
Oracle вернуть таблицу из функции
Я знаю, что это звучит как простая вещь, но я никогда не делал этого раньше.
Я хотел бы вернуть одну запись из существующей таблицы в результате функции Oracle PL / SQL. Я уже нашел несколько разных способов сделать это, но меня интересует лучшие способ сделать это (читайте: Я не очень доволен тем, что я нашел).
суть того, что я делаю это. У меня есть таблица под названием "пользователи" , и я хочу функцию "update_and_get_user", который дал имя пользователя (а также другую достоверную информацию о указанном пользователе), потенциально выполнит различные действия в таблице "пользователи", а затем вернет либо ноль, либо одну строку/запись из указанной таблицы.
Это основной набросок кода в моей голове на данный момент (читайте: не знаю, насколько синтаксис близок к правильному):
Я видел примеры, когда возвращается запись или таблица, тип записи или таблицы был создан / объявлено заранее, но похоже, что если таблица уже определена, я должен иметь возможность использовать это и, следовательно, не беспокоиться о синхронизации кода объявления типа, если изменения таблицы когда-либо будут сделаны.
Я открыт для всех потенциальных решений и комментариев, но я делаю действительно хотите сохранить это в одной функции PL / SQL (в отличие от кода на каком-либо другом языке / фреймворке, который взаимодействует с базой данных несколько раз, заканчивая некоторой формой 'SELECT * FROM users WHERE username=blah'), поскольку система, вызывающая функцию, и сама база данных могут быть разными городами. За пределами этого предела я готов изменить свое мышление.
вот как я бы это сделал. Переменные / имена таблиц / имена столбцов не учитывают регистр в Oracle, поэтому я бы использовал user_name вместо UserName .
функции update_and_get_user . Обратите внимание, что я возвращаю ROWTYPE вместо конвейерных таблиц.
и вот как вы бы это назвали. Вы не можете проверить ROWTYPE на NULL , но вы можете проверить username например.
решение с использованием PIPED ROWS ниже, но это так не бывает. Вы не можете обновлять таблицы внутри запроса.
Те, кто пришел в Oracle из MSSQL, наверняка столкнулись (как и я) с массой неожиданностей.
create function Foo1 (param1 nvarchar, param2 decimal(18,2))
return table (
id number,
nn nvarchar(50)
)
as
.
Знакомо, не правда ли? Если подобная функция прекрасно возвращала ADO Recordset из MS SQL, то в Oracle такой халявы нет. Однако получать наборы данных из функций через ADO просто необходимо, если мы хотим придерживаться грамотной структуры объектной модели.
Создадим две таблицы — сотрудников и подразделений.
--создание табличных пространств
create tablespace ALEX_DATA datafile 'C:\oracle\user_data\tblsp_alexdata.dat'
size 10M REUSE AUTOEXTEND ON NEXT 2M MAXSIZE 200M;
create tablespace ALEX_INDEX datafile 'C:\oracle\user_data\tblsp_alexix.dat'
size 1M REUSE AUTOEXTEND ON NEXT 1M MAXSIZE 200M;
/
--создание таблиц
create table ALEX.T_EMPLOYEES(
id number(5) not null,
id_department number(5) not null,
empinfo nvarchar2(50) not null
) tablespace ALEX_DATA;
create table ALEX.T_DEPARTMENTS(
id number(5) not null,
depinfo nvarchar2(50) not null
) tablespace ALEX_DATA;
/
--создание индексов
create index IXPK_T_EMPLOYEES on ALEX.T_EMPLOYEES(id)
tablespace ALEX_INDEX;
create index IXPK_T_DEPARTMENTS on ALEX.T_DEPARTMENTS(id)
tablespace ALEX_INDEX;
/
--создание реляционных связей
alter table ALEX.T_DEPARTMENTS
add constraint PK_T_DEPARTMENTS primary key (ID) using index IXPK_T_DEPARTMENTS;
/
alter table ALEX.T_EMPLOYEES
add constraint PK_T_EMPLOYEES primary key (ID) using index IXPK_T_EMPLOYEES
add constraint FK_T_DEPARTMENTS foreign key (id_department)
references ALEX.T_DEPARTMENTS(id);
/
--демо-данные
insert into ALEX.T_DEPARTMENTS (ID, DEPINFO)
values (1, 'Отдел кадров');
insert into ALEX.T_DEPARTMENTS (ID, DEPINFO)
values (2, 'Информационный отдел');
insert into ALEX.T_DEPARTMENTS (ID, DEPINFO)
values (3, 'Бухгалтерия');
insert into ALEX.T_EMPLOYEES (ID, ID_DEPARTMENT, EMPINFO)
values(1, 1, 'Иванов');
insert into ALEX.T_EMPLOYEES (ID, ID_DEPARTMENT, EMPINFO)
values(2, 1, 'Борисов');
insert into ALEX.T_EMPLOYEES (ID, ID_DEPARTMENT, EMPINFO)
values(3, 2, 'Сергеев');
insert into ALEX.T_EMPLOYEES (ID, ID_DEPARTMENT, EMPINFO)
values(4, 3, 'Никитин');
insert into ALEX.T_EMPLOYEES (ID, ID_DEPARTMENT, EMPINFO)
values(5, 3, 'Александров');
Наша цель — написать функцию, которая бы возвращала список сотрудников отдела, id которого передается в качестве параметра.
Для начала нам нужно описать тип данных, возвращаемый таблицей.
--тип данных строки, возвращаемой GetEmployees
type rowGetEmployees is record(
l_empinfo ALEX.T_EMPLOYEES.EMPINFO%TYPE, --привязка к типу поля empinfo
l_depinfo ALEX.T_DEPARTMENTS.DEPINFO%TYPE
);
Это тип данных строки. Атрибут TYPE объявляет для переменной тип, идентичный указанному полю. Создаем второй тип:
type tblGetEmployees is table of rowGetEmployees;
Это таблица из строк типа rowGetEmployees. Переменную этого типа будет возвращать наша функция:
function GetEmployees
(prm_depID number default null)
return tblGetEmployees
pipelined;
Если параметр не передан, будем возвращать список всех сотрудников. Атрибут pipelined означает, что функция является конвейерной, результат возвращается клиенту немедленно при вызове директивы pipe row, поэтому оператор return необязателен. Фактически, по результирующему набору из запроса в теле функции проходит курсор, который при каждой итерации добавляет в рекордсет текущую строку.
Поместим типы данных и функцию в пакет. На выходе имеем
create or replace package ALEX.P_MY1 is
--тип данных строки, возвращаемой GetEmployees
type rowGetEmployees is record(
l_empinfo ALEX.T_EMPLOYEES.EMPINFO%TYPE, --привязка к типу поля empinfo
l_depinfo ALEX.T_DEPARTMENTS.DEPINFO%TYPE
);
--тип данных таблицы из строк rowGetEmployees
type tblGetEmployees is table of rowGetEmployees;
--
function GetEmployees
(prm_depID number default null)
return tblGetEmployees
pipelined;
create or replace package body ALEX.P_MY1 is
function GetEmployees
(prm_depID number default null)
return tblGetEmployees
pipelined
is
begin
if prm_depID is null then
for curr in
(
select emp.empinfo, dep.depinfo
from ALEX.T_DEPARTMENTS dep inner join
ALEX.T_EMPLOYEES emp on dep.id = emp.id_department
) loop
pipe row (curr);
end loop;
else
for curr in
(
select emp.empinfo, dep.depinfo
from ALEX.T_DEPARTMENTS dep inner join
ALEX.T_EMPLOYEES emp on dep.id = emp.id_department
where dep.id = prm_depID
) loop
pipe row (curr);
end loop;
end if;
end GetEmployees;
В промышленных системах часто требуется выполнить преобразования данных с использованием pl/sql кода с возможностью обращения к этим данным в sql запросе. Для этого в oracle используются табличные функции.
Табличные функции – это функции возвращающие данные в виде коллекции, к которой мы можем обратиться в секции from запроса, как если бы эта коллекция была реляционной таблицей. Преобразование коллекции в реляционный набор данных осуществляется с помощью функции table().
Однако такие функции имеют один недостаток, так как в них сначала полностью наполняется коллекция, а только потом эта коллекция возвращается в вызывающую обработку. Каждая такая коллекция храниться в памяти и в высоконагруженных системах это может стать проблемой. Так же в вызывающей обработке происходит простой на время наполнения коллекции. Решить данный недостаток призваны табличные конвейерные функции.
Конвейерными функциями называются табличные функции, которые возвращают данные в виде коллекции, но делают это асинхронно, то есть получена одна запись коллекции и сразу же эта запись отдается в вызывающий код в котором она сразу же обрабатывается. В этом случае память сохраняется, простой по времени ликвидируется.
Рассмотрим, как создаются такие функции. В данном примере будет использована учебная схема hr и три ее таблицы: employees, departments, locations.
• employees — таблица сотрудников.
• departments — таблица отделов.
• locations — таблица географического местонахождения.
Данная схема и таблицы есть в каждой базовой сборке oracle по умолчанию.
В схеме hr я создам пакет test, в нем будет реализован наш код. Создаваемая функция будет возвращать данные по сотрудникам в конкретном отделе. Для этого в спецификации пакета нужно описать тип возвращаемых данных:
• employee_id – ид сотрудника
• first_name – имя
• last_name – фамилия
• email – электронный адрес
• phone_number – телефон
• salary – зарплата
• salary_recom – рекомендуемая зарплата
• department_id – ид отдела
• department_name — наименование отдела
• city – город
Далее опишем саму функцию:
Функция принимает на вход ид отдела и возвращает коллекцию созданного нами типа t_employees_table. Ключевое слово pipelined делает эту функцию конвейерной. В целом спецификация пакета следующая:
Рассмотрим тело пакета, в нем описано тело функции get_employees_dep:
В функции мы получаем набор данных по сотрудникам конкретного отдела, каждую строчку этого набора анализируем на предмет того, что если зарплата сотрудника меньше 8 000, то рекомендуемую зарплату устанавливаем в значение 10 000, дальше каждая строчка не дожидаясь окончания наполнения всей коллекции, отдается в вызывающую обработку. Обратите внимание, что в теле функции отсутствует ключевое слово return и присутствует pipe row (rec).
Осталось вызвать созданную функцию в pl/sql блоке:
Вот так вот просто с помощью конвейерных табличных функций мы получаем возможность сделать выборку, наполненную сколько угодно сложной логикой за счет использования pl/sql кода и не просесть в плане производительности, а в ряде случаем даже ее увеличить.

Табличной функцией SQL называется функция, которая может вызываться из секции FROM запроса, как если бы она была реляционной таблицей. Коллекции, возвращаемые табличными функциями, можно преобразовать оператором TABLE в структуру, к которой можно обращаться с запросами из языка SQL. Табличные функции особенно удобны в следующих ситуациях:
- Выполнение очень сложных преобразований данных, требующих использования PL/SQL , но с необходимостью обращаться к этим данным из команд SQL .
- Возвращение сложных результирующих наборов управляющей среде (отличной от PL/SQL ). Вы можете открыть курсорную переменную для запроса, основанного на табличной функции, чтобы управляющая среда могла выполнить выборку данных через курсорную переменную.
Табличные функции открывают массу полезных возможностей для разработчиков PL/SQL . Чтобы продемонстрировать некоторые из этих возможностей, мы поближе познакомимся с потоковыми и конвейерными табличными функциями.
Конвейерные табличные функции
Эти функции возвращают результирующий набор в конвейерном режиме, то есть данные поступают, пока функция продолжает выполняться. Добавьте секцию PARALLEL_ENABLE в заголовок конвейерной функции — и у вас появляется функция, которая будет выполняться параллельно в параллельном запросе.
До выхода Oracle Database 12c табличные функции могли возвращать только вложенные таблицы и VARRAY . Начиная с версии 12.1 появилась возможность определения табличных функций, возвращающих ассоциативные массивы с целочисленными индексами, тип которых определяется в спецификации пакета.
Давайте посмотрим, как определяются табличные функции и как использовать их в приложениях.
Вызов функции из секции FROM
Чтобы вызвать функцию из секции FROM , необходимо сделать следующее:
- Определить тип данных RETURN функции как тип коллекции (вложенная таблица или VARRAY ).
- Убедиться в том, что все остальные параметры функции имеют режим IN и тип данных SQL . (Например, из запроса не удастся вызвать функцию, аргумент которой относится к логическому типу или типу записи.)
- Встроить вызов функции в оператор TABLE (в Oracle8i придется использовать оператор cast).
Рассмотрим простой пример использования табличной функции. Мы начнем с создания типа вложенной таблицы на базе объектного типа pets :
Затем создается функция с именем pet_family . В ее аргументах передаются два объекта pet . Далее в зависимости от значения breed возвращается вложенная таблица с информацией обо всем семействе, определенной в коллекции:
Функция pet_family тривиальна; здесь важно понять, что функция PL/SQL может содержать сколь угодно сложную логику, которая реализуется средствами PL/SQL и выходит за рамки выразительных возможностей SQL .
Теперь эта функция может вызываться в секции FROM запроса :
Часть выходных данных:
Активизация параллельного выполнения функции
Одним из огромных достижений PL/SQL , появившихся в Oracle9i Database, стала возможность выполнения функций в контексте параллельных запросов. До выхода Oracle9i Database вызов функции PL/SQL в SQL переводил запрос в режим последовательного выполнения — существенная проблема для хранилищ данных большого объема. Теперь в заголовок конвейерной функции можно добавить информацию, которая подскажет исполнительному ядру, каким образом передаваемый функции набор данных следует разбить для параллельного выполнения.
В общем случае функция, предназначенная для параллельного выполнения, должна иметь один входной сильнотипизованный параметр REF CURSOR .
- Функция может выполняться параллельно, а данные, передаваемые этой функции, могут разбиваться произвольно:
В этом примере ключевое слово ANY выражает утверждение программиста о том, что результаты не зависят от порядка получения входных строк функцией. При использовании этого ключевого слова исполнительная система случайным образом разбивает данные между процессами запроса. Это ключевое слово подходит для функций, которые получают одну строку, работают с ее столбцами, а затем генерируют выходные строки по содержимому столбцов только этой строки. Если в вашей программе действуют другие зависимости, результат становится непредсказуемым.
- Функция может выполняться параллельно, все строки заданного отдела должны передаваться одному процессу, а передача осуществляется последовательно:
Oracle называет такой способ группировки записей кластерным; столбец, по которому осуществляется группировка (в данном случае department ), называется кластерным ключом. Здесь важно то, что для алгоритма несущественно, в каком порядке значений кластерного ключа он будет получать кластеры, и Oracle не гарантирует никакого конкретного порядка получения. Тем самым обеспечивается ускорение работы алгоритма по сравнению с кластеризацией и передачей строк в порядке значений кластерного ключа. Алгоритм выполняется со сложностью N вместо N log(N) , где N — количество записей.
В данном примере в зависимости от имеющейся информации о распределении значений можно выбрать между HASH (department) и RANGE (department). HASH работает быстрее, и является более естественным вариантом для использования с CLUSTER.. .BY .
- Функция должна выполняться параллельно, а строки, передаваемые конкретному процессу в соответствии с PARTITION. BY (для этого раздела), будут проходить локальную сортировку этим процессом.
Фактически происходит параллелизация сортировки, поэтому команда SELECT , используемая для вызова табличной функции, не должна содержать секции ORDER. BY (так как ее присутствие будет противоречить попытке параллелизации сортировки). Следовательно, в данном случае естественно использовать вариант RANGE в сочетании с ORDER. ..BY . Реализация будет работать медленнее, чем CLUSTER. BY , поэтому этот вариант следует использовать только в том случае, если алгоритм зависит от него.
Конструкция CLUSTER. BY не должна использоваться вместе с ORDER. BY в объявлении табличной функции. Это означает, что алгоритм, зависящий от кластеризации по одному ключу cl с последующим упорядочением набора записей с заданным значением cl, скажем, по c2, должен проходить параллелизацию с использованием ORDER. BY в объявлении табличной функции.

Функция PL/SQL представляет собой модуль, который возвращает значение командой RETURN (вместо аргументов OUT или IN OUT ). В отличие от вызова процедуры, который представляет собой отдельный оператор, вызов функции всегда является частью исполняемого оператора, то есть включается в выражение или служит в качестве значения по умолчанию, присваиваемого переменной при объявлении.
Возвращаемое функцией значение принадлежит к определенному типу данных. Функция может использоваться вместо выражения, которое имеет тот же тип данных, что и возвращаемое ею значение.
Функции играют важную роль в реализации модульного подхода. К примеру, реализацию отдельного бизнес-правила или формулы в приложении рекомендуется оформить в виде функции. Вместо того чтобы писать один и тот же запрос снова и снова («Получить имя работника по идентификатору», «Получить последнюю строку заказа из таблицы order для заданного идентификатора компании» и т. д.), поместите его в функцию и вызовите эту функцию в нужных местах. Такой код создает меньше проблем с отладкой, оптимизацией и сопровождением.
Некоторые программисты предпочитают вместо функций использовать процедуры, возвращающие информацию через список параметров. Если вы принадлежите к их числу, проследите за тем, чтобы ваши бизнес-правила, формулы и однострочные запросы были скрыты в процедурах!
В приложениях, которые не определяют и не используют функции, со временем обычно возникают трудности с сопровождением и расширением.
Метка END
Вы можете указать имя функции за завершающим ключевым словом END :
Имя служит меткой, явно связывающей конец программы с ее началом. Привыкните к использованию метки END. Она особенно полезна для функций, занимающих несколько страниц или входящих в серию процедур и функций в теле пакета.
Заголовок функции
Часть определения функции, предшествующая ключевому слову IS , называется заголовком функции, или сигнатурой. Заголовок предоставляет программисту всю информацию, необходимую для вызова функции:
- Имя функции.
- Модификаторы определения и поведения функции (детерминированность, возможность параллельного выполнения и т. д.).
- Список параметров (если имеется).
- Тип возвращаемого значения.
В идеале программист при виде заголовка функции должен понять, что делает эта функция и как она вызывается.
Заголовок упоминавшейся ранее функции total_sales выглядит так:
Он состоит из типа модуля, имени и списка из двух параметров и возвращаемого типа NUMBER . Это означает, что любое выражение или команда PL/SQL , в которых задействовано числовое значение, может вызвать total_sales для получения этого значения. Пример:
Тело функции
В теле функции содержится код, необходимый для реализации этой функции; тело состоит из объявления, исполняемого раздела и раздела исключений этой функции. Все, что следует за ключевым словом IS , образует тело функции.
Как и в случае с процедурами, разделы исключений и объявлений не являются обязательными. Если обработчики исключений отсутствуют, опустите ключевое слово EXCEPTION и завершите функцию командой END . Если объявления отсутствуют, команда BEGIN просто следует непосредственно за ключевым словом IS.
Исполняемый раздел функции должен содержать команду RETURN . Функция откомпилируется и без него, но если выполнение функции завершится без выполнения команды RETURN, Oracle выдаст ошибку: ORA-06503: PL/SQL: Function returned without value .
Эта ошибка не выдается, если функция передает наружу свое необработанное исключение.
Передача результатов вызова табличной функции в курсорной переменной
Табличные функции помогают решить проблему, с которой разработчики сталкивались в прошлом, — а именно как передать данные, полученные в программе PL/SQL (то есть данные, не хранящиеся в таблицах базы данных), в управляющую среду без поддержки PL/SQL ? Курсорные переменные позволяют легко передать результирующие наборы на базе SQL , допустим, в программу Java, потому что курсорные переменные поддерживаются в JDBC . Но если сначала нужно провести сложные преобразования в PL/ SQL , как вернуть эти данные вызывающей программе?
Теперь эта проблема решается объединением мощи и гибкости табличных функций с широкой поддержкой курсорных переменных в средах без поддержки PL/SQL . Допустим, я хочу сгенеририровать данные семейства животных (полученные вызовом функции pet_family из предыдущего раздела) и передать строки данных интерфейсному приложению, написанному на Java.
Это делается очень просто:
В этой программе я воспользуюсь преимуществами предопределенного слабого курсорного типа SYS_REFCURSOR (появившегося в Oracle9i Database ) для объявления курсорной переменной. Курсорная переменная открывается вызовом OPEN FOR и связывается с запросом, построенным на базе табличной функции pet_family .
Затем курсорная переменная передается интерфейсной части Java . Так как JDBC распознает курсорные переменные, код Java легко выполняет выборку строк данных и интегрирует их в приложение.
Функции без параметров
Если функция не имеет параметров, ее вызов может записываться с круглыми скобками или без них. Следующий код демонстрирует эту возможность на примере вызова метода age объектного типа pet_t:
Возвращаемый тип
Функция PL/SQL может возвращать данные практически любого типа, поддерживаемого PL/SQL , — от скаляров (единичных значений вроде даты или строки) до сложных структур: коллекций, объектных типов, курсорных переменных и т. д.
Несколько примеров использования RETURN :
- Возвращение строки:
- Возвращение числа функцией-членом объектного типа:
- Возвращение записи, имеющей ту же структуру, что и у таблицы books:
- Возвращение курсорной переменной с заданным типом REF CURSOR (базирующемся на типе записи):
Команда RETURN
В исполняемом разделе функции должна находиться по меньшей мере одна команда RETURN . Команд может быть и несколько, но в одном вызове функции должна выполняться только одна из них. После обработки команды RETURN выполнение функции прекращается, и управление передается вызывающему блоку PL/SQL .
Если ключевое слово RETURN в заголовке определяет тип данных возвращаемого значения, то команда RETURN в исполняемом разделе задает само это значение. При этом тип данных, указанный в заголовке, должен быть совместим с типом данных выражения, возвращаемого командой RETURN .
Любое допустимое выражение
Команда RETURN может возвращать любое выражение, совместимое с типом, обозначенным в секции RETURN . Это выражение может включать вызовы других функций, сложные вычисления и даже преобразования данных. Все следующие примеры использования RETURN допустимы:
Вы также можете возвращать сложные типы данных — экземпляры объектных типов, коллекции и записи.
Выражение в команде RETURN вычисляется в момент выполнения RETURN . При возврате управления в вызывающий блок также передается результат вычисленного выражения.
множественные команды RETURN
В функции total_sales на рис. 2 я использую две разные команды RETURN для обработки разных ситуаций в функции: если из курсора не удалось получить информацию, возвращается NULL (не нуль). Если же от курсора было получено значение, оно возвращается вызывающей программе. В обоих случаях команда RETURN возвращает значение: в одном случае NULL , в другом — переменную return_value.
Конечно, наличие нескольких команд RETURN в исполняемом разделе функции разрешено, однако лучше ограничиться одной командой RETURN, размещаемой в последней строке исполняемого раздела. Причины объясняются в следующем разделе.
RETURN как последняя исполняемая команда
В общем случае команду RETURN желательно делать последней исполняемой командой; это лучший способ гарантировать, что функция всегда возвращает значение. Объявите переменную с именем return_value (которое четко указывает, что в переменной будет храниться возвращаемое значение функции), напишите весь код вычисления этого значения, а затем в самом конце функции верните значение return_value командой RETURN :
Переработанная версия логики на рис. 2, в которой решена проблема множественных команд RETURN , выглядит так:
Остерегайтесь исключений! Помните, что инициированное исключение может «перепрыгнуть» через последнюю команду прямо в обработчик. Если обработчик исключения не содержит команды RETURN , то будет выдана ошибка ORA-06503: Function returned without value независимо от того, как было обработано исходное исключение.
Создание конвейерной функции
Конвейерной функцией называется табличная функция, которая возвращает результирующий набор как коллекцию, но делает это асинхронно с завершением самой функции. Другими словами, база данных уже не ожидает, пока функция отработает до конца и сохранит все вычисленные строки в коллекции PL/SQL, прежде чем выдать первые строки. Каждая запись, готовая к присваиванию в коллекцию, передается функцией как по конвейеру. В этом разделе описаны основы построения конвейерных табличных функций. Чтобы лучше понять, что необходимо для построения конвейерных функций, мы переработаем функцию stockpivot :
В следующей таблице перечислены некоторые изменения в исходной функциональности.
| Строки | Описание |
| 2 | По сравнению с исходной версией stockpivot добавлено ключевое слово PIPELINED |
| 4-5 | Объявление локального объекта и локальной записи, как и в первой версии. В этих строках интересно то, что не объявляется, — а именно вложенная таблица, которая будет возвращаться функцией. Намек на то, что будет дальше… |
| 7-9 | Начало простого цикла с выборкой каждой строки из курсорной переменной; цикл завершается, когда в курсоре не остается данных |
| 12-15 и 19-21 | Заполнение локального объекта для строк tickertable (на моменты открытия и закрытия) |
| 16-21 | Команда PIPE ROW (допустимая только в конвейерных функциях) немедленно передает объект, подготовленный функцией |
| 25 | В конце исполняемого раздела функция ничего не возвращает! Вместо этого она вызывает RETURN без указания значения (что прежде разрешалось только в процедурах) для возврата управления вызывающему блоку. Функция уже вернула все свои данные командами PIPE ROW |
Конвейерная функция вызывается так же, как и неконвейерная. Внешне никакие различия в поведении не проявляются (если только вы не настроили конвейерную функцию для параллельного выполнения в составе параллельного запроса — см. следующий раздел — или не включили логику, использующую асинхронное возвращение данных). Возьмем запрос, использующий псевдостолбец ROWNUM для ограничения строк, включаемых в выборку:
Мои тесты показывают, что в Oracle Database 10g и Oracle Database 11g при преобразовании 100 000 строк в 200 000 и последующем возвращении только первых 9 строк конвейерная версия завершает свою работу за 0,2 секунды, тогда как выполнение неконвейерной версии занимает 4,6 секунды.
Как видите, конвейерная передача строк работает, и обеспечивает существенный выигрыш!
Создание потоковой функции
Потоковая функция получает параметр с результирующим набором (через выражение CURSOR ) и возвращает результат в форме коллекции. Так как к коллекции можно применить оператор TABLE , а затем запросить данные командой SELECT , эти функции позволяют выполнить одно или несколько преобразований данных в одной команде SQL . Потоковые функции, поддержка которых добавилась в Oracle9i Database , позволяют скрыть алгоритмическую сложность за интерфейсом функции, и упростить SQL приложения. Приведенный ниже пример объясняет различные действия, которые необходимо выполнить для такого использования табличных функций.
Представьте следующую ситуацию: имеется таблица с информацией биржевых котировок, которая содержит строки с ценами на моменты открытия и закрытия биржи:
Эту информацию необходимо преобразовать в другую таблицу:
Иначе говоря, одна строка stocktable превращается в две строки tickertable . Эту задачу можно решить многими способами. Самое элементарное и традиционное решение на PL/SQL выглядит примерно так:
Также возможны решения, полностью основанные на SQL :
А теперь предположим, что для перемещения данных из stocktable в tickertable требуется выполнить очень сложное преобразование, требующее использования PL/ SQL . В такой ситуации табличная функция, используемая для передачи преобразуемых данных, потребует намного более эффективного решения.
Прежде всего, при использовании табличной функции нужно будет возвращать вложенную таблицу или массив VARRAY с данными. Я выбрал вложенную таблицу, потому что для VARRAY нужно задать максимальный размер, а я не хочу устанавливать это ограничение в своей реализации. Тип вложенной таблицы должен быть определен как тип на уровне схемы или в спецификации пакета, чтобы ядро SQL могло разрешить ссылку на коллекцию этого типа. Конечно, хотелось бы вернуть вложенную таблицу, основанную на самом определении таблицы, — то есть чтобы определение выглядело примерно так:
К сожалению, эта команда завершится неудачей, потому что %ROWTYPE не относится к числу типов, распознаваемых SQL. Этот атрибут доступен только в разделе объявлений PL/SQL . Следовательно, вместо этого придется создать объектный тип, который воспроизводит структуру реляционной таблицы, а затем определить тип вложенной таблицы на базе этого объектного типа:
Чтобы табличная функция передавала данные с одной стадии преобразования на другую, она должна получать аргумент с набором данных — фактически запрос. Это можно сделать только одним способом — передачей курсорной переменной, поэтому в списке параметров функции необходимо будет использовать тип REF CURSOR.
Я создал пакет для типа REF CURSOR , основанного на новом типе вложенной таблицы:
Работа завершается написанием функции преобразования:
Как и в случае с функцией pet_family , конкретный код не важен; в ваших программах логика преобразований будет качественно сложнее. Впрочем, основная последовательность действий с большой вероятностью будет повторена в вашем коде, поэтому я приведу краткую сводку в следующей таблице.
Итак, теперь у меня имеется функция, которая будет проделывать всю нетривиальную, но необходимую работу, и я могу использовать ее в запросе для передачи данных между таблицами:
Внутренняя команда SELECT извлекает все строки таблицы stocktable . Выражение CURSOR , в которое заключен запрос, преобразует итоговый набор в курсорную переменную, которая передается stockpivot. Функция возвращает вложенную таблицу, а оператор TABLE преобразует ее к формату реляционной таблицы, к которой можно обращаться с запросами.
Никакого волшебства, и все же выглядит немного волшебно, правда? Но вас ждет нечто еще более интересное — конвейерные функции!
Вызов функции
Функция может вызываться из любой части исполняемой команды PL/SQL , где допускается использование выражения. Следующие примеры демонстрируют вызовы функций, определения которых приводились в предыдущем разделе.
- Присваивание переменной значения по умолчанию вызовом функции:
- Использование функции-члена для объектного типа в условии:
- Вставка в запись строки с информацией о книге:
- Вызов пользовательской функции PL/SQL из запроса:
Вызов написанной вами функции из команды CREATE VIEW с использованием выражения CURSOR для передачи результирующего набора в аргументе функции:
В PL/SQL , в отличие от некоторых других языков программирования, невозможно просто проигнорировать возвращаемое значение функции, даже если оно не представляет интереса для вас. Например, для следующего вызова функции:
будет выдана ошибка PLS-00221: ‘FAVORITE_NICKNAME’ is not a procedure or is undefined .
Функцию нельзя использовать так, как если бы она была процедурой.
Структура функции
Функция (рис. 1) имеет почти такую же структуру, как и процедура, не считая того, что ключевое слово RETURN в ней играет совершенно другую роль:
Основные элементы этой структуры:
- схема — имя схемы, которой будет принадлежать функция (необязательный аргумент). По умолчанию применяется имя схемы текущего пользователя. Если значение схемы отлично от имени схемы текущего пользователя, то этот пользователь должен обладать привилегиями для создания функции в другой схеме.
- имя — имя функции.
- параметр — необязательный список параметров, которые применяются для передачи данных в функцию и возврата информации из нее в вызывающую программу.
- возвращаемый_тип — задает тип значения, возвращаемого функцией. Возвращаемый тип должен быть указан в заголовке функции; он более подробно рассматривается в следующем разделе.
- AUTHID — определяет, с какими разрешениями будет вызываться функция: создателя (владельца) или текущего пользователя. В первом случае (используется по умолчанию) применяется модель прав создателя, во втором — модель прав вызывающего.
- DETERMINISTIC — определяет функцию как детерминированную, то есть возвращаемое значение полностью определяется значениями ее аргументов. Если включить эту секцию, ядро SQL сможет оптимизировать выполнение функции при ее вызове в запросах.
- PARALLEL_ENABLE — используется для оптимизации и позволяет функции выполняться параллельно в случае, когда она вызывается из команды SELECT .
- PIPELINED — указывает, что результат табличной функции должен возвращаться в итеративном режиме с помощью команды PIPE ROW .
- RESULT_CACHE — указывает, что входные значения и результат вызова функции должен быть сохранен в кэше результатов. Эта возможность, появившаяся в Orade11g.
- ACCESSIBLE BY (Oracle Database 12c) — ограничивает доступ к функции программными модулями, перечисленными в круглых скобках.
- AGGREGATE — используется при определении агрегатных функций.
- EXTERNAL — определяет функцию с «внешней реализацией» — то есть написанную на языке C.
- объявления — объявления локальных идентификаторов этой функции. Если объявления отсутствуют, между ключевыми словами IS и BEGIN не будет никаких выражений.
- исполняемые команды — команды, выполняемые функцией при вызове. Между ключевыми словами BEGIN и END или EXCEPTION должна находиться по крайней мере одна исполняемая команда.
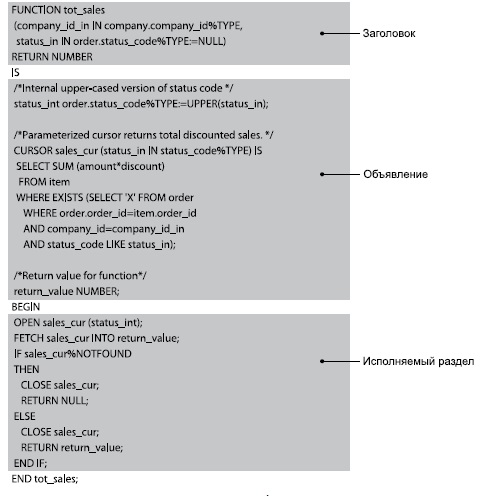
Рис. 1. Код функции
- обработчики исключений — необязательные обработчики исключений для функции. Если процедура не обрабатывает никаких исключений, слово EXCEPTION можно опустить и завершить исполняемый раздел ключевым словом END .
На рис. 1 изображено строение функции PL/SQL и ее различных разделов. Обратите внимание: функция total_sales не имеет раздела исключений.
Потоковые табличные функции
Потоковая передача данных позволяет переходить между процессами или стадиями без использования вспомогательных структур данных. Табличные функции в сочетании с выражением CURSOR позволяют организовать потоковую передачу данных через несколько промежуточных преобразований в одной команде SQL .
Читайте также: