
Освобождение памяти pascal abc
Данная глава является заключительной. Поэтому прежде чем сделать обзор нам необходимо изучить ещё две оставшиеся темы – это «Динамическая память» и «Исключения». Возможно, на первых порах вы не будете пользоваться данными темами, однако если вы станете настоящими программистоми, то будете применять их постоянно. В любом случае, вы должны иметь представление об этих темах и уметь применять их на практике.
§30. Динамическая память.
Динамическая память, указатели.
Все переменные, которые мы до сих пор создавали, хранятся в том же участке памяти, который отводится под память программы. Если нам понадобиться переменная, требующая большой объём памяти, то её необходимо хранить уже отдельно от программы, т.к. под программу, как правило, отводится не так много места.
То, что было сказано в предыдущем абзаце, не совсем точно. Однако на данном этапе развития можно воспринимать ситуацию с местоположением переменных именно таким образом.
Память, не занятая программой и в которой можно хранить переменные, называется динамической. Для того, что бы создать переменную, хранящуюся в динамической памяти отдельно от самой программы, используется указатель. Указатель – это переменная, хранящая в себе адрес кусочка оперативной памяти и его размер. Размер кусочка этой памяти соответствует типу переменной хранящейся в данном кусочке. Другими словами указатель указывает на какую-либо переменную, хранящуюся в оперативной памяти. Отсюда и название «указатель».
Объявляется указатель так же как и обычная переменная в разделе объявления переменных или в теле программы следующим образом:
var pi: ^ integer ;
Как видно из кода отличие составляет только символ «^» перед типом. Так же стоит сказать, что перед именем указателя, как правило, но не обязательно, ставится префикс p (от слова pointer-указатель).
Так как указатель – переменная, хранящая в себе адрес кусочка памяти, то при обращении к ней мы получим как раз этот адрес. Однако просто после объявления указатель ещё не на что не указывает, и вместо адреса мы получим константу nil:
Константа nil означает, что указатель на данный момент пуст и ни на что не указывает. Так же если мы присвоим указателю эту константу, то мы его освободим, и он перестанет на что-либо указывать. Однако из-за ряда причин таким способом пользоваться не рекомендуется. Для освобождения указателя существует специальная процедура, о которой будет сказано позже.
Для того, что бы заполнить указатель, и он начал указывать на определённый кусок оперативной памяти, эту память нужно выделить специальной процедурой new. В качестве параметра ей нужно передать как раз нужный нам указатель. Т.е. данная процедура выделяет кусочек памяти и присваивает адрес этого кусочка указателю, который передан в качестве параметра:
В последней строчке примера находится не понятная строка. Здесь стоит сделать небольшое отступление. Каждая ячейка любой компьютерной памяти имеет свой порядковый номер. Именно этот номер и является её адресом. Если в компьютере 4 Гб оперативной памяти, то соответственно последняя ячейка будет иметь адрес, который можно обозначить десятизначным десятеричным числом. Т.е. если выражать адреса десятеричными числами, то придётся оперировать со слишком большим количеством цифр. Понятно, что это неудобно. Поэтому, как правило, все адреса выражаются шестнадцатеричными числами. Они несколько короче десятеричных. О том, что такое десятеричное или шестнадцатеричное число, надеюсь, вы знаете. Так вот в последней строке примера как раз находится шестнадцатеричное число, которое означает адрес выделенного кусочка памяти. О том, что это именно шестнадцатеричное число, а не какое-либо другое, говорит символ «$», стоящий перед числом. На том, что обозначают буквы в таких числах, здесь останавливаться не будем.
Двигаемся дальше. Для того, что бы освободить указатель, и соответственно очистить оперативную память, используется процедура dispose:
Мы научились выделять и освобождать кусочки оперативной памяти, теперь осталось научиться записывать туда данные и считывать их оттуда. Для этого используется так называемая операция разыменования. В коде программы для разыменования указателя необходимо после его имени поставить символ «^»:
Как видно работа с разыменованным указателем аналогична работе с обычной переменной.
Операция разименования к такому указателю не применима.
Значение одного указателя можно присвоить другому. Так же указатели можно сравнивать друг с другом на равенство (=) или (<>), для того, что бы определить указывают ли они на один объект. Далее пример:
if p1=p2 then writeln( 'Указатели указывают на одну и ту же переменную' );
Указатели указывают на одну и ту же переменную
Теперь стоит сказать про операцию @, которая возвращает адрес объекта. Если поставить символ «@» пред именем переменной, то мы получим не значение этой переменной, а адрес кусочка памяти, в котором находится эта переменная. Этот адрес можно присвоить указателю и работать с переменной через указатель. Делается это следующим образом:
Работать с переменной через указатель удобно, например, в случае, если подпрограмма в результате своей работы должна изменить значения напрямую одной или нескольких локальных переменных, увидеть которые напрямую подпрограмма не может. В таком случае удобно в качестве параметров передать подпрограмме адреса этих переменных. Пример:
procedure P(p1,p2:^ integer );
p1^:=Random( 1 , 100 );
p2^:=Random( 1 , 100 );
var i1,i2: integer ;
writeln( 'i1=' ,i1, ' i2=' ,i2);
procedure P( var ii1,ii2: integer );
ii1:=Random( 1 , 100 );
ii2:=Random( 1 , 100 );
var i1,i2: integer ;
writeln( 'i1=' ,i1, ' i2=' ,i2);
С таким подходом вы уже хорошо знакомы. И в своих программах будете поступать именно так. Тем не менее мне хотелось что б вы знали и устаревший принцип, потому что в дальнейшем вам возможно придётся работать с какой-нибудь старой версией языка программирования.
В принципе про указатели сказать больше нечего. Ещё необходимо сказать несколько слов о динамической памяти. Само название говорит само за себя. Слово динамическая – значит меняющаяся во времени. Объём памяти, который выделен под программу, не меняется во время работы программы. Объём выделенной памяти под переменные, на которые указывают указатели может меняться во время работы программы, соответственно такую память называют динамической.
Теперь, когда мы рассмотрели данную тему, хочется поговорить об объектах. Для создания объекта необходимо вначале объявить переменную определённого класса, а затем вызвать конструктор этого класса. Так обстоит дело потому, что объекты хранятся не в памяти программы, а в динамической памяти. В памяти программы хранится переменная типа данного класса, а сам объект созданный конструктором, хранится именно в динамической памяти. По своей сути переменная типа класса является указателем на объект. Думаю, после этих слов вам стало ясно, почему при создании объекта необходимо помимо объявления переменной ещё создать объект с помощью конструктора.
Однако, если вам будет очень необходимо освободить память, то можете присвоить переменной указателю на объект константу nil. В таком случае память, занятая под объект освободиться, но объект при этом уничтожен не будет. Указатель, в свою очередь, не перестанет указывать на эту память, соответственно и на объект. И пока на место этой памяти не запишется что-либо другое, можно будет пользоваться объектом. Поэтому может создаться иллюзия, что после присвоения указателю на объект константы nil, ничего не произошло. Однако если вы будете продолжать пользоваться объектом через этот же указатель, и если на его место будет записано, что-либо новое, то возникнет ошибка.
Динамическим список называется потому, что его размер может меняться в течение работы программы, и потому, что заранее не известен даже его максимальный размер. В списке могут быть данные какого-либо одного и того же типа. Например, создадим список целых чисел типа integer.
Предлагаю, прежде чем читать дальше, подумать самостоятельно над вопросом: как можно организовать динамический список целых чисел? Сделаю подсказку. Динамический список можно организовать с помощью использования указателей. Если у вас появятся какие-либо идеи, то попробуйте их реализовать, прежде чем читать дальше. Думаю, в таком случае материал уложится лучше, и вам будет интереснее.
Итак, по какому принципу можно организовать динамический список? Принцип очень прост: каждый элемент списка должен иметь ссылку на следующий элемент списка. Т.е. помимо самого числа, элемент списка должен содержать адрес нахождения следующего элемента. Схематически этот принцип можно представить следующим образом:
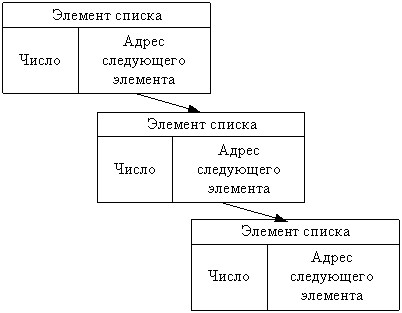
Теперь осталось только реализовать этот принцип в коде программы. Так как всё современное программирование не безосновательно построено на принципах ООП, то и список предлагаю оформить в виде класса TSpisok. Это даст возможность без особого труда создавать сколь угодно много объектов-списков, а так же можно будет использовать методы этого класса для работы с ними.
Далее представлено описание получившегося класса TSpisok и код программы, проверяющей работу этого класса:
Процедура Dispose в Паскале выполняет освобождение памяти. Синтаксис:
Освобождение памяти в Паскале (как и в большинстве других языков) требуется после того, как динамически выделенная память становится больше не нужна.
После работы с памятью ее надо освободить, иначе после завершения программы в памяти останется «мусор». Кроме того, хотя операционная система следит за тем, чтобы освобождать память после завершения программ, делает она это, прямо сказать, не всегда хорошо (речь о Windows, про другие системы не знаю).
Поэтому могут возникать такие неприятности, как утечка памяти. Что в худшем случае может привести к полному зависанию компьютера.
Поэтому любой порядочный программист должен убирать за собой, то есть после завершения программы освобождать память, которая была взята вашей программой у операционной системы.
Первая форма процедуры Dispose освобождает память, выделенную с помощью вызова процедуры New. Указатель Р должен быть типизированным. Освобожденная память возвращается в кучу.
Вторая форма процедуры Dispose принимает в качестве первого параметра указатель на тип объекта, а в качестве второго параметра - имя деструктора этого объекта. Деструктор будет вызван, и память, выделенная для объекта, будет освобождена.
Если указатель не связан с каким-либо местом в куче (например, является пустым), то при вызове процедуры Dispose возникнет ошибка времени выполнения.
Рассмотрим только пример использования первого варианта:
Где Указатель – переменная, которая ранее использовалась с процедурой New для выделения памяти. Соответственно, процедура Dispose освобождает блок памяти, выделенный ранее процедурой New.
Здесь, кроме освобождения памяти, мы ещё указателю присваиваем нулевое значение (то есть уничтожаем его). Это не обязательно, однако лучше это делать, иначе может возникнуть ошибка во время выполнения программы (в Паскале я такого не встречал, но в С++ бывало).
ПРИМЕЧАНИЕ
Если вы смутно представляете, что такое динамическая память и указатели, а такие слова как “куча” вызывают у вас недоумение, то советую ознакомиться с книгой “Куда указывают указатели”.
Обычно в языке Паскаль используются статические массивы вида:
var mas: array [1..10] of integer;
Границы статического массива изменить в ходе программы нельзя, так как они задаются в разделе объявлений «раз и навсегда».
Основным недостатком такого массива является то, что в случае, когда заранее не известно количество элементов массива, то приходится выделять память максимального размера, что называется «на всякий случай».
Рассмотрим работу с динамическим массивом.
Объявляется динамический массив в теле программы:
begin . var a: array of integer;
Или объявление с инициализацией:

А выделение памяти и размер такого массива задается уже по ходу программы:
var a: array of integer; var n:=readInteger; a:=new integer[n];
var a: array of integer; a:=new integer[readInteger];
var a: array of integer; var n:=readInteger; SetLength(a,n); // устанавливаем размер массива а
Ссылочная объектная модель: память выделяется служебным словом NEW
var a := new integer[5];

Организация памяти для массива a
Очистка динамического массива
Если в программе случайно создается повторно один и тот же массив:
var a: array of integer; a:=new integer[4]; . a:=new integer[5];
Но можно очистить память и принудительно:
В процессе очистки выполнение программы и всех процессов приостанавливается. По этой причине сборщик мусора в системах реального времени не используется.
Инициализация, присваивание и вывод
Возможна инициализация динамического массива при описании:
var a: array of integer := (1,2,3);
Новые способы заполнения массива (заполнители):
var a:=Arr(1,2,3);// по правой части - integer
var a:=ArrFill(5,2); // 2 2 2 2 2
Ввод с клавиатуры:
var a:=ReadArrInteger(5); var a:=ReadArrReal(5);
Заполнение случайными числами:
var a:=new integer[10]; a:=arrRandomInteger(10);
Или с разделителем между элементами:
Переприсваивание:
var a: array of integer := (1,2,3); var b:=a; // [1,2,3]

Но!
Если теперь переприсвоить значение элементов массива b , то изменится и массив a :
var a: array of integer := (1,2,3); var b:=a; b[2]:=1; print(a); //[1,2,1]
Для того, чтобы избежать данной ситуации, необходимо создать массив b , как копию массива a :
var a: array of integer := (1,2,3); var b:=Copy(a); b[2]:=1; print(a); //[1,2,3]
Примеры работы с динамическими массивами
Выполнение:
Выполним сначала БЕЗ использования обобщенной функции:
function IndexOf(a:array of integer;x:integer):integer; begin result:=-1; for var i:=0 to High(a) do if a[i]=x then begin result:=i; break end end; begin var a:=Arr(1,2,3,4,5); print(IndexOf(a,5)) end.
А теперь, выполним с использованием обобщенной функции:
function IndexOf(a:array of T;x:T):integer; begin . end; begin var a:=Arr(1,2,3,4,5); print(IndexOf(a,5)) end.
При вызове обобщенной функции компиляция будет в два этапа:
- Автовыведение типа Т, сравнение с реальными цифрами, и т.к. числа целые, то Т определится как integer.
- Берется тело функции и заменяется Т на integer (инстанцирование функции с конкретным типом)
Задачи на срезы
Пример: Дан массив A размера N и целое число K ( 1 ). Вывести его элементы с порядковыми номерами, кратными K :
Условный оператор не использовать.
Выполнение:
var n:=ReadInteger; var a:=ReadArrReal(n); var k:=ReadInteger; a[k-1 : : k].Print;
Задание srez2: Дан массив A размера N ( N - четное число). Вывести его элементы с четными номерами в порядке возрастания номеров:
Условный оператор не использовать.
Задание srez3: Дан массив A размера N ( N - нечетное число). Вывести его элементы с нечетными номерами в порядке убывания номеров:
Условный оператор не использовать.
Пример: Дан массив A размера N . Вывести сначала его элементы с четными номерами (в порядке возрастания номеров), а затем - элементы с нечетными номерами (также в порядке возрастания номеров):
Условный оператор не использовать
Выполнение:
var n:=ReadInteger; var a:=ReadArrReal(n); var srez:=a[1::2]+a[::2]; Print(srez);
Задание srez4: Дан массив A размера N . Вывести сначала его элементы с нечетными номерами (в порядке возрастания номеров), а затем - элементы с четными номерами (в порядке убывания номеров):
Условный оператор не использовать
Пример: Дан массив размера N и целые числа K и L ( 1 ). Найти среднее арифметическое элементов массива с номерами от K до L включительно
Выполнение:
var n:=ReadInteger; var a:=ReadArrReal(n); var k:=ReadInteger; var l:=ReadInteger; var srez:=a[k-1:l].Average; print(srez);
Задание srez5: Дан массив размера N и целые числа K и L ( 1 ). Найти сумму элементов массива кроме элементов с номерами от K до L включительно
Пример: Дан массив А размера N . Найти минимальный элемент из его элементов с четными номерами: а2, а4, а6. .
Выполнение:
var n:=ReadInteger; var a:=ReadArrReal(n); print(a[1::2].min);
Задание srez6: Дан массив. Поменять в нем первую половину со второй (считать, что длина массива - четное число). Порядок элементов в половинах не менять.
Например:
var n:=readinteger; var a:=readArrreal(n); var srez:=a[n-1:(n-1) div 2-(n mod 2):-1]+a[:n div 2]; srez.println
Двусвязные списки (двунаправленные)
Двусвязный список позволяет двигаться в обоих направлениях.
При работе с двусвязными списками создаются два указателя.
Стек — динамическая структура данных, в которой добавление и удаление элементов доступно только с одного конца (с верхнего (последнего) элемента).
Существуют такие сокращения:

Последовательные этапы засылки в стек чисел 1, 2, 3
Над стеком выполняются следующие операции:
- добавление в стек нового элемента;
- определение пуст ли стек;
- доступ к последнему включенному элементу, вершине стека;
- исключение из стека последнего включенного элемента.
Создание структуры узла:
Добавление элемента в стек:
procedure Push( var Head: PNode; x: char); var NewNode: PNode; begin New(NewNode); < выделение памяти >NewNode^.data := x; < запись символа >NewNode^.next := Head; < сделать первым узлом >Head := NewNode; end;
Забор элемента с вершины:
function Pop ( var Head: PNode ): char; var q: PNode; begin if Head = nil then begin < если стек пустой >Result := char(255); < неиспользуемый символ, т.е. ошибка >Exit; end; Result := Head^.data; < берем верхний символ >q := Head; < запоминаем вершину >Head := Head^.next; < удаляем вершину >Dispose(q); < удаление из памяти >end;
Проверка, пустой ли стек:
function isEmptyStack ( S: Stack ): Boolean; begin Result := (S = nil); end;
Объявления в основной программе:
var S: PNode; . S := nil;
Рассмотрим подробную работу со стеком на примере:

Пример: вводится символьная строка, в которой записаны теги в угловых скобках (<>). Определить, верно ли расставлены скобки (не обращая внимания на остальные символы).
Алгоритм выполнения задания:
- изначально стек пустой;
- в цикле просматриваем каждый символ строки;
- если текущий символ – открывающая угловая скобка, то вставляем ее на вершину стека;
- если текущий символ – закрывающая угловая скобка, то проверяем верхний элемент стека: там должна находиться открывающая угловая скобка (иначе — ошибка);
- в конце стек должен стать пустым, иначе — ошибка.
Создаем структуру стека:
const MAXSIZE = 50; type Stack = record < стек рассчитан на 50 символов >tags: array[1..MAXSIZE] of char; size: integer; < число элементов >end;
Процедура добавления элемента в стек:
procedure Push( var S: Stack; x: char); begin if S.size = MAXSIZE then Exit; // выход, если произошло переполнение стека S.size := S.size + 1; S.tags[S.size] := x; // добавляем элемент end;
Функция взятия элемента с вершины:
function Pop ( var S:Stack ): char; begin if S.size = 0 then begin Result := char(255); // 255 - пустой символ, ошибка - стек пуст Exit; end; Result := S.tags[S.size]; S.size := S.size - 1; end;
Создаем функцию для проверки, пустой ли стек:
function isEmptyStack ( S: Stack ): Boolean; begin Result := (S.size = 0); end;
var expr: string; br1, br2: char; < угловые скобки >i, k: integer; upper: char; < верхний символ, снятый со стека >error: Boolean; < признак ошибки >S: Stack; begin br1 := ''; S.size := 0; error := False; writeln('Введите html-текст'); readln(expr); . < здесь вставляется цикл с обработкой строки >if not error and isEmptyStack(S) then writeln('Текст верный.') else writeln('Текст составлен неверно.') end.
Обработка строки в цикле:
for i:=1 to length(expr) < проходимся по всем символам строки expr >do begin if expr[i] = br1 then begin < открывающая скобка < >Push(S, expr[i]); < втолкнуть в стек >break; end; if expr[i] = br2 then begin < закрывающая скобка < >upper := Pop(S); < снять символ со стека >error := upper <> br1; < ошибка: стек пуст или не та скобка >break; end; if error then break; // была ошибка, значит, прерываем цикл end;
Работа с элементами массива
for var i:=0 to High(a) do print(a[i]);;
foreach var x in a do print(x);
High(массив) — возвращает верхнюю границу динамического массива
Удаление и вставка элементов массива. Списки
Для расширения массива путем вставки какого-либо элемента, необходимо предусмотреть место в памяти. По этой причине для данных случаев проще использовать списки:
Списки — List — это тоже динамический массив, который может «расширяться» и «сужаться» по ходу программы (вставка и удаление элементов).
…
Очереди
Очередь — динамическая структура данных, у которой в каждый момент времени доступны только два элемента: первый и последний. Добавление элементов возможно только с одного конца (конца очереди), а удаление элементов – только с другого конца (начала очереди).
Существует сокращение для очереди: FIFO = First In – First Out, с английского — «Кто первым вошел, тот первым вышел».
Для очереди доступны следующие операции:
- добавить элемент в конец очереди (PushTail);
- удалить элемент с начала очереди (Pop).

Работа с очередью обычным массивом:
Это достаточно простой способ, который подразумевает два неблагоприятных момента: заблаговременное выделение массива, сдвиг элементов при удалении из очереди.
Работа с очередью с помощью кольцевого массива:


Если в очереди 1 элемент:

Если очередь пуста:

Если очередь заполнена:

Определение размера массива (при пустой и заполненной очереди):
Создание очереди посредством списка
Объявление узла:
type PNode = ^Node; Node = record data: integer; next: PNode; end; type Queue = record head, tail: PNode; end;

Добавляем новый элемент:
procedure PushTail( var Q: Queue; x: integer ); var NewNode: PNode; begin New(NewNode); NewNode^.data := x; NewNode^.next := nil; if Q.tail <> nil then Q.tail^.next := NewNode; Q.tail := NewNode; if Q.head = nil then Q.head := Q.tail; end;

Выбираем элемент из списка:
function Pop ( var S: Queue ): integer; var top: PNode; begin if Q.head = nil then begin Result := MaxInt; Exit; end; top := Q.head; Result := top^.data; Q.head := top^.next; if Q.head = nil then Q.tail := nil; Dispose(top); end;
Дек — англ. double ended queue, т.е. очередь с двумя концами – это динамическая структура данных, добавлять и удалять элементы в которой можно с обоих концов.
Решение задач
Двоичные деревья

В двоичном (бинарном) дереве каждый узел имеет не более двух дочерних узлов (сыновей).
Объявление:
type PNode = ^Node; < указатель на узел >Node = record data: integer; < данные >left, right: PNode; end;

Поиск по дереву:
При поиске в дереве используется понятие ключ. Ключ — это характеристика узла, по которой осуществляется поиск.
В левую сторону отходят узлы с меньшими ключами, а в правую — с большими.
- если дерево пустое, значит, ключ не найден;
- если ключ узла равен k, то остановка;
- если ключ узла меньше k, то искать k в левом поддереве;
- если ключ узла больше k, то искать k в правом поддереве.
Сравним поиск в массиве c n элементами с поиском в бинарном дереве:
![]()
Поиск в массиве: каждое сравнение — отбрасываем 1 элемент.
Число сравнений – N.

При каждом сравнении отбрасывается половина оставшихся элементов.
Число сравнений ~ log2N
Поиск в бинарном дереве на Паскале:
Создадим функцию для поиска. На вход функции из главной программы подаются два параметра: tree — адрес корня дерева и x — искомое число. Функция возвращает адрес узла с искомым значением или nil, если ничего не найдено.
function SearchInTree(Tree: PNode; x: integer): PNode; begin if Tree = nil then begin Result := nil; Exit; end; if x = Tree^.data then Result := Tree else if x < Tree^.data then Result := SearchInTree(Tree^.left, x) else Result := SearchInTree(Tree^.right, x); end;
Создание дерева поиска:

Для создания дерева воспользуемся процедурой с двумя параметрами: tree — адрес корня дерева, x — добавляемый элемент.
procedure AddToTree( var Tree: PNode; x: integer ); begin if Tree = nil then begin New(Tree); Tree^.data := x; Tree^.left := nil; Tree^.right := nil; Exit; end; if x < Tree^.data then AddToTree(Tree^.left, x) else AddToTree(Tree^.right, x); end;
Обход дерева:
Данное действие необходимо для перечисления всех узлов в определенном порядке.
Рассмотрим варианты обхода:

Создадим процедуру для обхода ЛКП дерева. Процедура имеет один параметр — tree — адрес корня.
procedure LKPObhod(Tree: PNode); begin if Tree = nil then Exit; LKPObhod(Tree^.left); write(' ', Tree^.data); LKPObhod(Tree^.right); end;
Сдвиги

Пример: дан массив, надо сдвинуть его элементы:
Стандартное выполнение:
var a:=Arr(1,2,3,4,5,6); var x:=a[0]; for var i:=0 to 4 do a[i]:=a[i+1]; a[5]:=x; print(a)

Если сдвиг вправо:
- либо задействовать еще один массив (𝜭 (n-k) — по времени)
- либо много раз запускать один и тот же алгоритм (𝜭 (1) — по памяти)
Деревья
Дерево – это структура данных, которая состоит из узлов и соединяющих их направленных ребер или дуг; в каждый узел за исключением корневого ведет только одна дуга.
- Корнем называется главный или начальный узел дерева.
- Листом называется узел, из которого не выходят дуги.
1 — предок для всех других узлов в дереве
6 — потомок для узлов 5, 3 и 1
3 — родитель узлов 4 и 5
5 — сын узла 3
5 — брат узла 4
Срезы
- Срезы доступны только на чтение, присваивать им значения нельзя.
- Тип среза такой же, как у массива.
- Срезы работают с массивами, строками и со списками.
var a:=Arr(1,2,3,4,5,6); print(a[1:5]) // [2,3,4,5]
a[1:5] — 1-й элемент включая, 5-й не включая
println(a[:5]); // [1,2,3,4,5] - с начала до 5-го не включая println(a[1:]); // [2,3,4,5,6] - до конца println(a[::2]); // [1,3,5] - третий параметр - это шаг
a[::-1] — получим 6 5 4 3 2 1

Т.о. выполнение при помощи срезов выглядит так:
Перестановка:
var a:=Arr(1,2,3,4,5,6); var k:=a.Length-1; // 6 - 1 a:=a[k:]+a[:k]; print(a) // [6,1,2,3,4,5]
Т.е. создан еще массив уже со сдвигом.
Время работы алгоритма n+n , 𝜭 (n)
Методы для работы с массивами
var a:=Arr(1,2,3,4,5); reverse(a); // [5,4,3,2,1]
var a:=Arr(2,3,1,4,5); //[1,2,3,4,5] sort(a);
Следующие методы не меняют сам массив:
a.Min
a.Max
a.Sum
a.Average — среднее арифметическое
Использование методов
Пример: Дан случайный массив. Найти сумму элементов между первым минимальным и последним максимальным. Сделайте 2 версии - с использованием методов и без их использования. Выдайте время работы каждой версии (для достаточно больших массивов) - можно использовать System.DateTime.Now
Выполнение:
Задание: Даны 2 упорядоченных массива. Создайте третий - их объединение с сохранением упорядоченности (сортировка - метод sort ). Как и для предыдущей задачи, сделайте хотя бы 2 варианта работы и сравните их.
Фрагмент кода:
procedure MySort(c: array of integer); begin // сортировка методом Пузырька for . for . . end; begin var a:=arr(1,3,5,6,12); var b:=arr(2,6,8,12,16); var c:=a+b; //использование методов var t:=System.DateTime.Now; . . var t1:=System.DateTime.Now; println('Время выполнения с методом: ',t1-t); t:=System.DateTime.Now; //без использования методов . . . end.


Таким образом, указатель может находиться в одном из трех состояний:
- пока не инициализирован;
- содержит адрес размещения;
- содержит значение константы NIL; такой указатель называется пустым, то есть не указывает ни на какую переменную.

var n, k: integer; pI: ^integer; begin n := 4; pI := @n; writeln('Адрес n =' , pI); writeln('n = ', pI^); k := 4*(7 - pI^); // k = 4*(7 - 4) = 12 pI^ := 4*(k - n); // n = 4*(12 – 4) = 32 end.

Другой вариант присваивания значений — использование служебного слова NEW:
var pI: ^integer; begin new(pI); pI^ := 4; writeln('Адрес =' , pI); writeln('Значение = ', pI^); end.
Type rec = Record Name : string[30]; Surname: string[30]; end; var P: ^rec; begin new(P); P^.Name:='Иван'; write(P^.Name); // Иван end.
Задание 1: Описать целочисленную переменную i. Описать указатель на целочисленную переменную i_ptr. Инициализировать i значением 2. Присвоить i_ptr значение i. Вывести значение, находящееся по адресу i_ptr.
Очередь в Паскале (использование кольцевого массива)

Создание структуры:
type Queue = record data: array[1..MAXSIZE] of integer; head, tail: integer; end;

Как добавить в очередь:
procedure PushTail( var Q: Queue; x: integer); begin if Q.head = (Q.tail+1) mod MAXSIZE + 1 then Exit; < очередь уже полна >Q.tail := Q.tail mod MAXSIZE + 1; Q.data[Q.tail] := x; end;

Как выбрать из очереди:
function Pop ( var S: Queue ): integer; begin if Q.head = Q.tail mod MAXSIZE + 1 then begin Result := MaxInt; Exit; end; Result := Q.data[Q.head]; Q.head := Q.head mod MAXSIZE + 1; end;
Списки
- Список состоит из конечного множества динамических элементов, размещающихся в разных областях памяти. Благодаря указателям элементы списка объединены в логически упорядоченную последовательность.
Каждый элемент списка организован следующим образом:
type ukazatel = ^elem_spiska; elem_spiska = record znach:integer; next: ukazatel; end; .
Рассмотрим потребность использования динамических структур — списков на примере:
Пример: В файле расположен текст. Необходимо в другой файл записать все слова из текста в алфавитном порядке и количество повторений для каждого слова (в столбик).
Так как количество слов заранее неизвестно, и определяется оно только в конце программы, то использование статических и динамических массивов невозможно. Необходимо использовать список.
Алгоритм выполнения программы:
- создать список;
- если слова в файле закончились, то остановка;
- считать слово и искать его в списке;
- если слово найдено, то увеличить счетчик повторов слов, иначе добавить слово в список;
- перейти к шагу 2.
- Список состоит из начального узла — головы — и связанного с ним списка.
- Каждый элемент списка содержит информационную и ссылочную части. Т.е. каждый элемент имеет информационное поле (поля) — полезная информация — и ссылку (ссылки), то есть адрес на другой элемент списка.
- Односвязный (линейный) список: структура, каждый элемент которой «знает» адрес только следующего за ним элемента.



Для доступа к списку достаточно необходимо знать адрес его головного элемента:
var Head: PNode; . Head := nil;

Для решения нашей задачи запрограммируем функцию для создания узла. На вход функции подается новое слово, возвращает функция адрес нового узла, созданного в памяти.
function CreateNode(NewWord: string): PNode; var NewNode: PNode; begin New(NewNode); NewNode^.word := NewWord; NewNode^.count := 1; NewNode^.next := nil; Result := NewNode; end;
Добавить узел можно:
- в начало списка;
- в конец списка;
- после заданного узла;
- до заданного узла.
Чтобы добавить узел в начало списка:
-
Установить ссылку нового узла на голову списка:


Выполним добавление узла списка на Паскале в виде процедуры:
procedure AddFirst ( var Head: PNode; NewNode: PNode ); begin NewNode^.next := Head; Head := NewNode; end;
Чтобы добавить узел после заданного:
-
Установить ссылку нового узла на узел, следующий за конкретным (p):


Для добавления узла в конец списка или перед заданным узлом необходимо уметь перемещаться по списку.
- устанавливаем дополнительный указатель pp на голову списка;
- в случае когда дошли до конца списка, т.е.если указатель pp равен значению nil, то делаем остановку;
- производим необходимые действия над узлом с адресом pp;
- делаем переход к следующему узлу — pp^.next.

var pp: PNode; . pp := Head; // начинаем с головы while pp <> nil do begin // цикл пока не достигнут конец . // выполняем действия с pp pp := pp^.next; // переходим к следующему узлу end;
Чтобы добавить узел в конец списка:
- определить последний узел pp, для которого pp^.next равен nil;
- использовать процедуру AddAfter для добавления узла после узла с адресом pp.
Если список пуст, то алгоритм выполнения изменяется:
procedure AddLast ( var Head: PNode; NewNode: PNode ); var pp: PNode; begin if Head = nil then AddFirst ( Head, NewNode ) // добавляем в пустой список else begin pp := Head; while pp^.next <> nil do // поиск последнего узла pp := pp^.next; AddAfter ( pp, NewNode ); // после узла pp добавляем узел end; end;
Чтобы добавить узел перед заданным:
Для такого случая необходимо знать адрес предыдущего узла, при этом проход назад невозможен.
Поэтому необходимо пройти с начала списка и найти предыдущий узел pp.
procedure AddBefore(var Head: PNode; p, NewNode: PNode); var pp: PNode; begin pp := Head; if p = Head then AddFirst ( Head, NewNode ) // добавление в начало списка else begin while (pp <> nil) and (pp^.next <> p) do // поиск узла, за которым следует узел p pp := pp^.next; if pp <> nil then AddAfter ( pp, NewNode ); // добавляем после узла pp end; end;
Пример: Определить, имеется ли в списке заданное слово либо установить, что заданное слово в списке отсутствует.
Создадим для поиска функцию FindWord, которая принимает слово в качестве параметра, а возвращает адрес узла, который содержит искомое слово либо значение nil, если слово не найдено.
function Find(Head: PNode; NewWord: string): PNode; var pp: PNode; begin pp := Head; // пока не конец списка и слово в просматриваемом узле не равно искомому while (pp <> nil) and (NewWord <> pp^.word) do pp := pp^.next; Result := pp; end;
Вставка слова в определенное место списка по алфавиту
Алгоритм выполнения:
Создадим функция для поиска «подходящего» места MakePlace.
На вход функции подается вставляемое слово, возвращает же функция адрес узла, перед которым необходимо добавить слово; возвращается nil, если слово должно быть вставлено в конец списка.
function FindPlace(Head: PNode; NewWord: string): PNode; var pp: PNode; begin pp := Head; while (pp <> nil) and (NewWord > pp^.word) do pp := pp^.next; Result := pp; // слово NewWord в алфавитном порядке находится перед pp^.word end;
Для удаления конкретного узла списка необходимо знать адрес предыдущего узла pp:

- создание нового узла с заполнением необходимых полей: функция CreateNode();
- поиск узла, перед которым добавляем слово: функция MakePlace();
- добавление узла: функция AddBefore().
Задание списки 1:
Составить из описанных выше функций программу, реализующую алфавитно-частотный словарь. Вывести на экран количество различных слов, т.е. количество элементов списка.
Задание списки 2:Создать список из десяти элементов и вывести его на экран. Затем вывести только четные элементы списка.
Задание списки 3:Дан односвязный (линейный) список. Найти максимальный и минимальный элементы в списке.
Простые задачи
Пример: Напишите функцию SumArray , возвращающую сумму элементов заданного динамического массива. Выведите длину и сумму элементов массива
Выполнение:
function SumArray(var a: array of integer): integer:=a.Sum; begin var a:=new integer[10]; a:=arrRandomInteger(10); foreach var x in a do print(x); println('длина массива = ',a.Length,' сумма = ',ArraySum(a)) end.
Пример: Дан массив, вывести его содержимое на экран, разделяя элементы точкой с запятой (процедура PrintArr ). Используйте для разделителя delim значение по умолчанию равное ‘ ; ‘
Выполнение:
Дополните код:
procedure PrintArr( a: array of integer; delim:string:='; '); begin foreach var . in . do print(x,delim); end; begin var a:=new integer[10]; a:=arrRandomInteger(10); . end.
Задание 2: Заполнить массив (b) первыми N ( N ≥ 0 ) положительными нечётными числами массива a. Необходимо реализовать два различных решения задачи:
- Функция MakeOddArrFunc с одним параметром N , возвращающая массив.
- Процедура MakeOddArrProc с двумя параметрами: входным — массив a и выходным параметром — массивом положительный нечетных чисел

function MakeOddArrFunc (a: array of integer; n:integer):array of integer; begin var b:= new integer[n]; var j:=0; for var i:=0 to . do if . then begin . ;. ;end; SetLength(. ); result:=b; end; procedure MakeOddArrProc (a: array of integer;var b: array of integer; n:integer); begin b:= new integer[n]; var j:=0; for var i:=0 to . do if . then begin . ;. ;end; SetLength(. ); end; begin var a:=arrRandomInteger(20); var b: array of integer; var n:=readInteger('введите N'); println('исходный массив ',a); println('результат работы с функцией ',MakeOddArrFunc(a,n)); MakeOddArrProc(a,b,n); print('результат работы с процедурой ',b) end.
Задание 3: Заполнить целочисленный массив первыми N ( N ≥ 0 ) числами Фибоначчи. Достаточно одной из реализаций: функции или процедуры
function MakeFibArr (n : integer):array of integer; begin var c:= new integer[n]; c[0]:=. ;c[1]:=. ; for var i:=2 to n-1 do . ; result:=c; end; begin var n:= readinteger; . ; end.

Задание 4: Дан целочисленный массив. Написать процедуру EvenMult с двумя параметрами: входным — целочисленным массивом и выходным — evensCnt — значением целого типа, которая увеличивает все элементы массива с чётными значениями в два раза и записывает в evensCnt количество таких элементов
Пример: Описать функцию MakeRandomRealArr с тремя параметрами: целым числом N ( N ≥ 0 ), вещественными параметрами a и b ( a ).
Функция должна возвращать массив (тип которого либо RealArr либо array of real ) из N случайных вещественных элементов в диапазоне a..b .
Продемонстрируйте заполнение и вывод на экран массива
Выполнение:
function MakeRandomRealArr (n : integer;a,b:real):array of real; begin var c:= ArrRandomReal(n,a,b); result:=c; end; begin var n:= readinteger; var a:=readReal; var b:=readReal; println('результат работы с функцией ',MakeRandomRealArr(n,a,b)); end.
Пример: Дан целочисленный массив. Обнулить все его элементы
с нечётными индексами (процедура SetToZeroOddIndexes ).
Условный оператор не использовать
Выполнение:
Задание: Дан целочисленный массив, содержащий не менее трёх элементов. Найти значение первого локального минимума (функция FirstLocMin ).
Пояснение: локальным минимумом считается тот элемент, который меньше каждого из своих соседей. Считать, что локальный минимум в массиве есть. Первый и последний элемент в качестве локальных минимумов не рассматривать.
Задание: Дан массив целых чисел, содержащий не менее трёх элементов. Найти значение и номер последнего локального максимума (процедура с двумя выходными параметрами)
Читайте также: