколько сценариев, при которых клиента обвиняют в сбое зря, а настоящая вина лежит на сервере.
2 ответа
Самое простое решение - это прочитать файлы в память самостоятельно, а затем передать их запросам. Обратите внимание, что в документах скажем: «Если вы хотите, вы можете отправлять строки для получения в виде файлов». Итак, сделай это.
Другими словами, вместо того, чтобы строить диктовку вот так:
. построить это так:
Теперь у вас есть только один открытый файл, гарантировано.
Это может показаться расточительным, но на самом деле это не так - requests просто перейдет к read во всех данных из всех ваших файлов, если вы этого не сделаете. *
Но в то же время позвольте мне ответить на ваши реальные вопросы, а не просто сказать вам, что делать вместо этого.
Поскольку у меня нет дескриптора для закрытия этих открытых файлов, мы видим эту ошибку.
Конечно, знаешь. У вас есть dict, значениями которого являются эти открытые файлы.
Фактически, если бы у вас не был их дескриптор, эта проблема, вероятно, возникла бы гораздо реже, потому что сборщик мусора (обычно, но не обязательно надежно / достаточно надежно, чтобы на него рассчитывать) заботиться о вещах за вас. Тот факт, что этого никогда не происходит, означает, что вы должны иметь с ними дело.
Есть ли способ закрыть эти файлы кусками?
Конечно. Я не знаю, как у вас дела с чанками, но, вероятно, каждый чанк - это список ключей или чего-то еще, и вы передаете files = , верно?
Итак, после запроса сделайте это:
Или, если вы создаете dict для каждого чанка, вот так:
. просто сделай это:
Модуль запросов закрывает открытые файлы автоматически?
Нет. Это нужно делать вручную.
Во многих случаях использования у вас ничего не получится, потому что переменная files исчезает вскоре после запроса, и как только никто не имеет ссылки на dict, она скоро очищается (немедленно, с CPython и, если есть) это не циклы, просто «скоро», если один из них не соответствует действительности), что означает, что все файлы будут вскоре очищены, после чего деструктор закроет их для вас. Но вы не должны полагаться на это. Всегда закрывайте свои файлы явно.
И причина, по которой files.clear() работает, заключается в том, что он делает то же самое, что и отпуск files : он заставляет диктанта забыть все файлы, удаляя последнюю ссылку на каждый из них, что означает скоро их почистят и т.д.
Просто реализуйте класс-оболочку для ваших файлов:
Таким образом, каждый файл открывается для чтения и закрытия по одному, поскольку requests выполняет итерацию по dict.
Обратите внимание, что хотя этот ответ и ответ abarnert в основном делают одно и то же прямо сейчас, requests может в будущем не строить запрос полностью в памяти, а затем отправлять его, но отправлять каждый файл в потоке, сохраняя использование памяти низкий. В этот момент этот код будет более эффективным для памяти.
Причина ошибки 429
Ошибка 429 - ужасный опыт, но это не значит, что ограничение скорости - это плохо. Напротив, этот предел велик; он может защитить большинство используемых API от преднамеренного и случайного злоупотребления услугами. Вы должны знать, что ограничения скорости широко используемых API, включая Twitter и Instagram, строже, чем другие.
Эта часть покажет вам, как устранить ошибку 429 в браузере Google Chrome, очистив кеши и историю браузера.
- Дважды щелкните значок приложения на рабочем столе, чтобы открыть Google Chrome. (Вы также можете открыть его, дважды щелкнув исполняемый файл в папке установки или выбрав Google Chrome в меню «Пуск».)
- Найдите вариант с тремя точками в правом верхнем углу открытия Chrome; он используется для настройки и управления Google Chrome.
- выберите Настройки из раскрывающегося меню (это третий вариант снизу).
- Прокрутите вниз, чтобы найти Конфиденциальность и безопасность (Вы можете перейти туда напрямую, нажав Конфиденциальность и безопасность на левой боковой панели.)
- Щелкните по первому варианту: Очистить данные просмотра (очистить историю, файлы cookie, кеш и т. Д.) .
- Убедитесь, что Базовый вкладка выбрана вверху.
- Проверьте Файлы cookie и другие данные сайта и Кешированные изображения и файлы .
- Нажми на Очистить данные кнопку в правом нижнем углу и дождитесь завершения действия.

Если этот метод не помог, вы можете попробовать следующие шаги: прокрутите вниз в окне настроек -> нажмите на Продвинутый кнопку, чтобы увидеть раскрывающиеся параметры -> перейдите к Сброс и очистка раздел -> попробовать Восстановить исходные настройки по умолчанию или же Очистить компьютер характерная черта.

Как восстановить удаленную историю в Google Chrome - полное руководство
Есть 8 эффективных методов, рассказывающих вам, как самостоятельно восстановить удаленную историю в Google Chrome.
Я использую модуль запросов для размещения нескольких файлов на сервере, это работает нормально в большинстве случаев. Однако, когда много файлов загружено> 256, я получаю IOError: [Errno 24] Слишком много открытых файлов. Проблема возникает из-за того, что я строю словарь со многими файлами, которые открываются, как показано в коде ниже. Поскольку у меня нет дескриптора для закрытия этих открытых файлов, мы видим эту ошибку. Это приводит к следующим вопросам
Модуль запросов закрывает открытые файлы автоматически?
Обходной путь, который я использую сейчас, это files.clear () после загрузки 4
Из-за чего всплывает Bad Request?
Есть 4 повода для возникновения ошибки сервера 400 Bad Request при попытке зайти на сайт:


Для Microsoft Edge
Если вы пользователь Microsoft Edge, вы можете прочитать эту часть. Теперь шаги следующие:
Шаг 1: Щелкните три горизонтальные точки в правом верхнем углу.
Шаг 2: Теперь щелкните Конфиденциальность и безопасность таб. Перейти к Выберите, что очистить часть и щелкните выберите, что очистить вариант. Проверить Файлы cookie и сохраненные данные веб-сайтов вариант.
Шаг 3: Теперь нажмите Очистить . Затем перезапустите браузер и проверьте, устранена ли проблема.
Проверяем адрес сайта
Банальщина, но необходимая банальщина. Перед тем как бежать куда-то жаловаться и предпринимать более серьезные шаги, повнимательнее взгляните на ссылку в адресной строке. Может, где-то затесалась опечатка или вы случайно написали большую букву вместо маленькой. Некоторые части адреса чувствительны к регистру.
Для Firefox
Шаг 1: Откройте Firefox и щелкните значок Параметры . Затем щелкните значок Конфиденциальность вариант.
Шаг 2: Выбрать История и щелкните Удалить отдельные файлы cookie вариант. Теперь найдите веб-сайт, который вас беспокоит, и удалите связанные с ним файлы cookie.
Проверяем состояние базы данных
Некоторые сторонние расширения для того же WordPress получают полный доступ к ресурсу и имеют право вносить изменения даже в подключенную базу данных. Если после удаления свежих плагинов ошибка 400 никуда не исчезла и появляется у всех, кто пытается зайти на сайт, стоит проверить, в каком состоянии находится база данных. Нужно вручную проверить все записи на наличие подозрительных изменений, которые могли быть сделаны установленными расширениями.
Удаляем свежие обновления и плагины
Иногда ошибка 400 Bad Request появляется после обновления CMS или установки новых плагинов. Если у вас она появилась из-за этого, то наиболее логичное решение — откатиться до более ранней версии CMS и удалить все новые плагины.
Главное, перед этим сделать резервную копию данных. И перед установкой обновлений тоже стоило бы.
Чуть подробнее об ошибке 400
Как и другие коды, начинающиеся на четверку, 400 Bad Request говорит о том, что возникла проблема на стороне пользователя. Зачастую сервер отправляет ее, когда появившаяся неисправность не подходит больше ни под одну категорию ошибок.
Стоит запомнить — код 400 напрямую связан с клиентом (браузером, к примеру) и намекает на то, что отправленный запрос со стороны пользователя приводит к сбою еще до того, как его обработает сервер (вернее, так считает сам сервер).
Сбрасываем параметры браузера
Этот метод срабатывает, если сервер отказывается принимать запросы из-за «битых» куки или других данных. Дело в том, что сайт использует куки-файлы, чтобы хранить информацию о пользователе у него же в браузере. При входе конкретного человека на ресурс, он пытается распознать куки и сравнить информацию с той, что уже есть на сервере.
Иногда случается, что куки-файлы одного или нескольких пользователей вступают в конфликт. В таком случае надо открыть настройки браузера, а потом удалить весь кэш, куки и прочие связанные элементы.
В зависимости от браузера процесс удаления куки-файлов может немного отличаться. В Chrome это работает так:
Читайте также: